实时流式计算 kafkaStream
文章目录
- 实时流式计算
- Kafka Stream
- Kafka Streams 的关键概念
- KStream
- Kafka Stream入门案例编写
- SpringBoot 集成 Kafka Stream
实时流式计算
一般流式计算会与批量计算相比较

流式计算就相当于上图的右侧扶梯,是可以源源不断的产生数据,源源不断的接收数据,没有边界。
一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。
流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。同时为了提高计算效率,往往尽可能采用增量计算代替全量计算。
应用场景
- 日志分析
网站的用户访问日志进行实时的分析,计算访问量,用户画像,留存率等等,实时的进行数据分析,帮助企业进行决策 - 大屏看板统计
可以实时的查看网站注册数量,订单数量,购买数量,金额等。 - 公交实时数据
可以随时更新公交车方位,计算多久到达站牌等 - 实时文章分值计算
头条类文章的分值计算,通过用户的行为实时文章的分值,分值越高就越被推荐。
技术方案选型
- Hadoop
- Apche Storm
- Flink
- Kafka Stream
可以轻松地将其嵌入任何Java应用程序中,并与用户为其流应用程序所拥有的任何现有打包,部署和操作工具集成。
Kafka Stream
Kafka Stream:提供了对存储于 Kafka内 的数据进行流式处理和分析的功能
Kafka Stream的特点如下:
- Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
- 除了Kafka外,无任何外部依赖
- 充分利用Kafka分区机制实现水平扩展和顺序性保证
- 通过可容错的state store实现高效的状态操作(如windowed join和aggregation)
- 支持正好一次处理语义
- 提供记录级的处理能力,从而实现毫秒级的低延迟
- 支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
- 同时提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)

Kafka Streams 的关键概念
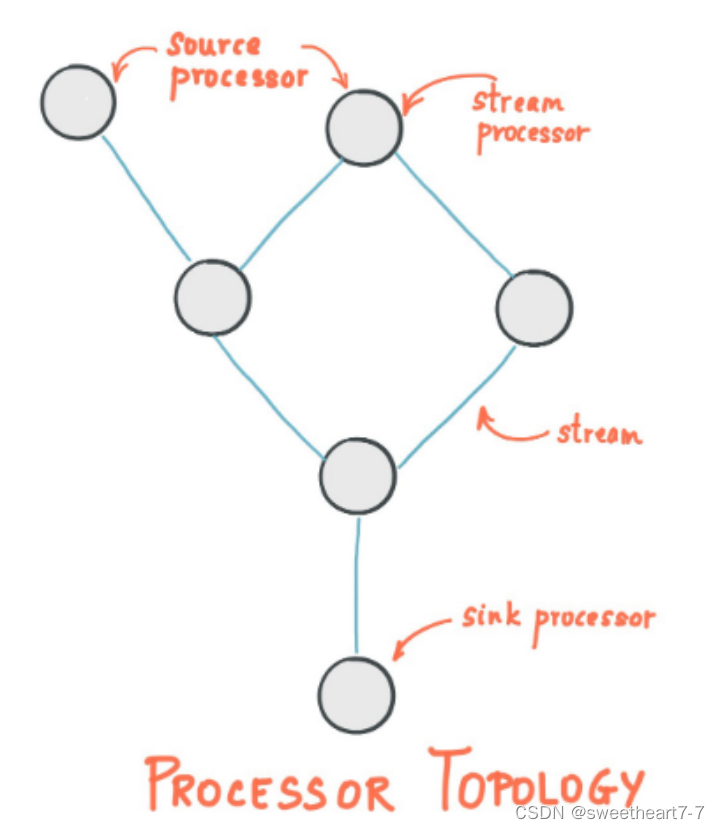
-
源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。
-
Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题
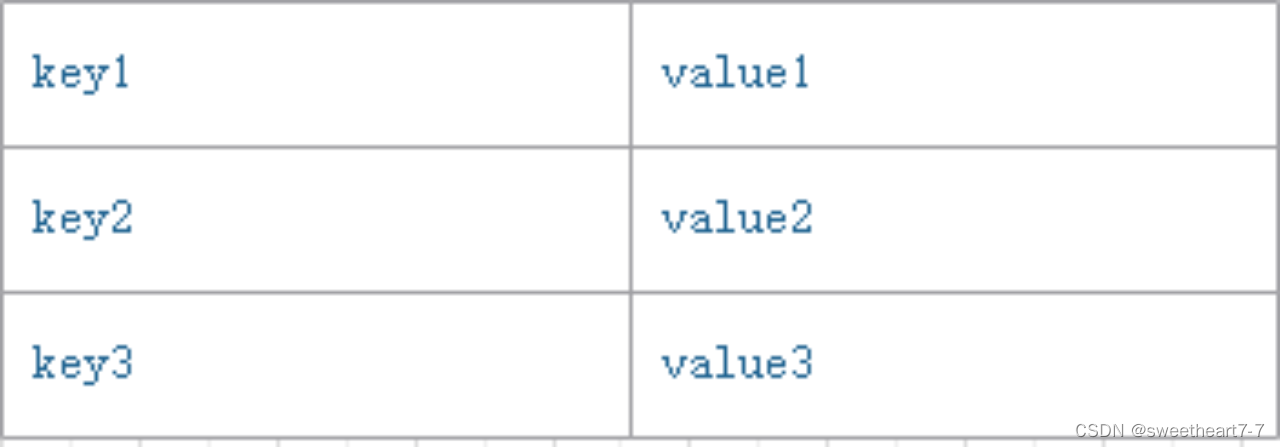
KStream
- 数据结构类似于map,如下图,
key-value键值对
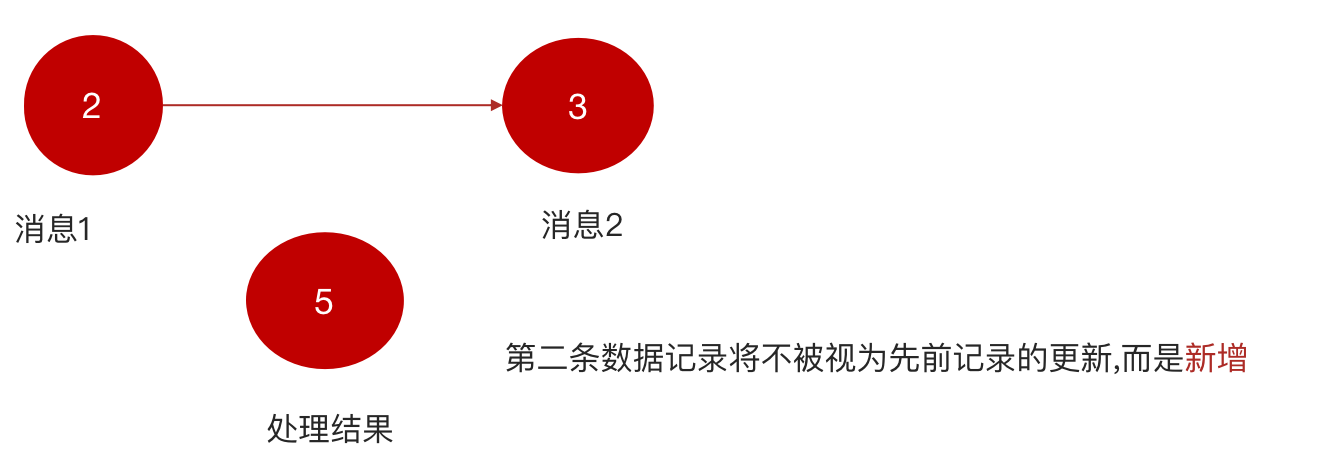
KStream数据流(data stream),即是一段顺序的,可以无限长,不断更新的数据集。
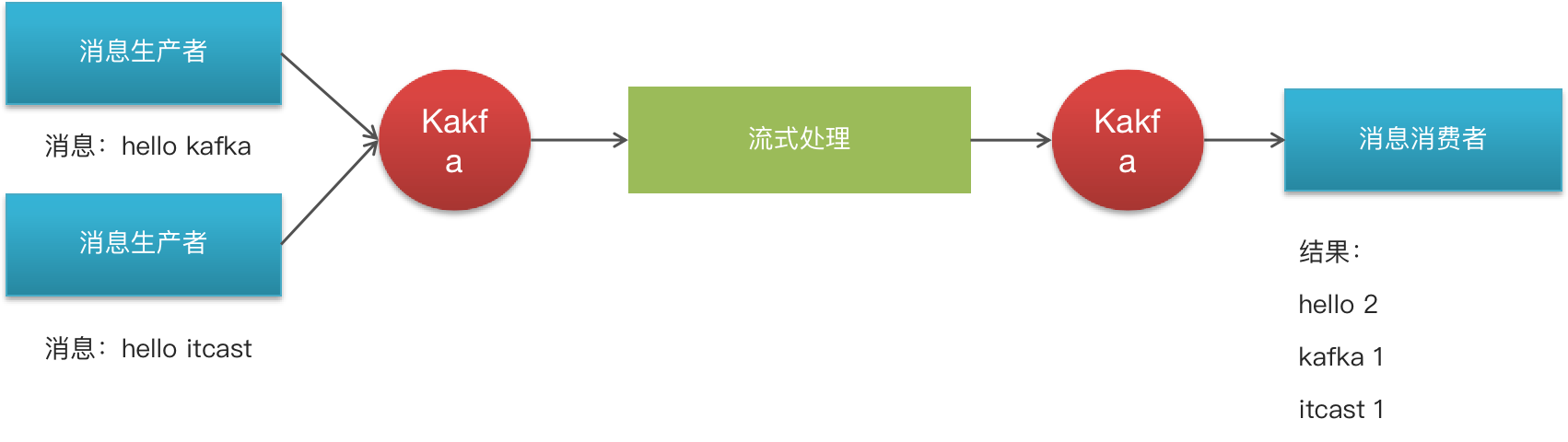
Kafka Stream入门案例编写
- 需求分析,求单词个数(word count)
- 创建原生的 kafka staream 入门案例
导入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><exclusions><exclusion><artifactId>connect-json</artifactId><groupId>org.apache.kafka</groupId></exclusion><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions>
</dependency>


package com.heima.kafka.sample;import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.TimeWindows;
import org.apache.kafka.streams.kstream.ValueMapper;import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;/*** 流式处理*/
public class KafkaStreamQuickStart {public static void main(String[] args) {//kafka的配置信心Properties prop = new Properties();prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.200.130:9092");prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"streams-quickstart");//stream 构建器StreamsBuilder streamsBuilder = new StreamsBuilder();//流式计算streamProcessor(streamsBuilder);//创建kafkaStream对象KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(),prop);//开启流式计算kafkaStreams.start();}/*** 流式计算* 消息的内容:hello kafka hello itcast* @param streamsBuilder*/private static void streamProcessor(StreamsBuilder streamsBuilder) {//创建kstream对象,同时指定从那个topic中接收消息KStream<String, String> stream = streamsBuilder.stream("itcast-topic-input");/*** 处理消息的value*/stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {@Overridepublic Iterable<String> apply(String value) {return Arrays.asList(value.split(" "));}})//按照value进行聚合处理.groupBy((key,value)->value)//时间窗口.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))//统计单词的个数.count()//转换为kStream.toStream().map((key,value)->{System.out.println("key:"+key+",vlaue:"+value);return new KeyValue<>(key.key().toString(),value.toString());})//发送消息.to("itcast-topic-out");}
}
- 测试准备
- 使用生产者在 topic 为:
itcast_topic_input中发送多条消息 - stream 接收
itcast_topic_input的数据,进行聚合操作后,将处理结果发送到itcast_topic_out - 使用消费者接收 topic 为:
itcast_topic_out
结果:
- 通过流式计算,会把生产者的多条消息汇总成一条发送到消费者中输出
SpringBoot 集成 Kafka Stream
- 配置
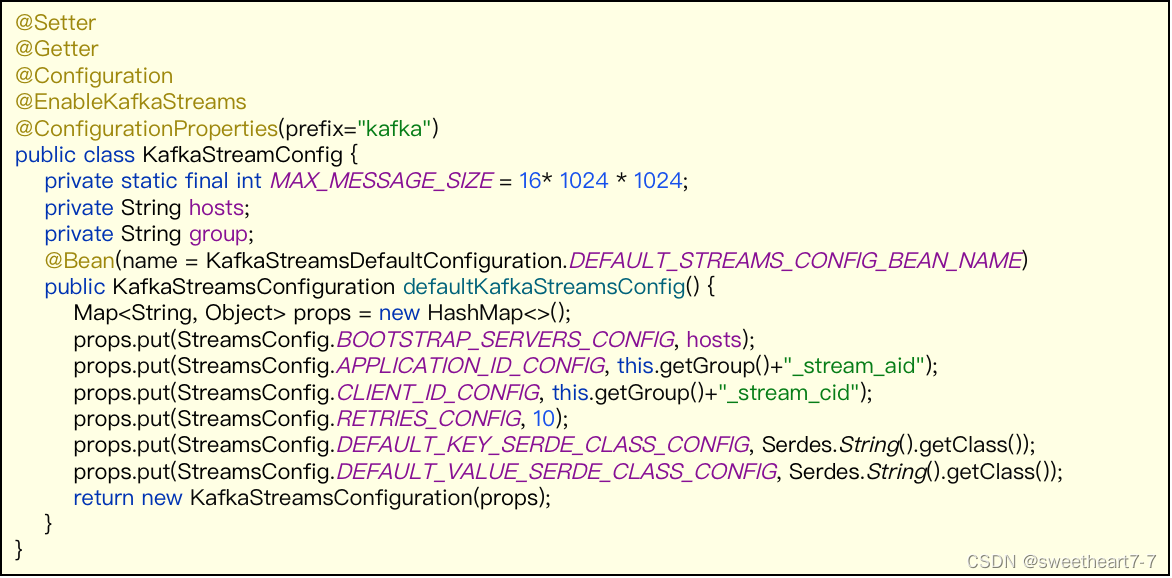
package com.heima.kafka.config;import lombok.Getter;
import lombok.Setter;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafkaStreams;
import org.springframework.kafka.annotation.KafkaStreamsDefaultConfiguration;
import org.springframework.kafka.config.KafkaStreamsConfiguration;import java.util.HashMap;
import java.util.Map;/*** 通过重新注册KafkaStreamsConfiguration对象,设置自定配置参数*/@Setter
@Getter
@Configuration
@EnableKafkaStreams
@ConfigurationProperties(prefix="kafka")
public class KafkaStreamConfig {private static final int MAX_MESSAGE_SIZE = 16* 1024 * 1024;private String hosts;private String group;@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)public KafkaStreamsConfiguration defaultKafkaStreamsConfig() {Map<String, Object> props = new HashMap<>();props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);props.put(StreamsConfig.APPLICATION_ID_CONFIG, this.getGroup()+"_stream_aid");props.put(StreamsConfig.CLIENT_ID_CONFIG, this.getGroup()+"_stream_cid");props.put(StreamsConfig.RETRIES_CONFIG, 10);props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());return new KafkaStreamsConfiguration(props);}
}
application.yml

kafka:hosts: 192.168.200.130:9092group: ${spring.application.name}
- 在配置类中定义方法
- 可注入StreamsBuilder
- 返回值必须是KStream且放入spring容器中

package com.heima.kafka.stream;import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.TimeWindows;
import org.apache.kafka.streams.kstream.ValueMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.time.Duration;
import java.util.Arrays;@Configuration
@Slf4j
public class KafkaStreamHelloListener {@Beanpublic KStream<String,String> kStream(StreamsBuilder streamsBuilder){//创建kstream对象,同时指定从那个topic中接收消息KStream<String, String> stream = streamsBuilder.stream("itcast-topic-input");stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {@Overridepublic Iterable<String> apply(String value) {return Arrays.asList(value.split(" "));}})//根据value进行聚合分组.groupBy((key,value)->value)//聚合计算时间间隔.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))//求单词的个数.count().toStream()//处理后的结果转换为string字符串.map((key,value)->{System.out.println("key:"+key+",value:"+value);return new KeyValue<>(key.key().toString(),value.toString());})//发送消息.to("itcast-topic-out");return stream;}
}
- 测试
启动 springboot 项目即可自动监听
相关文章:
实时流式计算 kafkaStream
文章目录 实时流式计算Kafka StreamKafka Streams 的关键概念KStreamKafka Stream入门案例编写SpringBoot 集成 Kafka Stream 实时流式计算 一般流式计算会与批量计算相比较 流式计算就相当于上图的右侧扶梯,是可以源源不断的产生数据,源源不断的接收数…...

西南科技大学模拟电子技术实验七(集成运算放大器的非线性应用)预习报告
一、计算/设计过程 说明:本实验是验证性实验,计算预测验证结果。是设计性实验一定要从系统指标计算出元件参数过程,越详细越好。用公式输入法完成相关公式内容,不得贴手写图片。(注意:从抽象公式直接得出结果,不得分,页数可根据内容调整) 预习计算内容根据运放的非线…...
Ubuntu与Windows通讯传输文件(FTP服务器版)(没用的方法,无法施行)
本文介绍再Windows主机上建立FTP服务器,并且在Ubuntu虚拟机上面访问Windows上FTP服务器的方法 只要按照上图配置就可以了 第二部:打开IIS管理控制台 右击网站,新建FTP站点。需要注意的一点是在填写IP地址的时候,只需要填写Window…...
2024年AI视频识别技术的6大发展趋势预测
随着人工智能技术的快速发展,AI视频识别技术也将会得到进一步的发展和应用。2023年已经进入尾声,2024年即将来临,那么AI视频识别技术又将迎来怎样的发展趋势?本文将对2023年的AI视频技术做一个简单的盘点并对2024年的发展趋势进行…...

一篇文章了解JDK的前世今生
我们每天都在开发Java,每天都在使用JDK,那么我们了解JDK的发展史吗,这篇文章将带你深入了解JDK的发展史。 JDK(Java Development Kit)是Java开发者工具包,是用于编写Java程序和运行Java程序的软件开发工具集。自从1995年Java语言首次发布以来,JDK已经经历了数十年的发展…...

Redisson出现问题总结
org.redisson.client.RedisAuthRequiredException: NOAUTH Authentication required… channel: 出现此问题的原因为没有redis权限。解决方案在setAddress()后面加上setPassword()方法。 config.useSingleServer().setAddress("redis://localhost:6379").setPasswo…...

领域驱动架构(DDD)建模
一、背景 常见的软件开发方式是拿到产品需求后,直接考虑数据库中表应该如何设计,这种方式已经将设计与业务需求脱节,而更多的是直接考虑应该如何实现了,这有点本末倒置。而DDD是从领域(问题域)为出发点进行的设计方法。 领域驱动…...
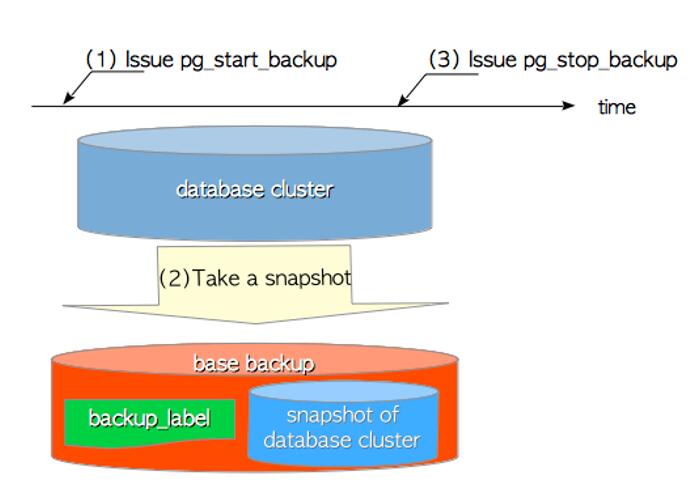
PostgreSQL从小白到高手教程 - 第38讲:数据库备份
PostgreSQL从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对PG基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱PG、学习PG的同学们有帮助,欢迎持续关注CUUG PG技术大讲堂。 第38讲&#…...
 和 eglCreateWindowSurface() 的对比和使用)
OpenGL ES eglCreatePbufferSurface() 和 eglCreateWindowSurface() 的对比和使用
一、介绍 相同点: eglCreatePbufferSurface 和 eglCreateWindowSurface 都是 OpenGL ES 中用于创建不同类型的EGL表面的函数,以便在OpenGL ES中进行渲染。 不同点: 选择使用哪种表面类型取决于你的需求。如果你只是需要在内存中进行离屏渲…...
)
python之马尔科夫链(Markov Chain)
马尔可夫链(Markov Chain)是一种随机过程,具有“马尔可夫性质”,即在给定当前状态的条件下,未来状态的概率分布仅依赖于当前状态,而与过去状态无关。马尔可夫链在很多领域都有广泛的应用,包括蒙…...
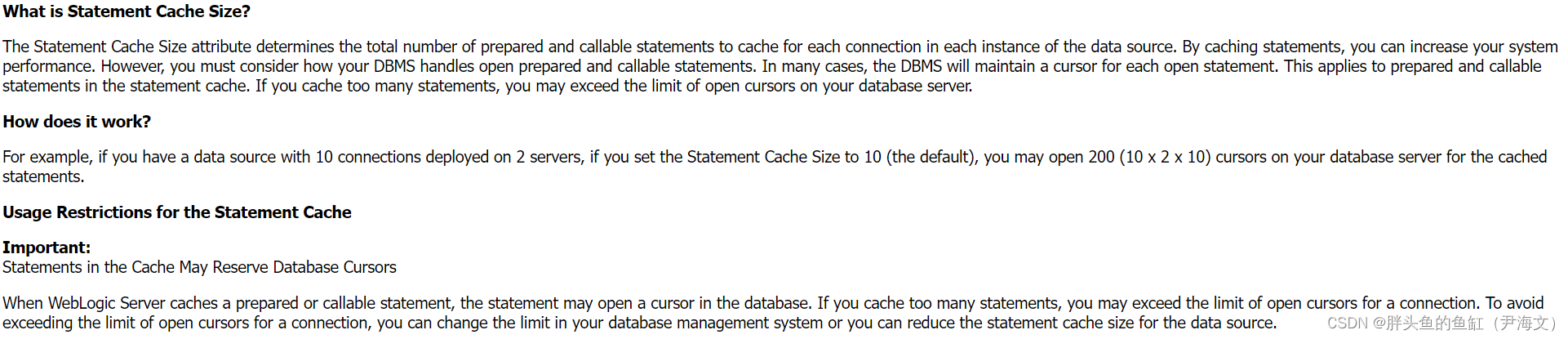
数据库管理-第123期 Oracle相关两个参数(202301205)
数据库管理-第123期 Oracle相关两个参数(202301205) 最近在群聊中看到俩和Oracle数据库相关的俩参数,一个是Oracle数据库本身的,一个是来自于Weblogic的,挺有趣的,本期研究一下。(本期涉及参数…...

掌握vue中国际化使用及配置
文章目录 🍁i18n组件安装🍁项目中配置 vue-i18n🍁编写语言包🍁国际化的使用 随着互联网的普及和全球化的发展,开发国际化的应用程序已经成为一种趋势。因此,将 VUE 应用程序国际化是非常有必要的。 以下是…...
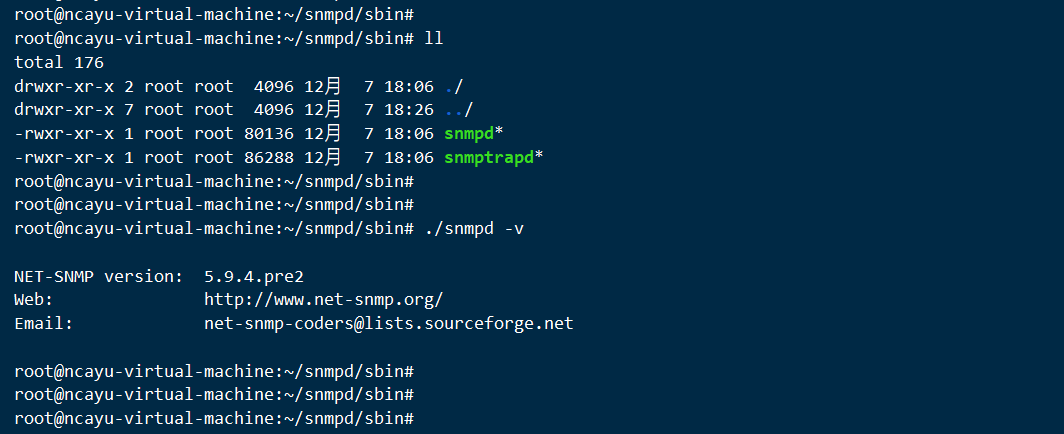
Ubuntu编译文件安装SNMP服务
net-snmp源码下载 http://www.net-snmp.org/download.html 编译步骤 指定参数编译 ./configure --prefix/root/snmpd --with-default-snmp-version"2" --with-logfile"/var/log/snmpd.log" --with-persistent-directory"/var/net-snmp" --wi…...
3D Web可视化平台助力Aras开发PLM系统:提供数据访问、可视化和发布功能
HOOPS中文网慧都科技是HOOPS全套产品中国地区指定授权经销商,提供3D软件开发工具HOOPS售卖、试用、中文试用指导服务、中文技术支持。http://techsoft3d.evget.com/ Aras是一个面向数字化工业应用的开放性平台,帮助世界领先的复杂互联产品制造商转变其产…...

Graphpad Prism10.1.0 安装教程 (含Win/Mac版)
GraphPad Prism GraphPad Prism是一款非常专业强大的科研医学生物数据处理绘图软件,它可以将科学图形、综合曲线拟合(非线性回归)、可理解的统计数据、数据组织结合在一起,除了最基本的数据统计分析外,还能自动生成统…...

【动态规划】路径问题_不同路径_C++
题目链接:leetcode不同路径 目录 题目解析: 算法原理 1.状态表示 2.状态转移方程 3.初始化 4.填表顺序 5.返回值 编写代码 题目解析: 题目让我们求总共有多少条不同的路径可到达右下角; 由题可得: 机器人位于…...
Python并发-线程和进程
一、线程和进程对应的问题 **1.进程:**CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可…...

微信小程序适配方案:rpx(responsive pixel响应式像素单位)
小程序适配单位:rpx 规定任何屏幕下宽度为750rpx 小程序会根据屏幕的宽度自动计算rpx值的大小 Iphone6下:1rpx 1物理像素 0.5css 小程序编译后,rpx会做一次px换算,换算是以375个物理像素为基准,也就是在一个宽度…...
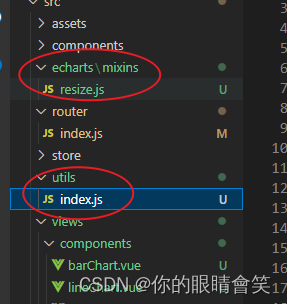
vue2 echarts饼状图,柱状图,折线图,简单封装以及使用
vue2 echarts饼状图,柱状图,折线图,简单封装以及使用 1. 直接上代码(复制可直接用,请根据自己的文件修改引用地址,图表只是简单封装,可根据自身功能,进行进一步配置。) …...
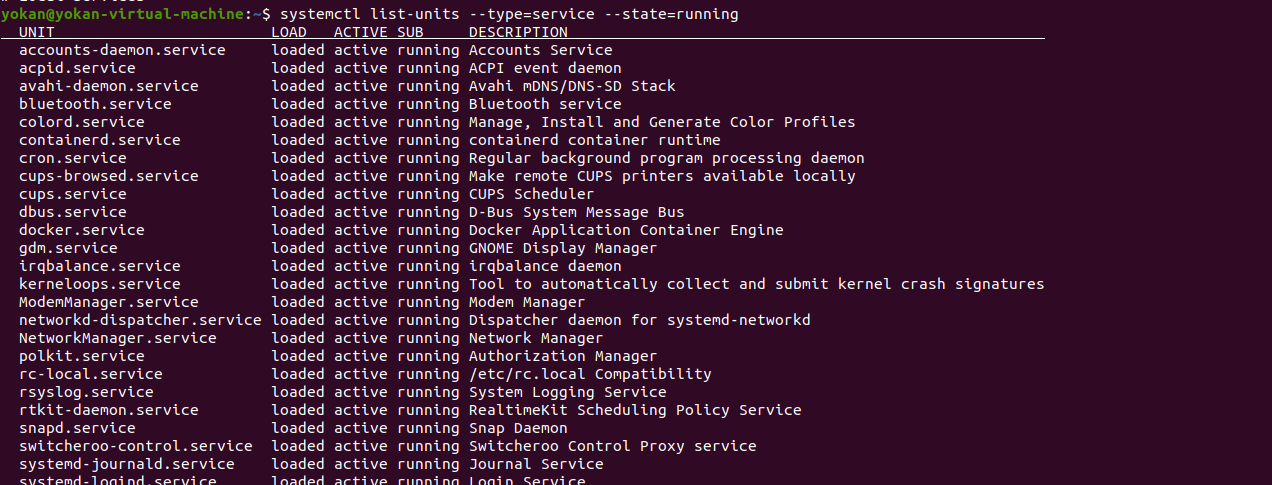
Linux信息收集
Linux信息收集 本机基本信息 #管理员 $普通用户 之前表示登录的用户名称,之后表示主机名,再之后表示当前所在目录 / 表示根目录 ~表示当前用户家目录1、内核,操作系统和设备信息 uname -a 打印所有可用的系统信息 uname -r 内核版本 u…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

Vite中定义@软链接
在webpack中可以直接通过符号表示src路径,但是vite中默认不可以。 如何实现: vite中提供了resolve.alias:通过别名在指向一个具体的路径 在vite.config.js中 import { join } from pathexport default defineConfig({plugins: [vue()],//…...
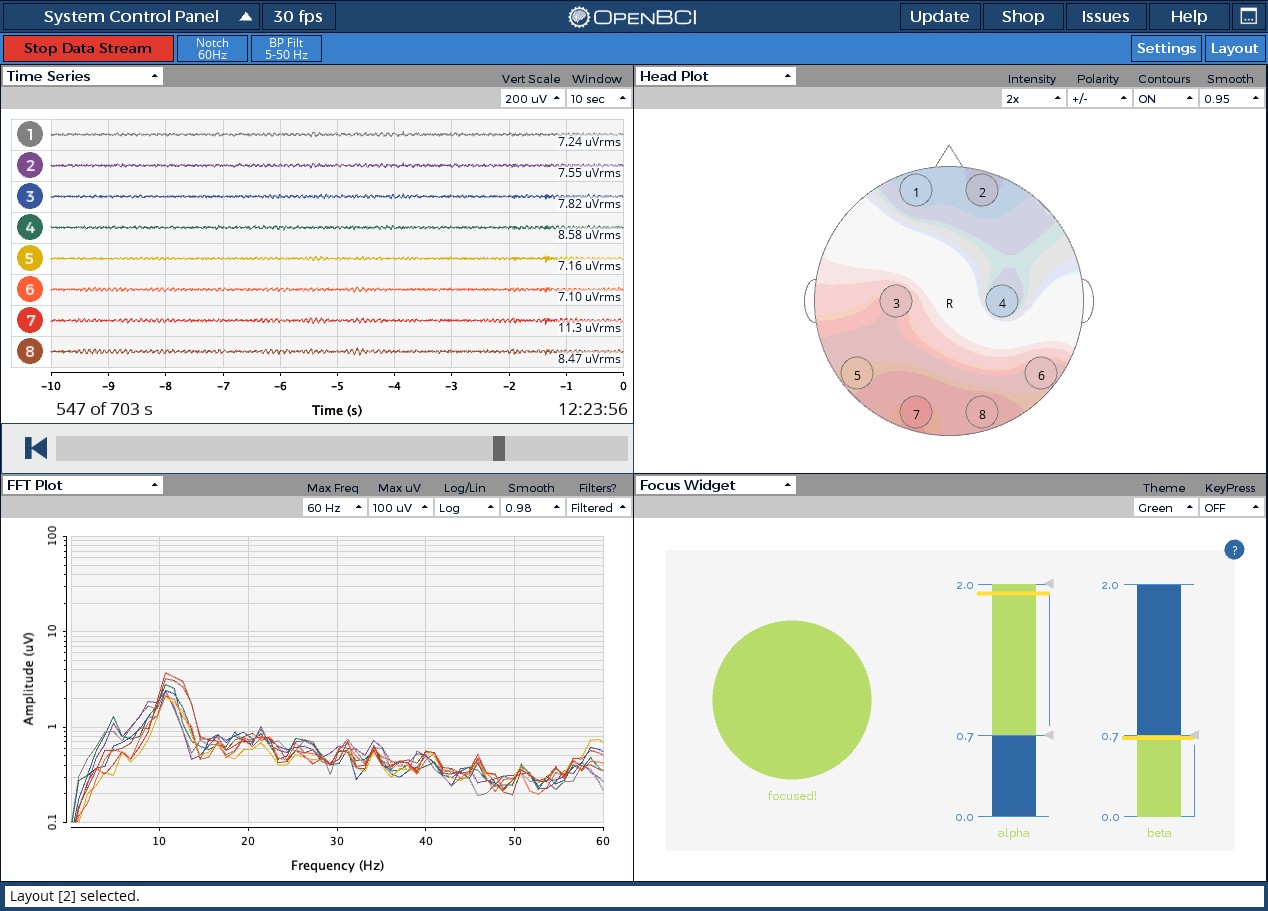
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...
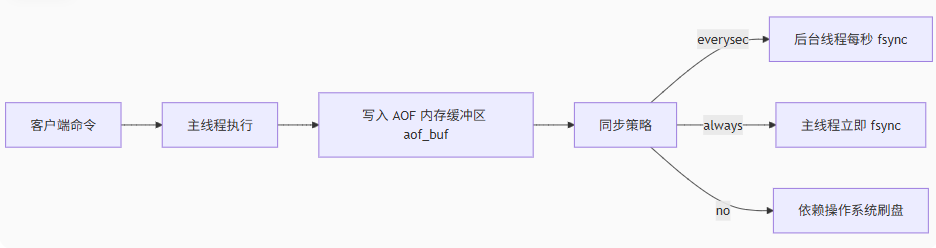
Redis上篇--知识点总结
Redis上篇–解析 本文大部分知识整理自网上,在正文结束后都会附上参考地址。如果想要深入或者详细学习可以通过文末链接跳转学习。 1. 基本介绍 Redis 是一个开源的、高性能的 内存键值数据库,Redis 的键值对中的 key 就是字符串对象,而 val…...