pytorch:YOLOV1的pytorch实现
pytorch:YOLOV1的pytorch实现
注:本篇仅为学习记录、学习笔记,请谨慎参考,如果有错误请评论指出。
参考:
动手学习深度学习pytorch版——从零开始实现YOLOv1
目标检测模型YOLO-V1损失函数详解
3.1 YOLO系列理论合集(YOLOv1~v3)代码仓库:https://gitee.com/wtryb/yolov1-pytorch-implement
模型权重:链接:https://pan.baidu.com/s/1ZSl-VwkjaRUPuD9CkA6sdg?pwd=blhj
提取码:blhj
YoloV1的预测过程

上图是作者在原论文Introduction部分对YoloV1检测器系统的大致介绍。对比R-CNN系列,YoloV1的结构相对来说简单很多。Yolo的主要思想就是将识别问题看作是一个回归问题。因为全连接层的存在YoloV1只能接受(448x448)尺寸(分辨率)的图片,因此需要将输入的图片进行resize然后输入到网络中,通过网络进行预测后的结果进行非极大值抑制得到最终结果。
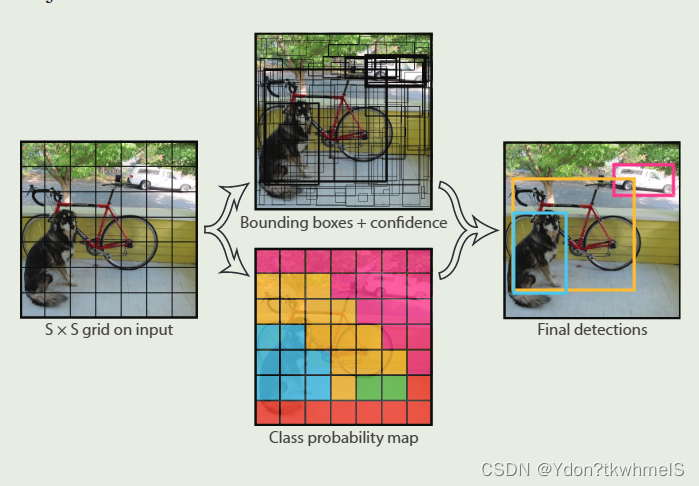
上图是作者在原论文中Introduction部分对网络预测过程解释的原图。虽然这张图有两个分支,但是是从一个网络中得到两个分支上的结果。网格会将输入图片分成(SxS)个小方格(grid cell),然后在每个小方格上预测边界框和类别概率,最后得到最后的预测结果。YoloV1这种将输入分为小网格的操作和锚框有些相似。
1、网络将输入分成SxS个小网格,S是超参数可以设置不同的值,原论文设置为7,也就是将输入图像分成了7x7个(64x64)的小网格。
2、如果某个对象(Objectness)的中心坐标落在了哪一个网格内,那个网格就负责预测这个物体。网格会预测B个边界框和C个类别概率,边界框数和类别数是超参数,可以设置网格预测多少个边界框原论文是2个以及有多少个类别就有多少个类别概率。而每个边界框会有5个参数:x,y,w,h,c,因此网络最终输出就是(batch, (B*5+C), S,S)。下面说明边界框预测参数的含义。
x , y x,y x,y:边界框的中心相对于网格左上角的坐标偏移。
w , h w,h w,h:边界框相对于整个图像的大小。
c c c:边界框的置信度。
这五个参数的取值范围都是[0,1]。其他四个参数都好理解,主要是C边界框置信度(confidence score)这个参数怎么理解。下面两个问题我认为是关键。
如何理解边界框置信度这个参数?
原论文中说明,边界框置信度(confidence score)就是网络认为网格中存在物体的置信度以及网络对于预测的边界框的准确率。也就是说这个值越高越好,越高越认为这个网格预测到了对象(objectness)而且很准确。
如何计算置信度?
论文中将C定义为了 P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr\left( Object \right) *IOU_{pred}^{truth} Pr(Object)∗IOUpredtruth。解释下这两个值的意思:
P r ( O b j e c t ) = { 1 有对象存在 0 无对象存在 Pr\left( Object \right) =\begin{cases} 1& \text{有对象存在}\\ 0& \text{无对象存在}\\ \end{cases} Pr(Object)={10有对象存在无对象存在
I O U p r e d t r u c h : G T 真实边界框与预测边界框的 I O U 值。 IOU_{pred}^{truch}:GT真实边界框与预测边界框的IOU值。 IOUpredtruch:GT真实边界框与预测边界框的IOU值。
那么两个值乘起来也就意味着,如果这个网格有对象存在,置信度就等于GT真实边界框与预测边界框的IOU值,如果没有对象存在就等于0。YoloV1对于采样区域策略以及正负样本区分做的很粗糙,因此训练时C的取值无非就是0和1,GT边界框中心落在哪个网格哪个网格的置信度就取1此外取0。推理预测时,哪个网格的置信度越接近于1,对象中心在那个网格的概率以及边界框预测准确率越高。
总而言之,置信度的取值衡量了,网格对于对象预测的质量,值越高越质量越好。
YoloV1的网络设计
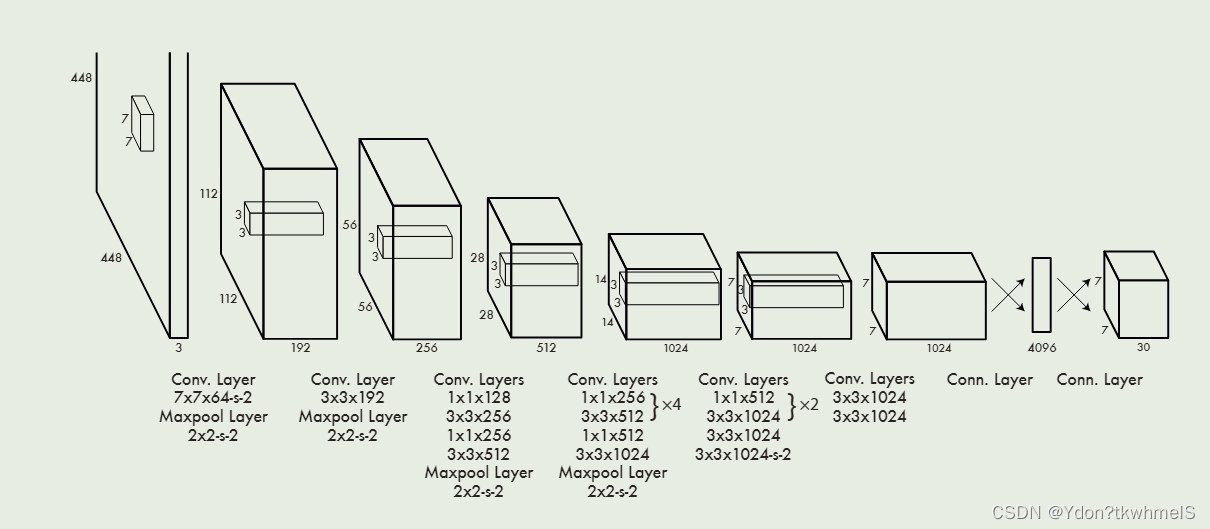
作者收到GoogleNet的启发,设计了Darknet,其结构如上图所示。随着Yolo系列的迭代,主干网络也在迭代。
YoloV1的损失函数设计
作者在论文中提到使用了平方误差和损失(sum-squared error)因为它易于优化,但是对于最终最大平均精度(maximizing average precision)的目标来说不是很合适,因为它没有区分开定位损失和类别损失,因此作者做了一些修改。下面来进行说明。
1、对正负样本的损失设置权重。在训练时,负样本的数量大大压过正样本,正负样本也就是存在和不存在对象的小网格,这会使得网络难以训练以及造成网络训练时的不稳定。
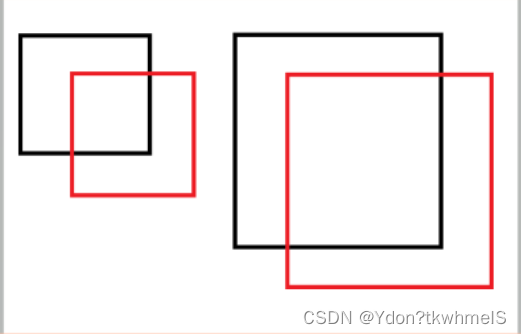
2、使用宽高的平方根计算损失。平方误差和损失将大边界框和小边界框的误差认为是同等程度的误差,而实际情况是相同的偏移误差对于小边界框影响更大。如下图,黑框是GT边界框,红框是预测边界框,小红框和大红框相对各自的GT边界框的坐标偏移是相同的,从视觉上来看相同的偏移对于小框影响更大。
3、采用于GT边界框最大IOU的边界框作为预测器。Yolo每个网格生成多个框,但是只采用于GT边界框IOU最大的边界框作为预测器,这种操作使得边界框有了分化,使得边界框在预测特定大小、宽高比、类别时更加准确。
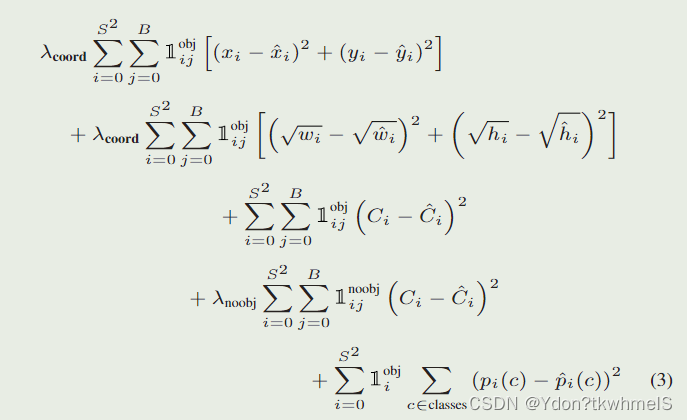
论文给出的损失函数如图。解释几个参数:
λ c o o r d :取 5 ,正样本的权重 \lambda _{coord}:取5,正样本的权重 λcoord:取5,正样本的权重
λ n o o b j :取 0.5 ,负样本的权重 \lambda _{noobj}:取0.5,负样本的权重 λnoobj:取0.5,负样本的权重
1 i j o b j :第 i 个网格的第 j 个边界框作为预测器时取 1 ,其余取 0 1_{ij}^{obj}:第i个网格的第j个边界框作为预测器时取1,其余取0 1ijobj:第i个网格的第j个边界框作为预测器时取1,其余取0
1 i j n o o b j :第 i 个网格的第 j 个边界框不作为预测器时取1,其余取 0 1_{ij}^{noobj}\text{:第}i\text{个网格的第}j\text{个边界框不作为预测器时取1,其余取}0 1ijnoobj:第i个网格的第j个边界框不作为预测器时取1,其余取0
S :网格的数量 S\text{:网格的数量} S:网格的数量
B :每个网格预测边界框的数量 B\text{:每个网格预测边界框的数量} B:每个网格预测边界框的数量
总体理解下YoloV1的损失函数:
正样本参与位置损失、置信度损失和类别损失的计算,负样本只计算置信度损失,同时为了减弱负样本数量过多的问题给正负样本的损失计算加上了权重。
YoloV1的优缺点
优点:
1、非常快
2、结构简单
缺点:
1、定位误差大
2、区域采样机制设计粗糙
YoloV1的Pytorch实现
1、构建数据集。
使用Pascal VOC2007数据集,这里不再多介绍。YoloV1的输入尺寸固定是(448x448)因此读入图片后需要进行resize,直接resize即可,不需要做其他操作。
VOC2007对于每张图片都有标注文件,读取标注文件中的边界框和类别,按照YoloV1的输出进行编码。
def yolo_encoder(boxes, labels, yolo_config):# print("进入编码器")target = torch.zeros(size= (30, yolo_config["num_grid"], yolo_config["num_grid"]), dtype= torch.float)# print("标签的形状: ", target.shape)cell_size = yolo_config["input_size"] / yolo_config["num_grid"]# print("网格大小:", cell_size)# print(f"一共处理{len(boxes)}个边界框 Boxes:{boxes}")for index, box in enumerate(boxes):# print(f"正在处理第{index+1}个边界框:", box)x_c, y_c, w, h = point_to_center(box)# print("归一化前 x_c, y_c", x_c, y_c)# print("归一化前 w, h", w, h)x_i = math.ceil(x_c // cell_size)y_i = math.ceil(y_c // cell_size)delta_x = float((x_c - x_i * cell_size) / cell_size)delta_y = float((y_c - y_i * cell_size) / cell_size)w = float(w / yolo_config["input_size"])h = float(h / yolo_config["input_size"])# print("物体中心所在网格:", (x_i, y_i))# print("得到边界框偏移:", (delta_x, delta_y))# print("归一化后边界框宽高:", w, h)# print(x_i, y_i)# 前两个值是中心坐标对网格左上角坐标的偏移,归一化到0-1target[0, x_i, y_i] = delta_xtarget[1, x_i, y_i] = delta_y# print("delta_x, delta_y", delta_x, delta_y)target[2, x_i, y_i] = wtarget[3, x_i, y_i] = h# print("w, h", w, h)# 每个网格预测两个边界框,每个边界框的最后一个参数是confidence score因为数据集里是真实框因此为1# 预测到了物体而且就是就是真实框,置信度就是1target[4, x_i, y_i] = 1target[5, x_i, y_i] = delta_xtarget[6, x_i, y_i] = delta_ytarget[7, x_i, y_i] = wtarget[8, x_i, y_i] = htarget[9, x_i, y_i] = 1# 把边界框对应的类在编码中的位置置为1,代表概率是1target[labels[index]+10, x_i, y_i] = 1# print(labels[index])# print("编码结果:", target[:, x_i, y_i])return target
class YoloV1Dataset(Dataset):def __init__(self, path):self.path = path# 从数据集中获取样本# 这个过程耗时很短self.obj_dict_list = pascal_VOC.xml_parse_dict(path)def __getitem__(self, index):# 按照索引获取对应的图片名称self.image_name = self.obj_dict_list[index]["image_name"]# print(self.image_name)# 读取图像img = cv2.imread(os.path.join(self.path, "JPEGImages",self.image_name))# 转换色彩通道img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 按照索引获取边界和对应标号boxes_and_label_list = self.obj_dict_list[index]["boxes"]# print("boxes_and_label_list", boxes_and_label_list)# print(boxes_and_label_list)# 放缩图片同时放缩边界框img, self.boxes = scale_img_with_box(img, [i[0:4] for i in boxes_and_label_list])# print("scale_img_with_box new boxes", self.boxes)self.labels = [i[4] for i in boxes_and_label_list]# self.boxes = [point_to_center(i) for i in self.boxes]# print("point_to_center self.boxes", self.boxes)# print(f"一共有{len(self.boxes)}个边界框")# 通过编码器,编码网络的标签target = yolo_encoder(self.boxes, self.labels, yolo_config)# print(target.shape)# 转换为张量img = transforms.ToTensor()(img)return img, targetdef __len__(self):# 图片的个数return len(self.obj_dict_list)2、构建YoloV1网络
使用Resnet34代替Darknet主干网络。
from torch import nn
from torchvision.models import resnet34, resnet18
import torchfrom torchsummary import summaryfrom yoloconfig import yolo_configclass yoloV1Resnet(nn.Module):def __init__(self):super(yoloV1Resnet, self).__init__()# 使用预训练#resnet = resnet18(pretrained= True)resnet = resnet34(pretrained=True)# print(resnet)# 记录卷积输出的通道数resnet_out_channels = resnet.fc.in_features# 构造网络,去掉resnet34的全连接层self.feature_extractor = nn.Sequential(*list(resnet.children())[:-2])# 以下是YOLOv1的最后四个卷积层self.Conv_layers = nn.Sequential(nn.Conv2d(resnet_out_channels, 1024, 3, padding=1),nn.BatchNorm2d(1024), # 为了加快训练,这里增加了BN层,原论文里YOLOv1是没有的nn.LeakyReLU(),nn.Conv2d(1024, 1024, 3, stride=2, padding=1),nn.BatchNorm2d(1024),nn.LeakyReLU(),nn.Conv2d(1024, 1024, 3, padding=1),nn.BatchNorm2d(1024),nn.LeakyReLU(),nn.Conv2d(1024, 1024, 3, padding=1),nn.BatchNorm2d(1024),nn.LeakyReLU(),)# 以下是YOLOv1的最后2个全连接层self.Conn_layers = nn.Sequential(nn.Linear(7 * 7 * 1024, 4096),nn.LeakyReLU(),nn.Linear(4096, 7 * 7 * 30),nn.Sigmoid() # 增加sigmoid函数是为了将输出全部映射到(0,1)之间,因为如果出现负数或太大的数,后续计算loss会很麻烦)def forward(self, input):input = self.feature_extractor(input)input = self.Conv_layers(input)input = input.view(input.size()[0], -1)input = self.Conn_layers(input)return input.reshape(-1, (5 * yolo_config["num_boxes"] + yolo_config["num_class"]), 7, 7) # 记住最后要reshape一下输出数据if __name__ == "__main__":if __name__ == '__main__':x = torch.randn((1, 3, 448, 448))net = yoloV1Resnet()print(net)y = net(x)print(y.size())
3、训练网络
from torch.utils.data import DataLoader
import torch
from MyLib.nnTools.Trainer import Trainerfrom network import yolo
from dataprocess import dataset
from network import yololossdef train_model():# PATH = r"E:\Postgraduate_Learning\Python_Learning\DataSets\pascal voc2012\VOCtrainval_11-May-2012\VOCdevkit\VOC2012"PATH = r"E:\Postgraduate_Learning\Python_Learning\DataSets\pascal_voc2007\VOCdevkit\VOC2007"# 定义yolo网络yolo_net = yolo.yoloV1Resnet()yolo_net.load_state_dict(torch.load("models/_keyboardInterrupt_.pth"))# 冻结卷积层的参数for layer in yolo_net.children():layer.requires_grad = Falsebreak# 定义数据集yolo_train_dataset = dataset.YoloV1Dataset(PATH)# 定义数据加载器0yolo_train_iter = DataLoader(dataset= yolo_train_dataset, shuffle= True, batch_size= 4)optimer = torch.optim.SGD(yolo_net.parameters(), lr=1e-3, weight_decay= 0.0005)StepLR = torch.optim.lr_scheduler.StepLR(optimer, step_size=7, gamma=0.65)loss = yololoss.yoloV1Loss()trainer = Trainer()trainer.config_trainer(net= yolo_net, dataloader= yolo_train_iter,optimer= optimer, loss= loss, lr_scheduler= StepLR)trainer.config_task(num_epoch= 60)trainer.start_task(True, "./models")if __name__ == "__main__":train_model()
4、推理预测
YoloV1的网络输出还需要进行一步解码才能获取边界框和类别。
def yolo_decoder(pred, class_name_list, yolo_config, confidence_thr= 0.0002, class_thr= 0.5):boxes = []cell_size = yolo_config["input_size"] / yolo_config["num_grid"]# 循环遍历每个批次for batch in range(pred.shape[0]):# 循环遍历x轴for x in range(yolo_config["num_grid"]):# 循环遍历y轴for y in range(yolo_config["num_grid"]):# 得到类别class_name = class_name_list[torch.argmax(pred[batch, 10:, x, y])]print("class predict", torch.max(pred[batch, 10:, x, y]).item())confidence_box1 = pred[batch, 4, x, y]# * torch.max(pred[batch, 10:, x, y])confidence_box2 = pred[batch, 9, x, y]# * torch.max(pred[batch, 10:, x, y])print(f"confidence_box1: {confidence_box1.item()}", f"confidence_box2: {confidence_box2.item()}")# 如果没有物体,跳过if confidence_box1 < confidence_thr or confidence_box2 < confidence_thr:continueif torch.max(pred[batch, 10:, x, y]).item() < class_thr:# print("不符合阈值的box1", pred[batch, 0:5, x, y], "不符合阈值的box1", pred[batch, 6:11, x, y])continue# print(f"有物体存在的网格",x,y)# 判断confidence scores哪个大哪个就是预测器if confidence_box1 >= confidence_box2:box = pred[batch, 0:5, x, y]# print(box)# print(f"解码前结果 box: ", box)box[0] = (box[0] * cell_size + x * cell_size).item()box[1] = (box[1] * cell_size + y * cell_size).item()box[2] = (box[2] * yolo_config["input_size"]).item()box[3] = (box[3] * yolo_config["input_size"]).item()# 转换坐标box_xy = center_to_point(box[0:4])# print(f"解码结果 box: ", box)# print(f"解码结果 class_name: ", class_name)boxes.append((*(box_xy), confidence_box1.item(), class_name))if confidence_box1 < confidence_box2:box = pred[batch, 6:11, x, y]# print(box)# print(f"解码前结果 box: ", box)box[0] = (box[0] * cell_size + x * cell_size).item()box[1] = (box[1] * cell_size + y * cell_size).item()box[2] = (box[2] * yolo_config["input_size"]).item()box[3] = (box[3] * yolo_config["input_size"]).item()# 转换坐标box_xy = center_to_point(box[0:4])# print(f"解码结果 box: ", box)# print(f"解码结果 class_name: ", class_name)boxes.append((*(box_xy), confidence_box2.item(), class_name))# print(box)return boxes
import cv2
import torchimport yoloconfig
from network import yolo
from network.encoder import calculate_iou, yolo_decoder
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
import numpy as npfrom MyLib.imgProcess.draw import cv2_draw_one_boxCOLOR = [(255,0,0),(255,125,0),(255,255,0),(255,0,125),(255,0,250),(255,125,125),(255,125,250),(125,125,0),(0,255,125),(255,0,0),(0,0,255),(125,0,255),(0,125,255),(0,255,255),(125,125,255),(0,255,0),(125,255,125),(255,255,255),(100,100,100),(0,0,0),] # 用来标识20个类别的bbox颜色,可自行设定
CLASS = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog','horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']def calculate_iou_1(box1, box2):# 计算两个边界框的交集面积x_left = max(box1[0], box2[0])y_top = max(box1[1], box2[1])x_right = min(box1[2], box2[2])y_bottom = min(box1[3], box2[3])if x_right < x_left or y_bottom < y_top:return 0.0intersection_area = (x_right - x_left) * (y_bottom - y_top)box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1])box2_area = (box2[2] - box2[0]) * (box2[3] - box2[1])iou = intersection_area / float(box1_area + box2_area - intersection_area)return ioudef nms(boxes, threshold):"""非极大值抑制算法(NMS):param boxes: 包含每个边界框的左上角和右下角坐标、置信度和类别的列表:param threshold: 重叠面积阈值:return: 保留的边界框列表"""if len(boxes) == 0:return []# 分别提取边界框的坐标、置信度和类别信息x1 = np.array([box[0] for box in boxes])y1 = np.array([box[1] for box in boxes])x2 = np.array([box[2] for box in boxes])y2 = np.array([box[3] for box in boxes])scores = np.array([box[4] for box in boxes])areas = (x2 - x1 + 1) * (y2 - y1 + 1)# 根据边界框置信度降序排列order = scores.argsort()[::-1]keep = []while len(order) > 0:i = order[0] # 取出当前置信度最高的边界框keep.append(i)xx1 = np.maximum(x1[i], x1[order[1:]])yy1 = np.maximum(y1[i], y1[order[1:]])xx2 = np.minimum(x2[i], x2[order[1:]])yy2 = np.minimum(y2[i], y2[order[1:]])w = np.maximum(0.0, xx2 - xx1 + 1)h = np.maximum(0.0, yy2 - yy1 + 1)intersection = w * hiou = intersection / (areas[i] + areas[order[1:]] - intersection)inds = np.where(iou <= threshold)[0]order = order[inds + 1]return [boxes[i] for i in keep]if __name__ == '__main__':model = yolo.yoloV1Resnet()# 2023.11.11 定位不准可能是单元格内边界框的置信度误差比较大,导致定位时,定位在了错误的网格# 训练时loss会震荡# 11.12 模型训练loss仍然下不来,可能是数据集太少的原因# 11.13 改小batch继续训练,之前尝试更换主体网络为resnet18不行,减小学习率不行model.load_state_dict(torch.load("models/_keyboardInterrupt_.pth")) # 加载训练好的模型model.eval()model.cuda()img = cv2.imread("./img/000229.jpg")img = cv2.resize(img, (448, 448))inputs = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)inputs = transforms.ToTensor()(inputs)inputs = inputs.to(torch.device("cuda:0"))inputs = torch.unsqueeze(inputs, dim=0)pred = model(inputs) # pred的尺寸是(1,30,7,7)pred = pred.detach().cpu()# pred = pred.squeeze(dim=0) # 压缩为(30,7,7)# pred = pred.permute((1, 2, 0)) # 转换为(7,7,30)print(pred[0, 4, :, :])print(pred[0, 9, :, :])boxes = yolo_decoder(pred, CLASS, yolo_config=yoloconfig.yolo_config, confidence_thr=0.1)print("boxes", boxes)box_boxes = []for i in boxes:if i[3] - i[1] <= 10:continueelse:box_boxes.append(i)# print("nms前", box_boxes)new_boxes = nms(box_boxes, 0.3)# print("nms后", new_boxes)for i in new_boxes:# print(i)cv2_draw_one_box(img, i, (255, 0, 255))cv2.imshow("aa", img)cv2.waitKey(0)相关文章:
pytorch:YOLOV1的pytorch实现
pytorch:YOLOV1的pytorch实现 注:本篇仅为学习记录、学习笔记,请谨慎参考,如果有错误请评论指出。 参考: 动手学习深度学习pytorch版——从零开始实现YOLOv1 目标检测模型YOLO-V1损失函数详解 3.1 YOLO系列理论合集(Y…...

YOLOv8配置文件yolov8.yaml解读
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 位置 该文件的位置位于 ./ultralytics/cfg/models/v8/yolov8.yaml 模型参数配置 # Parameters nc: 80 # number of classes scales: #…...

4-Tornado高并发原理
核心原理就是协程epoll事件循环,再使用协程之后,开销是特别的小,那具体如何提供高并发的呢? 异步非阻塞IO 这意味我们整套开发的模式不在与原来一样,正因为不再一样,所以有时我们在理解代码时就有可能会比…...
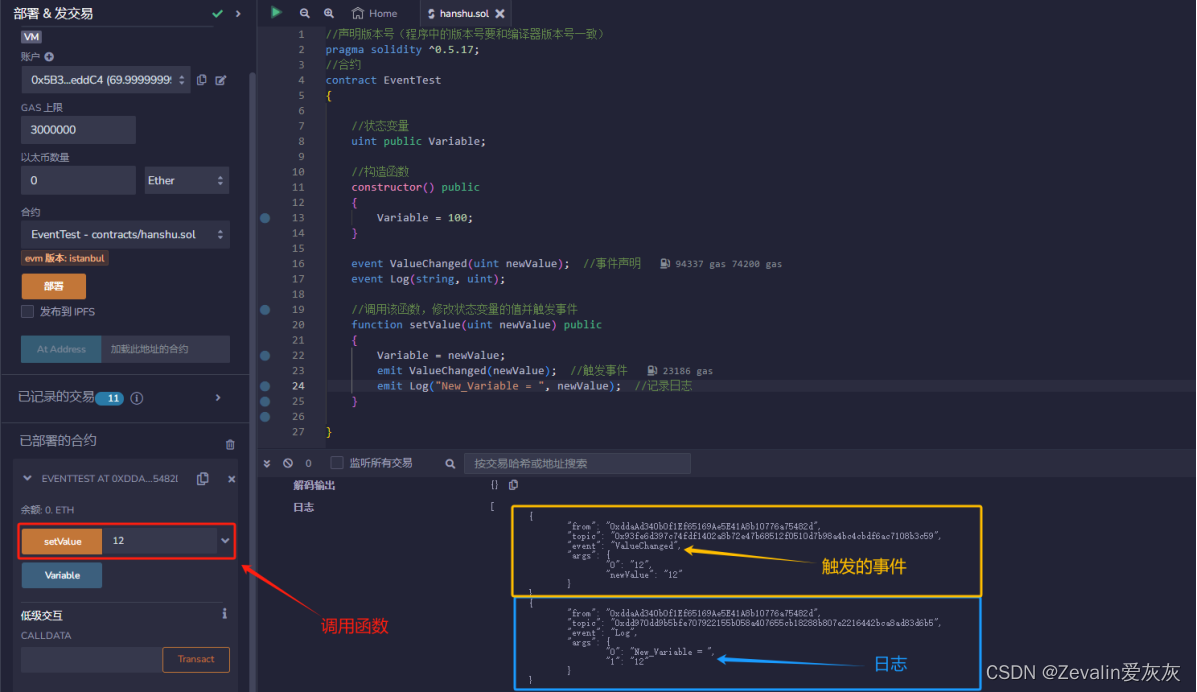
基于以太坊的智能合约开发Solidity(事件日志篇)
//声明版本号(程序中的版本号要和编译器版本号一致) pragma solidity ^0.5.17; //合约 contract EventTest {//状态变量uint public Variable;//构造函数constructor() public{Variable 100;}event ValueChanged(uint newValue); //事件声明event Log(…...
【BME2112】w11 notes
下周做老鼠实验 group analysis SPM group analysis 数据地址resting state 可以分析:correlation 计算两个脑区的相关性 静息态实验简单functional 成功的实验能看到激活区不成功的实验:比如被试头动太大,不是健康的被试 Spontaneous brain…...
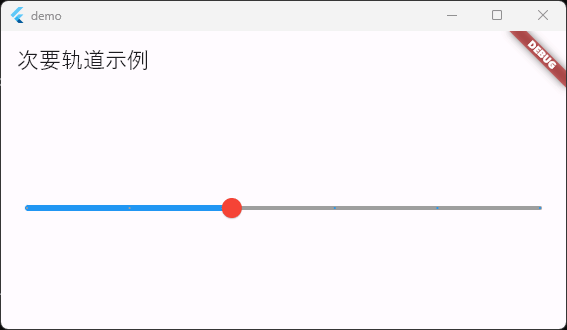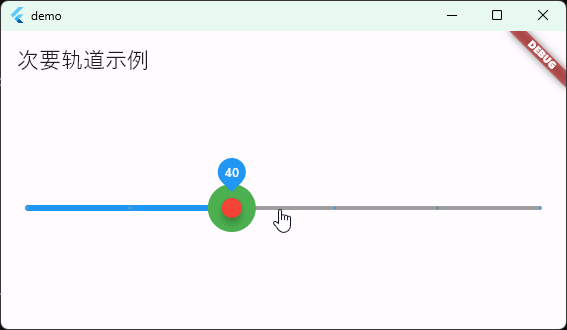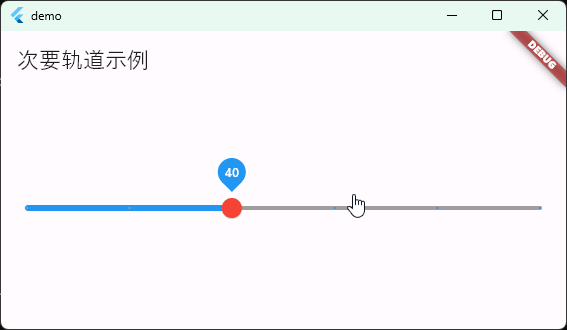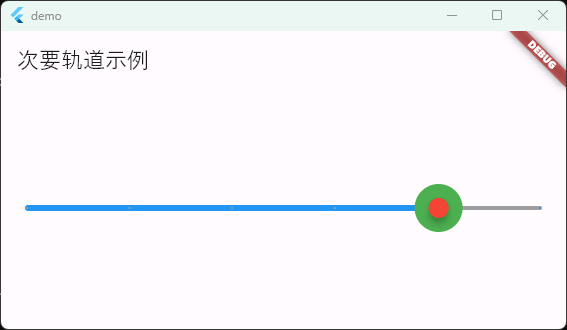
Flutter笔记:滑块及其实现分析1
Flutter笔记 滑块分析1 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/134900784 本文从设计角度&#…...
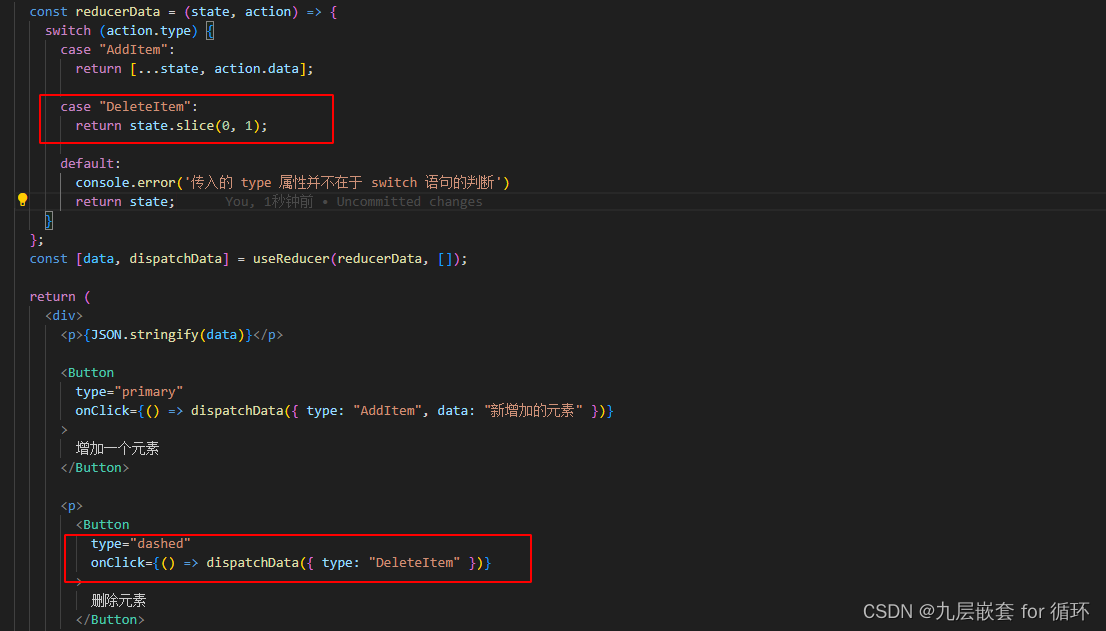
【React Hooks】useReducer()
useReducer 的三个参数是可选的,默认就是initialState,如果在调用的时候传递第三个参数那么他就会改变为你传递的参数,实际开发不建议这样写。会增加代码的不可读性。 使用方法: 必须将 useReducer 的第一个参数(函数…...

如何把kubernetes pod中的文件拷贝到宿主机上或者把宿主机上文件拷贝到kubernetes pod中
1. 创建一个 Kubernetes Pod 首先,下面是一个示例Pod的定义文件(pod.yaml): cat > nginx.yaml << EOF apiVersion: v1 kind: Pod metadata:name: my-nginx spec:containers:- name: nginximage: nginx EOF kubectl app…...
- ACodec(二))
Android 13 - Media框架(20)- ACodec(二)
这一节开始我们就来学习 ACodec 的实现 1、创建 ACodec ACodec 是在 MediaCodec 中创建的,这里先贴出创建部分的代码: mCodec mGetCodecBase(name, owner);if (mCodec NULL) {ALOGE("Getting codec base with name %s (owner%s) failed", n…...
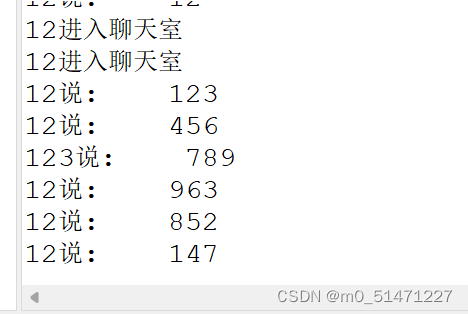
TCP单聊和UDP群聊
TCP协议单聊 服务端: import java.awt.BorderLayout; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.io.PrintWriter; import java.net.ServerSocket; import java.net.Socket; import java.util.V…...

智能优化算法应用:基于鲸鱼算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于鲸鱼算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于鲸鱼算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.鲸鱼算法4.实验参数设定5.算法结果6.参考文献7.MA…...
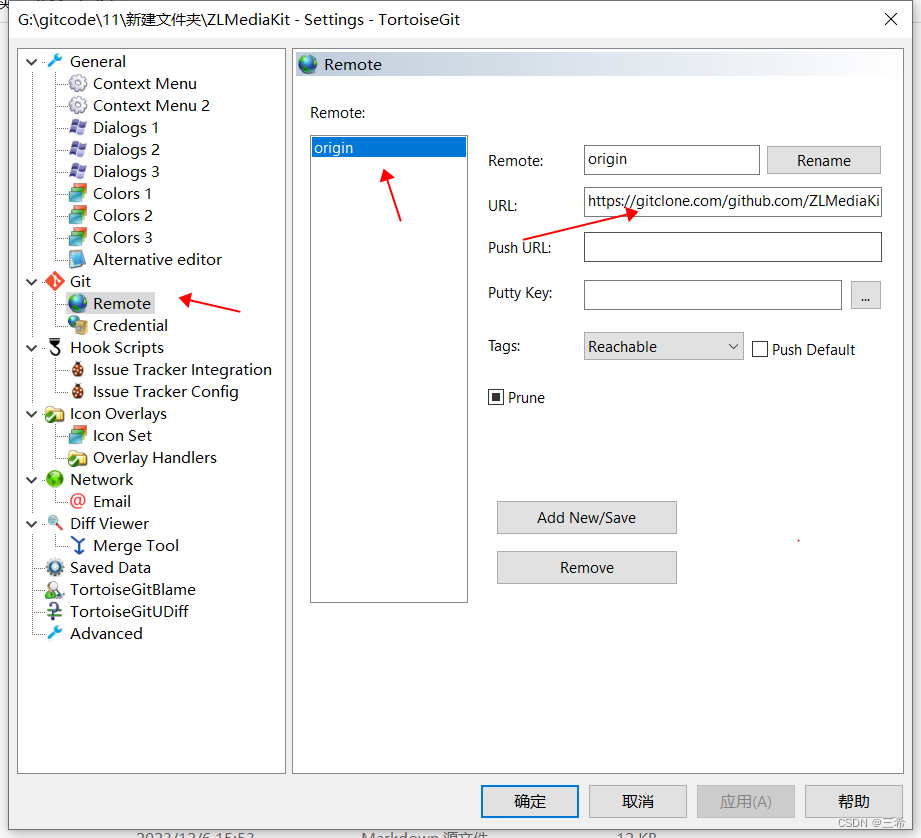
TortoiseGit 小乌龟svn客户端软件查看仓库地址
进入代码路径...

uniapp微信小程序分包,小程序分包
前言,都知道我是一个后端开发、所以今天来写一下uniapp。 起因是美工给我的切图太大,微信小程序不让了,在网上找了一大堆分包的文章,我心思我照着写的啊,怎么就一直报错呢? 错误原因 tabBar的页面被我放在分…...

『Linux升级路』进度条小程序
一、预备知识 在编写『Linux升级路』进度条小程序之前,我们需要了解一些预备知识。本文将详细介绍缓冲区和回车换行的概念。 1.1 缓冲区 缓冲区是计算机内存中的一块区域,用于临时存储数据。在编程中,我们经常使用缓冲区来临时保存数据&am…...
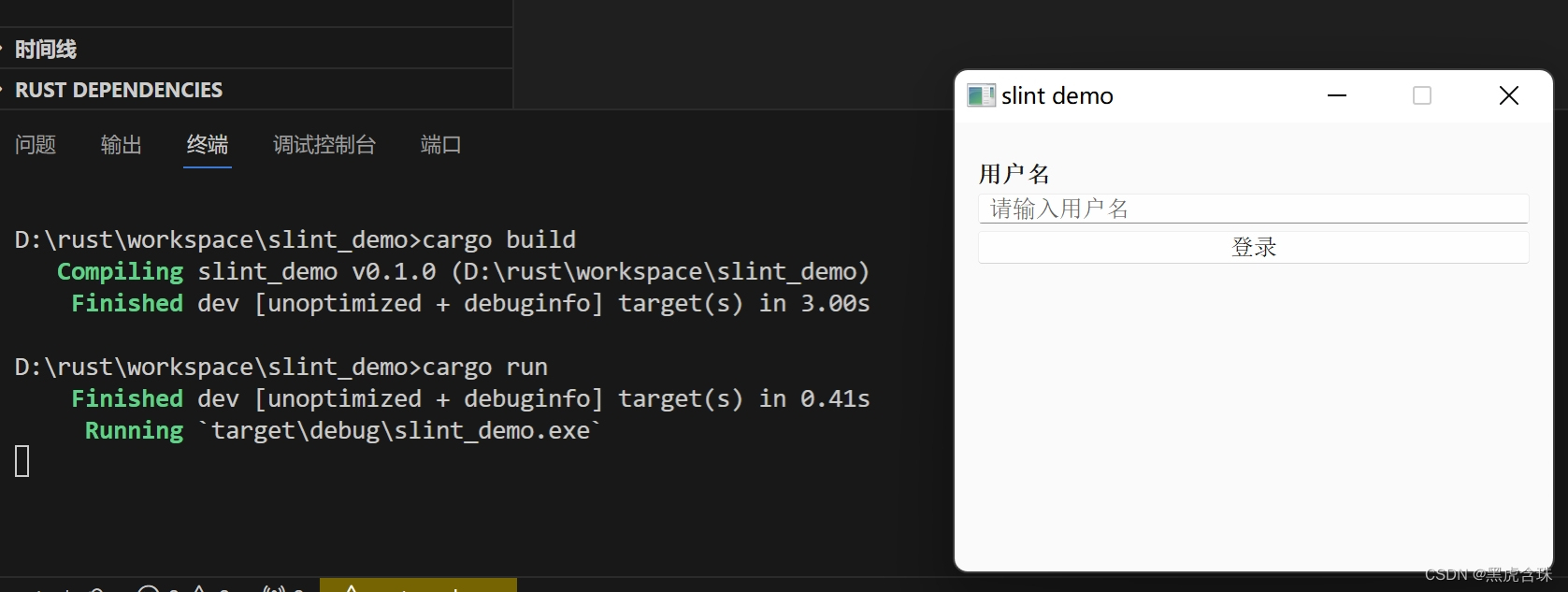
使用rust slint开发桌面应用
安装QT5,过程省略 安装rust,过程省略 创建工程 cargo new slint_demo 在cargo.toml添加依赖 [dependencies] slint "1.1.1" [build-dependencies] slint-build "1.1.1" 创建build.rs fn main() {slint_build::compile(&quo…...
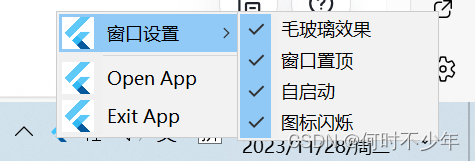
Flutter桌面应用程序定义系统托盘Tray
文章目录 概念实现方案1. tray_manager依赖库支持平台实现步骤 2. system_tray依赖库支持平台实现步骤 3. 两种方案对比4. 注意事项5. 话题拓展 概念 系统托盘:系统托盘是一种用户界面元素,通常出现在操作系统的任务栏或桌面顶部。它是一个水平的狭长区…...
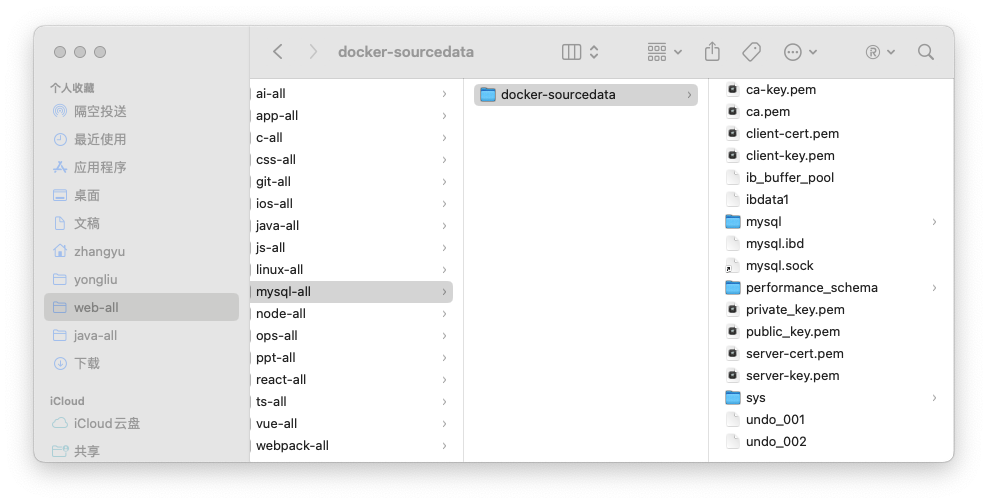
docker:安装mysql以及最佳实践
文章目录 1、拉取镜像2、运行容器3、进入容器方式一方式二方式三容器进入后连接mysql和在宿主机连接mysql的区别 持久化数据持久化数据最佳实践 1、拉取镜像 docker pull mysql2、运行容器 docker run -d -p 3307:3306 --name mysql-container -e MYSQL_ROOT_PASSWORD123456 …...
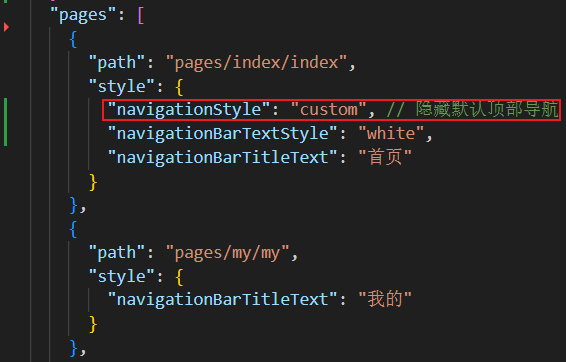
uniapp实战 —— 自定义顶部导航栏
效果预览 下图中的红框区域 范例代码 src\pages.json 配置隐藏默认顶部导航栏 "navigationStyle": "custom", // 隐藏默认顶部导航src\pages\index\components\CustomNavbar.vue 封装自定义顶部导航栏的组件(要点在于:获取屏幕边界…...

中国移动频段划分
1、900MHz(Band8)上行:889-904MHz,下行:934-949MHz,带宽共计15MHz,目前部署:2G/NB-IoT/4G 2、1800MHz(Band3)上行:1710-1735MHz,下行…...

《PySpark大数据分析实战》-01.关于数据
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...