快手数仓面试题附答案
题目
- 1 讲一下你门公司的大数据项目架构?
- 2 你在工作中都负责哪一部分
- 3 spark提交一个程序的整体执行流程
- 4 spark常用算子列几个,6到8个吧
- 5 transformation跟action算子的区别
- 6 map和flatmap算子的区别
- 7 自定义udf,udtf,udaf讲一下这几个函数的区别,编写的时候要继承什么类,实现什么方法
- 8 hive创建一个临时表有哪些方法
- 9 讲一下三范式,三范式解决了什么问题,有什么优缺点
- 10 讲一下维度建模的过程
- 11 维度表有哪几种
- 12 事实表有几种
- 13 什么是维度一致性,总线架构,事实一致性
- 14 什么是缓慢变化维,有哪几种?
- 15 什么是拉链表,如何实现?
- 16 什么是微型维度、支架表,什么时候会用到
- 17 讲几个你工作中常用的spark 或者hive 的参数,以及这些参数做什么用的
- 18 工作中遇到数据倾斜处理过吗?是怎么处理的,针对你刚刚提的方案讲一下具体怎么实现。用代码实现,以及用sql实现。
- 19 讲一下kafka对接flume 有几种方式。
- 20 讲一下spark是如何将一个sql翻译成代码执行的,里面的原理介绍一下?
- 21 spark 程序里面的count distinct 具体是如何执行的
- 22 不想用spark的默认分区,怎么办?(自定义Partitioner 实现里面要求的方法 )具体是哪几个方法?
- 23 有这样一个需求,统计一个用户的已经曝光了某一个页面,想追根溯是从哪几个页面过来的,然后求出在这几个来源所占的比例。你要怎么建模处理?
- 23 说一下你对元数据的理解,哪些数据算是元数据
- 24 有过数据治理的经验吗?
- 25 说一下你门公司的数据是怎么分层处理的,每一层都解决了什么问题
- 26 讲一下星型模型和雪花模型的区别,以及应用场景
答案
1 讲一下你门公司的大数据项目架构?
实时流和离线计算两条线
数仓输入(客户端日志,服务端日志,数据库)
传输过程(flume,kafka)
数仓输出(报表,画像,推荐等)
2 你在工作中都负责哪一部分
离线数据:数仓建模、数据治理、业务开发、稳定性
3 Spark提交一个程序的整体执行流程
包括向yarn申请资源、DAG切割、TaskScheduler、执行task等过程
Spark运行的基本流程:
- 用户在
Driver端提交任务,初始化运行环境(SparkContext等) - Driver根据配置向
ResoureManager申请资源(executors及内存资源) - ResoureManager资源管理器选择合适的
worker节点创建executor进程 Executor向Driver注册,并等待其分配task任务- Driver端完成
SparkContext初始化,创建DAG,分配taskset到Executor上执行。 - Executor启动线程执行task任务,返回结果。
Spark On Yarn的基本流程:
- Spark
Driver端提交程序,并向Yarn申请Application - Yarn接受请求响应,在NodeManager节点上创建AppMaster
AppMaster向Yarn ResourceManager申请资源(Container)- 选择合适的节点创建
Container(Executor进程) - 后续的Driver启动调度,运行任务
Yarn Client、Yarn Cluster模式在某些环节会有差异,但是基本流程类似。
参考:十分钟彻底弄懂Spark内存管理机制 - 掘金
Spark作业基本运行原理
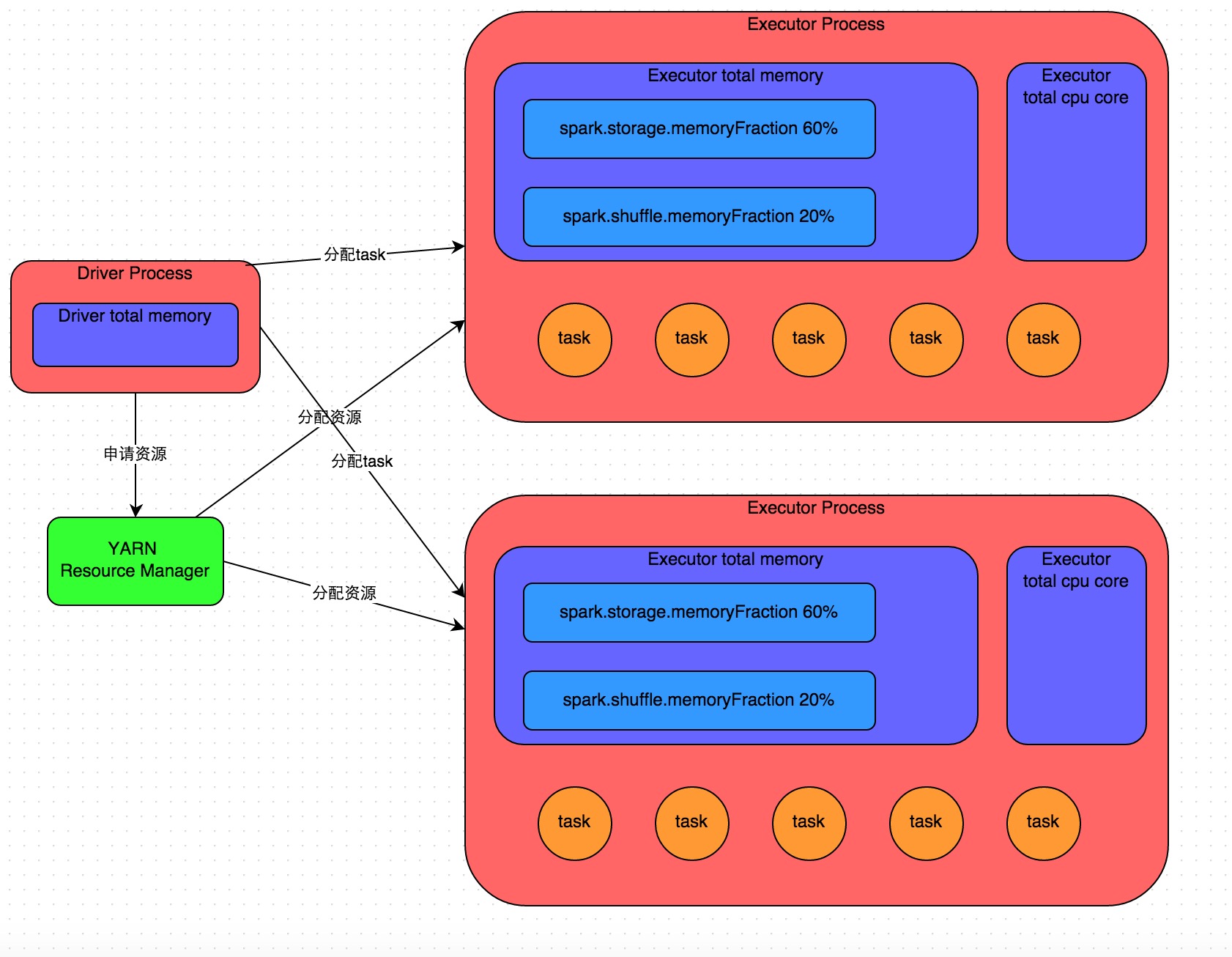
详细原理见上图。我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群,美团•大众点评使用的是YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
因此Executor的内存主要分为三块:第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;第三块是让RDD持久化时使用,默认占Executor总内存的60%。
task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
以上就是Spark作业的基本运行原理的说明,大家可以结合上图来理解。理解作业基本原理,是我们进行资源参数调优的基本前提。
参考:Spark性能优化指南——基础篇 - 美团技术团队
4 Spark常用算子列几个,6到8个吧
常用的RDD转换算子:
- filter(func) 筛选出满足函数func的元素,并返回一个新的数据集
- map(func) 将每个元素传递到函数func中,并将结果返回为一个新的数据集
- flatMap(func) 与map()相似,但每个输入元素都可以映射到0或多个输出结果
- groupByKey() 应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集
- reduceByKey(func) 应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中每个值是将每个key传递到函数func中进行聚合后的结果
行动操作常用算子:
- count() 返回数据集中的元素个数
- collect() 以数组的形式返回数据集中的所有元素
- first() 返回数据集中的第一个元素
- take(n) 以数组的形式返回数据集中的前n个元素
- reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
- foreach(func) 将数据集中的每个元素传递到函数func中运行
5 transformation跟action算子的区别
所有的transformation都是采用的懒策略,就是如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发。
- Transformation 变换/转换:这种变换并不触发提交作业,完成作业中间过程处理。Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
- Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业。
Action 算子会触发 Spark 提交作业(Job)。
transformation操作:
- map(func):对调用map的RDD数据集中的每个element都使用func,然后返回一个新的RDD,这个返回的数据集是分布式的数据集
- filter(func): 对调用filter的RDD数据集中的每个元素都使用func,然后返回一个包含使func为true的元素构成的RDD
- flatMap(func):和map差不多,但是flatMap生成的是多个结果
- mapPartitions(func):和map很像,但是map是每个element,而mapPartitions是每个partition
- mapPartitionsWithSplit(func):和mapPartitions很像,但是func作用的是其中一个split上,所以func中应该有index
- sample(withReplacement,faction,seed):抽样
- union(otherDataset):返回一个新的dataset,包含源dataset和给定dataset的元素的集合
- distinct([numTasks]):返回一个新的dataset,这个dataset含有的是源dataset中的distinct的element
- groupByKey(numTasks):返回(K,Seq[V]),也就是hadoop中reduce函数接受的key-valuelist
- reduceByKey(func,[numTasks]):就是用一个给定的reducefunc再作用在groupByKey产生的(K,Seq[V]),比如求和,求平均数
- sortByKey([ascending],[numTasks]):按照key来进行排序,是升序还是降序,ascending是boolean类型
- join(otherDataset,[numTasks]):当有两个KV的dataset(K,V)和(K,W),返回的是(K,(V,W))的dataset,numTasks为并发的任务数
- cogroup(otherDataset,[numTasks]):当有两个KV的dataset(K,V)和(K,W),返回的是(K,Seq[V],Seq[W])的dataset,numTasks为并发的任务数
- cartesian(otherDataset):笛卡尔积就是m*n,大家懂的
action操作:
- reduce(func):说白了就是聚集,但是传入的函数是两个参数输入返回一个值,这个函数必须是满足交换律和结合律的
- collect():一般在filter或者足够小的结果的时候,再用collect封装返回一个数组
- count():返回的是dataset中的element的个数
- first():返回的是dataset中的第一个元素
- take(n):返回前n个elements,这个士driverprogram返回的
- takeSample(withReplacement,num,seed):抽样返回一个dataset中的num个元素,随机种子seed
- saveAsTextFile(path):把dataset写到一个textfile中,或者hdfs,或者hdfs支持的文件系统中,spark把每条记录都转换为一行记录,然后写到file中
- saveAsSequenceFile(path):只能用在key-value对上,然后生成SequenceFile写到本地或者hadoop文件系统
- countByKey():返回的是key对应的个数的一个map,作用于一个RDD
- foreach(func):对dataset中的每个元素都使用func
参考:Spark常用算子详解_spark算子-CSDN博客
6 map和flatMap算子的区别
- map:执行完map后会得到一个新的分布式数据集,数据集中每个元素是之前的RDD映射得来的,与之前RDD每个元素存在一一对应的关系。
- flatmap:而flatmap有一点不同,每个输入的元素可以被映射为0个或者多个输出的元素,原RDD与新RDD的元素是一对多的关系。当然光看定义比较抽象,下面用一个图说明,
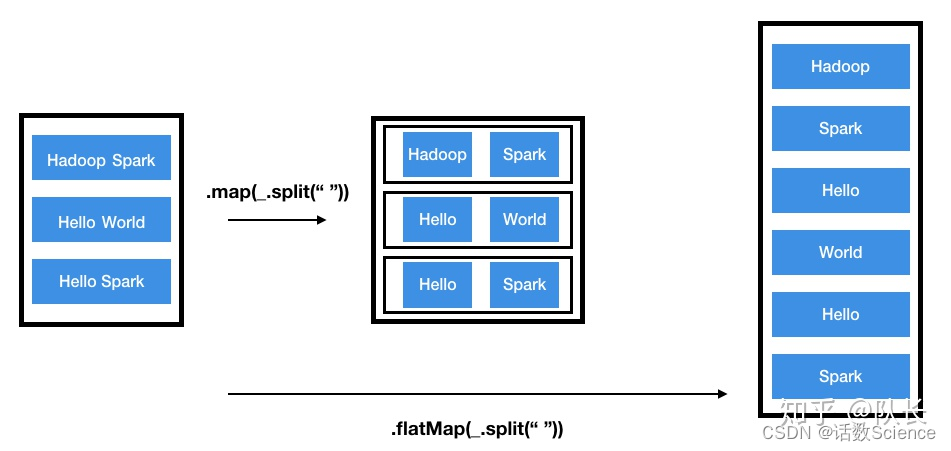
参考:Spark之Map VS FlatMap - 知乎
7 自定义udf,udtf,udaf讲一下这几个函数的区别,编写的时候要继承什么类,实现什么方法
区别:
- UDF:输入一行,输出一行
UDF:用户定义(普通)函数,只对单行数值产生作用; - UDTF:输入一行,输出多行,类似explode函数
UDTF:User-Defined Table-Generating Functions,用户定义表生成函数,用来解决输入一行输出多行; - UDAF:输入多行,输出一行,类似聚合函数
UDAF:User- Defined Aggregation Funcation;用户定义聚合函数,可对多行数据产生作用;等同与SQL中常用的SUM(),AVG(),也是聚合函数;
Hive实现:
| 类型 | 类 | 方法 |
| UDF | 类: GenericUDF
| initialize:类型检查,返回结果类型 evaluate:功能逻辑实现 入参:DeferredObject[] 出参:Object 出参:String close:关闭函数,释放资源等 出参:void |
| UDTF | 类: 包路径: | initialize:类型检查,返回结果类型 process:功能逻辑实现 入参:Object[] 出参:void 出参:void |
| UDAF | 类: 类:
AbstractAggregationBuffer | -----AbstractGenericUDAFResolver----- getEvaluator:获取计算器 ---------GenericUDAFEvaluator---------- init: getNewAggregationBuffer: 入参:无 出参:AggregationBuffer reset: 入参:AggregationBuffer 出参:void 入参:AggregationBuffer,Object[] 出参:void merge: 入参:AggregationBuffer,Object 出参:void
入参:AggregationBuffer 出参:Object 入参:AggregationBuffer 出参:Object --------AbstractAggregationBuffer------- 入参:无 出参:int |
UDAF说明
- 一个Buffer作为中间处理数据的缓冲:获取getNewAggregationBuffer、重置reset
- 四个阶段(Mode):
- PARTIAL1(Map阶段):
from original data to partial aggregation data:
iterate() and terminatePartial() will be called. - PARTIAL2(Map的Combiner阶段):
from partial aggregation data to partial aggregation data:
merge() and terminatePartial() will be called. - FINAL(Reduce 阶段):
from partial aggregation to full aggregation:
merge() and terminate() will be called. - COMPLETE(Map Only阶段):
from original data directly to full aggregation:
iterate() and terminate() will be called.
- PARTIAL1(Map阶段):
- 五个方法:
- 初始化init
- 遍历iterate:PARTIAL1和COMPLETE阶段
- 合并merge:PARTIAL2和FINAL阶段
- 终止terminatePartial:PARTIAL1和PARTIAL2阶段
- terminate:COMPLETE和FINAL阶段
Spark实现:
参考:Spark - 自定义函数(UDF、UDAF、UDTF) - 知乎
8 hive创建一个临时表有哪些方法
WITH创建临时表
如果这个临时表并不需要保存,并且下文只需要用有限的几次,我们可以采用下面的方法。
with as 也叫做子查询部分,首先定义一个sql片段,该sql片段会被整个sql语句所用到,为了让sql语句的可读性更高些,作为提供数据的部分,也常常用在union等集合操作中。
with as就类似于一个视图或临时表,可以用来存储一部分的sql语句作为别名,不同的是with as 属于一次性的,而且必须要和其他sql一起使用才可以!
其最大的好处就是适当的提高代码可读性,而且如果with子句在后面要多次使用到,这可以大大的简化SQL;更重要的是:一次分析,多次使用,这也是为什么会提供性能的地方,达到了“少读”的目标。
WITH t1 AS (SELECT *FROM a), t2 AS (SELECT *FROM b)
SELECT *
FROM t1
JOIN t2
;注意:
- 这里必须要整体作为一条sql查询,即with as语句后不能加分号,不然会报错。
- with子句必须在引用的select语句之前定义,同级with关键字只能使用一次,多个只能用逗号分割
- 如果定义了with子句,但其后没有跟select查询,则会报错!
- 前面的with子句定义的查询在后面的with子句中可以使用。但是一个with子句内部不能嵌套with子句!
Temporary创建临时表
create temporary table 临时表表名 as
select * from 表名- 创建的临时表仅仅在当前会话可见,数据会被暂存到hdfs上,退出当前会话表和数据将会被删除。数据将存储在用户的scratch目录中,并在会话结束时删除。
-
从Hive1.1开始临时表可以存储在内存或SSD,使用hive.exec.temporary.table.storage参数进行配置,该参数有三种取值:memory、ssd、default。
如果内存足够大,将中间数据一直存储在内存,可以大大提升计算性能。 - 如果临时表的命名的表名和hive的表名一样,当前会话则会查询临时表的数据,用户在这个会话内将不能使用原表,除非删除或者重命名临时表
- 临时表不支持分区字段,不支持创建索引。
参考:大数据开发之Hive篇7-Hive临时表 - 知乎
9 讲一下三范式,三范式解决了什么问题,有什么优缺点
三范式:
- 第一范式:列的原子性,字段值不可再分,比如某个字段的取值是姓名+手机号,那就要把姓名和手机号分成两个字段
- 第二范式:第一范式的基础上,非主键列不能依赖主键的一部分,例如字段a和字段b组成的主键,某个字段只依赖a,就需要把这个字段剥离到a对应的表
- 第三范式:第二范式的基础上,非主键列不能传递依赖主键,例如字段c依赖字段b,字段b依赖主键字段a,那么就可以把这个字段c剥离到字段b为主键的表
三范式是要解决字段冗余,节省存储空间,数据维护更方便,不需要多处更新同样的字段;
缺点是不方便查询,要进行多表join效率低,不适合分析类的查询。
范式化设计的优点:可以减少数据冗余,数据表体积小更新快,范式化的更新操作比 反范式化更快,范式化的表通常比反范式化更小。
缺点:对于查询需要对多个表,会关联多个表,在应用中,进行表关联的成本是很高
更难进行索引优化
反范式化设计的优点:可以减少表的关联,可以对查询更好的进行索引优化,
缺点:表结构存在数据冗余和数据维护异常,对数据的修改需要更多资源。因此在设计数据库结构的时候要将反范式化和范式化结合起来
参考:你了解数据库三大范式吗?用来解决什么问题?_数据库三范式解决了什么问题_我是等闲之辈的博客-CSDN博客mysql--数据库优化的目的、数据库设计的步骤以及什么是三范式、三范式的优缺点-CSDN博客
10 讲一下维度建模的过程
四个步骤:①选择业务过程 ②确定粒度 ③确定维度 ④确定事实表
维度模型是数据仓库领域的 Ralph Kimball 大师所倡导的,他的The Data Warehouse Toolkit-The Complete Guide to Dimensional Modeling 是数据仓库工程领域最流行的数据仓库建模的经典。
维度建模从分析决策的需求出发构建模型,为分析需求服务,因此它重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复杂查询的响应性能。其典型的代表是星形模型,以及在一些特殊场景下使用的雪花模型。其设计分为以下几个步骤。
第一步:选择业务过程
选择需要进行分析决策的业务过程。业务过程可以是单个业务事 件,比如交易的支付、退款等;也可以是某个事件的状态,比如 当前的账户余额等;还可以是一系列相关业务事件组成的业务流 程,具体需要看我们分析的是某些事件发生情况,还是当前状态, 或是事件流转效率。
第二步:确定粒度
选择粒度。在事件分析中,我们要预判所有分析需要细分的程度,从而决定选择的粒度。粒度是维度的一个组合。
第三步:确定维度
识别维表。选择好粒度之后,就需要基于此粒度设计维表,包括维度属性,用于分析时进行分组和筛选。
第四步:确定事实
选择事实。确定分析需要衡量的指标 。
参考:【总结】维度数据建模过程及举例-腾讯云开发者社区-腾讯云
11 维度表有哪几种
- 按是否规范化设计划分,分符合三范式的维表,和反规范化的维表,对应雪花模型和星型模型
- 按是否包含属性层次结构分,分包含层次结构的维表,和不包含层次结构的维表,如行业维表就是包含层次结构的维表,递归层次一般采用①扁平化、②层次桥接表两种方式设计
- 按水平拆分(基于业务类型)可以划分为,主维表(存放公共属性),子维度表(包含公共属性和特有属性)
- 按垂直拆分(基于性能)可以划分为:主维表(存放使用频率高的属性),扩展维表(存放使用频率低的属性)
- 按是否归档处理分为:历史维度表,普通表
- 按缓慢变化维划分:一种是使用代理键的就是Kimball中的8种类型的缓慢变化维度,如果不使用代理键则划分快照维表、采用极限存储的维度表
- 一些特殊维度类型:支架维度、杂项维度、行为维度(事实衍生维度,如买家常用地址)、多值维度
参考:数据仓库系列4-维度表 - 知乎
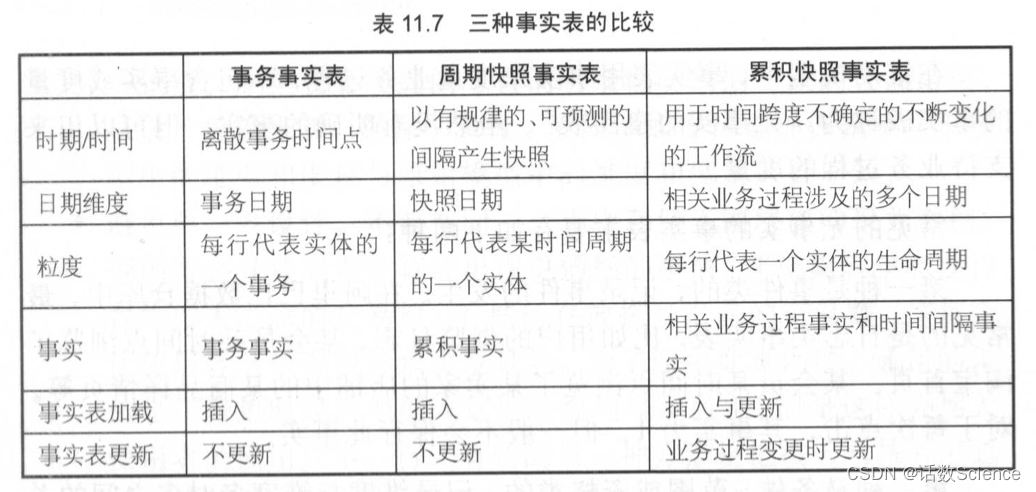
12 事实表有几种
- 事务性事实表:又分为单事务事实表,多事务事实表
- 周期快照事实表:又分为单维度的每天快照事实表,混合维度的每天快照事实表,全量快照事实表
- 累计快照事实表
13 什么是维度一致性,总线架构,事实一致性
维度建模的数据仓库中,有一个概念叫Conformed Dimension,中文一般翻译为“一致性维度”。一致性维度是Kimball的多维体系结构中的三个关键性概念之一,另两个是总线架构(Bus Architecture)和一致性事实(Conformed Fact)。
总线架构:初期进行需求沟通和整体设计的产物,汇总一致性维度和业务过程的表格
一致性维度:维度定义和维表实现的同一性
一致性事实:指标定义(包括单位)和实现的一致性
总线矩阵:业务过程和维度的交点;
一致性维度:同一集市的维度表,内容相同或包含;
一致性事实:不同集市的同一事实,需保证口径一致,单位统一。
参考:一篇文章搞懂数据仓库:总线架构、一致性维度、一致性事实-阿里云开发者社区
14 什么是缓慢变化维,有哪几种?
缓慢变化维,SCD(Slowly Changing Dimensions),数仓的特点之一就是反映历史变化,与增长较快的事实表相比,维度变化相对缓慢。Kimball整理的处理方法一共有8种,但往往只有3种比较常用(类型1、类型2、类型3)。
- 类型0:属性值不可能变,保留原样。
- 类型1:重写,覆盖原值,类型1不能反映历史。
- 类型2:新增一行,并生成新的代理键,事实表旧的记录使用旧的代理键,新的记录使用新的代理键,同时维表增加创建时间和截止时间来标识最新有效的记录和历史记录,新的记录有效期可以设置一个极大值,如9999.12.31,类型2的缺点是旧的记录只能用旧的维度分析,新的记录只能用新的维度进行分析。
- 类型3:类型1只能满足新维度分析的需求,类型2既不能满足新维度分析的需求,也不能满足旧维度分析的需求,如果要同时满足新旧两种维度分析的需求,可以考虑使用类型3。类型3是通过两个字段分别存储新旧值来满足这种两种同时都要的需求的,但是类型3的问题在,如果只变化一次还行,但如果变化第2次、第3次,就需要增加新的字段,会比较麻烦。
- 类型4:微型维度。解决的是高频变更导致的记录过多的问题,剥离高频变化的维度,如果是数值可以用范围值来减少数量,有多个高频变化的维度,就用这些维度的笛卡尔积来组合成维表,可以用组合缩写来生成代理键(注意微型维度没有自然键)。另外如果需要记录精确值,可以考虑无事实的事实表。需要注意的是,类型4只能在事实表中出现,如果维度表和微型维度发生的关联,那就是类型5。
- 类型5:类型1+微型维度。主维表通过类型1关联微信维度,反映最新值,微型维度与事实表进行关联,通过事实表来反映历史变化。
- 类型6:类型1+类型2+类型3。通过类型3构建新旧两列,同一个自然键的通过类型1更新为最新值,通过类型2处理历史变化。类型6的缺点是如果这种列很多,150个列,那就要翻倍来存300个列,这是可以考虑类型7。
- 类型7:双类型1+类型2。用类型2生成主维表,同时生成一个最新值的视图(取9999.12.31),事实表中存放两个外键或者单个外键连关联这两张维表。代理键可以反映当时的变化,自然键(超自然键)可以反映当前最新值。双重外键一个键存放主维表的代理键反映当时的情况,一个键存放最新视图的自然键(最好是超自然键)反映最新情况。单外键存的是主维表的代理键,视图里存当时的代理键和最新的代理键。
参考:深入解析缓慢变化维 - 知乎
15 什么是拉链表,如何实现?
拉链表
- 主要是为了记录历史变化,并节省存储空间。适合大数据量场景下,变化频率又不高的情况。如果每天存储全量表,很多都是重复的记录,造成浪费。
- 可以应用在维表也可以应用在事实表。比如某个员工维表为了反映部门历史变动,订单事实表为了反映订单状态的历史变化(未支付、已支付、已发货、已完成)。
实现过程
有些业务系统的表,不保存变更流水记录的,只保存最新的值,比如订单表,只保留订单的最新状态。如果要反映历史变化,需要跟进binlog日志或者定时采集来记录变化。具体实现步骤:
- 第一步:创建并初始化拉链表(执行一次)
- 第二步:合并当日新增和修改的数据到临时表(每天执行一次)
每日变更的记录uion all拉链表的记录,注意要修改历史记录的有效日期。 - 第三步:把临时表覆盖写入拉链表(每天执行一次)
进阶问题
拉链表如何回滚?参考:https://www.cnblogs.com/lxbmaomao/p/9821128.html
极限存储怎么实现?参考:拉链表-极限存储-CSDN博客
参考:
拉链表的详细实现过程(好文点赞收藏!!)_拉链表的实现过程_KG大数据的博客-CSDN博客
https://www.cnblogs.com/lxbmaomao/p/9821128.html
16 什么是微型维度、支架表,什么时候会用到
- 微型维度:缓慢变化维度类型4,参考第14题
- 支架表:
- 是一种受限的雪花维度,是星型模型和雪花模型之间的一种折中,如日期维度表、地址维度表
- 使用场景:当一个属性集合(例如日期、地点)在某个维度或多个维度表中反复出现时,就可以考虑使用支架表。
- 使用条件:
①在单个维度表中反复出现该支架属性时
②被调用的属性值较多时
③被多个维度、事实表调用,且被调用时的属性值定义完全相同
④基本不需要修改或修改频次极小
参考:
深入解析缓慢变化维 - 知乎
深入解析支架表 - 知乎
17 讲几个你工作中常用的spark 或者hive 的参数,以及这些参数做什么用的
hive参数
----------------------小文件合并----------------------
----------map输入端合并-----------
## Map端输入、合并文件之后按照block的大小分割(默认)
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
## Map端输入,不合并
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
------------输出端合并------------
## 是否合并Map输出文件, 默认值为true
set hive.merge.mapfiles=true;
## 是否合并Reduce端输出文件,默认值为false
set hive.merge.mapredfiles=true;
## 合并文件的大小,默认值为256000000 256M
set hive.merge.size.per.task=256000000;
## 每个Map 最大分割大小
set mapred.max.split.size=256000000;
## 一个节点上split的最少值
set mapred.min.split.size.per.node=1; // 服务器节点
## 一个机架上split的最少值
set mapred.min.split.size.per.rack=1; // 服务器机架
hive.merge.size.per.task 和 mapred.min.split.size.per.node 联合起来:##1、默认情况先把这个节点上的所有数据进行合并,如果合并的那个文件的大小超过了256M就开启另外一个文件继续合并
##2、如果当前这个节点上的数据不足256M,那么就都合并成一个逻辑切片。----------------------Map Task并行度----------------------
## 切片大小计算公式: long splitSize = Math.max(minSize, Math.min(maxSize, blockSize))
## dfs.blocksize:128MB split.minsize:1 split.maxsize:256MBset mapreduce.input.fileinputformat.split.minsize=1
set mapreduce.input.fileinputformat.split.maxsize=256000000## 输入文件总大小:total_size
## HDFS 设置的数据块大小:dfs_block_size
## default_mapper_num = total_size / dfs_block_size
## mapred.map.tasks这个参数设置只有在大于 default_mapper_num 的时候,才会生效
set mapred.map.tasks=10; ## 默认值是2## map task计算公式:
## split_size = max(mapred.min.split.size, dfs_block_size)
## split_num = total_size / split_size
## compute_map_num = Math.min(split_num, Math.max(default_mapper_num,
## mapred.map.tasks))## 总结:
## 1、如果想增加 MapTask 个数,可以设置 mapred.map.tasks 为一个较大的值
## 2、如果想减少 MapTask 个数,可以设置 maperd.min.split.size 为一个较大的值
## 3、如果输入是大量小文件,想减少 mapper 个数,可以通过设置 hive.input.format 合并小文----------------------Reduce Task并行度----------------------
## 参数1:hive.exec.reducers.bytes.per.reducer (默认256M)
## 参数2:hive.exec.reducers.max (默认为1009)
## 参数3:mapreduce.job.reduces (默认值为-1,表示没有设置,那么就按照以上两个参数进行设置)
## ReduceTask 的计算公式为:
## N = Math.min(参数2,总输入数据大小 / 参数1)----------------------Join 优化----------------------
----------开启map join-----------
## 是否根据输入小表的大小,自动将reduce端的common join 转化为map join,将小表刷入内存中。
## 对应逻辑优化器是MapJoinProcessor
set hive.auto.convert.join = true;
## 刷入内存表的大小(字节)
set hive.mapjoin.smalltable.filesize = 25000000;
## hive会基于表的size自动的将普通join转换成mapjoin
set hive.auto.convert.join.noconditionaltask=true;
## 多大的表可以自动触发放到内层LocalTask中,默认大小10M
set hive.auto.convert.join.noconditionaltask.size=10000000;----------开启bucket map join & SMB map join-----------
## 当用户执行bucket map join的时候,发现不能执行时,禁止查询
set hive.enforce.sortmergebucketmapjoin=false;
## 如果join的表通过sort merge join的条件,join是否会自动转换为sort merge join
set hive.auto.convert.sortmerge.join=true;
## 当两个分桶表 join 时,如果 join on的是分桶字段,小表的分桶数是大表的倍数时,可以启用
mapjoin 来提高效率。
# bucket map join优化,默认值是 false
set hive.optimize.bucketmapjoin=false;
## bucket map join 优化,默认值是 false
set hive.optimize.bucketmapjoin.sortedmerge=false;------------------数据倾斜优化-------------------
---------Map端聚合----------
## 开启Map端聚合参数设置
set hive.map.aggr=true;
# 设置map端预聚合的行数阈值,超过该值就会分拆job,默认值100000
set hive.groupby.mapaggr.checkinterval=100000
# 自动优化,有数据倾斜的时候进行负载均衡(默认是false) 如果开启设置为true
set hive.groupby.skewindata=false;
## 1、在第一个 MapReduce 任务中,map 的输出结果会随机分布到 reduce 中,每个 reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的`group by key`有可能分发到不同的 reduce 中,从而达到负载均衡的目的;
## 2、第二个 MapReduce 任务再根据预处理的数据结果按照 group by key 分布到各个 reduce 中,最后完成最终的聚合操作。---------join优化----------
# join的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.skewjoin.key=100000;
# 如果是join过程出现倾斜应该设置为true
set hive.optimize.skewjoin=false;------------------使用 vectorization 矢量查询技术-------------------
set hive.vectorized.execution.enabled=true ;
set hive.vectorized.execution.reduce.enabled=true;---------------本地执行优化------------------
## 打开hive自动判断是否启动本地模式的开关
set hive.exec.mode.local.auto=true;
## map任务数最大值,不启用本地模式的task最大个数
set hive.exec.mode.local.auto.input.files.max=4;
## map输入文件最大大小,不启动本地模式的最大输入文件大小
set hive.exec.mode.local.auto.inputbytes.max=134217728;---------------并行执行---------------
## 可以开启并行执行。
set hive.exec.parallel=true;
## 同一个sql允许最大并行度,默认为8。
set hive.exec.parallel.thread.number=16;---------------严格模式---------------
## 设置Hive的严格模式
set hive.mapred.mode=strict;
set hive.exec.dynamic.partition.mode=nostrict;
Spark参数
Spark提交任务参数设置
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 4g --classcom.abc.sparktuning.utils.InitUtil spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar指定集群模式和部署模式:
spark-submit中通过--master参数指定集群的资源管理器(也可以在代码中硬编码指定master),通过--deploy-mode参数指定以client模式运行还是以cluster模式运行。
master常用参数有local(Driver和Executor运行在同一个节点的同一个JVM中)、Spark Standalone集群(Spark自带的简易资源管理器,分Master节点和Worker节点)、mesos、yarn、k8s。
部署模式,client和cluster两种,client模式是Driver进程在提交任务的节点运行,cluster模式是Driver进程在Woker节点中运行Driver进程。
资源参数设置举例:
Executor内存设置:以单台服务器 128G 内存,32 核为例,考虑到系统基础服务和 HDFS 等组件的余量,yarn.nodemanager.resource.cpu-vcores 配置为:28核,每个 executor 的最大核数。根据经验实践,设定在 3~6 之间比较合理。这里设置为4,那么每个Yarn节点,可以同时跑28 / 4 = 7个executor。假设集群节点为 10,那么 num-executors = 7 * 10 = 70,所以num-executors是70,executor-cores是4
如果 yarn-nodemanager.resource.memory-mb=100G,那么每个 Executor 大概就是 100G/7≈14G,同时加上堆外内存要不大于 yarn.scheduler.maxinum-allocation-mb 容器最大内存设置,因为executor-memory指定的是堆内内存,除了堆内内存,还有堆外内存。
Driver内存设置:Yarn Client 和 Cluster 两种方式提交,Executor和Driver的内存分配情况也是不同的。Yarn中的ApplicationMaster都启用一个Container来运行;
Client模式下的Container默认有1G内存,1个cpu核,Cluster模式的配置则由driver-memory和driver-cpu来指定,也就是说Client模式下的driver是默认的内存值;Cluster模式下的dirver则是自定义的配置。
设置Kryo序列化降低RDD缓存磁盘占用
new SparkConf().set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
...
result.persist(StorageLevel.MEMORY_ONLY_SER)并行度参数设置
SparkConf conf = new SparkConf()
conf.set("spark.default.parallelism", "500")注意:
spark.default.parallelism只有在处理RDD时才会起作用,对Spark SQL的无效。
spark.sql.shuffle.partitions则是对Spark SQL专用的设置
我们也可以在提交作业的通过 --conf 来修改这两个设置的值,方法如下:
spark-submit --conf spark.sql.shuffle.partitions=500 --conf spark.default.parallelism=500
spark.default.parallelism:用户配置同一的并行度(统一性)
reduceByKey(1000)类shuffle算子:具体任务中可以特定配置的并行度。(特定性)
两者优先级:算子类传入的并行度 > 同一设置的并行度。
spark.sql.shuffle.partitions对sparksql中的joins和aggregations有效,但其他的无效,针对这种情况可以采用repartition算子对dataframe进行重分区
如果想要让任务运行的最快当然是一个 task 对应一个 vcore,但 是一般不会这样设置,为了合理利用资源,一般会将并行度(task 数)设置成并发度 (vcore数)的2倍到3倍。
设置2~3倍的具体原因参考如下:
因为实际情况,与理想情况不同的,有些task会运行的快一点,比如50s就完了,有些task,可能会慢一点,要1分半才运行完,所以如果你的task数量,刚好设置的跟cpu core数量相同,可能还是会导致资源的浪费,因为,比如150个task,10个先运行完了,剩余140个还在运行,但是这个时候,有10个cpu core就空闲出来了,就导致了浪费。那如果task数量设置成cpu core总数的2~3倍,那么一个task运行完了以后,另一个task马上可以补上来,就尽量让cpu core不要空闲,同时也是尽量提升spark作业运行的效率和速度,提升性能。
18 工作中遇到数据倾斜处理过吗?是怎么处理的,针对你刚刚提的方案讲一下具体怎么实现。用代码实现,以及用sql实现。
- 过滤无效的导致倾斜的key【适用场景不多】:比如过滤null、空字符串、非整数字符串等
方案一:剥离null不参与shuffle;方案二:对null加随机数打散shuffle - reduce join转为map join【适合小表join大表】:spark可以通过broadcast来广播小表
- 增加shuffle并行度【缓解】:shuffle算子入reduceByKey(1000)传入并行度数值,或者SparkSQL设置spark.sql.shuffle.partitions参数(默认200),都能提高shuffle read task的并行度
- 两阶段聚合(局部聚合+整体聚合)【适用于聚合类倾斜】
第一步,给每个key都打上一个随机前缀。
第二步,对打上随机前缀的key进行局部聚合。
第三步,去除每个key的随机前缀。
第四步,全局聚合。 - 采样倾斜key并分开join【适合大表join大表,一个大表有少数几个key倾斜,另一个比较均匀】:
通过sample采样出倾斜的key,然后包这些key从两张表里剥离出来,一张加随机数打散成n份,一张扩充n倍进行Join,剥离出key剩下的数据进行普通join即可,最后把结果合并在一起 - 全部数据加随机数打散N份+扩容N倍【大表Join大表,扩容导致内存消耗大】:对join类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
加随机数group by
with tmp1 as (select 1 as id, 'a' as label, 1 as valueunion allselect 1 as id, 'a' as label, 2 as valueunion allselect 1 as id, 'a' as label, 3 as valueunion allselect 2 as id, 'b' as label, 4 as value
)
select label, sum(cnt) as all from
(select rd, label, sum(1) as cnt from(select id, round(rand(),2) as rd, label, value from tmp1) as tmpgroup by rd, label
) as tmp
group by label;加随机数join
with t1 as (select 1 as id, 'a' as label, 1 as valueunion allselect 1 as id, 'a' as label, 2 as valueunion allselect 1 as id, 'a' as label, 3 as valueunion allselect 2 as id, 'b' as label, 4 as value
), t2 as (select 1 as id, 'a' as label, 10 as valueunion allselect 1 as id, 'a' as label, 20 as valueunion allselect 1 as id, 'a' as label, 30 as valueunion allselect 2 as id, 'b' as label, 40 as value
), tmp1 as (select id,round(rand(),1) as rd,label,value from t1
), tmp2 as (select id, rd, label, value from t2lateral viewexplode(split('0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0',',')) mytable as rd
), tmp3 as (select tmp1.rd as rd, tmp1.label as label, tmp1.value*tmp2.value as value fromtmp1jointmp2on tmp1.rd = tmp2.rd and tmp1.label = tmp2.label
), tmp4 as (select rd, label, sum(value) as value fromtmp3group by rd,label
)
select label,sum(value) as all from
tmp4
group by label;null处理
方案一:不参与shuffle
SELECT *
FROM log a
LEFT JOIN users bON a.user_id IS NOT NULLAND a.user_id = b.user_id
UNION ALL
SELECT *
FROM log a
WHERE a.user_id IS NULL;方案二:加随机数shfffle
SELECT *
FROM log a
LEFT JOIN users b
ON if(a.user_id is null,concat('hive',rand()),a.user_id)= b.user_id;参考:
[Hive]Hive数据倾斜(大表join大表)_大小表join hive 3.0-CSDN博客
Spark性能优化指南——高级篇 - 美团技术团队
19 讲一下kafka对接flume 有几种方式
三种:source、channel、sink
source和sink对接方式:Flume对接Kafka详细过程_flume kafka_杨哥学编程的博客-CSDN博客
channel对接方式:flume--KafkaChannel的使用_kafka channel为什么没有sink-CSDN博客
20 讲一下spark是如何将一个sql翻译成代码执行的,里面的原理介绍一下?
SparkSQL主要是通过Catalyst优化器,将SQL翻译成最终的RDD算子的
| 阶段 | 产物 | 执行主体 |
| 解析 | Unresolved Logical Plan(未解析的逻辑计划) | sqlParser |
| 分析 | Resolved Logical Plan(解析的逻辑计划) | Analyzer |
| 优化 | Optimized Logical Plan(优化后的逻辑计划) | Optimizer |
| 转换 | Physical Plan(物理计划) | Query Planner |
无论是使用 SQL语句还是直接使用 DataFrame 或者 DataSet 算子,都会经过Catalyst一系列的分析和优化,最终转换成高效的RDD的操作,主要流程如下:
1. sqlParser 解析 SQL,生成 Unresolved Logical Plan(未解析的逻辑计划)
2. 由 Analyzer 结合 Catalog 信息生成 Resolved Logical Plan(解析的逻辑计划)
3. Optimizer根据预先定义好的规则(RBO),对 Resolved Logical Plan 进行优化并生成 Optimized Logical Plan(优化后的逻辑计划)
4. Query Planner 将 Optimized Logical Plan 转换成多个 Physical Plan(物理计划)。然后由CBO 根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的 Physical Plan(最终执行的物理计划)
5. Spark运行物理计划,先是对物理计划再进行进一步的优化,最终映射到RDD的操作上,和Spark Core一样,以DAG图的方式执行SQL语句。 在最新的Spark3.0版本中,还增加了Adaptive Query Execution功能,会根据运行时信息动态调整执行计划从而得到更高的执行效率
整体的流程图如下所示:
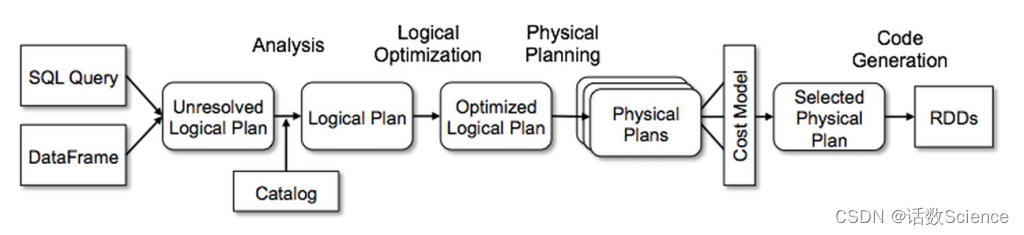
参考:SparkSQL运行流程浅析_简述spark sql的工作流程-CSDN博客
21 spark 程序里面的count distinct 具体是如何执行的
-
一般对count distinct优化就是先group by然后再count,变成两个mapreduce过程,先去重再count。
-
spark类似,会发生两次shuffle,产生3个stage,经过4个步骤:①先map端去重,②然后再shuffle到reduce端去重,③然后通过map做一次partial_count,④最后shuffle到一个reduce加总。
-
spark中多维count distinct,会发生数据膨胀问题,会把所有需要 count distinct 的N个key组合成List,行数就翻了N倍,这时最好分开来降低单个任务的数据量。
参考:大数据SQL COUNT DISTINCT实现原理 - 知乎
22 不想用spark的默认分区,怎么办?(自定义Partitioner 实现里面要求的方法 )具体是哪几个方法?
abstract class Partitioner extends Serializable {def numPartitions: Intdef getPartition(key: Any): Int
}
参考:Spark自定义分区器-CSDN博客
23 有这样一个需求,统计一个用户的已经曝光了某一个页面,想追根溯是从哪几个页面过来的,然后求出在这几个来源所占的比例。你要怎么建模处理?
(面试官的意思是将所有埋点按时间顺序存在一个List 里,然后可能需要自定义udf函数,更主要的是考虑一些异常情况,比如点击流中间是断开的,或者点击流不全,怎么应对)
参考:Hive基于SQL创建漏斗模型-CSDN博客
用户行为分析模型实践(二)—— 漏斗分析模型-腾讯云开发者社区-腾讯云
23 说一下你对元数据的理解,哪些数据算是元数据
技术元数据、业务元数据、操作元数据、管理元数据
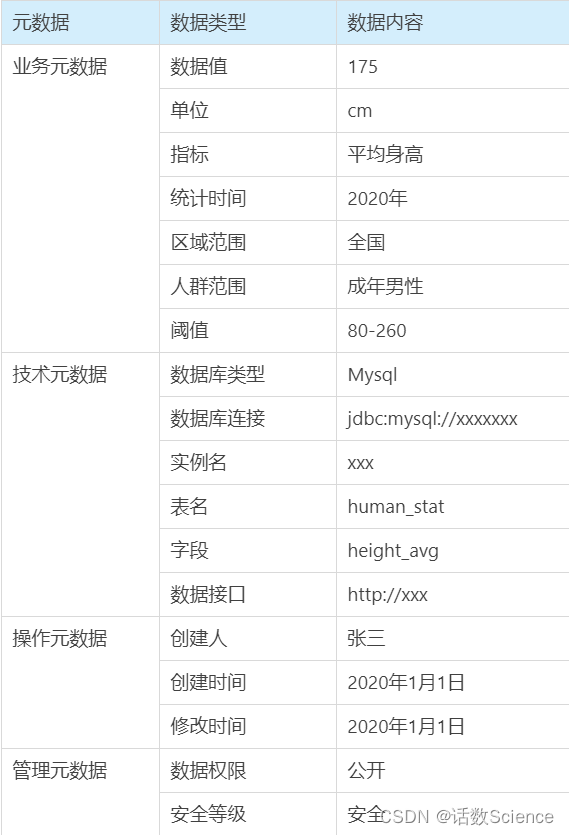
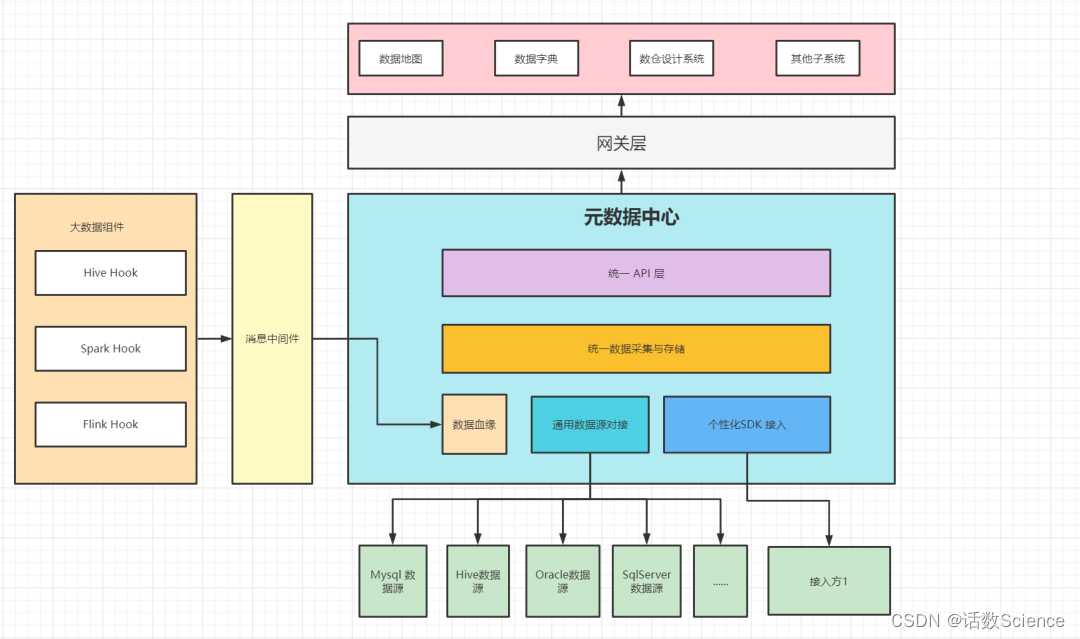
元数据管理技术架构
参考:元数据:数据治理的基石-腾讯云开发者社区-腾讯云
一文彻底了解元数据管理与架构设计-腾讯云开发者社区-腾讯云浅谈数仓的元数据管理 - 知乎
数据治理之元数据管理的利器——Atlas入门宝典-腾讯云开发者社区-腾讯云
你真的了解数仓元数据吗,数据地图你又知道多少? - 知乎
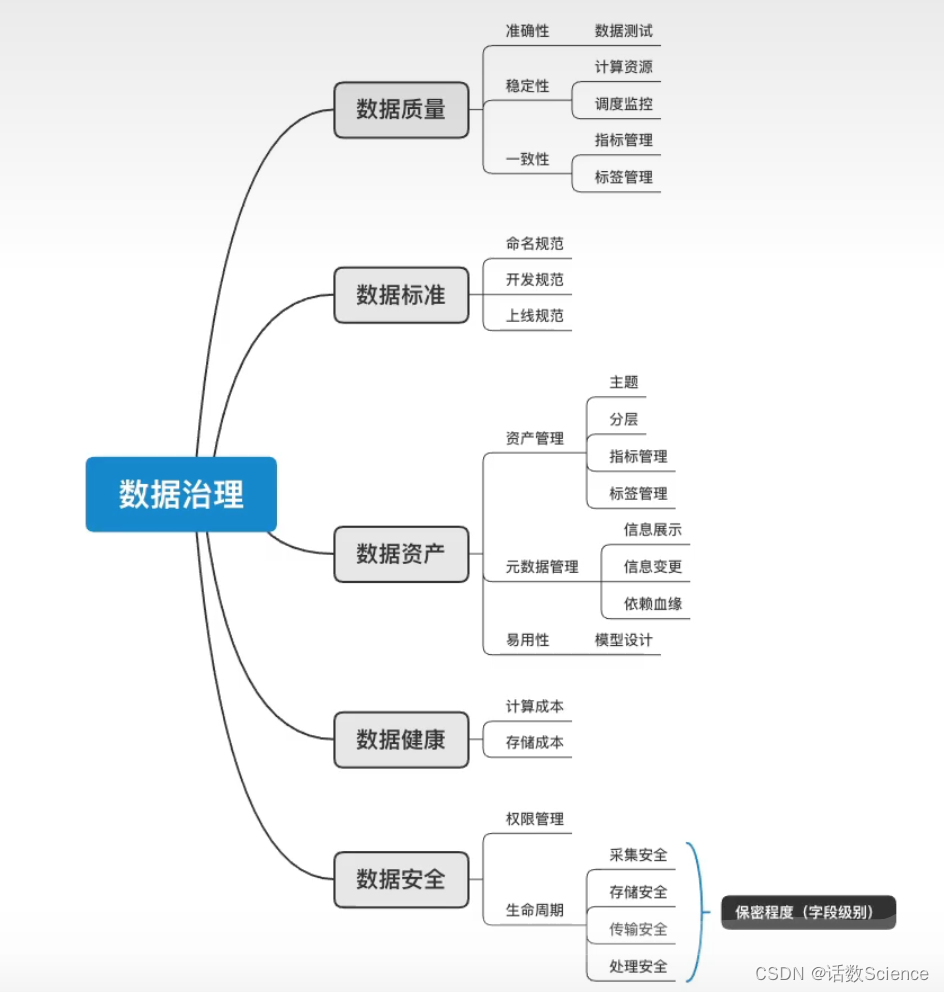
24 有过数据治理的经验吗?
数据治理涉及的方面
基于业务现状,面临的问题和挑战来讲。
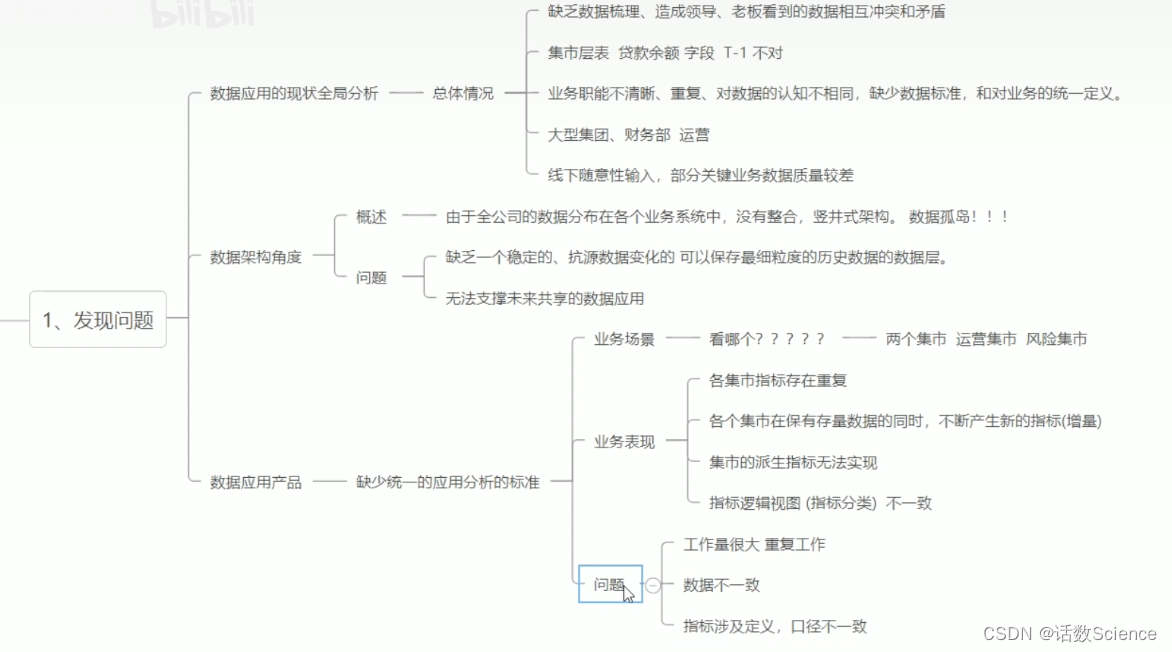
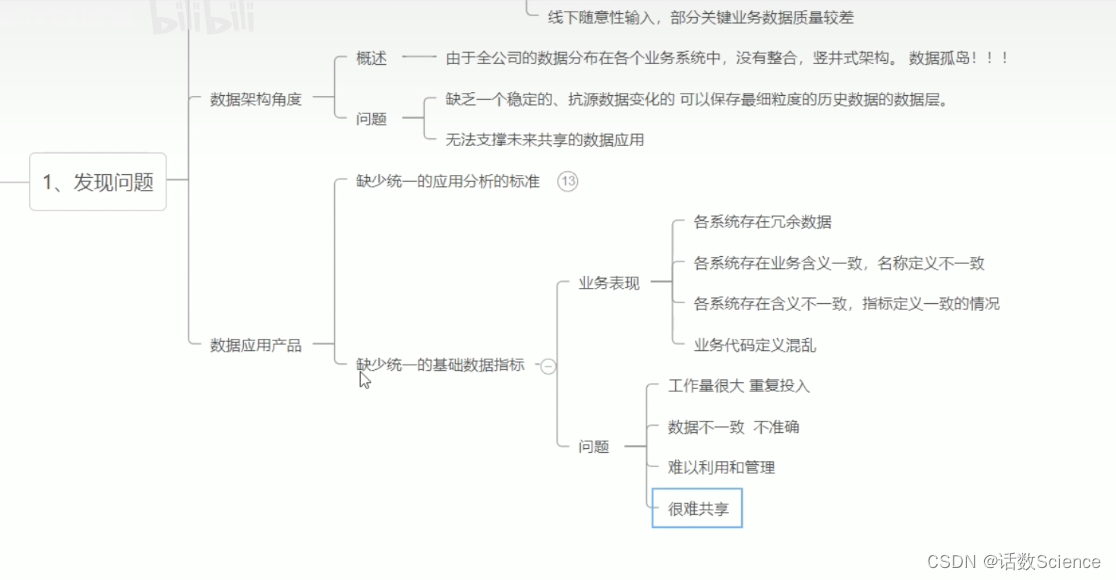
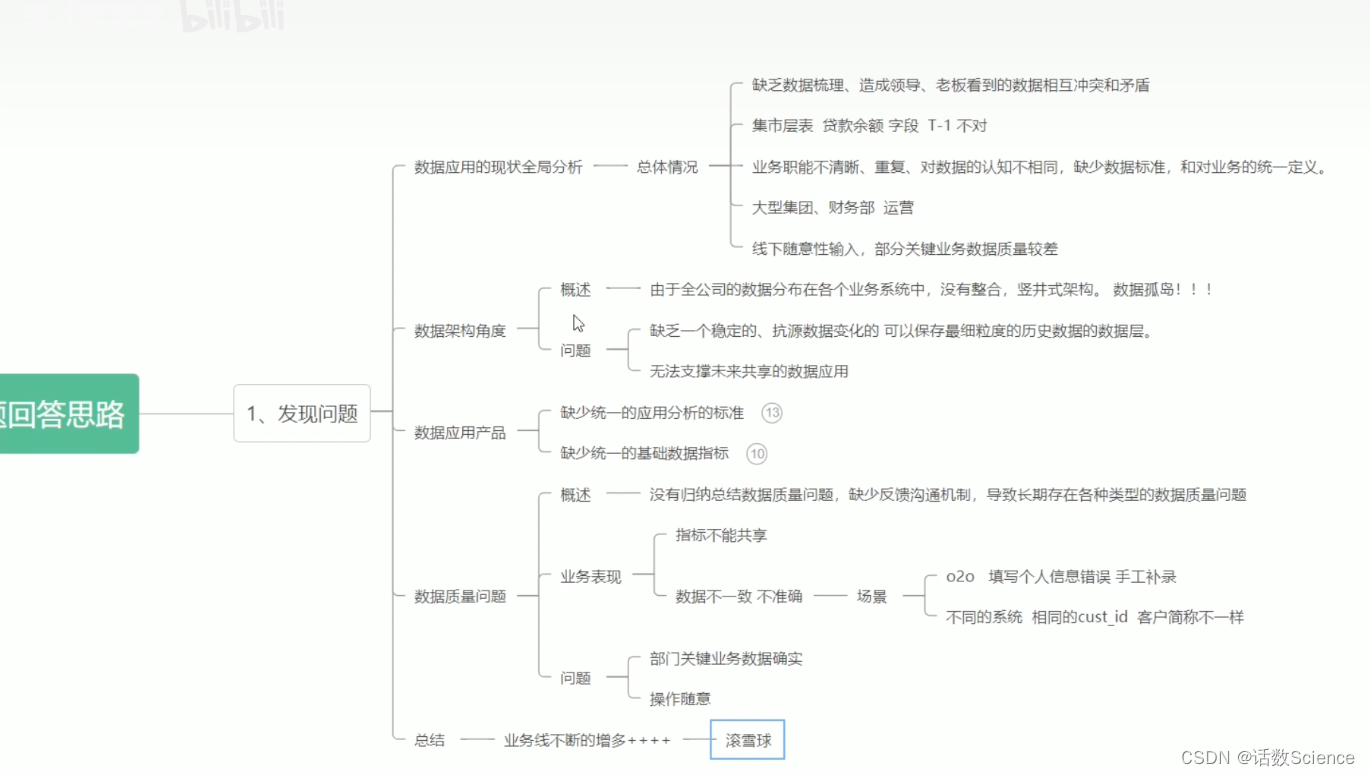
参考:业务数据治理体系化思考与实践 - 美团技术团队
DataMan-美团旅行数据质量监管平台实践 - 美团技术团队
数据治理一体化实践之体系化建模 - 美团技术团队
25 说一下你门公司的数据是怎么分层处理的,每一层都解决了什么问题
阿里

- 数据引入层(ODS,Operational Data Store,又称数据基础层)
- 数据公共层(CDM,Common Dimensions Model)
- 维度层(DIM,Dimension)
- 明细数据层(DWD,Data Warehouse Detail)
- 汇总数据层(DWS,Data Warehouse Summary)
- 数据应用层(ADS,Application Data Store)
美团

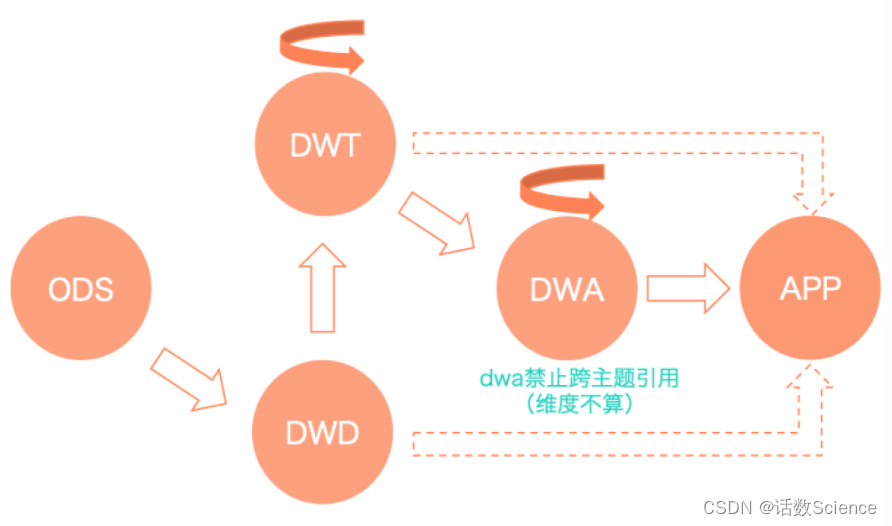

参考:业务数据治理体系化思考与实践 - 美团技术团队
OneData建设探索之路:SaaS收银运营数仓建设 - 美团技术团队
什么是数仓分层,各层有哪些用途_智能数据建设与治理 Dataphin-阿里云帮助中心
26 讲一下星型模型和雪花模型的区别,以及应用场景
- 雪花模型去除了冗余,设计复杂,可读性差,关联的维度表多,查询效率低,但是可扩展性好,适合OLAP
- 星型模型冗余度高,设计简单,可读性高,关联的维度表少,查询效率高,可扩展性低,适合OLTP
区别
星型模型和雪花模型最根本的区别就是,维度表是直接连接到事实表还是其他的维度表。
1)星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花模型要高。
2)星型模型不用考虑很多正规化的因素,设计和实现都比较简单。
3)雪花模型由于去除了冗余,有些统计就需要通过表的连接才能产生,所以效率不一定有星型模型高。
4)正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
数据仓库更适合使用星型模型来构建底层数据 hive 表,通过数据冗余来减少查询次数以提高查询效率。雪花模型在关系型数据库中(MySQL/Oracle)更加常见。在具体规划设计时,应结合具体场景及两者的优缺点来进行设计,找到一个平衡点去开展工作。
| 属性 | 星型模型 | 雪花模型 |
|---|---|---|
| 维表 | 一级维表 | 多层级维表 |
| 数据总量 | 多 | 少 |
| 数据冗余度 | 高 | 低 |
| 可读性 | 高 | 低 |
| 表个数 | 少 | 多 |
| 表宽度 | 宽 | 窄 |
| 查询逻辑 | 简单 | 复杂 |
| 查询性能 | 高 | 低 |
| 扩展性 | 差 | 好 |
参考:
维度建模 -- 星型模型和雪花模型的区别-CSDN博客
一文搞清楚数据仓库模型:星型模型和雪花模型的区别 - 简书
三大数据模型:星型模型、雪花模型、星座模型-腾讯云开发者社区-腾讯云
星型模型与雪花模型的区别、分别有哪些优缺点_星型模型和雪花模型的区别和使用场景?-CSDN博客
相关文章:
快手数仓面试题附答案
题目 1 讲一下你门公司的大数据项目架构?2 你在工作中都负责哪一部分3 spark提交一个程序的整体执行流程4 spark常用算子列几个,6到8个吧5 transformation跟action算子的区别6 map和flatmap算子的区别7 自定义udf,udtf,udaf讲一下…...

如何在Go中编写包
包由位于同一目录中的Go文件组成,这些文件在开头具有相同的package语句。你可以从包中包含额外的功能,使程序更复杂。有些包可以通过Go标准库获得,因此与Go安装一起安装。其他可以使用Go的go get命令安装。您还可以通过使用必要的package语句在要共享代码的相同目录中创建Go…...
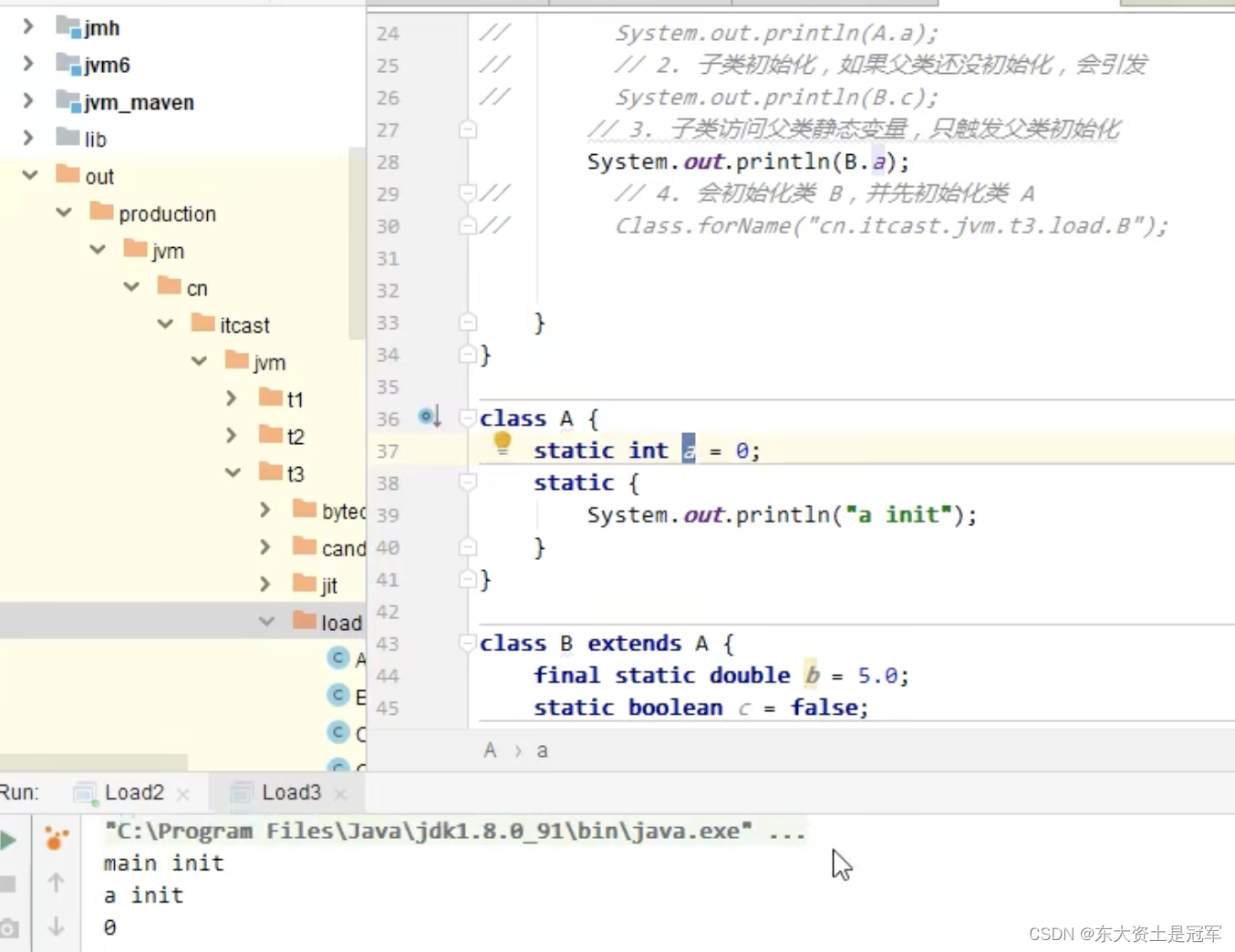
JVM类加载全过程
Java虚拟机类加载的全过程,即加载,验证,准备,解析,初始化 一、加载 加载 是 类加载过程中的一个阶段, 有以下三部分组成 1)通过一个类的全限定名来获取定义此类的二进制流 2)将这…...

Uniapp安卓原生插件开发Demo
文章目录 前言一、安装开发工具二、导入uni插件原生项目三、开发Module四、开发Component五、合并原生代码到uniapp项目中总结 前言 当HBuilderX中提供的能力无法满足App功能需求,需要通过使用Andorid/iOS原生开发实现时,可使用App离线SDK开发原生插件来…...
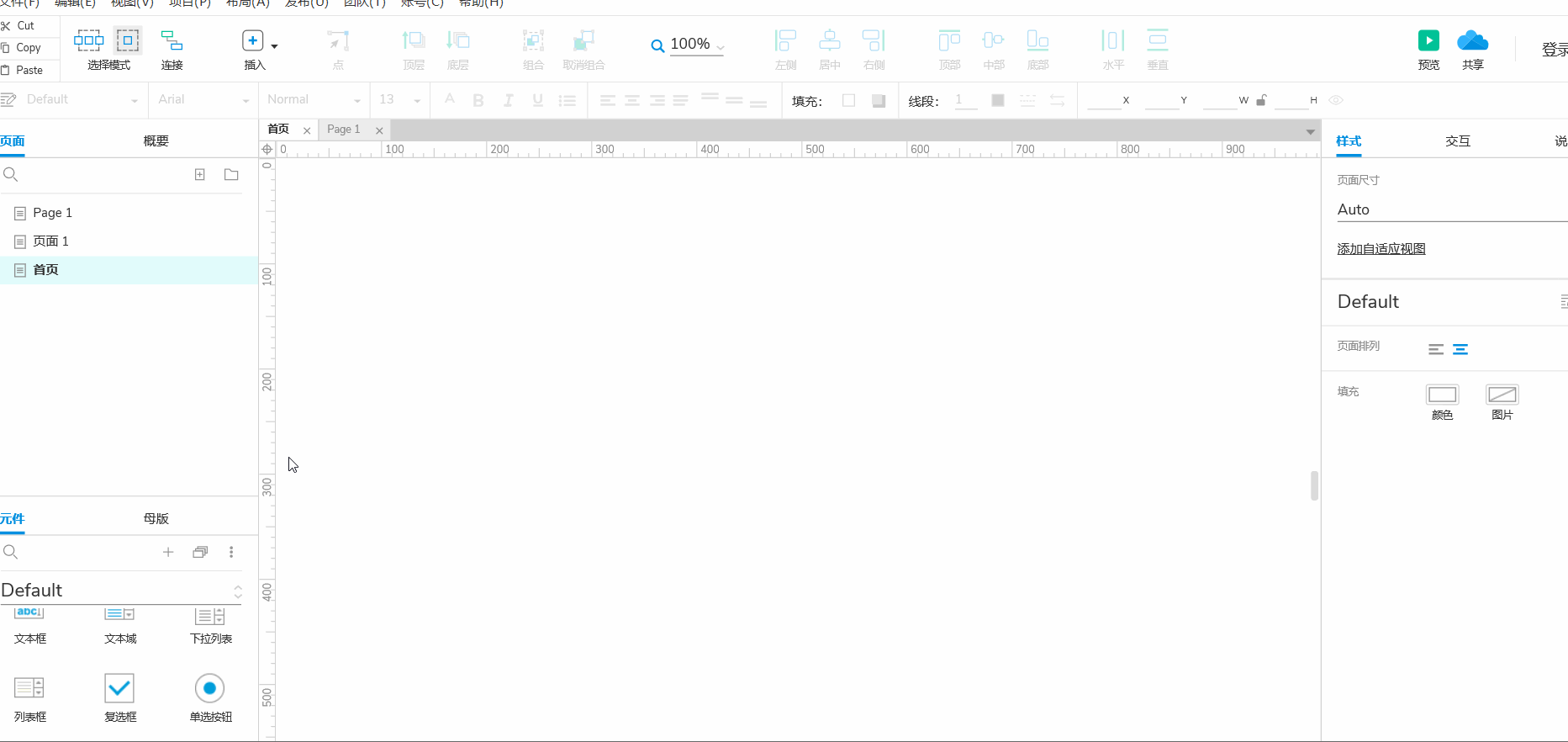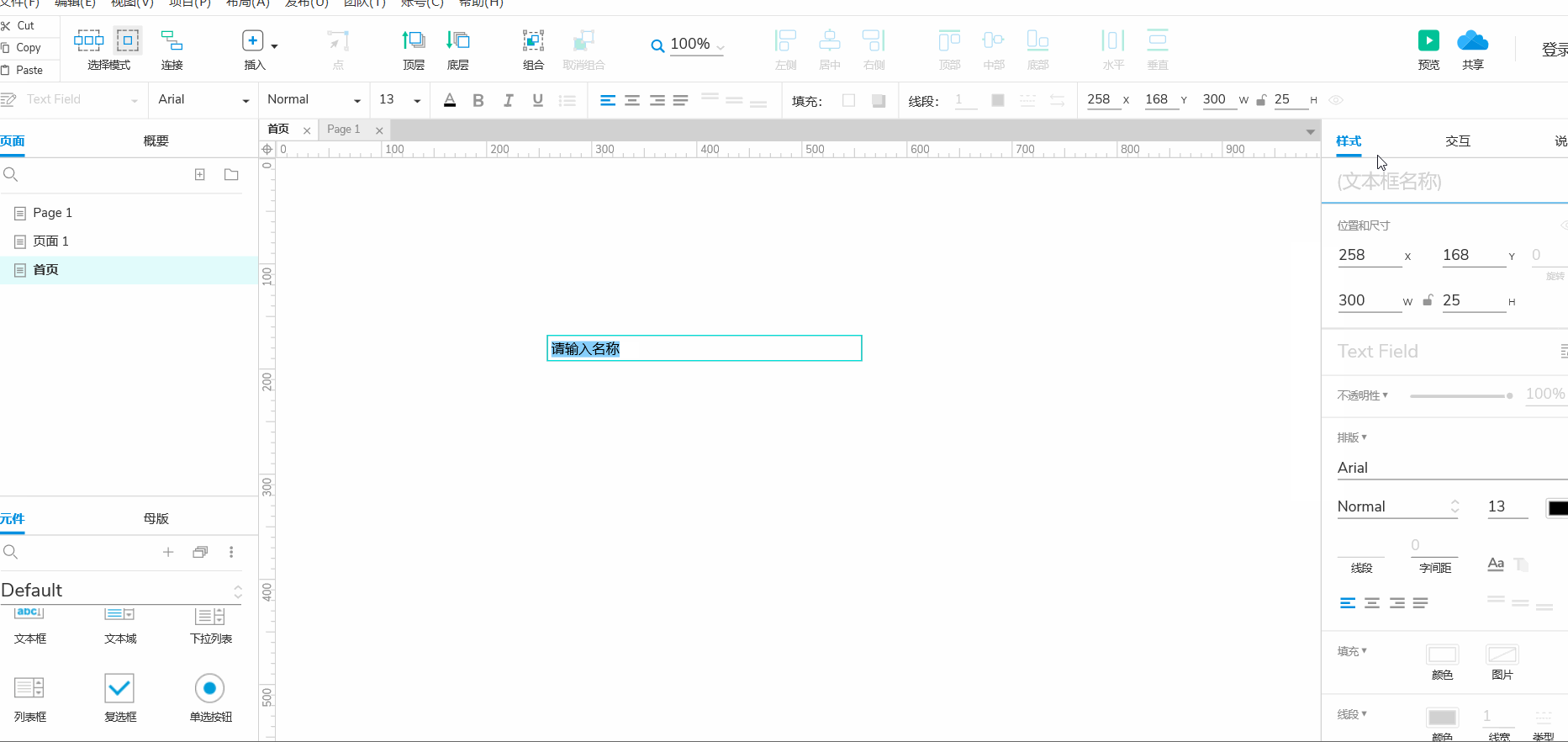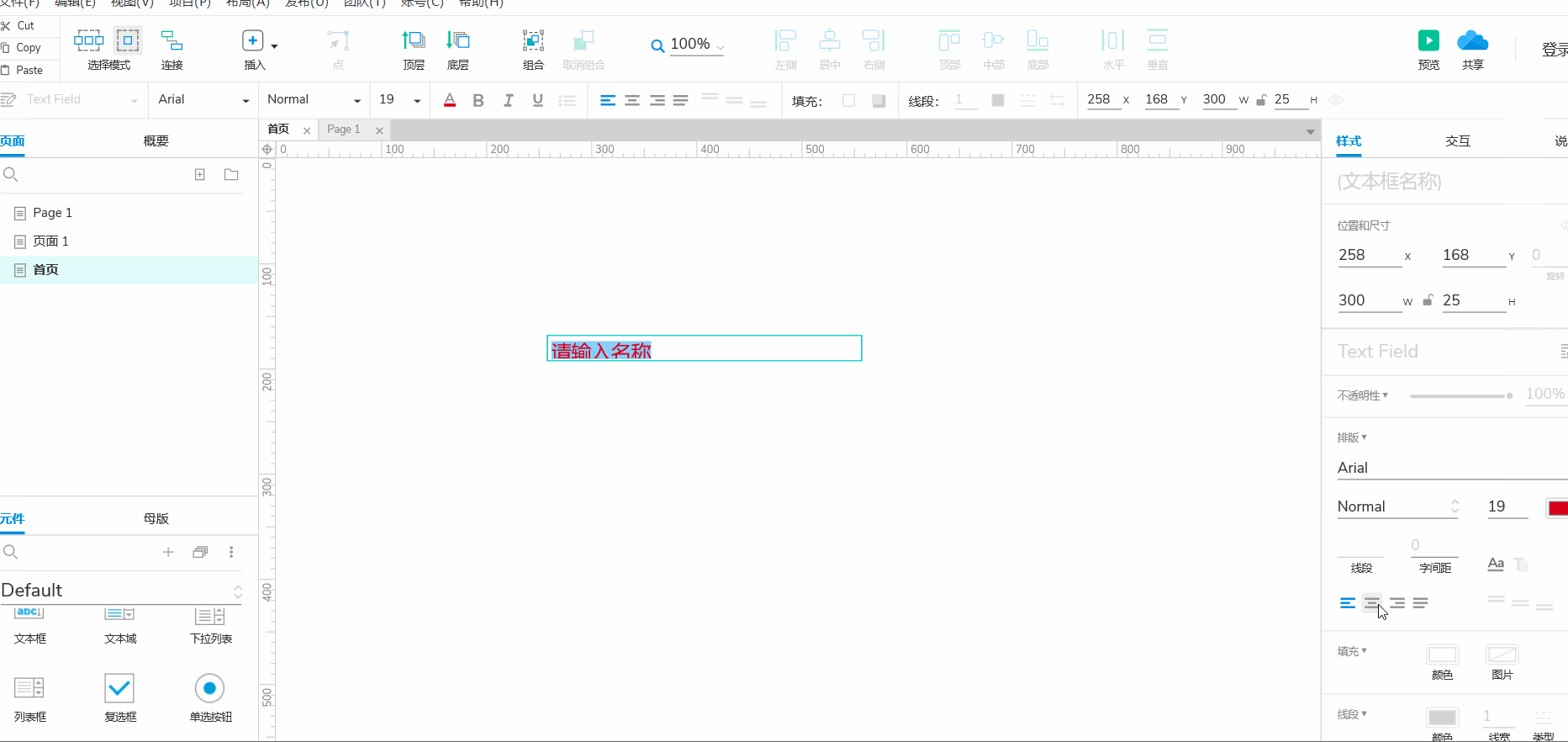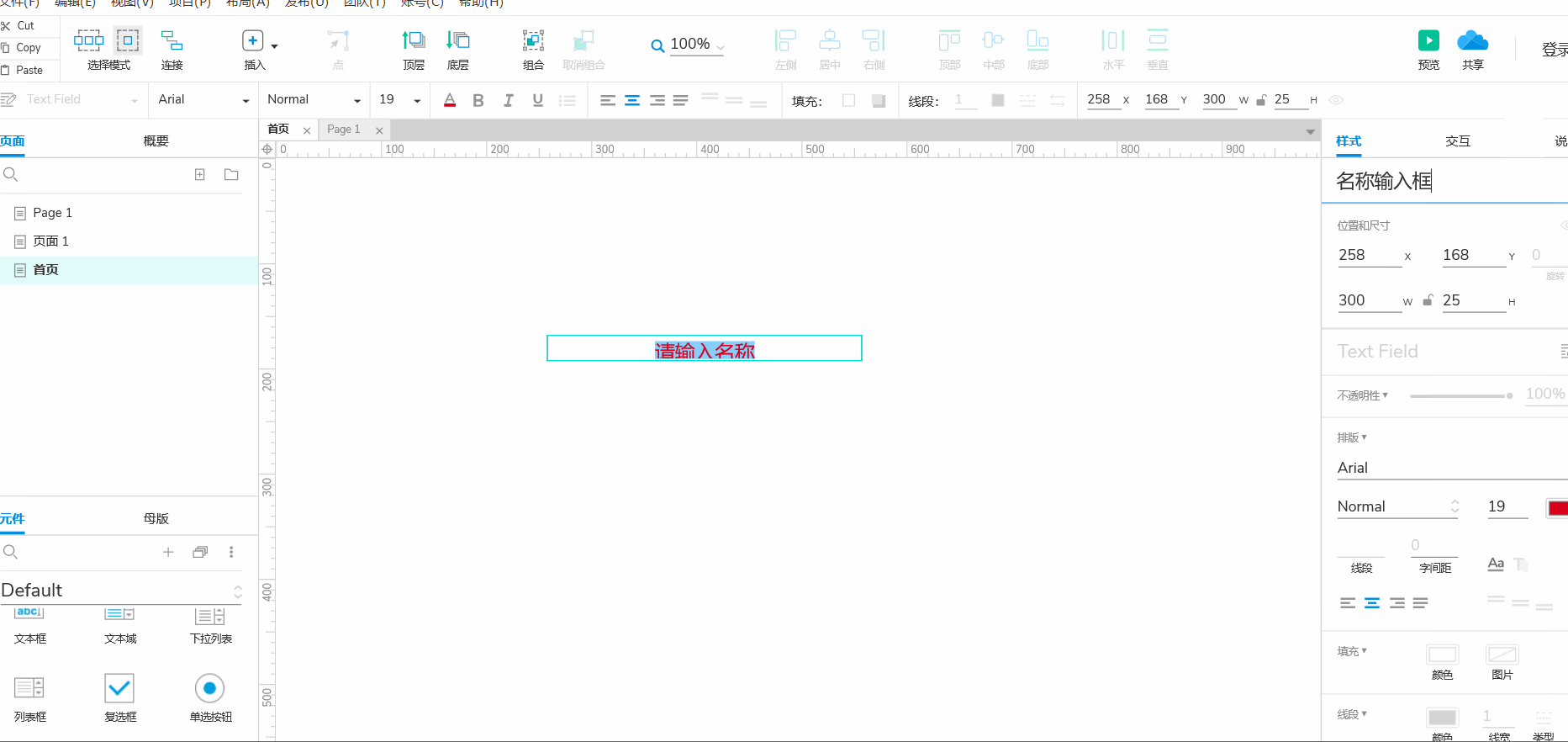
Axure的安装与基本使用
目录 一.Axure是什么 二.Axure安装 2.1 一键式安装 2.2 汉化 2.3 授权登录 三.Axure的界面介绍及基本使用 3.1 菜单栏的使用 3.2 工具栏的使用 3.3 页面概要的使用及组件的使用 3.4 组件的样式设计 一.Axure是什么 Axure是一个流行的交互式原型设计工具,一般是…...
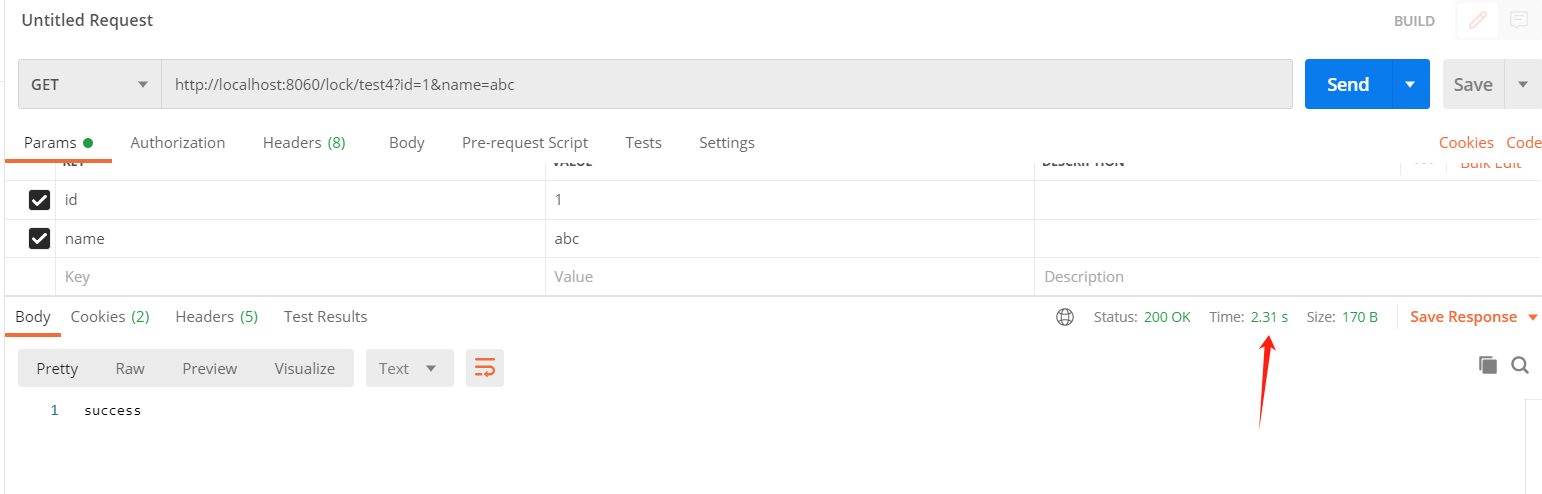
分布式锁实现方案 - Lock4j 使用
一、Lock4j 分布式锁工具 你是不是在使用分布式锁的时候,还在自己用 AOP 封装框架?那么 Lock4j 你可以考虑一下。 Lock4j 是一个分布式锁组件,其提供了多种不同的支持以满足不同性能和环境的需求。 立志打造一个简单但富有内涵的分布式锁组…...
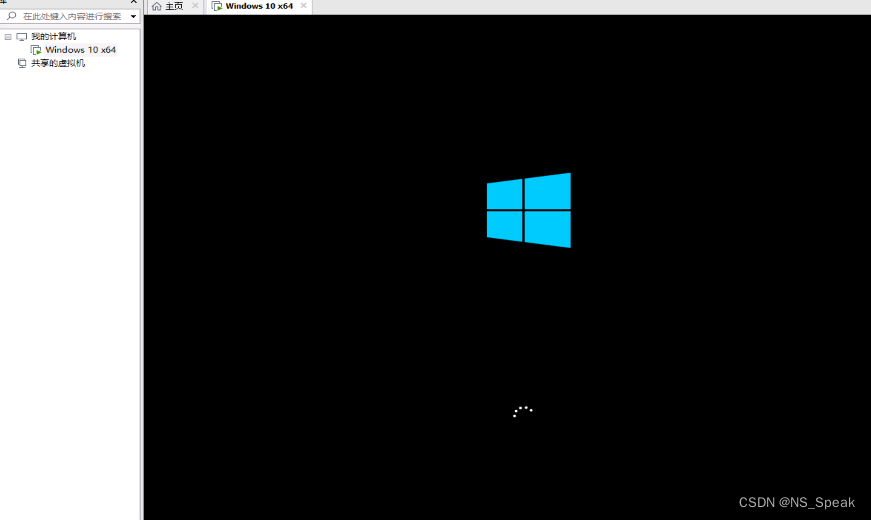
[虚拟机]使用VM打开虚拟机电脑重启解决方案。
问题:打开虚拟机点击启动后,电脑会自动重启。(WINDOWS10 20版本) 解决步骤: 1、对Windows功能进行操作。 上图三个启用。 上图一个取消。 再次打开后,不报警,显示下图问题: 继续解…...

Linux 详细介绍strace命令
system call(系统调用)是程序向内核请求服务的一种编程方式,strace是一个功能强大的工具,可以跟踪用户进程和 Linux 内核之间的交互。 要了解操作系统如何工作,首先需要了解系统调用如何工作。操作系统的主要功能之一是为用户程序提供了一个…...

【知识分享】__RS485-嵌入式常用的通信协议
目录 前言 一、RS485简介 什么是串口 什么是串行通信 什么是并行通信 二、接口原理 1. 连接方式 2. 差分信号 三、485通讯接口的优势 1. 接口电平低, 不易损坏芯片。 2. 传输速率高 3. 抗干扰能力强 4. 传输距离远,支持节点多。 四、常见…...
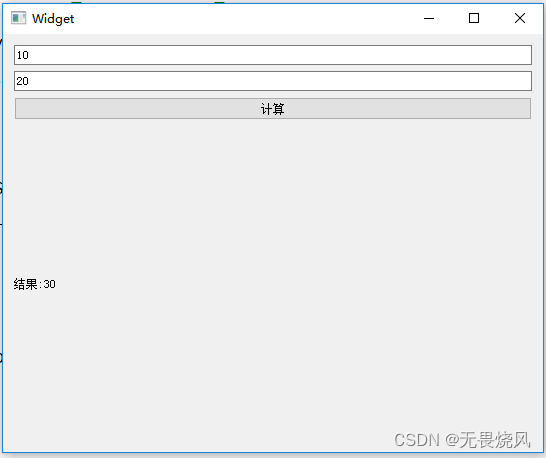
Qt生成动态链接库并使用动态链接库
项目结构 整个工程由一个主程序构成和一个模块构成(dll)。整个工程的结构目录如下 Define.priMyProject.proMyProject.pro.user ---bin ---MainProgrammain.cppMainProgram.proMainProgram.pro.userwidget.cppwidget.hwidget.ui ---MathDllMathDll.proMathDll.pro.userMyMath.…...

E4990A 阻抗分析仪,20 Hz 至 10/20/30/50/120 MHz
01 E4990A 阻抗分析仪 20 Hz 至 10/20/30/50/120 MHz 产品综述: E4990A 阻抗分析仪具有 20 Hz 至 120 MHz 的频率范围,可在宽阻抗范围内提供出色的 0.045%(典型值)基本准确度,并内置 40 V 直流偏置源,适…...
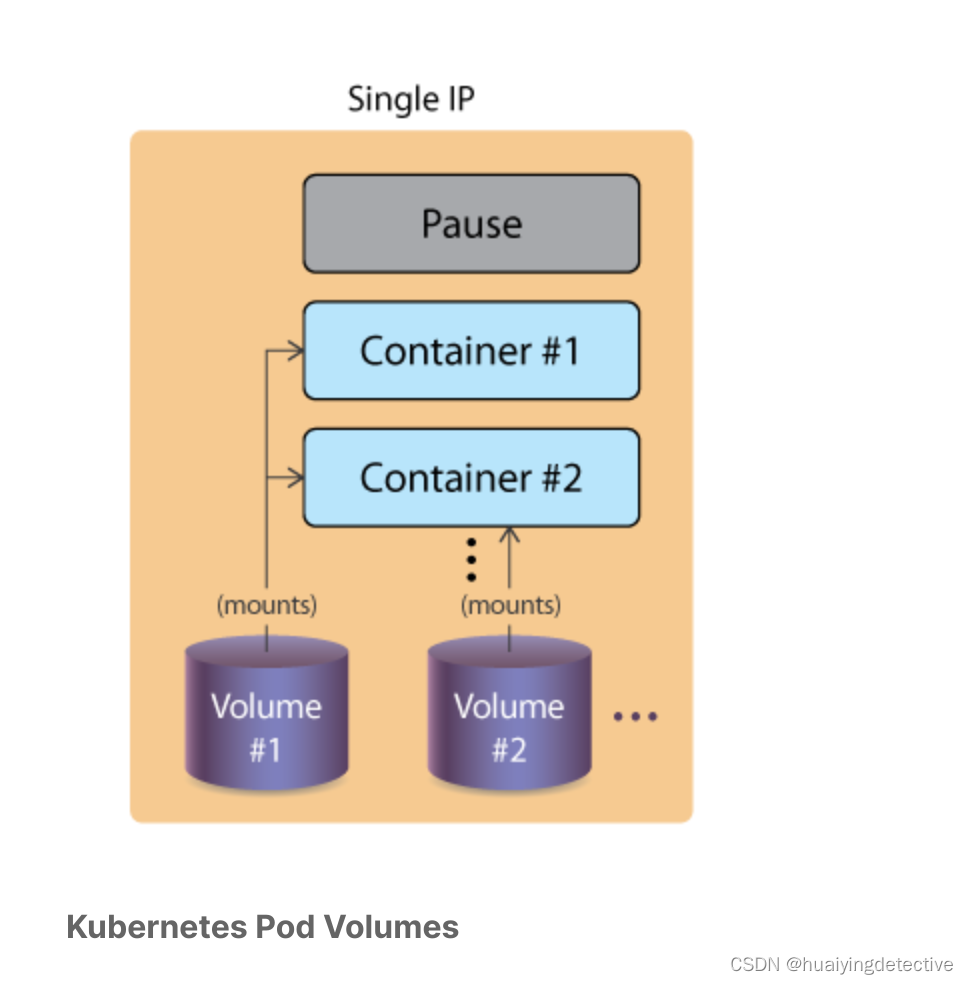
k8s volumes and data
Overview 传统上,容器引擎(Container Engine)不提供比容器寿命更长的存储。由于容器被认为是瞬态(transient)的,这可能会导致数据丢失或复杂的外部存储选项。Kubernetes卷共享 Pod 生命周期,而不是其中的容器。如果容器终止,数据…...

万宾科技智能水环境综合治理监测系统效果
水环境综合治理是一项旨在全面改善水环境质量的系统工程。它以水体为对象,综合考虑各种因素,通过科学规划和技术手段,解决水环境污染、生态退化等问题,核心理念是“统一规划、分步实施;标本兼治,重在治本&a…...
掌控安全 暖冬杯 CTF Writeup By AheadSec
本来结束时发到了学校AheadSec的群里面了的,觉得这比赛没啥好外发WP的,但是有些师傅来问了,所以还是发一下吧。 文章目录 Web签到:又一个计算题计算器PHP反序列化又一个PHP反序列化 Misc这是邹节伦的桌面背景图什么鬼?…...

jQuery-操作DOM
使用jQuery操作DOM dom : 文档对象模型 就是HTML元素 $() 函数的2个用法: 用法1:放入一个字符串(选择器)表示获取元素 例如 $("p") $("#abc") $(".del") 用法2:放入一个函数,表示文档就绪函数 例如 $(function(){代…...

高级网工在Linux服务器抓包,少不了这几条常用的tcpdump命令。
Linux 的命令太多,tcpdump 是一个非常强大的抓包命令。有时候想看线上发生的一些问题: nginx 有没有客户端连接过来…… 客户端连接过来的时候 Post 上来的数据对不对…… 我的 Redis 实例到底是哪些业务在使用…… tcpdump 作为网络分析神器就派上用场…...

Hough算法数学原理
直线的极坐标方程: x x 0 r cos θ x x_0 r\cos \theta xx0rcosθ y y 0 r sin θ y y_0 r\sin \theta yy0rsinθ x cos θ x 0 cos θ r cos 2 θ x \cos \theta x_0 \cos \theta r \cos^2 \theta xcosθx0cosθrcos2θ y sin θ…...

基于Debain安装 Docker 和 Docker Compose
一、安装Docker # 先升级一下系统 (Ubuntu / Debian 系) sudo apt-get update sudo apt-get upgrade# 如果你是 CentOS、红帽系列则使用: yum update yum upgrade# 安装 Docker curl -fsSL https://get.docker.com -o get-docker.sh sudo sh get-docker.sh二、Dock…...
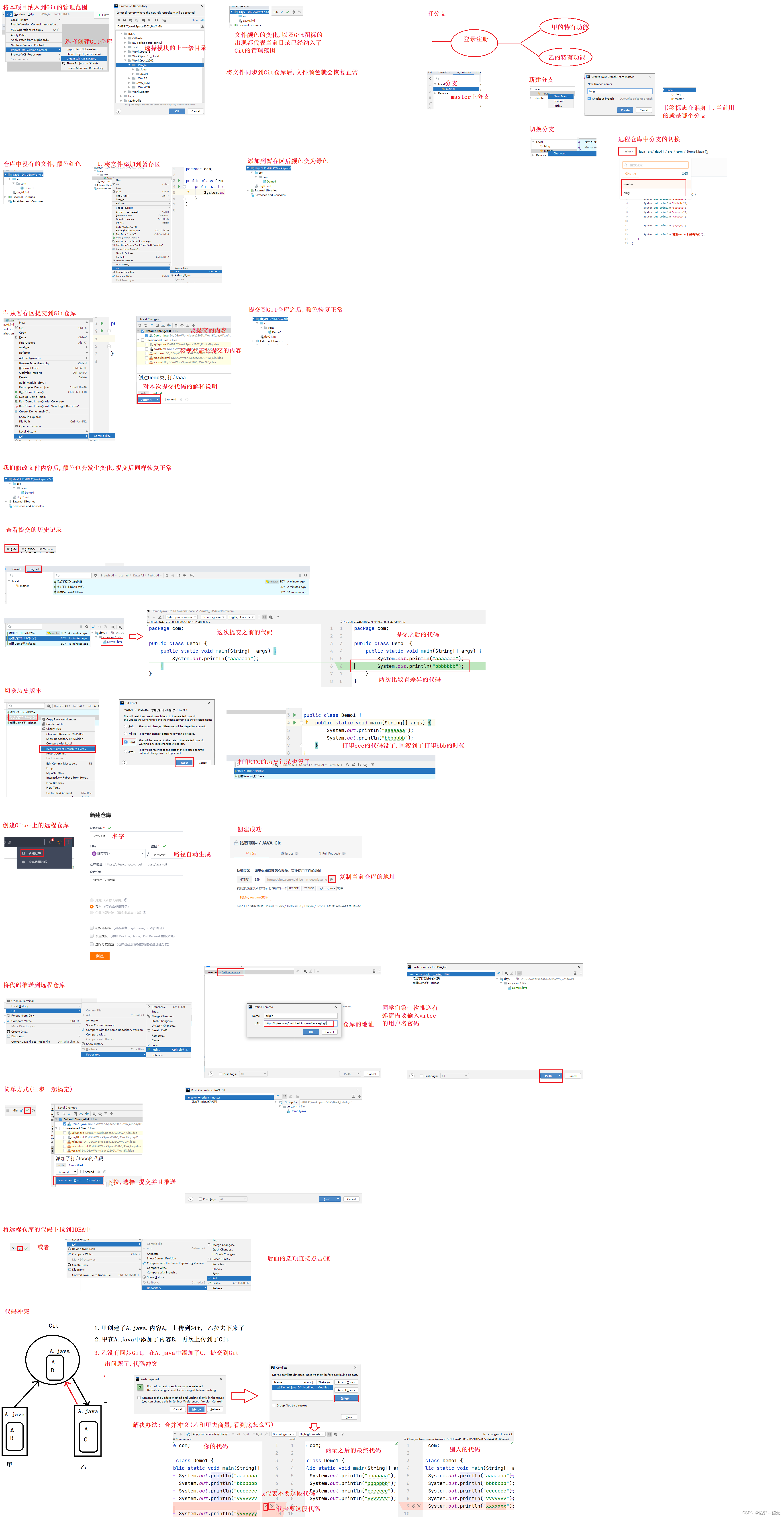
gittee使用教学
一、git简介 Git是一个开源的分布式版本控制系统,用于敏捷高效的处理任何大小项目的版本管理。 核心功能: 项目的版本管理 团队协同开发 二、准备工作 1、下载 Git 2、除了选择安装位置以外,其他都无脑安装 3、检查一下安装情况 win…...

q2-qt-多线程
是的,Qt框架中提供了专门用于线程池的API。Qt的线程池API位于QtConcurrent命名空间下,以及QThreadPool类中。 QtConcurrent命名空间提供了一些高级的API,可以方便地使用线程池来执行并行任务。其中,QtConcurrent::run()函数可以用…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...
:LeetCode 142. 环形链表 II(Linked List Cycle II)详解)
Java详解LeetCode 热题 100(26):LeetCode 142. 环形链表 II(Linked List Cycle II)详解
文章目录 1. 题目描述1.1 链表节点定义 2. 理解题目2.1 问题可视化2.2 核心挑战 3. 解法一:HashSet 标记访问法3.1 算法思路3.2 Java代码实现3.3 详细执行过程演示3.4 执行结果示例3.5 复杂度分析3.6 优缺点分析 4. 解法二:Floyd 快慢指针法(…...

土建施工员考试:建筑施工技术重点知识有哪些?
《管理实务》是土建施工员考试中侧重实操应用与管理能力的科目,核心考查施工组织、质量安全、进度成本等现场管理要点。以下是结合考试大纲与高频考点整理的重点内容,附学习方向和应试技巧: 一、施工组织与进度管理 核心目标: 规…...

Python常用模块:time、os、shutil与flask初探
一、Flask初探 & PyCharm终端配置 目的: 快速搭建小型Web服务器以提供数据。 工具: 第三方Web框架 Flask (需 pip install flask 安装)。 安装 Flask: 建议: 使用 PyCharm 内置的 Terminal (模拟命令行) 进行安装,避免频繁切换。 PyCharm Terminal 配置建议: 打开 Py…...
)
Vue3学习(接口,泛型,自定义类型,v-for,props)
一,前言 继续学习 二,TS接口泛型自定义类型 1.接口 TypeScript 接口(Interface)是一种定义对象形状的强大工具,它可以描述对象必须包含的属性、方法和它们的类型。接口不会被编译成 JavaScript 代码,仅…...

安宝特案例丨寻医不再长途跋涉?Vuzix再次以AR技术智能驱动远程医疗
加拿大领先科技公司TeleVU基于Vuzix智能眼镜打造远程医疗生态系统,彻底革新患者护理模式。 安宝特合作伙伴TeleVU成立30余年,沉淀医疗技术、计算机科学与人工智能经验,聚焦医疗保健领域,提供AR、AI、IoT解决方案。 该方案使医疗…...