语音识别从入门到精通——1-基本原理解释
文章目录
- 语音识别算法
- 1. 语音识别简介
- 1.1 **语音识别**
- 1.1.1 自动语音识别
- 1.1.2 应用
- 1.2 语音识别流程
- 1.2.1 预处理
- 1.2.2 语音检测和断句
- 1.2.3 音频场景分析
- 1.2.4 识别引擎(语音识别的模型)
- 1. 传统语音识别模型
- 2. 端到端的语音识别模型
- 基于Transformer的ASR模型
- 基于CNN的ASR模型
- Conformer
- Paraformer
- 1.2.5 工程调度 & 异常处理
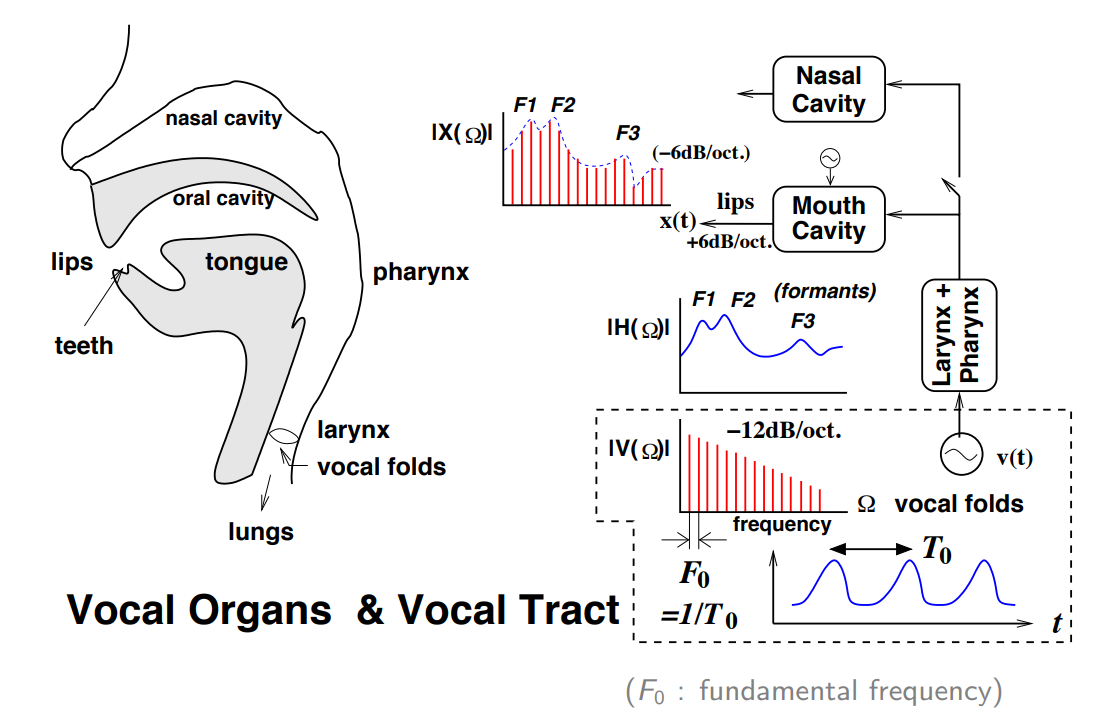
- 1.3 基础知识
- 2.语音预处理
- 2.1 数据预处理流程
- 2.1.1 时域与频域图显示
- 2.1.2 预加重(Pre-Emphasis)
- 2.1.3 分帧
- 2.1.4 加窗
- 2.1.5 快速傅里叶变换 (FFT)
- 2.1.6 FBank特征(Filter Banks)
- 2.1.7 MFCC
- 参考笔记
语音识别算法
1. 语音识别简介
1.1 语音识别
1.1.1 自动语音识别
(Automatic Speech Recognition,ASR),其目标是将人类的语音转换为文字。
1.1.2 应用
- 离线语音识别(非流式)
指包含语音的音频文件已经存在,需使用语音识别应用对音频的内容进行整体识别。典型应用有音视频会议记录转写、音频内容分析及审核、视频字幕生成等。
- 实时在线语音识别(流式)
指包含语音的实时音频流,被连续不断地送入语音识别引擎,过程中获得的识别结果即时返回给调用方。典型应用有手机语音输入法、交互类语音产品(如智能音箱、车载助手)、会场同声字幕生成和翻译、网络直播平台实时监控、电话客服实时质量检测等。
1.2 语音识别流程
1.2.1 预处理
预处理(格式转换、压缩编解码、音频数据抽取、声道选择(通常识别引擎只接收单声道数据)、采样率/重采样(常见的识别引擎和模型采样率一般为8kHz、16kHz),FBank特征提取。
语音信号被设备接收后 (比如麦克风),会通过 A / D A / D A/D 转换,将模拟信号转换为数字信号,一般会有采样、量化和编码三个步骤,采样率要遵循奈奎斯特采样定律: f s > = 2 f f s>=2 f fs>=2f ,比如电话语音的频率一般在 300 H z ∼ 3400 H z 300 \mathrm{~Hz} \sim 3400 \mathrm{~Hz} 300 Hz∼3400 Hz ,所以采用 8 k H z 8 \mathrm{kHz} 8kHz 的采样率足矣。
- 将音频文件读取到程序后,它们是一系列离散的采样点,通常采样率是16k/8k,即一秒钟采样16000/8000个点,每个采样点表示该时刻声音的振幅。
- 在这个采样率下,一条只有几秒钟的输入音频,其序列长度也会非常长,且每个采样点所包含的语音信息比较少,因此原始音频不适合直接作为模型的输入。无论是传统方法的语音识别技术还是基于神经网络的语音识别技术,都需要进行语音的预处理。
- 预处理流程的核心是快速傅立叶变换。快速傅立叶变换的作用看似杂乱无章的信号考虑分解为一定振幅、相位、频率的基本正弦(余弦)信号。傅里叶变换允许我们分解一个信号,以确定不同频率的波的相对强度。
1.2.2 语音检测和断句
对于离线语音识别应用,断句模块的作用是快速过滤并切分出音频文件中的人声片段,且尽最大可能保证每个片段都为完整的一句话;对于实时在线语音识别应用,断句模块则需要能够从一个持续的语音流中,第一时间检测出用户什么时候开始说话(也称为起点检测),以及什么时候说完(也称为尾点检测)。
1.2.3 音频场景分析
除断句外,由于一些应用本身的复杂性,导致原生的音频在被送入识别引擎之前,还需要进一步进行分析和过滤,我们把这类统称为音频场景分析。一般情况语种识别也会放在这里。
1.2.4 识别引擎(语音识别的模型)
1. 传统语音识别模型
-
经典的语音识别概率模型 ,分为声学模型和语言模型两部分,现将语音转换为音素,再将音素转换为单词。
-
对于声学模型来说,单词是一个比较大的建模单元,因此声学模型p(Y|w)中的单词序列w会被进一步拆分成一个音素序列。假设Q是单词序列w对应的发音单元序列,这里简化为音素序列,那么声学模型p(Y|w)可以被进一步转写为。一般会用隐马尔可夫模型来进行建模。音素表,由声学专家定义。
-
语言模型,使用n-gram模型。
-
传统语音识别 缺点,精度差;优点,速度快可部署在嵌入式设备。
2. 端到端的语音识别模型
2014年左右,谷歌的研究人员发现,在大量数据的支撑下,直接用神经网络可以从输入的音频或音频对应的特征直接预测出与之对应的单词,而不需要像我们上面描述的那样,拆分成声学模型和语言模型。简单来说构建一个模型,input :语音,output:文本即可。
基于Transformer的ASR模型
- ASR可以被看成是一种序列到序列任务,输入一段声音特征序列,通过模型计算后,输出对应的文字序列信号。在端到端ASR模型中,这种序列到序列的转换不需要经过中间状态,如音素等,而直接生成输出结果。
- 基于Transformer的ASR模型,**其输入是提取的FBank或MFCC语音特征。**由于语音特征序列一般比较长,在送入模型之前,通常会进行两层步长为2的卷积操作,将序列变为原来的1/4长。
- 基于Transformer的ASR模型编码器和解码器与原始Transformer没有差别,在编码器端,是一个多头注意力子层和一个前馈网络子层,它们分别进行残差连接和层标准化(LayerNorm)操作,而在解码器端则会多一个编码器-解码器多头注意力层,用于进行输入和输出之间的交互。
- 缺点:自注意力机制能够对全局的上下文进行建模,不擅长提取细粒度的局部特征模式
基于CNN的ASR模型
- 基于CNN来捕获局部的特征来进行语音识别,比如 ContextNet。
- 由于受感受野范围的限制,CNN只能够在局部的范围内对文本进行建模,相比于RNN或Transformer,缺乏全局的文本信息。ContextNet通过引入“压缩和激发(Squeeze-and-Excitation,SE)”层{Squeeze-and-excitation networks}来获取全局特征信息。
- Squeeze-and-Excitation,SE 模块捕获全局特征的能力, 在图像领域的应用很多。 目标检测,通过引该模块,可以再不损失提取局部特征的能力下,加强对全局特征的提取。即,添加注意力可以加强一定的全局特征提取。但只是通过平均池化和全连接来进行全局信息的交互,这种方法在语音识别领域仍然无法很好地获取全局特征。
Conformer
- 目前业界主流框架,通过一定的组合方式(Transfomer+CNN)应用到ASR任务上。考虑到语音序列建模的特点,Conformer加入了卷积模块,利用CNN的局部建模能力来获取序列的局部特征。
- Conformer结构是在Transformer模型编码器的基础上增加卷积模块, 构成Conformer 模块。
- WeNet 是一款面向工业落地应用的语音识别工具包(框架),提供了从语音识别模型的训练到部署的一条龙服务,也是目前业界最常用的开源框架。
Paraformer
-
Paraformer 是阿里INTERSPEECH 2022 提出的一个模型,并已经开源。一种具有高识别率与计算效率的单轮非自回归模型 Paraformer。
-
该模型开箱可用,该开源模型的实际识别效果和TEG 的模型效果差不多。是目前唯一开箱即用的开源预训练模型, 我认为主要原因是该模型的训练集中包含了工业级别的数据。
1.2.5 工程调度 & 异常处理
工程部署和异常类型处理
1.3 基础知识
- 声音(sound)是由物体振动产生的声波。是通过介质(空气或固体、液体)传播。
- 语音的产生基本原理还是振动。不同位置的震动频率不一样,信号也就不一样,不过信号由基频和一些谐波构成
- 一个振动产生的波是一个具有一定频率的振幅最大的正弦波叫基频。 这些高于基波频率的小波就叫作谐波。
- 采样率(Sample Rate):
- 采样率是指在单位时间内对连续模拟信号进行离散采样的次数。它通常以赫兹(Hz)为单位表示。
- 采样率决定了数字音频信号中每秒包含多少个采样点(样本)。例如,如果采样率为8000 Hz,表示每秒会对模拟音频信号进行8,000次采样,生成相应数量的离散样本。
- 采样率决定了数字音频信号的频率范围。根据奈奎斯特定理(Nyquist Theorem),为了正确重构连续信号,采样率必须至少是模拟信号中最高频率的两倍。
- 采样时长(Sampling Duration):
- 采样时长是指在连续模拟信号中,每个采样点之间的时间间隔。它通常以秒为单位表示。
- 采样时长是由采样率决定的,可以通过以下公式计算:采样时长 = 1 / 采样率。这表示采样率越高,采样时长越短。
- 采样时长决定了数字音频信号中相邻采样点之间的时间分辨率。较短的采样时长可以更精细地捕捉信号的瞬时变化。
2.语音预处理
2.1 数据预处理流程
2.1.1 时域与频域图显示
import numpy as np
from scipy.io import wavfile
from scipy.fftpack import dct
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
# 绘制时域图
def plot_time(signal, sample_rate):time = np.arange(0, len(signal)) * (1.0 / sample_rate)plt.figure(figsize=(20, 5))plt.plot(time, signal)plt.xlabel('Time(s)')plt.ylabel('Amplitude')plt.grid()plt.show()# 绘制频域图
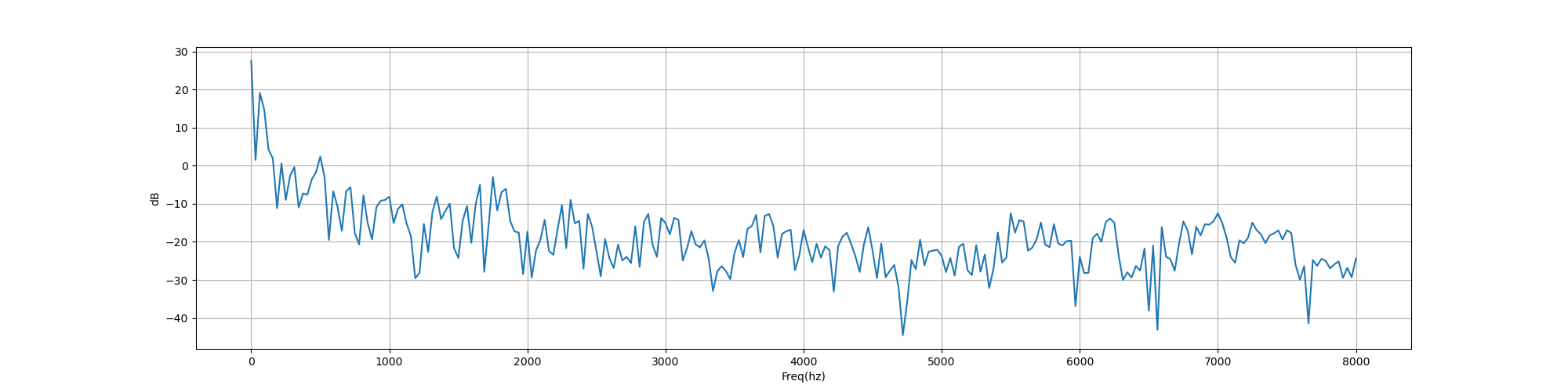
def plot_freq(signal, sample_rate, fft_size=512):xf = np.fft.rfft(signal, fft_size) / fft_sizefreqs = np.linspace(0, sample_rate/2, int(fft_size/2) + 1)xfp = 20 * np.log10(np.clip(np.abs(xf), 1e-20, 1e100))plt.figure(figsize=(20, 5))plt.plot(freqs, xfp)plt.xlabel('Freq(hz)')plt.ylabel('dB')plt.grid()plt.show()# 绘制频谱图
def plot_spectrogram(spec, note):fig = plt.figure(figsize=(20, 5))heatmap = plt.pcolor(spec)fig.colorbar(mappable=heatmap)plt.xlabel('Time(s)')plt.ylabel(note)plt.tight_layout()plt.show()if __name__ == '__main__':# signal 是音频信号,sample_rate 是采样率。fft_size 是用于离散傅里叶变换(FFT)的窗口大小。 spec 是频谱数据sample_rate, signal = wavfile.read('./zh.wav')# 打印采样率和信号长度的信息。signal = signal[0: int(3.5 * sample_rate)] # Keep the first 3.5 secondsprint('sample rate:', sample_rate, ', frame length:', len(signal))# plot_time函数绘制时域图,显示音频信号的波形。# plot_freq 函数绘制频域图,显示音频信号的频谱信息。plot_time(signal, sample_rate)plot_freq(signal, sample_rate)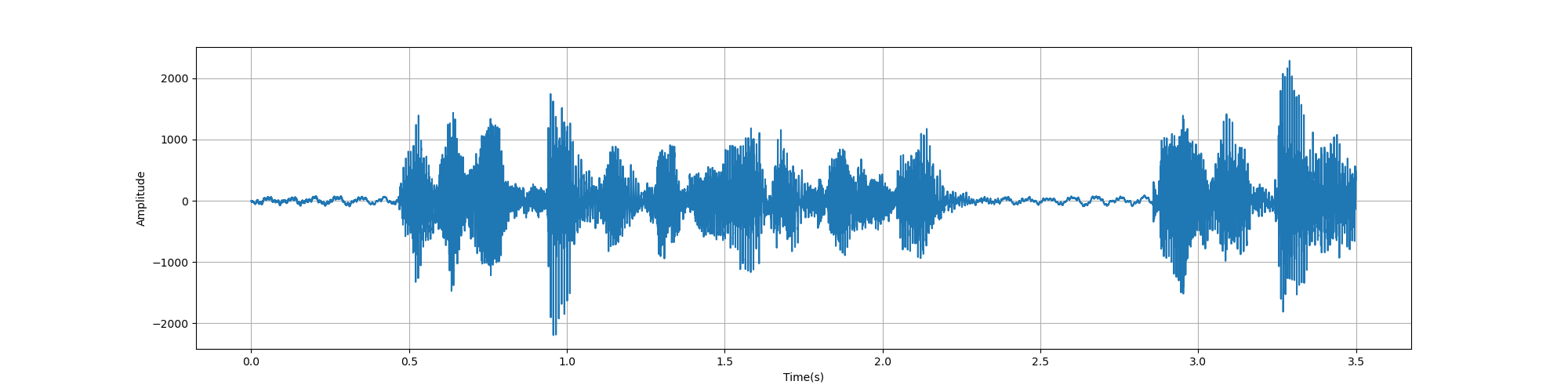
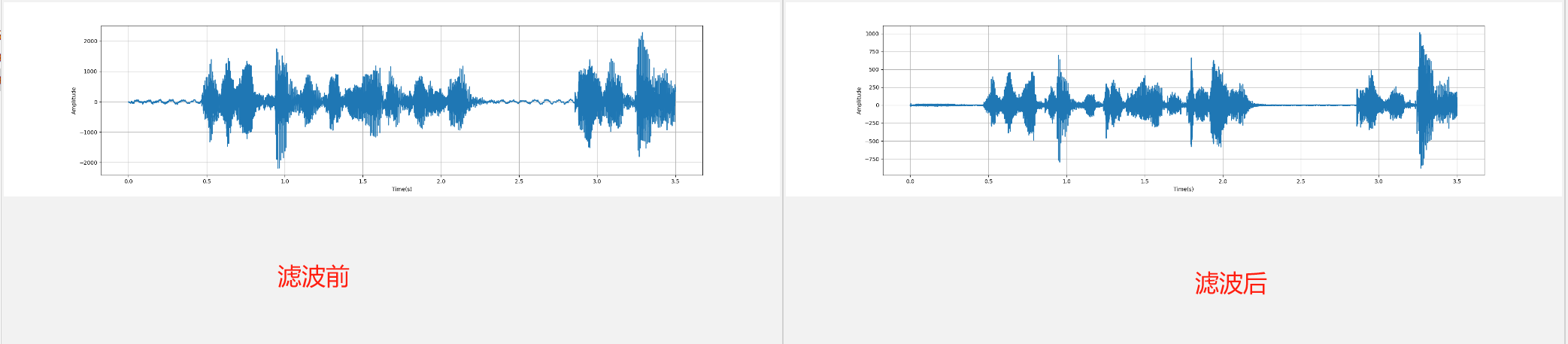
2.1.2 预加重(Pre-Emphasis)
-
在音频信号中突出重要的高频信息,减小低频噪音的影响,从而改善音频信号的特性,提高信噪比,以便更好地进行后续信号处理和特征提取
-
语音信号往往会有频谱倾斜(Spectral Tilt)现象,即高频部分的幅度会比低频部分的小,预加重在这里就是起到一个平衡频谱的作用,增大高频部分的幅度。它使用如下的一阶滤波器来实现:
y ( t ) = x ( t ) − α x ( t − 1 ) , 0.95 < α < 0.99 y(t)=x(t)-\alpha x(t-1), \quad 0.95<\alpha<0.99 y(t)=x(t)−αx(t−1),0.95<α<0.99
信号频率的高低主要是由信号电平变化的速度所决定,对信号做一阶差分时,高频部分(变化快的地方)差分值大,低频部分(变化慢的地方)差分值小,达到平衡频谱的作用。有助于减小信号的连续性,并提高语音特征的辨识度。一阶滤波器对音频信号中的快速变化进行增强,尤其是在高频部分。这有助于突出音频信号的高频成分,减小低频成分的影响。
添加以下代码:
pre_emphasis = 0.97
emphasized_signal = np.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
plot_time(emphasized_signal, sample_rate)
前后两张时域图对比:
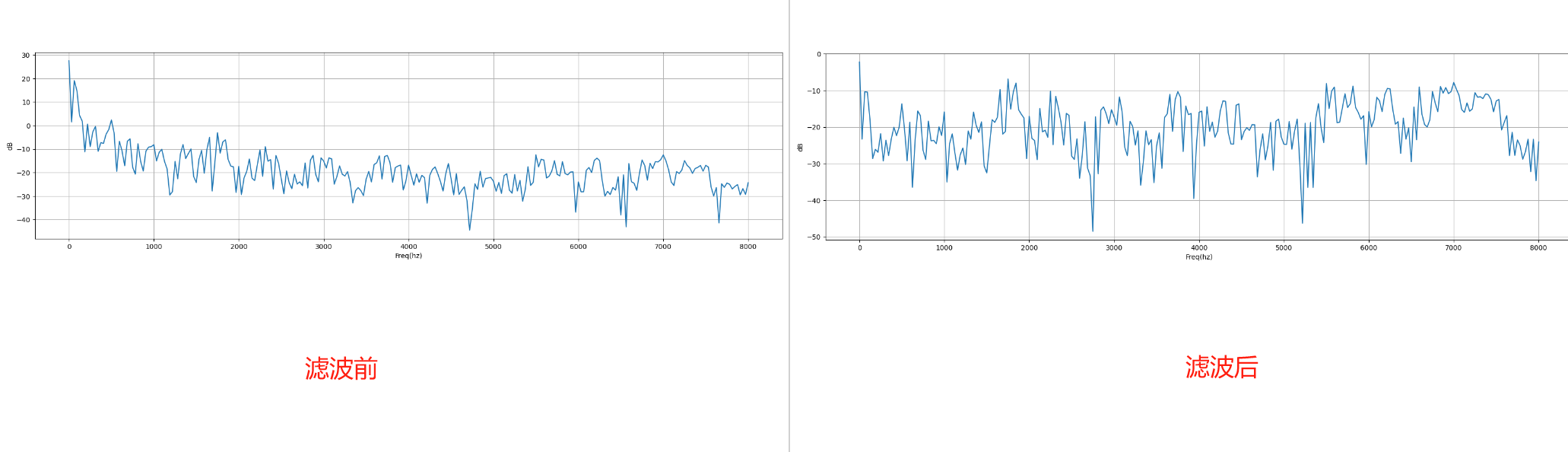
2.1.3 分帧
在预加重之后,需要将信号分成短时帧。分为短时帧原因如下:
- 时间-频域分析:语音信号通常是时域信号,通过分帧可以将长时间的语音信号分割成短时间的帧或段。也就是说:信号中的频率会随时间变化(不稳定的),一些信号处理算法(比如傅里叶变换)通常希望信号是稳定,认为每一帧之内的信号是短时不变的。每个帧可以视为短时间内的静态信号,这有助于进行时间-频域分析。语音信号在短时间内通常是稳态的,这使得在每个帧上进行频谱分析更加准确。
- 特征提取:在语音识别中,常常需要提取各种语音特征,例如梅尔频率倒谱系数(MFCC)、短时能量、短时过零率等。这些特征通常在每个帧上计算,然后用于训练和识别过程。分帧使得可以针对每个帧独立地计算这些特征,从而更好地捕获语音信号的动态特性。
- 噪声抑制:在分帧过程中,可以采用一些噪声抑制技术来减小每个帧上的噪声影响。这可以帮助提高语音识别系统的性能,尤其是在嘈杂环境中。
- 帧间重叠:通常,相邻帧之间会有一定的重叠,以确保语音信号的连续性。这有助于减小帧与帧之间的不连续性,使特征提取和识别过程更加平滑。
- 窗函数应用:在分帧过程中,通常会应用窗函数来减小每个帧的边界效应。常见的窗函数包括汉宁窗(Hanning window)和汉明窗(Hamming window)等。这些窗函数有助于减小帧边界处的振荡,提高频谱估计的准确性。
如何分帧:
- 采样率和帧长的选择:首先,需要确定音频信号的采样率和帧长。典型的采样率为8 kHz、16 kHz或者44.1 kHz等。帧长通常在20毫秒(ms)到30毫秒之间,常见的帧长是25 ms。帧移(帧之间的时间间隔)通常为10毫秒,以确保帧之间有重叠。
- 帧间重叠:为了减小帧与帧之间的不连续性,通常会应用帧间重叠。典型的重叠比例为50%或者75%,这意味着相邻帧之间有一半或三分之一的数据重叠。例如,对于25毫秒帧长,12.5毫秒的帧移可以实现50%的重叠。
- 窗函数的应用:在每个帧上应用窗函数以减小帧边界处的振荡。常用的窗函数包括汉宁窗(Hanning window)、汉明窗(Hamming window)、布莱克曼窗(Blackman window)等。窗函数的选择可以根据应用的具体需求来决定。
- 帧的提取:音频信号被划分为一系列重叠的帧。每个帧通常以时间域形式表示为一个一维数组。
- 特征提取:对每个帧进行特征提取,常用的特征包括梅尔频率倒谱系数(MFCC)、短时能量、短时过零率等。这些特征用于描述每个帧的频谱特性。
- 后续处理:提取的特征可以进一步进行处理,例如,进行降维、去除不相关的信息,或者用于语音识别系统的训练和分类。
# 定义帧的时长和帧之间的时间间隔(以秒为单位)
frame_size, frame_stride = 0.025, 0.01# 计算帧的长度和帧之间的时间间隔(以样本点数表示)
frame_length, frame_step = int(round(frame_size * sample_rate)), int(round(frame_stride * sample_rate))# 获取输入音频信号的长度
signal_length = len(emphasized_signal)# 计算需要的帧数量
num_frames = int(np.ceil(np.abs(signal_length - frame_length) / frame_step)) + 1# 计算填充后的信号长度,以确保能容纳所有帧
pad_signal_length = (num_frames - 1) * frame_step + frame_length# 创建一个零数组,用于填充信号,以满足长度要求
z = np.zeros((pad_signal_length - signal_length))
pad_signal = np.append(emphasized_signal, z)# 创建帧的索引矩阵
indices = np.arange(0, frame_length).reshape(1, -1) + np.arange(0, num_frames * frame_step, frame_step).reshape(-1, 1)# 提取每个帧并存储在 frames 数组中
frames = pad_signal[indices]# 打印帧数组的形状
print(frames.shape)2.1.4 加窗
- 改善信号的频谱分析窗函数
- (也称为窗口函数)是一种数学函数,它与原始信号相乘以限制信号在一段时间内的有效窗口,以减小频谱泄漏(spectral leakage)和改善频谱分辨率。加窗的主要目的包括以下几点:
- 减小频谱泄漏:频谱泄漏是指当你对一个信号进行傅立叶变换以进行频谱分析时,由于信号在无穷的时间范围内存在,导致频谱图中的能量泄漏到邻近的频率分量中。通过应用窗函数,你可以将信号限制在窗口内,减小了信号在窗口之外的影响,从而减小频谱泄漏。
- 窗口形状:窗口函数的形状可以根据需要选择,不同的窗口函数具有不同的性质。例如,汉宁窗(Hanning window)、汉明窗(Hamming window)和布莱克曼-哈里斯窗(Blackman-Harris window)等常见窗口函数具有不同的频谱特性,可用于调整频谱分析的性能。
- 频谱分辨率:窗口函数的选择会影响频谱分析的频率分辨率。某些窗口函数可以提供较高的频率分辨率,而其他窗口函数可以提供更低的频率分辨率。根据任务需求,可以选择适当的窗口函数来平衡时间分辨率和频率分辨率。
- 如果需要更精确的频谱分析和较低的频谱泄漏,则通常会选择布莱克曼-哈里斯窗。如果需要一般性能的窗口函数,可以考虑使用汉宁窗或汉明窗。选择窗口函数时,需要权衡频谱分辨率、频谱泄漏和计算复杂性等因素。
在分帧之后,通常需要对每帧的信号进行加窗处理。目的是让帧两端平滑地衰减,这样可以降低后续傅里叶变换后旁瓣的强度,取得更高质量的频谱。常用的窗有:矩形窗、汉明 (Hamming) 窗、汉宁窗 (Hanning),以汉明窗为例,其窗函数为:
w ( n ) = 0.54 − 0.46 cos ( 2 π n N − 1 ) w(n)=0.54-0.46 \cos \left(\frac{2 \pi n}{N-1}\right) w(n)=0.54−0.46cos(N−12πn)
这里的 0 < = n < = N − 1 , N 0<=n<=N-1 , N 0<=n<=N−1,N 是窗的宽度。
frames *= hamming
#%%
plot_time(frames[1], sample_rate)
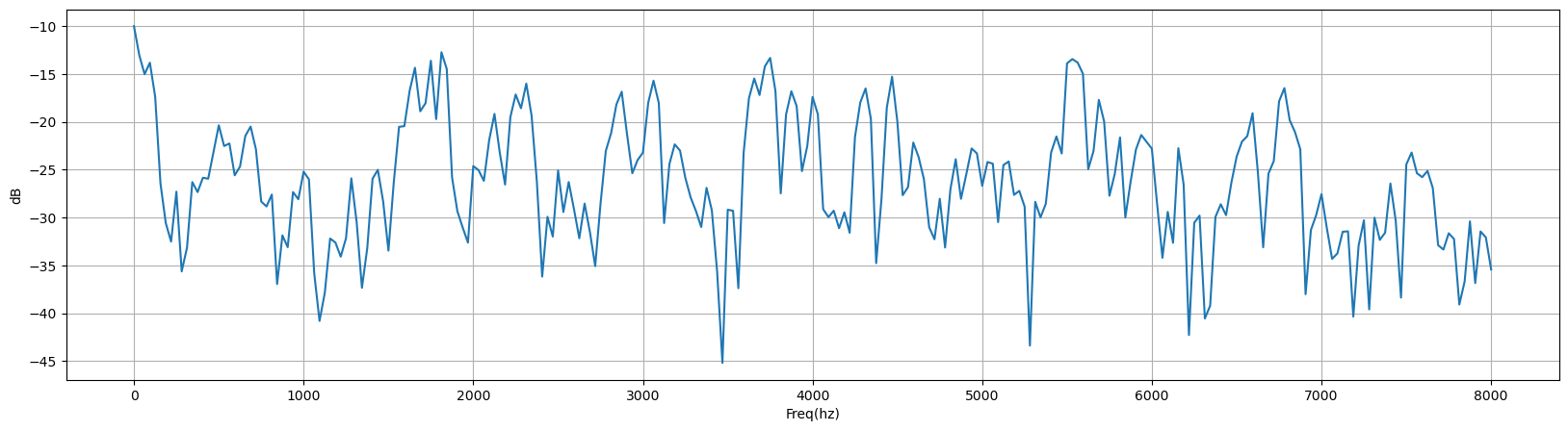
2.1.5 快速傅里叶变换 (FFT)
对于每一帧的加窗信号,进行N点FFT变换,也称短时傅里叶变换(STFT),N通常取256或512,然后用如下的公式计算能量谱:
P = ∣ F F T ( x i ) ∣ 2 N P=\frac{\left|F F T\left(x_i\right)\right|^2}{N} P=N∣FFT(xi)∣2
在信号处理中,对加窗后的信号进行快速傅里叶变换(FFT)的主要目的是将信号从时域转换为频域,以便进行频谱分析和频域特征提取。这个过程具有以下几个重要的原因和优势:
- 频谱分析: 加窗后的信号可以被视为有限持续时间的信号,这种信号的频谱是有限的,因此可以通过FFT来计算其频谱。频谱分析允许你了解信号在不同频率上的频率成分和能量分布。
- 频域特征提取: 对信号进行FFT后,可以提取各种频域特征,如频率、频谱幅度、相位等。这些特征对于信号识别、分析和处理非常有用,例如,在语音识别中提取声谱特征(MFCC)。
- 计算效率: 快速傅里叶变换(FFT)是一种高效的算法,可以快速计算大量数据点的频谱。与传统的傅里叶变换方法相比,FFT通常更快,因此适用于实时信号处理和大规模数据的频谱分析。
- 减小频谱泄漏: 使用窗口函数对信号加窗有助于减小频谱泄漏。频谱泄漏是指由于信号在时间轴上不是完美的周期信号,导致频谱中出现非目标频率分量的现象。通过加窗,你可以限制信号在窗口内,减小了信号在窗口之外的影响,从而减小了频谱泄漏。
NFFT = 512
mag_frames = np.absolute(np.fft.rfft(frames, NFFT))
pow_frames = ((1.0 / NFFT) * (mag_frames ** 2))
print(pow_frames.shape)
plt.figure(figsize=(20, 5))
plt.plot(pow_frames[1])
plt.grid()
2.1.6 FBank特征(Filter Banks)
过上面的步骤之后,在能量谱上应用Mel滤波器组,就能提取到FBank特征。Mel刻度,这是一个能模拟人耳接收声音规律的刻度,人耳在接收声音时呈现非线性状态,对高频的更不敏感,因此Mel刻度在低频区分辨度较高,在高频区分辨度较低,与频率之间的换算关系为:
m = 2595 log 10 ( 1 + f 700 ) f = 700 ( 1 0 m / 2595 − 1 ) \begin{gathered} m=2595 \log _{10}\left(1+\frac{f}{700}\right) \\ f=700\left(10^{m / 2595}-1\right) \end{gathered} m=2595log10(1+700f)f=700(10m/2595−1)
Mel滤波器组就是一系列的三角形滤波器,通常有 40 个或 80 个,在中心频率点响应值为 1 ,在两边的滤波器中心点衰减到0,如下图:
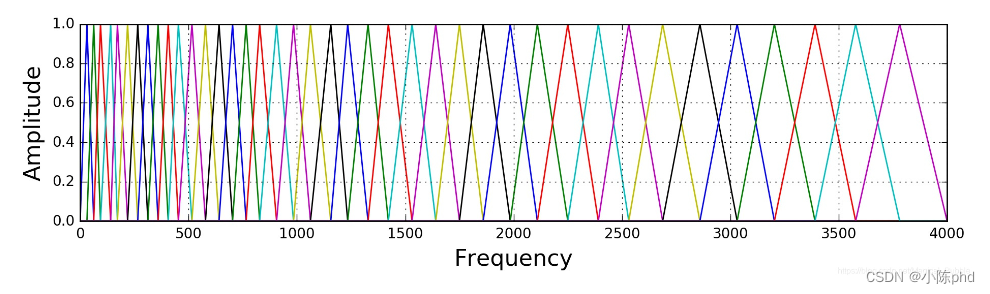
具体公式可以写为:
H m ( k ) = { 0 k < f ( m − 1 ) k − f ( m − 1 ) f ( m ) − f ( m − 1 ) f ( m − 1 ) ≤ k < f ( m ) 1 k = f ( m ) f ( m + 1 ) − k f ( m + 1 ) − f ( m ) f ( m ) < k ≤ f ( m + 1 ) 0 k > f ( m + 1 ) H_m(k)=\left\{\begin{array}{cl} 0 & k<f(m-1) \\ \frac{k-f(m-1)}{f(m)-f(m-1)} & f(m-1) \leq k<f(m) \\ 1 & k=f(m) \\ \frac{f(m+1)-k}{f(m+1)-f(m)} & f(m)<k \leq f(m+1) \\ 0 & k>f(m+1) \end{array}\right. Hm(k)=⎩ ⎨ ⎧0f(m)−f(m−1)k−f(m−1)1f(m+1)−f(m)f(m+1)−k0k<f(m−1)f(m−1)≤k<f(m)k=f(m)f(m)<k≤f(m+1)k>f(m+1)
最后在能量谱上应用Mel滤波器组,其公式为:
Y t ( m ) = ∑ k = 1 N H m ( k ) ∣ X t ( k ) ∣ 2 Y_t(m)=\sum_{k=1}^N H_m(k)\left|X_t(k)\right|^2 Yt(m)=k=1∑NHm(k)∣Xt(k)∣2
其中, k k k 表示FFT变换后的编号, m \mathrm{m} m 表示meli虑波器的编号。
low_freq_mel = 0
high_freq_mel = 2595 * np.log10(1 + (sample_rate / 2) / 700)
print(low_freq_mel, high_freq_mel)
nfilt = 40
mel_points = np.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # 所有的mel中心点,为了方便后面计算mel滤波器组,左右两边各补一个中心点
hz_points = 700 * (10 ** (mel_points / 2595) - 1)
fbank = np.zeros((nfilt, int(NFFT / 2 + 1))) # 各个mel滤波器在能量谱对应点的取值
bin = (hz_points / (sample_rate / 2)) * (NFFT / 2) # 各个mel滤波器中心点对应FFT的区域编码,找到有值的位置
for i in range(1, nfilt + 1):left = int(bin[i-1])center = int(bin[i])right = int(bin[i+1])for j in range(left, center):fbank[i-1, j+1] = (j + 1 - bin[i-1]) / (bin[i] - bin[i-1])for j in range(center, right):fbank[i-1, j+1] = (bin[i+1] - (j + 1)) / (bin[i+1] - bin[i])
print(fbank)
filter_banks = np.dot(pow_frames, fbank.T)
filter_banks = np.where(filter_banks == 0, np.finfo(float).eps, filter_banks)
filter_banks = 20 * np.log10(filter_banks) # dB
print(filter_banks.shape)
plot_spectrogram(filter_banks.T, 'Filter Banks')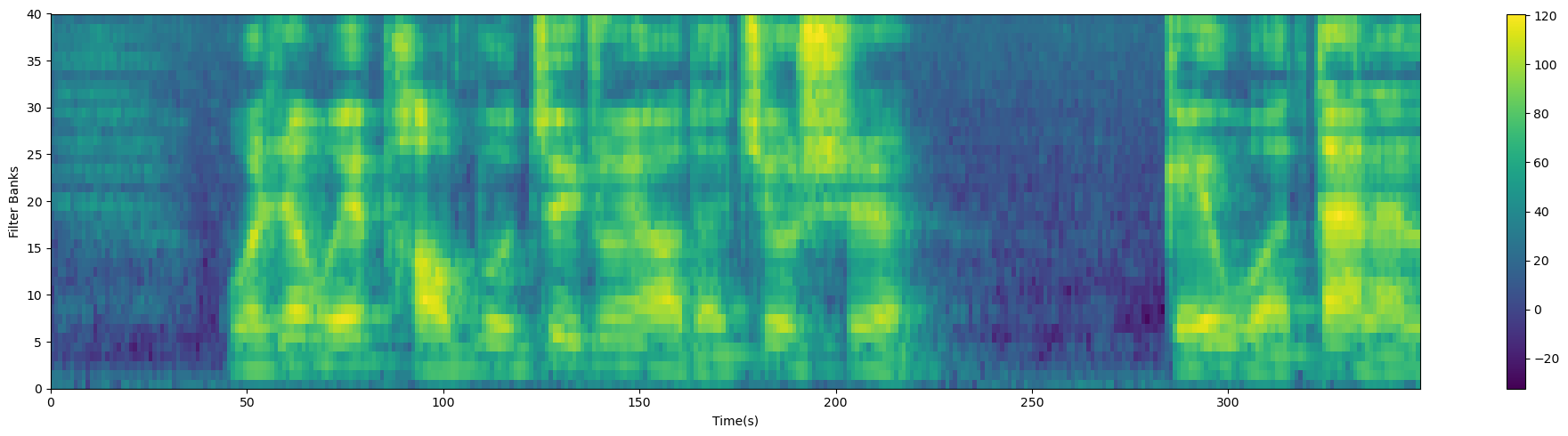
2.1.7 MFCC
Mel频率倒谱系数(MFCC)是一种常用于音频信号处理和语音识别的特征提取方法,它可以帮助捕捉声音的频谱信息。
对每个Mel滤波器通道的幅度谱取对数,以增加特征的动态范围,通常使用自然对数或对数变换。取对数后的结果表示为 l o g ( E ) log(E) log(E),其中 E E E 是能量。然后进行离散余弦变换(Discrete Cosine Transform,DCT): 对取对数后的Mel滤波器通道进行 D C T DCT DCT,以获得最终的 M F C C MFCC MFCC系数。 D C T DCT DCT的公式为:
C ( k ) = ∑ n = 0 N − 1 log ( E ( n ) ) ⋅ cos ( π N ⋅ k ⋅ ( n + 1 2 ) ) C(k) = \sum_{n=0}^{N-1} \log(E(n)) \cdot \cos\left(\frac{\pi}{N} \cdot k \cdot (n + \frac{1}{2})\right) C(k)=n=0∑N−1log(E(n))⋅cos(Nπ⋅k⋅(n+21))
其中, C ( k ) C(k) C(k) 是第 k k k 个 M F C C MFCC MFCC系数, N N N 是Mel滤波器通道的数量。
最终,得到的 M F C C MFCC MFCC系数 C ( k ) C(k) C(k) 可以用于进行音频特征的表示和分析,通常作为机器学习模型的输入用于语音识别等任务。这些系数捕捉了声音的频谱特征,具有很好的辨识性。
# MFCC绘制
num_ceps = 12
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1:(num_ceps+1)]
print(mfcc.shape)
plot_spectrogram(mfcc.T, 'MFCC Coefficients')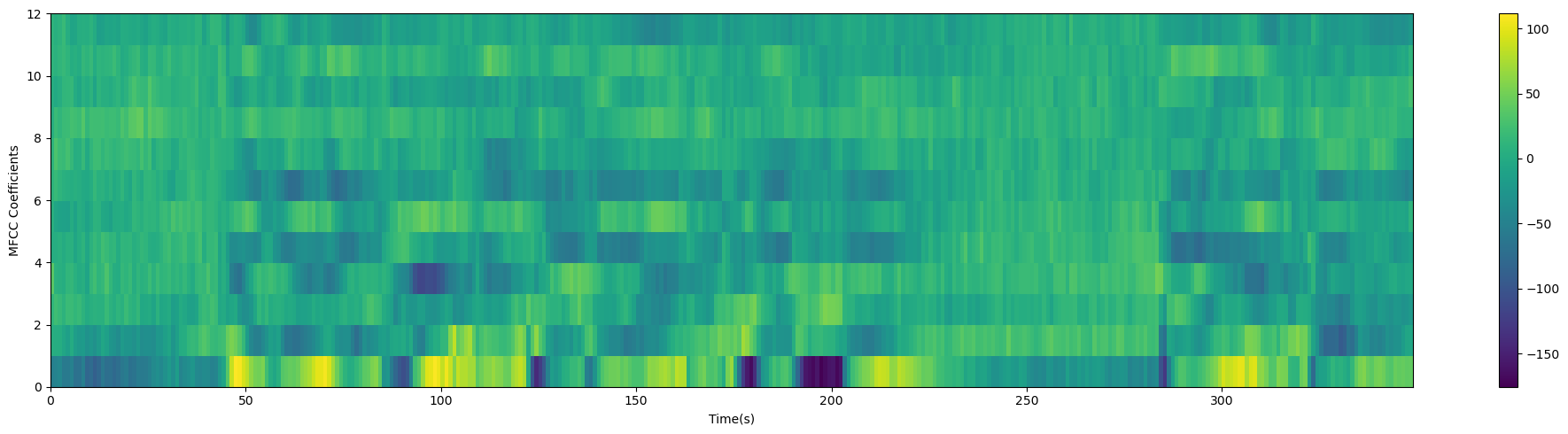
MFCC(Mel频率倒谱系数)计算通常包括一个正弦提升(cepstral mean normalization 或 cepstral mean subtraction)步骤,用于进一步改善MFCC特征的性能。正弦提升的目的是减小不同说话人和环境条件下的语音信号之间的差异,以提高语音识别系统的鲁棒性。
正弦提升的主要思想是在MFCC系数上应用一个谱凸显(spectral flattening)函数,以平滑MFCC系数之间的差异,并降低高频分量的权重,从而减小高频分量对语音识别的影响。正弦提升通常包括以下几个步骤:
-
计算MFCC系数:首先,计算原始MFCC系数,按照上述步骤计算出MFCC系数。
-
计算MFCC的均值:对于每个MFCC系数 (C(k)),计算在训练数据集中的所有样本中该系数的均值。这将得到一个均值向量,其中每个元素对应一个MFCC系数。
-
应用正弦提升:对于每个MFCC系数 (C(k)),将其减去相应的均值 (M(k)) 并乘以一个正弦提升系数(通常是一个谱凸显函数的系数),得到提升后的MFCC系数 (C’(k))。
C i ′ ( k ) = w C i ( k ) C'_i(k) = wC_i(k) Ci′(k)=wCi(k)w i = D 2 sin ( π ∗ i D ) w_i=\frac{D}{2} \sin \left(\frac{\pi * i}{D}\right) wi=2Dsin(Dπ∗i)
-
使用提升后的MFCC系数:可以使用提升后的MFCC系数 (C’(k)) 作为特征向量,用于语音识别或其他音频处理任务。
正弦提升有助于消除说话人和环境条件的变化,使MFCC特征更具判别性和鲁棒性。提升的程度通常由正弦提升系数的选择来控制,这个系数通常需要在训练数据上进行调整和优化。正弦提升是MFCC特征处理中的一个重要步骤,通常在计算MFCC后应用。
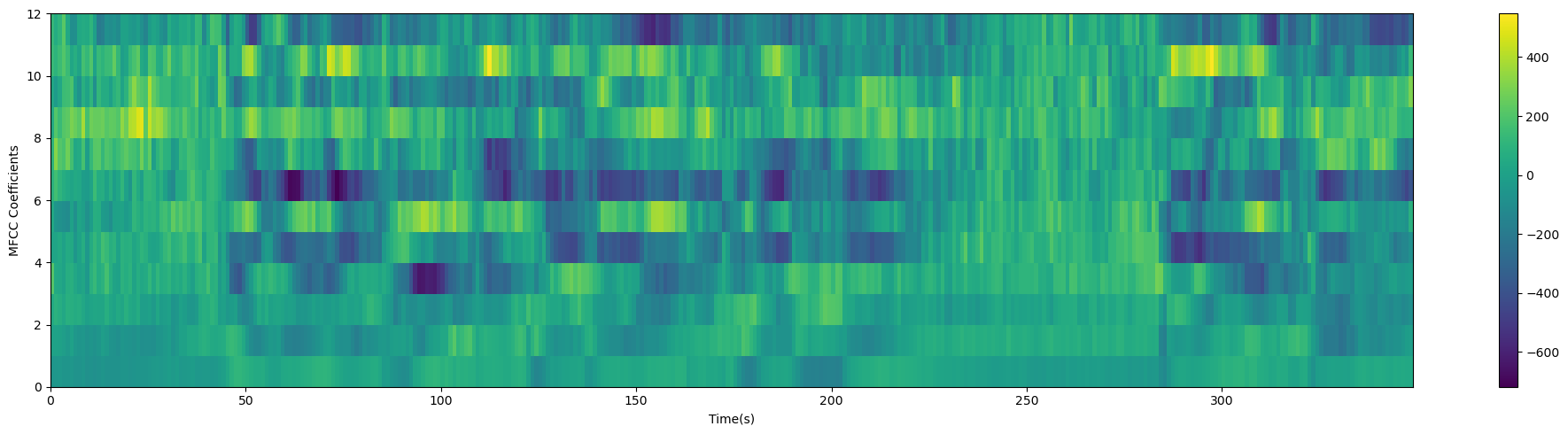
cep_lifter = 23
(nframes, ncoeff) = mfcc.shape
n = np.arange(ncoeff)
lift = 1 + (cep_lifter / 2) * np.sin(np.pi * n / cep_lifter)
mfcc *= lift
plot_spectrogram(mfcc.T, 'MFCC Coefficients')
参考笔记
通俗的讲解语音识别技术 - 知乎 (zhihu.com)
ASR中常用的语音特征之FBank和MFCC(原理 + Python实现)_完成fbank、mfcc两种声学特征提取的代码实现-CSDN博客
相关文章:
语音识别从入门到精通——1-基本原理解释
文章目录 语音识别算法1. 语音识别简介1.1 **语音识别**1.1.1 自动语音识别1.1.2 应用 1.2 语音识别流程1.2.1 预处理1.2.2 语音检测和断句1.2.3 音频场景分析1.2.4 识别引擎(语音识别的模型)1. 传统语音识别模型2. 端到端的语音识别模型基于Transformer的ASR模型基于CNN的ASR模…...

语音识别功能测试:90%问题,可以通过技术解决
现在市面上的智能电子产品千千万,为了达到人们使用更加方便的目的,很多智能产品都开发了语音识别功能,用来语音唤醒进行交互;另外,各大公司也开发出来了各种智能语音机器人,比如小米公司的“小爱”…...

【Go自学版】01-基础
// 变量 var a, b, c 8, 2.3, "hello" var d float64; e : 6var A []int; var B [10]int; C : [10]int{1, 2, 3, 4} for i : 0; i < len(B); i {} for _, value : range C {} D make([]int, 3) // len 4, cap 10, 扩容方式 cap*2 E : make([]int, 4, 10) E …...
软文开头怎么写才能拿捏用户?媒介盒子为您解答
软文标题是吸引用户点击的关键因素,那软文开头就是决定用户能否读下去的主要因素,很多运营er在写文案时经常会面临的情况之一就是好不容易想到一个标题,点击率不错,但是开头不行用户一看开头,跑了!如果不知…...
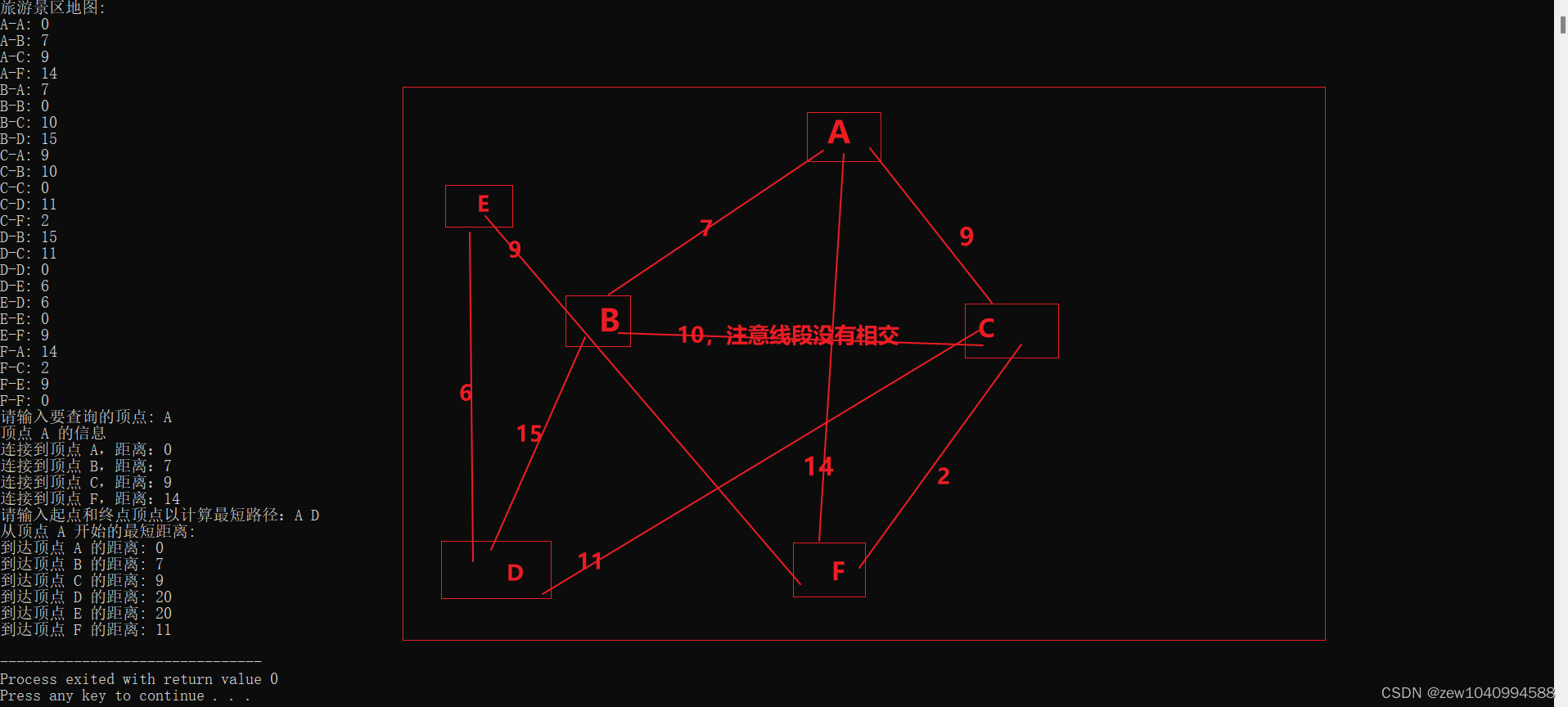
C语言算法与数据结构,旅游景区地图求最短路径
背景: 本次作业要求完成一个编程项目。请虚构一张旅游景区地图,景区地图包括景点(结点)和道路(边):地图上用字母标注出一些点,表示景点(比如,以点 A、B、C、…...

测试:SSE VS WebSocket
SSE(Server-Sent Events) SSE(Server-Sent Events)接口是一种实现服务器到客户端单向实时通信的技术。通过SSE,服务器可以主动向客户端推送数据,而不需要客户端不断地向服务器请求数据。这种技术特别适合于…...

Linux+Moba+虚拟机
软件: VMware Workstation ProMobaXterm 简介 是一款由VMware公司开发的强大的虚拟机软件。它可以在单台物理计算机上创建、运行和管理多个虚拟机,每个虚拟机都可以独立运行不同的操作系统和应用程序。 功能: 虚拟化:能…...

快手数仓面试题附答案
题目 1 讲一下你门公司的大数据项目架构?2 你在工作中都负责哪一部分3 spark提交一个程序的整体执行流程4 spark常用算子列几个,6到8个吧5 transformation跟action算子的区别6 map和flatmap算子的区别7 自定义udf,udtf,udaf讲一下…...

如何在Go中编写包
包由位于同一目录中的Go文件组成,这些文件在开头具有相同的package语句。你可以从包中包含额外的功能,使程序更复杂。有些包可以通过Go标准库获得,因此与Go安装一起安装。其他可以使用Go的go get命令安装。您还可以通过使用必要的package语句在要共享代码的相同目录中创建Go…...
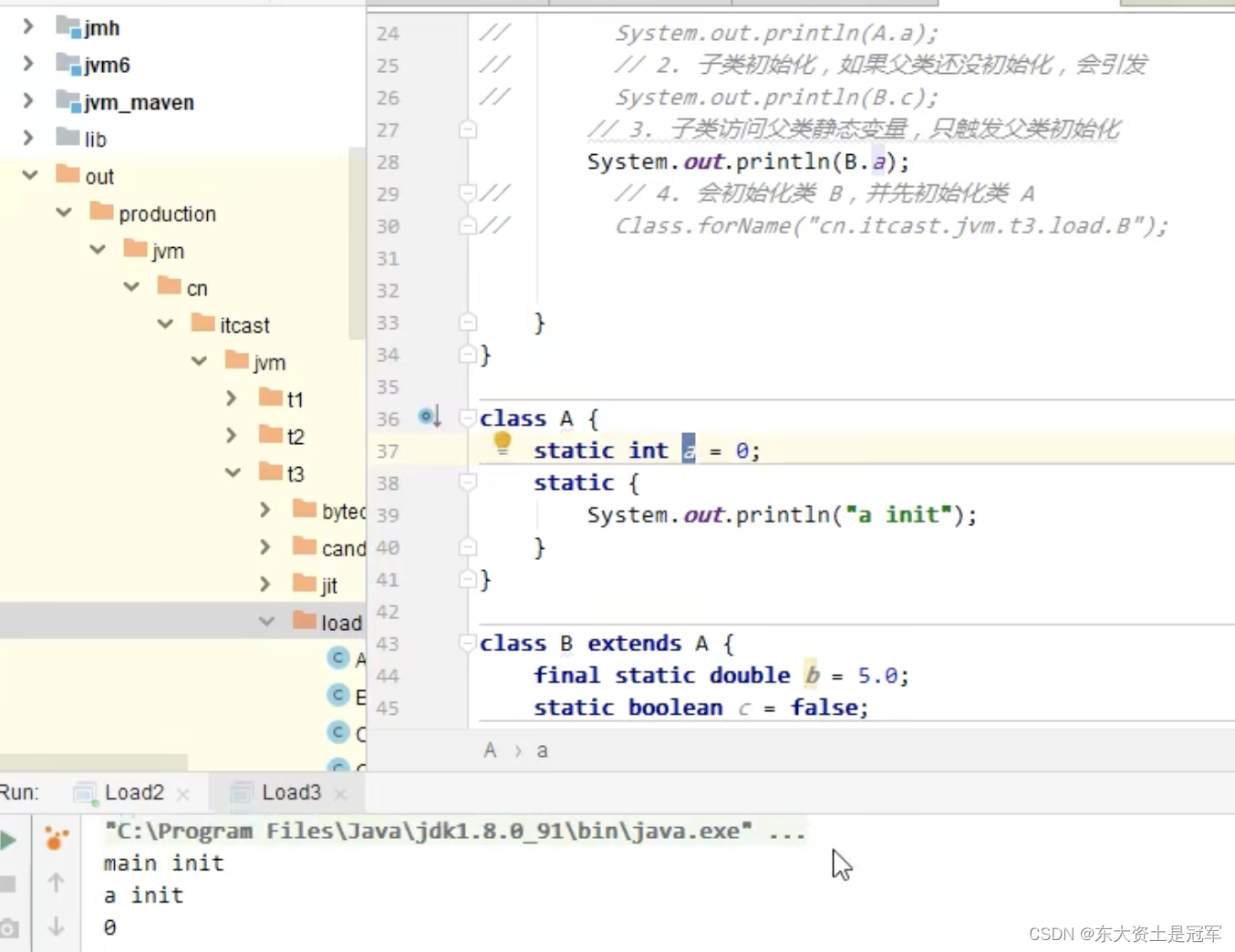
JVM类加载全过程
Java虚拟机类加载的全过程,即加载,验证,准备,解析,初始化 一、加载 加载 是 类加载过程中的一个阶段, 有以下三部分组成 1)通过一个类的全限定名来获取定义此类的二进制流 2)将这…...

Uniapp安卓原生插件开发Demo
文章目录 前言一、安装开发工具二、导入uni插件原生项目三、开发Module四、开发Component五、合并原生代码到uniapp项目中总结 前言 当HBuilderX中提供的能力无法满足App功能需求,需要通过使用Andorid/iOS原生开发实现时,可使用App离线SDK开发原生插件来…...
Axure的安装与基本使用
目录 一.Axure是什么 二.Axure安装 2.1 一键式安装 2.2 汉化 2.3 授权登录 三.Axure的界面介绍及基本使用 3.1 菜单栏的使用 3.2 工具栏的使用 3.3 页面概要的使用及组件的使用 3.4 组件的样式设计 一.Axure是什么 Axure是一个流行的交互式原型设计工具,一般是…...
分布式锁实现方案 - Lock4j 使用
一、Lock4j 分布式锁工具 你是不是在使用分布式锁的时候,还在自己用 AOP 封装框架?那么 Lock4j 你可以考虑一下。 Lock4j 是一个分布式锁组件,其提供了多种不同的支持以满足不同性能和环境的需求。 立志打造一个简单但富有内涵的分布式锁组…...
[虚拟机]使用VM打开虚拟机电脑重启解决方案。
问题:打开虚拟机点击启动后,电脑会自动重启。(WINDOWS10 20版本) 解决步骤: 1、对Windows功能进行操作。 上图三个启用。 上图一个取消。 再次打开后,不报警,显示下图问题: 继续解…...

Linux 详细介绍strace命令
system call(系统调用)是程序向内核请求服务的一种编程方式,strace是一个功能强大的工具,可以跟踪用户进程和 Linux 内核之间的交互。 要了解操作系统如何工作,首先需要了解系统调用如何工作。操作系统的主要功能之一是为用户程序提供了一个…...

【知识分享】__RS485-嵌入式常用的通信协议
目录 前言 一、RS485简介 什么是串口 什么是串行通信 什么是并行通信 二、接口原理 1. 连接方式 2. 差分信号 三、485通讯接口的优势 1. 接口电平低, 不易损坏芯片。 2. 传输速率高 3. 抗干扰能力强 4. 传输距离远,支持节点多。 四、常见…...
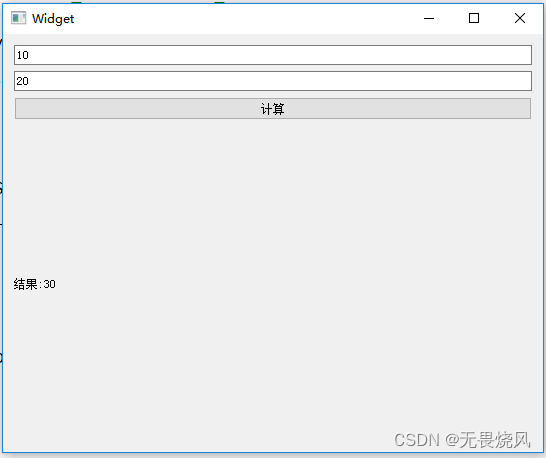
Qt生成动态链接库并使用动态链接库
项目结构 整个工程由一个主程序构成和一个模块构成(dll)。整个工程的结构目录如下 Define.priMyProject.proMyProject.pro.user ---bin ---MainProgrammain.cppMainProgram.proMainProgram.pro.userwidget.cppwidget.hwidget.ui ---MathDllMathDll.proMathDll.pro.userMyMath.…...

E4990A 阻抗分析仪,20 Hz 至 10/20/30/50/120 MHz
01 E4990A 阻抗分析仪 20 Hz 至 10/20/30/50/120 MHz 产品综述: E4990A 阻抗分析仪具有 20 Hz 至 120 MHz 的频率范围,可在宽阻抗范围内提供出色的 0.045%(典型值)基本准确度,并内置 40 V 直流偏置源,适…...
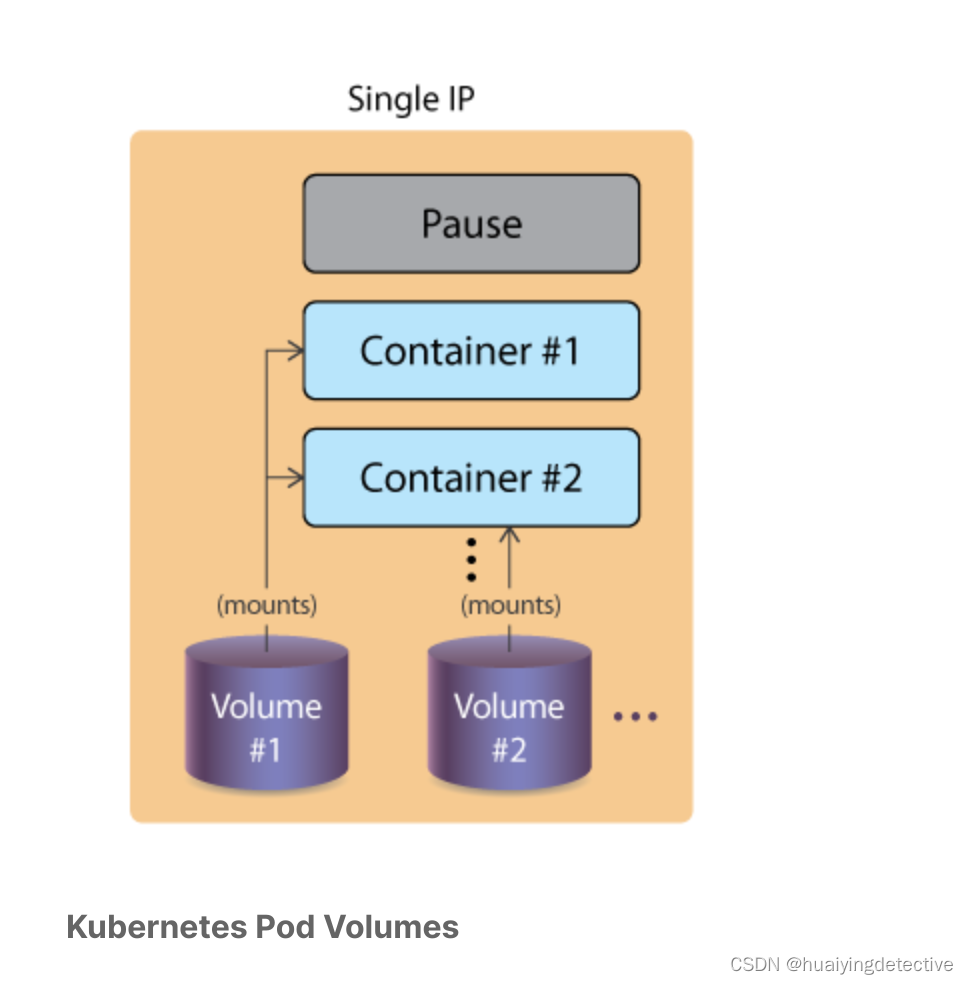
k8s volumes and data
Overview 传统上,容器引擎(Container Engine)不提供比容器寿命更长的存储。由于容器被认为是瞬态(transient)的,这可能会导致数据丢失或复杂的外部存储选项。Kubernetes卷共享 Pod 生命周期,而不是其中的容器。如果容器终止,数据…...

万宾科技智能水环境综合治理监测系统效果
水环境综合治理是一项旨在全面改善水环境质量的系统工程。它以水体为对象,综合考虑各种因素,通过科学规划和技术手段,解决水环境污染、生态退化等问题,核心理念是“统一规划、分步实施;标本兼治,重在治本&a…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...
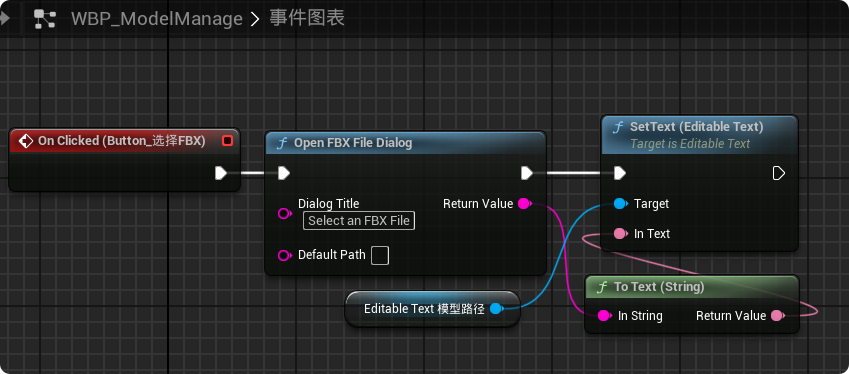
【UE5 C++】通过文件对话框获取选择文件的路径
目录 效果 步骤 源码 效果 步骤 1. 在“xxx.Build.cs”中添加需要使用的模块 ,这里主要使用“DesktopPlatform”模块 2. 添加后闭UE编辑器,右键点击 .uproject 文件,选择 "Generate Visual Studio project files",重…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...

用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法
用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法 大家好,我是Echo_Wish。最近刷短视频、看直播,有没有发现,越来越多的应用都开始“懂你”了——它们能感知你的情绪,推荐更合适的内容,甚至帮客服识别用户情绪,提升服务体验。这背后,神经网络在悄悄发力,撑起…...