RE2文本匹配调优实战
引言
在RE2文本匹配实战的最后,博主说过会结合词向量以及其他技巧来对效果进行调优,本篇文章对整个过程进行详细记录。其他文本匹配系列实战后续也会进行类似的调优,方法是一样的,不再赘述。
本文所用到的词向量可以在Gensim训练中文词向量实战文末找到,免费提供下载。
完整代码在文末。
数据准备
本次用的是LCQMC通用领域问题匹配数据集,它已经分好了训练、验证和测试集。
我们通过pandas来加载一下。
import pandas as pdtrain_df = pd.read_csv(data_path.format("train"), sep="\t", header=None, names=["sentence1", "sentence2", "label"])train_df.head()

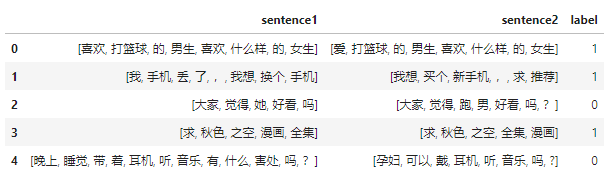
数据是长这样子的,有两个待匹配的句子,标签是它们是否相似。
下面用jieba来处理每个句子。
def tokenize(sentence):return list(jieba.cut(sentence))train_df.sentence1 = train_df.sentence1.apply(tokenize)
train_df.sentence2 = train_df.sentence2.apply(tokenize)
得到分好词的数据后,我们就可以得到整个训练语料库中的所有token:
train_sentences = train_df.sentence1.to_list() + train_df.sentence2.to_list()
train_sentences[0]
['喜欢', '打篮球', '的', '男生', '喜欢', '什么样', '的', '女生']
现在就可以来构建词表了,我们沿用之前的代码:
class Vocabulary:"""Class to process text and extract vocabulary for mapping"""def __init__(self, token_to_idx: dict = None, tokens: list[str] = None) -> None:"""Args:token_to_idx (dict, optional): a pre-existing map of tokens to indices. Defaults to None.tokens (list[str], optional): a list of unique tokens with no duplicates. Defaults to None."""assert any([tokens, token_to_idx]), "At least one of these parameters should be set as not None."if token_to_idx:self._token_to_idx = token_to_idxelse:self._token_to_idx = {}if PAD_TOKEN not in tokens:tokens = [PAD_TOKEN] + tokensfor idx, token in enumerate(tokens):self._token_to_idx[token] = idxself._idx_to_token = {idx: token for token, idx in self._token_to_idx.items()}self.unk_index = self._token_to_idx[UNK_TOKEN]self.pad_index = self._token_to_idx[PAD_TOKEN]@classmethoddef build(cls,sentences: list[list[str]],min_freq: int = 2,reserved_tokens: list[str] = None,) -> "Vocabulary":"""Construct the Vocabulary from sentencesArgs:sentences (list[list[str]]): a list of tokenized sequencesmin_freq (int, optional): the minimum word frequency to be saved. Defaults to 2.reserved_tokens (list[str], optional): the reserved tokens to add into the Vocabulary. Defaults to None.Returns:Vocabulary: a Vocubulary instane"""token_freqs = defaultdict(int)for sentence in tqdm(sentences):for token in sentence:token_freqs[token] += 1unique_tokens = (reserved_tokens if reserved_tokens else []) + [UNK_TOKEN]unique_tokens += [tokenfor token, freq in token_freqs.items()if freq >= min_freq and token != UNK_TOKEN]return cls(tokens=unique_tokens)def __len__(self) -> int:return len(self._idx_to_token)def __iter__(self):for idx, token in self._idx_to_token.items():yield idx, tokendef __getitem__(self, tokens: list[str] | str) -> list[int] | int:"""Retrieve the indices associated with the tokens or the index with the single tokenArgs:tokens (list[str] | str): a list of tokens or single tokenReturns:list[int] | int: the indices or the single index"""if not isinstance(tokens, (list, tuple)):return self._token_to_idx.get(tokens, self.unk_index)return [self.__getitem__(token) for token in tokens]def lookup_token(self, indices: list[int] | int) -> list[str] | str:"""Retrive the tokens associated with the indices or the token with the single indexArgs:indices (list[int] | int): a list of index or single indexReturns:list[str] | str: the corresponding tokens (or token)"""if not isinstance(indices, (list, tuple)):return self._idx_to_token[indices]return [self._idx_to_token[index] for index in indices]def to_serializable(self) -> dict:"""Returns a dictionary that can be serialized"""return {"token_to_idx": self._token_to_idx}@classmethoddef from_serializable(cls, contents: dict) -> "Vocabulary":"""Instantiates the Vocabulary from a serialized dictionaryArgs:contents (dict): a dictionary generated by `to_serializable`Returns:Vocabulary: the Vocabulary instance"""return cls(**contents)def __repr__(self):return f"<Vocabulary(size={len(self)})>"
主要修改是增加:
def __iter__(self):for idx, token in self._idx_to_token.items():yield idx, token
使得这个词表是可迭代的,其他代码参考完整代码。
模型实现
模型实现见RE2文本匹配实战,没有任何修改。
模型训练
主要优化在模型训练过程中,首先我们训练得更久——总epochs数设成50,同时我们引入早停策略,当模型不再优化则无需继续训练。
早停策略
class EarlyStopper:def __init__(self, patience: int = 5, mode: str = "min") -> None:self.patience = patienceself.counter = 0self.best_value = 0.0if mode not in {"min", "max"}:raise ValueError(f"mode {mode} is unknown!")self.mode = modedef step(self, value: float) -> bool:if self.is_better(value):self.best_value = valueself.counter = 0else:self.counter += 1if self.counter >= self.patience:return Truereturn Falsedef is_better(self, a: float) -> bool:if self.mode == "min":return a < self.best_valuereturn a > self.best_value
很简单,如果调用step()返回True,则触发了早停;通过best_value保存训练过程中的最佳指标,同时技术清零;其中patience表示最多忍耐模型不再优化次数;
学习率调度
当模型不再收敛时,还可以尝试减少学习率。这里引入的ReduceLROnPlateau就可以完成这件事。
lr_scheduler = ReduceLROnPlateau(optimizer, mode="max", factor=0.85, patience=0)for epoch in range(args.num_epochs):train(train_data_loader, model, criterion, optimizer, args.grad_clipping)acc, p, r, f1 = evaluate(dev_data_loader, model)# 当准确率不再下降,则降低学习率lr_scheduler.step(acc)
增加梯度裁剪值
梯度才才裁剪值增加到10.0。
载入预训练词向量
最重要的就是载入预训练词向量了:
def load_embedings(vocab, embedding_path: str, embedding_dim: int = 300, lower: bool = True
) -> list[list[float]]:word2vec = KeyedVectors.load_word2vec_format(embedding_path)embedding = np.random.randn(len(vocab), embedding_dim)load_count = 0for i, word in vocab:if lower:word = word.lower()if word in word2vec:embedding[i] = word2vec[word]load_count += 1print(f"loaded word count: {load_count}")return embedding.tolist()
首先加载word2vec文件;接着随机初始化一个词表大小的词向量;然后遍历(见上文)词表中的标记,如果标记出现在word2vec中,则使用word2vec的嵌入,并且计数加1;最后打印出工加载的标记数。
设定随机种子
def set_random_seed(seed: int = 666) -> None:np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed_all(seed)
为了让结果可复现,还实现了设定随机种子, 本文用的是 set_random_seed(seed=47),最终能达到测试集上84.6%的准确率,实验过程中碰到了85.0%的准确率,但没有复现。
训练
训练参数:
Arguments : Namespace(dataset_csv='text_matching/data/lcqmc/{}.txt', vectorizer_file='vectorizer.json', model_state_file='model.pth', pandas_file='dataframe.{}.pkl', save_dir='/home/yjw/workspace/nlp-in-action-public/text_matching/re2/model_storage', reload_model=False, cuda=True, learning_rate=0.0005, batch_size=128, num_epochs=50, max_len=50, embedding_dim=300, hidden_size=150, encoder_layers=2, num_blocks=2, kernel_sizes=[3], dropout=0.2, min_freq=2, project_func='linear', grad_clipping=10.0, num_classes=2)主要训练代码:
train_data_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True
)
dev_data_loader = DataLoader(dev_dataset, batch_size=args.batch_size)
test_data_loader = DataLoader(test_dataset, batch_size=args.batch_size)optimizer = torch.optim.AdamW(model.parameters(), lr=args.learning_rate)
criterion = nn.CrossEntropyLoss()lr_scheduler = ReduceLROnPlateau(optimizer, mode="max", factor=0.85, patience=0)best_value = 0.0early_stopper = EarlyStopper(mode="max")for epoch in range(args.num_epochs):train(train_data_loader, model, criterion, optimizer, args.grad_clipping)acc, p, r, f1 = evaluate(dev_data_loader, model)lr_scheduler.step(acc)if acc > best_value:best_value = accprint(f"Save model with best acc :{acc:4f}")torch.save(model.state_dict(), model_save_path)if early_stopper.step(acc):print(f"Stop from early stopping.")breakacc, p, r, f1 = evaluate(dev_data_loader, model)print(f"EVALUATE [{epoch+1}/{args.num_epochs}] accuracy={acc:.3f} precision={p:.3f} recal={r:.3f} f1 score={f1:.4f}")model.eval()acc, p, r, f1 = evaluate(test_data_loader, model)
print(f"TEST accuracy={acc:.3f} precision={p:.3f} recal={r:.3f} f1 score={f1:.4f}")model.load_state_dict(torch.load(model_save_path))
model.to(device)
acc, p, r, f1 = evaluate(test_data_loader, model)
print(f"TEST[best score] accuracy={acc:.3f} precision={p:.3f} recal={r:.3f} f1 score={f1:.4f}"
)
输出:
Arguments : Namespace(dataset_csv='text_matching/data/lcqmc/{}.txt', vectorizer_file='vectorizer.json', model_state_file='model.pth', pandas_file='dataframe.{}.pkl', save_dir='/home/yjw/workspace/nlp-in-action-public/text_matching/re2/model_storage', reload_model=False, cuda=True, learning_rate=0.0005, batch_size=128, num_epochs=50, max_len=50, embedding_dim=300, hidden_size=150, encoder_layers=2, num_blocks=2, kernel_sizes=[3], dropout=0.2, min_freq=2, project_func='linear', grad_clipping=10.0, num_classes=2)
Using device: cuda:0.
Loads cached dataframes.
Loads vectorizer file.
set_count: 4789
Model: RE2((embedding): Embedding((embedding): Embedding(4827, 300, padding_idx=0)(dropout): Dropout(p=0.2, inplace=False))(connection): AugmentedResidualConnection()(blocks): ModuleList((0): ModuleDict((encoder): Encoder((encoders): ModuleList((0): Conv1d((model): ModuleList((0): Sequential((0): Conv1d(300, 150, kernel_size=(3,), stride=(1,), padding=(1,))(1): GeLU())))(1): Conv1d((model): ModuleList((0): Sequential((0): Conv1d(150, 150, kernel_size=(3,), stride=(1,), padding=(1,))(1): GeLU()))))(dropout): Dropout(p=0.2, inplace=False))(alignment): Alignment((projection): Sequential((0): Dropout(p=0.2, inplace=False)(1): Linear((model): Sequential((0): Linear(in_features=450, out_features=150, bias=True)(1): GeLU()))))(fusion): Fusion((dropout): Dropout(p=0.2, inplace=False)(fusion1): Linear((model): Sequential((0): Linear(in_features=900, out_features=150, bias=True)(1): GeLU()))(fusion2): Linear((model): Sequential((0): Linear(in_features=900, out_features=150, bias=True)(1): GeLU()))(fusion3): Linear((model): Sequential((0): Linear(in_features=900, out_features=150, bias=True)(1): GeLU()))(fusion): Linear((model): Sequential((0): Linear(in_features=450, out_features=150, bias=True)(1): GeLU()))))(1): ModuleDict((encoder): Encoder((encoders): ModuleList((0): Conv1d((model): ModuleList((0): Sequential((0): Conv1d(450, 150, kernel_size=(3,), stride=(1,), padding=(1,))(1): GeLU())))(1): Conv1d((model): ModuleList((0): Sequential((0): Conv1d(150, 150, kernel_size=(3,), stride=(1,), padding=(1,))(1): GeLU()))))(dropout): Dropout(p=0.2, inplace=False))(alignment): Alignment((projection): Sequential((0): Dropout(p=0.2, inplace=False)(1): Linear((model): Sequential((0): Linear(in_features=600, out_features=150, bias=True)(1): GeLU()))))(fusion): Fusion((dropout): Dropout(p=0.2, inplace=False)(fusion1): Linear((model): Sequential((0): Linear(in_features=1200, out_features=150, bias=True)(1): GeLU()))(fusion2): Linear((model): Sequential((0): Linear(in_features=1200, out_features=150, bias=True)(1): GeLU()))(fusion3): Linear((model): Sequential((0): Linear(in_features=1200, out_features=150, bias=True)(1): GeLU()))(fusion): Linear((model): Sequential((0): Linear(in_features=450, out_features=150, bias=True)(1): GeLU())))))(pooling): Pooling()(prediction): Prediction((dense): Sequential((0): Dropout(p=0.2, inplace=False)(1): Linear((model): Sequential((0): Linear(in_features=600, out_features=150, bias=True)(1): GeLU()))(2): Dropout(p=0.2, inplace=False)(3): Linear((model): Sequential((0): Linear(in_features=150, out_features=2, bias=True)(1): GeLU()))))
)
New modelTRAIN iter=1866 loss=0.436723: 100%|██████████| 1866/1866 [01:55<00:00, 16.17it/s]
100%|██████████| 69/69 [00:01<00:00, 40.39it/s]
Save model with best accuracy :0.771302
EVALUATE [2/50] accuracy=0.771 precision=0.800 recal=0.723 f1 score=0.7598TRAIN iter=1866 loss=0.403501: 100%|██████████| 1866/1866 [01:57<00:00, 15.93it/s]
100%|██████████| 69/69 [00:01<00:00, 45.32it/s]
Save model with best accuracy :0.779709
EVALUATE [3/50] accuracy=0.780 precision=0.785 recal=0.770 f1 score=0.7777TRAIN iter=1866 loss=0.392297: 100%|██████████| 1866/1866 [01:45<00:00, 17.64it/s]
100%|██████████| 69/69 [00:01<00:00, 43.32it/s]
Save model with best accuracy :0.810838
EVALUATE [4/50] accuracy=0.811 precision=0.804 recal=0.822 f1 score=0.8130TRAIN iter=1866 loss=0.383858: 100%|██████████| 1866/1866 [01:46<00:00, 17.52it/s]
100%|██████████| 69/69 [00:01<00:00, 42.72it/s]
EVALUATE [5/50] accuracy=0.810 precision=0.807 recal=0.816 f1 score=0.8113TRAIN iter=1866 loss=0.374672: 100%|██████████| 1866/1866 [01:46<00:00, 17.55it/s]
100%|██████████| 69/69 [00:01<00:00, 44.62it/s]
Save model with best accuracy :0.816746
EVALUATE [6/50] accuracy=0.817 precision=0.818 recal=0.815 f1 score=0.8164TRAIN iter=1866 loss=0.369444: 100%|██████████| 1866/1866 [01:46<00:00, 17.52it/s]
100%|██████████| 69/69 [00:01<00:00, 45.27it/s]
EVALUATE [7/50] accuracy=0.815 precision=0.800 recal=0.842 f1 score=0.8203TRAIN iter=1866 loss=0.361552: 100%|██████████| 1866/1866 [01:47<00:00, 17.39it/s]
100%|██████████| 69/69 [00:01<00:00, 42.68it/s]
Save model with best accuracy :0.824926
EVALUATE [8/50] accuracy=0.825 precision=0.820 recal=0.832 f1 score=0.8262TRAIN iter=1866 loss=0.358231: 100%|██████████| 1866/1866 [01:50<00:00, 16.95it/s]
100%|██████████| 69/69 [00:01<00:00, 42.80it/s]
Save model with best accuracy :0.827312
EVALUATE [9/50] accuracy=0.827 precision=0.841 recal=0.808 f1 score=0.8239TRAIN iter=1866 loss=0.354693: 100%|██████████| 1866/1866 [01:55<00:00, 16.19it/s]
100%|██████████| 69/69 [00:01<00:00, 36.67it/s]
Save model with best accuracy :0.830607
EVALUATE [10/50] accuracy=0.831 precision=0.818 recal=0.851 f1 score=0.8340TRAIN iter=1866 loss=0.351138: 100%|██████████| 1866/1866 [02:02<00:00, 15.23it/s]
100%|██████████| 69/69 [00:02<00:00, 32.18it/s]
Save model with best accuracy :0.837991
EVALUATE [11/50] accuracy=0.838 precision=0.840 recal=0.836 f1 score=0.8376TRAIN iter=1866 loss=0.348067: 100%|██████████| 1866/1866 [01:52<00:00, 16.57it/s]
100%|██████████| 69/69 [00:01<00:00, 42.16it/s]
EVALUATE [12/50] accuracy=0.836 precision=0.836 recal=0.837 f1 score=0.8365TRAIN iter=1866 loss=0.343886: 100%|██████████| 1866/1866 [02:09<00:00, 14.43it/s]
100%|██████████| 69/69 [00:02<00:00, 32.44it/s]
Save model with best accuracy :0.839127
EVALUATE [13/50] accuracy=0.839 precision=0.838 recal=0.841 f1 score=0.8395TRAIN iter=1866 loss=0.341275: 100%|██████████| 1866/1866 [02:17<00:00, 13.60it/s]
100%|██████████| 69/69 [00:02<00:00, 32.74it/s]
Save model with best accuracy :0.842649
EVALUATE [14/50] accuracy=0.843 precision=0.841 recal=0.845 f1 score=0.8431TRAIN iter=1866 loss=0.339279: 100%|██████████| 1866/1866 [02:15<00:00, 13.74it/s]
100%|██████████| 69/69 [00:01<00:00, 42.64it/s]
Save model with best accuracy :0.846399
EVALUATE [15/50] accuracy=0.846 precision=0.858 recal=0.831 f1 score=0.8440TRAIN iter=1866 loss=0.338046: 100%|██████████| 1866/1866 [01:49<00:00, 17.00it/s]
100%|██████████| 69/69 [00:01<00:00, 42.64it/s]
EVALUATE [16/50] accuracy=0.844 precision=0.844 recal=0.843 f1 score=0.8436TRAIN iter=1866 loss=0.334223: 100%|██████████| 1866/1866 [01:59<00:00, 15.60it/s]
100%|██████████| 69/69 [00:02<00:00, 32.00it/s]
EVALUATE [17/50] accuracy=0.844 precision=0.836 recal=0.855 f1 score=0.8455TRAIN iter=1866 loss=0.331690: 100%|██████████| 1866/1866 [02:04<00:00, 15.01it/s]
100%|██████████| 69/69 [00:01<00:00, 42.16it/s]
EVALUATE [18/50] accuracy=0.844 precision=0.834 recal=0.860 f1 score=0.8465TRAIN iter=1866 loss=0.328178: 100%|██████████| 1866/1866 [01:49<00:00, 16.98it/s]
100%|██████████| 69/69 [00:01<00:00, 42.50it/s]
EVALUATE [19/50] accuracy=0.845 precision=0.842 recal=0.849 f1 score=0.8454TRAIN iter=1866 loss=0.326720: 100%|██████████| 1866/1866 [01:48<00:00, 17.12it/s]
100%|██████████| 69/69 [00:01<00:00, 41.95it/s]
Save model with best accuracy :0.847421
EVALUATE [20/50] accuracy=0.847 precision=0.844 recal=0.853 f1 score=0.8482TRAIN iter=1866 loss=0.324938: 100%|██████████| 1866/1866 [01:49<00:00, 16.99it/s]
100%|██████████| 69/69 [00:01<00:00, 43.29it/s]
EVALUATE [21/50] accuracy=0.845 precision=0.842 recal=0.848 f1 score=0.8452TRAIN iter=1866 loss=0.322923: 100%|██████████| 1866/1866 [01:48<00:00, 17.24it/s]
100%|██████████| 69/69 [00:01<00:00, 43.47it/s]
EVALUATE [22/50] accuracy=0.847 precision=0.844 recal=0.852 f1 score=0.8480TRAIN iter=1866 loss=0.322150: 100%|██████████| 1866/1866 [01:46<00:00, 17.51it/s]
100%|██████████| 69/69 [00:01<00:00, 42.77it/s]
Save model with best accuracy :0.849920
EVALUATE [23/50] accuracy=0.850 precision=0.839 recal=0.866 f1 score=0.8523TRAIN iter=1866 loss=0.320312: 100%|██████████| 1866/1866 [01:49<00:00, 17.06it/s]
100%|██████████| 69/69 [00:01<00:00, 41.91it/s]
EVALUATE [24/50] accuracy=0.847 precision=0.843 recal=0.853 f1 score=0.8479TRAIN iter=1866 loss=0.319144: 100%|██████████| 1866/1866 [01:49<00:00, 17.00it/s]
100%|██████████| 69/69 [00:01<00:00, 42.76it/s]
EVALUATE [25/50] accuracy=0.849 precision=0.841 recal=0.861 f1 score=0.8511TRAIN iter=1866 loss=0.318375: 100%|██████████| 1866/1866 [01:48<00:00, 17.20it/s]
100%|██████████| 69/69 [00:01<00:00, 43.52it/s]
EVALUATE [26/50] accuracy=0.850 precision=0.843 recal=0.859 f1 score=0.8512TRAIN iter=1866 loss=0.317125: 100%|██████████| 1866/1866 [01:48<00:00, 17.17it/s]
100%|██████████| 69/69 [00:01<00:00, 42.54it/s]
EVALUATE [27/50] accuracy=0.848 precision=0.841 recal=0.857 f1 score=0.8490TRAIN iter=1866 loss=0.316708: 100%|██████████| 1866/1866 [01:49<00:00, 17.03it/s]
100%|██████████| 69/69 [00:01<00:00, 42.04it/s]
Stop from early stopping.
100%|██████████| 98/98 [00:02<00:00, 38.74it/s]
TEST accuracy=0.846 precision=0.792 recal=0.938 f1 score=0.8587
100%|██████████| 98/98 [00:02<00:00, 39.47it/s]
TEST[best f1] accuracy=0.846 precision=0.793 recal=0.939 f1 score=0.8594一些结论
-
采用字向量而不是词向量,经实验比较自训练的词向量和字向量,后者效果更好;
-
有38个标记没有被word2vec词向量覆盖;
-
准确率达到84.6;
-
超过了网上常见的84.0;
-
训练了近30轮;
-
词向量word2vec仅训练了5轮,未调参,显然不是最优的,但也够用;
-
RE2模型应该还能继续优化,但没必要花太多时间调参;
从RE2模型开始,后续就进入预训练模型,像Sentence-BERT、SimCSE等。
但在此之前,计划先巩固下预训练模型的知识,因此文本匹配系列暂时不更新,等预训练模型更新差不多之后再更新。
完整代码
https://github.com/nlp-greyfoss/nlp-in-action-public/tree/master/text_matching/re2
相关文章:
RE2文本匹配调优实战
引言 在RE2文本匹配实战的最后,博主说过会结合词向量以及其他技巧来对效果进行调优,本篇文章对整个过程进行详细记录。其他文本匹配系列实战后续也会进行类似的调优,方法是一样的,不再赘述。 本文所用到的词向量可以在Gensim训练…...
Java - 线程间的通信方式
线程通信的方式 线程中通信是指多个线程之间通过某种机制进行协调和交互 线程通信主要可以分为三种方式,分别为共享内存、消息传递和管道流。每种方式有不同的方法来实现 共享内存:线程之间共享程序的公共状态,线程之间通过读-写内存中的公…...
【计算机网络】HTTP响应报文Cookie原理
目录 HTTP响应报文格式 一. 状态行 状态码与状态码描述 二. 响应头 Cookie原理 一. 前因 二. Cookie的状态管理 结束语 HTTP响应报文格式 HTTP响应报文分为四部分 状态行:包含三部分:协议版本,状态码,状态码描述响应头&a…...

2023年度盘点:智能汽车、自动驾驶、车联网必读书单
【文末送书】今天推荐几本自动驾驶领域优质书籍 前言 2023年,智能驾驶和新能源汽车行业仍然有着肉眼可见的新进展。自动驾驶技术继续尝试从辅助驾驶向自动驾驶的过渡,更重要的是相关技术成本的下降。根据《全球电动汽车展望2023》等行业报告,…...
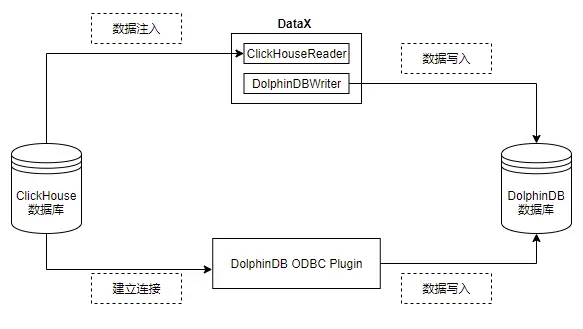
一文讲解如何从 Clickhouse 迁移数据至 DolphinDB
ClickHouse 是 Yandex 公司于2016年开源的 OLAP 列式数据库管理系统,主要用于 WEB 流量分析。凭借面向列式存储、支持数据压缩、完备的 DBMS 功能、多核心并行处理的特点,ClickHouse 被广泛应用于广告流量、移动分析、网站分析等领域。 DolphinDB 是一款…...
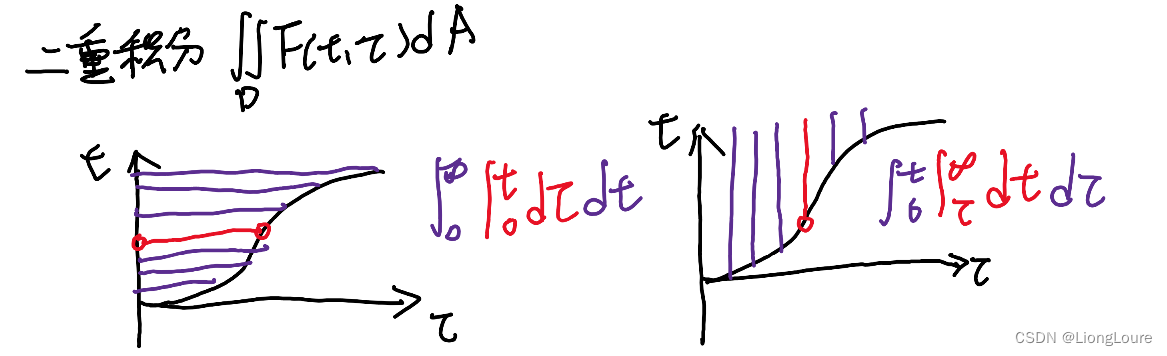
[足式机器人]Part2 Dr. CAN学习笔记-数学基础Ch0-5Laplace Transform of Convolution卷积的拉普拉斯变换
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记-数学基础Ch0-5Laplace Transform of Convolution卷积的拉普拉斯变换 Laplace Transform : X ( s ) L [ x ( t ) ] ∫ 0 ∞ x ( t ) e − s t d t X\left( s \right) \mathcal{L} \left[ x\lef…...
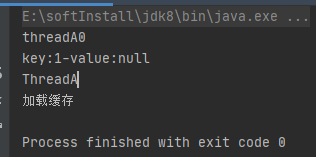
生产问题: 利用线程Thread预加载数据缓存,其它类全局变量获取缓存偶发加载不到
生产问题: 利用线程Thread预加载数据缓存偶发加载不到 先上代码 public class ThreadTest {//本地缓存Map<String, Object> map new HashMap<String, Object>();class ThreadA implements Runnable{Overridepublic void run() {System.out.println("Thread…...

Elasticsearch mapping 之 性能相关配置
ES 常见类型 通用类型: 二进制: binary 布尔型: boolean 字符串: keyword, constant_keyword, wildcard, text 别名: alias 对象: object, flattened, nested, join 结构化数据类型: Range, ip, version, murmur3 空间数据类型: geo_point, geo_shape, point, shape 性…...

adb push报错:remote couldn‘t create file: Is a directory
adb push报错:remote couldn‘t create file: Is a directory 出现这个问题可能是电脑本地目录中包含中文或者是目录地址中多包含了一个/ 比如说以下两种路径 1. test/测试音频文件1/a.mp3 2.test/test_audio/ 这两种都是不可以的(我是在as中执行的…...

GitLab 服务更换了机器,IP 地址或域名没有变化时,可能会出现无法拉取或提交代码的情况。
当 GitLab 服务更换了机器,但 IP 地址或域名没有变化时,可能会出现无法拉取或提交代码的情况。 这可能是由于 SSH 密钥或 SSL 证书发生了变化。以下是一些可能的解决步骤: 这可能是由于 SSH 密钥或 SSL 证书发生了变化。以下是一些可能的解决…...

【华为OD题库-076】执行时长/GPU算力-Java
题目 为了充分发挥GPU算力,需要尽可能多的将任务交给GPU执行,现在有一个任务数组,数组元素表示在这1秒内新增的任务个数且每秒都有新增任务。 假设GPU最多一次执行n个任务,一次执行耗时1秒,在保证GPU不空闲情况下&…...

持续集成交付CICD:Jenkins使用GitLab共享库实现前后端项目Sonarqube
目录 一、实验 1.Jenkins使用GitLab共享库实现后端项目Sonarqube 2.优化GitLab共享库 3.Jenkins使用GitLab共享库实现前端项目Sonarqube 4.Jenkins通过插件方式进行优化 二、问题 1.sonar-scanner 未找到命令 2.npm 未找到命令 一、实验 1.Jenkins使用GitLab共享库实现…...
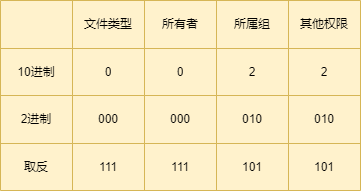
Linux文件结构与文件权限
基于centos了解Linux文件结构 了解一下文件类型 Linux采用的一切皆文件的思想,将硬件设备、软件等所有数据信息都以文件的形式呈现在用户面前,这就使得我们对计算机的管理更加方便。所以本篇文章会对Linux操作系统的文件结构和文件权限进行讲解。 首先…...

CentOS上安装和配置Apache HTTP服务器
在CentOS系统上安装和配置Apache HTTP服务器可以为您的网站提供可靠的托管环境。Apache是开源的Web服务器软件,具有广泛的支持和强大的功能。下面是在CentOS上安装和配置Apache HTTP服务器的步骤: 步骤一:安装Apache HTTP服务器 打开终端&am…...
———ES6迭代器)
前端知识(十二)———ES6迭代器
ES6中的迭代器是一种新的对象,它具有一个next()方法。next()方法返回一个对象,这个对象包含两个属性:value和done。value属性是迭代器中的下一个值,done属性是一个布尔值,表示迭代器是否已经遍历完所有的值。迭代器是一…...
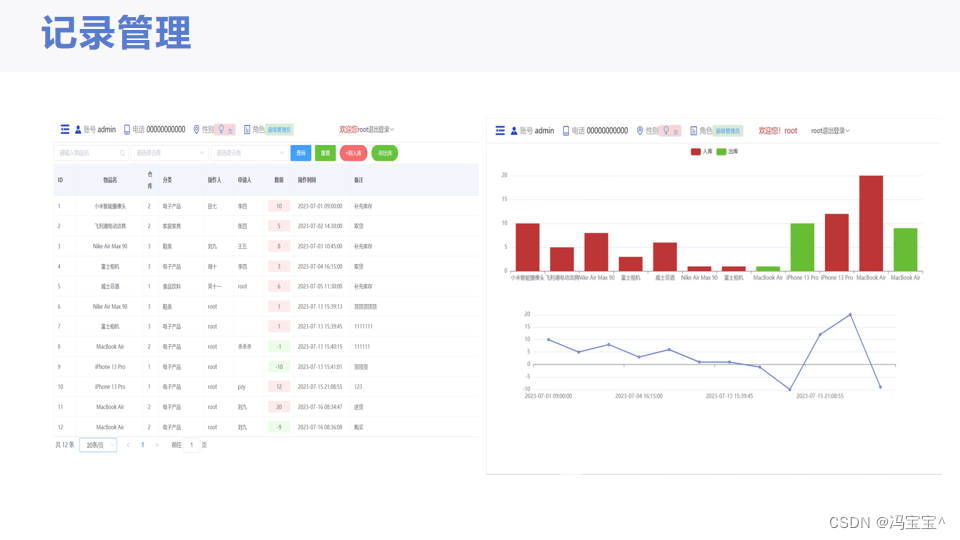
云端仓库平台
SpringBoot MySQL Vue 等技术实现的云端仓库 技术栈 核心框架:SpringBoot 持久层框架:MyBatis-Plus 前端框架:Vue 数据库:MySQL 项目包含源码和数据库文件。 效果图如下:...

php第三方skd自动加载
把mugou-sdk复制到项目下在composer.josn找到classmap加入sdk "autoload": {"classmap": ["mugou-sdk"] },在composer.josn找到files加入sdk "autoload": {"files":[mugou-sdk] },项目目录下运行 composer dump-autoload…...

Golang channle(管道)基本介绍、快速入门
channel(管道)-基本介绍 为什么需要channel?前面使用全局变量加锁同步来解决goroutine的通讯,但不完美 1)主线程在等待所有goroutine全部完成的时间很难确定,我们这里设置10秒,仅仅是估算。 2)如果主线程休眠时间长了,…...

盘点六款颇具潜力的伪原创AI工具
写作作为信息传递的主要媒介,在庞大的信息海洋中,为了在激烈的竞争中脱颖而出,伪原创AI工具成为越来越多写手的神秘利器。在本文中,我们将深入盘点六款颇具潜力的伪原创AI工具,为你揭开它们神秘的面纱。 1. 文心一言 …...
基于SSM的健身房预约系统设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

面试高频问题
文章目录 🚀 消息队列核心技术揭秘:从入门到秒杀面试官1️⃣ Kafka为何能"吞云吐雾"?性能背后的秘密1.1 顺序写入与零拷贝:性能的双引擎1.2 分区并行:数据的"八车道高速公路"1.3 页缓存与批量处理…...

二维FDTD算法仿真
二维FDTD算法仿真,并带完全匹配层,输入波形为高斯波、平面波 FDTD_二维/FDTD.zip , 6075 FDTD_二维/FDTD_31.m , 1029 FDTD_二维/FDTD_32.m , 2806 FDTD_二维/FDTD_33.m , 3782 FDTD_二维/FDTD_34.m , 4182 FDTD_二维/FDTD_35.m , 4793...

WebRTC调研
WebRTC是什么,为什么,如何使用 WebRTC有什么优势 WebRTC Architecture Amazon KVS WebRTC 其它厂商WebRTC 海康门禁WebRTC 海康门禁其他界面整理 威视通WebRTC 局域网 Google浏览器 Microsoft Edge 公网 RTSP RTMP NVR ONVIF SIP SRT WebRTC协…...
)
ArcPy扩展模块的使用(3)
管理工程项目 arcpy.mp模块允许用户管理布局、地图、报表、文件夹连接、视图等工程项目。例如,可以更新、修复或替换图层数据源,修改图层的符号系统,甚至自动在线执行共享要托管在组织中的工程项。 以下代码展示了如何更新图层的数据源&…...

ubuntu中安装conda的后遗症
缘由: 在编译rk3588的sdk时,遇到编译buildroot失败,提示如下: 提示缺失expect,但是实测相关工具是在的,如下显示: 然后查找借助各个ai工具,重新安装相关的工具,依然无解。 解决&am…...