Apache Doris 在某工商信息商业查询平台的湖仓一体建设实践
作者|某工商信息商业查询平台 高级数据研发工程师 李昂
信息服务行业可以提供多样化、便捷、高效、安全的信息化服务,为个人及商业决策提供了重要支撑与参考。对于行业相关企业来说,数据收集、加工、分析能力的重要性不言而喻。以某工商信息商业查询平台为例,其面对企业公开信息不断变化的挑战,如注册资本变更、股权结构变更、债务债权转移、对外投资变更等,这些信息的变更都要求平台及时更新。然而,面对庞大且频繁的数据变更,如何保证数据的准确性和实时性成为一项艰巨的任务。此外,随着数据量的不断增加,如何快速、高效的处理和分析这些数据成为另一个亟需解决的问题。
为应对上述挑战,该商业查询平台自 2020 年开始搭建数据分析平台,成功地实现了从传统 Lambda 架构到基于 Doris Multi-Catalog 的湖仓一体架构的演进。这种创新性的架构转变,使得该平台实现了离线及实时数仓的数据入口和查询出口的统一,满足了 BI 分析、离线计算、C 端高并发等业务需求,为企业内部、产品营销、客户运营等场景提供了强大的数据洞察及价值挖掘能力。
架构 1.0:传统 Lambda 架构
该商业查询平台成立之初,主要致力于 ToC 和 ToB 这两条业务线。ToC 业务线主要是为 C 端用户提供个性化、精准化的服务;而 ToB 业务线侧重于为 B 端客户提供数据接口服务与交付服务,同时也会处理一些公司内部数据分析需求,以数据驱动企业进行业务优化。
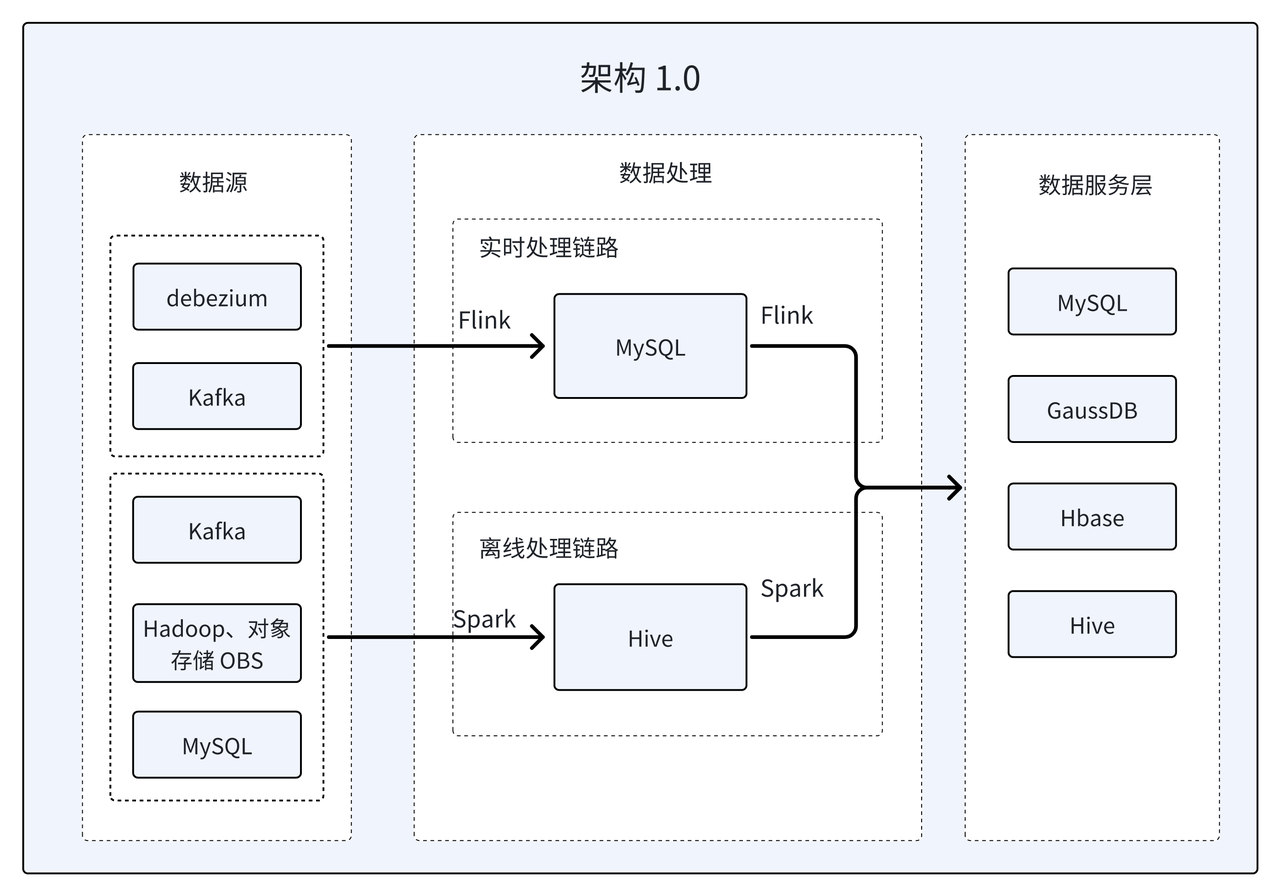
早期采用的是传统的 Lambda 架构,分为离线和实时两套处理流程。实时架构服务于对数据时效要求更高的 ToC 业务线, 离线架构侧重于存量数据修复与 T+7、T+15 的 ToB 数据交付服务等。该架构的优势在于项目开发可以灵活分段提测,并能快速响应业务需求的变化。但是在数据开发、运维管理等方面存在明显缺陷:
- 逻辑冗余:同一个业务方案需要开发离线和实时两套逻辑,代码复用率很低,这就增加了需求迭代成本和开发周期。此外,任务交接、项目管理以及架构运维的难度和复杂度也比较高,给开发团队带来较大的挑战。
- 数据不一致 :在当前架构中,当应用层数据来源存在多条链路时,极易出现数据不一致问题。这些问题不仅增加了数据排查的时间,还对数据的准确性和可靠性带来了负面影响。
- 数据孤岛:在该架构中,数据分散存储在不同的组件中。比如:普通商查表存储在 MySQL 中,主要支持 C 端的高并发点查操作;对于像 DimCount 涉及宽表频繁变更的数据,选择 HBase 的 KV 存储方式;对于单表数据量超过 60 亿的年度维表的点查,则借助 GaussDB 数据库实现。该方式虽然可以各自满足数据需求,但涉及组件较多且数据难以复用,极易造成数据孤岛,限制了数据的深度挖掘和利用。
除此之外,随着商业查询平台业务的不断扩展,新的业务需求不断涌现,例如需要支持分钟级灵活的人群包圈选与优惠券发放计算、订单分析与推送信息分析等新增数据分析需求。为了满足这些需求,该平台开始寻找一个能够集数据集成、查询、分析于一身的强大引擎,实现真正的 All In One。
OLAP 引擎调研
在选型调研阶段,该平台深入考察了 Apache Doris、ClickHouse、Greenplum 这三款数据库。结合早期架构痛点和新的业务需求,新引擎需要具备以下能力:
- 标准 SQL 支持:可使用 SQL 编写函数,学习和使用成本较低;
- 多表联合查询能力:支持人群包即时交并差运算、支持灵活配置的人群包圈选;
- 实时 Upsert 能力:支持 Push 推送日志数据的 Upsert 操作,每天需要更新的数据量高达 6 亿条;
- 运维难度:架构简单,轻量化部署及运维。
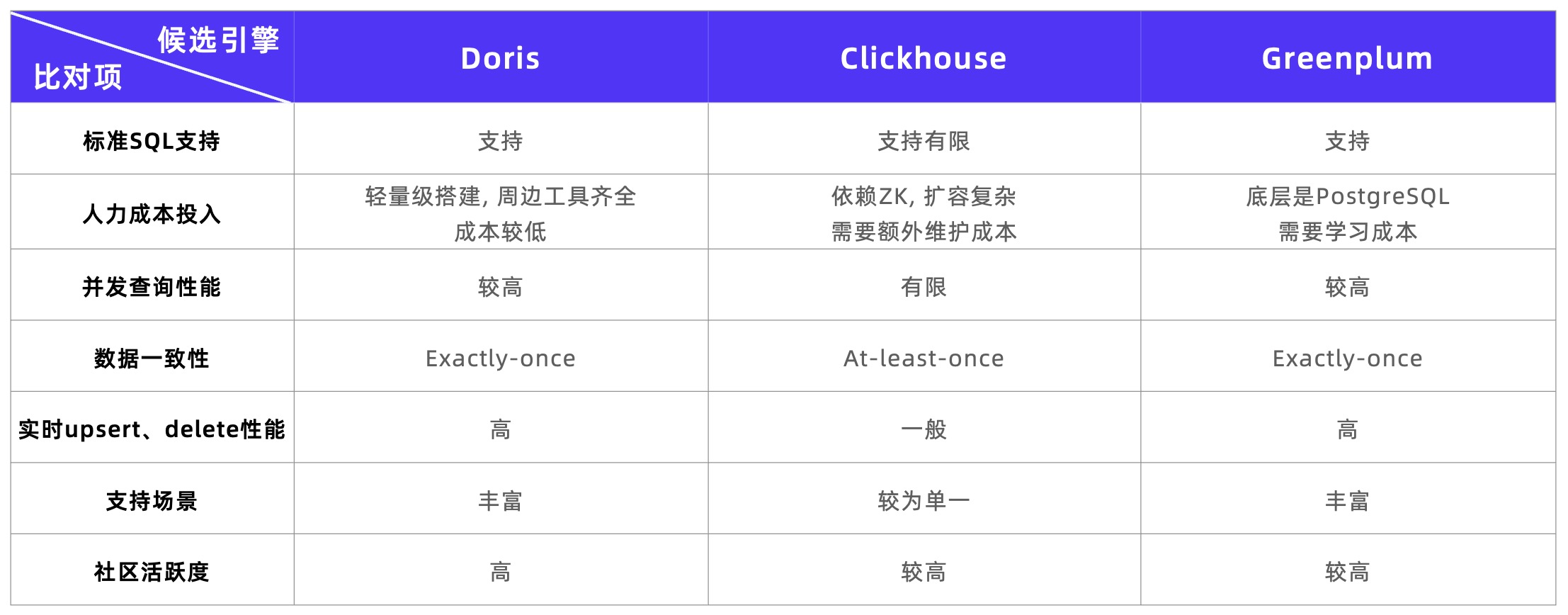
根据调研结果,可以发现 Apache Doris 优势明显、满足该平台的选型目标:
- 多种 Join 逻辑:通过 Colocation Join、Bucket Shuffle Join、Runtime Filter 等 Join 优化手段, 可在雪花模型的基础上进行高效的多表联合 OLAP 分析。
- 高吞吐 Upsert 写入:Unique Key 模型采用了 Merge-on-Write 写时合并模式,支持实时高吞吐的 Upsert 写入,并可以保证 Exactly-Once 的写入语义。
- 支持 Bitmap:Doris 提供了丰富的 Bitmap 函数体系,可便捷的筛选出符合条件的 ID 交并集,可有效提高人群圈选的效率。
- 极简易用:Doris 满足轻量化部署要求,仅有 FE、BE 两种进程,使得横向扩展变得简单,同时降低了版本升级的风险,更有利于维护。此外,Doris 完全兼容标准 SQL 语法,并在数据类型、函数等生态上提供了更全面的支持。
架构 2.0:数据服务层 All in Apache Doris
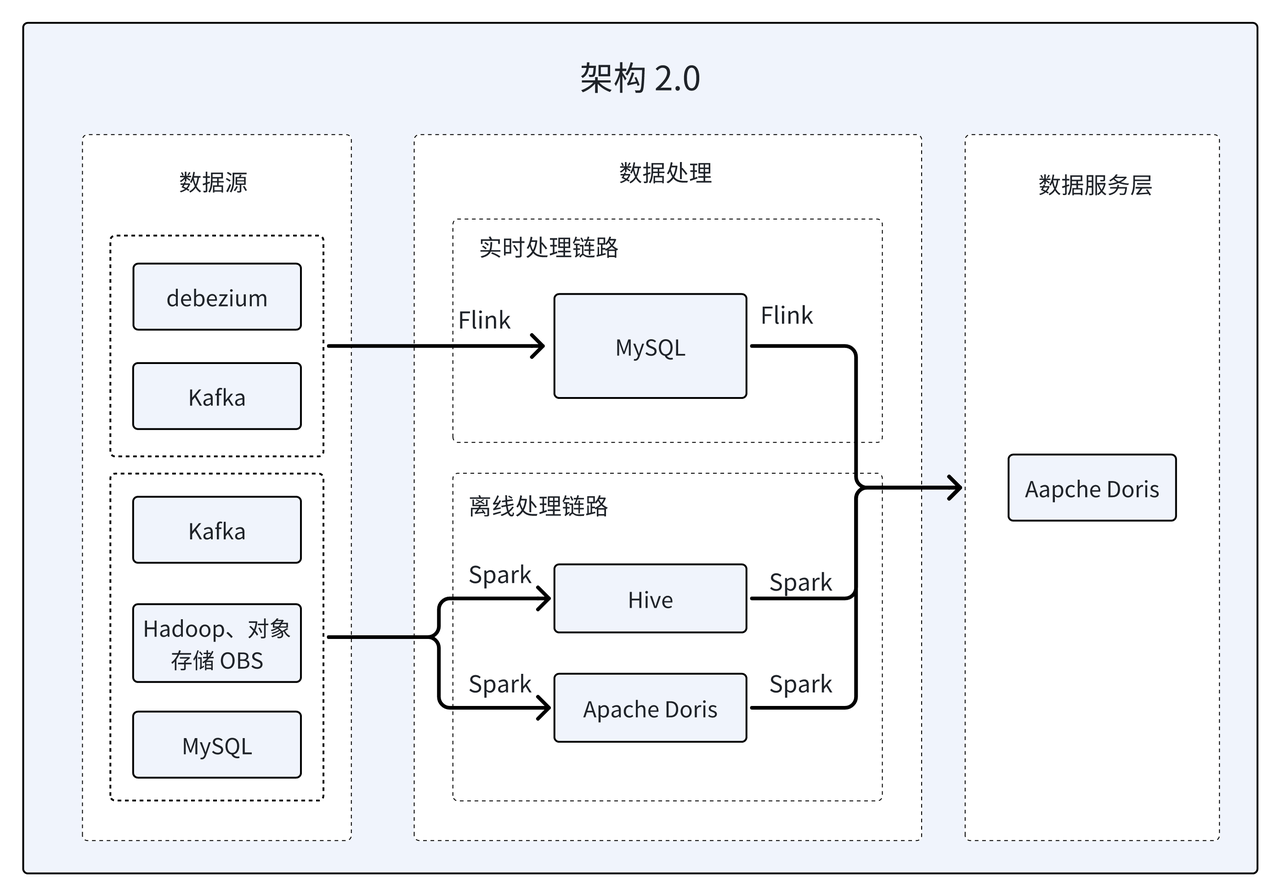
该商业查询平台基于 Apache Doris 升级了数据架构。首先使用 Apache Doris 替换了离线处理链路中的 Hive,其次通过对 Light Schema Change、Unique Key 写时合并等特性的尝试与实践,仅使用 Doris 就取代了早期架构中 GaussDB 、HBase、Hive 三种数据库,打破了数据孤岛,实现了数据服务层 All in Doris。
- 引入 Unique Key 写时合并机制 : 为了满足大表在 C 端常态并发下的点查需求,通过设置多副本并采用 Unique Key 写时合并机制,确保了数据的实时性和一致性。基于该机制 Doris 成功替代了 GaussDB,提供了更高效、更稳定的服务。
- 引入 Light Schema Change 机制 : 该机制使可以在秒级时间内完成 DimCount 表字段新增操作,提高了数据处理的效率。基于该机制 Doris 成功替代了 HBase,实现了更快速、更灵活的数据处理。
- 引入 PartialUpdate 机制 : 通过 Aggregate 模型的
REPLACE_IF_NOT_NULL,加速两表关联的开发,这一改进使得多表级联开发更加高效。
Apache Doris 上线后,其业务覆盖范围迅速扩大,并在短期内就取得了显著的成果:
- 2023 年 3 月,Apache Doris 正式上线后,运行了两个集群十余台 BE,这两个集群分别负责数分团队商业化分析与数据平台部架构优化,共同支撑大规模的数据处理分析的重要任务,每天支撑数据量高达 10 亿条,计算指标达 500+,支持人群包圈选、优惠券推送、充值订单分析及数据交付等需求。
- 2023 年 5 月,借助 Apache Doris 完成数分团队商业化分析集群 ETL 任务的流式覆写,近半离线定时调度任务迁移至 Doris 中,提高了离线计算任务的稳定性和时效性,同时绝大多数实时任务也迁移至 Apache Doris 中,整体集群规模达到二十余台。
尽管架构 2.0 中实现了数据服务层的 All in One,并且引入了 Doris 加速离线计算任务,但离线链路与实时链路仍然是割裂的状态,依旧面临处理逻辑重复、数据不一致的问题。其次,虽然引入 Doris 实现了大批量数据的实时更新与即时查询,但是对于时效性要求不高的离线任务,将其迁移至 Doris 集群可能会对在线业务的集群负载和稳定性产生一定的影响。因此,该平台计划进行下一步升级改造。
架构 3.0:基于 Doris Multi-Catalog 的湖仓一体架构
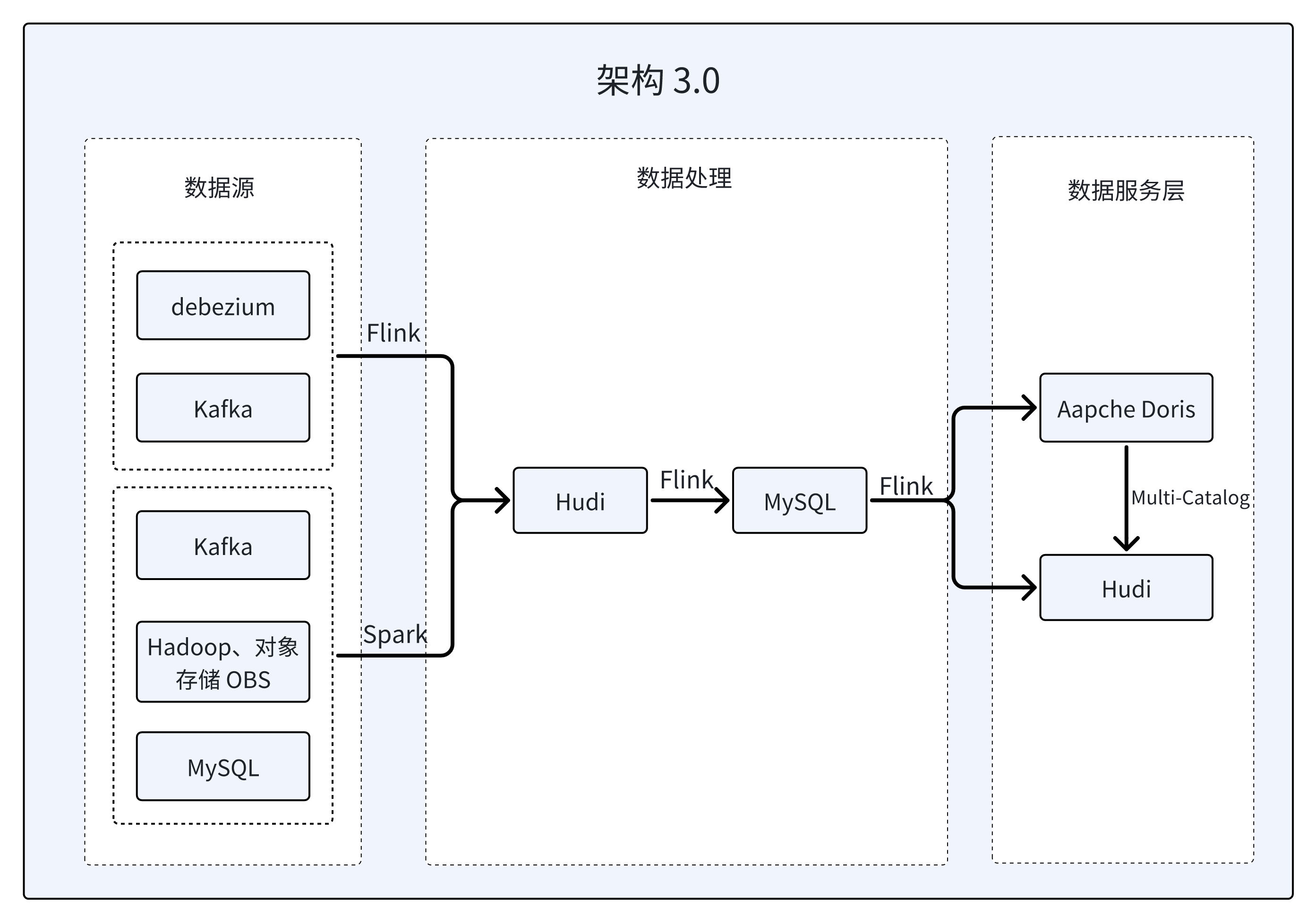
考虑到 Doris 多源 Catalog 具备的数据湖分析能力,该平台决定在架构中引入 Hudi 作为数据更新层,这样可以将 Doris 作为数据统一查询入口,对 Hudi 的 Read Optimized 表进行查询,并采用流批一体的方式将数据写入 Hudi,这样就实现了 Lambda 架构到 Kappa 架构的演进,完成了架构 3.0 的升级。
- 利用 Hudi 天然支持 CDC 的优势,在 ODS 层将 Hudi 作为 Queryable Kafka,实现贴源层数据接入。
- 使用 MySQL 作为 Queryable State 进行分层处理,最终结果首先会写入 MySQL,再根据数据用途同步到 Hudi 或 Doris 中。
- 对于存量数据的录入,通过自定义 Flink Source 实现全量数据的 Exactly Once 抽取至 Hudi,同时支持谓语下推与状态恢复。
根据不同业务的重要性程度,会将数据分别存储到 Doris 以及 Hudi 中,以最大程度地满足业务需求和性能要求:
- 针对进行人群圈选、Push 分析以及 C 端分析等在线业务,会将数据存储在 Doris 中,这样能够充分利用 Doris 的高性能特性响应线上的高并发查询,同时能够提升整体运营效率和客户满意度,确保关键数据的快速处理和高效访问。
- 其他偏离线业务的数据存储在 Hudi 中,通过 Doris 的 Hudi Catalog 进行联邦查询。通过存储和计算的分离可以降低 Tablet 的维护开销、提高集群的稳定性,同时这一架构也可以降低写入压力、提升计算时节点的 IO 与 CPU 利用率,实现更高效的数据处理和分析。
在架构 3.0 中,该查询平台将较为沉重的离线计算嵌入到数据湖中,使 Doris 能够专注于应用层计算,既能有效保证湖和仓在架构上的融合统一,也可以充分发挥湖和仓各自的能力优势。这一架构的演进也推进了集群规模的进一步扩展,截至目前 Doris 在该查询平台的机器规模已达数十台 ,数据探查、指标计算的维度超过 200 个、指标的总规模也超过了 1200。
实践经验
某工商信息商业查询平台在 C 端查询业务中面临的核心挑战如下:
- 超大规模明细表的高并发查询:平台中存在超 60 亿的超大规模明细表,需要提供对该明细表的高并发查询能力。
- 多维度深度分析:数据分析团队希望对 C 端数据进行多维度分析,深入挖掘更多隐藏维度及数据穿透关系,这需要强大的数据处理和灵活的数据分析能力,以便从大量数据中提取有价值的信息。
- 定制化实时看板:希望将某些固定模板的 SQL 定制为实时看板,并满足并发查询与分钟级数据新鲜度的要求。同时希望将实时数据看板嵌入到 C 端页面中,以增强 C 端功能性与便利性。
为应对 C 端提出的挑战,该平台利用了 Apache Doris 的多个特性,实现了单点查询速度提升 127 %、批量/全量数据条件查询速度提升 193% 、开发效率提升 100% 的显著提升,此外面向 C 端的并发能力显著增强,目前可以轻松承载高达 3000 QPS 的线上并发量。
01 引入 Merge-on-Write,百亿级单表查询提速近三倍
为解决年报相关表(数据量在 60 亿)在 C 端的高并发查询问题,同时实现降本增效的目标,该平台启用了 Doris 的 Unique Key Merge-on-Write 写时合并功能。
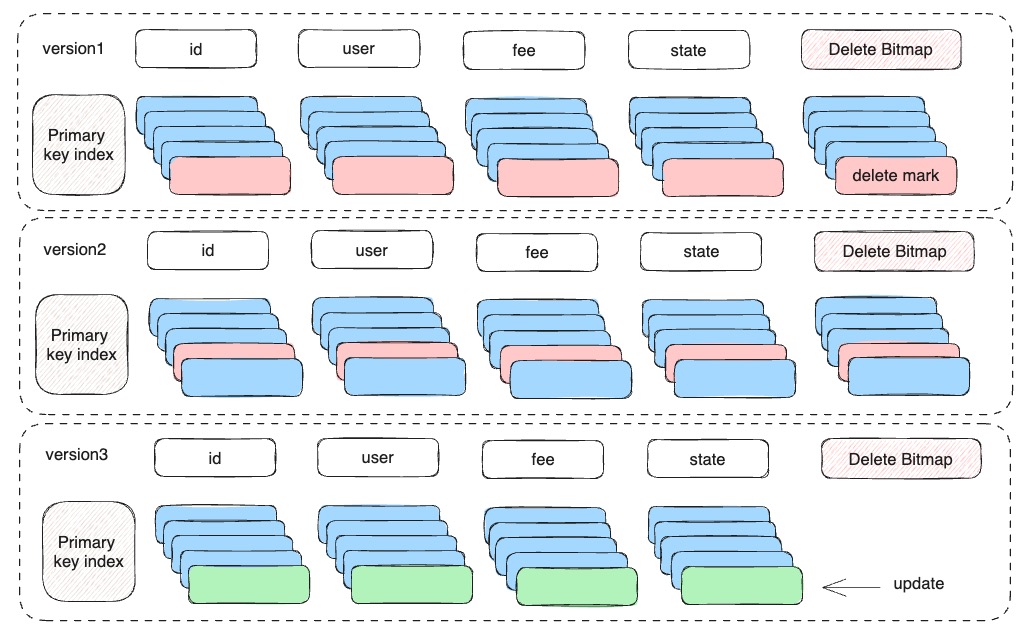
Merge-on-Write 写时合并是 Apache Doris 在 1.2.0 版本中引入的新特性,将 Unique Key 表的数据按主键去重工作从查询阶段转移到了写入阶段,因此在查询时可以获得与 Duplicate Key 表相当的性能。
具体来说,通过写时合并可以避免不必要的多路归并排序,始终保证有效的主键只出现在一个文件中(即在写入的时候保证了主键的唯一性),不需要在读取的时候通过归并排序来对主键进行去重,大大降低了 CPU 的计算资源消耗。同时也支持谓词下推,利用 Doris 丰富的索引在数据 IO 层面就能够进行充分的数据裁剪,大大减少数据的读取量和计算量,因此在很多场景的查询中都有比较明显的性能提升。
由于增加了写入流程去重的代价,写时合并的导入速度会受到一定影响,为尽可能的减少写时合并对导入性能的影响,Doris 使用了以下技术对数据去重的性能进行优化,因此在实时更新场景,去重代价可以做到用户感知不明显。
- 每个文件都生成一个主键索引, 用于快速定位重复数据出现的位置
- 每个文件都会维护一个 min/max key 区间,并生成一个区间树。查询重复数据时能够快速确定给定 key 可能存在于哪个文件中,降低查找成本
- 每个文件都维护一个 BloomFilter,当 Bloom Filter 命中时才会查询主键索引
- 通过多版本的 DeleteBitmap,来标记该文件被删除的行号
Unique Key 写时合并的使用比较简单, 只需要在表的 Properties 中开启即可。在此以 company_base_info 表为例,单表数据量约 3 亿行、单行数据约 0.8KB,单表全量数据写入耗时约 5 分钟。在开启 Merge-on-Write 写时合并后,执行查询的耗时从之前的 0.45 秒降低至 0.22 s,对批量或全量数据进行条件查询时耗时从 6.5 秒降低至 2.3 秒,平均性能提升接近 3 倍。
通过这种技术手段,实现了高性能的单点查询,大大提高了查询效率和响应速度,同时降低了查询成本。这一优化措施不仅满足了用户对数据查询的高要求,还为平台的稳定性和可持续性发展提供了有力保障
02 部分列数据更新,数据开发效率提升 100%
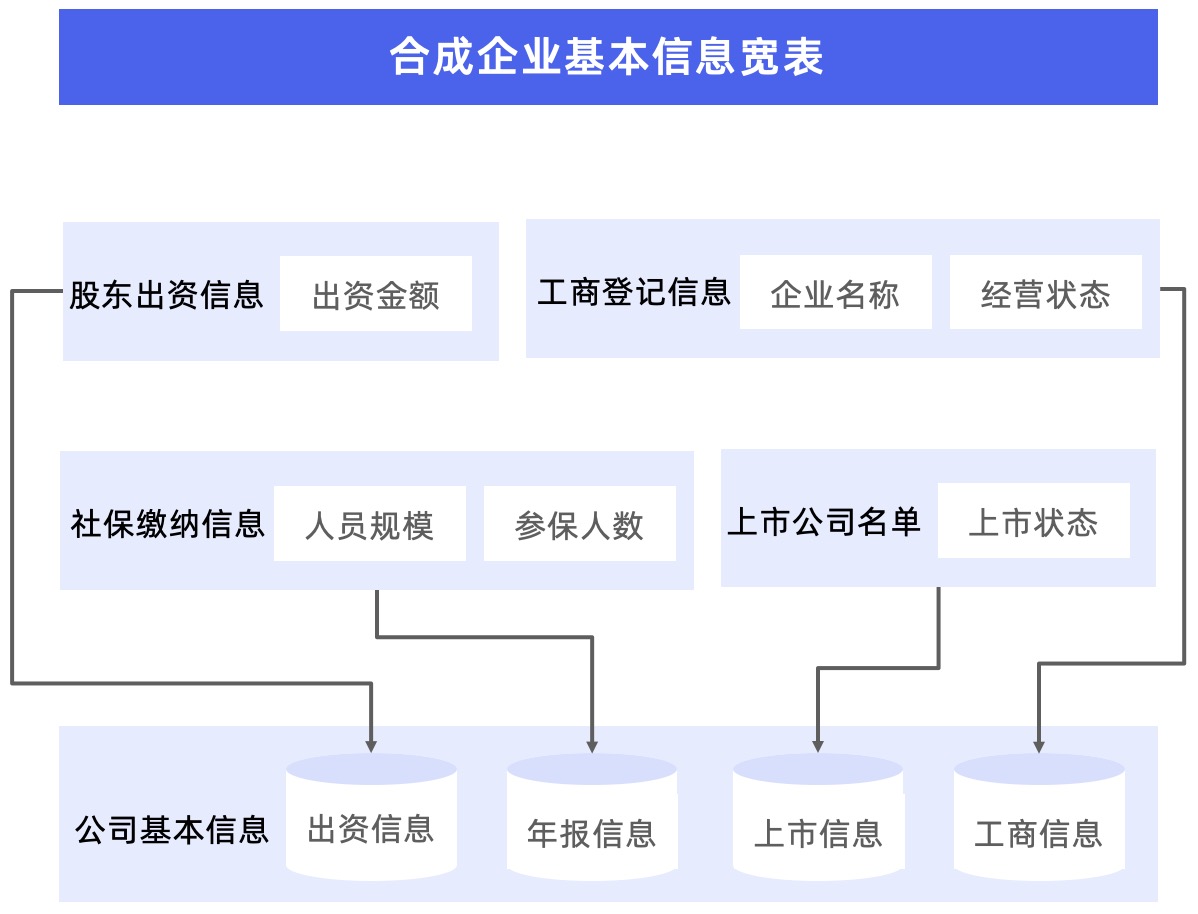
在该商业查询平台的业务场景中, 有一张包含企业各种维度的大宽表,而平台要求任意维度的数据变更都反映到落地表。在之前开发中,需要为每个维度开发一套类似 Lookup Join 的逻辑,以确保每个维度的变更都可以及时更新。
但是这种做法也带来一些问题,比如每新加入一个维度时,其他维度的逻辑也需要进行调整,这增加了开发和维护的复杂性和工作量。其次,为了保持上线的灵活性,该平台并没有将所有维度合并为一张表,而是将 3-5 个维
度拆分为一张独立的表,这种拆分方式也导致后续使用变得极为不方便。
@RequiredArgsConstructor
private static class Sink implements ForeachPartitionFunction<Row> {private final static Set<String> DIMENSION_KEYS = new HashSet<String>() {{add("...");}};private final Config config;@Overridepublic void call(Iterator<Row> rowIterator) {ConfigUtils.setConfig(config);DorisTemplate dorisTemplate = new DorisTemplate("dorisSink");dorisTemplate.enableCache();// config `delete_on` and `seq_col` if is uniqueDorisSchema dorisSchema = DorisSchema.builder().database("ads").tableName("ads_user_tag_commercial").build();while (rowIterator.hasNext()) {String json = rowIterator.next().json();Map<String, Object> columnMap = JsonUtils.parseJsonObj(json);// filter needed dimension columnsMap<String, Object> sinkMap = columnMap.entrySet().stream().filter(entry -> DIMENSION_KEYS.contains(entry.getKey())).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));dorisTemplate.update(new DorisOneRow(dorisSchema, sinkMap));}dorisTemplate.flush();}
}
为解决此问题,该平台采用了自定义的 DorisTemplate(内部封装 Stream Load),以实现对存量数据的处理。其核心思想是参考了 Kafka Producer 的实现方式,使用 Map 来缓存数据,并设立专门的 Sender 线程,根据时间间隔、数据条数或数据大小定期发送数据。
通过从源端过滤出所需的列,将其写入 Doris 的企业信息维表中。同时,针对两表 Join 场景,选择用 Agg 模型的 REPLACE_IF_NOT_NULL 进行优化,使得部分列的更新工作变得更加高效。
这种改进为开发工作带来了 100% 的效率提升,以单表三维度举例,以前需要 1 天的时间进行开发,而现在仅仅需要 0.5 天。这一改变提升了开发效率,使其能够更迅速地处理数据并满足业务需求。
值得一提的是,Apache Doris 在 2.0.0 版本中实现了 Unique Key 主键模型的部分列更新,在多张上游源表同时写入一张宽表时,无需由 Flink 进行多流 Join 打宽,直接写入宽表即可,减少了计算资源的消耗并大幅降低了数据处理链路的复杂性。
03 丰富 Join 的优化手段 ,整体查询速度最高提升近四倍

在该平台的业务场景中,超过 90% 的表都包含实体 ID 这一字段,因此对该字段构建了 Colocation Group,使查询时执行计划可以命中 Colocation Join,从而避免了数据 Shuffle 带来的计算开销。与普通的 Shuffle Join 相比,执行速度提升了 253%,极大地提高了查询效率。
对于一级维度下的某些二级维度,由于只存储了一级维度的主键 ID 而没有实体 ID 字段,如果使用传统的 Shuffle Join 进行查询,那么 A 表与 B 表都需要参与 Shuffle 操作。为了解决这个问题,该平台对查询语法进行了优化,使查询能够命中 Bucket Shuffle Join,从而降低了 50% 以上的 Shuffle 量,整体查询速度提升至少 77%。
04 Light Schema Change,线上 QPS 高达 3000+
为了提升 C 端并发能力,该平台为每个实体的每个维度都维护了一个 count 值。后端同学在查询数据前,会先查询该 count 值,只有在 count 值大于 0 的情况下,才会继续获取明细数据。为了适应维度不断扩张的迭代需求,选择采用了一套 SSD 存储的 HBase 集群,利用其 KV 存储特性维护了这套 count 值。
而 Doris Light Schema Change 在面对 5 亿的数据量时也可以实现秒级字段增加,因此该平台在架构 3.0 中 将 DimCount 程序从写 HBase 迁移到了写 Doris。在多副本与写时合并的功能的联合助力下,可以轻松承载高达 3000 的线上并发量。
当引入新的需要计算的维度时,处理流程如下:
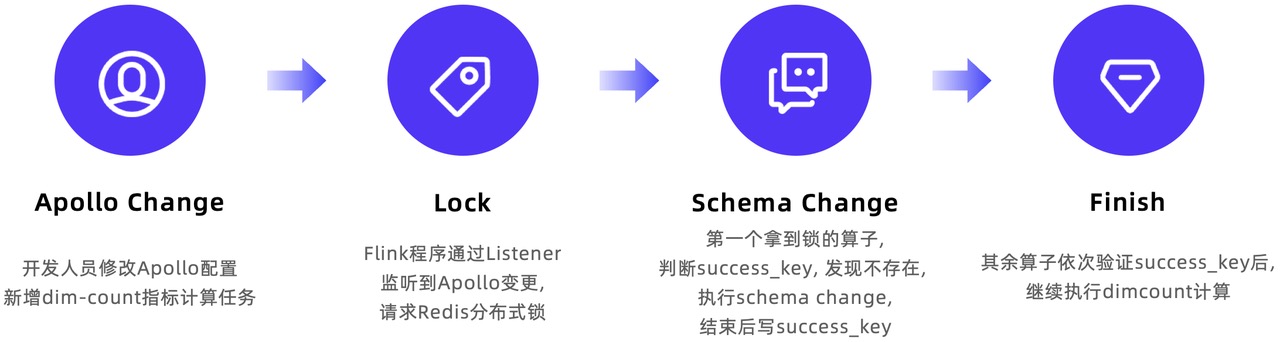
- 将其 KafkaTopic、查询 SQL 等信息录入 Apollo 配置平台
- Flink 程序通过 Apollo 的 Listener 检测到有新的指标,请求 Redis 分布式锁
- 查询该维度的
success_key, 判断是否完成过初始化 - 通过
alter table语句完成初始化,并设置success_key - 其他 subtask 顺次执行 2-4 步骤
- 程序继续执行,新的 count 值已经可以写入
05 优化实时 Join 场景,开发成本降低 70%
实时宽表 Join 的痛点在于多表外键关联,比如:select * from A join B on A.b_id=B.id join C on B.c_id = C.id 在实时模型构建时,A、B、C 三表都有可能各自发生实时变更,若要使得结果表对每个表的变化都进行实时响应,在 Flink 框架下有 2 种实现方式:
- A、B、C 三张表,每张表都开发一套关联另外两张表的 Lookup Join 逻辑。
- 设置 Flink 中 State 存储的 TTL 为更长时间,例如 3 天。这样可以保证在 3 天内的数据变化能够被实时感知和处理, 同时,通过每日离线计算,可以保证 3 天前的更新能够在 T+1 的时间内被处理和反映在数据中。
而以上并不是最优方式,还存在一些问题: - 随着宽表所需的子表数量不断增长,额外的开发成本和维护负担也随之线性上升。
- TTL 时间的设定是一把双刃剑,设定过长会增加 Flink 引擎状态存储的额外开销,而设定过短则可能导致更多的数据只能享受 T+1 的数据新鲜度。
在之前的业务场景中,该平台考虑将方案一与方案二进行结合,并进行了适当的折中。具体来说,只开发 A join B join C 的逻辑,并将产出的数据首先存储到 MySQL 中。每当 B、C 表出现数据变更时,通过 JDBC 查询结果表来获取所有发生变化的 A 表 ID,并据此重新进行计算。
然而,在引入 Doris 之后,通过写时合并、谓词下推、命中索引以及高性能的 Join 策略等技术,为该平台提供了一种查询时的现场关联方式,这不仅降低了开发的复杂度,还在三表关联的场景下,由原先需要的 3 人天的工作量降低只需要 1 人天,开发效率得到极大提升。
优化经验
在生产实践的过程中,该平台也遇到了一些问题、包括文件版本产生过多、事务挤压、FE 假死等问题报错。然而,通过参数调整和方案调试,最终解决了这些问题,以下是优化经验总结。
01 E-235(文件版本过多)
在凌晨调度 Broker Load 时, 由于调度系统任务挤占可能会导致同时并发多个任务,使得 BE 流量剧增,造成 IO 抖动、 产生文件版本过多的问题(E-235)。因此对此进行了以下优化,通过这些改动 E-235 问题未再发生:
- 使用 Stream Load 替代 Broker Load, 将 BE 流量分摊到全天。
- 自定义写入器包装 Stream Load, 实现异步缓存、限流削峰等效果, 充分保证数据写入的稳定性。
- 优化系统配置,调整 Compaction 和写入 Tablet 版本的相关参数,:
- max_base_compaction_threads : 4->8
- max_cumu_compaction_threads : 10->16
- compaction_task_num_per_disk : 2->4->8
- max_tablet_version_num : 500->1024
02 E-233(事务挤压)
在深入使用 Doris 的过程中,发现在多个 Stream Load 同时写入数据库时,如果上游进行多表数据清洗并且限速难以把控时,可能会出现 QPS 较大的问题,进而触发 E-233 报错。为了解决这个问题,该平台进行了以下调整,调整之后在面对实时写入 300+ 表时, 再未复现 E-233 问题:
- 将 DB 中的表进行更细致的分库,以实现每个 DB 的事务分摊
- 参数调整: max_running_txn_num_per_db : 100->1000->2048
03 FE 假死
通过 Grafana 监控发现, FE 经常出现宕机现象,主要原因是因为早期该平台采用 FE 和 BE 混合部署的方式,当 BE 进行网络 IO 传输的时候,可能会挤占同机器 FE 的 IO 与内存。其次,因运维团队的 Prometheus 对接的服务比较多,其稳定性与健壮性不足, 从而造成假象告警。为解决这些问题做了以下调整:
- 当前 BE 机器的内存是 128G, 使用 32G 的机器将 FE 节点迁出。
- Stream Load 过程中,Doris 会选定一个 BE 节点作为 Coordinator 节点,用于接收数据并分发至其他 BE 节点,并将最终导入结果返回给用户。用户可通过 HTTP 协议提交导入命令至 FE 或直接指定 BE 节点。该平台采用直接指定 BE 的方式,实现负载均衡,减少 FE 在 Stream Load 中的参与,以降低 FE 压力。
- 定时调度
show processlist命令进行探活, 同时及时 Kill 超时 SQL 或者超时连接。
结束语
截止目前,基于 Doris 的数据平台已经满足该商业查询平台在实时与离线的统一写入与查询,支持了 BI 分析、离线计算、C 端高并发等多个业务场景,为产品营销、客户运营、数据分析等场景提供数据洞察能力与价值挖掘能力。未来,该商业查询平台还计划进行以下升级与优化:
- 版本升级:升级 Apache Doris 2.0 版本,更进一步实现高并发点查和部分列更新等最新特性,进一步优化现有架构,为查询提效。
- 规模扩大:进一步扩大集群规模,并将更多的分析计算迁移到 Doris 中;
- 日志分析:随着节点数越来越多,日志数据也在不断产生,未来该平台计划将集群日志接入到 Doris 中统一收集管理和检索,便于问题的提示探查,因此倒排索引和日志分析也是后面重要的拓展场景;
- 自动化运维:在某些特定查询场景下,可能会导致集群 BE 节点宕机,虽然出现概率较低,但手动启动仍然比较麻烦,后续将引入自动重启能力,使节点能够快速恢复并重新投入运行。
- 提升数据质量:目前该平台大部分时间专注于业务的实现上,数据入口的统一收束和补齐,数据质量监控还存在短板,所以希望可以在这方面提升数据质量。
相关文章:
Apache Doris 在某工商信息商业查询平台的湖仓一体建设实践
作者|某工商信息商业查询平台 高级数据研发工程师 李昂 信息服务行业可以提供多样化、便捷、高效、安全的信息化服务,为个人及商业决策提供了重要支撑与参考。对于行业相关企业来说,数据收集、加工、分析能力的重要性不言而喻。以某工商信息…...

【尘缘送书第六期】2023年度学习:AIGC、AGI、GhatGPT、人工智能大模型实现必读书单
【文末送书】今天推荐几本AIGC、AGI、GhatGPT、人工智能大模型领域优质书籍。 目录 前言1 《ChatGPT 驱动软件开发》2 《ChatGPT原理与实战》3 《神经网络与深度学习》4 《AIGC重塑教育》5 《通用人工智能》6 文末送书 前言 2023年是人工智能大语言模型大爆发的一年࿰…...
我的 CSDN 三周年创作纪念日:2020-12-12
本人大叔一枚,自1992年接触电脑,持续了30年的业余电脑发烧爱好者,2022年CSDN博客之星Top58,阿里云社区“乘风者计划”专家博主。自某不知名财校毕业后进入国有大行工作至今,先后任职于某分行信息科技部、电子银行部、金…...

什么是css初始化
什么是css初始化 CSS初始化是指重设浏览器的样式。 因为浏览器的兼容问题,不同浏览器对有些标签的默认值是不同的,如果没对CSS初始化往往会出现浏览器之间的页面显示差异。 每次新开发网站或新网页时候通过初始化CSS样式的属性,为我们将用…...

谁会成为第一个MoE大模型基座呢?重磅!Mixtral MoE 8x7B!!!
文章目录 谁会成为第一个MoE大模型基座呢?重磅!Mixtral MoE 8x7B!!!前言重磅!Mixtral MoE 8x7B!!!Mixtral是啥模型介绍模型结构长啥样?表现如何?可…...

Linux升级nginx版本
处于漏洞修复目的服务器所用nginx是1.16.0版本扫出来存在安全隐患,需要我们升级到1.17.7以上。 一般nginx默认在 /usr/local/ 目录,这里我的nginx是自定义的路径安装在 /app/weblogic/nginx 。 1.查看生产环境nginx版本 cd /app/weblogic/nginx/sbin/…...
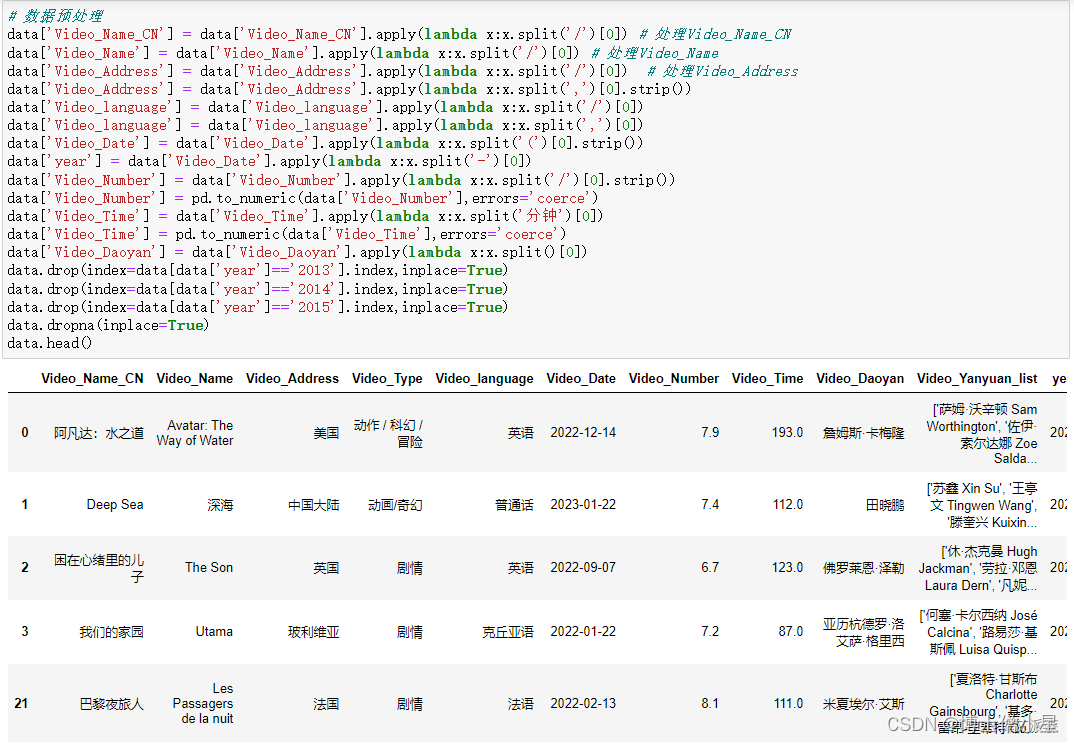
人工智能|网络爬虫——用Python爬取电影数据并可视化分析
一、获取数据 1.技术工具 IDE编辑器:vscode 发送请求:requests 解析工具:xpath def Get_Detail(Details_Url):Detail_Url Base_Url Details_UrlOne_Detail requests.get(urlDetail_Url, headersHeaders)One_Detail_Html One_Detail.cont…...

mac苹果笔记本电脑如何强力删除卸载app软件?
苹果电脑怎样删除app?不是把app移到废纸篓就行了吗,十分简单呢! 其实不然,因为在Mac电脑上,删除应用程序只是删除了应用程序的主要组件。大多数时候,系统会有一个相当长的目录,包含所有与应用程…...

net6中使用MongoDB
目录 一、MongoDB是什么? 二、使用步骤 1.安装驱动 2.设置连接字符串、配置类 3.建立实体类 4.服务层 5.在Program添加服务 6.在Controller注入服务 总结 一、MongoDB是什么? MongoDB 是一个开源的、可扩展的、跨平台的、面向文档的非关系型数据库&…...

vue中yarn install超时问题
囚笼中的网络固然可以稳定局势,不让猴子们得以随时醒悟!给你吃的你就好好吃,不要有其他的翻然醒悟的时刻。无论如何,愚蠢的活着也是一种幸福,听着那些耐心寻味的统计幸福指数,我们不由的幸福的一批。。 最…...

vue3 引入 markdown编辑器
参考文档 安装依赖 pnpm install mavon-editor // "mavon-editor": "3.0.1",markdown 编辑器 <mavon-editor></mavon-editor>新增文本 <mavon-editor ref"editorRef" v-model"articleModel.text" codeStyle"…...

算法----K 和数对的最大数目
题目 给你一个整数数组 nums 和一个整数 k 。 每一步操作中,你需要从数组中选出和为 k 的两个整数,并将它们移出数组。 返回你可以对数组执行的最大操作数。 示例 1: 输入:nums [1,2,3,4], k 5 输出:2 解释&…...
RocketMQ-源码架构
源码环境搭建 1、主要功能模块 RocketMQ官方Git仓库地址:GitHub - apache/rocketmq: Apache RocketMQ is a cloud native messaging and streaming platform, making it simple to build event-driven applications. RocketMQ的官方网站下载:下载 | R…...
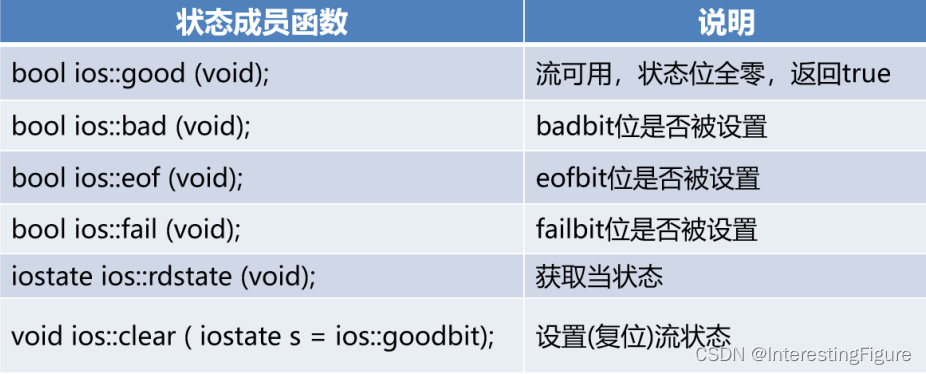
14-1、IO流
14-1、IO流 lO流打开和关闭lO流打开模式lO流对象的状态 非格式化IO二进制IO读取二进制数据获取读长度写入二进制数据 读写指针 和 随机访问设置读/写指针位置获取读/写指针位置 字符串流 lO流打开和关闭 通过构造函数打开I/O流 其中filename表示文件路径,mode表示打…...

每日一道算法题 1
借鉴文章:Java-敏感字段加密 - 哔哩哔哩 题目描述 给定一个由多个命令字组成的命令字符串; 1、字符串长度小于等于127字节,只包含大小写字母,数字,下划线和偶数个双引号 2、命令字之间以一个或多个下划线_进行分割…...

【网络奇缘】- 计算机网络|深入学习物理层|网络安全
🌈个人主页: Aileen_0v0🔥系列专栏: 一见倾心,再见倾城 --- 计算机网络~💫个人格言:"没有罗马,那就自己创造罗马~" 回顾链接:http://t.csdnimg.cn/ZvPOS 这篇文章是关于深入学习原理参考模型-物理层的相关知识点&…...

❀expect命令运用于bash❀
目录 ❀expect命令运用于bash❀ expect使用原理 expet使用场景 常用的expect命令选项 Expect脚本的结尾 常用的expect命令选参数 Expect执行方式 单一分支语法 多分支模式语法第一种 多分支模式语法第二种 在shell 中嵌套expect Shell Here Document(内…...

2023年团体程序设计天梯赛——总决赛题
F-L1-1 最好的文档 有一位软件工程师说过一句很有道理的话:“Good code is its own best documentation.”(好代码本身就是最好的文档)。本题就请你直接在屏幕上输出这句话。 输入格式: 本题没有输入。 输出格式: 在一…...

K8S 工具收集
杂货铺,我不用 K8S,把见过的常用工具放在这里,后面学的时候再来找 名称描述官网Pixie查看 k8s 的工具。集群性能、网络状态、pod 状态、热点图等HomeKubernetes Dashboard基于 Web 的 Kubernetes 集群用户界面。GithubGardenerSAP 开源的 K8…...
自动化测试之读取配置文件
前言: 在日常自动化测试开发工作中,经常要使用配置文件,进行环境配置,或进行数据驱动等。我们常常把这些文件放置在 resources 目录下,然后通过 getResource、ClassLoader.getResource 和 getResourceAsStream() 等方法…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...