ES-分析器
分析器
两种常用的英语分析器
1 测试工具
#可以通过这个来测试分析器 实际生产环境中我们肯定是配置在索引中来工作
GET _analyze
{"text": "My Mom's Son is an excellent teacher","analyzer": "english"
}
2 实际效果
比如我们有下面这样一句话:My Mom’s Son is an excellent teacher
GET _analyze
{"text": "My Mom's Son is an excellent teacher","analyzer": "english"
}
分析器分析以后,大写统一转换为了小写,is 被省了 等,所以经过这个分析器处理以后会得到下面的结果
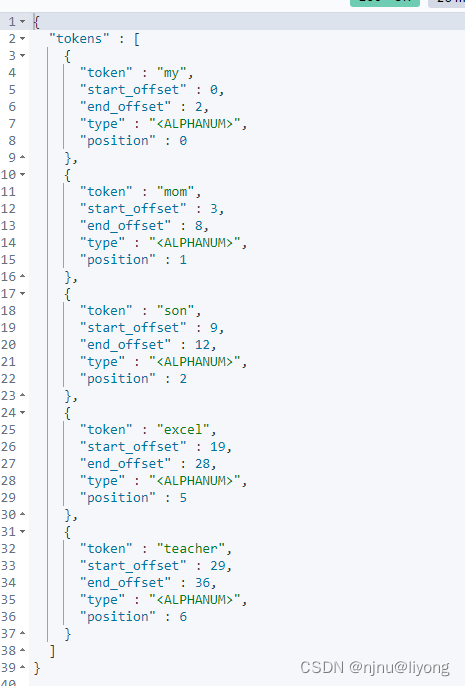
我们换一个分析器结果就会不一样
GET _analyze
{"text": "My Mom's Son is an excellent teacher","analyzer": "standard"
}
结果如下:

char_filter
- html_strip 用来处理html标签
PUT my_index
{"settings": {"analysis": {"char_filter": {#这里是申明"my_char_filter": {"type": "html_strip", #过滤html 标签 "escaped_tags": ["a" #忽略a标签]}},"analyzer": {#这里是使用"my_analyzer": {"char_filter": ["my_char_filter"],"tokenizer": "keyword"}}}}
}
GET /my_index/_analyze
{"text" : "<html>fdsf</html>","analyzer": "my_analyzer"
}
可以看到html这个表签被替换掉了:

- mapping 用来处理映射
PUT my_index
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "mapping","mappings": ["S=>*","B=>*"]}},"analyzer": {"my_analyzer": {"char_filter": ["my_char_filter"],"tokenizer": "keyword"}}}}
}
GET /my_index/_analyze
{"text" : "总是加班真SB","analyzer": "my_analyzer"
}结果如下:

- pattern_replace
PUT my_index
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "pattern_replace","pattern":"(\\d{3})\\d(\\d{4})","replacement" : "$1****$2"}},"analyzer": {"my_analyzer": {"char_filter": ["my_char_filter" #这里是可以写多个的],"tokenizer": "keyword"}}}}
}
GET /my_index/_analyze
{"text" : "1008610086","analyzer": "my_analyzer"
}
Filter
- synonym_graph
PUT my_index
{"settings": {"analysis": {"filter": {"my_filter": {"type": "synonym_graph","synonyms_path" : "analysis/analysis.txt" #这里修改文件好像是不能直接生效需要重新创建索引}},"analyzer": {"my_analyzer": {"filter": ["my_filter"],"tokenizer": "keyword"}}}}
}
GET /my_index/_analyze
{"text" : ["liyong","love","baby"],"analyzer": "my_analyzer"
}运行结果如下:

也可以直接写到下面:
PUT my_index
{"settings": {"analysis": {"filter": {"my_filter": {"type": "synonym_graph","synonyms" : ["liyong,love,baby=>99"] #直接把映射的东西写到这里}},"analyzer": {"my_analyzer": {"filter": ["my_filter"],"tokenizer": "keyword"}}}}
}GET /my_index/_analyze
{"text" : ["liyong","love","baby"],"analyzer": "my_analyzer"
}

GET my_index/_analyze
{"tokenizer": "standard","filter":{"type": "condition", #条件也就是根据下面的条件"filter":"uppercase", #转换为大写"script": {"source": "token.getTerm().length()<5" #小于5的字符串替换为大写}},"text":["assas assa sasa dsdsdsdsdsd sdsdsdss"]
}
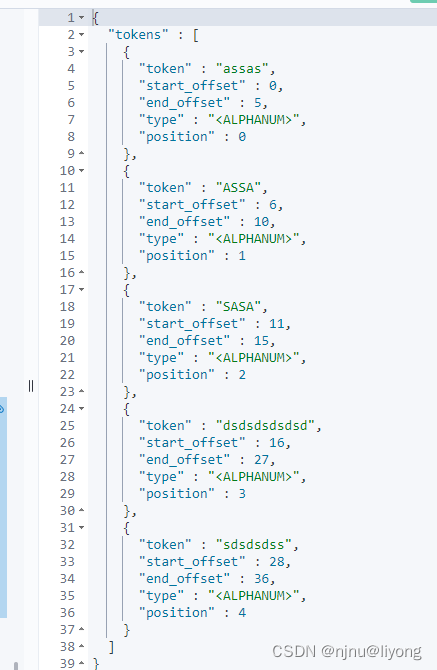
- stop
Stopwords⽤于删除不要的介词和词语,以下为简写
PUT my_index
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"type": "standard","stopwords": ["me","you"]}}}}
}也可以这样写:
PUT my_index
{"settings": {"analysis": {"filter": {"my_filter": {"type": "stop","stopwords": ["me","you"]}},"analyzer": {"my_analyzer": {"tokenizer": "standard","filter": ["my_filter"]}}}}
}
自定义分析器
PUT my_index
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "mapping","mappings": ["&=>and","|=>or"]}},"filter": {"my_filter": {"type": "stop","stopwords": ["is","in","a","at"]}},"tokenizer": {"my_tokenizer": {"type": "pattern","pattern": "[ ,.!]"}},"analyzer": {"my_analyzer": {"char_filter": ["my_char_filter"],"filter": ["my_filter"],"tokenizer": "my_tokenizer","type": "custom" #指定自定义}}}}
}
tokenizer 重写了分词方式 比如这个例子就是按照, . !来分割,然后进行后续的过滤处理,在实际生产环境中非常重要。
中文分词器
ik下载
安装到插件下面:
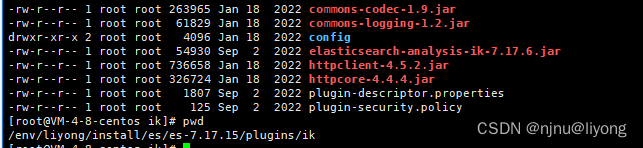
#由于没有对应的版本需要修改这个文件强行改成我们的版本
vim plugin-descriptor.properties
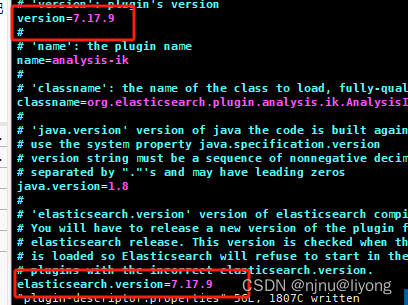
注意ik文件的所属用户和所属组
- 使用
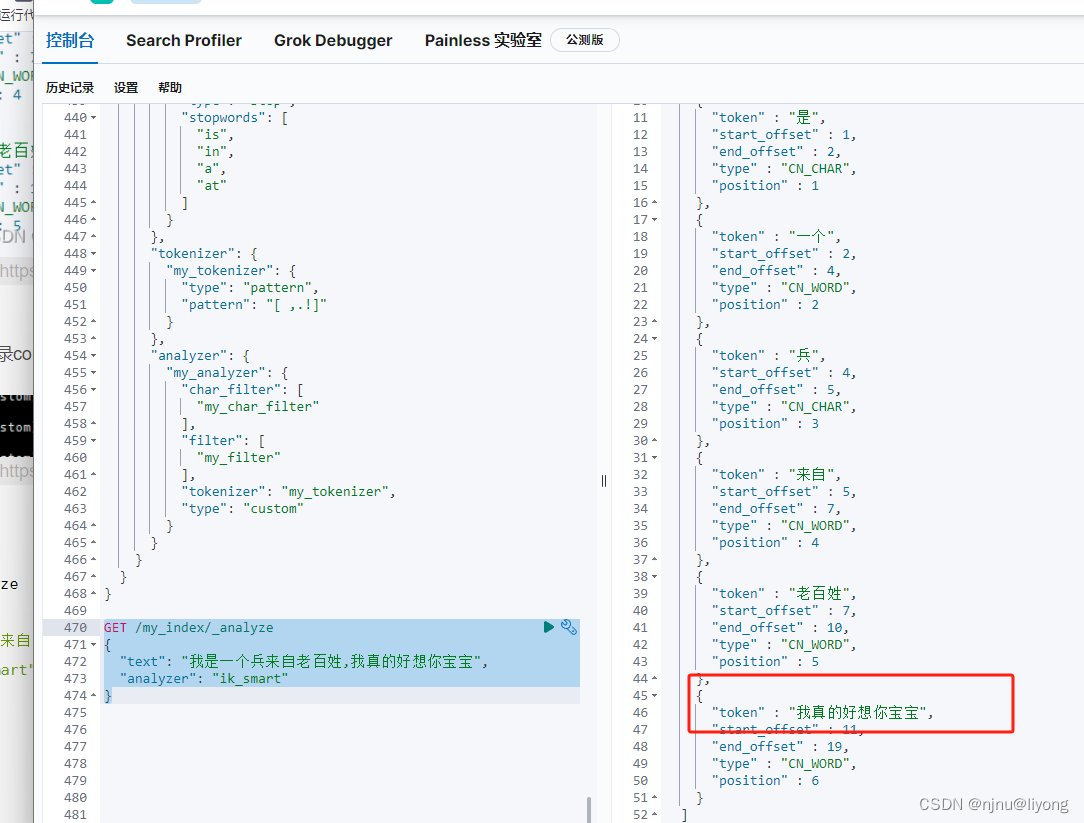
GET /my_index/_analyze
{"text": "我是一个兵来自老百姓","analyzer": "ik_smart"
}


- 自定义分词库
我再config 新建一个目录config/custom.dic 自定义输入

<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">./custom/custom.dic;./custom/custom1.dic</entry> #如果有多个用;隔开<!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --> #这里支持远程网址词典获取这样做的好处是不用重启es 这里就可以写一个controller 来把词典打印到网页上 https://blog.csdn.net/qq_34304427/article/details/123539694?spm=1001.2014.3001.5502 可以参考这篇博客<!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
GET /my_index/_analyze
{"text": "我是一个兵来自老百姓,我真的好想你宝宝","analyzer": "ik_smart"
}
相关文章:
ES-分析器
分析器 两种常用的英语分析器 1 测试工具 #可以通过这个来测试分析器 实际生产环境中我们肯定是配置在索引中来工作 GET _analyze {"text": "My Moms Son is an excellent teacher","analyzer": "english" }2 实际效果 比如我们有下…...
智能优化算法应用:基于缎蓝园丁鸟算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于缎蓝园丁鸟算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于缎蓝园丁鸟算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.缎蓝园丁鸟算法4.实验参数设定5.算法…...
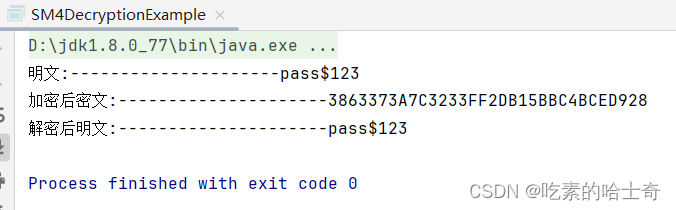
【开发问题】vue的前端和java的后台,用sm4,实现前台加密,后台解密
sm4加密 vue引入的包代码加密解密 javamaven代码运行结果 vue 引入的包 npm install sm-crypto代码加密解密 加密: key :代表着密钥,必须是16 字节的十六进制密钥 password :加密前的密码 sm4Password :代表sm4加密…...

【算法专题】分治 - 快速排序
分治 - 快速排序 分治 - 快速排序1. 颜色分类2. 排序数组(快速排序)3. 数组中的第K个最大元素4. 库存管理Ⅲ5. 排序数组(归并排序)6. 交易逆序对的总数7. 计算右侧小于当前元素的个数8. 翻转对 分治 - 快速排序 1. 颜色分类 做题链接 -> Leetcode -75.颜色分类 题目&…...
UG NX二次开发(C#)-求曲线在某一点处的法矢和切矢
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1、前言2、在UG NX中创建一个曲线3、直接放代码4、测试案例1、前言 最近确实有点忙了,好久没更新博客了。今天恰好有时间,就更新下,还请家人们见谅。 今天我们讲一下如何获取一条曲线上某一条曲…...
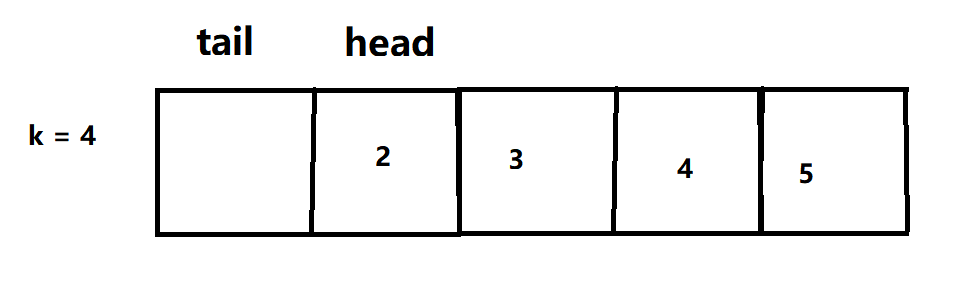
leetcode 622. 设计循环链表
这道题讲了两种方法,第一个代码是用数组实现的,第二个是用链表实现的,希望对你们有帮助 (最好在VS自己测试一遍,再放到 leetcode上哦) 下面的是主函数(作参考),静下心来…...
Linux:dockerfile编写搭建tomcat练习(9)
我使用的httpyum仓库 本地使用了5个文件,tomcat使用的官网解压直接用的包】 Dockerfile 主配置文件 基于centos基础镜像 jdk1.8.0_91 java环境 run.sh 启动脚本 centos.repo 仓库文件 tomcat 源码包 vim Dockerfile写入FROM centos MAINTAINER ta…...
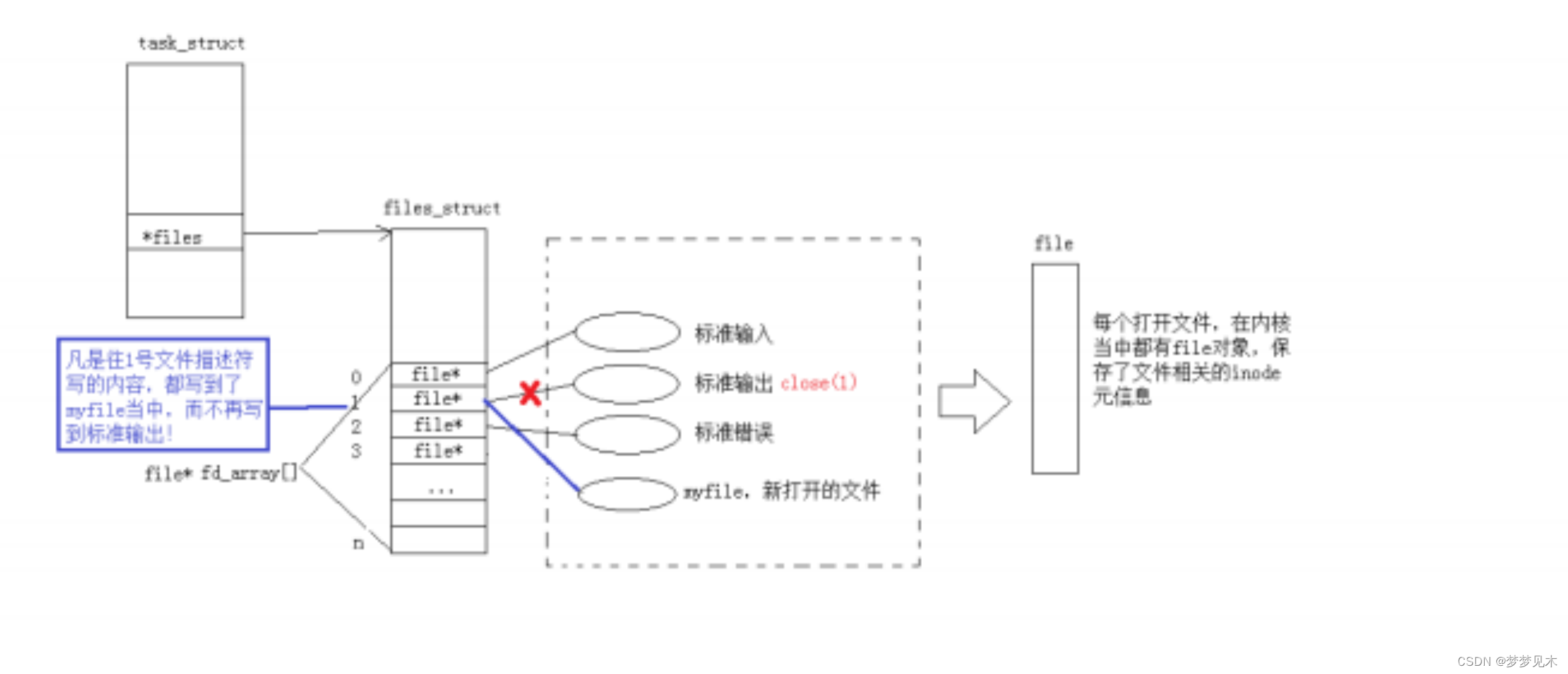
Linux 基础IO
文章目录 前言基础IO定义系统IO接口文件描述符重定向原理缓冲区刷新 前言 要知道每个函数/接口的全部参数和返回值建议去官网或者直接在Linux的man手册中查,这不是复制粘贴函数用法的文章。 C语言文件读写介绍链接 基础IO定义 IO是Input/Output的缩写,…...

uniapp 打开文件管理器上传(H5、微信小程序、android app三端)文件
H5跟安卓APP 手机打开的效果图: Vue页面: <template><view class"content"><button click"uploadFiles">点击上传</button></view> </template><script>export default {data() {return…...
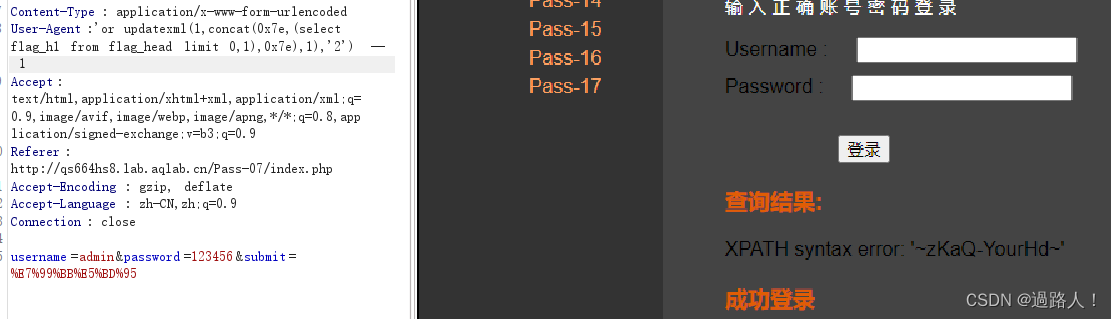
掌控安全 -- header注入
http header注入 该注入是指利用后端验证客户端口信息(比如常用的cookie验证)或者通过http header中获取客户端的一些信息(比如useragent用户代理等其他http header字段信息),因为这些信息是会重新返回拼接到后台中的&…...
如何激活Anconda Prompt虚拟环境)
windows批处理脚本(.bat)如何激活Anconda Prompt虚拟环境
通过call 来调用激活脚本, activate myenv指的是要激活的环境,若省略,则激活的是base环境。 call : 从另一个批处理程序调用一个批处理程序,而不停止父批处理程序。 call C:\ProgramData\Anaconda3\Scripts\activate.bat activate…...

扩散模型实战(十四):扩散模型生成音频
推荐阅读列表: 扩散模型实战(一):基本原理介绍 扩散模型实战(二):扩散模型的发展 扩散模型实战(三):扩散模型的应用 扩散模型实战(四ÿ…...

《微信小程序开发从入门到实战》学习四十七
4.4 云函数 4.4.5 云函数的定时触发 如果云函数需要定时执行,可以使用云函数定时触发器。配置了定时触发器,云函数会在相应时间点被自动触发。函数返回结果不会返回调用方 在需要添加触发器的云函数下新建文件config.json。格式如下: &quo…...

LeetCode刷题笔记之数组
一、二分查找 1. 704【二分查找】 题目: 给定一个 n 个元素 有序的(升序) 整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。代码:…...
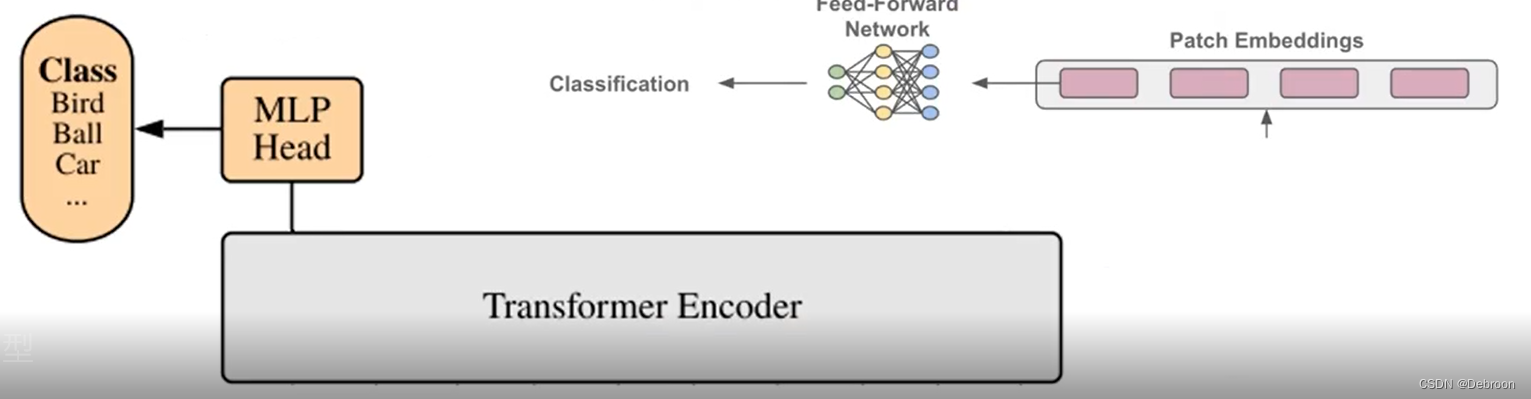
ViT:视觉 Transformer
ViT:视觉 Transformer 网络结构Transformer 编码器MLP 头CNN 和 Transformer 网络结构 Transformer 的优势:注意力机制相当于一个多标签检索系统,位置嵌入能知道每个单词的位置,而且适合并行。 尝试把 Transformer 迁移到视觉领…...
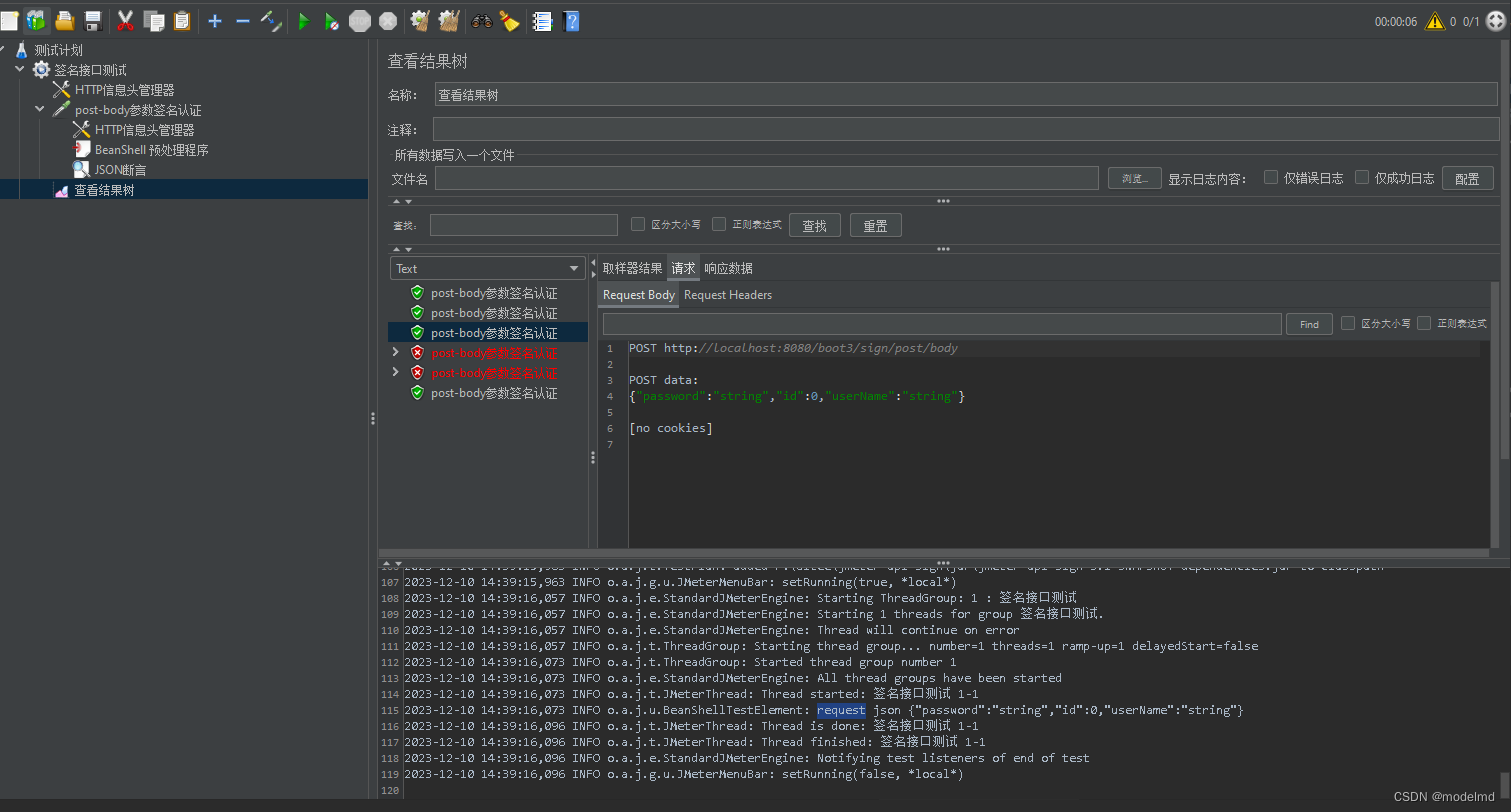
Jmeter 请求签名api接口-BeanShell
Jmeter 请求签名api接口-BeanShell 项目签名说明编译扩展jar包jmeter 使用 BeanShell 调用jar包中的签名方法 项目签名说明 有签名算法的api接口本地不好测试,使用BeanShell 扩展jar 包对参数进行签名,接口签名算法使用 sha512Hex 算法。签名的说明如下…...
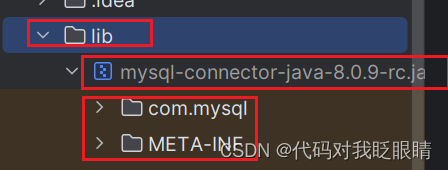
No suitable driver found for jdbc:mysql://localhost:3306(2023/12/7更新)
有两种情况: 压根没安装下载了但没设为库或方法不对 大多数为第一种情况: 一. 下载jdbc 打开网址选择一个版本进行下载 https://nowjava.com/jar/version/mysql/mysql-connector-java.html 二.安装jdbc 在项目里建一个lib文件夹 在把之前下载的jar文…...

word文档中数字格式转换(排版助手)
示例:李老师收入了234243.33元,产量3000公斤; 张老师收入了2324324元,产量45555公斤; 孙老师收入了600000元,产量2342公斤 王老师收入了1234443243元,产量1243142公斤。 1、数字批量转换成千…...

阿里云docker加速
文章目录 一、 阿里云镜像仓库配置二、配置加速1. CentOS2. Mac3. Windows注意 一、 阿里云镜像仓库配置 1.注册阿里云账号,并登陆到阿里云后台,进入控制台面板 2.进入控制台以后,找到左上方的三横的功能列表按钮,在弹出来的功能…...

Panalog 日志审计系统 sprog_deletevent.php SQL 注入漏洞复现
0x01 产品简介 Panalog大数据日志审计系统定位于将大数据产品应用于高校、 公安、 政企、 医疗、 金融、 能源等行业之中,针对网络流量的信息进行日志留存,可对用户上网行为进行审计,逐渐形成大数据采集、 大数据分析、 大数据整合的工作模式…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...

[免费]微信小程序问卷调查系统(SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序问卷调查系统(SpringBoot后端Vue管理端)【论文源码SQL脚本】,分享下哈。 项目视频演示 【免费】微信小程序问卷调查系统(SpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩_bilibili 项…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...

用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法
用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法 大家好,我是Echo_Wish。最近刷短视频、看直播,有没有发现,越来越多的应用都开始“懂你”了——它们能感知你的情绪,推荐更合适的内容,甚至帮客服识别用户情绪,提升服务体验。这背后,神经网络在悄悄发力,撑起…...