消息队列 面试题 整理
消息队列
为什么要使用消息队列?
异步解耦:关注的是通知而非处理。
流量削峰:将短时间内高并发的请求持久化,然后逐步处理,削平高峰期的请求。
日志收集:
事务最终一致性
系统间的消息通信方式:
远程过程调用的方式
消息队列的方式
消息队列的缺点?
系统的可用性降低:系统引入的外部依赖越多,越容易挂掉。
系统复杂度提高:需要考虑消息的重复、有序、不丢失。
消息队列由哪些角色组成?
生产者:负责生产消息
消费者:负责消费消息
消息代理:负责存储和转发消息。转发消息分为推模式和拉模式。
消息队列架构过程中的难点?
消息堆积:由于生产者和消费者的速率不一致,消息处理中心可能会导致堆积消息。消息队列要能感知处理中心的堆积情况,避免资源被耗尽。
消息持久化:内存vs文件vs数据库?
可靠投递:可靠投递是不允许消息丢失的情况的。从生产者到消息处理中心,消息处理中心持久化消息,消息处理中心到消费者。
消息重复:消息为了支持可靠传递会将消息持久化,然后发送给消费者。
消息的严格有序:有些业务场景需要严格按照生产消息的顺序来消费的情形。
消息的集群。考虑分布式系统的高可用性,一般的消息队列都要支持集群部署。
消息协议的选择?
amqp协议: RabbitMQ
mqtt协议:IBM开发的一个即时通信协议,主要用在物联网领域。
STOMP协议:轻量级消息协议。 ActiveMQ
AMQP协议的解析:
定义了各种角色比如生产者,消费者,路由器,队列,routingkey,channel等概念
定义了消息在生产端-路由器-队列-消费者之间传递的规则。
协议的分层属性,分为功能层和传输层。
定义了消息数据格式。不同的消息的帧类型。
还定义了消息信道复用,数据可见性保证,内容排序保证等等。
MQTT协议解析:
三种使用身份,发布者,代理、传播者。
消息队列的消费语义
消息至多被消费一次 :
消息从Producer到Broker的时候不需要Broker确认,Producer不需要关心消息是否到Broker了。
Broker对消息的持久性无要求。consumer从borker获取到消息后就可以从broker中删除消息。
消息至少被消费一次:
消息从Producer到Broker需要Broker确认,Broker必须持久化消息。consumer必须消费成功后,消息才能从Broker上删除。
消息仅被消费一次:
又细分为两种情况,一种是Broker上存储的消息仅被消费一次 和 Producer上的消息 仅被消费一次。
①Broker上存储的消息仅被消费一次:
消息从Producer到Broker的时候不需要Broker确认,Broker必须持久化消息, consumer获取到消息后需要记录消费的标识。以避免以后对这个消息的重复消费。
②Producer上的消息 仅被消费一次:
Producer需要产生一个唯一的消息标识。可以在中间件的框架层级去做,但是最稳妥的还是从业务层来保证消费的幂等性。
消息投递的方式
推模式 pull
优点:主动权在消费方,可以根据的自己的处理消息的速度进行拉取。
缺点:会有消息延迟。
拉模式 push
优点:及时性
缺点:受限于消费者的消费能力,消费者来不及处理消息。
目前的消息队列都是push+pull的方式,Broker仅告知consumer有新消息,具体的消息拉取还是consumer主动拉取。
如果保证消费者消息的幂等性?
由于网络的不可靠性,Producer可能会重试多次发送消息,Broker会重复投递。导致consumer会受到重复消息。处理方式有以下两种:
框架层统一实现,给消息一个排重唯一标识,消费的时候存入数据库或者kv数据库。消费方查询的时候查询这条数据是否被消费过。
业务层实现,先查询数据库是否已经被更新过了,或者是分布式锁、数据库唯一索引、乐观锁等技巧。推荐使用业务层实现。
如何保证消息传输的可靠性?
不同的消息队列其架构不同,所以实现消息的可靠性方法不同。
RabbitMQ
生产者:需要实现returnback接口和callback接口,分别代表消息是否到路由了,是否到队列了。如果没到需要重发。路由、队列要开启持久化,同时消息的deliverymode要设置为持久化。
消费者确认方式要改成手动ack。
或者使用事务消息,但是qps很低,不建议使用 。
Kafka
生产端:
①Producer 端设置 acks=all:这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了。
②在 Producer 端设置 retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了
Broker端:Kafka 某个 Broker 宕机,然后重新选举 Partition 的 leader。大家想想,要是此时其他的 follower 刚好还有些数据没有同步,结果此时 leader 挂了,然后选举某个 follower 成 leader 之后,就会发生数据丢失。需要设置以下参数解决:
①给 Topic 设置 replication.factor 参数:这个值必须大于 1,要求每个 partition 必须有至少 2 个副本
②在 Kafka 服务端设置 min.insync.replicas 参数:这个值必须大于 1 ,这个是要求一个 leader 至少感知到有至少一个 follower 还跟自己保持联系,没掉队,这样才能确保 leader 挂了还有一个 follower 吧
消费端:
①关闭自动提交 offset ,在处理完之后自己手动提交 offset
②消费端如果是消费之后入线程池或者队列的化需要实现优雅关机,否者会有丢消息的情况。
参考
https://blog.csdn.net/Johnnyz1234/article/details/98318528
RocketMQ
Producer:可以设置三次发送消息重试。
Broker :数据最大化的不丢,需要在搭建 Broker 集群时,设置为同步刷盘、同步复制。当然,带来了可靠性,也会一定程度降低性能.
Consumer: 如果我们在使用 Push 模式的情况下,只有我们消费返回成功,才会异步定期更新消费进度到 Broker 。消费端异常崩溃,可能导致消费进度未更新到 Broker 上,那么无非是 Consumer 可能重复拉取到已经消费过的消息。关于这个,就需要消费端做好消费的幂等性。
如何保证消息的顺序性?
全局顺序
全局使用一个生产者
全局使用一个消费者(并严格到一个消费线程)
全局使用一个分区(当然不同的表可以使用不同的分区或者topic实现隔离与扩展)
局部顺序
局部有序是指在某个业务功能场景下保证消息的发送和接收顺序是一致的。如:订单场景,要求订单的创建、付款、发货、收货、完成消息在同一订单下是有序发生的,即消费者在接收消息时需要保证在接收到订单发货前一定收到了订单创建和付款消息。
针对部分消息有序(message.key相同的message要保证消费顺序)场景,可以在producer往kafka插入数据时控制,同一key分发到同一partition上面
顺序与扩容、容错的问题
着先后顺序的消息A、B,正常情况下应该是A先发送完成后再发送B,但是在异常情况下,在A发送失败的情况下,B发送成功,而A由于重试机制在B发送完成之后重试发送成功了。这时对于本身顺序为AB的消息顺序变成了BA。
RabbitMQ
方案一,拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确实是麻烦点。
这个方式,有点模仿 Kafka 和 RocketMQ 中 Topic 的概念。例如说,原先一个 queue 叫 “xxx” ,那么多个 queue ,我们可以叫 “xxx-01”、“xxx-02” 等,相同前缀,不同后缀。
方案二,或者就一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
这种方式,就是讲一个 queue 里的,相同的“key” 交给同一个 worker 来执行。因为 RabbitMQ 是可以单条消息来 ack ,所以还是比较方便的。这一点,也是和 RocketMQ 和 Kafka 不同的地方。
Kafka
Kafka 本身,并不像 RocketMQ 一样,提供顺序性的消息
一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
单线程消费,然后写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
全局有序:Producer设置max.in.flight.requests.per.connection=1,保证每个消息发送的可见性。
RocketMQ
消费消息的顺序要同发送消息的顺序一致。由于 Consumer 消费消息的时候是针对 Message Queue 顺序拉取并开始消费,且一条 Message Queue 只会给一个消费者(集群模式下),所以能够保证同一个消费者实例对于 Queue 上消息的消费是顺序地开始消费(不一定顺序消费完成,因为消费可能并行)。
Consumer :在 RocketMQ 中,顺序消费主要指的是都是 Queue 级别的局部顺序。这一类消息为满足顺序性,必须 Producer 单线程顺序发送,且发送到同一个队列,这样 Consumer 就可以按照 Producer 发送的顺序去消费消息。
Producer :生产者发送的时候可以用 MessageQueueSelector 为某一批消息(通常是有相同的唯一标示id)选择同一个 Queue ,则这一批消息的消费将是顺序消息(并由同一个consumer完成消息)。或者 Message Queue 的数量只有 1 ,但这样消费的实例只能有一个,多出来的实例都会空跑。
RocketMQ 提供了两种顺序级别:
- 普通顺序消息 :Producer 将相关联的消息发送到相同的消息队列。
- 严格顺序消息 :在【普通顺序消息】的基础上,Consumer 严格顺序消费。
- 普通顺序消息
顺序消息的一种,正常情况下可以保证完全的顺序消息,但是一旦发生异常,Broker 宕机或重启,由于队列总数发生发化,消费者会触发负载均衡,而默认地负载均衡算法采取哈希取模平均,这样负载均衡分配到定位的队列会发化,使得队列可能分配到别的实例上,则会短暂地出现消息顺序不一致。
如果业务能容忍在集群异常情况(如某个 Broker 宕机或者重启)下,消息短暂的乱序,使用普通顺序方式比较合适。
- 严格顺序消息
顺序消息的一种,无论正常异常情况都能保证顺序,但是牺牲了分布式 Failover 特性,即 Broker 集群中只要有一台机器不可用,则整个集群都不可用,服务可用性大大降低。
如果服务器部署为同步双写模式,此缺陷可通过备机自动切换为主避免,不过仍然会存在几分钟的服务不可用。(依赖同步双写,主备自动切换,自动切换功能目前并未实现)
小结
目前已知的应用只有数据库 binlog 同步强依赖严格顺序消息,其他应用绝大部分都可以容忍短暂乱序,推荐使用普通的顺序消息。
实现原理
顺序消息的实现,相对比较复杂,想要深入理解的胖友,可以看看 《RocketMQ 源码分析 —— Message 顺序发送与消费》 。
消息队列如何实现的高可用?
RabbitMQ
RabbitMQ 的高可用,是基于主从做高可用性的。它有三种模式:
-
单机模式:一般用于本地开发或者测试环境。实际生产环境下,基本不会使用。
-
普通集群模式:多台机器上启动多个 RabbitMQ 实例,每个机器启动一个.创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据。消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。
-
镜像集群模式:在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。导致性能消耗很大,也没有办法线性扩展queue。
Kafka
Zookeeper 部署 2N+1 节点,形成 Zookeeper 集群,保证高可用。
Kafka Broker 部署集群。每个 Topic 的 Partition ,基于【副本机制】,在 Broker 集群中复制,形成 replica 副本,保证消息存储的可靠性。每个 replica 副本,都会选择出一个 leader 分区(Partition),提供给客户端(Producer 和 Consumer)进行读写。
Kafka Producer 无需考虑集群,因为和业务服务部署在一起。Producer 从 Zookeeper 拉取到 Topic 的元数据后,选择对应的 Topic 的 leader 分区,进行消息发送写入。而 Broker 根据 Producer 的 request.required.acks 配置,是写入自己完成就响应给 Producer 成功,还是写入所有 Broker 完成再响应。
Kafka Consumer 部署集群。每个 Consumer 分配其对应的 Topic Partition ,根据对应的分配策略。并且,Consumer 只从 leader 分区(Partition)拉取消息。另外,当有新的 Consumer 加入或者老的 Consumer 离开,都会将 Topic Partition 再均衡,重新分配给 Consumer 。
RocketMQ
- Producer
1、Producer 自身在应用中,所以无需考虑高可用。
2、Producer 配置多个 Namesrv 列表,从而保证 Producer 和 Namesrv 的连接高可用。并且,会从 Namesrv 定时拉取最新的 Topic 信息。
3、Producer 会和所有 Consumer 直连,在发送消息时,会选择一个 Broker 进行发送。如果发送失败,则会使用另外一个 Broker 。
4、Producer 会定时向 Broker 心跳,证明其存活。而 Broker 会定时检测,判断是否有 Producer 异常下线。
- Consumer
1、Consumer 需要部署多个节点,以保证 Consumer 自身的高可用。当相同消费者分组中有新的 Consumer 上线,或者老的 Consumer 下线,会重新分配 Topic 的 Queue 到目前消费分组的 Consumer 们。
2、Consumer 配置多个 Namesrv 列表,从而保证 Consumer 和 Namesrv 的连接高可用。并且,会从 Consumer 定时拉取最新的 Topic 信息。
3、Consumer 会和所有 Consumer 直连,消费相应分配到的 Queue 的消息。如果消费失败,则会发回消息到 Broker 中。
4、Consumer 会定时向 Broker 心跳,证明其存活。而 Broker 会定时检测,判断是否有 Consumer 异常下线。
- Namesrv
1、Namesrv 需要部署多个节点,以保证 Namesrv 的高可用。
2、Namesrv 本身是无状态,不产生数据的存储,是通过 Broker 心跳将 Topic 信息同步到 Namesrv 中。
3、多个 Namesrv 之间不会有数据的同步,是通过 Broker 向多个 Namesrv 多写。
- Broker
1、多个 Broker 可以形成一个 Broker 分组。每个 Broker 分组存在一个 Master 和多个 Slave 节点。
Master 节点,可提供读和写功能。Slave 节点,可提供读功能。
Master 节点会不断发送新的 CommitLog 给 Slave节点。Slave 节点不断上报本地的 CommitLog 已经同步到的位置给
Master 节点。
Slave 节点会从 Master 节点拉取消费进度、Topic 配置等等。
2、多个 Broker 分组,形成 Broker 集群。
Broker 集群和集群之间,不存在通信与数据同步。
3、Broker 可以配置同步刷盘或异步刷盘,根据消息的持久化的可靠性来配置。
总结
目前官方提供三套配置:
2m-2s-async
brokerClusterName
brokerName
brokerRole
brokerId
DefaultCluster
broker-a
ASYNC_MASTER
0
DefaultCluster
broker-a
SLAVE
1
DefaultCluster
broker-b
ASYNC_MASTER
0
DefaultCluster
broker-b
SLAVE
1
2m-2s-sync
brokerClusterName
brokerName
brokerRole
brokerId
DefaultCluster
broker-a
SYNC_MASTER
0
DefaultCluster
broker-a
SLAVE
1
DefaultCluster
broker-b
SYNC_MASTER
0
DefaultCluster
broker-b
SLAVE
1
2m-noslave
brokerClusterName
brokerName
brokerRole
brokerId
DefaultCluster
broker-a
ASYNC_MASTER
0
DefaultCluster
broker-b
ASYNC_MASTER
0
如何解决消息过期的问题?
假设你用的是 RabbitMQ,RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。那这就是第二个坑了。这就不是说数据会大量积压在 mq 里,而是大量的数据会直接搞丢。
这个情况下,就不是说要增加 consumer 消费积压的消息,因为实际上没啥积压,而是丢了大量的消息。我们可以采取一个方案,就是批量重导,这个我们之前线上也有类似的场景干过。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,比如大家一起喝咖啡熬夜到晚上12点以后,用户都睡觉了。这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去,把白天丢的数据给他补回来。也只能是这样了。
假设 1 万个订单积压在 mq 里面,没有处理,其中 1000 个订单都丢了,你只能手动写程序把那 1000 个订单给查出来,手动发到 mq 里去再补一次。
如何解决消息积压问题?
一般这个时候,只能临时紧急扩容了,具体操作步骤和思路如下:
先修复 consumer 的问题,确保其恢复消费速度,然后将现有 consumer 都停掉。
新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。
然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
各个MQ的功能对比
特性
ActiveMQ
RabbitMQ
RockerMQ
Kafka
开发语言
Java
erlang
Java
Scala
单机吞吐量
万级
万级
10万级
10万级
时效性
ms级
us级
ms级
ms级以内
可用性
高(主从架构)
高(主从架构)
非常高(分布式架构)
非常高(分布式架构)
功能特性
成熟的产品,较多的文档,各种协议支持友好
erlang开发,并发能力强,性能极其好,延时低,管理界面丰富
MQ功能比较完备,扩展性佳
只支持MQ的功能,像一些消息查询、消息回溯没有。大数据系统收集系统首选
消息队列的一般存储方式有哪些?
当前业界几款主流的MQ消息队列采用的存储方式主要有以下三种方式。
-
分布式KV存储
这类 MQ 一般会采用诸如 LevelDB 、RocksDB 和 Redis 来作为消息持久化的方式。由于分布式缓存的读写能力要优于 DB ,所以在对消息的读写能力要求都不是比较高的情况下,采用这种方式倒也不失为一种可以替代的设计方案。
消息存储于分布式 KV 需要解决的问题在于如何保证 MQ 整体的可靠性。 -
文件系统
目前业界较为常用的几款产品(RocketMQ / Kafka / RabbitMQ)均采用的是消息刷盘至所部署虚拟机/物理机的文件系统来做持久化(刷盘一般可以分为异步刷盘和同步刷盘两种模式)。刷盘指的是存储到硬盘。
消息刷盘为消息存储提供了一种高效率、高可靠性和高性能的数据持久化方式。除非部署 MQ 机器本身或是本地磁盘挂了,否则一般是不会出现无法持久化的故障问题。 -
关系型数据库 DB
Apache下开源的另外一款MQ—ActiveMQ(默认采用的KahaDB做消息存储)可选用 JDBC 的方式来做消息持久化,通过简单的 XML 配置信息即可实现JDBC消息存储。
由于,普通关系型数据库(如 MySQL )在单表数据量达到千万级别的情况下,其 IO 读写性能往往会出现瓶颈。因此,如果要选型或者自研一款性能强劲、吞吐量大、消息堆积能力突出的 MQ 消息队列,那么并不推荐采用关系型数据库作为消息持久化的方案。在可靠性方面,该种方案非常依赖 DB ,如果一旦 DB 出现故障,则 MQ 的消息就无法落盘存储会导致线上故障。
小结
因此,综合上所述从存储效率来说,文件系统 > 分布式 KV 存储 > 关系型数据库 DB ,
直接操作文件系统肯定是最快和最高效的,而关系型数据库 TPS 一般相比于分布式 KV 系统会更低一些(简略地说,关系型数据库本身也是一个需要读写文件 Server ,这时 MQ 作为 Client与其建立连接并发送待持久化的消息数据,同时又需要依赖 DB 的事务等,这一系列操作都比较消耗性能),所以如果追求高效的IO读写,那么选择操作文件系统会更加合适一些。但是如果从易于实现和快速集成来看,文件系统 > 分布式 KV 存储 > 关系型数据库 DB,但是性能会下降很多。
另外,从消息中间件的本身定义来考虑,应该尽量减少对于外部第三方中间件的依赖。一般来说依赖的外部系统越多,也会使得本身的设计越复杂,所以个人的理解是采用文件系统作为消息存储的方式,更贴近消息中间件本身的定义。
如果让你写一个消息队列,该如何进行架构设计
比如说这个消息队列系统,我们从以下几个角度来考虑一下:
首先这个 mq 得支持可伸缩性吧,就是需要的时候快速扩容,就可以增加吞吐量和容量,那怎么搞?设计个分布式的系统呗,参照一下 kafka 的设计理念,broker -> topic -> partition,每个 partition 放一个机器,就存一部分数据。如果现在资源不够了,简单啊,给 topic 增加 partition,然后做数据迁移,增加机器,不就可以存放更多数据,提供更高的吞吐量了?
其次你得考虑一下这个 mq 的数据要不要落地磁盘吧?那肯定要了,落磁盘才能保证别进程挂了数据就丢了。那落磁盘的时候怎么落啊?顺序写,这样就没有磁盘随机读写的寻址开销,磁盘顺序读写的性能是很高的,这就是 kafka 的思路。
其次你考虑一下你的 mq 的可用性啊?这个事儿,具体参考之前可用性那个环节讲解的 kafka 的高可用保障机制。多副本 -> leader & follower -> broker 挂了重新选举 leader 即可对外服务。
能不能支持数据 0 丢失啊?可以的,参考我们之前说的那个 kafka 数据零丢失方案。
mq 肯定是很复杂的,面试官问你这个问题,其实是个开放题,他就是看看你有没有从架构角度整体构思和设计的思维以及能力。确实这个问题可以刷掉一大批人,因为大部分人平时不思考这些东西。
相关文章:

消息队列 面试题 整理
消息队列 为什么要使用消息队列? 异步解耦:关注的是通知而非处理。 流量削峰:将短时间内高并发的请求持久化,然后逐步处理,削平高峰期的请求。 日志收集: 事务最终一致性 系统间的消息通信方式ÿ…...

【Java】对象比较大小
在Java中经常会涉及到对象数组的排序问题,那么就涉及到对象之间的比较问题。Java实现对象排序的方式有两种: 自然排序:java.lang.Comparable定制排序:java.util.Comparator 规则:需要我们自定义根据对象的某个或某些属…...
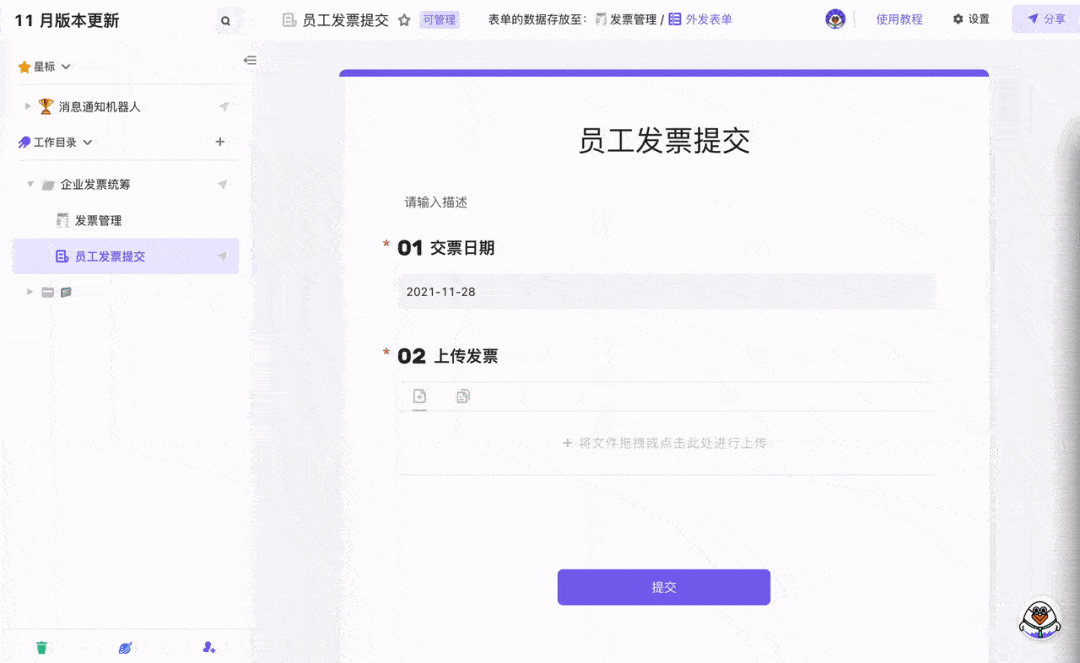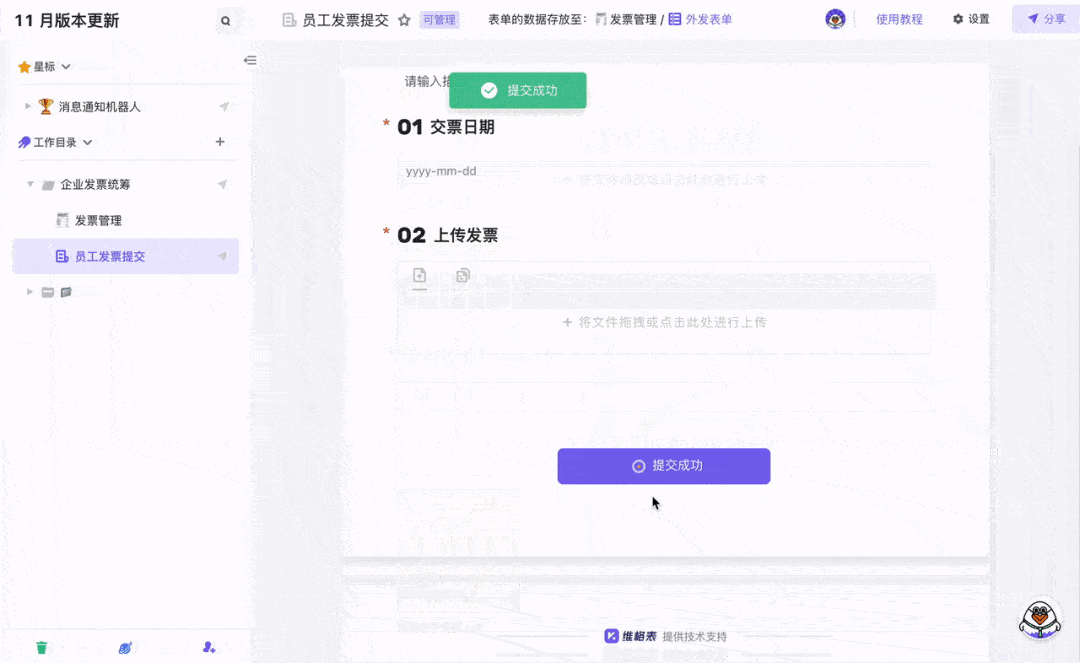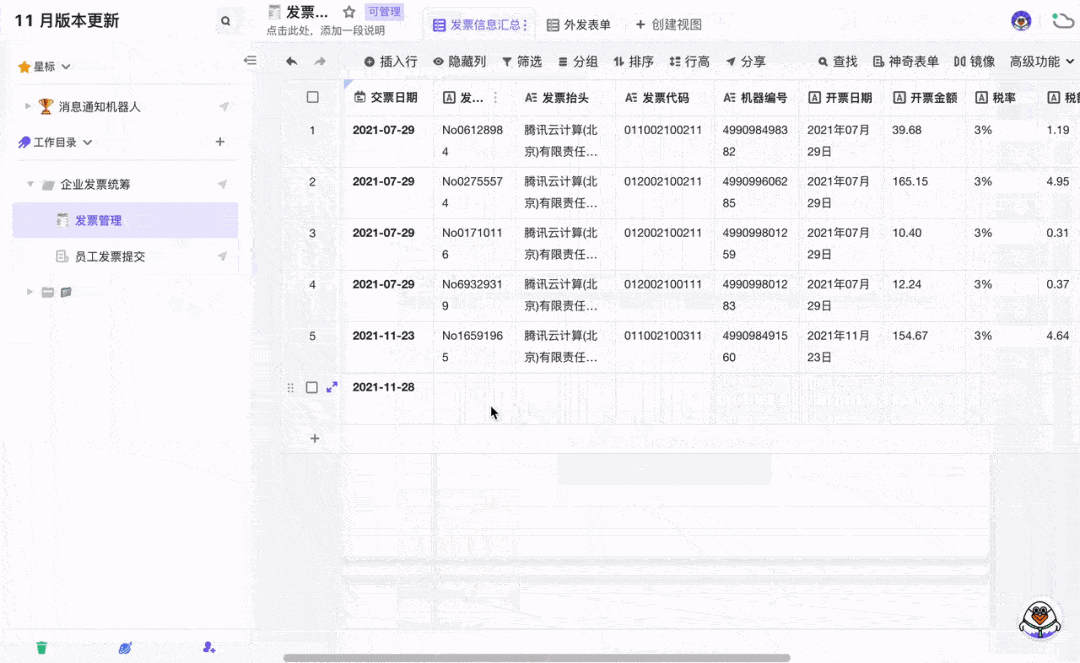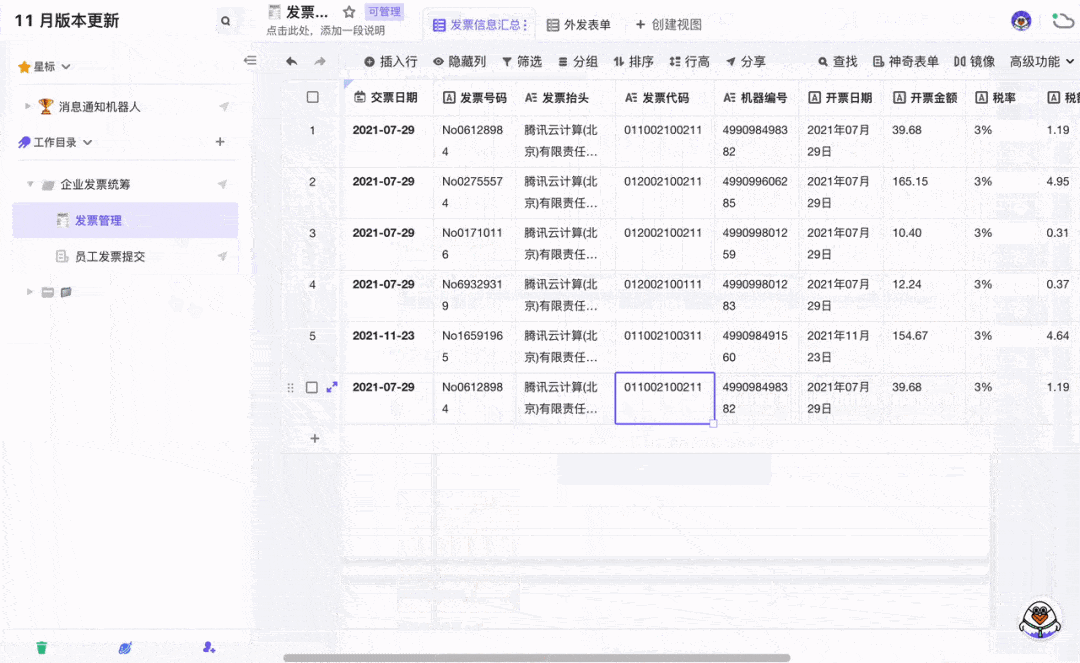
发票自动OCR识别并录入模板 3分钟免费配置
要问整个公司里和数据打交道最多的职能,非财务莫属了吧。除了每天要处理大量财务数据外,还有发票录入的工作让财务陷入“易燃易爆炸”的工作状态。发票报销看似简单,但发票的类型有很多种,每种发票需要录入的信息也有差别。再加上…...

Dubbo 配置说明
dubbo:scan:base-packages: com.ut.msdasw.services.appservice //这个会扫描该包下得全部接口protocol: //这个主要是配置传输的协议和端口,只是一个协议name: dubbo port: 30032registry: //这里是服务注册中心的地址address: spring-cloud://localhost consum…...

英飞凌TCxxx实战系列01_Alarm处理
目录 1.概述2. Alarm内部处理2.1关联的寄存器2.2 Alarm设置case3. SMU外部处理3.1 关联的寄存器4. WDT Alarm的特殊处理4.1 看门狗超时测试4.2 RecoveryTimer相关的Alarm1.概述 当MCU运行出现问题,如MCU温度过高、过低,看门狗超时等会触发一个Alarm,当SMU收到Alarm信号后,…...
飞桨全量支持业内AI科学计算工具——DeepXDE!
AI技术在跨学科融合创新方面扮演着日益重要的角色,特别是在Al for Science领域,AI技术的发展为跨学科、跨领域的融合创新带来了巨大的机会。AI已成为一个关键的研究工具,改变了基础科学的研究范式。依托AI技术开发的科学计算工具,…...

【c++基础】
C基础入门统一初始化输入输出输入输出符输入字符串const与指针c和c中const的区别const与指针的关系常变量与指针同类型指针赋值的兼容规则引用引用的特点const引用作为形参替换指针其他引用形式引用和指针的区别inline函数缺省参数函数重载判断函数重载的规则名字粉碎C编译时函…...

语音识别技术对比分析
文章目录一、语音识别产品对比二、百度语音识别产品1、套餐及价格:2、官网3、调研结果三、华为语音识别产品四、阿里云语音识别产品1、套餐及价格:2、官网地址3、调研结果五、科大讯飞语音识别产品1、套餐及价格:2、官网3、调研结果六、有道语…...

Idea git 回滚远程仓库版本
目标 回滚远程仓库到特定版本。 将【添加test03】版本回滚到【行为型模式】版本。 回滚前的效果图 步骤 ①复制需要回滚到的版本的版本号 ②右键项目,选择Git-Repository-Reset Head ③Reset Type选择Hard;To Commit填入步骤①复制的版本号ÿ…...

vscode C++配置
program:调试入口文件的地址cwd:程序启动调试的目录miDebuggerPath:调试器的路径launch.json// { // // Use IntelliSense to learn about possible attributes. // // Hover to view descriptions of existing attributes. // /…...

【微电网_储能】基于启发式状态机策略和线性程序策略优化方法的微电网中的储能研究【给定系统约束和定价的情况下】(Matlab代码实现)
👨🎓个人主页:研学社的博客💥💥💞💞欢迎来到本博客❤️❤️💥💥🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密…...

rk3288-android8-IR-mouse
IR问题: mouse按键使用不了 然后排查: 1.排查上报 ir_key6{ rockchip,usercode <0xbf00>;rockchip,key_table <0xff KEY_POWER>,<0xfe KEY_MUTE>, <0xfd KEY_1>, <0xfc KEY_2>, <0xfb KEY_3>, <0xfa KEY_4>, <0xf9 KEY_5>…...

2023-03-01干活小计
昨天组会,元气大伤,拖更直接。今天继续,三月加油! python魔术方法: __repr__:print()时候调用,注意函数返回值就是打印值。 __len__:len()时候调用 __call__:实例()时候调用 __getitem__:self[i]时候调…...
客户服务软件推荐榜:28款!
在这个竞争激烈的时代,做到服务对企业的存亡有着深刻的意义。改善客户服务,做好客户服务工作,是关键,因为客户服务团队代表着企业的形象,面孔,客户有可能 不大会记得企业的某个东西,但是他们将会…...

Spring注入和注解实现IOC
标题注入依赖注入的方式通过Set方法注入通过构造方法注入自动注入依赖注入的数据类型注入Bean对象注入基本数据类型和字符串注入List注入Set注入Map注入Properties注解实现IOCComponentRepository、Service、Controller注入 依赖注入的方式 在使用依赖注入时,如果…...
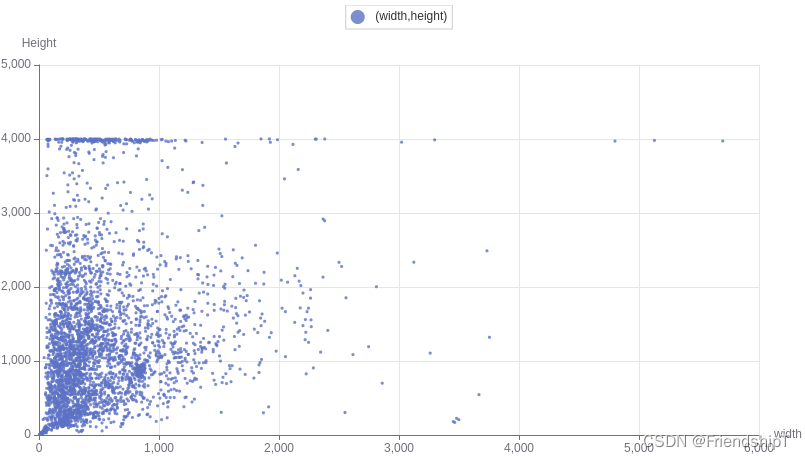
Python统计Labelme标注文件信息并绘制散点图
Python统计Labelme标注文件信息并绘制散点图前言前提条件相关介绍实验环境Python统计Labelme标注文件信息并绘制散点图前言 本文是个人使用Python处理文件的电子笔记,由于水平有限,难免出现错漏,敬请批评改正。更多精彩内容,可点击…...
 客户案例——ET Innovations)
远程接入方案 OpenText Exceed TurboX(ETX) 客户案例——ET Innovations
远程接入方案 OpenText Exceed TurboX(ETX) 客户案例——ET Innovations ET Innovations GmbH 助力奥地利各地的医疗保健专业人员提升患者体验 医疗保健信息系统开发商利用 OpenText™ Exceed™ TurboX 将远程访问其软件的稳定性提高了 95% 公司:ET I…...

Django4.1.7通过djongo1.3.6链接mongoDB6.0.4
网上中文版的djongo链接mongoDB基本都是抄袭州的先生大哥的文章。 文章成文比较久,至少是2019年成文的了,有一些情况发生了变化,今天就自己测试的情况做一些记录。 本文成文日期为:2023年3月2日,请注意参考 废话不多说…...

如何使用FindFunc在IDA Pro中寻找包含指定代码模式的函数代码
关于FindFunc FindFunc是一款功能强大的IDA Pro插件,可以帮助广大研究人员轻松查找包含了特定程序集、代码字节模式、特定命名、字符串或符合其他各种约束条件的代码函数。简而言之,FindFunc的主要目的就是在二进制文件中寻找已知函数。 使用规则过滤 …...
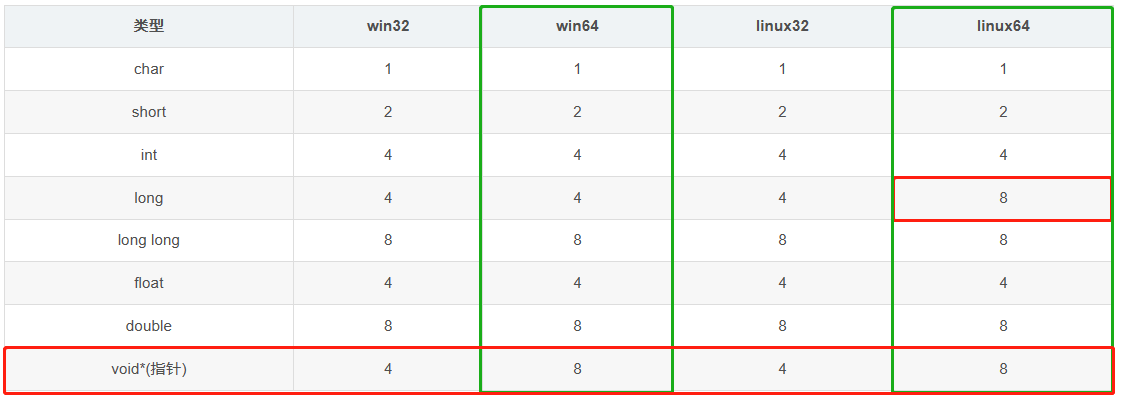
【C++】讲的最通透最易懂的关于结构体内存对齐的问题
目录1. 内存对齐规则2. 简单易懂的内存对齐示例2.1 简单结构体2.2 含位域的结构体2.3 空类的大小2.4 嵌套结构体3. 为什么需要内存对齐?4. 类型在不同系统下所占字节数1. 内存对齐规则 第一个成员在与结构体变量偏移量为0的位置处。其他成员变量要对齐到某个数字&a…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...