【scikit-learn基础】--『数据加载』之样本生成器
除了内置的数据集,scikit-learn还提供了随机样本的生成器。通过这些生成器函数,可以生成具有特定特性和分布的随机数据集,以帮助进行机器学习算法的研究、测试和比较。
目前,scikit-learn库(v1.3.0版)中有20个不同的生成样本的函数。本篇重点介绍其中几个具有代表性的函数。
1. 分类聚类数据样本
分类和聚类是机器学习中使用频率最高的算法,创建各种相关的样本数据,能够帮助我们更好的试验算法。
1.1. make_blobs
这个函数通常用于可视化分类器的学习过程,它生成由聚类组成的非线性数据集。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobsX, Y = make_blobs(n_samples=1000, centers=5)
plt.scatter(X[:, 0], X[:, 1], marker="o", c=Y, s=25)plt.show()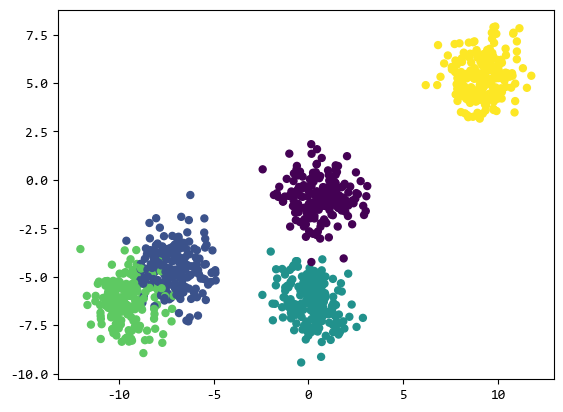
上面的示例生成了1000个点的数据,分为5个类别。
make_blobs的主要参数包括:
-
n_samples:生成的样本数。
-
n_features:每个样本的特征数。通常为2,表示我们生成的是二维数据。
-
centers:聚类的数量。即生成的样本会被分为多少类。
-
cluster_std:每个聚类的标准差。这决定了聚类的形状和大小。
-
shuffle:是否在生成数据后打乱样本。
-
random_state:随机数生成器的种子。这确保了每次运行代码时生成的数据集都是一样的。
1.2. make_classification
这是一个用于生成复杂二维数据的函数,通常用于可视化分类器的学习过程或者测试机器学习算法的性能。
import matplotlib.pyplot as plt
from sklearn.datasets import make_classificationX, Y = make_classification(n_samples=100, n_classes=4, n_clusters_per_class=1)
plt.scatter(X[:, 0], X[:, 1], marker="o", c=Y, s=25)plt.show()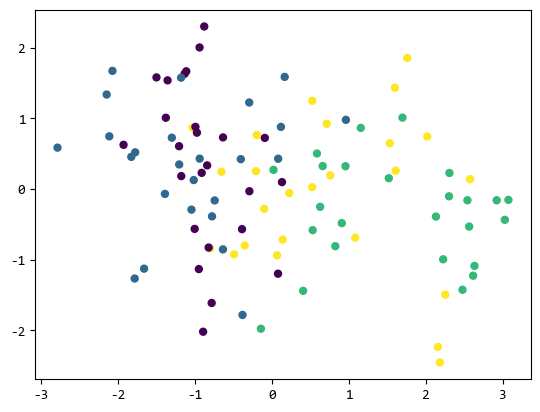
可以看出它生成的各类数据交织在一起,很难做线性的分类。
make_classification的主要参数包括:
-
n_samples:生成的样本数。
-
n_features:每个样本的特征数。这个参数决定了生成的数据集的维度。
-
n_informative:具有信息量的特征的数量。这个参数决定了特征集中的特征有多少是有助于分类的。
-
n_redundant:冗余特征的数量。这个参数决定了特征集中的特征有多少是重复或者没有信息的。
-
random_state:随机数生成器的种子。这确保了每次运行代码时生成的数据集都是一样的。
1.3. make_moons
和函数名称所表达的一样,它是一个用于生成形状类似于月牙的数据集的函数,通常用于可视化分类器的学习过程或者测试机器学习算法的性能。
from sklearn.datasets import make_moonsfig, ax = plt.subplots(1, 3)
fig.set_size_inches(9, 3)X, Y = make_moons(noise=0.01, n_samples=1000)
ax[0].scatter(X[:, 0], X[:, 1], marker="o", c=Y, s=25)
ax[0].set_title("noise=0.01")X, Y = make_moons(noise=0.05, n_samples=1000)
ax[1].scatter(X[:, 0], X[:, 1], marker="o", c=Y, s=25)
ax[1].set_title("noise=0.05")X, Y = make_moons(noise=0.5, n_samples=1000)
ax[2].scatter(X[:, 0], X[:, 1], marker="o", c=Y, s=25)
ax[2].set_title("noise=0.5")plt.show()
noise越小,数据的分类越明显。
make_moons的主要参数包括:
-
n_samples:生成的样本数。
-
noise:在数据集中添加的噪声的标准差。这个参数决定了月牙的噪声程度。
-
random_state:随机数生成器的种子。这确保了每次运行代码时生成的数据集都是一样的。
2. 回归数据样本
除了分类和聚类,回归是机器学习的另一个重要方向。scikit-learn同样也提供了创建回归数据样本的函数。
from sklearn.datasets import make_regressionfig, ax = plt.subplots(1, 3)
fig.set_size_inches(9, 3)X, y = make_regression(n_samples=100, n_features=1, noise=20)
ax[0].scatter(X[:, 0], y, marker="o")
ax[0].set_title("noise=20")X, y = make_regression(n_samples=100, n_features=1, noise=10)
ax[1].scatter(X[:, 0], y, marker="o")
ax[1].set_title("noise=10")X, y = make_regression(n_samples=100, n_features=1, noise=1)
ax[2].scatter(X[:, 0], y, marker="o")
ax[2].set_title("noise=1")plt.show()
通过调节noise参数,可以创建不同精确度的回归数据。
make_regression的主要参数包括:
-
n_samples:生成的样本数。
-
n_features:每个样本的特征数。通常为一个较小的值,表示我们生成的是一维数据。
-
noise:噪音的大小。它为数据添加一些随机噪声,以使结果更接近现实情况。
3. 流形数据样本
所谓流形数据,就是S形或者瑞士卷那样旋转的数据,可以用来测试更复杂的分类模型的效果。比如下面的make_s_curve函数,就可以创建S形的数据:
from sklearn.datasets import make_s_curveX, Y = make_s_curve(n_samples=2000)fig, ax = plt.subplots(subplot_kw={"projection": "3d"})
fig.set_size_inches((8, 8))
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=Y, s=60, alpha=0.8)
ax.view_init(azim=-60, elev=9)
plt.show()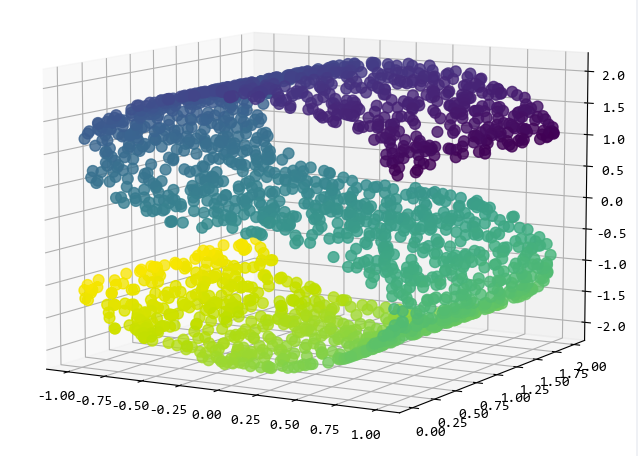
4. 总结
本文介绍的生成样本数据的函数只是scikit-learn库中各种生成器的一部分,还有很多种其他的生成器函数可以生成更加复杂的样本数据。
所有的生成器函数请参考文档:API Reference — scikit-learn 1.3.2 documentation
文章转载自:wang_yb
原文链接:https://www.cnblogs.com/wang_yb/p/17884401.html
相关文章:
【scikit-learn基础】--『数据加载』之样本生成器
除了内置的数据集,scikit-learn还提供了随机样本的生成器。通过这些生成器函数,可以生成具有特定特性和分布的随机数据集,以帮助进行机器学习算法的研究、测试和比较。 目前,scikit-learn库(v1.3.0版)中有2…...

基于 ESP32-S3 的 Walter 开发板
Walter 是一款基于 ESP32-S3 且拥有 5G LTE 连接功能的新型开源开发套件。 近日,比利时公司 DPTechnics BV 推出了一款基于乐鑫 ESP32-S3 且拥有 5G LTE 连接功能的新型开源开发套件。该套件即将在 Crowd Supply 平台上发布,您可以点击此处了解详情。 无…...
Gitlab+GitlabRunner搭建CICD自动化流水线将应用部署上Kubernetes
文章目录 安装Gitlab服务器准备安装版本安装依赖和暴露端口安装Gitlab修改Gitlab配置文件访问Gitlab 安装Gitlab Runner服务器准备安装版本安装依赖安装Gitlab Runner安装打包工具安装docker安装java17安装maven 注册Gitlab Runner 搭建自动化部署准备SpringBoot项目添加一个Co…...

待做-待补充-每个节点做事,时间,以及与角度的关系
文章目录 纲领1.是否可以通过遍历一遍二叉树得到答案2.是否可以通过两颗子树相同问题的答案推导出树的答案(形式为递归)无论哪种思维模式,都需要思考:单独一个二叉树节点,它需要做什么事情?需要在什么时候做 后序判断问题是否和子树相关&…...
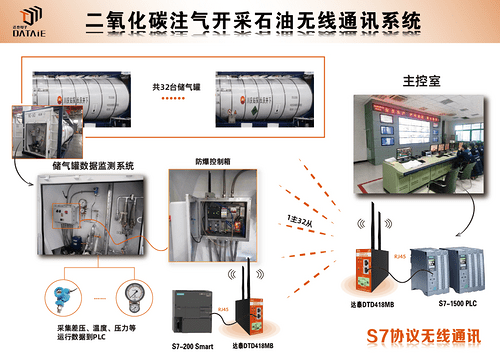
液态二氧化碳储存罐远程无线监测系统
二氧化碳强化石油开采技术,须先深入了解石油储层的地质特征和二氧化碳的作用机制。现场有8辆二氧化碳罐装车,每辆罐车上有4台液态二氧化碳储罐,每台罐的尾部都装有一台西门子S7-200 smart PLC。在注入二氧化碳的过程中,中控室S7-1…...

kafka学习笔记--安装部署、简单操作
本文内容来自尚硅谷B站公开教学视频,仅做个人总结、学习、复习使用,任何对此文章的引用,应当说明源出处为尚硅谷,不得用于商业用途。 如有侵权、联系速删 视频教程链接:【尚硅谷】Kafka3.x教程(从入门到调优…...
UE4 材质实现Glitch效果
材质实现Glitch效果 UE4 材质实现Glitch效果预览1预览2 UE4 材质实现Glitch效果 预览1 添加材质函数: MF_RandomNoise 添加材质: 预览2 添加材质函数MF_CustomPanner: 添加材质函数:MF_Glitch 材质添加: 下面用…...
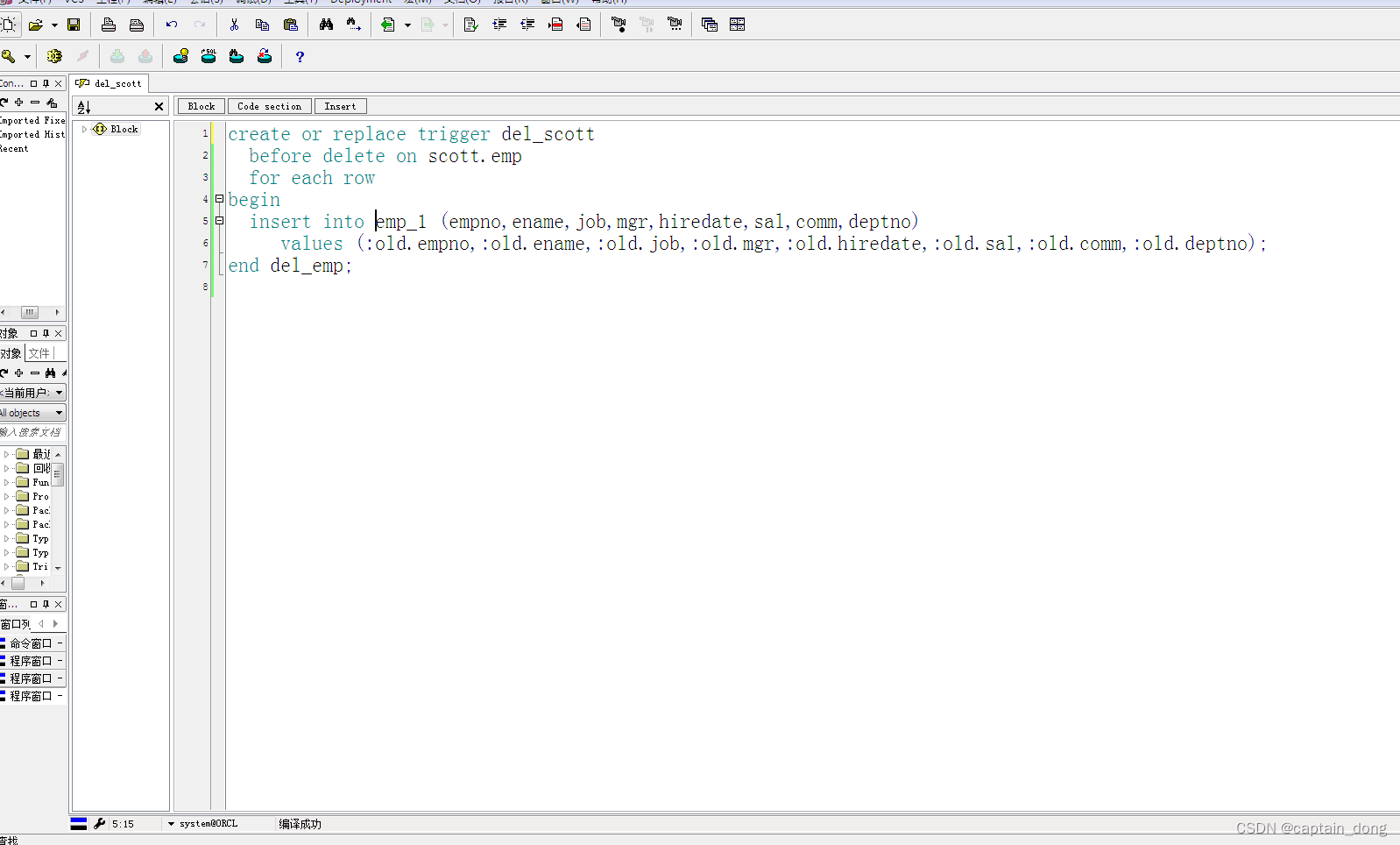
oracle实验2023-12-8--触发器
第十四周实验 【例】功能要求:增加一新表XS_1,表结构和表XS相同,用来存放从XS表中删除的记录。 分析: 1、创建表 xs_1 SQL> create table xs_1 as select * from xs; Table created SQL> truncate table xs_1; Table truncated题目&a…...

【Python百宝箱】贝叶斯统计的魅力:从PyMC3到ArviZ,探索数据背后的不确定性
标题:预测未来趋势的利器:深入贝叶斯统计和概率编程的世界 前言 贝叶斯统计和概率编程是一种强大的分析方法,可以帮助我们处理不确定性、建立灵活的模型以及进行参数估计和推断。本文将介绍几个常用的Python库,包括PyMC3、ArviZ…...

Knowledge Graph知识图谱—8. Web Ontology Language (OWL)
8. Web Ontology Language (OWL) 在RDFs不可能实现: Property cardinalities, Functional properties, Class disjointness, we cannot produce contradictions, circumvent the Non Unique Naming Assumption, circumvent the Open World Assumption 8.1 OWL Tr…...

排序算法——冒泡排序
排序算法是计算机科学中最基本的概念之一。在众多排序算法中,冒泡排序因其实现简单而被广泛学习。尽管它不是最高效的排序方法,但对于理解基本的排序概念非常有用。本文将深入探讨冒泡排序的原理、实现、优缺点以及应用场景。 1. 冒泡排序原理 冒泡排序…...
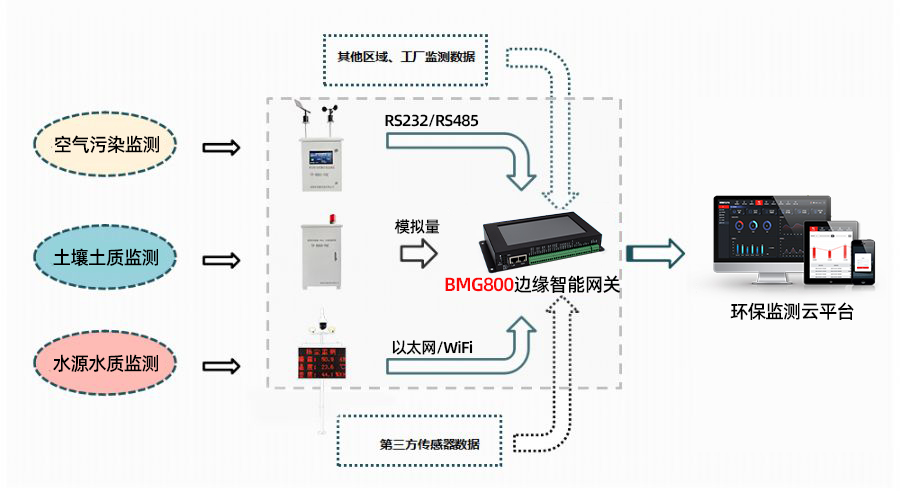
边缘智能网关如何应对环境污染难题
随着我国工业化、城镇化的深入推进,包括大气污染在内的环境污染防治压力继续加大。为应对环境污染防治难题,佰马综合边缘计算、物联网、智能感知等技术,基于边缘智能网关打造环境污染实时监测、预警及智能干预方案,可应用于大气保…...

uniapp定时器的应用
1、初始化定时器 data(){return{timer: null, //定时器} } 2、定时器的使用 定时器分两种,setInterval和setTimeout。 二者的区别: setInterval函数会无限执行下去,除非调用clearInterval函数来停止它。setTimeout函数只执行一次&#x…...

Docker中安装Oracle10g和oracle增删改查
Docker中安装Oracle 10g 一、Docker中安装Oracle 10安装步骤二、连接数据库登录三 oracle数据库的增删改查及联表查询的相关操作oracle数据库,创建students数据表,创建100万条数据增删改查 一、Docker中安装Oracle 10安装步骤 Docker中安装Oracle 10g 1.下载镜像 docker pull …...
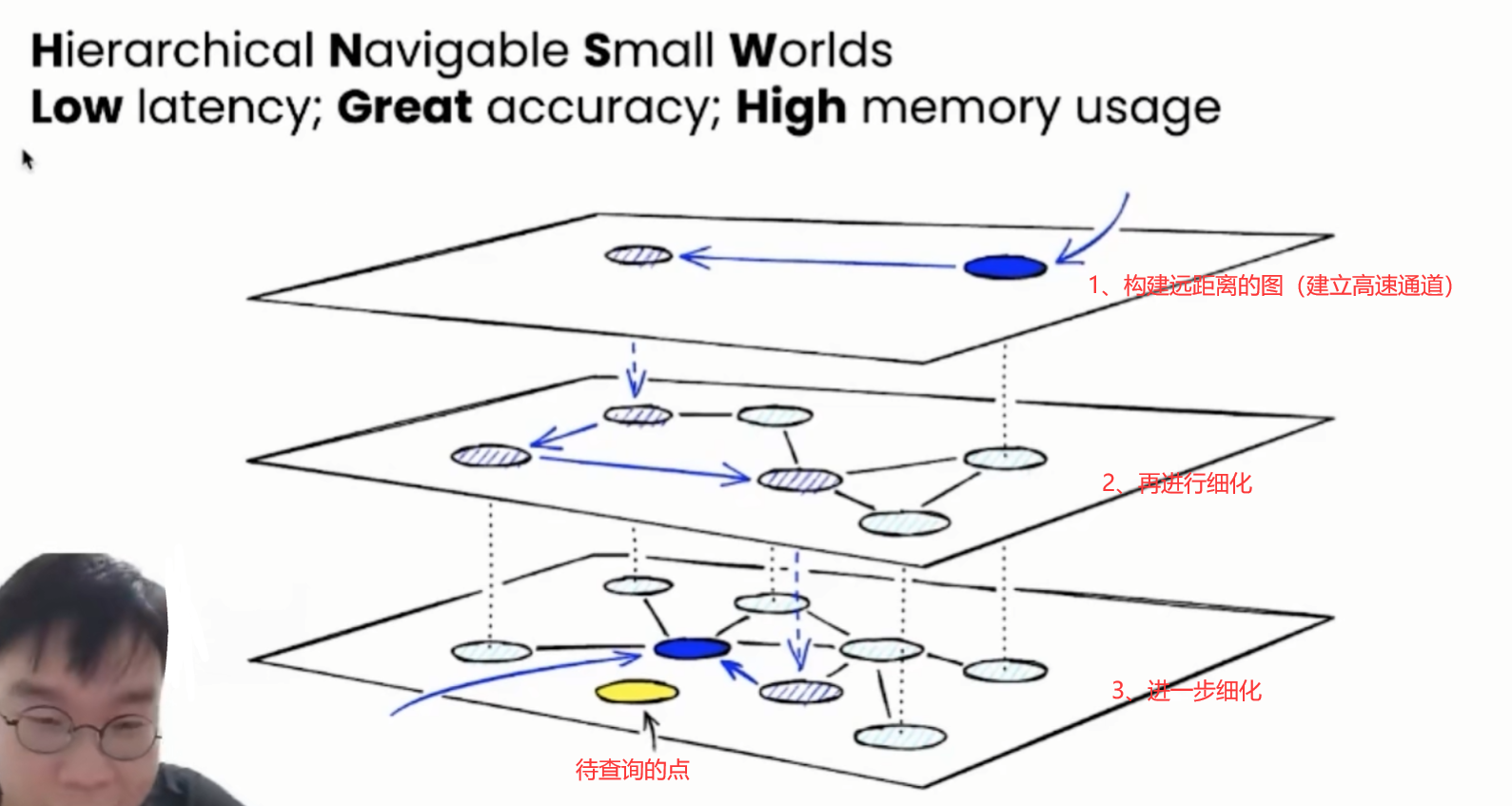
推荐算法:HNSW【推荐出与用户搜索的类似的/用户感兴趣的商品】
HNSW算法概述 HNSW(Hierarchical Navigable Small Word)算法算是目前推荐领域里面常用的ANN(Approximate Nearest Neighbor)算法了。其目的就是在极大量的候选集当中如何快速地找到一个query最近邻的k个元素。 要找到一个query的…...
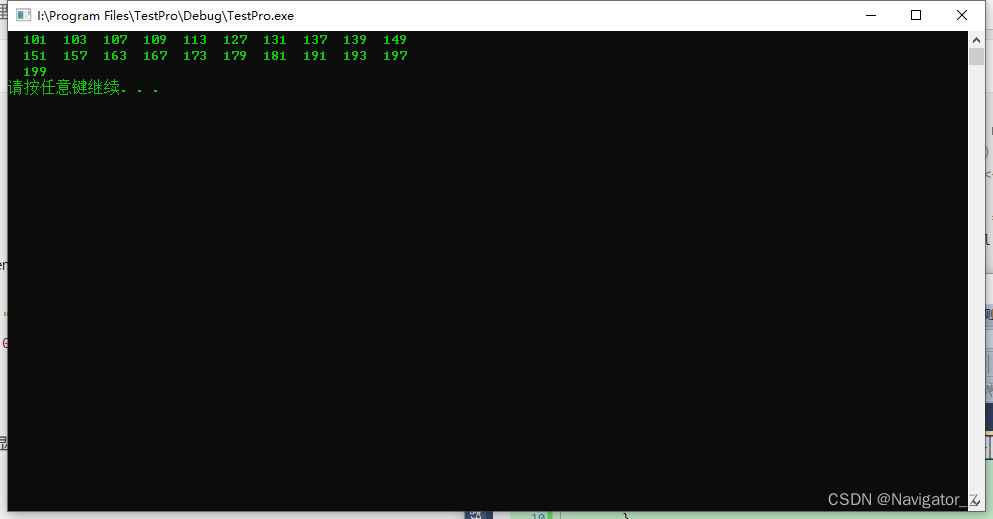
C++ //例3.14 找出100~200间的全部素数。
C程序设计 (第三版) 谭浩强 例3.14 例3.14 找出100~200间的全部素数。 IDE工具:VS2010 Note: 使用不同的IDE工具可能有部分差异。 代码块 方法:使用函数的模块化设计 #include <iostream> #include <iomanip> #i…...
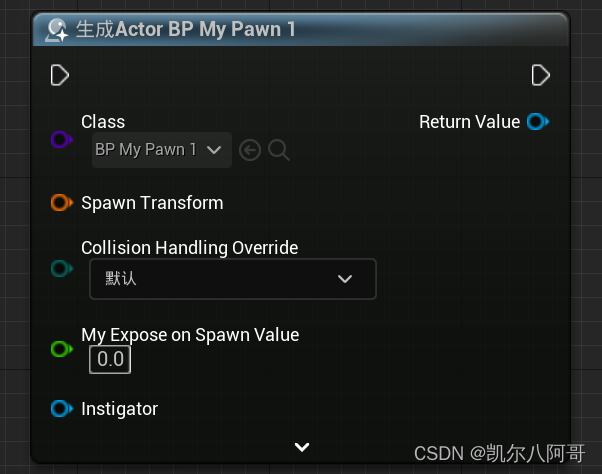
虚幻学习笔记11—C++结构体、枚举与蓝图的通信
一、前言 结构体的定义和枚举类似,枚举的定义有两种方式。区别是结构体必须以“F”开头命名,而枚举不用。 额外再讲了一下蓝图生成时暴露变量的方法。 二、实现 2.1、结构体 1、定义结构体 代码如下,注意这个定义的代码一定要在“UCLASS()”…...

【android开发-19】android中内容提供者contentProvider用法讲解
1,内容URI 在Android系统中,Content URI是一种用于唯一标识和访问应用程序中的数据的方法。它由Android系统提供,通过Content Provider来实现数据的共享和访问。 Content URI使用特定的格式来标识数据,通常以"content://&qu…...
)
浅谈排序——快速排序(最常用的排序)
快速排序(Quick Sort)是一种常见的排序算法,由英国计算机科学家东尼霍尔(Tony Hoare)在1960年发明。这是一种分治算法,基本思想是通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所…...

Springboot项目实现简单的文件服务器,实现文件上传+图片及文件回显
文章目录 写在前面一、配置1、application.properties2、webMvc配置3、查看效果 二、文件上传 写在前面 平常工作中的项目,上传的文件一般都会传到对象存储云服务中。当接手一个小项目,如何自己动手搭建一个文件服务器,实现图片、文件的回显…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...
在 Spring Boot 中使用 JSP
jsp? 好多年没用了。重新整一下 还费了点时间,记录一下。 项目结构: pom: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://ww…...

Unity中的transform.up
2025年6月8日,周日下午 在Unity中,transform.up是Transform组件的一个属性,表示游戏对象在世界空间中的“上”方向(Y轴正方向),且会随对象旋转动态变化。以下是关键点解析: 基本定义 transfor…...

CTF show 数学不及格
拿到题目先查一下壳,看一下信息 发现是一个ELF文件,64位的 用IDA Pro 64 打开这个文件 然后点击F5进行伪代码转换 可以看到有五个if判断,第一个argc ! 5这个判断并没有起太大作用,主要是下面四个if判断 根据题目…...
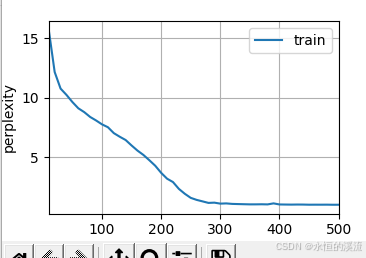
李沐--动手学深度学习--GRU
1.GRU从零开始实现 #9.1.2GRU从零开始实现 import torch from torch import nn from d2l import torch as d2l#首先读取 8.5节中使用的时间机器数据集 batch_size,num_steps 32,35 train_iter,vocab d2l.load_data_time_machine(batch_size,num_steps) #初始化模型参数 def …...
)
MySQL基本操作(续)
第3章:MySQL基本操作(续) 3.3 表操作 表是关系型数据库中存储数据的基本结构,由行和列组成。在MySQL中,表操作包括创建表、查看表结构、修改表和删除表等。本节将详细介绍这些操作。 3.3.1 创建表 在MySQL中&#…...