PyTorch深度学习实战(25)——自编码器
PyTorch深度学习实战(25)——自编码器
- 0. 前言
- 1. 自编码器
- 2. 使用 PyTorch 实现自编码器
- 小结
- 系列链接
0. 前言
自编码器 (Autoencoder) 是一种无监督学习的神经网络模型,用于数据的特征提取和降维,它由一个编码器 (Encoder) 和一个解码器 (Decoder) 组成,通过将输入数据压缩到低维表示,然后再重构出原始数据。在本节中,我们将学习如何使用自编码器,以在低维空间表示图像,学习以较少的维度表示图像有助于修改图像,可以利用低维表示来生成新图像。
1. 自编码器
我们已经学习了通过输入图像及其相应标签训练模型来对图像进行分类,进行分类的前提是是拥有带有类别标签的数据集。假设数据集中没有图像对应的标签,如果需要根据图像的相似性对图像进行聚类,在这种情况下,自编码器可以方便地识别和分组相似的图像。
自动编码器将图像作为输入,将其存储在低维空间中,并尝试通过解码过程输出相同图像,而不使用其他标签,因此 AutoEncoder 中的 Auto 表示能够再现输入。但是,如果我们只需要简单的在输出中重现输入,就不需要神经网络了,只需要将输入简单地原样输出即可。自编码器的作用在于它能够以较低维度对图像信息进行编码,因此称为编码器(将图像信息编码至较低维空间中),因此,相似的图像具有相似的编码。此外,解码器致力于根据编码矢量重建原始图像,以尽可能重现输入图像:

假设模型输入图像是 MNIST 手写数字图像,模型输出图像与输入图像相同。最中间的网络层是编码层,也称瓶颈层 (bottleneck layer),输入和瓶颈层之间发生的操作表示编码器,瓶颈层和输出之间的操作表示解码器。
通过瓶颈层,我们可以在低维空间中表示图像,也可以重建原始图像,换句话说,利用自编码器中的瓶颈层能够解决识别相似图像以及生成新图像的问题,具体而言:
- 具有相似瓶颈层值(编码表示,也称潜编码)的图像可能彼此相似
- 通过改变瓶颈层的节点值,可以改变输出图像。
2. 使用 PyTorch 实现自编码器
本节中,使用 PyTorch 构建自编码器,我们使用 MNIST 数据集训练此网络,MNIST 数据集中是一个手写数字的图像数据集,包含了 6 万个 28x28 像素的训练样本和 1 万个测试样本。
(1) 导入相关库并定义设备:
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.utils import make_grid
import numpy as np
from matplotlib import pyplot as plt
device = 'cuda' if torch.cuda.is_available() else 'cpu'
(2) 指定图像转换方法:
img_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),transforms.Lambda(lambda x: x.to(device))
])
通过以上代码,将图像转换为张量,对其进行归一化,然后将其传递到设备中。
(3) 创建训练和验证数据集:
trn_ds = MNIST('MNIST/', transform=img_transform, train=True, download=True)
val_ds = MNIST('MNIST/', transform=img_transform, train=False, download=True)
(4) 定义数据加载器:
batch_size = 256
trn_dl = DataLoader(trn_ds, batch_size=batch_size, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=batch_size, shuffle=False)
(5) 定义网络架构,在 __init__ 方法中定义了使用编码器-解码器架构的 AutoEncoder 类,以及瓶颈层的维度,latent_dim 和 forward 方法,并打印模型摘要信息。
定义 AutoEncoder 类和包含编码器、解码器以及瓶颈层维度的 __init__ 方法:
class AutoEncoder(nn.Module):def __init__(self, latent_dim):super().__init__()self.latend_dim = latent_dimself.encoder = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(True),nn.Linear(128, 64), nn.ReLU(True), #nn.Linear(64, 12), nn.ReLU(True), nn.Linear(64, latent_dim))self.decoder = nn.Sequential(#nn.Linear(latent_dim, 12), nn.ReLU(True),nn.Linear(latent_dim, 64), nn.ReLU(True),nn.Linear(64, 128), nn.ReLU(True), nn.Linear(128, 28 * 28), nn.Tanh())
定义前向计算方法 forward:
def forward(self, x):x = x.view(len(x), -1)x = self.encoder(x)x = self.decoder(x)x = x.view(len(x), 1, 28, 28)return x
打印模型摘要信息:
from torchsummary import summary
model = AutoEncoder(3).to(device)
print(summary(model, (1,28,28)))
模型架构信息输出如下:
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Linear-1 [-1, 128] 100,480ReLU-2 [-1, 128] 0Linear-3 [-1, 64] 8,256ReLU-4 [-1, 64] 0Linear-5 [-1, 3] 195Linear-6 [-1, 64] 256ReLU-7 [-1, 64] 0Linear-8 [-1, 128] 8,320ReLU-9 [-1, 128] 0Linear-10 [-1, 784] 101,136Tanh-11 [-1, 784] 0
================================================================
Total params: 218,643
Trainable params: 218,643
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.02
Params size (MB): 0.83
Estimated Total Size (MB): 0.85
----------------------------------------------------------------
从前面的输出中,可以看到 Linear: 2-5 层是瓶颈层,将每张图像都表示为一个 3 维向量;此外,解码器使用瓶颈层中的 3 维向量重建原始图像。
(6) 定义函数在批数据上训练模型 train_batch():
def train_batch(input, model, criterion, optimizer):model.train()optimizer.zero_grad()output = model(input)loss = criterion(output, input)loss.backward()optimizer.step()return loss
(7) 定义在批数据上进行模型验证的函数 validate_batch():
@torch.no_grad()
def validate_batch(input, model, criterion):model.eval()output = model(input)loss = criterion(output, input)return loss
(8) 定义模型、损失函数和优化器:
model = AutoEncoder(3).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-5)
(9) 训练模型:
num_epochs = 20
train_loss_epochs = []
val_loss_epochs = []
for epoch in range(num_epochs):N = len(trn_dl)trn_loss = []val_loss = []for ix, (data, _) in enumerate(trn_dl):loss = train_batch(data, model, criterion, optimizer)pos = (epoch + (ix+1)/N)trn_loss.append(loss.item())train_loss_epochs.append(np.average(trn_loss))N = len(val_dl)for ix, (data, _) in enumerate(val_dl):loss = validate_batch(data, model, criterion)pos = epoch + (1+ix)/Nval_loss.append(loss.item())val_loss_epochs.append(np.average(val_loss))
(10) 可视化训练期间模型的训练和验证损失随时间的变化情况:
epochs = np.arange(num_epochs)+1
plt.plot(epochs, train_loss_epochs, 'bo', label='Training loss')
plt.plot(epochs, val_loss_epochs, 'r-', label='Test loss')
plt.title('Training and Test loss over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()

(11) 使用测试数据集 val_ds 验证模型:
for _ in range(5):ix = np.random.randint(len(val_ds))im, _ = val_ds[ix]_im = model(im[None])[0]plt.subplot(121)# fig, ax = plt.subplots(1,2,figsize=(3,3)) plt.imshow(im[0].detach().cpu(), cmap='gray')plt.title('input')plt.subplot(122)plt.imshow(_im[0].detach().cpu(), cmap='gray')plt.title('prediction')
plt.show()

我们可以看到,即使瓶颈层只有三个维度,网络也可以非常准确地重现输入,但是图像并不像预期的那样清晰,主要是因为瓶颈层中的节点数量过少。具有不同瓶颈层大小 (2、3、5、10 和 50) 的网络训练后,可视化重建的图像如下所示:
def train_aec(latent_dim):model = AutoEncoder(latent_dim).to(device)criterion = nn.MSELoss()optimizer = torch.optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-5)num_epochs = 20train_loss_epochs = []val_loss_epochs = []for epoch in range(num_epochs):N = len(trn_dl)trn_loss = []val_loss = []for ix, (data, _) in enumerate(trn_dl):loss = train_batch(data, model, criterion, optimizer)pos = (epoch + (ix+1)/N)trn_loss.append(loss.item())train_loss_epochs.append(np.average(trn_loss))N = len(val_dl)trn_loss = []val_loss = []for ix, (data, _) in enumerate(val_dl):loss = validate_batch(data, model, criterion)pos = epoch + (1+ix)/Nval_loss.append(loss.item())val_loss_epochs.append(np.average(val_loss))epochs = np.arange(num_epochs)+1plt.plot(epochs, train_loss_epochs, 'bo', label='Training loss')plt.plot(epochs, val_loss_epochs, 'r-', label='Test loss')plt.title('Training and Test loss over increasing epochs')plt.xlabel('Epochs')plt.ylabel('Loss')plt.legend()plt.grid('off')plt.show()return modelaecs = [train_aec(dim) for dim in [50, 2, 3, 5, 10]]for _ in range(10):ix = np.random.randint(len(val_ds))im, _ = val_ds[ix]plt.subplot(1, len(aecs)+1, 1)plt.imshow(im[0].detach().cpu(), cmap='gray')plt.title('input')idx = 2for model in aecs:_im = model(im[None])[0]plt.subplot(1, len(aecs)+1, idx)plt.imshow(_im[0].detach().cpu(), cmap='gray')plt.title(f'prediction\nlatent-dim:{model.latend_dim}')idx += 1
plt.show()
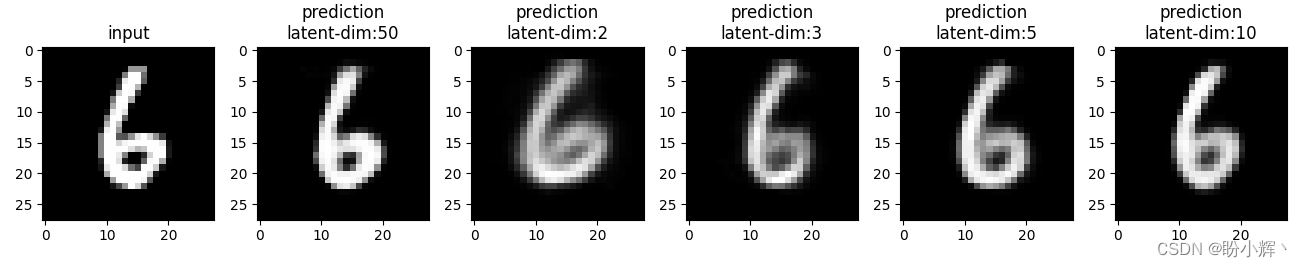
随着瓶颈层中向量维度的增加,重建图像的清晰度逐渐提高。
小结
自编码器是一种无监督学习的神经网络模型,用于数据的特征提取和降维。它由编码器和解码器组成,通过将输入数据压缩到低维表示,并尝试重构出原始数据来实现特征提取和数据的降维。自编码器的训练过程中,目标是最小化输入数据与重构数据之间的重建误差,以使编码器捕捉到数据的关键特征。自编码器在无监督学习和深度学习中扮演着重要的角色,能够从数据中学习有用的特征,并为后续的机器学习任务提供支持。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——使用U-Net架构进行图像分割
PyTorch深度学习实战(24)——从零开始实现Mask R-CNN实例分割
相关文章:
PyTorch深度学习实战(25)——自编码器
PyTorch深度学习实战(25)——自编码器 0. 前言1. 自编码器2. 使用 PyTorch 实现自编码器小结系列链接 0. 前言 自编码器 (Autoencoder) 是一种无监督学习的神经网络模型,用于数据的特征提取和降维,它由一个编码器 (Encoder) 和一…...

靠谱的车- 华为OD统一考试(C卷)
靠谱的车- 华为OD统一考试(C卷) OD统一考试(C卷) 分值: 100分 题解: Java / Python / C 题目描述 程序员小明打了一辆出租车去上班。出于职业敏感,他注意到这辆出租车的计费表有点问题…...

Apache Flink(十一):Flink集群部署-Standalone集群部署
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录 1. 节点划分...

vue的组件传值
Vue中组件之间的数据传递可以使用props和$emit来实现。 1.使用props传递数据:父组件可以通过子组件的props属性向子组件传递数据。 父组件中: <template><div><child-component :message"parentMessage"></child-comp…...
ue5材质预览界面ue 变黑
发现在5.2和5.1上都有这个bug 原因是开了ray tracing引起的,这个bug真是长时间存在,类似的bug还包括草地上奇怪的影子和地形上的影子等等 解决方法也很简单,就是关闭光追(不是…… 就是关闭预览,在材质界面preview sc…...

【SpringCloud篇】Eureka服务的基本配置和操作
文章目录 🌹简述Eureka🛸搭建Eureka服务⭐操作步骤⭐服务注册⭐服务发现 🌹简述Eureka Eureka是Netflix开源的一个基于REST的服务治理框架,主要用于实现微服务架构中的服务注册与发现。它由Eureka服务器和Eureka客户端组成&#…...

模拟目录管理 - 华为OD统一考试(C卷)
OD统一考试(C卷) 分值: 200分 题解: Java / Python / C++ 题目描述 实现一个模拟目录管理功能的软件,输入一个命令序列,输出最后一条命令运行结果。 支持命令: 1)创建目录命令: mkdir 目录名称,如mkdir abc为在当前目录创建abc目录,如果已存在同名目录则不执行任何操作…...

卷王开启验证码后无法登陆问题解决
问题描述 使用 docker 部署,后台设置开启验证,重启服务器之后,docker重启,再次访问系统,验证码获取失败,导致无法进行验证,也就无法登陆系统。 如果不了解卷王的,可以去官网看下。…...
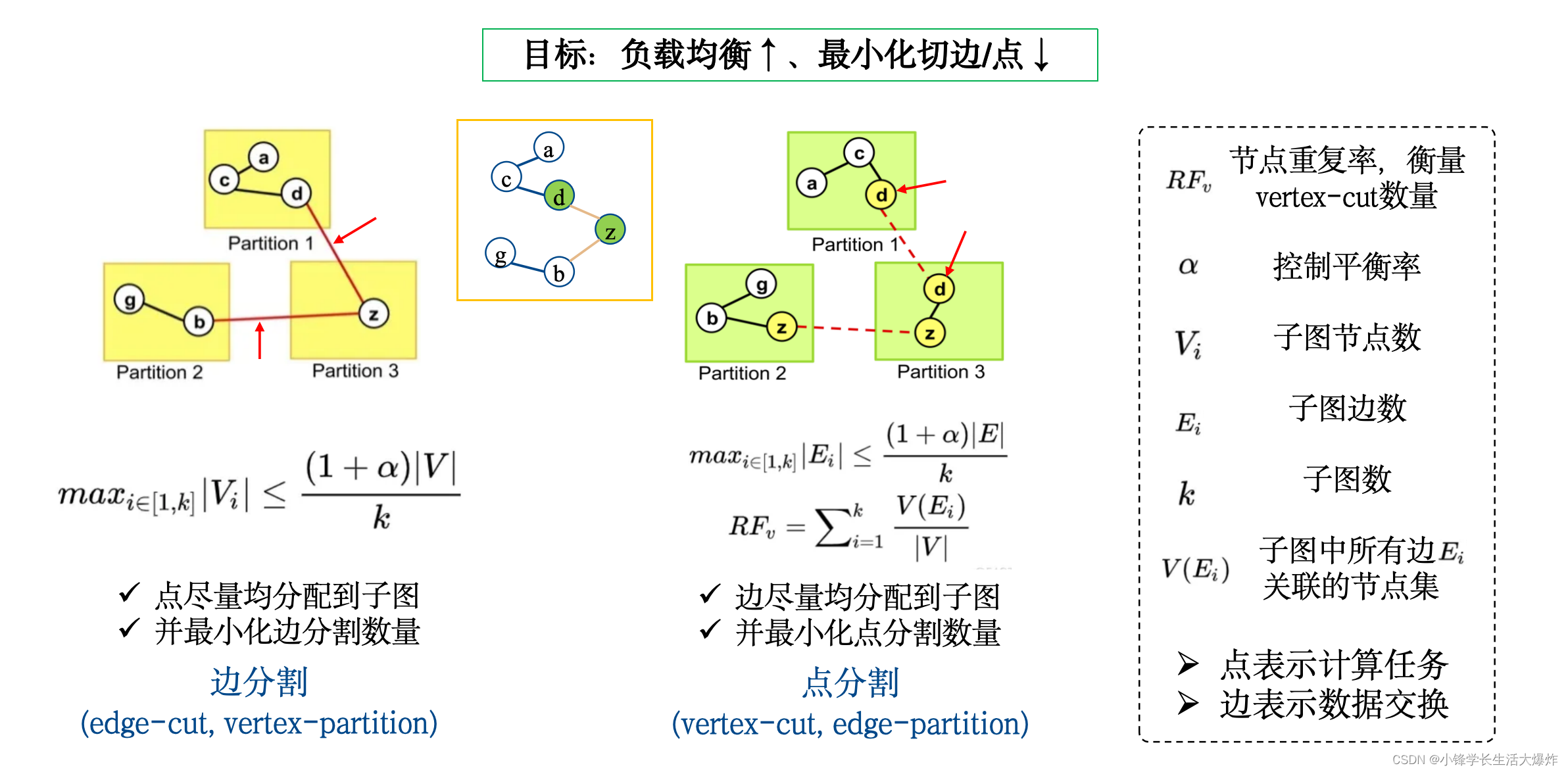
【知识】如何区分图论中的点分割和边分割
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 以下两个概念在现有中文博客下非常容易混淆: edge-cut(边切割) vertex-partition(点分割)vertex-cut(点切割) edge-partition(边分割) 实际上,初看中文时,真的会搞不清楚。但…...

【华为鸿蒙系统学习】- HarmonyOS4.0开发工具和环境配置问题总结|自学篇
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:"没有罗马,那就自己创造罗马~" 目录 官方链接 HUAWEI DevEco Studio和SDK下载和升级 | HarmonyOS开发者 安装教程 (…...
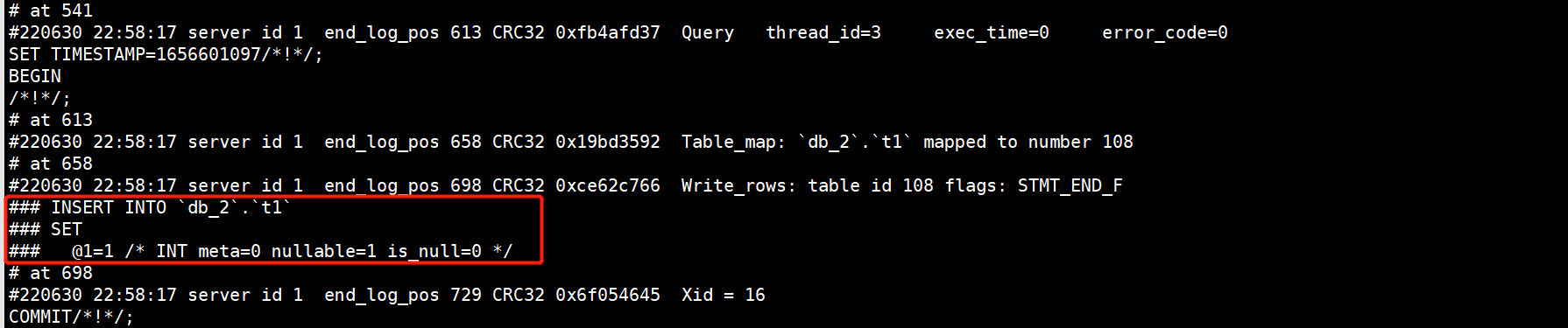
第78讲:MySQL数据库Binlog日志的核心概念与应用案例
文章目录 1.Binlog二进制日志的基本概念1.1.什么是Binlog二进制1.2.Binlog日志的三种记录格式1.3.Binlog日志中Event事件的概念 2.开启MySQL的Binlog二进制日志3.查看Binlog二进制日志中的Event事件信息3.1.查看当前数据库有那些Binlog日志3.2.产生一些DDL/DML语句3.3.观察Binl…...

MinGW编译Python至pyd踩坑整理
title: MinGW编译Python至pyd踩坑整理 tags: [Python,CC] categories: [开发记录,Python] date: 2023-12-12 13:48:20 description: sidebar: [‘toc’, ‘related’,‘recent’] 注意需要魔法 用scoop自动安装配置MinGw 需要魔法,不需要手动配置mingw scoop in…...

计算机毕业设计 基于SpringBoot的乡村政务办公系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
命令行参数(C语言)
目录 什么是命令行参数 main函数的可执行参数 不传参打印 传参打印 IDE传参 cmd传参 命令行参数的应用(文件拷贝) 什么是命令行参数 概念:命令行参数指的是在运行可执行文件时提供给程序的额外输入信息。它们通常以字符串形式出现&am…...

WT2003H4-16S语音芯片:扭蛋机新潮音乐,娱乐升级无限
在扭蛋机的乐趣世界里,唯创知音的WT2003H4-16S语音芯片,作为MP3音乐解码播放IC,为扭蛋机带来了更智能、更富有趣味的音乐体验,为玩家打开了娱乐升级的无限可能。 1. 机启音乐,欢迎扭蛋之旅 扭蛋机启动时,…...

Go 语言开发工具
Go 语言开发工具 VSCode VScode 安装教程参见:https://www.kxdang.com/topic//w3cnote/vscode-tutorial.html 然后我们打开 VSCode 的扩展(CtrlShiftP): 搜索 go: 点击安装,安装完成后我们就可以使用代码…...

神经网络是如何工作的? | 京东云技术团队
作为一名程序员,我们习惯于去了解所使用工具、中间件的底层原理,本文则旨在帮助大家了解AI模型的底层机制,让大家在学习或应用各种大模型时更加得心应手,更加适合没有AI基础的小伙伴们。 一、GPT与神经网络的关系 GPT想必大家已…...
C++ Qt开发:RadioButton单选框分组组件
Qt 是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍QRadioButton单选框组件以及与之交互的QButto…...
推荐开源项目-网络应用协议框架Socket.D
基于事件和语义消息流的网络应用协议 Socket.D 0 代码仓库地址1 该开源项目特点2 项目结构3 核心理念-协议帧Frame4 结束语 0 代码仓库地址 https://gitee.com/noear/socketd 1 该开源项目特点 代码风格优雅文档说明齐全测试用例非常人性化上手快,代码用例很多代…...
Redis缓存异常问题,常用解决方案总结
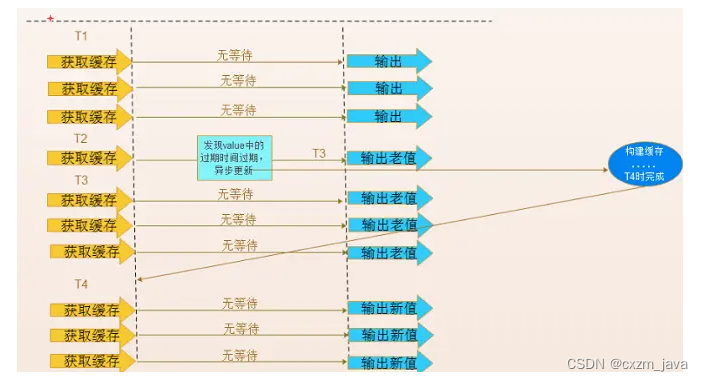
前言 Redis缓存异常问题分别是:1.缓存雪崩。2.缓存预热。3.缓存穿透。4.缓存降级。5.缓存击穿,以 及对应Redis缓存异常问题解决方案。 1.缓存雪崩 1.1、什么是缓存雪崩 如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...