机器学习---Adaboost算法
1. Adaboost算法介绍
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然
后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。Adaboost算法本身是通
过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类
的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每
次得到的分类器最后融合起来,作为最后的决策分类器。
目前,对Adaboost算法的研究以及应用大多集中于分类问题,同时近年也出现了一些在回归问题
上的应用。就其应用adaboost系列主要解决了:两类问题、多类单标签问题、多类多标签问题、大
类单标签问题,回归问题。它用全部的训练样本进行学习。使用adaboost分类器可以排除一些不必
要的训练数据特征,并将关键放在关键的训练数据上面。
该算法其实是一个简单的弱分类算法提升过程,这个过程通过不断的训练,可以提高对数据的分类
能力。
①先通过对N个训练样本的学习得到第一个弱分类器;
②将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第
二个弱分类器;
③将1和2都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学
习得到第三个弱分类器
④最终经过提升的强分类器。即某个数据被分为哪一类要通过......的多数表决。
对于boosting算法,存在两个问题:
①如何调整训练集,使得在训练集上训练的弱分类器得以进行;
②如何将训练得到的各个弱分类器联合起来形成强分类器。
针对以上两个问题,AdaBoost算法进行了调整:
①使用加权后选取的训练数据代替随机选取的训练样本,这样将训练的焦点集中在比较难分的训练
数据样本上;
②将弱分类器联合起来,使用加权的投票机制代替平均投票机制。让分类效果好的弱分类器具有较
大的权重,而分类效果差的分类器具有较小的权重。
与Boosting算法不同的是,AdaBoost算法不需要预先知道弱学习算法学习正确率的下限即弱分类
器的误差,并且最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度,这样可以深入挖
掘弱分类器算法的能力。
AdaBoost算法中不同的训练集是通过调整每个样本对应的权重来实现的。开始时,每个样本对应
的权重是相同的,即其中n为样本个数,在此样本分布下训练出一弱分类器。对于分类错误的样
本,加大其对应的权重;而对于分类正确的样本,降低其权重,这样分错的样本就被突显出来,从
而得到一个新的样本分布。在新的样本分布下,再次对样本进行训练,得到弱分类器。依次类推,
经过T次循环,得到T个弱分类器,把这T个弱分类器按一定的权重叠加(boost)起来,得到最终
想要的强分类器。
AdaBoost算法的具体步骤如下:
①给定训练样本集S,其中X和Y分别对应于正例样本和负例样本;T为训练的最大循环次数;
②初始化样本权重为1/n ,即为训练样本的初始概率分布;
③第一次迭代:(1)训练样本的概率分布相当,训练弱分类器;(2)计算弱分类器的错误率;(3)选取合
适阈值,使得误差最小;(4)更新样本权重;经T次循环后,得到T个弱分类器,按更新的权重叠
加,最终得到的强分类器。
Adaboost算法是经过调整的Boosting算法,其能够对弱学习得到的弱分类器的错误进行适应性
(Adaptive)调整。上述算法中迭代了T次的主循环,每一次循环根据当前的权重分布对样本x定一个
分布P,然后对这个分布下的样本使用弱学习算法得到一个弱分类器,对于这个算法定义的弱学习
算法,对所有的样本都有错误率,而这个错误率的上限并不需要事先知道,实际上。每一次迭代,
都要对权重进行更新。更新的规则是:减小弱分类器分类效果较好的数据的概率,增大弱分类器分
类效果较差的数据的概率。最终的分类器是个弱分类器的加权平均。
2. Adaboosting训练过程
基于AdaBoost算法的强分类器训练
输入:(1)训练样本集![]()
其中,y =-1,训练样本xi为负样本,y =+1,训练样本xi为正样本
(2)弱分类器的学习算法L
(3)弱分类器的数目M
输出:一个由M个弱分类器构成的强分类器
训练过程:
①初始化训练样本xi权重![]() 若正负样本数目一致,则
若正负样本数目一致,则![]()
若正负样本数目分别为N+,N-,则
②for m=1,...,M
训练弱分类器![]() 估计弱分类器fm(x)的分类错误率em,如:
估计弱分类器fm(x)的分类错误率em,如:
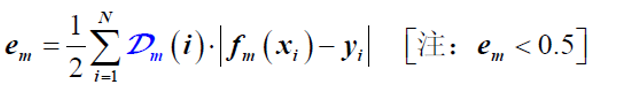
(3)估计弱分类器fm(x)的权重![]()
(4)基于弱分类器fm(x)调整各样本权重,并归一化调整:
归一化: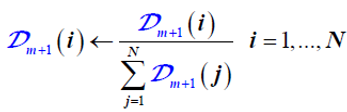 ,强分类器
,强分类器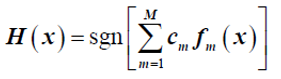 。
。
算法实现:

3. Adaboost算法例子
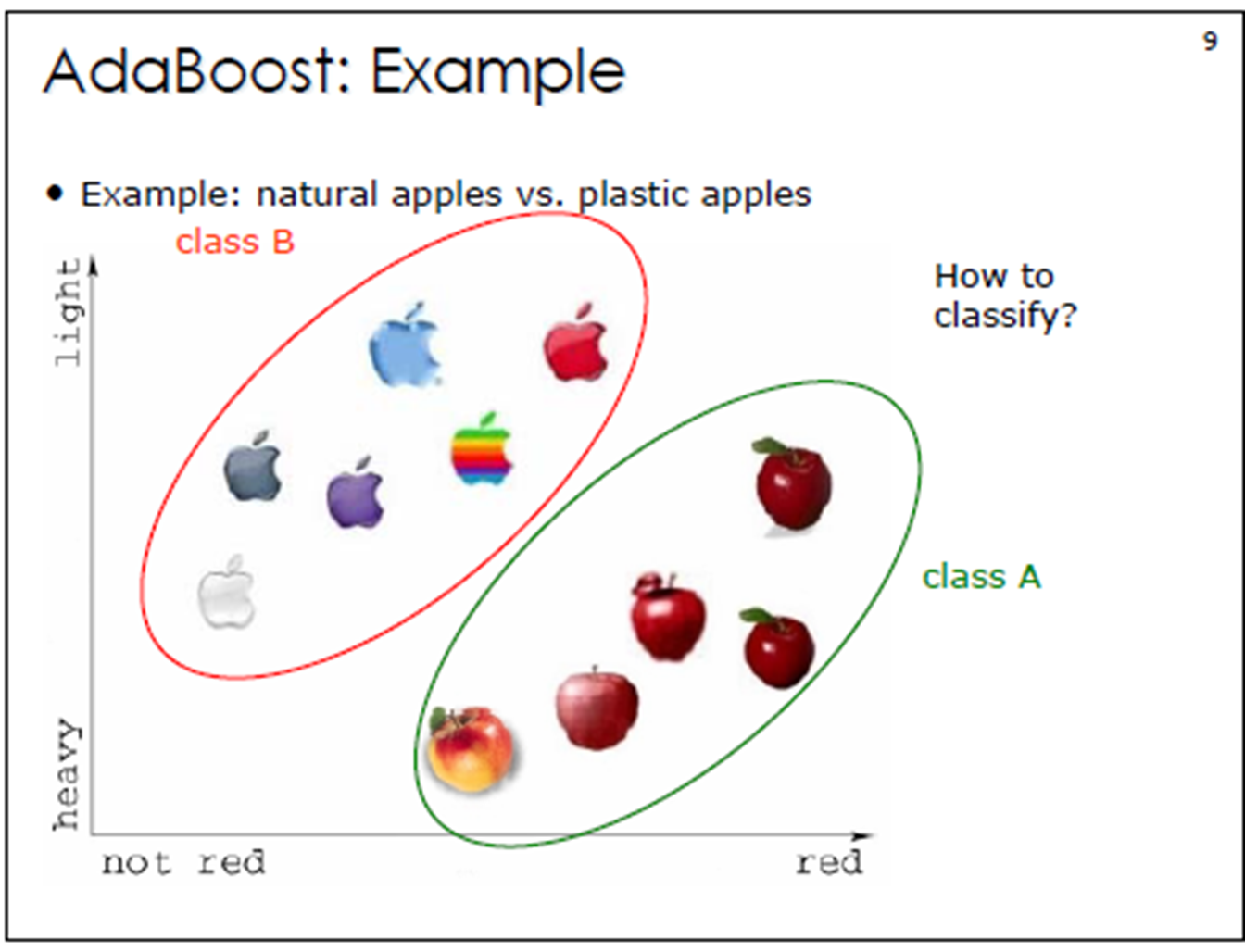






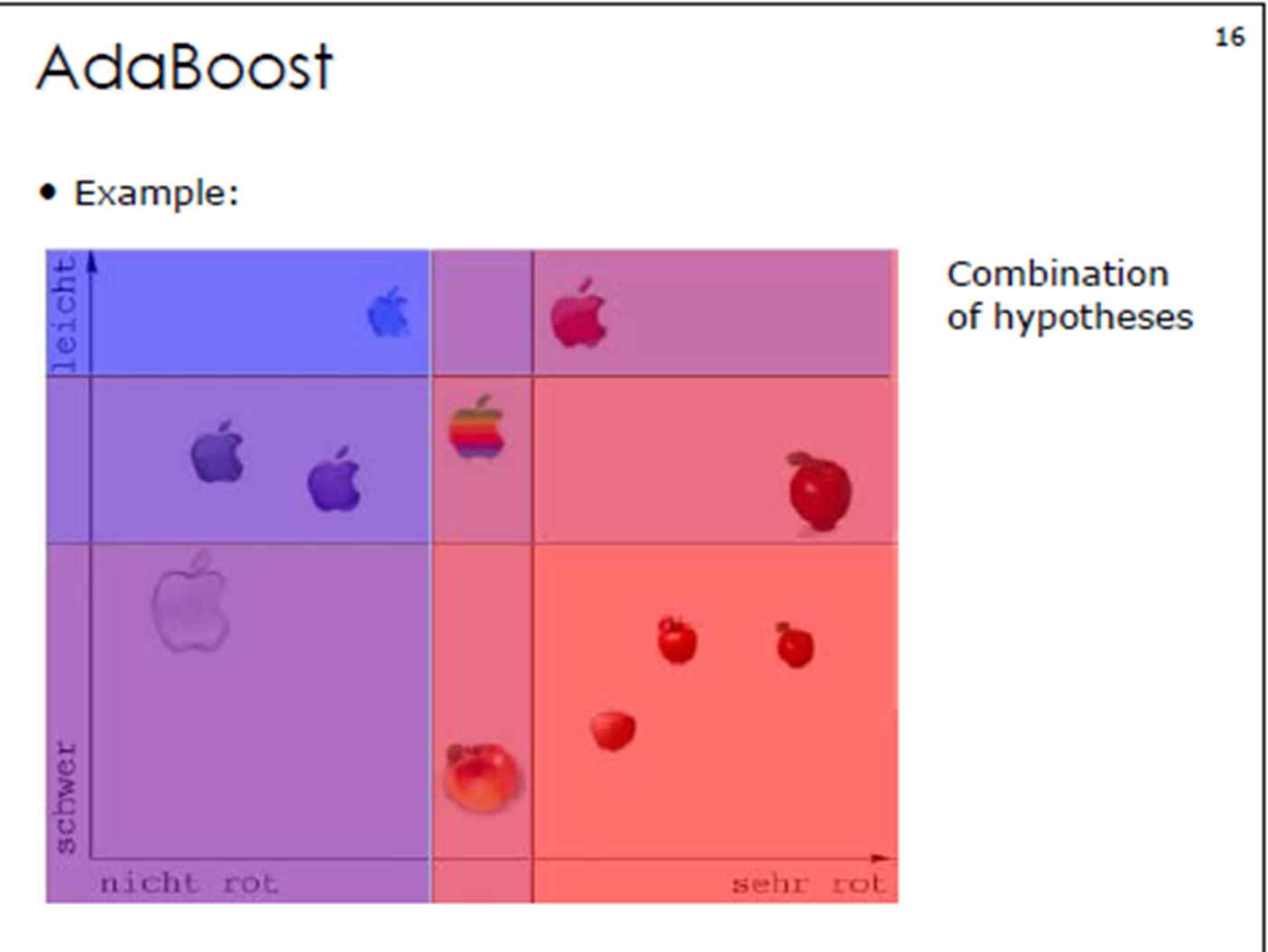
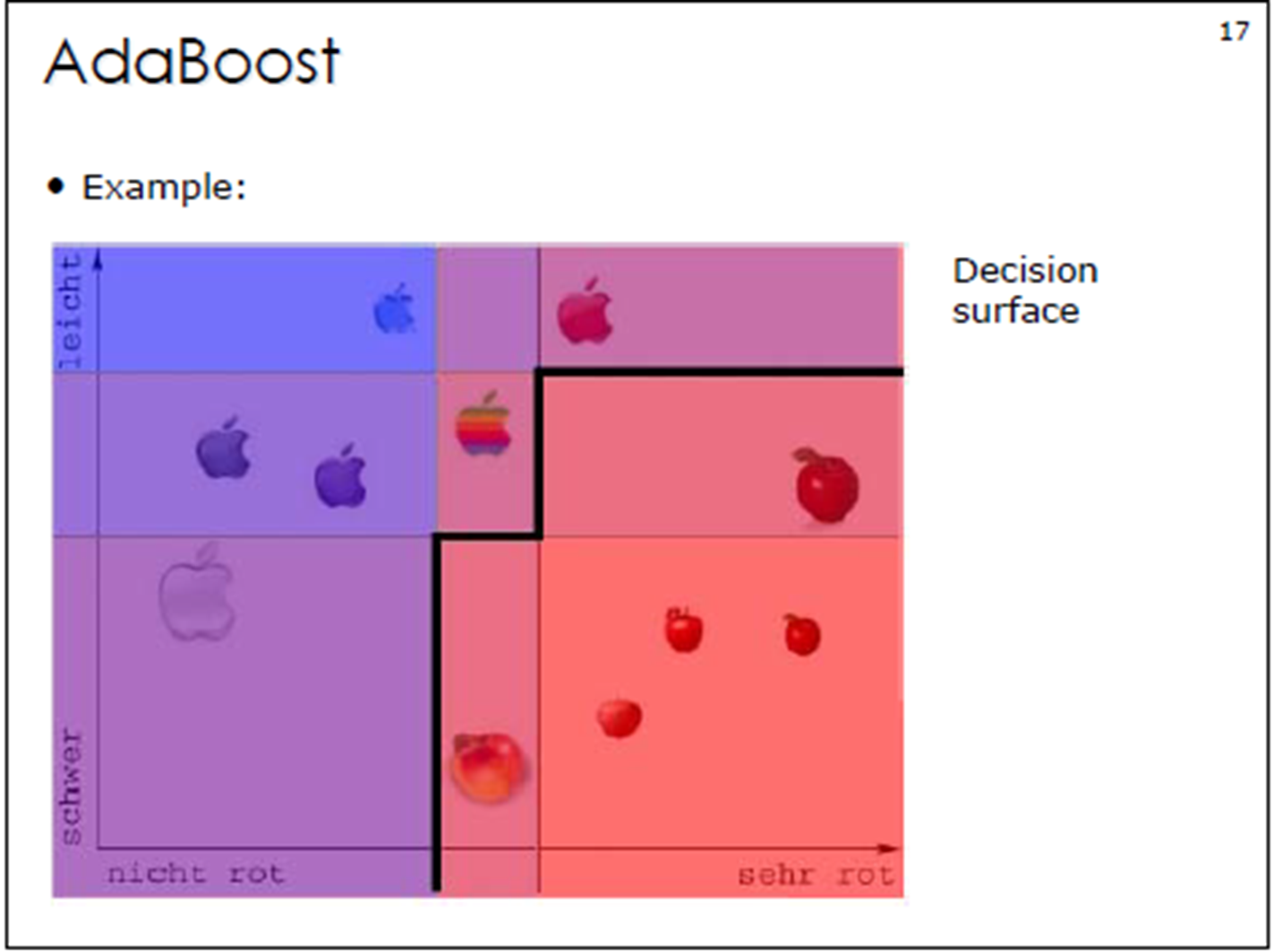
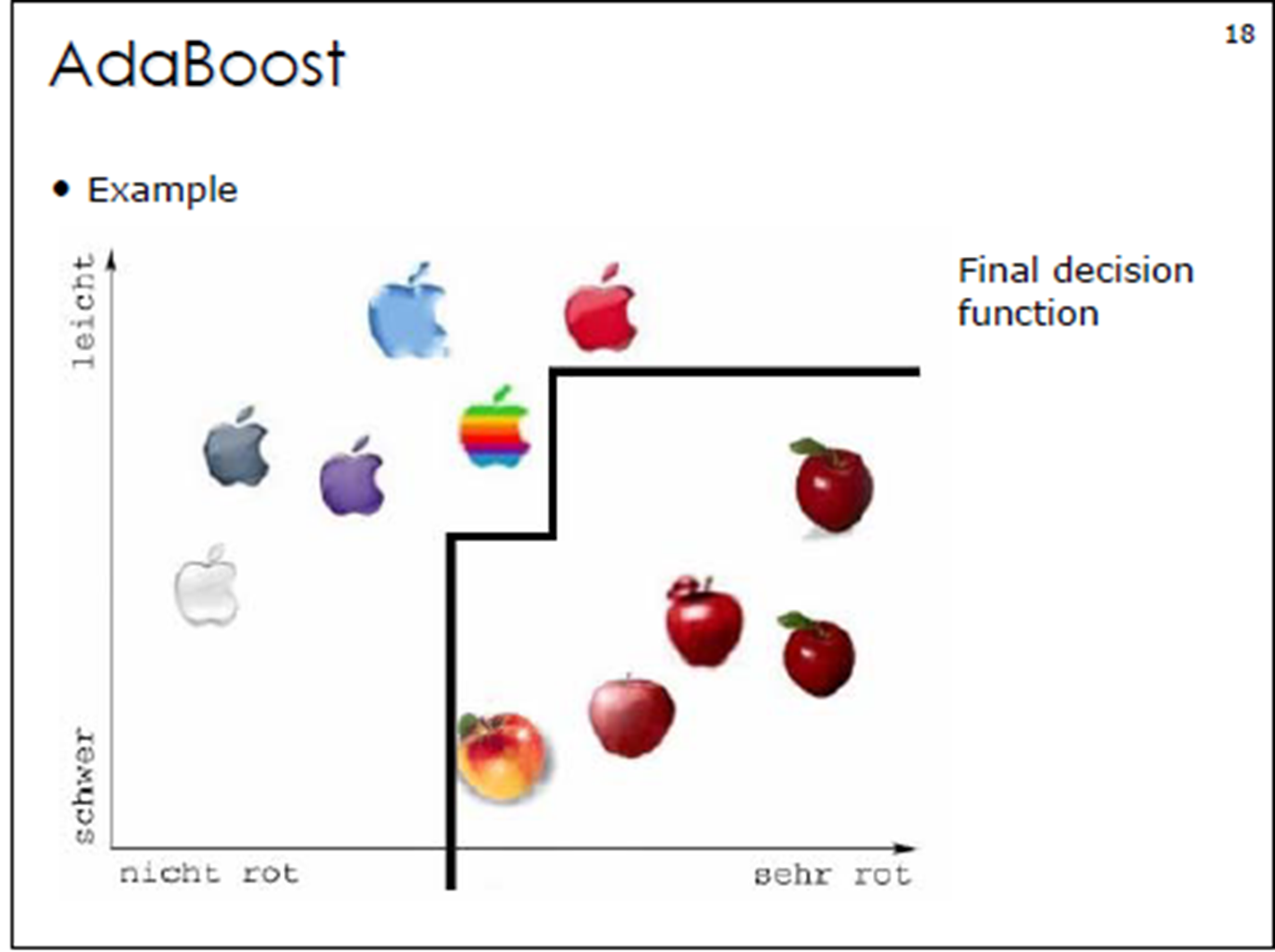
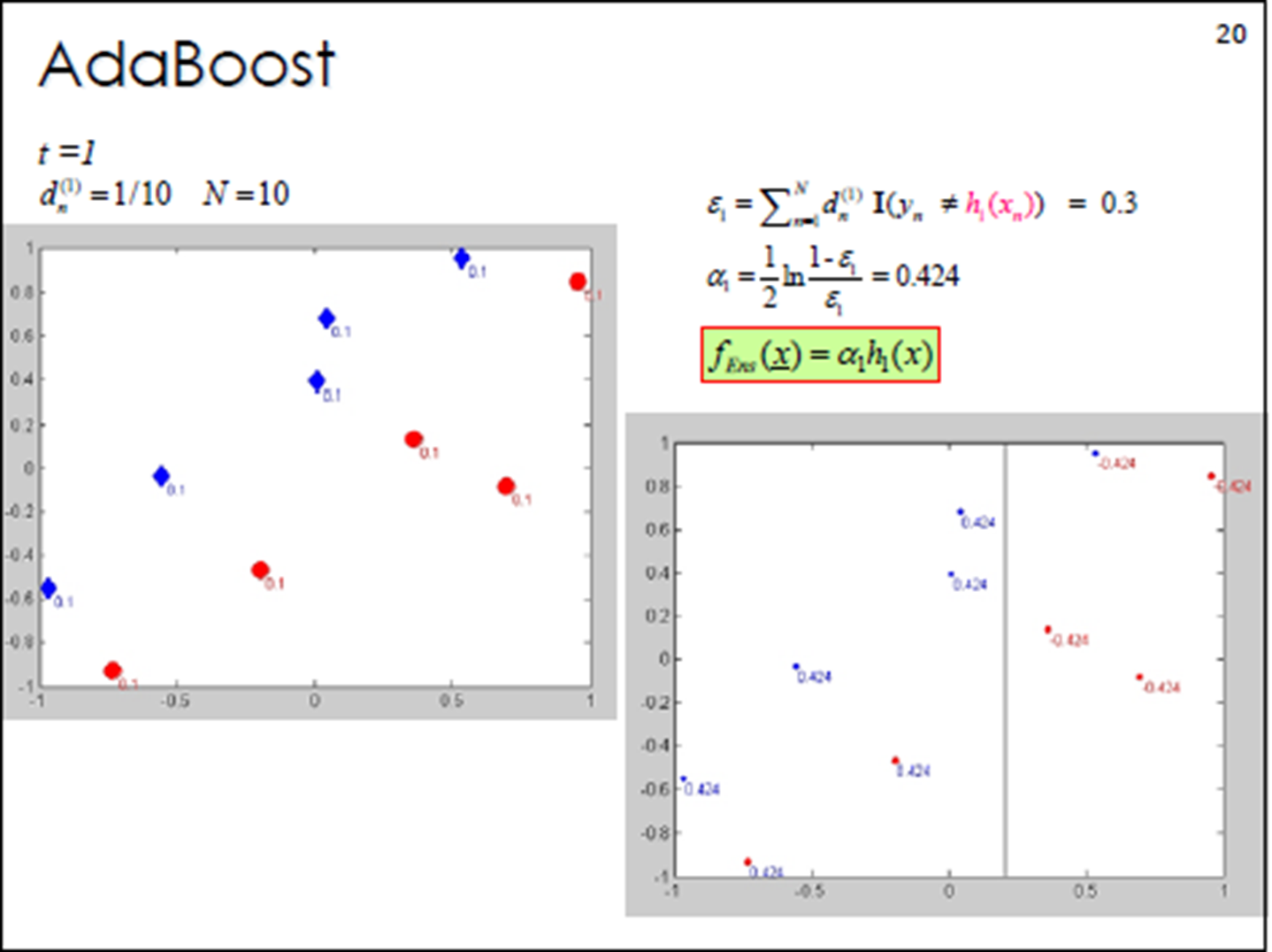
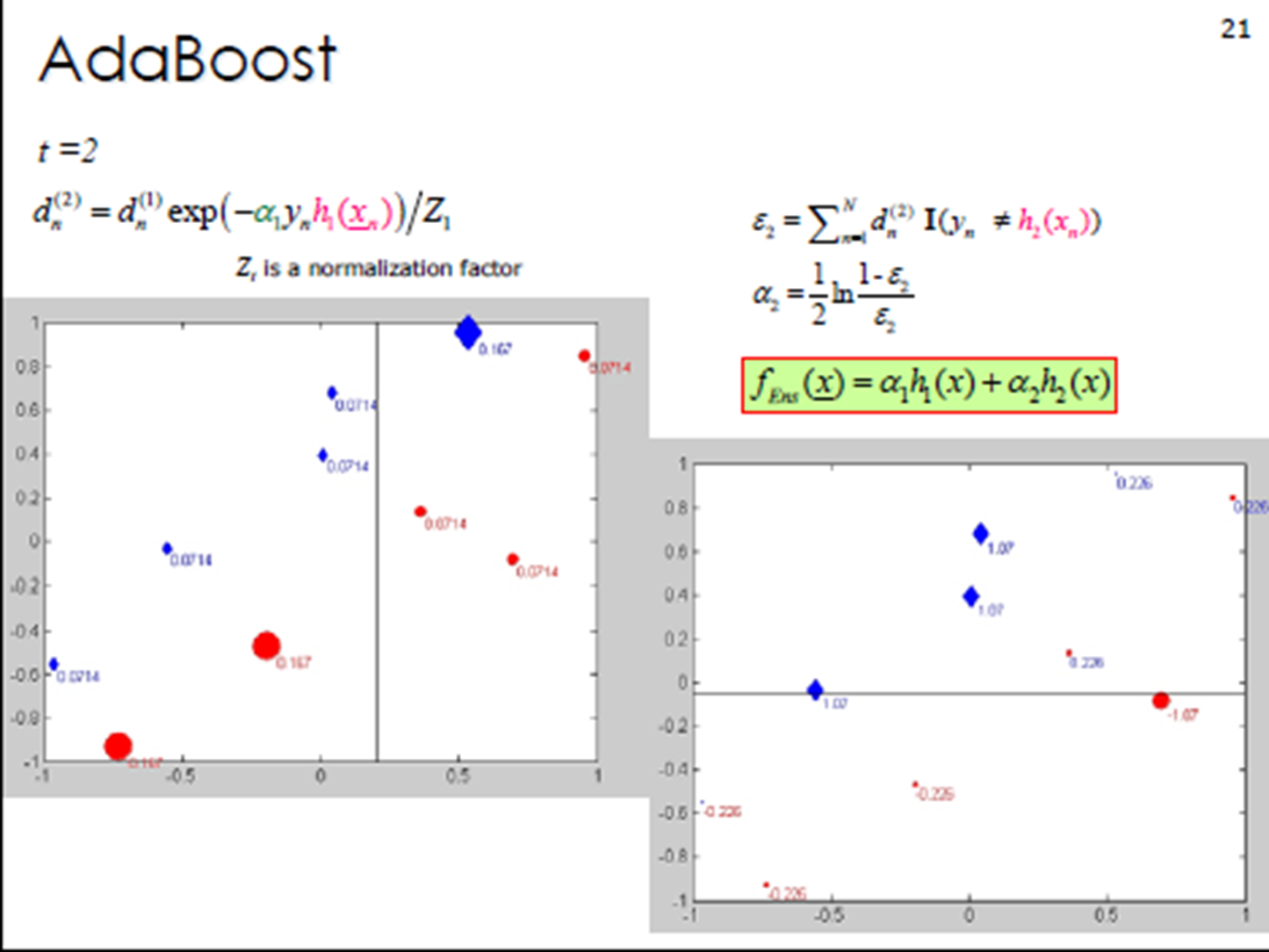
3. Adaboost算法计算案例
①初始化训练数据权重相等,训练第⼀个学习器。该假设每个训练样本在基分类器的学习中作用相
同,这⼀假设可以保证第⼀步能够在原始数据上学习基本分类器H1 (x)。
②AdaBoost反复学习基本分类器,在每⼀轮m = 1, 2, ..., M顺次的执⾏下列操作:
在权值分布为D的训练数据上,确定基分类器;
计算该学习器在训练数据中的错误率:![]()
计算该学习器的投票权重:![]()
根据投票权重,对训练数据重新赋权: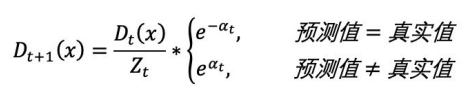
将下⼀轮学习器的注意⼒集中在错误数据上,重复执⾏上述计算步骤m次;
③对m个学习器进⾏加权投票: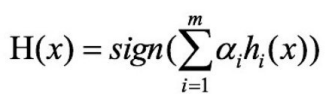
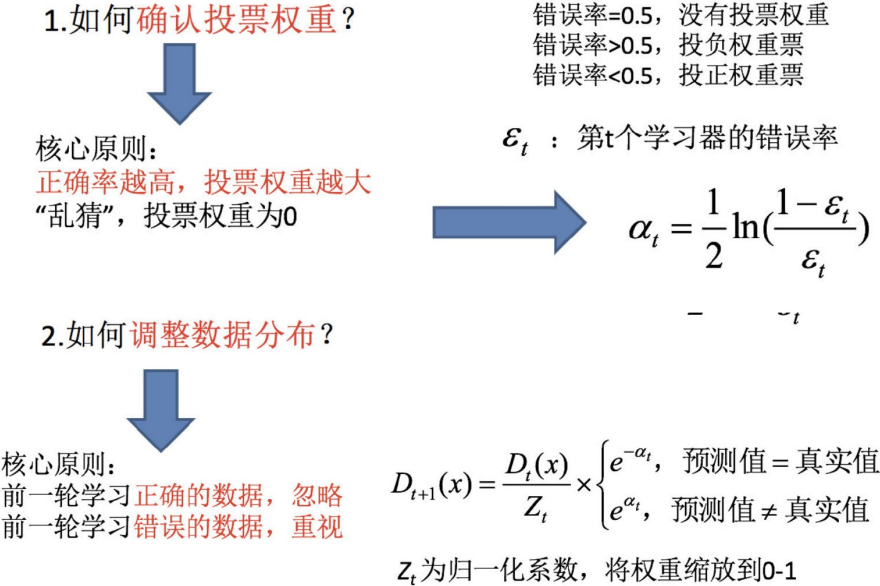
给定下⾯这张训练数据表所示的数据,假设弱分类器由xv产生,其阈值v使该分类器在训练数据集
上的分类误差率最低,试用Adaboost算法学习⼀个强分类器:

问题解答:
①初始化训练数据权重相等,训练第⼀个学习器:
![]()
![]()
②AdaBoost反复学习基本分类器,在每⼀轮m = 1, 2, ..., M顺次的执⾏下列操作:
当m=1的时候:在权值分布为D的训练数据上,阈值v取2.5时分类误差率最低,故基本分类器为:
![]() (6,7,8被分错)
(6,7,8被分错)
计算该学习器在训练数据中的错误率:![]()
计算该学习器的投票权重:![]()
根据投票权重,对训练数据重新赋权:![]()
根据下公式,计算各个权重值: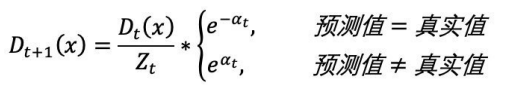
经计算得,D2的值为:![]()
计算过程: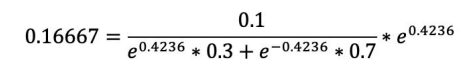
![]()
分类器H1(x)在训练数据集上有3个误分类点。
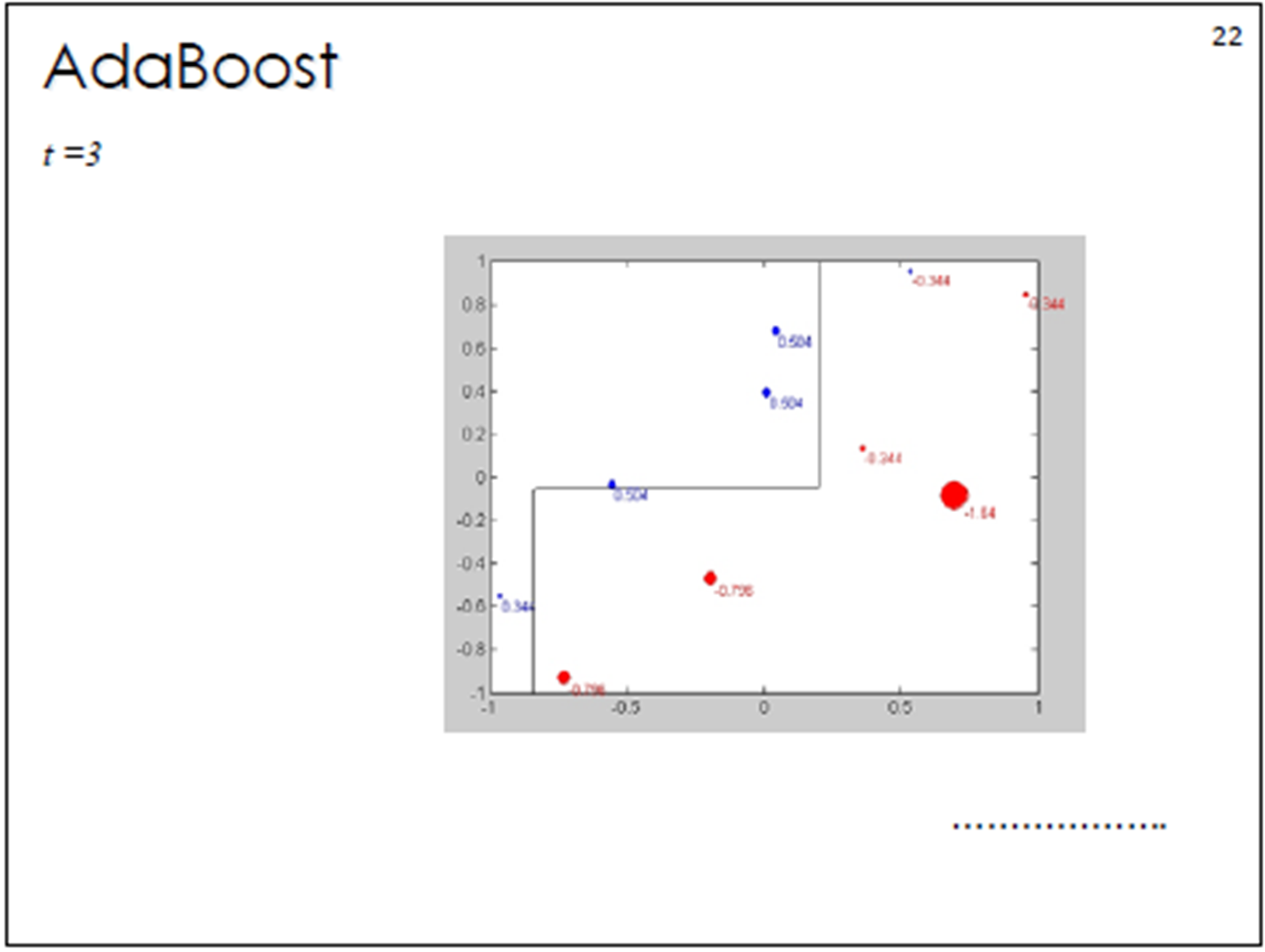
当m=2的时候:
在权值分布为D 的训练数据上,阈值v取8.5时分类误差率最低,故基本分类器为:
 (3,4,5被分错)
(3,4,5被分错)
计算该学习器在训练数据中的错误率:![]()
计算该学习器的投票权重:![]()
根据投票权重,对训练数据重新赋权:经计算得,D 的值为:

分类器H2(x)在训练数据集上有3个误分类点。
当m=3的时候:
在权值分布为D 的训练数据上,阈值v取5.5时分类误差率最低,故基本分类器为:
![]()
计算该学习器在训练数据中的错误率:![]()
计算该学习器的投票权重:![]()
根据投票权重,对训练数据重新赋权:经计算得,D4的值为:

分类器H3(x)在训练数据集上的误分类点个数为0。
③对m个学习器进行加权投票,获取最终分类器:
![]()
相关文章:
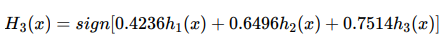
机器学习---Adaboost算法
1. Adaboost算法介绍 Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然 后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。Adaboost算法本身…...
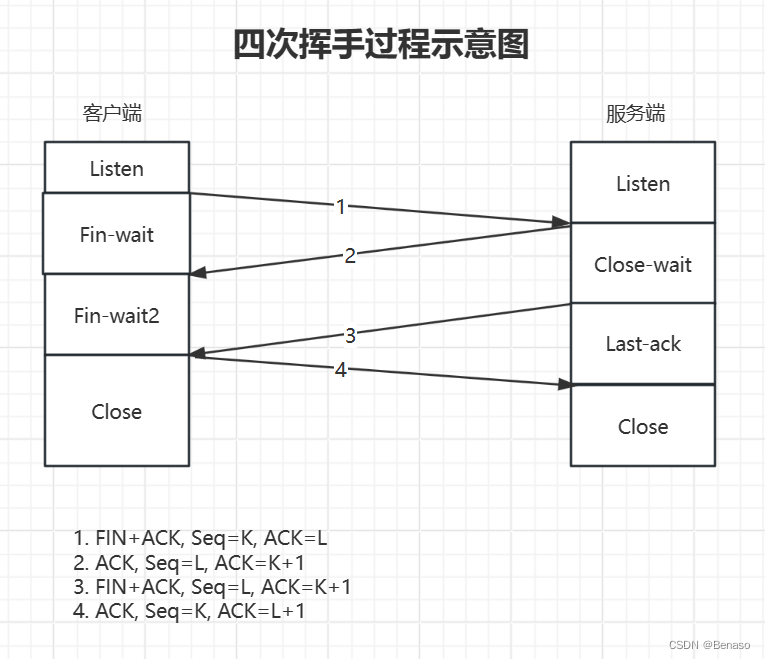
Java网络编程,使用UDP实现TCP(三), 基本实现四次挥手
简介 四次挥手示意图 在四次挥手过程中,第一次挥手中的Seq为本次挥手的ISN, ACK为 上一次挥手的 Seq1,即最后一次数据传输的Seq1。挥手信息由客户端首先发起。 实现步骤: 下面是TCP四次挥手的步骤: 第一次挥手&…...

“百里挑一”AI原生应用亮相,百度智能云千帆AI加速器首个Demo Day来了!
作者简介: 辭七七,目前大二,正在学习C/C,Java,Python等 作者主页: 七七的个人主页 文章收录专栏: 七七的闲谈 欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖…...
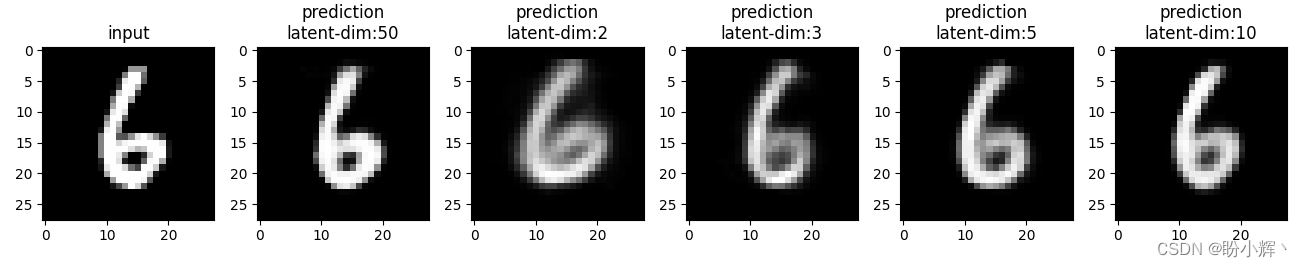
PyTorch深度学习实战(25)——自编码器
PyTorch深度学习实战(25)——自编码器 0. 前言1. 自编码器2. 使用 PyTorch 实现自编码器小结系列链接 0. 前言 自编码器 (Autoencoder) 是一种无监督学习的神经网络模型,用于数据的特征提取和降维,它由一个编码器 (Encoder) 和一…...

靠谱的车- 华为OD统一考试(C卷)
靠谱的车- 华为OD统一考试(C卷) OD统一考试(C卷) 分值: 100分 题解: Java / Python / C 题目描述 程序员小明打了一辆出租车去上班。出于职业敏感,他注意到这辆出租车的计费表有点问题…...

Apache Flink(十一):Flink集群部署-Standalone集群部署
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录 1. 节点划分...

vue的组件传值
Vue中组件之间的数据传递可以使用props和$emit来实现。 1.使用props传递数据:父组件可以通过子组件的props属性向子组件传递数据。 父组件中: <template><div><child-component :message"parentMessage"></child-comp…...
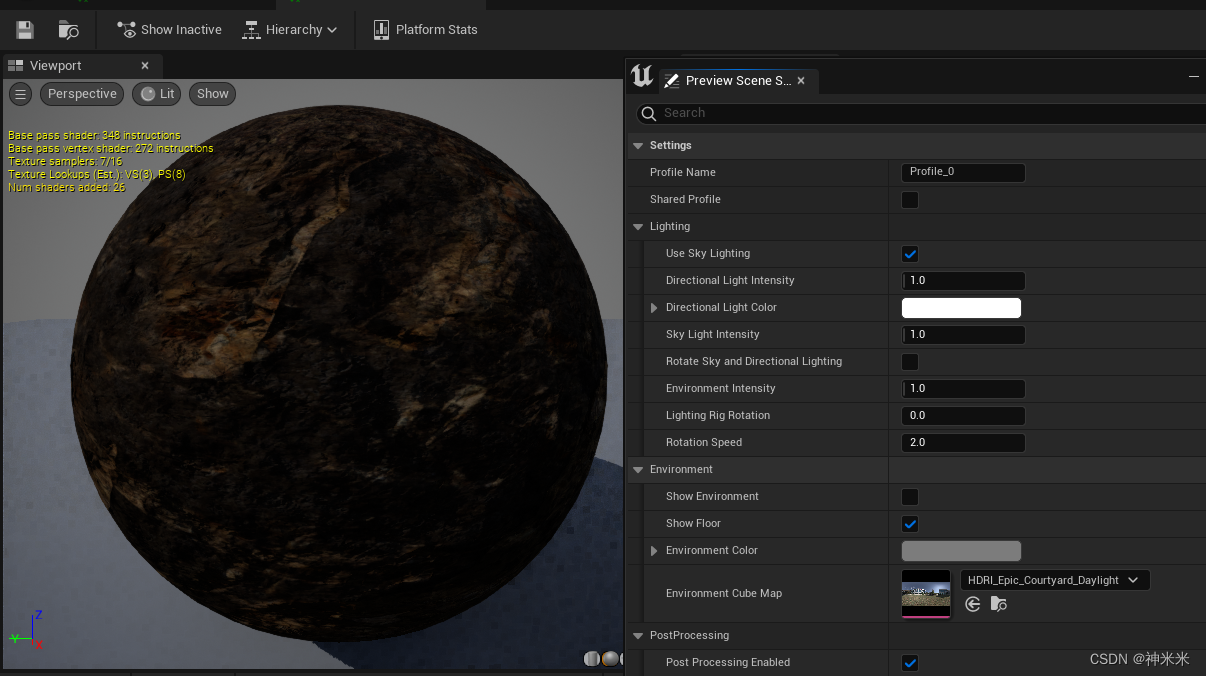
ue5材质预览界面ue 变黑
发现在5.2和5.1上都有这个bug 原因是开了ray tracing引起的,这个bug真是长时间存在,类似的bug还包括草地上奇怪的影子和地形上的影子等等 解决方法也很简单,就是关闭光追(不是…… 就是关闭预览,在材质界面preview sc…...

【SpringCloud篇】Eureka服务的基本配置和操作
文章目录 🌹简述Eureka🛸搭建Eureka服务⭐操作步骤⭐服务注册⭐服务发现 🌹简述Eureka Eureka是Netflix开源的一个基于REST的服务治理框架,主要用于实现微服务架构中的服务注册与发现。它由Eureka服务器和Eureka客户端组成&#…...

模拟目录管理 - 华为OD统一考试(C卷)
OD统一考试(C卷) 分值: 200分 题解: Java / Python / C++ 题目描述 实现一个模拟目录管理功能的软件,输入一个命令序列,输出最后一条命令运行结果。 支持命令: 1)创建目录命令: mkdir 目录名称,如mkdir abc为在当前目录创建abc目录,如果已存在同名目录则不执行任何操作…...

卷王开启验证码后无法登陆问题解决
问题描述 使用 docker 部署,后台设置开启验证,重启服务器之后,docker重启,再次访问系统,验证码获取失败,导致无法进行验证,也就无法登陆系统。 如果不了解卷王的,可以去官网看下。…...
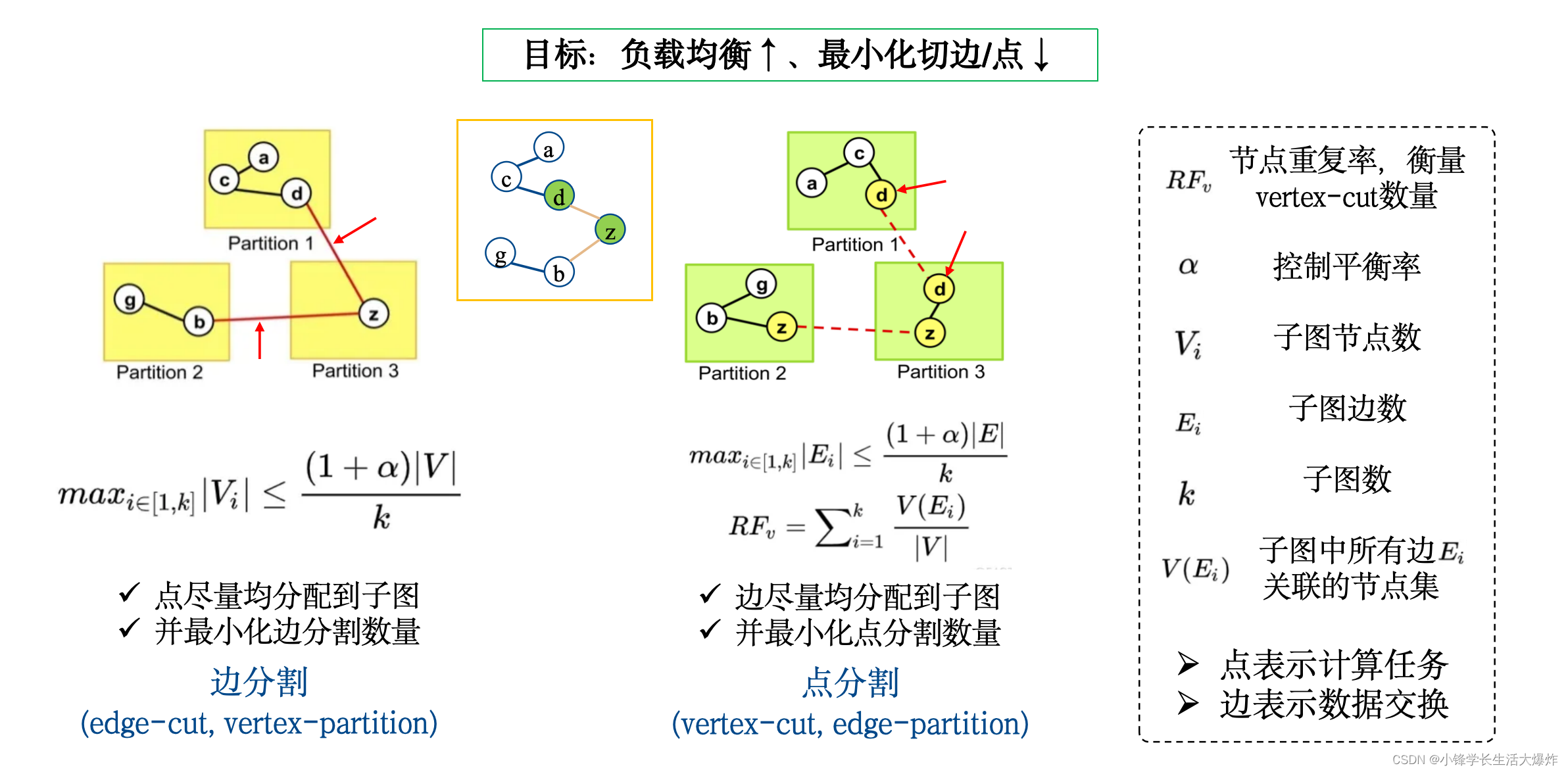
【知识】如何区分图论中的点分割和边分割
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 以下两个概念在现有中文博客下非常容易混淆: edge-cut(边切割) vertex-partition(点分割)vertex-cut(点切割) edge-partition(边分割) 实际上,初看中文时,真的会搞不清楚。但…...

【华为鸿蒙系统学习】- HarmonyOS4.0开发工具和环境配置问题总结|自学篇
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:"没有罗马,那就自己创造罗马~" 目录 官方链接 HUAWEI DevEco Studio和SDK下载和升级 | HarmonyOS开发者 安装教程 (…...
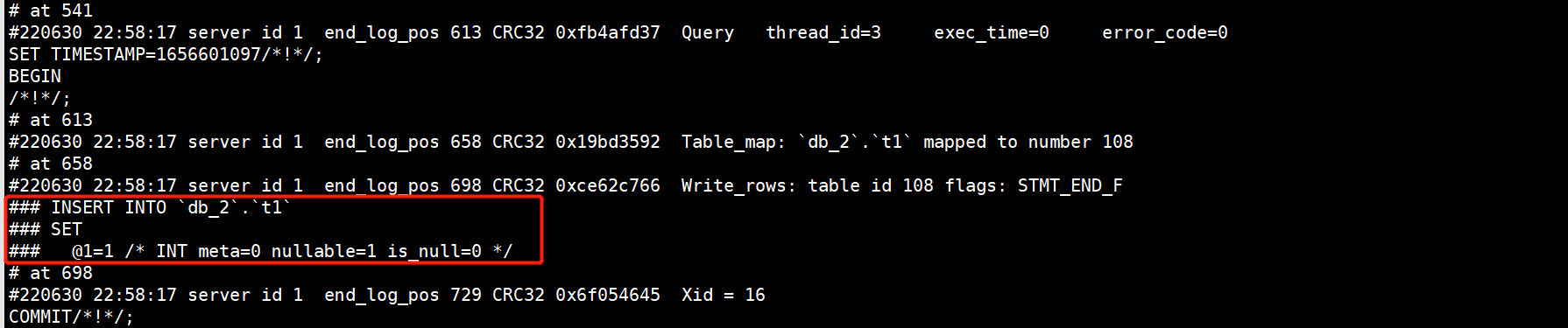
第78讲:MySQL数据库Binlog日志的核心概念与应用案例
文章目录 1.Binlog二进制日志的基本概念1.1.什么是Binlog二进制1.2.Binlog日志的三种记录格式1.3.Binlog日志中Event事件的概念 2.开启MySQL的Binlog二进制日志3.查看Binlog二进制日志中的Event事件信息3.1.查看当前数据库有那些Binlog日志3.2.产生一些DDL/DML语句3.3.观察Binl…...

MinGW编译Python至pyd踩坑整理
title: MinGW编译Python至pyd踩坑整理 tags: [Python,CC] categories: [开发记录,Python] date: 2023-12-12 13:48:20 description: sidebar: [‘toc’, ‘related’,‘recent’] 注意需要魔法 用scoop自动安装配置MinGw 需要魔法,不需要手动配置mingw scoop in…...

计算机毕业设计 基于SpringBoot的乡村政务办公系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
命令行参数(C语言)
目录 什么是命令行参数 main函数的可执行参数 不传参打印 传参打印 IDE传参 cmd传参 命令行参数的应用(文件拷贝) 什么是命令行参数 概念:命令行参数指的是在运行可执行文件时提供给程序的额外输入信息。它们通常以字符串形式出现&am…...

WT2003H4-16S语音芯片:扭蛋机新潮音乐,娱乐升级无限
在扭蛋机的乐趣世界里,唯创知音的WT2003H4-16S语音芯片,作为MP3音乐解码播放IC,为扭蛋机带来了更智能、更富有趣味的音乐体验,为玩家打开了娱乐升级的无限可能。 1. 机启音乐,欢迎扭蛋之旅 扭蛋机启动时,…...

Go 语言开发工具
Go 语言开发工具 VSCode VScode 安装教程参见:https://www.kxdang.com/topic//w3cnote/vscode-tutorial.html 然后我们打开 VSCode 的扩展(CtrlShiftP): 搜索 go: 点击安装,安装完成后我们就可以使用代码…...

神经网络是如何工作的? | 京东云技术团队
作为一名程序员,我们习惯于去了解所使用工具、中间件的底层原理,本文则旨在帮助大家了解AI模型的底层机制,让大家在学习或应用各种大模型时更加得心应手,更加适合没有AI基础的小伙伴们。 一、GPT与神经网络的关系 GPT想必大家已…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...

Spring AI Chat Memory 实战指南:Local 与 JDBC 存储集成
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...

Elastic 获得 AWS 教育 ISV 合作伙伴资质,进一步增强教育解决方案产品组合
作者:来自 Elastic Udayasimha Theepireddy (Uday), Brian Bergholm, Marianna Jonsdottir 通过搜索 AI 和云创新推动教育领域的数字化转型。 我们非常高兴地宣布,Elastic 已获得 AWS 教育 ISV 合作伙伴资质。这一重要认证表明,Elastic 作为 …...

Pydantic + Function Calling的结合
1、Pydantic Pydantic 是一个 Python 库,用于数据验证和设置管理,通过 Python 类型注解强制执行数据类型。它广泛用于 API 开发(如 FastAPI)、配置管理和数据解析,核心功能包括: 数据验证:通过…...