Python网络爬虫的基础理解-对应的自我理解误区
##通过一个中国大学大学排名爬虫的示例进行基础性理解
以软科中国最好大学排名为分析对象,基于requests库和bs4库编写爬虫程序,对2015年至2019年间的中国大学排名数据进行爬取:(1)按照排名先后顺序输出不同年份的前10位大学信息,并要求对输出结果的排版进行优化;访问的网址:https://www.shanghairanking.cn/rankings/bcur/2021
##网络爬虫定义
Python语言的简洁性和脚本特点非常适合链接和网页处理。
爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。 源代码里包含了网页的部分有用信息,所以只要把源代码获取下来,就可以从中提取想要的信息了。 前面讲了请求和响应的概念,向网站的服务器发送一个请求,返回的响应体便是网页源代码。
##基本的操作步骤
A:通过网络链接获取网页的内容
B:对获得到的网页内容进行处理
##所涉及到的库
##最主流的两个函数库:requests和beautifulsoup4
##requests库的使用
该库是一个简洁且简单的处理HTTP请求的第三方库,最大优点是程序编写过程更接近正常URL的访问过程。




##beautifulsoup4库的使用
使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,提取有用的信息。


##Robots协议
Robots 排除协议(Robots Exclusion Protocol) 也被称为爬虫协议,它是网站管理者表达是否希望爬虫自动获取网络信息意愿的方法。管理者可以在网站根目录放置一个 robots.txt文件,并在文件中列出哪些链接不允许爬虫爬取。一般搜索引擎的爬虫会首先捕获这个文件,并根据文件要求爬取网站内容。Robots排除协议重点约定不希望爬虫获取的内容,如果没有该文件则表示网站内容可以被爬虫获得,然而,Robots协议不是命令和强制手段,只是国际互联网的一种通用道德规范。绝大部分成熟的搜索引擎爬虫都会遵循这个协议,建议个人也能按照互联网规范要求合理使用爬虫技术。
(一般来说,不允许访问的网址,相应的网址会进行对应的加密操作。)
##代码示例
"""网络爬虫代码示例"""
import requests
from bs4 import BeautifulSoup
import bs4
#用来获取网页html
def getHTMLText(url):try:r = requests.get(url, timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return ""
#将对应的网页用python中对应的数据结构进行存储
def fillUnivList(ulist, html):soup = BeautifulSoup(html, "html.parser")#BeautifulSoup的一个对象for tr in soup.find('tbody').children:if isinstance(tr, bs4.element.Tag):#bs4.element.Tag用来访问html指定的元素标签a = tr('a')tds = tr('td')ulist.append([tds[0].text.strip(), a[0].text.strip(), tds[4].text.strip()])#strip()函数用来去除对应的字符#print(ulist)#及逆行格式设置用来设置美观的打印格式
def printUnivList(ulist, num):tplt = "{0:^5}\t{1:{3}^15}\t{2:^5}"print(tplt.format("排名", "学校名称", "学校总分", chr(12288)))for i in range(num):u = ulist[i]print(tplt.format(u[0], u[1], u[2], chr(12288)))print("suc" + str(num))
"""由于大学名称的被a标签包含,所以我们可以定义一个列表存放a标签中的内容(与td标签进行区分开来)
为了视觉方面更加美观,可采用中文字符的空格填充chr(12288),目的是为了对齐"""def main():uinfo = []url = 'https://www.shanghairanking.cn/rankings/bcur/2021'html = getHTMLText(url)fillUnivList(uinfo, html)printUnivList(uinfo, 10)main()##代码的运行结果:
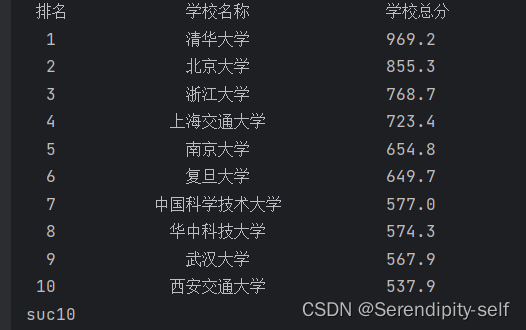
访问网址的源码示例:
##网络爬虫的一个自我小小误区
由于部分的网页的访问收到服务器的拒绝,因此通过自己制作网页来进行对应的访问,但是在这里忽略了一个特别重要的问题,自己所编写的网页并没有受到对应的服务器链接,只是一个单纯的html文件,因此我们的处理方法改成了访问html文件,然后利用request库beautifulsoup4库进行处理。
(真正的网址需要受到服务器的请求的处理才可以进行解析)
##test.html源文件代码
<!DOCTYPE html>
<html><head><meta charset="utf-8"><title></title></head><body><table border="1" ><caption>大学排名</caption><tr><td>排名</td><td>学校名称</td><td>省市</td><td>总分</td><td>培养规模</td></tr><tr><td>1</td><td>清华大学</td><td>北京市</td><td>95.9</td><td>37342</td></tr><tr><td>2</td><td>北京大学</td><td>北京市</td><td>82.6</td><td>36317</td></tr><tr><td>3</td><td>浙江大学</td><td>浙江省</td><td>80</td><td>41188</td></tr><tr><td>4</td><td>上海交通大学</td><td>上海市</td><td>78.7</td><td>40417</td></tr><tr><td>5</td><td>复旦大学</td><td>上海市</td><td>70.9</td><td>25519</td></tr><tr><td>6</td><td>南京大学</td><td>江苏省</td><td>66.1</td><td>20072</td></tr><tr><td>7</td><td>中国科学技术大学</td><td>安徽省</td><td>65.5</td><td>18507</td></tr><tr><td>8</td><td>哈尔冰工业大学</td><td>黑龙江省</td><td>63.5</td><td>25249</td></tr><tr><td>9</td><td>华中科技大学</td><td>湖北省</td><td>62.9</td><td>23503</td></tr><tr><td>10</td><td>中山大学</td><td>广东省</td><td>62.1</td><td>23837</td></tr></table></body>
</html>##效果显示图

##网页中显示的源码

##以文件形式处理的代码示例
"""网络爬虫"""
import requests
from bs4 import BeautifulSoup
alluniv = []def fillluniv(soup):data = soup.find_all("tr")for tr in data:ltd = tr.find_all("td")if len(ltd) == 0 :continueoneuniv = []for td in ltd :oneuniv.append(td.string)alluniv.append(oneuniv)# print(alluniv)def printUniv(num):print("{:^4}{:^10}{:^5}{:^8}{:^10}".format("排名","学校名称","省市","总分","培养规模"))for i in range(1,num+1):print("{:^4}{:^10}{:^5}{:^8}{:^10}".format(alluniv[i][0],alluniv[i][1],alluniv[i][2],alluniv[i][3],alluniv[i][4]))
with open("test.html",'r',encoding="utf-8") as file:content = file.read()soup = BeautifulSoup(content,"html.parser")
fillluniv(soup)
printUniv(10)##代码的运行结果
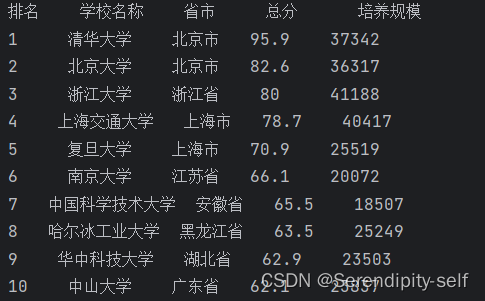
相关文章:
Python网络爬虫的基础理解-对应的自我理解误区
##通过一个中国大学大学排名爬虫的示例进行基础性理解 以软科中国最好大学排名为分析对象,基于requests库和bs4库编写爬虫程序,对2015年至2019年间的中国大学排名数据进行爬取:(1)按照排名先后顺序输出不同年份的前10…...
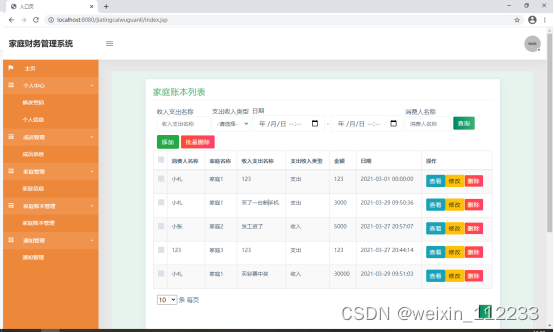
基于ssm的家庭财务管理系统设计与实现论文
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本家庭财务管理系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信息…...
———前端需要掌握的技术有哪些方面)
前端知识(八)———前端需要掌握的技术有哪些方面
前端开发需要掌握的技术包括以下几个方面: 1.HTML:HTML是网页的基础骨架,是网页内容的载体,负责网页内容的排列和布局。 2.CSS:CSS是网页的样式表,负责网页的外观和样式。 一般情况下HTMLCSS是在一起使用…...
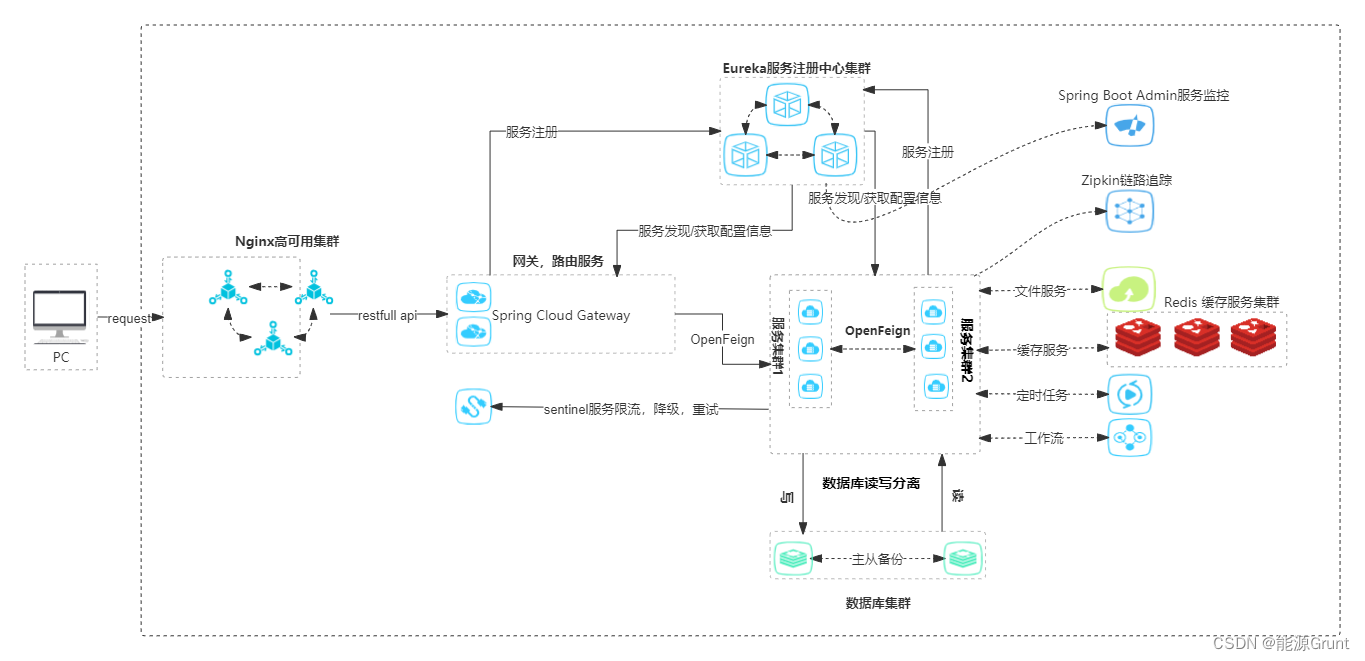
【九】spring、springmvc、springboot、springcloud
spring、springmvc 、springboot 、springcloud 简介 从事IT这么些年,经历了行业技术的更迭,各行各业都会有事务更新,IT行业技术更迭速度快的特点尤为突出,或许这也是从事这个行业的压力所在,但另一方面反应了这个行业…...

Core Web Vitals 是排名因素吗?
Core Web Vitals 会影响您的自然搜索排名吗?在本文中,我们将研究索赔、证据和判决。 Core Web Vitals 衡量页面体验信号,以确保为搜索用户提供引人入胜的用户体验。 但是 Core Web Vitals 会影响您的自然搜索排名吗? 声明&…...

“蒙企通”线上平台升级 助力内蒙古自治区民营经济发展
为进一步落实《中共中央、国务院关于促进民营经济发展壮大的意见》和内蒙古自治区党委、政府《关于进一步支持民营经济高质量发展的若干措施》,内蒙古自治区发展改革委联合自治区工商联共同开展“自治区促进民营经济发展项目”,为民营经营主体拓展市场、…...

电商早报 | 12月13日| 2023胡润男企业家榜发布:黄铮位于第三
2023胡润男企业家榜发布:拼多多创始人跻身前三 12月12日消息,胡润研究院发布《2023胡润男企业家榜》,列出了胡润百富榜中前50名中国男性企业家,总财富6.37万亿元,上榜门槛640亿元。 这是胡润研究院首次发布“男企业家…...
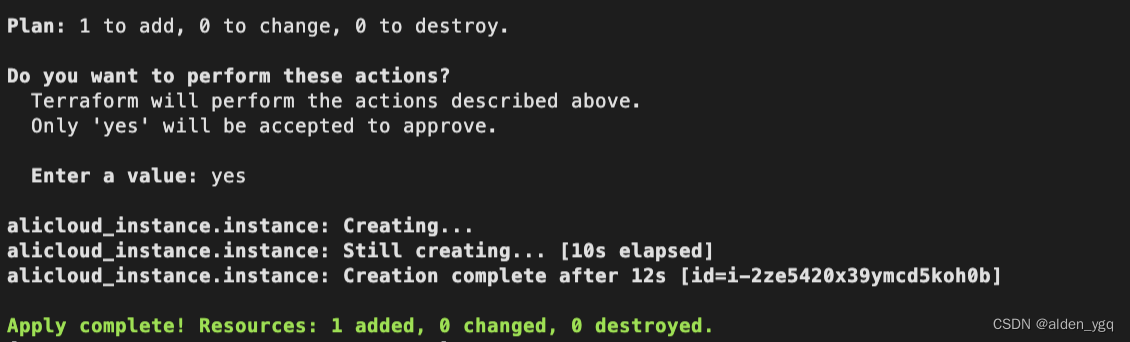
Terraform实战(二)-terraform创建阿里云资源
1 初始化环境 1.1 创建初始文件夹 $ cd /data $ mkdir terraform $ mkdir aliyun terraform作为terraform的配置文件夹,内部的每一个.tf,.tfvars文件都会被加载。 1.2 配置provider 创建providers.tf文件,配置provider依赖。 provider…...
ELADMIN - 免费开源 admin 后台管理系统,基于 Spring Boot 和 Vue ,包含前端和后端源码
一款简单好用、功能强大的 admin 管理系统,包含前端和后端源码,分享给大家。 ELADMIN 是一款基于 Spring Boot、Jpa 或 Mybatis-Plus、 Spring Security、Redis、Vue 的前后端分离的后台管理系统。 ELADMIN 的作者在 Github 和 Gitee 上看了很多的项目&…...

Centos安装docker显示 No Package Docker-Ce Available
安装docker 查看当前系统内核 查看方式 uname -r显示如下 [root@test ~]# uname -r 3.10.0-1127.19.1.el7.x86_64重要提示: docker内核版本必须是3.10+以上的版本 1、卸载老版本的 docker 及其相关依赖 yum remove docker docker-common container-selinux docker-selin…...
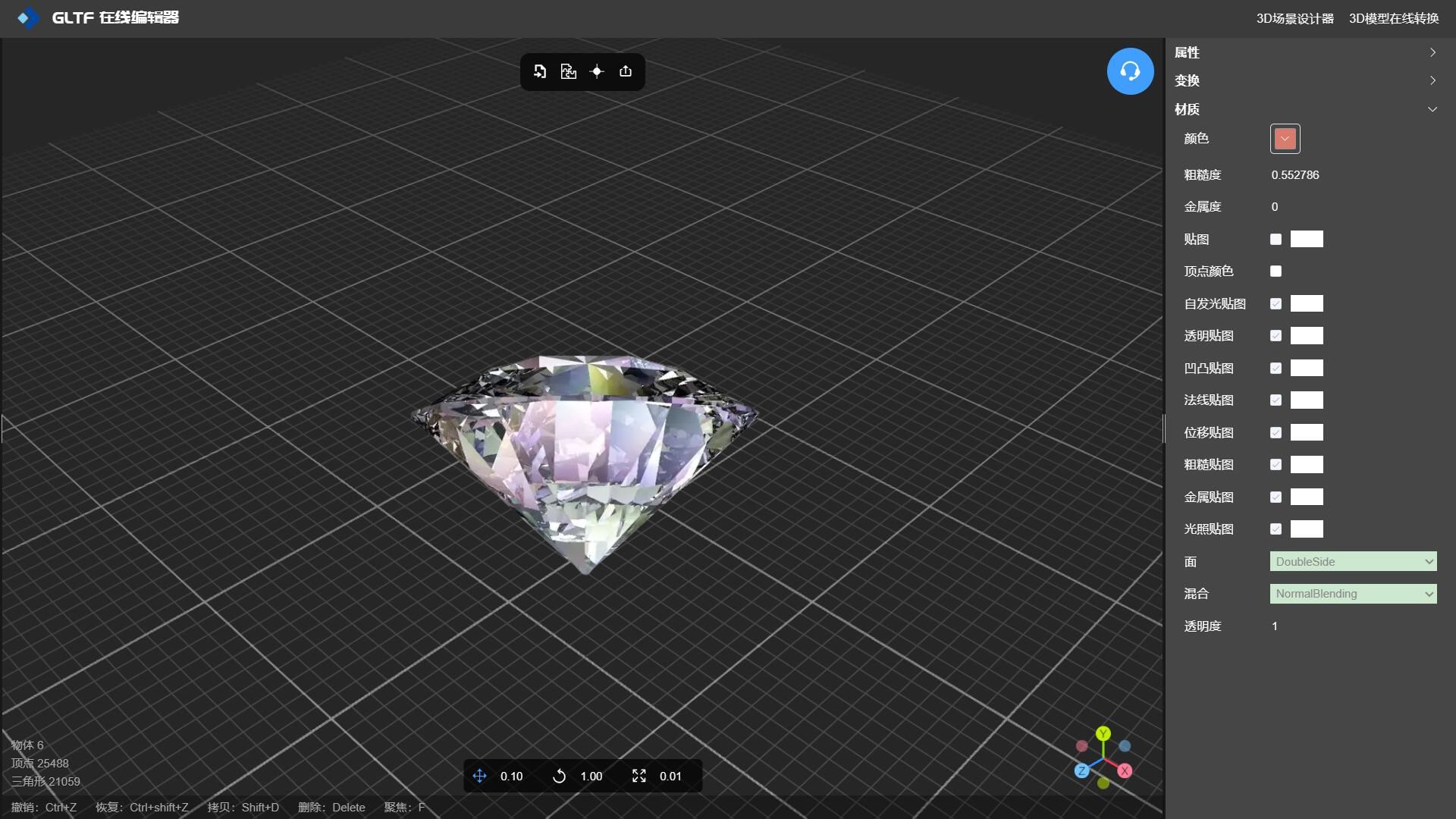
如何使用玻璃材质制作3D钻石模型
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 当谈到游戏角色的3D模型风格时,有几种不同的风格…...

工具:Jupyter
Jupyter是一个开源的交互式计算环境,由Fernando Perez和Brian Granger于2014年创立。它提供了一种方便的方式来展示、共享和探索数据,并且可以与多种编程语言和数据格式进行交互。Jupyter的历史可以追溯到2001年,当时Fernando Perez正在使用P…...
:实时音视频技术合集(Part2) [共17篇])
即时通讯技术文集(第27期):实时音视频技术合集(Part2) [共17篇]
为了更好地分类阅读 52im.net 总计1000多篇精编文章,我将在每周三推送新的一期技术文集,本次是第27 期。 [- 1 -] 专访微信视频技术负责人:微信实时视频聊天技术的演进 [链接] http://www.52im.net/thread-1201-1-1.html [摘要] 本次专访…...

synchronized关键字的使用和原理
synchronized关键字的使用和原理 synchronized:对象锁,保证了临界区内代码的原子性,采用互斥的方式让同一时刻至多只有一个线程能持有对象锁,其它线程获取这个对象锁时会阻塞,保证拥有锁的线程可以安全的执行临界区内…...
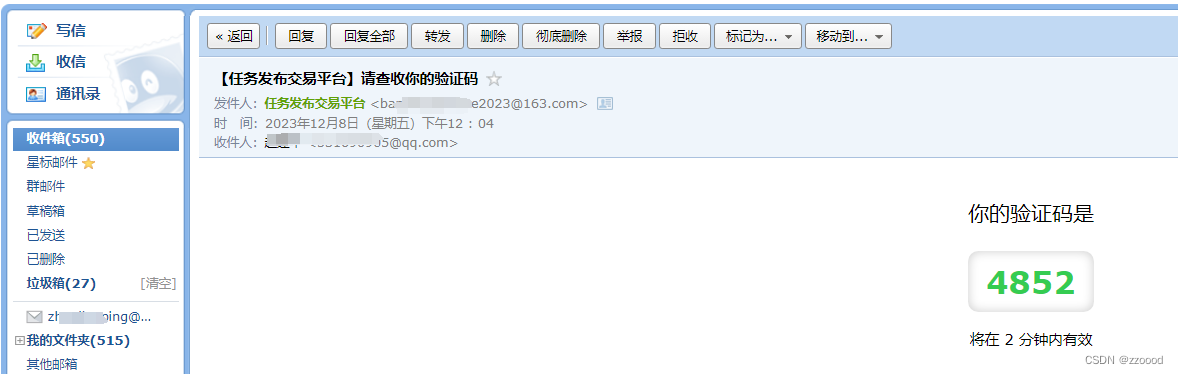
【PHP】php发送邮箱验证码格式美化,样式美化
效果展示: 格式美化前 格式美化后 代码 大多数框架都自带有封装好的发送email方法,就不多赘述,主要写格式: <? php// 验证码过期时间 $expire 120; // 发件人邮箱 $from_email xx163.com; // 收件人 $to_email to163.com…...

【EI会议征稿中】2024年第四届人工智能、自动化与高性能计算国际会议(AIAHPC 2024)
2024年第四届人工智能、自动化与高性能计算国际会议(AIAHPC 2024) 2024 4th International Conference on Artificial Intelligence, Automation and High Performance Computing 2024第四届人工智能、自动化与高性能计算国际会议(AIAHPC 2024)将于20…...
数据库设计规范编制文档
本文的目的是提出针对Oracle数据库的设计规范,使利用Oracle数据库进行设计开发的系统严格遵守本规范的相关约定,建立统一规范、稳定、优化的数据模型。 参照以下原则进行数据库设计: 1) 方便业务功能实现、业务功能扩展; 2) 方便设…...
RocketMq集成SpringBoot(待完善)
环境 jdk1.8, springboot2.7.3 Maven依赖 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.3</version><relativePath/> <!-- lookup parent from…...

刚学Python有点难怎么办?这是好事啊!
对于像我一样非计算机专业出身的学生,每当我们想自学一些编程技能的时候,就感觉困难重重,思考坚持下去有没有意义,因此我总结了以下7个小Tips,这些Tips曾经帮助我合理地安排时间,让自学Python的节奏保持起来…...
LNMP网站架构分布式搭建部署
1. 数据库的编译安装 1. 安装软件包 2. 安装所需要环境依赖包 3. 解压缩到软件解压缩目录,使用cmake进行编译安装以及模块选项配置(预计等待20分钟左右),再编译及安装 4. 创建mysql用户 5. 修改mysql配置文件,删除…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...