Python基本语法及高级特性总结
1. Python基本语法
1.1 变量和数据类型
在Python中,变量不需要预先声明,可以直接赋值。Python是一种动态类型语言,变量的类型会根据赋值的对象自动确定。例如:
a = 10 # a是整数类型变量
b = 3.14 # b是浮点数类型变量
c = "Hello, world!" # c是字符串类型变量
d = True # d是布尔类型变量
1.2 控制结构
Python支持if-else、while循环和for循环等控制结构。if-else语句用于根据条件执行不同的代码块,while循环和for循环则用于重复执行一段代码。例如:
if a > b: print("a is greater than b")
else: print("b is greater than or equal to a") for i in range(5): print(i) # 输出0到4
1.3 函数和模块
Python支持函数和模块的使用。函数是一段可重复使用的代码块,可以通过函数名来调用。模块是一组函数的集合,可以单独编译和测试。例如:
def add(x, y): return x + y # 定义一个名为add的函数,接受两个参数x和y,返回它们的和 import math # 导入math模块,该模块包含许多数学函数和常量
print(math.sqrt(16)) # 输出4.0,调用math模块中的sqrt函数计算16的平方根
1.4 异常处理
Python支持异常处理,可以通过try-except语句来捕获和处理异常。例如:
try: 1 / 0 # 会抛出ZeroDivisionError异常
except ZeroDivisionError: print("Cannot divide by zero!") # 捕获ZeroDivisionError异常并输出错误信息
2. Python高级特性
2.1 装饰器
装饰器是Python中的一种高级功能,它可以修改或增强其他函数的行为。装饰器是一个接受函数作为参数的函数,并返回一个新的函数。通过使用装饰器,我们可以轻松地修改函数的行为,而无需修改函数本身的代码。例如:
def my_decorator(func): def wrapper(): print("Before function call.") func() print("After function call.") return wrapper @my_decorator
def say_hello(): print("Hello!") say_hello() # 输出"Before function call."、"Hello!"和"After function call."
2.2 上下文管理器(with语句)
Python中的with语句是一种上下文管理器,它用于确保代码块在执行前和执行后执行一些操作。with语句通常用于处理资源密集型操作,如文件操作、线程锁等。例如:
with open("file.txt", "r") as f: # 使用with语句打开文件file.txt,并以只读模式读取文件内容 content = f.read() # 读取文件内容并存储到content变量中
print(content) # 输出文件内容到控制台中
2.3 生成器和迭代器
生成器和迭代器是Python中处理数据的强大工具。生成器可以用于创建自己的迭代器,而迭代器则提供了遍历数据结构(如列表、元组和字典)的接口。通过使用生成器和迭代器,我们可以轻松地处理大量数据,而无需将所有数据存储在内存中。例如:
def my_generator(): yield 1 yield 2 yield 3 for i in my_generator(): print(i) # 输出1、2和3
2.4 闭包和装饰器工厂
闭包是Python中的一个强大特性,它可以用于创建具有状态保持功能的函数。闭包可以用于实现函数工厂、高阶函数等高级功能。装饰器工厂则是装饰器的扩展,它可以用于创建可重用的装饰器。例如:
def counter(start=0): def counter_func(f): def wrapper(*args, **kwargs): wrapper.count += 1 # 增加计数器的值 return f(*args, **kwargs) # 调用被装饰的函数,并返回其结果 wrapper.count = start # 初始化计数器的值 return wrapper # 返回包装函数,作为装饰器工厂的返回值 return counter_func # 返回装饰器工厂的返回值,即包装函数(闭包)的引用
2.5 列表推导式
列表推导式是Python中的一种简洁的语法结构,用于创建和操作列表。通过使用列表推导式,我们可以轻松地生成新的列表,而无需使用循环或映射函数。例如:
numbers = [1, 2, 3, 4, 5]
squares = [x**2 for x in numbers] # 使用列表推导式生成一个包含数字平方的新列表
print(squares) # 输出[1, 4, 9, 16, 25]
2.6 多线程和多进程
Python支持多线程和多进程编程,可以用于实现并发和并行计算。通过使用threading和multiprocessing模块,我们可以轻松地创建和管理多个线程和进程。例如:
import threading def print_numbers(): for i in range(10): print(i) t1 = threading.Thread(target=print_numbers) # 创建一个新线程,并将print_numbers函数作为目标函数
t2 = threading.Thread(target=print_numbers) # 创建另一个新线程,并将print_numbers函数作为目标函数 t1.start() # 启动第一个线程
t2.start() # 启动第二个线程 t1.join() # 等待第一个线程执行完毕
t2.join() # 等待第二个线程执行完毕
2.7 异常处理和日志记录
Python提供了强大的异常处理和日志记录功能,可以用于捕获和处理程序中的错误和异常。通过使用try-except语句和logging模块,我们可以轻松地记录错误信息并调试程序。例如:
import logging logging.basicConfig(filename='example.log', level=logging.DEBUG) # 配置日志记录器,将日志记录到文件example.log中,并设置日志级别为DEBUG try: result = 10 / 0 # 执行一个会抛出ZeroDivisionError异常的操作
except ZeroDivisionError as e: # 捕获ZeroDivisionError异常,并将异常对象赋值给变量e logging.error('Caught an exception:', exc_info=True) # 记录错误信息到日志中,并输出到控制台中
2.8 网络编程和Web开发
Python支持网络编程和Web开发,可以用于构建Web应用程序和Web服务。通过使用socket、http、urllib等模块和Django、Flask等Web框架,我们可以轻松地实现网络通信、HTTP请求处理、Web页面渲染等功能。例如:
from http.server import BaseHTTPRequestHandler, HTTPServer
import urllib.parse class MyServer(BaseHTTPRequestHandler): # 创建一个自定义的HTTP请求处理程序类,继承自BaseHTTPRequestHandler类 def do_GET(self): # 实现do_GET方法,用于处理GET请求 query = urllib.parse.urlparse(self.path).query # 解析请求路径中的查询字符串,并存储到query变量中 self.send_response(200) # 发送HTTP响应状态码200(OK)给客户端 self.end_headers() # 结束HTTP响应头部信息的发送,准备发送HTTP响应主体内容给客户端 self.wfile.write(bytes(query, 'utf-8')) # 将查询字符串作为HTTP响应主体内容发送给客户端,使用utf-8编码将字符
2.9 数据分析与科学计算
Python在数据分析与科学计算领域也表现出色。我们可以使用pandas、numpy、scipy等库进行数据处理、统计分析、数值计算等。例如:
import pandas as pd
import numpy as np # 使用pandas读取数据
data = pd.read_csv('data.csv') # 使用numpy进行数值计算
a = np.array([1, 2, 3, 4, 5])
b = np.array([2, 3, 4, 5, 6])
c = a + b
print(c) # 输出[3 5 7 9 11]
2.10 机器学习与深度学习
Python在机器学习和深度学习领域也非常流行。我们可以使用scikit-learn、TensorFlow、PyTorch等库进行模型训练、预测等。例如:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier # 加载数据集
iris = load_iris()
X = iris.data
y = iris.target # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 训练模型
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train) # 预测测试集结果
y_pred = clf.predict(X_test)
print(y_pred) # 输出预测结果
2.11 数据库操作
Python提供了多种数据库操作库,如sqlite3、psycopg2、pymysql等,可以用于连接和操作数据库。通过使用这些库,我们可以轻松地执行SQL查询、插入、更新和删除等操作。例如:
import sqlite3 # 连接数据库
conn = sqlite2.connect('example.db') # 执行SQL查询
c = conn.cursor()
c.execute('SELECT * FROM table_name')
rows = c.fetchall()
for row in rows: print(row) # 输出查询结果 # 关闭数据库连接
conn.close()
2.12 Web框架与Web开发
Python提供了多种Web框架,如Django、Flask、Pyramid等,可以用于构建Web应用程序。这些框架提供了丰富的功能和工具,如路由、模板引擎、ORM等,可以简化Web开发过程。通过使用这些框架,我们可以轻松地构建出功能强大的Web应用程序。例如:
from flask import Flask, render_template app = Flask(__name__) @app.route('/')
def index(): return render_template('index.html') # 渲染index.html模板,并返回给客户端 if __name__ == '__main__': app.run() # 启动Web应用程序
2.13 正则表达式与文本处理
Python提供了re模块,可以用于处理正则表达式和文本处理。通过使用正则表达式,我们可以轻松地匹配、查找和替换文本中的特定模式。例如:
import re text = 'Hello, world! This is a test.'
pattern = 'world'
match = re.search(pattern, text)
if match: print('Match found!') # 输出"Match found!",因为text中包含"world"字符串
2.14 文件操作与文件处理
Python提供了多种文件操作和文件处理库,如os、shutil、io等。通过使用这些库,我们可以轻松地读取、写入、复制、移动和压缩文件。例如:
import os
import shutil
with open('file.txt', 'r') as f: # 打开文件file.txt,并以只读模式读取文件内容到变量f中 content = f.read() # 从变量f中读取文件内容到变量content中
print(content) # 输出文件内容到控制台中
shutil.copy('file.txt', 'backup.txt') # 将文件file.txt复制到backup.txt中
2.15 图形绘制与可视化
Python提供了多种图形绘制和可视化库,如matplotlib、seaborn、plotly等。通过使用这些库,我们可以轻松地绘制各种类型的图表,如折线图、柱状图、散点图等。这些库还提供了丰富的样式和功能,可以定制化我们的图表。例如:
import matplotlib.pyplot as plt # 创建数据
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11] # 绘制折线图
plt.plot(x, y)
plt.title('Example Plot')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.show() # 显示图表
2.16 多线程与多进程并行计算
Python支持多线程和多进程并行计算,可以用于提高程序的执行效率。通过使用threading和multiprocessing模块,我们可以创建多个线程或进程,并分配不同的任务给它们。这些模块还提供了同步和通信机制,可以方便地管理多个线程或进程之间的协作。例如:
import threading
import time def worker(): print('Worker thread is running') time.sleep(2) print('Worker thread finished') # 创建线程并启动
t = threading.Thread(target=worker)
t.start()
print('Main thread is running')
time.sleep(2)
print('Main thread finished')
t.join() # 等待线程执行完毕
2.17 网络编程与网络爬虫
Python在网络编程和网络爬虫领域也有广泛的应用。通过使用socket、requests、beautifulsoup等库,我们可以轻松地编写网络通信程序和网络爬虫。例如:
import requests
from bs4 import BeautifulSoup # 发送HTTP请求并获取响应内容
response = requests.get('https://www.example.com')
soup = BeautifulSoup(response.text, 'html.parser')
# 查找页面中的特定元素并提取信息
title = soup.title.string # 获取页面标题
相关文章:

Python基本语法及高级特性总结
1. Python基本语法 1.1 变量和数据类型 在Python中,变量不需要预先声明,可以直接赋值。Python是一种动态类型语言,变量的类型会根据赋值的对象自动确定。例如: a 10 # a是整数类型变量 b 3.14 # b是浮点数类型变量 c …...

03-详解网关的过滤器工厂和常见的网关过滤器路由过滤器,默认过滤器,全局过滤器的执行顺序
过滤器工厂 过滤器种类 GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务响应的结果做加工处理 Spring提供了31中不同的路由过滤器工厂 AddResponseHeader表示给请求添加响应头 default-filters: # 默认过滤器 - AddResponseHeaderX-Response-Default-R…...
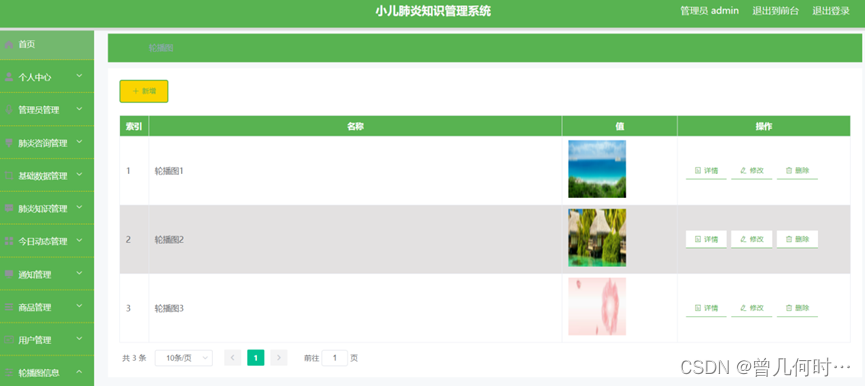
基于SSM的小儿肺炎知识管理系统设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

HuffMan tree
定义 给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。 基础知识 路…...
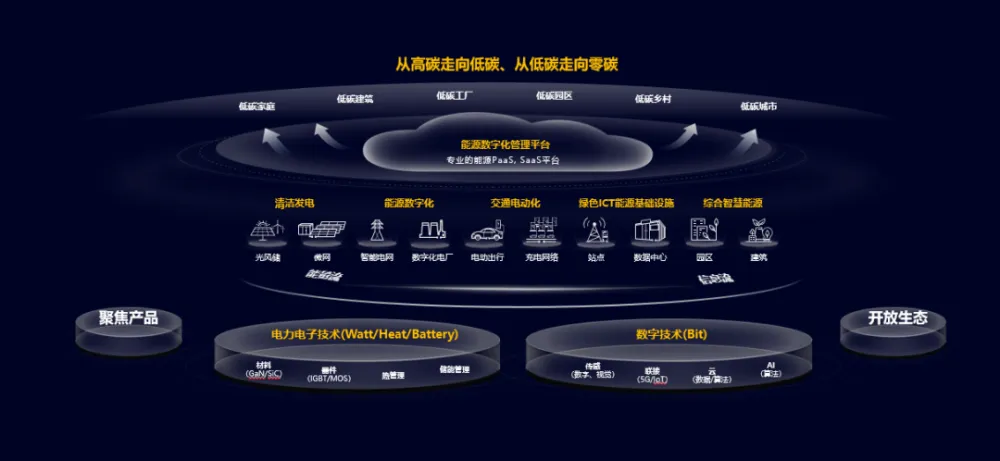
各地加速“双碳”落地,数字能源供应商怎么选?
作者 | 曾响铃 文 | 响铃说 随着我国力争2030年前实现“碳达峰”、2060年前实现“碳中和”的“双碳”目标提出,为各地区、各行业的低碳转型和绿色可持续发展制定“倒计时”时间表,一场围绕“数字能源”、“智慧能源”、“新能源”等关键词的创新探索进…...
19.java绘图
A.Graphics类 Graphics类是java.awt包中的一个类,它用于在图形用户界面(GUI)或其他图形应用程序中进行绘制。该类通常与Component的paint方法一起使用,以在组件上进行绘制操作。 一些Graphics类的常见用法和方法: 在组…...

提升工作效率,尽在Microsoft Office LTSC 2021 for Mac!
在当今的办公环境中,高效率的工作是每个人都追求的目标。作为全球领先的办公软件套装,Microsoft Office LTSC 2021 for Mac将为您提供一站式的解决方案,帮助您轻松应对各种工作任务。 首先,Microsoft Office LTSC 2021 for Mac拥…...

day24_java的反射机制
反射 一、反射的概念 反射:加载类,反射出类的各个组成部分(类的成员:构造方法,属性,方法) java反射机制:在运行状态中,对于任何一个类都能够知道这个类的所有属性和方…...
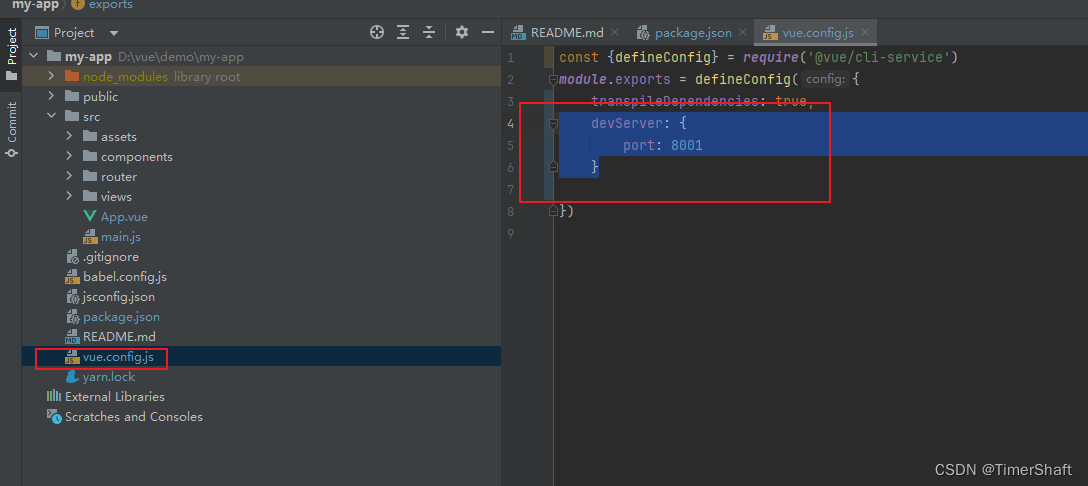
VUE学习二、创建一个前端项目
1.创建一个vue项目 使用命令 vue ui启动vue脚手架 vue ui 等待项目创建好 可以来任务栏启动项目 参数那里可以设置启动端口等参数 启动成功 成功访问 2. 用webstorm 打开项目 脚手架页面可安装基本依赖 比如路由 使用ws打开项目 启动项目 npm run serve 3.修改启动…...
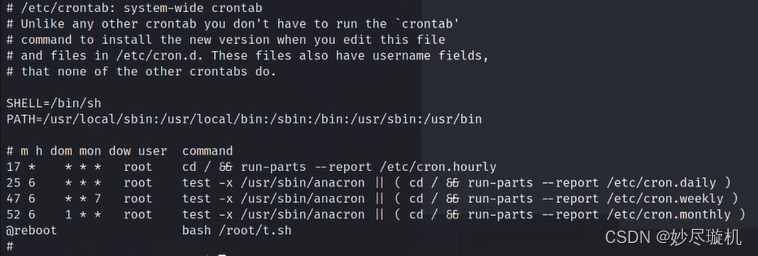
「红队笔记」靶机精讲:Prime1 - 信息收集和分析能力的试炼
「红队笔记」靶机精讲:Prime1 - 信息收集和分析能力的试炼 本文是作者在观看 B 站《红队笔记》后做的一些笔记及相关知识的补充。学渗透特别推荐大家去看。如有侵权,请联系作者,作者看到后会第一时间删除。 靶机精讲之Prime1,vu…...
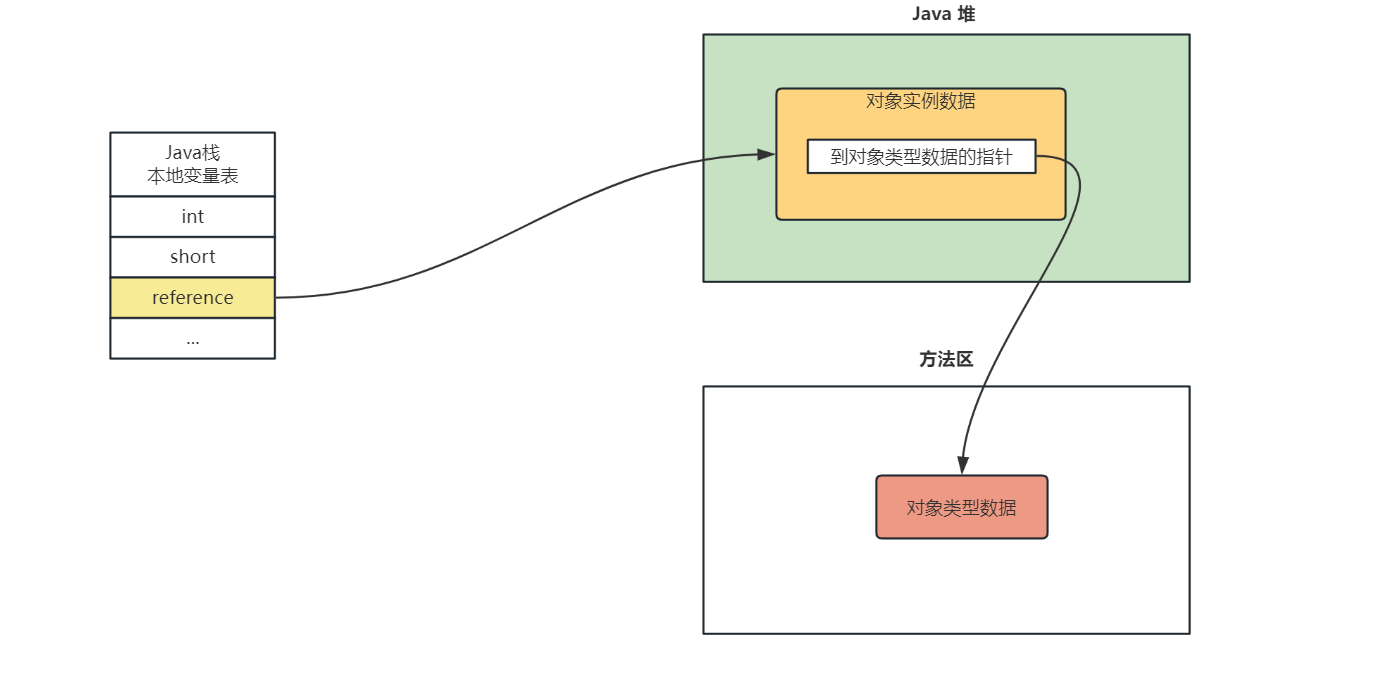
JVM虚拟机系统性学习-对象的创建流程及对象的访问定位
对象的创建流程与内存分配 对象创建流程如下: Java 中新创建的对象如何分配空间呢? new 的对象先放 Eden 区(如果是大对象,直接放入老年代)当 Eden 区满了之后,程序还需要创建对象,则垃圾回收…...

perf与火焰图-性能分析工具
参考链接 perf性能分析工具使用分享 如何读懂火焰图?-阮一峰 perf基本用法-record,report-知乎 火焰图抓取 准备: centos安装perf工具 dnf install perf下载火焰图解析代码 git clone https://github.com/brendangregg/FlameGraph.git抓取指定进程…...
UniGui使用CSSUniTreeMenu滚动条
有些人反应UniTreeMenu当菜单项目比较多的时候会超出但是没有出滚动条,只需要添加如下CSS 老规矩,unitreemeu的layout的componentcls里添加bbtreemenu,然后在css里添加 .bbtreemenu .x-box-item{ overflow-y: auto; } 然后当内容超出后就会…...

Spring框架中的五种常用设计模式
1、单例模式 Spring 的 Bean 默认是单例模式,通过 Spring 容器管理 Bean 的⽣命周期,保证每个 Bean 只被 创建⼀次,并在整个应⽤程序中重用。 2.工厂模式 Spring 使⽤⼯⼚模式通过 BeanFactory 和 ApplicationContext 创建并管理 Bean 对象…...

华纳云:docker启动报错的原因和解决方法
Docker 启动报错可能由多种原因引起。以下是一些建议,可用于解决 Docker 启动问题: 查看 Docker 日志: 查看 Docker 的日志可以提供更多的详细信息,有助于定位问题。 sudo journalctl -xe | grep docker 或者查看 Docker 服务的详…...

代码规范及开发工具
代码规范及开发工具: 前端(vscode、idea): JavaScript规范: 1. 谷歌开源项目风格指南:JavaScript 、TypeScript篇 https://zh-google-styleguide.readthedocs.io/en/latest/google-typescript-…...
证件照制作小程序源代码
17638103951(同v)...

自治调优!人大金仓解放DBA双手
数据库系统的性能是确保整个应用系统高效运转的关键因素,因此数据库性能调优工作至关重要。KingbaseES通过将人工调优过程内化为数据库内核,成功实现了自治调优。这种创新的调优方案为DBA提供了更高效且准确的性能调优途径,同时也显著降低了数…...
深度学习环境配置------windows系统(GPU)------Pytorch
深度学习环境配置------windows系统(GPU)------Pytorch 准备工作明确操作系统明确显卡系列 CUDA和Cudnn下载与安装1.下载2.安装 环境配置过程1.安装Anacoda2.配置环境1)创建一个新的虚拟环境2)pytorch相关库的安装 2.安装VScode1&…...
el-menu标题过长显示不全问题处理
项目基于vue-element-admin 问题 期望 处理方式 \src\layout\components\Sidebar\index.vue 文件后添加CSS <style scped> /* 侧栏导航菜单经典 文字超长溢出问题 CSS折行 */ .el-submenu__title {display: flex;align-items: center; } .el-submenu__title span {white-…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...