【SpringCloud】通过Redis手动更新Ribbon缓存来解决Eureka微服务架构中服务下线感知的问题
文章目录
- 前言
- 1.第一次尝试
- 1.1服务被调用方更新
- 1.2压测第一次尝试
- 1.3 问题分析
- 1.4 同步的不是最新列表
- 2.第二次尝试
- 2.1调用方过滤下线服务
- 2.2压测第二次尝试
- 2.3优化
- 写到最后
前言
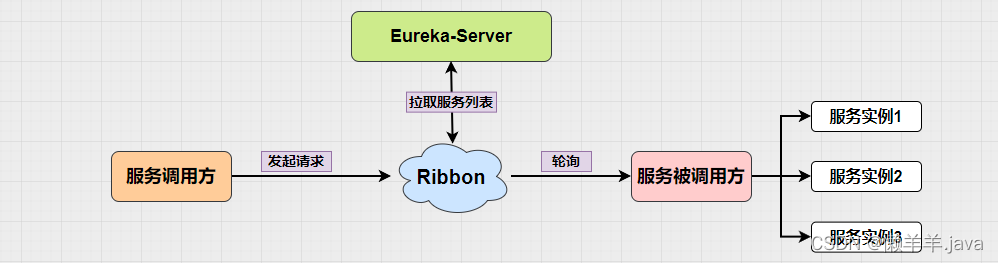
在上文的基础上,通过压测的结果可以看出,使用DiscoveryManager下线服务之后进行压测是不会出现异常情况的,但唯一缺点就是下线服务的方式是取消注册与续约,之后并没有结束进程。也就使得在调用api下线后的服务其实是还存在处理请求的能力的。加之eureka三种级别的缓存同步需要一定时间,Eureka-Client从三级缓存中拉取的并不是实时的服务列表,进而使得Ribbon从Eureka-Client拉取的也不是实时的服务列表。最终导致Ribbon负载均衡到了已经下线的服务实例,并且此时该实例(进程还未关闭)刚好能处理请求!就造成了下线了两个端口的服务实例,但是却还是被负载均衡到来处理请求!
按照这个思路,再去看这张图:
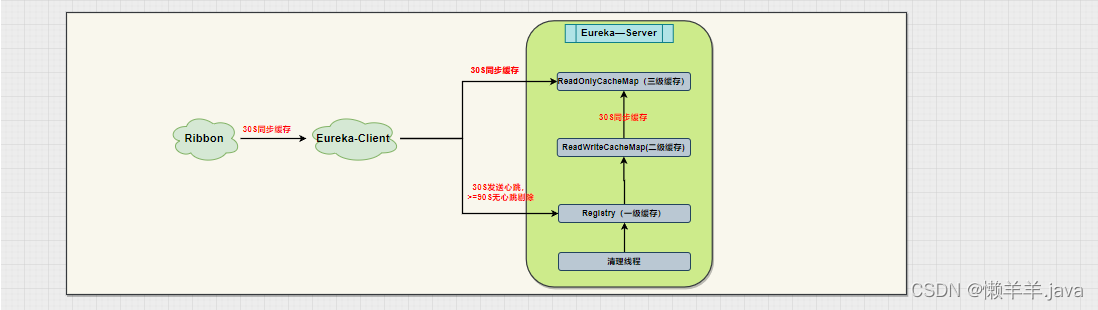
可不可以通过某种手段,当服务下线后去越过三级缓存直接去更新Ribbon缓存来缩短感知时间?
我先说答案——是可以的
1.第一次尝试
1.1服务被调用方更新
手动从Eureka-Client同步服务缓存信息:
在之前分析Ribbon源码的时候,说到了接口路径从http://服务名称/接口路径——>http://服务地址/接口路径,这个过程中调用方的请求被Ribbon拦截器拦截,并且通过负载均衡最终被改写成为了一个准确的服务地址,其中有一个非常重要的方法,getLoadBalancer(“服务名称”)
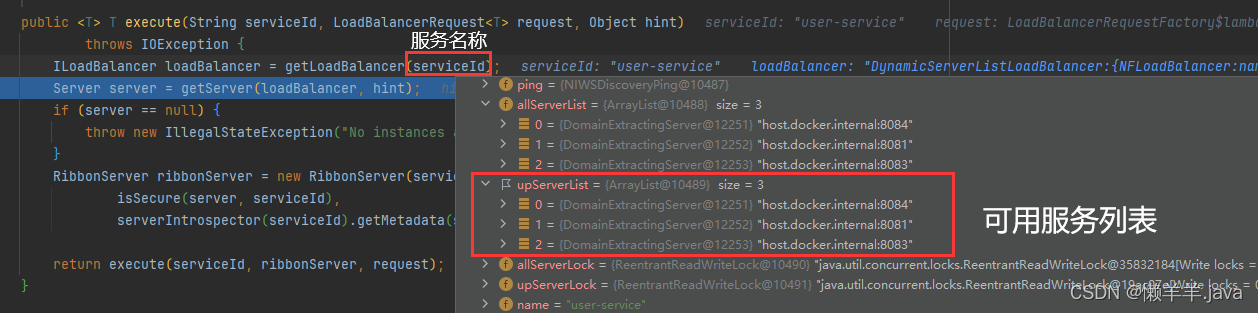
可见,他通过服务名称就拿到了该服务名称下的所有服务列表(allServerList)和可用服务列表(upServerList),我们通过这个操作可不可以直接获取到最新一手的可用服务列表并且手动去set进Ribbon的可用服务列表缓存里,让他不再去每过30S同步?
Tips:在我们的SpringCloud项目中有一个非常重要的组件SpringClientFactory是Spring Cloud中用于管理和获取客户端实例的工厂类。在这里面可以获取特定服务的负载均衡器(即ILoadBalancer)
于是,便有了下面的操作,专门配置一个Bean去更新Ribbon缓存,每当调用服务下线接口去下线指定服务后就去自动同步Ribbon缓存,不用再Ribbon每隔30S去自动同步:
@Configuration
@Slf4j
public class ClearRibbonCache {public void clearRibbonCache(SpringClientFactory clientFactory, List<Integer> portParams) {// 获取指定服务的负载均衡器ILoadBalancer loadBalancer = clientFactory.getLoadBalancer("user-service");//在主动拉取可用列表,而不是走拦截器被动的方式——这里List<Server> reachableServers = loadBalancer.getReachableServers();//这里从客户端获取,会等待客户端同步三级缓存// 在某个时机需要清除Ribbon缓存((BaseLoadBalancer) loadBalancer).setServersList(ableServers); // 清除Ribbon负载均衡器的缓存}
}
于是在下线服务的接口中,就多了一步自动更新缓存的操作(不熟悉这个接口的可以去看上一篇文章):
@GetMapping(value = "/service-down-list")public String offLine(@RequestParam List<Integer> portParams) {List<Integer> successList = new ArrayList<>();//得到服务信息List<InstanceInfo> instances = eurekaClient.getInstancesByVipAddress(appName, false);List<Integer> servicePorts = instances.stream().map(InstanceInfo::getPort).collect(Collectors.toList());//去服务列表里挨个下线OkHttpClient client = new OkHttpClient();log.error("开始时间:{}", System.currentTimeMillis());portParams.parallelStream().forEach(temp -> {if (servicePorts.contains(temp)) {String url = "http://" + ipAddress + ":" + temp + "/control/service-down";try {Response response = client.newCall(new Request.Builder().url(url).build()).execute();if (response.code() == 200) {log.debug(temp + "服务下线成功");successList.add(temp);} else {log.debug(temp + "服务下线失败");}} catch (IOException e) {log.error(e.toString());}}});log.debug("开始清除Ribbon缓存");clearRibbonCache.clearRibbonCache(clientFactory,portParams);return successList + "优雅下线成功";}
1.2压测第一次尝试
同样我们采用(100线程-3S)的JMeter压测模型去在调用服务下线接口后的15S,30S后压测,压测的接口即为一个普通的跨服务调用接口
下线服务:
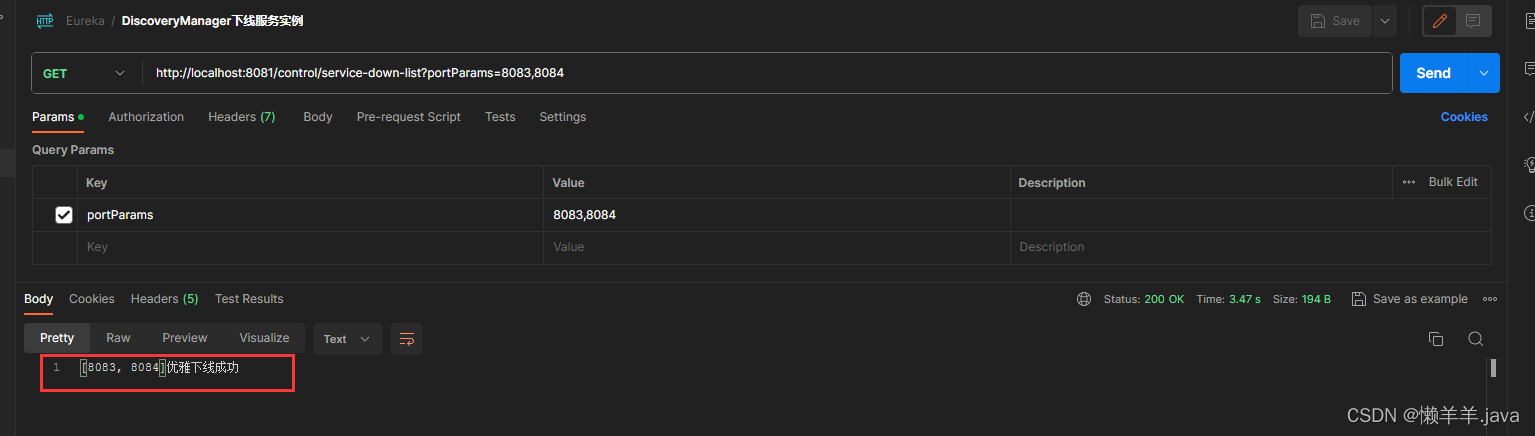
下线服务的15S:

此时,观察控制台的日志输出可以发现,已经下线的两个服务实例还是被负载均衡到了(已下线但进程未退出),好像更新了缓存没有任何效果诶。
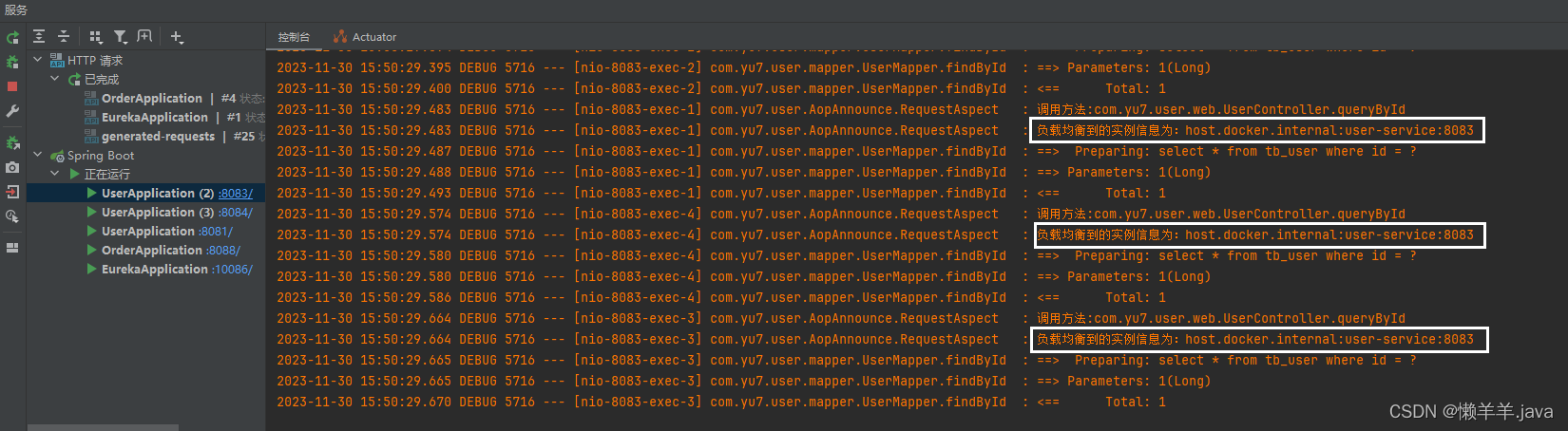
下线服务的30S:

情况和15S如出一辙,并且请求负载均衡到了已下线但进程未退出的服务上。
下线服务的45S:

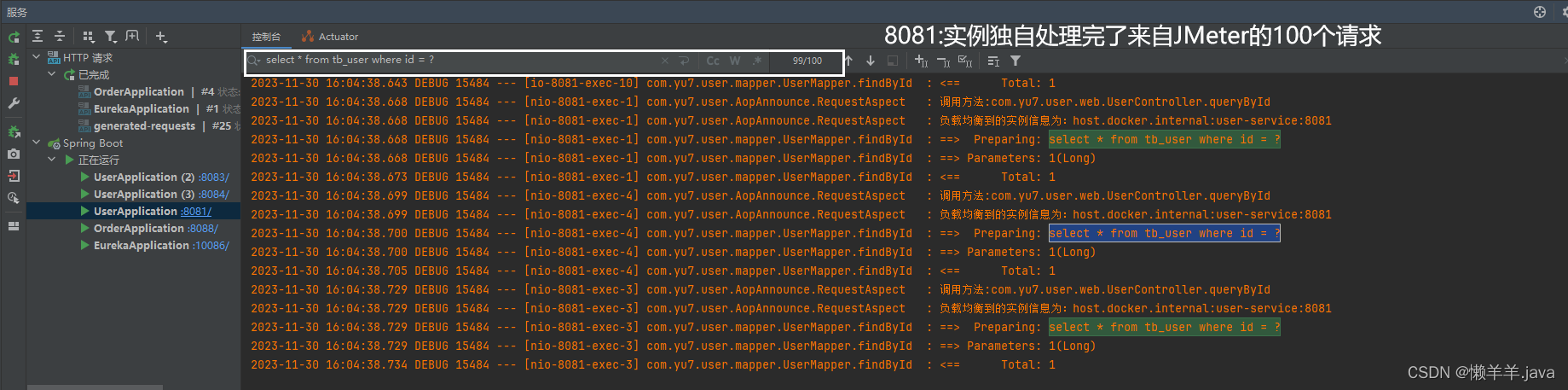
可见调用api下线服务直到45S左右,已经下线的服务才从每层缓存信息中完全清除,这个时间是非常致命的!
1.3 问题分析
在服务发布的场景就会出现这样一个业务问题:开发调用api下线了某两个服务,通知运维可以去关闭这两个服务进程了,运维kill-9杀掉了这两个进程准备发布新服务。但此时客户端(用户)向服务端发送了请求,刚好该请求涉及跨服务调用,并且由于Ribbon同步Eureka-Client缓存,Eureka-Client同步Eurek-Server中的三级缓存需要一定时间,Ribbon缓存中的可用服务列表不是最新的,同步过来已下线(进程也被kill)的服务。最后请求受到Ribbon负载均衡落到了一个开发通过api下线的服务实例,分发到了一个运维kill-9的服务实例上,造成接口返回500、404、connect time out、connect refused…等错误,造成频繁告警。
1.4 同步的不是最新列表
透过现象看本质:
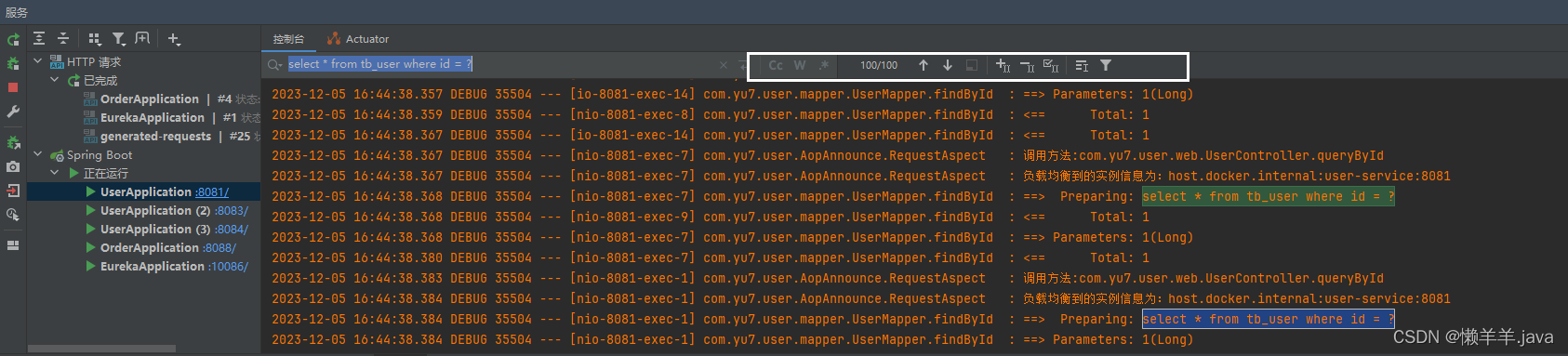
为什么手动同步Ribbon缓存没有起到效果?是不是同步的内容出了问题?下面打断点开启debug,看看服务下线后到底拿到的是什么服务列表:

意外发现,曾经天真以为可以拿到的实时的服务列表,到头来确实一场空,小丑竟是我自己。明明8083,8084已经下线可为什么还在可用服务列表里,并且还set到了Ribbon缓存中
原来啊,通过那个方法获取服务列表是从Eureka-client拿的,而这其实就是client去三级缓存那里同步的问题。 你说到为什么手动更新了缓存还是会有一段同步时间? 那就是client从三级缓存同步来的服务列表还存在没下线的服务,所以导致手动更新到ribbon缓存里的列表也还存在没下线的服务。看到这里,Eureka的“牺牲一致性保证高可用”是不是体现的淋漓尽致呢?
这个一致性难道真的不能解决了吗?
其实我还有一招
同时结合Eureka-Ribbon架构的服务调用链路,其实在服务调用方去更新Ribbon缓存才能更好保证Ribbon负载均衡的服务列表是我所控制的
PS:(这里节省了一次尝试,即在服务被调用方去引入过滤操作,尝试过压测结果还是和以前一样,所以就忽略了。直接去服务调用方尝试)
2.第二次尝试
2.1调用方过滤下线服务
从拿到的服务列表中过滤下线服务,并且在调用方执行:
在调用方执行?那被调用方下线的端口信息怎么让调用方知道呢,跨进程通信你选择MQ?还是Redis?这里我选择Redis
在上述更新缓存的操作中稍作更改,把更新操作移动到服务调用方,并且引入Redis来作为通信支持(这里采用hash的数据结结构),那么被调用方现在所需要的就是更新下线的端口信息到redis中:
@GetMapping(value = "/service-down-list")public String offLine(@RequestParam List<Integer> portParams) {List<Integer> successList = new ArrayList<>();//得到服务信息List<InstanceInfo> instances = eurekaClient.getInstancesByVipAddress(appName, false);List<Integer> servicePorts = instances.stream().map(InstanceInfo::getPort).collect(Collectors.toList());//去服务列表里挨个下线OkHttpClient client = new OkHttpClient();log.error("开始时间:{}", System.currentTimeMillis());portParams.parallelStream().forEach(temp -> {if (servicePorts.contains(temp)) {String url = "http://" + ipAddress + ":" + temp + "/control/service-down";try {Response response = client.newCall(new Request.Builder().url(url).build()).execute();if (response.code() == 200) {log.debug(temp + "服务下线成功");successList.add(temp);} else {log.debug(temp + "服务下线失败");}} catch (IOException e) {log.error(e.toString());}}});// todo Redis通知stringRedisTemplate.opsForHash().put("port-map","down-ports",portParams.toString());return successList + "优雅下线成功";}
并且以前更新Ribbon可用服务列表操作也有稍微变化,即新增了一个手动过滤操作:
@Configuration
@Slf4j
public class ClearRibbonCache {/*** 削减*/public static boolean cutDown(List<Integer> ports, Server index) {return ports.contains(index.getPort());}public void clearRibbonCache(SpringClientFactory clientFactory, String portParams) {// 获取指定服务的负载均衡器ILoadBalancer loadBalancer = clientFactory.getLoadBalancer("user-service");//在主动拉取可用列表,而不是走拦截器被动的方式——这里List<Server> reachableServers = loadBalancer.getReachableServers();//这里从客户端获取,会等待客户端同步三级缓存//过滤掉已经下线的端口,符合条件端口的服务过滤出来List<Integer> portList = StringChange.stringToList(portParams);List<Server> ableServers = reachableServers.stream().filter(temp -> !cutDown(portList, temp)).collect(Collectors.toList());log.debug("可用服务列表:{}", ableServers);// 在某个时机需要清除Ribbon缓存((BaseLoadBalancer) loadBalancer).setServersList(ableServers); // 清除Ribbon负载均衡器的缓存}
}
在服务调用方,每次进行跨服务调用前都去从Redis中获取出实时下线的端口并且去更新Ribbon缓存:
2.2压测第二次尝试
当下线完服务,立即进行压测,可以看到所有的跨服务调用请求都落在了还未下线的实例上,并且已下线但进程未关闭的服务实例没有再处理请求:
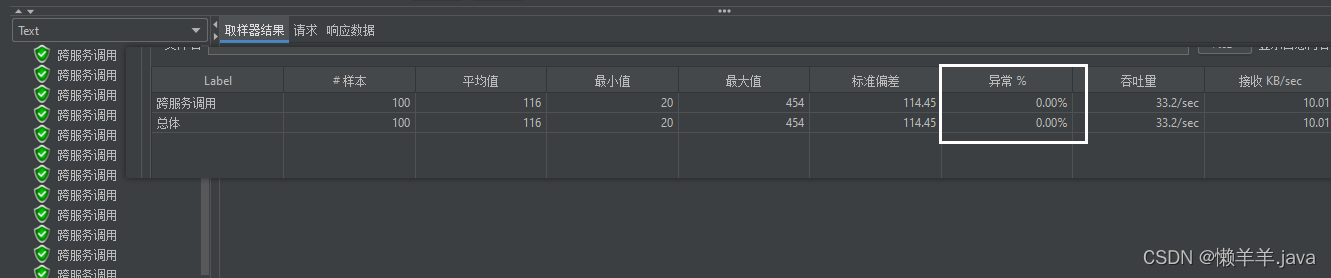
并且15S,30S的时间节点上,也没有任何异常:
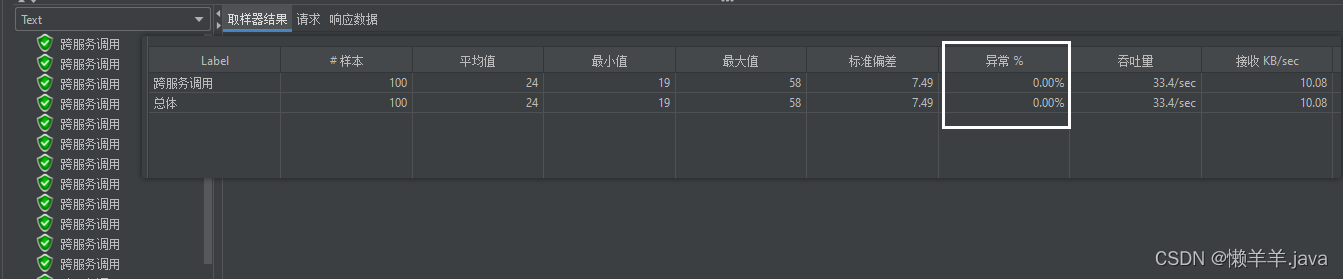
可见通过此种方式来主动更新Ribbon可用服务列表确实可行,特别是在运维那边发布新服务的一个特定场景下可以解决Eureka感知下线服务迟钝从而影响Ribbon负载到不可用的服务实例上这一问题。
2.3优化
其实,如果每次在新发布服务的场景下告警的接口都可以精确定位到,并且数量不多的情况我觉得在那几个业务接口里去手动同步一下Ribbon缓存没有什么大问题也可以解决问题。但是如果每次告警的接口有很多,并且不固定那上述的方法就显得有些许臃肿。而且这也是一种入侵式编程,我其实是不推荐的!
说起入侵式编程不禁就会想到无入侵式编程——Aop
直接把出现错误的模块作为切面,并把更新Ribbon的操作作为切入点写到表达式里,就完美做到了不改变已有业务而实现了更新功能,就像这样:
@Aspect
@Component
@Slf4j
public class RequestAspect {@ResourceSpringClientFactory springClientFactory;@ResourceClearRibbonCacheBean clearRibbonCacheBean;@Resourceprivate StringRedisTemplate stringRedisTemplate;@Before(value = "execution(* com.yu7.order.web.*.*(..))")public void refreshBefore(JoinPoint joinPoint) {String ports = (String) stringRedisTemplate.opsForHash().get("port-map", "down-ports");log.debug("从Redis获取的端口为:{}", ports);//下线了才会有值,没有值说明没下线不用更新if (ObjectUtils.isNotEmpty(ports)) {clearRibbonCacheBean.clearRibbonCache(springClientFactory, ports);}}
}
进行压测,结果和预期完全一致~
写到最后
我想说:其实我的方案只是相当于提出了一个大体框架和构想,粗略地实现了基于Eureka的微服务架构中服务状态感知的问题,当业务里存在不止一种调用关系,下线服务类型不一致,服务断断续续下线会造成value值丢失…方案就需要进一步细化(还存在硬编码问题,嘻嘻),并且为了切面不影响业务还应该给存到Redis的数据加上TTL等其他保险措施,总而言之也欢迎大家提出建议,共同精进,一起解决这一难题!
相关文章:
【SpringCloud】通过Redis手动更新Ribbon缓存来解决Eureka微服务架构中服务下线感知的问题
文章目录 前言1.第一次尝试1.1服务被调用方更新1.2压测第一次尝试1.3 问题分析1.4 同步的不是最新列表 2.第二次尝试2.1调用方过滤下线服务2.2压测第二次尝试2.3优化 写到最后 前言 在上文的基础上,通过压测的结果可以看出,使用DiscoveryManager下线服务…...
如何做好性能压测?压测环境设计和搭建的7个步骤你知道吗?
简介:一般来说,保证执行性能压测的环境和生产环境高度一致是执行一次有效性能压测的首要原则。有时候,即便是压测环境和生产环境有很细微的差别,都有可能导致整个压测活动评测出来的结果不准确。 1. 性能环境要考虑的要素 1.1 系…...
Qt12.13
...
(五))
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】SLAM(基础篇)(五)
目录 前言 几个相关概念 双目视惯雷达SLAM 相关工作 系统综述 视觉前端...
鸿蒙开发之页面与组件生命周期
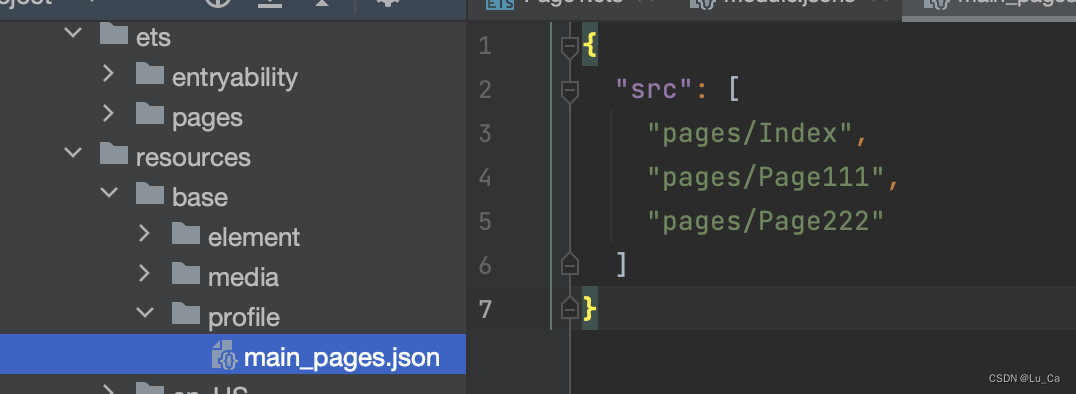
一、页面间的跳转 创建文件的时候记得选择创建page文件,这样就可以在main->resources->profile->main_pages.json中自动形成页面对应的路由了。如果创建的时候你选择了ArkTS文件,那么需要手动修改main_pages.json文件中,添加相应的…...
的详解一)
Kotlin开发之低功耗蓝牙(引用三方库)的详解一
在我们工作中,如果涉及到软硬结合,经常会用到蓝牙,而蓝牙有两种:一种是普通的蓝牙,一种是低功耗的蓝牙,今天我们主要讲解的是低功耗蓝牙:主要根据第三方库进行的讲解 第一步:在使用…...

5G/4G工业DTU扬尘在线监测:解决工地扬尘困扰的最佳方案
在如今快速发展的工业环境中,扬尘污染成为了一个严重的问题。工地扬尘不仅对环境造成污染,还对工作人员的健康产生负面影响。为了解决这一问题,5G/4G工业DTU扬尘在线监测应运而生。 5G/4G工业DTU扬尘在线监测原理 5G/4G工业DTU扬尘在线监测是…...

思源黑体某些字显示成日式中文,太先进了(附解法)
由于字体版权问题,公司外发的材料一般都需要把字体换成“思源黑体”才可以。 很久以前下载过显示为“Noto Sans CJK”的思源黑,后来改成了“SourceHanSans”,一直以为自己的思源黑体是正常的。 然后问题来了:在替换ppt里的字体后…...
.NET医院检验系统LIS源码,使用了oracle数据库,保证数据的隔离和安全性
医院检验系统LIS源码,LIS系统全套商业源码 LIS系统实现了实验室人力资源管理、标本管理、日常事务管理、网络管理、检验数据管理(采集、传输、处理、输出、发布)、报表管理过程的自动化,使实验室的操作人员和管理者从繁杂的手工劳…...

html实现动漫视频网站模板源码
文章目录 1.视频设计来源1.1 主界面1.2 动漫、电视剧、电影视频界面1.3 播放视频界面1.4 娱乐前线新闻界面1.5 关于我们界面 2.效果和源码2.1 动态效果2.2 源代码 源码下载 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/detail…...
python zblog API实现类似XMLRPC/发布文章
我发现python对Zblog的XML发布并不友好,虽然也有对应的模块,但是远远没有XPCRPC更直接方便,但是使用xmlRpc是直接给发布文章带来了不小的便利,但是对系统也并不友好,但是zblog也开放了Api,但是干部子弟不乐…...
后台业务管理系统原型模板,Axure后台组件库(整套后台管理页面)
后台业务系统需要产品经理超强的逻辑思维能力和业务理解能力,整理了一批后台原型组件及完整的用 Axure 8 制作的后台系统页面,方便产品经理们快速上手制作后台原型。 包括交互元件、首页、商品、订单、库存、用户、促销、运营、内容、统计、财务、设置、…...

kyuubi整合flink yarn application model
目录 概述配置flink 配置kyuubi 配置kyuubi-defaults.confkyuubi-env.shhive 验证启动kyuubibeeline 连接使用hive catalogsql测试 结束 概述 flink 版本 1.17.1、kyuubi 1.8.0、hive 3.1.3、paimon 0.5 整合过程中,需要注意对应的版本。 注意以上版本 姊妹篇 k…...

使用openpyxl调整Excel的宽度
逐行加载Excel,并将行宽调整为行中的最大字符数。 希望在打开 Excel 时能够看到所有字符。 失败代码: #失败代码: wb openpyxl.load_workbook(./targetExcelFile.xlsx) ws wb.worksheets[0]for col in ws.iter_cols():max_length 0colum…...

前端面试——CSS面经(持续更新)
1. CSS选择器及其优先级 !important > 行内样式 > id选择器 > 类/伪类/属性选择器 > 标签/伪元素选择器 > 子/后台选择器 > *通配符 2. 重排和重绘是什么?浏览器的渲染机制是什么? 重排(回流):当增加或删除dom节点&…...
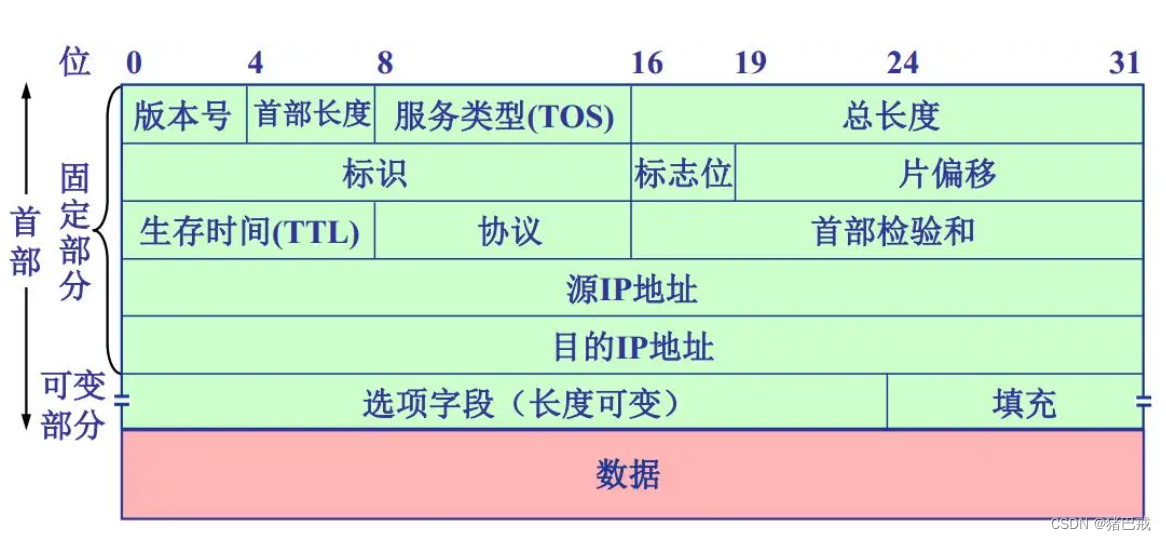
【C语言】结构体实现位段
引言 对位段进行介绍,什么是位段,位段如何节省空间,位段的内存分布,位段存在的跨平台问题,及位段的应用。 ✨ 猪巴戒:个人主页✨ 所属专栏:《C语言进阶》 🎈跟着猪巴戒,…...
学习资料)
IEEE RAS 机器人最优控制(Model-based Optimization for Robotics)学习资料
系列文章目录 前言 电气和电子工程师学会机器人模型优化技术委员会 一、学习资料 1.1 教程和暑期学校 2020 年 Memmo 欧盟项目暑期班2019年Memmo欧盟项目冬季学校Matthias Gerdts(德国慕尼黑联邦国防军大学)在拜罗伊特 OMPC 2013 上举办的最优控制教程…...
redis中缓存雪崩,缓存穿透,缓存击穿等
缓存雪崩 由于原有缓存失效(或者数据未加载到缓存中),新缓存未到期间(缓存正常从Redis中获取,如下图)所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,…...

C_8练习题答案
一、单项选择题(本大题共20小题,每小题2分,共40分。在每小题给出的四个备选项中,选出一个正确的答案,并将所选项前的字母填写在答题纸的相应位置上。) 编写C语言程序一般需经过的几个步骤依次是(B)。A.编辑、调试、编译、连接 B.编辑、编译、连接、运行 C.编译、调试、编辑、连…...
Web漏洞分析-文件解析及上传(中)
随着互联网的迅速发展,网络安全问题变得日益复杂,而文件解析及上传漏洞成为攻击者们频繁攻击的热点之一。本文将深入研究文件解析及上传漏洞,通过对文件上传、Web容器IIS、命令执行、Nginx文件解析漏洞以及公猫任意文件上传等方面的细致分析&…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

Chrome 浏览器前端与客户端双向通信实战
Chrome 前端(即页面 JS / Web UI)与客户端(C 后端)的交互机制,是 Chromium 架构中非常核心的一环。下面我将按常见场景,从通道、流程、技术栈几个角度做一套完整的分析,特别适合你这种在分析和改…...

PH热榜 | 2025-06-08
1. Thiings 标语:一套超过1900个免费AI生成的3D图标集合 介绍:Thiings是一个不断扩展的免费AI生成3D图标库,目前已有超过1900个图标。你可以按照主题浏览,生成自己的图标,或者下载整个图标集。所有图标都可以在个人或…...

基于stm32F10x 系列微控制器的智能电子琴(附完整项目源码、详细接线及讲解视频)
注:文章末尾网盘链接中自取成品使用演示视频、项目源码、项目文档 所用硬件:STM32F103C8T6、无源蜂鸣器、44矩阵键盘、flash存储模块、OLED显示屏、RGB三色灯、面包板、杜邦线、usb转ttl串口 stm32f103c8t6 面包板 …...