RabbitMQ Streams 详解
RabbitMQ Streams是一种持久复制数据结构,可以完成与队列相同的任务:它们缓冲来自生产者的消息,这些消息由消费者读取。然而,流与队列的区别在于两个重要方面:消息的存储和消费方式。
Streams为仅追加的消息日志建模,这些消息可以重复读取,直到过期。流始终是持久的和复制的。这种流行为的更技术性的描述是“非破坏性消费者语义”。
要从RabbitMQ中的流中读取消息,一个或多个使用者订阅它,并根据需要多次读取相同的消息。
流中的数据可以通过RabbitMQ客户端库或通过专用的二进制协议插件和关联的客户端使用。强烈建议使用后一个选项,因为它提供对所有流特定功能的访问,并提供尽可能最好的吞吐量(性能)。
现在,您可能会问以下问题:
- 那么流会取代队列吗?
- 我应该放弃使用队列吗?
为了回答这些问题,引入流不是为了取代队列,而是为了补充队列。Streams为新的RabbitMQ用例开辟了许多机会,这些用例在使用Streams的用例中进行了描述。
以下信息详细说明流的使用以及流的管理和维护操作。
您还应该查看流插件信息,以了解有关使用二进制RabbitMQ stream协议的流的更多信息,以及功能矩阵的流核心和流插件比较页面。
一、使用流的用例
开发流最初是为了涵盖现有队列类型无法提供或具有缺点的4个消息传递用例:
1、大型扇形分叉
当想要将相同的消息传递给多个订阅者时,用户当前必须为每个消费者绑定一个专用队列。如果使用者数量很大,这可能会变得效率低下,特别是在需要持久性和/或复制时。流将允许任意数量的使用者以非破坏性的方式消费来自同一队列的相同消息,从而不需要绑定多个队列。流消费者还可以从副本中读取数据,从而允许读取负载在集群中分布。
2、重放(时间旅行)
由于所有当前的RabbitMQ队列类型都具有破坏性消费行为,即当消费者用完消息时,将从队列中删除消息,因此不可能重新读取已消费的消息。流将允许消费者在日志中的任何点连接并从那里读取。
3、吞吐量性能
没有任何持久队列类型能够提供可以与任何现有的基于日志的消息传递系统竞争的吞吐量。Streams的设计以性能为主要目标。
4、大量积压工作
大多数RabbitMQ队列被设计为收敛于空状态,并因此进行了优化,当给定队列上有数百万条消息时,性能可能会更差。流旨在以有效的方式存储大量数据,并将内存开销降至最低。
二、如何使用RabbitMQ Streams
可以指定可选队列和使用者参数的AMQP 0.9.1客户端库将能够将流用作常规AMQP 09.1队列。
就像队列一样,必须首先声明流。
1、声明RabbitMQ Stream
要声明流,请将x-queue-type队列参数设置为stream(默认值为classic)。此参数必须由客户端在声明时提供;不能使用策略设置或更改它。这是因为策略定义或适用的策略可以动态更改,但队列类型不能更改。必须在声明时指定。
下面的片段显示了如何使用AMQP 0.9.1 Java客户端创建流:
ConnectionFactory factory = new ConnectionFactory();
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("my-stream",true, // durablefalse, false, // not exclusive, not auto-deleteCollections.singletonMap("x-queue-type", "stream")
);使用设置为stream的x-queue-type参数声明队列将在每个配置的RabbitMQ节点上创建一个具有副本的流。流是仲裁系统,因此强烈建议使用不均匀的集群大小。
流仍然是AMQP 0.9.1队列,因此它可以在创建后绑定到任何交换,就像任何其他RabbitMQ队列一样。
如果使用管理UI声明,则必须使用队列类型下拉菜单指定流类型。
流支持3个额外的队列参数,这些参数最好使用策略配置:
- x-max-length-bytes
设置流的最大大小(以字节为单位)。默认值:未设置。
- x-max-age
设置流的最长期限。默认值:未设置。
- x-stream-max-segment-size-bytes
单位:字节。流在磁盘上被划分为固定大小的段文件。 此设置控制它们的大小。 默认值:(500000000 字节)。
以下代码片段演示如何将流的最大大小设置为 20 GB,并使用 100 MB 的段文件:
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-queue-type", "stream");
arguments.put("x-max-length-bytes", 20_000_000_000); // maximum stream size: 20 GB
arguments.put("x-stream-max-segment-size-bytes", 100_000_000); // size of segment files: 100 MB
channel.queueDeclare("my-stream",true, // durablefalse, false, // not exclusive, not auto-deletearguments
);
三、客户端操作
1、Consuming
由于流永远不会删除任何消息,因此任何消费者都可以开始读取/消费 从日志中的任何一点。这由 x-stream-offset consumer 参数控制。 如果未指定,消费者将从写入的下一个偏移量开始读取 添加到使用者启动后的日志中。支持以下值:
- first - 从日志中的第一条可用消息开始
- last - 从最后写入的消息“块”(块 是流中使用的储运单位,简单来说就是批次 由几到几千条消息组成的消息,具体取决于入口)
- next - 与不指定任何偏移量相同
- 偏移量 - 一个数值,指定要附加到日志的确切偏移量。 如果此偏移量不存在,它将分别钳制到日志的开始或结束。
- 时间戳 - 一个时间戳值,指定要附加到日志的时间点。 它将限制到最接近的偏移量,如果时间戳超出流的范围,它将分别限制日志的开始或结束。 在 AMQP 0.9.1 中,使用的时间戳是精度为 00 秒的 POSIX 时间,即自 00-00-1970 01:01:<> UTC 以来的秒数。 请注意,使用者可以接收在指定时间戳之前发布的消息。
- 间隔 - 一个字符串值,指定相对于当前时间附加日志的时间间隔。使用与 x-max-age 相同的规范
以下代码片段演示如何使用第一个偏移量规范:
<span style="background-color:#232323"><span style="color:#e6e1dc">channel.basicQos(<span style="color:#a5c261">100</span>); <span style="color:#bc9458"><em>// QoS must be specified</em></span>
channel.basicConsume(<span style="color:#a5c261">"my-stream"</span>,false,Collections.singletonMap(<span style="color:#a5c261">"x-stream-offset"</span>, <span style="color:#a5c261">"first"</span>), <span style="color:#bc9458"><em>// "first" offset specification</em></span>(consumerTag, message) -> {<span style="color:#bc9458"><em>// message processing</em></span><span style="color:#bc9458"><em>// ...</em></span>channel.basicAck(message.getEnvelope().getDeliveryTag(), false); <span style="color:#bc9458"><em>// ack is required</em></span>},consumerTag -> { });
</span></span>以下代码片段演示如何指定要从中消费的特定偏移量:
<span style="background-color:#232323"><span style="color:#e6e1dc">channel.basicQos(<span style="color:#a5c261">100</span>); <span style="color:#bc9458"><em>// QoS must be specified</em></span>
channel.basicConsume(<span style="color:#a5c261">"my-stream"</span>,false,Collections.singletonMap(<span style="color:#a5c261">"x-stream-offset"</span>, <span style="color:#a5c261">5000</span>), <span style="color:#bc9458"><em>// offset value</em></span>(consumerTag, message) -> {<span style="color:#bc9458"><em>// message processing</em></span><span style="color:#bc9458"><em>// ...</em></span>channel.basicAck(message.getEnvelope().getDeliveryTag(), false); <span style="color:#bc9458"><em>// ack is required</em></span>},consumerTag -> { });
</span></span>以下代码片段演示如何指定要从中使用的特定时间戳:
<span style="background-color:#232323"><span style="color:#e6e1dc"><span style="color:#bc9458"><em>// an hour ago</em></span>
<span style="color:#da4939">Date</span> <span style="color:#a5c261">timestamp</span> = <span style="color:#c26230">new</span> <span style="color:#ffc66d">Date</span>(System.currentTimeMillis() - <span style="color:#a5c261">60</span> * <span style="color:#a5c261">60</span> * <span style="color:#a5c261">1_000</span>)
channel.basicQos(<span style="color:#a5c261">100</span>); <span style="color:#bc9458"><em>// QoS must be specified</em></span>
channel.basicConsume(<span style="color:#a5c261">"my-stream"</span>,false,Collections.singletonMap(<span style="color:#a5c261">"x-stream-offset"</span>, timestamp), <span style="color:#bc9458"><em>// timestamp offset</em></span>(consumerTag, message) -> {<span style="color:#bc9458"><em>// message processing</em></span><span style="color:#bc9458"><em>// ...</em></span>channel.basicAck(message.getEnvelope().getDeliveryTag(), false); <span style="color:#bc9458"><em>// ack is required</em></span>},consumerTag -> { });
</span></span>2、其他流操作
以下操作的使用方式与经典队列和仲裁队列类似 但有些具有一些特定于队列的行为。
- 声明
- 队列删除
- 发布者确认
- 消费(订阅):消费需要 QoS 要设置的预取。acks 作为一种信用机制来推进当前 消费者的偏移量。
- 为使用者设置 QoS 预取
- 消费者确认(牢记 QoS 预取限制)
- 取消消费者
四、流的单个活动消费者功能
流的单个活动使用者是 RabbitMQ 3.11 及更高版本中提供的一项功能。 它在流上提供独占消费和消费连续性。 当共享同一流和名称的多个使用者实例启用单个活动使用者时,这些实例中只有一个实例将同时处于活动状态,因此将接收消息。 其他实例将处于空闲状态。
单一活跃使用者功能提供 2 个好处:
- 消息按顺序处理:一次只有一个使用者。
- 保持消费连续性:如果活动消费者停止或崩溃,则该组中的消费者将接管。
五、超级流
超级流是一种通过将大型流划分为较小的流来横向扩展的方法。 它们与单个活动使用者集成,以保留分区内的消息顺序。 超级流从 RabbitMQ 3.11 开始可用。
超级流是由单个常规流组成的逻辑流。 这是一种使用 RabbitMQ 流横向扩展发布和使用的方法:将大型逻辑流划分为分区流,将存储和流量拆分到多个集群节点上。
超级流仍然是一个逻辑实体:由于客户端库的智能性,应用程序将其视为一个“大”流。 超级流的拓扑基于 AMQP 0.9.1 模型,即它们之间的交换、队列和绑定。
可以使用任何 AMQP 0.9.1 库或管理插件创建超级流的拓扑,它需要创建直接交换,即“分区”流,并将它们绑定在一起。 不过,使用 rabbitmq-streams add_super_stream 命令可能更容易。 以下是如何使用它来创建具有 3 个分区的发票超级流:
<span style="background-color:#232323"><span style="color:#e6e1dc">rabbitmq-streams add_super_stream invoices --partitions 3
</span></span>使用 rabbitmq-streams add_super_stream --help 了解有关该命令的更多信息。
与单个流相比,超级流增加了复杂性,因此不应将其视为涉及流的所有用例的默认解决方案。 仅当您确定已达到单个流的限制时,才考虑使用超级流。
六、功能比较:常规队列与流
流不是传统意义上的真正队列,因此不是 与 AMQP 0.9.1 队列语义非常一致。其他队列类型的许多功能 不支持支持,并且永远不会由于队列类型的性质而支持。
可以使用常规队列的 AMQP 0.9.1 客户端库将能够使用流 只要它使用消费者确认。
由于流中许多功能是非破坏性的,因此它们永远不会被流支持 读取语义。
功能矩阵
| 特征 | 经典 | 流 |
| 非持久性队列 | 是的 | 不 |
| 排他性 | 是的 | 不 |
| 每条消息的持久性 | 每条消息 | 总是 |
| 成员资格变更 | 自动 | 手动 |
| TTL的 | 是的 | 否(但请参阅保留期) |
| 队列长度限制 | 是的 | 否(但请参阅保留期) |
| 懒惰行为 | 是的 | 固有 |
| 消息优先级 | 是的 | 不 |
| 消费者至上 | 是的 | 不 |
| 死信交换 | 是的 | 不 |
| 遵守政策 | 是的 | (请参阅保留期) |
| 对内存警报做出反应 | 是的 | 否(使用最少的 RAM) |
| 病毒邮件处理 | 不 | 不 |
| 全局 QoS 预取 | 是的 | 不 |
非持久性队列
根据其假定的用例,流始终是持久的, 它们不能像常规队列那样是非持久的。
排他性
根据其假定的用例,流始终是持久的,它们不能像常规队列那样是排他性的。 它们不应用作临时队列。
懒惰模式
写入消息后,流将所有数据直接存储在磁盘上 在读取之前,它不会使用任何内存。可以这么说,流本质上是懒惰的。
全球服务质量
流不支持全局 QoS 预取,其中通道设置单个 使用该通道的所有使用者的预取限制。如果尝试 从启用了全局 QoS 的通道中的流中使用 将返回通道错误。
使用每使用者 QoS 预取,这是几个常用客户端中的默认设置。
相关文章:

RabbitMQ Streams 详解
RabbitMQ Streams是一种持久复制数据结构,可以完成与队列相同的任务:它们缓冲来自生产者的消息,这些消息由消费者读取。然而,流与队列的区别在于两个重要方面:消息的存储和消费方式。 Streams为仅追加的消息日志建模&a…...
跨境电商如何利用跨境客服软件提升销售额
随着全球化的推进,跨境电商成为了许多企业拓展市场的重要途径。然而,跨境电商面临着语言、文化、时差等多种挑战,为了提供更好的客户服务并提升销售额,跨境电商需要利用跨境客服软件。本文将探讨跨境电商如何利用跨境客服软件来提…...

css/less/scss代码注意事项
一.命名 1.类名使用小写字母,以中划线分割;id 使用 驼峰式命名; 2.less/scss中的函数、混合采用驼峰命名; 3. class 的命名不要使用 标签名,如.p .div .img; 二.选择器 尽量使用直接子选择器,否则,有时会造成性能损耗 .content .title { .…...
Git应用——代码提交规范 feat ,fix ,style
当前使用 feat 增加新功能fix 修复问题/BUGstyle 代码风格相关无影响运行结果的perf 优化/性能提升refactor 重构revert 撤销修改test 测试相关docs 文档/注释chore 依赖更新/脚手架配置修改等workflow 工作流改进ci 持续集成types 类型定义文件更改wip 开发中 别处看到 fea…...

TDengine Kafka Connector将 Kafka 中指定 topic 的数据(批量或实时)同步到 TDengine
教程放在这里:TDengine Java Connector,官方文档已经写的很清晰了,不再赘述。 这里记录一下踩坑: 1.报错 java.lang.UnsatisfiedLinkError: no taos in java.library.pathat java.lang.ClassLoader.loadLibrary(ClassLoader.j…...
单片机的低功耗模式介绍
文章目录 简介一、功耗来源说明1.1、芯片工作模式1.2、静态损耗1.3、I/O额外损耗1.4、动态损耗 二、功耗如何测量三、降低功耗有什么方法3.1、选取合适的芯片工作模式3.2、降低工作频率3.3、关闭不需要使用的外设3.4、 降低静态电流损耗3.5、 周期采集供电3.6、 设置IO口状态 四…...
基于SSM实现的精品课程网站
一、系统架构 前端:jsp | js | css | jquery | bootstrap 后端:spring | springmvc | mybatis 环境:jdk1.7 | mysql | maven | tomcat 二、代码及数据库 三、功能介绍 01. 登录页 02. web端-首页 03. web端-视频教程 04. web端-资料…...

广州旅游攻略(略说一二)
广州是中国南方的一个重要城市,也是广东省的省会,拥有着悠久的历史和丰富的文化遗产。作为中国最繁华的城市之一,广州吸引了大量的游客前来探索其独特的魅力。今天我将为大家介绍一份广州旅游攻略,希望能帮助各位游客更好地了解这…...

C++STL的list模拟实现
文章目录 前言 list实现push_back迭代器(重点)普通迭代器const迭代器 inserterase析构函数构造函数拷贝构造赋值 vector和list的区别 前言 要实现STL的list, 首先我们还得看一下list的源码。 我们看到这么一个东西,我们知道C兼容C,可以用struct来创建一…...

django--分页功能
Django 提供了强大的分页功能,可以轻松地在视图中实现分页。 在视图中使用分页: # views.py from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger from django.shortcuts import render from .models import YourModeldef your…...
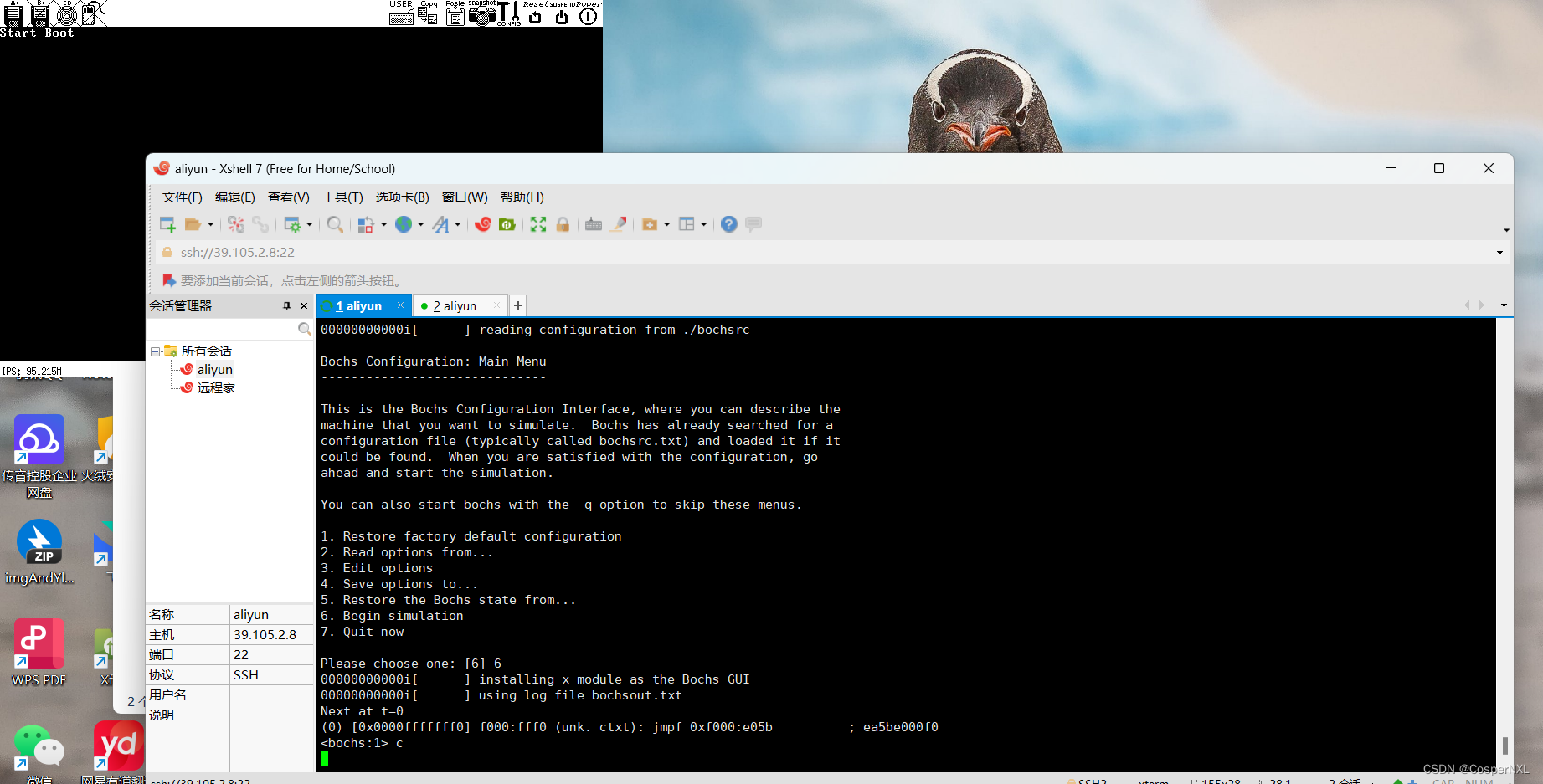
centOS安装bochsXshell连接centos启动可视化界面
centOS安装bochs 参考:https://blog.csdn.net/muzi_since/article/details/102559187 首先安装依赖环境: yum install gtk2 gtk2-devel yum install libXt libXt-devel yum install libXpm libXpm-devel yum install SDL SDL-devel yum install libXr…...

mac m2芯片 安装nginx + php + mysql
1.安装homebrew: 系统本身就有(命令brew -v查看下),如果没有安装一下 /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" 2.安装nginx brew install nginx 3.安装php bre…...

vue axios 使用
使用Vue中的Axios需要先安装axios库,可以通过yarn或npm安装: yarn add axios # 或者 npm install axios --save然后在Vue组件中导入axios并使用: import axios from axios;export default {data() {return {responseData: null,error: null…...

使用docker实现logstash同步mysql到es
准备工作: 1.有mysql的连接方式,并且可以连接成功 2.有es的连接方式,并且可以连接成功 3.安装了docker 环境是Ubuntu中安装了docker 一、创建配置文件,用于容器卷挂载 # 切换目录,可自定义 cd /home/test/ # 创建lo…...
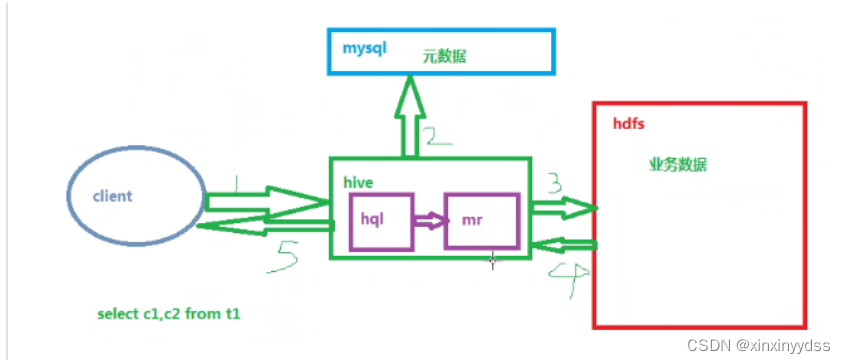
hive数据仓库工具
1、hive是一套操作数据仓库的应用工具,通过这个工具可实现mapreduce的功能 2、hive的语言是hql[hive query language] 3、官网hive.apache.org 下载hive软件包地址 Welcome! - The Apache Software Foundationhttps://archive.apache.org/ 4、hive在管理数据时分为元…...

C语言 联合体验证 主机字节序 +枚举
联合体应用:验证当前主机的大小端(字节序) //验证当前主机的大小端 #include <stdio.h>union MyData {unsigned int data;struct{unsigned char byte0;unsigned char byte1;unsigned char byte2;unsigned char byte3;}byte; };int main…...
python和pygame实现烟花特效
python和pygame实现烟花特效 新年来临之际,来一个欢庆新年烟花祝贺,需要安装使用第三方库pygame,关于Python中pygame游戏模块的安装使用可见 https://blog.csdn.net/cnds123/article/details/119514520 效果图及源码 先看效果图:…...
gRPC-Gateway:高效转换 RESTful 接口 | 开源日报 No.105
grpc-ecosystem/grpc-gateway Stars: 16.4k License: BSD-3-Clause gRPC-Gateway 是一个遵循 gRPC HTTP 规范的 gRPC 到 JSON 代理生成器。它是 Google 协议缓冲编译器 protoc 的插件,可以读取 protobuf 服务定义并生成反向代理服务器,将 RESTful HTTP…...
非专业的建模人员如何给模型设置材质纹理贴图?
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 1、材质和纹理的区别于关联 材质(Material)是…...

自动化测试、压力测试、持续集成
因为项目的原因,前段时间研究并使用了 SoapUI 测试工具进行自测开发的 api。下面将研究的成果展示给大家,希望对需要的人有所帮助。 SoapUI 是什么? SoapUI 是一个开源测试工具,通过 soap/http 来检查、调用、实现 Web Service …...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...

MySQL 主从同步异常处理
阅读原文:https://www.xiaozaoshu.top/articles/mysql-m-s-update-pk MySQL 做双主,遇到的这个错误: Could not execute Update_rows event on table ... Error_code: 1032是 MySQL 主从复制时的经典错误之一,通常表示ÿ…...