SQL进阶 | HAVING子句
概述
“HAVING”其用法和含义与“WHERE”关键词相似,但具有更高级别的限定性。在SELECT语句中,“HAVING”关键词用于过滤聚合函数的结果。与“WHERE”关键词不同的是,“HAVING”关键词不能用于过滤单个行,它主要用于过滤由GROUP BY子句分组的结果集。
寻找缺失的编号
有这样一张表,它的编号不是连续性的,需要判断这张表是否存在有缺失的编号。


select '存在缺失的编号' as gap
from seqtbl
having count(*) <> max(seq)如果这个查询结果有 1 行,说明存在缺失的编号;如果 1 行都没有,说明不存在缺失的编号。这是因为,如果用 COUNT(*) 统计出来的行数等于“连续编号”列的最大值,就说明编号从开始到最后是连续递增的,中间没有缺失。如果有缺失,COUNT(*) 会小于 MAX(seq),这样 HAVING 子句就变成真了。
而在这条SQL中,并没有与GROUP BY子句结合使用,由此可以看出HAVING子句也可以单独使用,对象则是整个查询结果集合。
接下来,再来查询一下缺失编号的最小值。求最小值要用 MIN 函数,因此我们像下面这样写SQL 语句。
-- 查询缺失编号的最小值
select min(seq + 1) as gap
from seqtbl
where (seq + 1) not in (select seq from seqtbl)
使用 NOT IN 进行的子查询针对某一个编号,检查了比它大 1 的编号是否存在于表中。然后,“3, 莱露”“6, 玛丽”“8, 本”这几行因为找不到紧接着的下一个编号,所以子查询的结果为真。如果没有缺失的编号,则查询到的结果是最大编号 8 的下一个编号 9。
用 HAVING 子句进行子查询 :求众数

-- 求众数的sql语句1:使用谓词
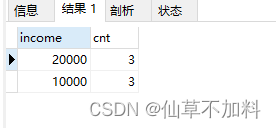
select income,count(*) as cnt from graduates
group by income
having count(*) >= all(select count(*) from graduates group by income);在子查询中对income分组,统计分组后每种收入的记录数,然后再使用ALL谓词判断分组后行号比子查询中所有的行号都大和相等的结果。
ALL 谓词用于 NULL 或空集时会出现问题,可以用极值函数来代替。
-- 求众数的sql语句2:使用极值函数
select income,count(*) as cnt
from graduates
group by income
having count(*) >= (select max(cnt)from (select count(*) as cntfrom graduatesgroup by income) tmp);在这条SQL中,子查询先获取分组后每个income的行数,再使用MAX函数获取最大值,最后判断分组后的行数大于等于最大的行数获取结果。
用 HAVING 子句进行自连接 :求中位数
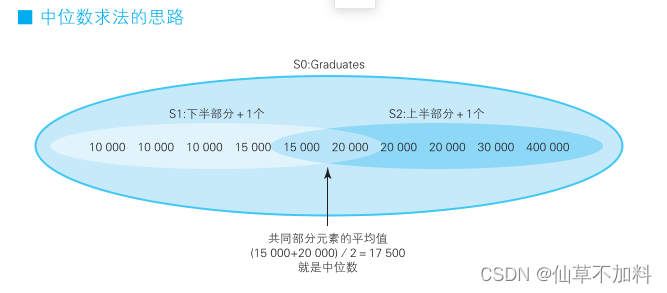
这里书上给的思路是将集合里的元素按照大小分为上半部分和下半部分两个子集,同时让这 2 个子集共同拥有集合正中间的元素。这样,共同部分的元素的平均值就是中位数,思路如下图所示。
-- 求中位数的sql语句:在having子句中使用非等值自连接
select avg(distinct income)
from (select t1.income from graduates t1,graduates t2 group by t1.income-- s1的条件having sum(case when t2.income >= t1.income then 1 else 0 end) >= count(*)/2-- s2的条件and sum(case when t2.income <= t1.income then 1 else 0 end) >= count(*)/2) tmp;
这里的代码不是很好理解,我们把这条SQL拆分来看。
-- 获取笛卡尔积
select t1.income,t2.income from graduates t1,graduates t2
-- 上半区条件:如果t1中income 大于 t2中的income,则flag记为 1,小于则记为 0
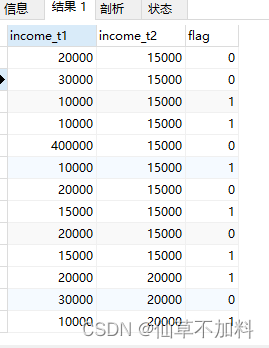
select t1.income as income_t1,t2.income as income_t2,(case when t1.income >= t2.income then 1 else 0 end) as flag
from graduates t1,graduates t2-- 下半区条件:如果t1中income 小于 t2中的income,则flag记为 1,小于则记为 0
select t1.income as income_t1,t2.income as income_t2,(case when t1.income <= t2.income then 1 else 0 end) as flag
from graduates t1,graduates t2
-- 分组统计 上半区条件
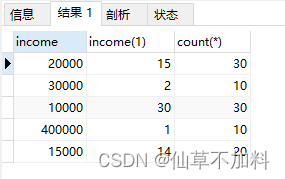
select t1.income,sum(case when t1.income >= t2.income then 1 else 0 end) as income,count(*)
from graduates t1,graduates t2
group by t1.income-- 分组统计 下半区条件
select t1.income,sum(case when t1.income <= t2.income then 1 else 0 end) as income,count(*)
from graduates t1,graduates t2
group by t1.income
-- 分组统计上半区s1
select t1.income,sum(case when t1.income >= t2.income then 1 else 0 end) as income,count(*)
from graduates t1,graduates t2
group by t1.income
having sum(case when t1.income >= t2.income then 1 else 0 end) >= count(*)/2-- 分组统计下半区s2
select t1.income,sum(case when t1.income <= t2.income then 1 else 0 end) as income,count(*)
from graduates t1,graduates t2
group by t1.income
having sum(case when t1.income >= t2.income then 1 else 0 end) >= count(*)/2
-- 求交集
select t1.income from graduates t1,graduates t2
group by t1.income having sum(case when t1.income >= t2.income then 1 else 0 end) >= count(*)/2
intersect
select t1.income from graduates t1,graduates t2
group by t1.income having sum(case when t1.income <= t2.income then 1 else 0 end) >= count(*)/2
拆分开来,这条SQL就清晰很多了。要点在于比较条件“>= COUNT(*)/2”里的等号,这个等号是有意地加上的。加上等号并不是为了清晰地分开子集 S1 和S2,而是为了让这 2 个子集拥有共同部分。如果去掉等号,将条件改成“> COUNT(*)/2”,那么当元素个数为偶数时,S1 和 S2 就没有共同的元素了,也就无法求出中位数了。
查询不包含 NULL 的集合

学生提交报告后,“提交日期”列会被写入日期,而提交之前是NULL。现在我们需要从这张表里找出哪些学院的学生全部都提交了报告(即理学院、经济学院)。做法是:对dpt进行分组,判断分组后个学院的记录数与提交日期不为空的记录数是否相等。
-- 查询“提交日期”列内不包含null的学院1:使用count函数
select dpt from students1
group by dpt
having count(*) = count(sbmt_date);-- 查询“提交日期”列内不包含null的学院2:使用case表达式
select dpt from students1
group by dpt
having count(*) = sum(case when sbmt_date is not null then 1 else 0 end);
用关系除法运算进行购物篮分析
假设有这样两张表:全国连锁折扣店的商品表 Items,以及各个店铺的库存管理表 ShopItems。
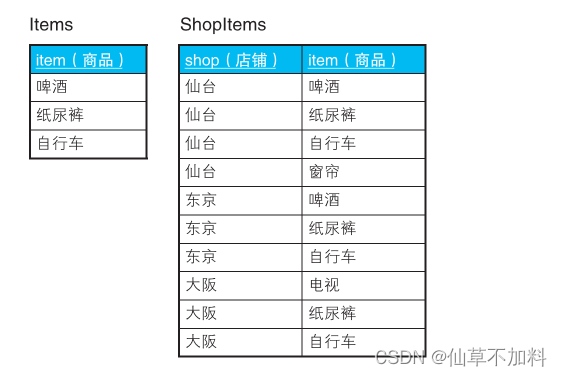
这次我们要查询的是囊括了表 Items 中所有商品的店铺。也就是说,要查询的是仙台店和东京店。
select si.shop from shopitems si,items i
where si.item = i.item
group by si.shop
having count(si.item) = (select count(item) from items);HAVING 子句的子查询 (SELECT COUNT(item) FROM Items) 的返回值是常量 3。因此,对商品表和店铺的库存管理表进行连接操作后结果是3 行的店铺会被选中;对没有啤酒的大阪店进行连接操作后结果是 2 行,所以大阪店不会被选中;而仙台店则因为(仙台 , 窗帘)的行在表连接时会被排除掉,所以也会被选中;另外,东京店则因为连接后结果是 3 行,所以当然也会被选中。

接下来我们把条件变一下,看看如何排除掉仙台店(仙台店的仓库中存在“窗帘”,但商品表里没有“窗帘”),让结果里只出现东京店。
-- 精确关系除法运算:使用外连接和count函数
select si.shop
from shopitems si left outer join items i on si.item = i.item
group by si.shop
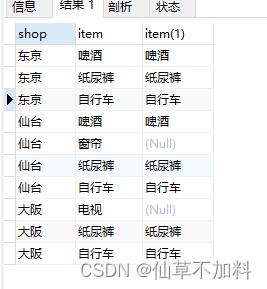
having count(si.item) = (select count(item) from items) -- 条件1and count(i.item) = (select count(item) from items); -- 条件2使用外连接查询到的结果集如下图所示。在条件1中 得到的结果是东京和大阪,条件2得到的结果只有东京,两者取交集得到最终的结果东京。
总结
- 表不是文件,记录也没有顺序,所以 SQL 不进行排序。
- SQL 不是面向过程语言,没有循环、条件分支、赋值操作。
- SQL 通过不断生成子集来求得目标集合。SQL 不像面向过程语言那样通过画流程图来思考问题,而是通过画集合的关系图来思考。
- GROUP BY 子句可以用来生成子集。
- WHERE 子句用来调查集合元素的性质,而 HAVING 子句用来调查集合本身的性质。
练习题
1.在“寻找缺失的编号”部分,我们写了一条 SQL 语句,让程序只在存在缺失的编号时返回结果。请将 SQL 语句修改成始终返回一行结果,即存在缺失的编号时返回“存在缺失的编号”,不存在缺失的编号时返回“不存在缺失的编号”。
-- 1-4-1 修改编号缺失的检查逻辑,是结果总是返回一行数据
select case when count(*) <> max(seq) then '存在缺失编号' else '不存在缺失编号' end as gap
from seqtbl2.使用正文中的表 Students,查询“全体学生都在 9 月份提交了报告的学院”。
-- 1-4-2 查询全体学生都在9月份提交了报告的学院
select dpt
from students1
group by dpt
having count(*) = sum(case when sbmt_date between '2005-09-01' and '2005-09-30' then 1 else 0 end);
3.对于没有备齐全部商品类型的店铺,我们也希望返回的一览表能展示这些店铺缺少多少种商品。my_item_cnt 是店铺的现有库存商品种类数,diff_cnt 是不足的商品种类数。
-- 1-4-3 查询没有备齐全部商品类型的店铺
select si.shop,count(si.item = i.item) as my_item_cnt,(select count(item) from items) - count(si.item = i.item) as diff_cnt
from shopitems si left join items i on si.item = i.item
group by si.shop;select si.shop,count(si.item) as my_item_cnt,(select count(item) from items) - count(si.item = i.item) as diff_cnt
from shopitems si,items i
where si.item = i.item
group by si.shop;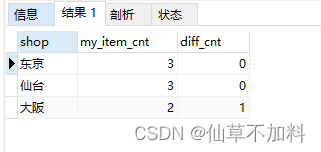
相关文章:
SQL进阶 | HAVING子句
概述 “HAVING”其用法和含义与“WHERE”关键词相似,但具有更高级别的限定性。在SELECT语句中,“HAVING”关键词用于过滤聚合函数的结果。与“WHERE”关键词不同的是,“HAVING”关键词不能用于过滤单个行,它主要用于过滤由GROUP B…...
【Marp】基于Markdown-Marp快速制作PPT
【Marp】基于Markdown-Marp快速制作PPT 文章目录 【Marp】基于Markdown-Marp快速制作PPT零、参考资料一、Marp基本语法(创建分页,排版图片,更换主题,Marp扩展指令修改样式)1、创建新的PPT页面2、插入图片 & 排版图…...
微服务项目部署
启动rabbitmq \RabbitMQ\rabbitmq_server-3.8.2\sbin 找到你的安装路径 找到\sbin路径下执行这些命令即可 rabbitmqctl status //查看当前状态 rabbitmq-plugins enable rabbitmq_management //开启Web插件 rabbitmq-server start //启动服务 rabbitmq-server stop //停止服务…...

vite+TypeScript+vue3+router4+Pinia+ElmPlus+axios+mock项目基本配置
1.viteTSVue3 npm create vite Project name:... yourProjectName Select a framework:>>Vue Select a variant:>>Typescrit2. 修改vite基本配置 配置 Vite {#configuring-vite} | Vite中文网 (vitejs.cn) vite.config.ts import { defineConfig } from vite …...
【rabbitMQ】模拟work queue,实现单个队列绑定多个消费者
上一篇: springboot整合rabbitMQ模拟简单收发消息 https://blog.csdn.net/m0_67930426/article/details/134904766?spm1001.2014.3001.5502 在这篇文章的基础上进行操作 基本思路: 1.在rabbitMQ控制台创建一个新的队列 2.在publisher服务中定义一个…...

pdf转png的两种方法
背景:pdf在一般公司,没有办公系统,又不是word/wps/Office系统,读不出来,识别不了,只能将其转化为图片png,因此在小公司或者一般公司就需要pdf转png的功能。本文将详细展开。 1、fitz库(也就是PyMuPDF) 直接pip安装PyMuPDF即可使用,直接使用fitz操作,无需其他库。 …...

【起草】1-2 讨论 ChatGPT 在自然语言处理领域的重要性和应用价值
【小结:ChatGPT 在自然语言处理领域的八种典型应用】 ChatGPT是一种基于Transformer模型的端到端生成式对话系统,采用自监督学习的方式ChatGPT是一种基于Transformer模型的端到端生成式对话系统,采用自监督学习的方式在海量无标注数据集上进…...

Mapreduce小试牛刀(1)
1.与hdfs一样,mapreduce基于hadoop框架,所以我们首先要启动hadoop服务器 --------------------------------------------------------------------------------------------------------------------------------- 2.修改hadoop-env.sh位置JAVA_HOME配…...
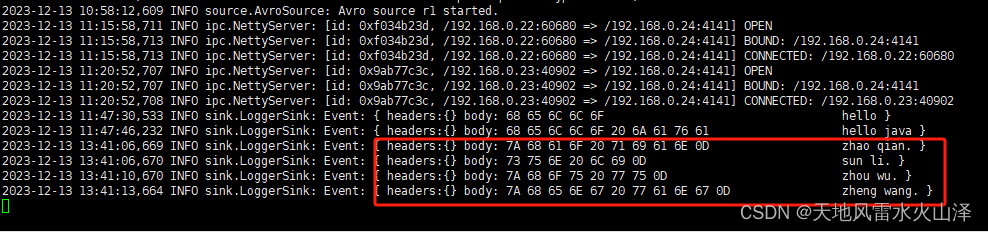
二百一十七、Flume——Flume拓扑结构之聚合的开发案例(亲测,附截图)
一、目的 对于Flume的聚合拓扑结构,进行一个开发测试 二、聚合 (一)结构含义 这种模式是我们最常见的,也非常实用。日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器产生的日志,处理起来…...

vue3+ts+vite+element plus 实现table勾选、点击单行都能实现多选
需求:table的多选栏太小,点击的时候要瞄着点,不然选不上,要求实现点击单行实现勾选 <ElTableborder:data"tableDataD"style"width: 100%"max-height"500"ref"multipleTableRef"selec…...
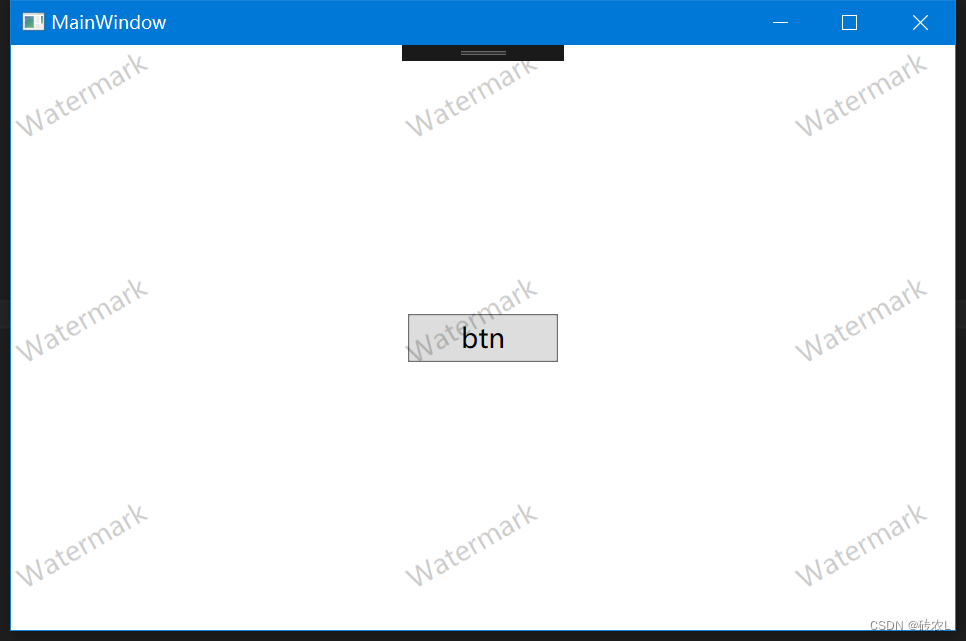
在WPF窗口中增加水印效果
** 原理: ** 以Canvas作为水印显示载体,在Canvas中创建若干个TextBlock控件用来显示水印文案,如下图所示 然后以每一个TextBlock的左上角为中心旋转-30,最终效果会是如图红线所示: 为了达到第一行旋转后刚好与窗口…...

wget下载到一半断了,重连方法
我是使用wget去下载 data.tar.gz 压缩包 wget https://deepgo.cbrc.kaust.edu.sa/data/deepgozero/data.tar.gz一开始下载的挺快,然后随着下载继续,下载速度就一直在下滑 下了大概2个小时后,已经下载了78%(6G/7.7G)就断了。无奈c…...

Docker笔记:docker compose部署项目, 常用命令与负载均衡
docker compose的作用 docker-compose是docker官方的一个开源项目可以实现对docker容器集群的快速编排docker-compose 通过一个配置文件来管理多个Docker容器在配置文件中,所有的容器通过 services来定义然后使用docker-compose脚本来启动,停止和重启容…...

Java单元测试:JUnit和Mockito的使用指南
引言: 在软件开发过程中,单元测试是一项非常重要的工作。通过单元测试,我们可以验证代码的正确性、稳定性和可维护性,帮助我们提高代码质量和开发效率。本文将介绍Java中两个常用的单元测试框架:JUnit和Mockito&#x…...

缓存雪崩问题与应对策略
目录 1. 缓存雪崩的原因 1.1 缓存同时失效 1.2 缓存层无法应对高并发 1.3 缓存和后端系统之间存在紧密关联 2. 缓存雪崩的影响 2.1 系统性能下降 2.2 数据库压力激增 2.3 用户请求失败率增加 3. 应对策略 3.1 多级缓存 3.2 限流与降级 3.3 异步缓存更新 3.4 并发控…...

python编程需要的电脑配置,python编程用什么电脑
大家好,小编来为大家解答以下问题,python编程对笔记本电脑配置的要求,python编程对电脑配置的要求有哪些,现在让我们一起来看看吧! 学习python编程需要什么配置的电脑 简单的来讲,Python的话普通电脑就可以…...
)
目标检测YOLO实战应用案例100讲-基于深度学习的跌倒检测(续)
目录 3.3 基于YOLOv7算法的损失函数优化 3.3.1 IoU损失策略 3.3.2 GIoU回归策略 3.3.3...
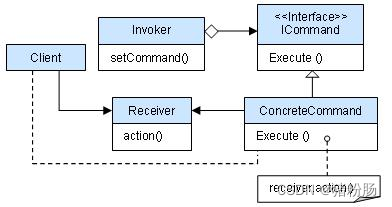
05-命令模式
意图(GOF定义) 将一个请求封装为一个对象,从而使你可用不同的请求对客户端进行参数化,对请求排队或者记录日志,以及可支持撤销的操作。 理解 命令模式就是把一些常用的但比较繁杂的工作归类为成一组一组的动作&…...

Docker安全及日志管理
DockerRemoteAPI访问控制 默认只开启了unix socket,如需开放http,做如下操作: 1、dockerd -H unix:///var/run/docker.sock -H tcp://192.168.180.210:2375 2、vim /usr/lib/systemd/system/docker.service ExecStart/usr/bin/dockerd -H uni…...

【LeetCode每日一题】152. 乘积最大子数组
题目: 给你一个整数数组 nums ,请你找出数组中乘积最大的非空连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。 思路 由于做了53. 最大子数组和 下意识觉得求出所有元素的以该元素结尾的连续…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...