AI编译器及TVM概述
AI编译器
AI编译器有许多不同的类型和品牌,以下是一些常见的AI编译器:
-
TensorFlow:谷歌开发的深度学习框架,它包含了一个用于优化和编译TensorFlow模型的编译器。
-
PyTorch:一个基于Python的开源深度学习框架,也提供了一个编译器用于执行和优化PyTorch模型。
-
ONNX:开放神经网络交换的标准,它定义了一个中间表示格式,允许不同的深度学习框架之间交换和执行模型。
-
TVM:一个开源的端到端深度学习编译器堆栈,它支持多种硬件后端,并提供了自动优化和调度的功能。
-
Glow:Facebook开发的一个用于编译和优化深度学习模型的开源工具,它可以在不同的硬件上执行高效的推理。
-
XLA:谷歌的加速线性代数(Accelerated Linear Algebra,XLA)编译器,它可以优化和编译TensorFlow图形。
这只是一小部分AI编译器的例子,还有许多其他的编译器和工具可用于优化和执行深度学习模型。
TVM概述
TVM(TVM stack)是一个深度学习和机器学习的通用端到端支持库和编译器堆栈,旨在为深度学习模型的开发、优化和部署提供全面的支持。TVM的整体架构包括以下几个关键组件:
-
前端(Frontend):TVM支持多种深度学习框架的前端,包括TensorFlow、PyTorch、Keras等。通过前端,用户可以将自己的深度学习模型导入到TVM中进行编译和优化。
-
中间表示(Intermediate Representation,IR):TVM使用一种中间表示来表示深度学习模型。这种中间表示是一种低级别的计算图表示,可以表示各种算子和操作。TVM提供了一种称为NNVM的中间表示,它是专门为深度学习模型设计的。
-
后端(Backend):TVM提供了多个后端,用于将中间表示转换为特定硬件的代码。目前TVM支持CPU、GPU和特定深度学习处理器(如Tensor Processing Unit)等多种后端。每个后端都可以生成特定硬件平台上高效的代码。
-
编译器优化(Compiler Optimization):TVM具备强大的编译器优化能力,可以对中间表示进行各种优化,以提高模型的性能和效率。这些优化包括自动图优化(如图剪枝、图融合、图量化等)、自动算子优化(如算子融合、算子特征优化等)等。
-
运行时(Runtime):TVM提供了一个运行时系统,用于在特定硬件上执行编译后的代码。运行时系统负责管理内存、调度任务、执行计算等操作,以实现深度学习模型的高效执行。
-
自动调度(AutoTuning):TVM还提供了自动调度功能,用于自动选择和调整编译器优化的参数,以达到最佳性能。自动调度使用神经网络模型和硬件特性的信息,通过启发式搜索和机器学习的技术,来寻找合适的优化策略。
总体来说,TVM的架构使得用户可以以高级的深度学习框架为基础,通过TVM提供的编译和优化功能,将模型高效地部署到特定硬件上运行。同时,TVM还支持灵活的自定义优化和扩展,以适应各种不同的应用场景和硬件平台。
TVM的整体架构可以分为以下几个部分:
-
前端模块:前端模块负责将各种深度学习框架(如TensorFlow、PyTorch等)的模型转化为TVM的中间表示IR(Intermediate Representation)格式。它包括了模型的解析、优化和转换等功能。
-
中间表示(IR):TVM使用一种中间表示IR来描述不同硬件上的计算图和计算操作。IR是一种高级的抽象语言,它将计算图表示为一系列的操作节点和数据流。IR既可以表示静态计算图,也可以表示动态计算图,可以支持各种操作类型和数据类型。
-
优化器:TVM的优化器模块负责对IR进行各种优化,以提高运行效率和降低资源消耗。优化器可以进行模块的重排、剪枝、融合等操作,以减少计算量和内存占用。
-
编译器:TVM的编译器模块将经过优化的IR编译为目标硬件的可执行代码。编译器可以根据硬件的特性进行代码重排和优化,以充分利用硬件资源。
-
运行时系统:TVM的运行时系统负责将编译好的代码加载到目标硬件上并执行。它提供了一个统一的接口,使得不同硬件上的计算操作可以以相同的方式调用。
-
后端模块:后端模块负责将TVM的中间表示IR转化为目标硬件上的具体指令集。它可以根据硬件的特性和限制进行指令生成和优化,以提高运行效率。
TVM的整体架构通过将深度学习模型的前端、中间表示、优化器、编译器、运行时系统和后端进行有机的整合,实现了跨平台、高效的深度学习模型部署和执行。它可以将深度学习模型转化为各种硬件上的高效代码,并提供了高度可定制的优化和调度功能,以适应不同硬件平台的特性和资源约束。
TVM的主要架构和实现有以下几个方面:
-
Relay:Relay是TVM的中间表示语言,它是一种高级的静态图表示,类似于计算图。Relay支持多种前端语言(如Python、C++)和后端目标(如CPU、GPU等),可以将多种前端语言的代码转换为中间表示,再进行优化和执行。
-
Pass System:TVM的优化和转换过程通过Pass System进行。Pass System是一种将一系列优化和转换操作串联起来的机制,每个操作称为一个Pass。TVM提供了一系列内置的Pass用于常见的优化和转换任务,同时也支持自定义的Pass。
-
Target and Device:TVM支持多种不同的目标和设备。目标(Target)指的是编译和优化的目标平台,如特定的CPU或GPU。设备(Device)指的是实际执行计算的硬件设备,如CPU、GPU等。TVM通过Target和Device的抽象,可以根据不同的目标和设备生成不同的优化代码。
-
Compiler:TVM的编译器负责将中间表示转换为目标平台上的优化代码。编译过程包括前端解析和类型推导,中间表示转换和优化,以及目标平台代码的生成。TVM提供了一系列的编译器工具和优化技术,可以将中间表示转换为高效的目标平台代码。
-
Runtime:TVM的运行时库负责执行优化后的代码。运行时库提供了执行计算图、管理内存、调度任务等功能,以及与不同硬件设备交互的接口。TVM的运行时库可以与不同的硬件设备集成,从而在不同的设备上执行优化后的代码。
以上是TVM的主要架构和实现。通过Relay作为中间表示语言,通过Pass System进行优化和转换,通过编译器生成优化代码,通过运行时库执行代码,并与不同硬件设备交互,TVM实现了跨平台、高效的深度学习模型部署和执行。
中间表示relay
TVM的relay是一个中间表示(IR)层,用于优化和部署深度学习模型。它提供了一种统一的编程模型,可以描述各种深度学习模型,包括卷积神经网络(CNN)、循环神经网络(RNN)等。
TVM的relay是一个静态图形表示,即通过定义计算图的方式表示模型。它支持基本的图形操作,例如卷积、池化、全连接等,并提供了丰富的高级操作,例如循环、条件语句等。通过relay,用户可以轻松地组合这些操作来定义复杂模型结构。
TVM的relay还提供了一套优化技术,例如自动求导、图优化和层次化调度,以提高模型的性能和效率。用户可以使用TVM的relay通过优化和调度策略,自动将模型转换为高效的前端和硬件特定代码,以实现模型的部署和执行。
总之,TVM的relay是一个中间表示层,可以描述深度学习模型,提供了丰富的操作和优化技术,以实现模型的高效部署和执行。
TVM的relay是一个高级的语义图形中间表示(IR),被设计为在深度学习编译中进行优化和执行的核心。relay的具体架构与实现如下:
-
前端:relay提供了前端接口,支持多种深度学习框架的模型导入,包括TensorFlow, PyTorch, ONNX等。前端负责将模型导入到relay的中间表示中。
-
中间表示:relay的中间表示是一种被称为High-Level Graph(HLG)的静态图表示。HLG是一个计算图,用于表示模型的计算流程,同时保留了模型的高级语义。HLG包括一个节点图和一个类型图,节点图描述了模型的计算流程,而类型图描述了模型的数据类型信息。
-
后端:relay通过后端支持多种不同的设备和编译目标。通过后端,relay能够将HLG转换为特定设备上可执行的低级代码。为不同的设备提供的后端包括CPU、GPU、FPGA等。
-
优化:relay提供了一系列的优化算法来优化中间表示的计算图,以提高模型的执行效率。这些优化算法包括图优化、算子融合、内存优化等。relay还支持用户自定义扩展的优化算法。
-
运行时:relay通过TVM运行时来执行优化后的模型。TVM运行时是一个高度优化的模块,具有自动调度和代码生成的能力,能够将模型的优化后的计算图转换为本地机器码,并进行高效的执行。
通过这样的架构和实现,relay能够提供高效的深度学习编译能力,使得深度学习模型的优化和部署更加容易和高效。
TVM后端代码生成
TVM后端的实现方式取决于具体的目标平台和硬件架构。TVM的主要目标是实现高效的、可移植的深度学习推理,因此它需要针对不同的硬件进行优化和调整。
下面是TVM后端实现的一般步骤:
-
收集目标平台的信息:后端实现需要了解目标平台的硬件指令集、内存架构、数据传输方式等信息。这些信息可以通过编译器和硬件供应商提供的文档或工具来收集。
-
图优化:TVM使用图优化技术对神经网络模型进行优化,以提高计算效率和减少内存占用。图优化包括常见的优化技术,如图剪枝、图融合、图分割等。
-
代码生成:通过将优化后的图转换为目标平台的特定代码,TVM后端可以生成适用于目标平台的可执行代码。这通常涉及到将中间表示(IR)转换为目标特定的汇编语言或机器指令。
-
代码优化:生成的代码通常需要进行进一步的优化,以提高性能和效率。这可能包括寄存器分配、循环展开、指令调度等优化技术,以充分利用目标平台的特性。
-
调试和测试:实现后端后,需要进行调试和测试来验证生成的代码在目标平台上的正确性和性能表现。这可能涉及到使用模拟器或硬件开发板来运行和比较实际结果。
总的来说,TVM后端的实现是一个复杂的过程,需要深入了解目标平台的特性和优化技术。利用TVM的优化能力和硬件特定的优化,可以实现高效的深度学习推理。
TVM是一个开源的深度学习编译器和优化器,可以将深度学习模型转化为最优的底层代码。下面是一个简单的示例,展示了如何使用TVM生成C语言代码:
import tvm
from tvm import relay# 定义简单的计算图
x = relay.var("x", shape=(1,), dtype="float32")
y = relay.var("y", shape=(1,), dtype="float32")
z = relay.add(x, y)# 生成relay模块
func = relay.Function([x, y], z)
mod = relay.Module.from_expr(func)# 设置编译目标为LLVM,并进行优化
target = "llvm"
with tvm.transform.PassContext(opt_level=3):lib = relay.build(mod, target=target)# 生成C代码
lib.export_library("add.so")上述代码中,我们首先定义了一个简单的计算图,然后使用relay.build函数将计算图转换为底层代码,并指定编译目标为LLVM。接着,我们可以通过export_library方法将编译好的库导出为C代码。
这只是TVM代码生成的一个简单示例,实际使用中,您可能需要更加复杂的计算图,以及其他的优化方式。您可以通过TVM的文档和示例代码进一步了解TVM的功能和使用方法。
TVM是一个开源的深度学习模型优化和代码生成的框架,支持多种后端,例如CPU、GPU、FPGA等。下面是TVM后端代码生成的详细实现过程:
-
定义计算图:首先,用户需要定义一个计算图,包括输入、操作和输出节点。TVM使用Halide中的IR定义,即用一系列操作符将计算图表示为一棵语法树。
-
优化:TVM提供了一系列的优化技术,以提高计算图的性能。这些优化技术包括算子融合、特定硬件的运算代换、内存优化等。
-
选择目标后端:用户需要选择一个目标后端,例如CPU或GPU。每个后端都有特定的代码生成策略和目标硬件的特性。
-
Target转换:TVM将目标后端抽象为一个Target对象,其中包含了计算设备的相关信息,例如硬件编码、指令集等。TVM使用Target对象将计算图转换为特定后端的优化后的计算图。
-
代码生成:TVM使用模板引擎将优化后的计算图转换为目标后端的代码。这些模板定义了不同操作符的代码生成规则和目标后端的特性。
-
代码编译:生成的代码会被编译为目标后端所需要的可执行代码。TVM使用LLVM作为后端编译器工具链,LLVM将代码优化和生成目标机器码。
-
运行:生成的目标机器码被加载到目标硬件上,并执行。
通过上述过程,TVM能够将深度学习模型优化为高效的硬件代码,并在目标设备上运行。
TVM是一个开源的深度学习和机器学习优化编译器框架,它能够将高级的深度学习模型自动优化为具体的底层后端代码。
TVM的代码生成过程大致分为以下几个步骤:
-
前端模型描述:TVM支持多种前端模型的描述格式,如ONNX、TFLite、Keras等。用户可以使用这些模型描述格式来定义深度学习模型。
-
模型分析与优化:TVM会对前端模型进行分析,提取模型的计算图结构及操作特性,以便后续的优化工作。TVM还会根据目标硬件平台的特性进行一些设备相关的优化,例如算子融合、数据布局优化等。
-
算子表示变换:TVM会将前端模型中的算子表示为一种中间表示IR(Intermediate Representation),这种IR是一种与具体后端无关的中间表示。TVM会对这些IR进行优化和深度学习缩减,以提高性能和减小模型体积。
-
后端代码生成:TVM根据特定的目标后端,使用特定的代码生成策略将IR转化为底层的后端代码。TVM支持多种后端,包括CPU、GPU、FPGA等。每个后端都有相应的代码生成规则,用于将IR转化为底层的后端代码。
-
后端编译与优化:生成的后端代码可能还需要经过后端编译器的进一步编译和优化,以提高执行效率。TVM会调用目标后端的编译器来进行这一步骤,以生成最终的可执行代码。
通过以上步骤,TVM能够将高级的深度学习模型转化为底层的具体后端代码,以在目标硬件上高效地执行。这种自动化的优化过程使得深度学习模型的部署变得更加简单和高效。
TVM运行时系统
TVM(Tensor Virtual Machine)是一个开源的深度学习编译器和运行时系统,它支持多种硬件平台和前端语言。TVM的运行时系统是其核心组件之一,它负责将编译好的模型部署到目标设备上并执行。
TVM的运行时系统具有以下特点:
-
跨平台:TVM的运行时系统可以在不同的硬件平台上运行,包括CPU、GPU、FPGA等。这使得用户可以在不同的设备上部署和执行模型,无需针对特定平台进行定制开发。
-
高性能:TVM使用了多种编译优化技术,包括图优化、内存优化和计算优化等,以提高模型的执行性能。此外,TVM还能够利用硬件加速器的计算能力,进一步提升性能。
-
动态图支持:TVM的运行时系统支持动态图模型的执行。这使得用户可以实时地加载、执行和调试模型,而无需重新编译整个模型。
-
灵活性:TVM的运行时系统支持不同的前端语言,包括Python、C++、Java等。用户可以使用自己熟悉的编程语言来定义和调用模型,从而提高开发效率。
在使用TVM的运行时系统时,用户需要进行以下步骤:
-
模型编译:用户首先需要使用TVM的编译器将模型源代码编译成可执行的计算图。编译过程会自动进行图优化、内存优化和计算优化等操作,以提高模型执行的性能。
-
设备部署:用户需要选择目标设备,并将编译好的模型部署到该设备上。TVM的运行时系统支持多种设备类型,用户可以根据具体需求选择合适的设备。
-
模型执行:一旦模型被部署到设备上,用户就可以使用TVM的运行时系统来执行模型。TVM提供了简单而灵活的API,用户可以调用相应的函数来加载、执行和调试模型。
总的来说,TVM的运行时系统是一个功能强大而灵活的模型执行引擎,它能够将编译好的模型部署到不同的硬件平台上,并实时执行和调试模型。用户可以使用自己熟悉的编程语言来定义和调用模型,从而提高开发效率。
相关文章:

AI编译器及TVM概述
AI编译器 AI编译器有许多不同的类型和品牌,以下是一些常见的AI编译器: TensorFlow:谷歌开发的深度学习框架,它包含了一个用于优化和编译TensorFlow模型的编译器。 PyTorch:一个基于Python的开源深度学习框架…...
排序-归并排序与计数排序
文章目录 一、归并排序1、概念2、过程3、代码实现4、复杂度5、稳定性 二、 计数排序1、思路2、代码实现3、复杂度:4、稳定性 一、归并排序 1、概念 是建立在归并操作上的一种有效,稳定的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已…...
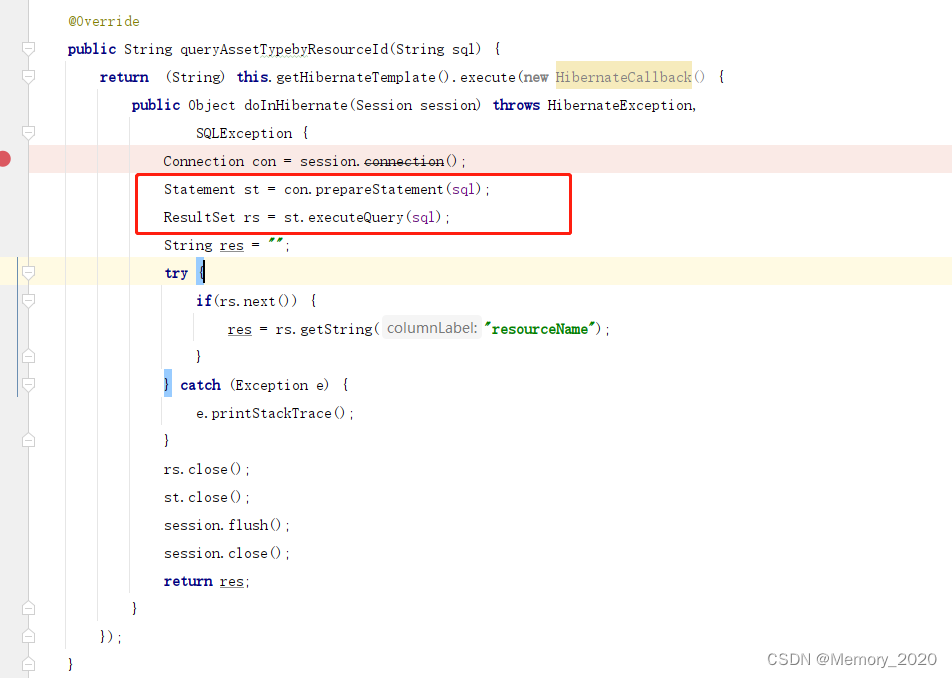
国产数据库适配-人大金仓(kingbase V8R3)
金仓数据库是基于POSTGRE_SQL 参考资料 国产数据库人大金仓踩坑记录和函数适配_金仓数据库关系不存在-CSDN博客 Springboot工程 适配人大金仓 kingbase V8R3 引入驱动包和方言包 hibernate-5.2.17.Finaldialect.jar kingbase8-8.2.0.jar application.yml文件 driver-cla…...
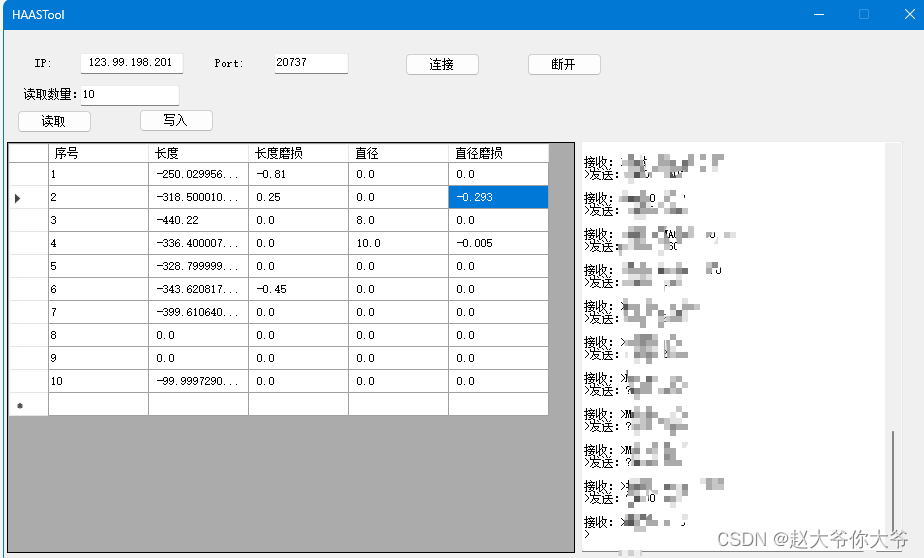
HAAS 哈斯机床 读写刀补数据
哈斯机床不管是串口机床还是网口机床 都提供了Q命令 可以使用Q命令 进行刀具补偿的读取和写入 最多支持200把刀的 读取和写入...
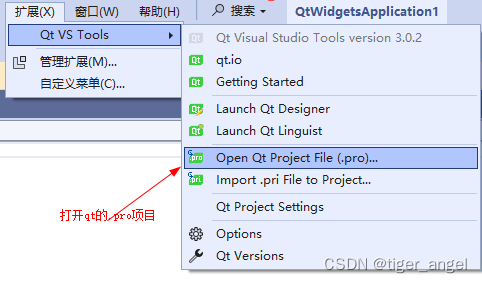
Visual studio+Qt开发环境搭建以及注意事项和打开qt的.pro项目
下载qt-然后安装5.14.2_msvc2017 不知道安装那个就全选5.14.2的父级按钮 https://download.qt.io/archive/qt/5.14/5.14.2/ 安装Visual studio,下载直接下一步就行 配置Visual studio的qt环境 在线安装-重启Visual studio会自动安装 离线安装-关闭Visual studio点击安装 关闭…...
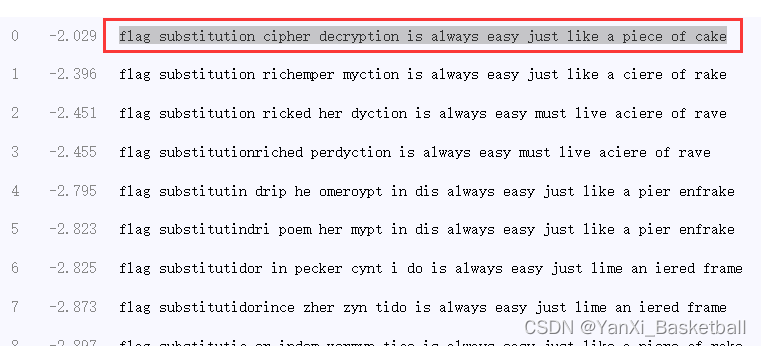
BUUCTF crypto做题记录(4)新手向
目录 一、大帝的密码武器 二、Windows系统密码 三、信息化时代的步伐 四、凯撒?替换?呵呵! 一、大帝的密码武器 下载的文件叫zip,应该是提示文件的后缀名是zip,把名字改成1.zip或者其他也行,主要保证后缀名是zip就…...
案例教程)
【ArcGIS微课1000例】0080:ArcGIS将shp转json(geojson)案例教程
本文以案例的形式,讲述在ArcGIS软件中,将矢量数据转为GeoJSON的方法。 扩展阅读:【GIS风暴】GeoJSON数据格式案例全解 文章目录 一、GeoJson简介二、ArcGIS将矢量数据转为GeoJSON一、GeoJson简介 GeoJSON是一种基于JSON的地理空间数据交换格式,它定义了几种类型JSON对象以…...

阿里云Centos8安装Dockers详细过程
一、卸载旧版本 较旧的 Docker 版本称为 docker 或 docker-engine 。如果已安装这些程序,请卸载它们以及相关的依赖项。 yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \do…...

leetcode 二数之和 三数之和 四数之和
leetcode 二数之和 三数之和 四数之和 又到了不想写博客的环节,不想归不想,有些事情还是要做的,今天总结的是多数之和的问题。 二数之和 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target …...

制衣厂生产ERP系统怎么样?制衣厂生产ERP软件哪个好
有很多的制衣厂在订单处理、物料、仓储、销售、仓储、物料编码、车间成本核算、计件工资核算等方面还存在不少改进空间。 而经过多年的发展,现如今制衣行业的竞争比较激烈,如何提升各业务部门协同效率,减少车间物料损耗,简化生产…...
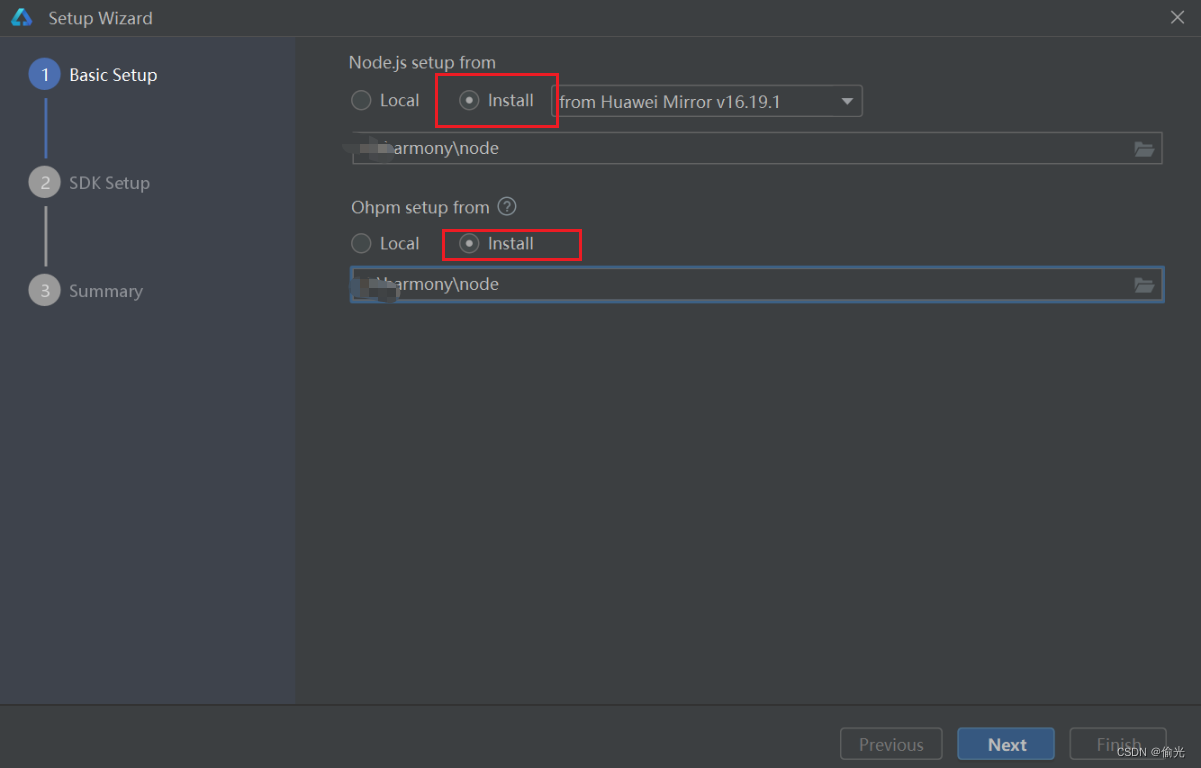
安装 DevEco Studio 后不能用本地 Node.js 打开
安装 DevEco Studio 后第一次打开时,不能用本地 Node.js 打开 答:因为本地 Node.js 文件夹名字中有空格 Node.js路径只能包含字母、数字、“。”、“_”、“-”、“:”和“V” 解决方法: 1.修改文件夹名称 2.重新下载 注意:找一…...
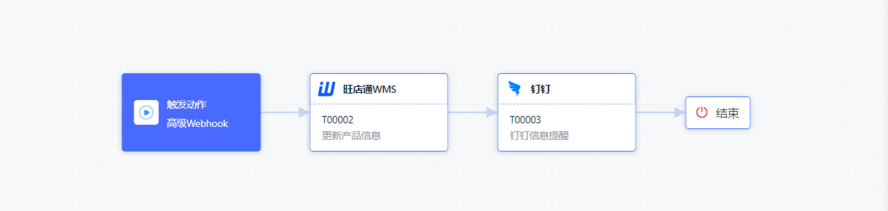
AppLink+WMS,实现仓储管理一体化
WMS像全能的库管员,可以在线还原真实仓库,让企业进行科学化、条理化、俯视化的仓库管理。 随着移动互联网和物流行业的快速发展,如何提高仓储管理的效率和准确性成为了企业关注的焦点。在这个背景下,结合AppLink和WMS系统&#x…...

如果是你,你选SOHO还是跟单?
昨天看到有人在讨论外贸跟单和外贸业务,谁的压力更大的问题?她们讨论的这个问题,源于一个年近四十准备二胎的宝妈,她做跟单十来年了,最近失业迷茫中,在纠结是否要SOHO?作为一个在工贸一体工厂做…...

大语言模型--能力
能力 大语言模型 能力从语言模型到任务模型的转化语言建模总结 从语言模型到任务模型的转化 在自然语言处理的世界中,语言模型 p p p是一种对代币序列 x 1 : L x_{1:L} x1:L这样的模型能够用于评估序列,例如 p ( t h e , m o u s e , a t e , t h e ,…...

安装LLaMA-Factory微调chatglm3,修改自我认知
安装git clone https://github.com/hiyouga/LLaMA-Factory.git conda create -n llama_factory python3.10 conda activate llama_factory cd LLaMA-Factory pip install -r requirements.txt 之后运行 单卡训练, CUDA_VISIBLE_DEVICES0 python src/train_web.py…...
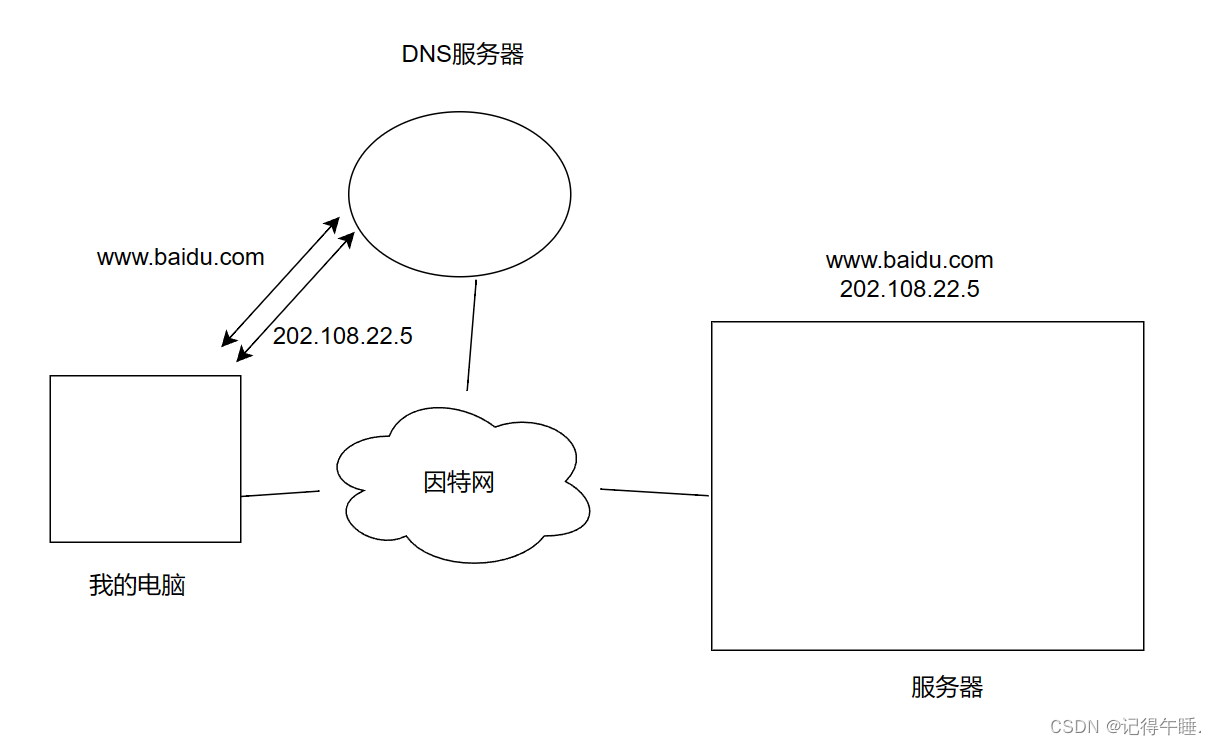
以太网协议与DNS
以太网协议 以太网协议DNS 以太网协议 以太网用于在计算机和其他网络设备之间传输数据,以太网既包含了数据链路层的内容,也包含了物理层的内容. 以太网数据报: 其中目的IP和源IP不是网络层的目的IP和源IP,而是mac地址.网络层的主要负责是整体的转发过程,数据链路层负责的是局…...

Spring Boot的日志
打印日志 打印日志的步骤: • 在程序中得到日志对象. • 使用日志对象输出要打印的内容 在程序中得到日志对象 在程序中获取日志对象需要使用日志工厂LoggerFactory,代码如下: package com.example.demo;import org.slf4j.Logger; import org.slf4j.LoggerFactory;public c…...
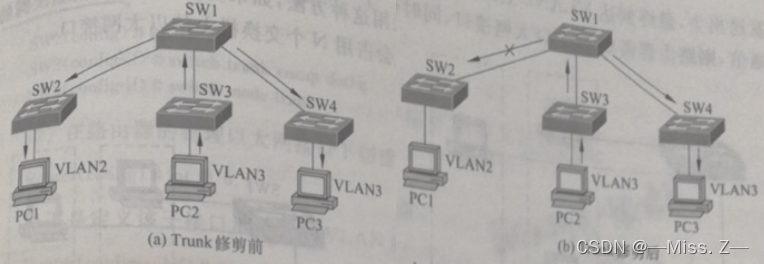
Cisco Packet Tracer配置命令——交换机篇
交换机VLAN配置 在简单的网络环境中,当交换机配置完端口后,即可直接应用,但若在复杂或规模较大的网络环境中,一般还要进行VLAN的规划,因此在交换机上还需进行 VLAN 的配置。交换机的VLAN配置工作主要有VLAN的建立与删…...

python单例模式
设计模式:单例模式(Singleton Pattern)。单例模式确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。 class Singleton:_instance Nonedef __new__(cls):if cls._instance is None:cls._instance super().__new__(cl…...

环境保护:人类生存的最后机会
随着科技的进步和人类文明的不断发展,地球上的自然资源也在以惊人的速度消耗殆尽。人类对于环境的无止境的掠夺,使得我们的地球正面临着前所未有的环境危机。环境污染、全球变暖、大规模灭绝等问题不断困扰着我们,似乎指向了人类生存的最后机…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...
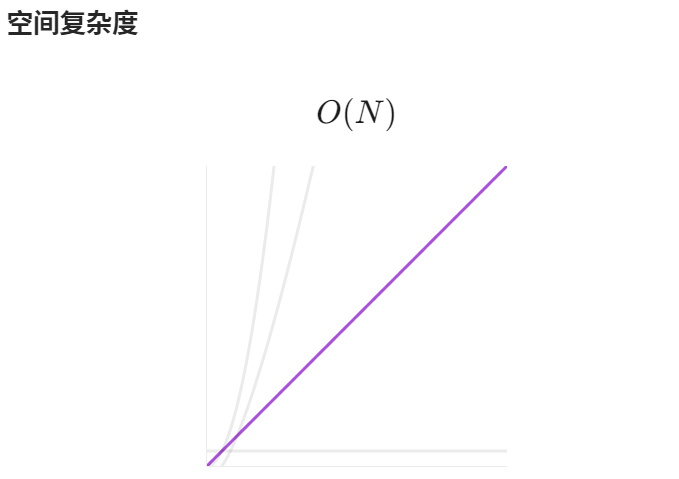
【LeetCode】算法详解#6 ---除自身以外数组的乘积
1.题目介绍 给定一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O…...