Paper Reading: (ACRST) 基于自适应类再平衡自训练的半监督目标检测

目录
- 简介
- 工作重点
- 方法
- CropBank
- FBR
- AFFR
- Two-stage Pseudo-label Filtering
- 实验
- 与SOTA比较
- 消融实验
简介
题目:《Semi-Supervised Object Detection with Adaptive Class-Rebalancing Self-Training》,AAAI’22, 基于自适应类再平衡自训练的半监督目标检测
日期:2021.7.11(v1),2022.6.28(AAAI’22)
单位:清华大学
论文地址:https://arxiv.org/abs/2107.05031
GitHub:-
作者


王斌,清华大学软件学院副教授,个人主页:https://binwangthss.github.io/

- 摘要
本研究深入研究了半监督对象检测(SSOD),以通过额外的未标记数据来提高检测器性能。最近,通过自我训练实现了最先进的SSOD表演,其中训练监督由GT和伪标签组成。在目前的研究中,我们观察到SSOD中的类失衡严重阻碍了自我训练的有效性。为了解决类不平衡问题,我们提出了一种新的内存模块CropBank的自适应类再平衡自训练(ACRST)。ACRST使用从CropBank中提取的前景实例自适应地重新平衡训练数据,从而缓解类不平衡。由于检测任务的高度复杂性,我们观察到自训练和数据再平衡在SSOD中都受到噪声伪标签的影响。因此,我们提出了一种新的两阶段滤波算法来生成准确的伪标签。我们的方法在MS-COCO和VOC基准方面取得了令人满意的改进。当在MS-COCO中仅使用1%的标记数据时,我们的方法比监督基线提高了17.02mAP,与最先进的方法相比提高了5.32mAP。
大多数真实世界的检测数据集都有偏差的类分布,其中很少的类占据了大多数实例,即前景前景不平衡,如图1(a)所示。而且,为了获得准确的伪标签,自我训练采用了高置信度阈值。该方案导致检测数据中前景实例分布稀疏,即前景-背景不平衡(见图1(b))

Fig1:1%COCO标准中伪标签的类不平衡。GT是标记数据的真实标签,伪标签由教师模型生成。
(a) 前景前景失衡在伪标签中加剧。 (b)前景背景失衡。在Faster RCNN中,背景实例在伪标签的训练目标中占主导地位。
针对这两个问题提出了,前景背景再平衡(FBR)和自适应前景前景再平衡(AFFR)
然而,如图2所示,伪标签的准确性是不可取的(Recall明显低于ACC?)。为了获得准确的伪标签,参考半监督的多标签学习(SSMLL)模块,该模块提供与原始检测置信阈值互补的图像级约束。
v1:因此,我们利用额外的高级语义来过滤有噪声的伪标签。提出了一种半监督多标签分类模块,用于为未标记的数据生成图像级伪标签。
设计了一个两阶段的过滤机制来过滤掉在分类置信度或多标签预测(v1:图像级伪标签)中激活负的伪标签。

Fig2:1%COCO-standard中每类伪标签的准确性和召回率
工作重点
我们设计了一个名为CropBank的新型存储模块,用于区分检测数据中的前/背景和前/前景实例。通过CropBank,我们进一步提出了自适应类再平衡自我训练(ACRST),以解决SSOD中的前景-背景和前景-前景不平衡问题。
提出了一个半监督多标签分类模块来从未标记的数据中挖掘高级语义。然后,我们提出了一种具有分类置信度和高级语义的两阶段伪标签过滤机制。该机制在伪标签去噪中是有效的,从而进一步促进FBR和AFFR。
所提出的数据再平衡和伪标签过滤算法对于任何基于自训练的SSOD框架来说都是即插即用的。此外,CropBank提供了一种有效的检测专用数据增强算法。
方法
为了解耦这些纠缠,我们引入了一种名为CropBank的新型内存模块,用于在标记/未标记的数据中存储前景实例的GT/伪标签。利用CropBank,我们提出了两种特定于检测的数据再平衡算法:前景背景再平衡(FBR)和自适应前景前景再平衡(AFFR)。将原来的自我训练范式扩展到基于FBR和AFFR的自适应类再平衡自我训练(ACRST)。
FBR解决SSOD中的前背景不平衡问题。FBR首先根据CropBank中存储的GT/伪标签从整个数据集中提取前景实例。此后,前景实例被增强并粘贴到训练图像中的随机位置。利用合成数据,FBR可以提高训练目标中前景实例的比例,缓解前景-背景的不平衡。
针对前景不平衡问题,提出了基于FBR的前景自适应再平衡(AFFR)算法。特别地,我们设计了一个称为伪召回的新标准来判断一个类在SSOD中是否被忽视或过度关注。此后,由于较高的负置信度,被忽略类的伪标签被更频繁地采样。因此,整个数据集的前景重新平衡,从而导致在随后的自我训练中为在线伪标记提供最小偏差检测器。

图3:我们的半监督对象检测框架概述。教师模型从弱增广的未标记数据生成伪标签,学生模型在具有基本事实和伪标签组合的强增广数据上进行训练。为了缓解SSOD中的类不平衡,我们首先设计了一个名为CropBank的内存模块。然后,将前景-背景再平衡(FBR)和自适应前景-前景再平衡(AFFR)应用于基于CropBank的自适应类再平衡自训练(ACRST)。我们还提出了一种两阶段伪标签过滤(TPF)方法和一种选择性监督方案,以帮助ACRST并生成准确的伪标签。
- Loss

CropBank
CropBank由两个子库组成,即Label CropBank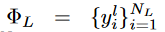
和Pseudo CropBank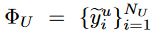
,其中NL/NU表示Label /Pseudo CropBank的大小,yli / yui表示第i个标记 / 未标记图像的gt / 伪标签。
在训练阶段,ΦL一旦生成就被固定,而ΦU在相互训练中用改进的伪标签定期更新。我们使用CropBank作为解耦实例的基础,并设计自适应类再平衡自训练(ACRST)来解决类不平衡问题。
CropBank的构成是少量的GT和大量的伪标签
FBR
foreground-background Rebalancing,前景-背景重平衡
给定训练mini batch 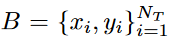
,我们根据采样分布P从每个图像xi的CropBank ΦL和ΦU中获取前景实例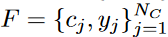
的集合,其中cj是从具有注释yj的原始图像中裁剪的前景实例。此后,如下生成新的训练mini batch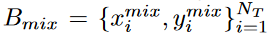 :
:

α:粘贴对象的二进制掩码,ymixi:表示混合注释,xmixi:表示混合图像
cj:基于CropBank中的实例级注释从图像中裁剪的矩形区域
在训练期间,cj被扩充并随后被粘贴到xi的随机位置。这种组合过程增加了前景实例在训练数据中的比例,用于前景-背景重平衡,还从整体角度探索了基本的上下文语义。混合图像准备好后,我们将它们作为Mean Teacher的管道来训练检测器。再平衡过程如图4所示。

AFFR
Adaptive foreground-foregroundRebalancing,自适应前景前景重平衡
在自我训练过程中被忽视的类中的样本被更频繁地选择。为了测量每一类的被忽略程度,我们提出了一个新的标准伪召回(PR)。对于每个类别k,我们根据经验使用低阈值(0.1)来过滤噪声预测。
使用PR,我们设计了一种自适应样本策略:
μk:选择类k的实例的概率,k:类别的数量。β:用于调整样本概率。
其中的PRk是累积来自教师检测器的针对每个前景实例的检测置信度:

ski:第i个伪标签的检测置信度。
PR定义了一个类在SSOD中被忽略的程度。高的PRk表明检测器对类k是肯定的,甚至是过度自信的。因此,应该将较低的样本概率分配给类k中的样本,以避免过度拟合。低PRk意味着检测器对检测类k的实例缺乏信心。因此,在随后的训练中应该更频繁地选择这些实例。
当类别被类似地忽略时,较低的PR被自适应地分配给尾部类别,并引起人们对它们越来越多的关注。PR的定义不依赖于任何未标记数据的先验信息。
该机制自适应地将较高/较低的采样率分配给被忽略/过度聚焦的实例。AFFR和FBR同时执行。
(v1版本)
提出了一种用于前景前景重平衡的自适应采样概率分布P。在训练过程中,被忽略类中的样本被更频繁地选择。为了衡量一类的被忽视程度,我们提出了一个新的标准pseudo recall伪召回(PR),它量化了伪标签与gt的比例。详细地,我们根据标记数据和未标记数据之间的分布相似性,从标记数据中估计未标记数据的类分布。假设数据集中有K个类{1,2,…K}。我们将第k类的伪召回计算为:

Nku / Nkl:第k类的伪标签和gt的数量
r:未标记数据与标记数据的比率
定义了在SSOD设置下一个类被忽略的程度。高PRk表明检测器对类k是肯定的,甚至是过度自信的。因此,应将较低的采样概率分配给类k中的样本,以减轻过度拟合。相反,低PRk意味着检测器对检测k类实例缺乏信心。因此,我们应该经常选择这些实例。
作为一种解决方案,我们根据伪召回按降序对类进行排序,并设计以下自适应采样策略:

μk:选择第k类实例的概率,β:用于调整采样概率
该机制自适应地将较高/较低的采样率分配给被忽略/过度聚焦的实例。
这种机制的一个潜在问题是,被忽略类中的伪标签的噪声被放大。因此,提出了一种两阶段伪标签过滤机制
Two-stage Pseudo-label Filtering
两阶段伪标签过滤,pipeline中杏黄和砖红的模块,黄色就是最基础的置信度过滤,红的标明的是高阶语义过滤,其实就是设置一个图像级伪标签,看成一个多标签分类问题,预测图像级伪标签的置信度并进行过滤
-
半监督多标签分类
针对分类任务,提出了基于Mean Teacher的半监督多标签分类模块。对于每个图像xi,预测其图像级伪标签vi={lk}Kk=1,lk∈{0,1},其中k是总类别数,lk确定图像中是否存在类k的实例。在训练阶段,教师模型的预测被转换为监督学生模型的图像级伪标签。我们利用焦点-二进制-交叉熵(focal–binary–cross-entropy)损失来优化学生模型。
与SSOD相比,SSMLL是一个容易得多的辅助任务,并且能够为两阶段伪标签选择生成可靠的参考。请注意,我们还扩展了ACRST以缓解SSMLL中的类不平衡,并且由于步骤更少、输入大小更小和框架更简化,SSMLL的总训练只需要SSOD的1/5分之一的时间。
-
两阶段伪标签过滤
对于来自教师模型的预测,我们采用两阶段伪标签过滤方案来获得 置信度得分为s的精确伪标签和图像级伪标签v。在第一阶段, 去除得分为s<τcls 的预测,以获得具有高对象性的伪标签。在第二阶段,去除具有在v中激活为负的类的预测(即激活值小于τml),以获得具有正确类标签的伪标签。请注意,我们使用消极而不是积极的多标签作为参考,因为消极学习比积极学习具有更高的准确性和回忆力。
-
选择性监督
虽然之前SSOD研究中的边界框回归损失(Liu et al.2021)由于回归不准确而被消除,但它们对我们的框架是有益的。我们将成功归功于CropBank,它减轻了部分检测到的实例的噪声,这些实例在有偏差的预测中占很大比例(在1%COCO标准中为81.2%)。使用这些嘈杂的伪标签盲目学习将严重恶化模型性能。然而,在我们的工作中,当从CropBank中部分检测到的实例被裁剪并粘贴到其他图像时,它们在新的背景中变得独立和完整,从而为回归学习提供了额外的准确监督。
在选择性监督的情况下,方程5中的损失函数Lunsup可以表示如下:

~ yiss:表示源自xiu的CropBank中的实例
实验
-
dataset:MS-COCO和PASCAL VOC
-
实验细节
使用带FPN的Faster RCNN和ResNet50,并在Detectron2的基础上构建我们的框架
标记和未标记图像的批量大小均为32。我们使用SGD优化器,lr=0.01,动量率=0.9。
设定λema=0.9996,τcls=0.7,λunsup=4。设置β=0.6,τml=0.2。
对于0.5/1/2/5/10%COCO标准,预训练需要3000/5000/5000/10000步,总训练需要180000步。
对于VOC,预培训需要5000步,总训练需要72000步。
我们对强增强应用颜色抖动、高斯模糊和剪切,对弱增强应用随机调整大小和翻转、剪切。广泛使用的mAP(AP50:95)用作比较的度量。
对于SSMLL,标记图像和未标记图像的批量大小均为64。
对于VOC/COCO-standard/COCO-addition,预训练需要2k/2k/6k步,总训练需要18k/36k/96k步,使用lr=1e-5的Adam优化器。数据扩充与SSOD相同,但图像的大小调整为576*576。
v1:
backbone:FPN Faster RCNN和ResNet-50
ResNet-50使用ImageNet预训练的权重进行初始化。我们设置超参数λunsup=2,β=2。对于两阶段伪标签滤波,我们使用分类置信阈值τcls=0.7和多标签置信阈值τml=0.2。我们使用AP50:95,即mAP作为评估指标。我们用所有训练设置的32个标记图像和32个未标记图像构建每个训练批次。
对于COCO-standard,0.5/1/2/5/10%的COCO-standard的预训练阶段为2500/5000/10000/20000/40000步,整个COCO标准训练阶段为180000步。对于COCOadditional,预训练阶段需要90000个步骤,总共需要270000个训练步骤。
对于VOC07和12,预训练阶段需要12000步,整个训练阶段需要36000步。
与SOTA比较
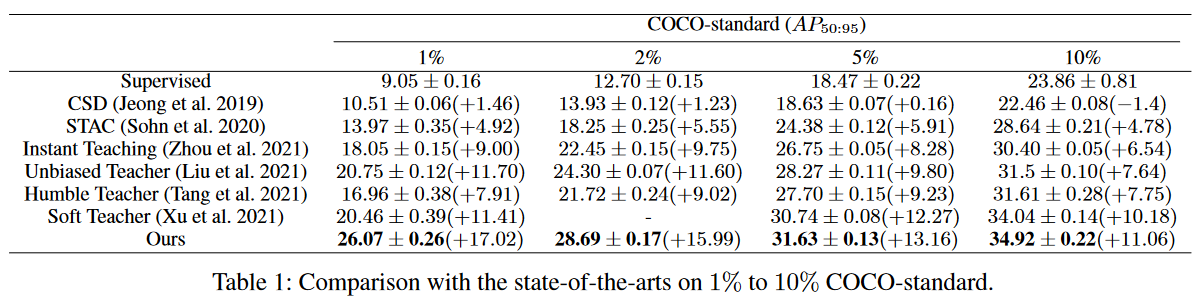
表1:在1%到10%的COCO-standard中与SOTA比较实验结果

表2:COCO-addition和0.5%COCO-standard与SOTA的比较。

表3:VOC07&12中与SOTA的比较实验结果。
消融实验

表4:1%COCO-standard下的消融实验。
来自具有大随机样本范围的Labeled和Pseudo-CropBank的采样实例实现了最高的mAP。

表5:CropBank和样本范围的消融实验。
第k类的数量?
当β=0时,AFFR相当于均匀样品,并降解为FBR。当β=0.6较大时,AFFR可提供1.04mAP的性能提升。注意,当β=0.4或β=0.8时,AFFR获得了类似的增益,这些结果证明了AFFR对唯一的超参数β不敏感

表6:AFFR中不同β值的结果。
如图4(a)所示,在FBR之后,前景实例的分布得到了重新平衡。
图4(b)表明,当使用AFFR时,KL散度从0.00024降低到0.00013。这一结果进一步证实了AFFR在处理伪标签中的前景-前景不平衡和生成无偏数据分布方面的有效性。
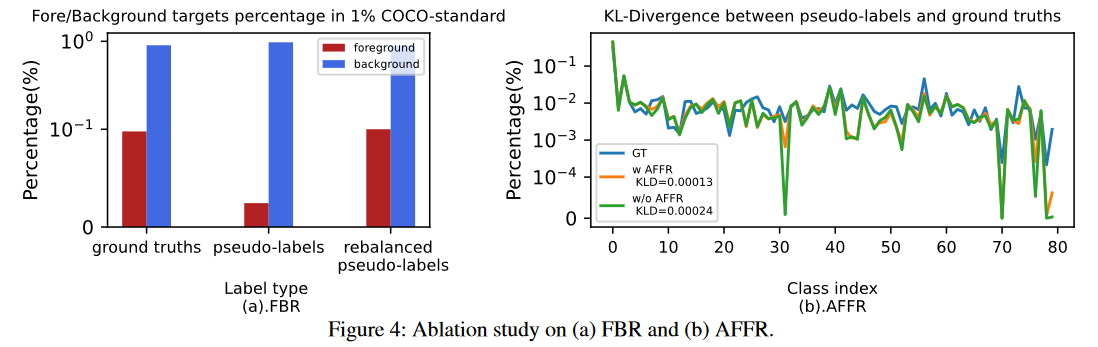
图4:FBR(a)和AFFR(b)的消融实验。
Fig5:(a) 具有/不具有两阶段伪标签过滤的伪标签的框精度。(b) 在有/没有选择性监督(SS)的情况下,伪标签和GT之间的框mIoU。
如图5(b)所示,选择性监督不断提高伪标签的mIoU。虽然选择性监督是利用SSOD中部分检测到的伪标签的有效方法,但仍有改进的空间。例如,当对象在伪标签中相互重叠时,当前策略无法处理噪声。

图5:1%COCO-standard中Box准确性和Box mIoU的伪标签改进。
最常见和最罕见类别的消融研究。我们对所提出的模块对图中过度聚焦(最频繁)/被忽视(最罕见)类别的影响进行了另一项消融研究。图6(a)和(b)表明,两阶段伪标签滤波(TPF)和ACRST在过聚焦/忽略类上都表现良好。如(b)所示,ACRST在具有AFFR的被忽略类上实现了显著的改进,而基线在最稀有的类中出现了性能下降。

图6:TPF和ACRST对1%COCO标准中被忽视/过度关注类的影响。
在STAC框架上的消融

表7:1%COCO-standard上的STAC的消融实验
为了验证CropBank的有效性,我们在表8中提供了来自Instant Teaching的结果(Zhou et al.2021)和不同的数据扩充。

在1%COCO-standard的不同数据扩充下的Instant Teaching性能。
具有不同τml和相应SSOD性能的半监督多标签学习(SSMLL)的结果。如表9所示,SSMLL生成准确的图像级伪标签,SSOD性能对τml不敏感。
当使用0.7阈值时,正图像水平的伪标签不太准确,准确度为0.740,召回率为0.325。

表9:1%COCO-standard上图像级负伪标签的准确性和召回率。
阐明了使用否定伪标签而不是肯定伪标签作为参考的原因。我们提供了三种设置的结果:(1)单阶段:过滤检测置信度低的预测。(2) 两阶段过滤:对检测置信度低或激活图像级伪标签中的负样本预测进行过滤。(3) 两阶段挖掘:保留具有高检测置信度的预测或激活图像级伪标签中的正样本预测。

表10:1%COCO-standard伪标签的模型性能、准确性和召回率
- Conclusion
本研究提出了一种简单而有效的ACRST来解决SSOD中的阶级失衡问题。通过CropBank,ACRST显著缓解了FBR和AFFR的前景-背景和前景-前景失衡。为了进一步改进FBR和AFFR,我们设计了一种具有检测置信度和高级语义的两阶段伪标签过滤算法。经过对重新平衡的训练数据的迭代,SSOD检测器变得无偏,并逐渐改善模型性能。大量的实验证明了我们方法的有效性。
相关文章:
Paper Reading: (ACRST) 基于自适应类再平衡自训练的半监督目标检测
目录 简介工作重点方法CropBankFBRAFFRTwo-stage Pseudo-label Filtering 实验与SOTA比较消融实验 简介 题目:《Semi-Supervised Object Detection with Adaptive Class-Rebalancing Self-Training》,AAAI’22, 基于自适应类再平衡自训练的半…...

2023年贺岁电影:一眼多,二眼好多
如果从11月末开始统计,今年贺岁档共有72部贺岁片,平均一天就有2部电影上映,看完总计需要花费7400分钟。 这个数量几乎快赶上2021年到2022年贺岁片的总和。 今年电影市场快速回暖以来,多部爆款作品接力上映,持续刺激市…...

软件测试面试中基础与功能的问题
一、 你们的测试流程是怎么样的? 答:1.项目开始阶段, BA (需求分析师) 从用户方收集需求并将需求转化为规格说明书,接 下来在 项目组领导 会组织需求评审。 2.需求评审通过后,BA 会组织 项目…...

map|二分查找|离线查询|LeetCode:2736最大和查询
本文涉及的基础知识点 二分查找算法合集 题目 给你两个长度为 n 、下标从 0 开始的整数数组 nums1 和 nums2 ,另给你一个下标从 1 开始的二维数组 queries ,其中 queries[i] [xi, yi] 。 对于第 i 个查询,在所有满足 nums1[j] > xi 且…...

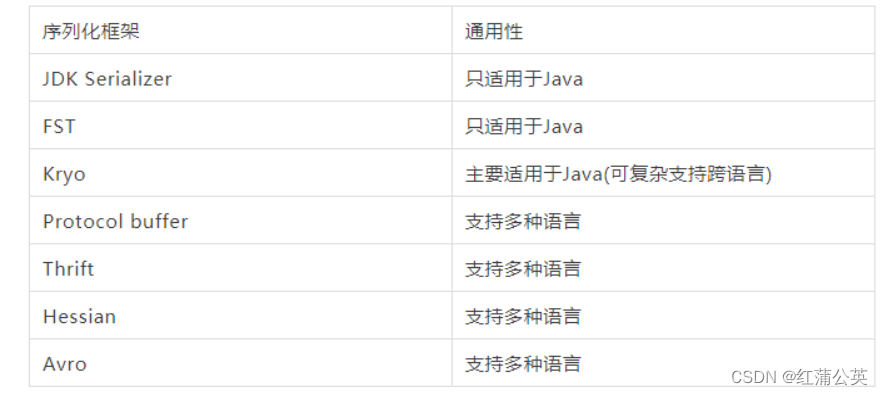
你知道Java中的BigInteger类和BigDecimal类吗?
BigInteger和BigDecimal: 我们在学习JavaSE基础的时候学习过int和double,前者是整形,后者是双精度浮点数,但它们是有最大值的,也就是说,他两并不支持无限大的数字。 其范围如下所示: 因此对于…...

33.搜索旋转排序数组
题目来源: leetcode题目,网址:33. 搜索旋转排序数组 - 力扣(LeetCode) 解题思路: 在二分查找时,分情况讨论即可。通过与第一个元素和最后一个元素的比较来获得 mid 处于第一个序列中还是第…...
【unity】【WebRTC】从0开始创建一个Unity远程媒体流app-设置输入设备
【项目源码】 包括本篇需要的脚本都打包在项目源码中,可以通过下面链接下载: https://download.csdn.net/download/weixin_41697242/88623091 【背景】 目前我们能投射到远端浏览器(或者任何其它Peer)的媒体流只有默认的MainCamera画面,其实我们还可以通过配置输入来传…...
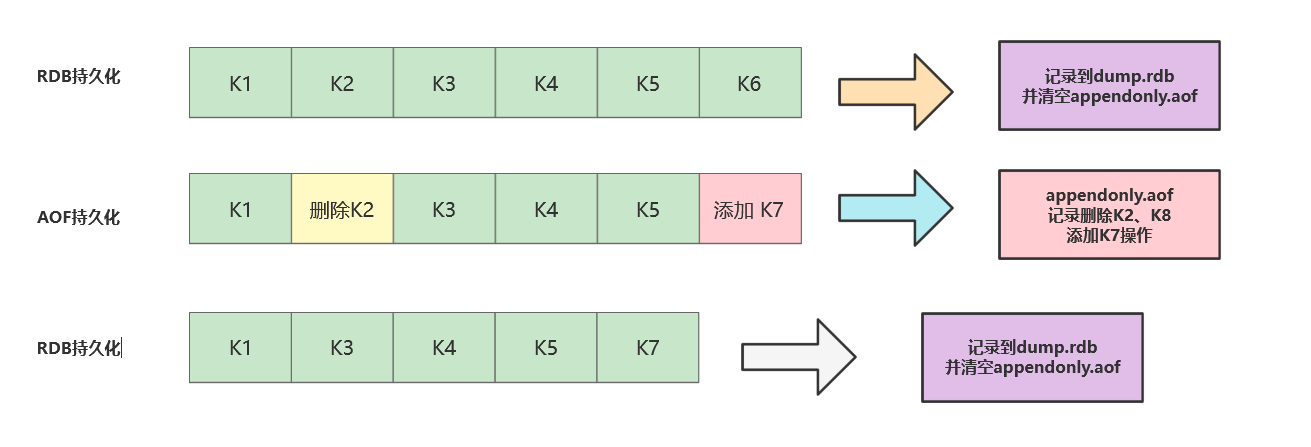
Redis持久化AOF详解
基础面试题 什么是AOF AOF(Append-Only File)用于将Redis服务器收到的写操作追加到日志文件,通过该机制可以保证服务器重启后依然可以依靠日志文件恢复数据。 它的工作过程大抵分为以下几步: 收到客户端的写入命令(例如SET、DE…...
基于ssm网络安全宣传网站设计论文
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本网络安全宣传网站就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信息…...

机器人行业数据闭环实践:从对象存储到 JuiceFS
JuiceFS 社区聚集了来自各行各业的前沿科技用户。本次分享的案例来源于刻行,一家商用服务机器人领域科技企业。 商用服务机器人指的是我们日常生活中常见的清洁机器人、送餐机器人、仓库机器人等。刻行采用 JuiceFS 来弥补对象存储性能不足等问题。 值得一提的是&am…...

墒情监测FDS-400 土壤温湿电导率盐分传感器
墒情监测FDS-400 土壤温湿电导率盐分传感器产品概述 土壤温度部分是由精密铂电阻和高精度变送器两部分组成。变送器部分由电源模块、温度传感模块、变送模块、温度补偿模块及数据处理模块等组成,解决铂电阻因自身特点导入的测量误差,变送器内有零漂电路…...
QT -CloudViewer工具
QT -CloudViewer工具 一、演示效果二、关键程序三、程序下载 一、演示效果 二、关键程序 void CloudViewer::doOpen(const QStringList& filePathList) {// Open point cloud file one by onefor (int i 0; i ! filePathList.size(); i) {timeStart(); // time startmycl…...
GoLong的学习之路,进阶,微服务之使用,RPC包(包括源码分析)
今天这篇是接上上篇RPC原理之后这篇是讲如何使用go本身自带的标准库RPC。这篇篇幅会比较短。重点在于上一章对的补充。 文章目录 RPC包的概念使用RPC包服务器代码分析如何实现的?总结Server还提供了两个注册服务的方法 客户端代码分析如何实现的?如何异步…...

uniapp x 相比于其他的开发系统框架怎么样?
首先我们要知道niapp这是一种基于Vue.js开发的跨平台应用框架,可以将同一套代码同时运行在多个平台上,包括iOS、Android、H5等。相比其他开发系统框架,他有什么优点呢?让我们共同探讨一下吧! 图片来源:unia…...

2024最新独立站建站教程!WordPress 搭建独立站的方法和步骤
不知道大家是否听说过 WordPress ?最近有个国外博主分享,她60岁的奶奶居然用WordPress建了个关于她宠物日常的小博客,看来 WordPress 在国外真的是很普及。其实,国外很多商家还利用 WordPress 搭建自己的电商网站,那说…...
:构建拖动操作栏)
深入React Flow Renderer(二):构建拖动操作栏
在上一篇博客中,我们介绍了如何启动React Flow Renderer并创建一个基本的工作流界面。本文将进一步深入,着重讨论如何构建一个可拖动的操作栏,它是用户与工作流交互的入口之一。 引言 操作栏是工作流界面的一部分,通常位于界面的…...

Java项目学生管理系统六后端补充
班级管理 1 班级列表:后端 编写JavaBean【已有】编写Mapper【已有】编写Service编写controller 编写Service 接口 package com.czxy.service;import com.czxy.domain.Classes;import java.util.List;/*** author 桐叔* email liangtongitcast.cn* description*/ p…...
PDF控件Spire.PDF for .NET【转换】演示:将 PDF 转换为线性化
PDF 线性化,也称为“快速 Web 查看”,是一种优化 PDF 文件的方法。通常,只有当用户的网络浏览器从服务器下载了所有页面后,用户才能在线查看多页 PDF 文件。然而,如果 PDF 文件是线性化的,即使完整下载尚未…...

猫头虎博主深度探索:Amazon Q——2023 re:Invent大会的AI革新之星
猫头虎博主深度探索:Amazon Q——2023 re:Invent大会的AI革新之星 授权说明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科…...

Spring框架-GOF代理模式之JDK动态代理
我们可以分成三步来完成jdk动态代理的实现 第一步:创建目标对象 第二步:创建代理对象 第三步:调用代理对象的代理方法 public class Client {public static void main(String[] args) {//创建目标对象final OrderService target new OrderS…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...