Python文本信息解析:从基础到高级实战‘[pp]]‘[

更多Python学习内容:ipengtao.com
大家好,我是彭涛,今天为大家分享 Python文本信息解析:从基础到高级实战,全文3600字,阅读大约10分钟。
文本处理是Python编程中一项不可或缺的技能,覆盖了广泛的应用领域,从字符串操作到正则表达式、自然语言处理和数据格式解析。在这篇文章中,将深入研究如何在Python中解析文本信息,提供详实的示例代码和实战指南,让大家更加全面地掌握文本处理的技术和应用。
基础字符串操作
从基础的字符串操作开始。通过示例代码展示了如何分割字符串、查找子串以及替换文本,这些是处理文本的常见操作。
text = "Python is a powerful programming language."# 分割字符串
words = text.split()
print("Words:", words)# 查找子串
substring = "powerful"
if substring in text:print(f"'{substring}' found in the text.")# 替换文本
new_text = text.replace("Python", "Ruby")
print("Updated Text:", new_text)正则表达式应用
正则表达式是处理文本的强大工具,通过示例展示了如何使用正则表达式匹配社会安全号(SSN)。
import repattern = r'\b\d{3}-\d{2}-\d{4}\b' # 匹配社会安全号
text = "John's SSN is 123-45-6789."match = re.search(pattern, text)
if match:ssn = match.group()print("SSN found:", ssn)使用NLTK进行自然语言处理
自然语言处理(NLP)在文本处理中占据重要地位。通过NLTK库展示了如何分词并去除停用词。
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwordsnltk.download('punkt')
nltk.download('stopwords')text = "Natural Language Processing is fascinating!"# 分词
tokens = word_tokenize(text)
print("Tokens:", tokens)# 去除停用词
filtered_tokens = [word for word in tokens if word.lower() not in stopwords.words('english')]
print("Filtered Tokens:", filtered_tokens)解析JSON数据
JSON是一种常见的数据格式,展示如何解析JSON数据并访问其中的字段。
import jsonjson_data = '{"name": "John", "age": 30, "city": "New York"}'# 解析JSON
parsed_data = json.loads(json_data)
print("Parsed Data:", parsed_data)# 访问JSON字段
print("Name:", parsed_data['name'])处理CSV文件
CSV文件是一种常见的数据存储格式。演示如何解析CSV文件并访问其中的数据。
import csvcsv_data = """Name, Age, City
John, 25, London
Alice, 30, Paris
Bob, 22, New York
"""# 解析CSV
csv_reader = csv.DictReader(csv_data.splitlines())
for row in csv_reader:print("Name:", row['Name'], "Age:", row[' Age'], "City:", row[' City'])使用Beautiful Soup解析HTML
Beautiful Soup是一个强大的HTML解析库,展示如何使用它解析HTML并提取文本内容。
from bs4 import BeautifulSouphtml_data = "<html><body><p>Hello, <b>world!</b></p></body></html>"# 解析HTML
soup = BeautifulSoup(html_data, 'html.parser')
text_content = soup.get_text()
print("Text Content:", text_content)利用正则表达式提取信息
再次展示正则表达式的应用,使用正则表达式提取文本中的邮箱地址。
import retext = "Contact us at support@example.com or sales@example.com"# 提取邮箱地址
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
emails = re.findall(email_pattern, text)
print("Emails:", emails)处理日期时间信息
演示如何解析日期字符串并将其转换为日期对象。
from datetime import datetimedate_string = "2023-01-15"# 解析日期字符串
parsed_date = datetime.strptime(date_string, "%Y-%m-%d")
print("Parsed Date:", parsed_date)文本信息分析与情感分析
文本信息分析涉及到对文本内容的深入理解和处理。
下面是一个简单的情感分析示例,使用TextBlob库。
from textblob import TextBlobtext = "Python is such a powerful language with a beautiful syntax."# 创建TextBlob对象
blob = TextBlob(text)# 分析情感
sentiment_score = blob.sentiment.polarity
if sentiment_score > 0:print("Positive sentiment!")
elif sentiment_score < 0:print("Negative sentiment!")
else:print("Neutral sentiment.")中文文本处理
针对中文文本处理,可以使用jieba库进行分词和关键词提取。
import jieba
from jieba.analyse import extract_tagschinese_text = "自然语言处理在中文信息处理中具有重要作用。"# 中文分词
seg_list = jieba.cut(chinese_text)
print("Chinese Segmentation:", "/".join(seg_list))# 提取关键词
keywords = extract_tags(chinese_text)
print("Chinese Keywords:", keywords)处理大型文本文件
对于大型文本文件,逐行读取是一个高效的方式。
以下是一个处理大型文本文件的示例:
file_path = "large_text_file.txt"# 逐行读取大型文本文件
with open(file_path, 'r') as file:for line in file:# 处理每行文本processed_line = line.strip()print(processed_line)使用Spacy进行高级自然语言处理
Spacy是一个强大的自然语言处理库,支持词性标注、命名实体识别等任务。
import spacynlp = spacy.load("en_core_web_sm")
text = "Spacy is an advanced NLP library."# 使用Spacy进行词性标注
doc = nlp(text)
for token in doc:print(f"Token: {token.text}, POS: {token.pos_}")总结
在本文中,深入研究了Python中解析文本信息的多个方面,从基础的字符串操作、正则表达式应用到高级的自然语言处理和大型文本文件处理。通过详实的示例代码,大家可以全面了解如何处理不同类型的文本数据,并运用强大的Python库和工具进行文本信息分析。
从处理英文文本的基础出发,介绍了字符串操作、正则表达式的妙用,以及自然语言处理库NLTK的应用。接着,展示了如何解析JSON数据、处理CSV文件,利用Beautiful Soup解析HTML,甚至深入到了情感分析和中文文本处理领域。对于大型文本文件,提供了逐行处理的高效方式,同时演示了Spacy库在高级自然语言处理中的应用。
这篇文章不仅提供了全面的文本处理技术,还为大家展示了如何根据任务需求选择合适的工具。从简单的字符串处理到复杂的自然语言处理,Python为文本数据的解析提供了强大的生态系统。
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
更多Python学习内容:ipengtao.com
干货笔记整理
100个爬虫常见问题.pdf ,太全了!
Python 自动化运维 100个常见问题.pdf
Python Web 开发常见的100个问题.pdf
124个Python案例,完整源代码!
PYTHON 3.10中文版官方文档
耗时三个月整理的《Python之路2.0.pdf》开放下载
最经典的编程教材《Think Python》开源中文版.PDF下载

点击“阅读原文”,获取更多学习内容
相关文章:
Python文本信息解析:从基础到高级实战‘[pp]]‘[
更多Python学习内容:ipengtao.com 大家好,我是彭涛,今天为大家分享 Python文本信息解析:从基础到高级实战,全文3600字,阅读大约10分钟。 文本处理是Python编程中一项不可或缺的技能,覆盖了广泛的…...

c语言多线程队列实现
为了用c语言实现队列进行多线程通信,用于实现一个状态机。 下面是实现过程 1.实现多线程队列入栈和出栈,不加锁 发送线程发送字符1,接收线程接收字符并打印。 多线程没有加锁,会有危险 #include "stdio.h" #include …...

一分钟带你了解电容
电容器中的电容究竟是怎么定义的? 一个电容器,如果带1库的电量时两级间的电势差是1伏,这个电容器的电容就是1法拉,即:CQ/U 。但电容的大小不是由Q(带电量)或U(电压)决定…...

SQLAlchemy 第一篇
安装SQLAlchemy pip install SQLAlchemy查看当前版本 # 查看当前版本import sqlalchemyprint(sqlalchemy.__version__)2.0.23创建数据库连接 此处我们以pymysql为mysql的数据库驱动 安装pymysql pip install pymysqlfrom sqlalchemy import create_engine engine create_…...

Node.js模块化的基本概念和分类及使用方法
1.模块概念 模块:指解决一个复杂问题的时候,自顶向下逐层把系统划分成若干模块的过程。对于整个系统来讲,模块是可以组合、分解和更换的单元。 在编辑领域中的模块,就是遵守固定的规则,把一个大文件拆成独立并且相互…...
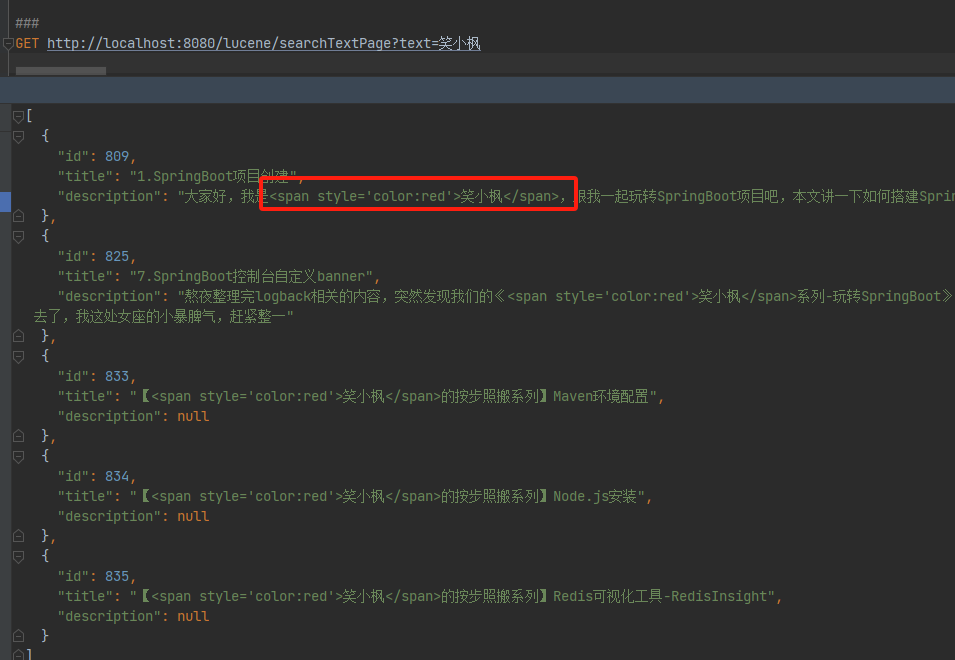
SpringBoot整合Lucene实现全文检索【详细步骤】【附源码】
笑小枫的专属目录 1. 项目背景2. 什么是Lucene3. 引入依赖,配置索引3.1 引入Lucene依赖和分词器依赖3.2 表结构和数据准备3.3 创建索引3.4 修改索引3.5删除索引 4. 数据检索4.1 基础搜索4.2 一个关键词,在多个字段里面搜索4.3 搜索结果高亮显示4.4 分页检…...

基于ssm生活缴费系统及相关安全技术的设计与实现论文
摘 要 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让信息都可以通过网络传播,搭配信息管理工具可以很好地为人们提供服务。针对生活缴费信息管理混乱,出错率高,信息安全性差…...
VS的python没有pandas(VS连接mysql数据库)
import pandas as pd from sqlalchemy import create_engine# 初始化数据库连接 engine create_engine(mysqlpymysql://root:556localhost:3306/仓库)sql_chaSELECT * FROM 库房 print(sql_cha) df_read pd.read_sql_query(sql_cha, engine); print(df_read);VS连接mysql如上…...

Java实现pdf文件合并
在maven项目中引入以下依赖包 <dependencies><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-examples</artifactId><version>3.0.1</version></dependency><dependency><groupId>co…...
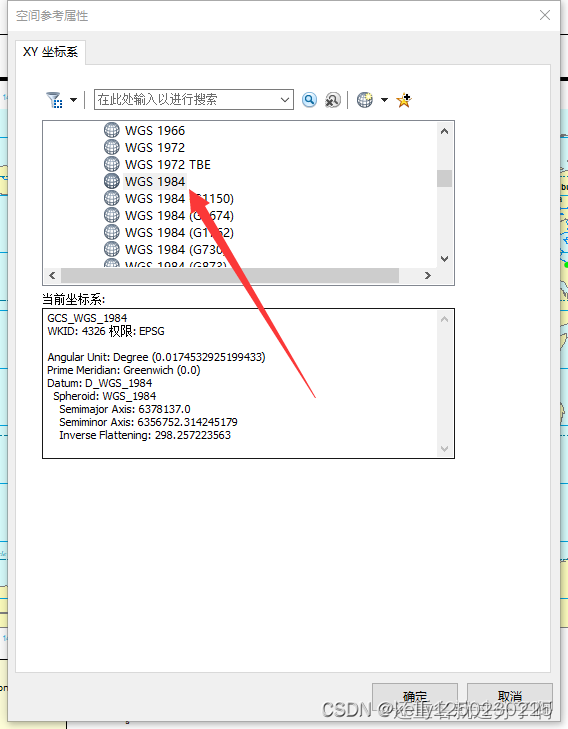
ArcGIS导入excel中的经纬度信息,绘制矢量
1.首先整理坐标信息 2.其次转成2003格式的excel文件 3.导入arcgis,点击右键添加excel数据 4.显示xy数据 5.显示经度和纬度信息 6:点击【地理坐标系】->【World】->【WGS 1984】->【确定】 7.投影带的确定方式: 因为自己一直…...
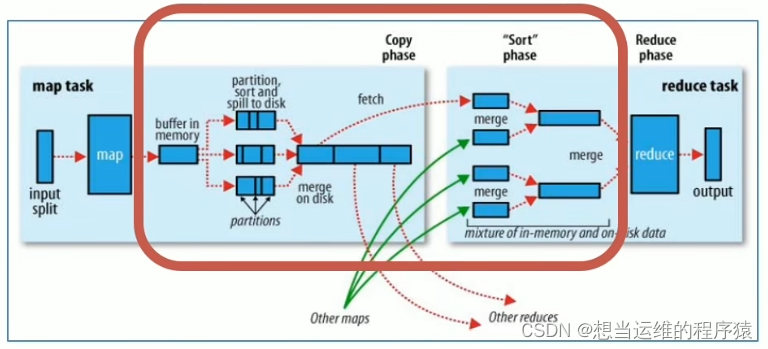
【Hadoop】
Hadoop是一个开源的分布式离线数据处理框架,底层是用Java语言编写的,包含了HDFS、MapReduce、Yarn三大部分。 组件配置文件启动进程备注Hadoop HDFS需修改需启动 NameNode(NN)作为主节点 DataNode(DN)作为从节点 SecondaryNameNode(SNN)主节点辅助分…...
GitHub帐户管理更改电子邮件
登录到您的 GitHub 帐户: 前往 GitHub 网站并使用您的凭据登录。 访问个人设置: 单击右上角的您的头像,然后选择“Settings”(设置)。 选择电子邮件选项卡: 在左侧边栏中选择“Emails”(电子邮…...

InsCode实践分享
一、背景介绍 随着社交媒体的普及,越来越多的品牌和商家开始关注如何利用社交媒体平台来提高品牌知名度和销售额。其中,Instagram作为一个以图片和视频为主要内容的社交媒体平台,已经成为了很多品牌和商家进行营销的重要渠道。InsCode是Inst…...

大一C语言作业 12.14
1.A A:将pa指向的元素赋值给x,即x a[0] B:将a数组第二个元素的值赋给x,即x a[1] C:将pa指向的下一个元素的值赋给x,即x a[1] D:将a数组第二个元素的值赋给x,即x a[1] 2. 6 2 3 …...

微服务技术 RabbitMQ SpringAMQP P61-P76
B站学习视频https://www.bilibili.com/video/BV1LQ4y127n4?p61&vd_source8665d6da33d4e2277ca40f03210fe53a 文档资料: 链接:https://pan.baidu.com/s/1P_Ag1BYiPaF52EI19A0YRw?pwdd03r 提取码:d03r 一 初始MQ 1. 同步通讯 2. 异步通讯 3. MQ常…...
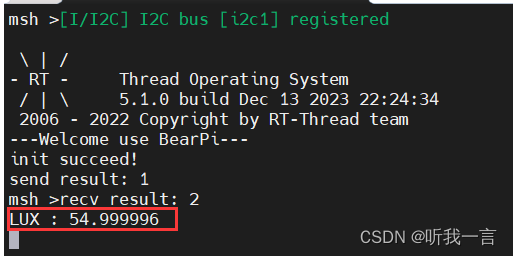
BearPi Std 板从入门到放弃 - 先天神魂篇(3)(RT-Thread I2C设备 读取光照强度BH1750)
简介 使用BearPi IOT Std开发板及其扩展板E53_SC1, SC1上有I2C1 的光照强度传感器BH1750 和 EEPROM AT24C02, 本次主要就是读取光照强度; 主板: 主芯片: STM32L431RCT6LED : PC13 \ 推挽输出\ 高电平点亮串口: Usart1I2C使用 : I2C1E53_SC1扩展板 : LE…...

中文分词演进(查词典,hmm标注,无监督统计)新词发现
查词典和字标注 目前中文分词主要有两种思路:查词典和字标注。 首先,查词典的方法有:机械的最大匹配法、最少词数法,以及基于有向无环图的最大概率组合,还有基于语言模型的最大概率组合,等等。 查词典的方法…...

Docker容器数据卷
一、概念 1.定义 卷就是目录或文件,存在于一个或多个容器中,由docker挂载到容器,但不属于联合文件系统,因此能够绕过Union File System提供一些用于持续存储或共享数据的特性。 卷的设计目的就是数据的持久化,完全独…...
chatGPT 国内版,嵌入midjourney AI创作工具
聊天GPT国内入口,免切网直达,可直接多语言对话,操作简单,无需复杂注册,智能高效,即刻使用.可以用作个人助理,学习助理,智能创作、新媒体文案创作、智能创作等各种应用场景! 地址: https://ai.wboat.cn/...

Yum仓库架构解析与搭建实践
1.Yum仓库搭建 1.1本地Yum仓库图解 1.2Linux本地仓库搭建 配置本地光盘镜像仓库 1)挂载 [roothadoop101 ~]# mount -t iso996 /dev/cdrom/mnt 2)查看 [rooothadoop101 ~] # df -h | |grep -i mnt /dev/sr0 4.6G 4.4G 3…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...