YOLOv8改进 | 2023Neck篇 | 利用RepGFPN改进特征融合层(附yaml文件+添加教程)
一、本文介绍
本文给大家带来的改进机制是Damo-YOLO的RepGFPN(重参数化泛化特征金字塔网络),利用其优化YOLOv8的Neck部分,可以在不影响计算量的同时大幅度涨点(亲测在小目标和大目标检测的数据集上效果均表现良好涨点幅度超级高!)。RepGFPN不同于以往提出的改进模块,其更像是一种结构一种思想(一种处理事情的方法),RepGFPN相对于BiFPN和之前的FPN均有一定程度上的优化效果。
适用检测目标:所有的目标检测均有一定的提点
推荐指数:⭐⭐⭐⭐⭐
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
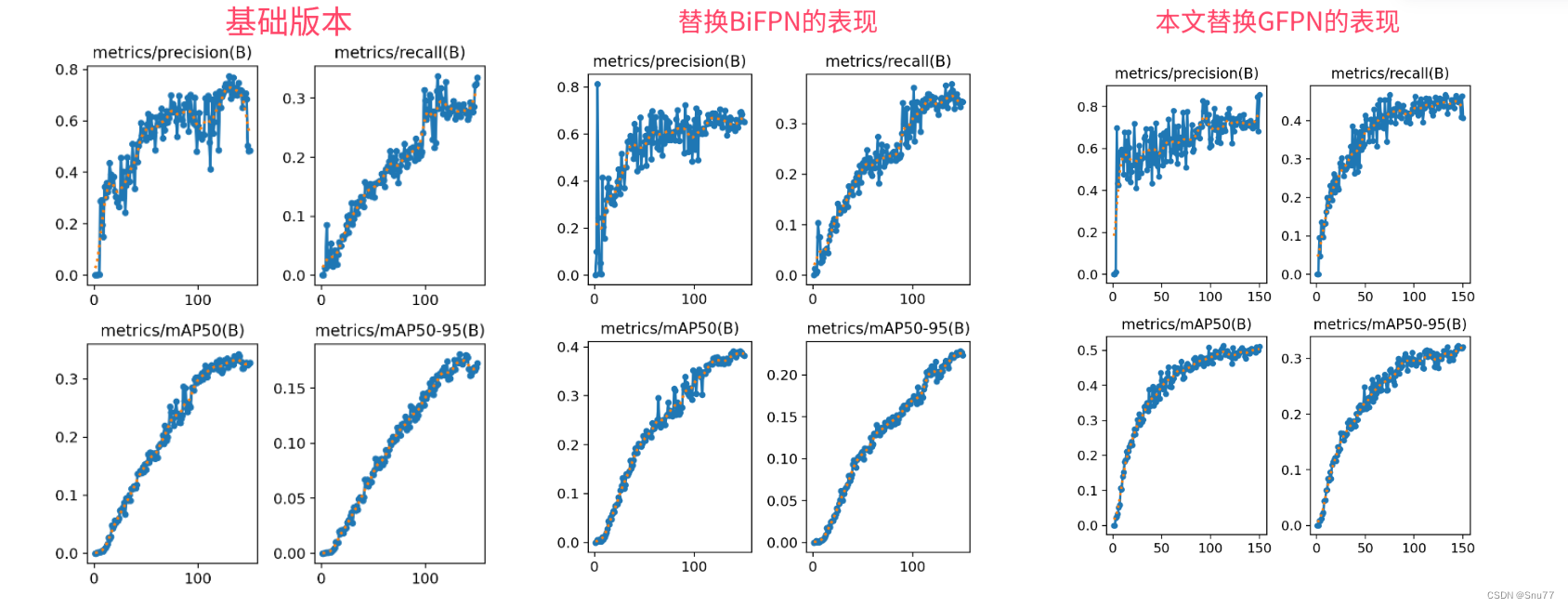
效果回顾展示->
图片分析->在我的数据集上大家可以看到mAP50大概增长了0.12左右这个涨点幅度是非常的高了以及,同时该模块是有二次创新的机会的,后期我会在接下来的文章进行二次创新,希望大家能够尽早关注我的专栏。
目录
一、本文介绍
二、GFPN的框架原理
编辑
三、GFPN的核心代码
四、手把手教你添加GFPN
4.1 修改一
4.2 修改二
五、GFPN的yaml文件
六、成功运行的截图
六、本文总结
二、GFPN的框架原理

官方论文地址: 官方论文地址
官方代码地址: 官方代码地址

RepGFPN(重参数化泛化特征金字塔网络)是DAMO-YOLO框架中用于实时目标检测的新方法。其主要主要原理是:RepGFPN改善了用于目标检测的特征金字塔网络(FPN)的概念,更高效地融合多尺度特征,对于捕捉高层语义和低层空间细节至关重要。
其主要改进机制包括->
- 不同尺度通道:它为不同尺度的特征图采用不同的通道维度,优化了计算资源下的性能。
- 优化的皇后融合机制:该方法通过修改的皇后融合机制增强了特征交互,通过去除额外的上采样操作减少延迟。
- 整合CSPNet和ELAN:它结合了CSPNet和高效层聚合网络(ELAN)以及重参数化,改善了特征融合,而不显著增加计算需求。
总结:RepGFPN更像是一种结构一种思想,其中的模块我们是可以用其它的机制替换的。
下面的图片是Damo-YOLO的网络结构图,其中我用红框标出来的部分就是RepGFPN的路径聚合图。

根据图片我们来说一下GFPN(重参数化特征金字塔网络):作为“颈部(也就是YOLOv8中的neck),用于优化和融合高层语义和低层空间特征。
在左上角的融合块(Fusion Block)中,我们可以看到反复出现的结构单元,它们由多个1x1卷积,一个3x3卷积组成,这些卷积后面通常跟着批量归一化(BN)和激活函数(Act)。这个复合结构在训练时和推理时有所不同,这是通过“简化Rep 3x3”结构来实现的,它在训练时使用3x3卷积,而在推理时则简化为1x1卷积,以提高效率(现在很多结构都使用在何种思想训练时候用复杂的模块,推理时换为简单的模块,这在大家自己的改进中也可以是一种思想)。
三、GFPN的核心代码
下面的代码是GFPN的核心代码,我们将其复制导'ultralytics/nn/modules'目录下,在其中创建一个文件,我这里起名为GFPN然后粘贴进去,其余使用方式看章节四。
import torch
import torch.nn as nn
import numpy as npclass swish(nn.Module):def forward(self, x):return x * torch.sigmoid(x)def autopad(k, p=None, d=1): # kernel, padding, dilation"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = swish() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initialize Conv layer with given arguments including activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Apply convolution, batch normalization and activation to input tensor."""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""Perform transposed convolution of 2D data."""return self.act(self.conv(x))class RepConv(nn.Module):default_act = swish() # default activationdef __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):"""Initializes Light Convolution layer with inputs, outputs & optional activation function."""super().__init__()assert k == 3 and p == 1self.g = gself.c1 = c1self.c2 = c2self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()self.bn = nn.BatchNorm2d(num_features=c1) if bn and c2 == c1 and s == 1 else Noneself.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)def forward_fuse(self, x):"""Forward process."""return self.act(self.conv(x))def forward(self, x):"""Forward process."""id_out = 0 if self.bn is None else self.bn(x)return self.act(self.conv1(x) + self.conv2(x) + id_out)def get_equivalent_kernel_bias(self):"""Returns equivalent kernel and bias by adding 3x3 kernel, 1x1 kernel and identity kernel with their biases."""kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)kernelid, biasid = self._fuse_bn_tensor(self.bn)return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasiddef _pad_1x1_to_3x3_tensor(self, kernel1x1):"""Pads a 1x1 tensor to a 3x3 tensor."""if kernel1x1 is None:return 0else:return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])def _fuse_bn_tensor(self, branch):"""Generates appropriate kernels and biases for convolution by fusing branches of the neural network."""if branch is None:return 0, 0if isinstance(branch, Conv):kernel = branch.conv.weightrunning_mean = branch.bn.running_meanrunning_var = branch.bn.running_vargamma = branch.bn.weightbeta = branch.bn.biaseps = branch.bn.epselif isinstance(branch, nn.BatchNorm2d):if not hasattr(self, 'id_tensor'):input_dim = self.c1 // self.gkernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)for i in range(self.c1):kernel_value[i, i % input_dim, 1, 1] = 1self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)kernel = self.id_tensorrunning_mean = branch.running_meanrunning_var = branch.running_vargamma = branch.weightbeta = branch.biaseps = branch.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta - running_mean * gamma / stddef fuse_convs(self):"""Combines two convolution layers into a single layer and removes unused attributes from the class."""if hasattr(self, 'conv'):returnkernel, bias = self.get_equivalent_kernel_bias()self.conv = nn.Conv2d(in_channels=self.conv1.conv.in_channels,out_channels=self.conv1.conv.out_channels,kernel_size=self.conv1.conv.kernel_size,stride=self.conv1.conv.stride,padding=self.conv1.conv.padding,dilation=self.conv1.conv.dilation,groups=self.conv1.conv.groups,bias=True).requires_grad_(False)self.conv.weight.data = kernelself.conv.bias.data = biasfor para in self.parameters():para.detach_()self.__delattr__('conv1')self.__delattr__('conv2')if hasattr(self, 'nm'):self.__delattr__('nm')if hasattr(self, 'bn'):self.__delattr__('bn')if hasattr(self, 'id_tensor'):self.__delattr__('id_tensor')class BasicBlock_3x3_Reverse(nn.Module):def __init__(self,ch_in,ch_hidden_ratio,ch_out,shortcut=True):super(BasicBlock_3x3_Reverse, self).__init__()assert ch_in == ch_outch_hidden = int(ch_in * ch_hidden_ratio)self.conv1 = Conv(ch_hidden, ch_out, 3, s=1)self.conv2 = RepConv(ch_in, ch_hidden, 3, s=1)self.shortcut = shortcutdef forward(self, x):y = self.conv2(x)y = self.conv1(y)if self.shortcut:return x + yelse:return yclass SPP(nn.Module):def __init__(self,ch_in,ch_out,k,pool_size):super(SPP, self).__init__()self.pool = []for i, size in enumerate(pool_size):pool = nn.MaxPool2d(kernel_size=size,stride=1,padding=size // 2,ceil_mode=False)self.add_module('pool{}'.format(i), pool)self.pool.append(pool)self.conv = Conv(ch_in, ch_out, k)def forward(self, x):outs = [x]for pool in self.pool:outs.append(pool(x))y = torch.cat(outs, axis=1)y = self.conv(y)return yclass CSPStage(nn.Module):def __init__(self,ch_in,ch_out,n,block_fn='BasicBlock_3x3_Reverse',ch_hidden_ratio=1.0,act='silu',spp=False):super(CSPStage, self).__init__()split_ratio = 2ch_first = int(ch_out // split_ratio)ch_mid = int(ch_out - ch_first)self.conv1 = Conv(ch_in, ch_first, 1)self.conv2 = Conv(ch_in, ch_mid, 1)self.convs = nn.Sequential()next_ch_in = ch_midfor i in range(n):if block_fn == 'BasicBlock_3x3_Reverse':self.convs.add_module(str(i),BasicBlock_3x3_Reverse(next_ch_in,ch_hidden_ratio,ch_mid,shortcut=True))else:raise NotImplementedErrorif i == (n - 1) // 2 and spp:self.convs.add_module('spp', SPP(ch_mid * 4, ch_mid, 1, [5, 9, 13]))next_ch_in = ch_midself.conv3 = Conv(ch_mid * n + ch_first, ch_out, 1)def forward(self, x):y1 = self.conv1(x)y2 = self.conv2(x)mid_out = [y1]for conv in self.convs:y2 = conv(y2)mid_out.append(y2)y = torch.cat(mid_out, axis=1)y = self.conv3(y)return y
四、手把手教你添加GFPN
上一节我们给出了GFPN的核心代码,这一节会教大家如何添加GFPN其实,GFPN的添加方式,和C2f是一模一样的,非常简单只需要修改几处即可。
同时给大家推荐我其它位置的修改教程的链接,当然你只使用本文的基础用本文的修改教程即可。
添加教程->YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
4.1 修改一
我们找到如下文件'ultralytics/nn/tasks.py'。在其中的开头我们导入我们的模块。

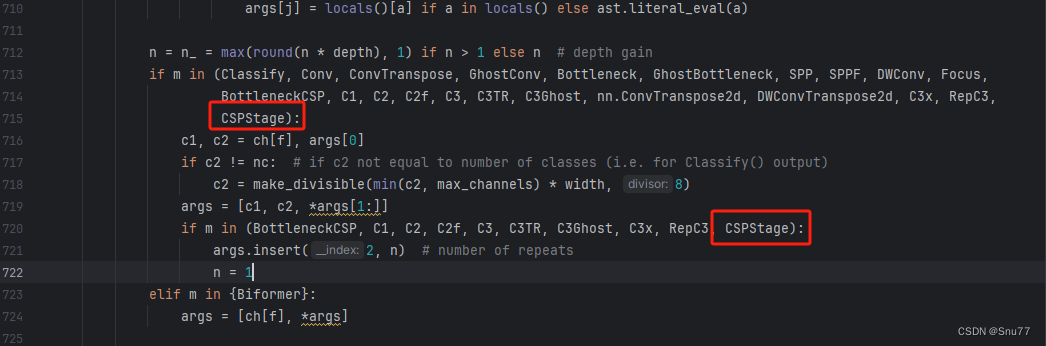
4.2 修改二
我们找到parse_model的函数,在其中进行修改,大约在700行,修改如下的两处即可。
五、GFPN的yaml文件
其实最主要的是yaml文件的配置,来复现Damo-YOLO的Neck部分,大家复制粘贴我的yaml文件运行即可。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# DAMO-YOLO GFPN Head
head:- [-1, 1, Conv, [512, 1, 1]] # 10- [6, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]]- [-1, 3, CSPStage, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, 'nearest']] #14- [4, 1, Conv, [256, 3, 2]] # 15- [[14, -1, 6], 1, Concat, [1]]- [-1, 3, CSPStage, [512]] # 17- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]]- [-1, 3, CSPStage, [256]] # 20- [-1, 1, Conv, [256, 3, 2]]- [[-1, 17], 1, Concat, [1]]- [-1, 3, CSPStage, [512]] # 23- [17, 1, Conv, [256, 3, 2]] # 24- [23, 1, Conv, [256, 3, 2]] # 25- [[13, 24, -1], 1, Concat, [1]]- [-1, 3, CSPStage, [1024]] # 27- [[20, 23, 27], 1, Detect, [nc]] # Detect(P3, P4, P5)
六、成功运行的截图
下面是成功运行的截图,确保我添加的机制是可以完美运行的给大家证明。

六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备

相关文章:
YOLOv8改进 | 2023Neck篇 | 利用RepGFPN改进特征融合层(附yaml文件+添加教程)
一、本文介绍 本文给大家带来的改进机制是Damo-YOLO的RepGFPN(重参数化泛化特征金字塔网络),利用其优化YOLOv8的Neck部分,可以在不影响计算量的同时大幅度涨点(亲测在小目标和大目标检测的数据集上效果均表现良好涨点…...

关于“Python”的核心知识点整理大全21
9.3.2 Python 2.7 中的继承 在Python 2.7中,继承语法稍有不同,ElectricCar类的定义类似于下面这样: class Car(object):def __init__(self, make, model, year):--snip-- class ElectricCar(Car):def __init__(self, make, model, year):supe…...

Sui承诺向流动性质押协议投入$SUI
Sui将提供SUI以支持三个流动性质押协议及其相应的流动性质押token( Liquid Staking Tokens,LST),为网络上不断增长的DeFi领域增加了流动性。此次注入将加强LST在交易和其他DeFi 用途中的流动性。 流动性质押让SUI所有者通过将其t…...
不知道CRM系统怎么选?这十款值得推荐
许多想要购买CRM软件的客户都因为市场上产品数量众多而不知从何下手。因此,我们以企业实力、品牌荣誉、企业在行业内的排名情况,结合网络口碑等多种因素为基础,为国内CRM软件建立了以下排行榜,并重点介绍排行榜前十的CRM软件供应商…...
智慧工地源码(微服务+Java+Springcloud+Vue+MySQL)
智慧工地系统是依托物联网、互联网、AI、可视化建立的大数据管理平台,是一种全新的管理模式,能够实现劳务管理、安全施工、绿色施工的智能化和互联网化。围绕施工现场管理的人、机、料、法、环五大维度,以及施工过程管理的进度、质量、安全三…...
有趣的数学 数学建模入门三 数学建模入门示例两例 利用微积分求解
一、入门示例1 1、问题描述 某宾馆有150间客房,经过一段时间的经营,该宾馆经理得到一些数据:如果每间客房定价为200元,入住率为55%;定价为180元,入住率为65%;定价为160元…...

【Monitor, Maintenance Operation, Script code/prgramme】
Summary of M,M&O,Program JD) Monitor & M&O Symbio信必优) Job chance/opportunities on Dec 12th, 20231.1) Content 招聘JD job description:1.2) suggestions from Ms Liang/Winnie on Wechat app1.3) Java微服务是什么?1.3.1) [URL Java 微服务](…...

python接口自动化测试(单元测试方法)
一、环境搭建 python unittest requests实现http请求的接口自动化Python的优势:语法简洁优美, 功能强大, 标准库跟第三方库灰常强大,建议大家事先了解一下Python的基础;unittest是python的标准测试库,相比于其他测试框架是python目前使用最广…...

【css】划过滚动条,滚动条加宽,划出时,变回原宽度
// 全局的滚动条样式 ::-webkit-scrollbar { //滚动条的宽度width: 4px;height: 6px; }::-webkit-scrollbar-thumb { //滚动条的滑块background-color: rgba(144, 147, 153, 0.6);border-radius: 4px; }// 内容区滚动条划过加宽 .content>div>div::-webkit-scrollbar {…...

飞天使-linux操作的一些技巧与知识点5-ansible之roles
文章目录 roles批量替换文件 role 的依赖关系role 的实际案例 roles tasks 和 handlers ,那怎样组织 playbook 才是最好的方式呢?简 单的回答就是:使用 Roles Roles 基于一个已知的文件结构,去自动的加载 vars,tasks 以…...
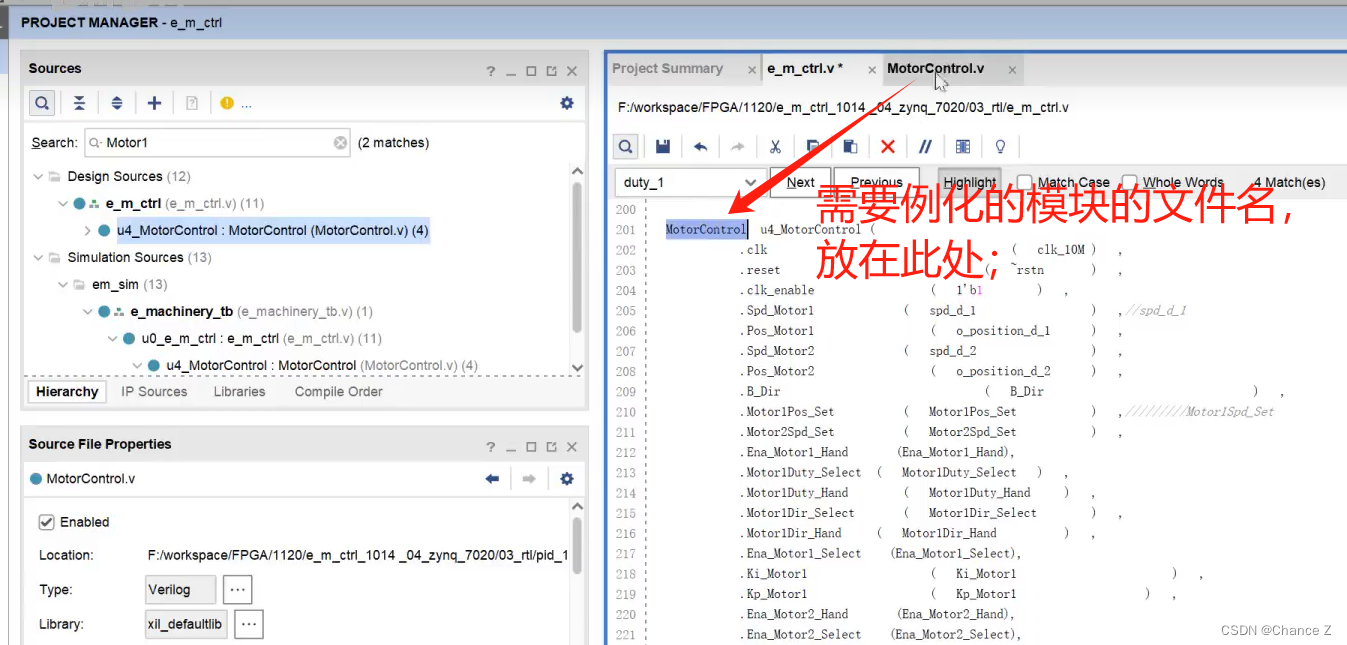
FPGA - 1、Simulink HDL coder模型例化到FPGA
Simulink HDL coder模型例化到FPGA 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 例如:第一章 Python 机器学习入门之pandas的使用 提示:写完文章后,目录可以自动生成,如何生成可参考右…...
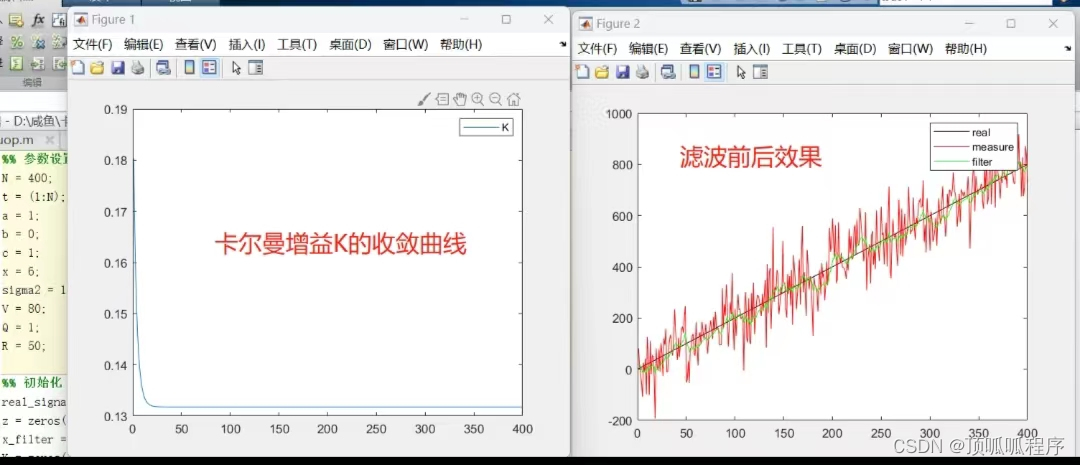
02基于matlab的卡尔曼滤波
基于matlab的卡尔曼滤波,可更改状态转移方程,控制输入,观测方程,设置生成的信号的噪声标准差,设置状态转移方差Q和观测方差R等参数,程序已调通,需要直接拍下。...

基础算法(3):排序(3)插入排序
1.插入排序实现 插入排序的工作原理是:通过构建有序序列,对于未排序数据,在已经排序的序列从后向前扫描,找到位置并插入,类似于平时打扑克牌时,将牌从大到小排列,每次摸到一张牌就插入到正确的位…...
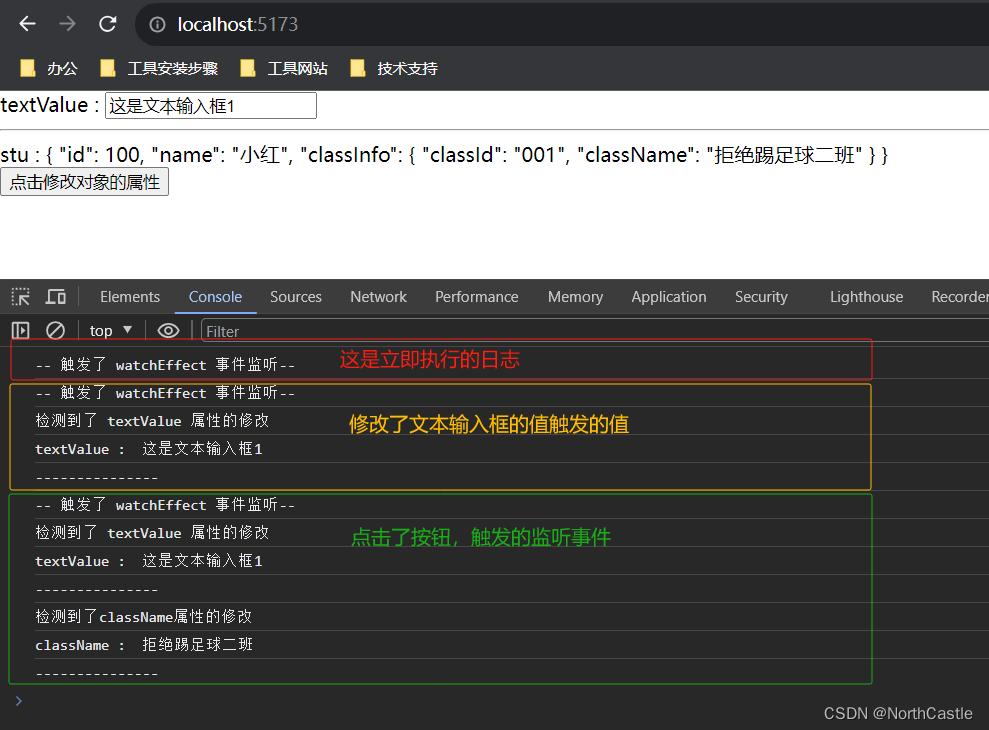
Vue3-18-侦听器watch()、watchEffect() 的基本使用
什么是侦听器 个人理解:当有一个响应式状态(普通变量 or 一个响应式对象)发生改变时,我们希望监听到这个改变,并且能够进行一些逻辑处理。那么侦听器就是来帮助我们实现这个功能的。侦听器 其实就是两个函数ÿ…...
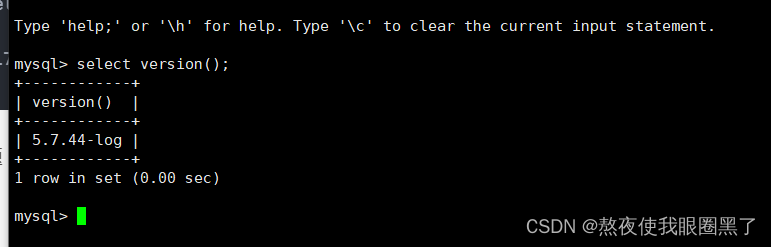
mysql 5.7.34升级到5.7.44修补漏洞
mysql 5.7.34旧版本,漏扫有漏洞,升级到最新版本 旧版本5.7.34在 /home/mysql/mysql中安装 备份旧版本数据还有目录 数据库备份升级 tar -xf mysql-5.7.44-el7-x86_64.tar #覆盖旧版本数据库文件 #注意看看文件是否和你起服务的用户一样 \cp -r mysql-5…...

基于电子密码锁具有掉电存储系统设计
**单片机设计介绍,基于电子密码锁具有掉电存储系统设计 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 电子密码锁是一种使用电子技术实现开关门的装置,通常由密码输入板、电控锁、控制电路等组成。其中&a…...

清华大学考研复试上机题之二叉树的遍历
问题描述: 编一个程序,读入用户输入的一串先序遍历字符串,根据此字符串建立一个二叉树(以指针方式存储)。 例如如下的先序遍历字符串:ABC##DE#G##F### 其中#表示的是空格,空格字符代表空树。…...

java全栈体系结构-架构师之路(持续更新中)
Java 全栈体系结构 数据结构与算法实战(已更)微服务解决方案数据结构模型(openresty/tengine)实战高并发JVM虚拟机实战性能调优并发编程实战微服务框架源码解读集合框架源码解读分布式架构解决方案分布式消息中间件原理设计模式JavaWebJavaSE新零售电商项…...

【C语言】超详解strncpystrncatstrncmpstrerrorperror的使⽤和模拟实现
🌈write in front :🔍个人主页 : 啊森要自信的主页 ✏️真正相信奇迹的家伙,本身和奇迹一样了不起啊! 欢迎大家关注🔍点赞👍收藏⭐️留言📝>希望看完我的文章对你有小小的帮助&am…...
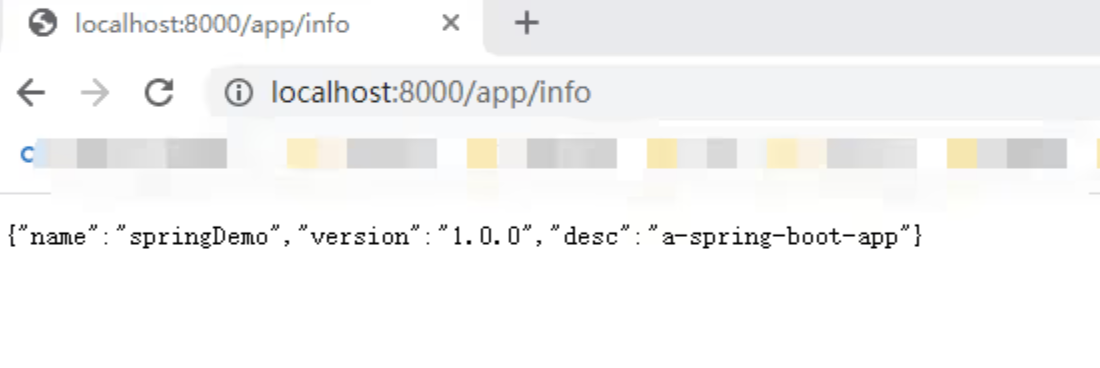
【Spring Boot 】Spring Boot 常用配置总结
文章目录 前言1.多环境配置application.propertiesapplication.yaml 2.常用配置3.配置读取4.自定义配置 前言 在涉及项目开发时,通常我们会灵活地把一些配置项集中在一起,如果你的项目不是很大的情况下,那么通过配置文件集中不失为一个很好的…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...
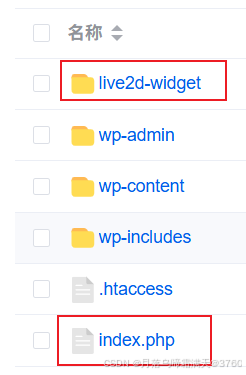
给网站添加live2d看板娘
给网站添加live2d看板娘 参考文献: stevenjoezhang/live2d-widget: 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platformEikanya/Live2d-model: Live2d model collectionzenghongtu/live2d-model-assets 前言 网站环境如下,文章也主…...