【ChatGLM3】第三代大语言模型多GPU部署指南
关于ChatGLM3
ChatGLM3是智谱AI与清华大学KEG实验室联合发布的新一代对话预训练模型。在第二代ChatGLM的基础之上,
- 更强大的基础模型:
ChatGLM3-6B的基础模型ChatGLM3-6B-Base采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base具有在10B以下的基础模型中最强的性能。 - 更完整的功能支持:
ChatGLM3-6B采用了全新设计的Prompt格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和Agent任务等复杂场景。 - 更全面的开源序列: 除了对话模型
ChatGLM3-6B外,还开源了基础模型ChatGLM3-6B-Base、长文本对话模型ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
关于部署前的准备
- 可以参考两篇文章
- 如果有GPU资源,可以参考【ChatGLM2-6B】从0到1部署GPU版本
- 如果只有CPU服务器,可以参考【ChatGLM2-6B】在只有CPU的Linux服务器上进行部署
- 本文主要针对
ChatGLM第三代模型ChatGLM3-6B进行部署,假设你已经成功部署过ChatGLM系列其它版本
ChatGLM3模型开源列表
| 模型 | 介绍 | 上下文token数 |
|---|---|---|
| ChatGLM3-6B | 第三代 ChatGLM 对话模型。ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。 | 8K |
| ChatGLM3-6B-base | 第三代ChatGLM基座模型。ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。 | 8K |
| ChatGLM3-6B-32k | 第三代ChatGLM长上下文对话模型。在ChatGLM3-6B的基础上进一步强化了对于长文本的理解能力,能够更好的处理最多32K长度的上下文。 | 32K |
本文以
ChatGLM3-6B-base为例进行部署,因为作者想体验长文本处理的效果
创建Python虚拟环境
conda创建虚拟环境:conda create --name ChatGLM3 python=3.10.6 -y
- –name 后面ChatGLM3为创建的虚拟环境名称
- python=之后输入自己想要的python版本
- -y表示后面的请求全部为yes,这样就不用自己每次手动输入yes了。
- 激活虚拟环境:
conda activate ChatGLM3
下载ChatGLM3代码仓库
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
# 使用 pip 安装依赖
pip install -r requirements.txt
下载模型
使用git命令下载
# 在ChatGLM3目录下创建THUDM,把模型文件放在THUDM目录里面
mkdir THUDM
cd THUDM
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b-32k.git
# 也可以根据自己的需要下载其它模型
#git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b-base.git
#git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
主要是其中的7个模型文件,比较大,下载时间稍长,约12G
1.4K Dec 6 15:36 config.json2.4K Dec 6 15:36 configuration_chatglm.py40 Dec 6 15:36 configuration.json55K Dec 6 15:36 modeling_chatglm.py4.1K Dec 6 15:36 MODEL_LICENSE1.8G Dec 6 15:38 pytorch_model-00001-of-00007.bin1.9G Dec 6 15:41 pytorch_model-00002-of-00007.bin1.8G Dec 6 15:44 pytorch_model-00003-of-00007.bin1.7G Dec 6 15:47 pytorch_model-00004-of-00007.bin1.9G Dec 6 15:50 pytorch_model-00005-of-00007.bin1.8G Dec 6 15:52 pytorch_model-00006-of-00007.bin1005M Dec 6 15:54 pytorch_model-00007-of-00007.bin20K Dec 6 15:54 pytorch_model.bin.index.json15K Dec 6 15:54 quantization.py5.0K Dec 6 15:36 README.md12K Dec 6 15:54 tokenization_chatglm.py244 Dec 6 15:54 tokenizer_config.json995K Dec 6 15:54 tokenizer.model
修改脚本
分别以web端浏览器访问和API访问两种最常用的场景进行脚本修改
浏览器访问脚本修改
- 复制一份
web_demo2.py到ChatGLM3目录
cp basic_demo/web_demo2.py ./web_demo2_32k.py
- 修改
MODEL_PATH路径
# 尽量使用绝对路径,这样可以避从Huggingface下载模型
MODEL_PATH = os.environ.get('MODEL_PATH', '/ChatGLM3/THUDM/chatglm3-6b-32k')
- 使用
2个GPU加载模型
@st.cache_resource
def get_model():tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)# if 'cuda' in DEVICE: # AMD, NVIDIA GPU can use Half Precision# model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).to(DEVICE).eval()# else: # CPU, Intel GPU and other GPU can use Float16 Precision Only# model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).float().to(DEVICE).eval()# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量import syssys.path.append('./openai_api_demo')from utils import load_model_on_gpusmodel = load_model_on_gpus(MODEL_PATH, num_gpus=2)return tokenizer, model
- 修改默认最大token数
# 设置max_length、top_p和temperature
max_length = st.sidebar.slider("max_length", 0, 32768, 32768, step=1)
- 启动大模型服务
# 后台方式运行,退出终端后服务不会停止运行
nohup streamlit run web_demo2_32k.py &
- 浏览器访问效果截图
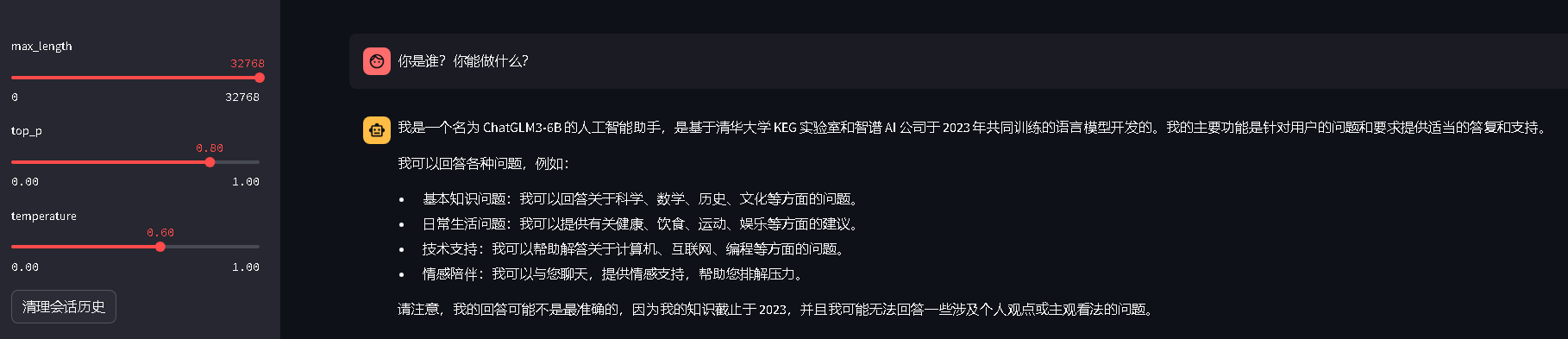
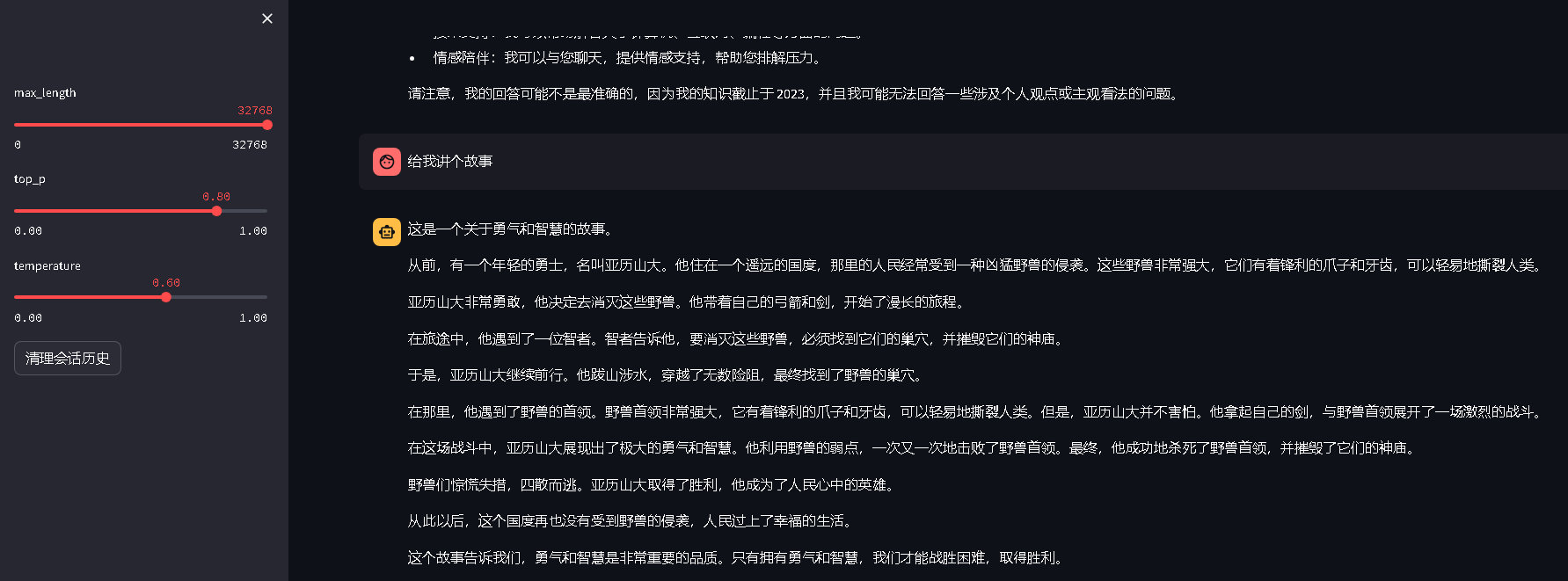
API访问脚本修改
- 复制一份
openai_api_demo/openai_api.py到ChatGLM3目录
cp openai_api_demo/openai_api.py ./openai_api_32k.py
- 修改导入包路径
import sys
sys.path.append('./openai_api_demo')
from utils import process_response, generate_chatglm3, generate_stream_chatglm3
- 修改
MODEL_PATH路径
# 尽量使用绝对路径,这样可以避从Huggingface下载模型
MODEL_PATH = os.environ.get('MODEL_PATH', '/ChatGLM3/THUDM/chatglm3-6b-32k')
- 使用
2个GPU加载模型
if __name__ == "__main__":tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)if 'cuda' in DEVICE: # AMD, NVIDIA GPU can use Half Precision#model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).to(DEVICE).eval()# Multi-GPU support, use the following two lines instead of the above line, num gpus to your actual number of graphics cardsimport syssys.path.append('./openai_api_demo')from utils import load_model_on_gpusmodel = load_model_on_gpus(MODEL_PATH, num_gpus=2)else: # CPU, Intel GPU and other GPU can use Float16 Precision Onlymodel = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).float().to(DEVICE).eval()uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
- 启动大模型服务
# 后台方式运行,退出终端后服务不会停止运行
nohup python openai_api_32k.py &
- API访问测试
curl -X POST "http://127.0.0.1:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
-d "{\"model\": \"chatglm3-6b\", \"messages\": [{\"role\": \"system\", \"content\": \"You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.\"}, {\"role\": \"user\", \"content\": \"你好,给我讲一个故事,大概100字\"}], \"stream\": false, \"max_tokens\": 100, \"temperature\": 0.8, \"top_p\": 0.8}"
大模型响应示例
{"model":"chatglm3-6b","object":"chat.completion","choices":[{"index":0,"message":{"role":"assistant","content":"有一天,在一个遥远的王国里,有一个勇敢的年轻人名叫杰克。他听说王国里有一座神秘的城堡,里面藏着传说中的宝藏。于是,杰克带着他的忠实伙伴——一只忠诚的狗一起踏上了寻找宝藏的旅程。\n\n他们跋山涉水,历经千辛万苦,终于来到了那座城堡。城堡的大门紧闭,门前还有一条恶龙在守护着。杰克并没有退缩,他知道这是他实现梦想的机会。","name":null,"function_call":null},"finish_reason":"stop"}],"created":1702003224,"usage":{"prompt_tokens":54,"total_tokens":154,"completion_tokens":100}}
总结
- 经过测试对比,
ChatGLM3比ChatGLM2强大了很多很多,可以在一定程度上满足商用 - ChatGLM系列大模型的迭代速度还是比较快的,可以感受到研究人员的努力
- 一款优秀的具有自主知识产权的国产大模型,数据安全有保障,有活跃的社区,有越来越丰富的文档资料
- 希望
ChatGLM可以早日超越ChatGPT
相关文章:
【ChatGLM3】第三代大语言模型多GPU部署指南
关于ChatGLM3 ChatGLM3是智谱AI与清华大学KEG实验室联合发布的新一代对话预训练模型。在第二代ChatGLM的基础之上, 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、…...

云原生Kubernetes系列 | Docker/Kubernetes的卷管理
云原生Kubernetes系列 | Docker/Kubernetes的卷管理 1. Docker卷管理2. Kubernetes卷管理2.1. 本地存储2.1.1. emptyDir2.1.2. hostPath2.2. 网络存储2.2.1. 使用NFS2.2.2. 使用ISCSI2.3. 持久化存储2.3.1. PV和PVC2.3.2. 访问模式2.3.3. 回收策略1. Docker卷管理...
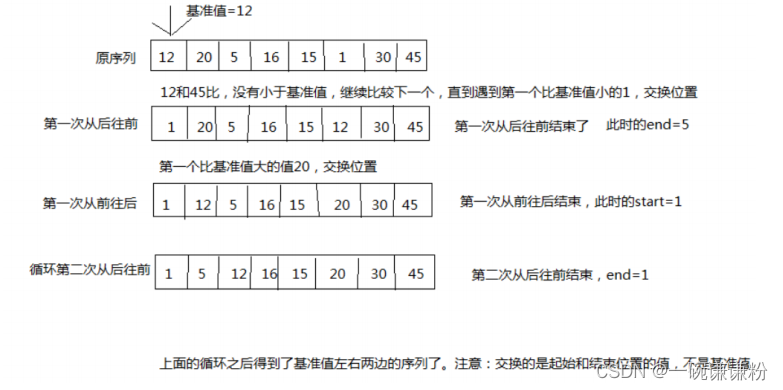
Java实现快速排序算法
快速排序算法 (1)概念:快速排序是指通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序。整个排序过程可以递归进行&…...
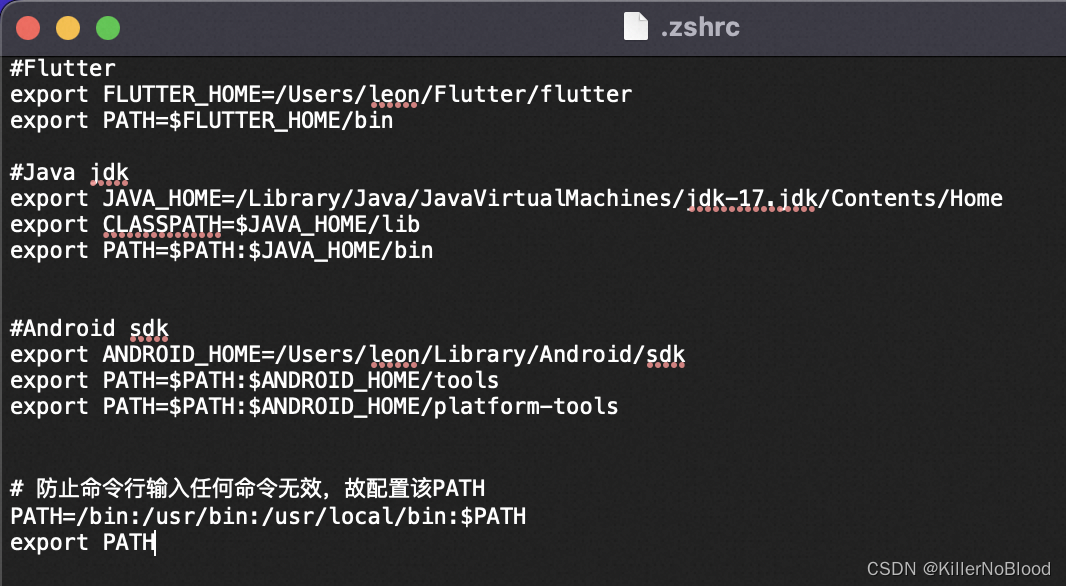
MAC配置环境变量
1、配置 JAVA JDK 1.1、查看 JDK 安装目录 (1)可以在Android Studio中查看,复制该路径 (2)也可以在官网下载 Java JDK下载地址 mac中的安装地址是"资源库->Java->JavaVirtualMachines"中 1.2、…...
系列五、DQL
一、DQL 1.1、概述 DQL的英文全称为:Data Query Language,中文意思为:数据查询语言,用大白话讲就是查询数据。对于大多数系统来说,查询操作的频次是要远高于增删改的,当我们去访问企业官网、电商网站&…...
【智能家居】七、人脸识别 翔云平台编程使用(编译openSSL支持libcurl的https访问、安装SSL依赖库openSSL)
一、翔云 人工智能开放平台 API文档开发示例下载 二、编译openSSL支持libcurl的https访问 安装SSL依赖库openSSL(使用工具wget)libcurl库重新配置,编译,安装运行(运行需添加动态库为环境变量) 三、编程实现人脸识别 四、Base6…...
基于node 安装express后端脚手架
1.首先创建文件件 2.在文件夹内打开终端 npm init 3.安装express: npm install -g express-generator注意的地方:这个时候安装特别慢,最后导致不成功 解决方法:npm config set registry http://registry.npm.taobao.org/ 4.依次执行 npm install -g ex…...
Mrdoc知识文档
MrDoc知识文档平台是一款基于Python开发的在线文档系统,适合作为个人和中小型团队的私有云文档、云笔记和知识管理工具,致力于成为优秀的私有化在线文档部署方案。我现在主要把markdown笔记放在上面,因为平时老是需要查询一些知识点ÿ…...

C语言中getchar函数
在 C 语言中,getchar() 是一个标准库函数,用于从标准输入(通常是键盘)读取单个字符。它的函数原型如下: int getchar(void);getchar() 函数的工作原理如下: 当调用 getchar() 函数时,它会等待…...

全栈开发组合
SpringBoot是什么? SpringBoot是一个基于Spring框架的开源框架,由Pivotal团队开发。它的设计目的是用来简化Spring应用的初始搭建以及开发过程。SpringBoot提供了丰富的Spring模块化支持,可以帮助开发者更轻松快捷地构建出企业级应用 Sprin…...

wpf TelerikUI使用DragDropManager
首先,我先创建事务对象ApplicationInfo,当暴露出一对属性当例子集合对于构成ListBoxes。这个类在例子中显示如下代码: public class ApplicationInfo { public Double Price { get; set; } public String IconPath { get; set; } public …...
Python+Appium自动化测试之元素等待方法与重新封装元素定位方法
在appium自动化测试脚本运行的过程中,因为网络不稳定、测试机或模拟器卡顿等原因,有时候会出现页面元素加载超时元素定位失败的情况,但实际这又不是bug,只是元素加载较慢,这个时候我们就会使用元素等待的方法来避免这种…...

详解Maven如何打包SpringBoot工程
目录 一、spring-boot-maven-plugin详解 1、添加spring-boot-maven-plugin插件到pom.xml 2、配置主类(Main Class) 3、配置打包的JAR文件名 4、包含或排除特定的资源文件 5、指定额外的依赖项 6、配置运行参数 7、自定义插件执行阶段 二、Maven打…...
PyQt6 QFrame分割线控件
锋哥原创的PyQt6视频教程: 2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~共计46条视频,包括:2024版 PyQt6 Python桌面开发 视频教程(无废话版…...

PostgreSql 序列
一、概述 在 PostgreSQL 中,序列用于生成唯一标识符,通常用于为表的主键列生成连续的唯一值。若目的仅是为表字段设置自增 id,可考虑序列类型来实现,可参考《PostgreSql 设置自增字段》 二、创建序列 2.1 语法 CREATE [ TEMPOR…...

【深度学习目标检测】六、基于深度学习的路标识别(python,目标检测,yolov8)
YOLOv8是一种物体检测算法,是YOLO系列算法的最新版本。 YOLO(You Only Look Once)是一种实时物体检测算法,其优势在于快速且准确的检测结果。YOLOv8在之前的版本基础上进行了一系列改进和优化,提高了检测速度和准确性。…...
Vue3上传图片和删除图片
<div class"illness-img"><van-uploader:after-read"onAfterRead"delete"onDeleteImg"v-model"fileList"max-count"9":max-size"5 * 1024 * 1024"upload-icon"photo-o"upload-text"上传图…...
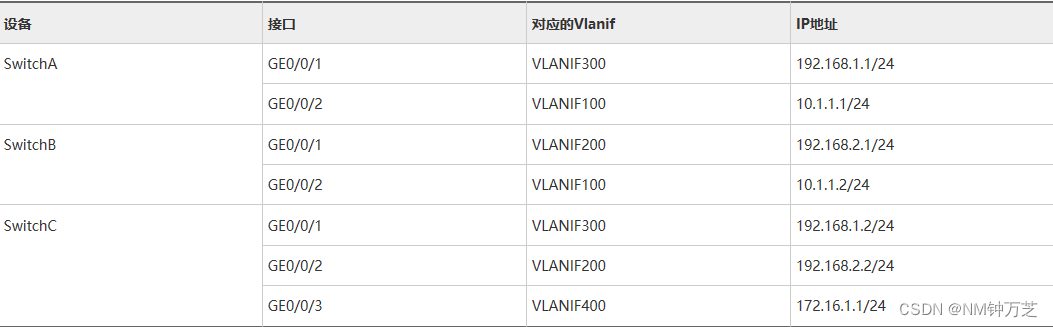
华为配置VRRP负载分担示例
组网需求 如图1所示,HostA和HostC通过Switch双归属到SwitchA和SwitchB。为减轻SwitchA上数据流量的承载压力,HostA以SwitchA为默认网关接入Internet,SwitchB作为备份网关;HostC以SwitchB为默认网关接入Internet,Switc…...

【Python】按升序排列 Excel 工作表
发现按名称对 Excel 工作表进行排序很麻烦,因此创建了一个代码来使用 Python 的 openpyxl 对它们进行排序。 1. 本次创建的代码概述 在GUI中指定一个Excel文件(使用Tkinter。这是一个标准模块,因此不需要安装)加载Excel文件&…...
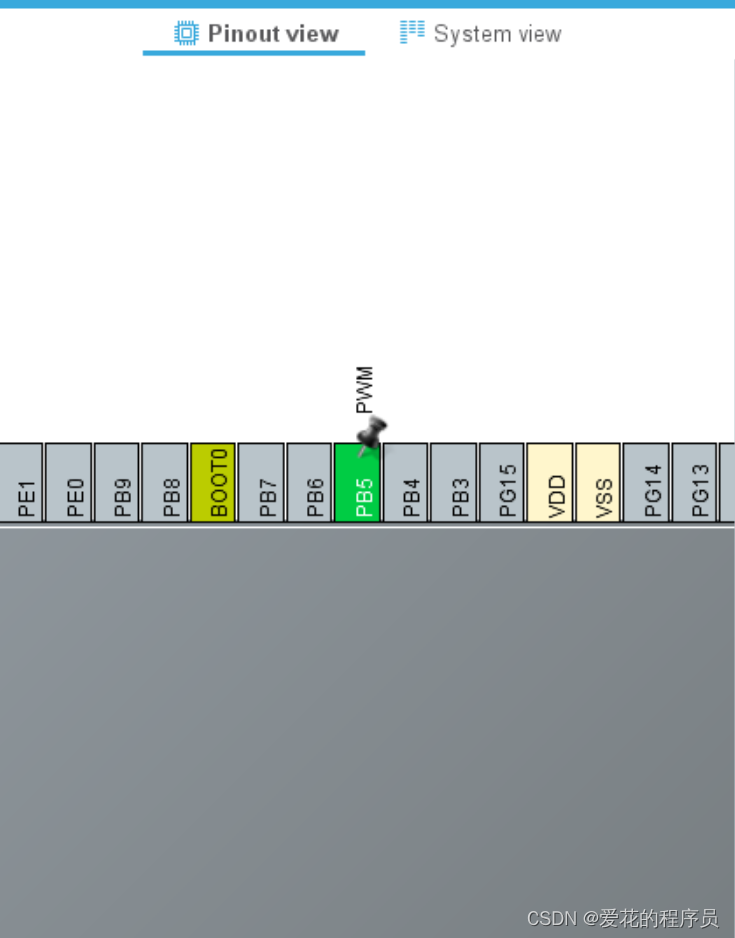
定时器TIM HAL库+cubeMX(上)
定时器时钟源APB1 36MHz 一.基本定时器 1.基本框图 2.溢出时间计算 3.配置定时器步骤 TIM_HandleTypeDef g_timx_handle;/* 定时器中断初始化函数 */ void btim_timx_int_init(uint16_t arr, uint16_t psc) {g_timx_handle.Instance TIM6;g_timx_handle.Init.Prescaler p…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...