1+X大数据平台运维职业技能等级证书中级
hadoop:
由于我的功能限制,我无法直接为您执行这些操作或提供实际的截图。但我可以为您提供一步步的指导,帮助您完成这些任务。
1. 解压JDK安装包到“/usr/local/src”路径,并配置环境变量。
- 解压JDK:`tar -zxf jdk-版本号-linux-x64.tar.gz` 到 `/usr/local/src/`
- 配置环境变量:编辑 `~/.bashrc` 或 `~/.bash_profile`,添加 `export JAVA_HOME=/usr/local/src/jdk-版本号` 和 `export PATH=$JAVA_HOME/bin:$PATH`
- 使环境变量生效:`source ~/.bashrc` 或 `source ~/.bash_profile`
2. 在指定目录下安装ssh服务,查看ssh进程。
- 安装SSH服务:`yum install openssh-server`
- 查看SSH进程:`ps -ef | grep ssh`
3. 创建SSH密钥,实现主节点与从节点的无密码登录。
- 在主节点创建密钥:`ssh-keygen -t rsa`
- 将公钥复制到从节点:`ssh-copy-id user@slave-node`
4. 修改每台主机host文件。
- 编辑 `/etc/hosts` 文件,添加或修改IP地址与主机名的映射关系。
5. 修改每台主机hostname文件配置IP与主机名映射关系。
- 编辑 `/etc/hostname` 文件,确保其中记录了正确的主机名。
6. 在主节点和从节点修改Hadoop环境变量。
- 编辑 `~/.bashrc` 或 `~/.bash_profile`,添加Hadoop的环境变量配置。
7. 安装Zookeeper组件。
- 根据Zookeeper的安装指南进行安装。
8. 修改namenode、datanode、journalnode等存放数据的公共目录。
- 编辑Hadoop配置文件,指定公共目录为 `/usr/local/hadoop/tmp`。
9. 修改Hadoop相关文件,并初始化Hadoop。
- 根据要求编辑Hadoop配置文件,初始化Hadoop集群。
10. 启动Hadoop,使用相关命令查看所有节点Hadoop进程。
- 启动Hadoop集群,使用 `jps` 命令查看节点进程。
11. 配置完成后在Hadoop平台上运行查看进程命令。
- 在Hadoop平台上执行 `jps` 或相应进程查看命令,并截屏保存结果。
12. 格式化主从节点。
- 使用Hadoop命令格式化主从节点。
13. 启动两个namenode和resourcemanager。
- 使用Hadoop命令启动两个namenode和resourcemanager。
14. 使用查看进程命令查看进程,并截图。
- 执行 `jps` 命令,并截取包含主机名称的图片。
- 访问两个namenode和resourcemanager的web界面,并截图保存包含URL和状态的信息。
15. 终止active的namenode进程,并使用Jps查看各个节点进程。
- 使用 `kill` 命令终止active的namenode进程。
- 使用 `jps` 命令查看节点进程,并截图。
- 访问两个namenode和resourcemanager的web界面,并截图保存包含URL和状态的信息。
16. 重启刚才终止的namenode,并查看jps进程。
- 重启namenode进程。
- 使用 `jps` 命令查看进程。
- 访问两个namenode的web界面,并截图保存。
请注意,以上步骤需要根据您的实际环境和配置进行调整。在执行操作时,应具备相应权限,并严格按照操作规范进行,避免对系统造成不必要的影
spark:
由于我的功能限制,我无法直接为您执行这些操作或提供实际的截图。但我可以为您提供一步步的指导,帮助您完成这些任务。
1. 需前置Hadoop环境,并检查Hadoop环境是否可用。
- 确保已经安装并配置好Hadoop环境。
- 使用 `hadoop version` 命令检查Hadoop版本,并截图保存结果。
2. 解压Scala安装包到“/etc/local/src”路径下,并更名为scala。
- 解压Scala安装包:`tar -zxf scala-版本号.tgz` 到 `/etc/local/src/`
- 重命名解压后的文件夹为 `scala`:`mv /etc/local/src/scala-版本号 /etc/local/src/scala`
3. 设置Scala环境变量,并使环境变量只对当前用户生效。
- 编辑 `~/.bashrc` 或 `~/.bash_profile`,添加 `export SCALA_HOME=/etc/local/src/scala` 和 `export PATH=$SCALA_HOME/bin:$PATH`
- 使环境变量生效:`source ~/.bashrc` 或 `source ~/.bash_profile`
- 使用 `echo $SCALA_HOME` 命令检查Scala环境变量,并截图保存结果。
4. 进入Scala并截图。
- 使用 `scala` 命令进入Scala交互式shell。
- 使用截图工具截取Scala交互式shell的界面,并保存结果。
5. 解压Spark安装包到“/etc/local/src”路径下,并更名为spark。
- 解压Spark安装包:`tar -zxf spark-版本号.tgz` 到 `/etc/local/src/`
- 重命名解压后的文件夹为 `spark`:`mv /etc/local/src/spark-版本号 /etc/local/src/spark`
6. 设置Spark环境变量,并使环境变量只对当前用户生效。
- 编辑 `~/.bashrc` 或 `~/.bash_profile`,添加 `export SPARK_HOME=/etc/local/src/spark` 和 `export PATH=$SPARK_HOME/bin:$PATH`
- 使环境变量生效:`source ~/.bashrc` 或 `source ~/.bash_profile`
- 使用 `echo $SPARK_HOME` 命令检查Spark环境变量,并截图保存结果。
7. 修改Spark参数配置,指定Spark slave节点。
- 编辑Spark配置文件 `spark-defaults.conf`,在文件中添加 `spark.workerNode Address` 配置项,指定slave节点的IP地址和端口。
- 使用 `cat` 或 `less` 命令查看配置文件内容,并截图保存结果。
8. 启动Spark,并使用命令查看webUI结果。
- 使用 `spark-submit` 命令启动Spark应用。
- 使用 `curl` 或浏览器访问Spark webUI,并截图保存结果。
请注意,以上步骤需要根据您的实际环境和配置进行调整。在执行操作时,应具备相应权限,并严格按照操作规范进行,避免对系统造成不必要的影
kafka:
由于我的功能限制,我无法直接为您执行这些操作或提供实际的截图。但我可以为您提供一步步的指导,帮助您完成这些任务。
1. 安装Zookeeper组件,与Kafka环境适配,启动Zookeeper。
- 根据Zookeeper的安装指南进行安装。
- 使用 `zkCli.sh` 命令启动Zookeeper,并截图保存结果。
2. 解压Kafka安装包到“/usr/local/src”路径,并修改解压后文件夹名为kafka。
- 解压Kafka安装包:`tar -zxf kafka_2.12-版本号.tgz` 到 `/usr/local/src/`
- 重命名解压后的文件夹为 `kafka`:`mv /usr/local/src/kafka_2.12-版本号 /usr/local/src/kafka`
3. 设置Kafka环境变量,并使环境变量只对当前root用户生效。
- 编辑 `~root/.bashrc` 或 `~root/.bash_profile`,添加 `export KAFKA_HOME=/usr/local/src/kafka` 和 `export PATH=$KAFKA_HOME/bin:$PATH`
- 使环境变量生效:`source ~/.bashrc` 或 `source ~/.bash_profile`
- 使用 `echo $KAFKA_HOME` 命令检查Kafka环境变量,并截图保存结果。
4. 修改Kafka相应文件。
- 根据实际需求修改Kafka配置文件,如 `server.properties`、`consumer.properties` 和 `producer.properties`。
- 使用 `cat` 或 `less` 命令查看修改后的配置文件内容,并截图保存结果。
5. 启动Kafka并保存命令输出结果。
- 使用 `kafka-server-start.sh` 命令启动Kafka服务。
- 使用 `tail` 命令查看Kafka日志输出,并截图保存结果。
6. 创建指定topic。
- 使用 `kafka-topics.sh` 命令创建topic,如 `kafka-topics.sh --create --topic mytopic --partitions 3 --replication-factor 2`
- 使用 `kafka-topics.sh --list` 命令查看创建的topic,并截图保存结果。
7. 查看所有的topic信息。
- 使用 `kafka-topics.sh --describe` 命令查看所有topic的详细信息,并截图保存结果。
8. 启动指定生产者(producer)。
- 使用 `kafka-console-producer.sh` 命令启动生产者,并截图保存结果。
9. 启动消费者(consumer)。
- 使用 `kafka-console-consumer.sh` 命令启动消费者,并截图保存结果。
10. 测试生产者(producer)。
- 在生产者终端输入数据,观察Kafka主题中是否出现数据,并截图保存结果。
11. 测试消费者(consumer)。
- 在消费者终端观察收到的数据,并截图保存结果。
请注意,以上步骤需要根据您的实际环境和配置进行调整。在执行操作时,应具备相应权限,并严格按照操作规范进行,避免对系统造成不必要的影
storm:
由于我的功能限制,我无法直接为您执行这些操作或提供实际的截图。但我可以为您提供一步步的指导,帮助您完成这些任务。
1. 前置安装Zookeeper集群。
- 根据Zookeeper的安装指南进行安装。
- 使用 `zkCli.sh` 命令检查Zookeeper集群状态,并截图保存结果。
2. 解压Storm安装包到“/usr/local/src”路径,并修改解压后文件夹名为storm。
- 解压Storm安装包:`tar -zxf storm-版本号.tgz` 到 `/usr/local/src/`
- 重命名解压后的文件夹为 `storm`:`mv /usr/local/src/storm-版本号 /usr/local/src/storm`
3. 配置“conf/storm.yaml”文件。
- 编辑 `conf/storm.yaml` 文件,根据实际需求进行配置。
- 使用 `cat` 或 `less` 命令查看配置文件内容,并截图保存结果。
4. 传送配置好的“conf/storm.yaml”文件。
- 使用 `scp` 或其他文件传输工具将配置好的 `conf/storm.yaml` 文件传送到从节点。
- 使用 `ls` 命令在从节点上确认文件已传输,并截图保存结果。
5. 配置nimbus.seeds文件。
- 编辑 `storm/Config.java` 文件,根据实际需求配置nimbus.seeds。
- 使用 `cat` 或 `less` 命令查看修改后的 `storm/Config.java` 文件内容,并截图保存结果。
6. 配置supervisor.slots.ports。
- 编辑 `storm.yaml` 文件,配置 supervisor.slots.ports 参数。
- 使用 `cat` 或 `less` 命令查看修改后的 `storm.yaml` 文件内容,并截图保存结果。
7. 拷贝主节点Storm包到从节点。
- 使用 `scp` 或其他文件传输工具将主节点的Storm包拷贝到从节点。
- 使用 `ls` 命令在从节点上确认Storm包已拷贝,并截图保存结果。
8. 设置Storm环境变量,并使环境变量只对当前root用户生效。
- 编辑 `~root/.bashrc` 或 `~root/.bash_profile`,添加 `export STORM_HOME=/usr/local/src/storm` 和 `export PATH=$STORM_HOME/bin:$PATH`
- 使环境变量生效:`source ~/.bashrc` 或 `source ~/.bash_profile`
- 使用 `echo $STORM_HOME` 命令检查Storm环境变量,并截图保存结果。
9. 在主节点和从节点启动Storm,并截图保存(要求截到url和状态)。
- 在主节点上使用 `storm nimbus` 命令启动Nimbus。
- 在从节点上使用 `storm supervisor` 命令启动Supervisor。
- 使用浏览器或 `curl` 命令访问Nimbus和Supervisor的WebUI,并截图保存结果。
请注意,以上步骤需要根据您的实际环境和配置进行调整。在执行操作时,应具备相应权限,并严格按照操作规范进行,避免对系统造成不必要的影

Guff_hys_python数据结构,大数据开发学习,python实训项目-CSDN博客
相关文章:
1+X大数据平台运维职业技能等级证书中级
hadoop: 由于我的功能限制,我无法直接为您执行这些操作或提供实际的截图。但我可以为您提供一步步的指导,帮助您完成这些任务。 1. 解压JDK安装包到“/usr/local/src”路径,并配置环境变量。 - 解压JDK:tar -zxf jd…...
网络基础(五):网络层协议介绍
目录 一、网络层 1、网络层的概念 2、网络层功能 3、IP数据包格式 二、ICMP协议 1、ICMP的作用和功能 2、ping命令的使用 2.1ping命令的通用格式 2.2ping命令的常用参数 2.3TypeCode:查看不同功能的ICMP报文 2.4ping出现问题 3、Tracert 4、冲突域 5、…...
浅显易懂 @JsonIgnore 的作用
1.JsonIgnore作用 在json序列化/反序列化时将java bean中使用了该注解的属性忽略掉 2.这个注解可以用在类/属性上 例如:在返回user对象时,在pwd属性上使用这个注解,返回user对象时会直接去掉pwd这个字段,不管这个属性有没…...

【计算机设计大赛作品】诗意千年—唐朝诗人群像的数字展现_附源码—信息可视化赛道获奖项目深入剖析【可视化项目案例-20】
🎉🎊🎉 你的技术旅程将在这里启航! 记得看本专栏里顶置的可视化宝典导航贴哦! 🚀🚀 本专栏为可视化专栏,包含现有的所有可视化技术。订阅专栏用户在文章底部可下载对应案例完整源码以供大家深入的学习研究。 🎓 每一个案例都会提供完整代码和详细的讲解,不论你…...
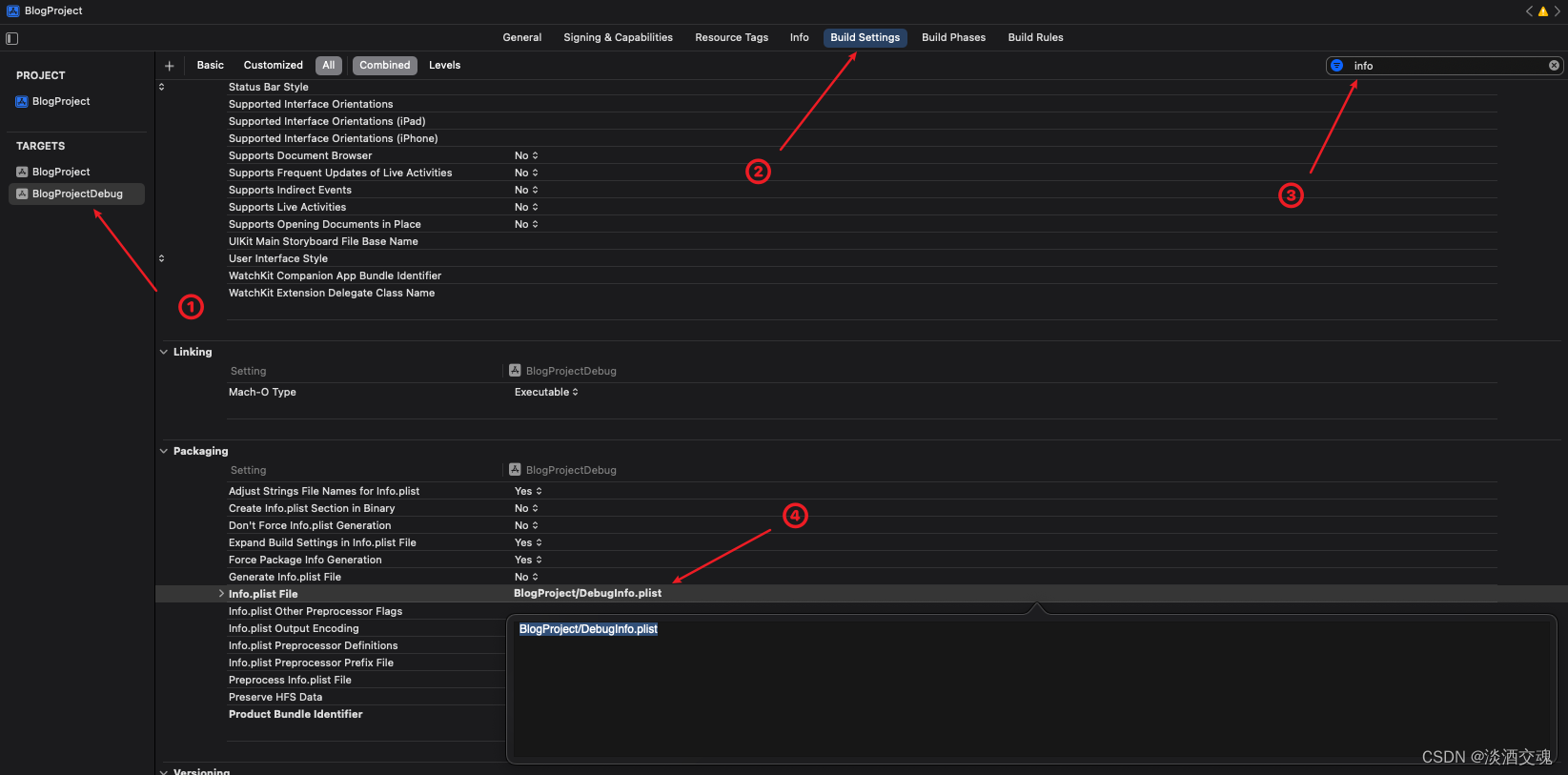
「Swift」Xcode多Target创建
前言:我们日常开发中会使用多个环境,如Dev、UAT,每个环境对应的业务功能都不同,但每个环境之间都只存在较小的差异,所以此时可以使用创建多个Target来实现,每个Target对应这个一个App,可以实现一…...

Python文件命名规则:批量重命名与规则匹配的文件
我从一个旧的 iOS 项目中获得了一个文件夹,其中包含许多类似于 image.png image2x.png another-image.png another-image2x.png然而,由于该项目现在只需要 2x.png 图像,我已经删除了所有的文件没有 2x 的名称。 但是我现在想知道如何轻松…...

『npm』一条命令快速配置npm淘宝国内镜像
📣读完这篇文章里你能收获到 一条命令快速切换至淘宝镜像恢复官方镜像 文章目录 一、设置淘宝镜像源二、恢复官方镜像源三、查看当前使用的镜像 一、设置淘宝镜像源 npm config set registry https://registry.npm.taobao.org服务器建议全局设置 sudo npm config…...
Java EE 多线程之线程安全的集合类
文章目录 1. 多线程环境使用 ArrayList1. 1 Collections.synchronizedList(new ArrayList)1.2 CopyOnWriteArrayList 2. 多线程环境使用队列2.1 ArrayBlockingQueue2.2 LinkedBlockingQueue2.3 PriorityBlockingQueue2.4 TransferQueue 3. 多线程环境使用哈希表3.1 Hashtable3.…...

明明随机数
明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性,他先用计算机生成了N个1到1000之间的随机整数(N<100),对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着不同的学生的学…...

优思学院|如何建立公司运营指标体系?如何推行六西格玛改进运营指标?
关键绩效指标 (KPI) 是测量您团队或组织朝重要商业目标进展表现如何的量化指标,组织会在多个层面使用 KPI,这视乎您想要追踪何指标而定,您可以设定全组织的、特定团队的、或甚至是个人 KPI。 良好的KPI能让公司管理者掌握组织的营运是否进度…...
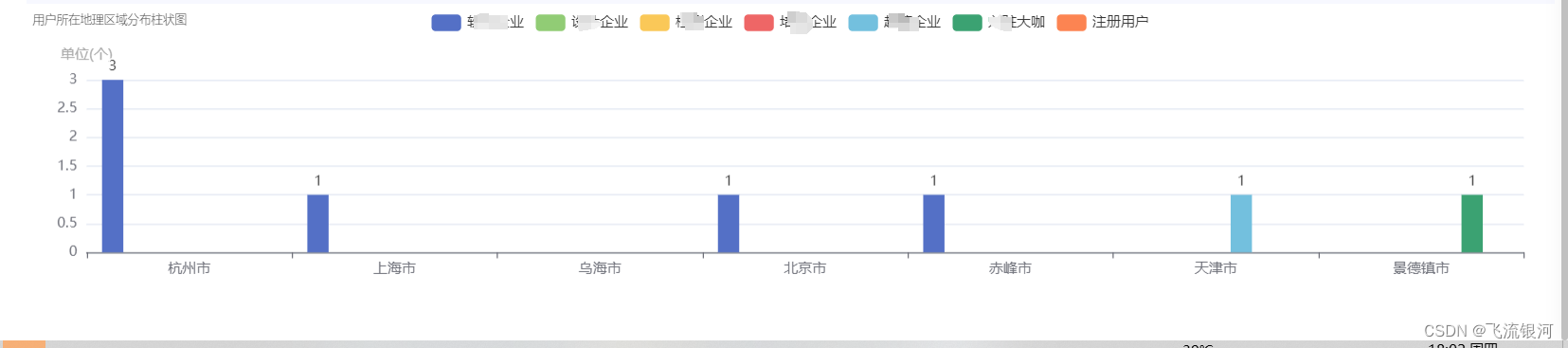
vue2 echarts不同角色多个类型数据的柱状图
前端代码: 先按照echarts插件。在页面里引用 import * as echarts from "echarts";设置div <div style"width:100%;height:250px;margin-top: 4px;" id"addressChart"></div>方法: addressEcharts() {const option {g…...

Mysql表的数据类型
数据类型 https://www.sjkjc.com/mysql/varchar/ MySQL 中的数据类型包括以下几个大类: 字符串类型 数字类型 日期和时间类型 二进制类型 地理位置数据类型 JSON 数据类型 MySQL 字符串数据类型 VARCHAR:纯文本字符串,字符串长度是可变的…...
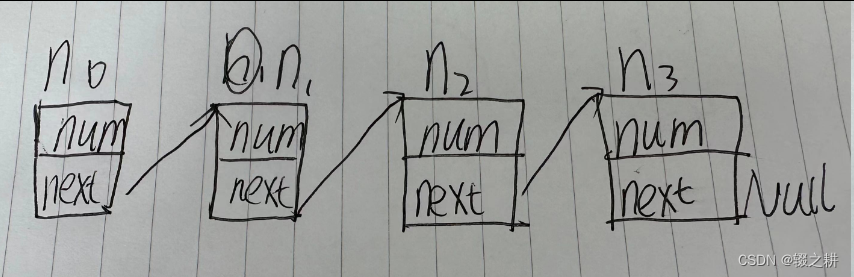
c语言单向链表
看如下代码,这是一个完整的可运行的c源文件,要注意的点: c语言程序运行不一定需要头文件NULL其实是 (void*)0,把指针赋值成(void*)0,就是防止程序员不想该指针被引用的时候被引用,引用地址为0的值程序会引起系统中断&…...

『番外篇三』Swift “乱弹”之带索引遍历异步序列(AsyncSequence)
概览 在 Swift 开发中,我们往往在遍历集合元素的同时希望获得元素对应的索引。在本课中,我们将向小伙伴们展示除 enumerated() 方法之外的几种实现思路。在玩转普通集合之后,我们将用“魔法棒”进一步搞定异步序列带索引遍历的实现。 在本篇博主中,您将学到以下内容: 概…...
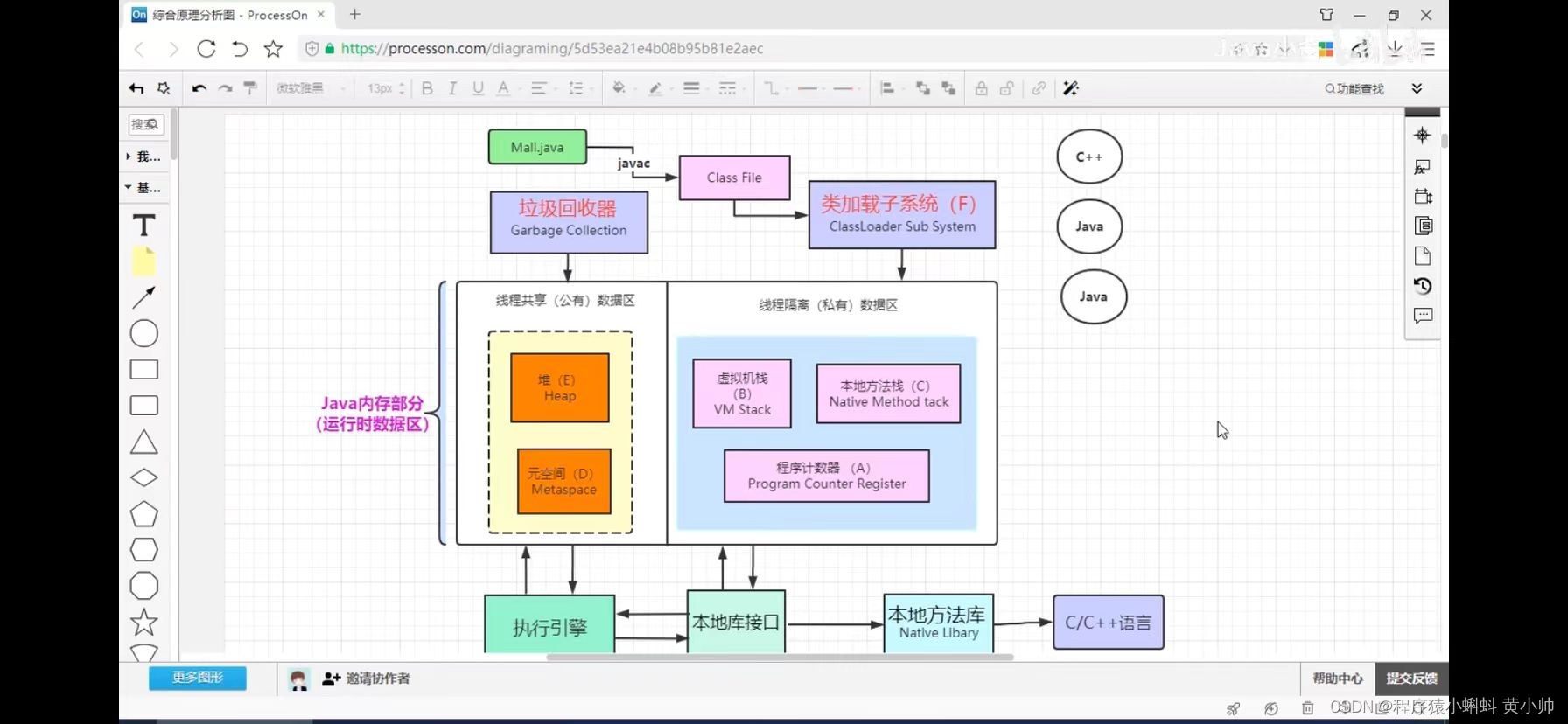
学习JVM
java虚拟机 流程:helloworld.java----(javac编译)----helloworld.class-------(java运行)——JVM——机器码JVM功能 *解释和运行 *内存管理 *即时编译(跨平台-慢一点)jit (反复用到的代码 解释保存再内存里面)…...
Oracle MongoDB
听课的时候第一次碰到,可以了解一下吧,就直接开了墨者学院的靶场 #oracle数据库 Oracle数据库注入全方位利用 - 先知社区 这篇写的真的很好 1.判断注入点 当时找了半天没找到 看样子是找到了,测试一下看看 id1 and 11 时没有报错 2.判断字段…...

Linux-RedHat系统-安装 中间件 Tuxedo
安装步聚 一、中间件安装包: tuxedo121300_64_Linux_01_x86 Tuxedo下载地址: Oracle Tuxedo Downloads 二、新建用户: (创建Oracle用户时,需要root权限操作) 创建用户: # useradd oracle …...

PHP中的依赖注入是怎样的?
依赖注入(Dependency Injection,DI)是一种设计模式,它用于解耦组件之间的依赖关系,提高代码的可维护性、可测试性和灵活性。在 PHP 中,依赖注入通常通过构造函数注入、方法注入或属性注入来实现。 以下是依…...

Python求小于m的最大10个素数
为了找到小于m的最大10个素数,我们首先需要确定m的值。然后,我们可以使用一个简单的算法来检查每一个小于m的数字是否是素数。 下面是一个Python代码示例,可以找到小于m的最大10个素数: def is_prime(n): if n < 1: …...
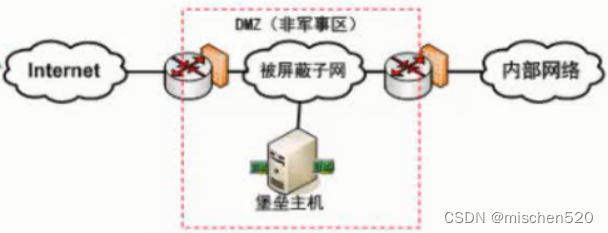
系统的安全性设计
要设计一个安全的系统,除了要了解一些前面讲到的常用的保护手段和技术措施外,还要对系统中可能出现的安全问题或存在的安全隐患有充分的认识,这样才能对系统的安全作有针对性的设计和强化,即“知己知彼,百战百胜”。 下…...

Neorg标签系统完整指南:高效组织笔记的终极方法
Neorg标签系统完整指南:高效组织笔记的终极方法 【免费下载链接】neorg Modernity meets insane extensibility. The future of organizing your life in Neovim. 项目地址: https://gitcode.com/gh_mirrors/ne/neorg Neorg作为一款现代化的Neovim笔记管理工…...
人脸检测实战:ResNet101模型适配PyTorch 2.6部署教程)
MogFace(CVPR 2022)人脸检测实战:ResNet101模型适配PyTorch 2.6部署教程
MogFace(CVPR 2022)人脸检测实战:ResNet101模型适配PyTorch 2.6部署教程 1. 引言:从零部署高精度人脸检测工具 你是否遇到过这样的情况:想要快速检测一张合影中有多少人,或者需要从照片中精准定位人脸位置…...

windows11安装Rust教程:从下载到环境配置
今天研究了一下构建跨平台桌面应用程序的框架Tauri,需要安装Rust环境,记录一下安装教程,防止遗忘。 第一步 前往 官网 下载适用于Windows的安装程序,根据你的电脑选择合适的版本下载。 下载成功后的rustup-init.exe:…...

OpenClaw知识库构建:ollama-QwQ-32B自动整理个人笔记体系
OpenClaw知识库构建:ollama-QwQ-32B自动整理个人笔记体系 1. 为什么需要自动化笔记管理 作为一个长期依赖Markdown记录技术笔记的人,我发现自己逐渐陷入"笔记越多越难找"的困境。上周为了解决一个Python异步编程问题,我明明记得半…...

用Python实战随机森林回归:从数据准备到模型评估的完整流程
Python实战随机森林回归:从数据清洗到模型调优的全流程指南 在数据科学领域,随机森林算法因其出色的预测能力和易用性,已成为解决回归问题的首选工具之一。不同于教科书式的理论讲解,本文将带您亲历一个完整的数据分析项目&#x…...
避开Flutter应用审核雷区:App Tracking Transparency权限的最佳实践指南
Flutter应用ATT权限实战:从合规配置到优雅降级方案 移动应用生态正经历一场深刻的隐私变革。去年某知名社交应用因未正确实现ATT权限被App Store下架,直接导致次日股价下跌4.2%。这警示我们:在Flutter跨平台开发中,ATT权限绝非简单…...
工程入门:从零编写高效指令的10个技巧)
CoPaw提示词(Prompt)工程入门:从零编写高效指令的10个技巧
CoPaw提示词(Prompt)工程入门:从零编写高效指令的10个技巧 1. 为什么需要学习提示词工程 你可能已经发现,同样的AI模型,不同人用起来效果天差地别。有人随便输入几个词就能得到专业级回答,有人写了一大段…...

Hunyuan-MT-7B镜像免配置:自动检测GPU型号并加载最优推理配置
Hunyuan-MT-7B镜像免配置:自动检测GPU型号并加载最优推理配置 1. 开篇:为什么选择这个翻译镜像 如果你正在寻找一个开箱即用的高质量翻译解决方案,特别是需要处理多种语言(包括中文少数民族语言)的翻译任务ÿ…...

万界星空奶油制造工厂MES系统完整解决方案
——覆盖原材料、全链路追溯、不合格品闭环、成本能效与智能合规的一体化乳品智造平台 一、行业背景与挑战奶油(稀奶油、黄油、无水奶油等)作为高敏感度乳制品,具有原料易变质、工艺复杂、保质期短(2–30天)、微生物风…...
实战:表、链、规则的高级查询与动态管理技巧)
nftables(3)实战:表、链、规则的高级查询与动态管理技巧
1. 从零掌握nftables查询基本功 刚接触nftables的朋友经常会被它的命令行语法劝退,但当你真正理解它的设计哲学后,会发现这套查询体系其实非常优雅。我最初从iptables转过来时,花了整整两周时间才适应这种新的操作方式,现在回头看…...