5. PyTorch——数据处理模块
1.数据加载
在PyTorch中,数据加载可通过自定义的数据集对象。数据集对象被抽象为Dataset类,实现自定义的数据集需要继承Dataset,并实现两个Python魔法方法:
__getitem__:返回一条数据,或一个样本。obj[index]等价于obj.__getitem__(index)__len__:返回样本的数量。len(obj)等价于obj.__len__()
这里以Kaggle经典挑战赛"Dogs vs. Cat"的数据为例。"Dogs vs. Cats"是一个分类问题,判断一张图片是狗还是猫,其所有图片都存放在一个文件夹下,根据文件名的前缀判断是狗还是猫。
import numpy as np
import torch as timport osfrom PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms as T
class DogCat(Dataset):def __init__(self, root):imgs = os.listdir(root) # 所有图片的相对路径self.imgs = [os.path.join(root, img) for img in imgs] # 这里不实际加载图片,只是指定路径,当调用__getitem__时才会真正读图片def __getitem__(self, index):img_path = self.imgs[index]# dog -> 1, cat -> 0label = 1 if 'dog' in img_path.split('/')[-1] else 0pil_img = Image.open(img_path)array = np.asarray(pil_img)data = t.from_numpy(array)return data, labeldef __len__(self):return len(self.imgs)
dataset = DogCat('data/dogcat/')for img, label in dataset:print(img.size(), img.float().mean(), label)
torch.Size([500, 497, 3]) tensor(106.4915) 0
torch.Size([499, 379, 3]) tensor(171.8085) 0
torch.Size([236, 289, 3]) tensor(130.3004) 0
torch.Size([374, 499, 3]) tensor(115.5177) 0
torch.Size([375, 499, 3]) tensor(116.8139) 1
torch.Size([375, 499, 3]) tensor(150.5079) 1
torch.Size([377, 499, 3]) tensor(151.7174) 1
torch.Size([400, 300, 3]) tensor(128.1550) 1
这里返回的数据不适合实际使用,因其具有如下两方面问题:
- 返回样本的形状不一,因每张图片的大小不一样,这对于需要取batch训练的神经网络来说很不友好
- 返回样本的数值较大,未归一化至[-1, 1]
针对上述问题,PyTorch提供了torchvision1。它是一个视觉工具包,提供了很多视觉图像处理的工具,其中transforms模块提供了对PIL Image对象和Tensor对象的常用操作。
对PIL Image的操作包括:
Scale:调整图片尺寸,长宽比保持不变CenterCrop、RandomCrop、RandomResizedCrop: 裁剪图片Pad:填充ToTensor:将PIL Image对象转成Tensor,会自动将[0, 255]归一化至[0, 1]
对Tensor的操作包括:
- Normalize:标准化,即减均值,除以标准差
- ToPILImage:将Tensor转为PIL Image对象
如果要对图片进行多个操作,可通过Compose函数将这些操作拼接起来,类似于nn.Sequential。注意,这些操作定义后是以函数的形式存在,真正使用时需调用它的__call__方法,这点类似于nn.Module。例如要将图片调整为 224 × 224 224\times 224 224×224,首先应构建这个操作trans = Resize((224, 224)),然后调用trans(img)。下面我们就用transforms的这些操作来优化上面实现的dataset。
transform = T.Compose([T.Resize(224), # 缩放图片Image,保持长宽比不变,最短边为224T.CenterCrop(224), # 从图片中间切出224*224的图片T.ToTensor(), # 将图片Image转成Tensor,归一化至[0,1]T.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5]) # 标准化至[-1,1],规定均值和标准差
])
class DogCat(Dataset):def __init__(self, root, transform):imgs = os.listdir(root)self.imgs = [os.path.join(root, img) for img in imgs]self.transform = transformdef __getitem__(self, index):img_path = self.imgs[index]# dog->0, cat->1label = 0 if 'dog' in img_path.split('/')[-1] else 1data = Image.open(img_path)if self.transform:data = self.transform(data)return data, labeldef __len__(self):return len(self.imgs)
dataset = DogCat('data/dogcat/', transform=transform)for img, label in dataset:print(img.size(), label)
torch.Size([3, 224, 224]) 1
torch.Size([3, 224, 224]) 1
torch.Size([3, 224, 224]) 1
torch.Size([3, 224, 224]) 1
torch.Size([3, 224, 224]) 0
torch.Size([3, 224, 224]) 0
torch.Size([3, 224, 224]) 0
torch.Size([3, 224, 224]) 0
torchvision已经预先实现了常用的Dataset,包括经典的CIFAR-10,以及ImageNet、COCO、MNIST、LSUN等数据集,可通过诸如torchvision.datasets.CIFAR10来调用,具体使用方法请参看官方文档1。在这里介绍一个会经常使用到的Dataset——ImageFolder,它的实现和上述的DogCat很相似。ImageFolder假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名,其构造函数如下:
ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
它主要有四个参数:
root:在root指定的路径下寻找图片transform:对PIL Image进行的转换操作,transform的输入是使用loader读取图片的返回对象target_transform:对label的转换loader:给定路径后如何读取图片,默认读取为RGB格式的PIL Image对象
label是按照文件夹名顺序排序后存成字典,即{类名:类序号(从0开始)},一般来说最好直接将文件夹命名为从0开始的数字,这样会和ImageFolder实际的label一致,如果不是这种命名规范,建议看看self.class_to_idx属性以了解label和文件夹名的映射关系。
from torchvision.datasets import ImageFolder
dataset = ImageFolder('data/dogcat_2/')
dataset.class_to_idx # cat文件夹的图片对应label 0, dog对应1
{'cat': 0, 'dog': 1}
dataset.imgs # 所有图片的路径和对应的label
[('data/dogcat_2/cat\\cat.12484.jpg', 0),('data/dogcat_2/cat\\cat.12485.jpg', 0),('data/dogcat_2/cat\\cat.12486.jpg', 0),('data/dogcat_2/cat\\cat.12487.jpg', 0),('data/dogcat_2/dog\\dog.12496.jpg', 1),('data/dogcat_2/dog\\dog.12497.jpg', 1),('data/dogcat_2/dog\\dog.12498.jpg', 1),('data/dogcat_2/dog\\dog.12499.jpg', 1)]
# 没有任何的transform,所以返回的还是PIL Image对象
dataset[0][1] # 第一维是第几张图,第二维为1返回label
dataset[0][0] # 为0返回图片数据

# 加上transform
normalize = T.Normalize(mean=[0.4, 0.4, 0.4], std=[0.2, 0.2, 0.2])
transform = T.Compose([T.RandomResizedCrop(224),T.RandomHorizontalFlip(),T.ToTensor(),normalize,
])
dataset = ImageFolder('data/dogcat_2/', transform=transform)
dataset[0][0].size() # 通道数×图片高×图片宽 C×H×W
torch.Size([3, 224, 224])
to_img = T.ToPILImage()
# 0.2和0.4是标准差和均值的近似
to_img(dataset[0][0]*0.2+0.4)

Dataset只负责数据的抽象,一次调用__getitem__只返回一个样本。前面提到过,在训练神经网络时,最好是对一个batch的数据进行操作,同时还需要对数据进行shuffle和并行加速等。对此,PyTorch提供了DataLoader帮助我们实现这些功能。
DataLoader的函数定义如下:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False)
- dataset:加载的数据集(Dataset对象)
- batch_size:batch size
- shuffle::是否将数据打乱
- sampler: 样本抽样,后续会详细介绍
- num_workers:使用多进程加载的进程数,0代表不使用多进程
- collate_fn: 如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可
- pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些
- drop_last:dataset中的数据个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃
from torch.utils.data import DataLoaderdataloader = DataLoader(dataset, batch_size=3, shuffle=True, num_workers=0, drop_last=False)
dataiter = iter(dataloader)
imgs, labels = next(dataiter)
imgs.size() # bach_size, channel, height, weight
torch.Size([3, 3, 224, 224])
dataloader是一个可迭代的对象,意味着我们可以像使用迭代器一样使用它,例如:
for batch_datas, batch_labels in dataloader:train()
或
dataiter = iter(dataloader)
batch_datas, batch_labesl = next(dataiter)
在数据处理中,有时会出现某个样本无法读取等问题,比如某张图片损坏。这时在__getitem__函数中将出现异常,此时最好的解决方案即是将出错的样本剔除。如果实在是遇到这种情况无法处理,则可以返回None对象,然后在Dataloader中实现自定义的collate_fn,将空对象过滤掉。但要注意,在这种情况下dataloader返回的batch数目会少于batch_size。
class NewDogCat(DogCat): # 继承前面实现的DogCat数据集def __getitem__(self, index):try:# 调用父类的获取函数,即DogCat.__getitem__(self, index)return super(NewDogCat, self).__getitem__(index)except:return None, None
from torch.utils.data.dataloader import default_collate # 导入默认的拼接方式def my_collate_fn(batch):batch = list(filter(lambda x:x[0] is not None, batch)) # 过滤为None的数据 if len(batch) == 0: return t.Tensor()return default_collate(batch)
dataset = NewDogCat('data/dogcat_wrong/', transform=transform)
dataset[5]
(tensor([[[ 0.9020, 1.3333, 2.0000, ..., -1.0196, -1.0784, -1.1176],[ 0.9608, 1.4314, 2.0196, ..., -0.9804, -1.0588, -1.1176],[ 1.0196, 1.5294, 2.0588, ..., -1.0000, -1.0588, -1.1176],...,[-0.2745, -0.1569, 0.1373, ..., 0.7843, 0.7451, 0.7059],[-0.3333, -0.1765, 0.2745, ..., 0.7255, 0.7059, 0.6667],[-0.4706, -0.2353, 0.3137, ..., 0.7255, 0.7255, 0.6863]],[[ 0.8235, 1.2549, 1.8824, ..., -0.4510, -0.4510, -0.4314],[ 0.7059, 1.1176, 1.8235, ..., -0.4510, -0.4510, -0.4706],[ 0.6863, 1.1176, 1.8235, ..., -0.4706, -0.4706, -0.4706],...,[-0.1961, -0.0588, 0.2549, ..., 0.6471, 0.6667, 0.6471],[-0.2157, -0.0392, 0.3529, ..., 0.6667, 0.6863, 0.6863],[-0.3333, -0.0980, 0.3725, ..., 0.7059, 0.7451, 0.7647]],[[-0.3529, 0.0000, 0.7647, ..., 0.1176, 0.1373, 0.1373],[-0.3333, 0.0588, 0.6863, ..., 0.0392, 0.0392, 0.0392],[-0.2745, 0.1373, 0.6863, ..., -0.0196, 0.0000, 0.0196],...,[-0.8039, -0.7647, -0.4902, ..., -0.2353, -0.1961, -0.2157],[-1.0588, -0.9608, -0.6078, ..., -0.2549, -0.1765, -0.2157],[-1.2941, -1.1569, -0.7059, ..., -0.2353, -0.1569, -0.1569]]]),0)
dataloader = DataLoader(dataset, 2, collate_fn=my_collate_fn, num_workers=0,shuffle=True)
for batch_datas, batch_labels in dataloader:print(batch_datas.size(),batch_labels.size())
torch.Size([2, 3, 224, 224]) torch.Size([2])
torch.Size([2, 3, 224, 224]) torch.Size([2])
torch.Size([1, 3, 224, 224]) torch.Size([1])
torch.Size([2, 3, 224, 224]) torch.Size([2])
torch.Size([1, 3, 224, 224]) torch.Size([1])
来看一下上述batch_size的大小。其中第2个的batch_size为1,这是因为有一张图片损坏,导致其无法正常返回。而最后1个的batch_size也为1,这是因为共有9张(包括损坏的文件)图片,无法整除2(batch_size),因此最后一个batch的数据会少于batch_szie,可通过指定drop_last=True来丢弃最后一个不足batch_size的batch。
对于诸如样本损坏或数据集加载异常等情况,还可以通过其它方式解决。例如但凡遇到异常情况,就随机取一张图片代替:
class NewDogCat(DogCat):def __getitem__(self, index):try:return super(NewDogCat, self).__getitem__(index)except:new_index = random.randint(0, len(self)-1)return self[new_index]
相比较丢弃异常图片而言,这种做法会更好一些,因为它能保证每个batch的数目仍是batch_size。但在大多数情况下,最好的方式还是对数据进行彻底清洗。
DataLoader里面并没有太多的魔法方法,它封装了Python的标准库multiprocessing,使其能够实现多进程加速。在此提几点关于Dataset和DataLoader使用方面的建议:
- 高负载的操作放在
__getitem__中,如加载图片等。 - dataset中应尽量只包含只读对象,避免修改任何可变对象,利用多线程进行操作。
第一点是因为多进程会并行的调用__getitem__函数,将负载高的放在__getitem__函数中能够实现并行加速。
第二点是因为dataloader使用多进程加载,如果在Dataset实现中使用了可变对象,可能会有意想不到的冲突。在多线程/多进程中,修改一个可变对象,需要加锁,但是dataloader的设计使得其很难加锁(在实际使用中也应尽量避免锁的存在),因此最好避免在dataset中修改可变对象。例如下面就是一个不好的例子,在多进程处理中self.num可能与预期不符,这种问题不会报错,因此难以发现。如果一定要修改可变对象,建议使用Python标准库Queue中的相关数据结构。
class BadDataset(Dataset):def __init__(self):self.datas = range(100)self.num = 0 # 取数据的次数def __getitem__(self, index):self.num += 1return self.datas[index]
使用Python multiprocessing库的另一个问题是,在使用多进程时,如果主程序异常终止(比如用Ctrl+C强行退出),相应的数据加载进程可能无法正常退出。这时你可能会发现程序已经退出了,但GPU显存和内存依旧被占用着,或通过top、ps aux依旧能够看到已经退出的程序,这时就需要手动强行杀掉进程。建议使用如下命令:
ps x | grep <cmdline> | awk '{print $1}' | xargs kill
ps x:获取当前用户的所有进程grep <cmdline>:找到已经停止的PyTorch程序的进程,例如你是通过python train.py启动的,那你就需要写grep 'python train.py'awk '{print $1}':获取进程的pidxargs kill:杀掉进程,根据需要可能要写成xargs kill -9强制杀掉进程
在执行这句命令之前,建议先打印确认一下是否会误杀其它进程
ps x | grep <cmdline> | ps x
PyTorch中还单独提供了一个sampler模块,用来对数据进行采样。常用的有随机采样器:RandomSampler,当dataloader的shuffle参数为True时,系统会自动调用这个采样器,实现打乱数据。默认的是采用SequentialSampler,它会按顺序一个一个进行采样。这里介绍另外一个很有用的采样方法:
WeightedRandomSampler,它会根据每个样本的权重选取数据,在样本比例不均衡的问题中,可用它来进行重采样。
构建WeightedRandomSampler时需提供两个参数:每个样本的权重weights、共选取的样本总数num_samples,以及一个可选参数replacement。权重越大的样本被选中的概率越大,待选取的样本数目一般小于全部的样本数目。replacement用于指定是否可以重复选取某一个样本,默认为True,即允许在一个epoch中重复采样某一个数据。如果设为False,则当某一类的样本被全部选取完,但其样本数目仍未达到num_samples时,sampler将不会再从该类中选择数据,此时可能导致weights参数失效。下面举例说明。
dataset = DogCat('data/dogcat/', transform=transform)# 狗的图片被取出的概率是猫的概率的两倍
# 两类图片被取出的概率与weight的绝对大小无关,只和比值有关
weights = [2 if label == 1 else 1 for data, label in dataset]
weights
[2, 2, 2, 2, 1, 1, 1, 1]
from torch.utils.data.sampler import WeightedRandomSampler
sampler = WeightedRandomSampler(weights,num_samples=9, replacement=True
)
dataloader = DataLoader(dataset,batch_size=3,sampler=sampler)for datas, labels in dataloader:print(labels.tolist())
[0, 1, 0]
[1, 1, 1]
[1, 1, 1]
http://pytorch.org/docs/master/torchvision/datasets.html ↩︎ ↩︎
相关文章:
5. PyTorch——数据处理模块
1.数据加载 在PyTorch中,数据加载可通过自定义的数据集对象。数据集对象被抽象为Dataset类,实现自定义的数据集需要继承Dataset,并实现两个Python魔法方法: __getitem__:返回一条数据,或一个样本。obj[in…...
Android 移动端编译 cityhash动态库
最近做项目, 硬件端 需要 用 cityhash 编译一个 动态库 提供给移动端使用,l 记录一下 编译过程 city .cpp // // Created by Administrator on 2023/12/12. // // Copyright (c) 2011 Google, Inc. // // Permission is hereby granted, free of charg…...
IO流学习
IO流:存储和读取数据的解决方案 import java.io.FileOutputStream; import java.io.IOException;public class Test {public static void main(String[] args) throws IOException {//1.创建对象//写出 输入流 OutputStream//本地文件fileFileOutputStream fos new FileOutputS…...

新手HTML和CSS的常见知识点
目录 1.HTML标题标签(到)用于定义网页中的标题,并按照重要性递减排列。例如: 2.HTML段落标签()用于定义网页中的段落。例如: 3.HTML链接标签()用于创建链接…...

RocketMQ系统性学习-RocketMQ领域模型及Linux下单机安装
MQ 之间的对比 三种常用的 MQ 对比,ActiveMQ、Kafka、RocketMQ 性能方面: 三种 MQ 吞吐量级别为:万,百万,十万消息发送时延:毫秒,毫秒,微秒可用性:主从,分…...
微服务架构之争:Quarkus VS Spring Boot
在容器时代(“Docker时代”),无论如何,Java仍然活着。Java在性能方面一直很有名,主要是因为代码和真实机器之间的抽象层,多平台的成本(一次编写,随处运行——还记得吗?&a…...
如何使用ArcGIS Pro拼接影像
为了方便数据的存储和传输,我们在网上获取到的影像一般都是分块的,正式使用之前需要对这些影像进行拼接,这里为大家介绍一下ArcGIS Pro中拼接影像的方法,希望能对你有所帮助。 数据来源 本教程所使用的数据是从水经微图中下载的…...
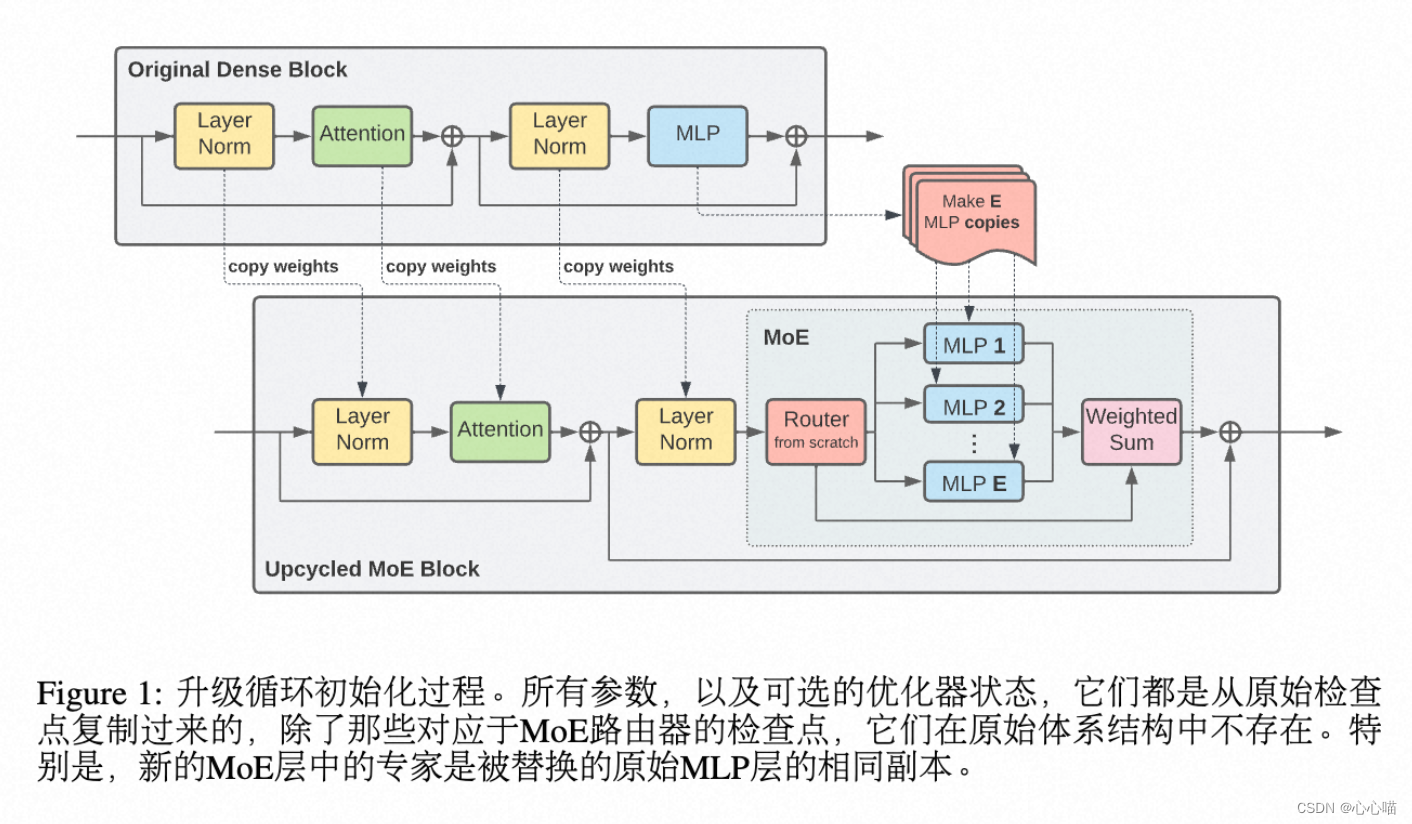
[论文笔记] chatgpt系列 SparseMOE—GPT4的MOE结构
SparseMOE: 稀疏激活的MOE Swtich MOE,所有token要在K个专家网络中,选择一个专家网络。 显存增加。 Experts Choice:路由MOE: 由专家选择token。这样不同的专家都选择到某个token,也可以不选择该token。 由于FFN层的时间复杂度和attention层不同,FFN层的时…...
C# WPF上位机开发(键盘绘图控制)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 在软件开发中,如果存在canvas图像的话,一般有几种控制方法。一种是鼠标控制;一种是键盘控制;还有一…...
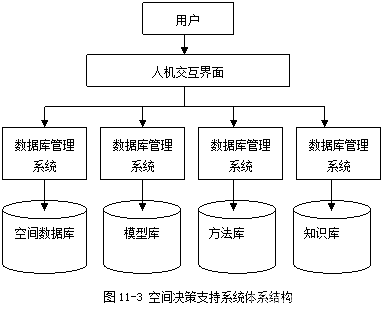
《地理信息系统原理》笔记/期末复习资料(10. 空间数据挖掘与空间决策支持系统)
目录 10. 空间数据挖掘与空间决策支持系统 10.1. 空间数据挖掘 10.1.1. 空间数据挖掘的概念 10.1.2. 空间数据挖掘的方法与过程 10.1.3. 空间数据挖掘的应用 10.2. 空间决策支持系统 10.2.1. 空间决策支持系统的概念 10.2.2. 空间决策支持系统的结构 10.2.3. 空间决策…...
uniapp播放 m3u8格式视频 兼容pc和移动端
支持全自动播放、设置参数 自己摸索出来的,花了一天时间,给点订阅支持下,订阅后,不懂的地方可以私聊我。 代码实现 代码实现 1.安装dplayer组件 npm i dplayer2. static/index.html下引入 hls 引入hls.min.js 可以存放在static项目hls下面<script src="/static…...
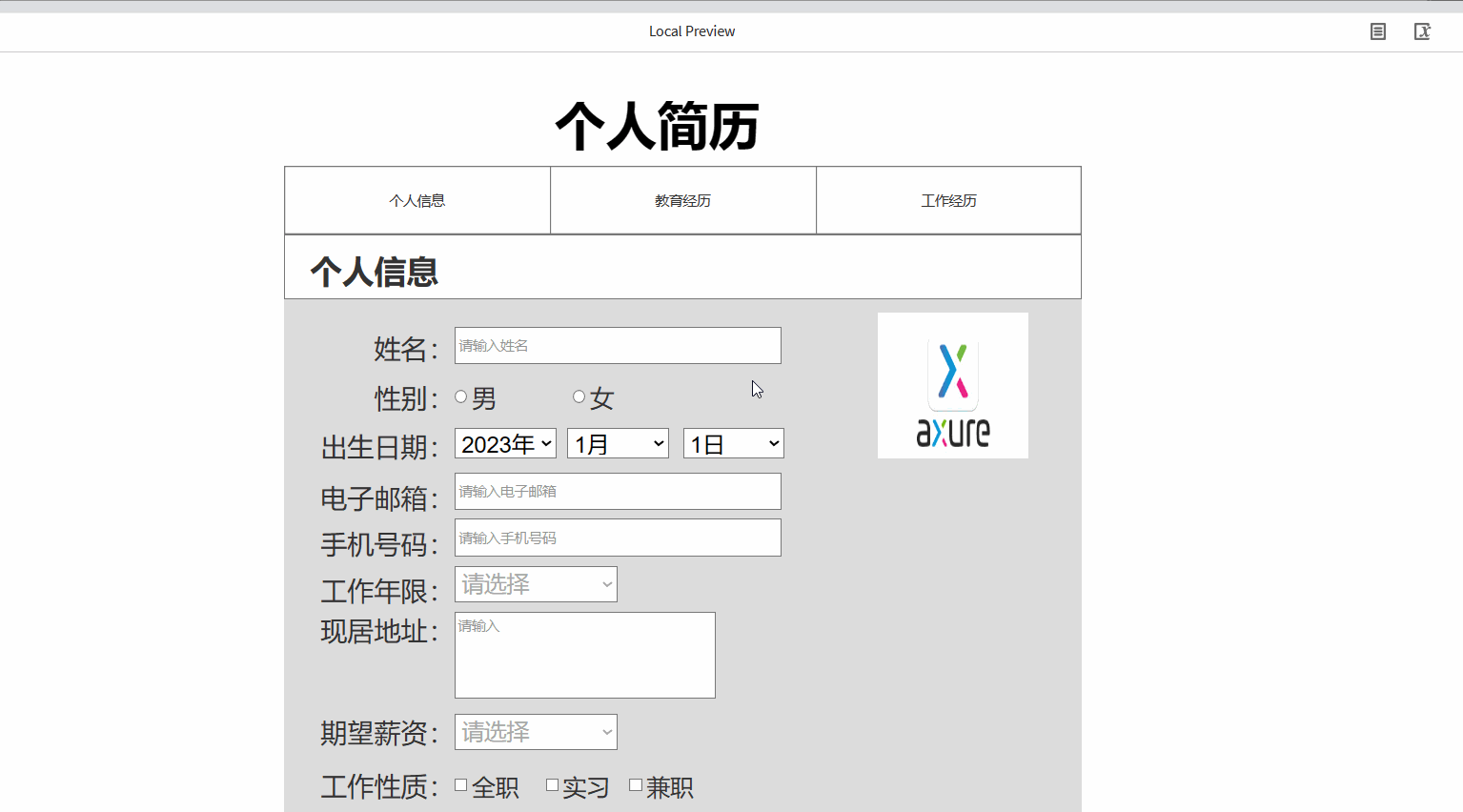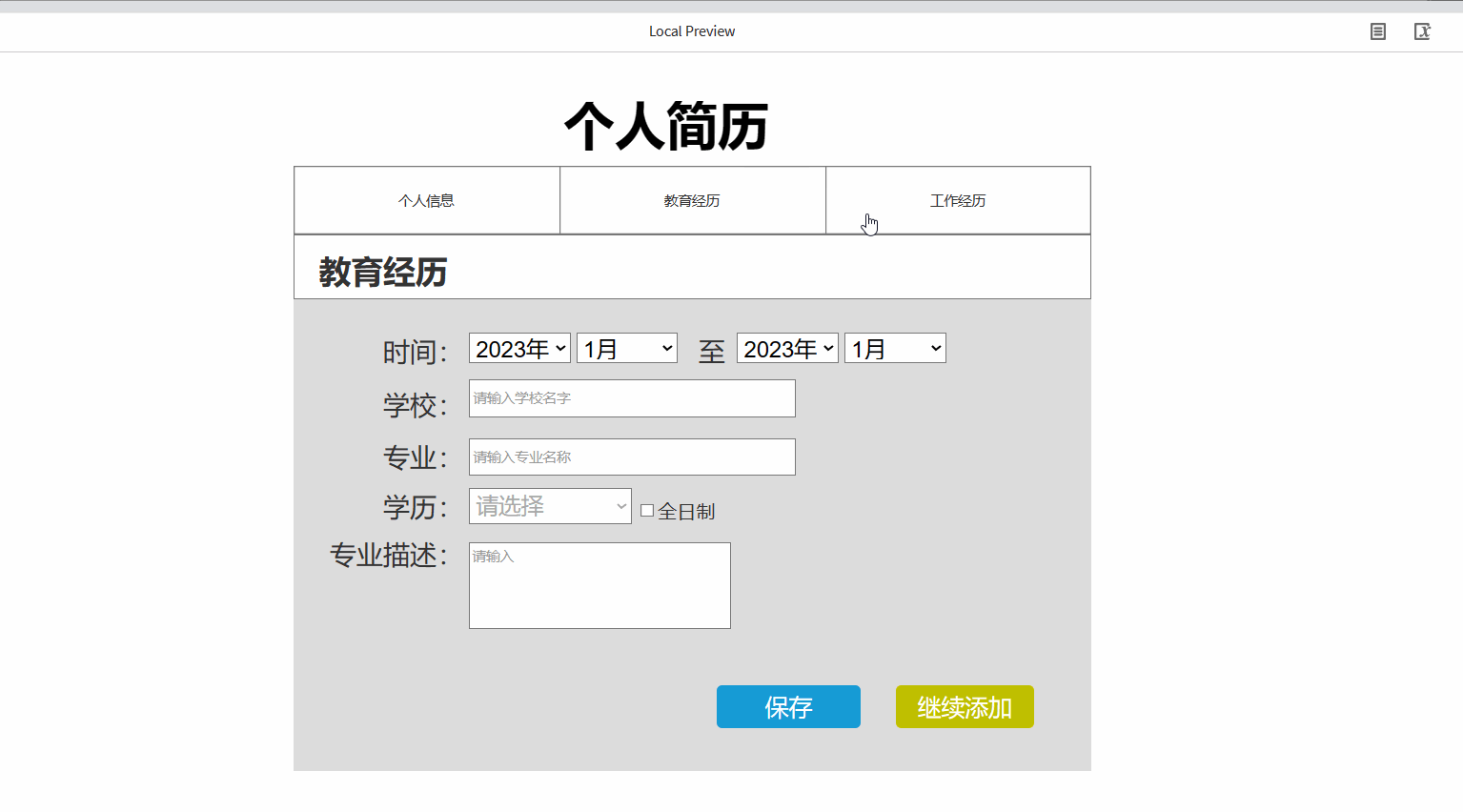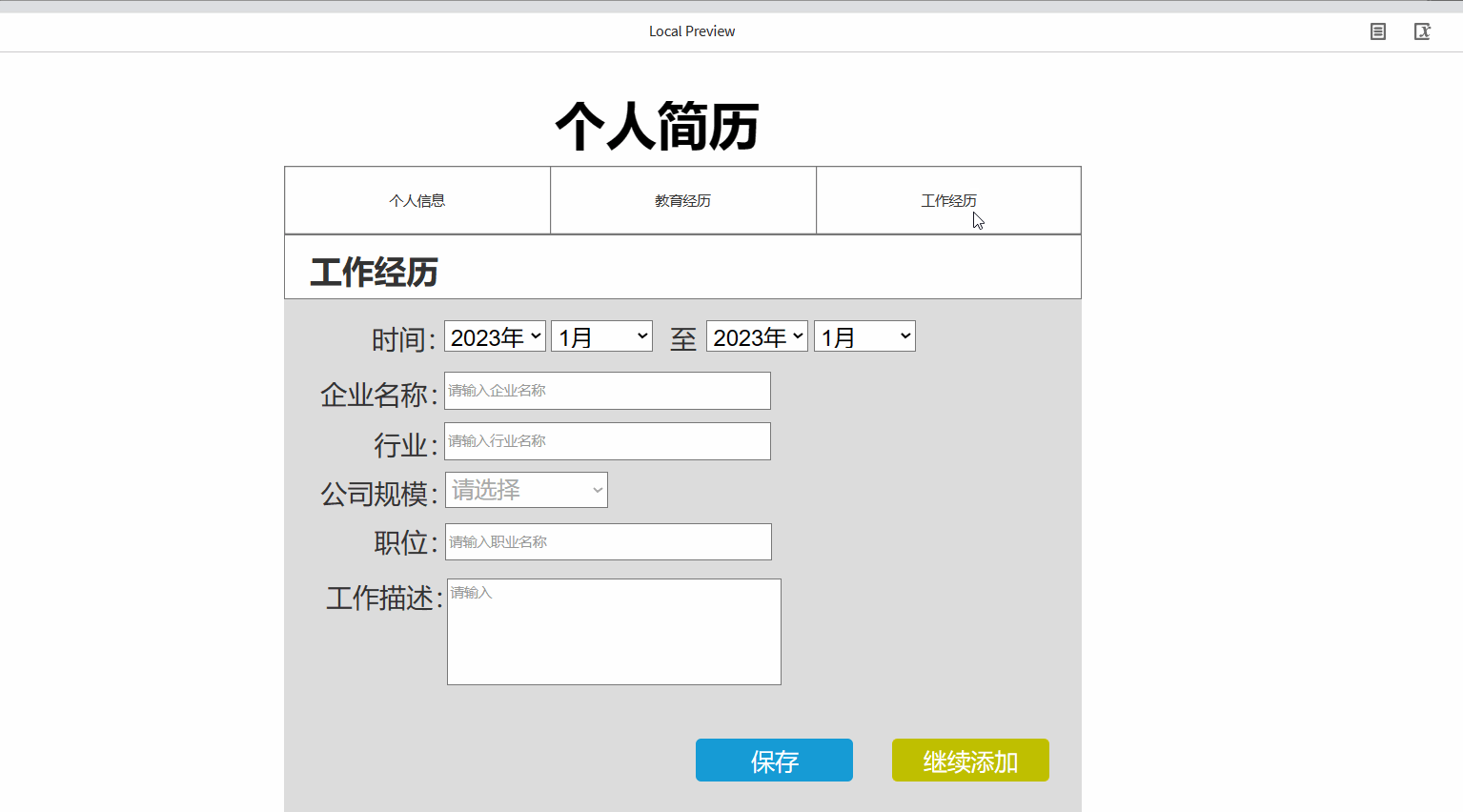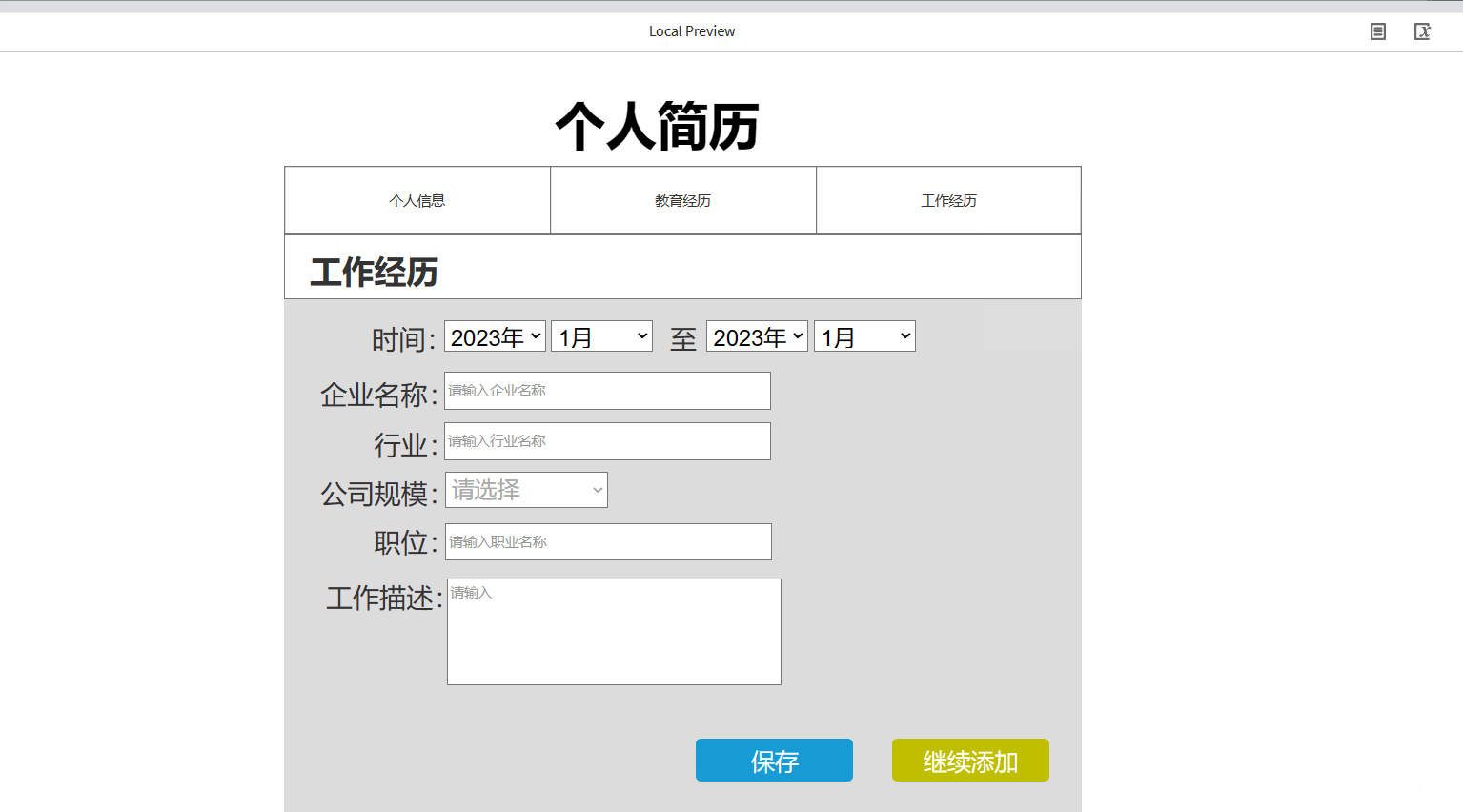
产品经理之Axure的元件库使用详细案例
⭐⭐ 产品经理专栏:产品专栏 ⭐⭐ 个人主页:个人主页 目录 前言 一.Axure的元件库的使用 1.1 元件介绍 1.2 基本元件的使用 1.2.1 矩形、按钮、标题的使用 1.2.2 图片及热区的使用 1.3 表单元件及表格元件的使用 1.3.1表单元件的使用 1.3.…...
数字化转型对企业有什么好处?
引言 数字化转型已经成为当今商业领域中的一股强大力量,它不仅仅是简单的技术更新,更是企业发展的重要战略转变。随着科技的迅猛发展和全球化竞争的加剧,企业们正在积极探索如何将数字化的力量融入到他们的运营和战略中。 数字化转型不仅是传…...

微信小程序:按钮禁用,避免按钮重复提交
wxml <view class"modal-buttons"><view class"one_btn" bindtap"submit">确认</view><view class"two_btn" bindtap"cancel">取消</view> </view> wxss /* 按钮 */ .modal-buttons…...
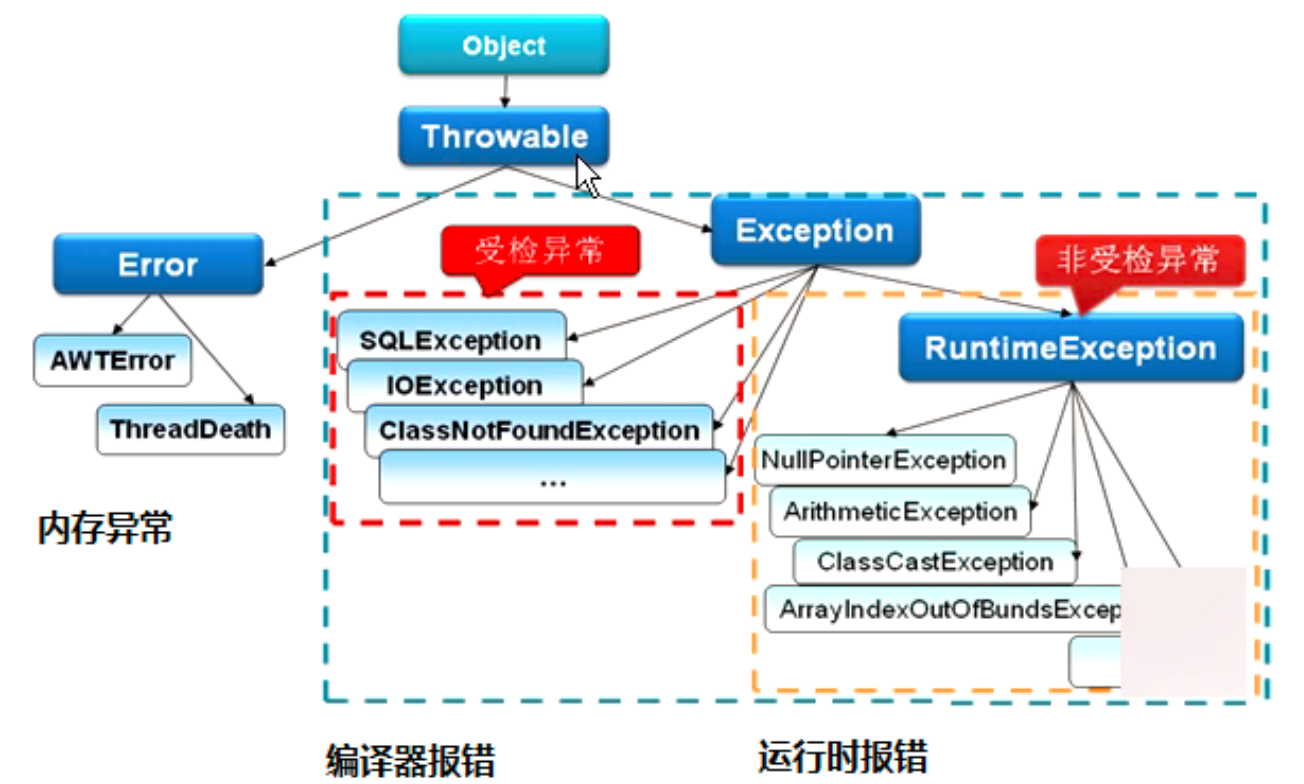
JAVA 异常分类及处理
JAVA 异常分类及处理 概念 如果某个方法不能按照正常的途径完成任务,就可以通过另一种路径退出方法。在这种情况下会抛出一个封装了错误信息的对象。此时,这个方法会立刻退出同时不返回任何值。另外,调用这个方法的其他代码也无法继续执行&…...
C语言--求数组的最大值和最小值【两种方法】
🍗方法一:用for循环遍历数组,找出最大值与最小值 🍗方法二:用qsort排序,让数组成为升序的有序数组,第一个值就是最小值,最后一个是最大值 完整代码: 方法一: …...
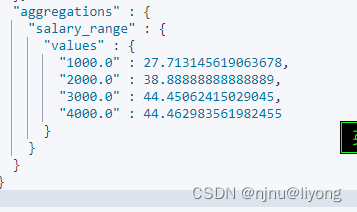
ES-组合与聚合
ES组合查询 1 must 满足两个match才会被命中 GET /mergeindex/_search {"query": {"bool": {"must": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}]}}…...
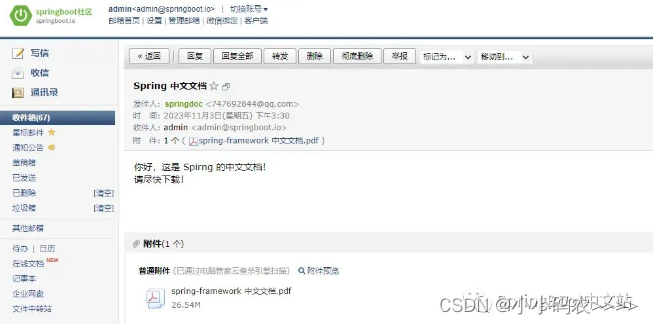
在 Spring Boot 中发送邮件简单实现
Spring Boot 对于发送邮件这种常用功能也提供了开箱即用的 Starter:spring-boot-starter-mail。 通过这个 starter,只需要简单的几行配置就可以在 Spring Boot 中实现邮件发送,可用于发送验证码、账户激活等等业务场景。 本文将通过实际的案…...
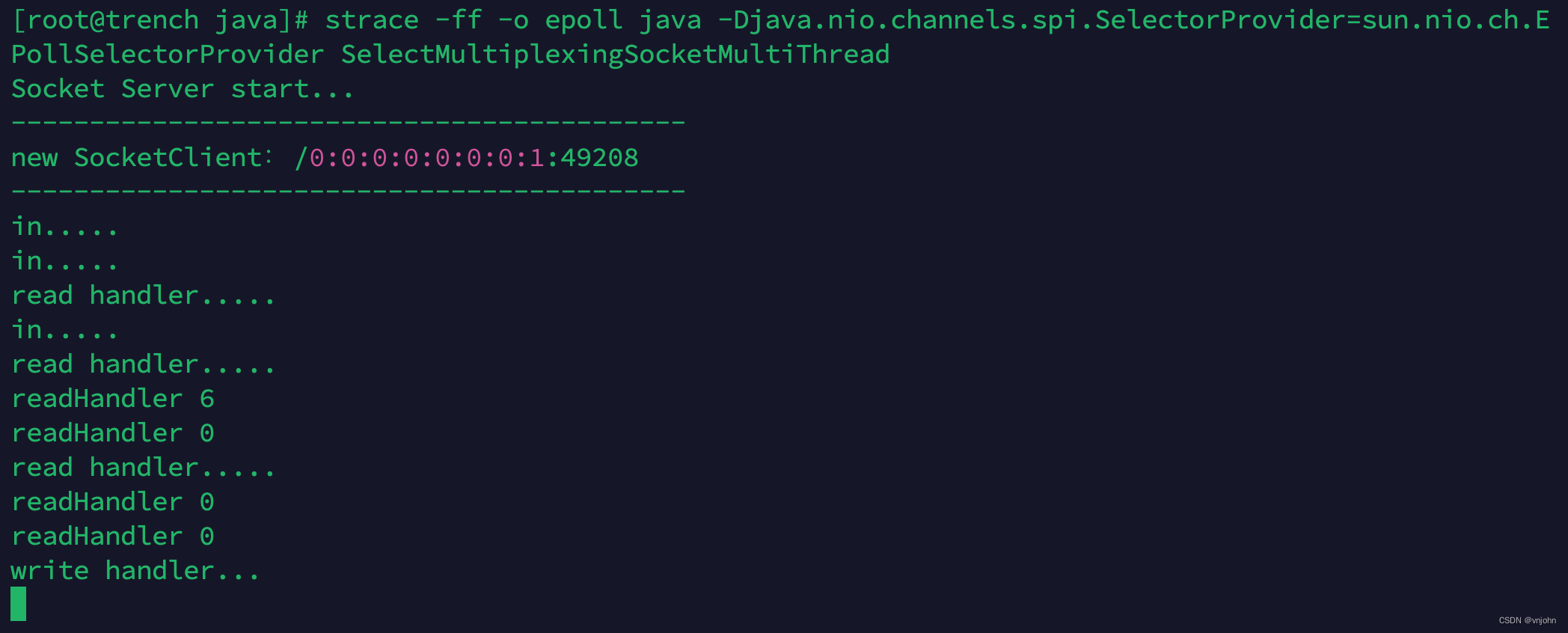
深入理解网络 I/O:单 Selector 多线程|单线程模型
🔭 嗨,您好 👋 我是 vnjohn,在互联网企业担任 Java 开发,CSDN 优质创作者 📖 推荐专栏:Spring、MySQL、Nacos、Java,后续其他专栏会持续优化更新迭代 🌲文章所在专栏&…...

Kafka Avro序列化之三:使用Schema Register实现
为什么需要Schema Register 注册表 无论是使用传统的Avro API自定义序列化类和反序列化类 还是 使用Twitter的Bijection类库实现Avro的序列化与反序列化,这两种方法都有一个缺点:在每条Kafka记录里都嵌入了schema,这会让记录的大小成倍地增加。但是不管怎样,在读取记录时…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...