大模型下开源文档解析工具总结及技术思考
1 基于文档解析工具的方法
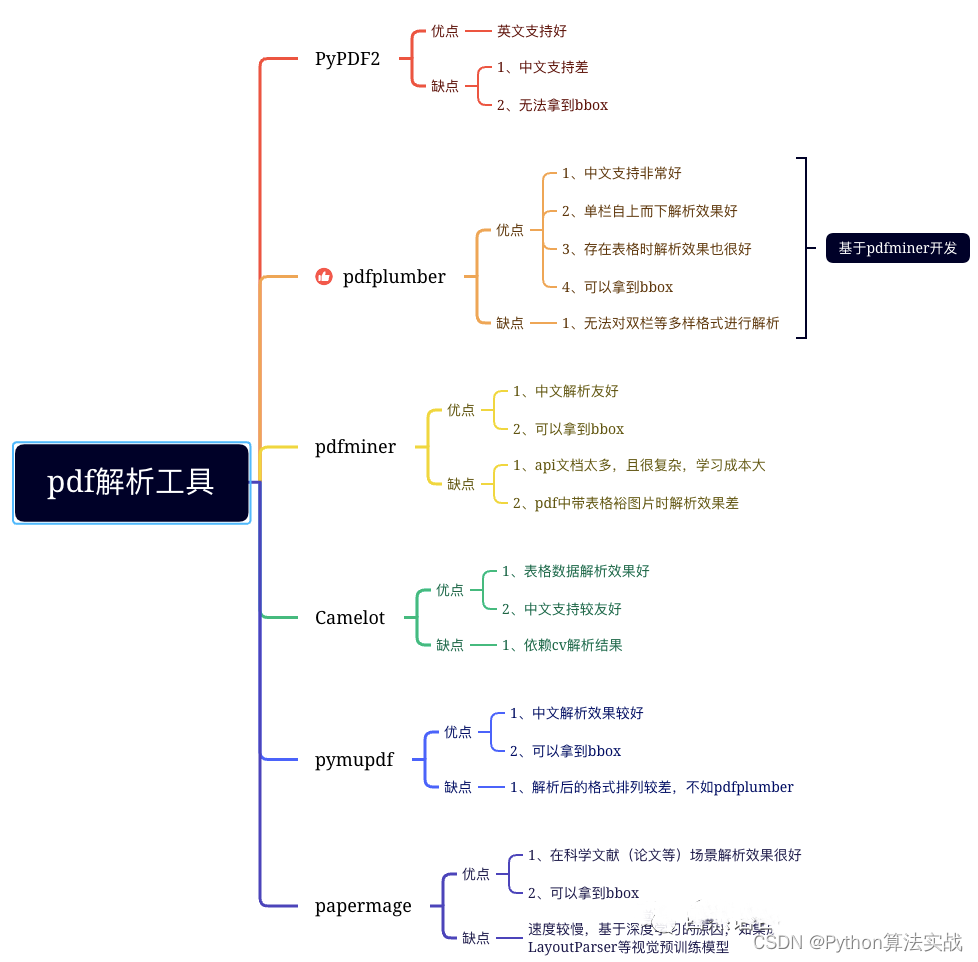
pdf解析工具
导图一览:
-
PyPDF2提取txt:
import PyPDF2 def extract_text_from_pdf(pdf_path):with open(pdf_path, 'rb') as file:pdf_reader = PyPDF2.PdfFileReader(file)num_pages = pdf_reader.numPagestext = ""for page_num in range(num_pages):page = pdf_reader.getPage(page_num)text += page.extractText()return textpdf_path = 'example.pdf' extracted_text = extract_text_from_pdf(pdf_path) print(extracted_text) -
pdfplumber提取text:
import pdfplumbertext = "" with pdfplumber.open('example.pdf') as pdf:for page in pdf.pages:text += page.extract_text()print(text) -
pdfminer提取text:
pdfminer是一款非常强大的pdf文档解析工具,值得根据自身的场景重写其中的部分工具函数。pdfminer通过布局分析返回的PDF文档中的每个页面LTPage对象。这个对象和页内包含的子对象,形成一个树结构,如图所示:结构如图:
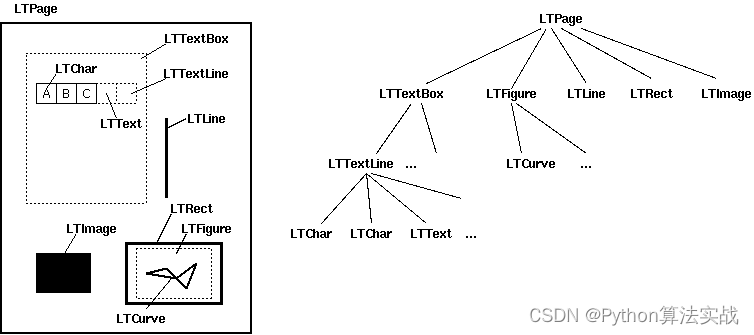
pdfminer
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import TextConverter from pdfminer.layout import LAParams from pdfminer.pdfpage import PDFPage from io import StringIO# 打开PDF文件 with open('example.pdf', 'rb') as file:# 创建一个PDFResourceManager对象resource_manager = PDFResourceManager()# 创建一个StringIO对象,用于存储提取的文本内容output = StringIO()# 创建一个TextConverter对象converter = TextConverter(resource_manager, output, laparams=LAParams())# 创建一个PDFPageInterpreter对象interpreter = PDFPageInterpreter(resource_manager, converter)# 逐页解析文档for page in PDFPage.get_pages(file):interpreter.process_page(page)# 获取提取的文本内容text = output.getvalue()print(text) -
pymupdf提取text:
import fitzdef MuPDF_extract_text_from_pdf(path):doc = fitz.open(path)all_content = []page_nums = 0for i in doc.pages():page_nums += 1all_content.append(i.get_text())text = '\n'.join(all_content)# text = ''.join(text.split('\n'))return text -
papermerge:EMNLP 2023 最佳 Demo
from papermage.recipes import CoreReciperecipe = CoreRecipe() doc = recipe.run("example.pdf") for page in doc.pages:for row in page.rows:print(row.text)
doc、docx解析工具
-
Python-dox:优点:能够解析docx格式文档;缺点:doc格式文档无法直接解析,需要进行转换为docx格式间接解析
import docxdef extract_text_from_word_document(file_path):document = docx.Document(file_path)text = '\n'.join([paragraph.text for paragraph in document.paragraphs])return textfile_path = 'example.docx' text = extract_text_from_word_document(file_path) print(text) -
tika:Python Tika是一个基于Apache Tika的python库,可以解析各种格式的文档,如PDF、Microsoft Office、OpenOffice、XML、HTML、TXT等等。它提供了一种非常方便的方法来获取文档内容,包括元数据、正文、各种格式、图片、表格等等。(注意:需要依赖java环境)
from tika import parserparsed = parser.from_file('example.pdf') content = parsed['content'] print(content)
图片型文档解析工具
-
paddleocr:
from paddleocr import PaddleOCRocr = PaddleOCR(use_angle_cls=True, lang="ch") img_path = 'example.jpg' result = ocr.ocr(img_path, cls=True) for idx in range(len(result)):res = result[idx]for line in res:print(line)
2 基于深度学习的文档解析方法
版面分析
- 基于开源项目的版面分析:ppstructure:项目地址:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/ppstructure/docs/quickstart.md
import os
import cv2
from paddleocr import PPStructure,save_structure_restable_engine = PPStructure(table=False, ocr=False, show_log=True)save_folder = './output'
img_path = 'ppstructure/docs/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])for line in result:line.pop('img')print(line)
-
基于自有场景的版面分析:常见的思路主要为,训练版面分析模型用于识别文档中各个信息区块,然后通过ocr工具解析特定区块中的文字信息。如果涉及复杂版面(如:双栏等),则需要根据启发式规则(根据bbox排序)进行信息区块的排序。常见的如:XY-CUT算法,xy_cut算法如:
import numpy as npdef xy_cut(bboxes, direction="x"):result = []K = len(bboxes)indexes = range(K)if len(bboxes) <= 0:return resultif direction == "x":# x firstsorted_ids = sorted(indexes, key=lambda k: (bboxes[k][0], bboxes[k][1]))sorted_boxes = sorted(bboxes, key=lambda x: (x[0], x[1]))next_dir = "y"else:sorted_ids = sorted(indexes, key=lambda k: (bboxes[k][1], bboxes[k][0]))sorted_boxes = sorted(bboxes, key=lambda x: (x[1], x[0]))next_dir = "x"curr = 0np_bboxes = np.array(sorted_boxes)for idx in range(len(sorted_boxes)):if direction == "x":# a new seg pathif idx != K - 1 and sorted_boxes[idx][2] < sorted_boxes[idx + 1][0]:rel_res = xy_cut(sorted_boxes[curr:idx + 1], next_dir)result += [sorted_ids[i + curr] for i in rel_res]curr = idx + 1else:# a new seg pathif idx != K - 1 and sorted_boxes[idx][3] < sorted_boxes[idx + 1][1]:rel_res = xy_cut(sorted_boxes[curr:idx + 1], next_dir)result += [sorted_ids[i + curr] for i in rel_res]curr = idx + 1result += sorted_ids[curr:idx + 1]return resultdef augment_xy_cut(bboxes,direction="x",lambda_x=0.5,lambda_y=0.5,theta=5,aug=False):if aug is True:for idx in range(len(bboxes)):vx = np.random.normal(loc=0, scale=1)vy = np.random.normal(loc=0, scale=1)if np.abs(vx) >= lambda_x:bboxes[idx][0] += round(theta * vx)bboxes[idx][2] += round(theta * vx)if np.abs(vy) >= lambda_y:bboxes[idx][1] += round(theta * vy)bboxes[idx][3] += round(theta * vy)bboxes[idx] = [max(0, i) for i in bboxes[idx]]res_idx = xy_cut(bboxes, direction=direction)res_bboxes = [bboxes[idx] for idx in res_idx]return res_idx, res_bboxesbboxes = [[58.54924774169922, 1379.6373291015625, 1112.8863525390625, 1640.0870361328125],[60.1091423034668, 483.88677978515625, 1117.4927978515625, 586.197021484375],[57.687435150146484, 1098.1053466796875, 387.9796142578125, 1216.916015625],[63.158992767333984, 311.2080993652344, 1116.2508544921875, 365.2145080566406],[138.85513305664062, 144.44039916992188, 845.18017578125, 198.04937744140625],[996.1032104492188, 1053.6279296875, 1126.1046142578125, 1071.3463134765625],[58.743492126464844, 634.3077392578125, 898.405029296875, 700.9544677734375],[61.35755920410156, 750.6771240234375, 1051.1060791015625, 850.3980712890625],[426.77691650390625, 70.69780731201172, 556.0884399414062, 109.58145141601562],[997.040283203125, 903.5933227539062, 1129.2984619140625, 921.10595703125],[59.40523910522461, 1335.1563720703125, 329.7382507324219, 1357.46533203125],[568.9025268554688, 14.365530967712402, 1087.898193359375, 32.60292434692383],[998.1250610351562, 752.936279296875, 1128.435546875, 770.4116821289062],[59.6968879699707, 947.9129638671875, 601.4513549804688, 999.4548950195312],[58.91489028930664, 1049.8773193359375, 487.3372497558594, 1072.2935791015625],[60.49456024169922, 902.8802490234375, 600.7571411132812, 1000.3502197265625],[60.188941955566406, 247.99755859375, 155.72970581054688, 272.1385192871094],[996.873291015625, 637.3861694335938, 1128.3558349609375, 655.1572875976562],[59.74936294555664, 1272.98828125, 154.8768310546875, 1295.870361328125],[58.835716247558594, 1050.5926513671875, 481.59027099609375, 1071.966796875],[60.60163116455078, 750.1132202148438, 376.1781921386719, 771.8764038085938],[57.982513427734375, 419.16058349609375, 155.35882568359375, 444.25115966796875],[1017.0194091796875, 1336.21826171875, 1128.002197265625, 1355.67724609375],[1019.8740844726562, 486.90814208984375, 1127.482421875, 504.61767578125]]res_idx, res_bboxes = augment_xy_cut(bboxes, direction="y") print(res_idx) # res_idx, res_bboxes = augment_xy_cut(bboxes, direction="x") # print(res_idx)new_boxs = [] for i in res_idx:# print(i)new_boxs.append(bboxes[i])print(new_boxs)常见的单模态(目标检测)深度学习模型方法:Yolo系列、mask-RCNN、faster-CNN等
常见的多模态深度学习模型方法:layoutlmv3等

3 文本分割模型在文档解析中的角色
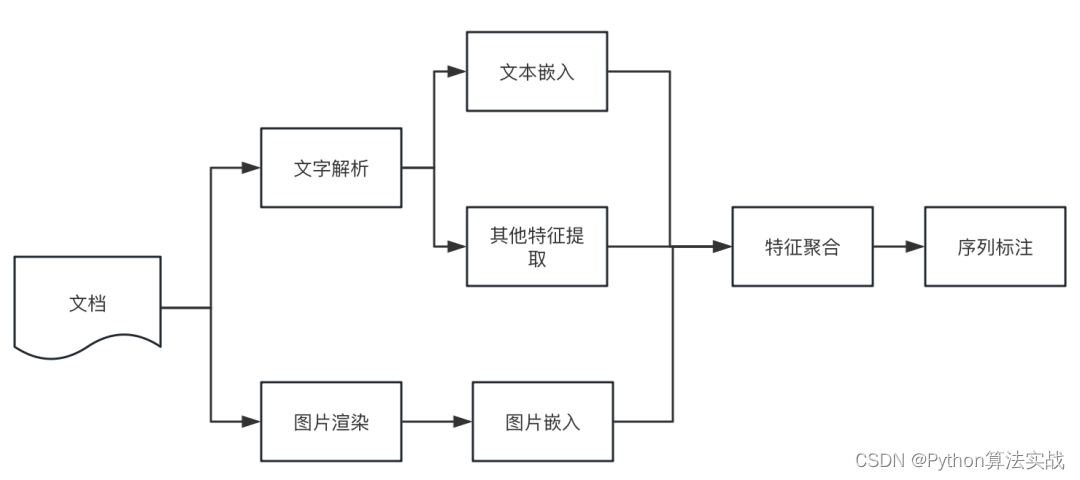
在经过以上的解析工具解析文本时,都会丢失文本原始的信息,包括:段落语义信息、字体、字号等文本特征信息。如何恢复原始的文本段落显得尤其重要,这关系到后续对文档的进一步的处理和分析。一般的,通过启发式规则根据坐标信息排列和聚合出段落,如:字坐标、行坐标等。但过程往往非常复杂且效果一般。因此,基于文本分割模型的版面分析算法显得尤为重要。最初的想法来源于序列标注模型,那么是否能应用序列标注的方法,来预测文本行之间的跳转概率?答案是肯定的,以pdf为例,具体实施步骤如下:

-
从pdf读取程序或ocr引擎中得到文本行及其坐标;
-
使用神经网络对第i行的文本进行编码,得到文本嵌入向量text_emb(i);
-
提取对应行的图像,得到图像嵌入向量img_emb(i);
-
提取字号、文字长度特征,并进行归一化得到特征向量;
-
聚合步骤2、3、4得到的向量,得到行嵌入line_emb(i);
-
使用神经网络对行向量序列[line_emb(i)]进行序列标注。
整体方案流程图如下:
4 单双栏区分
无论是文档parser还是版面分析的方法,解析后的信息区块都不是按照顺序进行返回的。因此需要重新组织“阅读顺序”。对于单栏文档,按照y坐标升降序就能完成顺序的组织,但是对于双栏文档,就需要进一步的分析处理。
在一些学术文档中,比较好办,一般找到文档的所有信息块的中心店坐标即可,用这一组横坐标的极差来判断即可,双栏论文的极差远远大于单栏论文,因此可以设定一个极差阈值。那么区别“阅读顺序”先找到中线,中线横坐标由求极差的横坐标+得到,然后将左右栏的区块分开,按照纵坐标排序即可。

对于更复杂的布局文档解析,这一块是一个难点,有相关资料是寻找信息区块的视觉间隙,从而切开重排信息区块。
总结
本文介绍了一些常见的文档解析工具和实现方法以及文本分割模型在文档解析中的充当的角色,并提供了相关技术实现思路。当然,如果粗糙的进行文档处理也是可以的,常见的有,基于LangChain的文档处理方式,但其底层技术很多都是上述文档parser工具的集成。在面对复杂文档,解析时还是存在一定的困难,基于布局的多模态版面分析是值得研究的点。虽然目前百模支撑的上下文长度能cover一本书的长度,但真正落地实施起来效果一般。并且,一些目前一些常见的LLM应用,如:DocQA,通常将文本切片后进行向量化存入向量数据库,然后基于检索召回与query相关的片段输入到LLM中,LLM与向量数据库还是分离的形式,做出来的文档问答系统自然效果也就一般。因此,文档解析后,如何进行重新划分并得到完整的语义块值的进一步的探索。
技术交流
建了技术交流群!想要进交流群、获取如下原版资料的同学,可以直接加微信号:dkl88194。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:dkl88194,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
资料1

资料2

参考文献
- PaperMage:https://github.com/allenai/papermage
相关文章:
大模型下开源文档解析工具总结及技术思考
1 基于文档解析工具的方法 pdf解析工具 导图一览: PyPDF2提取txt: import PyPDF2 def extract_text_from_pdf(pdf_path):with open(pdf_path, rb) as file:pdf_reader PyPDF2.PdfFileReader(file)num_pages pdf_reader.numPagestext ""f…...
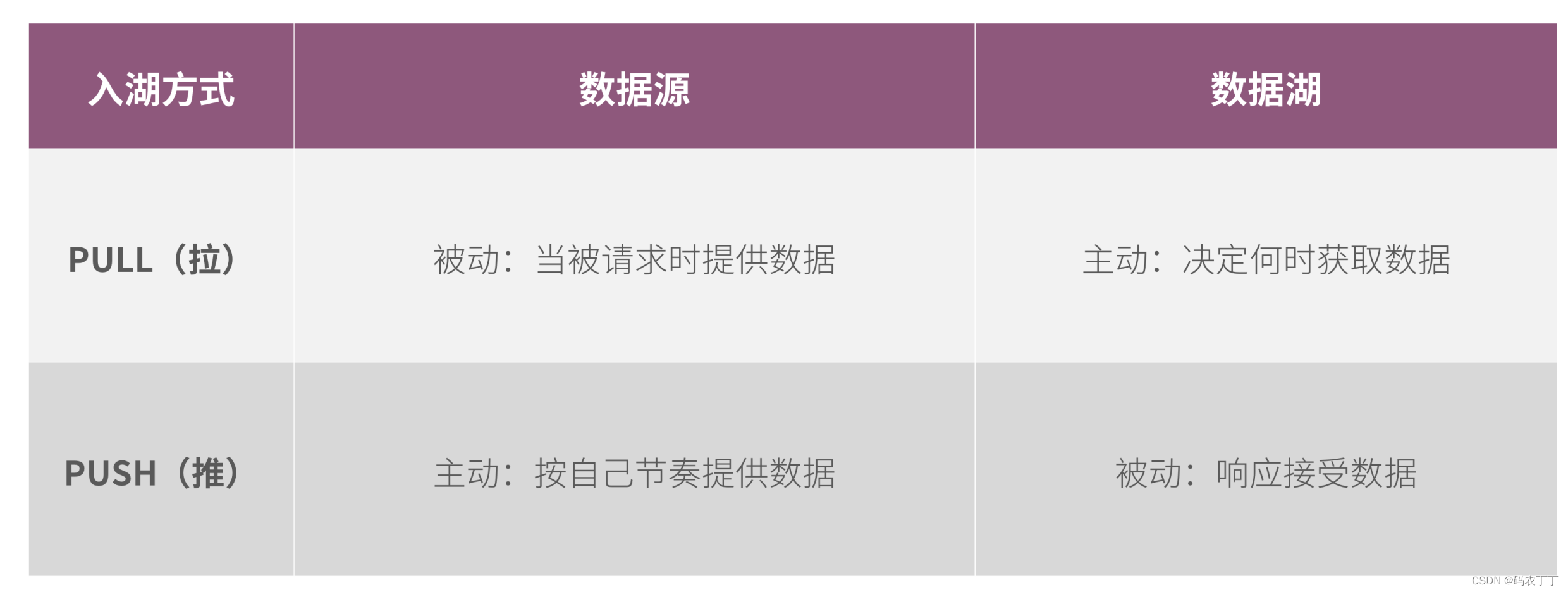
【华为数据之道学习笔记】5-4 数据入湖方式
数据入湖遵循华为信息架构,以逻辑数据实体为粒度入湖,逻辑数据实体在首次入湖时应该考虑信息的完整性。原则上,一个逻辑数据实体的所有属性应该一次性进湖,避免一个逻辑实体多次入湖,增加入湖工作量。 数据入湖的方式…...
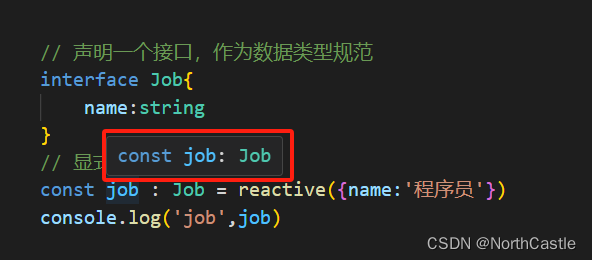
Vue3-03-reactive() 响应式基本使用
reactive() 的简介 reactive() 是vue3 中进行响应式状态声明的另一种方式; 但是,它只能声明 【对象类型】的响应式变量,【不支持声明基本数据类型】。reactive() 与 ref() 一样,都是深度响应式的,即对象嵌套属性发生了…...

OpenAI开源超级对齐方法:用GPT-2,监督、微调GPT-4
12月15日,OpenAI在官网公布了最新研究论文和开源项目——如何用小模型监督大模型,实现更好的新型对齐方法。 目前,大模型的主流对齐方法是RLHF(人类反馈强化学习)。但随着大模型朝着多模态、AGI发展,神经元…...
TeeChart.NET 2023.11.17 Crack
.NET 的 TeeChart 图表控件提供了一个出色的通用组件套件,可满足无数的图表需求,也针对重要的垂直领域,例如金融、科学和统计领域。 数据可视化 数十种完全可定制的交互式图表类型、地图和仪表指示器,以及完整的功能集,…...

计算机网络常见的缩写
计算机网络常见缩写 通讯控制处理机(Communication Control Processor)CCP 前端处理机(Front End Processor)FEP 开放系统互连参考模型 OSI/RM 开放数据库连接(Open Database Connectivity)ODBC 网络操作系…...
vue cli 脚手架之配置代理
方法二...
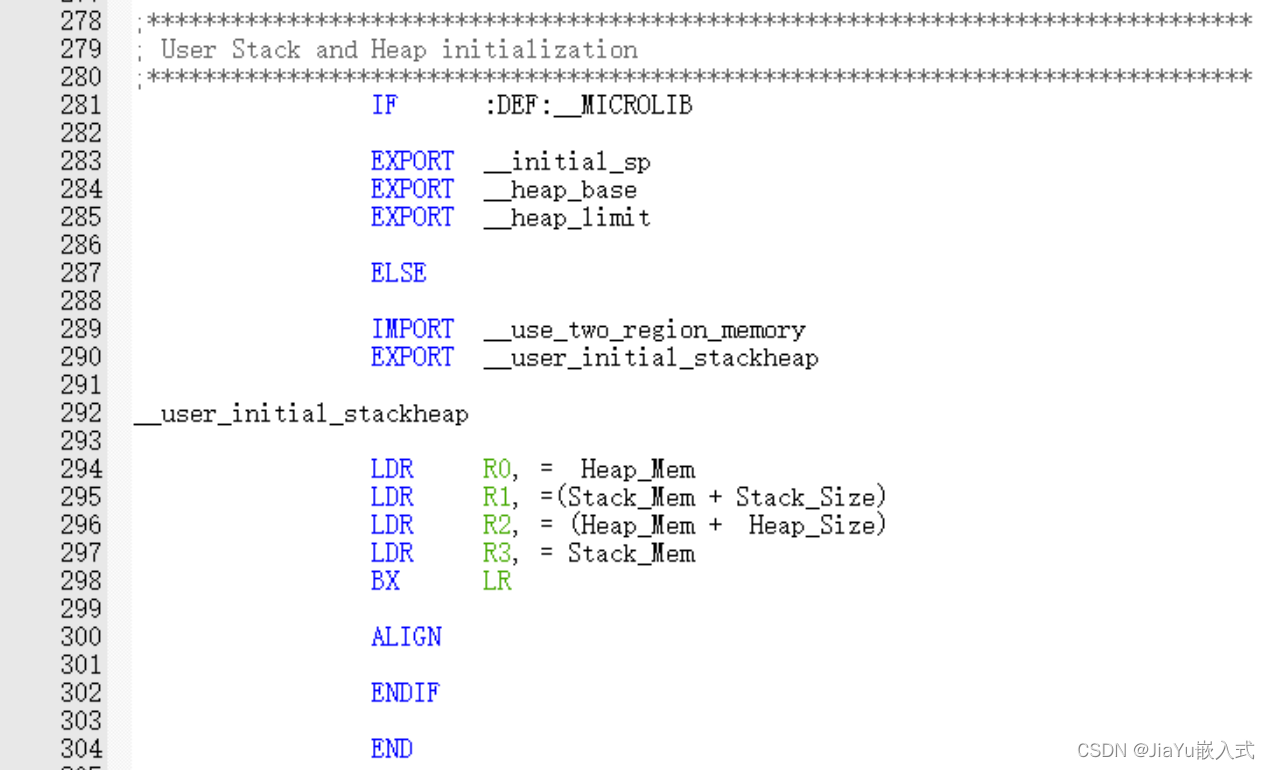
STM32启动流程详解(超全,startup_stm32xx.s分析)
单片机上电后执行的第一段代码 1.初始化堆栈指针 SP_initial_sp 2.初始化 PC 指针Reset_Handler 3.初始化中断向量表 4.配置系统时钟 5.调用 C 库函数_main 初始化用户堆栈,然后进入 main 函数。 在正式讲解之前,我们需要了解STM32的启动模式。 STM32的…...
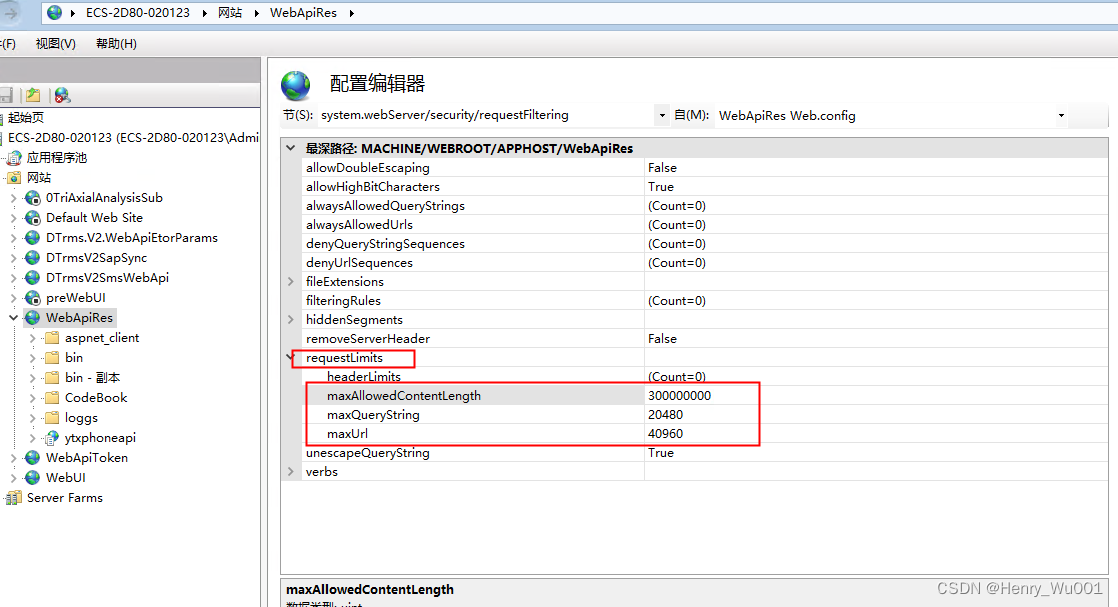
小程序接口OK,桌面调试接口不行
手机小程序OK,桌面版出现问题; 环境:iis反向url的tomcat服务,提供接口。 该接口post了一个很大的数组,处理时间比较久。 1)桌面调试出现错误,提示 用apipost调用接口同样出错, 502 - Web 服务器在作为网关或代理服…...

【贪心】LeetCode-406. 根据身高重建队列
406. 根据身高重建队列。 假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。 请你重新…...
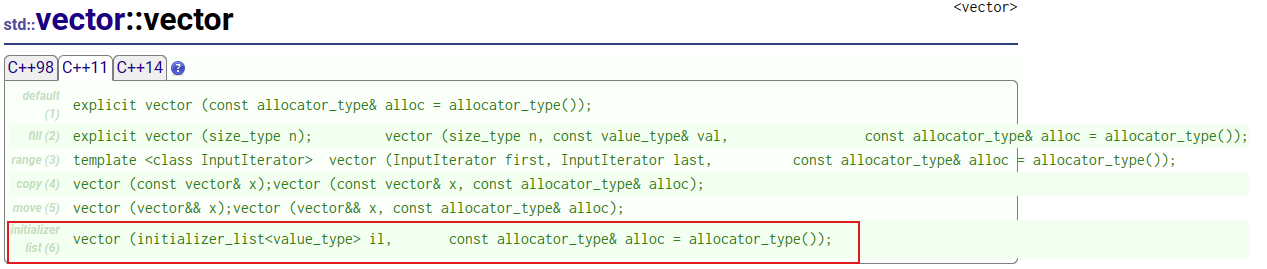
【C++11特性篇】C++11中新增的initializer_list——初始化的小利器
前言 大家好吖,欢迎来到 YY 滴C11系列 ,热烈欢迎! 本章主要内容面向接触过C的老铁 主要内容含: 欢迎订阅 YY滴C专栏!更多干货持续更新!以下是传送门! 目录 一.探究std::initializer_list是什么…...

springboot(ssm宠物美容机构CRM系统 宠物服务商城系统Java系统
springboot(ssm宠物美容机构CRM系统 客户关系管理系统Java系统 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0ÿ…...

LSTM 双向 Bi-LSTM
目录 一.Bi-LSTM介绍 二.Bi-LSTM结构 Bi-LSTM 代码实例 一.Bi-LSTM介绍 由于LSTM只能从序列里由前往后预测,为了既能够从前往后预测,也能从后往前预测,Bi-LSTM便被发明了出来。简单来说,BiLSTM就是由前向LSTM与后向LSTM组合而成。 二.Bi-LSTM结构 转自:...

2024测试开发面试题完整版本(附答案)
目录 1. 什么是软件测试, 谈谈你对软件测试的了解 2. 我看你简历上有写了解常见的开发模型和测试模型, 那你跟我讲一下敏捷模型 3. 我看你简历上还写了挺多开发技能的, 那你给我讲讲哈希表的实现流程 4. 谈一谈什么是线程安全问题, 如何解决 5. 既然你选择走测…...
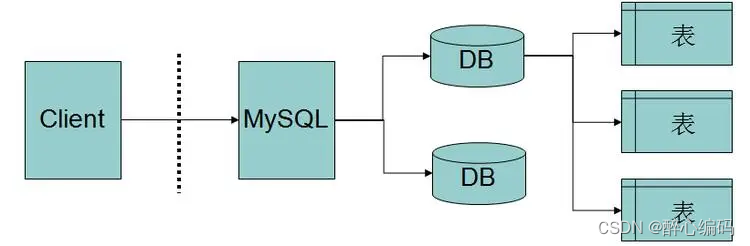
MySQL作为服务端的配置过程与实际案例
MySQL是一款流行的关系型数据库管理系统,广泛应用于各种业务场景中。作为服务端,MySQL的配置过程对于数据库的性能、安全性和稳定性至关重要。本文将详细介绍MySQL作为服务端的配置过程,并通过一个实际案例进行举例说明。 一、MySQL服务端配…...

Appium 自动化自学篇 —— 初识Appium自动化!
Appium 简介 随着移动终端的普及,手机应用越来越多,也越来越重要。而作为测试 的我们也要与时俱进,努力学习手机 App 的相关测试,文章将介绍手机自动化测试框架 Appium 。 那究竟什么是 Appium 呢? 接下来我们一起来学习PythonS…...
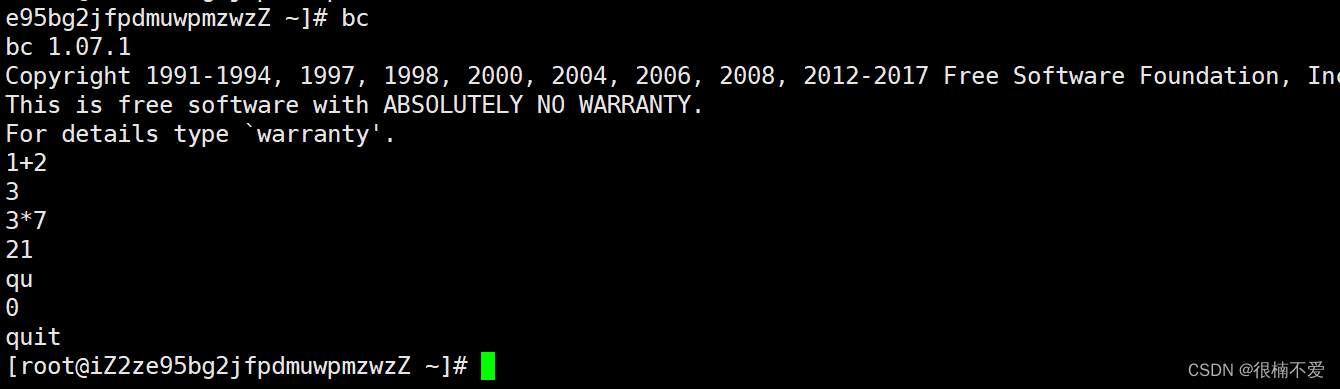
Linux基本操作指令
哈喽小伙伴们,从这篇文章开始,在学习数据结构的同时,我们开启一个新的篇章——Linux操作系统的学习,这将会是又一个新的开始,希望小伙伴们能够认真细心,不要掉队哦。 目录 一.什么是Linux 二.为什么要学习…...

探索SD-WAN技术对传统制造业实现智能制造的作用
在智能制造背景下,传统制造业面临着日益增长的信息化建设需求。随着企业趋向数字化转型,构建稳定、高效的网络基础设施成为提升企业核心竞争力的重要一环。 制造业企业信息化建设中的组网需求: 第一,连接多地分支机构,…...

C++基础-this指针详解
本文详细讲解C++this指针 定义 this 是 C++ 中的一个关键字,一个特殊的指针,它指向当前对象地址(换句话说,其值为 &object),通过它可以访问当前对象的所有成员。 类定义好后我们就可以通过类来创建多个实例对象,每个对象都有各自的实例属性(实例变量),但是非内…...
如何一键生成多个文件二维码?批量文件二维码制作技巧
文件能批量生成二维码吗?现在的二维码用途范围越来越广,比如常见的有图文、文件、问卷、音频或者视频等内容生成二维码图片,扫码查看内容。那么当需要将很多的文件每个都单独生成一个二维码时,有没有比较简单快捷的操作方法吗&…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...