循环神经网络-1
目录
1 数据集构建
1.1 数据集的构建函数
1.2 加载数据并进行数据划分
1.3 构造Dataset类
2 模型构建
2.1 嵌入层
2.2 SRN层
2.3 线性层
2.4 模型汇总
3 模型训练
3.1 训练指定长度的数字预测模型
3.2 多组训练
3.3 损失曲线展示
4 模型评价
总结
参考文献
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络.在循环神经网络中,神经元不但可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构.和前馈神经网络相比,循环神经网络更加符合生物神经网络的结构.目前,循环神经网络已经被广泛应用在语音识别、语言模型以及自然语言生成等任务上.
循环神经网络的记忆能力实验
循环神经网络的一种简单实现是简单循环网络(Simple Recurrent Network,SRN).
令向量表示在时刻$t$时网络的输入,
表示隐藏层状态(即隐藏层神经元活性值),则
不仅和当前时刻的输入
相关,也和上一个时刻的隐藏层状态
相关. 简单循环网络在时刻
的更新公式为:
其中为隐状态向量,
为状态-状态权重矩阵,
为状态-输入权重矩阵,
为偏置向量。
如图展示了一个按时间展开的循环神经网络

简单循环网络在参数学习时存在长程依赖问题,很难建模长时间间隔(Long Range)的状态之间的依赖关系。为了测试简单循环网络的记忆能力,本节构建一个数字求和任务进行实验。
数字求和任务的输入是一串数字,前两个位置的数字为0-9,其余数字随机生成(主要为0),预测目标是输入序列中前两个数字的加和。

如果序列长度越长,准确率越高,则说明网络的记忆能力越好.因此,我们可以构建不同长度的数据集,通过验证简单循环网络在不同长度的数据集上的表现,从而测试简单循环网络的长程依赖能力.
1 数据集构建
我们首先构建不同长度的数字预测数据集DigitSum.
1.1 数据集的构建函数
由于在本任务中,输入序列的前两位数字为 0 − 9,其组合数是固定的,所以可以穷举所有的前两位数字组合,并在后面默认用0填充到固定长度. 但考虑到数据的多样性,这里对生成的数字序列中的零位置进行随机采样,并将其随机替换成0-9的数字以增加样本的数量.
我们可以通过设置的数值来指定一条样本随机生成的数字序列数量.当生成某个指定长度的数据集时,会同时生成训练集、验证集和测试集。当
=3时,生成训练集。当
=1时,生成验证集和测试集. 代码实现如下:
import random
import numpy as np# 固定随机种子
random.seed(0)
np.random.seed(0)def generate_data(length, k, save_path):if length < 3:raise ValueError("The length of data should be greater than 2.")if k == 0:raise ValueError("k should be greater than 0.")# 生成100条长度为length的数字序列,除前两个字符外,序列其余数字暂用0填充base_examples = []for n1 in range(0, 10):for n2 in range(0, 10):seq = [n1, n2] + [0] * (length - 2)label = n1 + n2base_examples.append((seq, label))examples = []# 数据增强:对base_examples中的每条数据,默认生成k条数据,放入examplesfor base_example in base_examples:for _ in range(k):# 随机生成替换的元素位置和元素idx = np.random.randint(2, length)val = np.random.randint(0, 10)# 对序列中的对应零元素进行替换seq = base_example[0].copy()label = base_example[1]seq[idx] = valexamples.append((seq, label))# 保存增强后的数据with open(save_path, "w", encoding="utf-8") as f:for example in examples:# 将数据转为字符串类型,方便保存seq = [str(e) for e in example[0]]label = str(example[1])line = " ".join(seq) + "\t" + label + "\n"f.write(line)print(f"generate data to: {save_path}.")# 定义生成的数字序列长度
lengths = [5, 10, 15, 20, 25, 30, 35]
for length in lengths:# 生成长度为length的训练数据save_path = f"./datasets/{length}/train.txt"k = 3generate_data(length, k, save_path)# 生成长度为length的验证数据save_path = f"./datasets/{length}/dev.txt"k = 1generate_data(length, k, save_path)# 生成长度为length的测试数据save_path = f"./datasets/{length}/test.txt"k = 1generate_data(length, k, save_path)注意需要提前把文件夹建好了,如下图所示

结果如下:
1.2 加载数据并进行数据划分
为方便使用,本实验提前生成了长度分别为5、10、 15、20、25、30和35的7份数据,存放于“./datasets”目录下,读者可以直接加载使用。代码实现如下:
import os# 加载数据
def load_data(data_path):# 加载训练集train_examples = []train_path = os.path.join(data_path, "train.txt")with open(train_path, "r", encoding="utf-8") as f:for line in f.readlines():# 解析一行数据,将其处理为数字序列seq和标签labelitems = line.strip().split("\t")seq = [int(i) for i in items[0].split(" ")]label = int(items[1])train_examples.append((seq, label))# 加载验证集dev_examples = []dev_path = os.path.join(data_path, "dev.txt")with open(dev_path, "r", encoding="utf-8") as f:for line in f.readlines():# 解析一行数据,将其处理为数字序列seq和标签labelitems = line.strip().split("\t")seq = [int(i) for i in items[0].split(" ")]label = int(items[1])dev_examples.append((seq, label))# 加载测试集test_examples = []test_path = os.path.join(data_path, "test.txt")with open(test_path, "r", encoding="utf-8") as f:for line in f.readlines():# 解析一行数据,将其处理为数字序列seq和标签labelitems = line.strip().split("\t")seq = [int(i) for i in items[0].split(" ")]label = int(items[1])test_examples.append((seq, label))return train_examples, dev_examples, test_examples# 设定加载的数据集的长度
length = 5
# 该长度的数据集的存放目录
data_path = f"./datasets/{length}"
# 加载该数据集
train_examples, dev_examples, test_examples = load_data(data_path)
print("dev example:", dev_examples[:2])
print("训练集数量:", len(train_examples))
print("验证集数量:", len(dev_examples))
print("测试集数量:", len(test_examples))输出结果如下:

1.3 构造Dataset类
为了方便使用梯度下降法进行优化,我们构造了DigitSum数据集的Dataset类,函数__getitem__负责根据索引读取数据,并将数据转换为张量。代码实现如下:
from torch.utils.data import Dataset
import torchclass DigitSumDataset(Dataset):def __init__(self, data):self.data = datadef __getitem__(self, idx):example = self.data[idx]seq = torch.tensor(example[0], dtype=torch.int64)label = torch.tensor(example[1], dtype=torch.int64)return seq, labeldef __len__(self):return len(self.data)2 模型构建
使用SRN模型进行数字加和任务的模型结构为如图

整个模型由以下几个部分组成:
(1) 嵌入层:将输入的数字序列进行向量化,即将每个数字映射为向量;
(2) SRN 层:接收向量序列,更新循环单元,将最后时刻的隐状态作为整个序列的表示;
(3) 输出层:一个线性层,输出分类的结果.
2.1 嵌入层
本任务输入的样本是数字序列,为了更好地表示数字,需要将数字映射为一个嵌入(Embedding)向量。嵌入向量中的每个维度均能用来刻画该数字本身的某种特性。由于向量能够表达该数字更多的信息,利用向量进行数字求和任务,可以使得模型具有更强的拟合能力。
首先,我们构建一个嵌入矩阵(Embedding Matrix),其中第
行对应数字
的嵌入向量,每个嵌入向量的维度是
。如图所示。给定一个组数字序列
,其中
为批大小,
为序列长度,可以通过查表将其映射为嵌入表示
。

class Embedding(nn.Module):def __init__(self, num_embeddings, embedding_dim):super(Embedding, self).__init__()self.W = nn.init.xavier_uniform_(torch.empty(num_embeddings, embedding_dim), gain=1.0)def forward(self, inputs):# 根据索引获取对应词向量embs = self.W[inputs]return embsemb_layer = Embedding(10, 5)
inputs = torch.tensor([0, 1, 2, 3])
emb_layer(inputs)2.2 SRN层
数字序列经过嵌入层映射后,转换为
,其中
为批大小,
为序列长度,
为嵌入维度。
在时刻,SRN将当前的输入
与隐状态
进行线性变换和组合,并通过一个非线性激活函数
得到新的隐状态,SRN的状态更新函数为:
其中是可学习参数,
表示隐状态向量的维度。
代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as Ftorch.manual_seed(0)# SRN模型
class SRN(nn.Module):def __init__(self, input_size, hidden_size, W_attr=None, U_attr=None, b_attr=None):super(SRN, self).__init__()# 嵌入向量的维度self.input_size = input_size# 隐状态的维度self.hidden_size = hidden_size# 定义模型参数W,其shape为 input_size x hidden_sizeif W_attr == None:W = torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)else:W = torch.tensor(W_attr, dtype=torch.float32)self.W = torch.nn.Parameter(W)# 定义模型参数U,其shape为hidden_size x hidden_sizeif U_attr == None:U = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)else:U = torch.tensor(U_attr, dtype=torch.float32)self.U = torch.nn.Parameter(U)# 定义模型参数b,其shape为 1 x hidden_sizeif b_attr == None:b = torch.zeros(size=[1, hidden_size], dtype=torch.float32)else:b = torch.tensor(b_attr, dtype=torch.float32)self.b = torch.nn.Parameter(b)# 初始化向量def init_state(self, batch_size):hidden_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)return hidden_state# 定义前向计算def forward(self, inputs, hidden_state=None):# inputs: 输入数据, 其shape为batch_size x seq_len x input_sizebatch_size, seq_len, input_size = inputs.shape# 初始化起始状态的隐向量, 其shape为 batch_size x hidden_sizeif hidden_state is None:hidden_state = self.init_state(batch_size)# 循环执行RNN计算for step in range(seq_len):# 获取当前时刻的输入数据step_input, 其shape为 batch_size x input_sizestep_input = inputs[:, step, :]# 获取当前时刻的隐状态向量hidden_state, 其shape为 batch_size x hidden_sizehidden_state = F.tanh(torch.matmul(step_input, self.W) + torch.matmul(hidden_state, self.U) + self.b)return hidden_state这里只保留了简单循环网络的最后一个时刻的输出向量。
## 初始化参数并运行
U_attr = [[0.0, 0.1], [0.1, 0.0]]
b_attr = [[0.1, 0.1]]
W_attr = [[0.1, 0.2], [0.1, 0.2]]srn = SRN(2, 2, W_attr=W_attr, U_attr=U_attr, b_attr=b_attr)inputs = torch.tensor([[[1, 0], [0, 2]]], dtype=torch.float32)
hidden_state = srn(inputs)
print("hidden_state", hidden_state)
输出结果如下:
![]()
PyTorch框架内置了SRN的API torch.nn.RNN
# 这里创建一个随机数组作为测试数据,数据shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size = 8, 20, 32
inputs = torch.randn([batch_size, seq_len, input_size])# 设置模型的hidden_size
hidden_size = 32
torch_srn = nn.RNN(input_size, hidden_size)
self_srn = SRN(input_size, hidden_size)self_hidden_state = self_srn(inputs)
torch_outputs, torch_hidden_state = torch_srn(inputs)print("self_srn hidden_state: ", self_hidden_state.shape)
print("torch_srn outpus:", torch_outputs.shape)
print("torch_srn hidden_state:", torch_hidden_state.shape)
输出结果如下:

可以看到,两者的输出基本是一致的。另外,还可以进行对比两者在运算速度方面的差异。代码实现如下:
import time# 计算自己实现的SRN运算速度
model_time = 0
for i in range(100):strat_time = time.time()out = self_srn(inputs)if i < 10:continueend_time = time.time()model_time += (end_time - strat_time)
avg_model_time = model_time / 90
print('self_srn speed:', avg_model_time, 's')# 计算torch内置的SRN运算速度
model_time = 0
for i in range(100):strat_time = time.time()out = torch_srn(inputs)# 预热10次运算,不计入最终速度统计if i < 10:continueend_time = time.time()model_time += (end_time - strat_time)
avg_model_time = model_time / 90
print('torch_srn speed:', avg_model_time, 's')输出结果如下:

2.3 线性层
线性层会将最后一个时刻的隐状态向量进行线性变换,输出分类的对数几率(Logits)为:
其中,
为可学习的权重矩阵和偏置
> 提醒:在分类问题的实践中,我们通常只需要模型输出分类的对数几率(Logits),而不用输出每个类的概率。这需要损失函数可以直接接收对数几率来损失计算
线性层直接使用torch.nn.Linear算子
2.4 模型汇总
在定义了每一层的算子之后,我们定义一个数字求和模型Model_RNN4SeqClass,该模型会将嵌入层、SRN层和线性层进行组合,以实现数字求和的功能.
具体来讲,Model_RNN4SeqClass会接收一个SRN层实例,用于处理数字序列数据,同时在__init__函数中定义一个Embedding嵌入层,其会将输入的数字作为索引,输出对应的向量,最后会使用torch.nn.Linear定义一个线性层。
> 提醒:为了方便进行对比实验,我们将SRN层的实例化放在\code{Model_RNN4SeqClass}类外面。通常情况下,模型内部算子的实例化是放在模型里面。
在forward函数中,调用上文实现的嵌入层、SRN层和线性层处理数字序列,同时返回最后一个位置的隐状态向量。代码实现如下:
# 基于RNN实现数字预测的模型
class Model_RNN4SeqClass(nn.Module):def __init__(self, model, num_digits, input_size, hidden_size, num_classes):super(Model_RNN4SeqClass, self).__init__()# 传入实例化的RNN层,例如SRNself.rnn_model = model# 词典大小self.num_digits = num_digits# 嵌入向量的维度self.input_size = input_size# 定义Embedding层self.embedding = Embedding(num_digits, input_size)# 定义线性层self.linear = nn.Linear(hidden_size, num_classes)def forward(self, inputs):# 将数字序列映射为相应向量inputs_emb = self.embedding(inputs)# 调用RNN模型hidden_state = self.rnn_model(inputs_emb)# 使用最后一个时刻的状态进行数字预测logits = self.linear(hidden_state)return logits# 实例化一个input_size为4, hidden_size为5的SRN
srn = SRN(4, 5)
# 基于srn实例化一个数字预测模型实例
model = Model_RNN4SeqClass(srn, 10, 4, 5, 19)
# 生成一个shape为 2 x 3 的批次数据
inputs = torch.tensor([[1, 2, 3], [2, 3, 4]])
# 进行模型前向预测
logits = model(inputs)
print(logits)
输出结果如下:

3 模型训练
3.1 训练指定长度的数字预测模型
基于RunnerV3类进行训练,只需要指定length便可以加载相应的数据。设置超参数,使用Adam优化器,学习率为 0.001,实例化模型,使用第4.5.4节定义的Accuracy计算准确率。使用Runner进行训练,训练回合数设为500。代码实现如下:
(!首先在对应路径下创建两个文件夹命名为checkpoints、images)如下图所示

import os
import random
import torch
import numpy as np
from nndl import Accuracy
from nndl import RunnerV3
from torch.utils.data import DataLoader# 训练轮次
num_epochs = 500
# 学习率
lr = 0.001
# 输入数字的类别数
num_digits = 10
# 将数字映射为向量的维度
input_size = 32
# 隐状态向量的维度
hidden_size = 32
# 预测数字的类别数
num_classes = 19
# 批大小
batch_size = 8
# 模型保存目录
save_dir = "./checkpoints"# 通过指定length进行不同长度数据的实验
def train(length):print(f"\n====> Training SRN with data of length {length}.")# 加载长度为length的数据data_path = f"./datasets/{length}"train_examples, dev_examples, test_examples = load_data(data_path)train_set, dev_set, test_set = DigitSumDataset(train_examples), DigitSumDataset(dev_examples), DigitSumDataset(test_examples)train_loader = DataLoader(train_set, batch_size=batch_size)dev_loader = DataLoader(dev_set, batch_size=batch_size)test_loader = DataLoader(test_set, batch_size=batch_size)# 实例化模型base_model = SRN(input_size, hidden_size)model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes)# 指定优化器optimizer = torch.optim.Adam(lr=lr, params=model.parameters())# 定义评价指标metric = Accuracy()# 定义损失函数loss_fn = nn.CrossEntropyLoss()# 基于以上组件,实例化Runnerrunner = RunnerV3(model, optimizer, loss_fn, metric)# 进行模型训练model_save_path = os.path.join(save_dir, f"best_srn_model_{length}.pdparams")runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=100, log_steps=100, save_path=model_save_path)return runnernndl.py
import torchclass RunnerV3(object):def __init__(self, model, optimizer, loss_fn, metric, **kwargs):self.model = modelself.optimizer = optimizerself.loss_fn = loss_fnself.metric = metric # 只用于计算评价指标# 记录训练过程中的评价指标变化情况self.dev_scores = []# 记录训练过程中的损失函数变化情况self.train_epoch_losses = [] # 一个epoch记录一次lossself.train_step_losses = [] # 一个step记录一次lossself.dev_losses = []# 记录全局最优指标self.best_score = 0def train(self, train_loader, dev_loader=None, **kwargs):# 将模型切换为训练模式self.model.train()# 传入训练轮数,如果没有传入值则默认为0num_epochs = kwargs.get("num_epochs", 0)# 传入log打印频率,如果没有传入值则默认为100log_steps = kwargs.get("log_steps", 100)# 评价频率eval_steps = kwargs.get("eval_steps", 0)# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"save_path = kwargs.get("save_path", "best_model.pdparams")custom_print_log = kwargs.get("custom_print_log", None)# 训练总的步数num_training_steps = num_epochs * len(train_loader)if eval_steps:if self.metric is None:raise RuntimeError('Error: Metric can not be None!')if dev_loader is None:raise RuntimeError('Error: dev_loader can not be None!')# 运行的step数目global_step = 0# 进行num_epochs轮训练for epoch in range(num_epochs):# 用于统计训练集的损失total_loss = 0for step, data in enumerate(train_loader):X, y = data# 获取模型预测logits = self.model(X)loss = self.loss_fn(logits, y.long()) # 默认求meantotal_loss += loss# 训练过程中,每个step的loss进行保存self.train_step_losses.append((global_step, loss.item()))if log_steps and global_step % log_steps == 0:print(f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")# 梯度反向传播,计算每个参数的梯度值loss.backward()if custom_print_log:custom_print_log(self)# 小批量梯度下降进行参数更新self.optimizer.step()# 梯度归零self.optimizer.zero_grad()# 判断是否需要评价if eval_steps > 0 and global_step > 0 and \(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")# 将模型切换为训练模式self.model.train()# 如果当前指标为最优指标,保存该模型if dev_score > self.best_score:self.save_model(save_path)print(f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")self.best_score = dev_scoreglobal_step += 1# 当前epoch 训练loss累计值trn_loss = (total_loss / len(train_loader)).item()# epoch粒度的训练loss保存self.train_epoch_losses.append(trn_loss)print("[Train] Training done!")# 模型评估阶段,使用'torch.no_grad()'控制不计算和存储梯度@torch.no_grad()def evaluate(self, dev_loader, **kwargs):assert self.metric is not None# 将模型设置为评估模式self.model.eval()global_step = kwargs.get("global_step", -1)# 用于统计训练集的损失total_loss = 0# 重置评价self.metric.reset()# 遍历验证集每个批次for batch_id, data in enumerate(dev_loader):X, y = data# 计算模型输出logits = self.model(X)# 计算损失函数loss = self.loss_fn(logits, y.long()).item()# 累积损失total_loss += loss# 累积评价self.metric.update(logits, y)dev_loss = (total_loss / len(dev_loader))dev_score = self.metric.accumulate()# 记录验证集lossif global_step != -1:self.dev_losses.append((global_step, dev_loss))self.dev_scores.append(dev_score)return dev_score, dev_loss# 模型评估阶段,使用'torch.no_grad()'控制不计算和存储梯度@torch.no_grad()def predict(self, x, **kwargs):# 将模型设置为评估模式self.model.eval()# 运行模型前向计算,得到预测值logits = self.model(x)return logitsdef save_model(self, save_path):torch.save(self.model.state_dict(), save_path)def load_model(self, model_path):state_dict = torch.load(model_path)self.model.load_state_dict(state_dict)class Accuracy():def __init__(self, is_logist=True):# 用于统计正确的样本个数self.num_correct = 0# 用于统计样本的总数self.num_count = 0self.is_logist = is_logistdef update(self, outputs, labels):# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务if outputs.shape[1] == 1: # 二分类outputs = torch.squeeze(outputs, dim=-1)if self.is_logist:# logist判断是否大于0preds = torch.tensor((outputs >= 0), dtype=torch.float32)else:# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0preds = torch.tensor((outputs >= 0.5), dtype=torch.float32)else:# 多分类时,使用'torch.argmax'计算最大元素索引作为类别preds = torch.argmax(outputs, dim=1)# 获取本批数据中预测正确的样本个数labels = torch.squeeze(labels, dim=-1)batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).cpu().numpy()batch_count = len(labels)# 更新num_correct 和 num_countself.num_correct += batch_correctself.num_count += batch_countdef accumulate(self):# 使用累计的数据,计算总的指标if self.num_count == 0:return 0return self.num_correct / self.num_countdef reset(self):# 重置正确的数目和总数self.num_correct = 0self.num_count = 0def name(self):return "Accuracy"
3.2 多组训练
srn_runners = {}lengths = [10, 15, 20, 25, 30, 35]
for length in lengths:runner = train(length)srn_runners[length] = runner
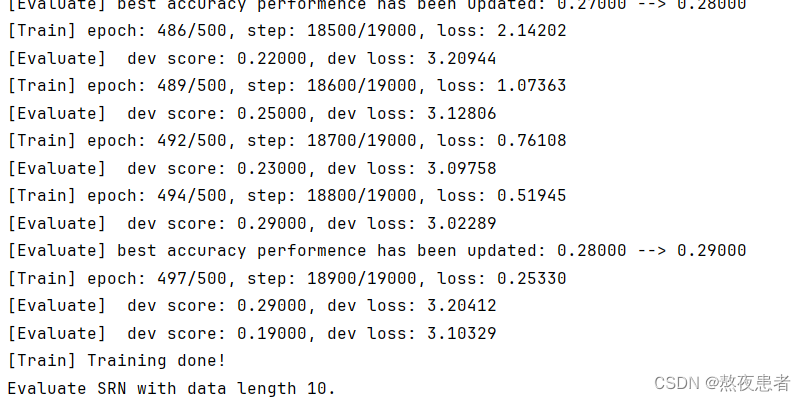
训练结果如下;
3.3 损失曲线展示
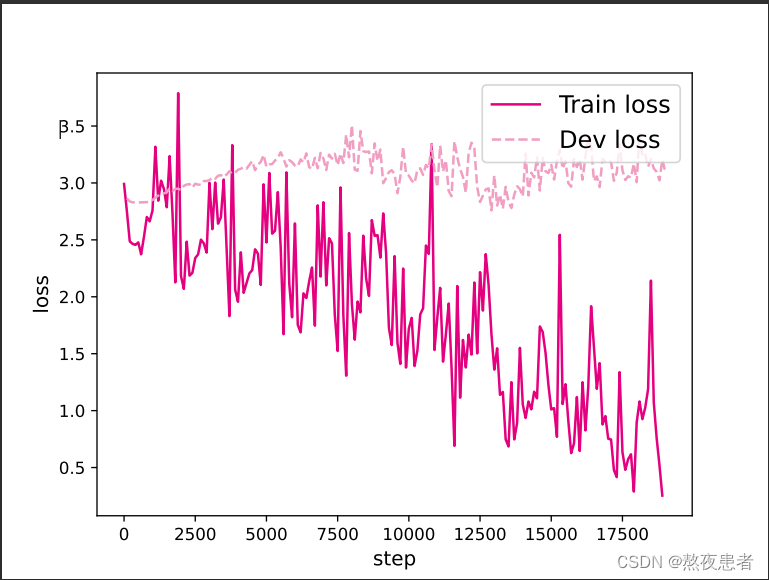
画出各个长度的数字预测模型训练过程中,在训练集和验证集上的损失曲线,实现代码实现如下:
import matplotlib.pyplot as plt
def plot_training_loss(runner, fig_name, sample_step):plt.figure()train_items = runner.train_step_losses[::sample_step]train_steps = [x[0] for x in train_items]train_losses = [x[1] for x in train_items]plt.plot(train_steps, train_losses, color='#e4007f', label="Train loss")dev_steps = [x[0] for x in runner.dev_losses]dev_losses = [x[1] for x in runner.dev_losses]plt.plot(dev_steps, dev_losses, color='#f19ec2', linestyle='--', label="Dev loss")# 绘制坐标轴和图例plt.ylabel("loss", fontsize='large')plt.xlabel("step", fontsize='large')plt.legend(loc='upper right', fontsize='x-large')plt.savefig(fig_name)plt.show()# 画出训练过程中的损失图
for length in lengths:runner = srn_runners[length]fig_name = f"./images/6.6_{length}.pdf"plot_training_loss(runner, fig_name, sample_step=100)
当L = 10、15、20、25、30、35时的图像如下:





4 模型评价
在模型评价时,加载不同长度的效果最好的模型,然后使用测试集对该模型进行评价,观察模型在测试集上预测的准确度. 同时记录一下不同长度模型在训练过程中,在验证集上最好的效果。代码实现如下。
srn_dev_scores = []
srn_test_scores = []
for length in lengths:print(f"Evaluate SRN with data length {length}.")runner = srn_runners[length]# 加载训练过程中效果最好的模型model_path = os.path.join(save_dir, f"best_srn_model_{length}.pdparams")runner.load_model(model_path)# 加载长度为length的数据data_path = f"./datasets/{length}"train_examples, dev_examples, test_examples = load_data(data_path)test_set = DigitSumDataset(test_examples)test_loader = DataLoader(test_set, batch_size=batch_size)# 使用测试集评价模型,获取测试集上的预测准确率score, _ = runner.evaluate(test_loader)srn_test_scores.append(score)srn_dev_scores.append(max(runner.dev_scores))for length, dev_score, test_score in zip(lengths, srn_dev_scores, srn_test_scores):print(f"[SRN] length:{length}, dev_score: {dev_score}, test_score: {test_score: .5f}")输出结果如下:

接下来,将SRN在不同长度的验证集和测试集数据上的表现,绘制成图片进行观察。
import matplotlib.pyplot as pltplt.plot(lengths, srn_dev_scores, '-o', color='#e4007f', label="Dev Accuracy")
plt.plot(lengths, srn_test_scores,'-o', color='#f19ec2', label="Test Accuracy")#绘制坐标轴和图例
plt.ylabel("accuracy", fontsize='large')
plt.xlabel("sequence length", fontsize='large')
plt.legend(loc='upper right', fontsize='x-large')fig_name = "./images/6.7.pdf"
plt.savefig(fig_name)
plt.show()
输出结果如下:
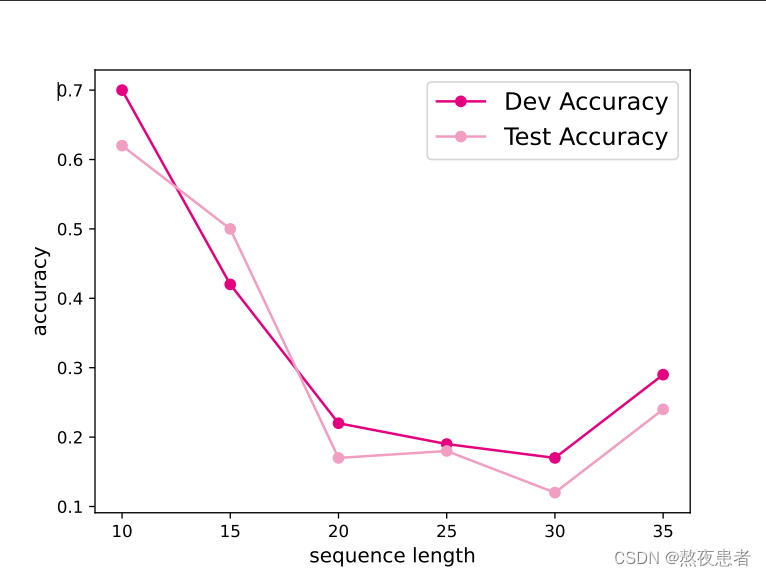
展示了SRN模型在不同长度数据训练出来的最好模型在验证集和测试集上的表现。可以看到,随着序列长度的增加,验证集和测试集的准确度整体趋势是降低的,这同样说明SRN模型保持长期依赖的能力在不断降低.
总结
本次实验代码的总量较大,但是paddle转torch却只需要很少的一部分代码,但是最开始训练的时候,没注意到需要创建两个文件夹,多跑了两次,之后为了观看数据也还多跑了三次,但是我发现这组数据的波动很大,大部分正确率也不高,应该是后来的为了梯度爆炸打的实验做铺垫。
参考文献
[1].邱锡鹏.《神经网络与深度学习》[J].中文信息学报,2020,34(07):4.
相关文章:
循环神经网络-1
目录 1 数据集构建 1.1 数据集的构建函数 1.2 加载数据并进行数据划分 1.3 构造Dataset类 2 模型构建 2.1 嵌入层 2.2 SRN层 2.3 线性层 2.4 模型汇总 3 模型训练 3.1 训练指定长度的数字预测模型 3.2 多组训练 3.3 损失曲线展示 4 模型评价 总结 参考文献 循环神经网络&…...
MFC画折线图,基于x64系统
由于项目的需要,需要画一个折线图。 传统的Teechart、MSChart、HighSpeedChart一般是只能配置在x86系统下,等到使用x64系统下运行就是会报出不知名的错误,这个地方让人很苦恼。 我在进行配置的过程之中,使用Teechart将x86配置好…...
JDK8安装教程分享
🧋🧋今天,在博客社区看到一篇非常好的,关于JDK8的安装教程,亲试有用,现分享给大家。。。 JDK8安装...

CentOS 7 部署 dnsmasq
文章目录 (1)概述(2)dnsmasq的解析流程(3)重要参数说明(4)部署dnsmasq(5)其他内容(6)域名劫持(7)dns污染验证&…...

DBA面试题
Oracle体系结构 (1)、Oracle实例内存中包含哪些部分? 答: sga与pga sga:是一组共享的内存区域,包含数据字典缓存、库缓存、重做日志缓冲区 Pga:为每个服务器进程分配的非共享内存,存储会话状态和私有SOL工作区 在Oracle数据库中&…...
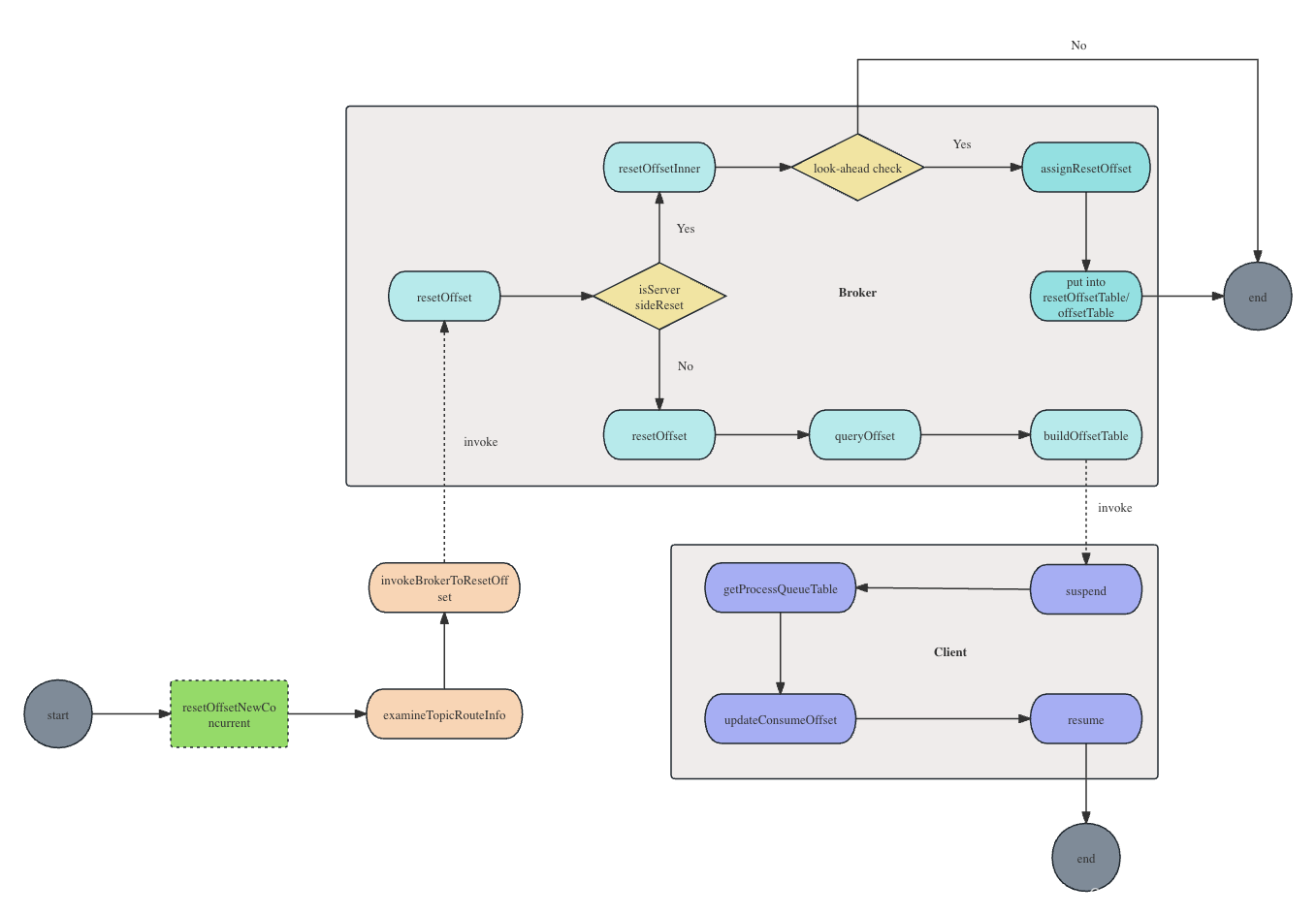
源码解析:Apache RocketMQ重置消费位点
引入 reset offset,即重置消费进度,一般在以下场景中使用: 需要重新消费已经消费过的消息,重置到最早位置或根据时间进行重置。消息积压,不需要消费积压的消息,重置到最新位置,使其从最新位置…...

Python 自动化之处理docx文件(一)
批量筛选docx文档中关键词 文章目录 批量筛选docx文档中关键词前言一、做成什么样子二、基本架构三、前期输入模块1.引入库2.路径输入3.关键词输入 三、数据处理模块1.基本架构2.如果是docx文档2.1.读取当前文档内容2.2.遍历匹配关键字2.3.触发匹配并记录日志 3.如果目录下还有…...

Vue mixins详解
文章目录 前言Vue中的mixins详解什么是mixins简单例子mixins的特点mixins与vuex的区别mixins与公共组件的区别前言 在Vue中,mixins是一种可重用的代码片段,可以在多个组件中共享。它可以包含组件的选项,如data、methods、computed等,以及生命周期钩子函数。 本文将详细介…...
ssl证书问题导致本地启动前端服务报500
报错如下:注意查看报错信息 问题:系统原是http,后台调整为https后,ssl证书有点问题, vue项目本地服务,使用代理,webpack默认,证书强校验,导致请求无法发出,后…...

Rust 学习
Rust 官网:https://www.rust-lang.org/zh-CN/ 模块 库:https://crates.io/ 1、Rust 简介 Rust 语言的主要目标之一是解决传统 系统级编程语言(如 C 和 C)中常见的安全性问题,例如空指针引用、数据竞争等。为了实现这个…...
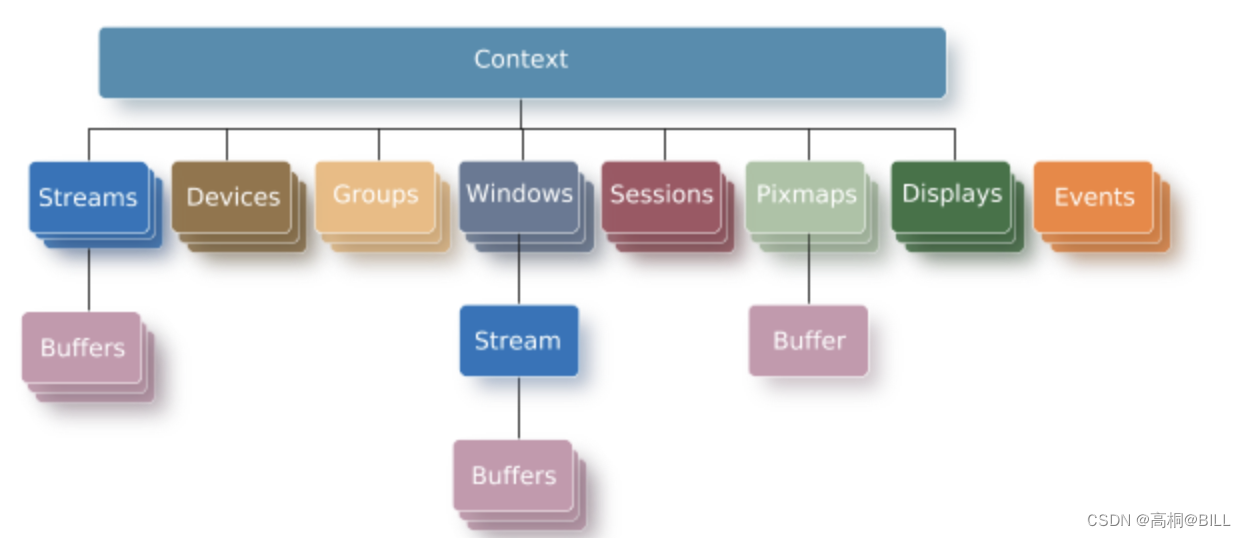
1.1 【应用开发】应用开发简介
写在前面 Screen图形子系统基于客户端/服务器模型,其中应用程序是请求图形服务的客户端(Screen)。它包括一个合成窗口系统作为这些服务之一,这意味着所有应用程序渲染都是在离屏缓冲区上执行的,然后可以在稍后用于更新…...

在windows系统搭建LVGL模拟器(codeblock工程)
1.codeblock准备 下载codeblock(mingw),安装。可参考网上教程。 2.pc_simulator_win_codeblocks 工程获取 仓库地址:lvgl/lv_port_win_codeblocks: Windows PC simulator project for LVGL embedded GUI Library (github.com) 拉取代码到本地硬盘&…...

2023第十四届蓝桥杯国赛 C/C++ 大学 B 组
文章目录 前言试题 A: 子 2023作者思考题解答案 试题 B: 双子数作者思考题解 试题 C: 班级活动作者思考题解 试题 D: 合并数列作者思考题解 试题 E: 数三角作者思考题解 试题 F: 删边问题作者思考题解 试题 G: AB 路线作者思考题解 试题 H: 抓娃娃作者思考题解 试题 I: 拼数字试…...

如何在页面中加入百度地图
官方文档:jspopularGL | 百度地图API SDK (baidu.com) 添加一下代码就可以实现 <!DOCTYPE html> <html> <head><meta name"viewport" content"initial-scale1.0, user-scalableno"/><meta http-equiv"Conten…...

Windows VC++提升当前进程权限到管理员权限
Windows VC提升当前进程权限 Windows VC提升当前进程权限到管理员权限 Windows VC提升当前进程权限到管理员权限 有时候Windows下我们需要提升当前进程的权限到管理员权限,相关VC代码如下: #ifndef SAFE_CLOSE_HANDLE #define SAFE_CLOSE_HANDLE(handl…...
算法leetcode|92. 反转链表 II(rust重拳出击)
文章目录 92. 反转链表 II:样例 1:样例 2:提示:进阶: 分析:题解:rust:go:c:python:java: 92. 反转链表 II: 给你单链表的…...
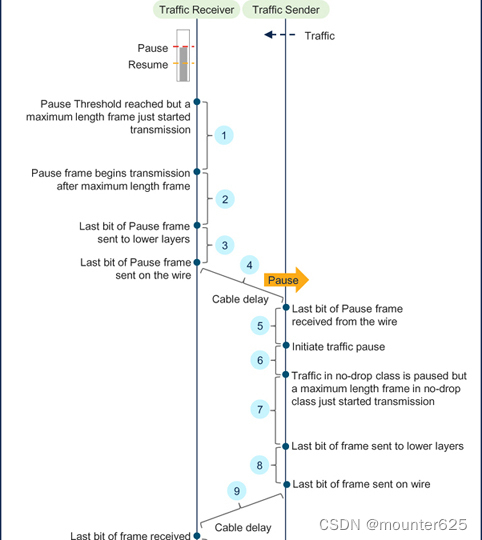
Chapter 7 - 3. Congestion Management in Ethernet Storage Networks以太网存储网络的拥塞管理
Pause Threshold for Long Distance Links长途链路的暂停阈值 This section uses the following basic concepts: 本节使用以下基本概念: Bit Time (BT): It is the time taken to transmit one bit. It is the reciprocal of the bit rate. For example, BT of a 10 GbE po…...
优雅玩转实验室服务器(二)传输文件
使用服务器最重要的肯定是传输文件了,我们不仅需要本地的一些资源上传到服务器,好进行实验,也需要将服务器计算得到的实验结果传输到本地,来进行预览或者报告撰写。 首先,由于涉及到服务器操作,我强烈推荐…...

动态面板简介以及ERP原型图案列
动态面板简介以及ERP原型图案列 1.Axure动态面板简介2.使用Axure制作ERP登录界面3.使用Asure完成左侧菜单栏4.使用Axuer完成公告栏5.使用Axuer完成左边侧边栏 1.Axure动态面板简介 在Axure RP中,动态面板是一种强大的交互设计工具,它允许你创建可交互的…...

漏刻有时百度地图API实战开发(12)(切片工具的使用、添加自定义图层TileLayer)
TileLayer向地图中添加自定义图层 var tileLayer new BMap.TileLayer();tileLayer.getTilesUrl function (tileCoord, zoom) {var x tileCoord.x;var y tileCoord.y;return images/tiles/ zoom /tile- x _ y .png;}var lockMap new BMap.MapType(lock_map, tileLaye…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...