Flume使用入门
目录
一. Flume简单介绍
1. Agent
2. Source
3. Sink
4. Channel
5. Event
二. 环境安装
1. 创建日志目录
2. 修改日志配置文件
3.修改运行堆内存
4. 确定日志打印的位置
5. 修改flume使用内存 内存调大
三. 校验flume
1. 安装netcat工具和net-tools工具
2. 判断44444端口是否被占用,选择一个没有被占用的端口用于数据接收
3. 在配置conf目录下创建数据采集的配置文件nc_to_log.conf文件
4. 修改配置内容
5. 启动Flume
6.发送数据验证
四 .各种常用的场景配置
1.组件
2. source配置
2.1. 文件
2.2 Avro
3. channel配置
3.2. 文件 File Channel
4. sink配置
4.1. HDFS
4.2. 网路端口Avro
4.3. 文件File Roll
4.4. 控制台
4.5. 自定义Sink
5. 组装
5.1. 最简 一对一组装
5.2. 一对多组装
5.3. 路由
五. 自定义开发
1.source开发
2.sink开发
六. 完整示例
1. 采集端口数据到控制台
2. 采集端口数据将部分数据发送到控制台,另一部分发送到其他端口
七. Flume监控工具Ganglia (web gmetad gmod)
1. 部署Flume节点
2. 部署监控节点
2.1. 修改配置文件ganglia.conf
2.2. 修改配置文件gmetad
2.3. 修改配置文件config
2.4. 重启selinux 本次生效关闭必须重启
2.5. 赋值ganglia使用权限
3. 启动监控
3.1. 在所有节点上启动gmond
3.2. 在web监控节点上启动httpd和gmetad
4.发送数据监控结果
八. 数据传输截断bug
1.创建类org.apache.flume.serialization.LineDeserializer
2.编译成class文件
3.覆盖LineDeserializer.class文件
4.覆盖flume-ng-core
一. Flume简单介绍
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单,由java源码编写,可通过java自定义扩展
Flume 官网地址 各个版本点击下载 下面安装用的是版本1.9.0
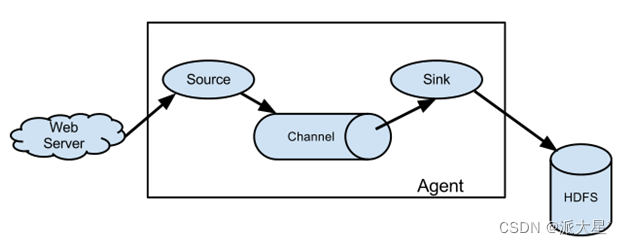
Flume由三部分组成,Source、Channel、Sink
1. Agent
Agent是一个由Flume启动的JVM进程,它以事件的形式将数据从源头送至目的地。Agent主要有3个部分组成,Source、Channel、Sink
2. Source
负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据
3. Sink
不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent
4. Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作
5. Event
传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组
二. 环境安装
解压后修改配置文件
1. 创建日志目录
mkdir <flume_home>/logs2. 修改日志配置文件
vim <flume_hme>/conf/log4j.properties3.修改运行堆内存
mv <flume_hme>/conf/flume-env.sh.template <flume_hme>/conf/flume-env.sh
vim<flume_hme>/conf/flume-env.sh增加缓存Channel 的堆内存
export JAVA_OPTS="-Xms4000m -Xmx4000m -Dcom.sun.management.jmxremote"4. 确定日志打印的位置
#flume.root.logger=DEBUG,console console表示输出到控制台
flume.root.logger=INFO,LOGFILE
flume.log.dir=/home/tools/flume/flume-1.9.0/logs
flume.log.file=flume.log5. 修改flume使用内存 内存调大
vim <flume_home>/bin/flume-ngJAVA_OPTS="-Xms4096m -Xmx4096m -Dcom.sun.management.jmxremote"安装完成
三. 校验flume
使用Flume监听一个端口,收集该端口数据,并打印到控制台
1. 安装netcat工具和net-tools工具
yum install -y nc
yum install net-tools -y2. 判断44444端口是否被占用,选择一个没有被占用的端口用于数据接收
netstat -nlp | grep 444443. 在配置conf目录下创建数据采集的配置文件nc_to_log.conf文件
vim conf/nc_to_log.conf4. 修改配置内容
# 组件定义
a1.sources = r1
a1.channels = c1
a1.sinks = k1# sources配置
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444# sink配置
a1.sinks.k1.type = logger# channels配置
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 连接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c15. 启动Flume
bin/flume-ng agent -c conf/ -n a1 -f conf/nc_to_log.conf -Dflume.root.logger=console启动命令中 a1是采集数据配置文件中定义的agent的名称
启动参数解释
| --conf/-c | 配置文件存储在conf/目录 系统会去这个目录下 读取系统配置 例如:日志配置 脚本等 |
| --name/-n | 表示给agent起名为a1 |
| --conf-file/-f | flume本次启动读取的agent配置文件 是在conf文件夹下的nc-flume-log.conf文件 |
| -Dflume.root.logger=console | -D表示flume运行时动态修改参数属性值打印控制台 |
6.发送数据验证
nc localhost 44444
四 .各种常用的场景配置
官方文档 点击官
1.组件
# 组件定义 agent为a1 sources为r1,sinks为k1,hannels为c1,可以配置多个例如 sources = r1 r2,使用逗号隔开
a1.sources = r1
a1.channels = c1
a1.sinks = k12. source配置
2.1. 文件
# 必选 指定类型为文件采集
a1.sources.r1.type = TAILDIR
# 必选 指定采集的多个组,每个组个可以对应一个路径
a1.sources.r1.filegroups = f1 f2
# 必选 指定组采集的文件路径,必须精确到文件,可以写匹配表达式匹配多个文件
a1.sources.r1.filegroups.f1 = /home/myuser/data/2022/2022.*.log
a1.sources.r1.filegroups.f2 = /home/myuser/data/2023/2023.*.log
# 可选 断点续传配置
a1.sources.r1.positionFile = /home/myuser/data/tmp/taildir.json2.2 Avro
# 必选 类型向avro网络端口接收
a1.sources.r1.type = avro
# 必选 发送主机
a1.sources.r1.bind = localhost
# 必选 发送端口
a1.sources.r1.port = 4444
# 可选 数据发送线程数
a1.sources.r1.threads = 43. channel配置
3.1. 内存 Memory Channel
#必选 channels配置类型为内存
a1.channels.c1.type = memory
#可选 缓存中存储的最大数据量
a1.channels.c1.capacity = 1000
#可选 通道在每个事务中从源获取或提供给接收器的最大事件数
a1.channels.c1.transactionCapacity = 1003.2. 文件 File Channel
# 必选 channels配置类型为文件
a1.channels.c1.type = file
# 可选 缓存位置
a1.channels.c1.checkpointDir = /home/myuser/data/channel/checkpoint
# 可选 是否备份检查点,如果不备份,不用配置备份目录
a1.channels.c1.useDualCheckpoints = true
# 可选 检查点备份的目录
a1.channels.c1.backupCheckpointDir = /home/myuser/data/channel/backup
# 可选 存储日志文件的目录列表
a1.channels.c1.dataDirs = /home/myuser/data/channel/data
# 可选 传输最大支持的事物大小
a1.channels.c1.transactionCapacity = 10000
# 可选 检查点时间间隔 毫秒
a1.channels.c1.checkpointInterval = 30000
# 可选 单个日志文件最大容量
a1.channels.c1.maxFileSize = 21464350713.3. 自定义Source
package com.filtrer.flume;
import org.apache.flume.Context;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.source.AbstractSource;
import java.util.HashMap;
import java.util.UUID;
public class MySource extends AbstractSource implements Configurable, PollableSource {//定义配置文件将来要读取的字段private String param;//初始化配置信息@Overridepublic void configure(Context context) {param = context.getString("param", "msg");}@Overridepublic Status process() throws EventDeliveryException {try {HashMap<String, String> header = new HashMap<>();//创建事件头信息SimpleEvent event = new SimpleEvent();//创建事件//循环封装事件for (int i = 0; i < 100; i++) {event.setHeaders(header);//给事件设置头信息event.setBody((param + UUID.randomUUID()).getBytes());//给事件设置内容getChannelProcessor().processEvent(event);//将事件写入 channel,循环量推荐与transactionCapacity保持一直,默认100}} catch (Exception e) {e.printStackTrace();return Status.BACKOFF;}return Status.READY;}@Overridepublic long getBackOffSleepIncrement() {return 0;}@Overridepublic long getMaxBackOffSleepInterval() {return 0;}
}4. sink配置
4.1. HDFS
# 必选 类型为HDFS
a1.sinks.k1.type = hdfs
# 必选 HDFS存储路径目录,hdfs的HA模式 可以使用hdfs-site.xml文件的dfs.nameservices的名称替换ip:端口需要hdfs的配置目录文件
a1.sinks.k1.hdfs.path = hdfs://node2:8020/flume/%Y%m%d/%H_%M
#a1.sinks.k1.hdfs.path = hdfs://mycluster/flume/%Y%m%d/%H_%M
# 可选 存储文件前缀后缀配置
a1.sinks.k1.hdfs.filePrefix =
a1.sinks.k1.hdfs.fileSuffix = .log
# 可选 临时文件前缀后缀配置
a1.sinks.k1.hdfs.inUsePrefix =
a1.sinks.k1.hdfs.inUseSuffix = .tmp
# 可选 压缩格式 gzip, bzip2, lzo, lzop, snappy
a1.sinks.k1.hdfs.codeC =
# 文件类型 分为二进制文件SequenceFile 文本文件DataStream(不能压缩) CompressedStream(可以压缩)
a1.sinks.k1.hdfs.fileType = DataStream
# 可选 是否将时间记录为sink写入hdfs的时刻
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 可选 临时文件等待多少秒后滚动文件 (滚动含义:将临时文件转化为存储文件,并重新创建临时文件)
a1.sinks.k1.hdfs.rollInterval = 30
# 可选 临时文件大小达到多少字节后滚动,推荐配置一个hdfs块大小
a1.sinks.k1.hdfs.rollSize = 67108864
# 可选 临时文件数据量达到多少条后滚动,0表示与数据量无关
a1.sinks.k1.hdfs.rollCount = 10flume1.9.0连接hadop3.1.3会报错 报错信息为
ERROR - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:459)] process failed
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
这是因为flume内依赖的guava.jar和hadoop内的版本不一致造成的。
查看hadoop安装目录下share/hadoop/common/lib内guava.jar版本与flume安装目录下lib内guava.jar的版本,如果两者不一致,删除版本低的,并拷贝高版本过去。
4.2. 网路端口Avro
# 必选 类型为向avro网络端口传输数据
a1.sinks.k1.type = avro
# 必选 传输主机
a1.sinks.k1.hostname = localhost
# 必选 传输端口
a1.sinks.k1.port = 4444
# 可选 批处理数据量
a1.sinks.k1.batch-size = 100
# 可选 第一次连接超时时间(毫秒)
a1.sinks.k1.connect-timeout = 20000
# 可选 传输数据超时时间(毫秒)
a1.sinks.k1.request-timeout = 200004.3. 文件File Roll
# 必选 类型为写入本地目录(会生成空文件 不适用)
a1.sinks.k1.type = file_roll
# 必选 写入目录配置
a1.sinks.k1.sink.directory = /home/myuser/data
# 可选 滚动时间间隔
a1.sinks.k1.sink.rollInterval = 30
# 可选 批处理数据量大小
a1.sinks.k1.sink.batchSize = 1004.4. 控制台
# 必选 直接打印到控制台
a1.sinks.k1.type = logger4.5. 自定义Sink
# 必选 实现AbstractSink接口,通过getChannel方法获取数据
a1.sinks.k1.type = com.filtrer.flume.MySink
# 配置的param参数,可以在自定义实现类中获取
a1.sinks.k1.param = message5. 组装
5.1. 最简 一对一组装
#sources r1
#channel c1
#sinks k1
# 连接组件 r1-> c1 k1 <- c1 即 r1-> c1 -> k1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c15.2. 一对多组装
# sources r1
# channel c1 c2
# sinks k1 k2
# 数据存两份分别到c1和c2
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c25.3. 路由
通过代码自定义拦截规则路由分发
pom坐标
<dependencies><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version></dependency>
</dependencies>拦截器代码打包上传<flume_home>/lib目录下
package com.filtrer.flume;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.List;
import java.util.Map;
public class MyInterceptor implements Interceptor {public static class MyBuilder implements Interceptor.Builder{@Overridepublic Interceptor build() {return new MyInterceptor();}@Overridepublic void configure(Context context) {}}@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {//配合选择器往header中添加key key的名字叫my_key value有type_number/default default表示默认byte[] body = event.getBody();//获取数据Map<String, String> headers = event.getHeaders();//获取headerif(body[0] >= '0' && body[0] <= '9'){headers.put("my_key","type_number");}return event;}@Overridepublic List<Event> intercept(List<Event> list) {for (Event event : list) {intercept(event);}return list;}@Overridepublic void close() {}
}
# sources r1
# channels c1 c2
# sinks k1 k2
# 连接组件
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
# 可选 对需要发送的channels使用什么分发策略(默认 复制replication)/(路由multiplexing) 配置了路由需要指定路由规则以及规则以及拦截器
a1.sources.r1.selector.type = multiplexing
# 路由规则 my_key 代码中声明了
a1.sources.r1.selector.header = my_key
# 路由1 type_number 代码编写命中规则
a1.sources.r1.selector.mapping.type_number = c1
# 路由2 default 默认未命中的走向
a1.sources.r1.selector.default = c2
# 拦截器名称
a1.sources.r1.interceptors = my_interceptors
# 拦截器对应的class类 将类名中的"."修改为"$"
a1.sources.r1.interceptors.my_interceptors.type = com.filtrer.flume.MyInterceptor$MyBuilderFlume支持的数据传输形式
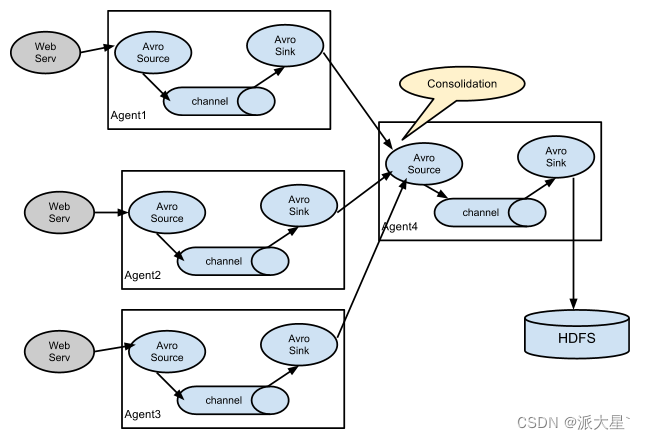
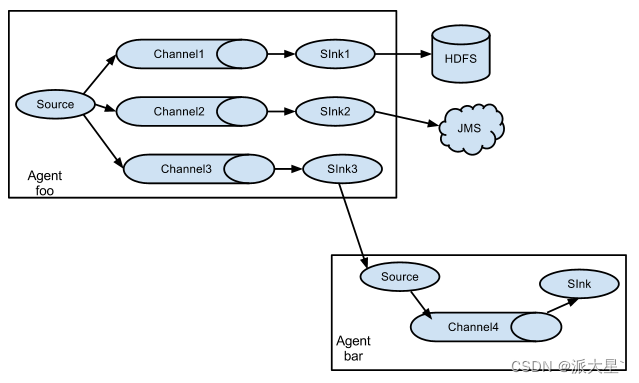
五. 自定义开发
导入pom坐标
<dependencies><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version></dependency>
</dependencies>1.source开发
2.sink开发
package com.filtrer.flume;import org.apache.flume.*;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink;public class MySink extends AbstractSink implements Configurable {private String param;@Overridepublic void configure(Context context) {param= context.getString("param", "msg");//获取配置内容并设置默认值}@Overridepublic Status process() throws EventDeliveryException {Channel channel = getChannel();//获取Channel并开启事务Transaction transaction = channel.getTransaction();transaction.begin();try {Event event;//抓取数据while (true) {event = channel.take();if (event != null) {break;}}//处理数据System.out.println(String.format("%s %s",param,new String(event.getBody())));transaction.commit();//提交事务return Status.READY;} catch (Exception e) {//异常回滚事物transaction.rollback();return Status.BACKOFF;} finally {transaction.close();}}
}六. 完整示例
1. 采集端口数据到控制台
# 组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1a1.sources.r1.type = avro
# # 必选 发送主机
a1.sources.r1.bind = node1
# # 必选 发送端口
a1.sources.r1.port = 55555
# # 可选 数据发送线程数# sink配置
a1.sinks.k1.type = logger# channels配置
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 连接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2. 采集端口数据将部分数据发送到控制台,另一部分发送到其他端口
# 组件定义
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2# sources配置
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444a1.channels.c1.type = memory
a1.channels.c2.type = memorya1.sinks.k1.type = loggera1.sinks.k2.type = avro
a1.sinks.k2.hostname = node1
a1.sinks.k2.port = 55555# 连接组件
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2# 拦截器
a1.sources.r1.selector.type = multiplexing
# 路由规则 my_key 代码中声明了
a1.sources.r1.selector.header = my_key
# 路由1 type_number 代码编写命中规则
a1.sources.r1.selector.mapping.type_number = c1
# 路由2 default 默认未命中的走向
a1.sources.r1.selector.default = c2
# 拦截器名称
a1.sources.r1.interceptors = my_interceptors
# 拦截器对应的class类 将类名中的"."修改为"$"
a1.sources.r1.interceptors.my_interceptors.type = com.filtrer.flume.MyInterceptor$MyBuilder
七. Flume监控工具Ganglia (web gmetad gmod)
在所有部署flume节点的机器上安装gmod用于采集监控数据,在单独的整体监控节点上安装web gmetad用于整合信息并web可视化
部署方式
| 节点名称 | 部署内容 | host |
| Flume节点1 | gmod flume | node1 |
| Flume节点2 | gmod flume | node2 |
| ...... | gmod flume | node* |
| Flume节点9 | gmod flume | node9 |
| Flume监控节点 | gmod gmetad web | node10 |
1. 部署Flume节点
先在所有要部署的节点上安装epel-release依赖
yum -y install epel-release所有节点安装gmond 并修改配置文件gmond.conf
yum -y install ganglia-gmondvim /etc/ganglia/gmond.conf 修改所有节点的配置内容如下
cluster {
name = "web展示节点的host"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel {
#bind_hostname = yes # Highly recommended, soon to be default.
# This option tells gmond to use a source address
# that resolves to the machine's hostname. Without
# this, the metrics may appear to come from any
# interface and the DNS names associated with
# those IPs will be used to create the RRDs.
# mcast_join = 239.2.11.71
# 数据发送给web展示节点
host = node10
port = 8649
ttl = 1
}
udp_recv_channel {
# mcast_join = 239.2.11.71
port = 8649
# 接收来自任意连接的数据
bind = 0.0.0.0
retry_bind = true
# Size of the UDP buffer. If you are handling lots of metrics you really
# should bump it up to e.g. 10MB or even higher.
# buffer = 10485760
}
2. 部署监控节点
安装
yum -y install ganglia-gmetad
yum -y install ganglia-web
2.1. 修改配置文件ganglia.conf
vim /etc/httpd/conf.d/ganglia.confAlias /ganglia /usr/share/ganglia
<Location /ganglia>Require all granted
</Location>
2.2. 修改配置文件gmetad
vim /etc/ganglia/gmetad.conf# 修改为当前节点
data_source "node10" node102.3. 修改配置文件config
vim /etc/selinux/configSELINUX=disabled
SELINUXTYPE=targeted2.4. 重启selinux 本次生效关闭必须重启
setenforce 02.5. 赋值ganglia使用权限
chmod -R 777 /var/lib/ganglia3. 启动监控
3.1. 在所有节点上启动gmond
systemctl start gmond3.2. 在web监控节点上启动httpd和gmetad
systemctl start httpd
systemctl start gmetad访问 http://node3/gangliahttp://node3/ganglia
4.发送数据监控结果
监控需要flume启动任务的时候指定监控节点,将flume的信息发送到监控节点上
指定使用什么工具监控 | -Dflume.monitoring.type=ganglia |
| 监控数据发往哪一台节点 | -Dflume.monitoring.hosts=node10:8649 |
bin/flume-ng agent -c conf/ -n a1 -f conf/nc-flume-log.conf -Dflume.monitoring.type=ganglia -Dflume.monitoring.hosts=node10:8649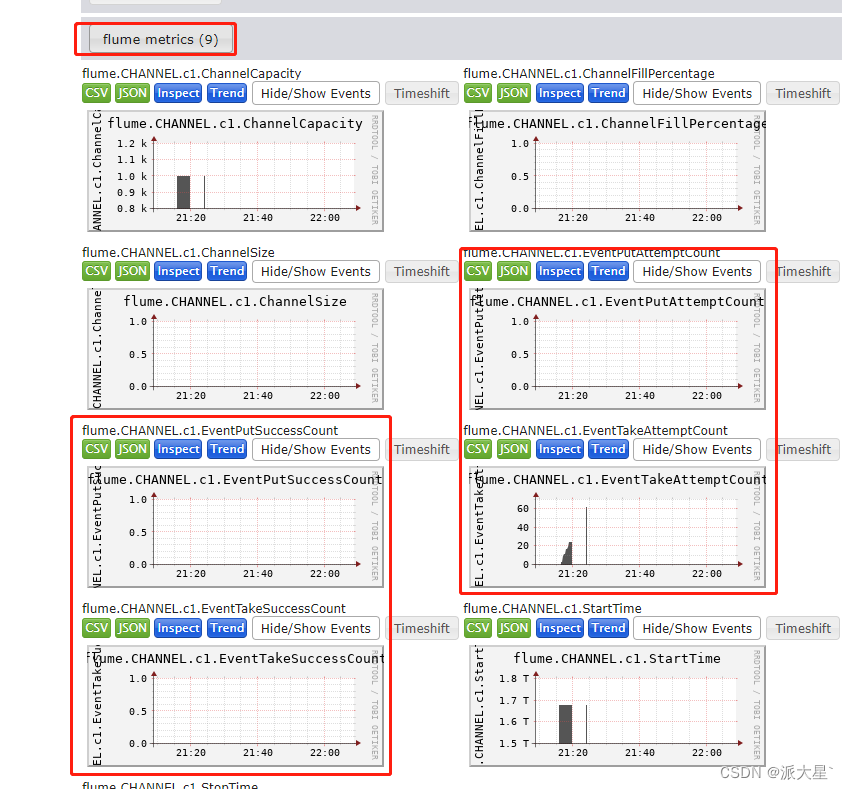
八. 数据传输截断bug
数据传输过程中,一条数据的大小超过默认大下2048字节,这一条数据会被拆成两条数据,导致数据格式异常
处理方法,修改类LineDeserializer
位置 org.apache.flume.serialization.LineDeserializer
1.创建类org.apache.flume.serialization.LineDeserializer
复制LineDeserializer之前的代码,并修改MAXLINE_DFLT参数,数值调大,保证数据不断的长度
2.编译成class文件
javac LineDeserializer.java3.覆盖LineDeserializer.class文件
将编译完成的class文件放入flume-ng-core-1.9.0.jar包中,替换这个包之前的LineDeserializer类
4.覆盖flume-ng-core
用这个被修改的core包替换linux服务器中 目录<flume_home>/lib下的flume-ng-core包
相关文章:
Flume使用入门
目录 一. Flume简单介绍 1. Agent 2. Source 3. Sink 4. Channel 5. Event 二. 环境安装 1. 创建日志目录 2. 修改日志配置文件 3.修改运行堆内存 4. 确定日志打印的位置 5. 修改flume使用内存 内存调大 三. 校验flume 1. 安装netcat工具和net-tools工具 2. 判…...
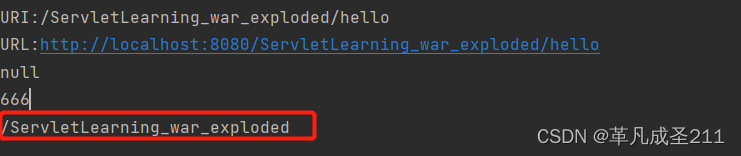
【Servlet篇2】Servlet的工作过程,Servlet的api——HttpServletRequest
一、Servlet的工作过程 二、Tomcat的初始化 步骤1:寻找到当前目录下面所有需要加载的Servlet(也就是类) 步骤2:根据类加载的结果创建实例(通过反射),并且放入集合当中 步骤3:实例创建好之后,调用Servlet的init()方…...

【JAVASE】注解
文章目录1.概述2.JDK内置注解2.1override注解2.2 Deprecated注解3.元注解4.注解中定义属性4.1 属性value4.2 属性是一个数组5. 反射注解6.注解在开发中的作用1.概述 注解,也叫注释,是一种引用数据类型。编译后也同样生成class字节码文件。 语法 [修饰…...
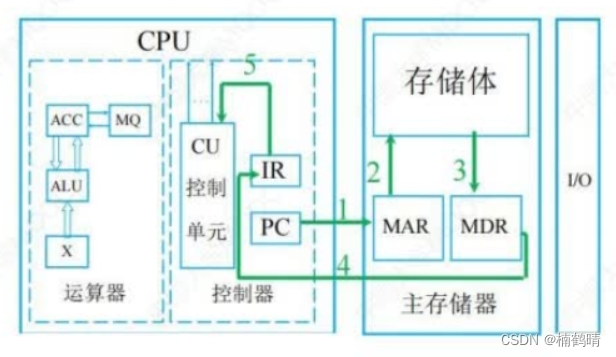
【408之计算机组成原理】计算机系统概述
目录前言一、计算机的发展历程1. 计算机发展的四代变化2. 计算机元件的更新换代3. 计算机软件的发展二、计算机系统层次结构1. 计算机系统的组成2. 冯诺依曼体系结构3. 计算机的功能部件1. 输入设备2. 输出设备3. 存储器4. 运算器5. 控制器三、 分析计算机各个部件在执行代码中…...
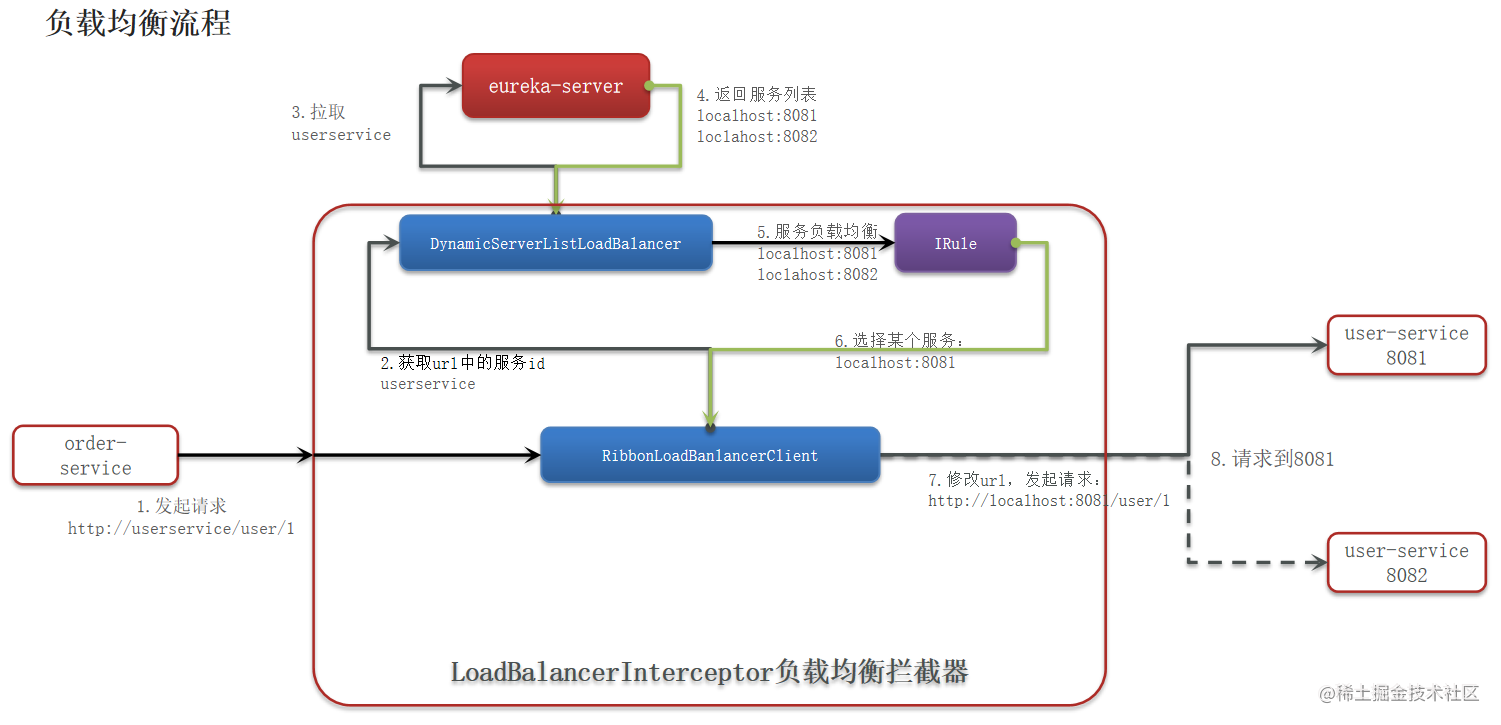
1.Spring Cloud (Hoxton.SR10) 学习笔记—基础知识
本文目录如下:一、Spring Cloud基础知识什么是微服务架构?服务拆分 有哪些注意事项?什么是分布式集群?分布式的 CAP 原则?组件 - Spring Cloud 哪几个组件比较重要?组件 - 为什么要使用这些组件?组件 - Na…...

嵌入式开发工具箱【持续更新中】【VMware、Ubuntutftp、nfs、SecureCRT、XShell、Source Insight 4.0】
一、概述 本文主要介绍嵌入式开发过程中需要用到的工具及简单的使用方法。避免在搭建嵌入式开发环境时,需要四处寻找文档,收藏此文章,一文搞定。 大多数嵌入式开发环境是使用Linux作为目标开发系统,所以开发主机一般都是Linux系统…...

深究Java Hibernate框架下的Deserialization
写在前面 Hibernate是一个开源免费的、基于 ORM 技术的 Java 持久化框架。通俗地说,Hibernate 是一个用来连接和操作数据库的 Java 框架,它最大的优点是使用了 ORM 技术。 Hibernate 支持几乎所有主流的关系型数据库,只要在配置文件中设置好…...
微服务一 实用篇 - Docker安装
《微服务一 实用篇 - Docker安装》 提示: 本材料只做个人学习参考,不作为系统的学习流程,请注意识别!!! 《微服务一 实用篇 - Docker安装》《微服务一 实用篇 - Docker安装》0.安装Docker1.CentOS安装Docker1.1.卸载(可选)1.2.安装docker1.3.启动docker…...

JavaSE22-集合2-map
文章目录一、集合概念二、map集合1、Map集合的特点2、HashMap2.1 HashMap特点2.2 创建对象2.3 常用方法2.4 遍历2.4.1 使用entrySet遍历2.4.2 使用keySet遍历3、HashMap的key去重原理一、集合概念 集合就是用于存储多个数据的容器。相对于具有相同功能的数组来说,集…...
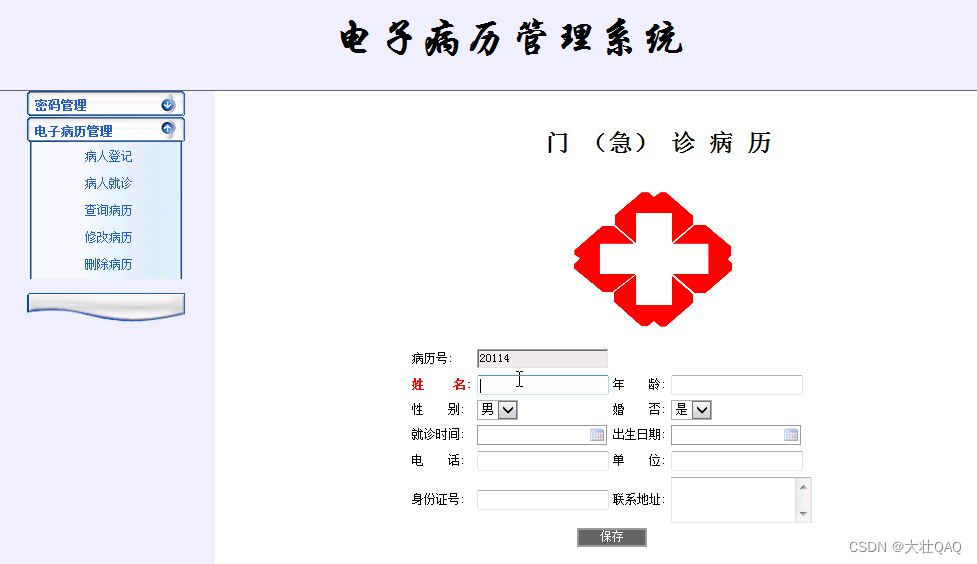
【项目精选】病历管理系统设计与实现(源码+视频)
点击下载源码 企业财务管理系统主要用于电子病历来提高医院各项工作的效率和质量,促进医学科研、教学;减轻各类事务性工作的劳动强度,使他们腾出更多的精力和时间来服务于病人。本系统结构如下: 电子病例系统: 病人登…...
如何用Python把篮球和鸡联系起来
文章目录画个球让球转起来画个球 不管篮球和不和鸡联系起来,都首先得有个球,或者说要有一个球面,用参数方程可以表示为 xrcosϕcosθyrcosϕsinθzrsinϕ\begin{aligned} x & r\cos\phi\cos\theta\\ y & r\cos\phi\sin\th…...
【RocketMQ】消息的刷盘机制
刷盘策略 CommitLog的asyncPutMessage方法中可以看到在写入消息之后,调用了submitFlushRequest方法执行刷盘策略: public class CommitLog {public CompletableFuture<PutMessageResult> asyncPutMessage(final MessageExtBrokerInner msg) {// …...

AMBA-AXI(一)burst 传输-INCR/WRAP/Fixed
💡Note:本文是根据AXI协议IHI0022F_b_amba_axi_protocol_spec.pdf(issue F)整理的。主要是分享AXI3.0和4.0部分。如果内容有问题请大家在评论区中指出,有补充或者疑问也可以发在评论区,互相学习ὤ…...
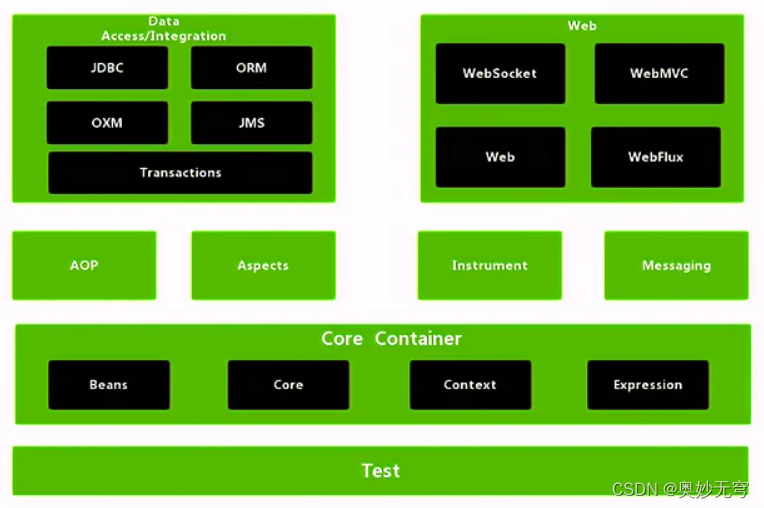
Java知识复习(八)Spring基础
1、什么是Spring框架? Spring :是一款开源的轻量级 Java 开发框架,旨在提高开发人员的开发效率以及系统的可维护性 2、Spring、SpringMVC和SpringBoot的区别 Spring主要指Spring Framework,就是指如上图所示的各项功能模块Spr…...

WuThreat身份安全云-TVD每日漏洞情报-2023-02-27
漏洞名称:OTFCC 缓冲区错误漏洞 漏洞级别:中危 漏洞编号:CVE-2022-35060,CNVD-2023-11996,CNNVD-202209-1527 相关涉及:OTFCC OTFCC 漏洞状态:EXP 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2022-23648 漏洞名称:MuYucms 存在任意代码执行漏洞 漏洞级别:高危…...

上海交大陈海波教授、夏虞斌教授领衔巨作上市:《操作系统:原理与实现》
❤️作者主页:小虚竹 ❤️作者简介:大家好,我是小虚竹。2022年度博客之星评选TOP 10🏆,Java领域优质创作者🏆,CSDN博客专家🏆,华为云享专家🏆,掘金年度人气作…...

dpi数据接入shell脚
原文:dpi数据接入shell脚本_weixin_34416754的博客-CSDN博客 ##############从ftp服务器拿数据文件 #!/bin/bash #获取感知优良率DPI数据 #DCN服务器信息 uSichuan pS988188# ip137.192.5.53 #获取日期,根据日期抓取文件 Tdate -d "3 days ago&…...
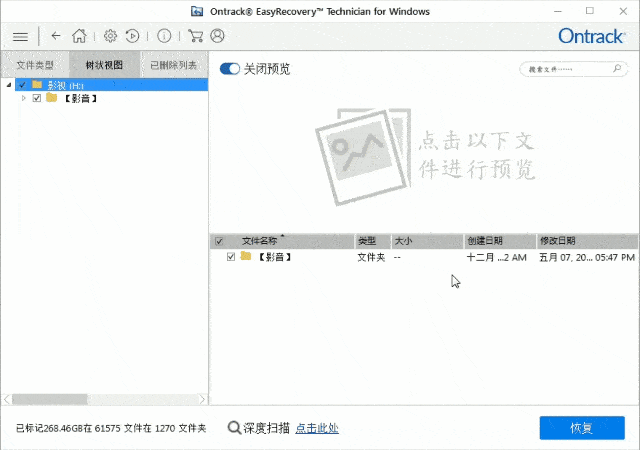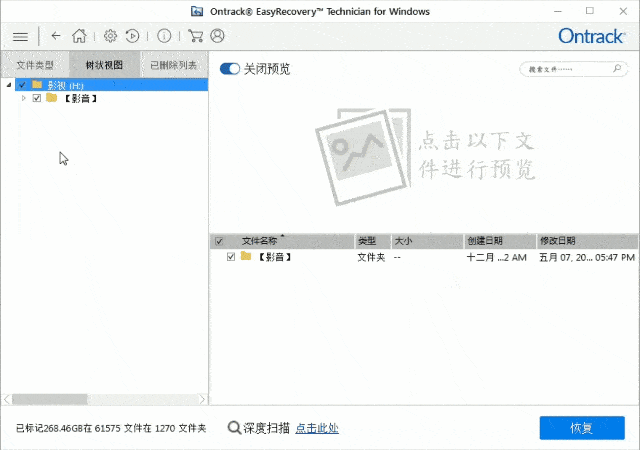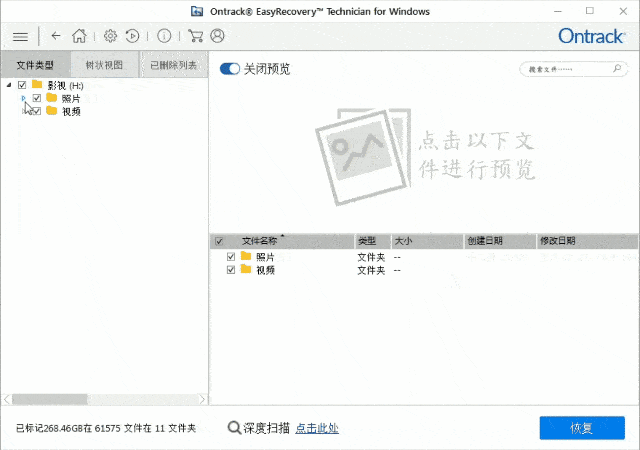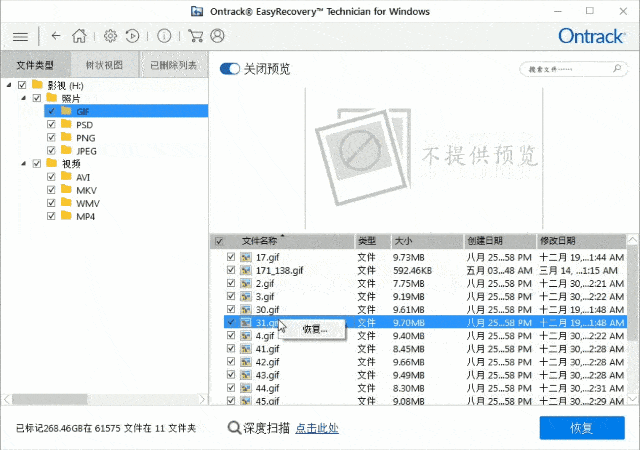
Easyrecovery数据恢复软件工作原理及使用介绍教程
Easyrecovery是一款强大的数据恢复软件,它专门解决磁盘数据恢复问题。在计算机世界里,数据丢失经常是一件令人头疼的事情,但是有了Easyrecovery,您可以放心大胆地享受数据备份和恢复的乐趣。EasyRecovery使用Ontrack公司复杂的模式…...

【面试题】社招中级前端笔试面试题总结
大厂面试题分享 面试题库后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库typeof null 的结果是什么,为什么?typeof null 的结果是Object。在 JavaScript 第一个版本中,所有值都存储在…...
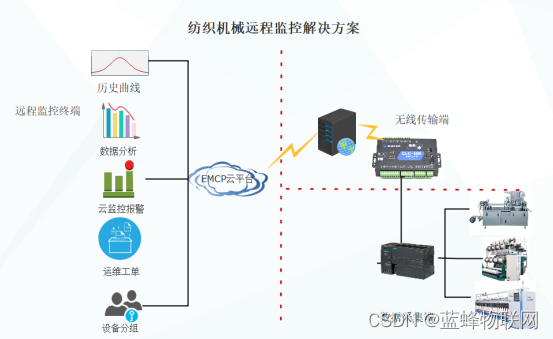
设备运行状况不能远程手机查看。难道就妥协吗?为何不试试这个办法
一、背景 随着国家经济结构逐步调整,纺织行业自动化、智能化水平逐步提高,业内竞争程度也将加大;整个市场变化快,并呈现出智能化、通用化、网络化、复杂化的新发展趋势。客户订单小批量、个性化、快速交货的特点越来越明显&#…...

慕尼黑电子展深度攻略:从技术侦察到资源对接的实战指南
1. 展会项目概述与核心价值解析又到了一年一度的行业盛会密集期,对于身处电子、嵌入式、物联网这些硬科技赛道的从业者来说,参加一场高质量的线下展会,其价值远不止是“逛一逛”那么简单。它更像是一次集中的行业体检、一次高效的技术社交和一…...

XRDP 远程桌面连接 Ubuntu:从安装到优化的完整实践指南
1. 为什么选择XRDP连接Ubuntu? 对于需要远程管理Ubuntu系统的用户来说,图形化界面操作往往比纯命令行更直观高效。XRDP作为开源的远程桌面协议实现,相比TeamViewer等商业方案,它完全免费且性能出色;相比VNC,…...

从零打造会发光的航天飞机模型:焊接入门与PCB组装实战
1. 项目概述:从零打造一台会发光的航天飞机模型如果你对电子制作感兴趣,或者一直想亲手焊接点什么,但又觉得从零开始画电路板、写代码门槛太高,那么这个Space Shuttle Discovery焊接套件绝对是为你量身定做的“入门神作”。它巧妙…...

抖音下载器技术架构解析:从零构建高效内容采集系统
抖音下载器技术架构解析:从零构建高效内容采集系统 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

魔兽争霸III终极优化指南:7个实用方案让经典游戏完美适配现代硬件
魔兽争霸III终极优化指南:7个实用方案让经典游戏完美适配现代硬件 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸III作为一款经典…...

基于英创ARM9嵌入式主板实现双CAN接口的硬件设计与Linux驱动配置实战
1. 项目概述:为什么需要双CAN接口? 在工业自动化、汽车电子、新能源设备这些领域里,CAN总线就像设备之间的“神经系统”,负责传递各种控制指令和状态数据。一个CAN接口是基础,但当你需要同时连接两个独立的CAN网络&…...

FPGA实战:用Z80与8051软核构建可运行BASIC的复古计算机
1. 项目概述:在FPGA上复活经典8位计算机如果你和我一样,对上世纪七八十年代那些经典的8位计算机架构——比如Zilog Z80和Intel 8051——抱有浓厚的兴趣,同时又对现代FPGA技术着迷,那么这个项目绝对会让你兴奋。它不是一个简单的仿…...

Cursor对话历史导出扩展:基于DOM逆向的AI协作数据备份方案
1. 项目概述:一个为开发者解放生产力的“数据保险箱”如果你和我一样,日常重度依赖 Cursor 这款 AI 编程神器,那你一定有过这样的焦虑:那些与 AI 深度对话产生的宝贵上下文、精心调教出的项目特定提示词、甚至是 AI 帮你重构的代码…...

终极Python通达信数据读取指南:5分钟快速入门量化分析
终极Python通达信数据读取指南:5分钟快速入门量化分析 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易领域,通达信数据读取一直是Python开发者面临…...

WorkshopDL完全指南:三步实现跨平台游戏模组下载的终极解决方案
WorkshopDL完全指南:三步实现跨平台游戏模组下载的终极解决方案 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在Epic、GOG等非Steam平台购买了游戏…...