【Spark精讲】Spark与MapReduce对比
目录
对比总结
MapReduce流程
编辑
MapTask流程
ReduceTask流程
MapReduce原理
阶段划分
Map shuffle
Partition
Collector
Sort
Spill
Merge
Reduce shuffle
Copy
Merge Sort
对比总结
- Map端读取文件:都是需要通过split概念来进行逻辑切片,概念相同,底层具体实现和参数略有差异;
- 业务逻辑实现方式:MapReduce引擎是通过用户自定义实现Mapper和Reducer类来实现业务逻辑的;而Spark提供了丰富的算子以及上层DataFrame、DataSet的抽象;
- 计算引擎:MapReduce是基于标准的map reduce计算理念的实现,map任务和reduce任务数据交换通过读写文件的方式进行的,运行效率低;Spark是基于内存的(RDD),同时Spark的计算引擎是基于DAG方式实现的(类似Tez),除了shuffle会通过文件进行数据交换外,每个阶段的计算是基于内存的,运行效率高,基于内存有利于进行性能优化,同时提供缓存和广播机制有利于计算结果复用,适合算法迭代计算,此外不但可以使用堆内内存还可以使用堆外内存;
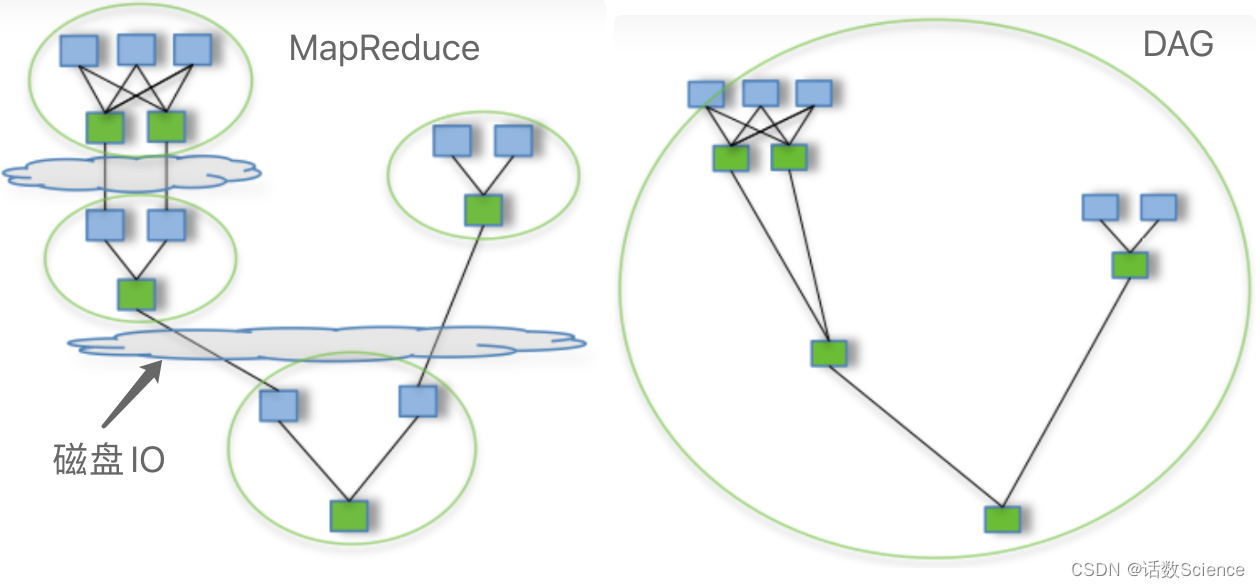
- 部署方式:都可以基于YARN,MapReduce基于YARN实现了MRAppMaster,Spark基于YARN实现了ApplicationMaster;
- Shuffle方式:MapReduce采用了基于排序的数据聚集策略(按Key排序),而该策略是不可定制的,不可以使用其他数据聚集算法(如Hash聚集);而Spark默认也需要排序,但一定条件下也可以不进行排序(ByPass和Tungsten方式)。
- 运行方式:MapReduce的Job是基于JVM进程的;而Spark的Driver和Executor是JVM进程,Task运行是基于线程的。
MapReduce流程
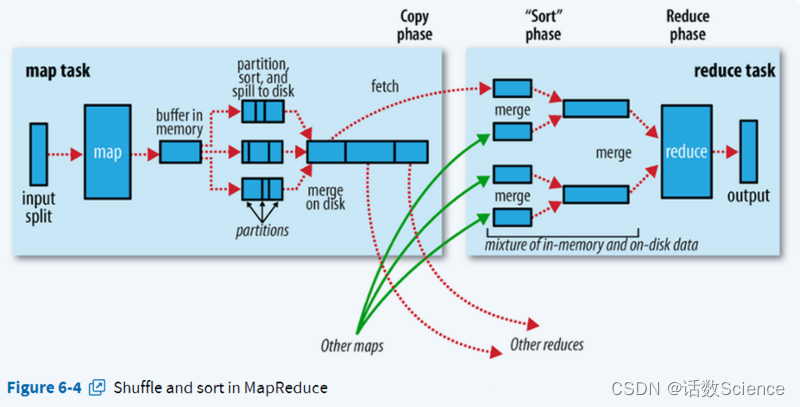
MapTask流程
- Read阶段:Map Task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
- Map阶段:该阶段主要是讲解析的key/value交给用户编写的map()函数处理,并产生一些列新的key/value。
- Collect阶段:在用户编写的map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分片(通过调用Partitioner),并写入一个环形内存缓冲区中。
- Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要主要的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
- Combine阶段:当所有数据处理完成后,Map Task对所有临时文件进行一次合并,以确保最终只是生成一个数据文件。
ReduceTask流程
- Shuffle阶段:也称之为Copy阶段。Reduce Task从各个Map Task远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
- Merge阶段:在远程拷贝数据的同时,Reduce Task启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
- Sort阶段:按照MapReduce语义,用户编写的reduce()函数输入数据是按Key进行聚集的一组数据。为了将Key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个Map Task已经实现对自己的处理结果进行了局部排序。因此Reduce Task只需对所有数据进行一次归并排序即可。
- Reduce阶段:在该阶段中,Reduce Task将每组数据依次交给用户编写的reduce()函数处理。
- Write阶段:reduce()函数将计算结果写到HDFS上。
MapReduce原理
阶段划分
我们知道MapReduce计算模型主要由三个阶段构成:Map、shuffle、Reduce。
- Map是映射,负责数据的过滤分法,将原始数据转化为键值对;
- Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。
- Shuffle:为了让Reduce可以并行处理Map的结果,必须对Map的输出进行一定的排序与分割,然后再交给对应的Reduce,而这个将Map输出进行进一步整理并交给Reduce的过程就是Shuffle。
整个MR的大致过程如下:

Map和Reduce操作需要我们自己定义相应Map类和Reduce类,以完成我们所需要的化简、合并操作,而shuffle则是系统自动帮我们实现的,了解shuffle的具体流程能帮助我们编写出更加高效的Mapreduce程序。
Shuffle过程包含在Map和Reduce两端,即Map shuffle和Reduce shuffle。
Map shuffle
在Map端的shuffle过程是对Map的结果进行分区、排序、分割,然后将属于同一划分(分区)的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件,分区有序的含义是map输出的键值对按分区进行排列,具有相同partition值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排列(默认),其流程大致如下:

Partition
对于map输出的每一个键值对,系统都会给定一个partition,partition值默认是通过计算key的hash值后对Reduce task的数量取模获得。如果一个键值对的partition值为1,意味着这个键值对会交给第一个Reducer处理。
我们知道每一个Reduce的输出都是有序的,但是将所有Reduce的输出合并到一起却并非是全局有序的,如果要做到全局有序,我们该怎么做呢?最简单的方式,只设置一个Reduce task,但是这样完全发挥不出集群的优势,而且能应对的数据量也很受限。最佳的方式是自己定义一个Partitioner,用输入数据的最大值除以系统Reduce task数量的商作为分割边界,也就是说分割数据的边界为此商的1倍、2倍至numPartitions-1倍,这样就能保证执行partition后的数据是整体有序的。
另一种需要我们自己定义一个Partitioner的情况是各个Reduce task处理的键值对数量极不平衡。对于某些数据集,由于很多不同的key的hash值都一样,导致这些键值对都被分给同一个Reducer处理,而其他的Reducer处理的键值对很少,从而拖延整个任务的进度。当然,编写自己的Partitioner必须要保证具有相同key值的键值对分发到同一个Reducer。
Collector
Map的输出结果是由collector处理的,每个Map任务不断地将键值对输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
这个数据结构其实就是个字节数组,叫Kvbuffer,名如其义,但是这里面不光放置了数据,还放置了一些索引数据,给放置索引数据的区域起了一个Kvmeta的别名,在Kvbuffer的一块区域上穿了一个IntBuffer(字节序采用的是平台自身的字节序)的马甲。数据区域和索引数据区域在Kvbuffer中是相邻不重叠的两个区域,用一个分界点来划分两者,分界点不是亘古不变的,而是每次Spill之后都会更新一次。初始的分界点是0,数据的存储方向是向上增长,索引数据的存储方向是向下增长,如图所示:
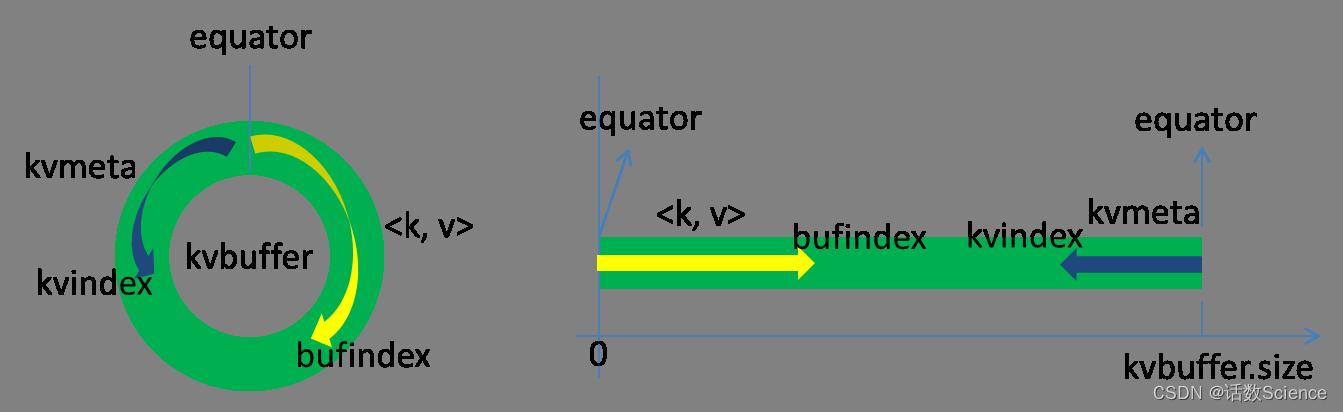
Kvbuffer的存放指针bufindex是一直闷着头地向上增长,比如bufindex初始值为0,一个Int型的key写完之后,bufindex增长为4,一个Int型的value写完之后,bufindex增长为8。
索引是对在kvbuffer中的键值对的索引,是个四元组,包括:value的起始位置、key的起始位置、partition值、value的长度,占用四个Int长度,Kvmeta的存放指针Kvindex每次都是向下跳四个“格子”,然后再向上一个格子一个格子地填充四元组的数据。比如Kvindex初始位置是-4,当第一个键值对写完之后,(Kvindex+0)的位置存放value的起始位置、(Kvindex+1)的位置存放key的起始位置、(Kvindex+2)的位置存放partition的值、(Kvindex+3)的位置存放value的长度,然后Kvindex跳到-8位置,等第二个键值对和索引写完之后,Kvindex跳到-12位置。
Kvbuffer的大小可以通过io.sort.mb设置,默认大小为100M。但不管怎么设置,Kvbuffer的容量都是有限的,键值对和索引不断地增加,加着加着,Kvbuffer总有不够用的那天,那怎么办?把数据从内存刷到磁盘上再接着往内存写数据,把Kvbuffer中的数据刷到磁盘上的过程就叫Spill,多么明了的叫法,内存中的数据满了就自动地spill到具有更大空间的磁盘。
关于Spill触发的条件,也就是Kvbuffer用到什么程度开始Spill,还是要讲究一下的。如果把Kvbuffer用得死死得,一点缝都不剩的时候再开始Spill,那Map任务就需要等Spill完成腾出空间之后才能继续写数据;如果Kvbuffer只是满到一定程度,比如80%的时候就开始Spill,那在Spill的同时,Map任务还能继续写数据,如果Spill够快,Map可能都不需要为空闲空间而发愁。两利相衡取其大,一般选择后者。Spill的门限可以通过io.sort.spill.percent,默认是0.8。
Spill这个重要的过程是由Spill线程承担,Spill线程从Map任务接到“命令”之后就开始正式干活,干的活叫SortAndSpill,原来不仅仅是Spill,在Spill之前还有个颇具争议性的Sort。
Sort
当Spill触发后,SortAndSpill先把Kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
Spill
Spill线程为这次Spill过程创建一个磁盘文件:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out”的文件。Spill线程根据排过序的Kvmeta挨个partition的把数据吐到这个文件中,一个partition对应的数据吐完之后顺序地吐下个partition,直到把所有的partition遍历完。一个partition在文件中对应的数据也叫段(segment)。在这个过程中如果用户配置了combiner类,那么在写之前会先调用combineAndSpill(),对结果进行进一步合并后再写出。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。那哪些场景才能使用Combiner呢?Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
所有的partition对应的数据都放在这个文件里,虽然是顺序存放的,但是怎么直接知道某个partition在这个文件中存放的起始位置呢?强大的索引又出场了。有一个三元组记录某个partition对应的数据在这个文件中的索引:起始位置、原始数据长度、压缩之后的数据长度,一个partition对应一个三元组。然后把这些索引信息存放在内存中,如果内存中放不下了,后续的索引信息就需要写到磁盘文件中了:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out.index”的文件,文件中不光存储了索引数据,还存储了crc32的校验数据。spill12.out.index不一定在磁盘上创建,如果内存(默认1M空间)中能放得下就放在内存中,即使在磁盘上创建了,和spill12.out文件也不一定在同一个目录下。每一次Spill过程就会最少生成一个out文件,有时还会生成index文件,Spill的次数也烙印在文件名中。索引文件和数据文件的对应关系如下图所示:

在Spill线程如火如荼的进行SortAndSpill工作的同时,Map任务不会因此而停歇,而是一无既往地进行着数据输出。Map还是把数据写到kvbuffer中,那问题就来了:只顾着闷头按照bufindex指针向上增长,kvmeta只顾着按照Kvindex向下增长,是保持指针起始位置不变继续跑呢,还是另谋它路?如果保持指针起始位置不变,很快bufindex和Kvindex就碰头了,碰头之后再重新开始或者移动内存都比较麻烦,不可取。Map取kvbuffer中剩余空间的中间位置,用这个位置设置为新的分界点,bufindex指针移动到这个分界点,Kvindex移动到这个分界点的-16位置,然后两者就可以和谐地按照自己既定的轨迹放置数据了,当Spill完成,空间腾出之后,不需要做任何改动继续前进。分界点的转换如下图所示:

Map任务总要把输出的数据写到磁盘上,即使输出数据量很小在内存中全部能装得下,在最后也会把数据刷到磁盘上。
Merge
Map任务如果输出数据量很大,可能会进行好几次Spill,out文件和Index文件会产生很多,分布在不同的磁盘上。最后把这些文件进行合并的merge过程闪亮登场。
Merge过程怎么知道产生的Spill文件都在哪了呢?从所有的本地目录上扫描得到产生的Spill文件,然后把路径存储在一个数组里。Merge过程又怎么知道Spill的索引信息呢?没错,也是从所有的本地目录上扫描得到Index文件,然后把索引信息存储在一个列表里。到这里,又遇到了一个值得纳闷的地方。在之前Spill过程中的时候为什么不直接把这些信息存储在内存中呢,何必又多了这步扫描的操作?特别是Spill的索引数据,之前当内存超限之后就把数据写到磁盘,现在又要从磁盘把这些数据读出来,还是需要装到更多的内存中。之所以多此一举,是因为这时kvbuffer这个内存大户已经不再使用可以回收,有内存空间来装这些数据了。(对于内存空间较大的土豪来说,用内存来省却这两个io步骤还是值得考虑的。)
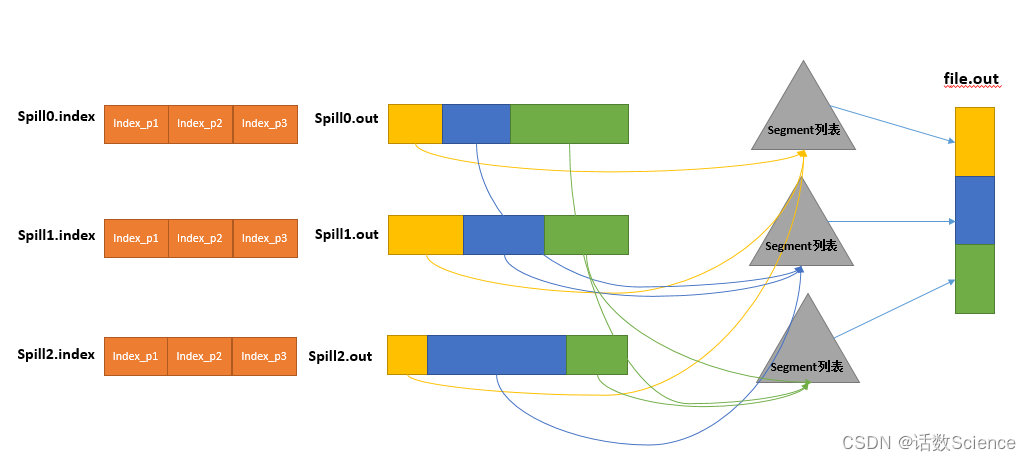
然后为merge过程创建一个叫file.out的文件和一个叫file.out.Index的文件用来存储最终的输出和索引,一个partition一个partition的进行合并输出。对于某个partition来说,从索引列表中查询这个partition对应的所有索引信息,每个对应一个段插入到段列表中。也就是这个partition对应一个段列表,记录所有的Spill文件中对应的这个partition那段数据的文件名、起始位置、长度等等。
然后对这个partition对应的所有的segment进行合并,目标是合并成一个segment。当这个partition对应很多个segment时,会分批地进行合并:先从segment列表中把第一批取出来,以key为关键字放置成最小堆,然后从最小堆中每次取出最小的输出到一个临时文件中,这样就把这一批段合并成一个临时的段,把它加回到segment列表中;再从segment列表中把第二批取出来合并输出到一个临时segment,把其加入到列表中;这样往复执行,直到剩下的段是一批,输出到最终的文件中。最终的索引数据仍然输出到Index文件中。
Reduce shuffle
在Reduce端,shuffle主要分为复制Map输出、排序合并两个阶段。
Copy
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据。Map任务成功完成后,会通知父TaskTracker状态已经更新,TaskTracker进而通知JobTracker(这些通知在心跳机制中进行)。所以,对于指定作业来说,JobTracker能记录Map输出和TaskTracker的映射关系。Reduce会定期向JobTracker获取Map的输出位置,一旦拿到输出位置,Reduce任务就会从此输出对应的TaskTracker上复制输出到本地,而不会等到所有的Map任务结束。
Merge Sort
Copy过来的数据会先放入内存缓冲区中,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会化简压缩合并的map输出。Reduce的内存缓冲区可通过mapred.job.shuffle.input.buffer.percent配置,默认是JVM的heap size的70%。内存到磁盘merge的启动门限可以通过mapred.job.shuffle.merge.percent配置,默认是66%。
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。
相关文章:
【Spark精讲】Spark与MapReduce对比
目录 对比总结 MapReduce流程 编辑 MapTask流程 ReduceTask流程 MapReduce原理 阶段划分 Map shuffle Partition Collector Sort Spill Merge Reduce shuffle Copy Merge Sort 对比总结 Map端读取文件:都是需要通过split概念来进行逻辑切片&…...
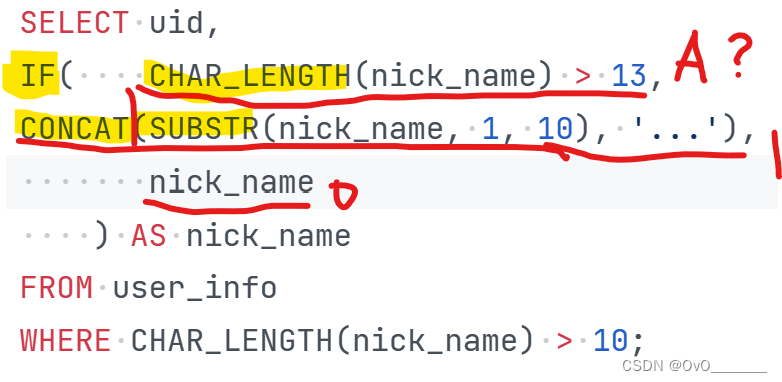
SQL错题集3
1.薪水第二多的员工的emp_no以及其对应的薪水salary limit a,b 其中a表示查询数据的起始位置,b表示返回的数量。 (MySQL数据库中的记录是从0开始的) 注意从0开始 2.员工编号emp_no为10001其自入职以来的薪水salary涨幅值growth 聚合函数不能…...
Elasticsearch:使用 OpenAI 生成嵌入并进行向量搜索 - nodejs
在我之前的文章: Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (一)(二)(三)(四) 我详细地描述了如何使用…...

[python高级编程]:02-类
此系列主要用于记录Python学习过程中查阅的优秀文章,均为索引方式。其中内容只针对本作者一人,作者熟悉了解的内容不再重复记录。 目录 01-装饰器 overload -- 方法重载 02-多态 多态和鸭子类型 03-设计模式 抽象基类和接口 01-装饰器 overload -- 方…...

java.lang.UnsupportedOperationException异常解决
在执行如下代码时,发现当apps.add("...");代码执行时,会报java.lang.UnsupportedOperationException错误 List<String> apps Arrays.asList("...");apps.add("..."); 问题出现的原因如下: 1、ArrayLi…...
openmediavault debian linux安装配置企业私有网盘(三 )——raid5与btrfs文件系统无损原数据扩容
一、适用环境 1、企业自有物理专业服务器,一些敏感数据不外流时,使用openmediavault自建NAS系统; 2、在虚拟化环境中自建NAS系统,用于内网办公,或出差外网办公时,企业内的文件共享; 3、虚拟化环…...
设计模式)
Two Phase Termination(两阶段)设计模式
Two Phase Termination设计模式是针对任务由两个环节组成,第一个环节是处理业务相关的内容,第二个阶段是处理任务结束时的同步、释放资源等操作。在进行两阶段终结的时候,需要考虑: 第二阶段终止操作必须保证线程安全。 要百分百…...
闲人闲谈PS之四十九——PLM和SAP集成常见的问题
惯例闲话:天气突变,没想到珠三角也骤降了10几度,昨晚还吹风扇模式,早上起来一下子感觉丝丝凉意。闲人还是喜欢冬天,冷,能让人思维清晰,提高工作效率。趁着天气适宜,赶紧加班擦屁股去…...

帆软BI目录
数据导入ORACLE库 写法 SELECT * FROM (SELECT a.id ,a.expandType,a.parentId,a.displayName,a.sortIndex,LEVEL lv ,replace(sys_connect_by_path(displayName,//),//Dec-Entry_Management//,) AS 路径FROM FINE_AUTHORITY_OBJECT aSTART WITH a.id decision-directory-ro…...
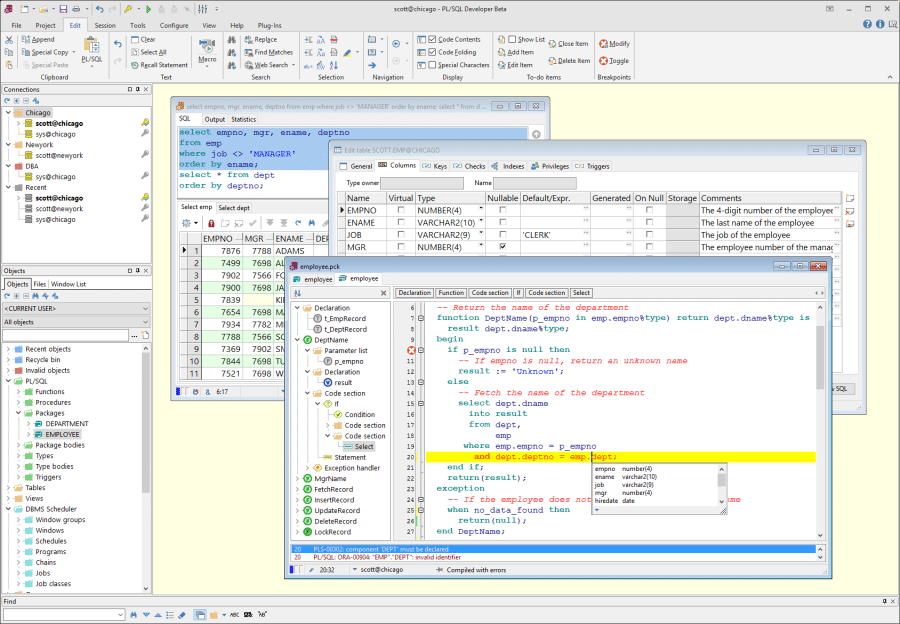
(第8天)保姆级 PL/SQL Developer 安装与配置
PL/SQL Developer 安装与配置(第8天) 咱们前面分享了很多 Oracle 数据库的安装,但是还没有正式使用过 Oracle 数据库,怎么连接 Oracle 数据库?今天就来讲讲我学习中比较常用的 Oracle 数据库连接工具:PL/SQL DEVELOPER。 PL/SQL Developer 的安装和配置对于新手来说还是…...

【CSS】前端点点点加载小点样式css动画过程实现
对话的 ... 加载动画,直接用 CSS 就可以实现,样式可以自己改,逻辑大差不差 <div class"loading-text"><span class"dot1"></span><span class"dot2"></span><span class&quo…...

【LeetCode: 2415. 反转二叉树的奇数层 | BFS + DFS】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...

期货股市联动(期股联动助推资本市场上扬)
期股联动——期货股市助推资本市场上扬 随着我国资本市场的不断发展,期货和股票这两个市场也在逐渐紧密地联系起来。期货和股票的相互作用是一种“期股联动”,它能够促进资本市场的上扬。 期货与股票市场 期货市场是一种标准化的场外交易市场…...

生成式AI的力量,释放RPA的无限潜能
回首即将过去的2023年,互联网行业似乎始终处在各种新概念的热潮激荡之中。其中,最引人注目的话题无疑是AI科技。自人工智能技术实现大规模突破以来,我们见证了一系列生成式AI的涌现。从ChatGPT到百度文心一言,它们纷纷登场&#x…...
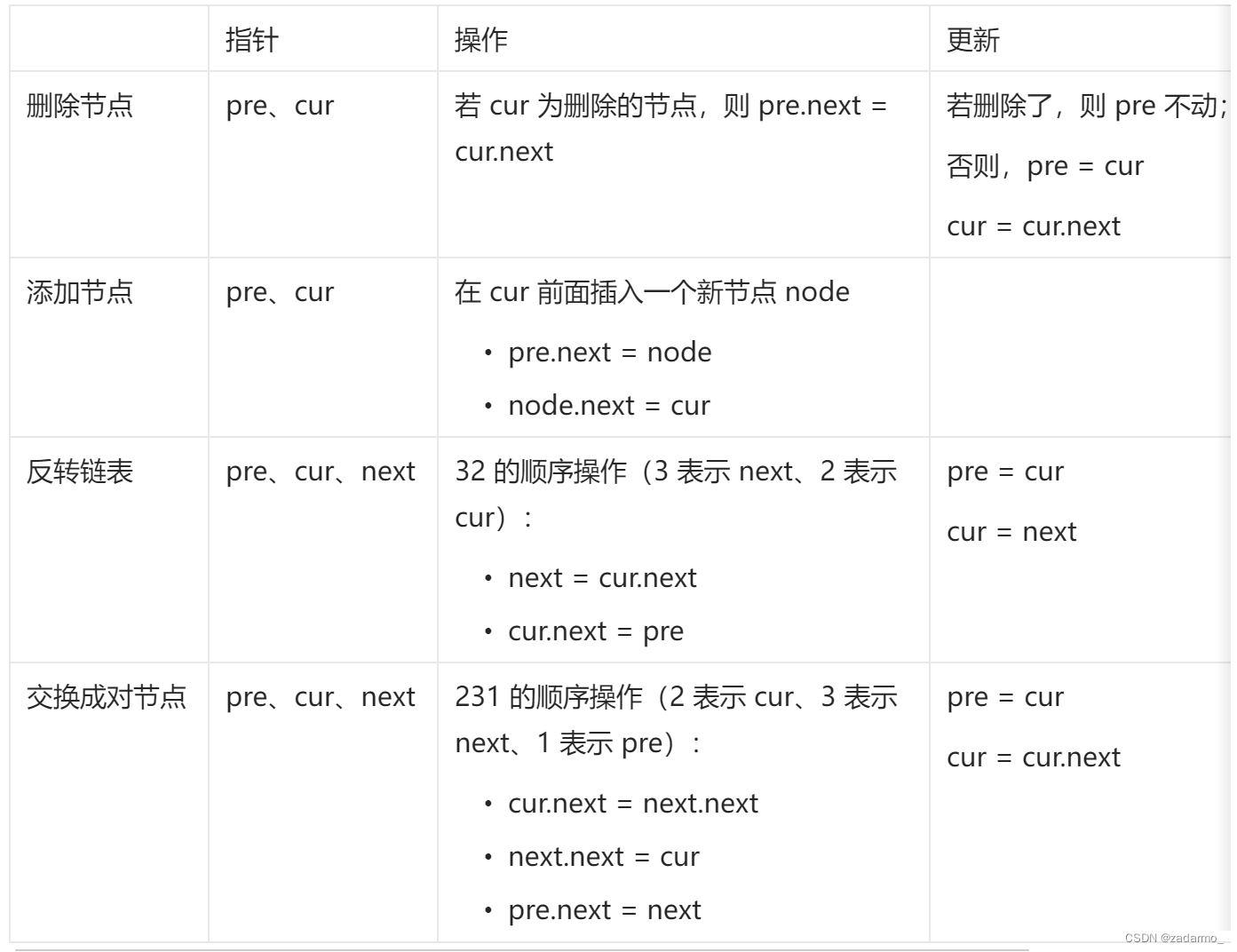
【leetcode】链表总结
说明:本文内容来自于代码随想录 链表基本操作 https://leetcode.cn/problems/design-linked-list/ 删除节点 https://leetcode.cn/problems/remove-linked-list-elements/description/,删除节点,虚拟头节点。定义两个节点,分别…...

焦虑,其实是你自愿选择的
如果一个人想要焦虑,他可以永远焦虑下去 从上学,到找工作,从买房到结婚生娃,他总是可以选择用自己的头脑去过度思考未来还没有发生的事情,从而让自己无限焦虑下去,直到生命终结。 我们的生命是存在于当下…...

4G无线工业级路由器在智能制造设备互联互通中的角色
随着工业技术的不断发展和进步,智能制造已经成为了现代制造业的重要趋势和发展方向。而在智能制造过程中,设备之间的互联互通是至关重要的一环。在这个过程中,4G无线工业级路由器扮演着重要的角色,它提供了稳定可靠的网络连接&…...
gitbash下载安装
参考教程 零、下载 官网地址 2.43.0win64 链接:https://pan.baidu.com/s/16urs_nmky7j20-qNzUTTkg 提取码:7jaq 一、安装 图标组件(Additional icons):选择是否创建桌面快捷方式;桌面浏览(Win…...
系列一、Linux中安装MySQL
一、Linux中安装MySQL 1.1、下载MySQL安装包 官网:https://dev.mysql.com/downloads/file/?id523327 我分享的: 链接:https://pan.baidu.com/s/188_9RnBYlWVzFb_UJH5aaQ?pwdyyds 提取码:yyds 1.2、上传至/opt目录 & 解压…...

开辟“护眼绿洲”,荣耀何以为师?
文 | 智能相对论 作者 | 佘凯文 俗话说,眼睛是心灵的窗户,可如今,人们对于这扇“窗户”的保护,似乎越来越不重视。 据人民日报今年发布的调查显示,中国眼病患病人数2.1亿,近视患者人数多达6亿࿰…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

小智AI+MCP
什么是小智AI和MCP 如果还不清楚的先看往期文章 手搓小智AI聊天机器人 MCP 深度解析:AI 的USB接口 如何使用小智MCP 1.刷支持mcp的小智固件 2.下载官方MCP的示例代码 Github:https://github.com/78/mcp-calculator 安这个步骤执行 其中MCP_ENDPOI…...

高效的后台管理系统——可进行二次开发
随着互联网技术的迅猛发展,企业的数字化管理变得愈加重要。后台管理系统作为数据存储与业务管理的核心,成为了现代企业不可或缺的一部分。今天我们要介绍的是一款名为 若依后台管理框架 的系统,它不仅支持跨平台应用,还能提供丰富…...
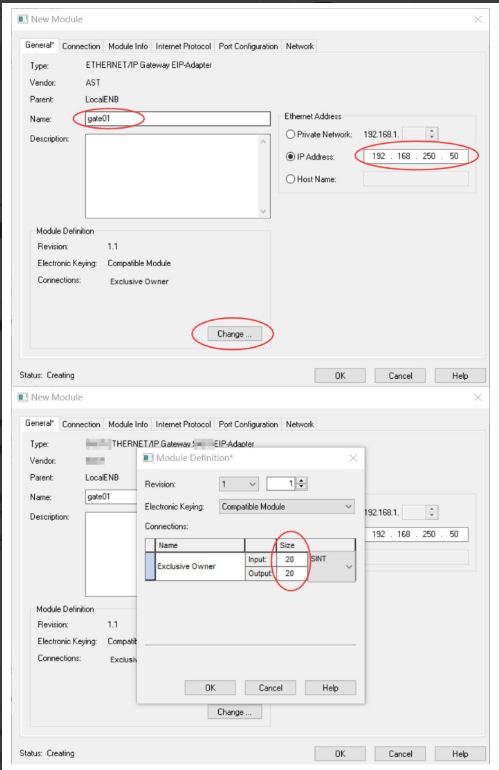
开疆智能Ethernet/IP转Modbus网关连接鸣志步进电机驱动器配置案例
在工业自动化控制系统中,常常会遇到不同品牌和通信协议的设备需要协同工作的情况。本案例中,客户现场采用了 罗克韦尔PLC,但需要控制的变频器仅支持 ModbusRTU 协议。为了实现PLC 对变频器的有效控制与监控,引入了开疆智能Etherne…...

Vue.js教学第二十一章:vue实战项目二,个人博客搭建
基于 Vue 的个人博客网站搭建 摘要: 随着前端技术的不断发展,Vue 作为一种轻量级、高效的前端框架,为个人博客网站的搭建提供了极大的便利。本文详细介绍了基于 Vue 搭建个人博客网站的全过程,包括项目背景、技术选型、项目架构设计、功能模块实现、性能优化与测试等方面。…...