软件工程期末复习+数据仓库ETL
一、软件工程
请用基本路径测试方法为下列程序设计测试用例,并写明中间过程:

第1步:画出流程图

1.菱形用于条件判断。用在有分支的地方。
2.矩形表示一个基本操作。
3.圆形是连接点
第2步:计算程序环路复杂性
流图G的环路复杂度V(G)定义为:V(G)=E-N+2 (E为流图中的边数量,N为流图中的节点数量)。
V(G)也可以定义为:V(G)=P+1 其中:P为流图中的判断节点数量。
第3步:给出独立路径集
需要注意的是:路径集对每个循环至多只执行一次,所以第2次不会进入已经进入过的循环中。
(1)2.1 - 2.2.1 - 2.2.2 - 15 - 16
表示不满足i-1后大于等于0,即i-1后小于0,于是直接15,16退出。
(2)2.1 - 2.2.1 - 3 - 4.1 - 4.2 - 12 - 13 - 16
表示i-1后等于0,即i原本为1,即数组中只有1个数,i-1后i值为0,因为j=0,所以不满足j<i,直接退出循环,直接进入12,13,16退出
(3)2.1 - 2.2.1 - 2.2.2 - 3 - 4.1 - 4.2 - 5 - 10 - 4.3 - 4.2 - 12 - 13 - 16
(4)2.1 - 2.2.1 - 2.2.2 - 3 - 4.1 - 4.2 - 5 - 10 - 4.3 - 4.2 - 12 - 2.2.1 - 2.2.2 - 15 - 16
(5)2.1 - 2.2.1 - 2.2.2 - 3 - 4.1 - 4.2 - 5 - 6,7,8,9 - 10 - 4.3 - 4.2 - 12 - 13 - 16
(6)2.1 - 2.2.1 - 2.2.2 - 3 - 4.1 - 4.2 - 5 - 6,7,8,9 - 10 - 4.3 - 4.2 - 12 - 2.2.1 - 2.2.2 - 15 - 16
第4步:测试用例
(1)输入空值
(2)输入只有一个元素的数组,比如数组[3]
(3)输入升序排序的数组,比如数组[2,3,6,9]
(4)同样也是输入升序排序的数组,比如数组[2,3,6,9]
(5)输入数组[1,5,2]
(6)输入降序排序的数组,比如数组[9,5,3,2]
二、数据仓库

要解决的几个问题:
1.如何从数据库中抽取数据
如果你需要导入的数据量很小(如只有两张表,每张表大约一千行数据),你可能不需要使用Sqoop。Sqoop更适合批量数据传输和数据仓库场景,对于少量数据的导入,可以考虑以下几种简单的替代方法:直接导出/导入:使用MySQL的导出工具(例如mysqldump)导出表为SQL文件,然后在Hive命令行界面中运行这些SQL语句。
或者,如果数据表结构不复杂,可以将MySQL表数据导出为CSV文件,然后在Hive中创建表,并使用LOAD DATA LOCAL INPATH命令加载CSV文件。2.如何进行数据转换,是否需要数据转换,需要使用什么工具,在哪个步骤中进行转换(是当数据在数据库中,还是要通过别的工具,还是要在数据仓库中转换??)
使用Hive SQL:你可以编写Hive SQL脚本来进行数据转换。例如,通过CREATE TABLE AS SELECT (CTAS) 语句创建新表,并在这个过程中对数据进行转换。
通过Hive的内置函数或自定义函数(UDF)对数据进行转换。
使用INSERT OVERWRITE 语句将转换后的数据写入到新的表或分区中。
使用ETL工具:你可以使用ETL(Extract, Transform, Load)工具,如Apache NiFi, Talend, Informatica等,来在数据进入Hive之前进行转换。
这些工具可以帮助你从多种源提取数据,应用复杂的转换逻辑,然后将其加载到Hive数据仓库中。
在Hadoop生态系统中进行转换:使用如Apache Spark, Apache Pig等其他Hadoop生态系统工具来进行数据的预处理和转换,然后再将数据加载到Hive。编写转换脚本: 可以在IDEA中编写Hive SQL脚本、Spark程序(使用Scala或Python)或其他任何数据处理脚本,这些脚本可以用来进行数据转换。连接数据库和数据仓库: IDEA支持数据库插件,如Database Navigator或DataGrip功能,可以连接到Hive或其他数据库系统,从而可以直接运行SQL脚本来进行数据转换。3.如何进行数据清洗,是否需要数据清洗,需要使用什么工具,在哪个步骤中进行清洗(是当数据在数据库中,还是要通过别的工具,还是要在数据仓库中转换??)
数据探索与评估: 在开始清洗之前,首先需要对数据进行探索和评估,确定需要进行哪些清洗操作。这一步骤可以通过SQL查询、数据可视化工具或者数据探索工具来完成。数据清洗操作: 包括但不限于去除重复数据、填充或删除缺失值、标准化数据格式、校验和更正数据错误等。在Hive中,这通常通过编写HiveQL脚本来完成。在数据库中清洗: 如果原始数据已经在Hive或其他数据库中,可以直接在数据库中使用SQL脚本进行清洗。
使用ETL工具: 可以使用ETL工具(如Apache NiFi、Talend、Informatica等)来设计数据清洗流程。
在数据仓库中转换: 有时候,数据在加载到数据仓库之后进行清洗和转换,尤其是在使用Hive这样的大数据平台时。
使用IDEA进行数据清洗: 可以在IntelliJ IDEA中编写HiveQL脚本或Spark程序来进行数据清洗,然后将这些脚本运行在Hive上。4.如何进行数据装载,如何将数据库中的数据导入数据仓库?是通过某种工具,还是通过IDEA这类编译器编写代码脚本的方式?
使用HiveQL命令:可以使用Hive提供的HiveQL命令来装载数据,这些命令可以在Hive的CLI(命令行界面)、通过Beeline客户端、或者在任何支持Hive连接的IDE中执行。例如,可以使用LOAD DATA命令来将数据从本地文件系统或者Hadoop的HDFS导入Hive表中。
-- 将本地文件系统中的数据导入Hive表
LOAD DATA LOCAL INPATH '/path/to/local/data.txt' INTO TABLE your_table;
-- 将HDFS中的数据导入Hive表
LOAD DATA INPATH '/path/to/hdfs/data.txt' INTO TABLE your_table;
关于使用IDEA进行数据装载,IntelliJ IDEA是一个集成开发环境,它支持连接Hive,并可以执行HiveQL脚本。你可以通过在IDEA中配置Hive连接,然后在SQL脚本编辑器中编写并执行HiveQL命令来进行数据装载。以下是在IDEA中进行数据装载的基本步骤:
在IDEA中安装Database Navigator插件或使用已内置的数据库支持功能。
配置Hive连接:你需要提供Hive服务器的JDBC URL、用户名和密码。
打开IDEA的数据库视图,右键点击创建的Hive连接,选择"Console"打开一个新的查询窗口。
在查询窗口中编写上述提到的LOAD DATA命令,并执行。5.如何在数据仓库中建表,导入的数据在数据仓库中是一种怎么样的组织形式?
创建表的步骤:打开Hive的CLI(命令行界面),Beeline客户端,或者任何支持Hive连接的IDE(如IntelliJ IDEA)。使用CREATE TABLE语句定义表的结构,包括列名和数据类型。可以指定表的存储格式(如TEXTFILE、SEQUENCEFILE、ORC、PARQUET等)和位置(HDFS上的路径)。可以为表设置分区(PARTITIONED BY)和桶(CLUSTERED BY)等属性来优化查询性能和数据组织。CREATE TABLE IF NOT EXISTS my_table (id INT,name STRING,age INT,created_at TIMESTAMP
)
COMMENT 'This is a sample table'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/hive/warehouse/my_database/my_table';TEXTFILE:默认格式,以纯文本形式存储数据,字段通常由特定分隔符(如逗号或制表符)分隔。
SEQUENCEFILE:二进制格式,适用于键值对数据,可以压缩。
ORC (Optimized Row Columnar):高效的列存储格式,适合大型数据集,支持高度压缩和快速读取。
PARQUET:另一种列式存储格式,广泛用于Hadoop生态系统。
6.如何对数据仓库中的数据进行可视化?是通过某种工具还是?
BI工具集成:
有许多商业智能(BI)工具可以连接到Hive并对其数据进行可视化,这些包括但不限于:Tableau
Power BI
QlikView
Looker
Apache Superset
这些工具通常提供了一个用户友好的界面,通过JDBC或ODBC驱动与Hive进行交互,并且允许用户创建图表、报表和仪表板。
数据分析平台:
一些数据分析平台如Zeppelin或Jupyter Notebook可以与Hive直接交互,允许用户写Hive查询并利用Python、R等语言中的可视化库(如matplotlib、seaborn、ggplot2等)来展示结果。
Hadoop生态集成工具:Hue:Hue是一个开源的SQL助手,为Hive提供了一个易于使用的Web界面,可以执行查询并查看结果。Hue也有基本的图表和可视化功能。
Apache Drill:可以通过SQL查询Hive和其他数据源,并且与BI工具集成,提供数据可视化能力。
自定义应用程序:
可以使用各种编程语言(如Java、Python、Scala等)通过Hive的JDBC或Thrift API连接到Hive,执行查询并获取数据。然后,可以使用图形库(如Python中的matplotlib或JavaScript中的D3.js)来创建自定义的可视化。



相关文章:
软件工程期末复习+数据仓库ETL
一、软件工程 请用基本路径测试方法为下列程序设计测试用例,并写明中间过程: 第1步:画出流程图 1.菱形用于条件判断。用在有分支的地方。 2.矩形表示一个基本操作。 3.圆形是连接点 第2步:计算程序环路复杂性 流图G的环路复杂…...

学习C语言——体会计算机中的0和1
/* 把hello隐写入一个整型数组,这个小程序可以考察是否清楚数据在内存中存储的具体细节。 具体的说,int类型在小端机器上的存储方式是高位在高地址,低位在低地址,从视觉习惯上和我们的日常书写习惯相反; char类型占用…...
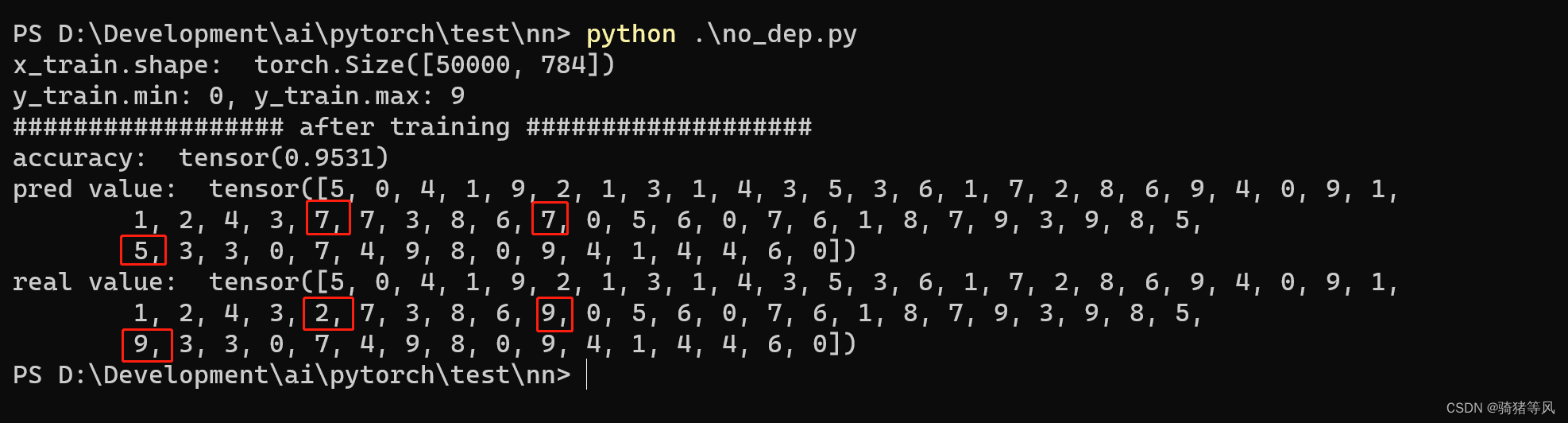
PyTorch官网demo解读——第一个神经网络(1)
神经网络如此神奇,feel the magic 今天分享一下学习PyTorch官网demo的心得,原来实现一个神经网络可以如此简单/简洁/高效,同时也感慨PyTorch如此强大。 这个demo的目的是训练一个识别手写数字的模型! 先上源码: fr…...

升华 RabbitMQ:解锁一致性哈希交换机的奥秘【RabbitMQ 十】
欢迎来到我的博客,代码的世界里,每一行都是一个故事 升华 RabbitMQ:解锁一致性哈希交换机的奥秘【RabbitMQ 十】 前言第一:该插件需求为什么需要一种更智能的消息路由方式?一致性哈希的基本概念: 第二&…...
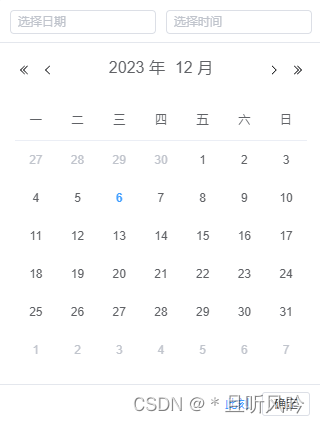
vue3 element-plus 日期选择器 el-date-picker 汉化
vue3 项目中,element-plus 的日期选择器 el-date-picker 默认是英文版的,如下: 页面引入: //引入汉化语言包 import locale from "element-plus/lib/locale/lang/zh-cn" import { ElDatePicker, ElButton, ElConfigP…...
面试题 35:复杂链表的复制)
剑指 Offer(第2版)面试题 35:复杂链表的复制
剑指 Offer(第2版)面试题 35:复杂链表的复制 剑指 Offer(第2版)面试题 35:复杂链表的复制解法1:模拟 剑指 Offer(第2版)面试题 35:复杂链表的复制 题目来源&…...

自定义指令Custom Directives
<script setup langts> import { ref } from "vue"const state ref(false)/*** Implement the custom directive* Make sure the input element focuses/blurs when the state is toggled* */ // 以v开头的驼峰式命名的变量都可以作为一个自定义指令 const VF…...
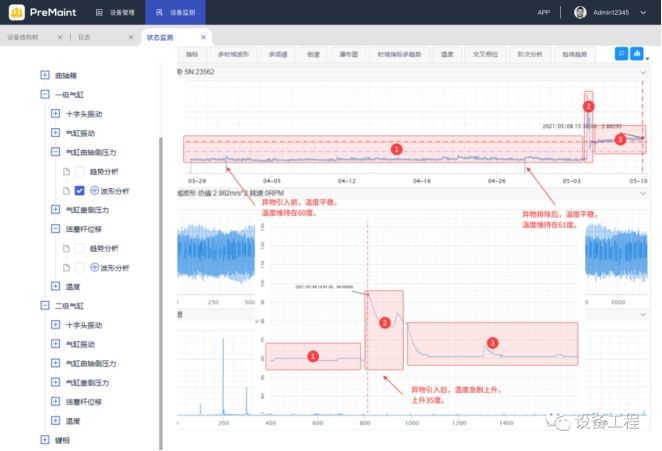
预测性维护对制造企业设备管理的作用
制造企业设备管理和维护对于生产效率和成本控制至关重要。然而,传统的维护方法往往无法准确预测设备故障,导致生产中断和高额维修费用。为了应对这一挑战,越来越多的制造企业开始采用预测性维护技术。 预测性维护是通过传感器数据、机器学习和…...

华为、新华三、锐捷常用命令总结
华为、新华三、锐捷常用命令总结 一、华为交换机基础配置命令二、H3C交换机的基本配置三、锐捷交换机基础命令配置 一、华为交换机基础配置命令 1、创建vlan: <Quidway> //用户视图,也就是在Quidway模式下运行命令。 <Quidway>system-view…...
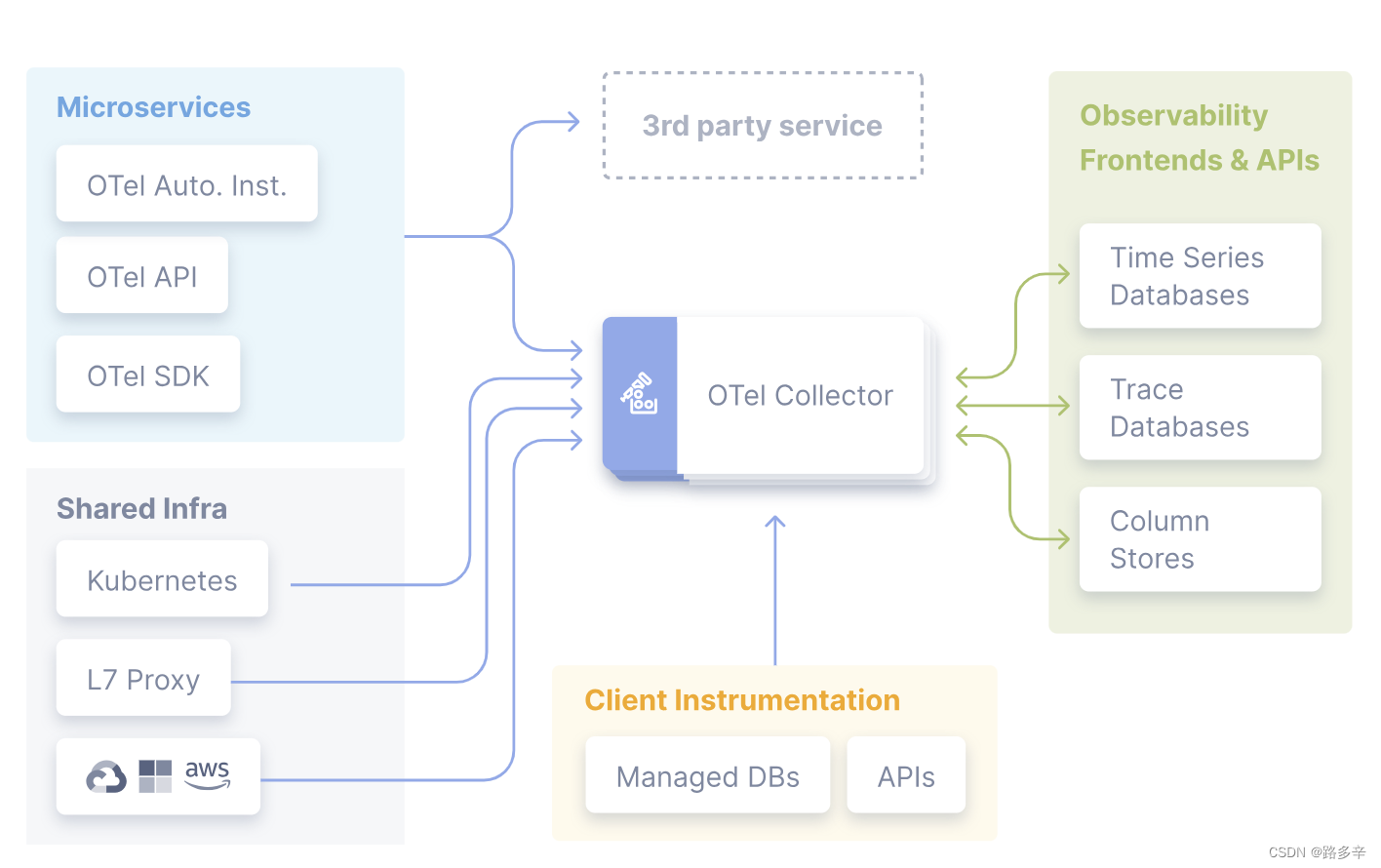
链路追踪详解(四):分布式链路追踪的事实标准 OpenTelemetry 概述
目录 OpenTelemetry 是什么? OpenTelemetry 的起源和目标 OpenTelemetry 主要特点和功能 OpenTelemetry 的核心组件 OpenTelemetry 的工作原理 OpenTelemetry 的特点 OpenTelemetry 的应用场景 小结 OpenTelemetry 是什么? OpenTelemetry 是一个…...
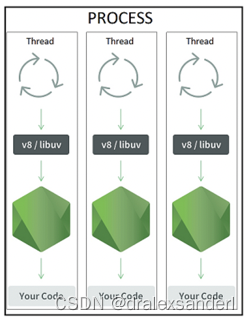
Node.js 工作线程与子进程:应该使用哪一个
Node.js 工作线程与子进程:应该使用哪一个 并行处理在计算密集型应用程序中起着至关重要的作用。例如,考虑一个确定给定数字是否为素数的应用程序。如果我们熟悉素数,我们就会知道必须从 1 遍历到该数的平方根才能确定它是否是素数ÿ…...

python matplotlib 三维图形添加文字且不随图形变动而变动
要在三维图形中添加文字并使其不随图形变动而变动,可以使用 annotate() 方法。这个方法可以在三维图形中添加文字,并且可以指定文字的位置、对齐方式和字体大小等属性。 下面是一个示例代码,演示如何在三维图形中添加文字: impo…...

Ubuntu设置kubelet启动脚本关闭swap分区
查看swap分区 swapon -s打开swap分区 swapon -a查看/etc/fstab下所有固化的swap分区,注释 vi /etc/fstab修改kubelet.conf文件 vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf添加 ExecStartPre/sbin/swapoff -a生效 systemctl daemon-reload sys…...

MySQL数据库存储
MySQL数据库存储 MySQL数据库简介MySQL开发环境MySQL安装图形化界面工具Navicat使用 表的操作表的概念3.2 创建表3.3 修改表 数据的操作-增删改查4.1 增加数据4.2 删除数据4.3 修改数据4.4 查询数据4.4.1 基础查询4.4.2 分组查询和聚合函数4.4.4 having语句4.4.5 排序4.5 多表联…...
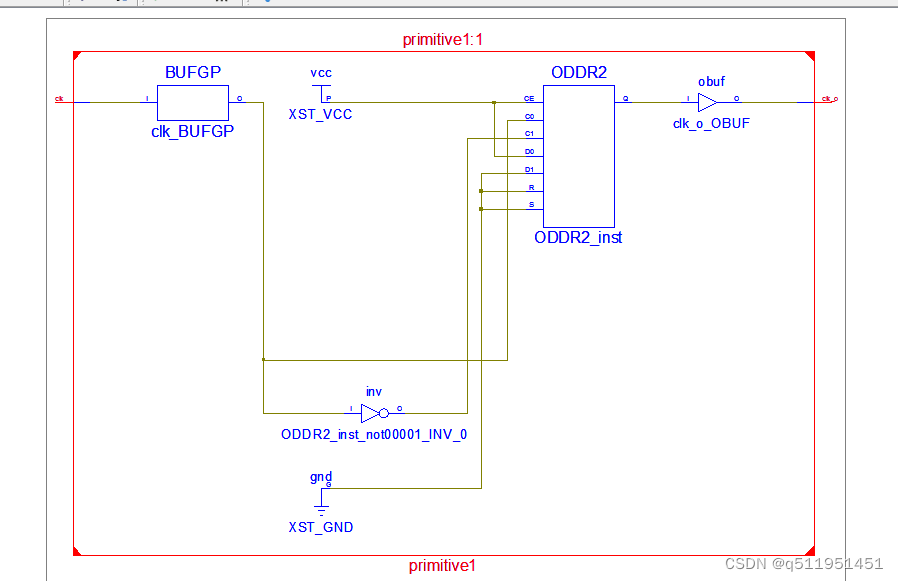
verilog语法进阶,时钟原语
概述: 内容 1. 时钟缓冲 2. 输入时钟缓冲 3. ODDR2作为输出时钟缓冲 1. 输入时钟缓冲 BUFGP verilog c代码,clk作为触发器的边沿触发,会自动将clk综合成时钟信号。 module primitive1(input clk,input a,output reg y); always (posed…...
案例069:基于微信小程序的计算机实验室排课与查询系统
文末获取源码 开发语言:Java 框架:SSM JDK版本:JDK1.8 数据库:mysql 5.7 开发软件:eclipse/myeclipse/idea Maven包:Maven3.5.4 小程序框架:uniapp 小程序开发软件:HBuilder X 小程序…...
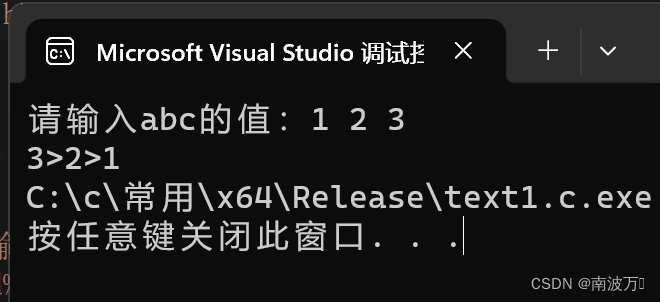
C语言:将三个数从大到小输出
#include<stdio.h> int main() {int a 0;int b 0;int c 0;printf("请输入abc的值:");scanf_s("%d%d%d", &a, &b, &c);if (b > a){int tmp a;a b;b tmp;}if (c > a){int tmp a;a c;c tmp;}if (b < c){int t…...

基于Hadoop的铁路货运大数据平台设计与应用
完整下载:基于Hadoop的铁路货运大数据平台设计与应用 基于Hadoop的铁路货运大数据平台设计与应用 Design and Application of Railway Freight Big Data Platform based on Hadoop 目录 目录 2 摘要 3 关键词 4 第一章 绪论 4 1.1 研究背景 4 1.2 研究目的与意义 5 …...

Java基础题2:类和对象
1.下面代码的运行结果是() public static void main(String[] args){String s;System.out.println("s"s);}A.代码编程成功,并输出”s” B.代码编译成功,并输出”snull” C.由于String s没有初始化,代码不能…...

冒泡排序学习
冒泡排序(Bubble Sort)是一种简单的排序算法,它通过重复地交换相邻的元素来排序。具体实现如下: 1. 从待排序的数组中的第一个元素开始,依次比较相邻的两个元素。 2. 如果前一个元素大于后一个元素,则交换…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...