【数据库设计和SQL基础语法】--查询数据--分组查询
一、分组查询概述
1.1 什么是分组查询
分组查询是一种 SQL 查询技术,通过使用 GROUP BY 子句,将具有相同值的数据行分组在一起,然后对每个组应用聚合函数(如 COUNT、SUM、AVG等)。这允许在数据集中执行汇总和统计操作,以便更清晰地理解和分析数据的特征。分组查询常用于对大量数据进行聚合和摘要,提供有关数据分布和特征的洞察。
1.2 分组查询的作用
以下是分组查询的一些主要作用:
- 数据汇总: 分组查询可以用于对数据进行汇总,计算每个分组的总和、平均值、最大值、最小值等统计信息。这对于了解数据的整体特征以及各个分组之间的差异非常有用。
- 数据分类: 当需要按照某个列对数据进行分类时,分组查询是很有帮助的。例如,你可以按照地区、部门、时间等将数据进行分组,以便更好地理解和分析。
- 统计分析: 分组查询支持对数据进行更深入的统计分析。通过结合分组查询和聚合函数,可以得到更详细的数据摘要,有助于发现数据中的模式和趋势。
- 筛选数据: 通过将数据分组并应用条件,可以轻松地筛选出符合特定条件的数据子集。这使得可以对关键数据进行更有针对性的分析。
- 提高查询性能: 在处理大量数据时,分组查询有时可以优化查询性能。通过将数据分组,数据库引擎可以更有效地执行聚合计算,减少处理的数据量,提高查询速度。
示例(使用SQL语句):
-- 以部门为单位,计算每个部门的员工数量和平均工资
SELECT department, COUNT(*) AS employee_count, AVG(salary) AS average_salary
FROM employees
GROUP BY department;
在上面的示例中,数据按照部门进行分组,然后分别计算每个部门的员工数量和平均工资。这样就能够以更清晰的方式了解不同部门的情况。
二、GROUP BY 子句
2.1 GROUP BY 的基本语法
在 SQL 中,GROUP BY 语句用于对结果集进行分组。其基本语法如下:
SELECT column1, column2, aggregate_function(column3)
FROM table
WHERE condition
GROUP BY column1, column2;
- SELECT: 要检索的列或表达式。
- FROM: 数据来源的表。
- WHERE: (可选)筛选条件,用于过滤要分组的数据。
- GROUP BY: 指定分组的列。查询结果将按照这些列中的值进行分组。
- aggregate_function: 对每个分组执行的聚合函数,如 COUNT、SUM、AVG、MAX、MIN 等。
以下是一个具体的例子:
-- 以部门为单位,计算每个部门的员工数量和平均工资
SELECT department, COUNT(*) AS employee_count, AVG(salary) AS average_salary
FROM employees
GROUP BY department;
在这个例子中,employees 表按照 department 列进行分组,然后对每个部门计算员工数量和平均工资。
Tip:SELECT 中的列必须是 GROUP BY 子句中列的函数,或者是聚合函数。如果在 SELECT 中引用了未在 GROUP BY 中列出的列,那么该列的值将是该分组中第一个遇到的值,这在某些数据库系统中是允许的,但在其他系统中可能导致错误。
2.2 GROUP BY 的多列分组
在 GROUP BY 子句中,你可以指定多列进行分组,以更精细地组织数据。多列分组的基本语法如下:
SELECT column1, column2, aggregate_function(column3)
FROM table
WHERE condition
GROUP BY column1, column2;
这里 column1 和 column2 是你希望用来进行分组的列。查询结果将按照这两列中的值进行分组。
举个例子,假设你有一个订单表(orders),包含了订单信息,包括订单日期(order_date)、客户ID(customer_id)和订单总额(total_amount)。你想要按照订单日期和客户ID对订单进行分组,并计算每个组的订单总额。
-- 按照订单日期和客户ID分组,计算每个组的订单总额
SELECT order_date, customer_id, SUM(total_amount) AS total_order_amount
FROM orders
GROUP BY order_date, customer_id;
在这个例子中,订单表按照订单日期和客户ID进行了分组,并计算了每个组的订单总额。通过 GROUP BY 子句,你可以看到每个特定日期和客户ID的订单总额。这种多列分组使你能够更详细地了解数据的组织结构。
2.3 GROUP BY 与聚合函数结合
GROUP BY 与聚合函数结合使用是非常常见的数据库查询模式。通过将 GROUP BY 与聚合函数一起使用,可以对分组的数据执行各种聚合计算。以下是一个示例,演示了如何使用 GROUP BY 与聚合函数:
假设有一个销售订单表(sales_orders),包含了订单的信息,如订单日期(order_date)、产品ID(product_id)和销售数量(quantity)。
-- 按照产品ID分组,计算每个产品的总销售数量和平均销售数量
SELECT product_id, SUM(quantity) AS total_sales, AVG(quantity) AS average_sales
FROM sales_orders
GROUP BY product_id;
在这个例子中,我们按照产品ID进行分组,并使用了两个聚合函数,SUM 和 AVG。SUM 计算了每个产品的总销售数量,而 AVG 计算了每个产品的平均销售数量。通过 GROUP BY,查询结果中的每一行表示一个产品ID,以及与之相关的总销售数量和平均销售数量。
其他常用的聚合函数还包括 COUNT、MAX、MIN 等,可以根据需要选择适当的聚合函数。GROUP BY 与聚合函数结合使用,可以提供对数据更详细的摘要信息,帮助分析和理解数据。
三、HAVING 子句
3.1 HAVING 的作用
HAVING 子句是在 SQL 查询中用于过滤分组后的结果集的一种方式。它通常与 GROUP BY 一起使用,用于对分组数据应用条件过滤。HAVING 子句允许你筛选基于聚合函数计算的值,而 WHERE 子句则用于筛选原始数据行。
基本语法如下:
SELECT column1, aggregate_function(column2)
FROM table
WHERE condition
GROUP BY column1
HAVING condition;
其中,HAVING 子句的作用是对分组进行条件筛选,而 WHERE 子句是对原始数据行进行条件筛选。
举个例子,假设你有一个订单表(orders),包含了订单信息,包括订单日期(order_date)、客户ID(customer_id)和订单总额(total_amount)。你想找到总订单额超过1000的客户,并计算其总订单额。
-- 按照客户ID分组,计算每个客户的总订单额,然后筛选总订单额超过1000的客户
SELECT customer_id, SUM(total_amount) AS total_order_amount
FROM orders
GROUP BY customer_id
HAVING SUM(total_amount) > 1000;
在这个例子中,首先按照客户ID进行分组,然后使用 HAVING 子句筛选出总订单额超过1000的客户。这种方式可以用来对分组后的结果进行更细粒度的筛选,以便只保留满足特定条件的分组。
3.2 HAVING 的语法
HAVING 子句的语法如下:
SELECT column1, aggregate_function(column2)
FROM table
WHERE condition
GROUP BY column1
HAVING condition;
在这个语法中:
SELECT: 指定要检索的列或表达式。FROM: 指定数据来源的表。WHERE: (可选)用于过滤原始数据行的条件。GROUP BY: 指定分组的列。HAVING: 用于对分组进行条件筛选的子句。
具体来说,HAVING 子句通常用于对分组后的结果应用条件。这些条件基于聚合函数计算的值,而不是原始数据行。这使得你可以过滤出满足特定聚合条件的分组结果。
以下是一个更具体的例子:
-- 按照部门分组,计算每个部门的平均工资,并只显示平均工资大于50000的部门
SELECT department, AVG(salary) AS average_salary
FROM employees
GROUP BY department
HAVING AVG(salary) > 50000;
在这个例子中,HAVING 子句筛选出平均工资大于50000的部门,从而仅显示符合条件的分组结果。
四、分组排序
4.1 使用 ORDER BY 对分组结果排序
ORDER BY 子句用于对查询结果进行排序。当与 GROUP BY 一起使用时,ORDER BY 可以用来对分组结果进行排序。以下是使用 ORDER BY 对分组结果排序的基本语法:
SELECT column1, aggregate_function(column2)
FROM table
WHERE condition
GROUP BY column1
HAVING condition
ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...;
在这个语法中:
ORDER BY: 用于指定排序的列。ASC: 升序排序(默认)。DESC: 降序排序。
举例说明,假设你有一个销售订单表(sales_orders),包含了订单的信息,如订单日期(order_date)、产品ID(product_id)和销售数量(quantity)。你想要按照产品ID分组,计算每个产品的总销售数量,并按照总销售数量降序排序。
-- 按照产品ID分组,计算每个产品的总销售数量,按照总销售数量降序排序
SELECT product_id, SUM(quantity) AS total_sales
FROM sales_orders
GROUP BY product_id
ORDER BY total_sales DESC;
在这个例子中,ORDER BY total_sales DESC 指定了按照总销售数量降序排序。你可以根据需要指定多个排序条件,以便更精细地控制结果的排序顺序。
总的来说,ORDER BY 子句允许你对查询结果进行排序,使结果更易读或更符合你的需求。
4.2 GROUP BY 与 ORDER BY 的区别
GROUP BY 和 ORDER BY 是 SQL 查询中两个不同的子句,它们有着不同的作用:
- GROUP BY:
- 作用:
GROUP BY用于对查询结果进行分组,将相同的值放在一起,然后对每个组应用聚合函数,计算汇总值。 - 使用场景: 当你想要对数据进行分组,并对每个组应用聚合函数(如 COUNT、SUM、AVG)以计算统计信息时,你会使用
GROUP BY。
- 作用:
SELECT column1, COUNT(column2)
FROM table
GROUP BY column1;
- ORDER BY:
- 作用:
ORDER BY用于对查询结果进行排序,可以按照一个或多个列的值进行升序或降序排序。 - 使用场景: 当你想要对查询结果按照某一列或多列的值进行排序时,你会使用
ORDER BY。
- 作用:
SELECT column1, column2
FROM table
ORDER BY column1 DESC, column2 ASC;
区别总结:
GROUP BY用于分组和聚合数据,通常与聚合函数一起使用。ORDER BY用于对查询结果进行排序,以更好地组织展示结果,不涉及数据的分组和聚合。
Tip:如果在
SELECT语句中使用了GROUP BY子句,那么ORDER BY子句通常放在GROUP BY子句之后。这是因为排序通常是在分组之后进行的。例如:SELECT column1, COUNT(column2) AS count_column2 FROM table GROUP BY column1 ORDER BY count_column2 DESC;
五、分组集
5.1 GROUPING SETS 的概念
GROUPING SETS 是 SQL 中用于同时对多个分组集合进行聚合查询的一种语法。它允许你在单个查询中同时指定多个不同的分组,从而获取多个层次上的聚合结果。这样,你可以一次性获取多个聚合级别的数据,而不必多次执行相似的查询。
基本语法如下:
SELECT column1, column2, aggregate_function(column3)
FROM table
GROUP BY GROUPING SETS ((column1, column2), (column1), (column2), ());
其中,GROUPING SETS 子句的参数是一个包含多个分组集合的括号列表。每个分组集合都由一个或多个列组成,代表一个要进行聚合的分组。空括号 () 表示全局总计。
举个例子,假设你有一个销售订单表(sales_orders),包含了订单的信息,如订单日期(order_date)、产品ID(product_id)、区域(region)和销售数量(quantity)。你想同时获取按照产品ID、区域和全局总计的销售数量。
SELECT product_id, region, SUM(quantity) AS total_sales
FROM sales_orders
GROUP BY GROUPING SETS ((product_id, region), (product_id), (region), ());
在这个例子中,GROUPING SETS 子句允许你一次性获取按照产品ID、区域和全局总计的销售数量。这样,你可以在单个查询中获取多个层次上的聚合结果,而不必分别执行多个查询。
5.2 使用 GROUPING SETS 进行多组分组
GROUPING SETS 允许你一次性对多个组进行分组,并在同一查询中获取多个层次上的聚合结果。以下是一个示例,演示如何使用 GROUPING SETS 进行多组分组:
假设有一个销售订单表(sales_orders),包含了订单的信息,如订单日期(order_date)、产品ID(product_id)、区域(region)和销售数量(quantity)。
-- 使用 GROUPING SETS 进行多组分组,计算销售数量的总和
SELECT product_id, region, SUM(quantity) AS total_sales
FROM sales_orders
GROUP BY GROUPING SETS ((product_id, region), (product_id), (region), ());
在这个例子中,GROUP BY GROUPING SETS 指定了三个不同的分组集合:
(product_id, region): 按照产品ID和区域进行分组。(product_id): 按照产品ID进行分组。(region): 按照区域进行分组。()(空括号): 表示全局总计。
这样,查询结果将包含按照产品ID和区域、按照产品ID、按照区域以及全局总计的销售数量。你可以在同一查询中获得这些不同层次的汇总信息。
六、ROLLUP 和 CUBE
6.1 ROLLUP 的使用
ROLLUP 是 SQL 中用于进行多层次聚合的操作符之一。它允许你在查询中指定多个层次的分组,并在同一查询中获取这些层次的汇总结果。ROLLUP 会生成包含从最精细到最总体的所有可能的组合的聚合结果。
基本的 ROLLUP 语法如下:
SELECT column1, column2, aggregate_function(column3)
FROM table
GROUP BY ROLLUP (column1, column2);
在这个语法中,ROLLUP 子句指定了要进行多层次分组的列,生成的结果将包含每个列组合的聚合值,以及每个列的总计值。
举个例子,假设你有一个销售订单表(sales_orders),包含了订单的信息,如订单日期(order_date)、产品ID(product_id)、区域(region)和销售数量(quantity)。
-- 使用 ROLLUP 进行多层次聚合,计算销售数量的总和
SELECT product_id, region, SUM(quantity) AS total_sales
FROM sales_orders
GROUP BY ROLLUP (product_id, region);
在这个例子中,ROLLUP (product_id, region) 将生成按照产品ID和区域、按照产品ID、按照区域和全局总计的销售数量的聚合结果。这样,你可以在同一查询中获得不同层次的汇总信息。
ROLLUP 提供了一种方便的方式,通过单一查询获取多个层次上的聚合结果,避免了多次执行类似的查询。需要注意的是,ROLLUP 生成的总计行会有 NULL 值,表示在该列上的总计。
6.2 CUBE 的使用
CUBE 是 SQL 中用于进行多维度聚合的操作符之一。它允许在同一查询中指定多个维度,并生成包含所有可能组合的聚合结果。CUBE 操作符生成的结果比 ROLLUP 更全面,因为它包含了所有可能的组合。
基本的 CUBE 语法如下:
SELECT column1, column2, aggregate_function(column3)
FROM table
GROUP BY CUBE (column1, column2);
在这个语法中,CUBE 子句指定了要进行多维度分组的列,生成的结果将包含每个列组合的聚合值,以及所有可能的列组合的总计值。
举个例子,假设你有一个销售订单表(sales_orders),包含了订单的信息,如订单日期(order_date)、产品ID(product_id)、区域(region)和销售数量(quantity)。
-- 使用 CUBE 进行多维度聚合,计算销售数量的总和
SELECT product_id, region, SUM(quantity) AS total_sales
FROM sales_orders
GROUP BY CUBE (product_id, region);
在这个例子中,CUBE (product_id, region) 将生成按照产品ID、按照区域、按照产品ID和区域、以及全局总计的销售数量的聚合结果。这样,你可以在同一查询中获得多个维度上的汇总信息。
CUBE 提供了一种方便的方式,通过单一查询获取多个维度上的聚合结果,避免了多次执行类似的查询。需要注意的是,CUBE 生成的总计行会有 NULL 值,表示在该列上的总计。
6.3 ROLLUP 与 CUBE 的区别
ROLLUP 和 CUBE 都是 SQL 中用于进行多层次聚合的操作符,它们的主要区别在于生成的聚合结果的全面性和维度的不同。
- ROLLUP:
- 语法: 使用
ROLLUP时,你指定一个列列表,表示要进行多层次分组的列。ROLLUP生成一个包含每个列组合的聚合值,以及每个列的总计值。 - 示例:
SELECT column1, column2, aggregate_function(column3) FROM table GROUP BY ROLLUP (column1, column2); - 生成结果: 生成的结果包含了每个列的每个组合的聚合值,以及每个列的总计值。
- CUBE:
- 语法: 使用
CUBE时,你同样指定一个列列表,表示要进行多维度分组的列。CUBE生成一个包含每个列组合的聚合值,以及所有可能的列组合的总计值。 - 示例:
SELECT column1, column2, aggregate_function(column3) FROM table GROUP BY CUBE (column1, column2); - 生成结果: 生成的结果包含了每个列的每个组合的聚合值,以及所有可能的列组合的总计值,更全面。
- 区别总结:
-
结果全面性:
ROLLUP生成的结果包含每个列的每个组合的聚合值,以及每个列的总计值。CUBE生成的结果不仅包含每个列的每个组合的聚合值,还包含所有可能的列组合的总计值。
-
维度数量:
ROLLUP用于指定一组列进行分组。CUBE用于指定一组列进行多维度分组。
-
语法:
ROLLUP使用ROLLUP子句。CUBE使用CUBE子句。
选择使用 ROLLUP 还是 CUBE 取决于你需要的分组层次和全面性。如果你只需要在一组列上进行层次分组,可以使用 ROLLUP。如果你希望同时获取多个列的所有可能组合的总计值,可以使用 CUBE。
七、 最佳实践和注意事项
在进行分组查询时,有一些最佳实践和注意事项可以帮助你编写更有效和可维护的 SQL 查询:
-
选择适当的聚合函数: 根据你的需求选择正确的聚合函数,如 COUNT、SUM、AVG、MAX、MIN 等。确保聚合函数与你关心的信息一致。
-
理解 GROUP BY 子句的含义: GROUP BY 子句指定了分组的条件,确保你理解每个分组的含义,以便正确计算聚合函数。
-
使用别名提高可读性: 为列和聚合函数使用有意义的别名,提高查询结果的可读性。
SELECT department, COUNT(*) AS employee_count FROM employees GROUP BY department; -
*谨慎使用 SELECT : 尽量避免使用
SELECT *,而是选择明确指定所需的列。这有助于提高查询的性能和可维护性。 -
合理使用 WHERE 子句: 在 GROUP BY 之前使用 WHERE 子句过滤数据,以减小分组的数据集,提高查询性能。
-
了解 HAVING 子句的使用场景: HAVING 子句用于在分组后对聚合结果进行筛选,要谨慎使用。通常,它用于过滤聚合值,而不是原始数据行。
-
避免在 GROUP BY 中使用过多列: 尽量保持 GROUP BY 中列的数量较少,以防止生成过多的组合,从而降低性能。
-
理解 ROLLUP 和 CUBE 的用途: ROLLUP 和 CUBE 允许你在一个查询中获得多个分组层次的聚合结果。选择使用它们时要确保理解它们的效果。
-
考虑索引的影响: 确保表中使用了适当的索引,以提高 GROUP BY 操作的性能。
-
测试和优化: 对于复杂的分组查询,进行测试和性能优化是重要的。使用数据库性能分析工具,确保查询在处理大量数据时仍然高效。
-
文档化查询: 对于复杂的查询,添加注释以解释查询的目的和分组策略,提高查询的可理解性。
通过遵循这些最佳实践,你可以更好地编写和优化分组查询,以满足业务需求并提高查询性能。
八、总结
分组查询是SQL中重要的功能,通过GROUP BY子句将数据按指定列分组,结合聚合函数计算统计信息。ROLLUP和CUBE提供了多层次聚合的方式。在实践中,选择适当的聚合函数和理解GROUP BY的含义至关重要。使用别名、谨慎使用SELECT *、合理利用WHERE子句,都有助于提高可读性和性能。注意避免过多列的GROUP BY,理解HAVING的用途,以及测试和优化查询。最终,文档化查询并遵循最佳实践可确保编写高效、清晰的分组查询。
相关文章:

【数据库设计和SQL基础语法】--查询数据--分组查询
一、分组查询概述 1.1 什么是分组查询 分组查询是一种 SQL 查询技术,通过使用 GROUP BY 子句,将具有相同值的数据行分组在一起,然后对每个组应用聚合函数(如 COUNT、SUM、AVG等)。这允许在数据集中执行汇总和统计操作…...

使用对象处理流ObjectOutputStream读写文件
注意事项: 1.创建的对象必须实现序列化接口,如果属性也是类,那么对应的类也要序列化 2.读写文件路径问题 3.演示一个例子 (1)操作的实体类FileModel,实体类中有Map,HashMap这些自带的本身就实现了序列化。 public class File…...
【高级网络程序设计】Block1总结
这一个Block分为四个部分,第一部分是Introduction to Threads and Concurrency ,第二部分是Interruptting and Terminating a Thread,第三部分是Keep Threads safety:the volatile variable and locks,第四部分是Beyon…...
linux下查看进程资源ulimit
ulimit介绍与使用 ulimit命令用于查看和修改进程的资源限制。下面是ulimit命令的使用方法: 查看当前资源限制: ulimit -a 这将显示当前进程的所有资源限制,包括软限制和硬限制。查看或设置单个资源限制: ulimit -<option> …...

C++ I/O操作---输入输出
本文主要介绍C I/O操作中的输入输出流。 目录 1 输入输出 2 输入输出流分类 3 C中的输入输出流 4 iostream 5 std::ofstream 6 std::fstream 7 std::getline 1 输入输出 C的输入输出是数据在不同设备之间的传输,即在硬盘、内存和外设之间的传输。 数据如水流…...
会 C# 应该怎么学习 C++?
会 C# 应该怎么学习 C? 在开始前我有一些资料,是我根据自己从业十年经验,熬夜搞了几个通宵,精心整理了一份「C的资料从专业入门到高级教程工具包」,点个关注,全部无偿共享给大家!!&a…...

CentOS 7 部署frp穿透内网
本文将介绍如何在CentOS 7.9上部署frp,并通过示例展示如何配置和测试内网穿透。 文章目录 (1)引言(2)准备工作(4)frps服务器端配置(5)frpc客户端配置(6&#…...

高效网络爬虫:代理IP的应用与实践
💂 个人网站:【 海拥】【神级代码资源网站】【办公神器】🤟 基于Web端打造的:👉轻量化工具创作平台🤟 代理 IP 推荐:👉品易 HTTP 代理 IP 💅 想寻找共同学习交流的小伙伴,…...
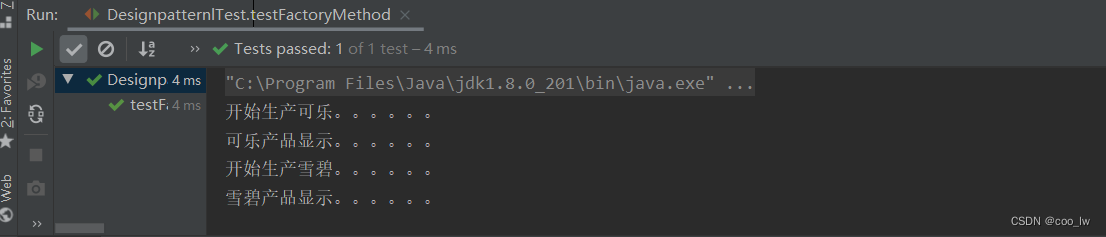
java设计模式-工厂方法模式
1.工厂方法(FactoryMethod)模式的定义 定义一个创建产品对象的工厂接口,将产品对象的实际创建工作推迟到具体子工厂类当中。这满足创建型模式中所要求的“创建与使用相分离”的特点。 2.工厂方法模式的主要优缺点 优点: 用户只需要知道具体工厂的名称…...

Python实验项目9 :网络爬虫与自动化
实验 1:爬取网页中的数据。 要求:使用 urllib 库和 requests 库分别爬取 http://www.sohu.com 首页的前 360 个字节的数据。 # 要求:使用 urllib 库和 requests 库分别爬取 http://www.sohu.com 首页的前 360 个字节的数据。 import urllib.r…...

实验三:指令调度和延迟分支
一、实验目的 加深对指令调度技术的理解。加深对延迟分支技术的理解。熟练掌握用指令调度技术来解决流水线中的数据冲突的方法。进一步理解指令调度技术对CPU性能的改进。进一步理解延迟分支技术对CPU性能的改进。 二、实验内容和步骤 首先要掌握MIPSsim模拟器的使用方法。见…...

【Oracle】PL/SQL语法、存储过程,触发器
一、Oracle数据类型 Orcle数据类型说明类比MySQL数据类型字符型CHAR固定长度的字符类型CHAR字符型VARCHAR2可变长度的字符类型VARCHAR字符型LONG大文本类型,最大2G数值型NUMBER数值类型,整数小数都可以,number(5)表示长度5的整数,…...
2020年第九届数学建模国际赛小美赛C题亚马逊野火解题全过程文档及程序
2020年第九届数学建模国际赛小美赛 C题 亚马逊野火 原题再现: 野火是指发生在乡村或荒野地区的可燃植被中的任何不受控制的火灾。这样的环境过程对人类生活有着重大的影响。因此,对这一现象进行建模,特别是对其空间发生和扩展进行建模&…...

保姆级 Keras 实现 YOLO v3 三
保姆级 Keras 实现 YOLO v3 三 一. 分配 anchor box二. 正负样本匹配规则三. 为每一个 anchor box 打标签3.1 anchor box 长什么样?3.2 每一个 anchor box 标签需要填充的信息有哪些?3.3 ( Δ x , Δ y , Δ w , Δ h ) (\Delta x, \Delta y, \Delta w, \Delta h) (Δx,Δy,…...
HPM6750系列--第十篇 时钟系统
一、目的 上一篇中《HPM6750系列--第九篇 GPIO详解(基本操作)》我们讲解了HPM6750 GPIO相关内容,再进一步讲解其他外设功能之前,我们有必要先讲解一下时钟系统。 时钟可以说是微控制器系统中的心脏,外设必须依赖时钟才…...
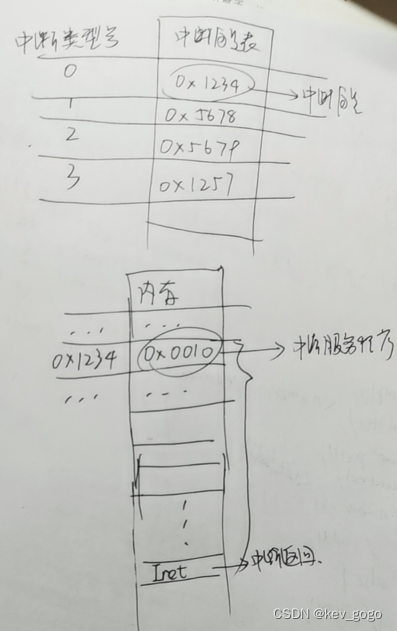
【简单总结】中断类型号 中断向量 中断入口地址
通过中断类型号可以计算出中断向量的地址。 然后根据该地址可以在中断向量表中取出中断服务程序的入口地址(中断向量)。 而中断向量就是中断服务程序入口地址。 做个不严谨的图: 1:通过中断类型号找到中断向量 2:通…...

【Python百宝箱】从传感器到云端:深度解析Python在物联网中的多面应用
迈向智能未来:Python与物联网生态系统的完美融合 前言 随着物联网技术的不断发展,Python作为一种灵活且强大的编程语言,逐渐成为物联网开发的重要工具之一。本文将深入探讨物联网领域中常用的Python库和框架,涵盖了从轻量级通信…...
)
weston 1: 编译与运行傻瓜教程(补充)
系统kubuntu23.10 git clone https://gitlab.freedesktop.org/wayland/wayland.git 86588fbdebe7f6ac9363d98f524e4ae14bd4b019 meson build/ --prefix$WLD ninja -C build/ install git clone https://gitlab.freedesktop.org/wayland/wayland-protocols.git c4f559866f13…...

微服务保护--线程隔离(舱壁模式)
一、线程隔离的实现方式 线程隔离有两种方式实现: 线程池隔离 信号量隔离(Sentinel默认采用) 如图: 线程池隔离:给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果 信号量隔离:…...
集群监控Zabbix和Prometheus
文章目录 一、Zabbix入门概述1、Zabbix概述2、Zabbix 基础架构3、Zabbix部署3.1 前提环境准备3.2 安装Zabbix3.3 配置Zabbix3.4 启动停止Zabbix 二、Zabbix的使用与集成1、Zabbix常用术语2、Zabbix实战2.1 创建Host2.2 创建监控项(Items)2.3 创建触发器&…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...

Python竞赛环境搭建全攻略
Python环境搭建竞赛技术文章大纲 竞赛背景与意义 竞赛的目的与价值Python在竞赛中的应用场景环境搭建对竞赛效率的影响 竞赛环境需求分析 常见竞赛类型(算法、数据分析、机器学习等)不同竞赛对Python版本及库的要求硬件与操作系统的兼容性问题 Pyth…...

Windows 下端口占用排查与释放全攻略
Windows 下端口占用排查与释放全攻略 在开发和运维过程中,经常会遇到端口被占用的问题(如 8080、3306 等常用端口)。本文将详细介绍如何通过命令行和图形化界面快速定位并释放被占用的端口,帮助你高效解决此类问题。 一、准…...

python打卡第47天
昨天代码中注意力热图的部分顺移至今天 知识点回顾: 热力图 作业:对比不同卷积层热图可视化的结果 def visualize_attention_map(model, test_loader, device, class_names, num_samples3):"""可视化模型的注意力热力图,展示模…...