大数据技术10:Flink从入门到精通
导语:前期入门Flink时,可以直接编写通过idea编写Flink程序,然后直接运行main方法,无需搭建环境。我碰到许多初次接触Flink的同学,被各种环境搭建、提交作业、复杂概念给劝退了。前期最好的入门方式就是直接上手写代码,main方法跑demo,快速了解概念,等入门之后再去实践集群环境、各种作业提交、各种复杂概念。
Flink官网:Apache Flink Documentation | Apache Flink
一、Flink实时计算
1.1、Flink定义
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。截止目前2023年12月Flink最新版本为v1.18.0。
说白了,Flink就是个实时处理数据任务的框架,这个框架帮助开发者执行数据处理的任务,让开发者无需关心高可用、性能等问题。如果你有一些数据任务需要执行,比如数据监控、数据分析、数据同步,那就可以考虑使用Flink。所谓流计算就是对源源不断的数据进行计算,中间的计算结果存放在内存或者外部存储,这就是有状态的流计算。
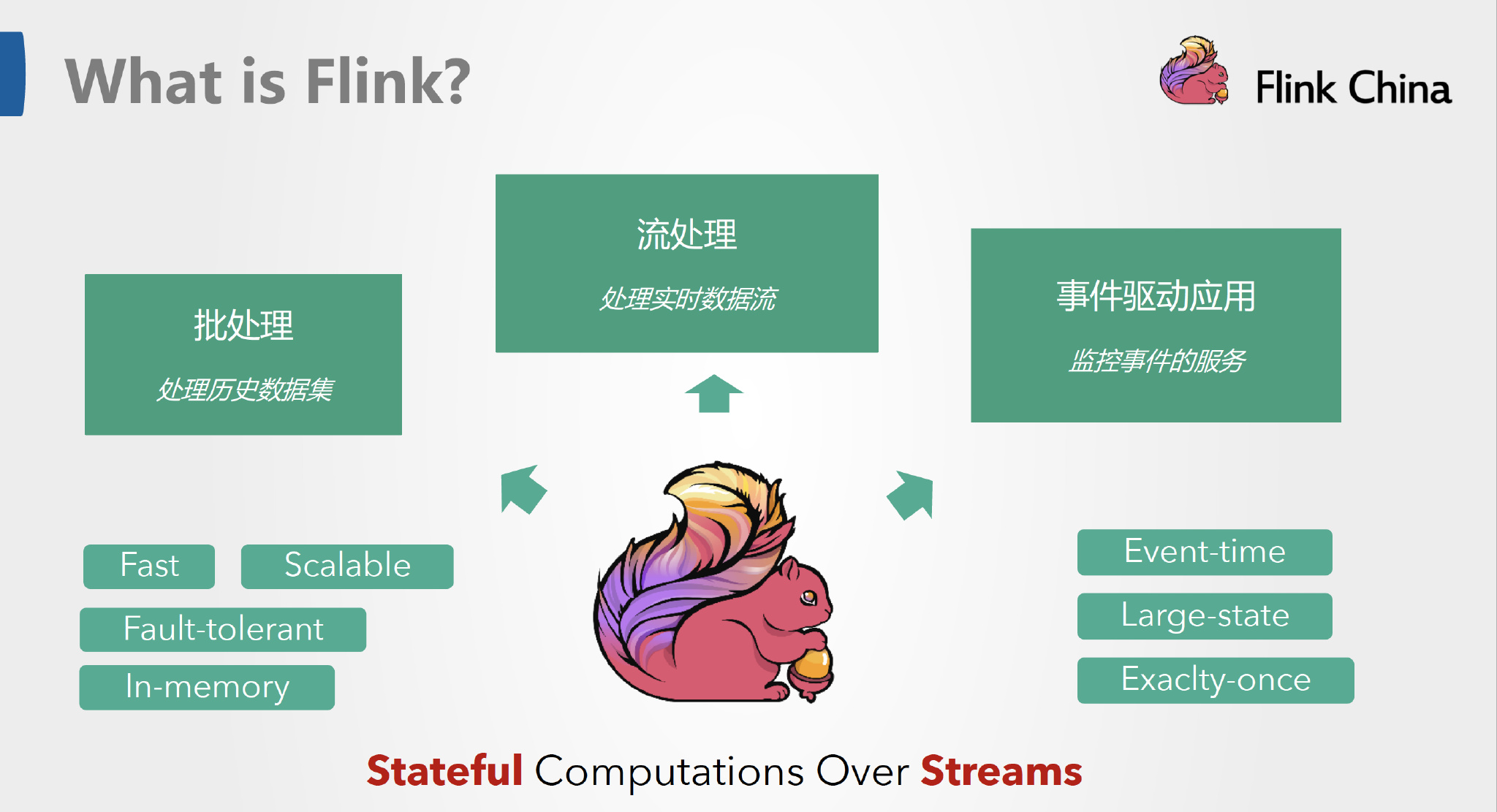
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多要求严苛的流处理应用都运行在 Flink 之上。
1.2、Flink分层API
Flink 根据抽象程度分层,提供了三种不同的 API。每一种 API 在简洁性和表达力上有着不同的侧重,并且针对不同的应用场景。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sD2aHoNE-1612775779487)(/Users/bytedance/Desktop/nJou61.jpg)]](https://img-blog.csdnimg.cn/img_convert/090df542e30617dbca744a038763dbbe.jpeg)
Flink分层API
-
ProcessFunction:可以处理一或两条输入数据流中的单个事件或者归入一个特定窗口内的多个事件。它提供了对于时间和状态的细粒度控制。开发者可以在其中任意地修改状态,也能够注册定时器用以在未来的某一时刻触发回调函数。因此,你可以利用ProcessFunction实现许多有状态的事件驱动应用所需要的基于单个事件的复杂业务逻辑。
-
DataStream API:为许多通用的流处理操作提供了处理原语。这些操作包括窗口、逐条记录的转换操作,在处理事件时进行外部数据库查询等。DataStream API 支持 Java 和 Scala 语言,预先定义了例如
map()、reduce()、aggregate()等函数。你可以通过扩展实现预定义接口或使用 Java、Scala 的 lambda 表达式实现自定义的函数。 -
SQL & Table API:Flink 支持两种关系型的 API,Table API 和 SQL。这两个 API 都是批处理和流处理统一的 API,这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型 API 会以相同的语义执行查询,并产生相同的结果。Table API和SQL借助了 Apache Calcite来进行查询的解析,校验以及优化。它们可以与DataStream和DataSet API无缝集成,并支持用户自定义的标量函数,聚合函数以及表值函数。Flink 的关系型 API 旨在简化数据分析、数据流水线和 ETL 应用的定义。
1.3、Flink主要组件
存储层:Flink本身并没有提供分布式文件系统,因此Flink的分析大多依赖外部存储。
调度层:Flink自带一个简易的资源调度器,称为独立调度器(Standalone)。若集群中没有任何资源管理器,则可以使用自带的独立调度器。当然,Flink也支持在其他的集群管理器上运行,包括Hadoop YARN、Apache Mesos等。
计算层:Flink的核心是一个对由很多计算任务组成的、运行在多个工作机器或者一个计算集群上的应用进行调度、分发以及监控的计算引擎,为API工具层提供基础服务。
工具层:在Flink Runtime的基础上,Flink提供了面向流处理(DataStream API)和批处理(DataSetAPI)的不同计算接口,并在此接口上抽象出了不同的应用类型组件库,例如基于流处理的CEP(复杂事件处理库)、Table&SQL(结构化表处理库)和基于批处理的Gelly(图计算库)、FlinkML(机器学习库)、Table&SQL(结构化表处理库)。
1.4、Flink特点
Apache Flink是一个集合众多具有竞争力特性于一身的第三代流处理引擎,它的以下特点使得它能够在同类系统中脱颖而出。
-
同时支持高吞吐、低延迟、高性能。
-
Flink是目前开源社区中唯一一套集高吞吐、低延迟、高性能三者于一身的分布式流式处理框架。像Apache Spark也只能兼顾高吞吐和高性能特性,主要因为在Spark Streaming流式计算中无法做到低延迟保障;而流式计算框架Apache Storm只能支持低延迟和高性能特性,但是无法满足高吞吐的要求。
-
-
同时支持事件时间和处理时间语义。
-
在流式计算领域中,窗口计算的地位举足轻重,但目前大多数框架窗口计算采用的都是处理时间,也就是事件传输到计算框架处理时系统主机的当前时间。Flink能够支持基于事件时间语义进行窗口计算,也就是使用事件产生的时间,这种基于事件驱动的机制使得事件即使乱序到达,流系统也能够计算出精确的结果,保证了事件原本的时序性。
-
-
支持有状态计算,并提供精确一次的状态一致性保障。
-
所谓状态就是在流式计算过程中将算子的中间结果数据保存着内存或者文件系统中,等下一个事件进入算子后可以从之前的状态中获取中间结果中计算当前的结果,从而不须每次都基于全部的原始数据来统计结果,这种方式极大地提升了系统的性能,并降低了数据计算过程的资源消耗。
-
-
基于轻量级分布式快照实现的容错机制。
-
Flink能够分布式运行在上千个节点上,将一个大型计算任务的流程拆解成小的计算过程,然后将Task分布到并行节点上进行处理。在任务执行过程中,能够自动发现事件处理过程中的错误而导致的数据不一致问题,在这种情况下,通过基于分布式快照技术的Checkpoints,将执行过程中的状态信息进行持久化存储,一旦任务出现异常终止,Flink就能够从Checkpoints中进行任务的自动恢复,以确保数据中处理过程中的一致性。
-
-
保证了高可用,动态扩展,实现7 * 24小时全天候运行。
-
支持高可用性配置(无单点失效),和Kubernetes、YARN、Apache Mesos紧密集成,快速故障恢复,动态扩缩容作业等。基于上述特点,它可以7 X 24小时运行流式应用,几乎无须停机。当需要动态更新或者快速恢复时,Flink通过Savepoints技术将任务执行的快照保存在存储介质上,当任务重启的时候可以直接从事先保存的Savepoints恢复原有的计算状态,使得任务继续按照停机之前的状态运行。
-
-
支持高度灵活的窗口操作。
-
Flink将窗口划分为基于Time、Count、Session,以及Data-driven等类型的窗口操作,窗口可以用灵活的触发条件定制化来达到对复杂流传输模式的支持,用户可以定义不同的窗口触发机制来满足不同的需求。
-
1.5、Flink应用场景
在实际生产的过程中,大量数据在不断地产生,例如金融交易数据、互联网订单数据、GPS定位数据、传感器信号、移动终端产生的数据、通信信号数据等,以及我们熟悉的网络流量监控、服务器产生的日志数据,这些数据最大的共同点就是实时从不同的数据源中产生,然后再传输到下游的分析系统。
针对这些数据类型主要包括以下场景,Flink对这些场景都有非常好的支持。
-
实时智能推荐
利用Flink流计算帮助用户构建更加实时的智能推荐系统,对用户行为指标进行实时计算,对模型进行实时更新,对用户指标进行实时预测,并将预测的信息推送给Web/App端,帮助用户获取想要的商品信息,另一方面也帮助企业提高销售额,创造更大的商业价值。
-
复杂事件处理
例如工业领域的复杂事件处理,这些业务类型的数据量非常大,且对数据的时效性要求较高。我们可以使用Flink提供的CEP(复杂事件处理)进行事件模式的抽取,同时应用Flink的SQL进行事件数据的转换,在流式系统中构建实时规则引擎。
-
实时欺诈检测
在金融领域的业务中,常常出现各种类型的欺诈行为。运用Flink流式计算技术能够在毫秒内就完成对欺诈判断行为指标的计算,然后实时对交易流水进行规则判断或者模型预测,这样一旦检测出交易中存在欺诈嫌疑,则直接对交易进行实时拦截,避免因为处理不及时而导致的经济损失
-
实时数仓与ETL
结合离线数仓,通过利用流计算等诸多优势和SQL灵活的加工能力,对流式数据进行实时清洗、归并、结构化处理,为离线数仓进行补充和优化。另一方面结合实时数据ETL处理能力,利用有状态流式计算技术,可以尽可能降低企业由于在离线数据计算过程中调度逻辑的复杂度,高效快速地处理企业需要的统计结果,帮助企业更好的应用实时数据所分析出来的结果。
-
流数据分析
实时计算各类数据指标,并利用实时结果及时调整在线系统相关策略,在各类投放、无线智能推送领域有大量的应用。流式计算技术将数据分析场景实时化,帮助企业做到实时化分析Web应用或者App应用的各种指标。
-
实时报表分析
实时报表分析说近年来很多公司采用的报表统计方案之一,其中最主要的应用便是实时大屏展示。利用流式计算实时得出的结果直接被推送到前段应用,实时显示出重要的指标变换,最典型的案例就是淘宝的双十一实时战报。
二、Flink架构
我们可以建立一个Flink大体上的框架,助力快速上手Flink。学习Flink最有效的方式是先入门了解框架和概念,然后边写代码边实践,然后再把官网看一遍。

Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
接下来,我们来介绍一下 Flink 架构中的重要方面。
2.1、批与流
-
批处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
-
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在Spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。而在Flink的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
2.2、处理无界和有界数据
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 流 或者 有界 流来处理。
-
无界流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
-
有界流 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。

Apache Flink 擅长处理无界和有界数据集 精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
通过探索 Flink 之上构建的用例来加深理解。
2.3、部署应用到任意地方
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器, 例如 Hadoop YARN、 Apache Mesos 和 Kubernetes, 但同时也可以作为独立集群运行。
Flink 被设计为能够很好地工作在上述每个资源管理器中,这是通过资源管理器特定(resource-manager-specific)的部署模式实现的。Flink 可以采用与当前资源管理器相适应的方式进行交互。
部署 Flink 应用程序时,Flink 会根据应用程序配置的并行性自动标识所需的资源,并从资源管理器请求这些资源。在发生故障的情况下,Flink 通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都是通过 REST 调用进行的,这可以简化 Flink 与各种环境中的集成。
2.3、运行任意规模应用
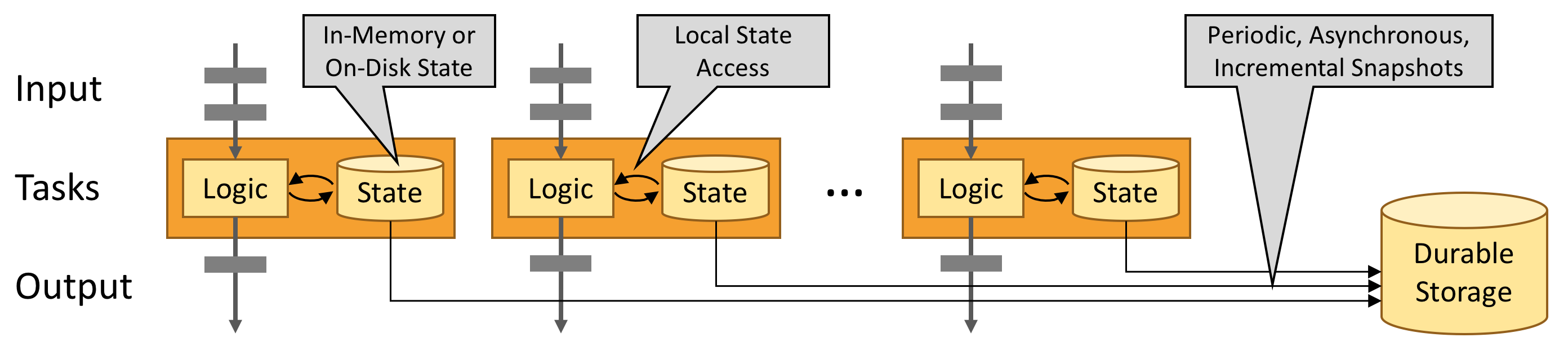
Flink 旨在任意规模上运行有状态流式应用。因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。而且 Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
-
处理每天处理数万亿的事件,
-
应用维护几TB大小的状态,
-
应用在数千个内核上运行。
2.4、利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
三、Flink VS Spark
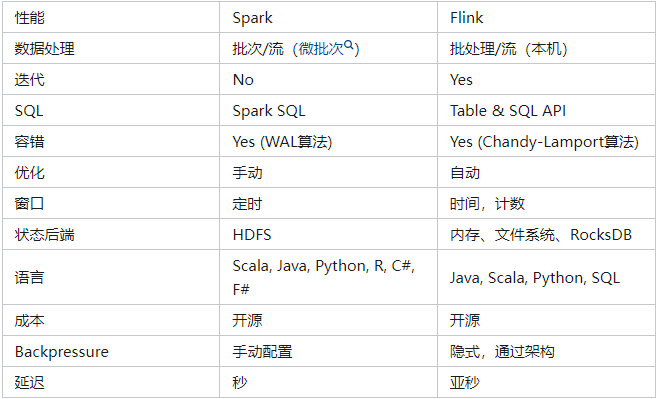
3.1、Spark和Flink中的功能集在很多方面都不同,如下表所示:
3.2、Flink VS Spark Streaming
-
数据模型
-
Flink基本数据模型是数据流,以及事件序列。
-
Spark采用RDD模型,Spark Streaming的DStream实际上也就是一组组小批 数据RDD的集合。
-
-
运行时架构
-
Flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节 点进行处理。
-
Spark是批计算,将DAG划分为不同的Stage,一个完成后才可以计算下一个。
-
参考链接:
10分钟入门Flink--了解Flink - 知乎
什么是Flink?Flink能用来做什么?[通俗易懂]-腾讯云开发者社区-腾讯云
相关文章:
大数据技术10:Flink从入门到精通
导语:前期入门Flink时,可以直接编写通过idea编写Flink程序,然后直接运行main方法,无需搭建环境。我碰到许多初次接触Flink的同学,被各种环境搭建、提交作业、复杂概念给劝退了。前期最好的入门方式就是直接上手写代码&…...
IDEA中工具条中的debug按钮不能用了显示灰色
IDEA中工具条中的debug按钮不能用了显示灰色 1. 问题描述 IDEA上的DEBUG按钮突然变成了灰色: 2. 解决办法 一通搜索,终于找到解决办法 点击 File -> Project Structure如下图操作 3. 重启,解决 4. 参考 https://www.cnblogs.com…...
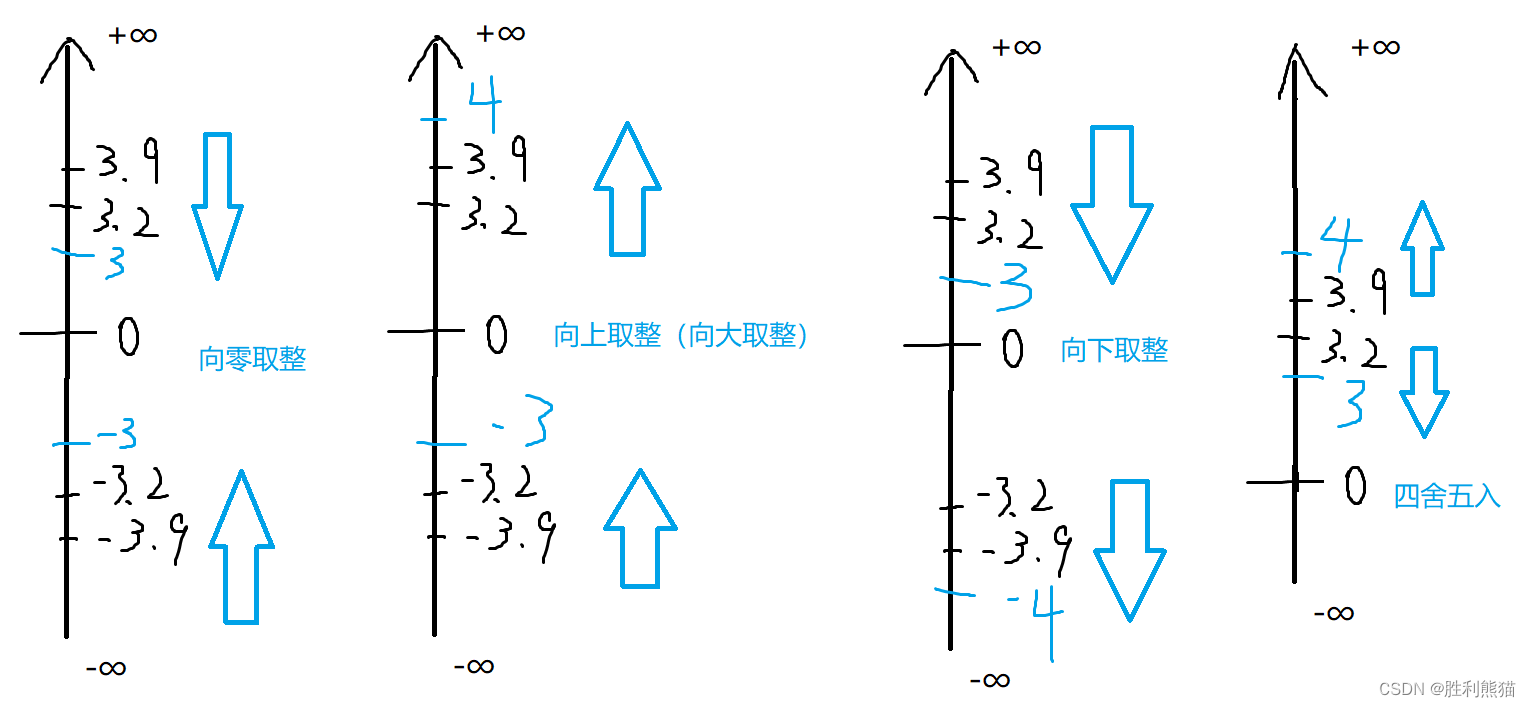
【MySQL内置函数】
目录: 前言一、日期函数获取日期获取时间获取时间戳在日期上增加时间在日期上减去时间计算两个日期相差多少天当前时间案例:留言板 二、字符串函数查看字符串字符集字符串连接查找字符串大小写转换子串提取字符串长度字符串替换字符串比较消除左右空格案…...
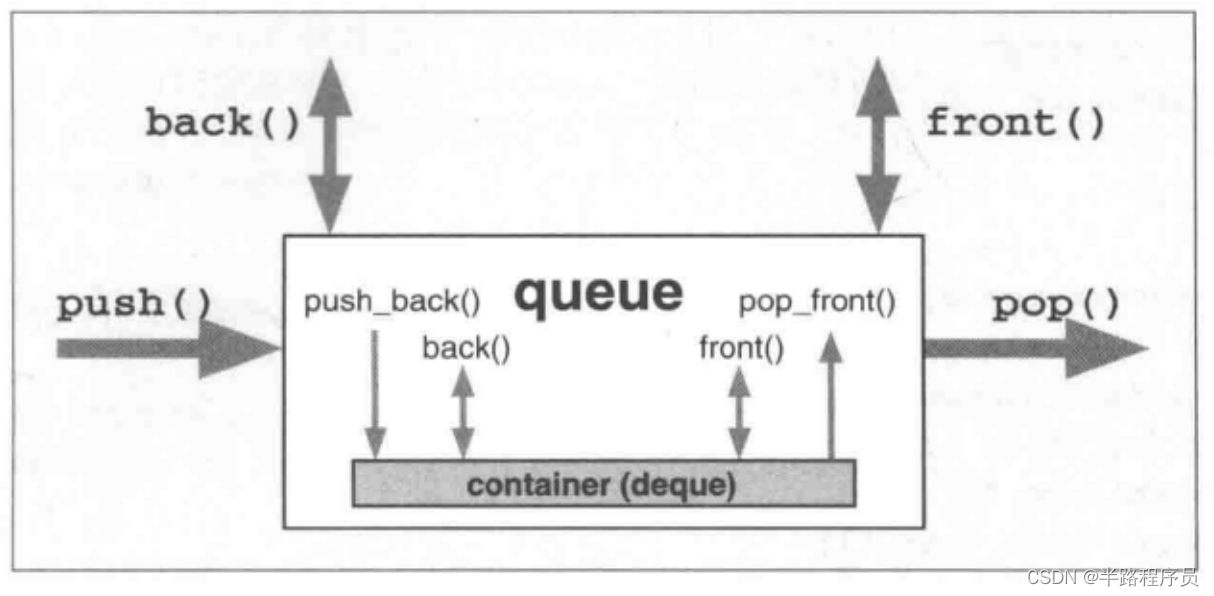
C++相关闲碎记录(14)
1、数值算法 (1)运算后产生结果accumulate() #include "algostuff.hpp"using namespace std;int main() {vector<int> coll;INSERT_ELEMENTS(coll, 1, 9);PRINT_ELEMENTS(coll);cout << "sum: " << accumulate(…...
:菜单权限,按钮权限,打包,发布nginx)
18、vue3(十八):菜单权限,按钮权限,打包,发布nginx
目录 一、菜单权限和路由拆分 1.思路分析 2.深拷贝插件 3.代码实现 4.效果展示...

04 在Vue3中使用setup语法糖
概述 Starting from Vue 3.0, Vue introduces a new syntactic sugar setup attribute for the <script> tag. This attribute allows you to write code using Composition API (which we will discuss further in Chapter 5, The Composition API) in SFCs and shorte…...

vite+ts——user.ts——ts接口定义+axios请求的写法
import axios from axios; import qs from query-string; import {UserState} from /store/modules/user/types;export interface LoginData{username:string;password:string;grant_type?:string;scope?:string;client_id?:string;client_secret?:string;response_type?:…...
环境搭建及源码运行_java环境搭建_mysql安装
书到用时方恨少、觉知此时要躬行;拥有技术,成就未来,抖音视频教学地址: 1、介绍 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle旗下产品。MySQL是最…...
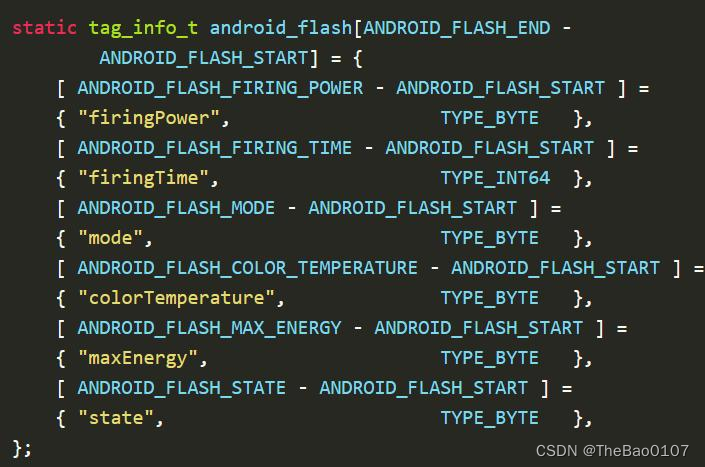
Android camera的metadata
一、实现 先看一下metadata内部是什么样子: 可以看出,metadata 内部是一块连续的内存空间。 其内存分布大致可概括为: 区域一 :存 camera_metadata_t 结构体定义,占用内存 96 Byte 区域二 :保留区&#x…...

ElasticSearch面试题
1.介绍下es的架构? es采用的是分布式的架构,es集群中会有多个结点,而结点的角色主要有下面几种。 协调结点: 请求路由能力,将请求内容将请求转发给对应的结点进行处理。 master结点: 结点管理ÿ…...

C++ 数据结构知识点合集-C/C++ 数组允许定义可存储相同类型数据项的变量-供大家学习研究参考
#include <iostream> #include <cstring>using namespace std;// 声明一个结构体类型 Books struct Books {char title[50];char author[50];char subject[100];int book_id; };int main( ) {Books Book1; // 定义结构体类型 Books 的变量 Book1Books …...

【机器学习】5分钟掌握机器学习算法线上部署方法
5分钟掌握机器学习算法线上部署方法 1. 三种情况2. 如何转换PMML,并封装PMML2.1 什么是PMML2.2 PMML的使用方法范例3. 各个算法工具的工程实践4. 只用Linux的Shell来调度模型的实现方法5. 注意事项参考资料本文介绍业务模型的上线流程。首先在训练模型的工具上,一般三个模型训…...
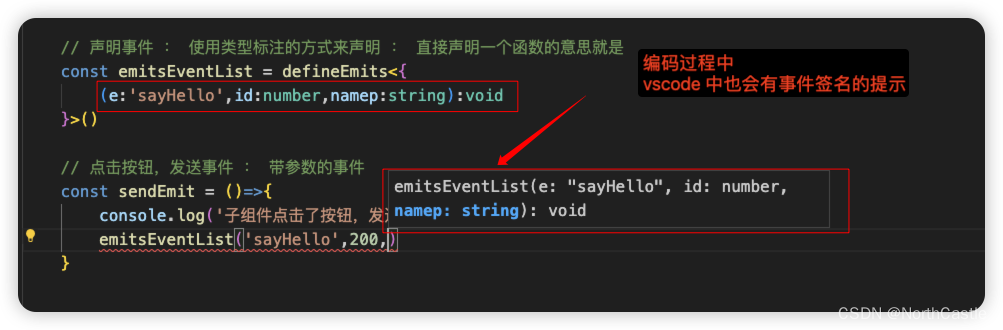
Vue3-21-组件-子组件给父组件发送事件
情景描述 【子组件】中有一个按钮,点击按钮,触发一个事件, 我们希望这个事件的处理逻辑是,给【父组件】发送一条消息过去, 从而实现 【子组件】给【父组件】通信的效果。这个问题的解决就是 “发送事件” 这个操作。 …...
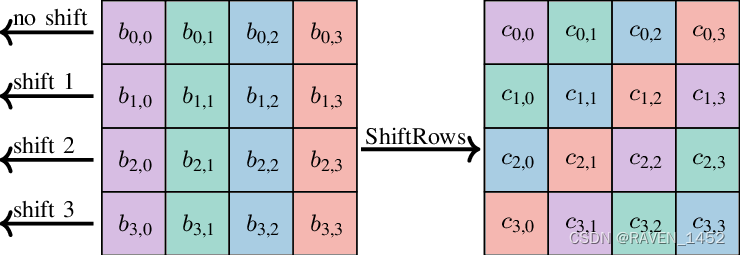
[密码学]AES
advanced encryption standard,又名rijndael密码,为两位比利时数学家的名字组合。 分组为128bit,密钥为128/192/256bit可选,对应加密轮数10/12/14轮。 基本操作为四种: 字节代换(subBytes transformatio…...

CentOS 7 部署pure-ftp
文章目录 (1)简介(2)准备工作(3)更新系统(4)安装依赖环境(5)下载和解压pure-ftp源码包(6)编译和安装pure-ftp(7࿰…...
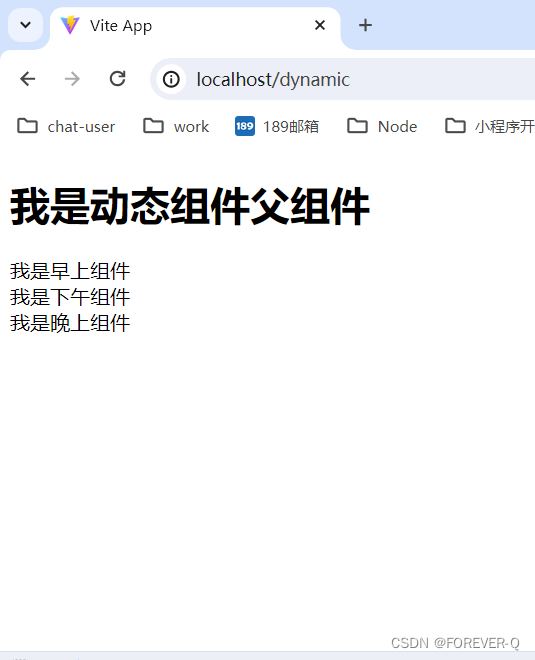
Vue2-动态组件案例
1.component介绍 说明: Type: string | ComponentDefinition | ComponentConstructor Explanation: String: 如果你传递一个字符串给 is,它会被视为组件的名称,用于动态地渲染不同类型的组件。这是一个在运行时动态切换组件类型的常见用例。…...
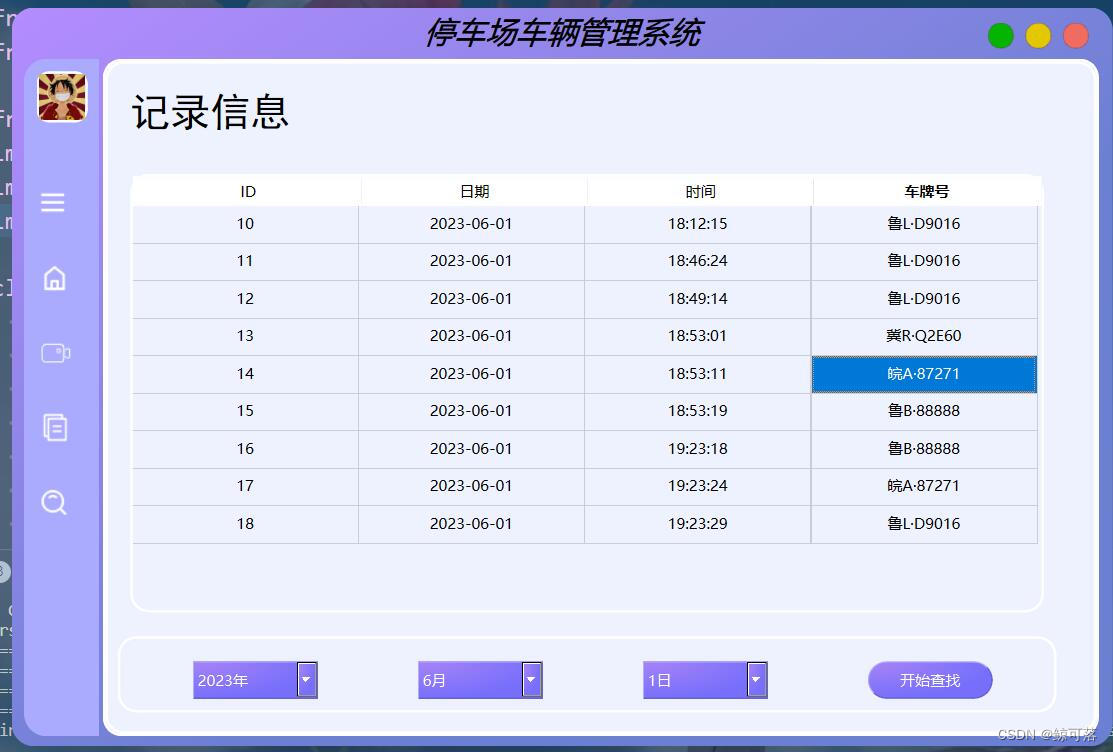
【源码】车牌检测+QT界面+附带数据库
目录 1、基本介绍2、基本环境3、核心代码3.1、车牌识别3.2、车牌定位3.3、车牌坐标矫正 4、界面展示4.1、主界面4.2、车牌检测4.3、查询功能 5、演示6、链接 1、基本介绍 本项目采用tensorflow,opencv,pyside6和pymql编写,pyside6用来编写UI界…...
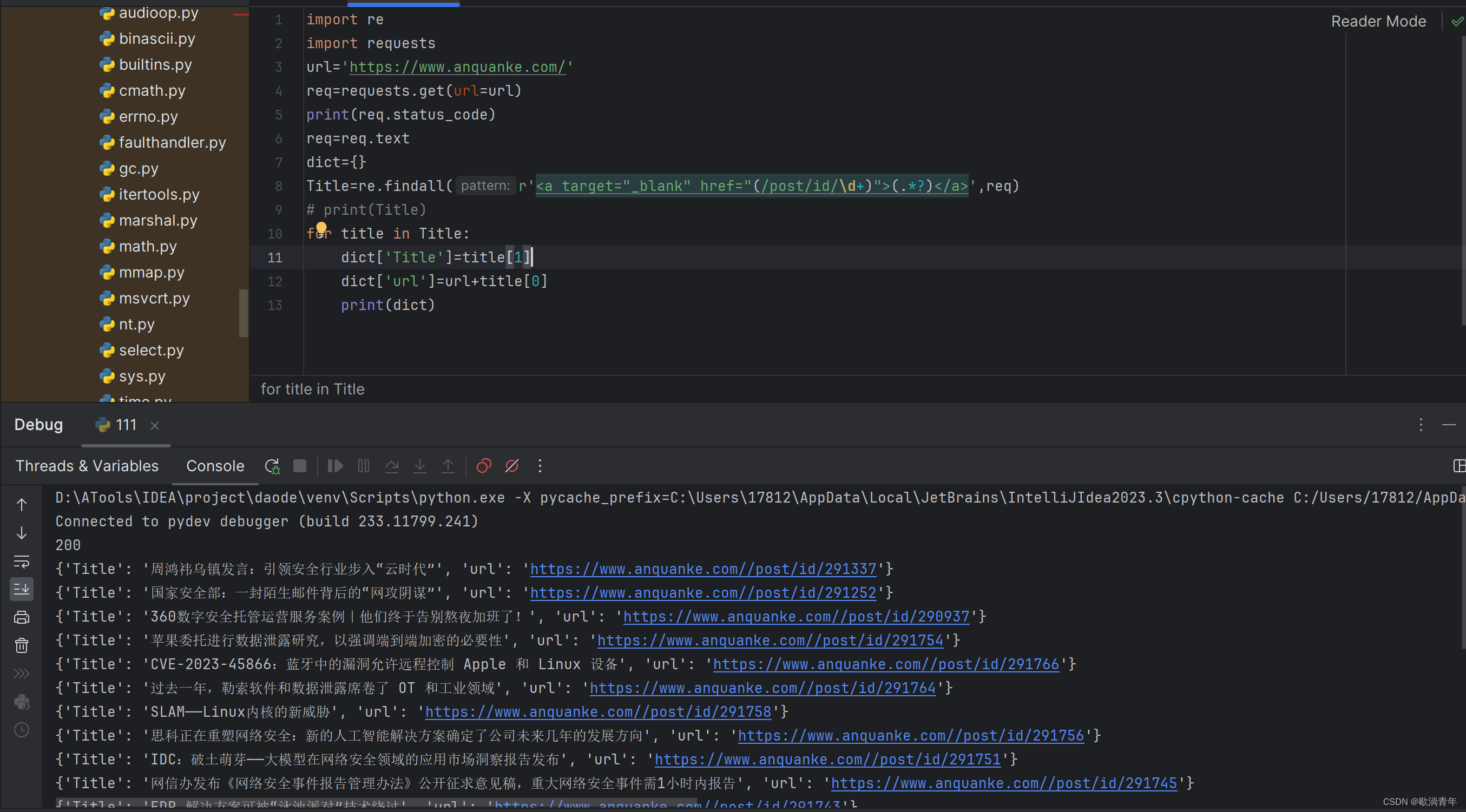
实战1-python爬取安全客新闻
一般步骤:确定网站--搭建关系--发送请求--接受响应--筛选数据--保存本地 1.拿到网站首先要查看我们要爬取的目录是否被允许 一般网站都会议/robots.txt目录,告诉你哪些地址可爬,哪些不可爬,以安全客为例子 2. 首先测试在不登录的…...
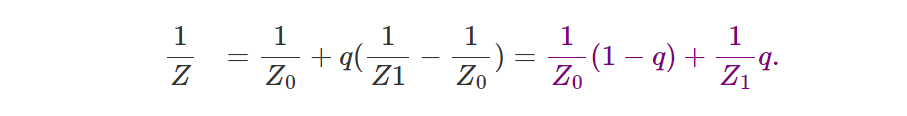
光栅化渲染:可见性问题和深度缓冲区算法
在前面第二章中,我们了解到,在投影点(屏幕空间中的点)的第三个坐标中,我们存储原始顶点 z 坐标(相机空间中点的 z 坐标): 当一个像素与多个三角形重叠时,查找三角形表面上…...
docker入门小结
docker是什么?它有什么优势? 快速获取开箱即用的程序 docker使得所有的应用传输就像我们日常通过聊天工具文件传输一样,发送方将程序传输到超级码头而接收方也只需通过超级码头进行获取即可,就像一只鲸鱼拖着货物来回运输一样。…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

C语言中提供的第三方库之哈希表实现
一. 简介 前面一篇文章简单学习了C语言中第三方库(uthash库)提供对哈希表的操作,文章如下: C语言中提供的第三方库uthash常用接口-CSDN博客 本文简单学习一下第三方库 uthash库对哈希表的操作。 二. uthash库哈希表操作示例 u…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...
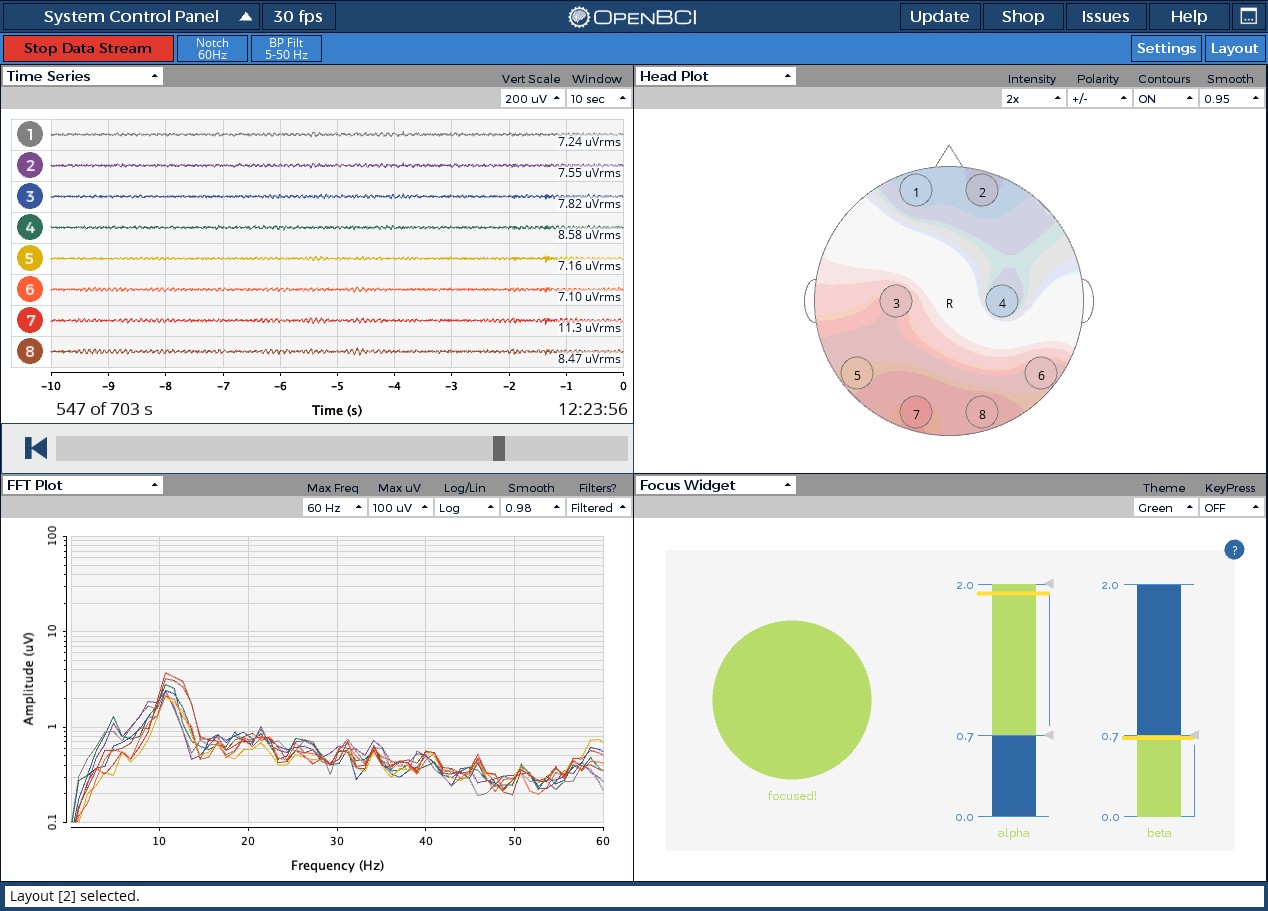
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...