大数据存储技术(3)—— HBase分布式数据库
目录
一、HBase简介
(一)概念
(二)特点
(三)HBase架构
二、HBase原理
(一)读流程
(二)写流程
(三)数据 flush 过程
(四)数据合并过程
三、HBase安装与配置
(一)解压并安装HBase
(二)配置HBase
(三)配置Spark
四、HBase的使用
(一)进入HBase shell
(二)表的管理
(三)表数据的增删改查
一、HBase简介
(一)概念
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
(二)特点
1、海量存储
HBase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与HBase的极易扩展性息息相关。正式因为HBase良好的扩展性,才为海量数据的存储提供了便利。
2、列式存储
这里的列式存储其实说的是列族存储,HBase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3、极易扩展
HBase 的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS) 。通过横向添加RegionSever的机器,进行水平扩展,提升HBase 上层的处理能力,提升HBsae服务更多Region 的能力。
备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升 HBase的数据存储能力和提升后端存储的读写力。
4、高并发
由于目前大部分使用HBase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,HBase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5、稀疏
稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
(三)HBase架构
HBase架构如图所示。
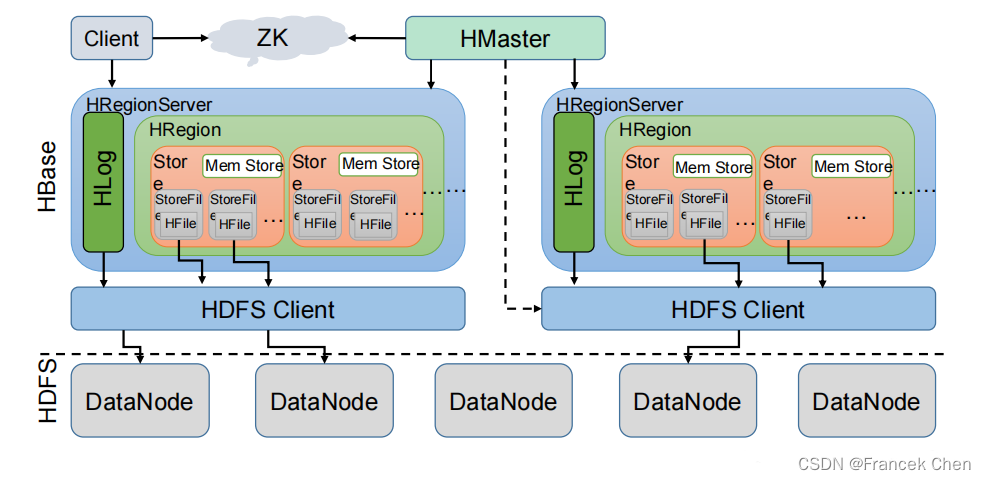
从图中可以看出 HBase 是由 Client、Zookeeper、Master、HRegionServer、HDFS 等几个组件组成,下面来介绍一下几个组件的相关功能:
1、Client
Client 包含了访问 HBase 的接口,另外 Client 还维护了对应的 cache 来加速 HBase 的访问,比如 cache 的.META.元数据的信息。
2、Zookeeper
HBase 通过 Zookeeper 来做 master 的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
(1)通过 Zoopkeeper 来保证集群中只有 1 个 master 在运行,如果 master 异常,会通过竞争机制产生新的 master 提供服务。
(2)通过 Zoopkeeper 来监控 RegionServer 的状态,当 RegionSevrer 有异常的时候,通过回调的形式通知 Master RegionServer 上下线的信息。
(3)通过 Zoopkeeper 存储元数据的统一入口地址。
3、Hmaster
master 节点的主要职责如下:
为 RegionServer 分配 Region
维护整个集群的负载均衡
维护集群的元数据信息
发现失效的 Region,并将失效的 Region 分配到正常的 RegionServer 上
当 RegionSever 失效的时候,协调对应 Hlog 的拆分
4、HregionServer
HregionServer 直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下:
管理 master 为其分配的 Region
处理来自客户端的读写请求
负责和底层 HDFS 的交互,存储数据到 HDFS
负责 Region 变大以后的拆分
负责 Storefile 的合并工作
5、HDFS
HDFS 为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高可用(Hlog 存储在HDFS)的支持,具体功能概括如下:
提供元数据和表数据的底层分布式存储服务
数据多副本,保证的高可靠和高可用性
二、HBase原理
(一)读流程

1、Client 先访问 zookeeper,从 meta 表读取 region 的位置,然后读取 meta 表中的数据。meta 中又存储了用户表的 region 信息;
2、根据 namespace、表名和 rowkey 在 meta 表中找到对应的 region 信息;
3、找到这个 region 对应的 regionserver;
4、查找对应的 region;
5、先从 MemStore 找数据,如果没有,再到 BlockCache 里面读;
6、BlockCache 还没有,再到 StoreFile 上读(为了读取的效率);
7、如果是从 StoreFile 里面读取的数据,不是直接返回给客户端,而是先写入 BlockCache,再返回给客户端。
(二)写流程
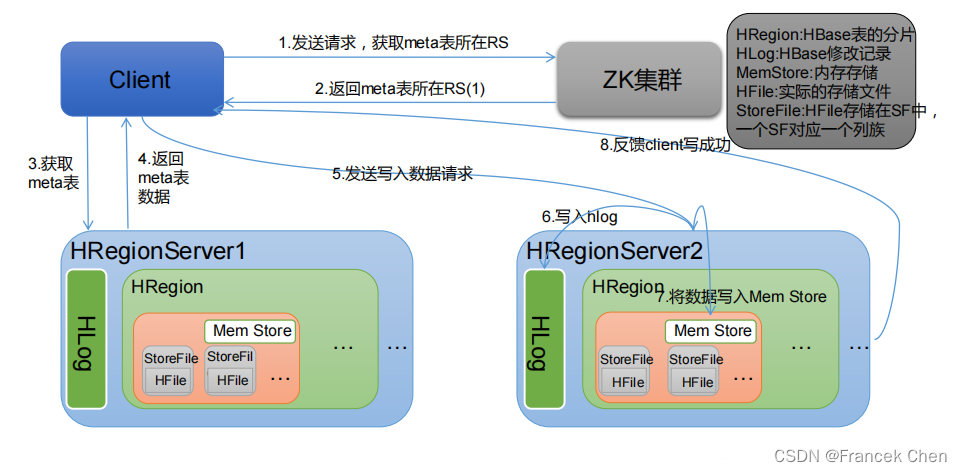
1、Client 向 HregionServer 发送写请求;
2、HregionServer 将数据写到 HLog(write ahead log)。为了数据的持久化和恢复;
3、HregionServer 将数据写到内存(MemStore);
4、反馈 Client 写成功。
(三)数据 flush 过程
1、当 MemStore 数据达到阈值(默认是 128M,老版本是 64M),将数据刷到硬盘,将内存中的数据删除,同时删除 HLog 中的历史数据;
2、并将数据存储到 HDFS 中;
3、在 HLog 中做标记点。
(四)数据合并过程
1、当数据块达到 4 块,Hmaster 触发合并操作,Region 将数据块加载到本地,进行合并;
2、当合并的数据超过 256M,进行拆分,将拆分后的 Region 分配给不同的 HregionServer 管理; 3、当HregionServer宕机后,将HregionServer上的hlog拆分,然后分配给不同的HregionServer加载,修改.META.;
4、注意:HLog 会同步到 HDFS。
三、HBase安装与配置
(一)解压并安装HBase
首先,到HBase官网将HBase安装包下载到 /usr/local/uploads 目录下,再切换到该目录下解压安装到 /usr/local/servers 目录下。
Apache HBase – Apache HBase Downloads![]() https://hbase.apache.org/downloads.html
https://hbase.apache.org/downloads.html
[root@bigdata zhc]# cd /usr/local/uploads
[root@bigdata uploads]# tar -zxvf hbase-2.4.14-bin.tar.gz -C /usr/local/servers
[root@bigdata uploads]# cd ../servers
[root@bigdata servers]# mv hbase-2.4.14/ hbase
这些就是HBase包含的文件:

(二)配置HBase

1、修改环境变量hbase-env.sh
[root@bigdata conf]# vi hbase-env.sh在文件开头加入如下内容:
export JAVA_HOME=/usr/local/servers/jdk
export HBASE_CLASSPATH=/usr/local/servers/hbase/conf
export HBASE_MANAGES_ZK=true指定了jdk路径和HBase路径。

注意:另外,定位到(HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true")这一行。还要将如下图所示红框标出的那一行前面的“#”删掉,防止后面启动HBase日志冲突。

2、修改配置文件hbase-site.xml
[root@bigdata conf]# vi hbase-site.xml在两个<configuration>标签之间加入如下内容:
<property><name>hbase.rootdir</name><value>hdfs://localhost:9000/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>/usr/local/servers/zookeeper/data</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property>
3、设置环境变量,编辑系统配置文件/etc/profile。
[root@bigdata conf]# vi /etc/profile
[root@bigdata conf]# source /etc/profile #使文件生效将下面代码加到文件末尾。
export HBASE_HOME=/usr/local/servers/hbase
export PATH=$PATH:$HBASE_HOME/bin
export CLASSPATH=$CLASSPATH:$HBASE_HOME/lib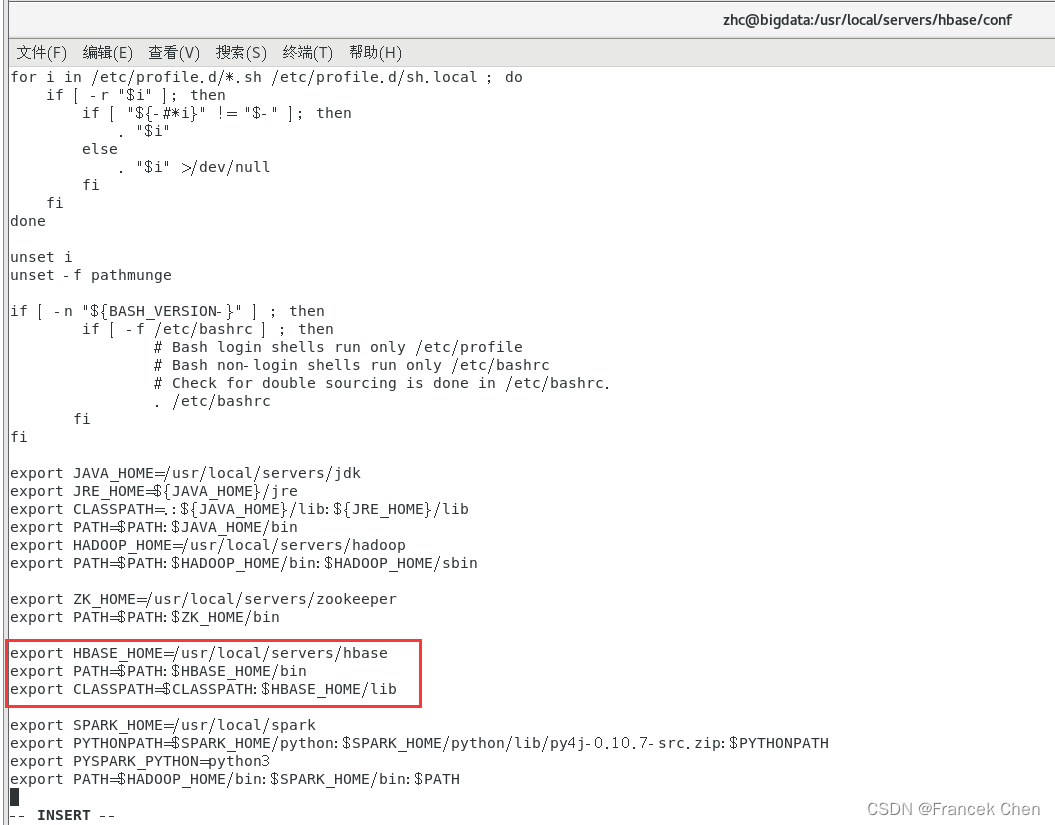
4、启动并验证HBase
由于HBase是基于Hadoop的,所以要先启动Hadoop。
[root@bigdata conf]# start-dfs.sh
[root@bigdata conf]# start-hbase.sh
这便是有无日志冲突的区别!(下图是有日志冲突的)
所以务必要将 HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true" 这一行前的“#”删除!

由此可以发现,多了HRegionServer、HQuorumPeer、HMaster 三个进程。
进入HBase-shell,并输入“version”查看当前HBase版本。
[root@bigdata hbase]# hbase shell
hbase:001:0> version

(三)配置Spark
配置Spark的目的是为了以后可以通过pypark向HBase中读取和写入数据。
把HBase的lib目录下的一些jar文件拷贝到Spark中,这些都是编程时需要引入的jar包,需要拷贝的jar文件包括:所有hbase开头的jar文件、guava-11.0.2.jar和protobuf-java-2.5.0.jar。
执行如下命令:
[root@bigdata hbase]# cd /usr/local/spark/jars
[root@bigdata jars]# mkdir hbase
[root@bigdata jars]# cd hbase
[root@bigdata hbase]# cp /usr/local/servers/hbase/lib/hbase*.jar ./
[root@bigdata hbase]# cp /usr/local/servers/hbase/lib/guava-11.0.2.jar ./
[root@bigdata hbase]# cp /usr/local/servers/hbase/lib/protobuf-java-2.5.0.jar ./
htrace-core-3.1.0-incubating.jar 下载地址:
https://repo1.maven.org/maven2/org/apache/htrace/htrace-core/3.1.0-incubating/htrace-core-3.1.0-incubating.jar![]() https://repo1.maven.org/maven2/org/apache/htrace/htrace-core/3.1.0-incubating/htrace-core-3.1.0-incubating.jar
https://repo1.maven.org/maven2/org/apache/htrace/htrace-core/3.1.0-incubating/htrace-core-3.1.0-incubating.jar
[root@bigdata hbase]# cp /usr/local/uploads/htrace-core-3.1.0-incubating.jar ./此外,在Spark 2.0以上版本中,缺少把HBase数据转换成Python可读取数据的jar包,需要另行下载。可以访问下面地址下载spark-examples_2.11-1.6.0-typesafe-001.jar:
https://mvnrepository.com/artifact/org.apache.spark/spark-examples_2.11/1.6.0-typesafe-001![]() https://mvnrepository.com/artifact/org.apache.spark/spark-examples_2.11/1.6.0-typesafe-001
https://mvnrepository.com/artifact/org.apache.spark/spark-examples_2.11/1.6.0-typesafe-001
[root@bigdata hbase]# cp /usr/local/uploads/spark-examples_2.11-1.6.0-typesafe-001.jar ./拷贝完成后,/usr/local/spark/jars/hbase 目录下的 jar 包如下图所示;

然后,使用vim编辑器打开spark-env.sh文件,设置Spark的spark-env.sh文件,告诉Spark可以在哪个路径下找到HBase相关的jar文件,命令如下:
[root@bigdata hbase]# cd /usr/local/spark/conf
[root@bigdata conf]# vi spark-env.sh打开spark-env.sh文件以后,可以在文件最前面增加下面一行内容:
export SPARK_DIST_CLASSPATH=$(/usr/local/servers/hadoop/bin/hadoop classpath):$(/usr/local/servers/hbase/bin/hbase classpath):/usr/local/spark/jars/hbase/*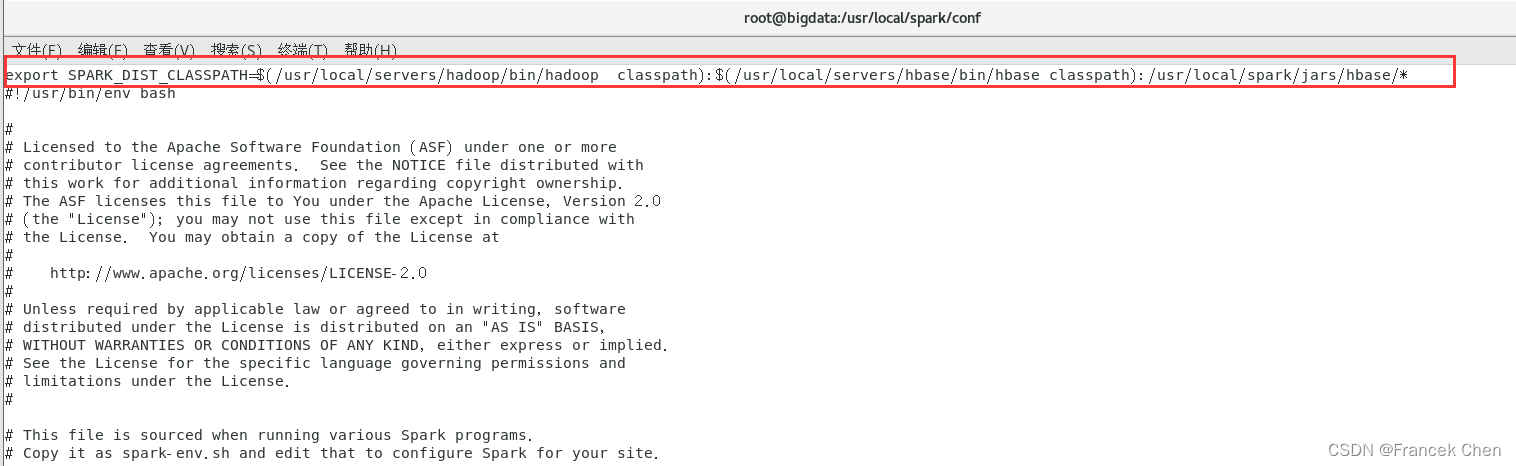
这样,后面编译和运行过程才不会出错。
四、HBase的使用
(一)进入HBase shell
[root@bigdata conf]# cd /usr/local/servers/hbase
[root@bigdata hbase]# hbase shell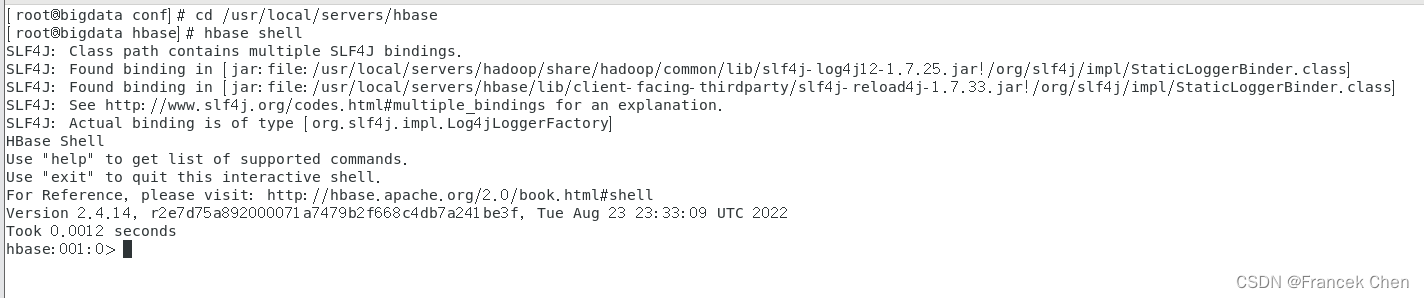
(二)表的管理
1、列举表
命令如下:
hbase(main)> list2、创建表
语法格式:create <table>,{NAME => <family>,VERSIONS => <VERSIONS>}
例如,创建表t1,有两个family name:f1、f2,且版本数均为2,
命令如下:
hbase(main)> create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2}3、删除表
删除表分两步:首先使用disable 禁用表,然后再用drop命令删除表。
例如,删除表t1操作如下:
hbase(main)> disable 't1'
hbase(main)> drop 't1'4、查看表的结构
语法格式:describe <table>
例如,查看表t1的结构,命令如下:
hbase(main)> describe 't1'5、修改表的结构
修改表结构必须用disable禁用表,才能修改。
语法格式:alter 't1',{NAME => 'f1'},{NAME => 'f2',METHOD => 'delete'}
例如,修改表test1的cf的TTL为180天,命令如下:
hbase(main)> disable 'test1'
hbase(main)> alter 'test1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'}
hbase(main)> enable 'test1'6、权限管理
① 分配权限
语法格式:grant <user> <permissions> <table> <column family> <column qualifier>
说明:参数后面用逗号分隔。
权限用“RWXCA”五个字母表示,其对应关系为:
READ('R')、WRITE('W')、EXEC('X')、CREATE('C')、ADMIN('A')。
例如,为用户‘test’分配对表t1有读写的权限,命令如下:
hbase(main)> grant 'test','RW','t1'② 查看权限
语法格式:user_permission <table>
例如,查看表t1的权限列表,命令如下:
hbase(main)> user_permission 't1'③ 收回权限
与分配权限类似,语法格式:revoke <user> <table> <column family> <column qualifier>
例如,收回test用户在表t1上的权限,命令如下:
hbase(main)> revoke 'test','t1'(三)表数据的增删改查
1、添加数据
语法格式:put <table>,<rowkey>,<family:column>,<value>,<timestamp>
例如,给表t1的添加一行记录,其中,rowkey是rowkey001,family name是f1,column name是col1,value是value01,timestamp为系统默认。则命令如下:
hbase(main)> put 't1','rowkey001','f1:col1','value01'2、查询数据
① 查询某行记录
语法格式:get <table>,<rowkey>,[<family:column>,....]
例如,查询表t1,rowkey001中的f1下的col1的值,命令如下:
hbase(main)> get 't1','rowkey001', 'f1:col1'或者用如下命令:
hbase(main)> get 't1','rowkey001', {COLUMN=>'f1:col1'}查询表t1,rowke002中的f1下的所有列值,命令如下:
hbase(main)> get 't1','rowkey001'② 扫描表
语法格式:scan <table>,{COLUMNS => [ <family:column>,.... ],LIMIT => num}
另外,还可以添加STARTROW、TIMERANGE和FITLER等高级功能。
例如,扫描表t1的前5条数据,命令如下:
hbase(main)> scan 't1',{LIMIT=>5}③ 查询表中的数据行数
语法格式:count <table>,{INTERVAL => intervalNum,CACHE => cacheNum}
其中,INTERVAL设置多少行显示一次及对应的rowkey,默认为1000;CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度。
例如,查询表t1中的行数,每100条显示一次,缓存区为500,命令如下:
hbase(main)> count 't1', {INTERVAL => 100, CACHE => 500}3、删除数据
① 删除行中的某个值
语法格式:delete <table>,<rowkey>,<family:column>,<timestamp>
这里必须指定列名。
例如,删除表t1,rowkey001中的f1:col1的数据,命令如下:
hbase(main)> delete 't1','rowkey001','f1:col1' ② 删除行
语法格式:deleteall <table>,<rowkey>,<family:column>,<timestamp>
这里可以不指定列名,也可删除整行数据。
例如,删除表t1,rowk001的数据,命令如下:
hbase(main)> deleteall 't1','rowkey001'③ 删除表中的所有数据
语法格式:truncate <table>
其具体过程是:disable table -> drop table -> create table
例如,删除表t1的所有数据,命令如下:
hbase(main)> truncate 't1'最后友情提醒:使用完HBase和Hadoop后,要先关闭HBase,再关闭Hadoop!
相关文章:
大数据存储技术(3)—— HBase分布式数据库
目录 一、HBase简介 (一)概念 (二)特点 (三)HBase架构 二、HBase原理 (一)读流程 (二)写流程 (三)数据 flush 过程 …...

docker容器日志占用磁盘空间过大问题
docker服务运行一段时间后,发现磁盘空间占用很高 其中磁盘占用主要以下目录: /var/lib/docker/containers # 查询占用磁盘较大的文件-升序 du -d1 -h /var/lib/docker/containers | sort -h 控制容器日志大小 法一:容器运行时控制 # max-…...
飞天使-docker知识点6-容器dockerfile各项名词解释
文章目录 docker的小技巧dockerfile容器为什么会出现启动了不暂停查看docker 网桥相关信息 docker 数据卷 docker的小技巧 [rootlight-test playbook-vars[]# docker inspect -f "{{.NetworkSettings.IPAddress}}" d3a9ae03ae5f 172.17.0.4docker d3a9ae03ae5f:/etc…...

oracle-关闭审计功能
1.查看审计功能是否开启 su – oraclesqlplus “/as sysdba”SQL> show parameter audit_trail NAME TYPE VALUE audit_trail string DB 注:VALUE值为DB时,表明审计功能为开启的状态 2.关闭oracle的审计功能 SQL> alter system set audit_trailFALSE scopespfile; Sy…...

three.js(一)
文章目录 three.js环境搭建正文补充 示例效果知识点补充1:一个标准的html知识点补充2:原生的前端框架和Vue框架的区别原生的前端框架Vue框架声明式编程和响应式编程 three.js环境搭建 正文 搭建 Three.js 的环境通常包括以下几个步骤: 1.创建项目目录:…...

Python基础入门:语法与数据类型
Python基础入门:语法与数据类型 一、引言 Python是一种简单易学、功能强大的编程语言,广泛应用于数据分析、机器学习、Web开发等领域。本文将介绍Python的基础语法和数据类型,帮助初学者快速入门。 二、Python基础语法 缩进 Python中的缩…...
@Scheduled任务调度/定时任务-非分布式
1、功能概述 任务调度就是在规定的时间内执行的任务或者按照固定的频率执行的任务。是非常常见的功能之一。常见的有JDK原生的Timer, ScheduledThreadPoolExecutor以及springboot提供的Schduled。分布式调度框架如QuartZ、Elasticjob、XXL-JOB、SchedulerX、PowerJob等。 本文…...
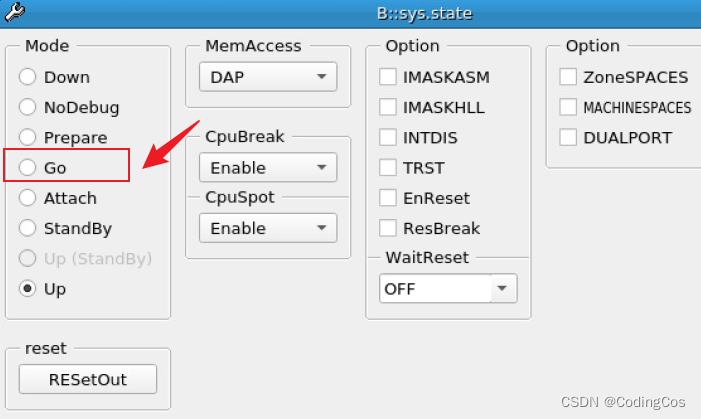
【ARM Trace32(劳特巴赫) 使用介绍 14 -- Go.direct 介绍】
请阅读【Trace32 ARM 专栏导读】 文章目录 Trace32 Go.directGo配合程序断点使用Go 配合读写断点使用Go 快速回到上一层函数 System.Mode Go Trace32 Go.direct TRACE32调试过程中,会经常对芯片/内核进行控制,比如全速运行、暂停、单步等等。这篇文章先…...
)
第二十章 : Spring Boot 集成RabbitMQ(四)
第二十章 : Spring Boot 集成RabbitMQ(四) 前言 本章知识点:死信队列的定义、场景、作用以及原理、TTL方法的使用以及演示代码示例。 Springboot 版本 2.3.2.RELEASE ,RabbitMQ 3.9.11,Erlang 24.2死信队列 定义:什么是死信队列? 在RabbitMQ中,并没有提供真正意义…...
防止反编译,保护你的SpringBoot项目
ClassFinal-maven-plugin插件是一个用于加密Java字节码的工具,它能够保护你的Spring Boot项目中的源代码和配置文件不被非法获取或篡改。下面是如何使用这个插件来加密test.jar包的详细步骤: 安装并设置Maven: 首先确保你已经在你的开发环境中…...
OpenCV开发:MacOS源码编译opencv,生成支持java、python、c++各版本依赖库
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库。它为开发者提供了丰富的工具和函数,用于处理图像和视频数据,以及执行各种计算机视觉任务。 以下是 OpenCV 的一些主要特点和功能ÿ…...

【数据库设计和SQL基础语法】--查询数据--分组查询
一、分组查询概述 1.1 什么是分组查询 分组查询是一种 SQL 查询技术,通过使用 GROUP BY 子句,将具有相同值的数据行分组在一起,然后对每个组应用聚合函数(如 COUNT、SUM、AVG等)。这允许在数据集中执行汇总和统计操作…...

使用对象处理流ObjectOutputStream读写文件
注意事项: 1.创建的对象必须实现序列化接口,如果属性也是类,那么对应的类也要序列化 2.读写文件路径问题 3.演示一个例子 (1)操作的实体类FileModel,实体类中有Map,HashMap这些自带的本身就实现了序列化。 public class File…...
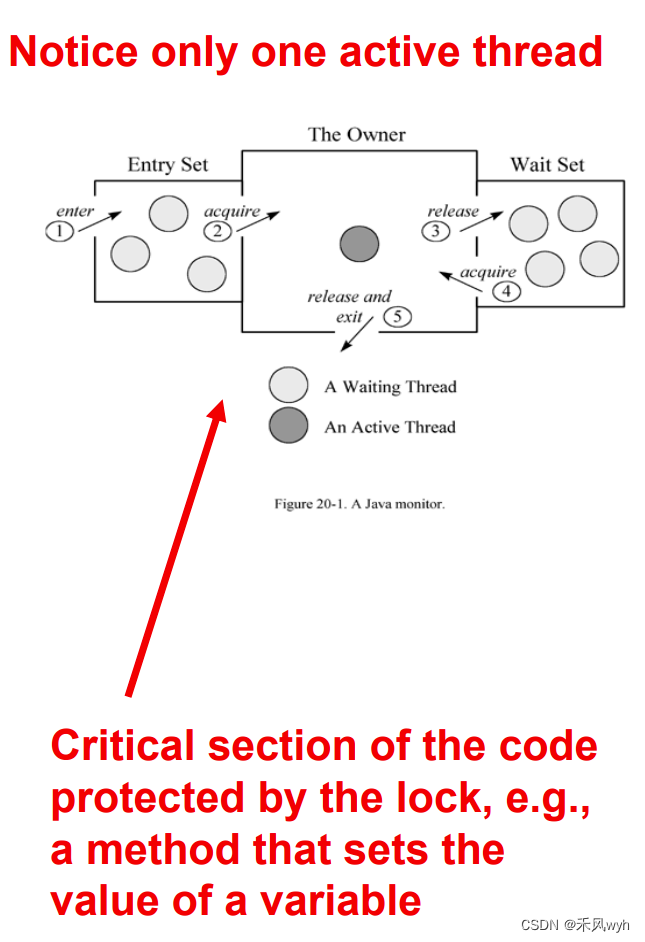
【高级网络程序设计】Block1总结
这一个Block分为四个部分,第一部分是Introduction to Threads and Concurrency ,第二部分是Interruptting and Terminating a Thread,第三部分是Keep Threads safety:the volatile variable and locks,第四部分是Beyon…...
linux下查看进程资源ulimit
ulimit介绍与使用 ulimit命令用于查看和修改进程的资源限制。下面是ulimit命令的使用方法: 查看当前资源限制: ulimit -a 这将显示当前进程的所有资源限制,包括软限制和硬限制。查看或设置单个资源限制: ulimit -<option> …...

C++ I/O操作---输入输出
本文主要介绍C I/O操作中的输入输出流。 目录 1 输入输出 2 输入输出流分类 3 C中的输入输出流 4 iostream 5 std::ofstream 6 std::fstream 7 std::getline 1 输入输出 C的输入输出是数据在不同设备之间的传输,即在硬盘、内存和外设之间的传输。 数据如水流…...
会 C# 应该怎么学习 C++?
会 C# 应该怎么学习 C? 在开始前我有一些资料,是我根据自己从业十年经验,熬夜搞了几个通宵,精心整理了一份「C的资料从专业入门到高级教程工具包」,点个关注,全部无偿共享给大家!!&a…...

CentOS 7 部署frp穿透内网
本文将介绍如何在CentOS 7.9上部署frp,并通过示例展示如何配置和测试内网穿透。 文章目录 (1)引言(2)准备工作(4)frps服务器端配置(5)frpc客户端配置(6&#…...

高效网络爬虫:代理IP的应用与实践
💂 个人网站:【 海拥】【神级代码资源网站】【办公神器】🤟 基于Web端打造的:👉轻量化工具创作平台🤟 代理 IP 推荐:👉品易 HTTP 代理 IP 💅 想寻找共同学习交流的小伙伴,…...
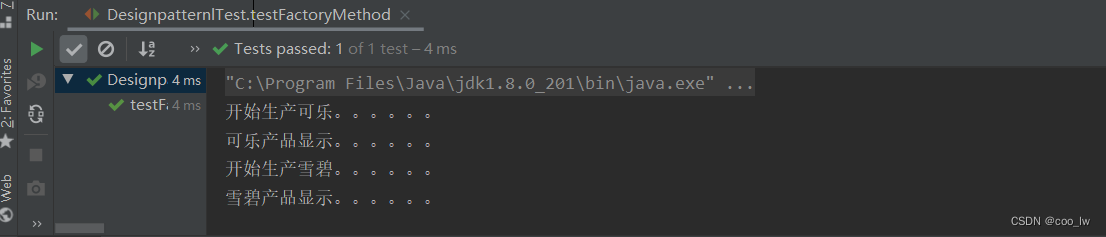
java设计模式-工厂方法模式
1.工厂方法(FactoryMethod)模式的定义 定义一个创建产品对象的工厂接口,将产品对象的实际创建工作推迟到具体子工厂类当中。这满足创建型模式中所要求的“创建与使用相分离”的特点。 2.工厂方法模式的主要优缺点 优点: 用户只需要知道具体工厂的名称…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...