【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分
- 概述
- NLP 简介
- 文本处理
- 词嵌入
- 上下文理解
- 文本数据加载
- to_device 函数
- 构造
- 数据加载
- 样本数量 len
- 获取样本 getitem
- 分词
- 构造函数
- 调用函数
- 轮次嵌入
- Roberta
- Roberta 创新点
- NSP (Next Sentence Prediction)
- Roberta 构造函数
- Roberta 前向传播
- 计算发言人相似度
- 推理模式 (Inference Mode)
- 训练模式 (Training Mode)
- Deberta
- Deberta 创新点
- Deberta 构造函数
- Deberta 前向传播
- 训练
- 验证
- 参考文献
概述
现今技术日新月异, Artificial Intelligence 的发展正在迅速的改变我们的生活和工作方式. 尤其是在自然语言处理 (Natural Linguistic Processing) 和计算机视觉 (Computer Vision) 等领域.
传统的多模态对话研究主要集中在单一用户与系统之间的交互, 而忽视了多用户场景的复杂性. 视觉信息 (Visual Info) 往往会被边缘化, 仅作为维嘉信息而非对话的核心部分. 在实际应用中, 算法需要 “观察” 并与多个用户的交互, 这些用户有可能不是当前的发言人.
【CCF BDCI 2023】多模态多方对话场景下的发言人识别, 核心思想是通过多轮连续对话的内容和每轮对应的帧, 以及对应的人脸 bbox 和 name label, 从每轮对话中识别出发言人 (speaker).
NLP 简介
书接上文, 在上一篇博客中小白带大家详解了 Baseline 中的 CNN 模型部分. 今天我们来详解一下 NLP 部分. 包括 Roberta 和 Deberta 模型及其应用.

文本处理
文本处理是 NLP 任务的第一步. 我们需要将原始文本转化成模型可以处理的格式.
步骤包含:
- 清洗 (Cleaning): 去除无用信息, 常见的有标点符号, 特殊字符, html, 停用词等
- 分词 (Tokenization): 将文本按词 (Word) 为单位进行分割, 并转换为数字数据.
- 常见单词, 例如数据中的人名:
Rachel对应 token id5586Chandler对应 token id13814Phoebe对应 token id18188- 上述 token id 对应 bert 的 vocab 中, roberta 的 vocab 表在服务器上, 懒得找了
- 特殊字符:
[CLS]: token id101, 表示句子的开始[SEP]: token id102, 表示分隔句子或文本片段[PAD]: token id0, 表示填充 (Padding), 当文本为达到指定长度时, 例如 512, 会用[PAD]进行填充[MASK]: token id0, 表示填充 (Padding), 当文本为达到指定长度时, 例如 512, 会用[PAD]进行填充
- 常见单词, 例如数据中的人名:
上述字符在 Bert & Bert-like 模型中扮演着至关重要的角色, 在不同的任务重, 这些 Token ID 都是固定的, 例如 Bert 为 30522 个.
FYI: 上面的超链接是 jieba 分词的一个简单示例.
词嵌入
词嵌入 (Word Embedding) 是将文本中的词汇映射到向量空间的过程. 词向量 (Word Vector) 对应为词汇的语义信息, 具有相似含义的词汇在向量空间中距离接近.
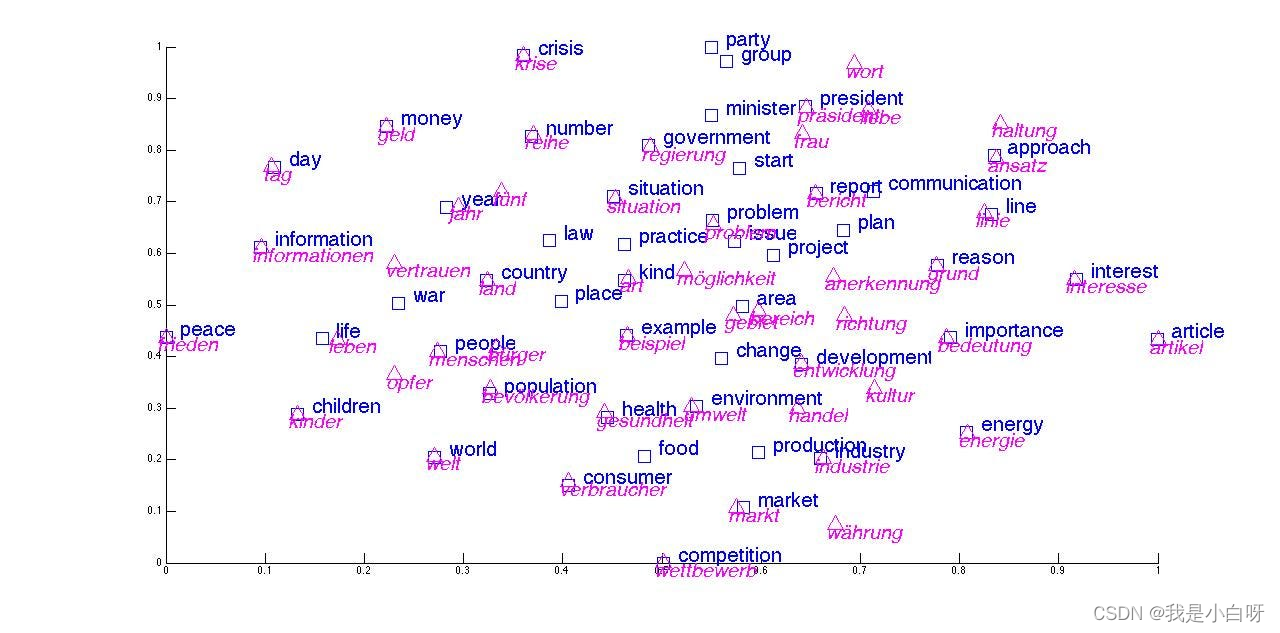
常见的词嵌入技术包含:
- Word2Vec: 通过神经网络模型学习词汇的分布式
- GloVe: 基于全局词共现统计信息构建词向量 (Word Vector)
- Bert Embedding: 使用 Bert 模型生成上下文相关的词嵌入
FYI: 想要了解词向量和 Word2Vec 的具体原理, 参考我上面超链接的博客.
上下文理解
在多方对话中, 上下文的理解至关重要, 包括对话的语境, 参与者之间的关系和对话的流程.
具体技术:
- Transformers 模型, 如 Bert, Roberta, Deberta 等, 通过捕捉长距离依赖关系, 理解整个句子 / 对话的上下文
- 注意力机制 (Attention Mechanism): 模型在处理一个单词 / 短语时, 考虑到其他相关部分的信息.
文本数据加载
SpeakerIdentificationDataset是用于加载多模态多方对话场景下的发言人识别任务中的数据的一个类. 下面小白带大家来逐行解析.

to_device 函数
to_device 函数左右为将数据移动到指定设备, 例如 GPU:0.
def to_device(obj, dev):if isinstance(obj, dict):return {k: to_device(v, dev) for k, v in obj.items()}if isinstance(obj, list):return [to_device(v, dev) for v in obj]if isinstance(obj, tuple):return tuple([to_device(v, dev) for v in obj])if isinstance(obj, torch.Tensor):return obj.to(dev)return obj
- 如果传入对象为
obj, dict则递归的对这个字典的每个值进行to_device操作, 将结果汇总在一个新的字典上, key 不变, value.to(device) - 如果传入对象为
obj, list则递归对列表的每个元素镜像``to_device```操作, 将结果汇总在一个新的列表上 - 如果传入对象为
obj, tuple, 同理, 返回元组 - 如果传入对象为
obj, torch.tensor, 将张量移动到指定的设备, 如: CPU->GPU
构造
class SpeakerIdentificationDataset:def __init__(self, base_folder, bos_token='<bos>', split='train', dataset='friends', data_aug=False, debug=False):self.base_folder = base_folderself.debug = debugself.dataset = datasetself.split = splitself.bos_token = bos_token
- base_folder: 数据集存放路径
- bos_token: 句子开始时的特殊字符
- split: 分割 (train, valid, test)
- dataset: 默认 friends
数据加载
if dataset == 'friends':if split == 'test':metadata = json.load(open(os.path.join(base_folder, 'test-metadata.json')))else:if data_aug:metadata = json.load(open(os.path.join(base_folder, 'train-metadata-aug.json')))else:metadata = json.load(open(os.path.join(base_folder, 'train-metadata.json')))self.examples = list()for dialog_data in metadata:# 我们选择s01作为验证集好了if split == 'valid' and not dialog_data[0]['frame'].startswith('s01'):continueif split == 'train' and dialog_data[0]['frame'].startswith('s01'):continueself.examples.append(dialog_data)
else:if dataset == 'ijcai2019':self.examples = [json.loads(line) for line in open(os.path.join(base_folder, '%s.json' % (split.replace('valid', 'dev'))))]if dataset == 'emnlp2016':self.examples = [json.loads(line) for line in open(os.path.join(base_folder, '10_%s.json' % (split.replace('valid', 'dev'))))]self.examples = [example for example in self.examples if len(example['ctx_spk']) != len(set(example['ctx_spk']))]
和前面的 CNN Dataset 一样, 还是使用 s01 的 dialog 数据做为 valid, 剩下的作为 train.
样本数量 len
def __len__(self):return len(self.examples) if not self.debug else 32
- 和 CNN 的 Dataset 一样, 非 Debug 模式下返回范本数量, Debug 模型下返回 32
获取样本 getitem
def __getitem__(self, index):example = self.examples[index]if self.dataset == 'friends':speakers, contents, frame_names = [i['speaker'] for i in example], [i['content'] for i in example], [i['frame'] for i in example]else:speakers, contents = example['ctx_spk'], example['context']frame_names = ['%d-%d' % (index, i) for i in range(len(speakers))]labels = list()for i, speaker_i in enumerate(speakers):for j, speaker_j in enumerate(speakers):if i != j and speaker_i == speaker_j:labels.append([i, j])input_text = self.bos_token + self.bos_token.join(contents)return input_text, labels, frame_names
- 从数据集提取单个 Sample
- 提取发言人, 对话内容和帧名
- 生成标签, 并标记发言人的位置
- 将对话内容拼接成一个长文本, 用于模型输入
这么说可能大家有点晕, 我来大大家拿 train 的第一个 dialog 演示一下.
Dialog[0] (sample), 5 句话组成:
[{"frame": "s06e07-000377", "speaker": "phoebe", "content": "Yeah, I know because you have all the good words. What do I get? I get \"it\u2019s,\" \"and\" oh I'm sorry, I have \"A.\" Forget it.", "start": 297, "end": 491, "faces": [[[752, 135, 881, 336], "rachel"], [[395, 111, 510, 329], "leslie"]]}, {"frame": "s06e07-000504", "speaker": "rachel", "content": "Phoebe, come on that's silly.", "start": 498, "end": 535, "faces": [[[466, 129, 615, 328], "phoebe"]]}, {"frame": "s06e07-000552", "speaker": "phoebe", "content": "All right, so let's switch.", "start": 535, "end": 569, "faces": [[[426, 120, 577, 320], "phoebe"]]}, {"frame": "s06e07-000629", "speaker": "rachel", "content": "No, I have all of the good words. OK, fine, fine, we can switch.", "start": 569, "end": 689, "faces": [[[420, 125, 559, 328], "phoebe"], [[652, 274, 771, 483], "rachel"]]}, {"frame": "s06e07-000892", "speaker": "phoebe", "content": "Please...wait, how did you do that?", "start": 879, "end": 906, "faces": [[[424, 133, 573, 334], "phoebe"], [[816, 197, 925, 399], "bonnie"]]}]
得到的 input_test:
<bos>Yeah, I know because you have all the good words. What do I get? I get "it’s," "and" oh I'm sorry, I have "A." Forget it.<bos>Phoebe, come on that's silly.<bos>All right, so let's switch.<bos>No, I have all of the good words. OK, fine, fine, we can switch.<bos>Please...wait, how did you do that?
得到的 labels:
[[0, 2], [0, 4], [1, 3], [2, 0], [2, 4], [3, 1], [4, 0], [4, 2]]
得到的 frame_names:
['s06e07-000377', 's06e07-000504', 's06e07-000552', 's06e07-000629', 's06e07-000892']
具体说明一下 labels 部分, 上述的 dialog 中的 5 个发言人, 依次为:
- Phoebe
- Rachel
- Phoebe
- Rachel
- Phoebe
其中:
- Phoebe 在 1, 3, 5 句子中发言
- Rachel 在 2, 4 句子中发言
所以我们可以得到:
- [0, 2]: 1, 3 句子都是同一个人发言 (Phoebe)
- [0, 4[: 1, 5 句子都是同一个人发言 (Phoebe)
- [1, 3]: 2, 4 句子都素同一个人发言 (Rachel)
- [2, 0]: 3, 1 句子都是通一个人发言 (Phoebe)
- [2, 4]: 3, 5 句子都是同一个人发言 (Phoebe)
- [3, 1]: 4, 2 句子都是同一个人发言 (Rachel)
- [4, 0]: 5, 1 句子都是同一个人发言 (Phoebe)
- [4, 2]: 5, 3 句子都是同一个人发言 (Phoebe)
然后补充一下 input_text 部分:
- 在上面我们提到了一些特殊Token ID,
<bos>就是一个特殊的 Token ID, 用于表示句子的开始, 帮助模型在生成文本和处理序列时确定起始点 - 在处理对话时,
<bos>可以用来分隔不同的语句
补充, <sep>和<bos>区别:
<bos>用于标记句子的开始,<sep>用于分隔句子的不同部分

分词
Collator 类的主要作用是将批次 (Batch) 样本, tokenize 后转换为模型需要的输入格式.
构造函数
def __init__(self, tokenizer, max_length=512, temperature=1.0, use_turn_emb=False):self.tokenizer = tokenizerself.max_length = max_lengthself.temperature = temperatureself.use_turn_emb = use_turn_embself.print_debug = True
- tokenizer: 用于文本 tokenize, 例如: RobertaTokenizer
- max_length: 最大长度限制, 默认为 512
- temperature: 模型温度参数, 默认为 1
- use_turn_emb: 是否使用轮次嵌入
调用函数
def __call__(self, examples):input_texts = [i[0] for i in examples]labels = [i[1] for i in examples]frame_names = [i[2] for i in examples]model_inputs = self.tokenizer(input_texts, add_special_tokens=False, truncation=True, padding='longest', max_length=self.max_length, return_tensors='pt')model_inputs = dict(model_inputs)
- 获取 input_texts, labels, frame_names
- tokenize 文本
new_labels = list()
for input_id, label in zip(model_inputs['input_ids'], labels):num_bos_tokens = torch.sum(input_id == self.tokenizer.bos_token_id).item()label = [l for l in label if l[0] < num_bos_tokens and l[1] < num_bos_tokens] # 如果遇到了truncation,将被truncate掉的turn删除new_labels.append(torch.tensor(label))
model_inputs['labels'] = new_labels
- 创建空列表存放标签
- 遍历每个样本
- 计算 bos 标记数量
- 更新标签
举个例子:
input_text:
Yeah, I know because you have all the good words. What do I get? I get "it’s," "and" oh I'm sorry, I have "A." Forget it.[CLS]Phoebe, come on that's silly.[CLS]All right, so let's switch.[CLS]No, I have all of the good words. OK, fine, fine, we can switch.[CLS]Please...wait, how did you do that?
tokenize 后:
[101, 3398, 1010, 1045, 2113, 2138, 2017, 2031, 2035, 1996, 2204, 2616, 1012, 2054, 2079, 1045, 2131, 1029, 1045, 2131, 1000, 2009, 1521, 1055, 1010, 1000, 1000, 1998, 1000, 2821, 1045, 1005, 1049, 3374, 1010, 1045, 2031, 1000, 1037, 1012, 1000, 5293, 2009, 1012, 101, 18188, 1010, 2272, 2006, 2008, 1005, 1055, 10021, 1012, 101, 2035, 2157, 1010, 2061, 2292, 1005, 1055, 6942, 1012, 101, 2053, 1010, 1045, 2031, 2035, 1997, 1996, 2204, 2616, 1012, 7929, 1010, 2986, 1010, 2986, 1010, 2057, 2064, 6942, 1012, 101, 3531, 1012, 1012, 1012, 3524, 1010, 2129, 2106, 2017, 2079, 2008, 1029, 102]
注: 这边我用的是 Bert [CLS], 等同于<bos>
new_labels:
[[0, 2], [0, 4], [1, 3], [2, 0], [2, 4], [3, 1], [4, 0], [4, 2]]
因为上面的 5 个句子加起来并没有达到 512 个词, 所以 label 并没有进行删减. 如果 比如<bos只有4 个, 即最后一个句子被裁剪 (truncation) 了, 此时就要去掉所有包括句子 5 的 label.
假设上面句子只有三句半, new_labels 为:
[[0, 2], [1, 3], [2, 0], [3, 1]]
轮次嵌入
if self.use_turn_emb:model_inputs['token_type_ids'] = torch.cumsum(model_inputs['input_ids'] == self.tokenizer.bos_token_id, dim=1)
model_inputs['frame_names'] = frame_names
model_inputs['temperature'] = self.temperature
计算轮次嵌入: 使用torch.cumsum函数计算累积和. model_inputs['input_ids'] == self.tokenizer.bos_token_id创建了一个布尔张亮, 每个句子开始<bos>标记的位置为 True, 其他位置为 False
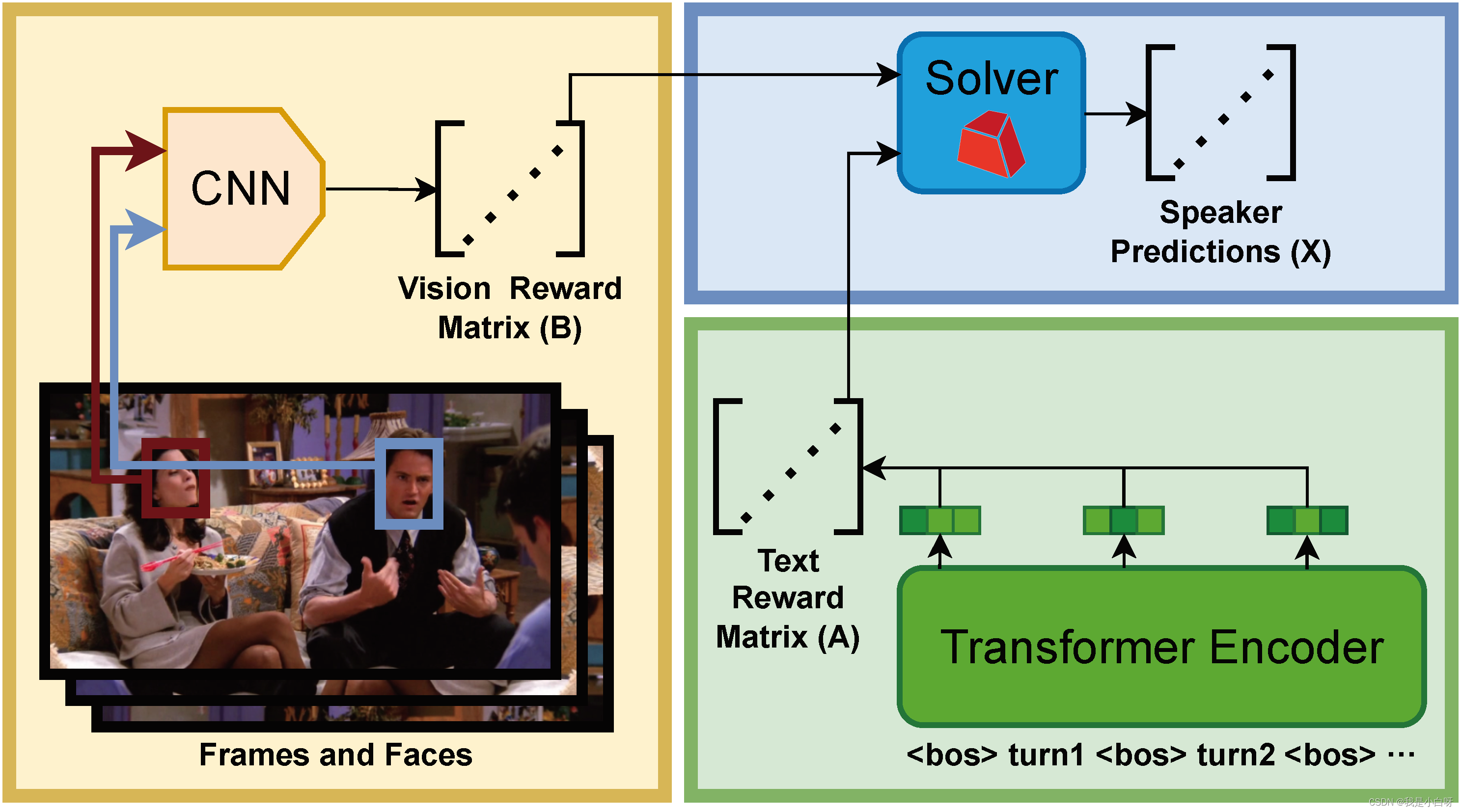
对话:
Yeah, I know because you have all the good words. What do I get? I get "it’s," "and" oh I'm sorry, I have "A." Forget it.
[CLS]
Phoebe, come on that's silly.
[CLS]
All right, so let's switch.
[CLS]
No, I have all of the good words. OK, fine, fine, we can switch.
[CLS]
Please...wait, how did you do that?
轮次嵌入前的 token_type_ids:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
轮次嵌入后的 token_type_ids:
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5]
类似:
1: ["Yeah", ",", "I", "know", "because", "you", "have", "all", "the", "good", "words", ".", "What", "do", "I", "get", "?", "I", "get", "it’s", ",", "and", "oh", "I", "'m", "sorry", ",", "I", "have", "A", ".", "Forget", "it", "."]
2: ["Phoebe", ",", "come", "on", "that", "'s", "silly", "."]
3: ["All", "right", ",", "so", "let", "'s", "switch", "."]
4: ["No", ",", "I", "have", "all", "of", "the", "good", "words", ".", "OK", ",", "fine", ",", "fine", ",", "we", "can", "switch", "."]
5: ["Please", "...", "wait", ",", "how", "did", "you", "do", "that", "?"]
轮次嵌入的作用:
轮次嵌入对处理对话和交互文本时至关重要. 轮次嵌入为模型提供了关于每个单词属于哪个对话, 对于模型理解对话结构和上下文非常重要.
在上面的例子中, 我们有 5 句话组成的 dialog, 经过轮次嵌入, 第一句的单词会被标记为 1, 第二句为 2, 第三句为 3, 第四句为 4, 第五句为 5. 通过 1, 2, 3, 4, 5 的标记, 可以帮助模型区分不同句子的语境, 以更好的处理每个对话.
Roberta
Roberta (Robustly Optimized BERT Approach) 是一种基于 BERT (Bidirectional Encoder Representations from Transformers) 的 NLP 模型.
Roberta 创新点
Roberta 在 Bert 的基础上创新了训练过程和数据处理方式. First, Roberta 使用的语料库更大, 数据更难多, 模型更更好的理解和处理复杂的语言模式. Second, Roberta 取消了 Bert 中的下句预测 (Next Sentence Prediction). Third, Roberta 对输入数据的处理方式也进行了优化, 具体表现为更长序列进行的训练, 因此 Roberta 的长文本处理能力也更为优秀.
NSP (Next Sentence Prediction)
- NSP (Next Sentence Prediction) 目的是改善模型 (Bert) 对句子关系的理解, 特别是在理解段落或文档中句子之间的关系方面
- NSP 任务重, 模型呗训练来预测两个句子是否在原始文本中相邻. 举个栗子: A & B 俩句子, 模型需要判断 B 是否是紧跟在 A 后面的下一句. 在 Training 过冲中, Half time B 确实是 A 的下一句, 另一半时间 B 则是从语料库中随机选取的与 A 无关的句子. NSP 就是基于这些句子判断他们是否是连续的
- 句子 A: “我是小白呀今年才 18 岁”
- 句子 B: “真年轻”
- NSP: 连续, B 是对 A 的回应 (年龄), 表达了作者 “我” 十分年轻
- 句子 A: “意大利面要拌”
- 句子 B: “42 号混凝土”
- NSP: 不连续, B 和 A 内容完全无关
- NSP 对诸如系统问答, 文本摘要等任务十分重要, 但是 Roberta 发现去除也一样, 因为 Bert 底层的双向结构十分强大. 后续的新模型, Roberta, Xlnet, Deberta 都去除了 NSP
Roberta 构造函数
构造函数:
def __init__(self, config):super().__init__(config)self.bos_token_id = config.bos_token_idself.loss_fct = CrossEntropyLoss(reduction='none')...以下省略
- bos_token_id: 句子起始标记
- los_fct: 损失函数, 这边为交叉熵损失 (CrossEntropyLoss)
Roberta 前向传播
def forward(...):...以上省略outputs = self.roberta(...)last_hidden_state = outputs[0]...以下省略
- last_hidden_state: 获取 Roberta 输出的隐层状态
计算发言人相似度
这边的计算发言人相似度分为两个模式, 分别为推理模式 (Inference Mode) 和训练模式 (Training Mode).
推理模式 (Inference Mode)
在 labels == None 的时候, 模型进行推理模式 (Inference Mode). 在这种模式下, 模型的主要任务是计算并返回每个句子的隐层状态和相似度得分, 而不是进行模型的训练. 用于 valid 和 test.
if labels is None:# inference modeselected_hidden_state_list, logits_list = list(), list()for i, (hidden_state, input_id) in enumerate(zip(last_hidden_state, input_ids)):indices = input_id == self.bos_token_idselected_hidden_state = hidden_state[indices]if not self.linear_sim:selected_hidden_state = F.normalize(selected_hidden_state, p=2, dim=-1)logits = torch.matmul(selected_hidden_state, selected_hidden_state.t())logits += torch.eye(len(logits), device=logits.device) * -100000.0 # set elements on the diag to -infelse:num_sents, hidden_size = selected_hidden_state.size()# concatenated_hidden_state = torch.zeros(num_sents, num_sents, hidden_size*4, device=selected_hidden_state.device)concatenated_hidden_state = torch.zeros(num_sents, num_sents, hidden_size*3, device=selected_hidden_state.device)concatenated_hidden_state[:, :, :hidden_size] = selected_hidden_state.unsqueeze(1)concatenated_hidden_state[:, :, hidden_size:hidden_size*2] = selected_hidden_state.unsqueeze(0)concatenated_hidden_state[:, :, hidden_size*2:hidden_size*3] = torch.abs(selected_hidden_state.unsqueeze(0) - selected_hidden_state.unsqueeze(1))# concatenated_hidden_state[:, :, hidden_size*3:hidden_size*4] = selected_hidden_state.unsqueeze(0) + selected_hidden_state.unsqueeze(1)logits = self.sim_head(self.dropout(concatenated_hidden_state)).squeeze() # 但要注意,这里的logits就不能保证是在0-1之间了。需要过sigmoid才能应用在之后的任务中selected_hidden_state_list.append(selected_hidden_state) # 不同对话的轮数可能不一样,所以结果可能不能stack起来。logits_list.append(logits)
推理模式下的步骤:
- 提取隐层状态 (Hidden State): 从前面的 Roberta 模型提取每个句子的 hidden state
- 计算相似度得分: 线性相似度头
sim_head来计算不同句子之间的相似度得分. 这些得分表示句子间的相似性, 用于判断是否是同一个发言人 (Speaker)
训练模式 (Training Mode)
当 label != None, 模型进行训练模式 (Training Mode). 在这种模式下, 模型的主要任务是通过损失函数来优化模型.
else:# training modeselected_hidden_state_list = list()batch_size = len(labels)for hidden_state, input_id in zip(last_hidden_state, input_ids):indices = input_id == self.bos_token_idselected_hidden_state = hidden_state[indices]if not self.linear_sim:selected_hidden_state = F.normalize(selected_hidden_state, p=2, dim=-1)selected_hidden_state_list.append(selected_hidden_state)losses, logits_list = list(), list()for i, (selected_hidden_state, label) in enumerate(zip(selected_hidden_state_list, labels)):if not self.linear_sim:other_selected_hidden_states = torch.cat([selected_hidden_state_list[j] for j in range(batch_size) if j != i])all_selected_hidden_states = torch.cat([selected_hidden_state, other_selected_hidden_states])logits = torch.matmul(selected_hidden_state, all_selected_hidden_states.t())logits += torch.cat([torch.eye(len(logits), device=logits.device) * -100000.0, torch.zeros(len(logits), len(other_selected_hidden_states), device=logits.device)], dim=-1)if label.numel():losses.append(self.loss_fct(logits[label[:, 0]] / temperature, label[:, 1]))else:num_sents, hidden_size = selected_hidden_state.size()# concatenated_hidden_state = torch.zeros(num_sents, num_sents, hidden_size*4, device=selected_hidden_state.device)concatenated_hidden_state = torch.zeros(num_sents, num_sents, hidden_size*3, device=selected_hidden_state.device)concatenated_hidden_state[:, :, :hidden_size] = selected_hidden_state.unsqueeze(1)concatenated_hidden_state[:, :, hidden_size:hidden_size*2] = selected_hidden_state.unsqueeze(0)concatenated_hidden_state[:, :, hidden_size*2:hidden_size*3] = torch.abs(selected_hidden_state.unsqueeze(0) - selected_hidden_state.unsqueeze(1))# concatenated_hidden_state[:, :, hidden_size*3:hidden_size*4] = selected_hidden_state.unsqueeze(0) + selected_hidden_state.unsqueeze(1)logits = self.sim_head(self.dropout(concatenated_hidden_state)).squeeze() # 但要注意,这里的logits就不能保证是在0-1之间了。需要过sigmoid才能应用在之后的任务中# 使用mse作为loss。loss包括两部分,一个是和gold的,一个是和自己的转置的logits = nn.Sigmoid()(logits)real_labels = torch.zeros_like(logits)if label.numel():real_labels[label[:, 0], label[:, 1]] = 1real_labels += torch.eye(len(logits), device=logits.device)loss = nn.MSELoss()(real_labels, logits) + nn.MSELoss()(logits, logits.transpose(0, 1))losses.append(loss)logits_list.append(logits)loss = torch.mean(torch.stack(losses))return MaskedLMOutput(loss=loss, logits=logits_list, hidden_states=selected_hidden_state_list)
训练模式下的具体步骤:
- 提取隐层状态 (Hidden State): 从前面的 Roberta 模型提取每个句子的 hidden state
- 计算相似度得分: 使用模型输出的相似度 logits
- 计算损失函数: 通过计算 logits 和 real_label 之间的差异
- 优化模型: 根据 loss 进行梯度下降, 反向传播 (Backpropagation)
以防大家没看懂, 下面我们来逐行解析:
提取隐层状态:
selected_hidden_state_list = list()
for hidden_state, input_id in zip(last_hidden_state, input_ids):indices = input_id == self.bos_token_idselected_hidden_state = hidden_state[indices]if not self.linear_sim:selected_hidden_state = F.normalize(selected_hidden_state, p=2, dim=-1)selected_hidden_state_list.append(selected_hidden_state)
- 通过
<bos>标注每个句子开始, 并选取对应句子的隐藏状态
线性层计算相似度:
losses, logits_list = list(), list()
for i, (selected_hidden_state, label) in enumerate(zip(selected_hidden_state_list, labels)):# 根据配置选择相似度计算方法if not self.linear_sim:# 非线性相似度计算...else:# 线性相似度计算concatenated_hidden_state = ...logits = self.sim_head(self.dropout(concatenated_hidden_state)).squeeze()logits = nn.Sigmoid()(logits)real_labels = torch.zeros_like(logits)if label.numel():real_labels[label[:, 0], label[:, 1]] = 1real_labels += torch.eye(len(logits), device=logits.device)loss = nn.MSELoss()(real_labels, logits) + nn.MSELoss()(logits, logits.transpose(0, 1))losses.append(loss)logits_list.append(logits)
- 在线相似度计算中, 使用
sim_head来计算句子间的相似度得分 - 计算损失函数. 损失函数的计算分为两部分:
- 第一部分: y_predict 和 y_true 之间的差异. 具体为
loss_similarity = nn.MSELoss()(real_labels, logits) - 第二部分: 计算矩阵的对称性. 因为句子的相似度是双向的 (A -> B & B -> A 的相似度应该相同) 所以这边有一个对称项来确保 loss 矩阵的对称性:
loss_symmetry = nn.MSELoss()(logits, logits.transpose(0, 1)) - 相加:
loss = loss_similarity + loss_symmetry
- 第一部分: y_predict 和 y_true 之间的差异. 具体为
注: Baseline 代码为loss = nn.MSELoss()(real_labels, logits) + nn.MSELoss()(logits, logits.transpose(0, 1)), 我就是拆开了而已, 勿喷.
Deberta
Deberta (Decoding-enhanced Bert with Disentangled Attention) 也是一种 NLP 模型. Deberta 在 Bert (Bidirectional Encoder Representations from Transformers) 和 Roberta (Robustly Optimized Bert Approach) 的基础上进行了创新和改进, 主要为独特的注意力机制 (Attention) 和编码策略, 使得 Deberta 在 NLP 任务重表现出色.
Deberta 创新点
Deberta 的主要创新点:
- 解耦注意力机制 (Disentangled Attention Mechanism): Deberta 的解耦注意力机制, 将内容和位置信息分开处理. 在传统 Bert 和 Roberta 模型重, 注意力机制 (Attention) 同时考虑了内容和位置信息. Deberta 将这两种信息分离, 允许模型更灵活的学习单词之间的以来关系
- 增强的位置编码 (Positional Encoding). Deberta 的位置编码方案不仅考虑了单词之间相对位置, 还考虑他们在序列中的绝对位置. 这种双重位置编码使得 Deberta 能够更准确的捕捉文本中的结构信息
- 动态卷积 (Dynamic Convolution): 相较于 CNN 中的标准卷积, 动态卷积具有更高的灵活性和适应性:
- 权重的动态生成: 标准卷积中, 权重 (W) 在整个测试集上是固定不变的, 而动态卷积是动态生成的, 根据输入数据不同而改变
- 适应性强: 由于卷积核的权重是针对每个输入样本动态生成的, 能更好的适应不同的语言模式和上下文环境
- 捕获局部依赖: 动态卷积特别删除捕捉文本中的局部依赖关系, 如短语或局部语义结构, 对于理解复杂的语言表达至关重要
Deberta 构造函数
Deberta 构造函数:
def __init__(self, config):super().__init__(config)self.bos_token_id = config.bos_token_idself.loss_fct = CrossEntropyLoss(reduction='none')
Deberta 前向传播
同 Roberta
训练
同 cnn
验证
同 cnn
参考文献
比赛链接
Baseline 完整代码
相关文章:
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分 概述NLP 简介文本处理词嵌入上下文理解 文本数据加载to_device 函数构造数据加载样本数量 len获取样本 getitem 分词构造函数调用函数轮次嵌入 RobertaRoberta 创新点NSP (Next Sentence Prediction…...

推免那些事
平生第一次搞推免,也是最后一次。错失了一些机会,也有幸获得了一些机会,值得祝庆,也值得反思。 以下记录为个人流水账。 个人背景 我的背景可以算不是非常好了,况且今年211受歧视比较严重。 学校:211&…...

华清远见嵌入式学习——QT——作业2
作业要求: 代码运行效果图: 登录失败 和 最小化 和 取消登录 登录成功 和 X号退出 代码: ①:头文件 #ifndef LOGIN_H #define LOGIN_H#include <QMainWindow> #include <QLineEdit> //行编辑器类 #include…...
C# Winfrm 编写一个天气查看助手
#前言# 最近这个北方的天气啊经常下雪,让我想起来我上学时候写的那个天气预报小功能了,今天又复现了一下,哈哈哈,大家当个乐子看哈! 1.创建项目 2.添加引用 上图所示,下载所需天气预报标识,网站…...

基于SpringBoot和微信小程序的农场信息管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于SpringBoot和微信小程序的农场信息管…...

Linux统计网卡流量
cat /proc/net/dev Linux 内核提供了一种通过 /proc 文件系统,在运行时访问内核内部数据结构、改变内核设置的机制。proc文件系统是一个伪文件系统,它只存在内存当中,而不占用外存空间。它以文件系统的方式为访问系统内核数据的操作提供接口。…...
设计可编辑表格组件
前言 什么是可编辑表格呢?简单来说就是在一个表格里面进行表单操作,执行增删改查。这在一些后台管理系统中是尤为常见的。 今天我们根据vue2 element-ui来设计一个表单表格组件。(不涉及完整代码,想要使用完整功能可以看底部连…...

低代码是美食!!!
一、什么是低代码 低代码是一种软件开发方法,通过图形化界面和少量手写代码,让开发者能够更迅速、简单地构建应用程序。相比传统的编码方式,低代码平台提供了可视化的开发工具和预构建的组件,使开发过程更加快捷高效。 二、低代码…...
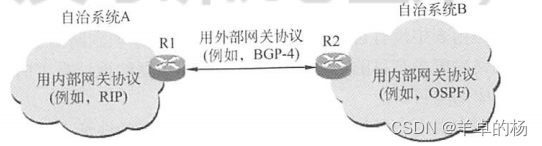
计算机网络网络层(期末、考研)
计算机网络总复习链接🔗 目录 路由算法静态路由与动态路由距离-向量算法链路状态路由算法层次路由 IPv4(这个必考)IPv4分组IPv4地址与NAT子网划分与子网掩码、CIDRARP、DHCP与ICMP地址解析协议ARP动态主机配置协议DHCP IPv6IPv6特点 路由协议…...

LCR 120. 寻找文件副本
解题思路: 利用增强for循环遍历documents,将遇见的id加入hmap中,如果id在hamp中存在,则直接返回id class Solution {public int findRepeatDocument(int[] documents) {Set<Integer> hmapnew HashSet<>();for(int d…...

git切换分支
切换到你想要保留的分支: 确保你在本地已经切换到了你想要保留的分支。 git checkout 要保留的分支名更改远程仓库地址: 如果你还没有更改远程仓库地址,使用 git remote set-url 来更改它。 git remote set-url origin 新的仓库地址推送当前分…...

Android 在UploadEventService使用ThreadPoolManager线程管理传递数据给后台
Android 在UploadEventService使用ThreadPoolManager线程管理传递数据给后台,如何实现呢? 可以通过以下步骤使用ThreadPoolManager线程管理传递数据给后台: 创建一个ThreadPoolManager类来管理线程池,比如: public cl…...
网络(十)ACL和NAT
前言 网络管理在生产环境和生活中,如何实现拒绝不希望的访问连接,同时又要允许正常的访问连接?当下公网地址消耗殆尽,且公网IP地址费用昂贵,企业访问Internet全部使用公网IP地址不够现实,如何让私网地址也…...
)
JavaScript算法46- 最长连续序列(leetCode:128middle)
128. 最长连续序列 一、题目 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 示例 输入:nums [100,4,200,1,3,2] 输出…...

提升 API 可靠性的五种方法
API 在我们的数字世界中发挥着关键的作用,使各种不同的应用能够相互通信。然而,这些 API 的可靠性是保证依赖它们的应用程序功能正常、性能稳定的关键因素。本文,我们将探讨提高 API 可靠性的五种主要策略。 1.全面测试 要确保 API 的可靠性…...
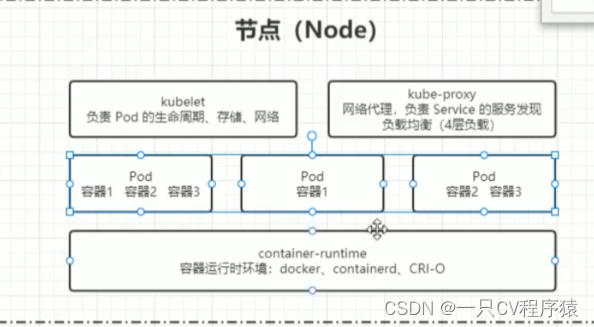
【K8S 系列】认识k8s、k8s架构
一、什么是k8s? Kubernetes 简称 k8s,是支持云原生部署的一个平台,k8s 本质上就是用来简化微服务的开发和部署的,用于自动化部署、扩展和管理容器化应用的开源容器编排技术。对于传统的docker其实也提供了容器编排的技术docker-compose&…...

通过这5步,快速成为数据分析师
1. 学习基础知识:掌握统计学、数学和编程等基础知识是成为数据分析师的第一步。你可以参加在线课程、教育平台或自学来提高自己的技能。 2. 学习数据分析工具:熟练使用数据分析工具如Python、R和SQL等是必要的。这些工具可以帮助你处理和分析大量的数据…...

深入解析 Spring 和 Spring Boot 的区别
目录 引言 1. 设计理念 1.1 Spring 框架的设计理念 1.2 Spring Boot 的设计理念 2. 项目配置 2.1 Spring 框架的项目配置 2.2 Spring Boot 的项目配置 3. 自动配置 3.1 Spring 框架的自动配置 3.2 Spring Boot 的自动配置 4. 微服务支持 4.1 Spring 框架的微服务支持…...

Python日期范围按旬和整月以及剩余区间拆分
昨天见到了一个比较烧脑的问题: 咋一看可能理解问题比较费劲,可以直接看结果示例: 当然这个结果在原问题上基础上有一定改进,例如将同一天以单个日期的形式展示。 如何解决这个问题呢?大家可以先拿测试用例自己试一下…...
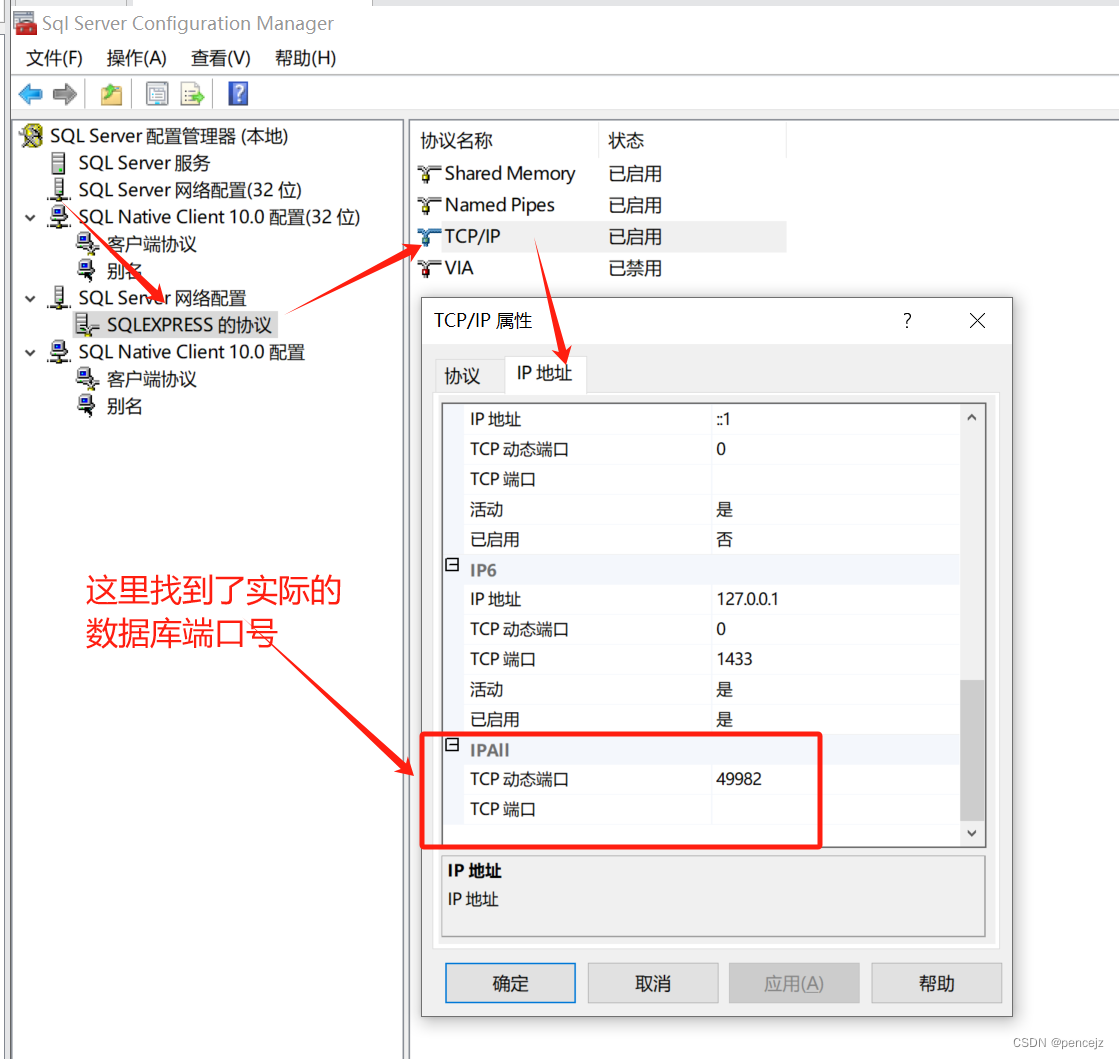
windows安装sqlserver2008后连接失败问题
刚安装好的sqlserver在安装服务器上,直接使用Windows身份认证登录就报错 未找到或无法访问服务器。请验证实例名称是否正确并且SQL Server已配置为允许远程连接。(provider:命名管道提供程序,error:40 -无法打开到SQLS…...

ThinkPHP5防跨目录访问报错?手把手教你如何安全解除LNMP的open_basedir限制
ThinkPHP5跨目录访问难题:LNMP环境下open_basedir限制的深度解析与安全实践 当你在LNMP环境中部署ThinkPHP5应用时,是否遇到过这样的报错信息?那些红色的"Warning"和"Fatal error"不仅打断了安装流程,更让人对…...

Sequel批量插入性能终极指南:如何快速处理百万级数据
Sequel批量插入性能终极指南:如何快速处理百万级数据 【免费下载链接】sequel Sequel: The Database Toolkit for Ruby 项目地址: https://gitcode.com/gh_mirrors/seq/sequel Sequel作为Ruby的强大数据库工具包,提供了高效处理数据的能力&#x…...

mysql如何审计误删除数据操作_mysql binlog逆向分析追踪
需用mysqlbinlog解析ROW格式binlog,查找DELETE_ROWS_EVENT及邻近GTID/QUERY事件中的用户、时间、线程信息,结合时间窗口与应用日志交叉定位误删操作。怎么从 binlog 找到谁删了哪条记录MySQL 本身不记录“谁在什么时间删了 id123 的数据”,但…...

SolidWorks 扫掠实战:从零构建带倒角的方形螺旋管
1. 从零开始理解方形螺旋管建模 第一次用SolidWorks做方形螺旋管时,我盯着屏幕发呆了半小时——明明圆形螺旋管点几下就能搞定,换成方形截面怎么就报错连连?后来才发现,这种带倒角的异形螺旋管建模,关键不在于操作步骤…...

别再纠结选哪个了!手把手教你根据项目需求选对Go框架:Gin、Kratos还是Zero?
实战指南:如何为你的Go项目精准匹配框架——Gin、Kratos与Zero深度解析 当启动一个新项目时,选择正确的框架往往决定了后续开发的顺畅程度。面对Gin、Kratos和Zero这三个主流Go框架,很多开发者会陷入选择困难。本文将带你从实际项目需求出发&…...

作业2:6位数码管静态显示
文章目录1、数码管显示6个91.1 效果图截屏1.2 代码2、数码管显示2个7(一头一尾)2.1 效果图截屏2.2 代码3、数码管轮播显示6位3.1 效果图截屏3.2 代码4、数码管轮播显示2位4.1 效果图截屏4.2 代码1、数码管显示6个9 1.1 效果图截屏 1.2 代码 #include&l…...

ARM 架构 JuiceFS 性能优化:基于 MLPerf 的实践与调优廖
Qt是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本笔记将重点介绍QSpinBox数值微调组件的常用方法及灵活应用。…...

嵌入式舵机精确控制:基于硬件定时器的PWM脉宽稳定实现
1. Servo库技术解析:面向嵌入式系统的单路舵机精确控制实现1.1 库定位与工程价值Servo库是一个轻量级、面向资源受限嵌入式平台的单路舵机控制库。其核心设计哲学并非追求功能堆砌,而是聚焦于时间精度、脉宽稳定性与硬件抽象解耦三大关键指标。在STM32F0…...

5分钟搞定PySide2串口助手:从QT Designer到Python打包全流程
5分钟打造PySide2串口助手:从UI设计到跨平台部署的极速开发指南 1. 开发环境配置与工具链搭建 对于嵌入式开发者和物联网爱好者而言,快速构建一个功能完善的串口调试工具是硬件调试的刚需。PySide2作为Qt官方维护的Python绑定库,结合Python的…...

即插即用模块-Attention篇:SCA简化通道注意力如何重塑轻量级视觉模型
1. 为什么需要简化通道注意力? 在移动端和边缘计算设备上跑视觉模型,就像让一辆小排量汽车拉重货——既要省油又要动力足。传统通道注意力模块(Channel Attention)虽然能提升模型性能,但它的计算开销就像给车子装了个大…...