Lesson 6.5 机器学习调参基础理论与网格搜索
文章目录
- 一、机器学习调参理论基础
- 1. 机器学习调参目标及基本方法
- 2. 基于网格搜索的超参数的调整方法
- 2.1 参数空间
- 2.2 交叉验证与评估指标
- 二、基于 Scikit-Learn 的网格搜索调参
- 1. sklearn 中网格搜索的基本说明
- 2. sklearn 中 GridSearchCV 的参数解释
- 3. sklearn 中 GridSearchCV 的使用方法
- 3.1 GridSearchCV 评估器训练过程
- 3.2 GridSearchCV 评估器结果查看
- 在上一小节执行完手动调参之后,接下来我们重点讨论关于机器学习调参的理论基础,并且介绍 sklearn 中调参的核心工具—— GridSearchCV。
# 科学计算模块
import numpy as np
import pandas as pd
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
# 自定义模块
from ML_basic_function import *
# Scikit-Learn相关模块
# 评估器类
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
# 实用函数
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
一、机器学习调参理论基础
- 在利用 sklearn 进行机器学习调参之前,我们先深入探讨一些和调参相关的机器学习基础理论。
- 尽管我们都知道,调参其实就是去寻找一组最优参数,但最优参数中的“最优”如何定义?面对模型中的众多参数又该如何“寻找”?
- 要回答这些问题,我们就必须补充更加完整的关于机器学习中参数和调参的理论知识。
1. 机器学习调参目标及基本方法
- 首先需要明确的一点,我们针对哪一类参数进行调参,以及围绕什么目的进行调参?
- 参数与超参数
- 根据此前对参数的划分,我们知道,影响机器学习建模结果的参数有两类,其一是参数,其二是超参数。
- 其中参数的数值计算由一整套数学过程决定,在选定方法后,其计算过程基本不需要人工参与。
- 因此我们经常说的模型调参,实际上是调整模型超参数。
- 超参数种类繁多,而且无法通过一个严谨的数学流程给出最优解,因此需要人工参与进行调节。
- 而在围绕具体的机器学习评估器进行调参时,其实就是在调整评估器实例化过程中所涉及到的那些超参数,例如此前进行逻辑回归参数解释时的超参数。
- 当然,这也是我们为什么需要对评估器进行如此详细的超参数的解释的原因之一。
| 参数 | 解释 |
|---|---|
| penalty | 正则化项 |
| dual | 是否求解对偶问题* |
| tol | 迭代停止条件:两轮迭代损失值差值小于tol时,停止迭代 |
| C | 经验风险和结构风险在损失函数中的权重 |
| fit_intercept | 线性方程中是否包含截距项 |
| intercept_scaling | 相当于此前讨论的特征最后一列全为1的列,当使用liblinear求解参数时用于捕获截距 |
| class_weight | 各类样本权重* |
| random_state | 随机数种子 |
| solver | 损失函数求解方法* |
| max_iter | 求解参数时最大迭代次数,迭代过程满足max_iter或tol其一即停止迭代 |
| multi_class | 多分类问题时求解方法* |
| verbose | 是否输出任务进程 |
| warm_start | 是否使用上次训练结果作为本次运行初始参数 |
| l1_ratio | 当采用弹性网正则化时,l1l1l1正则项权重,就是损失函数中的ρ\rhoρ |
- 超参数调整目标
- 那么紧接着的问题就是,超参数的调整目标是什么?是提升模型测试集的预测效果么?
- 无论是机器学习还是统计模型,只要是进行预测的模型,其实核心的建模目标都是为了更好的进行预测,也就是希望模型能够有更好的预测未来的能力,换而言之,就是希望模型能够有更强的泛化能力。
- 而在 Lesson 3 中我们曾谈到,机器学习类算法的可信度来源则是训练集和测试集的划分理论,也就是机器学习会认为,只要能够在模拟真实情况的测试集上表现良好,模型就能够具备良好的泛化能力。
- 也就是说,超参数调整的核心目的是为了提升模型的泛化能力,而测试集上的预测效果只是模型泛化能力的一个具体表现,并且相比与一次测试集上的运行结果,其实借助交叉验证,能够提供更有效、更可靠的模型泛化能力的证明。
- 交叉验证与评估指标
- 如果需要获得更可靠的模型泛化能力的证明,则需要进行交叉验证,通过多轮的验证,来获得模型的更为一般、同时也更为准确的运行结果。当然,我们还需要谨慎的选择一个合适的评估指标对其进行结果评估。
- 如何提升模型泛化能力
- 如果拥有了一个更加可信的、用于验证模型是否具有泛化能力的评估方式之后,那么接下来的问题就是,我们应该如何提升模型泛化能力呢?
- 当然,这其实是一个很大的问题,我们可以通过更好的选择模型(甚至是模型创新)、更好的特征工程、更好的模型训练等方法来提高模型泛化能力,而此处我们将要介绍的,是围绕某个具体的模型、通过更好的选择模型中的超参数,来提高模型的泛化能力。
- 不过正如此前所说,超参数无法通过一个严谨的数学流程给出最优解,因此超参数的选择其实是经验 + 一定范围内枚举(也就是网格搜索)的方法来决定的。
- 这个过程虽然看起来不是那么的 cooooool,但确实目前机器学习超参数选择的通用方式,并且当我们深入进行了解之后就会发现,尽管是经验 + 枚举,但经验的积累和枚举技术的掌握,其实也是机器学习水平的一种重要证明。
2. 基于网格搜索的超参数的调整方法
- 在了解机器学习中调参的基础理论之后,接下来我们考虑一个更加具体的调参流程。
- 实际上,尽管对于机器学习来说超参数众多,但能够对模型的建模结果产生决定性影响的超参数却不多,对于大多数超参数,我们都主要采用“经验结合实际”的方式来决定超参数的取值,如数据集划分比例、交叉验证的折数等等。
- 而对于一些如正则化系数、特征衍生阶数等,则需要采用一个流程来对其进行调节。而这个流程,一般来说就是进行搜索与枚举,或者也被称为网格搜索(gridsearch)。
- 所谓搜索与枚举,指的是将备选的参数一一列出,多个不同参数的不同取值最终将组成一个参数空间(parameter space),在这个参数空间中选取不同的值带入模型进行训练,最终选取一组最优的值作为模型的最终超参数。
- 当然,正如前面所讨论的,此处“最优”的超参数,应该是那些尽可能让模型泛化能力更好的参数。
- 在这个过程中,有两个核心问题需要注意,其一是参数空间的构成,其二是选取能够代表模型泛化能力的评估指标。接下来我们对其进行逐个讨论。
2.1 参数空间
- 参数空间的定义
- 所谓参数空间,其实就是我们挑选出来的、接下来需要通过枚举和搜索来进行数值确定的参数取值范围所构成的空间。
- 例如对于逻辑回归模型来说,如果选择 penalty 参数和 C 来进行搜索调参,则这两个参数就是参数空间的不同维度,而这两个参数的不同取值就是这个参数空间中的一系列点。
- 例如 (penalty=‘l1’, C=1)、(penalty=‘l1’, C=0.9)、(penalty=‘l2’, C=0.8) 等等,就是这个参数空间内的一系列点,接下来我们就需要从中挑选组一个最优组合。
- 参数空间构造思路
- 那么我们需要带入那些参数去构造这个参数空间呢?也就是我们需要选择那些参数进行调参呢?
- 调参的目的是为了提升模型的泛化能力,而保证泛化能力的核心是同时控制模型的经验风险和结构风险(既不让模型过拟合也不让模型前拟合)。
- 因此,对于逻辑回归来说,我们需要同时带入能够让模型拟合度增加、同时又能抑制模型过拟合倾向的参数来构造参数空间,即需要带入特征衍生的相关参数、以及正则化的相关参数。
- 一个建模流程中的特征衍生的相关参数,也是可以带入同一个参数空间进行搜索的。
2.2 交叉验证与评估指标
- 实际的超参数的搜索过程和我们上面讨论的模型结构风险一节中的参数选取过程略有不同,此前我们的过程是:先在训练集中训练模型,然后计算训练误差和泛化误差,通过二者误差的比较来观察模型是过拟合还是欠拟合(即评估模型泛化能力),然后再决定这些超参数应该如何调整。
- 而在一个更加严谨的过程中,我们需要将上述“通过对比训练误差和测试误差的差异,来判断过拟合还是欠拟合”的这个偏向主观的过程变成一个更加客观的过程,即我们需要找到一个能够基于目前模型建模结果的、能代表模型泛化能力的评估指标。
- 这即是模型建模流程更加严谨的需要,同时也是让测试集回归其本来定位的需要。
- 评估指标选取
- 而这个评估指标,对于分类模型来说,一般来说就是 ROC-AUC 或 F1-Score,并且是基于交叉验证之后的指标。
- 我们通常会选取 ROC-AUC 或 F1-Score,其实也是因为这两个指标的敏感度要强于准确率(详见Lesson 5 中的讨论),并且如果需要重点识别模型识别 1 类的能力,则可考虑 F1-Score,其他时候更推荐使用 ROC-AUC。
- 交叉验证过程
- 而为何要进行交叉验证,则主要原因是超参数的调整也需要同时兼顾模型的结构风险和经验风险,而能够表示模型结构风险的,就是不带入模型训练、但是能够对模型建模结果进行评估并且指导模型进行调整的验证集上的评估结果。
- 上述过程可以具体表示成如下步骤:
- (1) 在训练集中进行验证集划分(几折待定);
- (2) 带入训练集进行建模、带入验证集进行验证,并输出验证集上的模型评估指标;
- (3) 计算多组验证集上的评估指标的均值,作为该超参数下模型最终表现。
- 因此,在大多数情况下,网格搜索(gridsearch)都是和交叉验证(CV)同时出现的,这也是为什么 sklearn 中执行网格搜索的类名称为 GridSearchCV 的原因。
- 另外需要强调的一点是,由于交叉验证的存在,此时测试集的作用就变成了验证网格搜索是否有效,而非去验证模型是否有效(此时模型是否有效由验证集来验证)。
- 由于此时我们提交给测试集进行测试的,都是经过交叉验证挑选出来的最好的一组参数、或者说至少是在验证集上效果不错的参数(往往也是评估指标比较高的参数)。
- 而此时如果模型在测试集上运行效果不好、或者说在测试集上评估指标表现不佳,则说明模型仍然还是过拟合,之前执行的网格搜索过程并没有很好的控制住模型的结构风险,据此我们需要调整此前的调参策略,如调整参数空间、或者更改交叉验证策略等。
- 当然,如果是对网格搜索的过程比较自信,也可以不划分测试集,直接带入全部数据进行模型训练。
二、基于 Scikit-Learn 的网格搜索调参
- 在了解机器学习调参基础理论之后,接下来我们来借助 sklearn 中的相关工具,来执行更加高效的调参工作。
1. sklearn 中网格搜索的基本说明
- 由于网格搜索确定超参数的过程实际上帮助进行模型筛选,因此我们可以在 sklearn 的 model_selection 模块查找相关内容。
- 要学习 sklearn 中的网格搜索相关功能,最好还是从查阅官网的说明文档开始,我们可以在 sklearn 的 User Guide 的 3.2 节中我们能看到关于网格搜索的相关内容。
- 首先介绍官网给出的相关说明:

- 该说明文档开宗明义的介绍了网格搜索根本目的是为了调整超参数(Hyper-parameters),也就是评估器(estimators)中的参数,每个评估器中的参数可以通过 .get_params() 的方法来查看,并且建议配合交叉验证来执行。
- 同时,该说明文档重点指出了网格搜索中的核心要素,分别是:评估器、参数空间、搜索策略、交叉验证以及评估指标。
- 其中参数空间、交叉验证以及评估指标我们都在此前介绍过了,而根据下文的介绍,sklearn 中实际上是集成了两种不同的进行参数搜索的方法,分别是
GridSearchCV和RandomizedSearchCV:

- 尽管都是进行网格搜索,但两种方法还是各有不同,GridSearchCV 会尝试参数空间内的所有组合,而 RandomizedSearchCV 则会先进行采样再来进行搜索,即对某个参数空间的某个随机子集进行搜索。
- 并且上文重点强调,这两种方法都支持先两两比对、然后逐层筛选的方法来进行参数筛选,即 HalvingGridSearchCV 和 HalvingRandomSearchCV方 法。
- 当然,说明文档中也再次强调,由于 sklearn 的评估器中集成了非常多的参数,而并非所有参数都对最终建模结果有显著影响,因此为了不增加网格搜索过程计算量,推荐谨慎的构造参数空间,部分参数仍然以默认参数为主。
- 在介绍完基本说明文档后,接下来我们尝试调用sklearn中集成的相关方法来进行建模试验。
2. sklearn 中 GridSearchCV 的参数解释
- 接下来我们详细介绍 GridSearchCV 的相关参数,我们知道该方法的搜索策略是“全搜索”,即对参数空间内的所有参数进行搜索,该方法在 model_selection 模块下,同样也是以评估器形式存在,我们可以通过如下方式进行导入:
from sklearn.model_selection import GridSearchCV
- 不难发现该评估器的参数主体就是此前介绍的评估器、参数空间、交叉验证以及评估指标,我们对该评估器的完整参数进行解释:
GridSearchCV?
| Name | Description |
|---|---|
| estimator | 调参对象,某评估器 |
| param_grid | 参数空间,可以是字典或者字典构成的列表,稍后介绍参数空间的创建方法 |
| scoring | 评估指标,支持同时输出多个参数 |
| n_jobs | 设置工作时参与计算的CPU核数 |
| iid | 交叉验证时各折数据是否独立,该参数已在0.22版中停用,将在0.24版中弃用,此处不做介绍 |
| refit | 挑选评估指标和最佳参数,在完整数据集上进行训练 |
| cv | 交叉验证的折数 |
| verbose | 输出工作日志形式 |
| pre_dispatch | 多任务并行时任务划分数量 |
| error_score | 当网格搜索报错时返回结果,选择’raise’时将直接报错并中断训练过程,其他情况会显示警告信息后继续完成训练 |
| return_train_score | 在交叉验证中是否显示训练集中参数得分 |
- 整体来看,上面的主要参数分为三类,分别是核心参数、评估参数和性能参数。
- 核心参数
- 所谓性能参数,也就是涉及评估器训练(fit)的最核心参数,也就是 estimator 参数和 param_grid 参数,同时也是实例化评估器过程中最重要的参数。
- 评估参数
- 所谓评估参数,指的是涉及到不同参数训练结果评估过程方式的参数,主要是 scoring、refit 和 cv三个参数。
- 当然这三个参数都不是必要参数,但这三个参数却是直接决定模型结果评估过程、并且对最终模型参数选择和模型泛化能力提升直观重要的三个参数。
- 这三个参数各自都有一个默认值,我们先解释在默认值情况下这三个参数的运作方式,然后在下一个应用阶段讨论如何对这三个参数进行修改。
- 首先是关于 scoring 参数的选取,scoring 表示选取哪一项评估指标来对模型结果进行评估。
- 而根据参数说明文档我们知道,在默认情况下 scoring 的评估指标就是评估器的 .score 方法默认的评估指标,对于逻辑回归来说也就是准确率。
- 也就是说在默认情况下如果是围绕逻辑回归进行网格搜索,则默认评估指标是准确率。
- 此外,scoring 参数还支持直接输入可调用对象(评估函数)、代表评估函数运行方式的字符串、字典或者 list。
- 而 refit 参数则表示选择一个用于评估最佳模型的评估指标,然后在最佳参数的情况下整个训练集上进行对应评估指标的计算。
- 而 cv 则是关于交叉验证的相关参数,默认情况下进行 5 折交叉验证,并同时支持自定义折数的交叉验证、输入交叉验证评估器的交叉验证、以及根据指定方法进行交叉验证等方法。当然此组参数有非常多的设计方法,我们将在下一个应用阶段进行进一步的详解。
- 性能参数
- 第三组则是关于网格搜索执行性能相关的性能参数,主要包括 n_jobs 和 pre_dispatch 参数两个,用于规定调用的核心数和一个任务按照何种方式进行并行运算。
- 在网格搜索中,由于无需根据此前结果来确定后续计算方法,所以可以并行计算。
- 在默认情况下并行任务的划分数量和 n_jobs 相同。当然,这组参数的合理设置能够一定程度提高模型网格搜索效率。
- 但如果需要大幅提高执行速度,建议使用 RandomizedSearchCV、或者使用 Halving 方法来进行加速。
3. sklearn 中 GridSearchCV 的使用方法
- 在了解了 GridSearchCV 的基本方法之后,接下来我们以逻辑回归在鸢尾花数据集上建模为例,来尝试使用 GridSearchCV 方法进行网格调参,并同时介绍网格搜索的一般流程:
3.1 GridSearchCV 评估器训练过程
- Step 1. 创建评估器
- 首先我们还是需要实例化一个评估器,这里可以是一个模型、也可以是一个机器学习流,网格搜索都可以对其进行调参。此处我们先从简单入手,尝试实例化逻辑回归模型并对其进行调参。
# 数据导入
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=24)clf = LogisticRegression(max_iter=int(1e6), solver='saga')
- 此处将 solver 设置成 saga,也是为了方便后续同时比较 l1l1l1 正则化和 l2l2l2 正则化时无需更换求解器。
clf.get_params()
#{'C': 1.0,
# 'class_weight': None,
# 'dual': False,
# 'fit_intercept': True,
# 'intercept_scaling': 1,
# 'l1_ratio': None,
# 'max_iter': 1000000,
# 'multi_class': 'auto',
# 'n_jobs': None,
# 'penalty': 'l2',
# 'random_state': None,
# 'solver': 'saga',
# 'tol': 0.0001,
# 'verbose': 0,
# 'warm_start': False}
- Step 2. 创建参数空间
- 接下来,我们就需要挑选评估器中的超参数构造参数空间。
- 这里需要注意的是,我们需要挑选能够控制模型拟合度的超参数来进行参数空间的构造,例如挑选类似 verbose、n_jobs 等此类参数构造参数是毫无意义的。
- 此处我们挑选 penalty 和 C 这两个参数来进行参数空间的构造。
- 参数空间首先可以是一个字典:
param_grid_simple = {'penalty': ['l1', 'l2'],'C': [1, 0.5, 0.1, 0.05, 0.01]}
- 其中,字典的 Key 用参数的字符串来代表不同的参数,对应的 Value 则用列表来表示对应参数不同的取值范围。
- 也就是字典的 Key 是参数空间的维度,而 Value 则是不同纬度上可选的取值。而后续的网格搜索则是在上述参数的不同组合中挑选出一组最优的参数取值。
- 当然,由于如此构造方法,此处自然会衍生出一个新的问题,那就是如果某个维度的参数取值对应一组新的参数,应该如何处理?
- 例如,对于逻辑回归来说,如果 penalty 参数中选择弹性网参数,则会衍生出一个新的参数 l1_ratio,如果我们还想考虑 penalty 参数选取 elasticnet 参数,并且同时评估 l1_ratio 取不同值时模型效果,则无法将上述参数封装在一个参数空间内。
- 因为当 penalty 取其他值时 l1_ratio 并不存在。为了解决这个问题,我们可以创造多个参数空间(字典),然后将其封装在一个列表中,而该列表则表示多个参数空间的集成。
- 例如上述问题可以进行如下表示:
param_grid_ra = [{'penalty': ['l1', 'l2'], 'C': [1, 0.5, 0.1, 0.05, 0.01]}, {'penalty': ['elasticnet'], 'C': [1, 0.5, 0.1, 0.05, 0.01], 'l1_ratio': [0.3, 0.6, 0.9]}
]
- 即可表示网格搜索在 l1+1、l1+0.5…空间与 elasticnet+1+0.3、elasticnet+1+0.6…空间同时进行搜索。
- Step 3. 实例化网格搜索评估器
- 和 sklearn 中其他所有评估器一样,网格搜索的评估器的使用也是先实例化然后进行对其进行训练。
- 此处先实例化一个简单的网格搜索评估器,需要输入此前设置的评估器和参数空间。
search = GridSearchCV(estimator=clf,param_grid=param_grid_simple)
- Step 4. 训练网格搜索评估器
- 同样,我们通过fit方法即可完成评估器的训练。
search.fit(X_train, y_train)
#GridSearchCV(estimator=LogisticRegression(max_iter=1000000, solver='saga'),
# param_grid={'C': [1, 0.5, 0.1, 0.05, 0.01],
# 'penalty': ['l1', 'l2']})
- 需要知道的是,所谓的训练网格搜索评估器,本质上是在挑选不同的参数组合进行逻辑回归模型训练,而训练完成后相关结果都保存在 search 对象的属性中。
3.2 GridSearchCV 评估器结果查看
- 此处我们先介绍关于网格搜索类的所有属性和方法,再来查看挑选其中重要属性的结果进行解读。
| Name | Description |
|---|---|
| cv_results_ | 交叉验证过程中的重要结果 |
| best_estimator_ | 最终挑选出的最优 |
| best_score_ | 在最优参数情况下,训练集的交叉验证的平均得分 |
| best_params_ | 最优参数组合 |
| best_index_ | CV过程会对所有参数组合标号,该参数表示最优参数组合的标号 |
| scorer | 在最优参数下,计算模型得分的方法 |
| n_splits_ | 交叉验证的折数 |
- best_estimator_:训练完成后的最佳评估器
- 实际上返回的就是带有网格搜索挑选出来的最佳参数(超参数)的评估器。
search.best_estimator_
#LogisticRegression(C=1, max_iter=1000000, penalty='l1', solver='saga')
- 上述评估器就相当于一个包含最佳参数的逻辑回归评估器,可以调用逻辑回归评估器的所有属性:
# 查看参数
search.best_estimator_.coef_
#array([[ 0. , 0. , -3.47349066, 0. ],
# [ 0. , 0. , 0. , 0. ],
# [-0.55506614, -0.34227663, 3.03238721, 4.12147362]])# 查看训练误差、测试误差
search.best_estimator_.score(X_train,y_train), search.best_estimator_.score(X_test,y_test)
#(0.9732142857142857, 0.9736842105263158)# 查看参数
search.best_estimator_.get_params()
#{'C': 1,
# 'class_weight': None,
# 'dual': False,
# 'fit_intercept': True,
# 'intercept_scaling': 1,
# 'l1_ratio': None,
# 'max_iter': 1000000,
# 'multi_class': 'auto',
# 'n_jobs': None,
# 'penalty': 'l1',
# 'random_state': None,
# 'solver': 'saga',
# 'tol': 0.0001,
# 'verbose': 0,
# 'warm_start': False}
- best_score_:最优参数时交叉验证平均得分
search.best_score_
#0.9644268774703558
- 在默认情况下(未修改网格搜索评估器中评估指标参数时),此处的 score 就是准确率。此处有两点需要注意:
- 其一:该指标和训练集上整体准确率不同,该指标是交叉验证时验证集准确率的平均值,而不是所有数据的准确率;
- 其二:该指标是网格搜索在进行参数挑选时的参照依据。
- 其他属性方法测试
search.cv_results_search.best_params_
#{'C': 1, 'penalty': 'l1'}search.best_index_
#0# 等价于search.best_estimator_.score
search.score(X_train,y_train), search.score(X_test,y_test)
#(0.9732142857142857, 0.9736842105263158)search.n_splits_
#5search.refit_time_
#0.07661604881286621
- 至此,我们就执行了一个完整的网格搜索的调参过程。
- 但该过程大多只使用了默认参数在小范围内进行的运算,如果我们希望更换模型评估指标、并且在一个更加完整的参数范围内进行搜索,则需要对上述过程进行修改,并更近一步掌握关于评估器中 scoring 参数和 refit 参数的相关使用方法,相关内容我们将在后续的文章当中进行详细讨论。
相关文章:
Lesson 6.5 机器学习调参基础理论与网格搜索
文章目录一、机器学习调参理论基础1. 机器学习调参目标及基本方法2. 基于网格搜索的超参数的调整方法2.1 参数空间2.2 交叉验证与评估指标二、基于 Scikit-Learn 的网格搜索调参1. sklearn 中网格搜索的基本说明2. sklearn 中 GridSearchCV 的参数解释3. sklearn 中 GridSearch…...

leetcode: Two Sum
leetcode: Two Sum1. 题目1.1 题目描述2. 解答2.1 baseline2.2 基于baseline的思考2.3 优化思路的实施2.3.1 C中的hashmap2.3.2 实施2.3.3 再思考2.3.4 最终实施3. 总结1. 题目 1.1 题目描述 Given an array of integers nums and an integer target, return indices of the …...

共享模型之无锁(三)
1.原子累加器 示例代码: public class TestAtomicAdder {public static void main(String[] args) {for (int i 0; i < 5; i) {demo(() -> new AtomicLong(0),(adder) -> adder.getAndIncrement());}for (int i 0; i < 5; i) {demo(() -> new LongAdder(),(…...
微信小程序 Springboot校运会高校运动会管理系统
3.1小程序端 小程序登录页面,用户也可以在此页面进行注册并且登录等。 登录成功后可以在我的个人中心查看自己的个人信息或者修改信息等 在广播信息中我们可以查看校运会发布的一些信息情况。 在首页我们可以看到校运会具体有什么项目运动。 在查看具体有什么活动我…...

走进独自开,带你轻松干副业
今天给大家分享一个开发者的福利平台——独自开(点击直接注册),让你在家就能解决收入问题。 文章目录一、平台介绍二、系统案例三、获取收益四、使用平台1、用户注册2、用户认证3、任务报价五、文末总结一、平台介绍 简单说明 独自开信息科技…...
SpringBoot+Vue实现师生健康信息管理系统
文末获取源码 开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7/8.0 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9 浏…...

数据库第四章节第三次作业内容
1、显示所有职工的基本信息。 2、查询所有职工所属部门的部门号,不显示重复的部门号。 3、求出所有职工的人数。 4、列出最高工和最低工资。 5、列出职工的平均工资和总工资。 6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表…...

一篇五分生信临床模型预测文章代码复现——FIgure 9.列线图构建,ROC分析,DCA分析 (四)
之前讲过临床模型预测的专栏,但那只是基础版本,下面我们以自噬相关基因为例子,模仿一篇五分文章,将图和代码复现出来,学会本专栏课程,可以具备发一篇五分左右文章的水平: 本专栏目录如下: Figure 1:差异表达基因及预后基因筛选(图片仅供参考) Figure 2. 生存分析,…...

神经网络实战--使用迁移学习完成猫狗分类
前言: Hello大家好,我是Dream。 今天来学习一下如何使用基于tensorflow和keras的迁移学习完成猫狗分类,欢迎大家一起前来探讨学习~ 本文目录:一、加载数据集1.调用库函数2.加载数据集3.数据集管理二、猫狗数据集介绍1.猫狗数据集介…...
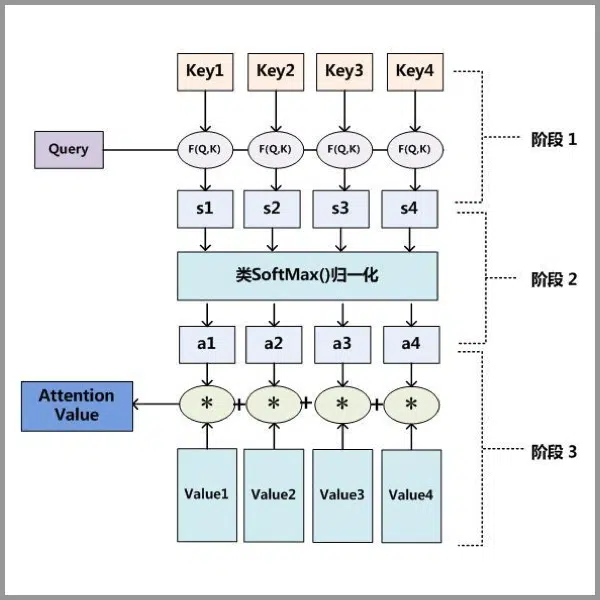
Attention机制 学习笔记
学习自https://easyai.tech/ai-definition/attention/ Attention本质 Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是“从关注全部到关注重点”。 比如我们人在看图片时,对图片的不同地方的注意力…...

数据类型与运算符
1.字符型作用: 字符型变量用于显示单个字符语法: char cc a ;注意1: 在显示字符型变量时,用单引号将字符括起来,不要用双引号注意2: 单引号内只能有一个字符,不可以是字符串C和C中字符型变量只占用1个字节。字符型变是并不是把字符本身放到内存中存储&am…...

算法刷题-二叉树的锯齿形层序遍历、用栈实现队列 栈设计、买卖股票的最佳时机 IV
文章目录二叉树的锯齿形层序遍历(树、广度优先搜索)用栈实现队列(栈、设计)买卖股票的最佳时机 IV(数组、动态规划)二叉树的锯齿形层序遍历(树、广度优先搜索) 给定一个二叉树&…...
| 代码编写思路+核心知识点)
华为OD机试 - 最小传递延迟(Python)| 代码编写思路+核心知识点
最小传递延迟 题目 通讯网络中有 N 个网络节点 用 1 ~ N 进行标识 网络通过一个有向无环图进行表示 其中图的边的值,表示节点之间的消息传递延迟 现给定相连节点之间的延时列表 times[i]={u,v,w} 其中 u 表示源节点,v 表示目的节点,w 表示 u 和 v 之间的消息传递延时 请计…...
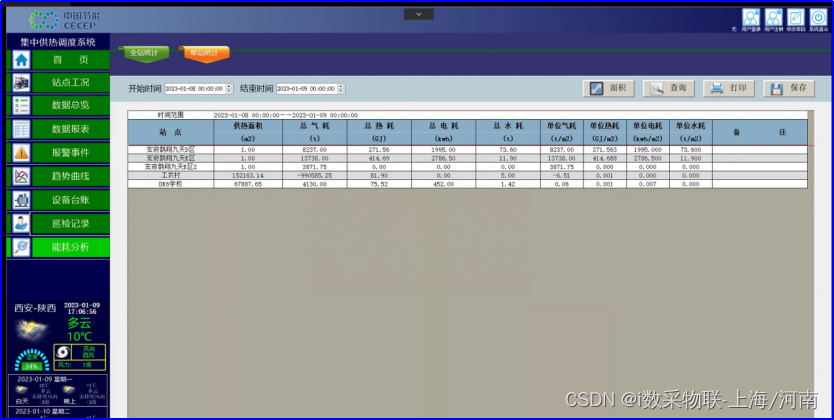
集中供热调度系统天然气仪表内网仪表图像识别案例
一、项目需求 出于能耗采集与冬季集中供暖工作的节能和能耗分析需要,要采集现场的6块天然气表计,并存储进入客户的mySQL数据库中,现场采集的表计不允许接线,且网络环境为内网环境,需要采集表计数据并存入数据库&#…...

笔试题-2023-复旦微-数字IC设计【纯净题目版】
回到首页:2023 数字IC设计秋招复盘——数十家公司笔试题、面试实录 推荐内容:数字IC设计学习比较实用的资料推荐 题目背景 笔试时间:2022.07.26应聘岗位:数字前端工程师笔试时长:120min笔试平台:赛码题目类型:基础题(10道)、选做题(10道)、验证题(5道)主观评价 难…...
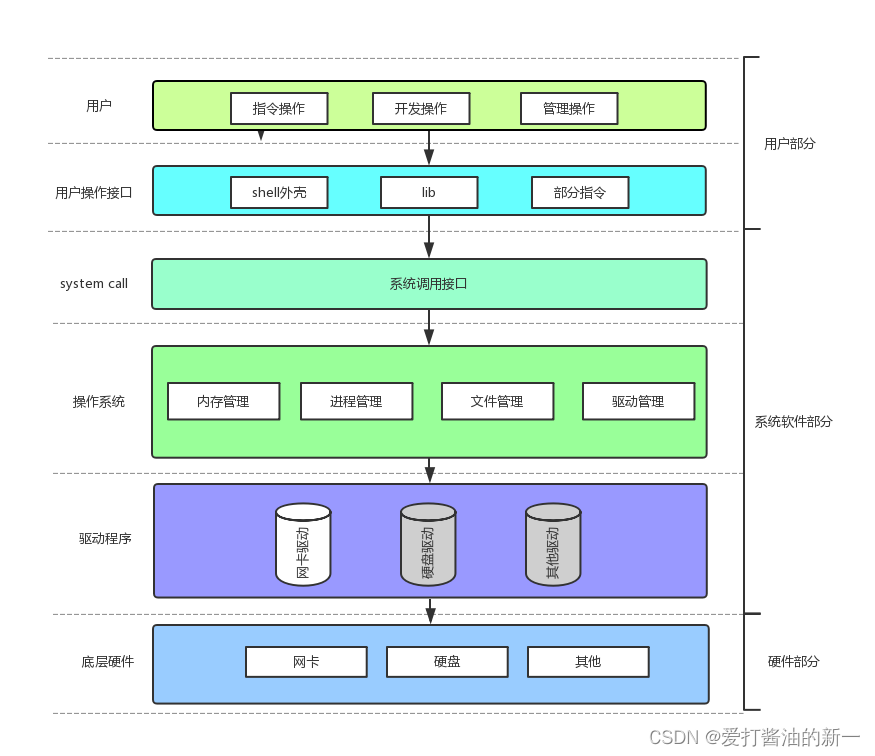
【Linux】冯诺依曼体系结构和操作系统概念
文章目录🎪 冯诺依曼体系结构🚀1.体系概述🚀2.CPU和内存的数据交换🚀3.体系结构中数据的流动🎪 操作系统概念理解🚀1.简述🚀2.设计目的🚀3.定位🚀4.理解🚀5.管…...
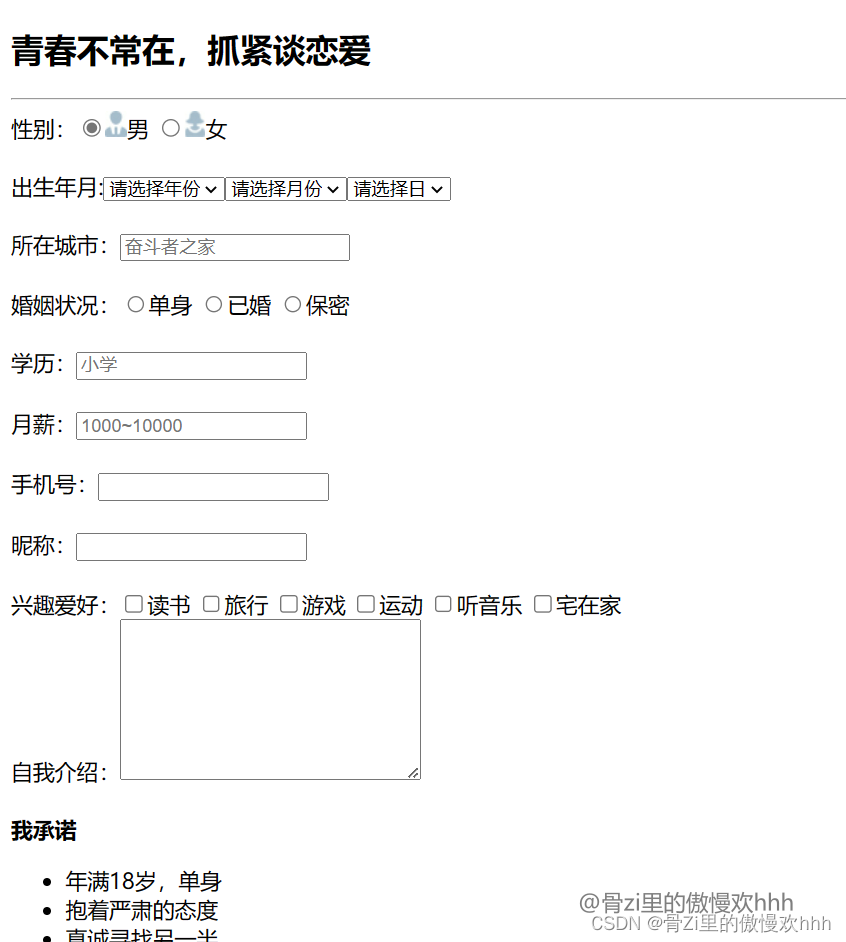
HTML5之HTML基础学习笔记
列表标签 列表的应用场景 场景:在网页中按照行展示关联性的内容,如:新闻列表、排行榜、账单等特点:按照行的方式,整齐显示内容种类:无序列表、有序列表、自定义列表 这是老师PPT上的内容, 列表…...

FreeRTOS信号量 | FreeRTOS十
目录 说明: 一、信号量 1.1、信号量简介 1.2、信号量特点 二、二值信号量 2.1、二值信号量简介 2.2、获取与释放二值信号量函数 2.3、二值信号量使用过程与相关API函数 2.4、创建二值信号量函数了解 2.5、释放二值信号量了解 2.6、获取二值信号量了解 三…...

【SpringBoot】SpringBoot常用注解
一、前言首先这里说的SpringBoot常用注解是指在我们开发项目过程中,我们经常使用的注解,包含Spring、SpringBoot、SpringCloud、SpringMVC等这些框架中的注解,而不仅仅是SpringBoot中的注解。这里只是作一个注解列举,每个注解具体…...
数据一致性
目录一、AOP 动态代理切入方法(1) Aspect Oriented Programming(2) 切入点表达式二、SpringBoot 项目扫描类(1) ResourceLoader 扫描类(2) Map 的 computeIfAbsent 方法(3) 反射几个常用 api① 创建一个测试注解② 创建测试 PO 类③ 反射 api 获取指定类的指定注解信息(4) 返回…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...