【PyTorch】现代卷积神经网络
文章目录
- 1. 理论介绍
- 1.1. 深度卷积神经网络(AlexNet)
- 1.1.1. 概述
- 1.1.2. 模型设计
- 1.2. 使用块的网络(VGG)
- 1.3. 网络中的网络(NiN)
- 1.4. 含并行连结的网络(GoogLeNet)
- 1.5. 批量规范化
- 1.6. 残差网络(ResNet)
- 1.7. 稠密连接网络(DenseNet)
- 2. 实例解析
- 2.1. 实例描述
- 2.2. 代码实现
- 2.2.1. 在FashionMNIST数据集上训练模型
- 2.2.2. 模型设置
- 2.2.2.1. AlexNet
- 2.2.2.2. VGG-11
- 2.2.2.3. NiN
- 2.2.2.4. GoogLeNet
- 2.2.2.5. 加入批量规范化层的LeNet
- 2.2.2.6. ResNet
- 2.2.2.7. DenseNet
- 2.2.3. 输出结果
- 2.2.3.1. AlexNet
- 2.2.3.2. VGG-11
- 2.2.3.3. NiN
- 2.2.3.4. GoogLeNet
- 2.2.3.5. 加入批量规范化层的LeNet
- 2.2.3.6. ResNet
- 2.2.3.7. DenseNet
1. 理论介绍
1.1. 深度卷积神经网络(AlexNet)
1.1.1. 概述
- 特征本身应该被学习,而且在合理地复杂性前提下,特征应该由多个共同学习的神经网络层组成,每个层都有可学习的参数。在机器视觉中,最底层可能检测边缘、颜色和纹理,更高层建立在这些底层表示的基础上,以表示更大的特征。
- 包含许多特征的深度模型需要大量的有标签数据,才能显著优于基于凸优化的传统方法(如线性方法和核方法)。ImageNet挑战赛为研究人员提高超大规模的数据集。
- 深度学习对计算资源要求很高,训练可能需要数百个迭代轮数,每次迭代都需要通过代价高昂的许多线性代数层传递数据。用GPU训练神经网络大大提高了训练速度,相比于CPU,GPU由100~1000个小的处理单元(核心)组成,庞大的核心数量使GPU比CPU快几个数量级;GPU核心更简单,功耗更低;GPU拥有更高的内存带宽;卷积和矩阵乘法,都是可以在GPU上并行化的操作。
- AlexNet首次证明了学习到的特征可以超越手工设计的特征。
1.1.2. 模型设计
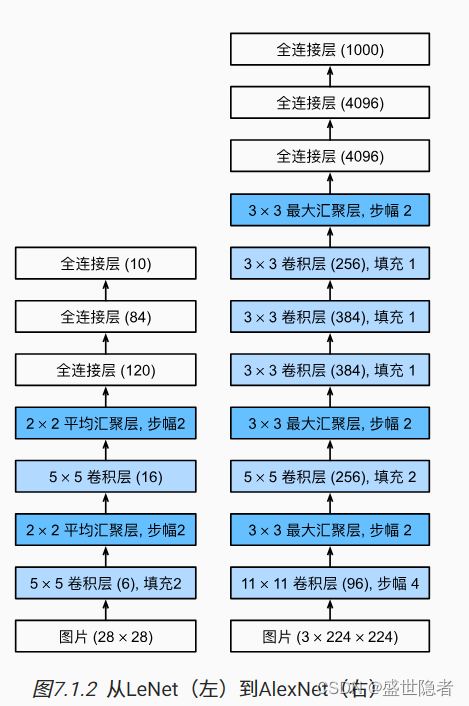
- AlexNet使用ReLU而不是sigmoid作为其激活函数。
- 在最后一个卷积层后有两个全连接层,分别有4096个输出。 这两个巨大的全连接层拥有将近1GB的模型参数。 由于早期GPU显存有限,原版的AlexNet采用了双数据流设计,使得每个GPU只负责存储和计算模型的一半参数。
- AlexNet通过暂退法控制全连接层的模型复杂度。
- 为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。 这使得模型更健壮,更大的样本量有效地减少了过拟合。
1.2. 使用块的网络(VGG)
- 经典卷积神经网络的基本组成部分
- 带填充以保持分辨率的卷积层
- 非线性激活函数
- 池化层
- VGG块由一系列卷积层组成,后面再加上用于空间下采样的最大池化层。深层且窄的卷积(即 3 × 3 3\times3 3×3)比较浅层且宽的卷积更有效。不同的VGG模型可通过每个VGG块中卷积层数量和输出通道数量的差异来定义。
- VGG网络由几个VGG块和全连接层组成。超参数变量
conv_arch指定了每个VGG块里卷积层个数和输出通道数。全连接模块则与AlexNet中的相同。 - VGG-11有5个VGG块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层,共8个卷积层。 第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。
1.3. 网络中的网络(NiN)
- 网络中的网络(NiN)在每个像素的通道上分别使用多层感知机。
- NiN块以一个普通卷积层开始,后面是两个 1 × 1 1\times1 1×1的卷积层。这两个 1 × 1 1\times1 1×1卷积层充当带有ReLU激活函数的逐像素全连接层。
- NiN网络使用窗口形状为 11 × 11 11\times11 11×11、 5 × 5 5\times5 5×5和 3 × 3 3\times3 3×3的卷积层,输出通道数量与AlexNet中的相同。 每个NiN块后有一个最大池化层,池化窗口形状为 3 × 3 3\times3 3×3,步幅为2。 NiN和AlexNet之间的一个显著区别是NiN完全取消了全连接层。NiN使用一个NiN块,其输出通道数等于标签类别的数量。最后放一个全局平均池化层,生成一个对数几率 (logits)。
- 移除全连接层可减少过拟合,同时显著减少NiN的参数。
1.4. 含并行连结的网络(GoogLeNet)
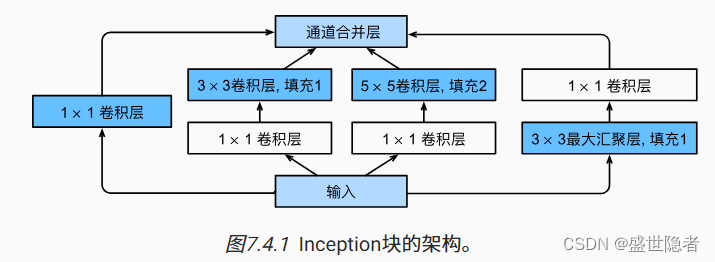
- 使用不同大小的卷积核组合是有利的,因为可以有效地识别不同范围的图像细节。
- Inception块由四条并行路径组成。四条路径都使用合适的填充来使输入与输出的高和宽一致。超参数是每层输出通道数。
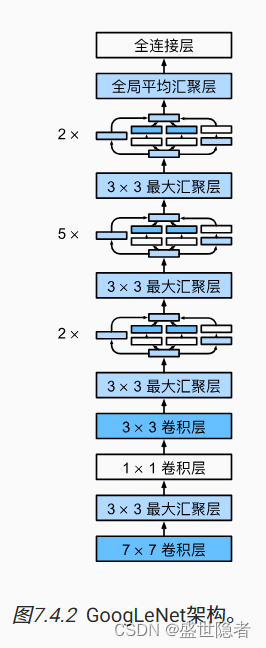
- GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。
1.5. 批量规范化
- 批量规范化可持续加速深层网络的收敛速度。在模型训练过程中,批量规范化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定。
- 数据预处理的方式通常会对最终结果产生巨大影响。
- 中间层中的变量分布偏移可能会阻碍网络的收敛。
- 更深层的网络很复杂,容易过拟合。 这意味着正则化变得更加重要。
- 在每次训练迭代中,我们首先规范化输入,即通过减去其均值并除以其标准差,其中两者均基于当前小批量处理。 接下来,我们应用比例系数和比例偏移。
- 只有使用足够大的小批量,批量规范化这种方法才是有效且稳定的。如果我们尝试使用大小为1的小批量应用批量规范化,我们将无法学到任何东西。 这是因为在减去均值之后,每个隐藏单元将为0。
- 批量标准化公式 B N ( x ) = γ ⊙ x − μ ^ B σ ^ B + β , x ∈ B \mathrm{BN}(\mathbf{x}) = \boldsymbol{\gamma} \odot \frac{\mathbf{x} - \hat{\boldsymbol{\mu}}_\mathcal{B}}{\hat{\boldsymbol{\sigma}}_\mathcal{B}} + \boldsymbol{\beta}, \mathbf{x}\in \mathcal{B} BN(x)=γ⊙σ^Bx−μ^B+β,x∈B其中拉伸参数 γ \boldsymbol{\gamma} γ和偏移参数 β \boldsymbol{\beta} β是待学习的参数。 应用标准化后,生成的小批量的平均值为0和单位方差为1。
- 我们在方差估计值中添加一个小的常量 ϵ > 0 \epsilon > 0 ϵ>0,以确保我们永远不会尝试除以零。
- 批量规范化最适应50~100范围中的中等批量大小。
- 批量规范化层在训练模式通过小批量统计数据规范化,在预测模式通过利用移动平均估计对整个训练集统计规范化。
- 我们将批量规范化层置于全连接层中的仿射变换和激活函数之间。
- 我们可以在卷积层之后和非线性激活函数之前应用批量规范化。 当卷积有多个输出通道时,我们需要对这些通道的每个输出执行批量规范化,每个通道都有自己的拉伸和偏移参数,这两个参数都是标量。
1.6. 残差网络(ResNet)
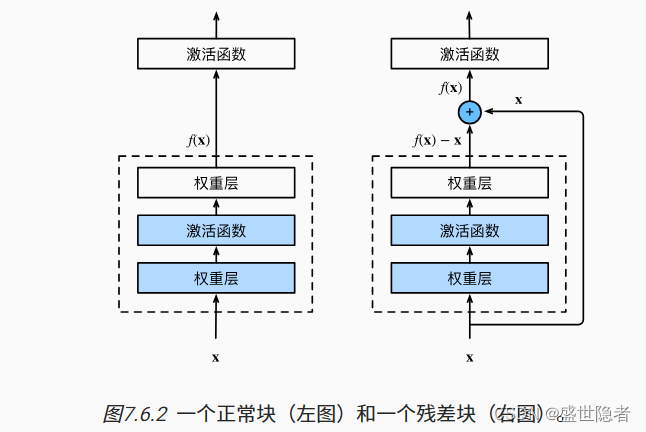
- 只有当较复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能。
- 对于深度神经网络,如果我们能将新添加的层训练成恒等映射 f ( x ) = x f(\mathbf{x})=\mathbf{x} f(x)=x,新模型和原模型将同样有效。同时,由于新模型可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。
- 残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
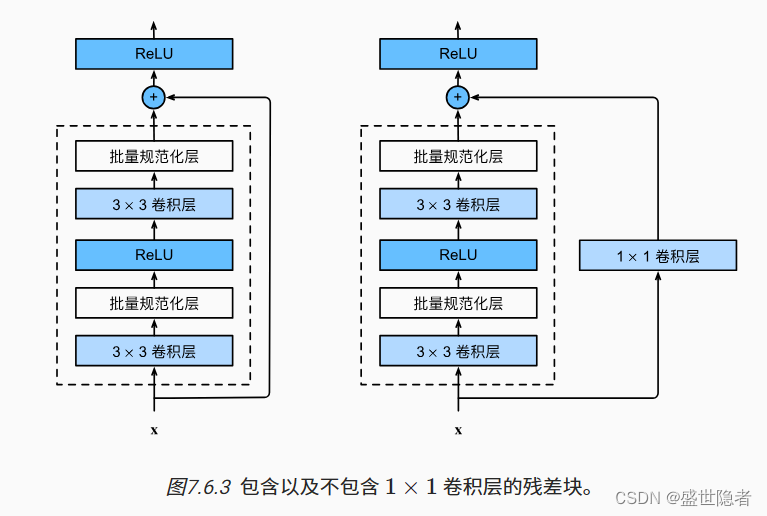
- 残差块
- 输入可以通过层间的残余连接更快地向前传播。
1.7. 稠密连接网络(DenseNet)
- ResNet将 f ( x ) f(\mathbf{x}) f(x)展开为 f ( x ) = x + g ( x ) f(\mathbf{x})=\mathbf{x}+g(\mathbf{x}) f(x)=x+g(x),DenseNet将 f ( x ) f(\mathbf{x}) f(x)展开成超过两部分,DenseNet输出是连接。
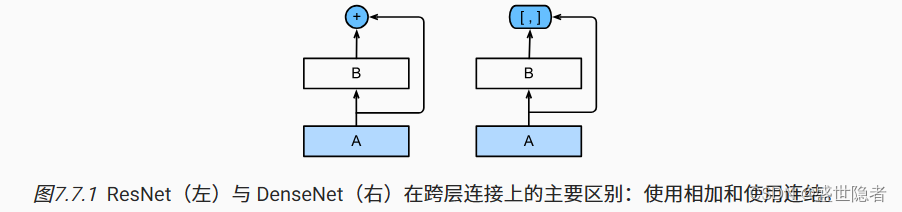
- 稠密网络主要由稠密块和过渡层构成。 前者定义如何连接输入和输出,而后者则控制通道数量,使其不会太复杂。
- 稠密块由多个卷积块组成,每个卷积块使用相同数量的输出通道。 然而,在前向传播中,我们将每个卷积块的输入和输出在通道维上连结。卷积块的通道数控制了输出通道数相对于输入通道数的增长,因此也被称为增长率。
- 过渡层通过 1 × 1 1\times1 1×1卷积层来减小通道数,并使用步幅为2的平均汇聚层减半高和宽,从而进一步降低模型复杂度。
2. 实例解析
2.1. 实例描述
- 在FashionMNIST数据集上训练AlexNet。注:输入图像调整到 224 × 224 224\times224 224×224,不使用跨GPU分解模型。
- 在FashionMNIST数据集上训练VGG-11。注:输入图像调整到 224 × 224 224\times224 224×224,可以按比例缩小通道数以减少参数量,学习率可以设置得略高。
- 在FashionMNIST数据集上训练NiN。注:输入图像调整到 224 × 224 224\times224 224×224。
- 在FashionMNIST数据集上训练GoogLeNet。注:输入图像调整到 96 × 96 96\times96 96×96。
- 在FashionMNIST数据集上训练加入批量规范化层的LeNet。注:学习率可以设置得略高。
- 在Fashion-MNIST数据集上训练ResNet-18。注:输入图像调整到 96 × 96 96\times96 96×96。
- 在Fashion-MNIST数据集上训练DenseNet。注:输入图像调整到 96 × 96 96\times96 96×96。
2.2. 代码实现
2.2.1. 在FashionMNIST数据集上训练模型
import os
from tensorboardX import SummaryWriter
from alive_progress import alive_bar
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision.transforms import Compose, ToTensor, Resize
from torchvision.datasets import FashionMNISTdef load_dataset(size):"""加载数据集"""root = "./dataset"if size is None:transform = Compose([ToTensor()])else:transform = Compose([Resize(size), ToTensor()])mnist_train = FashionMNIST(root, True, transform, download=True)mnist_test = FashionMNIST(root, False, transform, download=True)dataloader_train = DataLoader(mnist_train, batch_size, shuffle=True, num_workers=num_workers, pin_memory=True,)dataloader_test = DataLoader(mnist_test, batch_size, shuffle=False,num_workers=num_workers, pin_memory=True,)return dataloader_train, dataloader_testdef train_on_FashionMNIST(title, size=None):"""在FashionMNIST数据集上训练指定模型"""# 创建记录器def log_dir():root = "runs"if not os.path.exists(root):os.mkdir(root)order = len(os.listdir(root)) + 1return f'{root}/exp{order}'writer = SummaryWriter(log_dir=log_dir())# 数据集配置dataloader_train, dataloader_test = load_dataset(size)# 模型配置def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)nn.init.zeros_(m.bias)net.apply(init_weights)criterion = nn.CrossEntropyLoss(reduction='none')optimizer = optim.SGD(net.parameters(), lr=lr)# 训练循环metrics_train = torch.zeros(3, device=device) # 训练损失、训练准确度、样本数metrics_test = torch.zeros(2, device=device) # 测试准确度、样本数with alive_bar(num_epochs, theme='classic', title=title) as bar:for epoch in range(num_epochs):net.train()for X, y in dataloader_train:X, y = X.to(device, non_blocking=True), y.to(device, non_blocking=True)loss = criterion(net(X), y)optimizer.zero_grad()loss.mean().backward()optimizer.step()net.eval()with torch.no_grad():metrics_train.zero_()for X, y in dataloader_train:X, y = X.to(device, non_blocking=True), y.to(device, non_blocking=True)y_hat = net(X)loss = criterion(y_hat, y)metrics_train[0] += loss.sum()metrics_train[1] += (y_hat.argmax(dim=1) == y).sum()metrics_train[2] += y.numel()metrics_train[0] /= metrics_train[2]metrics_train[1] /= metrics_train[2]metrics_test.zero_()for X, y in dataloader_test:X, y = X.to(device, non_blocking=True), y.to(device, non_blocking=True)y_hat = net(X)metrics_test[0] += (y_hat.argmax(dim=1) == y).sum()metrics_test[1] += y.numel()metrics_test[0] /= metrics_test[1]_metrics_train = metrics_train.cpu().numpy()_metrics_test = metrics_test.cpu().numpy()writer.add_scalars('metrics', {'train_loss': _metrics_train[0],'train_acc': _metrics_train[1],'test_acc': _metrics_test[0]}, epoch)bar()writer.close()
2.2.2. 模型设置
2.2.2.1. AlexNet
if __name__ == "__main__":# 全局参数设置num_epochs = 10batch_size = 128num_workers = 3lr = 0.01device = torch.device('cuda')# 模型配置net = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 10)).to(device, non_blocking=True)train_on_FashionMNIST('AlexNet', 224)
2.2.2.2. VGG-11
if __name__ == '__main__':# 全局参数配置num_epochs = 10batch_size = 128num_workers = 3lr = 0.1device = torch.device('cuda')# 模型配置def vgg_block(num_convs, in_channels, out_channels):"""定义VGG块"""layers = []for _ in range(num_convs):layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))layers.append(nn.ReLU())in_channels = out_channelslayers.append(nn.MaxPool2d(kernel_size=2, stride=2))return nn.Sequential(*layers)def vgg(conv_arch):"""定义VGG网络"""vgg_blocks = []in_channels = 1out_channels = 0for num_convs, out_channels in conv_arch:vgg_blocks.append(vgg_block(num_convs, in_channels, out_channels))in_channels = out_channelsreturn nn.Sequential(*vgg_blocks, nn.Flatten(),nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 10),)ratio = 4conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]net = vgg(small_conv_arch).to(device, non_blocking=True)# 在FashionMNIST数据集上训练模型train_on_FashionMNIST('VGG', 224)
2.2.2.3. NiN
if __name__ == '__main__':# 全局参数配置num_epochs = 10batch_size = 128num_workers = 3lr = 0.1device = torch.device('cuda')# 模型配置def nin_block(in_channels, out_channels, kernel_size, strides, padding):"""定义NiN块"""return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding), nn.ReLU(),nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())net = nn.Sequential(nin_block(1, 96, kernel_size=11, strides=4, padding=0),nn.MaxPool2d(kernel_size=3, stride=2),nin_block(96, 256, kernel_size=5, strides=1, padding=2),nn.MaxPool2d(kernel_size=3, stride=2),nin_block(256, 384, kernel_size=3, strides=1, padding=1),nn.MaxPool2d(kernel_size=3, stride=2),nn.Dropout(0.5),nin_block(384, 10, kernel_size=3, strides=1, padding=1),nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten()).to(device, non_blocking=True)# 在FashionMNIST数据集上训练模型train_on_FashionMNIST('NiN', 224)
2.2.2.4. GoogLeNet
if __name__ == '__main__':# 全局参数配置num_epochs = 10batch_size = 128num_workers = 3lr = 0.1device = torch.device('cuda')# 模型配置class Inception(nn.Module):# c1--c4是每条路径的输出通道数def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):super(Inception, self).__init__(**kwargs)# 线路1,单1x1卷积层self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)# 线路2,1x1卷积层后接3x3卷积层self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)# 线路3,1x1卷积层后接5x5卷积层self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)# 线路4,3x3最大汇聚层后接1x1卷积层self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)def forward(self, x):p1 = F.relu(self.p1_1(x))p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))p4 = F.relu(self.p4_2(self.p4_1(x)))# 在通道维度上连结输出return torch.cat((p1, p2, p3, p4), dim=1)b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),nn.ReLU(),nn.Conv2d(64, 192, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),Inception(256, 128, (128, 192), (32, 96), 64),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),Inception(512, 160, (112, 224), (24, 64), 64),Inception(512, 128, (128, 256), (24, 64), 64),Inception(512, 112, (144, 288), (32, 64), 64),Inception(528, 256, (160, 320), (32, 128), 128),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),Inception(832, 384, (192, 384), (48, 128), 128),nn.AdaptiveAvgPool2d((1,1)),nn.Flatten())net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10)).to(device, non_blocking=True)# 在FashionMNIST数据集上训练模型train_on_FashionMNIST('GoogLeNet', 96)
2.2.2.5. 加入批量规范化层的LeNet
if __name__ == '__main__':# 全局参数设置num_epochs = 10batch_size = 256num_workers = 3lr = 1.0device = torch.device('cuda')# 模型配置net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),nn.Linear(84, 10)).to(device, non_blocking=True)train_on_FashionMNIST('LeNet_BN')
2.2.2.6. ResNet
if __name__ == '__main__':# 全局参数设置num_epochs = 10batch_size = 256num_workers = 3lr = 0.05device = torch.device('cuda')# 模型配置class Residual(nn.Module):def __init__(self, input_channels, num_channels,use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels,kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels,kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels,kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)def resnet_block(input_channels, num_channels, num_residuals,first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels,use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blkb1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))b3 = nn.Sequential(*resnet_block(64, 128, 2))b4 = nn.Sequential(*resnet_block(128, 256, 2))b5 = nn.Sequential(*resnet_block(256, 512, 2))net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(), nn.Linear(512, 10)).to(device, non_blocking=True)train_on_FashionMNIST('ResNet', 96)
2.2.2.7. DenseNet
if __name__ == '__main__':# 全局参数设置num_epochs = 10batch_size = 256num_workers = 3lr = 0.1device = torch.device('cuda')# 模型配置def conv_block(input_channels, num_channels):return nn.Sequential(nn.BatchNorm2d(input_channels), nn.ReLU(),nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1))class DenseBlock(nn.Module):def __init__(self, num_convs, input_channels, num_channels):super(DenseBlock, self).__init__()layer = []for i in range(num_convs):layer.append(conv_block(num_channels * i + input_channels, num_channels))self.net = nn.Sequential(*layer)def forward(self, X):for blk in self.net:Y = blk(X)# 连接通道维度上每个块的输入和输出X = torch.cat((X, Y), dim=1)return Xdef transition_block(input_channels, num_channels):return nn.Sequential(nn.BatchNorm2d(input_channels), nn.ReLU(),nn.Conv2d(input_channels, num_channels, kernel_size=1),nn.AvgPool2d(kernel_size=2, stride=2))b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))# num_channels为当前的通道数num_channels, growth_rate = 64, 32num_convs_in_dense_blocks = [4, 4, 4, 4]blks = []for i, num_convs in enumerate(num_convs_in_dense_blocks):blks.append(DenseBlock(num_convs, num_channels, growth_rate))# 上一个稠密块的输出通道数num_channels += num_convs * growth_rate# 在稠密块之间添加一个转换层,使通道数量减半if i != len(num_convs_in_dense_blocks) - 1:blks.append(transition_block(num_channels, num_channels // 2))num_channels = num_channels // 2net = nn.Sequential(b1, *blks,nn.BatchNorm2d(num_channels), nn.ReLU(),nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(),nn.Linear(num_channels, 10)).to(device, non_blocking=True)train_on_FashionMNIST('DenseNet', 96)
2.2.3. 输出结果
2.2.3.1. AlexNet

2.2.3.2. VGG-11
2.2.3.3. NiN
2.2.3.4. GoogLeNet
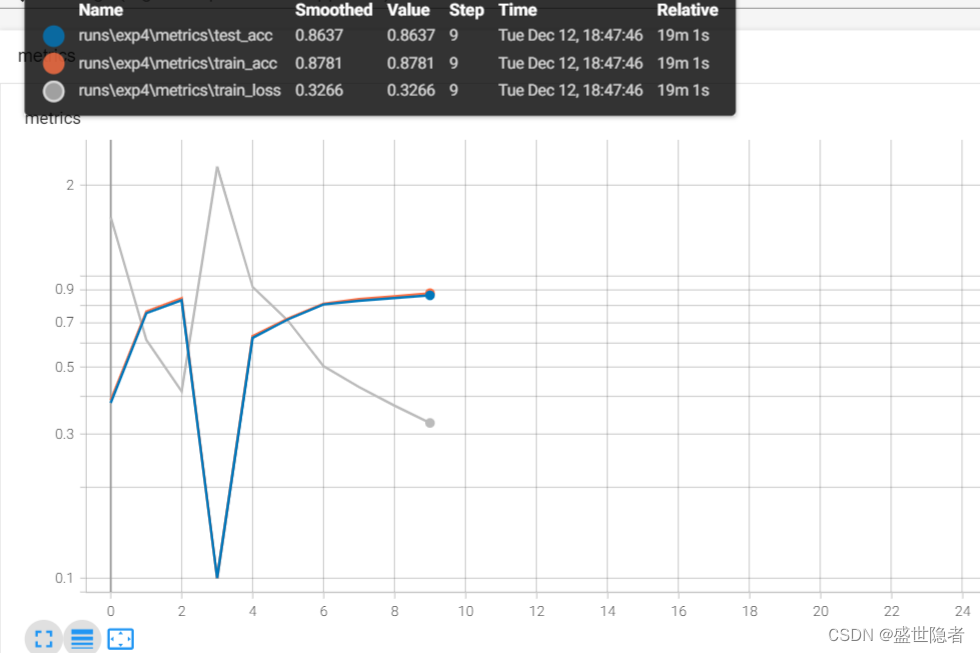
2.2.3.5. 加入批量规范化层的LeNet
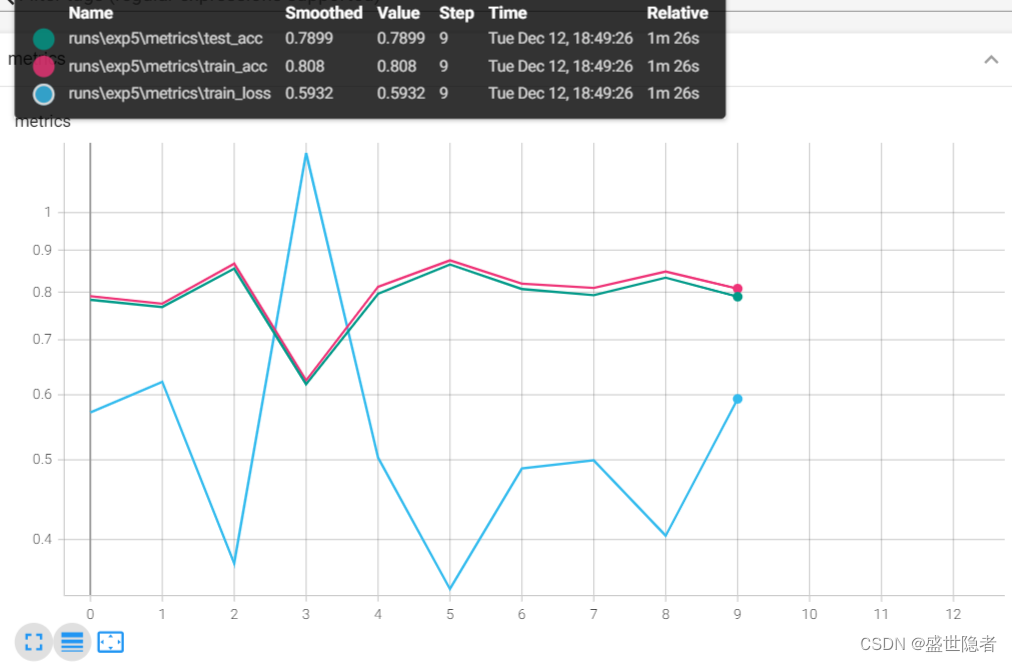
2.2.3.6. ResNet
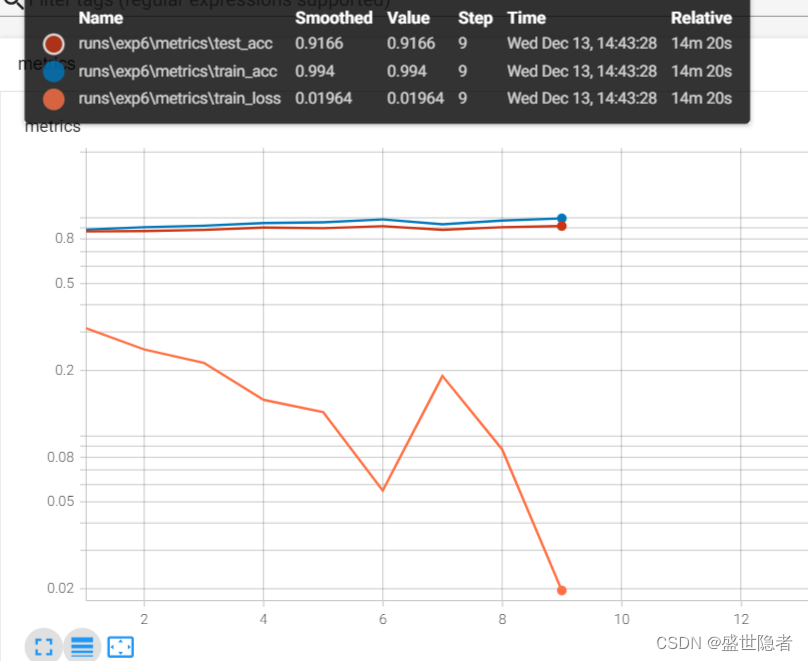
2.2.3.7. DenseNet

相关文章:
【PyTorch】现代卷积神经网络
文章目录 1. 理论介绍1.1. 深度卷积神经网络(AlexNet)1.1.1. 概述1.1.2. 模型设计 1.2. 使用块的网络(VGG)1.3. 网络中的网络(NiN)1.4. 含并行连结的网络(GoogLeNet)1.5. 批量规范化…...

用python编写九九乘法表
1 问题 我们在学习一门语言的过程中,都会练习到编写九九乘法表这个代码,下面介绍如何编写九九乘法表的流程。 2 方法 (1)打开pycharm集成开发环境,创建一个python文件,并编写第一行代码,主要构建…...
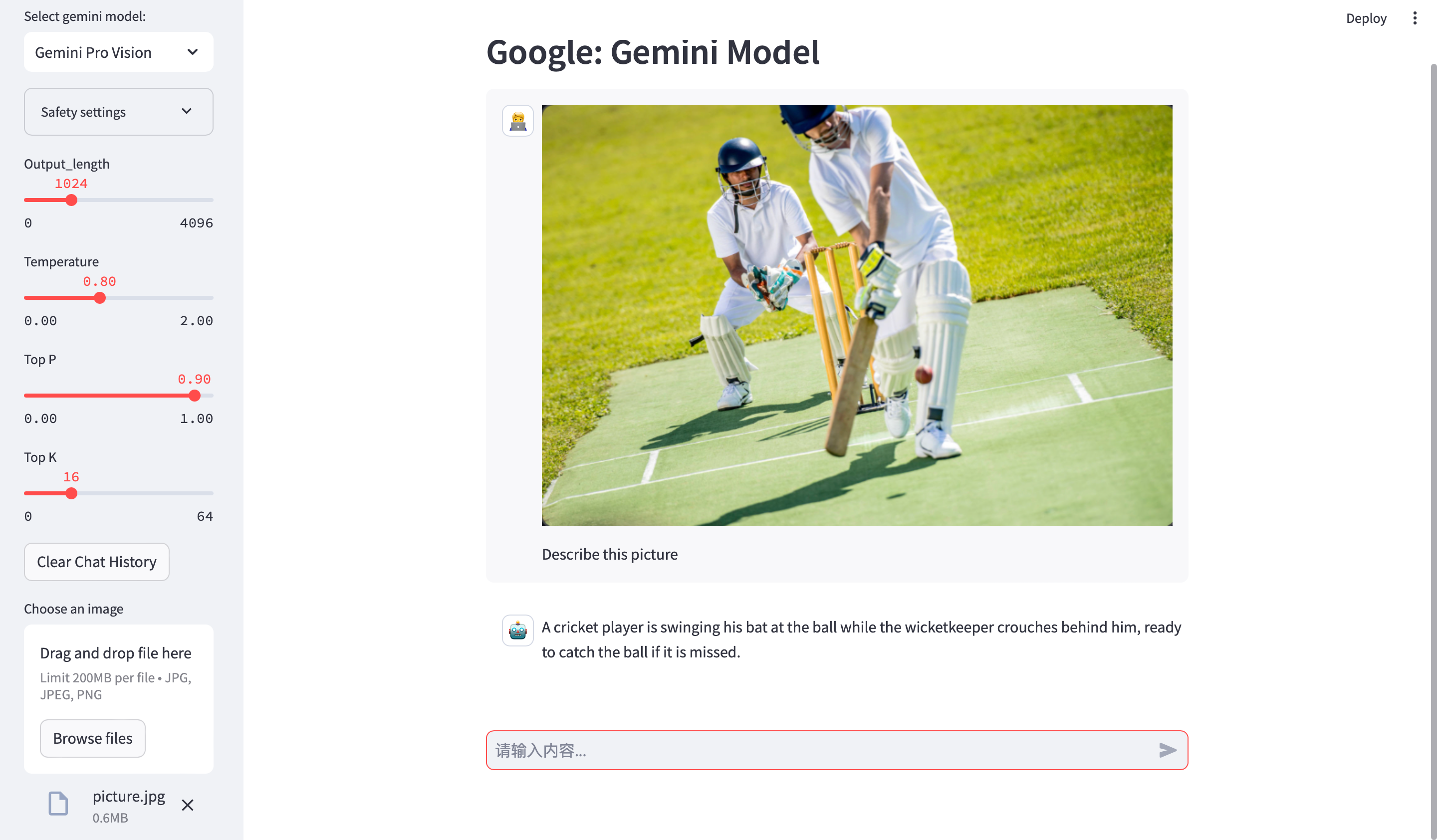
Google Gemini 模型本地可视化
Google近期发布了Gemini模型,而且开放了Gemini Pro API,Gemini Pro 可免费使用! Gemini Pro支持全球180个国家的38种语言,目前接受文本、图片作为输入并生成文本作为输出。 Gemini Pro的表现超越了其他同类模型,当前版…...

数据修复:.BlackBit勒索病毒来袭,安全应对方法解析
导言: 黑色数字罪犯的新玩具——.BlackBit勒索病毒,近来成为网络安全领域的头号威胁。这种恶意软件以其高度隐秘性和毁灭性而引起广泛关注。下面是关于.BlackBit勒索病毒的详细介绍,如不幸感染这个勒索病毒,您可添加我们的技术服…...

拓扑排序实现循环依赖判断 | 京东云技术团队
本文记录如何通过拓扑排序,实现循环依赖判断 前言 一般提到循环依赖,首先想到的就是Spring框架提供的Bean的循环依赖检测,相关文档可参考: https://blog.csdn.net/cristianoxm/article/details/113246104 本文方案脱离Spring Be…...
Java的NIO工作机制
文章目录 1. 问题引入2. NIO的工作方式3. Buffer的工作方式4. NIO数据访问方式 1. 问题引入 在网络通信中,当连接已经建立成功,服务端和客户端都会拥有一个Socket实例,每个Socket实例都有一个InputStream和OutputStream,并通过这…...

一个简单的光线追踪渲染器
前言 本文参照自raytracing in one weekend教程,地址为:https://raytracing.github.io/books/RayTracingInOneWeekend.html 什么是光线追踪? 光线追踪模拟现实中的成像原理,通过模拟一条条直线在场景内反射折射,最终…...
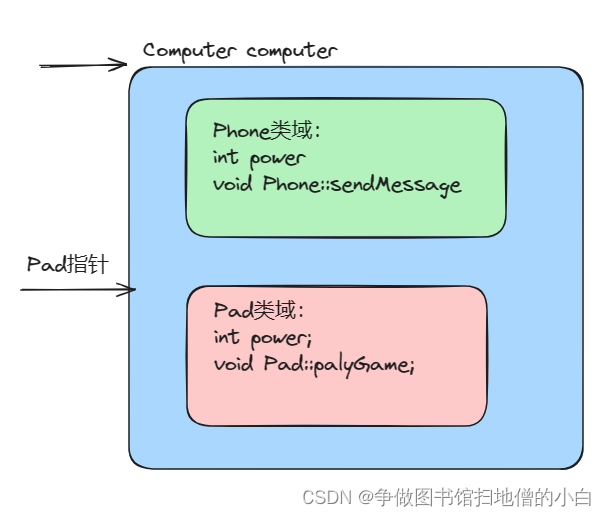
C++学习笔记(十二)------is_a关系(继承关系)
你好,这里是争做图书馆扫地僧的小白。 个人主页:争做图书馆扫地僧的小白_-CSDN博客 目标:希望通过学习技术,期待着改变世界。 提示:以下是本篇文章正文内容,下面案例可供参考 文章目录 前言 一、继承关系…...

DC电源模块的设计与制造技术创新
BOSHIDA DC电源模块的设计与制造技术创新 DC电源模块的设计与制造技术创新主要涉及以下几个方面: 1. 高效率设计:传统的DC电源模块存在能量转换损耗较大的问题,技术创新可通过采用高效率的电路拓扑结构、使用高性能的功率开关器件和优化控制…...

Sketch for Mac:实现你的创意绘图梦想的矢量绘图软件
随着数字时代的到来,矢量绘图软件成为了广告设计、插画创作和UI设计等领域中必不可少的工具。在众多矢量绘图软件中,Sketch for Mac(矢量绘图软件)以其强大的功能和简洁的界面脱颖而出,成为了众多设计师的首选。 Sket…...

ReactNative0.73发布,架构升级与更好的调试体验
这次更新包含了多种提升开发体验的改进,包括: 更流畅的调试体验: 通过 Hermes 引擎调试支持、控制台日志历史记录和实验性调试器,让调试过程更加高效顺畅。稳定的符号链接支持: 简化您的开发工作流程,轻松将文件或目录链接到其他…...

SVN忽略文件的两种方式
当使用版本管理工具时,提交到代码库的文档我们不希望存在把一些临时文件也推送到仓库中,这样就需要用到忽略文件。SVN的忽略相比于GIT稍显麻烦,GIT只需要在.gitignore添加忽略规则即可。而SVN有两种忽略方式,一个是全局设置&#…...

手写VUE后台管理系统10 - 封装Axios实现异常统一处理
目录 前后端交互约定安装创建Axios实例拦截器封装请求方法业务异常处理 axios 是一个易用、简洁且高效的http库 axios 中文文档:http://www.axios-js.com/zh-cn/docs/ 前后端交互约定 在本项目中,前后端交互统一使用 application/json;charsetUTF-8 的请…...

JavaScript装饰者模式
JavaScript装饰者模式 1 什么是装饰者模式2 模拟装饰者模式3 JavaScript的装饰者4 装饰函数5 AOP装饰函数6 示例:数据统计上报 1 什么是装饰者模式 在程序开发中,许多时候都我们并不希望某个类天生就非常庞大,一次性包含许多职责。那么我们就…...

C++学习笔记01
01.C概述(了解) c语言在c语言的基础上添加了面向对象编程和泛型编程的支持。 02.第一个程序helloworld(掌握) #define _CRT_SECURE_NO_WARNINGS #include<iostream> using namespace std;//标准命名空间int main() {//co…...
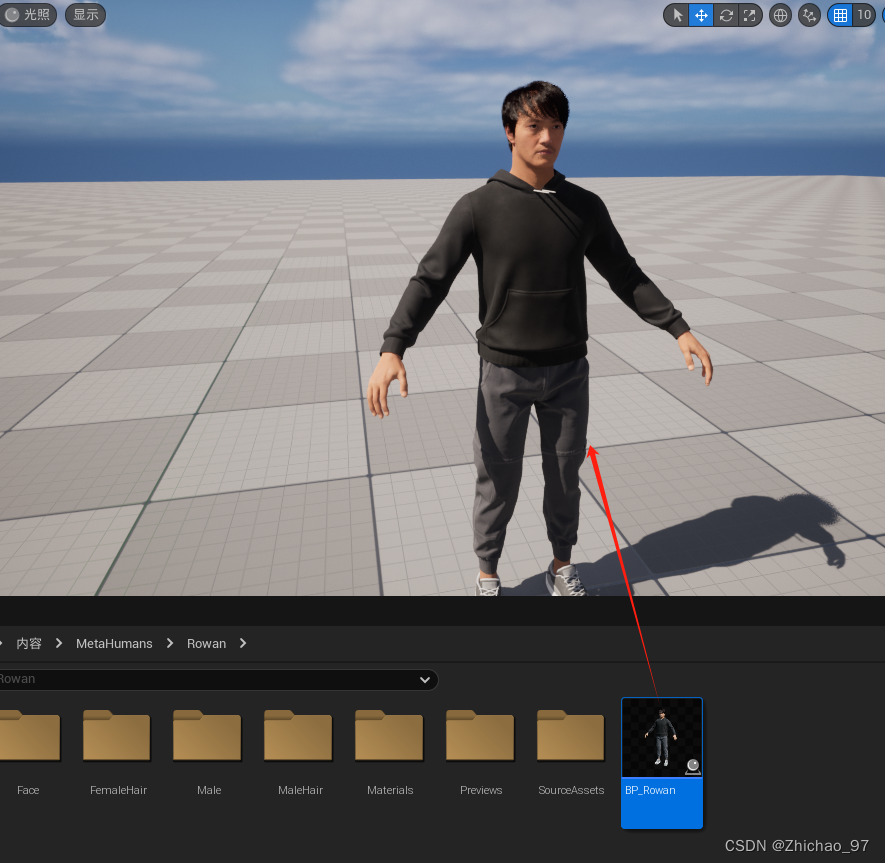
【UE5】初识MetaHuman 创建虚拟角色
步骤 在UE5工程中启用“Quixel Bridge”插件 打开“Quixel Bridge” 点击“MetaHumans-》MetaHuman Presets UE5” 点击“START MHC” 在弹出的网页中选择一个虚幻引擎版本,然后点击“启动 MetaHuman Creator” 等待一段时间后,在如下页面点击选择一个人…...

物流实时数仓:数仓搭建(DWD)一
系列文章目录 物流实时数仓:采集通道搭建 物流实时数仓:数仓搭建 物流实时数仓:数仓搭建(DIM) 物流实时数仓:数仓搭建(DWD)一 文章目录 系列文章目录前言一、文件编写1.目录创建2.b…...

MATLAB安装
亲自验证有效,多谢这位网友的分享: https://blog.csdn.net/xiajinbiaolove/article/details/88907232...
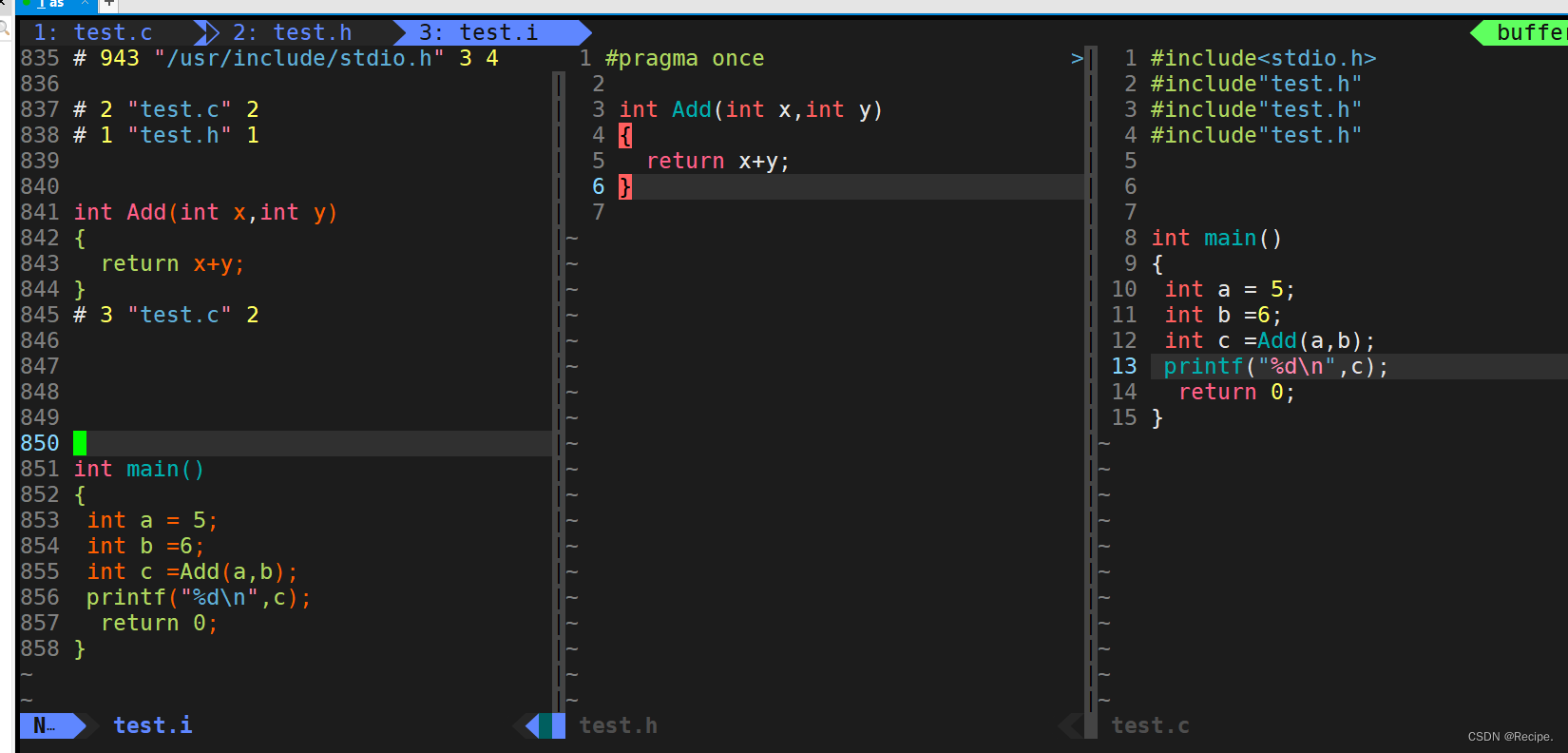
C语言——预处理详解(#define用法+注意事项)
#define 语法规定 #define定义标识符 语法: #define name stuff #define例子 #include<stdio.h> #define A 100 #define STR "abc" #define FOR for(;;)int main() {printf("%d\n", A);printf("%s\n", STR);FOR;return 0; } 运行结果…...

Linux(23):Linux 核心编译与管理
编译前的任务:认识核心与取得核心原始码 Linux 其实指的是核心。这个【核心(kernel)】是整个操作系统的最底层,他负责了整个硬件的驱动,以及提供各种系统所需的核心功能,包括防火墙机制、是否支持 LVM 或 Quota 等文件系统等等&a…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...