Redis第1讲——入门简介
Java并发编程的总结和学习算是告一段落了,这段时间思来想去,还是决定把Redis再巩固和学习一下。毕竟Redis不论是在面试还是实际应用中都是极其重要的,在面试中诸如Redis的缓存问题、热key、大key、过期策略、持久化机制等;还有在实际应用中的Redis缓存、分布式锁、Reids实现排行榜、分布式限流功能、Redis做延迟队列、消息队列、发布订阅等。相信大家对这并不陌生,而作者想要做的就是在其基础上,把它们进行总结、整理、扩展并深入。
一、为什么要学Redis?
目前大多数系统都是集群部署,那么在用传统的锁和缓存时就会出现以下问题:
- 缓存失效:在分布式集群中,每个节点之间的数据不是共享的,而本地缓存是本地的,因此,在一个节点上的本地缓存可能会缓存旧数据,而在另一个节点上的数据已经更新。这就会导致数据不一致性问题,从而影响系统的正确性。
- 互斥锁问题:传统的锁(Synchronized、Lock)是基于但服务实现的,多个服务之间无法共享锁的状态,简单来说就是锁失效,那么也会出现数据不一致等问题。
可以通过Redis的分布式缓存和分布式锁来解决上述问题。
还有就是有的功能使用关系型数据库来解决可能很复杂,而用Redis这种非关系型数据库实现就比较简单,比如聊天室功能:
- 如果用关系型数据库,一般都需要使用JOIN来进行多表查询,而在线的聊天室通常是非常频繁的读写操作,JOIN多表查询再加上频繁读写,不仅实现起来比较复杂,性能也很差。
- 如果用Redis,那就可以非常容易实现而且性能也远超关系型数据库。比如用Redis的List或Hash数据结构,将聊天室中的所有消息按照时间戳存储在一个列表中,用户发送的消息可以通过Redis的集合或队列存储,再使用Redis的发布订阅功能就可以实现消息的广播和接收。
二、什么是Redis?
Redis(Remote Dictionary Server),即远程字段服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis的作者——Antirez最初创建Redis是为了扩展实时日志分析工具LLOOGG,早先LLOOGG是基于MySQL的,但很快就遇到了性能瓶颈,Antirez相信使用内存可以解决这个问题,于是便开始了Redis的开发工作(原名为LLOOGG Memory Database),之后便有了这个功能强大、高性能、可扩展、易于使用的存储系统。
ps:这就是大佬思维,我们再遇到问题时第一想法是网上搜,而大佬的思维是自己开发一个,膜拜🤗。
- Redis最重要的功能是做缓存,查询效率远高于Mysql数据库。
- Redis是基于内存存储数据的,读写性能贼高。
- Redis 4.0之前,读的速度是110000次/S,写的速度是81000次/S;Redis6.0引入多线程后性能几乎翻倍,读的速度可达200000次/s,写的速度可达170000次/S。
- Redis不仅仅是Key-Value存储结构,针对Value还有多种数据结构。
- Redis也提供了相应的持久化方案(RDB、AOF)。
- Redis提供了主从复制、哨兵模式和Cluster等方案实现高可用。
- Redis提供了强大的功能,比如事务、发布订阅、Lua脚本等。
优点还有很多,不一一列举了....
Reids是一种非关系型数据库(NoSql),此外,常见的还有以下几种:
- key-value存储:将数据以键值对的形式存储,常用于缓存,比如Reids、MemCache等。
- 文档型存储:以类似于JSON或XML格式的文档形式存储,适用于存储和查询复杂的、半结构化的数据,比如Elasticsearch、MongDB等。
- 面向列存储:将数据按列存储,而不是按行,适用于大规模数据处理和分析,比如HBase、Apache Cassandra等。
- 图形化存储:以图的形式存储数据,适用于需要处理复杂关系和图算法的常见,比如Neo4j、OrientDB等。
三、Redis为什么要自己定义SDS?
从这开始就正式介绍Redis了。我们知道Redis是C语言实现的,但他并没有直接使用C语言中的字符数组的方式来实现字符串,而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS),并将SDS用作Redis的默认字符串表示,这是为什么呢?
我们先回顾下C语言中字符串的实现。C语言使用长度N+1的字符串数组来表示长度未N的字符串,并且字符串数组的最后一个元素总是为空字符'\0'。
那么这就会产生两个问题:
- 首先它就不能保存任意内容了,至少'\0'就不能保存了,因为遇到它时就直接截断了。
- 其次就是C语言中用'\0'来表示字符串结束的方式,所以计算长度、字符串追加等操作,都需要从头遍历,直到遇到'\0'才会返回长度或追加,那么它的性能就不是很高了。
因此,Redis自己定义了一个SDS来解决以上两个问题:
- 在用字符串数据表示字符串的同时,在这个字符串中增加一个表示分配给该字符串数组的总长度的alloc字段和一个表示字符串现有长度的len字段,这样在获取长度的时候就不依赖于'\0'了,直接返回len就行了。
- 在字符串做追加操作时,只需要判断新追加的部分的len加上已有的len是否大于alloc,如果超过就重新申请新空间,反之直接追加就行了。
ps:此外,SDS还被用作缓冲区(buffer):AOF模块中的AOF缓冲区,客户端状态中的输入缓冲区。
四、Redis的数据类型与数据结构
我们常见的数据类型比如string、hash、list、set、zset等类型其实在Redis中是一个个对象,是由简单动态字符串(SDS)、哈希表、整数集合、压缩列表、跳跃表等数据结构实现的。
Reids中的每个对象都由一个redisObject结构表示,该结构中和保存数据有关的有三个属性:
- type:记录对象的类型,比如字符串对象(string)、列表对象(list)等,可用type key命令查看value的存储类型。
- encoding:记录对象使用的编码,比如int、embstr等(下面会提到)。
- ptr:ptr指针指向对象底层实现数据结构,这些结构则是由encoding决定的。
对应关系如下(不是很全但够用):

上图为Redis常用的5种基本类型及Reids 5.0版本的stream类型和Redis的9种编码方式和7种底层数据结构对应的关系。下面我们详细的介绍下。
五、九种数据类型
5.1 String类型
5.1.1 简介
String类型是Redis最基本的数据类型,它可以存储任意类型的数据,比如数字、文本或者是序列化后的对象,最大可存储512MB的数据。
底层实现是SDS,由长度、空闲空间和字节数组三部分组成,并且有3种编码方式:
- int编码:用于存储整型数据,是以Long类型存储,未使用SDS类型。

- embstr编码:当存储的字符串长度小于等于32字节,用embstr编码。
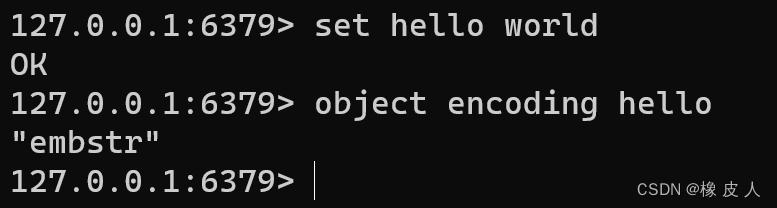
- raw编码:当存储的字符串长度大于32字节,用raw编码。

5.1.2 应用场景
应用场景还是非常广泛的,比如:
- 缓存:提高性能,降低数据库压力。
- 计数器:利用incr和decr命令实现原子性加减操作。
- 分布式锁:利用setnx命令。
- 限流:利用计数器的功能来实现限流。
5.1.3 常用命令
- SET key value:设置指定 key 的值为指定的 value。
- GET key:获取指定 key 的值。
- INCR key:将指定 key 的值加 1,并返回加 1 后的值。
- DECR key:将指定 key 的值减 1,并返回减 1 后的值。
- APPEND key value:将指定 key 的值追加指定的 value。
- STRLEN key:返回指定 key 的值长度。
- SETEX key seconds value:设置指定 key 的值,并指定过期时间,单位为秒。
5.2 hash类型
5.2.1 简介
hash是一个键值对集合,可以存储多个字段和值,简单的说它的value就是一个Map集合,一个hash最多可以存储2^32-1个字段。
底层实现其实有三种:
ziplist:压缩列表,当ziplist元素超过512个或单个元素超过64字节(可在redis的配置文件中设置),会转为hashtable。
listpack:紧凑列表,在Redis7.0之后,listpack取代ziplist,同样,到达上述阈值会转化为hashtable。
hashtable:哈希表,类似map。

下面我们来看下它们编码转换的情况:

5.2.2 应用场景
存储对象或实体属性:比如用户信息、商品信息。
存储配置信息:比如连接字符串、端口号、默认配置等。
5.2.3 常用命令
- HSET:设置 hash 中的字段和值。用法:HSET key field value
- HGET:获取指定 hash 字段的值。用法:HGET key field
- HMSET:同时设置 hash 中多个字段和值。用法:HMSET key field1 value1 [field2 value2 …]
- HMGET:获取指定 hash 中多个字段的值。用法:HMGET key field1 [field2 …]
- HGETALL:获取 hash 中所有字段和值。用法:HGETALL key
- HDEL:删除 hash 中的一个或多个字段。用法:HDEL key field1 [field2 …]
- HEXISTS:检查指定的字段在 hash 中是否存在。用法:HEXISTS key field
- HINCRBY:将 hash 中指定字段的值增加指定增量。用法:HINCRBY key field increment
- HINCRBYFLOAT:将 hash 中指定字段的浮点数值增加指定增量。用法:HINCRBYFLOAT key field increment
- HKEYS:获取 hash 中所有的字段。用法:HKEYS key
- HVALS:获取 hash 中所有的值。用法:HVALS key
- HLEN:获取 hash 中的字段数量。用法:HLEN key
- HSCAN:迭代遍历 hash 中的字段和值。用法:HSCAN key cursor [MATCH pattern] [COUNT count]
5.3 List类型
5.3.1 简介
List是一个存取有序的字符串列表,按照插入顺序排序,有下标,并且支持两端插入或删除元素。一个list的键最多可以存储2^32-1个元素。
底层实现是linkedlist和zipList:
- ziplist:当ziplist的结点超过512个或节点内存大于64字节时会转为linkedlist,当然,这个在Redis配置文件中也可以修改。
- linkedlist:双端链表。

下面介绍一下,不同版本的Redis其list的实现:
- Reids3.2之前:list使用linkedlist和ziplist。
- Reids3.2至Redis7.0:list使用的是quicklist,linkedlist和ziplist的结合。
- Reids7.0之后:list使用的也是quicklist,不过将ziplist转为listpack,其实就是listpack和linkedlist结合。
5.3.2 应用场景
- 消息队列:将消息以先后顺序添加到list中,然后可以用lpop命令从列表的左侧弹出消息并处理。
- 实时排行榜:将用户的得分或其它评价指标作为list的值,在该指标上进行排序。通过lpush、rpush和ltrim命令可以动态地更新排行榜。
- 发布/订阅:发布者使用rpush命令将消息推送到列表中,订阅者用blpop或brpop命令在列表上进行阻塞弹出接收消息。
- 历史记录:将聊天记录、日志信息等存储为list的值,使用lpush和lrange命令可以存储和查询最近的几条消息。
5.3.3 常用命令
- LPUSH:从列表的左侧添加一个或多个元素。用法:LPUSH key value1 [value2 …]
- RPUSH:从列表的右侧添加一个或多个元素。用法:RPUSH key value1 [value2 …]
- LPOP:从列表的左侧弹出第一个元素。用法:LPOP key
- RPOP:从列表的右侧弹出最后一个元素。用法:RPOP key
- LRANGE:获取列表中指定范围的元素。用法:LRANGE key start stop
- LINDEX:获取列表中指定索引位置的元素。用法:LINDEX key index
- LLEN:获取列表的长度(即元素数量)。用法:LLEN key
- LTRIM:修剪列表,只保留指定范围内的元素,其余元素删除。用法:LTRIM key start stop
- LINSERT:在列表中指定元素的前面或后面插入一个新元素。用法:LINSERT key BEFORE|AFTER pivot value
- LREM:从列表中删除指定数量的匹配元素。用法:LREM key count value
5.4 set类型
5.4.1 简介
set是一个无序的字符串集合,不允许重复,没有下标,一个set类型的键最多可以存储2^32-1个元素。
底层实现为intset和hashtable:
intset:当使用intset进行存储时,redis会自动的进行递增排序,因此,只存整型的话,其是一个有顺序的结构,但是并非只存整型数据就一直用intset,当整型的元素个数超过512个元素时,会转为hashtable。当存的是非整形时,也会转为hashtable进行存储。
hashtable:与hash类型的哈希表相同,将元素存储在一个数组中,并通过哈希函数计算元素在数组中的索引。


5.4.2 应用场景
- 去重:利用sadd和scard命令实现元素的去重并计数。
- 粉丝和关注系统:使用两个set分别存储用户的关注者和粉丝,使用sadd命令和srem命令来添加和移除关注,使用sinter和sunion命令可以计算共同关注和推荐关注。
- 抽奖:将用户存储在set中,使用sadd和srem命令增加和删除参与资格,通过srandmember命令从set中随机选择一个或多个参与者。
5.4.3 常用命令
- SADD:向 set 中添加一个或多个元素。用法:SADD key member1 [member2 …]
- SREM:从 set 中删除一个或多个元素。用法:SREM key member1 [member2 …]
- SMEMBERS:获取 set 中的所有元素。用法:SMEMBERS key
- SISMEMBER:检查元素是否在 set 中。用法:SISMEMBER key member
- SUNION:获取多个 set 的并集。用法:SUNION key1 [key2 …]
- SINTER:获取多个 set 的交集。用法:SINTER key1 [key2 …]
- SDIFF:获取两个 set 的差集(第一个 set 中有,第二个 set 中没有的元素)。用法:SDIFF key1 key2
- SCARD:获取 set 的元素数量(即集合的基数)。用法:SCARD key
- SPOP:从 set 中随机弹出一个元素。用法:SPOP key
- SRANDMEMBER:从 set 中随机获取一个或多个元素。用法:SRANDMEMBER key [count]
5.5 zset类型
5.5.1 简介
zset数据类型存取有序、不允许重复、有下标,并且给每个元素赋予了一个排序权重值(score)。Redis通过权重值来给集合中的元素进行从小到大排序,权重值可以重复。一个zset类型的键最多可以存储2^32-1个元素。
其底层存储结构也用了两种,ziplist和skiplist,也有切换关系:
- ziplist:ziplist存储元素超过128个或内存超过64字节,会转为skiplist。redis7.0之前是ziplist,之后为listpack。
- skiplist:跳跃表(之后详解)。

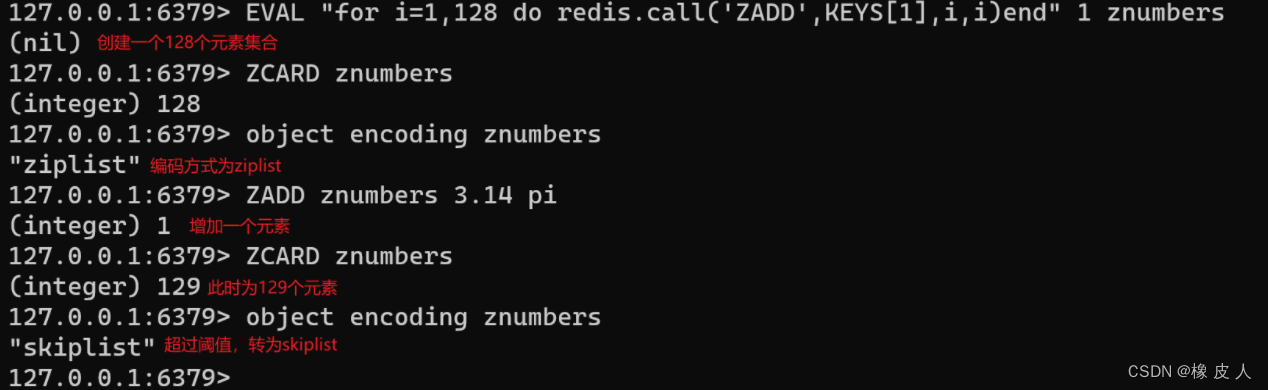
ps:这让我想起了之前面试官问zset类型底层是什么,当时大言不惭的说跳跃表的场景😅(当时对此深信不疑)。
5.5.2 应用场景
- 排行榜:将用户的得分、浏览量、商品销量等排序信息存储在有序集合中,使用zadd命令添加元素,使用zrange或zrevrange命令获取排行榜的前几名或全部成员,使用zrank或zrevrank命令获取指定成员在排行榜中的排名。
- 延迟队列:将任务及其执行时间存储在 zset 中,使用任务执行时间作为元素的分值,可以使用 zadd 命令添加任务和执行时间,使用 zrange 和 zrem 命令按执行时间获取任务。
- 区间查询:通过 zrangebyscore 或者 zrevrangebyscore 命令根据分值范围获取元素。
5.5.3 常用命令
- ZADD:向 zset 中添加一个或多个元素,以及它们的分值。用法:ZADD key score1 member1 [score2 member2 …]
- ZREM:从 zset 中删除一个或多个元素。用法:ZREM key member1 [member2 …]
- ZSCORE:获取指定元素的分值。用法:ZSCORE key member
- ZRANK:获取指定元素在 zset 中的排名(按升序)。用法:ZRANK key member
- ZREVRANK:获取指定元素在 zset 中的倒序排名(按降序)。用法:ZREVRANK key member
- ZRANGE:按升序获取 zset 中的一定范围元素。用法:ZRANGE key start stop [WITHSCORES]
- ZREVRANGE:按降序获取 zset 中的一定范围元素。用法:ZREVRANGE key start stop [WITHSCORES]
- ZCOUNT:统计 zset 中指定分值范围内的元素数量。用法:ZCOUNT key min max
- ZINCRBY:增减指定元素的分值。用法:ZINCRBY key increment member
- ZCARD:获取 zset 中元素的数量(即集合的基数)。用法:ZCARD key
5.6 stream类型
5.6.1 简介
stream是Redis5.0新加的一个数据类型,通常被视为一个日志或消息队列,它是一个由多个键值对组成的可持久化、有序、可重复的数据流。一个stream类型的键最多可以存储2^64-1个键值对。
底层实现是rax tree(基数树)和listpack,rax是一种压缩的前缀树结构,消息ID是作为rax中的key,消息具体数据是使用listpack保存,并作为value和消息ID一起保存到rax tree中。
5.6.2 应用场景
- 消息队列:生产者可以使用XADD命令将消息添加到stream中,消费者可以使用XREAD或XREADGROUP命令消费消息。
- 实时日志:每个日志视为一个消息,可以根据时间戳、唯一的消息ID、消息内容等属性进行查询和筛选。通过XADD命令添加日志,XREAD或XREADGROUP命令获取日志。
- 事件流处理:例如用户活动流、系统监控事件等。事件流中的每个事件被视为一个消息,可以根据事件类型、时间戳、事件属性等条件进行查询和分析。
5.6.3 常用命令
- XADD:向 Stream 中添加一条消息。用法:XADD key [MAXLEN [~|~count] [LIMIT count]] * field1 value1 [field2 value2 …] 示例:XADD mystream * name Alice age 25
- XLEN:获取 Stream 中的消息数量。用法:XLEN key 示例:XLEN mystream
- XRANGE:按照 ID 范围获取 Stream 中的消息列表。用法:XRANGE key start end [COUNT count] 示例:XRANGE mystream 0-0 10
- XREAD:读取 Stream 中的消息。用法:XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key …] id [id …] 示例:XREAD COUNT 10 STREAMS mystream 0
- XDEL:删除 Stream 中的消息。用法:XDEL key id [id …] 示例:XDEL mystream 1578854095166-0 1578854095166-1
- XGROUP CREATE:创建消费者组。用法:XGROUP CREATE key groupname id_or_$ [MKSTREAM] 示例:XGROUP CREATE mystream mygroup $
- XGROUP SETID:设置消费者组的消费位置。用法:XGROUP SETID key groupname id_or_$ 示例:XGROUP SETID mystream mygroup 0-0
- XREADGROUP:消费者组读取 Stream 中的消息。用法:XREADGROUP GROUP groupname consumerkey [COUNT count] [BLOCK milliseconds] STREAMS key [key …] id [id …] 示例:XREADGROUP GROUP mygroup consumer1 COUNT 10 STREAMS mystream >
- XACK:消费者确认已消费的消息。用法:XACK key groupname id [id …] 示例:XACK mystream mygroup 1578854095166-0 1578854095166-1
- XCLAIM:消费者从待处理列表中获取消息。用法:XCLAIM key groupname consumer min-idle-time ID [ID …] [IDLE ms] [TIME ms-unix-time] [RETRYCOUNT count] [FORCE] 示例:XCLAIM mystream mygroup consumer1 60000 1578854095166-0
5.7 Hyperloglog类型
5.7.1 简介
Hyperloglog是一种概率数据结构,算法的最本源则是伯努利过程。用在恒定的内存大小下估计集合的计数(不同元素的个数),以及对多个集合进行并、交运算等。优点是可以使用极少的内存空间,同时可以保证较高的准确性。每个Hyperloglog键秩序要花费12KB内存,便可计算接近2^64个不同元素的基数。
底层实现是HLL_DENSE(稠密矩阵)和HLL_SPARSE(稀疏矩阵):
稀疏矩阵:计数较少时使用。
稠密矩阵:计数增多,超过阈值后,会转为稠密矩阵。
5.7.2 应用场景
- 计算网站的UV(unique visitor)数量:通过记录用户请求的 IP 地址(或浏览器 cookie 等标识符),使用 HyperLogLog 可以快速估计出网站的独立访客数。
- 统计在线用户数量:通过记录用户登录名、客户端ID等信息,使用 HyperLogLog 可以快速估计在一段时间内在线用户的数量。
- 统计数据库中某字段的不同取值数量:通过记录字段值,使用 HyperLogLog 可以估算不同取值的数量,例如估算某个表中年龄、地区等字段的不同取值数量。
5.7.3 常用命令
- PFADD:向 HyperLogLog 中添加一个或多个元素。用法:PFADD key element [element …] 示例:PFADD myloglog user1 user2 user3
- PFCOUNT:获取 HyperLogLog 的基数估计值。用法:PFCOUNT key [key …] 示例:PFCOUNT myloglog
- PFMERGE:将多个 HyperLogLog 合并为一个。用法:PFMERGE destkey sourcekey [sourcekey …] 示例:PFMERGE mergedloglog myloglog1 myloglog2
- PEXPIRE:设置 HyperLogLog 的过期时间。用法:PEXPIRE key milliseconds 示例:PEXPIRE myloglog 60000
- PTTL:获取 HyperLogLog 的剩余过期时间。用法:PTTL key 示例:PTTL myloglog
- PERSIST:移除 HyperLogLog 的过期时间。用法:PERSIST key 示例:PERSIST myloglog
5.8 GEO类型
5.8.1 简介
GEO(地理位置)是一个键值对集合,其中每个元素都包含一个经度和纬度,可以用于存储地理位置信息并支持基于位置的搜索。
它是基于zset数据类型实现的,利用geohash算法将经纬度编码为二进制字符串,并作为zset的score值。在使用GEORADIUS和GEORADIUSBYMEMBER命令搜索元素时,Redis会构建一个跳跃表,以实现高效的搜索。
5.8.2 应用场景
- 附近的人/商家搜索:通过将用户/商家的地理位置坐标存储在 Redis 的 GEO 数据结构中,可以根据用户当前的地理位置快速查询附近的人或商家,实现定位服务和位置搜索功能。
- 地点推荐:通过存储地点的坐标和属性,可以根据用户当前的地理位置快速推荐附近的景点、餐厅、酒店等地点,并按距离排序。
- 打车/配送系统:可以使用 GEO 数据类型来存储司机的位置和乘客的位置,以便快速匹配附近的司机和乘客,并计算两者之间的距离。
- 热点地理位置统计:通过记录用户地理位置的访问次数,可以统计热门地点,用于展示热门景点、餐厅等信息。
5.8.3 常用命令
- PFADD:向 HyperLogLog 中添加元素。用法:PFADD key element [element …] 示例:PFADD myloglog a b c
- PFCOUNT:获取 HyperLogLog 的近似基数(唯一元素数量)。用法:PFCOUNT key [key …] 示例:PFCOUNT myloglog
- PFMERGE:将多个 HyperLogLog 合并为一个 HyperLogLog。用法:PFMERGE destkey sourcekey [sourcekey …] 示例:PFMERGE merged myloglog1 myloglog2 myloglog3
- PEXPIRE:设置 HyperLogLog 的过期时间。用法:PEXPIRE key milliseconds 示例:PEXPIRE myloglog 60000
- PTTL:获取 HyperLogLog 的剩余过期时间。用法:PTTL key 示例:PTTL myloglog
- PERSIST:移除 HyperLogLog 的过期时间。用法:PERSIST key 示例:PERSIST myloglog
5.9 bitmap类型
5.9.1简介
bitmap是一种紧凑的数据结构,可以用于表示一个只有0和1的数组。位图可以用于高效地存储大规模的布尔值,以及进行位运算、位图图形化等操作。一个bitmap最多可以存储2^32-1个二进制位。
底层使用了一种“压缩位图”的数据结构。通过使用两个数组来存储位图数据:一个存储实际位的值,另一个存储每个字节中1的个数。这种方式可大大压缩位图数据的大小。
5.9.2 应用场景
- 统计在线用户:与统计用户活跃类似,可以使用 Bitmap 来实现对在线用户的统计。比如将一个 key 对应的字符串的每个比特位表示一个用户,当某个用户在线时,将对应的比特位置为 1。此时使用 BITCOUNT 命令来计算在线的用户数。
- Bloom Filter:利用 SETBIT 和 GETBIT命令实现快速判断一个元素是否存在于一个集合中。
- 统计用户访问情况:可以利用 Bitmap 记录用户的访问情况,如记录用户是否已浏览一篇文章。可以使用 SETBIT 命令为特定文章的每个用户设置一个比特位,并在用户浏览过该文章时,将其对应的比特位设置为 1。这些比特位的数据将存储在同一个键值下,以记住哪个用户看过哪些文章。
- 实现位图索引:利用 bitop 和 bitpos 命令实现对多个条件进行位运算和定位
5.9.3 常用命令
- SETBIT:设置位图在指定偏移量的值。用法:SETBIT key offset value 示例:SETBIT mybitmap 0 1
- GETBIT:获取位图在指定偏移量的值。用法:GETBIT key offset 示例:GETBIT mybitmap 0
- BITCOUNT:计算位图中值为1的位的数量。用法:BITCOUNT key [start end] 示例:BITCOUNT mybitmap 0 10
- BITOP:对多个位图执行位运算操作,并将结果保存在指定位图中。用法:BITOP operation destkey key [key …] 示例:BITOP AND result mybitmap1 mybitmap2 mybitmap3
- BITPOS:查找位图中指定bit(0或1)第一次出现的偏移量。用法:BITPOS key bit [start] [end] 示例:BITPOS mybitmap 0 100
- BITFIELD:使用位域操作位图。用法:BITFIELD key [GET type offset] [SET type offset value] 示例:BITFIELD mybitmap GET u4 0
End:希望对大家有所帮助,如果有纰漏或者更好的想法,请您一定不要吝啬你的赐教🙋。
相关文章:
Redis第1讲——入门简介
Java并发编程的总结和学习算是告一段落了,这段时间思来想去,还是决定把Redis再巩固和学习一下。毕竟Redis不论是在面试还是实际应用中都是极其重要的,在面试中诸如Redis的缓存问题、热key、大key、过期策略、持久化机制等;还有在实…...

数据科学知识库
我的博客是一个技术分享平台,涵盖了机器学习、数据可视化、大数据分析、数学统计学、推荐算法、Linux命令及环境搭建,以及Kafka、Flask、FastAPI、Docker等组件的使用教程。 在这个信息时代,数据已经成为了一种新的资源,而机…...
设计模式——责任链模式(行为模式)
引言 责任链模式是一种行为设计模式, 允许你将请求沿着处理者链进行发送。 收到请求后, 每个处理者均可对请求进行处理, 或将其传递给链上的下个处理者。 问题 假如你正在开发一个在线订购系统。 你希望对系统访问进行限制, 只允…...
【谭浩强C语言:前八章编程题(多解)】
文章目录 第一章1. 求两个整数之和(p7) 第二章2. 求三个数中的较大值(用函数)(p14、p107)3.求123...n(求n的阶乘,用for循环与while循环)(P17)1.循环求n的阶乘2.递归求n的阶乘(n< 10) 4.有M个学生,输出成绩在80分以上的学生的学…...
程序人生15年人生感悟
计算机程序员并不是一件什么高大上的职业。而仅仅是一份普通的工作。就像医生能治病救人,我们能治蓝屏救程序,我们都在为这个世界默默的做出自己的贡献。刻意或无意宣扬某个职业高大上,其实质是对其它行业从业者的不公平。但是有些人却常常这…...

React与AJAX
大家好,欢迎来到 《React与AJAX》 课程。在这一课中,我们将学习如何在 React 中使用 AJAX。 什么是 AJAX? AJAX(Asynchronous JavaScript and XML)是一种使用 JavaScript 在浏览器和服务器之间进行异步通信的技术。A…...

C++ STL泛型算法
泛型算法 <algorithm>定义了大约 80 个标准算法。 它们操作由一对迭代器定义的(输入)序列或单一迭代器定义的(输出)序列。 当对两个序列进行拷贝、比较操作时,第一个序列由一对迭代器[b,e)表示,但第…...

使用OpenSSL生成PKCS#12格式的证书和私钥
要使用OpenSSL生成PKCS12格式的证书和私钥,可以按照以下步骤进行操作: 1. 安装OpenSSL 首先,确保已在计算机上安装了OpenSSL。可以从OpenSSL官方网站(https://www.openssl.org/)下载并安装适用于您的操作系统的版本。…...
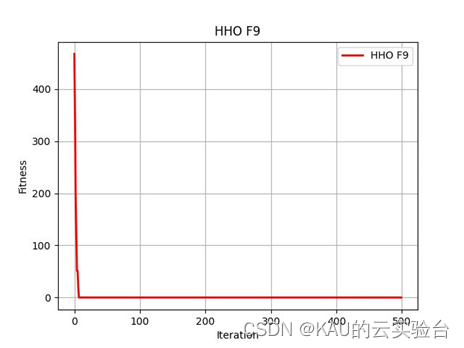
超详细 | 哈里斯鹰优化算法原理、实现及其改进与利用(Matlab/Python)
测试函数为F9 在MATLAB中执行程序结果如下: 在Python中执行程序结果如下: 哈里斯鹰优化算法(Harris Hawks Optimization , HHO)是 Heidari等[1]于2019年提出的一种新型元启发式算法,设计灵感来源于哈里斯鹰在捕食猎物过程中的合作行为以及突…...

git 切换远程地址分支 推送到指定地址分支 版本回退
切换远程地址 1、切换远程仓库地址: 方式一:修改远程仓库地址 【git remote set-url origin URL】 更换远程仓库地址,URL为新地址。 git remote set-url https://gitee.com/xxss/omj_gateway.git 方式二:先删除远程仓库地址&…...

YOLOv3-YOLOv8的一些总结
0 写在前面 这个文档主要总结YOLO系列的创新点,以YOLOv3为baseline。参考(抄)了不少博客,就自己看看吧。有些模型的trick不感兴趣就没写进来,核心的都写了。 YOLO系列的网络都由四个部分组成:Input、Backbone、Neck、Prediction…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)控件的部分公共属性和事件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)控件的部分公共属性和事件 一、操作环境 操作系统: Windows 10 专业版 IDE:DevEco Studio 3.1 SDK:HarmonyOS 3.1 二、公共属性 常用的公共属性有: 宽(with)、高(height)、…...
最新同步云盘推荐:实现轻松管理与便捷同步的理想选择
同步云盘——可以轻松管理文件,同步不同设备之间的文件,受到了许多用户的青睐!目前国内有什么值得推荐的同步云盘? Zoho Workdrive同步云盘,助您轻松管理文件,进行多设备同步,便捷使用文件&…...
Oracle 数据泵转换分区表)
(第27天)Oracle 数据泵转换分区表
在Oracle数据库中,分区表的使用是很常见的,使用数据泵也可以进行普通表到分区表的转换,虽然实际场景应用的不多。 创建测试表 sys@ORADB 2022-10-13 11:54:12> create table lucifer.tabs as select * from dba_objects;Table created.sys...

业务上需要顺序消费,怎么保证时序性?
消息传输和消费的有序性,是消息队列应用中一个非常重要的问题,在分布式系统中,很多业务场景都需要考虑消息投递的时序。例如,电商中的订单状态流转、数据库的 binlog 分发,都会对业务的有序性有要求。今天我们一起来看…...
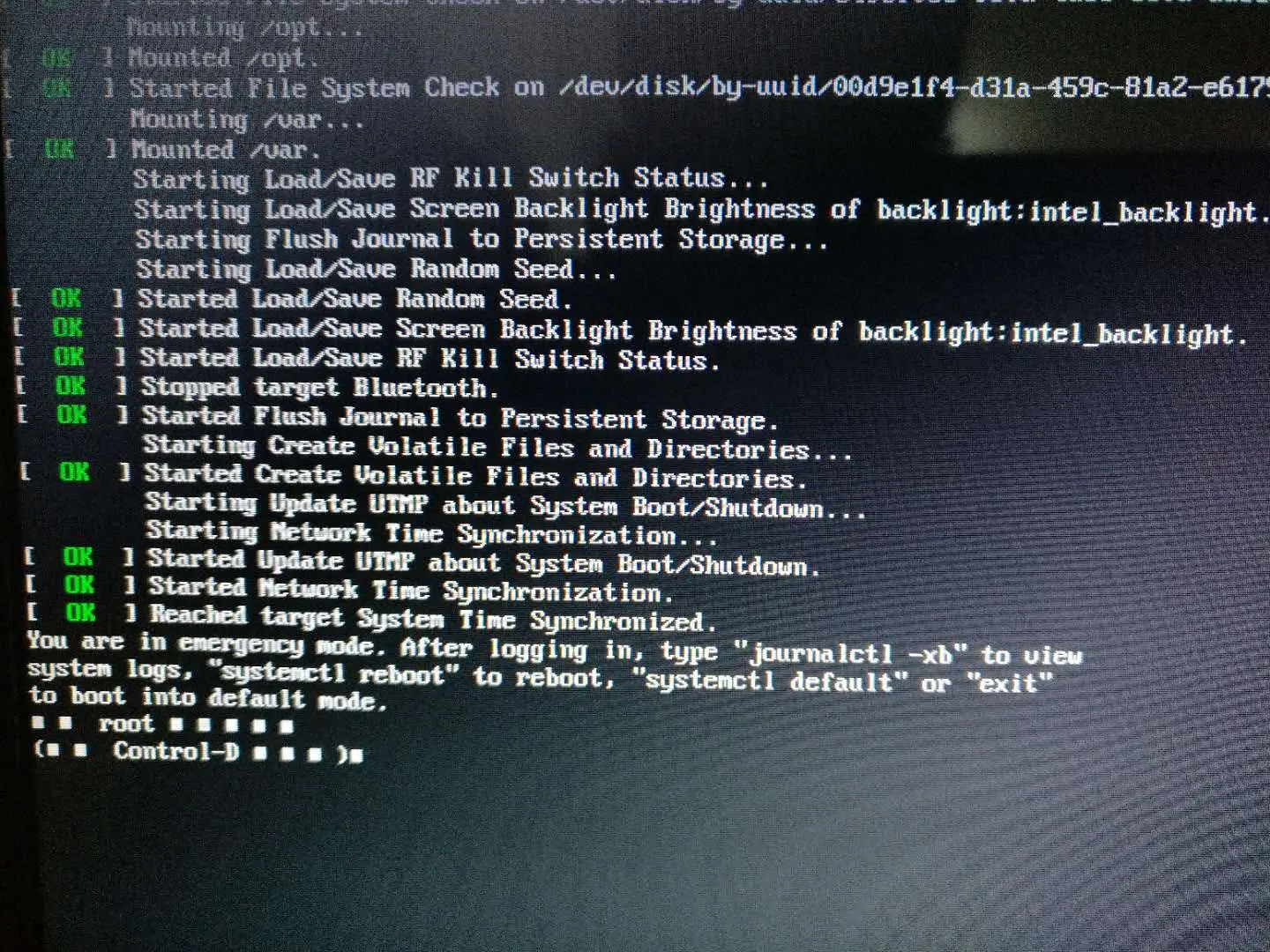
ubuntu 开机提示 you are in emergency mode,journalctl -xb
进入系统界面 回车输入: journalctl -xb -p3 查看出问题的盘符类型。 然后 lsblk 查看挂载情况 我的是/dev/sda3没有挂载上,对应/home目录,注意这时候不要直接mount 需要先修复 fsck -y /dev/sda3等待修复完成,在重新挂载 moun…...
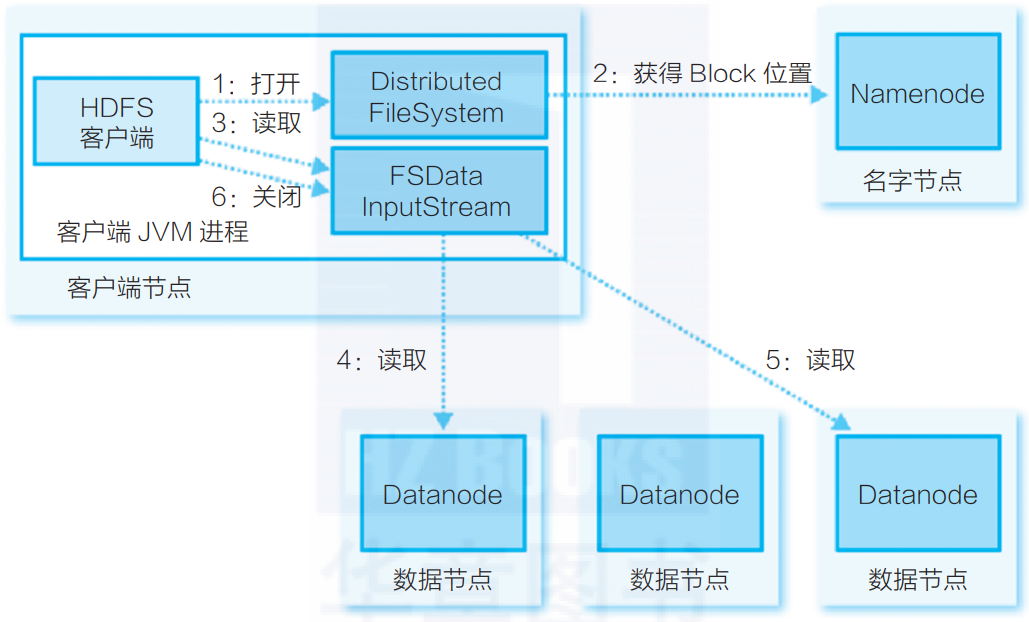
【Hadoop面试】HDFS读写流程
HDFS(Hadoop Distributed File System)是GFS的开源实现。 HDFS架构 HDFS是一个典型的主/备(Master/Slave)架构的分布式系统,由一个名字节点Namenode(Master) 多个数据节点Datanode(Slave)组成。其中Namenode提供元数…...
B01、JVM与Java体系结构-01
字节码与多语言混合编程 字节码概述: 我们平时说的java字节码,指的是用java语言编译成的字节码。准确的说任何能在jvm平台上执行的字节码格式都是一样的。所以应该统称为:jvm字节码。不同的编译器,可以编译出相同的字节码文件&…...

Python:Jupyter
Jupyter是一个开源的交互式计算环境,由Fernando Perez和Brian Granger于2014年创立。它提供了一种方便的方式来展示、共享和探索数据,并且可以与多种编程语言和数据格式进行交互。Jupyter的历史可以追溯到2001年,当时Fernando Perez正在使用P…...

macos苹果电脑开启tftp server上传fortigate60e固件成功
cat /System/Library/LaunchDaemons/tftp.plist<?xml version"1.0" encoding"UTF-8"?> <!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...