使用Pytorch从零开始构建StyleGAN2
这篇博文是关于 StyleGAN2 的,来自论文Analyzing and Improving the Image Quality of StyleGAN,我们将使用 PyTorch 对其进行干净、简单且可读的实现,并尝试尽可能地还原原始论文。
如果您没有阅读 StyleGAN2 论文。或者不知道它是如何工作的并且你想了解它,我强烈建议你看看扫一下原始论文,了解其主要思想。
我们在本博客中使用的数据集是来自 Kaggle 的数据集,其中包含 16240 件女性上衣,分辨率为 256*192。
依赖项加载
一如既往,让我们首先加载我们需要的所有依赖项。
我们首先导入 torch,因为我们将使用 PyTorch,然后从那里导入 nn. 这将帮助我们创建和训练网络,并让我们导入 optim,一个实现各种优化算法(例如 sgd、adam 等)的包。我们从 torchvision 导入数据集和转换来准备数据并应用一些转换。
我们将从 torch.nn 导入 F 函数,从 torch.utils.data 导入 DataLoader 以创建小批量大小,从 torchvision.utils 导入 save_image 以保存一些假样本,log2 和 sqrt 形成数学,Numpy 用于线性代数,操作系统用于交互使用操作系统,tqdm 显示进度条,最后使用 matplotlib.pyplot 绘制一些图像。
import torch
from torch import nn, optim
from torchvision import datasets, transforms
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from math import log2, sqrt
import numpy as np
import os
from tqdm import tqdm
import matplotlib.pyplot as plt
超参数
- 通过真实图像的路径初始化DATASET。
- 如果可用,则使用 Cuda 初始化设备,否则使用 CPU,将 epoch 数设为 300,将学习率设为 0.001,将批量大小设为 32。
- 将 LOG_RESOLUTION 初始化为 7,因为我们试图生成 128*128 图像,并且 2^7 = 128。您可以根据所需的假图像的分辨率更改该值。
- 在原始论文中,他们将 Z_DIM 和 W_DIM 初始化为 512,但我将它们初始化为 256,以减少 VRAM 使用和加速训练。如果我们将它们加倍,我们甚至可能会得到更好的结果。
- 对于 StyleGAN2,我们可以使用任何我们想要的 GAN 损失函数,因此我使用论文“ Improved Training of Wasserstein GAN”中的 WGAN-GP 。该损失包含一个参数名称 λ,通常设置 λ = 10。
DATASET = "Women clothes"
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
EPOCHS = 300
LEARNING_RATE = 1e-3
BATCH_SIZE = 32
LOG_RESOLUTION = 7 #for 128*128
Z_DIM = 256
W_DIM = 256
LAMBDA_GP = 10
获取数据加载器
现在让我们创建一个函数get_loader来:
- 对图像应用一些转换(将图像大小调整为我们想要的分辨率(2^LOG_RESOLUTION by 2^LOG_RESOLUTION),将它们转换为张量,然后应用一些增强,最后将它们标准化为从 -1 到1)。
- 使用 ImageFolder 准备数据集,因为它已经以良好的方式构建。
- 使用 DataLoader 创建小批量大小,该 DataLoader 通过打乱数据来获取数据集和批量大小。
- 最后,返回loader。
def get_loader():transform = transforms.Compose([transforms.Resize((2 ** LOG_RESOLUTION, 2 ** LOG_RESOLUTION)),transforms.ToTensor(),transforms.RandomHorizontalFlip(p=0.5),transforms.Normalize([0.5, 0.5, 0.5],[0.5, 0.5, 0.5],),])dataset = datasets.ImageFolder(root=DATASET, transform=transform)loader = DataLoader(dataset,batch_size=BATCH_SIZE,shuffle=True,)return loader
模型实现
现在让我们使用论文中的关键属性来实现 StyleGAN2 网络。我们将尽力使实现紧凑,但同时保持其可读性和可理解性。具体来说,有以下几个要点:
- 噪声映射网络
- 权重解调(而非自适应实例归一化 (AdaIN))
- 跳跃连接(而非渐进式增长)
- 感知路径长度标准化
噪声映射网络
让我们创建将从 nn.Module 继承的 MappingNetwork 类。
在init部分,我们发送 z_dim 和 w_din,并定义包含 8 个 EqualizedLinear 的网络映射,这是我们稍后将实现的用于均衡学习率的类,以及作为激活函数的 ReLu
在前一部分中,我们使用像素范数初始化 z_dim,然后返回网络映射。
class MappingNetwork(nn.Module):def __init__(self, z_dim, w_dim):super().__init__()self.mapping = nn.Sequential(EqualizedLinear(z_dim, w_dim),nn.ReLU(),EqualizedLinear(z_dim, w_dim),nn.ReLU(),EqualizedLinear(z_dim, w_dim),nn.ReLU(),EqualizedLinear(z_dim, w_dim),nn.ReLU(),EqualizedLinear(z_dim, w_dim),nn.ReLU(),EqualizedLinear(z_dim, w_dim),nn.ReLU(),EqualizedLinear(z_dim, w_dim),nn.ReLU(),EqualizedLinear(z_dim, w_dim))def forward(self, x):x = x / torch.sqrt(torch.mean(x ** 2, dim=1, keepdim=True) + 1e-8) # for PixelNorm return self.mapping(x)
生成器
在下图中,您可以看到生成器架构,它以初始常量开始。然后它有一系列的块。每个块的特征图分辨率加倍。每个块输出一个 RGB 图像,它们被放大并求和以获得最终的 RGB 图像。
toRGB还有一个风格调制,为简单起见,图中未显示。
为了使代码尽可能简洁,在生成器的实现中,我们将使用稍后定义的三个类(StyleBlock、toRGB 和 GeneratorBlock)。

- 在初始化部分,我们发送 log_resolution,它是图像分辨率的 log2,W_DIM,它是w 的维数, n_featurese,它 是最高分辨率(最终块)卷积层中的特征数量,max_features,它是最大值任何生成器块中的功能数量。我们计算每个块的特征数量,得到生成器块的数量,并初始化可训练的 4x4 常量、4×4 分辨率的第一个样式块、获取 RGB 的层和生成器块。
- 在前一部分中,我们为每个生成器块发送 w ,它具有形状 [ n_blocks, batch_size, W-dim ] 和 input_noise ,它是每个块的噪声,它是噪声张量对的列表,因为每个块(除了初始)在每个卷积层之后有两个噪声输入(见上图)。我们获取批量大小,扩展学习的常量以匹配批量大小,将其运行到第一个样式块,获取 RGB 图像,然后在上采样后再次将其运行到其余的生成器块中。最后,以 tanh 作为激活函数返回最后一张 RGB 图像。我们使用 tanh 的原因是它将作为输出(生成的图像),并且我们希望像素的范围在 1 到 -1 之间。
class Generator(nn.Module):def __init__(self, log_resolution, W_DIM, n_features = 32, max_features = 256):super().__init__()features = [min(max_features, n_features * (2 ** i)) for i in range(log_resolution - 2, -1, -1)]self.n_blocks = len(features)self.initial_constant = nn.Parameter(torch.randn((1, features[0], 4, 4)))self.style_block = StyleBlock(W_DIM, features[0], features[0])self.to_rgb = ToRGB(W_DIM, features[0])blocks = [GeneratorBlock(W_DIM, features[i - 1], features[i]) for i in range(1, self.n_blocks)]self.blocks = nn.ModuleList(blocks)def forward(self, w, input_noise):batch_size = w.shape[1]x = self.initial_constant.expand(batch_size, -1, -1, -1)x = self.style_block(x, w[0], input_noise[0][1])rgb = self.to_rgb(x, w[0])for i in range(1, self.n_blocks):x = F.interpolate(x, scale_factor=2, mode="bilinear")x, rgb_new = self.blocks[i - 1](x, w[i], input_noise[i])rgb = F.interpolate(rgb, scale_factor=2, mode="bilinear") + rgb_newreturn torch.tanh(rgb)
生成器block
在下图中,您可以看到生成器block架构,它由两个风格blocks(带有风格调制的 3×3 卷积)和 RGB 输出组成。

class GeneratorBlock(nn.Module):def __init__(self, W_DIM, in_features, out_features):super().__init__()self.style_block1 = StyleBlock(W_DIM, in_features, out_features)self.style_block2 = StyleBlock(W_DIM, out_features, out_features)self.to_rgb = ToRGB(W_DIM, out_features)def forward(self, x, w, noise):x = self.style_block1(x, w, noise[0])x = self.style_block2(x, w, noise[1])rgb = self.to_rgb(x, w)return x, rgb- 在init部分,我们发送 W_DIM(即 w 的维数)、 in_features(即输入特征图中的特征数量)和 out_features(即输出特征图中的特征数量),然后我们初始化两个风格blocks并到RGB层。
- 在前向部分中,我们发送形状为 [ batch_size, in_features, height, width ] 的输入特征图 x,形状为 [ batch_size, W_DIM ] 的 w,以及形状为两个噪声张量的元组的噪声。 [ batch_size, 1, height, width ],然后我们将 x 运行到两个风格blocks中,并使用 toRGB 层获得 RGB 图像。最后,我们返回 x 和 RGB 图像。
风格blocks

- 在init部分,我们发送 W_DIM、in_features 和 out_features,然后用从 w 获得的风格向量(图中用A表示)初始化 to_style,并使用稍后实现的均衡学习率线性层 (EqualizedLinear) 、权重调制卷积层、噪声尺度、偏差和激活函数。
- 在前向部分,我们发送x、w和噪声,然后得到风格向量s,将x和s运行到权重调制卷积中,缩放并添加噪声,最后添加偏差并评估激活函数。
class StyleBlock(nn.Module):def __init__(self, W_DIM, in_features, out_features):super().__init__()self.to_style = EqualizedLinear(W_DIM, in_features, bias=1.0)self.conv = Conv2dWeightModulate(in_features, out_features, kernel_size=3)self.scale_noise = nn.Parameter(torch.zeros(1))self.bias = nn.Parameter(torch.zeros(out_features))self.activation = nn.LeakyReLU(0.2, True)def forward(self, x, w, noise):s = self.to_style(w)x = self.conv(x, s)if noise is not None:x = x + self.scale_noise[None, :, None, None] * noisereturn self.activation(x + self.bias[None, :, None, None])
转RGB

- 在初始化部分,我们发送 W_DIM 和特征,然后通过从 w 获得的风格向量(图中用A表示)、权重调制卷积层、偏差和激活函数来初始化 to_style 。
- 在前向部分,我们发送 x 和 w,然后我们得到样式向量 style,我们将 x 和 style 运行到权重调制卷积中,最后,我们添加偏差并评估激活函数。
class ToRGB(nn.Module):def __init__(self, W_DIM, features):super().__init__()self.to_style = EqualizedLinear(W_DIM, features, bias=1.0)self.conv = Conv2dWeightModulate(features, 3, kernel_size=1, demodulate=False)self.bias = nn.Parameter(torch.zeros(3))self.activation = nn.LeakyReLU(0.2, True)def forward(self, x, w):style = self.to_style(w)x = self.conv(x, style)return self.activation(x + self.bias[None, :, None, None])
卷积与权重调制和解调
此类通过样式向量缩放卷积权重,并通过对其进行归一化来解调。
- 在init部分,我们发送 in_features、out_features、kernel_size、demodulates(是否按标准差对权重进行归一化的标志)和 eps(用于归一化的ϵ),然后初始化输出特征的数量、解调、填充大小,使用我们稍后将实现的类 EqualizedWeight 和 eps 来设置具有均衡学习率的权重参数。
- 在前向部分,我们发送输入特征图 x 和基于样式的缩放张量 s,然后我们从 x 中获取批量大小、高度和宽度,重塑尺度,获得均衡的学习率权重,然后调制 x 和 s,如果 demodulates 为 True,则使用以下方程解调它们,其中i是输入通道,j是输出通道,k是内核索引。最后,我们返回 x。

class Conv2dWeightModulate(nn.Module):def __init__(self, in_features, out_features, kernel_size,demodulate = True, eps = 1e-8):super().__init__()self.out_features = out_featuresself.demodulate = demodulateself.padding = (kernel_size - 1) // 2self.weight = EqualizedWeight([out_features, in_features, kernel_size, kernel_size])self.eps = epsdef forward(self, x, s):b, _, h, w = x.shapes = s[:, None, :, None, None]weights = self.weight()[None, :, :, :, :]weights = weights * sif self.demodulate:sigma_inv = torch.rsqrt((weights ** 2).sum(dim=(2, 3, 4), keepdim=True) + self.eps)weights = weights * sigma_invx = x.reshape(1, -1, h, w)_, _, *ws = weights.shapeweights = weights.reshape(b * self.out_features, *ws)x = F.conv2d(x, weights, padding=self.padding, groups=b)return x.reshape(-1, self.out_features, h, w)鉴别器
在下图中,您可以看到鉴别器架构。它首先将分辨率为 2 L O G _ R E S O L U T I O N x 2 L O G _ R E S O L U T I O N 2 ^{LOG\_RESOLUTION} x 2^{LOG\_RESOLUTION} 2LOG_RESOLUTIONx2LOG_RESOLUTION的图像转换 为相同分辨率的特征图,然后通过一系列具有残差连接的块来运行它。每个块的分辨率下采样 2 倍,同时特征数量加倍。

- 在init部分,我们发送log_resolution、n_feautures和max_features,计算每个块的特征数量,然后初始化一个名为from_rgb的层,将RGB图像转换为具有n_features特征数量、鉴别器数量的特征图块、鉴别器块、添加标准差图后的特征数、最终的 3×3 卷积层和最终的线性层以获得分类。
- 对于判别器上的 Minibatch std,我们在为每个示例(跨所有通道和像素)获取 std 时添加minibatch_std部分,然后我们对单个通道重复它并将其与图像连接。通过这种方式,鉴别器将获得有关批次/图像变化的信息。
- 在前向部分,我们发送 x,它是形状 [ batch_size, 3, height, width ] 的输入图像,然后运行它并抛出 from_RGB 层、鉴别器块、minibatch_std、3×3 卷积、展平和分类分数。
class Discriminator(nn.Module):def __init__(self, log_resolution, n_features = 64, max_features = 256):super().__init__()features = [min(max_features, n_features * (2 ** i)) for i in range(log_resolution - 1)]self.from_rgb = nn.Sequential(EqualizedConv2d(3, n_features, 1),nn.LeakyReLU(0.2, True),)n_blocks = len(features) - 1blocks = [DiscriminatorBlock(features[i], features[i + 1]) for i in range(n_blocks)]self.blocks = nn.Sequential(*blocks)final_features = features[-1] + 1self.conv = EqualizedConv2d(final_features, final_features, 3)self.final = EqualizedLinear(2 * 2 * final_features, 1)def minibatch_std(self, x):batch_statistics = (torch.std(x, dim=0).mean().repeat(x.shape[0], 1, x.shape[2], x.shape[3]))return torch.cat([x, batch_statistics], dim=1)def forward(self, x):x = self.from_rgb(x)x = self.blocks(x)x = self.minibatch_std(x)x = self.conv(x)x = x.reshape(x.shape[0], -1)return self.final(x)
鉴别器blocks
在下图中,您可以看到判别器blocks架构,它由两个带有残差连接的 3×3 卷积组成。

- 在init部分,我们发送in_features和out_features,并初始化包含下采样和用于残差连接的1×1卷积层的残差块,该块层包含两个以Leaky Rely作为激活的3×3卷积函数,使用 AvgPool2d 的 down_sample 层,以及添加残差后我们将使用的比例因子。
- 在前向部分中,我们发送 x 并运行它抛出残差连接以获得名为残差的变量,然后运行 x 抛出卷积和下采样,然后添加残差和缩放,然后返回它。
class DiscriminatorBlock(nn.Module):def __init__(self, in_features, out_features):super().__init__()self.residual = nn.Sequential(nn.AvgPool2d(kernel_size=2, stride=2), # down sampling using avg poolEqualizedConv2d(in_features, out_features, kernel_size=1))self.block = nn.Sequential(EqualizedConv2d(in_features, in_features, kernel_size=3, padding=1),nn.LeakyReLU(0.2, True),EqualizedConv2d(in_features, out_features, kernel_size=3, padding=1),nn.LeakyReLU(0.2, True),)self.down_sample = nn.AvgPool2d(kernel_size=2, stride=2) # down sampling using avg poolself.scale = 1 / sqrt(2)def forward(self, x):residual = self.residual(x)x = self.block(x)x = self.down_sample(x)return (x + residual) * self.scale
学习率均衡线性层
现在是时候实现EqualizedLinear了,我们之前在几乎每个类中都使用它来均衡线性层的学习率。
- 在init部分,我们发送 in_features、out_features 和偏差。我们通过稍后定义的类 EqualizedWeight 来初始化权重,并初始化偏差。
- 在前向部分,我们发送 x 并返回 x、权重和偏差的线性变换.
class EqualizedLinear(nn.Module):def __init__(self, in_features, out_features, bias = 0.):super().__init__()self.weight = EqualizedWeight([out_features, in_features])self.bias = nn.Parameter(torch.ones(out_features) * bias)def forward(self, x: torch.Tensor):return F.linear(x, self.weight(), bias=self.bias)
学习率均衡 2D 卷积层
现在让我们实现之前用来均衡卷积层学习率的EqualizedConv2d 。
- 在init部分,我们发送 in_features、out_features、kernel_size 和 padding。我们通过稍后定义的类 EqualizedWeight 初始化填充、权重以及偏差。
- 在前向部分,我们发送 x 并返回 x、权重、偏差和填充的卷积。
class EqualizedConv2d(nn.Module):def __init__(self, in_features, out_features,kernel_size, padding = 0):super().__init__()self.padding = paddingself.weight = EqualizedWeight([out_features, in_features, kernel_size, kernel_size])self.bias = nn.Parameter(torch.ones(out_features))def forward(self, x: torch.Tensor):return F.conv2d(x, self.weight(), bias=self.bias, padding=self.padding)
学习率均衡权重参数
现在让我们实现在学习率均衡线性层和学习率均衡 2D 卷积层中使用的EqualizedWeight类。
这是基于 ProGAN 论文中引入的均衡学习率。他们不是将权重初始化为 N(0, c ),而是将权重初始化为 N(0,1),然后在使用时将其乘以c。
- 在初始化部分,我们以权重参数的形式发送,我们用 N(0,1) 初始化常数 c 和权重。
- 在前面的部分,我们将权重乘以c并返回。
class EqualizedWeight(nn.Module):def __init__(self, shape):super().__init__()self.c = 1 / sqrt(np.prod(shape[1:]))self.weight = nn.Parameter(torch.randn(shape))def forward(self):return self.weight * self.c
感知路径长度标准化
感知路径长度归一化鼓励w中的固定大小步长,以导致图像中固定大小的变化。

其中 J w J_w Jw使用以下等式计算,w 从映射网络中采样,y是带有噪声 N(0, I) 的图像,a是训练过程中的指数移动平均值。

- 在 init部分, 我们发送 beta,它是用于计算指数移动平均线a 的常数β 。初始化beta,steps为计算出的步数N, exp_sum_a为 J w T y J_w^T y JwTy的指数和。
- 在前向部分,我们发送x,它是形状为[ batch_size, W_DIM ]的w的批次,x是生成的形状为[ batch_size, 3, height, width ]的图像,获取设备和像素数,计算上面的方程,更新指数和,增加N,并返回惩罚。
class PathLengthPenalty(nn.Module):def __init__(self, beta):super().__init__()self.beta = betaself.steps = nn.Parameter(torch.tensor(0.), requires_grad=False)self.exp_sum_a = nn.Parameter(torch.tensor(0.), requires_grad=False)def forward(self, w, x):device = x.deviceimage_size = x.shape[2] * x.shape[3]y = torch.randn(x.shape, device=device)output = (x * y).sum() / sqrt(image_size)sqrt(image_size)gradients, *_ = torch.autograd.grad(outputs=output,inputs=w,grad_outputs=torch.ones(output.shape, device=device),create_graph=True)norm = (gradients ** 2).sum(dim=2).mean(dim=1).sqrt()if self.steps > 0:a = self.exp_sum_a / (1 - self.beta ** self.steps)loss = torch.mean((norm - a) ** 2)else:loss = norm.new_tensor(0)mean = norm.mean().detach()self.exp_sum_a.mul_(self.beta).add_(mean, alpha=1 - self.beta)self.steps.add_(1.)return loss
Utils
梯度惩罚
在下面的代码片段中,您可以找到 WGAN-GP 损失的gradient_penalty 函数。
def gradient_penalty(critic, real, fake,device="cpu"):BATCH_SIZE, C, H, W = real.shapebeta = torch.rand((BATCH_SIZE, 1, 1, 1)).repeat(1, C, H, W).to(device)interpolated_images = real * beta + fake.detach() * (1 - beta)interpolated_images.requires_grad_(True)# Calculate critic scoresmixed_scores = critic(interpolated_images)# Take the gradient of the scores with respect to the imagesgradient = torch.autograd.grad(inputs=interpolated_images,outputs=mixed_scores,grad_outputs=torch.ones_like(mixed_scores),create_graph=True,retain_graph=True,)[0]gradient = gradient.view(gradient.shape[0], -1)gradient_norm = gradient.norm(2, dim=1)gradient_penalty = torch.mean((gradient_norm - 1) ** 2)return gradient_penaltySample W
该函数对 Z 进行随机采样,并从映射网络中获取 W。
def get_w(batch_size):z = torch.randn(batch_size, W_DIM).to(DEVICE)w = mapping_network(z)return w[None, :, :].expand(LOG_RESOLUTION, -1, -1)噪声生成
该函数为每个生成器block组生成噪声
def get_noise(batch_size):noise = []resolution = 4for i in range(LOG_RESOLUTION):if i == 0:n1 = Noneelse:n1 = torch.randn(batch_size, 1, resolution, resolution, device=DEVICE)n2 = torch.randn(batch_size, 1, resolution, resolution, device=DEVICE)noise.append((n1, n2))resolution *= 2return noise
在下面的代码片段中,您可以找到generate_examples函数,它接受生成器gen 、epoch数和n=100。该函数的目标是生成n 个假图像并将它们保存为每个epoch的结果。
def generate_examples(gen, epoch, n=100):gen.eval()alpha = 1.0for i in range(n):with torch.no_grad():w = get_w(1)noise = get_noise(1)img = gen(w, noise)if not os.path.exists(f'saved_examples/epoch{epoch}'):os.makedirs(f'saved_examples/epoch{epoch}')save_image(img*0.5+0.5, f"saved_examples/epoch{epoch}/img_{i}.png")gen.train()
训练
在本节中,我们将训练 StyleGAN2。
让我们首先创建训练函数,该函数采用判别器/批评器、生成器 gen、每 16 个 epoch 使用的 path_length_penalty、加载器和网络优化器。我们首先循环使用 DataLoader 创建的所有小批量大小,并且只获取图像,因为我们不需要标签。
然后,当我们想要最大化E(critic(real)) - E(critic(fake))时,我们为判别器\Critic 设置训练。这个方程意味着评论家可以区分真实和虚假图像的程度。
之后,当我们想要最大化E(critic(fake))时,我们为生成器和映射网络设置训练,并且每 16 个时期向该函数添加一个感知路径长度。
最后,我们更新循环。
def train_fn(critic,gen,path_length_penalty,loader,opt_critic,opt_gen,opt_mapping_network,
):loop = tqdm(loader, leave=True)for batch_idx, (real, _) in enumerate(loop):real = real.to(DEVICE)cur_batch_size = real.shape[0]w = get_w(cur_batch_size)noise = get_noise(cur_batch_size)with torch.cuda.amp.autocast():fake = gen(w, noise)critic_fake = critic(fake.detach())critic_real = critic(real)gp = gradient_penalty(critic, real, fake, device=DEVICE)loss_critic = (-(torch.mean(critic_real) - torch.mean(critic_fake))+ LAMBDA_GP * gp+ (0.001 * torch.mean(critic_real ** 2)))critic.zero_grad()loss_critic.backward()opt_critic.step()gen_fake = critic(fake)loss_gen = -torch.mean(gen_fake)if batch_idx % 16 == 0:plp = path_length_penalty(w, fake)if not torch.isnan(plp):loss_gen = loss_gen + plpmapping_network.zero_grad()gen.zero_grad()loss_gen.backward()opt_gen.step()opt_mapping_network.step()loop.set_postfix(gp=gp.item(),loss_critic=loss_critic.item(),)现在让我们初始化加载器、网络和优化器,并使网络处于训练模式
loader = get_loader()gen = Generator(LOG_RESOLUTION, W_DIM).to(DEVICE)
critic = Discriminator(LOG_RESOLUTION).to(DEVICE)
mapping_network = MappingNetwork(Z_DIM, W_DIM).to(DEVICE)
path_length_penalty = PathLengthPenalty(0.99).to(DEVICE)opt_gen = optim.Adam(gen.parameters(), lr=LEARNING_RATE, betas=(0.0, 0.99))
opt_critic = optim.Adam(critic.parameters(), lr=LEARNING_RATE, betas=(0.0, 0.99))
opt_mapping_network = optim.Adam(mapping_network.parameters(), lr=LEARNING_RATE, betas=(0.0, 0.99))gen.train()
critic.train()
mapping_network.train()
现在让我们使用训练循环来训练网络,并在每 50 个 epoch 中保存一些假样本。
loader = get_loader() for epoch in range(EPOCHS):train_fn(critic,gen,path_length_penalty,loader,opt_critic,opt_gen,opt_mapping_network,)if epoch % 50 == 0:generate_examples(gen, epoch)
结论
在本文中,我们使用 PyTorch 从头开始为 StyleGAN2 这个大型项目制作了一个干净、简单且可读的实现。我们尝试尽可能地复制原始论文。
相关文章:
使用Pytorch从零开始构建StyleGAN2
这篇博文是关于 StyleGAN2 的,来自论文Analyzing and Improving the Image Quality of StyleGAN,我们将使用 PyTorch 对其进行干净、简单且可读的实现,并尝试尽可能地还原原始论文。 如果您没有阅读 StyleGAN2 论文。或者不知道它是如何工作…...
C++ Qt 开发:ListWidget列表框组件
Qt 是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍ListWidget列表框组件的常用方法及灵活运用。…...

手机天线市场分析:预计2029年将达到576亿美元
手机天线,即手机上用于接收信号的设备,旧式手机有外凸式天线,新式手机多数已隐藏在机身内。这类天线主要都在手机内部,手机外观上看不到里面的东西。 手机天线主要就内置及外置天线两种,内置天线客观上必然比外置天线弱…...

FPGA引脚分配的问题
今天在做一个FPGA的实验时,在引脚分配时失败了,出现了如下报错: 我当时分配的引脚是PIN_AE19,然而奇怪的是我之前并未分配这个引脚,我使用的开发工具是Quartus II 9.1 Web Edition,算个老版本了。 有的网站…...
)
面试经典150题(27-28)
leetcode 150道题 计划花两个月时候刷完,今天(第十三天)完成了2道(27-28)150: 今天这两道是真的汗流浃背!!! 27.(209. 长度最小的子数组)题目描述: 给定一…...

计算机图形学头歌合集(题集附解)
目录 CG1-v1.0-点和直线的绘制 第1关:OpenGL点的绘制 第2关:OpenGL简单图形绘制 第3关:OpenGL直线绘制 第4关:0<1直线绘制-dda算法<> 第5关:0<1直线绘制-中点算法<> 第6关:一般直线绘…...
MacBook Air提供了丰富多彩的截图选项,大到整个屏幕,小到具体的区域
本指南将带你了解在MacBook Air笔记本电脑上进行屏幕截图的各种方法。它涵盖了所有用于截屏的键盘快捷键,还包括如何启动MacBook Air屏幕录制和更改屏幕截图设置的信息。 如何在MacBook Air上进行屏幕截图 在MacBook上进行整个屏幕截图的最快、最简单的方法是使用command+sh…...
【CMU 15-445】Lecture 12: Query Execution I 学习笔记
Query Execution I Processing ModelsIterator ModelMaterialization ModelVectorization Model Access MethodsSequential ScanIndex Scan Modification QueriesHalloween Problem 本节课主要介绍SQL语句执行的相关机制。 Processing Models 首先是处理模型,它定义…...

低代码开发平台的优势及应用场景分析
文章目录 低代码是什么?低代码起源低代码分类低代码的能力低代码的需求市场需要专业开发者需要数字化转型需要 低代码的趋势如何快速入门低代码开发低代码应用领域 低代码是什么? 低代码(Low-code)是著名研究机构Forrester于2014…...

ES常见查询总结
目录 1:查询总数2:查询所有数据3:查询指定条数4:根据ID查询5:一个查询字符串搜索6:match搜索7:term搜索8:bool搜索9:must多条件匹配查询10:Should满足一个条件查询11: must_not必须不匹配查询12:多个字段查询内容13:一个字段查询多个内容14:通配符和正则匹配15:前缀查询16:短语…...

Spring Boot Docker Compose 支持中文文档
本文为官方文档直译版本。原文链接 Spring Boot Docker Compose 支持中文文档 引言服务连接自定义镜像跳过特定的容器使用特定Compose文件等待容器就绪控制 Docker Compose 的生命周期激活 Docker Compose 配置文件 引言 Docker Compose 是一种流行的技术,可用于为…...
智慧城市/一网统管建设:人员危险行为检测算法,为城市安全保驾护航
随着人们压力的不断增加,经常会看见在日常生活中由于小摩擦造成的大事故。如何在事故发生时进行及时告警,又如何在事故发生后进行证据搜索与事件溯源?旭帆科技智能视频监控人员危险行为/事件检测算法可以给出答案。 全程监控,有源…...
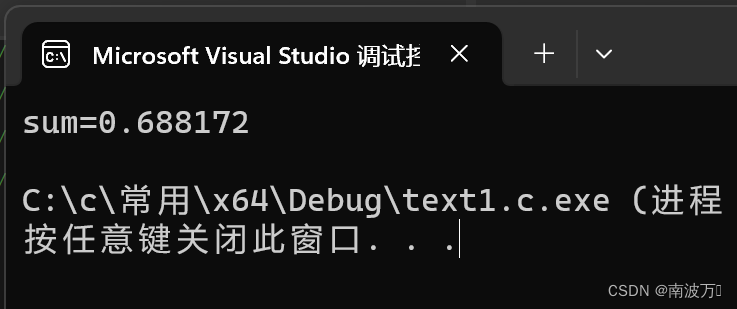
C语言:求和1+1/2-1/3+1/4-1/5+……-1/99+1/100
#include<stdio.h> int main() {int i 0;double sum 0.0;int flag 1;for (i 1;i < 100;i){sum 1.0 / i * flag;flag -flag;}printf("sum%lf\n", sum);return 0; }...

学习什么知识不会过时
近况💁🏻 最近这段时间,我真的很糟糕。工作中满负荷做需求,闲了就想玩游戏放松,业余搞些东西的时间很少。本来就有些焦虑,这种状态下更是有些 suffering。究其原因,都是因为部门转换的问题。 一…...
C# WPF上位机开发(ExtendedWPFToolkit扩展包使用)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 虽然个人人为当前的c# wpf内容已经足够多,但是肯定还是有很多个性化的需求没有满足。比如说不够好看,比如说动画效果不好&a…...
【IOS开发】传感器 SensorKit
资源 官方文档 https://developer.apple.com/search/?qmotion%20graph&typeDocumentation SensorKit 使应用程序能够访问选定的原始数据或系统从传感器处理的指标。 步骤信息加速度计或旋转速率数据用户手腕上手表的配置物理环境中的环境光有关用户日常通勤或旅行的详细…...

【C++】封装:练习案例-点和圆的关系
练习案例:点和圆的关系 设计一个圆形类(Circle),和一个点类(Point),计算点和圆的关系。 思路: 1)创建点类point.h和point.cpp 2)创建圆类circle.h和circle…...

【vue】正则表达式限制input的输入:
文章目录 1、只能输入大小写字母、数字、下划线:/[^\w_]/g2、只能输入小写字母、数字、下划线:/[^a-z0-9_]/g3、只能输入数字和点:/[^\d.]/g4、只能输入小写字母、数字、下划线:/[^\u4e00-\u9fa5]/g5、只能输入数字:/\…...
.getPrincipal()获取LoginUser对象导致的缓存删除失败问题)
异步导入中使用SecurityUtils.getSubject().getPrincipal()获取LoginUser对象导致的缓存删除失败问题
结论 SecurityUtils.getSubject().getPrincipal()实际用的也是ThreadLocal,而ThreadLocal和线程绑定,异步会导致存数据丢失,注意! 业务背景 最近,系统偶尔会出现excel导入成功,但系统却提示存在进行中的…...
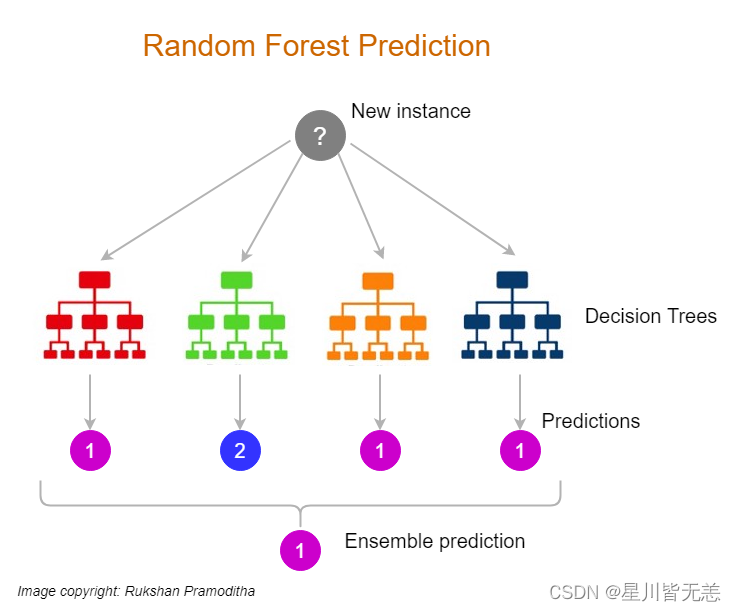
大数据机器学习深度解读决策树算法:技术全解与案例实战
大数据机器学习深度解读决策树算法:技术全解与案例实战 本文深入探讨了机器学习中的决策树算法,从基础概念到高级研究进展,再到实战案例应用,全面解析了决策树的理论及其在现实世界问题中的实际效能。通过技术细节和案例实践&…...

7步完整解决Windows 11安装失败:从错误代码到成功激活的高效指南
7步完整解决Windows 11安装失败:从错误代码到成功激活的高效指南 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat…...

Mem Reduct终极指南:如何用免费工具轻松解决Windows内存卡顿问题
Mem Reduct终极指南:如何用免费工具轻松解决Windows内存卡顿问题 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memredu…...

G-Helper终极指南:5分钟掌握华硕笔记本性能控制
G-Helper终极指南:5分钟掌握华硕笔记本性能控制 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, an…...

这个 Plugin 让 OpenClaw 减少Skill 90%Token消耗
别让 Skill 列表烧光你的 Token——用一个 Plugin 让 OpenClaw 瘦身 90% 95 个 Skill,每轮对话就消耗 5000 多个 Token?本文将分享我们如何通过 Elasticsearch 语义搜索和一个 OpenClaw Plugin,将 Skill 列表从“全量注入”变为“按需加载”&…...

从实战案例出发:面阵与线阵相机选型策略及镜头配置全解析
1. 面阵与线阵相机的本质区别 第一次接触工业相机选型时,我也曾被各种参数搞得晕头转向。直到有次在产线上亲眼看到两种相机的实际表现,才真正理解了它们的差异。简单来说,面阵相机就像我们平时用的数码相机,一次拍摄就能获取整个…...

SEO优化与网站内链优化有什么区别_SEO优化的方法论有哪些
SEO优化与网站内链优化有什么区别 在现代数字营销中,SEO优化和网站内链优化是两个紧密相关但又各有侧重的领域。了解它们之间的区别,对于提升网站的整体流量和搜索引擎排名至关重要。本文将详细探讨这两者的不同之处,并为你提供一些SEO优化的…...

如何用abcjs在浏览器中快速生成专业五线谱:完整免费教程
如何用abcjs在浏览器中快速生成专业五线谱:完整免费教程 【免费下载链接】abcjs javascript for rendering abc music notation 项目地址: https://gitcode.com/gh_mirrors/ab/abcjs 在数字化音乐创作与分享的时代,abcjs作为一个强大的JavaScript…...

GHelper:重新定义华硕设备的硬件控制体验
GHelper:重新定义华硕设备的硬件控制体验 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, and othe…...
及修复方案)
Z-Image-GGUF快速上手:新手常见错误(如误点默认工作流)及修复方案
Z-Image-GGUF快速上手:新手常见错误(如误点默认工作流)及修复方案 1. 为什么你的第一张AI图总是生成失败? 如果你刚接触Z-Image-GGUF,很可能遇到过这样的情况:兴冲冲地打开界面,看到一堆复杂的…...

5分钟部署MGeo:中文地址相似度识别零基础教程
5分钟部署MGeo:中文地址相似度识别零基础教程 你是不是遇到过这样的问题?手里有两份地址数据,一份来自电商订单,一份来自物流系统,明明应该是同一个地方,但写法五花八门——“北京市朝阳区望京街1号”、“…...