【图像分类】【深度学习】【Pytorch版本】 ResNeXt模型算法详解
【图像分类】【深度学习】【Pytorch版本】 ResNeXt模型算法详解
文章目录
- 【图像分类】【深度学习】【Pytorch版本】 ResNeXt模型算法详解
- 前言
- ResNeXt讲解
- 分组卷积(Group Converlution)
- 分割-变换-合并策略(split-transform-merge)
- ResNeXt模型结构
- ResNeXt Pytorch代码
- 完整代码
- 总结
前言
ResNeXt是加利福尼亚大学圣迭戈分校的Xie, Saining等人在《Aggregated Residual Transformations for Deep Neural Networks【CVPR-2017】》【论文地址】一文中提出的模型,结合ResNet【参考】的卷积块堆叠的思想以及Inception【参考】的分割-变换-合并的策略,在不明显增加参数量级的情况下提升了模型的准确率。
ResNeXt讲解
Inception系列模型则证明精心设计的拓扑结构(采用分割-转换-合并策略),在拥有不错的表示能力同时计算复杂度大大降低:首先通过1×1的卷积将输入分割成多个低维度的嵌入,然后通过一组专门的过滤器(3×3,5×5等)分别进行转换,最后通过串联进行合并。
但是Inception系列的实现一直伴随着一系列复杂的因素:卷积核的数量和大小是为每个变换单独定制的,网络中的Inception模块也是逐个定制的。随着网络深度的增加,网络的超参数(卷积核个数、大小和步长等)也在增加,设计更好的网络架构以学习表征变得越来越困难。ResNets继承了VGGNet简单而有效的方法,采用相同拓扑结构的模块堆叠构建深度网络,不需要每层都单独设置超参数,减少了超参数的自由选择。
因此在论文中,ResNeXt提出了一个简单的架构,它以一种简单、可扩展的方式采用了ResNets的重复层策略,同时利用了Inception的分割-变换-合并策略。
分组卷积(Group Converlution)
在分组卷积中,将输入特征图的通道分成多个组,每个组内的通道只与相应组内的卷积核进行卷积运算,最后将各个组的输出特征图连接在一起,形成最终的输出特征图。
以下是博主绘制的普通卷积和分组卷积的示意图:

实际上无论普通卷积还是分组卷积,卷积核的数量没有发生改变,只不过分组卷积的卷积核的通道数变小了。
分组卷积的主要目的是减少卷积操作的计算量,特别适用于在计算资源有限的情况下进行模型设计。
分割-变换-合并策略(split-transform-merge)
注意:这个小节比较考验读者的对卷积过程的认知功底,建议大家好好理解下,有助于大家夯实基本功。
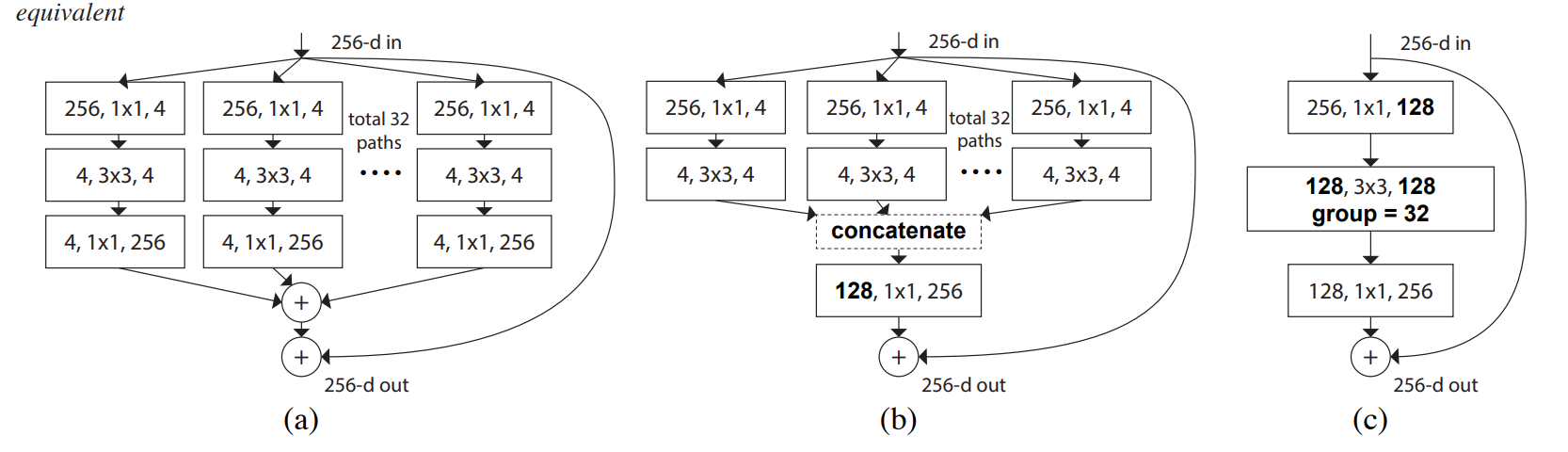
先说结论,下图是原论文中给出的结构示意图,a图结构是分割-变换-合并策略的体现,c图结构则是使用分组卷积后的对a图结构的等价替换。
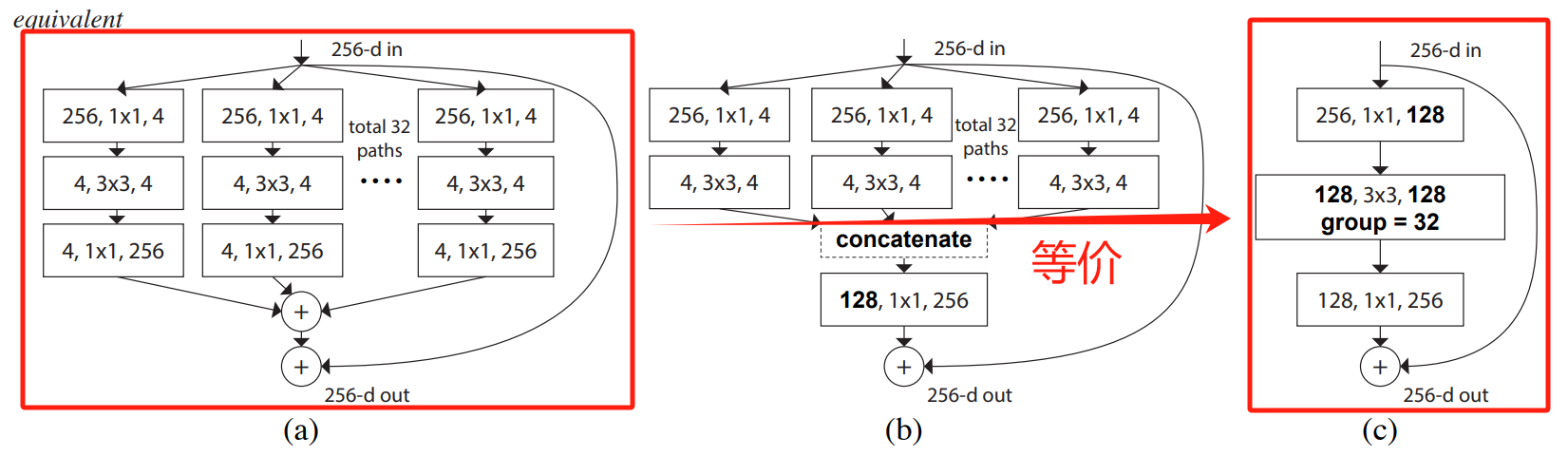
接下来博主就将详细讲解分割-变换-合并策略中每一个步骤的过程和作用,为了方便大家理解,博主采用了a图的结构进行讲解。
ResNeXt通过将输入数据分割成多个子集,每个子集进行独立的变换操作,网络可以学习到更多不同的特征表示。而通过合并操作,网络可以将这些不同的特征表示进行组合,从而得到更丰富的特征表达能力。
-
split:分割输入数据。
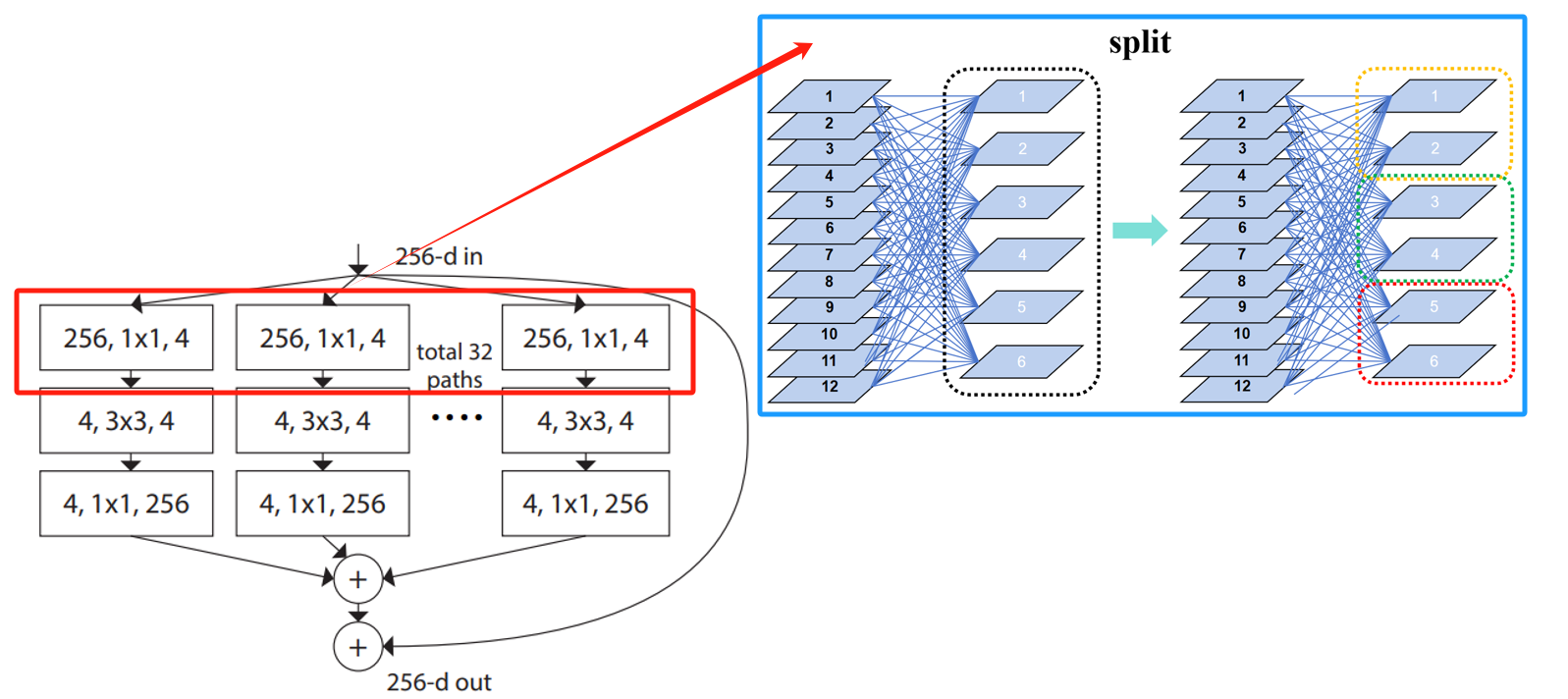
分割可以理解为将多个卷积核划分到不同组,每个组的卷积核个数一致。如示意图所示,将一层大卷积层拆分成多个小卷积层后处理同一个输入,假设将多个小卷积层的输出(子集)拼接成一起就等价于大卷积层的输出,因此俩者是等效的。个人理解:其实可以只用一个卷积层进行卷积,将输出的特征图按照组进行拆分即可,不需要对多个小卷积层单独分组。
-
transform:子集独立变换。
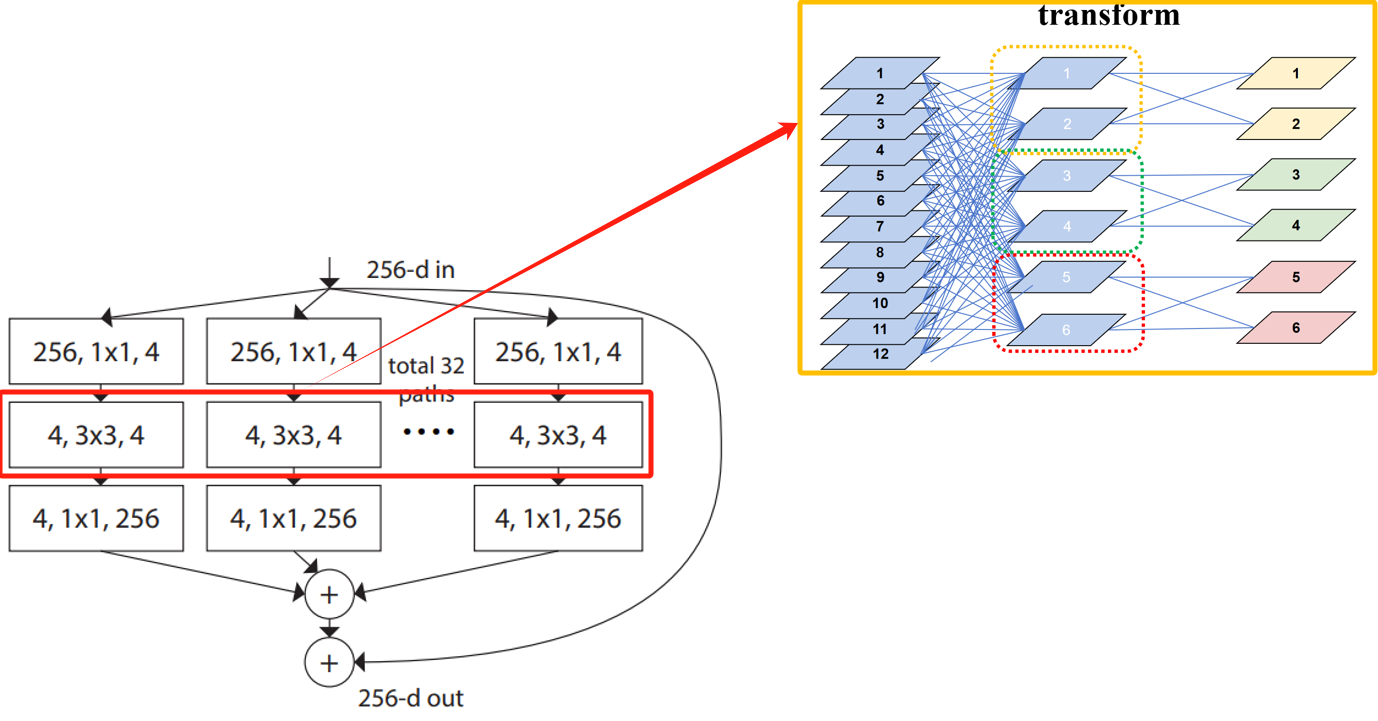
每个小卷积层的输出(子集)再经过一层各自的卷积层进行卷积变换。如示意图所示,等价于分组卷积。个人理解:早期深度学习框架不支持分组卷积,因此分组卷积的实现,需要在分组卷积事先将输入按照分组进行拆分,也是就split过程,然后对分组后的输入子集再进行小组内卷积。
-
merge:合并特征图。
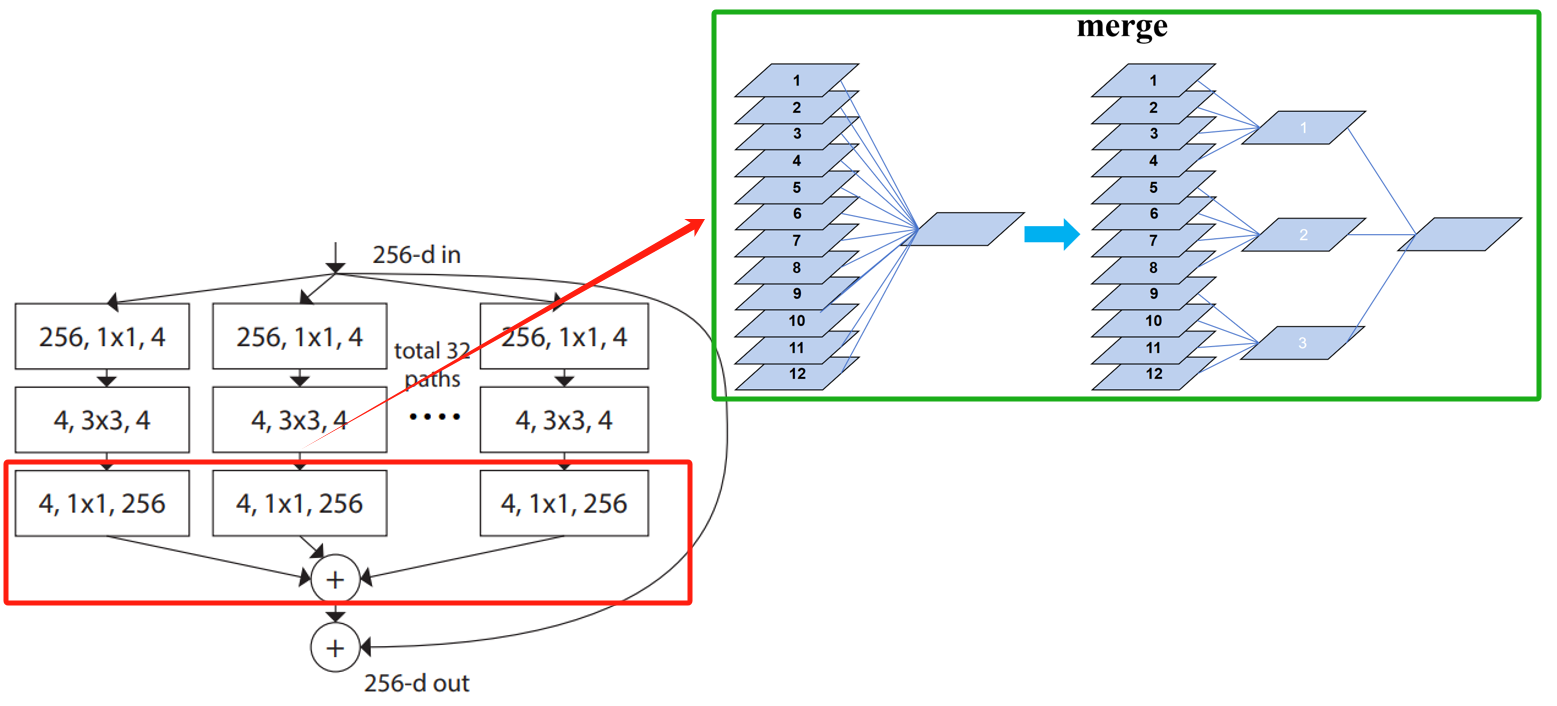
合并可以理解为将一个大卷积核划分成多个小卷积核,每个小卷积核拥有大卷积核的一部分通道,每个小卷积核的通道数量一致。如示意图所示,大卷积核通道数和拆分后的小卷积核的总通道数是一致的。回顾以下,传统的卷积运算(大卷积核)的输出特征是由每个通道的权重与对应输入特征进行运算和相加而来,即1到12一次性相加,那么小卷积就是将这个过程进行了拆分,即先是1到4、5到8和9到12分别相加,然后再对三个相加结果再进行相加。个人理解:其实先将多组输入的特征图进行拼接,只用一个大卷积核组成的卷积层进行卷积即可,不需要用多个小卷积核组成的卷积层。
ResNeXt模型结构
ResNeXt对ResNet进行了改进,采用了多分支的策略,在论文中作者提出了三种等价的模型结构,最后的ResNeXt采用了图c的结构来构建ResNeXt,因为c结构比较简洁而且速度更快。
ResNeXt通过增加cardinality(group)参数,可以灵活地控制子集的数量,增加基数可以提高模型的性能,提高特征提取的能力,且要比增加宽度和深度更有效。
下图是原论文给出的关于ResNeXt模型结构的详细示意图:
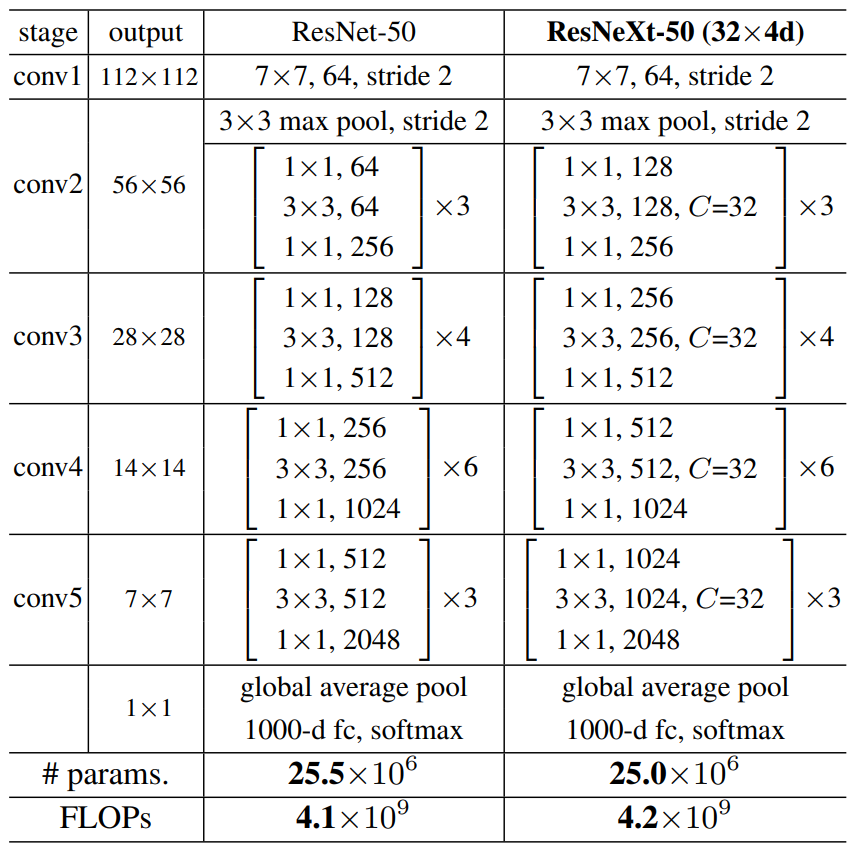
ResNeXt与ResNet一样也是构建基于两个准则:1.同阶段中的残差块使用相同的卷积核个数和卷积核尺寸;2.特征图减小时增加卷积核个数。基于上述准则,在ResNet-50模型的基础上,提出了ResNeXt-50模型。
ResNeXt在图像分类中分为两部分:backbone部分: 主要由残差结构、卷积层和池化层(汇聚层)组成,分类器部分:由全局平均池化层和全连接层组成 。
ResNeXt只能在残差块的深度超过2层时使用,所以ResNeXt不在ResNet18和34进行修改的原因。
ResNeXt Pytorch代码
分组卷积层:
# 3×3分组卷积
nn.Conv2d(in_channels=width, out_channels=width, groups=groups,kernel_size=3, stride=stride, bias=False, padding=1)
残差结构Bottleneck: 卷积层(或分组卷积层)+BN层+激活函数
class Bottleneck(nn.Module):expansion = 4# 残差结构参考了resnet的残差结构def __init__(self, in_channel, out_channel, stride=1, downsample=None,groups=1, width_per_group=64):super(Bottleneck, self).__init__()# 是为了保证卷积核个数能被组数整除,每组的卷积核个数不出现小数width = int(out_channel * (width_per_group / 64.)) * groups# 第一层(降维)self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,kernel_size=1, stride=1, bias=False) # squeeze channelsself.bn1 = nn.BatchNorm2d(width)# 第二层(分组卷积)self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,kernel_size=3, stride=stride, bias=False, padding=1)self.bn2 = nn.BatchNorm2d(width)# 第三层(升维)self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,kernel_size=1, stride=1, bias=False) # unsqueeze channelsself.bn3 = nn.BatchNorm2d(out_channel*self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampledef forward(self, x):identity = xif self.downsample is not None:identity = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)out += identityout = self.relu(out)return out
完整代码
import torch.nn as nn
import torch
from torchsummary import summaryclass Bottleneck(nn.Module):expansion = 4# 残差结构参考了resnet的残差结构def __init__(self, in_channel, out_channel, stride=1, downsample=None,groups=1, width_per_group=64):super(Bottleneck, self).__init__()# 是为了保证卷积核个数能被组数整除,每组的卷积核个数不出现小数width = int(out_channel * (width_per_group / 64.)) * groups# 第一层(降维)self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,kernel_size=1, stride=1, bias=False) # squeeze channelsself.bn1 = nn.BatchNorm2d(width)# 第二层(分组卷积)self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,kernel_size=3, stride=stride, bias=False, padding=1)self.bn2 = nn.BatchNorm2d(width)# 第三层(升维)self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,kernel_size=1, stride=1, bias=False) # unsqueeze channelsself.bn3 = nn.BatchNorm2d(out_channel*self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampledef forward(self, x):identity = xif self.downsample is not None:identity = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)out += identityout = self.relu(out)return outclass ResNeXt(nn.Module):def __init__(self,blocks_num,num_classes=1000,groups=1,width_per_group=64):super(ResNeXt, self).__init__()self.in_channel = 64# 组数self.groups = groups# 每组包含的卷积个数self.width_per_group = width_per_groupself.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,padding=3, bias=False)self.bn1 = nn.BatchNorm2d(self.in_channel)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# 第一组残差块组self.layer1 = self._make_layer(Bottleneck, 64, blocks_num[0])# 第二组残差块组self.layer2 = self._make_layer(Bottleneck, 128, blocks_num[1], stride=2)# 第三组残差块组self.layer3 = self._make_layer(Bottleneck, 256, blocks_num[2], stride=2)# 第四组残差块组self.layer4 = self._make_layer(Bottleneck, 512, blocks_num[3], stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)self.fc = nn.Linear(512 * Bottleneck.expansion, num_classes)# 权重初始化for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')def _make_layer(self, block, channel, block_num, stride=1):downsample = Noneif stride != 1 or self.in_channel != channel * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(channel * block.expansion))layers = []layers.append(block(self.in_channel,channel,downsample=downsample,stride=stride,groups=self.groups,width_per_group=self.width_per_group))self.in_channel = channel * block.expansionfor _ in range(1, block_num):layers.append(block(self.in_channel,channel,groups=self.groups,width_per_group=self.width_per_group))return nn.Sequential(*layers)def forward(self, x):# backbone主干网络部分# resnext50为例# N x 3 x 224 x 224x = self.conv1(x)# N x 64 x 112 x 112x = self.bn1(x)# N x 64 x 112 x 112x = self.relu(x)# N x 64 x 112 x 112x = self.maxpool(x)# N x 64 x 56 x 56x = self.layer1(x)# N x 256 x 56 x 56x = self.layer2(x)# N x 512 x 28 x 28x = self.layer3(x)# N x 1024 x 14 x 14x = self.layer4(x)# N x 2048 x 7 x 7x = self.avgpool(x)# N x 2048 x 1 x 1x = torch.flatten(x, 1)# N x 2048x = self.fc(x)# N x 1000return xdef resnext50_32x4d(num_classes=1000):# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pthgroups = 32width_per_group = 4return ResNeXt([3, 4, 6, 3],num_classes=num_classes,groups=groups,width_per_group=width_per_group)def resnext101_32x8d(num_classes=1000):# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pthgroups = 32width_per_group = 8return ResNeXt([3, 4, 23, 3],num_classes=num_classes,groups=groups,width_per_group=width_per_group)if __name__ == '__main__':device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = resnext50_32x4d().to(device)summary(model, input_size=(3, 224, 224))
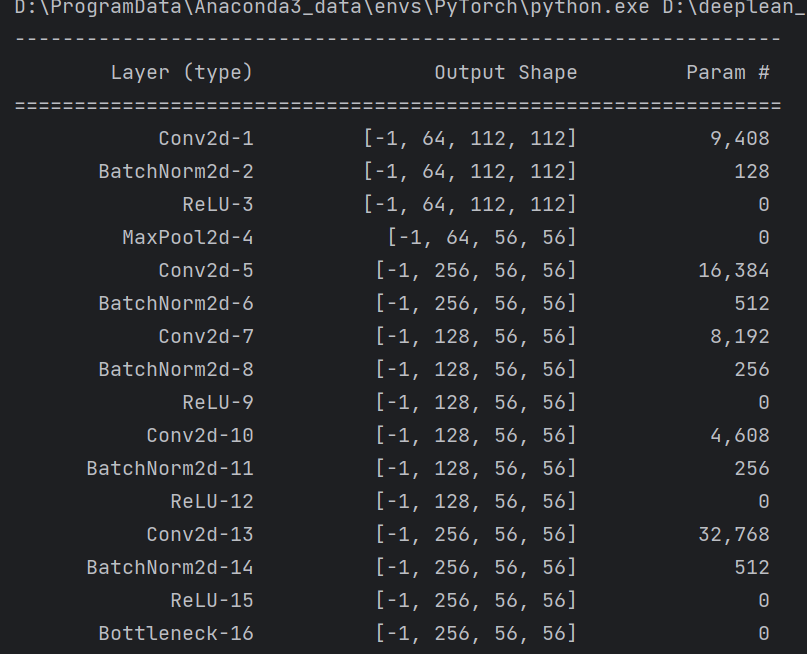
summary可以打印网络结构和参数,方便查看搭建好的网络结构。
总结
尽可能简单、详细的介绍了分组卷积的原理和在卷积神经网络中的作用,讲解了ResNeXt模型的结构和pytorch代码。
相关文章:
【图像分类】【深度学习】【Pytorch版本】 ResNeXt模型算法详解
【图像分类】【深度学习】【Pytorch版本】 ResNeXt模型算法详解 文章目录 【图像分类】【深度学习】【Pytorch版本】 ResNeXt模型算法详解前言ResNeXt讲解分组卷积(Group Converlution)分割-变换-合并策略(split-transform-merge)ResNeXt模型结构 ResNeXt Pytorch代码完整代码总…...

Android 14 应用适配指南
Android 14 应用适配指南:https://dev.mi.com/distribute/doc/details?pId1718 Android 14 功能和变更列表 | Android 开发者 | Android Developers 1.获取Android 14 1.1 谷歌发布时间表 https://developer.android.com/about/versions/14/overview#timeli…...

【AI美图提示词】第07期效果图,AI人工智能自动绘画,精选绝美版美图欣赏
AI诗配画 山水画中景如画,云雾缭绕峰峦间。桥畔流水潺潺响,诗意盎然山水间。上面的诗句和图片全部来自AI自动化完成,这就是技术的力量,接下来我们进行模型生成学习: 先上原始底图: 下面是模型生成效果图&a…...
前端知识(十三)——JavaScript监听按键,禁止F12,禁止右键,禁止保存网页【Ctrl+s】等操作
禁止右键 document.oncontextmenu new Function("event.returnValuefalse;") //禁用右键禁止按键 // 监听按键 document.onkeydown function () {// f12if (window.event && window.event.keyCode 123) {alert("F12被禁用");event.keyCode 0…...
单例模式的奇异递归模板CRTP实现)
面向对象设计与分析(28)单例模式的奇异递归模板CRTP实现
前面我们介绍了单例模式的两种实现:懒汉模式和饿汉模式,今天我们以新的方式来实现可复用的单例模式。 奇异递归模板是指父类是个模板类,模板类型是子类类型,即父类通过模板参数可以知道子类的类型。 // brief: a singleton base…...
微信小程序 - 龙骨图集拆分
微信小程序 - 龙骨图集拆分 注意目录结构演示动画废话一下业务逻辑注意点龙骨JSON图集结构 源码分享dragonbones-split.jsdragonbones-split.jsondragonbones-split.wxmldragonbones-split.wxssimgUtil.js 参考资料 注意 只支持了JSON版本 目录结构 演示动画 Spine播放器1.5.…...

使用React 18和WebSocket构建实时通信功能
1. 引言 WebSocket是一种在Web应用中实现双向通信的协议。它允许服务器主动向客户端推送数据,而不需要客户端发起请求。在现代的实时应用中,WebSocket经常用于实时数据传输、聊天功能、实时通知和多人协作等场景。在本篇博客中,我们将探索如…...
vue3使用vue-router嵌套路由(多级路由)
文章目录 1、Vue3 嵌套路由2、项目结构3、编写相关页面代码3.1、编写route文件下 index.ts文件3.2、main.ts文件代码:3.3、App.vue文件代码:3.4、views文件夹下的Home文件夹下的index.vue文件代码:3.5、views文件夹下的Home文件夹下的Tigerhh…...

openGauss学习笔记-164 openGauss 数据库运维-备份与恢复-导入数据-使用COPY FROM STDIN导入数据-处理错误表
文章目录 openGauss学习笔记-164 openGauss 数据库运维-备份与恢复-导入数据-使用COPY FROM STDIN导入数据-处理错误表164.1 操作场景164.2 查询错误信息164.3 处理数据导入错误 openGauss学习笔记-164 openGauss 数据库运维-备份与恢复-导入数据-使用COPY FROM STDIN导入数据-…...
QT Widget - 随便画个圆
简介 实现在界面中画一个圆, 其实目的是想画一个LED效果的圆。代码 #include <QApplication> #include <QWidget> #include <QPainter> #include <QColor> #include <QPen>class LEDWidget : public QWidget { public:LEDWidget(QWidget *pare…...

js输入框部分内容不可编辑,其余正常输入,el-input和el-select输入框和多个下拉框联动后的内容不可修改
<tr>//格式// required自定义指令<e-td :required"!read" label><span>地区:</span></e-td><td>//v-if"!read && this.data.nationCode 148"显示逻辑<divclass"table-cell-flex"sty…...

分布式文件存储系统minio了解下
什么是minio minio 是一个基于 Apache License v2.0 开源协议的对象存储服务。非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小。 是一种海量、安全、低成本、高可靠的云存储…...
迅为RK3568开发板使用OpenCV处理图像-ROI区域-位置提取ROI
在图像处理过程中,我们可能会对图像的某一个特定区域感兴趣,该区域被称为感兴趣区域(Region of Interest, ROI)。在设定感兴趣区域 ROI 后,就可以对该区域进行整体操作。 位置提取 ROI 本小节代码在配套资料“iTOP-3…...

重新认识Word——尾注
重新认识Word——尾注 参考文献格式文献自动生成器插入尾注将数字带上方括号将参考文献中的标号改为非上标 多处引用一篇文献多篇文献被一处引用插入尾注有横线怎么删除?删除尾注 前面我们学习了如何给图片,公式自动添加编号,今天我们来看看毕…...

所有学前教育专业,一定要刷到这篇啊
我是真的希望所有学前教育的宝子都能刷到这篇啊啊,只要输入需求,几秒它就给你写出来了,而且不满意还可以重新写多,每次都是不一样的内容。重复率真的不高,需求越多,生成的文字内容越精准!&#…...
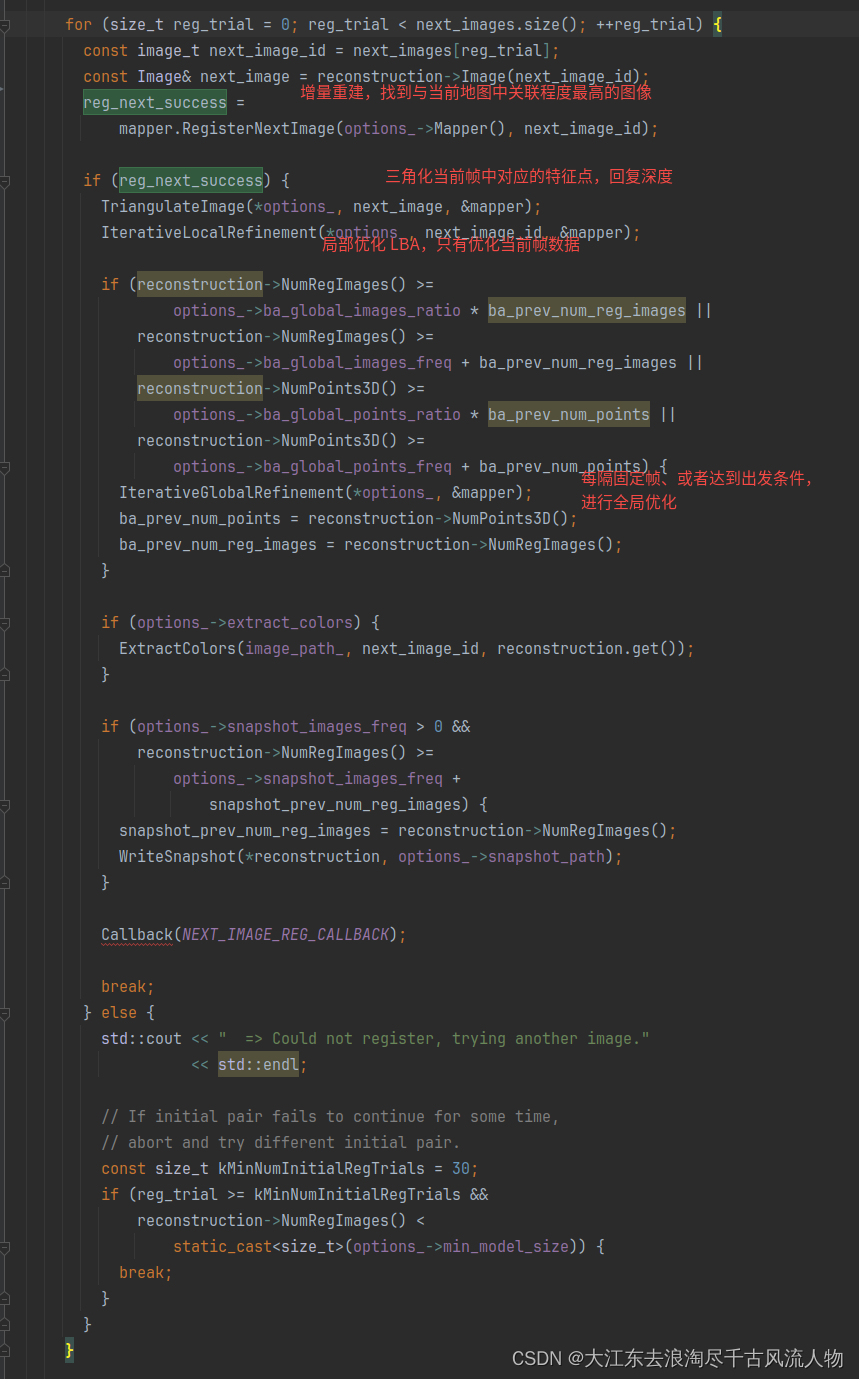
colmap三维重建核心逻辑梳理
colmap三维重建核心逻辑梳理 1. 算法流程束流2. 初始化3. 重建主流程 1. 算法流程束流 重建核心逻辑见 incremental_mapper.cc 中 IncrementMapperController 中 Reconstruct 初始化变量和对象判断是否有初始重建模型,若有,则获取初始重建模型数量&am…...
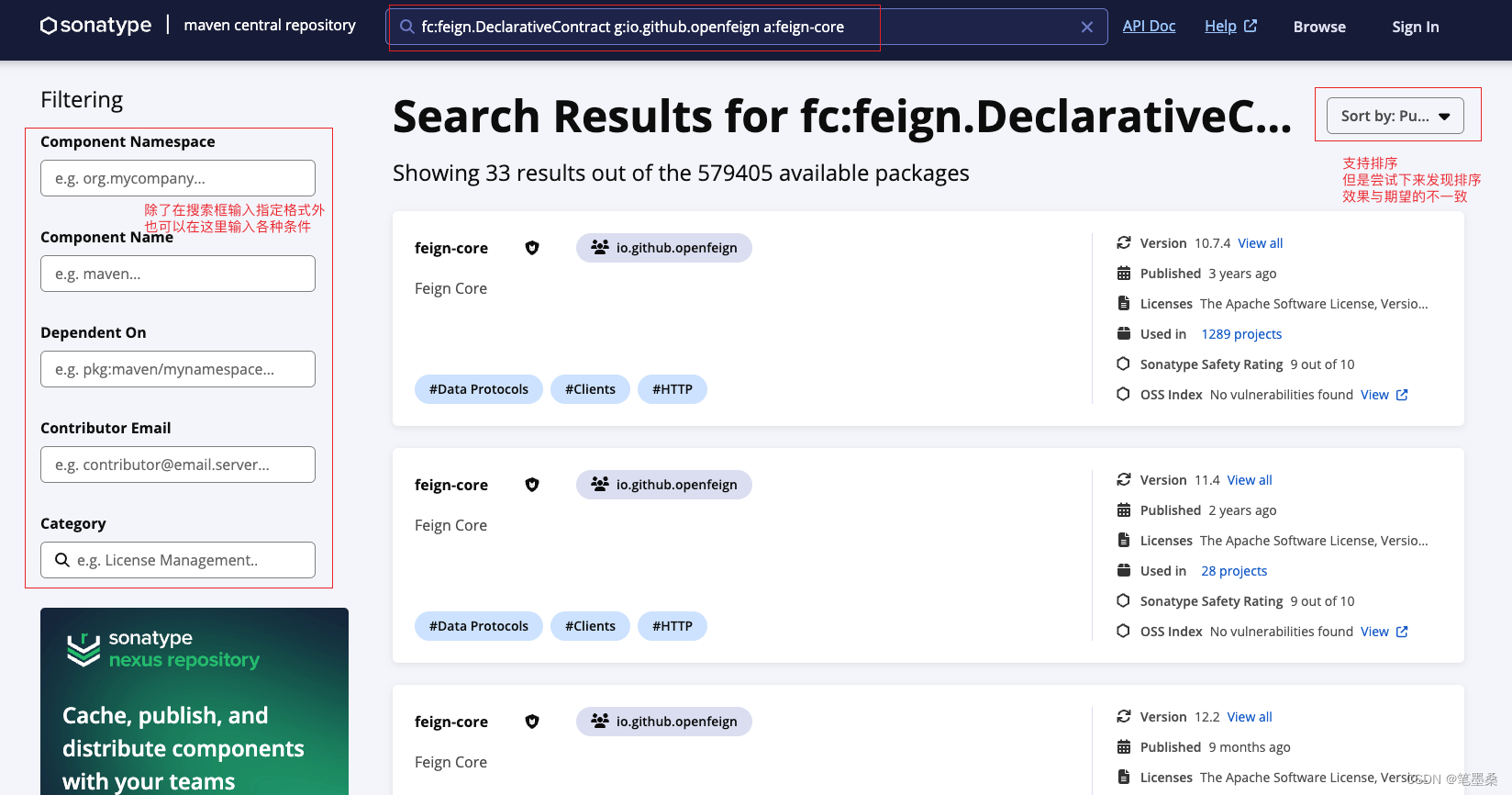
查询某个类是在哪个JAR的什么版本开始出现的方法
背景 我们在依赖第三方JAR时,同时也会间接的依赖第三方JAR引用的依赖,而当我们项目中某个依赖的版本与第三方JAR依赖的版本不一致时,可能会导致第三方JAR的在运行时无法找到某些方法或类,从而无法正常使用。 如我正在开发的一个…...

Linux本地搭建StackEdit Markdown编辑器结合内网穿透实现远程访问
文章目录 1. docker部署Stackedit2. 本地访问3. Linux 安装cpolar4. 配置Stackedit公网访问地址5. 公网远程访问Stackedit6. 固定Stackedit公网地址 StackEdit是一个受欢迎的Markdown编辑器,在GitHub上拥有20.7k Star!,它支持将Markdown笔记保…...

k8s中ConfigMap、Secret创建使用演示、配置文件存储介绍
目录 一.ConfigMap(cm) 1.适用场景 2.创建并验证configmap (1)以yaml配置文件创建configmap,验证变化是是否同步 (2)--from-file以目录或文件 3.如何使用configmap (1&#x…...
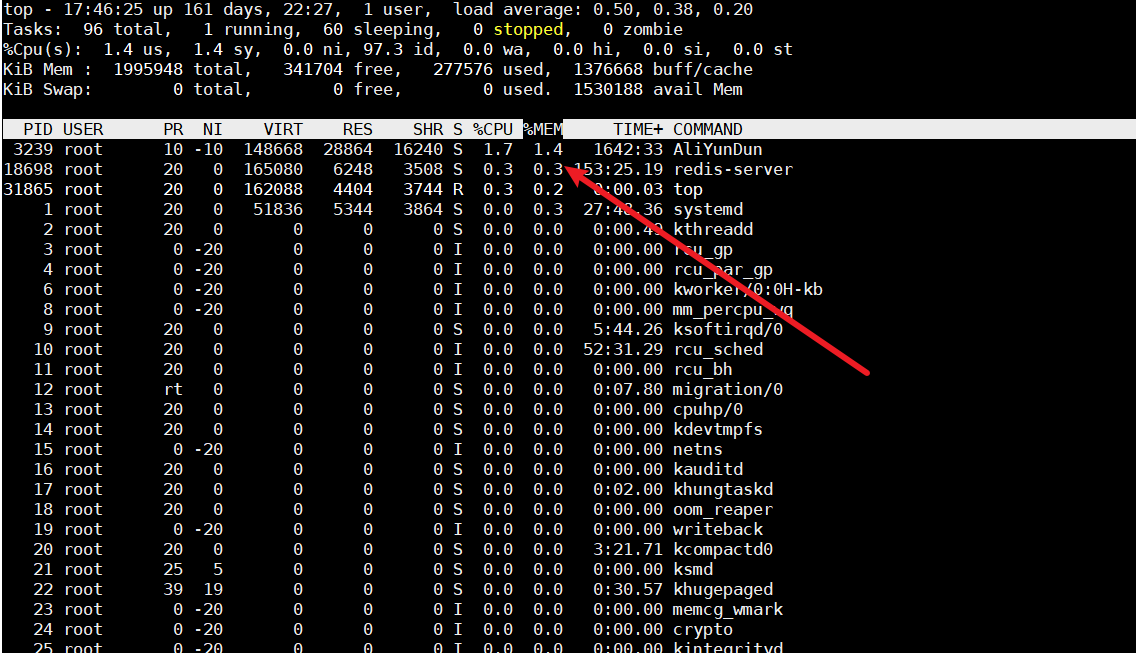
Linux服务器性能优化小结
文章目录 生产环境监测常见专业名词扫盲服务器平均负载服务器平均负载的定义如何判断平均负载值以及好坏情况如果依据平均负载来判断服务器当前状况系统平均负载和CPU使用率的区别 CPU上下文切换基本概念3种上下文切换进程上下文切换线程上下文切换中断上下文切换 查看上下文切…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...