《PySpark大数据分析实战》-11.Spark on YARN模式安装Hadoop
📋 博主简介
- 💖 作者简介:大家好,我是wux_labs。😜
热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。
通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP)、TiDB数据库认证SQL开发专家(PCSD)认证。
通过了微软Azure开发人员、Azure数据工程师、Azure解决方案架构师专家认证。
对大数据技术栈Hadoop、Hive、Spark、Kafka等有深入研究,对Databricks的使用有丰富的经验。- 📝 个人主页:wux_labs,如果您对我还算满意,请关注一下吧~🔥
- 📝 个人社区:数据科学社区,如果您是数据科学爱好者,一起来交流吧~🔥
- 🎉 请支持我:欢迎大家 点赞👍+收藏⭐️+吐槽📝,您的支持是我持续创作的动力~🔥
《PySpark大数据分析实战》-11.Spark on YARN模式安装Hadoop
- 《PySpark大数据分析实战》-11.Spark on YARN模式安装Hadoop
- 前言
- 安装Hadoop集群
- 配置环境变量
- 配置Hadoop集群
- 环境信息同步
- 格式化NameNode
- 结束语
《PySpark大数据分析实战》-11.Spark on YARN模式安装Hadoop
前言
大家好!今天为大家分享的是《PySpark大数据分析实战》第2章第4节的内容:Spark on YARN模式安装Hadoop。

图书在:当当、京东、机械工业出版社以及各大书店有售!
Spark独立集群模式还可以部署成高可用模式,在集群中部署多个Master节点,其中一个Master是Active的,其余是StandBy的。Spark独立集群、Spark高可用独立集群都是可用于生产环境的集群部署模式,在这两种集群模式下,Spark除了担任计算引擎,还需要承担资源管理的工作。Spark本身定位于一个计算引擎,而不是资源管理框架,Spark已经将资源管理模块做了抽象,支持外部资源管理框架对Spark的集群资源进行管理,再用独立集群模式自己做资源管理调度就没那么必要了。
在企业中,涉及大数据处理的,通常都会部署Hadoop集群、HDFS文件系统,同时就会有YARN资源管理调度框架,完全可以将Spark的资源管理工作交给YARN来做,YARN承担资源管理调度工作,Spark专注于计算,因此就有了Spark on YARN的集群模式。本节将介绍Spark on YARN的安装,Spark on YARN的安装,至少需要3台服务器,在安装之前,按照本章第1节步骤准备好3台服务器。
安装Hadoop集群
Hadoop的安装非常简单,将下载的Hadoop软件安装包解压到目标位置、配置Hadoop相关的环境变量即安装完成。Spark on YARN模式下,Spark应用程序在提交执行的时候,YARN会根据集群的资源情况选择分配执行应用程序的节点,从选中的节点启动Spark,为了保证Spark能启动成功,需要在Hadoop集群的每台服务器节点上都安装有Spark软件。Hadoop和Spark软件解压到目录路径,命令如下:
$ tar -xzf hadoop-3.3.5.tar.gz -C apps
$ tar -xzf spark-3.4.0-bin-hadoop3.tgz -C apps
需要在集群的每个节点上都安装Hadoop和Spark,可以复制软件安装包到每个节点进行分别安装,也可以将安装好软件的apps目录同步到每个节点上。
Hadoop的目录结构如图所示。

- bin目录下存放的是Hadoop相关的常用命令,例如操作HDFS的hdfs命令,以及hadoop、yarn等命令。
- etc目录下存放的是Hadoop的配置文件,对HDFS、MapReduce、YARN以及集群节点列表的配置都在这个里面。
- sbin目录下存放的是管理集群相关的命令,例如启动集群、启动HDFS、启动YARN、停止集群等的命令。
- share目录下存放了一些Hadoop的相关资源,例如文档以及各个模块的Jar包。
配置环境变量
在集群的每个节点上都配置Hadoop和Spark相关的环境变量,Hadoop集群在启动的时候可以使用start-all.sh一次性启动集群中的HDFS和YARN,而Spark的集群启动命令也是start-all.sh,在Spark on YARN下不需要启动Spark集群,为了防止在启动Hadoop集群的时候命令冲突,需要将Hadoop相关的路径配置在PATH变量的前面部分,Spark相关的路径配置在PATH变量的后面部分,执行启动集群start-all.sh的时候会优先寻找到并使用Hadoop的启动命令,正确启动Hadoop集群。在node1上配置环境变量,命令如下:
$ vi .bashrc
环境变量配置内容如下:
export HADOOP_HOME=/home/hadoop/apps/hadoop-3.3.5
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-3.3.5/etc/hadoop
export YARN_CONF_DIR=/home/hadoop/apps/hadoop-3.3.5/etc/hadoop
export SPARK_HOME=/home/hadoop/apps/spark-3.4.0-bin-hadoop3
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PATH
环境变量配置完成后,执行命令让新配置的环境变量生效,命令如下:
$ source ~/.bashrc
配置Hadoop集群
Hadoop软件安装完成后,每个节点上的Hadoop都是独立的软件,需要进行配置才能组成Hadoop集群。Hadoop的配置文件在$HADOOP_HOME/etc/hadoop目录下,主要配置文件有:
- hadoop-env.sh主要配置Hadoop环境相关的信息,例如安装路径、配置文件路径等。
- core-site.xml是Hadoop的核心配置文件,主要配置Hadoop的NameNode的地址、Hadoop产生的文件目录等。
- hdfs-site.xml是HDFS相关的配置文件,主要配置文件的副本数、HDFS文件系统在本地对应的目录等。
- mapred-site.xml是MapReduce相关的配置文件,主要配置MapReduce如何运行、依赖类库路径等。
- yarn-site.xml是YARN相关的配置文件,主要配置YARN的管理节点ResourceManager的地址、NodeManager获取数据的方式等。
- workers是集群中节点列表的配置文件,只有在这个文件里面配置了的节点才会加入到Hadoop集群中,否则就是一个独立节点。
这几个配置文件如果不存在,可以通过复制配置模板的方式创建,也可以通过创建新文件的方式创建。需要保证在集群的每个节点上这6个配置保持同步,在node1上配置所有配置文件。
hadoop-env.sh配置命令如下:
$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
hadoop-env.sh配置内容如下:
export JAVA_HOME= /usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/home/hadoop/apps/hadoop-3.3.5
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-3.3.5/etc/hadoop
export HADOOP_LOG_DIR=/home/hadoop/logs/hadoop
core-site.xml配置命令如下:
$ vi $HADOOP_HOME/etc/hadoop/core-site.xml
core-site.xml配置内容如下:
<configuration><property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/works/hadoop/temp</value></property><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property>
</configuration>
hdfs-site.xml配置命令如下:
$ vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
hdfs-site.xml配置内容如下:
<configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.name.dir</name><value>/home/hadoop/works/hadoop/hdfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>/home/hadoop/works/hadoop/hdfs/data</value></property>
</configuration>
mapred-site.xml配置命令如下:
$ vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
mapred-site.xml配置内容如下:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value></property>
</configuration>
yarn-site.xml配置命令如下:
$ vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
yarn-site.xml配置内容如下:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>node1</value></property>
</configuration>
workers配置命令如下:
$ vi $HADOOP_HOME/etc/hadoop/workers
workers配置内容如下:
node1
node2
node3
环境信息同步
确保3台服务器上的配置文件完全一致,为了防止配置出错,直接使用命令将node1上的配置文件复制到其他服务器上,复制命令如下:
$ scp -r .bashrc apps node2:~/
$ scp -r .bashrc apps node3:~/
格式化NameNode
所有节点上都安装完成Hadoop、Spark的软件,完成所有节点的环境变量配置、域名解析配置、配置文件配置,在启动集群之前还需要进行NameNode的格式化操作,在NameNode所在的node1节点上执行格式化,命令如下:
$ hdfs namenode -format
NameNode格式化完成后,在目录/home/hadoop/works/hadoop/hdfs/name下会生成current目录,在current目录中会包含fsimage文件,它是NameNode的一个元数据文件,记录了当前HDFS文件系统中的所有目录和文件的元数据信息。
结束语
好了,感谢大家的关注,今天就分享到这里了,更多详细内容,请阅读原书或持续关注专栏。
相关文章:
《PySpark大数据分析实战》-11.Spark on YARN模式安装Hadoop
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…...

多架构容器镜像构建实战
最近在一个国产化项目中遇到了这样一个场景,在同一个 Kubernetes 集群中的节点是混合架构的,也就是说,其中某些节点的 CPU 架构是 x86 的,而另一些节点是 ARM 的。为了让我们的镜像在这样的环境下运行,一种最简单的做法…...
通过层进行高效学习:探索深度神经网络中的层次稀疏表示
一、介绍 深度学习中的层次稀疏表示是人工智能领域日益重要的研究领域。本文将探讨分层稀疏表示的概念、它们在深度学习中的意义、应用、挑战和未来方向。 最大限度地提高人工智能的效率和性能:深度学习系统中分层稀疏表示的力量。 二、理解层次稀疏表示 分层稀疏表…...

自然语言处理阅读第二弹
HuggingFace 镜像网站模型库 HuggingFace中bert实现 下游任务介绍重要源码解读 NLP中的自回归模型和自编码模型 自回归:根据上文内容预测下一个可能的单词,或者根据下文预测上一个可能的单词。只能利用上文或者下文的信息,不能同时利用上…...
利用canvas封装录像时间轴拖动(uniapp),封装上传uniapp插件市场
gitee项目地址,项目是一个空项目,其中包含了封装的插件,自己阅读,由于利用了canvas所以在使用中暂不支持.nvue,待优化; 项目也是借鉴了github上的一个项目,timeline-canvas, ...
PDF转为图片
PDF转为图片 背景pdf展示目标效果 发展过程最终解决方案:python PDF转图片pdf2image注意:poppler 安装 背景 最近接了一项目,主要的需求就是本地的文联单位,需要做一个电子刊物阅览的网站,将民族的刊物发布到网站上供…...

隐私计算介绍
这里只对隐私计算做一些概念性的浅显介绍,作为入门了解即可 目录 隐私计算概述隐私计算概念隐私计算背景国外各个国家和地区纷纷出台了围绕数据使用和保护的公共政策国内近年来也出台了数据安全、隐私和使用相关的政策法规 隐私计算技术发展 隐私计算技术安全多方计…...

HTML有哪些列表以及具体的使用!!!
文章目录 一、HTML列表二、列表的应用1、无序列表2、有序列表3、自定义列表 三、总结 一、HTML列表 html的列表有三种,一种是无序列表,一种是有序列表,还有一种为自定义列表。 二、列表的应用 1、无序列表 <ul> <li>无序列表…...
DriveWorks Solo捕获参数(二)
捕获参数-帧 顶门框 现在让我们捕获框架。它由2部分组成;两者都有一个需要捕捉的维度。 1.通过单击“捕获资源管理器”中的标题来激活“捕获的模型”部分。 2.展开框架组件。 3.双击任务窗格树中的模型顶门侧柱。 这将在SOLIDWORKS中打开模型顶门门框,并…...
基于开源的JAVA mongodb jdbc 驱动 使用教程
基于开源的JAVA mongodb jdbc 驱动 使用教程介绍 介绍 本文介绍一款开源的基于JAVA的 Mongodb JDBC 驱动使用教程 开源地址 https://gitee.com/bgong/jdbc-mongodb-driver功能价值 与mybaits融合:复用mybatis的功能特性,如:缓存,if动态判断标签等特…...

[RK-Linux] RK3399使用RK开源SPL,修改U-Boot为FIT打包方式,裁剪trust分区
文章目录 一、启动方式二、FIT打包三、RK3568相关配置参考四、RK3399支持与调试一、启动方式 RK3399平台根据前级Loader代码是否开源,目前有两套启动方式: // 前级loader闭源 BOOTROM => ddr bin => Miniloader => TRUST => U-BOOT => KERNEL // 前级loader…...

【网络安全】-Linux操作系统—VMWare软件
文章目录 VMWare软件的安装选择VMWare版本下载VMWare安装过程 VMWare的常用操作创建新的虚拟机配置虚拟机启动和关闭虚拟机安装VMWare Tools VMWare的克隆和快照克隆(Clone)快照(Snapshot) 总结 VMWare是一种流行的虚拟化软件&…...

关于chatgpt一点肤浅认识
001 词向量 用数字向量表示单词。它是计算机更好地理解单词 1、预训练 – 就是先训练一个模型,用于以后特定任务的微调,比如将 BERT这个模型用于特定的NLP任务,比如情感分析 2、one-hot: 用只有一个元素是1,其他是0的向量表示物体…...

Redis结合SpringBoot 基本使用
1.1 简介 1.1.1 概述 Spring Data 中有一个成员 Spring Data Redis,他提供了 RedisTemplate 可以在 Spring 应用中更简便的访问 Redis 以及异常处理及序列化,支持发布订阅等操作。 1.2 RedisTemplate 常见 API RedisTemplate 针对 jedis 客户端中大…...
JAVA主流日志框架梳理学习及使用
前言:目前市面上有挺多JAVA的日志框架,比如JUL(JDK自带的日志框架),Log4j,Logback,Log4j2等,有人可能有疑问说还有slf4j,不过slf4j不是一种日志框架的具体实现,而是一种日志门面(日志门面可以理解为是一种统…...

java多个设计模式解决大量if-else堆积
当面对大量的 if-else 语句时,可以考虑使用以下几种常见的设计模式来减少代码的复杂性和维护成本: 策略模式(Strategy Pattern):将各个分支的逻辑封装成不同的策略类,然后通过一个上下文类来根据条件选择合…...
)
js DOM的一些小操作 获取节点集合Node( getElementsByClassName等)
1. getElementsByClassName(names) 返回文档中所有含有指定类名的节点 document.getElementsByClassName(a) 返回所有类名为a的节点 2.getElementsByName(name) 返回文档中所有指定name的节点。 标签可以有name属性。 3. querySelectorAll(selectors) 返回文档中所有匹配…...
Arcgis导出为tiff
原有一幅影像,在进行一些操作之后,需要导出为tiff 比如我对他进行一个重采样,48m分辨率变为96m 在重采样后的数据图层上右键,导出数据 为什么有时会导出为.gdb格式的呢? 可能是位置处在一个文件地理数据库.gdb下...

nginx中的root and alias命令的区别
Ubuntu关于Nginx的命令: 1、安装Nginx: apt-get install nginx2、查看Nginx运行状态: systemctl status nginx3、启动Nginx: systemctl start nginx4、停止Nginx: systemctl stop nginx5、重启Nginx: …...

python提取图片型pdf中的文字(提取pdf扫描件文字)
前言 文字型pdf提取,python的库一大堆,但是图片型pdf和pdf扫描件提取,还是有些难度的,我们需要用到OCR(光学字符识别)功能。 一、准备 1、安装OCR(光学字符识别)支持库 首先要安…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...
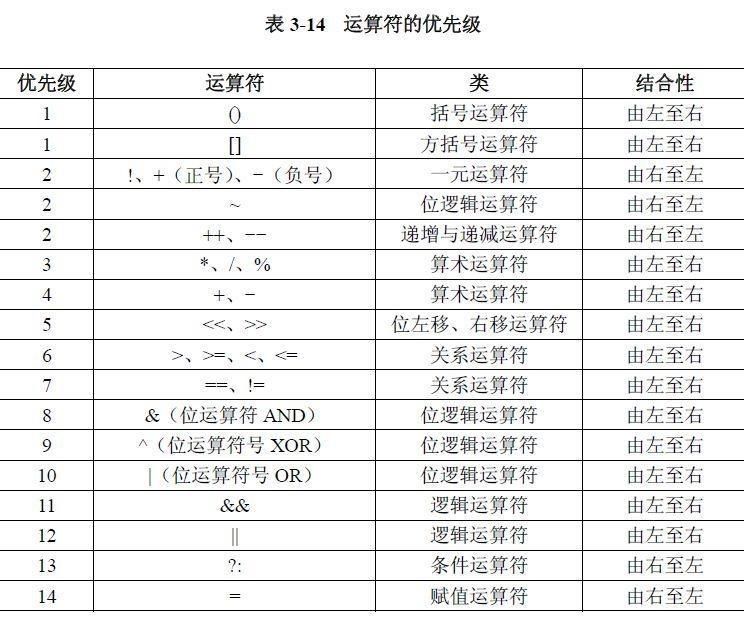
02.运算符
目录 什么是运算符 算术运算符 1.基本四则运算符 2.增量运算符 3.自增/自减运算符 关系运算符 逻辑运算符 &&:逻辑与 ||:逻辑或 !:逻辑非 短路求值 位运算符 按位与&: 按位或 | 按位取反~ …...

土建施工员考试:建筑施工技术重点知识有哪些?
《管理实务》是土建施工员考试中侧重实操应用与管理能力的科目,核心考查施工组织、质量安全、进度成本等现场管理要点。以下是结合考试大纲与高频考点整理的重点内容,附学习方向和应试技巧: 一、施工组织与进度管理 核心目标: 规…...