Elasticsearch 8.9 search命令执行查询源码
- 一、相关的API的handler
- 1、接收HTTP请求的handler
- 2、往数据节点发送查询请求的action(TransportSearchAction)
- 3、通过transportService把查询请求发送到指定的数据节点
- 二、数据节点收到请求的处理逻辑
- 1、尝试从缓存中加载查询结果
- 2、不通过缓存查询,直接执行查询
- (1)executeQuery和executeRank两种查询方式
- (2)、根据搜索上下文,在查询之前添加各种查询搜集器
- (3) 执行查询操作(遍历此索引在此数据节点所有的分片)
这里只是HTTP发送查询请求到主节点,主节点再转发到数据节点,数据节点再到调用
lucene.search实际查询数据之前如何处理的源码逻辑
一、相关的API的handler
在ActionModule.java
registerHandler.accept(new RestSearchAction(restController.getSearchUsageHolder()));actions.register(SearchAction.INSTANCE, TransportSearchAction.class);1、接收HTTP请求的handler
下面这个类RestSearchAction有长,该省略的方法我都已经省略了,首先通过
routes请求到这个方法的prepareRequest(主要是组装searchRequest),这个方法内部会调用parseSearchSource(主要是组装searchSourceBuilder)
public class RestSearchAction extends BaseRestHandler {@Overridepublic List<Route> routes() {return List.of(new Route(GET, "/_search"),new Route(POST, "/_search"),new Route(GET, "/{index}/_search"),new Route(POST, "/{index}/_search"),Route.builder(GET, "/{index}/{type}/_search").deprecated(TYPES_DEPRECATION_MESSAGE, RestApiVersion.V_7).build(),Route.builder(POST, "/{index}/{type}/_search").deprecated(TYPES_DEPRECATION_MESSAGE, RestApiVersion.V_7).build());}//入口 @Overridepublic RestChannelConsumer prepareRequest(final RestRequest request, final NodeClient client) throws IOException {SearchRequest searchRequest;if (request.hasParam("min_compatible_shard_node")) {searchRequest = new SearchRequest(Version.fromString(request.param("min_compatible_shard_node")));} else {searchRequest = new SearchRequest();}/** 我们必须拉出对 'source().size(size)' 的调用,因为 _update_by_query 和 _delete_by_query 使用相同的解析路径,但在看到 'size' url 参数时设置了不同的变量* 请注意,我们不能使用 'searchRequest.source()::size',因为 'searchRequest.source()' 现在是 null。我们不必防止它在 IntConsumer 中为 null,因为它以后不能为 null。*///组装SearchRequestIntConsumer setSize = size -> searchRequest.source().size(size);request.withContentOrSourceParamParserOrNull(parser -> parseSearchRequest(searchRequest, request, parser, client.getNamedWriteableRegistry(), setSize, searchUsageHolder));//请求发送return channel -> {RestCancellableNodeClient cancelClient = new RestCancellableNodeClient(client, request.getHttpChannel());cancelClient.execute(SearchAction.INSTANCE, searchRequest, new RestChunkedToXContentListener<>(channel));};}//组装searchRequest,public static void parseSearchRequest(SearchRequest searchRequest,RestRequest request,@Nullable XContentParser requestContentParser,NamedWriteableRegistry namedWriteableRegistry,IntConsumer setSize,@Nullable SearchUsageHolder searchUsageHolder) throws IOException {//检查请求的 REST API 版本和参数是否兼容,并在必要时记录警告日志。if (request.getRestApiVersion() == RestApiVersion.V_7 && request.hasParam("type")) {request.param("type");deprecationLogger.compatibleCritical("search_with_types", TYPES_DEPRECATION_MESSAGE);}//如果搜索请求的源为空,创建一个新的 SearchSourceBuilder 作为源if (searchRequest.source() == null) {searchRequest.source(new SearchSourceBuilder());}//将请求中的索引参数解析为一个索引数组,并设置到搜索请求中。searchRequest.indices(Strings.splitStringByCommaToArray(request.param("index")));//如果提供了 requestContentParser,则解析请求内容,if (requestContentParser != null) {//并根据是否提供了 searchUsageHolder 参数选择解析方式if (searchUsageHolder == null) {searchRequest.source().parseXContent(requestContentParser, true);} else {searchRequest.source().parseXContent(requestContentParser, true, searchUsageHolder);}}//设置批量减少大小参数。final int batchedReduceSize = request.paramAsInt("batched_reduce_size", searchRequest.getBatchedReduceSize());searchRequest.setBatchedReduceSize(batchedReduceSize);//如果请求中包含了 pre_filter_shard_size(预过滤器分片大小) 参数,则设置搜索请求的 preFilterShardSize。if (request.hasParam("pre_filter_shard_size")) {searchRequest.setPreFilterShardSize(request.paramAsInt("pre_filter_shard_size", SearchRequest.DEFAULT_PRE_FILTER_SHARD_SIZE));}//如果请求中包含了 enable_fields_emulation 参数,则忽略该参数(从8.0版本开始已不再使用)。if (request.hasParam("enable_fields_emulation")) {// this flag is a no-op from 8.0 on, we only want to consume it so its presence doesn't cause errorsrequest.paramAsBoolean("enable_fields_emulation", false);}//如果请求中包含了 max_concurrent_shard_requests(最大并发分片请求数) 参数,则设置搜索请求的 maxConcurrentShardRequests。if (request.hasParam("max_concurrent_shard_requests")) {final int maxConcurrentShardRequests = request.paramAsInt("max_concurrent_shard_requests",searchRequest.getMaxConcurrentShardRequests());searchRequest.setMaxConcurrentShardRequests(maxConcurrentShardRequests);}//如果请求中包含了 allow_partial_search_results(允许部分搜索结果) 参数,则设置搜索请求的 allowPartialSearchResults。if (request.hasParam("allow_partial_search_results")) {//仅当我们传递了参数以覆盖集群级默认值时才设置searchRequest.allowPartialSearchResults(request.paramAsBoolean("allow_partial_search_results", null));}//设置搜索类型参数。searchRequest.searchType(request.param("search_type"));//调用 parseSearchSource 方法解析搜索源。parseSearchSource(searchRequest.source(), request, setSize);//设置请求缓存参数searchRequest.requestCache(request.paramAsBoolean("request_cache", searchRequest.requestCache()));//解析并设置滚动参数。String scroll = request.param("scroll");if (scroll != null) {searchRequest.scroll(new Scroll(parseTimeValue(scroll, null, "scroll")));}//设置路由参数。searchRequest.routing(request.param("routing"));//设置首选项参数。searchRequest.preference(request.param("preference"));//设置索引选项。searchRequest.indicesOptions(IndicesOptions.fromRequest(request, searchRequest.indicesOptions()));//验证搜索请求。validateSearchRequest(request, searchRequest);//如果搜索请求中有 pointInTimeBuilder,则准备点在时间请求。if (searchRequest.pointInTimeBuilder() != null) {preparePointInTime(searchRequest, request, namedWriteableRegistry);} else {//否则,设置 ccsMinimizeRoundtrips 参数searchRequest.setCcsMinimizeRoundtrips(request.paramAsBoolean("ccs_minimize_roundtrips", searchRequest.isCcsMinimizeRoundtrips()));}//如果请求中包含了 force_synthetic_source 参数,则设置搜索请求的 forceSyntheticSource。if (request.paramAsBoolean("force_synthetic_source", false)) {searchRequest.setForceSyntheticSource(true);}}//组装searchSourceBuilderprivate static void parseSearchSource(final SearchSourceBuilder searchSourceBuilder, RestRequest request, IntConsumer setSize) {//RestRequest对象的URL参数转换为QueryBuilder对象,QueryBuilder queryBuilder = RestActions.urlParamsToQueryBuilder(request);//并将其设置为SearchSourceBuilder对象的查询条件if (queryBuilder != null) {searchSourceBuilder.query(queryBuilder);}//如果RestRequest对象包含from参数,则将其转换为整数并设置为SearchSourceBuilder对象的from属性if (request.hasParam("from")) {searchSourceBuilder.from(request.paramAsInt("from", 0));}if (request.hasParam("size")) {int size = request.paramAsInt("size", SearchService.DEFAULT_SIZE);if (request.getRestApiVersion() == RestApiVersion.V_7 && size == -1) {// we treat -1 as not-set, but deprecate it to be able to later remove this funny extra treatmentdeprecationLogger.compatibleCritical("search-api-size-1","Using search size of -1 is deprecated and will be removed in future versions. "+ "Instead, don't use the `size` parameter if you don't want to set it explicitly.");} else {setSize.accept(size);}}if (request.hasParam("explain")) {searchSourceBuilder.explain(request.paramAsBoolean("explain", null));}if (request.hasParam("version")) {searchSourceBuilder.version(request.paramAsBoolean("version", null));}if (request.hasParam("seq_no_primary_term")) {searchSourceBuilder.seqNoAndPrimaryTerm(request.paramAsBoolean("seq_no_primary_term", null));}if (request.hasParam("timeout")) {searchSourceBuilder.timeout(request.paramAsTime("timeout", null));}if (request.hasParam("terminate_after")) {int terminateAfter = request.paramAsInt("terminate_after", SearchContext.DEFAULT_TERMINATE_AFTER);searchSourceBuilder.terminateAfter(terminateAfter);}StoredFieldsContext storedFieldsContext = StoredFieldsContext.fromRestRequest(SearchSourceBuilder.STORED_FIELDS_FIELD.getPreferredName(),request);if (storedFieldsContext != null) {searchSourceBuilder.storedFields(storedFieldsContext);}String sDocValueFields = request.param("docvalue_fields");if (sDocValueFields != null) {if (Strings.hasText(sDocValueFields)) {String[] sFields = Strings.splitStringByCommaToArray(sDocValueFields);for (String field : sFields) {searchSourceBuilder.docValueField(field, null);}}}FetchSourceContext fetchSourceContext = FetchSourceContext.parseFromRestRequest(request);if (fetchSourceContext != null) {searchSourceBuilder.fetchSource(fetchSourceContext);}if (request.hasParam("track_scores")) {searchSourceBuilder.trackScores(request.paramAsBoolean("track_scores", false));}if (request.hasParam("track_total_hits")) {if (Booleans.isBoolean(request.param("track_total_hits"))) {searchSourceBuilder.trackTotalHits(request.paramAsBoolean("track_total_hits", true));} else {searchSourceBuilder.trackTotalHitsUpTo(request.paramAsInt("track_total_hits", SearchContext.DEFAULT_TRACK_TOTAL_HITS_UP_TO));}}String sSorts = request.param("sort");if (sSorts != null) {String[] sorts = Strings.splitStringByCommaToArray(sSorts);for (String sort : sorts) {int delimiter = sort.lastIndexOf(":");if (delimiter != -1) {String sortField = sort.substring(0, delimiter);String reverse = sort.substring(delimiter + 1);if ("asc".equals(reverse)) {searchSourceBuilder.sort(sortField, SortOrder.ASC);} else if ("desc".equals(reverse)) {searchSourceBuilder.sort(sortField, SortOrder.DESC);}} else {searchSourceBuilder.sort(sort);}}}String sStats = request.param("stats");if (sStats != null) {searchSourceBuilder.stats(Arrays.asList(Strings.splitStringByCommaToArray(sStats)));}SuggestBuilder suggestBuilder = parseSuggestUrlParameters(request);if (suggestBuilder != null) {searchSourceBuilder.suggest(suggestBuilder);}}
}2、往数据节点发送查询请求的action(TransportSearchAction)
下面这个TransportSearchAction也有点长,主要流程是
doExecute->executeLocalSearch->executeSearch->接口SearchPhaseProvider的实现类AsyncSearchActionProvider
public class TransportSearchAction extends HandledTransportAction<SearchRequest, SearchResponse> {//执行方法@Overrideprotected void doExecute(Task task, SearchRequest searchRequest, ActionListener<SearchResponse> listener) {executeRequest((SearchTask) task, searchRequest, listener, AsyncSearchActionProvider::new);}//主要功能是执行搜索请求,并根据不同的情况选择执行本地搜索或远程搜索void executeRequest(SearchTask task,SearchRequest original,ActionListener<SearchResponse> listener,Function<ActionListener<SearchResponse>, SearchPhaseProvider> searchPhaseProvider) {//获取相对开始时间戳和时间提供器final long relativeStartNanos = System.nanoTime();final SearchTimeProvider timeProvider = new SearchTimeProvider(original.getOrCreateAbsoluteStartMillis(),relativeStartNanos,System::nanoTime);//使用重写监听器对搜索请求进行重写,并根据重写后的请求获取搜索上下文和远程集群索引。ActionListener<SearchRequest> rewriteListener = ActionListener.wrap(rewritten -> {//搜索上下文final SearchContextId searchContext;//远程集群索引。final Map<String, OriginalIndices> remoteClusterIndices;if (ccsCheckCompatibility) {checkCCSVersionCompatibility(rewritten);}if (rewritten.pointInTimeBuilder() != null) {//则获取搜索上下文的 ID,并从中获取索引信息,并将结果保存在 remoteClusterIndices 中。searchContext = rewritten.pointInTimeBuilder().getSearchContextId(namedWriteableRegistry);remoteClusterIndices = getIndicesFromSearchContexts(searchContext, rewritten.indicesOptions());} else {//将 searchContext 设置为 null,并通过 remoteClusterService.groupIndices(rewritten.indicesOptions(), rewritten.indices()) 方法获取远程集群索引。searchContext = null;remoteClusterIndices = remoteClusterService.groupIndices(rewritten.indicesOptions(), rewritten.indices());}//从 remoteClusterIndices 中移除 RemoteClusterAware.LOCAL_CLUSTER_GROUP_KEY 对应的本地索引,并将结果保存在 localIndices 中。OriginalIndices localIndices = remoteClusterIndices.remove(RemoteClusterAware.LOCAL_CLUSTER_GROUP_KEY);//获取当前集群状态 clusterState。final ClusterState clusterState = clusterService.state();//如果远程集群索引为空,则执行本地搜索if (remoteClusterIndices.isEmpty()) {executeLocalSearch(task,timeProvider,rewritten,localIndices,clusterState,SearchResponse.Clusters.EMPTY,searchContext,searchPhaseProvider.apply(listener));} else {//如果远程集群索引不为空,则根据是否需要最小化往返次数选择执行远程搜索或本地搜索。//省略,目前不涉及到远程集群}}}, listener::onFailure);Rewriteable.rewriteAndFetch(original, searchService.getRewriteContext(timeProvider::absoluteStartMillis), rewriteListener);}void executeLocalSearch(Task task,SearchTimeProvider timeProvider,SearchRequest searchRequest,OriginalIndices localIndices,ClusterState clusterState,SearchResponse.Clusters clusterInfo,SearchContextId searchContext,SearchPhaseProvider searchPhaseProvider) {executeSearch((SearchTask) task,timeProvider,searchRequest,localIndices,Collections.emptyList(),(clusterName, nodeId) -> null,clusterState,Collections.emptyMap(),clusterInfo,searchContext,searchPhaseProvider);}private void executeSearch(SearchTask task,SearchTimeProvider timeProvider,SearchRequest searchRequest,OriginalIndices localIndices,List<SearchShardIterator> remoteShardIterators,BiFunction<String, String, DiscoveryNode> remoteConnections,ClusterState clusterState,Map<String, AliasFilter> remoteAliasMap,SearchResponse.Clusters clusters,@Nullable SearchContextId searchContext,SearchPhaseProvider searchPhaseProvider) {//检查全局集群阻塞状态是否允许读取操作clusterState.blocks().globalBlockedRaiseException(ClusterBlockLevel.READ);//检查搜索请求中是否定义了allowPartialSearchResults(允许部分搜索结果)参数,如果没有,则应用集群服务的默认设置。if (searchRequest.allowPartialSearchResults() == null) {//默认允许部分搜索结果searchRequest.allowPartialSearchResults(searchService.defaultAllowPartialSearchResults());}final List<SearchShardIterator> localShardIterators;final Map<String, AliasFilter> aliasFilter;final String[] concreteLocalIndices;//根据搜索上下文的存在与否,确定本地和远程的索引和别名过滤器。if (searchContext != null) {assert searchRequest.pointInTimeBuilder() != null;aliasFilter = searchContext.aliasFilter();concreteLocalIndices = localIndices == null ? new String[0] : localIndices.indices();localShardIterators = getLocalLocalShardsIteratorFromPointInTime(clusterState,localIndices,searchRequest.getLocalClusterAlias(),searchContext,searchRequest.pointInTimeBuilder().getKeepAlive(),searchRequest.allowPartialSearchResults());} else {//解析本地索引,获取Index对象数组indices。final Index[] indices = resolveLocalIndices(localIndices, clusterState, timeProvider);//将indices数组中的每个Index对象的名称提取出来,并存储在concreteLocalIndices数组中。concreteLocalIndices = Arrays.stream(indices).map(Index::getName).toArray(String[]::new);//解析索引名称表达式,获取与搜索请求中的索引相关的索引和别名的集合indicesAndAliases。final Set<String> indicesAndAliases = indexNameExpressionResolver.resolveExpressions(clusterState, searchRequest.indices());//构建索引别名过滤器aliasFilter = buildIndexAliasFilters(clusterState, indicesAndAliases, indices);//将remoteAliasMap中的所有映射添加到aliasFilter中aliasFilter.putAll(remoteAliasMap);//取本地分片迭代器localShardIterators,localShardIterators = getLocalShardsIterator(clusterState,searchRequest,searchRequest.getLocalClusterAlias(),indicesAndAliases,concreteLocalIndices);}//合并创建一个GroupShardsIterator<SearchShardIterator>对象,并赋值给shardIterators变量。final GroupShardsIterator<SearchShardIterator> shardIterators = mergeShardsIterators(localShardIterators, remoteShardIterators);//检查shardIterators的大小是否超过了集群设定的分片数量限制,如果超过则抛出异常。failIfOverShardCountLimit(clusterService, shardIterators.size());//WaitForCheckpointsbuwei1if (searchRequest.getWaitForCheckpoints().isEmpty() == false) {if (remoteShardIterators.isEmpty() == false) {throw new IllegalArgumentException("Cannot use wait_for_checkpoints parameter with cross-cluster searches.");} else {validateAndResolveWaitForCheckpoint(clusterState, indexNameExpressionResolver, searchRequest, concreteLocalIndices);}}Map<String, Float> concreteIndexBoosts = resolveIndexBoosts(searchRequest, clusterState);//shardIterators的大小调整搜索类型。adjustSearchType(searchRequest, shardIterators.size() == 1);//获取集群的节点信息。final DiscoveryNodes nodes = clusterState.nodes();//构建一个连接查询函数connectionLookup,用于根据索引和节点名称获取连接对象。BiFunction<String, String, Transport.Connection> connectionLookup = buildConnectionLookup(searchRequest.getLocalClusterAlias(),nodes::get,remoteConnections,searchTransportService::getConnection);//创建一个异步搜索执行器asyncSearchExecutor,用于执行异步搜索。final Executor asyncSearchExecutor = asyncSearchExecutor(concreteLocalIndices);//根据条件判断是否需要预过滤搜索分片。final boolean preFilterSearchShards = shouldPreFilterSearchShards(clusterState,searchRequest,concreteLocalIndices,localShardIterators.size() + remoteShardIterators.size(),defaultPreFilterShardSize);//调用searchPhaseProvider的newSearchPhase方法,开始执行搜索阶段//searchPhaseProvider的实现用的是AsyncSearchActionProvidersearchPhaseProvider.newSearchPhase(task,searchRequest,asyncSearchExecutor,shardIterators,timeProvider,connectionLookup,clusterState,Collections.unmodifiableMap(aliasFilter),concreteIndexBoosts,preFilterSearchShards,threadPool,clusters).start();}//一个接口interface SearchPhaseProvider {SearchPhase newSearchPhase(SearchTask task,SearchRequest searchRequest,Executor executor,GroupShardsIterator<SearchShardIterator> shardIterators,SearchTimeProvider timeProvider,BiFunction<String, String, Transport.Connection> connectionLookup,ClusterState clusterState,Map<String, AliasFilter> aliasFilter,Map<String, Float> concreteIndexBoosts,boolean preFilter,ThreadPool threadPool,SearchResponse.Clusters clusters);}//接口SearchPhaseProvider的一个实现类private class AsyncSearchActionProvider implements SearchPhaseProvider {private final ActionListener<SearchResponse> listener;AsyncSearchActionProvider(ActionListener<SearchResponse> listener) {this.listener = listener;}@Overridepublic SearchPhase newSearchPhase(SearchTask task,SearchRequest searchRequest,Executor executor,GroupShardsIterator<SearchShardIterator> shardIterators,SearchTimeProvider timeProvider,BiFunction<String, String, Transport.Connection> connectionLookup,ClusterState clusterState,Map<String, AliasFilter> aliasFilter,Map<String, Float> concreteIndexBoosts,boolean preFilter,ThreadPool threadPool,SearchResponse.Clusters clusters) {if (preFilter) {//省略} else {final QueryPhaseResultConsumer queryResultConsumer = searchPhaseController.newSearchPhaseResults(executor,circuitBreaker,task::isCancelled,task.getProgressListener(),searchRequest,shardIterators.size(),exc -> searchTransportService.cancelSearchTask(task, "failed to merge result [" + exc.getMessage() + "]"));//该阶段用于计算分布项频率以实现更准确的评分if (searchRequest.searchType() == DFS_QUERY_THEN_FETCH) {//省略} else {//对所有分片执行查询assert searchRequest.searchType() == QUERY_THEN_FETCH : searchRequest.searchType();return new SearchQueryThenFetchAsyncAction(logger,searchTransportService,connectionLookup,aliasFilter,concreteIndexBoosts,executor,queryResultConsumer,searchRequest,listener,shardIterators,timeProvider,clusterState,task,clusters);}}}}
}
其中searchType 有以下几种
public enum SearchType {/*** 与 {@link QUERY_THEN_FETCH} 相同,但初始散射阶段除外,该阶段用于计算分布项频率以实现更准确的评分。*/DFS_QUERY_THEN_FETCH((byte) 0),/** 对所有分片执行查询,但仅返回足够的信息(而不是文档内容)。然后对结果进行排序和排名,并基于此,* 仅要求相关分片提供实际文档内容。返回的命中数与大小中指定的命中数完全相同,因为它们是唯一被提取的命中数。当索引有很多分片(不是副本、分片 ID 组)时,这非常方便。*/QUERY_THEN_FETCH((byte) 1);// 2 used to be DFS_QUERY_AND_FETCH// 3 used to be QUERY_AND_FETCH/** * 默认搜索类型*/public static final SearchType DEFAULT = QUERY_THEN_FETCH;
}
SearchQueryThenFetchAsyncAction的实现如下
class SearchQueryThenFetchAsyncAction extends AbstractSearchAsyncAction<SearchPhaseResult> {private final SearchProgressListener progressListener;// informations to track the best bottom top doc globally.private final int topDocsSize;private final int trackTotalHitsUpTo;private volatile BottomSortValuesCollector bottomSortCollector;SearchQueryThenFetchAsyncAction(final Logger logger,final SearchTransportService searchTransportService,final BiFunction<String, String, Transport.Connection> nodeIdToConnection,final Map<String, AliasFilter> aliasFilter,final Map<String, Float> concreteIndexBoosts,final Executor executor,final QueryPhaseResultConsumer resultConsumer,final SearchRequest request,final ActionListener<SearchResponse> listener,final GroupShardsIterator<SearchShardIterator> shardsIts,final TransportSearchAction.SearchTimeProvider timeProvider,ClusterState clusterState,SearchTask task,SearchResponse.Clusters clusters) {super("query",logger,searchTransportService,nodeIdToConnection,aliasFilter,concreteIndexBoosts,executor,request,listener,shardsIts,timeProvider,clusterState,task,resultConsumer,request.getMaxConcurrentShardRequests(),clusters);//省略代码}//父类的performPhaseOnShard方法会调用这个方法protected void executePhaseOnShard(final SearchShardIterator shardIt,final SearchShardTarget shard,final SearchActionListener<SearchPhaseResult> listener) {ShardSearchRequest request = rewriteShardSearchRequest(super.buildShardSearchRequest(shardIt, listener.requestIndex));getSearchTransport().sendExecuteQuery(getConnection(shard.getClusterAlias(), shard.getNodeId()), request, getTask(), listener);}//省略代码
}
其中上面的executeSearch方法中searchPhaseProvider.newSearchPhase().start(),实际执行的是SearchQueryThenFetchAsyncAction的父类AbstractSearchAsyncAction中的start方法
abstract class AbstractSearchAsyncAction<Result extends SearchPhaseResult> extends SearchPhase implements SearchPhaseContext {/*** 这是搜索的主要入口点。此方法启动初始阶段的搜索执行。*/public final void start() {if (getNumShards() == 0) {//省略return;}executePhase(this);}private void executePhase(SearchPhase phase) {try {phase.run();} catch (Exception e) {if (logger.isDebugEnabled()) {logger.debug(() -> format("Failed to execute [%s] while moving to [%s] phase", request, phase.getName()), e);}onPhaseFailure(phase, "", e);}}@Overridepublic final void run() {//toSkipShardsIts中的每个SearchShardIterator对象,调用skip()方法并断言其返回值为true,然后调用skipShard()方法for (final SearchShardIterator iterator : toSkipShardsIts) {assert iterator.skip();skipShard(iterator);}//如果shardsIts的大小大于0,if (shardsIts.size() > 0) {//省略代码//如果请求中"允许部分搜索结果"为falseif (request.allowPartialSearchResults() == false) {//省略代码}//对于shardsIts中的每个索引,获取对应的SearchShardIterator对象shardRoutings,然后执行performPhaseOnShard()方法。//这里会遍历每一个分片for (int i = 0; i < shardsIts.size(); i++) {final SearchShardIterator shardRoutings = shardsIts.get(i);assert shardRoutings.skip() == false;assert shardIndexMap.containsKey(shardRoutings);int shardIndex = shardIndexMap.get(shardRoutings);performPhaseOnShard(shardIndex, shardRoutings, shardRoutings.nextOrNull());}}}protected void performPhaseOnShard(final int shardIndex, final SearchShardIterator shardIt, final SearchShardTarget shard) { if (shard == null) {//该分片未分配给任何节点,会触发onShardFailure方法处理该情况assert assertExecuteOnStartThread();SearchShardTarget unassignedShard = new SearchShardTarget(null, shardIt.shardId(), shardIt.getClusterAlias());onShardFailure(shardIndex, unassignedShard, shardIt, new NoShardAvailableActionException(shardIt.shardId()));} else {//创建一个Runnable对象,并执行executePhaseOnShard方法来在分片上执行搜索操作。final PendingExecutions pendingExecutions = throttleConcurrentRequests? pendingExecutionsPerNode.computeIfAbsent(shard.getNodeId(), n -> new PendingExecutions(maxConcurrentRequestsPerNode)): null;Runnable r = () -> {final Thread thread = Thread.currentThread();try {executePhaseOnShard(shardIt, shard, new SearchActionListener<Result>(shard, shardIndex) {//定义了一个SearchActionListener的匿名子类,用于处理搜索操作的响应。@Overridepublic void innerOnResponse(Result result) {try {在响应成功时,会调用onShardResult方法处理搜索结果;onShardResult(result, shardIt);} catch (Exception exc) {//在响应失败时,会调用onShardFailure方法处理错误情况onShardFailure(shardIndex, shard, shardIt, exc);} finally {//无论成功还是失败,最后都会调用executeNext方法执行下一个操作。executeNext(pendingExecutions, thread);}}@Overridepublic void onFailure(Exception t) {try {onShardFailure(shardIndex, shard, shardIt, t);} finally {executeNext(pendingExecutions, thread);}}});} catch (final Exception e) {try {fork(() -> onShardFailure(shardIndex, shard, shardIt, e));} finally {executeNext(pendingExecutions, thread);}}};//如果throttleConcurrentRequests为true,则会使用pendingExecutions对象来限制并发请求的数量。否则,直接执行r.run()方法。if (throttleConcurrentRequests) {pendingExecutions.tryRun(r);} else {r.run();}} }/*** 这个抽象方法由子类SearchQueryThenFetchAsyncAction实现* 将请求发送到实际分片。*/protected abstract void executePhaseOnShard(SearchShardIterator shardIt,SearchShardTarget shard,SearchActionListener<Result> listener);
}
3、通过transportService把查询请求发送到指定的数据节点
在SearchTransportService类中
public static void registerRequestHandler(TransportService transportService, SearchService searchService) {transportService.registerRequestHandler(QUERY_ACTION_NAME,ThreadPool.Names.SAME,ShardSearchRequest::new,(request, channel, task) -> searchService.executeQueryPhase(request,(SearchShardTask) task,new ChannelActionListener<>(channel)));
}public void sendExecuteQuery(Transport.Connection connection,final ShardSearchRequest request,SearchTask task,final SearchActionListener<? super SearchPhaseResult> listener) {// we optimize this and expect a QueryFetchSearchResult if we only have a single shard in the search request// this used to be the QUERY_AND_FETCH which doesn't exist anymore.//我们对此进行了优化,如果我们在搜索请求中只有一个分片,则期望 QueryFetchSearchResult,这曾经是不再存在的QUERY_AND_FETCH。final boolean fetchDocuments = request.numberOfShards() == 1&& (request.source() == null || request.source().rankBuilder() == null);Writeable.Reader<SearchPhaseResult> reader = fetchDocuments ? QueryFetchSearchResult::new : in -> new QuerySearchResult(in, true);final ActionListener<? super SearchPhaseResult> handler = responseWrapper.apply(connection, listener);//上面根据QUERY_ACTION_NAME注册的,实际调用的是 searchService.executeQueryPhasetransportService.sendChildRequest(connection,QUERY_ACTION_NAME,request,task,new ConnectionCountingHandler<>(handler, reader, clientConnections, connection.getNode().getId()));}
二、数据节点收到请求的处理逻辑
public void executeQueryPhase(ShardSearchRequest request, SearchShardTask task, ActionListener<SearchPhaseResult> listener) {assert request.canReturnNullResponseIfMatchNoDocs() == false || request.numberOfShards() > 1: "empty responses require more than one shard";//根据request对象获取一个IndexShard对象final IndexShard shard = getShard(request);//调用rewriteAndFetchShardRequest方法对shard和request进行重写和获取请求。rewriteAndFetchShardRequest(shard, request, listener.delegateFailure((l, orig) -> {// check if we can shortcut the query phase entirely.//检查我们是否可以完全缩短查询阶段if (orig.canReturnNullResponseIfMatchNoDocs()) {assert orig.scroll() == null;final CanMatchShardResponse canMatchResp;try {//创建一个ShardSearchRequest对象的副本clone,并调用canMatch方法进行匹配检查。ShardSearchRequest clone = new ShardSearchRequest(orig);canMatchResp = canMatch(clone, false);} catch (Exception exc) {l.onFailure(exc);return;}if (canMatchResp.canMatch() == false) {l.onResponse(QuerySearchResult.nullInstance());return;}}//其中会执行executeQueryPhase方法的递归调用。ensureAfterSeqNoRefreshed(shard, orig, () -> executeQueryPhase(orig, task), l);}));}/** 返回的 {@link SearchPhaseResult} 的引用计数将通过此方法递增。调用方有责任确保在不再需要对象时正确递减引用计数。*/private SearchPhaseResult executeQueryPhase(ShardSearchRequest request, SearchShardTask task) throws Exception {//创建或获取ReaderContext对象。final ReaderContext readerContext = createOrGetReaderContext(request);try (//创建SearchContext对象,并设置相关参数。Releasable scope = tracer.withScope(task);Releasable ignored = readerContext.markAsUsed(getKeepAlive(request));SearchContext context = createContext(readerContext, request, task, ResultsType.QUERY, true)) {//开始跟踪执行查询阶段。tracer.startTrace("executeQueryPhase", Map.of());final long afterQueryTime;//使用SearchOperationListenerExecutor执行加载或执行查询阶段的操作。try (SearchOperationListenerExecutor executor = new SearchOperationListenerExecutor(context)) {loadOrExecuteQueryPhase(request, context);//检查查询结果是否具有搜索上下文,并根据需要释放ReaderContext对象。if (context.queryResult().hasSearchContext() == false && readerContext.singleSession()) {freeReaderContext(readerContext.id());}afterQueryTime = executor.success();} finally {//停止跟踪执行查询阶段。tracer.stopTrace();}//根据条件判断是否需要执行提取阶段if (request.numberOfShards() == 1 && (request.source() == null || request.source().rankBuilder() == null)) {//我们已经有了查询结果,但我们可以同时运行 fetchcontext.addFetchResult();//如果需要执行提取阶段,则将提取结果添加到SearchContext对象,并调用executeFetchPhase方法执行提取阶段。return executeFetchPhase(readerContext, context, afterQueryTime);} else {//将RescoreDocIds对象传递给queryResult,并返回context.queryResult()。//将 rescoreDocIds 传递给 queryResult,以将它们发送到协调节点,并在提取阶段接收它们。我们还将 rescoreDocIds 传递给 LegacyReaderContext,以防搜索状态需要保留在数据节点中final RescoreDocIds rescoreDocIds = context.rescoreDocIds();context.queryResult().setRescoreDocIds(rescoreDocIds);readerContext.setRescoreDocIds(rescoreDocIds);context.queryResult().incRef();return context.queryResult();}} catch (Exception e) {// execution exception can happen while loading the cache, strip itif (e instanceof ExecutionException) {e = (e.getCause() == null || e.getCause() instanceof Exception)? (Exception) e.getCause(): new ElasticsearchException(e.getCause());}logger.trace("Query phase failed", e);processFailure(readerContext, e);throw e;}}
其中
/*** 如果调用方可以处理 null 响应 {@link QuerySearchResultnullInstance()},* 则返回 true。默认值为 false,因为协调器节点至少需要一个分片响应来构建全局响应。*/public boolean canReturnNullResponseIfMatchNoDocs() {return canReturnNullResponseIfMatchNoDocs;}
1、尝试从缓存中加载查询结果
/*** 如果无法使用缓存,请尝试从缓存加载查询结果或直接执行查询阶段。*/private void loadOrExecuteQueryPhase(final ShardSearchRequest request, final SearchContext context) throws Exception {final boolean canCache = IndicesService.canCache(request, context);context.getSearchExecutionContext().freezeContext();if (canCache) {indicesService.loadIntoContext(request, context);} else {QueryPhase.execute(context);}}
/*** 加载缓存结果,根据需要通过执行查询阶段进行计算,否则将缓存值反序列化为 {@link SearchContextqueryResult() 上下文的查询结果}。* load + compute 的组合允许进行单个加载操作,这将导致具有相同密钥的其他请求等待,直到其加载并重用相同的缓存。*/public void loadIntoContext(ShardSearchRequest request, SearchContext context) throws Exception {assert canCache(request, context);//context 的搜索器(searcher)的目录阅读器(DirectoryReader)final DirectoryReader directoryReader = context.searcher().getDirectoryReader();//创建了一个布尔类型的数组 loadedFromCache,并将其初始值设为 trueboolean[] loadedFromCache = new boolean[] { true };//代码通过调用 request 的 cacheKey 方法生成一个缓存键(cacheKey),并使用该键将一些结果缓存到分片级别(cacheShardLevelResult)。BytesReference cacheKey = request.cacheKey(requestCacheKeyDifferentiator);BytesReference bytesReference = cacheShardLevelResult(context.indexShard(),context.getSearchExecutionContext().mappingCacheKey(),directoryReader,cacheKey,//代码执行了一些查询操作(QueryPhase.execute),并将查询结果写入到输出流(out)中,同时将 loadedFromCache 的值设为 false。out -> {QueryPhase.execute(context);context.queryResult().writeToNoId(out);loadedFromCache[0] = false;});//loadedFromCache 的值,如果为 true,则表示结果已从缓存加载。//在这种情况下,代码将缓存的查询结果恢复到上下文中,并设置一些其他属性。if (loadedFromCache[0]) {// restore the cached query result into the contextfinal QuerySearchResult result = context.queryResult();StreamInput in = new NamedWriteableAwareStreamInput(bytesReference.streamInput(), namedWriteableRegistry);result.readFromWithId(context.id(), in);result.setSearchShardTarget(context.shardTarget());} else if (context.queryResult().searchTimedOut()) {//上下文的查询结果超时(searchTimedOut),则代码会执行一些操作来使缓存无效//这样做的原因是,如果缓存了一个超时的查询结果,不能简单地抛出异常来通知外部世界,因为如果有多个请求等待计算缓存条目,它们都会失败并抛出相同的异常。//相反,代码会使缓存结果无效,并返回超时结果给其他使用相同缓存键的搜索。同时,在导致超时的线程中使结果无效。indicesRequestCache.invalidate(new IndexShardCacheEntity(context.indexShard()),context.getSearchExecutionContext().mappingCacheKey(),directoryReader,cacheKey);//如果启用了日志跟踪(logger.isTraceEnabled()),代码还会记录一条日志,说明查询超时并且缓存条目被无效。if (logger.isTraceEnabled()) {logger.trace("Query timed out, invalidating cache entry for request on shard [{}]:\n {}",request.shardId(),request.source());}}}
/*** 缓存在分片级别计算的内容*/private BytesReference cacheShardLevelResult(IndexShard shard,//shard:索引分片对象MappingLookup.CacheKey mappingCacheKey,//mappingCacheKey:映射缓存键DirectoryReader reader, //reader:目录阅读器对象BytesReference cacheKey, //cacheKey:缓存键CheckedConsumer<StreamOutput, IOException> loader //一个带有StreamOutput参数的回调函数,用于加载数据) throws Exception {//创建一个IndexShardCacheEntity对象,用于表示索引分片的缓存实体IndexShardCacheEntity cacheEntity = new IndexShardCacheEntity(shard);//创建一个CheckedSupplier对象,用于生成缓存数据。CheckedSupplier<BytesReference, IOException> supplier = () -> {//这个对象内部使用BytesStreamOutput,它允许指定预期的字节大小,// 但默认使用16k作为页面大小。为了避免对小查询结果浪费太多内存,将预期大小设置为512字节。final int expectedSizeInBytes = 512;//在BytesStreamOutput中执行loader回调函数,将数据写入输出流中try (BytesStreamOutput out = new BytesStreamOutput(expectedSizeInBytes)) {loader.accept(out);//将输出流的字节表示返回作为缓存数据。return out.bytes();}};//通过调用indicesRequestCache.getOrCompute方法,使用缓存实体、缓存数据生成器、映射缓存键、目录阅读器和缓存键作为参数,获取或计算缓存数据,return indicesRequestCache.getOrCompute(cacheEntity, supplier, mappingCacheKey, reader, cacheKey);}
这里要知道supplier内部会执行loader.accept(out);而传过来的loader是如下
out -> {QueryPhase.execute(context);context.queryResult().writeToNoId(out);loadedFromCache[0] = false;}
其实意味着,如果执行了loader,说明缓存中没有,而是直接查询的,继续往下
BytesReference getOrCompute(CacheEntity cacheEntity,CheckedSupplier<BytesReference, IOException> loader,MappingLookup.CacheKey mappingCacheKey,DirectoryReader reader,BytesReference cacheKey) throws Exception {final ESCacheHelper cacheHelper = ElasticsearchDirectoryReader.getESReaderCacheHelper(reader);assert cacheHelper != null;final Key key = new Key(cacheEntity, mappingCacheKey, cacheHelper.getKey(), cacheKey);Loader cacheLoader = new Loader(cacheEntity, loader);BytesReference value = cache.computeIfAbsent(key, cacheLoader);if (cacheLoader.isLoaded()) {key.entity.onMiss();//看看这是否是我们第一次看到这个读取器,并确保注册一个清理密钥CleanupKey cleanupKey = new CleanupKey(cacheEntity, cacheHelper.getKey());if (registeredClosedListeners.containsKey(cleanupKey) == false) {Boolean previous = registeredClosedListeners.putIfAbsent(cleanupKey, Boolean.TRUE);if (previous == null) {cacheHelper.addClosedListener(cleanupKey);}}} else {key.entity.onHit();}return value;}
/***如果指定的键尚未与值关联(或映射到 null),则尝试使用给定的映射函数计算其值,并将其输入到此映射中,除非为 null。给定键的 load 方法最多调用一次。*在同一键上同时使用不同的 {@link CacheLoader} 实现可能会导致仅调用第一个加载器函数,* 而第二个加载器函数将返回第一个加载器函数提供的结果,包括执行第一个加载器函数期间引发的任何异常*/public V computeIfAbsent(K key, CacheLoader<K, V> loader) throws ExecutionException {//首先,获取当前时间戳。long now = now();// we have to eagerly evict expired entries or our putIfAbsent call below will fail//尝试从缓存中获取与给定键关联的值,如果值已过期,则会在获取前将其删除。V value = get(key, now, true);if (value == null) {//我们需要同步加载给定键的值;但是,在调用 load 时按住段锁可能会导致由于依赖键加载而对另一个线程进行死锁;// 因此,我们需要一种机制来确保最多调用一次 load,但我们不会在按住段锁时调用 load;// 为此,我们原子地在映射中放置一个可以加载值的 future,然后在赢得竞赛的线程上从这个 future 中获取值,以将 future 放入 segment map 中//首先,获取与给定键关联的缓存段(CacheSegment)。CacheSegment segment = getCacheSegment(key);CompletableFuture<Entry<K, V>> future;//创建一个CompletableFuture对象,用于在加载完成后获取值。CompletableFuture<Entry<K, V>> completableFuture = new CompletableFuture<>();//使用段锁,将键和CompletableFuture对象放入段的映射(Map)中。try (ReleasableLock ignored = segment.writeLock.acquire()) {if (segment.map == null) {segment.map = new HashMap<>();}future = segment.map.putIfAbsent(key, completableFuture);}BiFunction<? super Entry<K, V>, Throwable, ? extends V> handler = (ok, ex) -> {//如果ok不为空if (ok != null) {promote(ok, now);return ok.value;} else {//如果ok为空,获取一个写锁 (segment.writeLock.acquire()),并使用try-with-resources语句来确保锁被释放。try (ReleasableLock ignored = segment.writeLock.acquire()) {//检查segment.map是否为空,如果不为空,则尝试从segment.map中获取与key对应的CompletableFuture<Entry<K, V>>对象CompletableFuture<Entry<K, V>> sanity = segment.map == null ? null : segment.map.get(key);if (sanity != null && sanity.isCompletedExceptionally()) {//如果sanity不为空且已经完成异常,则从segment.map中移除key。segment.map.remove(key);if (segment.map.isEmpty()) {//如果segment.map为空,则将其赋值为null。segment.map = null;}}}return null;}};CompletableFuture<V> completableValue;//如果该键之前不存在映射,则说明当前线程赢得了竞争,需要执行加载操作。if (future == null) {future = completableFuture;completableValue = future.handle(handler);V loaded;//调用加载器的load方法加载值,并将其放入CompletableFuture对象中。try {loaded = loader.load(key);} catch (Exception e) {future.completeExceptionally(e);throw new ExecutionException(e);}if (loaded == null) {NullPointerException npe = new NullPointerException("loader returned a null value");future.completeExceptionally(npe);throw new ExecutionException(npe);} else {//将加载的值包装成一个Entry对象,并完成CompletableFuture对象。future.complete(new Entry<>(key, loaded, now));}} else {//说明该键存在映射,直接调用completableValue = future.handle(handler);}//通过completableValue.get()获取加载完成的值try {value = completableValue.get();// check to ensure the future hasn't been completed with an exceptionif (future.isCompletedExceptionally()) {future.get(); // call get to force the exception to be thrown for other concurrent callersthrow new IllegalStateException("the future was completed exceptionally but no exception was thrown");}} catch (InterruptedException e) {throw new IllegalStateException(e);}}return value;}
这里面在从缓存中没有得到指定的CacheSegment ,则会调用loader.load(key) 里面实际调用的是QueryPhase.execute(context); 最后放入到缓存中,再从completableValue 把得到的数据当方法结果返回
2、不通过缓存查询,直接执行查询
这里就看一下
QueryPhase.execute(context);的实现源码
/*** //搜索请求的查询阶段,用于运行查询并从每个分片中获取有关匹配文档的信息*/
public class QueryPhase {if (searchContext.rankShardContext() == null) {executeQuery(searchContext);} else {executeRank(searchContext);}}
(1)executeQuery和executeRank两种查询方式
static void executeRank(SearchContext searchContext) throws QueryPhaseExecutionException {//获取排名的上下文信息和查询结果信息RankShardContext rankShardContext = searchContext.rankShardContext();QuerySearchResult querySearchResult = searchContext.queryResult();//然后根据条件判断是否需要执行组合布尔查询以获取总命中数或聚合结果,if (searchContext.trackTotalHitsUpTo() != TRACK_TOTAL_HITS_DISABLED || searchContext.aggregations() != null) {//需要的话,则size=0,再执行executeQuery,,来获取总命中数和聚合结果searchContext.size(0);QueryPhase.executeQuery(searchContext);} else {//将查询结果的topDocs设置为空(即命中文档为空)。searchContext.queryResult().topDocs(new TopDocsAndMaxScore(new TopDocs(new TotalHits(0, TotalHits.Relation.EQUAL_TO), Lucene.EMPTY_SCORE_DOCS), Float.NaN),new DocValueFormat[0]);}List<TopDocs> rrfRankResults = new ArrayList<>();boolean searchTimedOut = querySearchResult.searchTimedOut();long serviceTimeEWMA = querySearchResult.serviceTimeEWMA();int nodeQueueSize = querySearchResult.nodeQueueSize();//迭代rankShardContext.queries()中的每个排名查询来执行排名操作for (Query rankQuery : rankShardContext.queries()) {//如果搜索超时,将中断排名操作,并返回部分结果if (searchTimedOut) {break;}//对于每个排名查询,创建一个RankSearchContext对象RankSearchContext rankSearchContext = new RankSearchContext(searchContext, rankQuery, rankShardContext.windowSize());//并添加收集器和搜索操作QueryPhase.addCollectorsAndSearch(rankSearchContext);//然后将查询结果添加到rrfRankResults列表中,并更新服务时间、节点队列大小和搜索超时的状态。QuerySearchResult rrfQuerySearchResult = rankSearchContext.queryResult();rrfRankResults.add(rrfQuerySearchResult.topDocs().topDocs);serviceTimeEWMA += rrfQuerySearchResult.serviceTimeEWMA();nodeQueueSize = Math.max(nodeQueueSize, rrfQuerySearchResult.nodeQueueSize());searchTimedOut = rrfQuerySearchResult.searchTimedOut();}//将排名结果通过rankShardContext.combine方法进行合并,并将相关的值记录到querySearchResult中querySearchResult.setRankShardResult(rankShardContext.combine(rrfRankResults));//包括搜索超时状态、服务时间和节点队列大小。// record values relevant to all queriesquerySearchResult.searchTimedOut(searchTimedOut);querySearchResult.serviceTimeEWMA(serviceTimeEWMA);querySearchResult.nodeQueueSize(nodeQueueSize);}
static void executeQuery(SearchContext searchContext) throws QueryPhaseExecutionException {//检查searchContext是否只有建议(suggest)操作,如果是,就执行建议阶段的操作,并返回一个空的查询结果if (searchContext.hasOnlySuggest()) {SuggestPhase.execute(searchContext);searchContext.queryResult().topDocs(new TopDocsAndMaxScore(new TopDocs(new TotalHits(0, TotalHits.Relation.EQUAL_TO), Lucene.EMPTY_SCORE_DOCS), Float.NaN),new DocValueFormat[0]);return;}if (LOGGER.isTraceEnabled()) {LOGGER.trace("{}", new SearchContextSourcePrinter(searchContext));}// Pre-process aggregations as late as possible. In the case of a DFS_Q_T_F// request, preProcess is called on the DFS phase, this is why we pre-process them// here to make sure it happens during the QUERY phase//聚合(aggregation)进行预处理操作AggregationPhase.preProcess(searchContext);//添加收集器(collectors)并执行搜索操作addCollectorsAndSearch(searchContext);//执行重新评分(rescore)阶段的操作RescorePhase.execute(searchContext);//再次执行建议阶段的操作。SuggestPhase.execute(searchContext);//执行聚合阶段的操作。AggregationPhase.execute(searchContext);//如果searchContext中包含性能分析器(profiler),则对查询阶段的性能结果进行分析。if (searchContext.getProfilers() != null) {searchContext.queryResult().profileResults(searchContext.getProfilers().buildQueryPhaseResults());}}
这两种最后还是要调用 QueryPhase.addCollectorsAndSearch进行查询,只是executeRank 会多一层判断,执行两遍addCollectorsAndSearch
(2)、根据搜索上下文,在查询之前添加各种查询搜集器
static void addCollectorsAndSearch(SearchContext searchContext) throws QueryPhaseExecutionException {//获取搜索器和索引阅读器对象。final ContextIndexSearcher searcher = searchContext.searcher();final IndexReader reader = searcher.getIndexReader();QuerySearchResult queryResult = searchContext.queryResult();//设置查询结果的超时状态queryResult.searchTimedOut(false);try {//起始位置和大小。queryResult.from(searchContext.from());queryResult.size(searchContext.size());//重写查询,并通过断言确认查询已经重写。Query query = searchContext.rewrittenQuery();assert query == searcher.rewrite(query); // already rewritten//如果是滚动查询final ScrollContext scrollContext = searchContext.scrollContext();if (scrollContext != null) {//如果是第一轮滚动查询,不做任何优化if (scrollContext.totalHits == null) {// first roundassert scrollContext.lastEmittedDoc == null;// there is not much that we can optimize here since we want to collect all// documents in order to get the total number of hits//我们在这里可以优化的不多,因为我们想收集所有文档以获得总点击数} else {//如果不是第一轮滚动查询,根据排序条件判断是否可以提前终止查询,并构建新的查询对象。final ScoreDoc after = scrollContext.lastEmittedDoc;if (canEarlyTerminate(reader, searchContext.sort())) {// now this gets interesting: since the search sort is a prefix of the index sort, we can directly// skip to the desired doc//由于搜索排序是索引排序的前缀,我们可以直接跳到所需的文档if (after != null) {query = new BooleanQuery.Builder().add(query, BooleanClause.Occur.MUST).add(new SearchAfterSortedDocQuery(searchContext.sort().sort, (FieldDoc) after), BooleanClause.Occur.FILTER).build();}}}}//创建顶部文档收集器。// create the top docs collector last when the other collectors are knownfinal TopDocsCollectorManagerFactory topDocsFactory = createTopDocsCollectorFactory(searchContext,searchContext.parsedPostFilter() != null || searchContext.minimumScore() != null);CollectorManager<Collector, Void> collectorManager = wrapWithProfilerCollectorManagerIfNeeded(searchContext.getProfilers(),topDocsFactory.collectorManager(),topDocsFactory.profilerName);//根据条件添加收集器//如果设置了terminate_after参数,添加一个用于终止查询的收集器。if (searchContext.terminateAfter() != SearchContext.DEFAULT_TERMINATE_AFTER) {// add terminate_after before the filter collectors// it will only be applied on documents accepted by these filter collectorsTerminateAfterCollector terminateAfterCollector = new TerminateAfterCollector(searchContext.terminateAfter());final Collector collector = collectorManager.newCollector();collectorManager = wrapWithProfilerCollectorManagerIfNeeded(searchContext.getProfilers(),new SingleThreadCollectorManager(MultiCollector.wrap(terminateAfterCollector, collector)),REASON_SEARCH_TERMINATE_AFTER_COUNT,collector);}//如果存在后置过滤器,添加一个用于过滤结果的收集器。if (searchContext.parsedPostFilter() != null) {// add post filters before aggregations// it will only be applied to top hitsfinal Weight filterWeight = searcher.createWeight(searcher.rewrite(searchContext.parsedPostFilter().query()),ScoreMode.COMPLETE_NO_SCORES,1f);final Collector collector = collectorManager.newCollector();collectorManager = wrapWithProfilerCollectorManagerIfNeeded(searchContext.getProfilers(),new SingleThreadCollectorManager(new FilteredCollector(collector, filterWeight)),REASON_SEARCH_POST_FILTER,collector);}//如果存在聚合操作,添加一个用于聚合的收集器。if (searchContext.aggregations() != null) {final Collector collector = collectorManager.newCollector();final Collector aggsCollector = searchContext.aggregations().getAggsCollectorManager().newCollector();collectorManager = wrapWithProfilerCollectorManagerIfNeeded(searchContext.getProfilers(),new SingleThreadCollectorManager(MultiCollector.wrap(collector, aggsCollector)),REASON_SEARCH_MULTI,collector,aggsCollector);}//如果设置了最小分数,添加一个用于过滤低分结果的收集器。if (searchContext.minimumScore() != null) {final Collector collector = collectorManager.newCollector();// apply the minimum score after multi collector so we filter aggs as wellcollectorManager = wrapWithProfilerCollectorManagerIfNeeded(searchContext.getProfilers(),new SingleThreadCollectorManager(new MinimumScoreCollector(collector, searchContext.minimumScore())),REASON_SEARCH_MIN_SCORE,collector);}//根据超时设置,添加查询超时检查的任务。final Runnable timeoutRunnable = getTimeoutCheck(searchContext);if (timeoutRunnable != null) {searcher.addQueryCancellation(timeoutRunnable);}try {//使用收集器管理器执行查询,并更新查询结果。searchWithCollectorManager(searchContext, searcher, query, collectorManager, timeoutRunnable != null);queryResult.topDocs(topDocsFactory.topDocsAndMaxScore(), topDocsFactory.sortValueFormats);//获取线程池执行器对象,并根据类型更新查询结果的节点队列大小和服务时间指数加权移动平均值。ExecutorService executor = searchContext.indexShard().getThreadPool().executor(ThreadPool.Names.SEARCH);assert executor instanceof TaskExecutionTimeTrackingEsThreadPoolExecutor|| (executor instanceof EsThreadPoolExecutor == false /* in case thread pool is mocked out in tests */): "SEARCH threadpool should have an executor that exposes EWMA metrics, but is of type " + executor.getClass();if (executor instanceof TaskExecutionTimeTrackingEsThreadPoolExecutor rExecutor) {queryResult.nodeQueueSize(rExecutor.getCurrentQueueSize());queryResult.serviceTimeEWMA((long) rExecutor.getTaskExecutionEWMA());}} finally {// Search phase has finished, no longer need to check for timeout// otherwise aggregation phase might get cancelled.//取消查询超时检查的任务if (timeoutRunnable != null) {searcher.removeQueryCancellation(timeoutRunnable);}}} catch (Exception e) {//并处理异常情况。throw new QueryPhaseExecutionException(searchContext.shardTarget(), "Failed to execute main query", e);}}
会通过searchWithCollectorManager 来执行查询
private static void searchWithCollectorManager(SearchContext searchContext,ContextIndexSearcher searcher,Query query,CollectorManager<Collector, Void> collectorManager,boolean timeoutSet) throws IOException {//如果profilers不为null,则获取当前查询的分析器,并将collectorManager设置为InternalProfileCollectorManager的getCollectorTree方法。if (searchContext.getProfilers() != null) {searchContext.getProfilers().getCurrentQueryProfiler().setCollectorManager(((InternalProfileCollectorManager) collectorManager)::getCollectorTree);}//获取searchContext的查询结果对象queryResult。QuerySearchResult queryResult = searchContext.queryResult();try {//使用searcher和collectorManager执行查询操作。searcher.search(query, collectorManager);} catch (TerminateAfterCollector.EarlyTerminationException e) {//如果查询被TerminateAfterCollector.EarlyTerminationException异常提前终止,则将queryResult的terminatedEarly属性设置为true。queryResult.terminatedEarly(true);} catch (TimeExceededException e) {assert timeoutSet : "TimeExceededException thrown even though timeout wasn't set";//如果查询超时且timeoutSet为true,则检查searchContext的request是否允许部分搜索结果。if (searchContext.request().allowPartialSearchResults() == false) {//如果不允许部分搜索结果,则抛出QueryPhaseExecutionException异常,指示查询超时。// Can't rethrow TimeExceededException because not serializablethrow new QueryPhaseExecutionException(searchContext.shardTarget(), "Time exceeded");}//如果允许部分搜索结果,则将queryResult的searchTimedOut属性设置为true。queryResult.searchTimedOut(true);}//如果searchContext的terminateAfter属性不等于SearchContext.DEFAULT_TERMINATE_AFTER且queryResult的terminatedEarly属性为null,则将queryResult的terminatedEarly属性设置为false。if (searchContext.terminateAfter() != SearchContext.DEFAULT_TERMINATE_AFTER && queryResult.terminatedEarly() == null) {queryResult.terminatedEarly(false);}}
(3) 执行查询操作(遍历此索引在此数据节点所有的分片)
@Overridepublic <C extends Collector, T> T search(Query query, CollectorManager<C, T> collectorManager) throws IOException {//通过collectorManager创建一个收集器(Collector)的实例firstCollector。final C firstCollector = collectorManager.newCollector();// Take advantage of the few extra rewrite rules of ConstantScoreQuery when score are not needed.//根据firstCollector的评分模式(scoreMode)判断是否需要评分,如果需要评分,则使用rewrite方法对查询进行重写;如果不需要评分,则使用ConstantScoreQuery对查询进行重写。query = firstCollector.scoreMode().needsScores() ? rewrite(query) : rewrite(new ConstantScoreQuery(query));//根据重写后的查询(query)、评分模式(scoreMode)和权重(Weight)创建一个权重对象(weight)。final Weight weight = createWeight(query, firstCollector.scoreMode(), 1);//调用search方法,传入权重对象、收集器管理器和第一个收集器,执行搜索操作,并返回结果。return search(weight, collectorManager, firstCollector);}
/**每个元素表示一个分片的信息*LeafSlice的数量就代表了索引的分片数量。每个LeafSlice对象代表了一个分片的信息和上下文。* 如果一个索引在这个数据节点有5个分片,则这个的长度为5*/private final LeafSlice[] leafSlices;/*
*类似于 lucene 实现,但它会等待所有线程 fisinsh 然后返回,即使抛出错误也是如此。
在这种情况下,将忽略其他异常,并在所有线程完成后引发第一个异常
*/private <C extends Collector, T> T search(Weight weight, CollectorManager<C, T> collectorManager, C firstCollector) throws IOException {//如果queueSizeBasedExecutor为空或者leafSlices的长度小于等于1,//LeafSlice关键字解释:是IndexSearcher用来管理和表示索引搜索分片的类,如果小于等于1,则此数据节点只有一个分片if (queueSizeBasedExecutor == null || leafSlices.length <= 1) {//那么直接在leafContexts上执行搜索操作search(leafContexts, weight, firstCollector);//,并通过collectorManager.reduce方法将结果收集起来返回。return collectorManager.reduce(Collections.singletonList(firstCollector));} else {//根据leafSlices的长度创建多个收集器,final List<C> collectors = new ArrayList<>(leafSlices.length);collectors.add(firstCollector);final ScoreMode scoreMode = firstCollector.scoreMode();//并使用collectorManager创建新的收集器。for (int i = 1; i < leafSlices.length; ++i) {final C collector = collectorManager.newCollector();collectors.add(collector);if (scoreMode != collector.scoreMode()) {throw new IllegalStateException("CollectorManager does not always produce collectors with the same score mode");}}//创建一个FutureTask列表listTasks,用于异步执行搜索操作final List<FutureTask<C>> listTasks = new ArrayList<>();//遍历leafSlices,对每个leafSlices创建一个FutureTask,并将其添加到listTasks中。for (int i = 0; i < leafSlices.length; ++i) {final LeafReaderContext[] leaves = leafSlices[i].leaves;final C collector = collectors.get(i);FutureTask<C> task = new FutureTask<>(() -> {search(Arrays.asList(leaves), weight, collector);return collector;});listTasks.add(task);}//使用queueSizeBasedExecutor的invokeAll方法执行所有的listTasks,等待它们的执行完成。queueSizeBasedExecutor.invokeAll(listTasks);RuntimeException exception = null;final List<C> collectedCollectors = new ArrayList<>();//遍历listTasks,获取每个任务的结果,并将其添加到collectedCollectors列表中。for (Future<C> future : listTasks) {try {collectedCollectors.add(future.get());// TODO: when there is an exception and we don't want partial results, it would be great// to cancel the queries / threads} catch (InterruptedException e) {//省略代码} catch (ExecutionException e) {//省略代码}}//通过collectorManager.reduce方法将所有收集器的结果进行组合,并返回最终结果。return collectorManager.reduce(collectedCollectors);}}
需要注意leafSlices 这个数组,代表的此索引在此数据节点的所有分片信息
@Overridepublic void search(List<LeafReaderContext> leaves, Weight weight, Collector collector) throws IOException {collector.setWeight(weight);for (LeafReaderContext ctx : leaves) { // search each subreadersearchLeaf(ctx, weight, collector);}}
1、主节点将查询请求路由(根据分片找到数据节点)到对应的数据节点,执行查询请求,因为数据节点无法知道查询请求是否仅针对某一个具体的分片。数据节点会在所有分片上执行查询操作,并将结果进行合并、去重和处理,以产生最终的结果。
2、因此,即使主节点发送的查询请求只涉及一个分片,但在实际查询过程中,数据节点会遍历该数据节点上所有与该索引对应的分片,以保证查询结果的完整性。
但是至少遍历多个分片用的是异步同时进行查询的方式
private void searchLeaf(LeafReaderContext ctx, Weight weight, Collector collector) throws IOException {//检查是否取消了搜索操作。cancellable.checkCancelled();//获取当前叶子节点的LeafCollector。,用于收集匹配的文档。final LeafCollector leafCollector;try {//获取当前叶子节点的存活文档集合。leafCollector = collector.getLeafCollector(ctx);} catch (CollectionTerminatedException e) {return;}//获取当前叶子节点的存活文档集合(位集合),表示哪些文档未被删除Bits liveDocs = ctx.reader().getLiveDocs();//将存活文档集合转换为稀疏位集合BitSet liveDocsBitSet = getSparseBitSetOrNull(liveDocs);//如果存活文档集合不是稀疏位集合,那么使用BulkScorer进行评分操作。if (liveDocsBitSet == null) {BulkScorer bulkScorer = weight.bulkScorer(ctx);if (bulkScorer != null) {if (cancellable.isEnabled()) {bulkScorer = new CancellableBulkScorer(bulkScorer, cancellable::checkCancelled);}try {//使用BulkScorer对匹配的文档进行评分操作。bulkScorer.score(leafCollector, liveDocs);} catch (CollectionTerminatedException e) {// collection was terminated prematurely// continue with the following leaf}}} else {//如果存活文档集合为稀疏位集合//获取权重对象的Scorer,用于计算每个候选文档的得分,Scorer scorer = weight.scorer(ctx);if (scorer != null) {try {// 使用Scorer和稀疏位集合(liveDocsBitSet)对匹配的文档进行交集计算并进行评分操作。intersectScorerAndBitSet(scorer,liveDocsBitSet,leafCollector,this.cancellable.isEnabled() ? cancellable::checkCancelled : () -> {});} catch (CollectionTerminatedException e) {// collection was terminated prematurely// continue with the following leaf}}}}
liveDocsBitSet 的作用是在搜索阶段过滤掉已被删除的文档,并仅处理存活文档。通过与其他集合的结合使用,可以在执行搜索和评分操作时仅处理存活的有效文档,可以大大减少内存占用。从而提升搜索性能和准确性。
其他集合(例如Bits、BulkScorer和Scorer)可能用于执行搜索和评分操作,但往往与存活文档集合无直接关联
//在给定的Scorer、BitSet、LeafCollector和checkCancelled函数的基础上,计算它们的交集,并将结果收集到collector中。static void intersectScorerAndBitSet(Scorer scorer, BitSet acceptDocs, LeafCollector collector, Runnable checkCancelled)throws IOException {//将scorer设置为collector的scorer。collector.setScorer(scorer);// ConjunctionDISI uses the DocIdSetIterator#cost() to order the iterators, so if roleBits has the lowest cardinality it should// be used first://创建一个迭代器iterator,通过将acceptDocs和scorer的迭代器传递给ConjunctionUtils.intersectIterators()方法来计算它们的交集。DocIdSetIterator iterator = ConjunctionUtils.intersectIterators(Arrays.asList(new BitSetIterator(acceptDocs, acceptDocs.approximateCardinality()), scorer.iterator()));int seen = 0;checkCancelled.run();//通过迭代器遍历交集中的文档,对于每个文档,如果满足一定条件,则将其收集到collector中。for (int docId = iterator.nextDoc(); docId < DocIdSetIterator.NO_MORE_DOCS; docId = iterator.nextDoc()) {//在每次遍历一定数量的文档后,调用checkCancelled函数检查是否取消操作。if (++seen % CHECK_CANCELLED_SCORER_INTERVAL == 0) {checkCancelled.run();}collector.collect(docId);}//最后再次调用checkCancelled函数。checkCancelled.run();}
相关文章:

Elasticsearch 8.9 search命令执行查询源码
一、相关的API的handler1、接收HTTP请求的handler2、往数据节点发送查询请求的action(TransportSearchAction)3、通过transportService把查询请求发送到指定的数据节点 二、数据节点收到请求的处理逻辑1、尝试从缓存中加载查询结果2、不通过缓存查询,直接执行查询(1…...

【PHP】身份证正则验证、校验位验证
目录 1.正则 简单正则 详细正则 2.校验位验证 1.正则 简单正则 function isValidIdCardNumber($idCardNumber) {// 身份证号长度为 15 位或 18 位$pattern /^(?:\d{15}|\d{17}[\dxX])$/;return preg_match($pattern, $idCardNumber); }$idCardNumber 12345678901234567…...
Matlab示例-Examine 16-QAM Using MATLAB学习笔记
工作之余学习16-QAM 写在前面 网上看到许多示例,但一般都比较难以跑通。所以,还是老方法,先将matlab自带的例子研究下。 Examine 16-QAM Using MATLAB Examine 16-QAM Using MATLAB 或者,在matlab中,键入&#x…...

ArcGIS Pro SDK运行消息只提示一次
工具大部分都是异步执行,所以提示信息需要异步执行完再进行,所以注意async和await的使用。 相关async和await的文章请查看C# 彻底搞懂async/await_c# async await-CSDN博客 public async Task InformationPrompt() {string message String.Empty;await ArcGIS.De…...
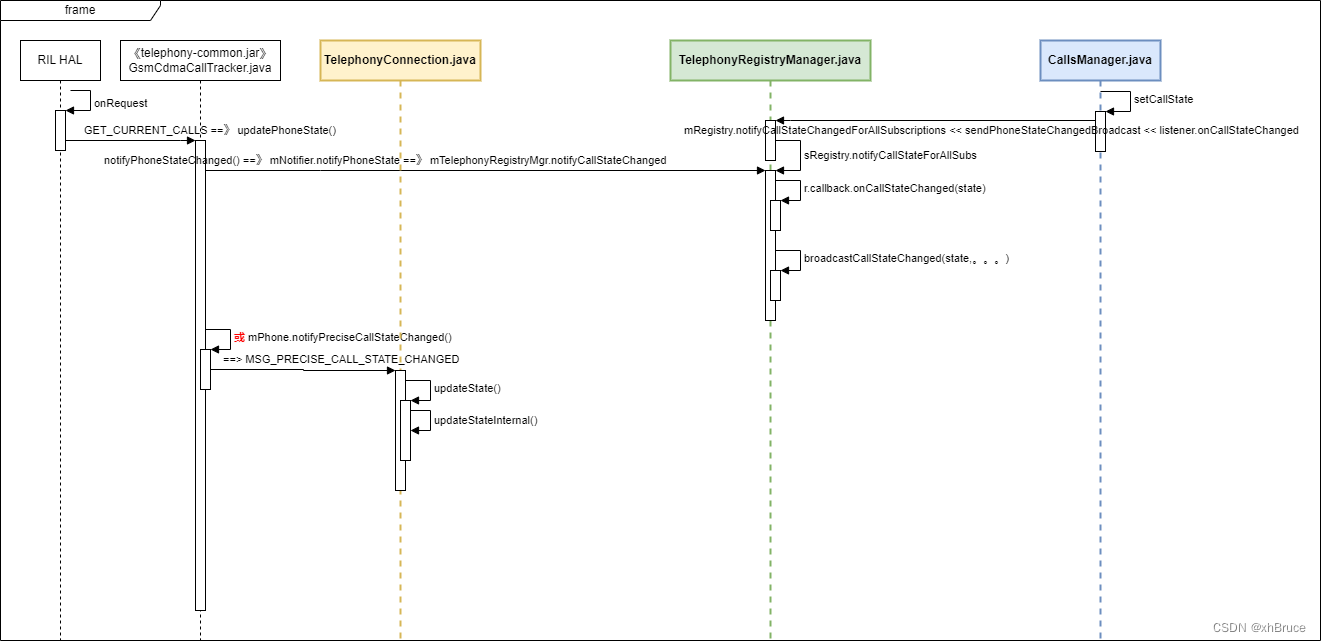
通话状态监听-Android13
通话状态监听-Android13 1、Android Telephony 模块结构2、监听和广播获取通话状态2.1 注册2.2 通话状态通知2.3 通话状态 3、通知状态流程* 关键日志 frameworks/base/core/java/android/telephony/PhoneStateListener.java 1、Android Telephony 模块结构 Android Telephony…...
无懈可击的防泄密之旅:迅软DSE在民营银行的成功实践
客户简要介绍 某股份有限公司主体是中部地区的民营银行,由其母公司联合9家知名民营企业共同发起设立。正式开业于2016年,紧紧围绕目标产业生态圈和消费金融,着力打造产业银行、便捷银行、数字银行、财富管理银行为一体的BEST银行,…...

【送书活动】智能汽车、自动驾驶、车联网的发展趋势和关键技术
文章目录 前言01 《智能汽车》推荐语 02 《SoC底层软件低功耗系统设计与实现》推荐语 03 《SoC设计指南》推荐语 05 《智能汽车网络安全权威指南(上册)》推荐语 06 《智能汽车网络安全权威指南(下册)》推荐语 后记赠书活动 前言 …...

不同版本QT使用qmake时创建QML项目的区别
不同版本QT使用qmake时创建QML项目的区别 文章目录 不同版本QT使用qmake时创建QML项目的区别一、QT5新建QML项目1.1 目录结构1.2 .pro 文件内容1.3 main.cpp1.4 main.qml 二、QT6新建QML项目2.1 目录结构2.2 .pro文件内容2.3 main.cpp2.4 main.qml 三、两个版本使用资源文件的区…...
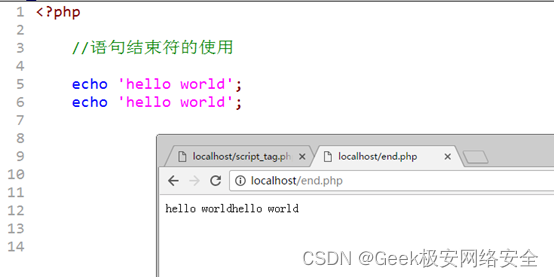
【PHP入门】1.1-PHP初步语法
-PHP语法初步- PHP是一种运行在服务器端的脚本语言,可以嵌入到HTML中。 1.1.1PHP代码标记 在PHP历史发展中,可以使用多种标记来区分PHP脚本 ASP标记: <% php代码 %>短标记: <? Php代码 ?>,以上两种…...
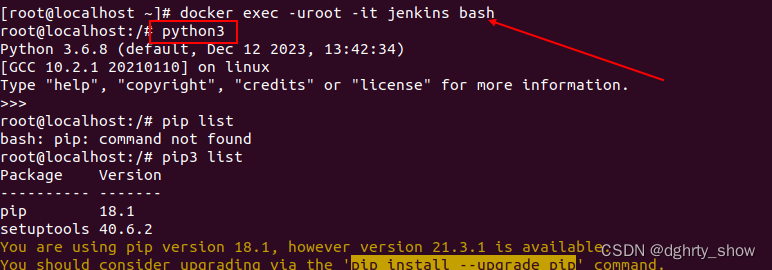
如何在jenkins容器中安装python+httprunner+pytest+git+allure(一)
背景: API接口自动化使用python语言实现,利用httprunner框架编写自动化用例场景(执行的时候还是依赖pytest),使用jenkins自动构建git上的源代码,并产生allure报告可视化展示API执行结果。 步骤 1.进入jenkins容器 注意使用roo…...

Android终端模拟器Termux上使用Ubuntu
Termux 上安装各种 Linux 系统是通过 proot-distro 工具来实现的,所以先安装一下 proot-distro 工具。 ~ $ pkg install proot-distro 查看Termux支持安装那些Linux ~ $ proot-distro listSupported distributions:* Alpine LinuxAlias: alpineInstalled: noComme…...
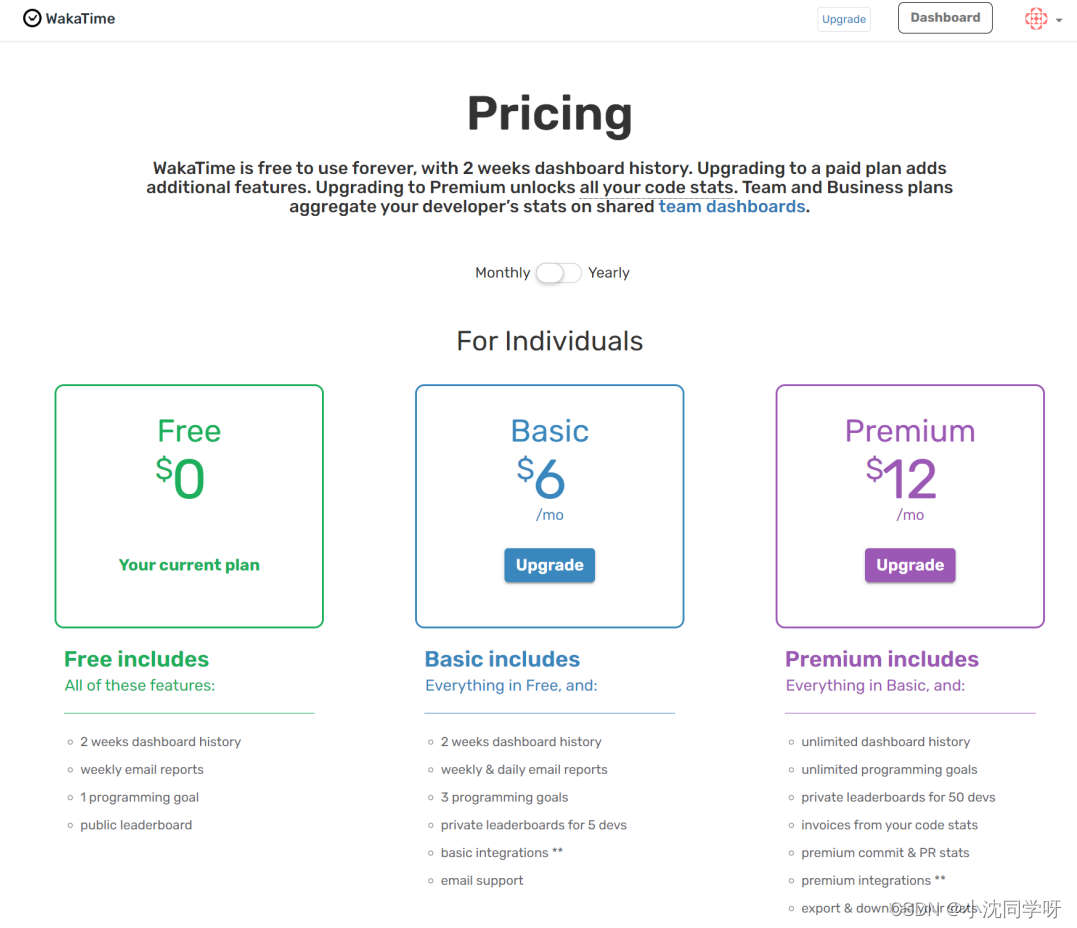
【神器】wakatime代码时间追踪工具
文章目录 wakatime简介支持的IDE安装步骤API文档插件费用写在最后 wakatime简介 wakatime就是一个IDE插件,一个代码时间追踪工具。可自动获取码编码时长和度量指标,以产生很多的coding图形报表。这些指标图形可以为开发者统计coding信息,比如…...
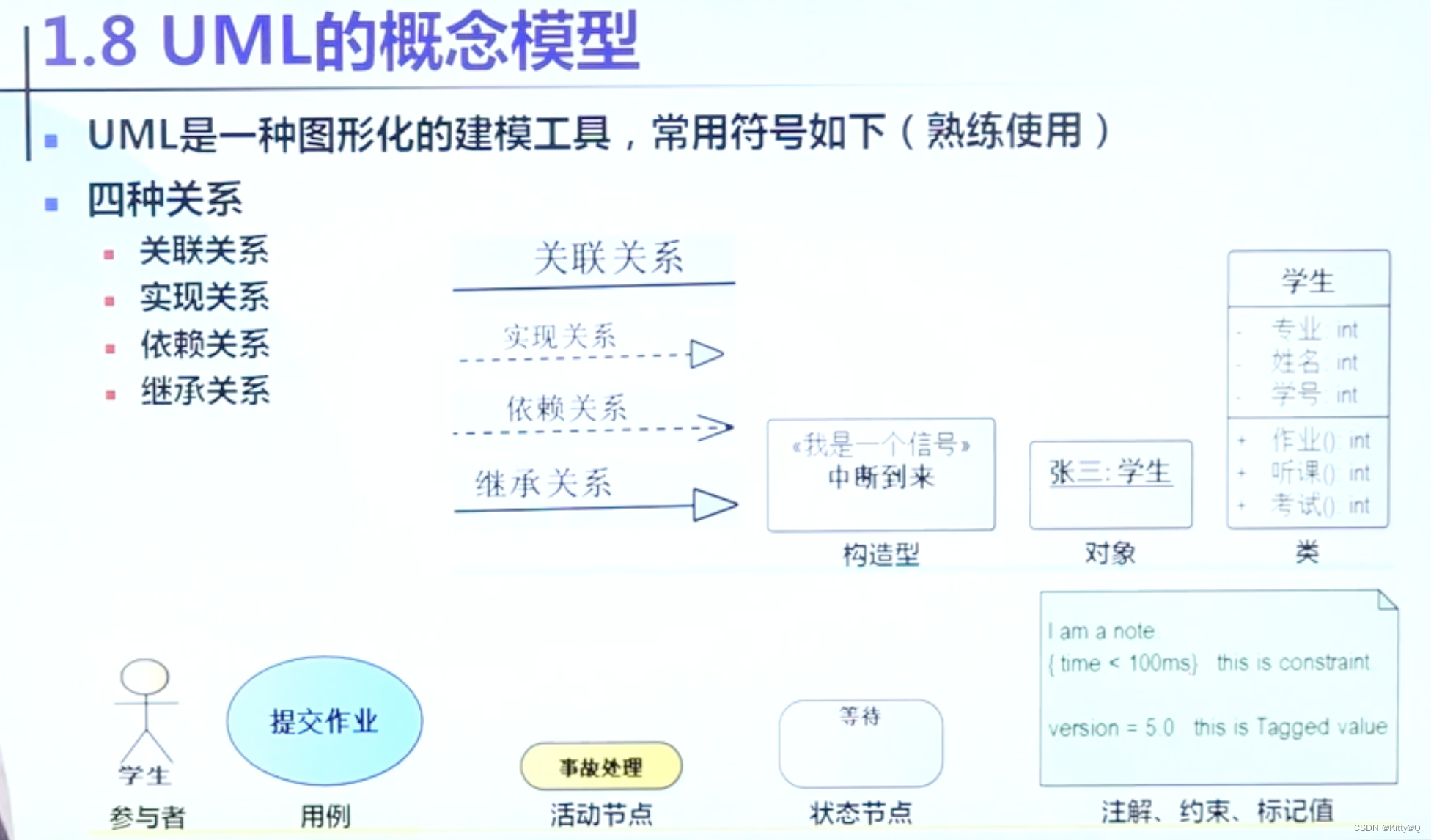
UML统一建模语言
一、建模语言的背景: 通俗地阐述就是:客户一开始不知道要什么,开发通过客户的阐述进行理解和分析,这个过程中间可能会产生一些误解。为了避免此类事件,所以需要建模。类似于要建造一栋楼,建筑设计师根据住…...

Linux命令行控制小米电源开关
飞灵科技产品 flyelf-tech.com,flyelf.taobao.com 最近有需求通过命令控制局域网内小米电源开关,以便于写脚本对产品进行反复上电的启动测试。参考了这篇文章:https://blog.csdn.net/2301_77209380/article/details/129797846 获取小米设备的…...

docker nginx 部署静态网站
1、dockerfile FROM nginx AS baseWORKDIR /appEXPOSE 80COPY . /app2、dockercompose.yaml version: 3 services:adminservice:container_name: adminwebbuild:context: ./dockerfile: Dockerfileports:- "5000:80"labels:description: adminwebrestart: always3、…...
uniapp之屏幕右侧出现滚动条去掉、隐藏、删除【好用!】
目录 问题解决大佬地址最后 问题 解决 在最外层view上加上class“content”;输入以下样式。注意:两个都必须存在在生效。 .content {/* 跟屏幕高度一样高,不管view中有没有内容,都撑开屏幕高的高度 */height: 100vh; overflow: auto; } .content::-webkit-scrollb…...

Linux 系统开机启动流程
可能没有完全理解,后期整理完Linux的内容,应该理解会深入一些,试着用更简洁的方式和图形来记录,以及一些概念的完善 2023-12-14 一、开机流程 BIOS MBR/GPT 加载 BIOS 的硬件信息与进行自检,并依据设定取得第一个可…...

vue2源码解析---watch和computed
监听属性watch 监听属性介绍 我们可以使用 watch 函数在每次响应式状态发生变化时触发回调函数wach 可以用于异步任务 监听属性的初始化 watch和computed都先走initSate判断传入选项 export function initState(vm) {const opts vm.$options; // 获取所有的选项if (opts.…...
)
【云原生】华为云踩坑日志(更新于2023.12.10)
1、华为云建议我们把sfs容量型升级到turbo版本,但是CCE产品storageclass sfs-turbo共享存储卷不支持动态绑定,官网文档可以实现动态创建子目录,建议大家直接选择这个,不要踩坑了 2、CCE 涉及到的产品,有的需要查看产品…...
)
计算机网络:自顶向下第八版学习指南笔记和课后实验--网络层(控制平面)
网络层:控制平面 记录一些学习计算机网络:自顶向下的学习笔记和心得 Github地址,欢迎star ⭐️⭐️⭐️⭐️⭐️ 控制平面作为一种网络范围的逻辑,不仅控制沿着从源主机到目的主机的端到端路径间的路由器如何转发数据报,而且控制…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...