JMESPath语言
JMESPath(JSON Matching Expression Path)
一种查询语言。
主要用于从JSON文档中检索和过滤数据。
通过写表达式提取和处理JSON数据,而无需编写复杂的代码。
功能:数据提取、过滤、转换、排序。
场景:处理API响应、数据分析、数据转换 etc。
数据提取:从复杂的JSON文档中提取所需的信息。例如,从包含多个嵌套对象和数组的JSON文档中提取特定属性。
数据过滤:基于特定条件过滤JSON数据。例如,从一个包含多个对象的数组中过滤出满足特定属性值条件的对象。
数据转换:将JSON数据转换为其他格式。例如,将一个包含多个属性的对象转换为一个只包含部分属性的新对象,或将一个数组转换为一个新的数组,其中的元素经过特定计算或操作。
数据排序:根据特定属性对JSON数据进行排序。
JMESPath — JMESPath![]() https://jmespath.org/
https://jmespath.org/
本文主要以 JMESPath Tutorial and Examples 为操作示例,还有包括一些其他常用示例:
目录
一些常用调用方式
一些常用表达式
一些常用嵌套语句
一些常用调用方式
| 源 | jmespath | 结果 | 备注 |
| { "demo": "hello world" } | demo | "hello world" | str |
| { "demo": 1 } | demo | 1 | int |
| { "demo": ["1", "2"] } | demo / demo[*] / demo[:] / demo[] | ["1","2" ] | array |
| { "demo": { "key": "value", "k": "v", "a": {"b": "c"} } } | demo | {"key": "value","k": "v","a": {"b": "c"}
} | object |
| {} | demo | null | null |
元素获取
| 源 | jmespath | 结果 | 备注 |
| { "demo": { "key": "value", "k": "v", "a": {"b": "c"} } } | demo.key / demo."key" | "value" | |
| 同上 | demo.a.b | "c" | |
| 同上 | demo.[key, k] | [ "value","v" ] | |
| 同上 | demo.{"k1": key, "k2": k} / demo.{k1: key, k2: k} | {"k1": "value","k2": "v"
} | |
| {"d":{}} | d | {} | |
| { "demo": [1, 2, 3] } | demo[0] / demo[:1] | 1 | |
| {"d":[]} | d | [] | |
| 同上 | demo[2:] | 3 | slice:[start:stop:step]或[start:stop],step为负则倒取 |
| 同上 | demo[3] | null | |
| 同上 | demo[1:3] | [2, 3] | slice |
| 同上 | demo[::-1] | [3, 2, 1] | slice |
| 同上 | demo[::2] | [1,3] | slice |
一些常用表达式
| 源 | jmespath | 结果 | 备注 |
| { "demo": [1, 2, 3] } | to_string(demo) | "[1,2,3]" | 转字符串 to_string(打平显示使用) |
| 同上 | length(demo) | 3 | 长度 length |
| 同上 | type(demo) | "array" | |
| { "demo": { "key": "value", "k": "v", "a": {"b": "c"} } } | to_string(demo) | "{\"key\":\"value\",\"k\":\"v\",\"a\":{\"b\":\"c\"}}" | |
| 同上 | length(demo) | 3 | |
| 同上 | type(demo) | "object" | |
| {"a": "1.1"} | to_number(a) | 1.1 | to number转数字 |
| { "demo": [1, 2, 19] } | max(demo) | 19 | max最大值 |
| 同上 | min(demo) | 1 | min最小值 |
| 同上 | avg(demo) | 7.333333333333333 | avg平均数(显示长度控制在16位) |
| 同上 | sum(demo) | 22 | sum和 |
| 同上 | hhh || demo[0] | 1 | || |
| 同上 | demo[1] || demo[2] | 2 | |
| 同上 | demo[1] && demo[2] | 19 | && |
| { "a": [ { "b1": "James", "b2": "d", "c": 30 }, { "b1": "Jacob", "b2": "e", "c": 35 }, { "b1": "Jayden", "b2": "f", "c": 25 } ] } | a[?c > `18`] | [{"b1": "Jacob","b2": "e","c": 20},{"b1": "Jayden","b2": "f","c": 23}
] | 条件选择 filter |
| 同上 | a[?c > `18`].{b1: b1, age: c} | [{"b1": "Jacob","age": 20},{"b1": "Jayden","age": 23}
] | |
| 同上 | a[?c==`18`] | [{"b1": "James","b2": "d","c": 18}
] | |
| 同上 | a[?c==`18`].{b1: b1, age: c} | [{"b1": "James","age": 18}
] | |
| 同上 | a[?c==`20`].[b1, b2] | [["Jacob","e"] ] | |
| 同上 | a[?c==`20`].[b1, b2] | [] / a[?c==`20`].[b1, b2] | [0] | ["Jacob","e" ] | 管道表达式。 | [] 或 | [0]的写法能消除嵌套下的外[] |
| 同上 | a | [0] / a | [] | {"b1": "James","b2": "d","c": 18
} | |
| 同上 | a | [1] | {"b1": "Jacob","b2": "e","c": 20
} | |
| {"a":[{"b1":"詹姆斯","b2":"d","c":30},{"b1":"雅各布","b2":"e","c":35},{"b1":"杰登","b2":"f","c":25}]} | sort_by(a, &c) | [{"b1": "杰登","b2": "f","c": 25},{"b1": "詹姆斯","b2": "d","c": 30},{"b1": "雅各布","b2": "e","c": 35}
] | sort_by排序 |
| 同上 | join(' ', [a[0].b1, a[1].b1, a[2].b1]) | "詹姆斯 雅各布 杰登" | join字符串拼接 |
| { "a": [ "foo", "foobar", "barfoo", "bar", "barbaz", "barfoobaz" ] } | a[?contains(@, 'foo') == `true`] | ["foo","foobar","barfoo",barfoobaz] | 字符匹配 contains与匿名@ |
一些常用嵌套语句
嵌套调用
| 源 | jmespath | 结果 | 备注 |
| {"a": { "c": [ {"d": [0, [1, 2]]} ] }} | a.c[0].d[1][0] | 1 | |
| { "a": [ { "b1": "James", "b2": "d", "c": 30 }, { "b1": "Jacob", "b2": "e", "c": 35 }, { "b1": "Jayden", "b2": "f", "c": 25 } ] } | a[*].b1 / a[].b1 / a[:].b1 | ["James","Jacob","Jayden" ] | |
| 同上 | a[*].[b1, b2] | [ ["James", "d"], ["Jacob", "e"], ["Jayden", "f"] ] | |
| 同上 | a[*].[*] | [ [["James", "d", 30]], [["Jacob", "e", 35]], [["Jayden", "f", 25]] ] | |
| 同上 | a[*].{b1: b1, "b2": `1`} | [{"b1": "James","b2": 1},{"b1": "Jacob","b2": 1},{"b1": "Jayden","b2": 1}
] | |
| 同上 | a[::2].{b1: b1, "b2": `1`} | [{"b1": "James","b2": 1},{"b1": "Jayden","b2": 1}
] | |
| { "a": { "a1": { "b1": "James", "b2": "d", "c": 30 }, "a2": { "b1": "Jacob", "b2": "e", "c": 35 }, "a3": { "b1": "Jayden", "b2": "f", "c": 25 } } } | a.*.c | [30,35,25 ] | |
| 同上 | a.*.* | [ ["James", "d", 30], ["Jacob", "e", 35], ["Jayden", "f", 25] ] |
相关文章:
JMESPath语言
JMESPath(JSON Matching Expression Path) 一种查询语言。 主要用于从JSON文档中检索和过滤数据。 通过写表达式提取和处理JSON数据,而无需编写复杂的代码。 功能:数据提取、过滤、转换、排序。 场景:处理API响应…...
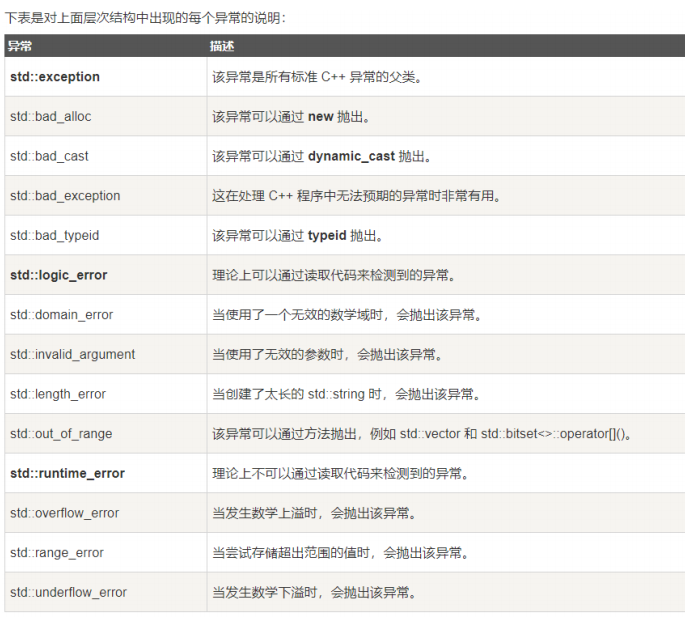
【C++高阶(七)】C++异常处理的方式
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:C从入门到精通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学习C 🔝🔝 异常处理的方式 1. 前言2. C语言处理异常的方式…...

在Idea中创建基于工件的本地服务
目录 1、创建基于工件的Tomcat服务器: 2、修改名称: 3、修改服务器项: 4、部署项 5、最后记得点右下角的【应用】和【确定】保存。 1、创建基于工件的Tomcat服务器: 运行->编辑配置->【Tomcat服务器】->本地 2、修…...

十六、YARN和MapReduce配置
1、部署前提 (1)配置前提 已经配置好Hadoop集群。 配置内容: (2)部署说明 (3)集群规划 2、修改配置文件 MapReduce (1)修改mapred-env.sh配置文件 export JAVA_HOM…...

自己动手写编译器:语法解析的基本原理
在前面系列章节中我们完成了词法解析。词法解析的基本任务就是判断给定字符串是否符合特定规则,如果符合那么就给这个字符串分配一个标签(token)。词法解析完成后接下来的工作就要分配给语法解析,后者的任务就是判断一系列标签的组合是否符合特定规范。 …...
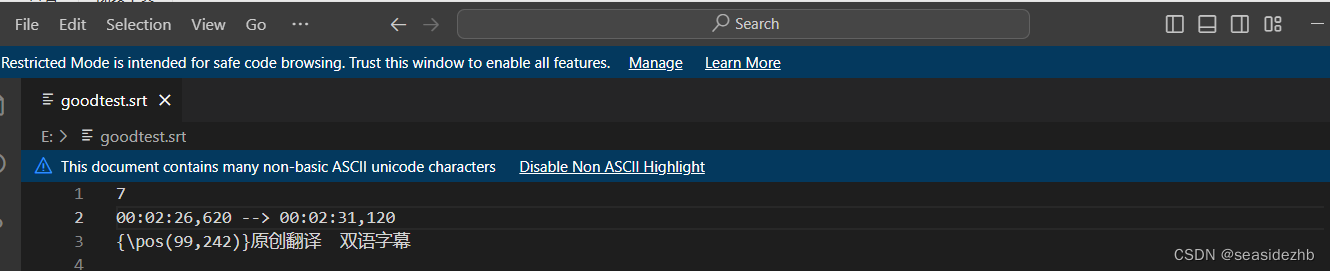
VS Code解决乱码
在上边搜索栏输入“>Change File Encoding”,更改编码格式,解决乱码格式。 VS Code会帮助确认编码格式,然后选择就好。 最后完成如下:...
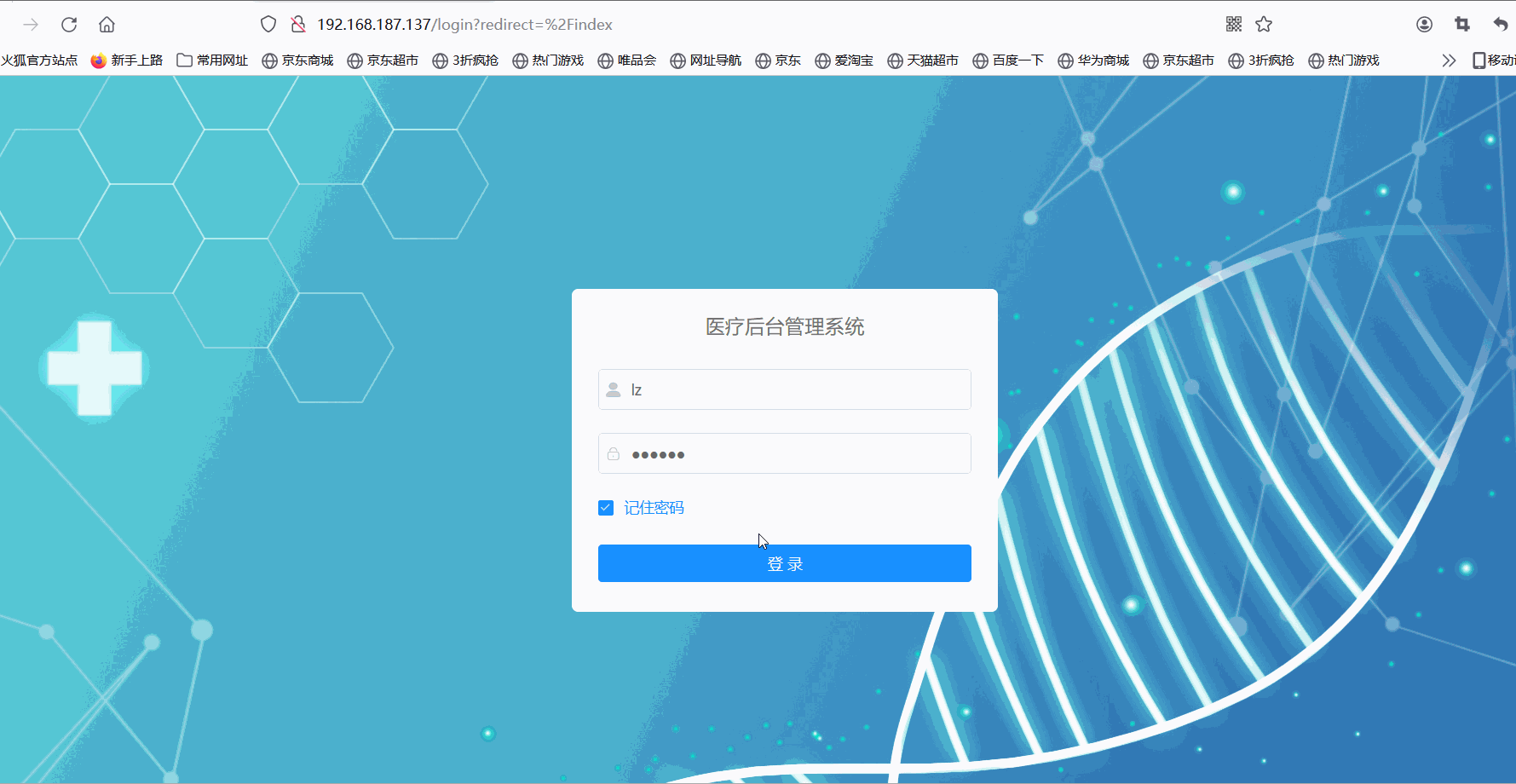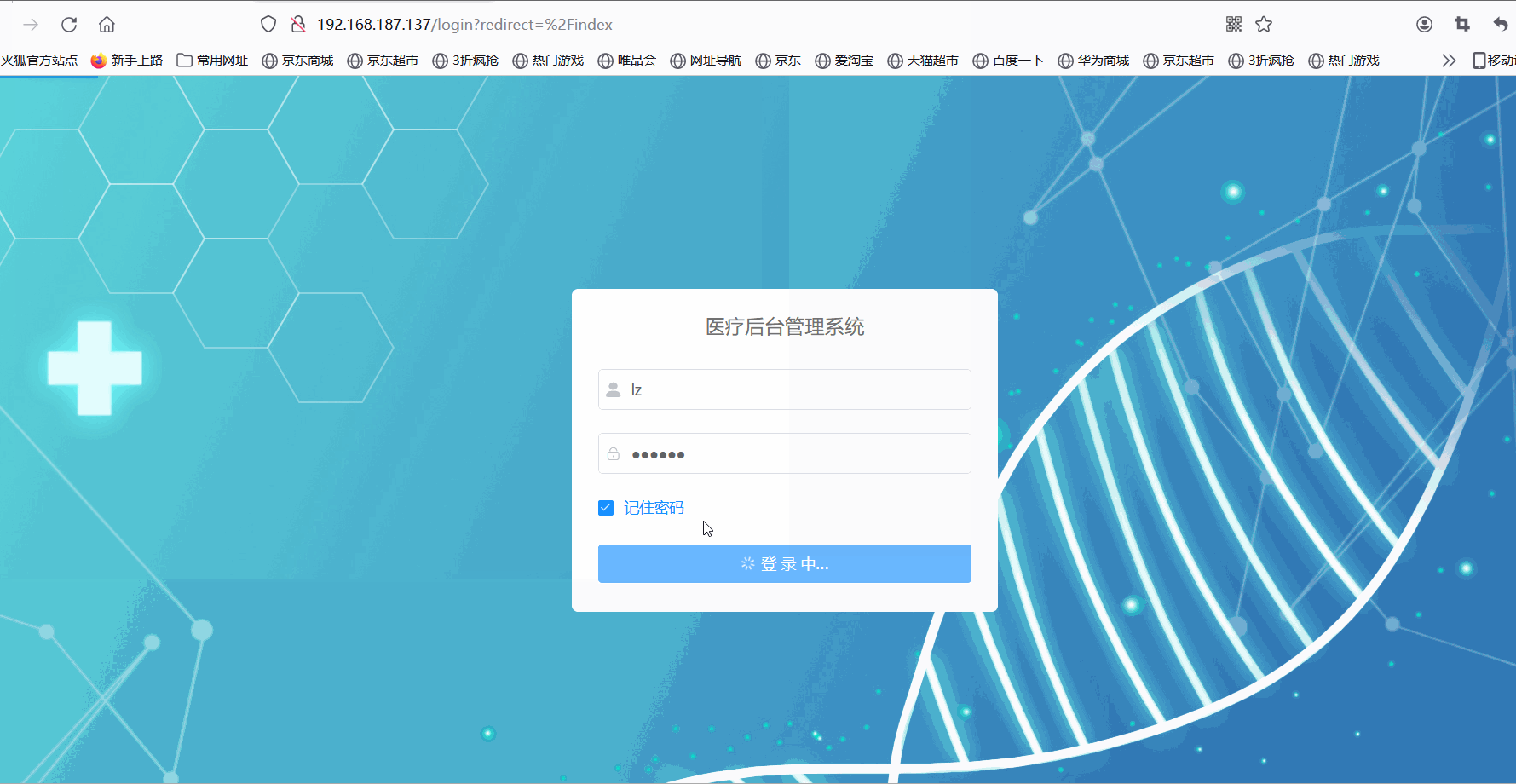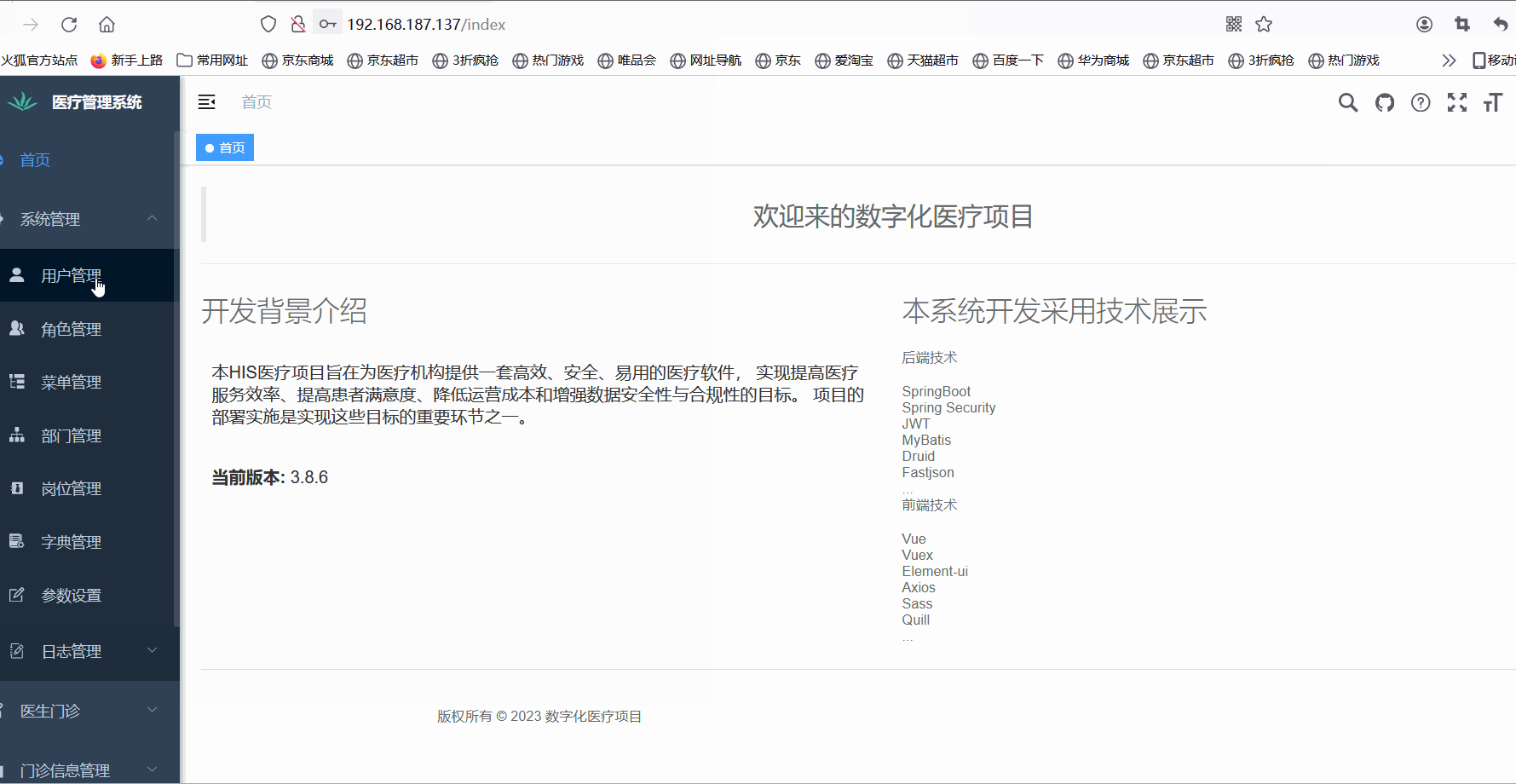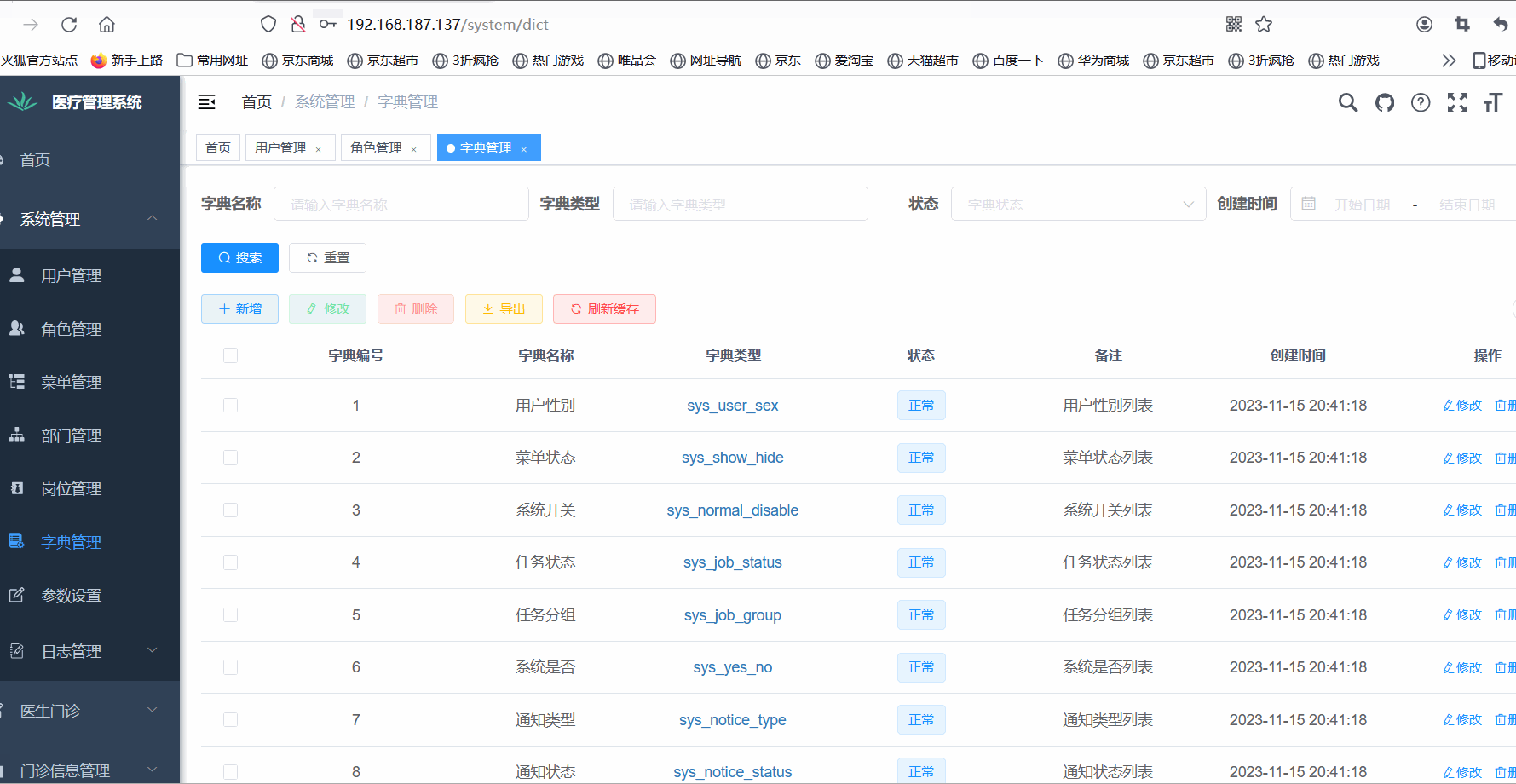
宝塔Linux:部署His医疗项目通过jar包的方式
📚📚 🏅我是默,一个在CSDN分享笔记的博主。📚📚 🌟在这里,我要推荐给大家我的专栏《Linux》。🎯🎯 🚀无论你是编程小白,还是有…...

Vim命令大全(超详细,适合反复阅读学习)
Vim命令大全 Vim简介Vim中的模式光标移动命令滚屏与跳转文本插入操作文本删除操作文本复制、剪切与粘贴文本的修改与替换文本的查找与替换撤销修改、重做与保存编辑多个文件标签页与折叠栏多窗口操作总结 Vim是一款文本编辑器,是Vi编辑器的增强版。Vim的特点是快速、…...

爬虫持久化保存
## open方法- 方法名称及参数markdown **open(file, moder, bufferingNone, encodingNone, errorsNone, newlineNone, closefdTrue)****file** 文件的路径,需要带上文件名包括文件后缀(c:\\1.txt)**mode** 打开的方式(r,w,a,x,b,t…...
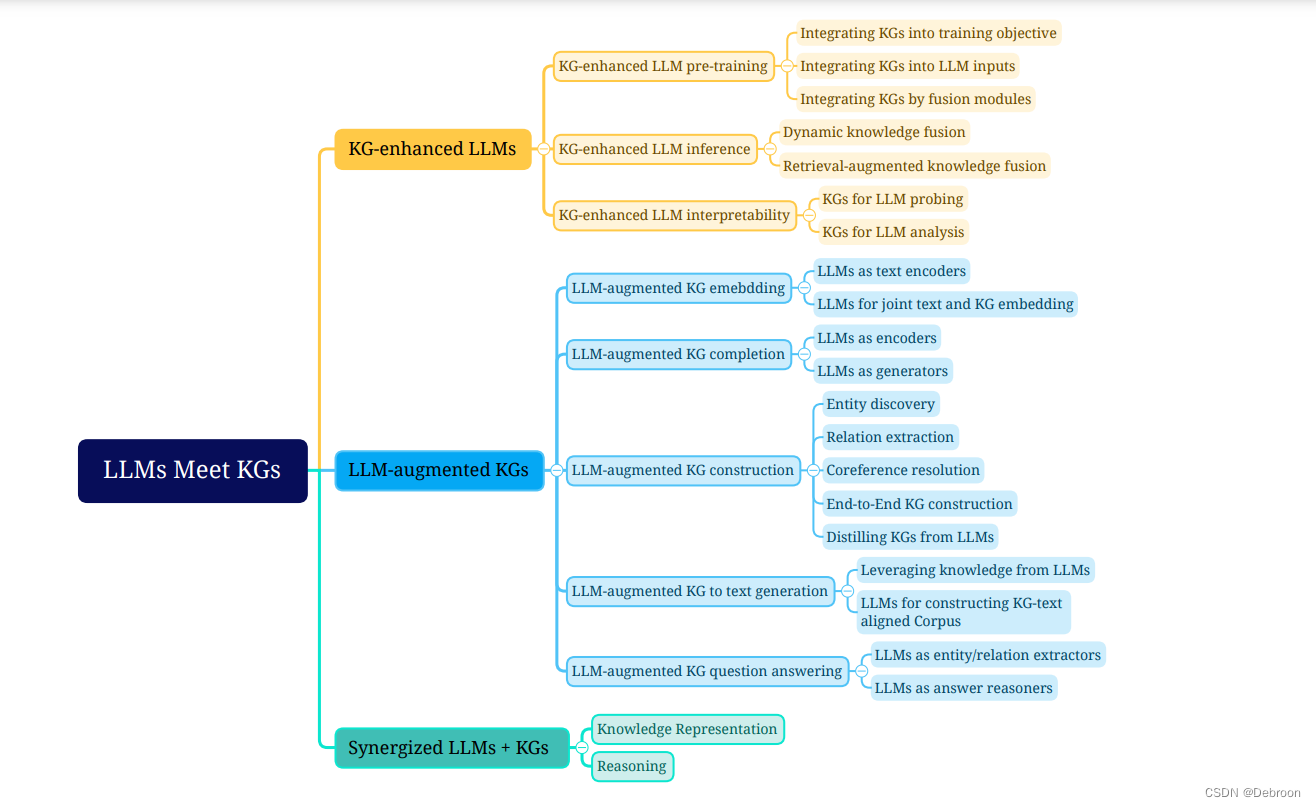
统一大语言模型和知识图谱:如何解决医学大模型-问诊不充分、检查不准确、诊断不完整、治疗方案不全面?
统一大语言模型和知识图谱:如何解决医学大模型问诊不充分、检查不准确、诊断不完整、治疗方案不全面? 医学大模型问题如何使用知识图谱加强和补足专业能力?大模型结构知识图谱增强大模型的方法 医学大模型问题 问诊。偏离主诉和没抓住核心。…...

读写分离之同步延迟测试
背景 读写分离是快速提高数据库性能的手段,主库只负责写入,从库负责查询。但在性能得到提升的同时,编程的复杂度就会提升。由其碰到主从同步延迟的情况,在数据写入后,在从库无法读取到最新数据,会对业务逻…...

SpringBoot+OCR 实现PDF 内容识别
一、SpringBootOCR对pdf文件内容识别提取 1、在 Spring Boot 中,您可以结合 OCR(Optical Character Recognition)库来实现对 PDF 文件内容的识别和提取。 一种常用的 OCR 库是 Tesseract,而 pdf2image 是一个用于将 PDF 转换为图…...

Go和Java实现抽象工厂模式
Go和Java实现抽象工厂模式 本文通过简单数据库操作案例来说明抽象工厂模式的使用,使用Go语言和Java语言实现。 1、抽象工厂模式 抽象工厂模式是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创 建型模式,它…...

深入理解Java虚拟机---内存分配
深入理解Java虚拟机---内存分配 GC日志内存分配与回收策略对象优先在Eden分配大对象直接进入老年代长期存活的对象将进入老年代动态对象年龄判定空间分配担保 GC日志 以下两段典型的GC日志: 33.125: [GC [DefNew: 3324K->152K(3712K), 0.0025925 secs] 3324K-&…...

计算机网络2
OSI参考模型七层: 1.应用层 2.表示层 3.会话层 4.传输层 5.网络层 6.数据链路层 7.物理层 TCP/IP模型 5层参考模型...

jenkins-Generic Webhook Trigger指定分支构建
文章目录 1 需求分析1.1 关键词 : 2、webhooks 是什么?3、配置步骤3.1 github 里需要的仓库配置:3.2 jenkins 的主要配置3.3 option filter配置用于匹配目标分支 实现指定分支构建 1 需求分析 一个项目一般会开多个分支进行开发,测试&#x…...

源码解析8-QSS原理-案例-Qt的qss特殊设置多个子控件的颜色与伪状态
Qt源码解析 索引 源码解析8-QSS原理-案例-Qt的qss特殊设置多个子控件的颜色与伪状态 有些时候我们想特殊设置QSS,比如某一类标题栏目,某一个窗口中的颜色。 重要的是我们需要同时设置多个特殊的按钮等。 统一设置所有 单一按钮全局设置 QPushButton…...
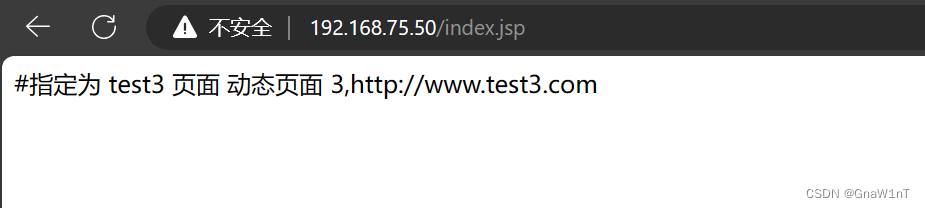
Nginx+Tomcat实现负载均衡和动静分离
目录 前瞻 动静分离和负载均衡原理 实现方法 实验(七层代理) 部署Nginx负载均衡服务器(192.168.75.50:80) 部署第一台Tomcat应用服务器(192.168.75.60:8080) 多实例部署第二台Tomcat应用服务器(192.168.75.70:80…...
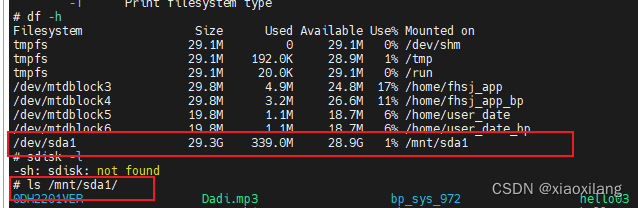
linux系统的u盘/mmc/sd卡等的支持热插拔和自动挂载行为
1.了解mdev mdev是busybox自带的一个简化版的udev。udev是从Linux 2.6 内核系列开始的设备文件系统(DevFS)的替代品,是 Linux 内核的设备管理器。总的来说,它取代了 devfs 和 hotplug,负责管理 /dev 中的设备节点。同时…...
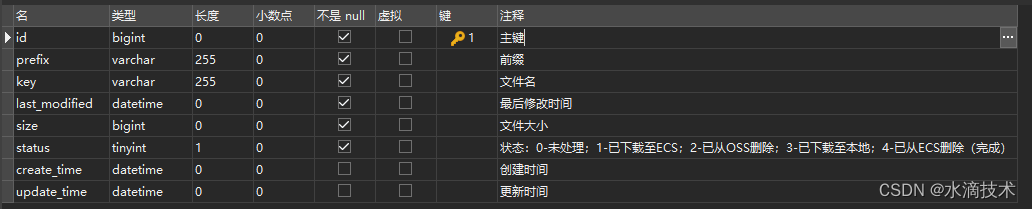
使用Python将OSS文件免费下载到本地:项目分析和准备工作
大家好,我是水滴~~ 本文将介绍如何使用Python编程语言将OSS(对象存储服务)中的文件免费下载到本地计算机。我们先进行项目分析和准备工作,为后续的编码及实施提供基础。 《Python入门核心技术》专栏总目录・点这里 文章目录 1. 前…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...
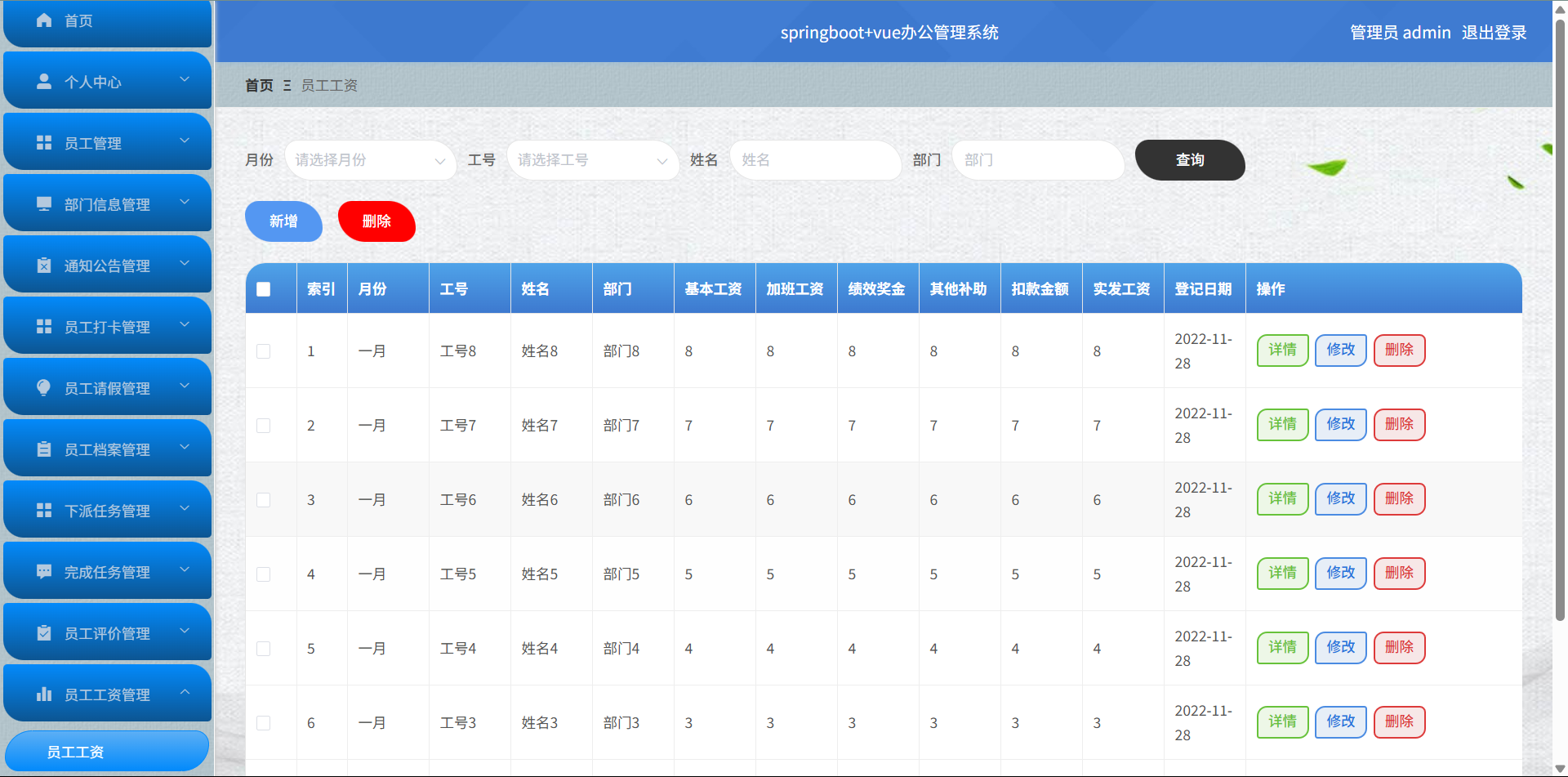
基于Springboot+Vue的办公管理系统
角色: 管理员、员工 技术: 后端: SpringBoot, Vue2, MySQL, Mybatis-Plus 前端: Vue2, Element-UI, Axios, Echarts, Vue-Router 核心功能: 该办公管理系统是一个综合性的企业内部管理平台,旨在提升企业运营效率和员工管理水…...
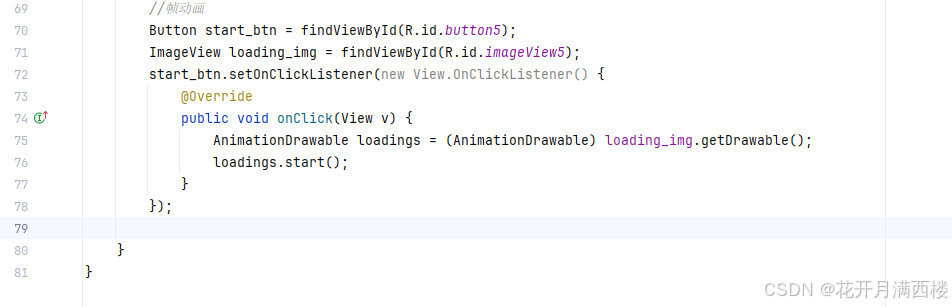
保姆级【快数学会Android端“动画“】+ 实现补间动画和逐帧动画!!!
目录 补间动画 1.创建资源文件夹 2.设置文件夹类型 3.创建.xml文件 4.样式设计 5.动画设置 6.动画的实现 内容拓展 7.在原基础上继续添加.xml文件 8.xml代码编写 (1)rotate_anim (2)scale_anim (3)translate_anim 9.MainActivity.java代码汇总 10.效果展示 逐帧…...
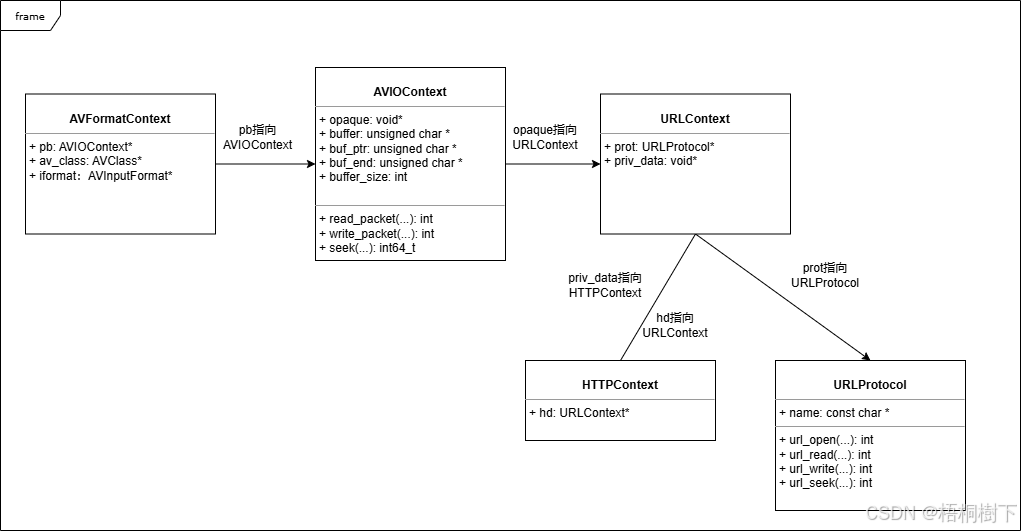
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...
阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘 安装虚拟环境: 1、安装virtualenv pip install virtualenv 2.创建新的虚拟环境: virtualenv myenv 3、激活虚拟环境(激活环境可以在当前环境下安装包) source myenv/bin/activate 此时,终端…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...

32位寻址与64位寻址
32位寻址与64位寻址 32位寻址是什么? 32位寻址是指计算机的CPU、内存或总线系统使用32位二进制数来标识和访问内存中的存储单元(地址),其核心含义与能力如下: 1. 核心定义 地址位宽:CPU或内存控制器用32位…...