2312llvm,02前端
前端
编译器前端,在生成目标相关代码前,把源码变换为编译器的中间表示.因为语言有独特语法和语义,所以一般,前端只处理一个语言或一组类似语言.
比如Clang,处理C,C++,objective-C源码.
介绍Clang
Clang项目是C,C++,Objective-C官方的LLVM前端.Clang的官方网站在此.
实际编译器(clang -cc1命令实现).clang -cc1中的编译器不单用Clang库实现,还大量使用了LLVM库以实现编译器的中端和后端,及整合的汇编器.
这里,重点讨论Clang库和LLVM的C族前端.
为了理解驱动和编译器工作原理,从分析clang编译器驱动的命令行开始.
$ clang hello.c -o hello
解析命令行参数后,Clang驱动用-cc1选项,启动自身的另一个实例来调用内部编译器.
在编译器驱动中,使用-Xclang <option>,来向工具传递具体参数.
如,clang -cc1工有个可打印Clang的(AST)抽象语法树的特殊选项.可用下面命令:
$ clang -Xclang -ast-dump hello.c
也可直接而不用驱动调用clang -cc1:
$ clang -cc1 -ast-dump hello.c
然而,记住,驱动任务之一是为调用编译器,准备所有必需的参数.用-###选项,运行驱动,可查看调用clang -cc1编译器的参数.
如,如果手动调用clang -cc1,也需要通过-I选项,指定系统头文件位置.
前端动作
clang -cc1工具,不仅实现了编译器前端,而且用LLVM库,构建了编译所必需的所有其它LLVM组件.
因此,几乎实现了完整的编译器.典型地,对X86目标,clang -cc1在生成目标文件后,就中止了,因为LLVM链接器还在实验,还没有整合进来.
此时,它把控制权传给驱动,后者再调用外部工具链接.-###选项会如下,显示Clang驱动调用的程序清单:
$ clang hello.c -###
...内容略...
第一行显示clang -cc1从C源文件开始编译,直到生成目标文件.然后,第二行显示Clang仍依赖系统链接器来完成编译.
每次clang -cc1调用都是由一个主要前端动作来控制的.在include/clang/Frontend/FrontendOptions.h源文件中,定义完整的动作集.
下面,描述了clang -cc1可能执行的不同任务:
| 动作 | 描述 |
|---|---|
ASTView | 解析抽象语法树并用Graphviz显示 |
EmitBC | 输出LLVM的位码.bc文件 |
EmitObj | 输出目标相关的.o文件 |
FixIt | 解析并应用所有fixit到源码 |
PluginAction | 运行插件动作 |
RunAnalysis | 分析源码 |
-cc1选项触发执行cc1_main函数.
如,当通过clang hello.c -o hello间接调用-cc1时,函数初化目标相关信息,创建诊断基础设施,执行EmitObj动作.
该动作由FrontendAction的一个CodeGenAction子类实现.
此代码会实例化所有Clang和LLVM组件,并指挥它们生成目标文件.
不同前端动作的共存,让Clang可为了编译外目的运行编译管线,如静态分析.
而且,可通过-target命令行参数,为clang指定目标,根据该目标,加载不同的ToolChain对象.
通过执行不同前端动作,会改变-cc1执行的任务,及外部工具.
如,可用GNU汇编器和GNU链接器编译某个目标,而用LLVM整合的汇编器和GNU链接器编译另一个.
如果不清楚Clang使用的外部工具,总是可用-###选项打印驱动命令.
库
以后,按实现前端,而不是驱动和编译器应用的库对待Clang.这样,Clang是多个库组成的模块化设计的库.
libclang是为外部Clang用户设计的最重要的接口,它通过CAPI提供了大量的前端功能.
它包含多个也可单独使用的Clang库,并同你的项目链接在一起.下面列举一些相关库:
1,libclangLex:预处理和分析词法,处理宏,令牌,pragma构造
2,libclangAST:构建操作遍历抽象语法树
3,libclangParse:用词法阶段结果解析程序逻辑
4,libclangSema:为AST验证提供动作,并分析语义
5,libclangCodeGen:用目标相关信息,处理LLVMIR生成代码
6,libclangAnalysis:静态分析资源
7,libclangRewrite:代码覆盖,编译重构代码
8,libclangBasic:实用工具:分配内存抽象,源码位置,诊断等.
使用libclang
用实例介绍libclang的C接口.尽管不是直接访问Clang内部类的C++API,使用clang很大优势就是它的稳定;
然而无论何时,可随意地使用普通的C++LLVM接口,如在前面实例中,用普通的C++LLVM接口读取位码函数名.
在LLVM安装目录的include子目录中,查看clang-c子目录,它保存libclang的C头文件.为了运行示例,需要包含ClangC接口主入口的Index.h头文件.
如下为示例准备的通用Makefile,注意用了返回完整LLVM库清单的无参llvm-config -libs选项.
LLVM_CONFIG =llvm-config
ifndef VERBOSE
QUIET:=@
endif
SRC_DIR =$(PWD)
LDFLAGS+=$(shell $(LLVM_CONFIG) --ldflags)
COMMON_FLAGS=-Wall -Wextra
CXXFLAGS+=$(COMMON_FLAGS) $(shell $(LLVM_CONFIG) --cxxflags) -fno-rtti
CPPFLAGS+=$(shell $(LLVM_CONFIG) --cppflags) -I$(SRC_DIR)
CLANGLIBS=\-Wl,--start-group\-lclang\-lclangFrontend\-lclangDriver\-lclangSerialization\-lclangParse\-lclangSema\-lclangAnalysis\-lclangEdit\-lclangAST\-lclangLex\-lclangBasic\-Wl,--end-group
LLVMLIBS=$(shell $(LLVM_CONFIG) --libs)
SYSTEMLIBS=$(shell $(LLVM_CONFIG) --system-libs)
PROJECT=myproject
PROJECT_OBJECTS=project.o
default: $(PROJECT)
%.o : $(SRC_DIR)/%.cpp@echo Compiling $*.cpp$(QUIET)$(CXX) -c $(CPPFLAGS) $(CXXFLAGS) $<
$(PROJECT) : $(PROJECT_OBJECTS)@echo Linking $@$(QUIET)$(CXX) -o $@ $(CXXFLAGS) $(LDFLAGS) $^ $(CLANGLIBS) $(LLVMLIBS) $(SYSTEMLIBS)
clean::$(QUIET)rm -f $(PROJECT) $(PROJECT_OBJECTS)
如果使用动态库,而在非标准位置安装LLVM,记住仅配置PATH环境变量是不够的,动态链接器和加载器需要知道LLVM共享库位置.
否则,运行程序时,如果链接了任意一个函数,它会报找不到共享库错误.按以下方式配置库路径:
$ export LD_LIBRARY_PATH=$(LD_LIBRARY_PATH):/your/llvm/installation/lib
用你的LLVM安装位置的完整路径替代/your/llvm/installation.
理解Clang诊断
诊断信息是编译器和用户交互必不可少的部分.编译器传给用户的消息,指示错误,警告或建议.Clang以良好的编译诊断信息为特色,且打印优美,C++错误消息的可读性高.
内部,Clang根据分类划分诊断信息:不同前端阶段都有独特分类及它自己的诊断集合.
如,在include/clang/Basic/DiagnosticParseKinds.td文件中定义了诊断信息.Clang还根据所报告问题的严重程度分类诊断信息:NOTE,WARNING,EXTENSION,EXTWARN,ERROR.
它按Diagnostic::Level枚举映射这些严重程度.
可在include/clang/Basic/Diagnostic*Kinds.td文件中增加新的TableGen定义,编写可检测期望条件代码,输出相应诊断信息,来引入新的诊断机制.
在LLVM源码中,所有的.td文件,都是用TableGen语言编写的.
TableGen是一个LLVM编译系统,用它为编译器的多个部分生成C++代码,并自动合并这些代码的LLVM工具.
该想法开始来自,可基于目标机器的描述来生成大量代码的LLVM后端,如今整个LLVM项目都这样.TableGen通过记录简明表达信息.
如,DiagnosticParseKinds.td包含如下表达诊断信息的记录定义:
def err_invalid_sign_spec : Error<"'%0' cannot be signed or unsigned">;
def err_invalid_short_spec: Error<"'short %0' is invalid">;
此例中,def是TableGen定义新记录的关键字.根据TableGen的后端,决定记录必须包含的字段,对生成文件的每个类型,都有个具体的后端.
TableGen总是输出另一个LLVM源文件包含的.inc文件.这里,TableGen需要生成解释每种诊断方法宏定义的DiagnosticsParseKinds.inc.
err_invalid_sign_spec和err_invalid_short_spec是记录标识,而Error是TableGen的类.注意,该语义跟C++有点不同.
不同于C++,每个TableGen类,是定义了其它字段可继承信息字段的记录模板.然而,如同C++,TableGen支持类层级.
模板一样的语法来为基于按参数接收单个串Error的类定义指定参数.所有从该类继承的定义都是ERROR类型的诊断,而在类参数中编码具体消息,如'short %0' is invalid.
TableGen的语法相当简单,同时,但在TableGen项中,编码信息量很大,易困惑,更多见文档.
阅读诊断
下面给出一例,用libclang的C接口读取并输出所有Clang读给定源文件时产生的诊断信息.
extern "C" {
#include "clang-c/Index.h"
}
#include "llvm/Support/CommandLine.h"
#include <iostream>
using namespace llvm;
static cl::opt<std::string>
FileName(cl::Positional ,cl::desc("Input file"),cl::Required);
int main(int argc, char** argv)
{cl::ParseCommandLineOptions(argc, argv, "Diagnostics Example\n");CXIndex index = clang_createIndex(0,0);const char *args[] = {"-I/usr/include","-I."};CXTranslationUnit translationUnit =clang_parseTranslationUnit(index, FileName.c_str(), args, 2, NULL, 0, CXTranslationUnit_None);unsigned diagnosticCount = clang_getNumDiagnostics(translationUnit);for (unsigned i = 0; i < diagnosticCount; ++i) {CXDiagnostic diagnostic = clang_getDiagnostic(translationUnit, i);CXString category = clang_getDiagnosticCategoryText(diagnostic);CXString message = clang_getDiagnosticSpelling(diagnostic);int severity = clang_getDiagnosticSeverity(diagnostic);CXSourceLocation loc = clang_getDiagnosticLocation(diagnostic);CXString fName;unsigned line = 0, col = 0;clang_getPresumedLocation(loc, &fName, &line, &col);std::cout << "Severity: " << severity << " File: "<< clang_getCString(fName) << " Line: "<< line << " Col: " << col << " Category: \""<< clang_getCString(category) << "\" Message: "<< clang_getCString(message) << std::endl;clang_disposeString(fName);clang_disposeString(message);clang_disposeString(category);clang_disposeDiagnostic(diagnostic);}clang_disposeTranslationUnit(translationUnit);clang_disposeIndex(index);return 0;
}
此C++源文件中,包含libclangC头文件之前,用了extern"C"环境,让C++编译器按C代码编译头文件.
再次使用了解析程序命令行参数的cl名字空间.然后使用了libclang接口的多个函数.
1,首先,调用clang_createIndex()函数创建一个libclang所用顶层环境结构的索引.
它按参数接收两个整数编码的布尔值:第一个为真,表示想排除(PCH)预编译头文件的声明;第二个为真,表示想显示诊断信息.
因为想自己显示诊断信息,把两个都设为假(零).
2,接着,让Clang通过clang_parseTranslationUnit()函数解析一个翻译单元.
它按参数接收从FileName全局变量中取得的待解析源文件的名字.该变量对应用它启动工具的一个串参数.
还需要通过一组(两个)参数,指定include文件的位置.
解析信息并在CXTranslationUnit中存储所有C数据结构后,实现遍历Clang产生的所有诊断,并把它们输出到屏幕的循环.
为此,先用clang_getNumDiagnostics()取解析该文件时产生的诊断数量,并决定循环的边界.
然后,对每次循环遍历,
1,用clang_getDiagnostic()取当前诊断,
2,用clang_getDiagnosticCategoryText()取描述该诊断类型的串
3,用clang_getDiagnosticSpelling()取显示给用户的消息,
4,用clang_getDiagnosticLocation()取准确代码位置.
5,用clang_getDiagnosticSeverity()取诊断严重程度的(NOTE,WARNING,EXTENSION,EXTWARN,或ERROR)枚举数字,但是为了简单,把它变换为正数,并按数字打印它.
因为该C接口缺少C++string类,处理串时,这些函数经常返回特殊的CXString对象,需要调用clang_getCString()得到内部的char指针来打印它,之后调用clang_disposeString()来删除它.
记住,输入源文件可能包含了其它文件,要求诊断引擎除了记录行号和列号,还要记录文件名.文件,行号,列号三元组,让你可定位引用代码位置.
一个特殊的CXSourceLocation对象代表该三元组.为了翻译为文件名,行号,列号,必须按相应填充引用的CXString和int输入参数,调用clang_getPresumedLocation()函数.
完成之后,通过clang_disposeDiagnostic(),clang_disposeTranslationUnit(),clang_disposeIndex()函数删除各个对象.
用如下的hello.c文件测试一下:
int main() {printf("hello, world!\n")
}
该C源文件有两个错误:缺少包含正确的头文件,漏写一个分号.编译项目,然后运行它,看看Clang给出怎样的诊断:
$ make
$ ./myproject hello.c
...诊断略...
可见,由前端的语义和(语法)解析两个不同阶段产生的两个诊断.
通过Clang学习前端
为了按LLVMIR位码转换源码,源码必须经历几个中间步骤:
源码->词法->语法 ->语义->生成代码
分析词法
前端第一步,处理源码的文本输入,按一组单词和令牌分解语言结构,去除注释,空白,制表符等.
每个单词或令牌必须是语言子集的部分,按编译器内部表示转换语言的关键字.
include/clang/Basic/TokenKinds.def文件定义了关键字.如,下面TokenKinds.def摘要中,两个已知的C/C++令牌,while关键字和<符号,高亮了它们.
TOK(identifier)//abcde123 C++11 串字面.呜
TOK(utf32_string_literal)//
...
PUNCTUATOR(r_paren, ")")
PUNCTUATOR(l_brace, "{")
PUNCTUATOR(r_brace, "}")
PUNCTUATOR(starequal, "*=")
PUNCTUATOR(plus, "+")
PUNCTUATOR(plusplus, "++")
PUNCTUATOR(arrow, "->")
PUNCTUATOR(minusminus, "--")
PUNCTUATOR(less, "<")//..
...
KEYWORD(float , KEYALL)
KEYWORD(goto , KEYALL)
KEYWORD(inline , KEYC99|KEYCXX|KEYGNU)
KEYWORD(int , KEYALL)
KEYWORD(return , KEYALL)
KEYWORD(short , KEYALL)
KEYWORD(while , KEYALL)//..
该文件在tok名字空间中.这样,编译器要在词法处理后检查是否是关键字,可通过该名字空间访问它们.
如,可通过枚举元素tok::l_brace,tok::less,tok::kw_goto,tok::kw_while访问{,<,goto,while结构.
考虑下面的min.c的C代码:
int min(int a, int b) {if (a < b)return a;return b;
}
每个令牌都包含一个记录源码中位置的SourceLocation类的实例.记住,已用了它的C版CXSourceLocation,但是两者引用相同数据.
可用下面的clang -cc1命令行,从分析词法中输出令牌和SourceLocation结果:
$ clang -cc1 -dump-tokens min.c
如,高亮的if语句输出是:
if 'if' [StartOfLine] [LeadingSpace] Loc=<min.c:2:3>
l_paren '(' [LeadingSpace] Loc=<min.c:2:6>
identifier 'a' Loc=<min.c:2:7>
less '<' [LeadingSpace] Loc=<min.c:2:9>
identifier 'b' [LeadingSpace] Loc=<min.c:2:11>
r_paren ')' Loc=<min.c:2:12>
return 'return' [StartOfLine] [LeadingSpace] Loc=<min.c:3:5>
identifier 'a' [LeadingSpace] Loc=<min.c:3:12>
semi ';' Loc=<min.c:3:13>
注意每个语言结构都以它的类型为前缀:)是r_paren,<是less,未匹配关键字的串是标识等.
练习词法错误
考虑lex.c源码:
int a = 08000;
此代码中的错误在错误拼写了八进制常数:一个八进制常数不能含有大于7的数字.这会触发词法错误,如下:
$ clang -c lex.c
下面,以该示例运行程序:
$ ./myproject lex.c
报错..
可见如期,程序识别出词法问题.
用词法器编写libclang代码
这里演示一个运用libclang用LLVM词法器令牌化(tokenize)源文件前60个字符流的示例:
extern "C" {
#include "clang-c/Index.h"
}
#include "llvm/Support/CommandLine.h"
#include <iostream>
using namespace llvm;
static cl::opt<std::string>
FileName(cl::Positional ,cl::desc("Input file"),cl::Required);
int main(int argc, char** argv)
{cl::ParseCommandLineOptions(argc, argv, "My tokenizer\n");CXIndex index = clang_createIndex(0,0);const char *args[] = {"-I/usr/include","-I."};CXTranslationUnit translationUnit =clang_parseTranslationUnit(index, FileName.c_str(), args, 2, NULL, 0, CXTranslationUnit_None);CXFile file = clang_getFile(translationUnit, FileName.c_str());CXSourceLocation loc_start =clang_getLocationForOffset(translationUnit, file, 0);CXSourceLocation loc_end =clang_getLocationForOffset(translationUnit, file, 60);CXSourceRange range = clang_getRange(loc_start, loc_end);unsigned numTokens = 0;CXToken *tokens = NULL;clang_tokenize(translationUnit, range, &tokens, &numTokens);for (unsigned i = 0; i < numTokens; ++i) {enum CXTokenKind kind = clang_getTokenKind(tokens[i]);CXString name = clang_getTokenSpelling(translationUnit, tokens[i]);switch (kind) {case CXToken_Punctuation:std::cout << "PUNCTUATION(" << clang_getCString(name) << ") ";break;case CXToken_Keyword:std::cout << "KEYWORD(" << clang_getCString(name) << ") ";break;case CXToken_Identifier:std::cout << "IDENTIFIER(" << clang_getCString(name) << ") ";break;case CXToken_Literal:std::cout << "COMMENT(" << clang_getCString(name) << ") ";break;default:std::cout << "UNKNOWN(" << clang_getCString(name) << ") ";break;}clang_disposeString(name);}std::cout << std::endl;clang_disposeTokens(translationUnit, tokens, numTokens);clang_disposeTranslationUnit(translationUnit);return 0;
}
为了构建,开头用相同样板代码初化命令行参数,调用前面见过的clang_createIndex()/clang_parseTranslationUnit().
变化在后面.不是查询诊断,而是为运行Clang词法器,并返回令牌流的clang_tokenize()准备参数.
为此,必须创建指定想运行词法器的(起点和终点)源码区间的CXSourceRange对象.
该对象由两个CXSourceLocation对象组成,一个指向起点,另一个指向终点.
从返回用clang_getFile()取得的CXFile的特定偏移的CXSourceLocation的clang_getLocationForOffset()函数得到.
为了从两个CXSourceLocation创建CXSourceRange,调用clang_getRange()函数.
有了它,就可按引用输入两个重要参数来调用clang_tokenize()函数:
存储令牌流的CXToken指针及返回流令牌数目的正类型指针.根据该数目,创建循环结构,并遍历所有令牌.
对每个令牌,用clang_getTokenKind()得到它的类型,并用clang_getTokenSpelling()得到相应代码.然后用switch结构,根据令牌类型打印不同文本,及对应令牌的代码.
下例中,会看到结果.
把下面代码输入程序:
#include <stdio.h>
int main() {printf("hello, world!");
}
运行令牌化程序后,得到下面输出:
PUNCTUATION(#) IDENDIFIER(include) PUNCTUATION(<) IDENDIFIER(stdio) PUNCTUATION(.) IDENTIFIER(h) PUNCTUATION(>) KEYWORD(int) IDENTIFIER(main) PUNCTUATION(() PUNCTUATION()) PUNCTUATION({) IDENTIFIER(printf) PUNCTUATION(() COMMENT("hello, world!") PUNCTUATION()) PUNCTUATION(;) PUNCTUATION(})
预处理
C/C++预处理器,在分析语义前运行,负责展开宏,包含文件,或根据各种#开头的预处理器指示略去部分代码.
预处理器和词法器紧密关联,两者不断相互交互.因为预处理器在前端早期工作,在语义解析器试从代码中提取意思前,可用宏干各种奇怪的事情,如用宏展开改变函数声明.
为了展开宏,可用-E选项运行编译器驱动,它只运行预处理器,不再进一步分析,然后中断编译.
预处理器允许转换源码为难以理解的文本片段.词法器预处理令牌流,来处理如宏和pragma等预处理指示.
预处理器用一个符号表保存定义的宏,有宏实例时,用存储在符号表中的令牌替代当前的令牌.
如果安装了扩展工具,可在命令行运行pp-trace来显示预处理器的动作.
考虑下例pp.c:
#define EXIT_SUCCESS 0
int main() {return EXIT_SUCCESS;
}
如果用-E选项运行编译器驱动,会看到如下输出:
$ clang -E pp.c -o pp2.c && cat pp2.c
...
int main() {return 0;
}
如果运行pp-trace工具,会看到下面输出:
$ pp-trace pp.c
...
- Callback: MacroDefinedMacroNameTok: EXIT_SUCCESSMacroDirective: MD_Define
- Callback: MacroExpandsMacroNameTok: EXIT_SUCCESSMacroDirective: MD_DefineRange: ["/examples/pp.c:3:10", "/examples/pp.c:3:10"]Args: (null)
- Callback: EndOfMainFile
省略了在开始预处理实际文件前pp-trace输出的很长的内置宏的列表.如果想知道驱动编译源码时默认定义的宏,该列表非常有用.
通过覆盖预处理器回调函数来实现pp-trace.
即,可在预处理器采取动作时执行功能函数来实现你的工具.
此例中,有两次动作:
1,读取EXIT_SUCCESS宏定义.
2,在第3行展开它.
如果实现了MacroDefined回调函数,pp-trace工具还会打印你的工具接收的参数.
该工具相当小,如果想实现预处理器回调函数,阅读它的源码是个好的开始.
分析语法
在分析词法令牌化源码后,就是分组令牌以形成式,语句,函数体等的分析语法了.
它结合物理布局,检查一组令牌是否有意义,但是不分析代码的意思.
该分析也叫解析,它按输入接收令牌流,并输出(AST)语法树.
理解ClangAST节点
一个AST节点表示声明,语句,类型.因此,有三种表示AST的核心类:Decl,Stmt,Type.
在Clang中,按一个C++类表示每个C或C++语言构造,它们必须继承上述核心类之一.
如,IfStmt类(表示一个完整的if语句体)直接从Stmt类继承.另一方面,用来保存函数和变量的声明或定义的FunctionDecl和VarDecl,从多个类继承,且只是间接继承Decl.
顶层AST节点是TranslationUnitDecl.它是所有其它AST节点的根,代表整个翻译单元.以min.c源码为例,记住可用-ast-dump开关输出它的AST:
$ clang -fsyntax-only -Xclang -ast-dump min.c
TranslationUintDecl ...
|-TypedefDecl ... __int128_t '__int128'
|-TypedefDecl ... __uint128_t 'unsigned __int128'
|-TypedefDecl ... __builtin_va_list '__va_list_tag [1]' `-FunctionDecl ... <min.c:1:1, line:5:1> min 'int (int, int)'|-ParmVarDecl ... <line:1:7, col:11> a 'int'|-ParmVarDecl ... <col:14, col:18> b 'int'`-CompoundStmt ... <col:21, line:5:1>
...
注意出现了TranslationUnitDecl顶层翻译单元的声明,和FunctionDecl表示的min函数的声明.CompoundStmt声明包含了其它的语句和式.
可用下面命令得到,AST的图形视图:
$ clang -fsyntax-only -Xclang -ast-view min.c
//借助-ast-view的外部工具.
AST节点CompoundStmt包含IfStmt和ReturnStmt表示的if和return语句.如C标准要求的,每次使用a和b都生成一个到int类型的ImplicitCastExpr.
ASTContext类包含翻译单元的完整AST.可用ASTContext::getTranslationUnitDecl()接口,从顶层TranslationUnitDecl实例开始,可访问任意AST节点.
用调试器理解解析器动作
解析器接收并处理词法阶段生成的令牌序列,每当发现一组期望的令牌时,生成一个AST节点.
如,每当发现tok::kw_if令牌时,就调用ParseIfStatement函数,处理if语句体中的所有令牌,为它们生成所有必需的子AST节点,及一个IfStmt根节点.
看看下面代码,
//lib/Parse/ParseStmt.cpp:
...case tok::kw_if: //C99 6.8.4.1:if语句return ParseIfStatement(TrailingElseLoc);case tok::kw_switch: //C99 6.8.4.2:猜语句return ParseSwitchStatement(TrailingElseLoc);
...
在调试器中输出调用栈,可更好地理解Clang编译min.c时,怎样调用ParseIfStatement函数:
$ gdb clang
$ b ParseStmt.cpp:213
$ r -cc1 -fsyntax-only min.c
...
213 return ParseIfStatement(TrailingElseLoc);
(gdb) backtrace
#0 clang::Parser::ParseStatementOrDeclarationAfterAttributes
#1 clang::Parser::ParseStatementOrDeclaration
#2 clang::Parser::ParseCompoundStatementBody
#3 clang::Parser::ParseFunctionStatementBody
#4 clang::Parser::ParseFunctionDefinition
#5 clang::Parser::ParseDeclGroup
#6 clang::Parser::ParseDeclOrFunctionDefInternal
#7 clang::Parser::ParseDeclarationOrFunctionDefinition
#8 clang::Parser::ParseExternalDeclaration
#9 clang::Parser::ParseTopLevelDecl
#10 clang::ParseAST
#11 clang::ASTFrontendAction::ExecuteAction
#12 clang::FrontendAction::Execute
#13 clang::CompilerInstance::ExecuteAction
#14 clang::ExecuteCompilerInvocation
#15 cc1_main
#16 main
ParseAST()函数先用Parser::ParseTopLevelDecl()读取顶层声明来解析一个翻译单元.
然后,它处理所有后续AST节点,消费关联令牌,把每个新AST节点附加到它的父AST节点.
当解析器消费了所有令牌,才会返回到ParseAST().接着,解析器的用户就可从顶级TranslationUnitDecl访问各个AST节点.
练习解析错误
考虑下面parse.c中的for语句:
void func() {int n;for (n = 0 n < 10; n++);
}
此代码中的错误是n=0之后漏掉一个分号.下面是Clang编译它时输出的诊断信息:
$ clang -c parse.c
parse.c:3:14: error: expected ';' in 'for' statement specifierfor (n = 0 n < 10; n++);^
1 error generated.
下面运行诊断程序:
$ ./myproject parse.c
Severity: 3 File: parse.c Line: 3 Col: 14 Category: "Parse Issue" Message: expected ';' in 'for' statement specifier
示例中的所有令牌都是正确的,因此词法器成功地结束了,没有产生诊断信息.
然而,在构建AST时,把多个令牌组合在一起,看看是否有意义,解析器注意到for结构漏掉一个分号.
此时,诊断器归类为(ParseIssue)解析问题.
写遍历ClangAST的代码
libclang接口,让你可通过指向当前AST节点的光标对象遍历ClangAST.
可用clang_getTranslationUnitCursor()函数得到顶层节点指针.
下例,我编写了个输出C或C++源文件中包含的所有C或C++函数或方法的一个工具:
extern "C" {
#include "clang-c/Index.h"
}
#include "llvm/Support/CommandLine.h"
#include <iostream>
using namespace llvm;
static cl::opt<std::string>
FileName(cl::Positional ,cl::desc("Input file"),cl::Required);
enum CXChildVisitResult visitNode (CXCursor cursor, CXCursor parent, CXClientData client_data) {if (clang_getCursorKind(cursor) == CXCursor_CXXMethod ||clang_getCursorKind(cursor) == CXCursor_FunctionDecl) {CXString name = clang_getCursorSpelling(cursor);CXSourceLocation loc = clang_getCursorLocation (cursor);CXString fName;unsigned line = 0, col = 0;clang_getPresumedLocation(loc, &fName, &line, &col);std::cout << clang_getCString(fName) << ":"<< line << ":" << col << " declares "<< clang_getCString(name) << std::endl;clang_disposeString(fName);clang_disposeString(name);return CXChildVisit_Continue;}return CXChildVisit_Recurse;
}
int main(int argc, char** argv)
{cl::ParseCommandLineOptions(argc, argv, "AST Traversal Example\n");CXIndex index = clang_createIndex(0,0);const char *args[] = {"-I/usr/include","-I."};CXTranslationUnit translationUnit =clang_parseTranslationUnit(index, FileName.c_str(), args, 2, NULL, 0, CXTranslationUnit_None);CXCursor cur = clang_getTranslationUnitCursor(translationUnit);clang_visitChildren(cur, visitNode, NULL);clang_disposeTranslationUnit(translationUnit);clang_disposeIndex(index);return 0;
}
此例中,最重要的函数是递归访问按参数传递的光标的所有子节点,且每次访问调用回调函数的clang_visitChildren()函数.
通过定义叫visitNode()的回调函数开始代码.该函数必须返回CXChildVisitResult枚举的一个成员值,它仅有三个可能:
1,期望clang_visitChildren()继续遍历AST,访问当前节点的子节点时,返回CXChildVisit_Recurse.
2,期望继续访问,但是跳过当前节点子节点,则返回CXChildVisit_Continue;
3,已满足,期望clang_visitChildren()不再访问更多的节点时,返回CXChildVisit_Break.
回调函数接收三个参数:代表当前正在访问的AST节点的光标;代表该节点父节点的另一个光标;及一个void指针typedef的CXClientData对象.
该空指针让你可在跨回调函数调用间传递包含维护状态的任意数据结构.假如想创建一个分析,它是有用的.
注意
虽然可用此代码结构创建分析,但是,如果分析很复杂,需要像(CFG)控制流图等结构,就不要用光标或libclang.
按直接调用ClangC++API用AST创建CFG的Clang插件实现你的分析更合适
见插件和CFG::buildCFG方法.一般,直接根据AST``创建分析比用CFG创建分析更难.
前例中,忽略了client_data和parent参数.简单用clang_getCursorKind()函数检测当前光标是否指向C函数声明(CXCursor_FunctionDecl)或C++方法(CXCursor_CXXMethod).
确定正在访问正确的光标时,会用几个函数从光标提取信息:
1,用clang_getCursorSpelling()得到该AST节点对应的代码,
2,用clang_getCursorLocation()得到和它关联的CXSourceLocation对象.
接着,打印这些信息,并返回CXChildVisit_Continue以结束函数.这里不存在嵌套函数声明,不必继续遍历访问该光标的子节点.
如果光标不是期望的,就简单地通过返回CXChildVisit_Recurse,继续递归遍历AST.
实现了visitNode回调函数后,剩余代码相当简单.用最初样板代码解析命令行参数和输入文件.接着,用顶层光标和回调函数调用visitChildren().最后参数是用户数据,不用它,设为NULL.
对下面输入文件运行该程序:
#include <stdio.h>
int main() {printf("hello, world!");
}
输出如下:
$ ./myproject hello.c
`hello.c:2:5declaresmain`
...
用预编译头文件序化AST
可序化ClangAST,并保存它到PCH扩展文件中.在项目源文件中,该特性避免每次包含相同头文件时,重复处理它们,加快了编译速度.
选择使用PCH文件时,按单个PCH文件预编译所有头文件,编译翻译单元时,编译器快捷地从预编译头文件取得信息.
如,想为C生成PCH文件,应该用与GCC一样的语法,即如下用-xc-header选项开启预编译头文件生成:
$ clang -x c-header myheader.h -o myheader.h.pch
想用你的新PCH文件,应该如下用-include选项:
$ clang -include myheader.h myproject.c -o myproject
分析语义
分析语义,借助符号表检验代码没有违反语言类型系统.该表存储标识(符号)和它们各自类型间的映射等.
简单检查类型方法是,解析后,遍历AST的同时,从符号表收集类型信息.
与众不同的是,Clang并不在解析后遍历AST.相反,它在生成AST节点过程中,即时就检查类型.看看解析min.c的示例.
此例中,ParseIfStatement函数调用ActOnIfStmt语义动作,为if语句检查语义,并输出相应诊断.
//lib/Parse/ParseStmt.cpp
...return Actions.ActOnIfStmt(IfLoc, FullCondExp, ...);
...
//控制转移,分析语义.
为了协助分析语义,DeclContext基类对每个域包含所有Decl节点的引用.
这样可轻松分析语义,因为分析语义引擎,可通过查看从DeclContext继承的AST节点找到符号声明,以查找名字引用的符号,并同时检查符号类型及是否有符号.
此AST节点的示例有TranslationUnitDecl,FunctionDecl,LabelDecl.
以min.c为例,可如下用Clang输出声明环境:
$ clang -fsyntax-only -Xclang -print-decl-contexts min.c
[translation unit] 0x7faf320288f0<typedef> __int128_t<typedef> __uint128_t<typedef> __builtin_va_list[function] f(a, b)<parameter> a<parameter> b
注意,结果中只有TranslationUnitDecl和FunctionDecl间的声明,因为只有它们是从DeclContext继承的节点.
练习语义错误
下面的sema.c文件包含两个用a标识的定义:
int a[4];
int a[5];
错误在,两个不同类型变量用了相同名字.必须在分析语义时发现该错误,相应地Clang报告了该问题:
$ clang -c sema.c
sema.c:3:5: error: redefinition of 'a' with a different type
int a[5];^
sema.c:2:5: note: previous definition is here
int a[4];^
1 error generated.
如果运行诊断程序,会得到以下输出:
$ ./myproject sema.c
Severity: 3 File: sema.c Line: 2 Col:5 Category: "Semantic Issue" Message: redefinition of 'a' with a different type: 'int [5]' vs 'int [4]'
生成LLVMIR代码
经过解析和分析语义后,ParseAST函数调用HandleTranslationUnit方法以触发消费最终AST的客户.
如果编译器驱动使用CodeGenAction前端动作,该用户就是,遍历AST,生成实现完全相同的语法树所表示程序行为的LLVMIR的BackendConsumer.
从顶层的TranslationUnitDecl声明开始翻译到LLVMIR.
继续考察min.c示例,
在lib/CodeGen/CGStmt.cpp文件中,通过EmitIfStmt函数变换if语句为LLVMIR,
用栈跟踪,可见,从ParseAST函数到EmitIfStmt的调用路径:
$ gdb clang
(gdb) b CGStmt.cpp:130
(gdb) r -cc1 -emit-obj min.c
...
130 case Stmt::IfStmtClass: EmitIfStmt(cast<IfStmt>(*S)); break;
(gdb) backtrace
#0 clang::CodeGen::CodeGenFunction::EmitStmt
#1 clang::CodeGen::CodeGenFunction::EmitCompoundStmtWithoutScope
#2 clang::CodeGen::CodeGenFunction::EmitFunctionBody
#3 clang::CodeGen::CodeGenFunction::GenerateCode
#4 clang::CodeGen::CodeGenModule::EmitGlobalFunctionDefinition
#5 clang::CodeGen::CodeGenModule::EmitGlobalDefinition
#6 clang::CodeGen::CodeGenModule::EmitGlobal
#7 clang::CodeGen::CodeGenModule::EmitTopLevelDecl
#8 (anonymous namespace)::CodeGeneratorImpl::HandleTopLevelDecl
#9 clang::BackendConsumer::HandleTopLevelDecl
#10 clang::ParseAST
翻译代码为LLVMIR时,前端就结束了.如果继续正常流程,接着,LLVMIR库会优化LLVMIR代码,后端生成目标代码.
组合在一起
本例中,介绍不再依赖libclangC接口的ClangC++接口.创建内部用ClangC++类的词法器,解析器,分析语义来操作输入文件的程序.
这样,工作变为干简单的FrontendAction对象的活.可继续使用前面的Makefile.然而,要关闭-Wall-Wextra编译器选项.
下面是该示例源码:
#include "llvm/ADT/IntrusiveRefCntPtr.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Support/Host.h"
#include "clang/AST/ASTContext.h"
#include "clang/AST/ASTConsumer.h"
#include "clang/Basic/Diagnostic.h"
#include "clang/Basic/DiagnosticOptions.h"
#include "clang/Basic/FileManager.h"
#include "clang/Basic/SourceManager.h"
#include "clang/Basic/LangOptions.h"
#include "clang/Basic/TargetInfo.h"
#include "clang/Basic/TargetOptions.h"
#include "clang/Frontend/ASTConsumers.h"
#include "clang/Frontend/CompilerInstance.h"
#include "clang/Frontend/TextDiagnosticPrinter.h"
#include "clang/Lex/Preprocessor.h"
#include "clang/Parse/Parser.h"
#include "clang/Parse/ParseAST.h"
#include <iostream>using namespace llvm;
using namespace clang;
static cl::opt<std::string>
FileName(cl::Positional, cl::desc("Input file"), cl::Required);
int main(int argc, char **argv) {cl::ParseCommandLineOptions(argc, argv, "My simple front end\n");CompilerInstance CI;DiagnosticOptions diagnosticOptions;CI.createDiagnostics();IntrusiveRefCntPtr<TargetOptions> PTO(new TargetOptions());PTO->Triple = sys::getDefaultTargetTriple();TargetInfo *PTI = TargetInfo::CreateTargetInfo(CI.getDiagnostics(),PTO);CI.setTarget(PTI);CI.createFileManager();CI.createSourceManager(CI.getFileManager());CI.createPreprocessor(TU_Complete);CI.getPreprocessorOpts().UsePredefines = false;ASTConsumer *astConsumer = CreateASTPrinter(NULL, "");CI.setASTConsumer(astConsumer);CI.createASTContext();CI.createSema(TU_Complete, NULL);const FileEntry *pFile = CI.getFileManager().getFile(FileName);if (!pFile) {std::cerr << "File not found: " << FileName << std::endl;return 1;}CI.getSourceManager().createMainFileID(pFile);CI.getDiagnosticClient().BeginSourceFile(CI.getLangOpts(), 0);ParseAST(CI.getSema());//打印`AST`统计信息CI.getASTContext().PrintStats();CI.getASTContext().Idents.PrintStats();return 0;
}
以上代码,对输入源文件运行词法器,解析器,分析语义,可用命令行指定输入文件.它打印解析的源码和AST统计,然后结束.此代码执行了以下步骤:
1,CompilerInstance类,管理整个编译过程的基础设施.第一步实例化该类,保存为CI.
2,一般,clang -cc1会实例化一个具体执行这里介绍的所有步骤的FrontendAction.因为想向你暴露这些步骤,所以不使用FrontendAction;
相反,配置自己的CompilerInstance.用一个CompilerInstance方法创建诊断引擎,并从系统取目标三元组来设置当前目标.
3,现在实例化三个新资源:一个文件管理器,一个源码管理器,一个预处理器.第一个是读源文件所必需的,第二个负责管理词法器和解析器用的SourceLocation实例.
4,创建一个传给CI的ASTConsumer引用.这让前端客户(在解析和分析语义后)可按自己方式消费最终的AST.
如,如果想让驱动生成LLVMIR代码,就需要提供一个具体的(叫BackendConsumer)生成代码的ASTConsumer实例,这正好是CodeGenAction设置它的CompilerInstance的ASTConsumer的方式.
此例中,包含了提供各式各样的实验consumer(消费者)的ASTConsumers.h头文件,这里仅用了个借助CreateASTPrinter()调用创建的打印AST到控制台的consumer.
如果感兴趣,可花时间实现自己的ASTConsumer子类,执行感兴趣的前端分析.lib/Frontend/ASTConsumers.cpp中有些示例.
5,创建一个新的分别为解析器和语义解析器所用的ASTContext和Sema,并传递给CI对象.还初化了诊断consumer(这里,标准consumer也仅打印诊断到屏幕).
6,调用ParseAST以执行词法和语法分析,它们借助HandleTranslationUnit函数调用,调用ASTConsumer.
如果前端发现严重错误,Clang也会打印诊断并中断流程.
打印AST统计信息到标准输出.
用下面的文件测试该简单前端工具:
int main() {char *msg = "Hello, world!\n";write(1, msg, 14);return 0;
}
产生如下输出:
$ ./myproject test.c
int main() {char *msg = "Hello, world!\n";write(1, msg, 14);return 0;
}
*** AST Context Stats:39 types total.31 Builtin types3 Complex types3 Pointer types1 ConstantArray types1 FunctionNoProto types
Total bytes = 544
0/0 implicit default constructors created
0/0 implicit copy constructors created
0/0 implicit copy assignment operators created
0/0 implicit destructors created
Number of memory regions: 1
Bytes used: 1594
Bytes allocated: 4096
Bytes wastes: 2502 (includes alignment, etc)
clang语法树
clang设计
相关文章:

2312llvm,02前端
前端 编译器前端,在生成目标相关代码前,把源码变换为编译器的中间表示.因为语言有独特语法和语义,所以一般,前端只处理一个语言或一组类似语言. 比如Clang,处理C,C,objective-C源码. 介绍Clang Clang项目是C,C,Objective-C官方的LLVM前端.Clang的官方网站在此. 实际编译器(…...
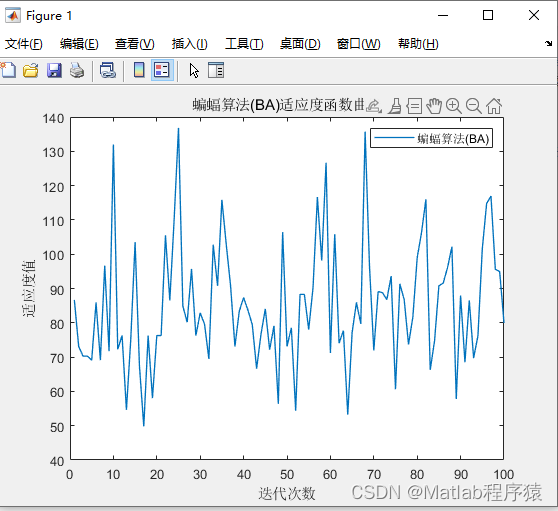
【MATLAB源码-第101期】基于matlab的蝙蝠优化算BA)机器人栅格路径规划,输出做短路径图和适应度曲线。
操作环境: MATLAB 2022a 1、算法描述 蝙蝠算法(BA)是一种基于群体智能的优化算法,灵感来源于蝙蝠捕食时的回声定位行为。这种算法模拟蝙蝠使用回声定位来探测猎物、避开障碍物的能力。在蝙蝠算法中,每只虚拟蝙蝠代表…...
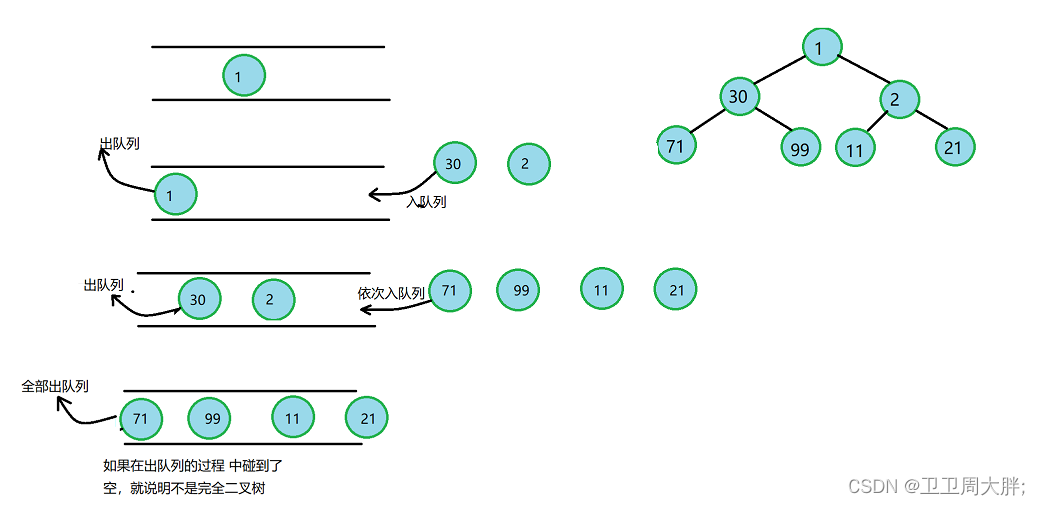
【数据结构】二叉树的模拟实现
前言:前面我们学习了堆的模拟实现,今天我们来进一步学习二叉树,当然了内容肯定是越来越难的,各位我们一起努力! 💖 博主CSDN主页:卫卫卫的个人主页 💞 👉 专栏分类:数据结构 👈 &…...
open3d bug:pcd转txt前后位姿发生改变
1、open3d bug:pcd转txt前后位姿发生改变 open3d会对原有结果进行一个微小位姿变换 import open3d as o3d import numpy as np# 读取PCD点云文件 pcd o3d.io.read_point_cloud(/newdisk/darren_pty/zoom_centered_s2.pcd)# 获取点云坐标 points pcd.points# 指定…...

持续集成交付CICD:Jenkins使用GitLab共享库实现基于Ansible的CD流水线部署前后端应用
目录 一、实验 1.部署Ansible自动化运维工具 2.K8S 节点安装nginx 3.Jenkins使用GitLab共享库实现基于Ansible的CD流水线部署前后端应用 二、问题 1.ansible安装报错 2.ansible远程ping失败 3. Jenkins流水线通过ansible命令直接ping多台机器的网络状态报错 一、实验 …...

OpenAI 疑似正在进行 GPT-4.5 灰度测试!
大家好,我是二狗。 今天,有网友爆料OpenAI疑似正在进行GPT-4.5灰度测试! 当网友询问ChatGPT API调用查询模型的确切名称是什么时? ChatGPT的回答竟然是 gpt-4.5-turbo。 也有网友测试之后发现仍然是GPT-4模型。 这是有网友指…...
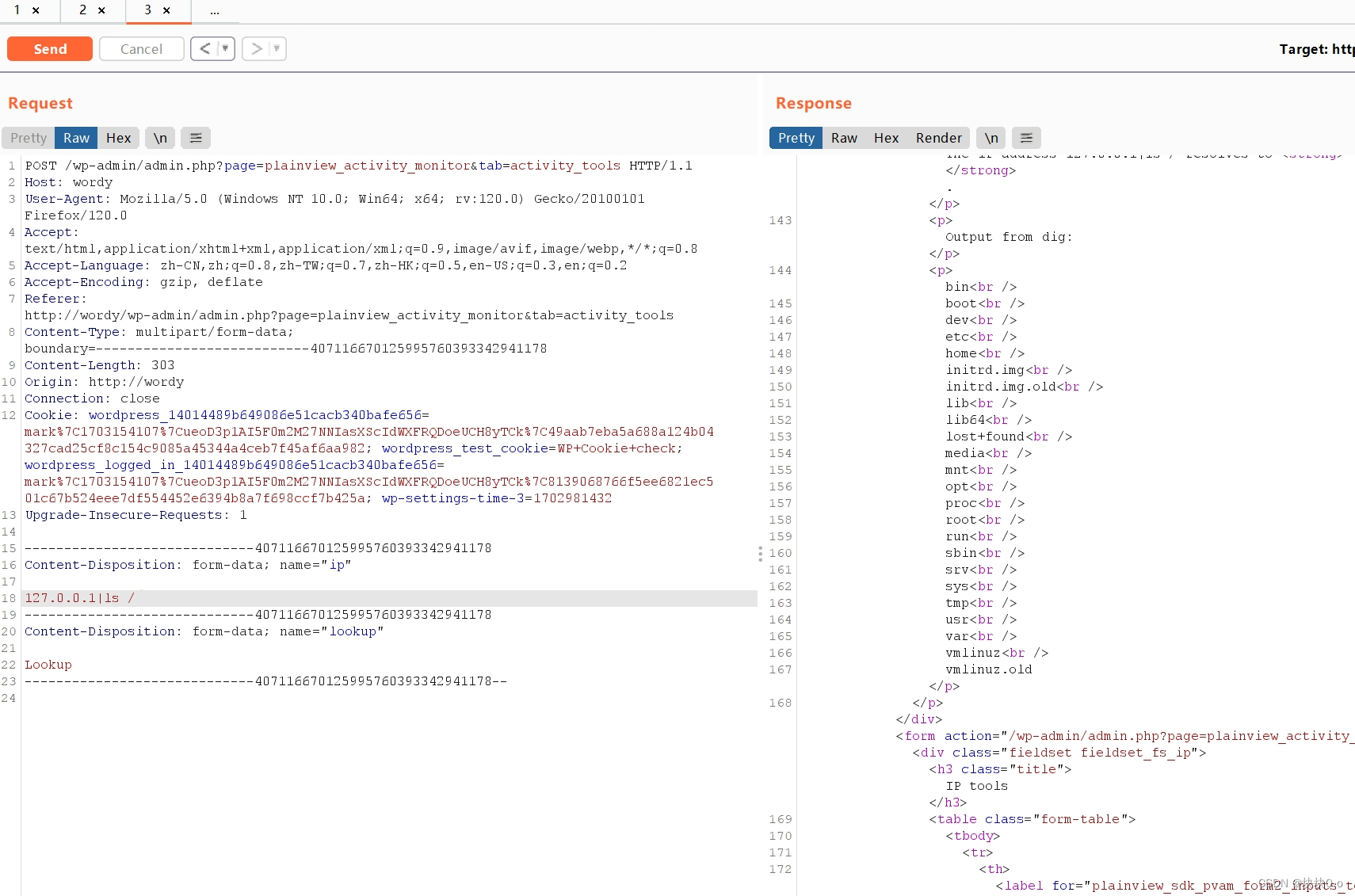
DC-6靶场
DC-6靶场下载: https://www.five86.com/downloads/DC-6.zip 下载后解压会有一个DC-3.ova文件,直接在vm虚拟机点击左上角打开-->文件-->选中这个.ova文件就能创建靶场,kali和靶机都调整至NAT模式,即可开始渗透 首先进行主…...
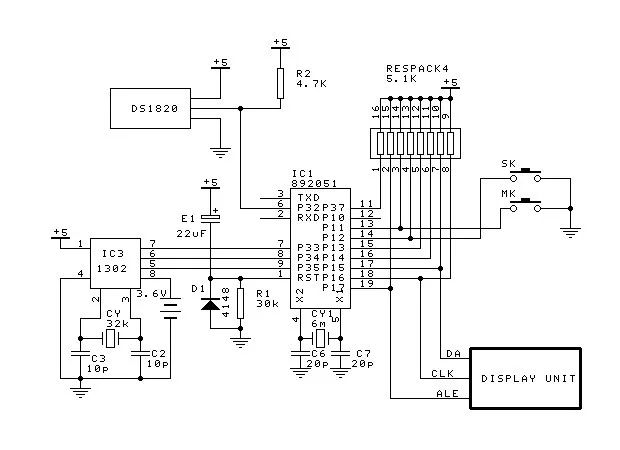
单片机应用实例:LED显示电脑电子钟
本例介绍一种用LED制作的电脑电子钟(电脑万年历)。其制作完成装潢后的照片如下图: 上图中,年、月、日及时间选用的是1.2寸共阳数码管,星期选用的是2.3寸数码管,温度选用的是0.5寸数码管,也可根据…...

会议剪影 | 思腾合力受邀出席首届CCF数字医学学术年会
首届CCF数字医学学术年会(CCF Digital Medicine Symposium,DMS)于2023年12月15日-17日在苏州CCF业务总部召开。这次会议的成功召开,标志着数字医学领域进入了一个新的时代,计算机技术和人工智能在医学领域的应用和发展…...

node.js mongoose中间件(middleware)
目录 简介 定义模型 注册中间件 创建doc实例,并进行增删改查 方法名和注册的中间件名相匹配 执行结果 分析 错误处理中间件 手动抛出错误 注意点 简介 在mongoose中,中间件是一种允许在执行数据库操作前(pre)或后&…...
[Toolschain cpp ros cmakelist python vscode] 记录写每次项目重复的设置和配置 不断更新
写在前面 用以前的设置,快速配置项目,以防长久不用忘记,部分资料在资源文件里还没有整理 outline cmakelist 复用vscode 找到头文件vscode debug现有代码直接关联远端gitros杂记repo 杂记glog杂记 cmakelist 复用 包含了根据系统路径找库…...
【每日OJ—有效的括号(栈)】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 1、有效的括号题目: 1.1方法讲解: 1.2代码实现: 总结 前言 世上有两种耀眼的光芒,一种是正在升起的太阳&#…...

.gitignore和git lfs学习
The ninth day——12.18 1. .gitignore 忽略规则优先级 从命令行中读取可用的忽略规则当前目录定义的规则父级目录定义的规则,依次递推$GIT_DIR/info/exclude 文件中定义的规则core.excludesfile中定义的全局规则 忽略规则匹配语法 空格不匹配任意文件ÿ…...

2023-12-18 C语言实现一个最简陋的B-Tree
点击 <C 语言编程核心突破> 快速C语言入门 C语言实现一个最简陋的B-Tree 前言要解决问题:想到的思路:其它的补充: 一、C语言B-Tree基本架构: 二、可视化总结 前言 要解决问题: 实现一个最简陋的B-Tree, 研究B-Tree的性质. 对于B树, 我是心向往之, 因为他是数据库的基…...
vite与webpack?
vite对比react-areate-app 1、构建速度 2、打包速度 3、打包文件体积...
算法和冲突驱动子句学习)
距离矩阵路径优化Python Dijkstra(迪杰斯特拉)算法和冲突驱动子句学习
Dijkstra算法 Dijkstra 算法是一种流行的寻路算法,通常用于基于图的问题,例如在地图上查找两个城市之间的最短路径、确定送货卡车可能采取的最短路径,甚至创建游戏地图。其背后的直觉基于以下原则:从起始顶点访问所有相邻顶点&am…...
Selenium安装WebDriver:ChromeDriver与谷歌浏览器版本快速匹配_最新版120
最近在使用通过selenium操作Chrome浏览器时,安装中遇到了Chrome版本与浏览器驱动不匹配的的问题,在此记录安装下过程,如何快速找到与谷歌浏览器相匹配的ChromeDriver驱动版本。 1. 确定Chrome版本 我们首先确定自己的Chrome版本 Chrome设置…...
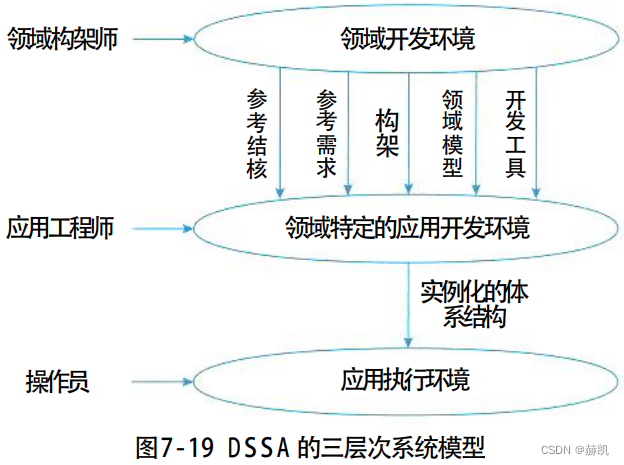
系统架构设计师教程(七)系统架构设计基础知识
系统架构设计基础知识 7.1 软件架构概念7.1.1 软件架构的定义7.1.2 软件架构设计与生命周期需求分析阶段设计阶段实现阶段构件组装阶段部署阶段后开发阶段 7.1.3 软件架构的重要性 7.2 基于架构的软件开发方法7.2.1 体系结构的设计方法概述7.2.2 概念与术语7.2.3 基于体系结构的…...
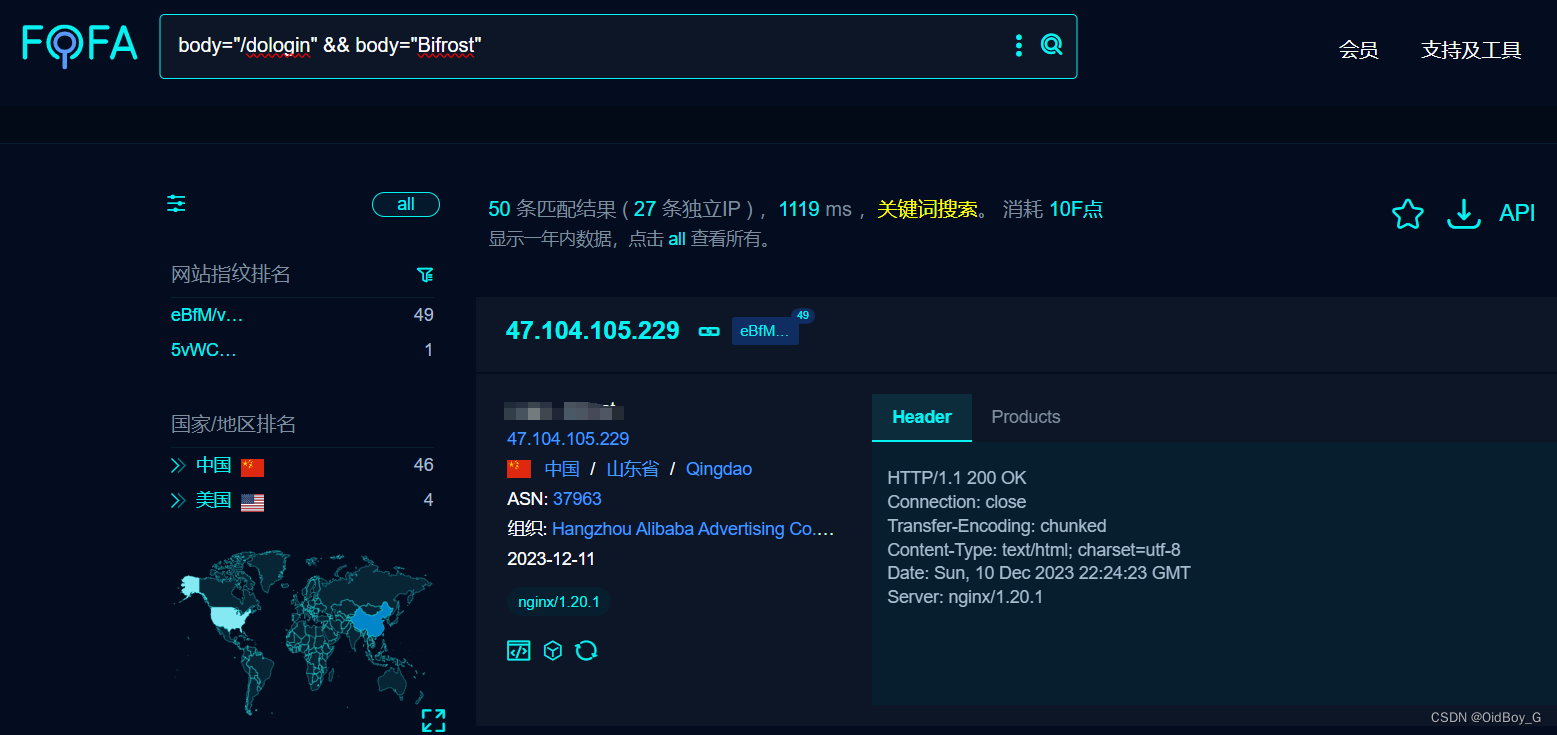
Bifrost 中间件 X-Requested-With 系统身份认证绕过漏洞复现
0x01 产品简介 Bifrost是一款面向生产环境的 MySQL,MariaDB,kafka 同步到Redis,MongoDB,ClickHouse等服务的异构中间件 0x02 漏洞概述 Bifrost 中间件 X-Requested-With 存在身份认证绕过漏洞,未经身份认证的攻击者可未授权创建管理员权限账号,可通过删除请求头实现身…...

OpenSSL 3.2.0新增Argon2支持——防GPU暴力攻击
1. 引言 OpenSSL新发布的3.20版本中,引入了一些新特性,包括: post-quantum方法Brainpool曲线QUICArgon2:Argon2 是一种慢哈希函数,在 2015 年获得 Password Hashing Competition 冠军,利用大量内存计算抵…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...

Xela矩阵三轴触觉传感器的工作原理解析与应用场景
Xela矩阵三轴触觉传感器通过先进技术模拟人类触觉感知,帮助设备实现精确的力测量与位移监测。其核心功能基于磁性三维力测量与空间位移测量,能够捕捉多维触觉信息。该传感器的设计不仅提升了触觉感知的精度,还为机器人、医疗设备和制造业的智…...

如何配置一个sql server使得其它用户可以通过excel odbc获取数据
要让其他用户通过 Excel 使用 ODBC 连接到 SQL Server 获取数据,你需要完成以下配置步骤: ✅ 一、在 SQL Server 端配置(服务器设置) 1. 启用 TCP/IP 协议 打开 “SQL Server 配置管理器”。导航到:SQL Server 网络配…...

算术操作符与类型转换:从基础到精通
目录 前言:从基础到实践——探索运算符与类型转换的奥秘 算术操作符超级详解 算术操作符:、-、*、/、% 赋值操作符:和复合赋值 单⽬操作符:、--、、- 前言:从基础到实践——探索运算符与类型转换的奥秘 在先前的文…...