2023-02-10 - 6 聚合
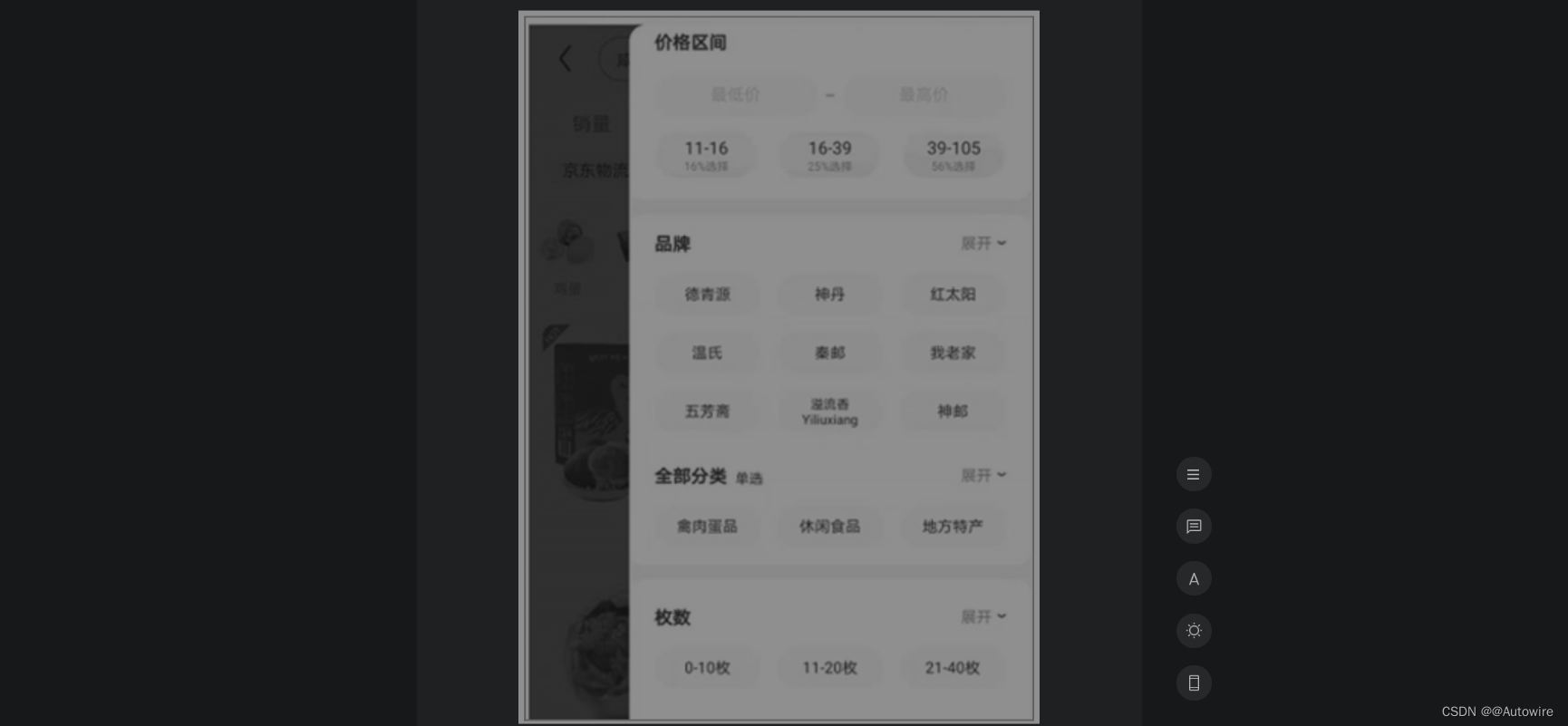
当用户使用搜索引擎完成搜索后,在展示结果中需要进行进一步的筛选,而筛选的维度需要根据当前的搜索结果进行汇总,这就用到了聚合技术。聚合的需求在很多应用程序中都有所体现,例如在京东App中搜索“咸鸭蛋”,然后单击搜索界面中的“筛选”按钮,在弹出的界面中可以对当前的搜索结果进行进一步的过滤。例如,可以从价格区间、品牌、分类、枚数等维度分别进行筛选,如图7.1所示。
ES支持丰富的聚合操作,不仅可以使用聚合功能对文档进行计数,还可以计算文档字段的平均值、最大值和最小值等。ES还提供了桶聚合的功能,以便于对多维度数据进行聚合。本章将结合实例介绍这些内容。另外,如果希望搜索结果和聚合结果一起返回,其中绕不开的一个主题就是分页和排序,本章也会对这两部内容进行介绍。
为方便介绍,下面重新定义酒店的索引。
PUT /hotel
{ "settings": { "number_of_shards": 1 }, "mappings": { "properties": { "title": { "type": "text" }, "city": { "type": "keyword" }, "price": { "type": "double" }, "create_time": { "type": "keyword" }, "full_room": { "type": "boolean" },"tags": { "type": "keyword" }} }
}
接着向索引中写入示例数据,具体如下:
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title": "文雅酒假日酒店","city":"北京","price": 556.00,"create_time": "20200418120000","full_room":true, "tags":["wifi","小型电影院"],"comment_info":{"favourable_comment":20, "negative_comment":10}}
{"index":{"_index":"hotel","_id":"002"}}
{"title": "金都嘉怡假日酒店","city":"北京","create_time":"20210315200000", "full_room":false,"tags": ["wifi","免费早餐"],"comment_info":{"favourable_comment":20,"negative_ comment":10}}
{"index":{"_index":"hotel","_id":"003"}}
{"title": "金都假日酒店","city":"北京","price": 200.00,"create_time": "20210509160000","full_room":true,"comment_info":{"favourable_comment":20,"negative_comment":10}}
{"index":{"_index":"hotel","_id":"004"}}
{"title": "金都假日酒店","city":"天津","price": 500.00,"create_time": "20210218080000","full_room":false,"tags":["wifi","免费车位"]}
{"index":{"_index":"hotel","_id":"005"}}
{"title": "文雅精选酒店","city":"天津","price": 800.00,"create_time": "20210101080000","full_room":true,"tags":["wifi","充电车位"],"comment_info":{"favourable_comment" :20,"negative_comment":10}}
1 聚合指标
在进行聚合搜索时,聚合的指标业务需求不仅是文档数量。例如,在酒店搜索场景中,我们希望能看到以当前位置为中心点,周边各个区域酒店的平均价格。本节将对ES支持的聚合指标进行介绍。
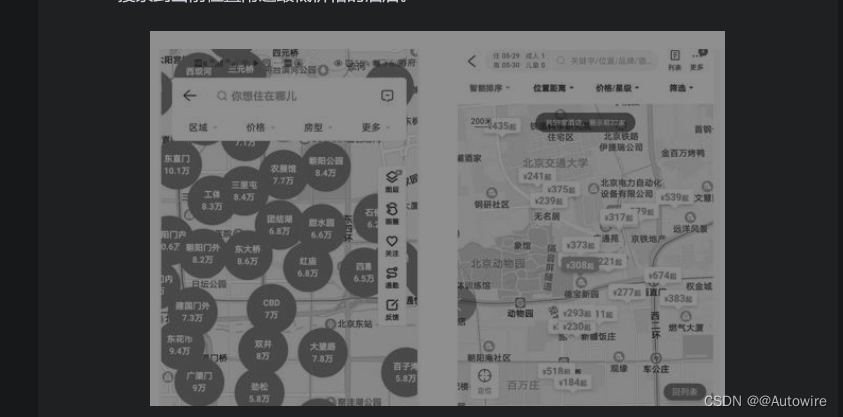
在搜索聚合时,用户可能会关注字段的相关统计信息,例如平均值、最大值、最小值及加和值等。例如,用户在使用一个二手房交易搜索引擎进行搜索时,可能会关注当前城市各个区域的房产平均价格。再例如,用户在搜索酒店时,也可能会关注附近各个区域酒店的最低价格。如图7.2所示,左图为在链家App的地图模式,可以搜索到当前位置附近的二手房平均交易价格;右图为携程App的地图模式,可以搜索到当前位置附近最低价格的酒店。
ES聚合请求的地址也是索引的搜索地址,可以使用aggs子句封装聚合请求。
当使用avg子句进行平均值的聚合时,可以在avg子句中指定聚合的字段。在默认情况下,查询将匹配所有文档,如果不需要返回匹配的文档信息,最好将返回的文档个数设置为0。这样既可以让结果看起来更整洁,又可以提高查询速度。下面的DSL将查询所有酒店的平均价格并且不返回匹配的文档信息。
GET /hotel/_search
{ "size": 0, "aggs": { "my_agg": { //聚合名称 "avg": { "field": "price" //计算文档的平均价格 } } }
}
在上面的DSL中,设定avg聚合的字段为price字段,并设置size参数的值为0。该DSL被执行后,ES的返回结果如下:
{ … "hits" : { //命中的文档列表 "total" : { "value" : 5, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { //聚合结果 "my_agg" : { //聚合名称 "value" : 514.0 //聚合指标值 } }
}
在上面的搜索结果中,索引中的5个文档全部命中,由于DSL设置size为0,所以命中文档的信息没有显示。在搜索结果的aggregations子句中存储着聚合结果,其中my_agg是聚合的名称,其对应的value值就是具体聚合结果,即酒店的平均价格。
如果聚合的指标字段不是ES的基本类型,例如object类型,则可以使用点运算符进行引用。下面的DSL演示了该用法:
GET /hotel/_search
{ "size": 0, "aggs": { "my_agg": { "avg": { //使用点运算符引用object类型字段的数据 "field": "comment_info.favourable_comment" } } }
}
与平均值类似,最大值、最小值及加和值分别使用max、min和sum子句进行聚合,这里不再赘述。
以下代码演示了在Java中使用聚合计算平均值的逻辑。
public void getAvgAggSearch() throws IOException{ //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String aggName="my_agg"; //聚合的名称 //定义avg聚合,指定字段为price AvgAggregationBuilder aggregationBuilder = AggregationBuilders.avg
(aggName).field("price"); searchSourceBuilder.aggregation(aggregationBuilder); //添加聚合 searchRequest.source(searchSourceBuilder); //设置查询请求 //执行查询 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Avg avg = aggregations.get(aggName); //获取avg聚合返回的对象 String key=avg.getName(); //获取聚合名称 double avgValue = avg.getValue(); //获取聚合值 System.out.println("key="+key+",avgValue="+avgValue); //打印结果
}
为了避免多次请求,ES还提供了stats聚合。stats聚合可以将对应字段的最大值、最小值、平均值及加和值一起计算并返回计算结果。下面的DSL展示了stats的用法。
GET /hotel/_search
{ "size": 0, "aggs": { "my_agg": { "stats": { //使用stats运算符计算多个指标 "field": "price" } } }
}
在上面的DSL中,对所有酒店进行了常用统计指标的聚合,查询结果如下:
{ "… "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "my_agg" : { "count" : 4, //文档数量 "min" : 200.0, //聚合的价格最小值 "max" : 800.0, //聚合的价格最大值 "avg" : 514.0, //聚合的价格平均值 "sum" : 2056.0 //聚合的价格加和值 } }
}
以下代码演示了在Java中使用stats聚合的逻辑。
public void getStatsAggSearch () throws IOException{ //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String aggName="my_agg"; //聚合的名称 //定义stats聚合,指定字段为price StatsAggregationBuilder aggregationBuilder = AggregationBuilders.stats
(aggName).field("price"); searchSourceBuilder.aggregation(aggregationBuilder); //添加聚合 searchRequest.source(searchSourceBuilder); //设置查询请求 //执行查询 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Stats stats = aggregations.get(aggName); //获取stats聚合返回的对象 String key=stats.getName(); //获取聚合名称 double sumVal =stats.getSum() ; //获取聚合加和值 double avgVal =stats.getAvg() ; //获取聚合平均值 long countVal =stats.getCount() ; //获取聚合文档数量值 double maxVal =stats.getMax() ; //获取聚合最大值 double minVal =stats.getMin() ; //获取聚合最小值 System.out.println("key="+key); //打印聚合名称 System.out.println("sumVal="+sumVal+",avgVal="+avgVal+",countVal=
"+countVal+",maxVal="+maxVal+",minVal="+minVal); //打印结果
}
2 空值处理
在索引中的一部分文档很可能其某些字段是缺失的,在介绍空值处理之前,首先介绍ES聚合查询提供的value_count聚合,该聚合用于统计字段非空值的个数。以下示例使用value_count聚合统计了price字段中非空值的个数。
GET /hotel/_search
{ "size": 0, "aggs": { "my_agg": { "value_count": { //统计price字段中非空值的个数 "field": "price" } } }
}
执行上述DSL后,ES返回的结果如下:
{ .. "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "my_agg" : { //price字段中非空值的个数 "value" : 4 } }
}
通过上述结果可以看到,当前索引中price字段中的非空值有4个。
下面的代码演示了在Java中使用value_count对price字段进行聚合的逻辑。
public void getValueCountAggSearch () throws IOException{ //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String aggName="my_agg"; //聚合的名称 //定义value_count聚合,指定字段为price ValueCountAggregationBuilder aggregationBuilder = AggregationBuilders.
count(aggName).field("price"); aggregationBuilder.missing("200"); searchSourceBuilder.aggregation(aggregationBuilder); //添加聚合 searchRequest.source(searchSourceBuilder); //设置查询请求 //执行查询 SearchResponse searchResponse =client.search(searchRequest,
RequestOptions.DEFAULT); //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); //获取value_count聚合返回的对象 ValueCount valueCount = aggregations.get(aggName); String key=valueCount.getName(); //获取聚合名称 long count = valueCount.getValue(); //获取聚合值 System.out.println("key="+key+",count="+count); //打印结果
}
需要指出的是,如果判断的字段是数组类型,则value_count统计的是符合条件的所有文档中该字段数组中非空元素个数的总和,而不是数组的个数总和。下面的DSL用于统计tags字段数组中非空元素个数的总和。
GET /hotel/_search
{ "size": 0, "aggs": { "my_agg": { "value_count": { //统计tags字段数组中非空元素的个数 "field": "tags" } } }
}
在索引的5个文档中,除去文档003没有tags字段外,其他4个文档的tags字段数组中各有两个元素,因此聚合的值为2×4=8个。下面来看一下ES返回的内容:
{ …. "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "my_agg" : { "value" : 8 //tags字段数组中非空元素的个数 } }
}
上面的结果中,aggregations.my_agg.value的值为8,这和前面计算的数值相等,验证了使用value_count对数组字段进行聚合时,ES返回的结果是所有数组元素的个数总和这一结论。
如果需要以空值字段的数据作为聚合指标对其进行聚合,可以在指标统计中通过missing参数指定填充值对空值进行填充。以下示例演示了对price字段进行聚合,并设定了当字段值为空值时使用100进行替代的查询请求。
GET /hotel/_search
{ "size": 0, "aggs": { "my_agg": { "sum": { "field": "price", "missing":100 //计算加和值时将price字段中的空值用100代替 } } }
}
在索引中,文档002的price字段为空,因此被填充为100,文档001、003、004和005的price字段分别为556、200、500和800,因此符合聚合的值应该是556+100+200+500+800=2156。ES返回的结果如下:
{ … "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "my_agg" : { "value" : 2156.0 //将price字段中的空值用100代替后的加和结果 } }
}
以下代码演示了在Java中当聚合指标为空值时指定填充值的逻辑。
public void getSumAggSearch () throws IOException{ //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String aggName="my_agg"; //聚合的名称 //定义sum聚合,指定字段为price SumAggregationBuilder aggregationBuilder = AggregationBuilders.sum
(aggName).field("price"); aggregationBuilder.missing("100"); searchSourceBuilder.aggregation(aggregationBuilder); //添加聚合 searchRequest.source(searchSourceBuilder); //设置查询请求 //执行查询 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Sum sum = aggregations.get(aggName); //获取sum聚合返回的对象 String key=sum.getName(); //获取聚合名称 double sumVal = sum.getValue(); //获取聚合值 System.out.println("key="+key+",count="+sumVal); //打印结果
}
3 桶聚合
前面介绍的聚合指标是指符合条件的文档字段的聚合,有时还需要根据某些维度进行聚合。例如在搜索酒店时,按照城市、是否满房、标签和创建时间等维度统计酒店的平均价格。这些字段统称为“桶”,在同一维度内有一个或者多个桶。例如城市桶,有“北京”“天津”等,是否满房桶,有“满房”“非满房”。
1 单维度桶聚合
最简单的桶聚合是单维度桶聚合,指的是按照一个维度对文档进行分组聚合。在桶聚合时,聚合的桶也需要匹配,匹配的方式有terms、filter和ranges等。本节只介绍比较有代表性的terms查询和ranges查询,对其他匹配方式感兴趣读者可以阅读相关文档进行学习,这里不再赘述。
terms聚合是按照字段的实际完整值进行匹配和分组的,它使用的维度字段必须是keyword、bool、keyword数组等适合精确匹配的数据类型,因此不能对text字段直接使用terms聚合,如果对text字段有terms聚合的需求,则需要在创建索引时为该字段增加多字段功能。
以下的DSL描述的是按照城市进行聚合的查询:
GET /hotel/_search
{ "size": 0, "aggs": { "my_agg": { "terms": { //按照城市进行聚合 "field": "city" } } }
}
因为ES支持多桶聚合,所以每个桶聚合需要定义一个名字,此处定义了一个桶聚合,名字为my_agg。在这个桶聚合中使用了一个terms聚合,聚合字段选择了城市,目的是统计各个城市的酒店的文档个数。在聚合外面,因为不希望返回任何文档,所以指定查询返回的文档为0。执行该DSL后,ES返回的结果如下:
{ … "hits" : { … "hits" : [ ] }, "aggregations" : { "my_agg" : { //单维度聚合的名称 "doc_count_error_upper_bound" : 0, //可能被遗漏的文档数量的最大值 "sum_other_doc_count" : 0, //除了返回给用户的文档外剩下的文档总数 "buckets" : [ //聚合桶 { "key" : "北京", "doc_count" : 3 //该聚合桶下的文档数量 }, { "key" : "天津", "doc_count" : 2 //该聚合桶下的文档数量 } ] } }
}
在默认情况下,进行桶聚合时如果不指定指标,则ES默认聚合的是文档计数,该值以doc_count为key存储在每一个bucket子句中。在聚合结果的buckets的两个bucket中,key字段的值分别为“北京”“天津”,表示两个bucket的唯一标识;doc_count字段的值分别为3和2,表示两个bucket的文档计数。返回的doc_count是近似值,并不是一个准确数,因此在聚合外围,ES给出了两个参考值doc_count_error_upper_bound和sum_other__doc_count,doc_count_error_upper表示被遗漏的文档数量可能存在的最大值,sum_other_doc_count表示除了返回给用户的文档外剩下的文档总数。
以下DSL是按照满房状态进行聚合的查询,注意该字段是bool型:
GET /hotel/_search
{ "size": 0, "aggs": { "my_agg": { "terms": { "field": "full_room" //按照满房状态进行聚合 } } }
}
执行DSL后,ES返回的结果如下:
{ … "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "my_agg" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : 1, "key_as_string" : "true", //聚合桶的字符串形式 "doc_count" : 3 }, { "key" : 0, "key_as_string" : "false", //聚合桶的字符串形式 "doc_count" : 2 } ] } }
}
从上述结果中可以看到,在满房和非满房的bucket结果中多出了一个字段,名称为key_as_string,其值分别是true和false。另外,这两个bucket的key值分别为1和0。这是因为,如果桶字段类型不是keyword类型,ES在聚合时会将桶字段转换为Lucene存储的实际值进行识别。true在Lucene中存储为1,false在Lucene中存储为0,这就是为什么满房和非满房的key字段分别为1和0的原因。这种情况给用户的使用带来了一些困惑,因为和原始值的差别比较大。针对这个问题,我们可以使用ES提供的key_as_string桶识别字段,它是原始值的字符串形式,和原始值的差别比较小。
以下代码演示了在Java中使用terms聚合进行单维度桶聚合的逻辑:
public void getBucketDocCountAggSearch() throws IOException { //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String termsAggName = "my_terms"; //指定聚合的名称 //定义terms聚合,指定字段为城市 TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.
terms(termsAggName).field("full_room"); searchSourceBuilder.aggregation(termsAggregationBuilder); //添加聚合 searchRequest.source(searchSourceBuilder); //设置查询请求 //执行查询 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Terms terms = aggregations.get(termsAggName); //获取聚合返回的对象 for (Terms.Bucket bucket : terms.getBuckets()) { String bucketKey = bucket.getKeyAsString(); //获取桶名称 long docCount = bucket.getDocCount(); //获取文档个数 System.out.println("termsKey=" + bucketKey + ",docCount=" + docCount); }
}
除了terms聚合,ranges聚合也是经常使用的一种聚合。它匹配的是数值字段,表示按照数值范围进行分组。用户可以在ranges中添加分组,每个分组用from和to表示分组的起止数值。注意该分组包含起始数值,不包含终止数值。以下DSL演示了使用ranges进行聚合的方法:
GET /hotel/_search
{ "size": 0, "aggs": { "my_agg": { "range": { "field": "price", "ranges": [ //多个范围桶 { "to": 200 //不指定from,默认from为0 }, { "from": 200, "to": 500 }, { "from": 500 //不指定to,默认to为该字段最大值 } ] } } }
}
执行上述DSL后,ES返回的结果如下:
{ … "hits" : { … "hits" : [ ] }, "aggregations" : { "my_agg" : { //range聚合名称 "buckets" : [ //范围聚合桶 { "key" : "*-200.0", "to" : 200.0, "doc_count" : 0 }, { "key" : "200.0-500.0", "from" : 200.0, "to" : 500.0, "doc_count" : 1 }, { "key" : "500.0-*", "from" : 500.0, "doc_count" : 3 } ] } }
}
在上面的分组划分中,第一个分组规则为price<200,没有文档与其匹配,因此其doc_count为0;第二个分组规则为200≤price<500,文档003与其匹配,因此其doc_count为1;第三个分组规则为price>500,文档001、004和005与其匹配,因此其doc_count值为3。
以下代码演示了在Java中使用ranges聚合的逻辑:
public void getRangeDocCountAggSearch() throws IOException { //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String rangeAggName = "my_range"; //聚合的名称 //定义ranges聚合,指定字段为price RangeAggregationBuilder rangeAgg = AggregationBuilders.range(rangeAggName).
field("price"); rangeAgg.addRange(new RangeAggregator.Range(null,null,200d)); rangeAgg.addRange(new RangeAggregator.Range(null,200d,500d)); rangeAgg.addRange(new RangeAggregator.Range(null,500d,null)); searchSourceBuilder.aggregation(rangeAgg); //添加ranges聚合 searchRequest.source(searchSourceBuilder); //设置查询请求 //执行查询 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Range range = aggregations.get(rangeAggName);//获取range聚合返回的对象 for (Range.Bucket bucket : range.getBuckets()) { String bucketKey = bucket.getKeyAsString(); //获取桶名称 long docCount = bucket.getDocCount(); //获取聚合文档个数 System.out.println("bucketKey=" + bucketKey + ",docCount=" + docCount); }
}
有时还需要对单维度桶指定聚合指标,聚合指标单独使用子aggs进行封装,该aggs子句的使用方式和上一节介绍的聚合指标相同。以下请求表示按照城市维度进行聚合,统计各个城市的平均酒店价格:
GET /hotel/_search
{ "size": 0, "aggs": { "my_agg": { //单维度聚合名称 "terms": { //定义单维度桶 "field": "city" }, "aggs": { //用于封装单维度桶下的聚合指标 "my_sum": { //聚合指标名称 "sum": { //对price字段进行加和 "field": "price", "missing": 200 } } } } }
}
执行上述DSL后,ES返回的结果如下:
{ … "hits" : { … }, "aggregations" : { "my_agg" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ //单维度桶列表 { //具体的单维度桶 "key" : "北京", "doc_count" : 3, "my_sum" : { //聚合指标 "value" : 956.0 } }, { //具体的单维度桶 "key" : "天津", "doc_count" : 2, "my_sum" : { //聚合指标 "value" : 1300.0 } } ] } }
}
在上面的结果中,聚合桶的维度是城市,当前索引中城市为“北京”的文档个数为3,城市为“天津”的文档个数为2。将这两组文档的聚合结果在buckets子句中进行了封装,可以根据key字段进行聚合桶的识别,每个聚合的组中既有文档个数又有价格的加和值。
以下代码演示了在Java中使用桶聚合和指标聚合的逻辑:
public void getBucketAggSearch () throws IOException{ //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String termsAggName="my_terms"; //聚合的名称 //定义terms聚合,指定字段为城市 TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.
terms(termsAggName).field("city"); String sumAggName="my_sum"; //sum聚合的名称 //定义sum聚合,指定字段为价格 SumAggregationBuilder sumAggregationBuilder = AggregationBuilders.
sum(sumAggName).field("price"); //定义聚合的父子关系 termsAggregationBuilder.subAggregation(sumAggregationBuilder); searchSourceBuilder.aggregation(termsAggregationBuilder); //添加聚合 searchRequest.source(searchSourceBuilder); //设置查询请求 //执行查询 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Terms terms = aggregations.get(termsAggName); //获取聚合返回的对象 for(Terms.Bucket bucket:terms.getBuckets()){ String termsKey=bucket.getKey().toString(); System.out.println("termsKey="+termsKey); Sum sum =bucket.getAggregations().get(sumAggName); String key=sum.getName(); //获取聚合名称 double sumVal = sum.getValue(); //获取聚合值 System.out.println("key="+key+",count="+sumVal); //打印结果 }
}
2 多维度桶嵌套聚合
在某些业务需求中,不仅需要一个维度的桶聚合,而且还可能有多维度桶嵌套聚合的需求。例如在搜索酒店时,可能需要统计各个城市的满房和非满房状态下的酒店平均价格。ES支持嵌套桶聚合,进行嵌套时,可以使用aggs子句进行子桶的继续嵌套,指标放在最里面的子桶内。以下DSL演示了多维度桶的使用方法:
GET /hotel/_search
{ "size": 0, "aggs": { "group_city": { //多维度桶名称 "terms": { "field": "city" }, "aggs": { //单维度桶 "group_full_room": { "terms": { "field": "full_room" }, "aggs": { //聚合指标 "my_sum": { "avg": { "field": "price", "missing": 200 } } } } } } }
}
上述DSL被执行后,ES返回的结果如下:
{ … "hits" : {…}, "aggregations" : { "group_city" : { //多维度聚合名称 "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ //第一层桶聚合列表 { "key" : "北京", //第一层桶的key "doc_count" : 3, "group_full_room" : { //第二层桶聚合 "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ //单维度聚合列表 { "key" : 1, "key_as_string" : "true", "doc_count" : 2, "my_sum" : { //聚合指标 "value" : 378.0 } }, { "key" : 0, "key_as_string" : "false", "doc_count" : 1, "my_sum" : { "value" : 200.0 } } ] } }, { "key" : "天津", "doc_count" : 2, "group_full_room" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : 0, "key_as_string" : "false", "doc_count" : 1, "my_sum" : { "value" : 500.0 } }, { "key" : 1, "key_as_string" : "true", "doc_count" : 1, "my_sum" : { "value" : 800.0 } } ] } } ] } }
}
结果中可以看到,第一层的分桶先按照城市分组分为“北京”“天津”;第二层在“北京”“天津”桶下面继续分桶,分为“满房”“非满房”桶,对应的聚合指标即价格的加和值存储在内部的my_sum字段中。
以下代码演示了在Java中使用多维度桶进行聚合的逻辑:
public void getExternalBucketAggSearch () throws IOException{ //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String aggNameCity="my_terms_city"; //按城市聚合的名称 //定义terms聚合,指定字段为城市 TermsAggregationBuilder termsAggCity = AggregationBuilders.terms
(aggNameCity).field("city"); String aggNameFullRoom="my_terms_full_room"; //按满房状态聚合的名称 //定义terms聚合,指定字段为满房状态 TermsAggregationBuilder termsArrFullRoom = AggregationBuilders.terms
(aggNameCity).field("full_room"); String sumAggName="my_sum"; //sum聚合的名称 //定义sum聚合,指定字段为价格 SumAggregationBuilder sumAgg = AggregationBuilders.sum(sumAggName).
field("price"); //定义聚合的父子关系 termsArrFullRoom.subAggregation(sumAgg); termsAggCity.subAggregation(termsArrFullRoom); searchSourceBuilder.aggregation(termsAggCity); //添加聚合 searchRequest.source(searchSourceBuilder); //设置查询请求 //执行查询 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Terms terms = aggregations.get(aggNameCity); //获取聚合返回的对象 for(Terms.Bucket bucket:terms.getBuckets()){ //遍历第一层bucket //获取第一层bucket名称 String termsKeyCity=bucket.getKey().toString(); System.out.println("--------"+"termsKeyCity="+termsKeyCity+
"--------"); Terms termsFullRom =bucket.getAggregations().get(aggNameCity); //遍历第二层bucket for(Terms.Bucket bucketFullRoom:termsFullRom.getBuckets()){ //获取第二层bucket名称 String termsKeyFullRoom=bucketFullRoom.getKeyAsString(); System.out.println("termsKeyFullRoom="+termsKeyFullRoom); //获取聚合指标 Sum sum =bucketFullRoom.getAggregations().get(sumAggName); String key=sum.getName(); //获取聚合指标名称 double sumVal = sum.getValue(); //获取聚合指标值 System.out.println("key="+key+",count="+sumVal); //打印结果 } }
}
4 聚合方式
ES支持灵活的聚合方式,它不仅支持聚合和查询相结合,而且还可以使聚合的过滤条件不影响搜索条件,并且还支持在聚合后的结果中进行过滤筛选。本节将介绍这些聚合方式。
1 直接聚合
直接聚合指的是聚合时的DSL没有query子句,是直接对索引内的所有文档进行聚合。前面介绍的示例都属于直接聚合,这里不再进行演示。
2 先查询再聚合
与直接聚合相对应,这种查询方式需要增加query子句,query子句和普通的query查询没有区别,参加聚合的文档必须匹配query查询。下面的DSL演示了这种用法:
GET /hotel/_search
{ "size": 0, "query": { //指定查询query逻辑 "term": { "city": { "value": "北京" } } }, "aggs": { //指定聚合逻辑 "my_agg": { "avg": { "field": "price" } } }
}
以下代码演示了在Java中先查询再聚合的逻辑:
public void getQueryAggSearch() throws IOException { //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String avgAggName = "my_avg"; //avg聚合的名称 //定义sum聚合,指定字段为价格 AvgAggregationBuilder avgAgg = AggregationBuilders.avg(avgAggName).
field("price"); searchSourceBuilder.aggregation(avgAgg); //添加聚合 //构建query查询 searchSourceBuilder.query(QueryBuilders.termQuery("city", "北京")); searchRequest.source(searchSourceBuilder); //设置查询请求 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //执行搜索 SearchHits searchHits = searchResponse.getHits(); //获取搜索结果集 System.out.println("---------------hit--------------"); for (SearchHit searchHit : searchHits) { //遍历搜索结果集 String index = searchHit.getIndex(); //获取索引名称 String id = searchHit.getId(); //获取文档_id Float score = searchHit.getScore(); //获取得分 String source = searchHit.getSourceAsString(); //获取文档内容 System.out.println("index=" + index + ",id=" + id + ",source=" +
source); //打印数据 } System.out.println("---------------agg--------------"); //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); ParsedAvg avg = aggregations.get(avgAggName); //获取聚合返回的对象 String avgName = avg.getName(); //获取聚合名称 double avgVal = avg.getValue(); //获取聚合值 //打印结果 System.out.println("avgName=" + avgName + ",avgVal=" + avgVal);
}
3 前过滤器
有时需要对聚合条件进一步地过滤,但是又不能影响当前的查询条件。例如用户进行酒店搜索时的搜索条件是天津的酒店,但是聚合时需要将非满房的酒店平均价格进行聚合并展示给用户。此时不能变更用户的查询条件,需要在聚合子句中添加过滤条件。下面的DSL展示了在聚合时使用过滤条件的用法:
GET /hotel/_search
{ "size": 0, "query": { //指定查询的query逻辑 "term": { "city": { "value": "天津" } } }, "aggs": { "my_agg": { "filter": { //指定过滤器逻辑 "term": { "full_room": false } }, "aggs": { //指定聚合逻辑 "my_avg": { "avg": { "field": "price" } } } } }
}
执行上述DSL后,ES返回的结果如下:
{ … "hits" : { "total" : { "value" : 2, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "my_agg" : { "doc_count" : 1, //只有文档004没有被过滤 "my_avg" : { "value" : 500.0 } } }
}
通过上述结果可以知道,满足查询条件的文档个数为2,命中的文档为004和005,但是在聚合时要求匹配非满房的酒店,只有文档004满足聚合条件,因此酒店的平均值为文档004的price字段值。
以下代码演示了在Java中使用前过滤器的逻辑:
public void getFilterAggSearch() throws IOException { //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String filterAggName = "my_terms"; //聚合的名称 TermQueryBuilder termQueryBuilder=QueryBuilders.termQuery("full_room",
true); FilterAggregationBuilder filterAggregationBuilder=AggregationBuilders.
filter(filterAggName,termQueryBuilder); String avgAggName = "my_avg"; //avg聚合的名称 //定义聚合,指定字段为价格 AvgAggregationBuilder avgAgg= AggregationBuilders.avg(avgAggName).
field("price"); //为filter聚合添加子聚合 filterAggregationBuilder.subAggregation(avgAgg); searchSourceBuilder.aggregation(filterAggregationBuilder); //添加聚合 //构建term查询 searchSourceBuilder.query(QueryBuilders.termQuery("city", "天津")); searchRequest.source(searchSourceBuilder); //设置查询请求 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //执行搜索 //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); //获取sum聚合返回的对象 ParsedFilter filter = aggregations.get(filterAggName); Avg avg =filter.getAggregations().get(avgAggName); String key = avg.getName(); //获取聚合名称 double avgVal = avg.getValue(); //获取聚合值 System.out.println("key=" + key + ",avgVal=" + avgVal); //打印结果
}
4 后过滤器
在有些场景中,需要根据条件进行数据查询,但是聚合的结果集不受影响。例如在酒店搜索场景中,用户的查询词为“假日”,此时应该展现标题中带有“假日”的酒店。但是在该页面中,如果还希望给用户呈现出全国各个城市的酒店的平均价格,这时可以使用ES提供的后过滤器功能。该过滤器是在查询和聚合之后进行过滤的,因此它的过滤条件对聚合没有影响。以下的DSL展示了后过滤器的使用:
GET /hotel/_search
{ "size": 0, "query": { //指定查询的query逻辑 "match": { "title": "假日" } }, "post_filter": { //指定后过滤器逻辑 "term": { "city": "北京" } }, "aggs": { //指定聚合逻辑 "my_agg": { "avg": { "field": "price", "missing":200 } } }
}
在上面的查询中,使用match匹配title中包含“假日”的酒店,并且查询出这些酒店的平均价格,最后使用post_filter设置后过滤器的条件,将酒店的城市锁定为“北京”,执行该DSL后,ES返回的结果如下:
{ … "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "my_agg" : { //聚合时酒店的城市锁定为“北京” "value" : 364.0 } }
}
根据查询结果可知,match查询命中了4个文档,对这4个文档的price字段取平均值为364,最后通过post_filter将其中的文档004过滤掉,因此hits子句中的total数量为3。
以下代码演示了在Java中使用后过滤器的逻辑:
public void getPostFilterAggSearch() throws IOException { //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String avgAggName = "my_avg"; //avg聚合的名称 //定义sum聚合,指定字段为价格 AvgAggregationBuilder avgAgg= AggregationBuilders.avg(avgAggName).
field("price"); avgAgg.missing(200); //设置默认值为200 searchSourceBuilder.aggregation(avgAgg); //添加聚合 //构建term查询 searchSourceBuilder.query(QueryBuilders.matchQuery("title", "假日")); TermQueryBuilder termQueryBuilder=QueryBuilders.termQuery("city","北京"); searchSourceBuilder.postFilter(termQueryBuilder); searchRequest.source(searchSourceBuilder); //设置查询请求 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //执行搜索 //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Avg avg =aggregations.get(avgAggName); String key = avg.getName(); //获取聚合名称 double avgVal = avg.getValue(); //获取聚合值 System.out.println("key=" + key + ",avgVal=" + avgVal); //打印结果
}
5 聚合排序
根据前面的介绍可知,ES对于聚合结果的默认排序规则有时并非是我们期望的。可以使用ES提供的sort子句进行自定义排序,有多种排序方式供用户选择:可以按照聚合后的文档计数的大小进行排序;可以按照聚合后的某个指标进行排序;还可以按照每个组的名称进行排序。下面将介绍以上3种排序功能。
1 按文档计数排序
在聚合排序时,业务需求可能有按照每个组聚合后的文档数量进行排序的场景。此时可以使用_count来引用每组聚合的文档计数进行排序。以下DSL演示了按照城市的酒店平均价格进行聚合,并按照聚合后的文档计数进行升序排列的请求:
GET /hotel/_search
{ "size": 0, "aggs": { "group_city": { "terms": { "field": "city", "order": { //按照文档计数进行升序排列 "_count": "asc" } }, "aggs": { "my_avg": { "avg": { //使用价格平均值作为聚合指标 "field": "price", "missing": 200 } } } } }
}
执行上述DSL后,ES返回的结果如下:
{ … "hits" : {…}, "aggregations" : { "group_city" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ //按照文档计数对桶聚合进行排序 { "key" : "天津", "doc_count" : 2, "my_avg" : { "value" : 650.0 } }, { "key" : "北京", "doc_count" : 3, "my_avg" : { "value" : 318.6666666666667 } } ] } }
}
以下代码演示了在Java中使用文档计数进行聚合排序的逻辑:
public void getAggDocCountOrderSearch() throws IOException { //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String termsAggName = "my_terms"; //聚合的名称 //定义terms聚合,指定字段为城市 TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.
terms(termsAggName).field("city"); BucketOrder bucketOrder=BucketOrder.count(true); termsAggregationBuilder.order(bucketOrder); String avgAggName = "my_avg"; //avg聚合的名称 //定义sum聚合,指定字段为价格 SumAggregationBuilder avgAgg = AggregationBuilders.sum(avgAggName).
field("price"); //定义聚合的父子关系 termsAggregationBuilder.subAggregation(avgAgg); searchSourceBuilder.aggregation(termsAggregationBuilder); //添加聚合 searchRequest.source(searchSourceBuilder); //设置查询请求 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //执行搜索 SearchHits searchHits = searchResponse.getHits(); //获取搜索结果集 //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Terms terms = aggregations.get(termsAggName); //获取聚合返回的对象 for (Terms.Bucket bucket : terms.getBuckets()) { String bucketKey = bucket.getKey().toString(); System.out.println("termsKey=" + bucketKey); Sum sum = bucket.getAggregations().get(avgAggName); String key = sum.getName(); //获取聚合名称 double sumVal = sum.getValue(); //获取聚合值 System.out.println("key=" + key + ",count=" + sumVal); //打印结果 }
}
2 按聚合指标排序
在聚合排序时,业务需求可能有按照每个组聚合后的指标值进行排序的场景。此时可以使用指标的聚合名称来引用每组聚合的文档计数。以下DSL演示了按照城市的酒店平均价格进行聚合,并按照聚合后的平均价格进行升序排列的请求:
GET /hotel/_search
{ "size": 0, "aggs": { "group_city": { "terms": { "field": "city", "order": { //按照聚合指标进行升序排列 "my_avg": "asc" } }, "aggs": { "my_avg": { //定义聚合指标 "avg": { "field": "price", "missing": 200 } } } } }
}
执行上述DSL后,ES返回的结果如下:
… "hits" : {…}, "aggregations" : { "group_city" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ //按照价格平均值对桶聚合升序排列 { "key" : "北京", "doc_count" : 3, "my_avg" : { "value" : 318.6666666666667 } }, { "key" : "天津", "doc_count" : 2, "my_avg" : { "value" : 650.0 } } ] } }
}
以下代码演示了在Java中按照聚合指标进行聚合排序的逻辑:
public void getAggMetricsOrderSearch() throws IOException { //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String termsAggName = "my_terms"; //聚合的名称 //定义terms聚合,指定字段为城市 String avgAggName = "my_avg"; //avg聚合的名称 TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.
terms(termsAggName).field("city"); BucketOrder bucketOrder=BucketOrder.aggregation(avgAggName,true); termsAggregationBuilder.order(bucketOrder); //定义sum聚合,指定字段为价格 AvgAggregationBuilder avgAgg = AggregationBuilders.avg(avgAggName).
field("price"); //定义聚合的父子关系 termsAggregationBuilder.subAggregation(avgAgg); searchSourceBuilder.aggregation(termsAggregationBuilder); //添加聚合 searchRequest.source(searchSourceBuilder); //设置查询请求 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //执行搜索 //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Terms terms = aggregations.get(termsAggName); //获取聚合返回的对象 for (Terms.Bucket bucket : terms.getBuckets()) { String bucketKey = bucket.getKey().toString(); System.out.println("termsKey=" + bucketKey); Avg avg = bucket.getAggregations().get(avgAggName); String key = avg.getName(); //获取聚合名称 double avgVal = avg.getValue(); //获取聚合值 System.out.println("key=" + key + ",avgVal=" + avgVal);//打印结果 }
}
3按分组key排序
在聚合排序时,业务需求可能有按照每个分组的组名称排序的场景。此时可以使用_key来引用分组名称。以下DSL演示了按照城市的酒店平均价格进行聚合,并按照聚合后的分组名称进行升序排列的请求:
GET /hotel/_search
{ "size": 0, "aggs": { "group_city": { "terms": { "field": "city", "order": { //按照分组key的自然顺序升序排列 "_key": "asc" } }, "aggs": { "my_avg": { //定义聚合指标 "avg": { "field": "price", "missing": 200 } } } } }
}
执行上述DSL后,ES返回的结果如下:
{ … "hits" : {…}, "aggregations" : { "group_city" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ //按照分组key的自然顺序对桶聚合升序排列 { "key" : "北京", "doc_count" : 3, "my_avg" : { "value" : 318.6666666666667 } }, { "key" : "天津", "doc_count" : 2, "my_avg" : { "value" : 650.0 } } ] } }
}
以下代码演示了在Java中按照分组key进行聚合排序的逻辑:
public void getAggKeyOrderSearch() throws IOException { //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String termsAggName = "my_terms"; //聚合的名称 //定义terms聚合,指定字段为城市 String avgAggName = "my_avg"; //avg聚合的名称 TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.
terms(termsAggName).field("city"); BucketOrder bucketOrder=BucketOrder.key(true); termsAggregationBuilder.order(bucketOrder); //定义sum聚合,指定字段为价格 SumAggregationBuilder avgAgg = AggregationBuilders.sum(avgAggName).
field("price"); //定义聚合的父子关系 termsAggregationBuilder.subAggregation(avgAgg); searchSourceBuilder.aggregation(termsAggregationBuilder); //添加聚合 searchRequest.source(searchSourceBuilder); //设置查询请求 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //执行搜索 SearchHits searchHits = searchResponse.getHits(); //获取搜索结果集 //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Terms terms = aggregations.get(termsAggName); //获取sum聚合返回的对象 for (Terms.Bucket bucket : terms.getBuckets()) { String bucketKey = bucket.getKey().toString(); System.out.println("termsKey=" + bucketKey); Sum sum = bucket.getAggregations().get(avgAggName); String key = sum.getName(); //获取聚合名称 double sumVal = sum.getValue(); //获取聚合值 System.out.println("key=" + key + ",count=" + sumVal);//打印结果 }
}
4 聚合分页
ES支持同时返回查询结果和聚合结果,前面介绍聚合查询时,查询结果和聚合结果各自封装在不同的子句中。但有时我们希望聚合的结果按照每组选出前N个文档的方式进行呈现,最常见的一个场景就是电商搜索,如搜索苹果手机6S,搜索结果应该展示苹果手机6S型号中的一款手机即可,而不论该型号手机的颜色有多少种。另外,当聚合结果和查询结果封装在一起时,还需要考虑对结果分页的问题,此时前面介绍的聚合查询就不能解决这些问题了。ES提供的Top hits聚合和Collapse聚合可以满足上述需求,但是这两种查询的分页方案是不同的。本节将介绍Top hits聚合和Collapse聚合,并分别给出这两种查询的分页方案。
1 Top hits聚合
顾名思义,Top hits聚合指的是聚合时在每个分组内部按照某个规则选出前N个文档进行展示。例如,搜索“金都”时,如果希望按照城市分组,每组按照匹配分数降序展示3条文档数据,DSL如下:
GET /hotel/_search
{ "size": 0, "query": { "match": { "title": "金都" } }, "aggs": { "group_city": { //按照城市进行桶聚合 "terms": { "field": "city" }, "aggs": { "my_avg": { "top_hits": { //指定返回每个桶的前3个文档 "size": 3 } } } } }
}
执行上述查询后,ES返回的结果如下:
{ … "hits" : { … "hits" : [ ] }, "aggregations" : { "group_city" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ //每个桶聚合中返回前3个文档 { "key" : "北京", "doc_count" : 2, "my_avg" : { "hits" : { … "hits" : [ { "_index" : "hotel", "_type" : "_doc", "_id" : "003", "_score" : 1.0928286, "_source" : { … } }, { "_index" : "hotel", "_type" : "_doc", "_id" : "002", "_score" : 0.96817136, "_source" : { … } ] } } }, { "key" : "天津", "doc_count" : 1, "my_avg" : { "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 1.0928286, "hits" : [ { "_index" : "hotel", "_type" : "_doc", "_id" : "004", "_score" : 1.0928286, "_source" : { … } } ] } } } ] } }
}
可以看到,在索引中一共有3个文档命中match查询条件,在聚合结果中按照城市分成了两个组“北京”“天津”,在“北京”下面有两个文档命中,并且按照得分将展示文档进行了降序排列,“天津”只有一个文档命中。
以下代码演示了在Java中使用Top hits聚合的逻辑:
public void getAggTopHitsSearch() throws IOException { //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); String termsAggName = "my_terms"; //聚合的名称 TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.
terms(termsAggName).field("city"); BucketOrder bucketOrder=BucketOrder.key(true); termsAggregationBuilder.order(bucketOrder); String topHitsAggName = "my_top"; //聚合的名称 TopHitsAggregationBuilder topHitsAgg=AggregationBuilders.topHits
(topHitsAggName); topHitsAgg.size(3); //定义聚合的父子关系 termsAggregationBuilder.subAggregation(topHitsAgg); //添加聚合 searchSourceBuilder.aggregation(termsAggregationBuilder); searchSourceBuilder.query(QueryBuilders.matchQuery("title","金都")); searchRequest.source(searchSourceBuilder); //设置查询请求 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //执行搜索 //获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); //获取sum聚合返回的对象 Terms terms = aggregations.get(termsAggName); for (Terms.Bucket bucket : terms.getBuckets()) { String bucketKey = bucket.getKey().toString(); System.out.println("termsKey=" + bucketKey); TopHits topHits = bucket.getAggregations().get(topHitsAggName); SearchHit[] searchHits=topHits.getHits().getHits(); for(SearchHit searchHit:searchHits){ System.out.println(searchHit.getSourceAsString()); } } }
Top hits聚合能满足“聚合的结果按照每组选出N个文档的方式进行呈现”的需求,但是很遗憾,它不能完成自动分页功能。如果在聚合中使用Top hits聚合并期望对数据进行分页,则要求聚合的结果一定不能太多,因为需要由客户端自行进行分页,此时对分页内存的存储能力是一个挑战。可以一次性获取聚合结果并将其存放在内存中或者Redis中,然后自行实现翻页逻辑,完成翻页。假设数据一次性存储到Redis的list结构中,以下示例代码演示了从Redis分页取数据的逻辑:
import org.springframework.stereotype.Service;
import org.springframework.data.redis.core.StringRedisTemplate;
import java.util.List; @Service
public class CacheServiceImpl { @Resource private StringRedisTemplate stringRedisTemplate; //Redis客户端 public List<String> getRecommendData(String key, Integer pageNo,
Integer pageSize) { long start = (pageNo - 1) * pageSize; //计算分页的起始位置 long end = pageNo * pageSize - 1; //计算分页的终止位置 //从Redis中取数据并将数据返回 return stringRedisTemplate.opsForList().range(key, start, end); }
}2 Collapse聚合
如前面所述,当在索引中有大量数据命中时,Top hits聚合存在效率问题,并且需要用户自行排序。针对上述问题,ES推出了Collapse聚合,即用户可以在collapse子句中指定分组字段,匹配query的结果按照该字段进行分组,并在每个分组中按照得分高低展示组内的文档。当用户在query子句外指定from和size时,将作用在Collapse聚合之后,即此时的分页是作用在分组之后的。以下DSL展示了Collapse聚合的用法:
GET /hotel/_search
{ "from": 0, //指定分页的起始位置 "size": 5, //指定每页返回的数量 "query": { //指定查询的query逻辑 "match": { "title": "金都" } }, "collapse": { //指定按照城市进行Collapse聚合 "field": "city" }
}
执行上述DSL后,ES返回的结果如下:
{ … "hits" : { … "hits" : [ { … "_id" : "003", "_score" : 1.0928286, "_source" : { … }, "fields" : { //按照城市进行Collapse聚合 "city" : [ "北京" ] } }, { … "_id" : "004", "_score" : 1.0928286, "_source" : { … }, "fields" : { //按照城市进行Collapse聚合 "city" : [ "天津" ] } } ] }
}
从结果中可以看到,与Top hits聚合不同,Collapse聚合的结果是封装在hit中的。在索引中一共有3个文档命中match查询条件,在聚合结果中已经按照城市分成了两个组,即“北京”“天津”,在“北京”下面有两个文档命中,其中得分最高的文档为003,“天津”只有一个文档命中。上述结果不仅能按照得分进行排序,并且具备分页功能。
以下代码演示了在Java中使用Collapse聚合的逻辑:
public void getCollapseAggSearch() throws IOException{ //按照spu进行分组 //按照城市进行分组 CollapseBuilder collapseBuilder = new CollapseBuilder("city"); SearchRequest searchRequest = new SearchRequest(); //新建搜索请求 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //新建match查询 searchSourceBuilder.query(QueryBuilders.matchQuery("title", "金都")); searchSourceBuilder.collapse(collapseBuilder); //设置Collapse聚合 searchRequest.source(searchSourceBuilder); //设置查询 SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //执行搜索 SearchHits searchHits = searchResponse.getHits(); //获取搜索结果集 for (SearchHit searchHit : searchHits) { //遍历搜索结果集 String index = searchHit.getIndex(); //获取索引名称 String id = searchHit.getId(); //获取文档_id Float score = searchHit.getScore(); //获取得分 String source = searchHit.getSourceAsString(); //获取文档内容 System.out.println("index=" + index + ",id=" + id + ",score=" + score
+ ",source=" + source); //打印数据 }
}
相关文章:
2023-02-10 - 6 聚合
当用户使用搜索引擎完成搜索后,在展示结果中需要进行进一步的筛选,而筛选的维度需要根据当前的搜索结果进行汇总,这就用到了聚合技术。聚合的需求在很多应用程序中都有所体现,例如在京东App中搜索“咸鸭蛋”,然后单击搜…...
Servlet实现表白墙
目录 一、表白墙简介 二、代码实现 1、约定前后端交互的接口 2、后端代码实现 3、前端代码实现 三、效果演示 一、表白墙简介 在表白墙页面中包含三个文本框,分别表示表白者,表白对象,表白内容,在文本框中输入内容之后&…...

[python入门㊸] - python测试函数
目录 ❤ 测试函数 ❤ 单元测试和测试用例 ❤ 可通过的测试 ❤ 不能通过的测试 ❤ 测试未通过时怎么办 ❤ 添加新测试 ❤ 测试函数 学习测试,得有测试的代码。下面是一个简单的函数: name_function.py def get_formatted_name(first, last):…...

通讯录文件操作化
宝子,你不点个赞吗?不评个论吗?不收个藏吗? 最后的最后,关注我,关注我,关注我,你会看到更多有趣的博客哦!!! 喵喵喵,你对我真的很重…...

为什么 Web3 社交将超越其 Web2 同行
我们最近听到了很多关于 web3 社交媒体平台的消息。但如果你没有跟上,你可能想知道为什么我们已经有了 Twitter、Facebook、Instagram 等,我们还需要 web3 社交。好吧,这一切都取决于谁拥有权力。 在 web2 中,权力掌握在寻求收入最…...
当资深程序员深夜去“打劫”会发生什么?——打家劫舍详解
文章目录一、前言二、概述三、打家劫舍第一晚四、打家劫舍第二晚五、打家劫舍第三晚......一、前言 大家好久不见,正如标题所示,今天我不打算聊一些枯燥的算法理论,我们来聊一聊程序员有多厉害! 注意!!&am…...

linux 线程
文章目录1、线程的概念1.1、进程 vs 线程1.2、线程的种类2、线程的控制2.1、线程的创建2.2、线程的退出2.3、线程的取消2.4、线程的等待2.5、线程的分离2.5、线程清理函数线程清理函数响应的时机线程清理函数不响应的时机3、线程的同步和互斥3.1、锁机制3.1.1、锁的类型3.1.2、…...

Windows 安装appium环境
1 windows Appium环境 1.1 安装Node.js Node.js的安装相对简单,下载安装包安装(安装包node-v19.6.0-x64.msi), nodejs 安装 然后一路狂点下一步就可以了 安装完成后,在终端中输入node -v,显示版本号则表示安装成功 node-v16.13.1 1.2 JDK安装及环境变…...
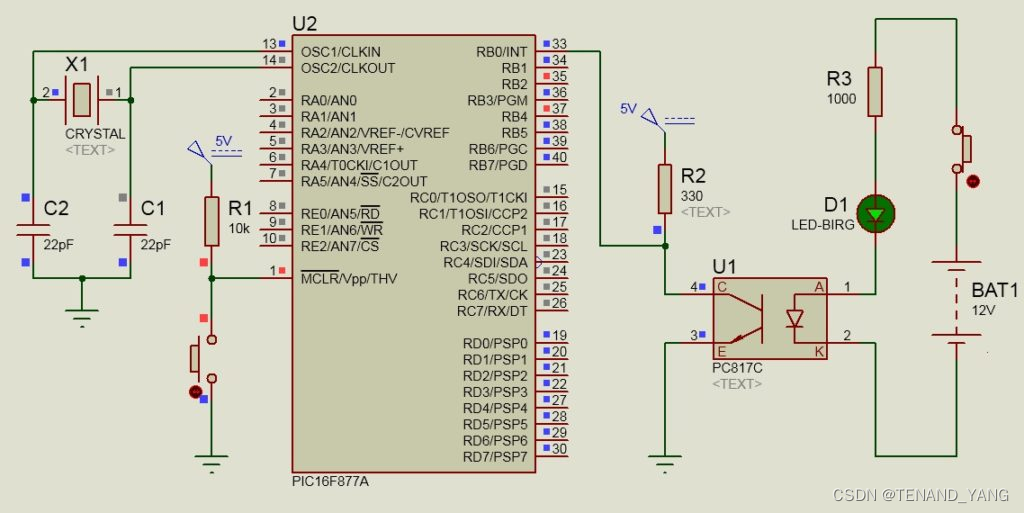
为什么要在电子产品中使用光耦合器?
介绍 光耦合器不仅可以保护敏感电路,还可以使工程师设计各种硬件应用。光耦合器通过保护元件,可以避免更换元件的大量成本。然而,光耦合器比保险丝更复杂。光耦合器还可以通过光耦合器连接和断开两个电路,从而方便地控制两个电路…...

Vue3 如何实现一个函数式右键菜单(ContextMenus)
前言: 最近在公司 PC 端的项目中使用到了右键出现菜单选项这样的一个工作需求,并且自己现在也在实现一个偶然迸发的 idea( 想用前端实现一个 windows 系统从开机到桌面的 UI),其中也要用到右键弹出菜单这样的一个功能,…...
ffmpeg转码转封装小工具开发
如下图所示,是本人开发的一个转码转封装小工具 其中目标文件视频编码格式支持:H264,H265,VP8,VP9。 目标文件封装格式支持:mp4,mkv,avi,mov,flv。 目标文件音频编码格式支持两个,COPY和AAC&am…...

重入和线程安全
在整个文档中,重入和线程安全用于标记类和函数,从而表明怎样在多线程应用中使用它们。 线程安全函数可以从多个线程同时调用,即使调用使用共享数据也是如此,因为对共享数据的所有引用都是序列化的。也可以从多个线程同时调用重入…...

MySQL数据库06——条件查询(WHERE)
MySQL条件查询,主要是对数据库里面的数据按照一定条件进行筛选,主要依靠的是WHERE语句进行。 先来了解一下基础的条件运算。 关系运算符 逻辑运算符 逻辑运算符优先级:NOT>AND>OR,关系运算符>逻辑运算符 SQL特殊运算符…...

Lesson 6.5 机器学习调参基础理论与网格搜索
文章目录一、机器学习调参理论基础1. 机器学习调参目标及基本方法2. 基于网格搜索的超参数的调整方法2.1 参数空间2.2 交叉验证与评估指标二、基于 Scikit-Learn 的网格搜索调参1. sklearn 中网格搜索的基本说明2. sklearn 中 GridSearchCV 的参数解释3. sklearn 中 GridSearch…...

leetcode: Two Sum
leetcode: Two Sum1. 题目1.1 题目描述2. 解答2.1 baseline2.2 基于baseline的思考2.3 优化思路的实施2.3.1 C中的hashmap2.3.2 实施2.3.3 再思考2.3.4 最终实施3. 总结1. 题目 1.1 题目描述 Given an array of integers nums and an integer target, return indices of the …...

共享模型之无锁(三)
1.原子累加器 示例代码: public class TestAtomicAdder {public static void main(String[] args) {for (int i 0; i < 5; i) {demo(() -> new AtomicLong(0),(adder) -> adder.getAndIncrement());}for (int i 0; i < 5; i) {demo(() -> new LongAdder(),(…...
微信小程序 Springboot校运会高校运动会管理系统
3.1小程序端 小程序登录页面,用户也可以在此页面进行注册并且登录等。 登录成功后可以在我的个人中心查看自己的个人信息或者修改信息等 在广播信息中我们可以查看校运会发布的一些信息情况。 在首页我们可以看到校运会具体有什么项目运动。 在查看具体有什么活动我…...

走进独自开,带你轻松干副业
今天给大家分享一个开发者的福利平台——独自开(点击直接注册),让你在家就能解决收入问题。 文章目录一、平台介绍二、系统案例三、获取收益四、使用平台1、用户注册2、用户认证3、任务报价五、文末总结一、平台介绍 简单说明 独自开信息科技…...
SpringBoot+Vue实现师生健康信息管理系统
文末获取源码 开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7/8.0 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9 浏…...

数据库第四章节第三次作业内容
1、显示所有职工的基本信息。 2、查询所有职工所属部门的部门号,不显示重复的部门号。 3、求出所有职工的人数。 4、列出最高工和最低工资。 5、列出职工的平均工资和总工资。 6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...
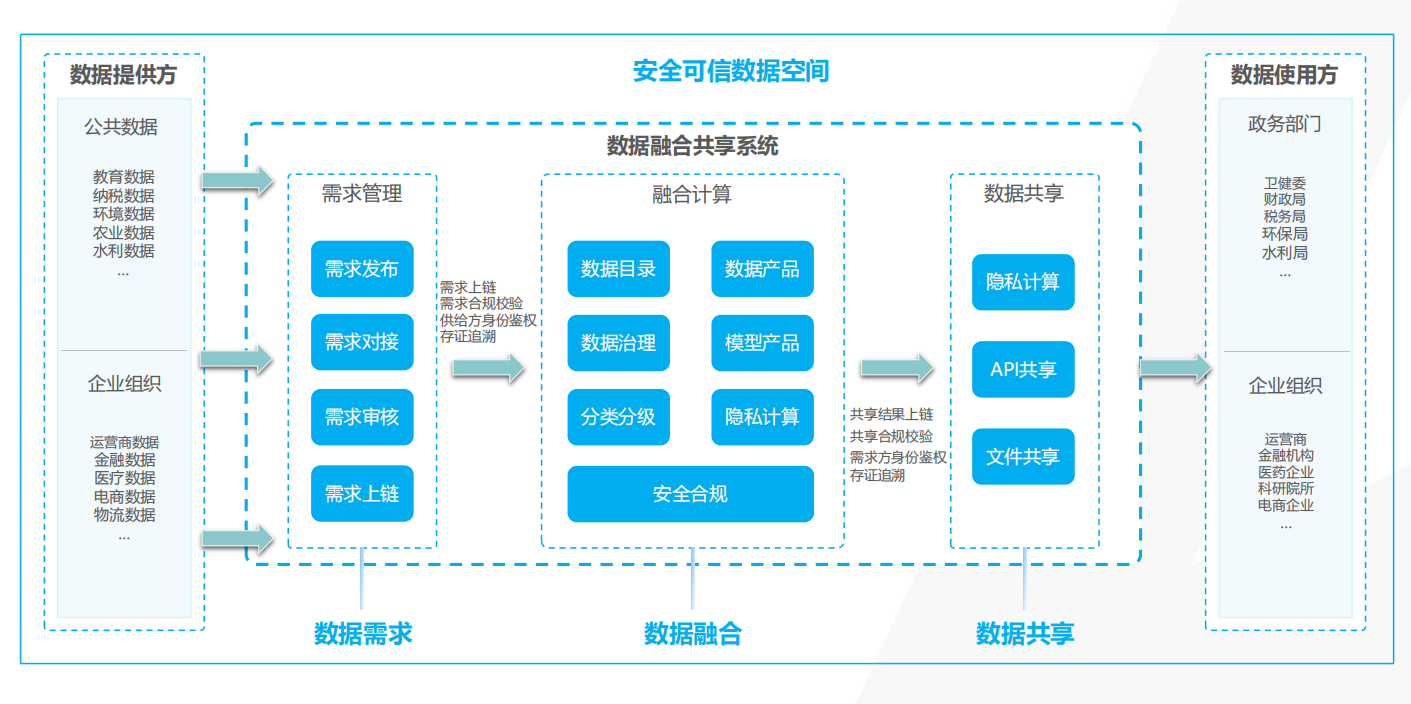
热烈祝贺埃文科技正式加入可信数据空间发展联盟
2025年4月29日,在福州举办的第八届数字中国建设峰会“可信数据空间分论坛”上,可信数据空间发展联盟正式宣告成立。国家数据局党组书记、局长刘烈宏出席并致辞,强调该联盟是推进全国一体化数据市场建设的关键抓手。 郑州埃文科技有限公司&am…...
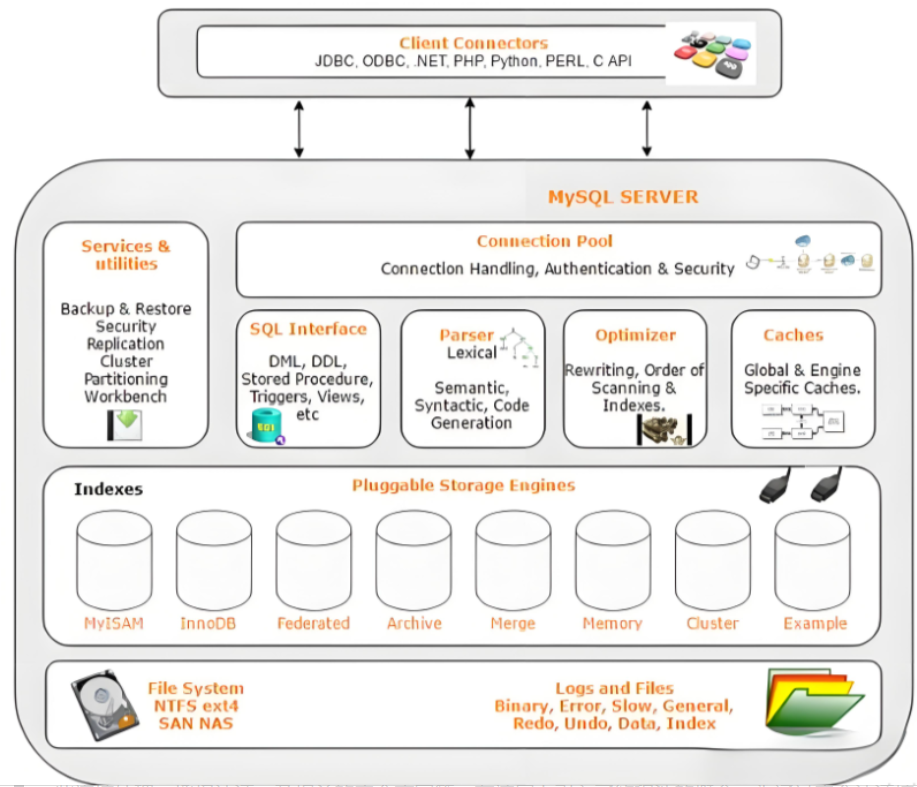
Mysql故障排插与环境优化
前置知识点 最上层是一些客户端和连接服务,包含本 sock 通信和大多数jiyukehuduan/服务端工具实现的TCP/IP通信。主要完成一些简介处理、授权认证、及相关的安全方案等。在该层上引入了线程池的概念,为通过安全认证接入的客户端提供线程。同样在该层上可…...

webpack面试题
面试题:webpack介绍和简单使用 一、webpack(模块化打包工具)1. webpack是把项目当作一个整体,通过给定的一个主文件,webpack将从这个主文件开始找到你项目当中的所有依赖文件,使用loaders来处理它们&#x…...

CSS 工具对比:UnoCSS vs Tailwind CSS,谁是你的菜?
在现代前端开发中,Utility-First (功能优先) CSS 框架已经成为主流。其中,Tailwind CSS 无疑是市场的领导者和标杆。然而,一个名为 UnoCSS 的新星正以其惊人的性能和极致的灵活性迅速崛起。 这篇文章将深入探讨这两款工具的核心理念、技术差…...