hive企业级调优策略之数据倾斜
测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511
本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
数据倾斜概述
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往同一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
Hive中的数据倾斜常出现在分组聚合和join操作的场景中
分组聚合导致的数据倾斜
优化说明
前文提到过,Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
如果group by分组字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
由分组聚合导致的数据倾斜问题,有以下两种解决思路:
(1)Map-Side聚合
开启Map-Side聚合后,数据会现在Map端完成部分聚合工作。这样一来即便原始数据是倾斜的,经过Map端的初步聚合后,发往Reduce的数据也就不再倾斜了。最佳状态下,Map-端聚合能完全屏蔽数据倾斜问题。
相关参数如下:
–启用map-side聚合
set hive.map.aggr=true;
–用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
–用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
–map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
(2)Skew-GroupBy优化
Skew-GroupBy的原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合。
相关参数如下:
–启用分组聚合数据倾斜优化
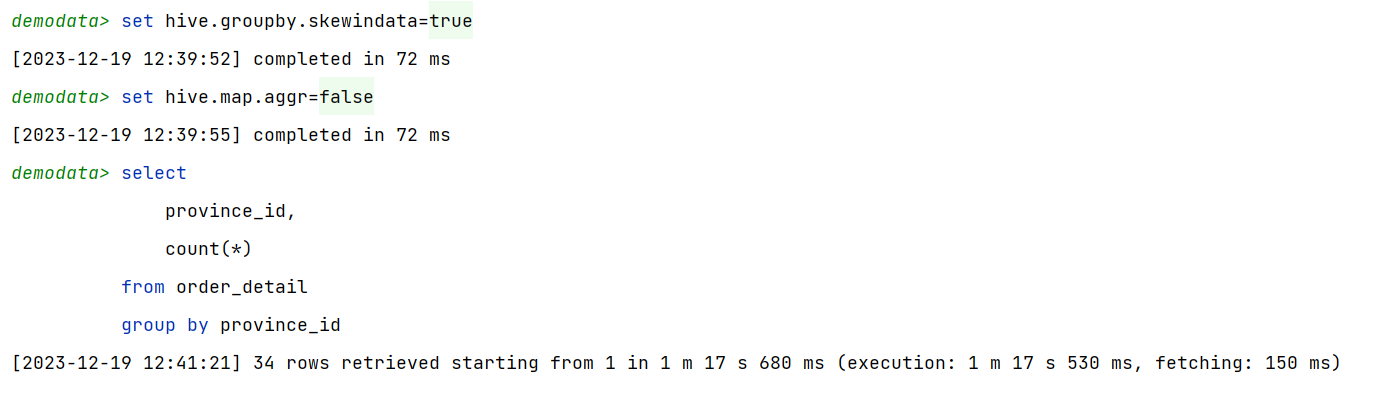
set hive.groupby.skewindata=true;
优化案例
(1)示例SQL语句
selectprovince_id,count(*)
from order_detail
group by province_id;
(2)优化前
该表数据中的province_id字段是存在倾斜的,若不经过优化,通过观察任务的执行过程,是能够看出数据倾斜现象的。
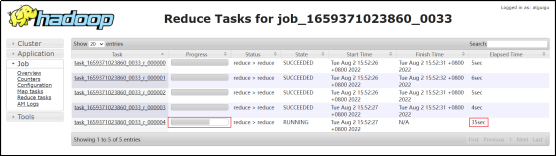
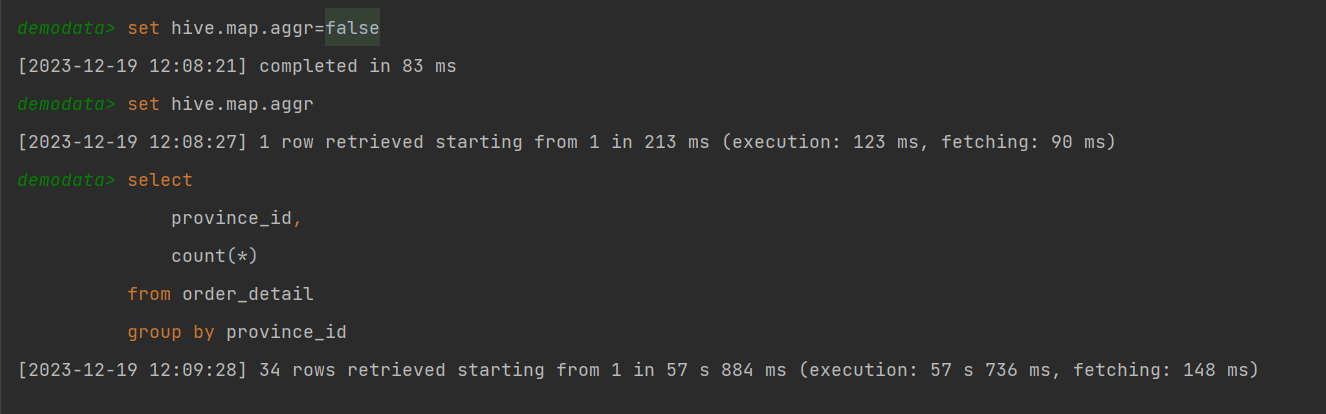
需要注意的是,hive中的map-side聚合是默认开启的,若想看到数据倾斜的现象,需要先将hive.map.aggr参数设置为false。
(3)优化思路
通过上述两种思路均可解决数据倾斜的问题。下面分别进行说明:
(1)Map-Side聚合
设置如下参数
–启用map-side聚合
set hive.map.aggr=true;
–关闭skew-groupby
set hive.groupby.skewindata=false;
开启map-side聚合后的执行计划如下图所示:

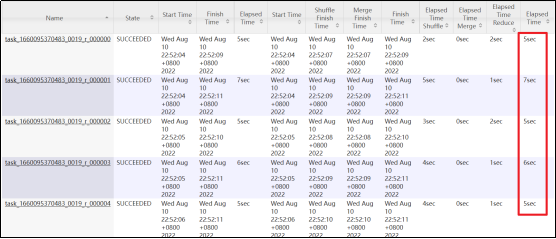
很明显可以看到开启map-side聚合后,reduce数据不再倾斜。
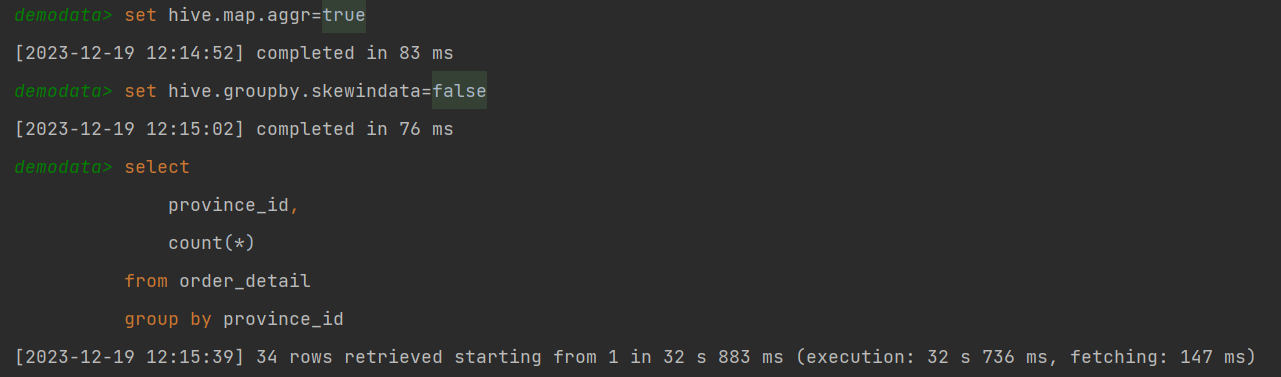
(2)Skew-GroupBy优化
设置如下参数
–启用skew-groupby
set hive.groupby.skewindata=true;
–关闭map-side聚合
set hive.map.aggr=false;
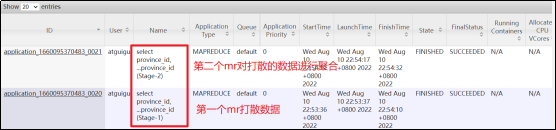
开启Skew-GroupBy优化后,可以很明显看到该sql执行在yarn上启动了两个mr任务,第一个mr打散数据,第二个mr按照打散后的数据进行分组聚合。
Join导致的数据倾斜
优化说明
前文提到过,未经优化的join操作,默认是使用common join算法,也就是通过一个MapReduce Job完成计算。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
如果关联字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
由join导致的数据倾斜问题,有如下三种解决方案:
(1)map join
使用map join算法,join操作仅在map端就能完成,没有shuffle操作,没有reduce阶段,自然不会产生reduce端的数据倾斜。该方案适用于大表join小表时发生数据倾斜的场景。
相关参数如下:
–启动Map Join自动转换
set hive.auto.convert.join=true;
–一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
set hive.mapjoin.smalltable.filesize=250000;
–开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
–无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
set hive.auto.convert.join.noconditionaltask.size=10000000;
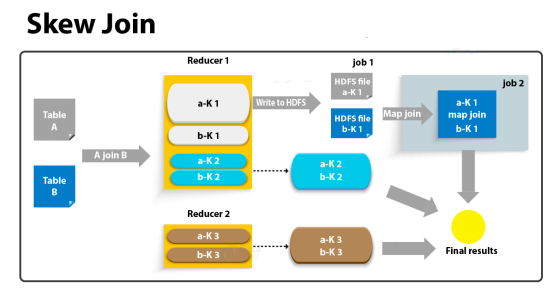
(2)skew join
skew join的原理是,为倾斜的大key单独启动一个map join任务进行计算,其余key进行正常的common join。原理图如下:
相关参数如下:
–启用skew join优化
set hive.optimize.skewjoin=true;
–触发skew join的阈值,若某个key的行数超过该参数值,则触发
set hive.skewjoin.key=100000;
这种方案对参与join的源表大小没有要求,但是对两表中倾斜的key的数据量有要求,要求一张表中的倾斜key的数据量比较小(方便走mapjoin)。
(3)调整SQL语句
若参与join的两表均为大表,其中一张表的数据是倾斜的,此时也可通过以下方式对SQL语句进行相应的调整。
假设原始SQL语句如下:A,B两表均为大表,且其中一张表的数据是倾斜的。
select*
from A
join B
on A.id=B.id;
其join过程如下:
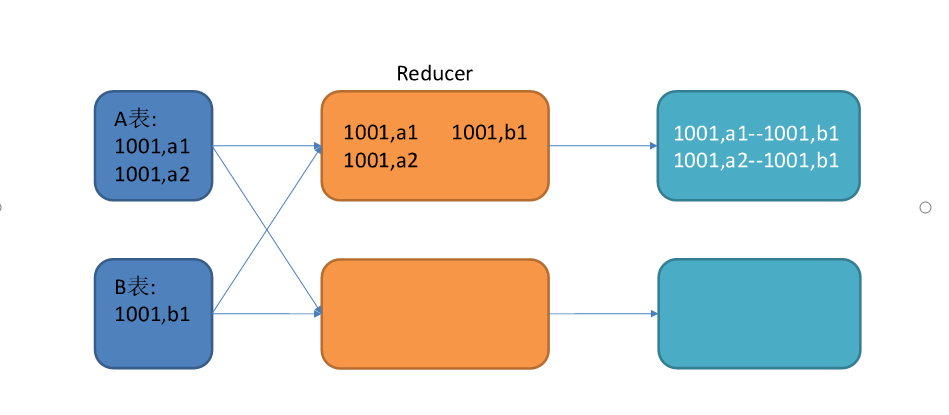
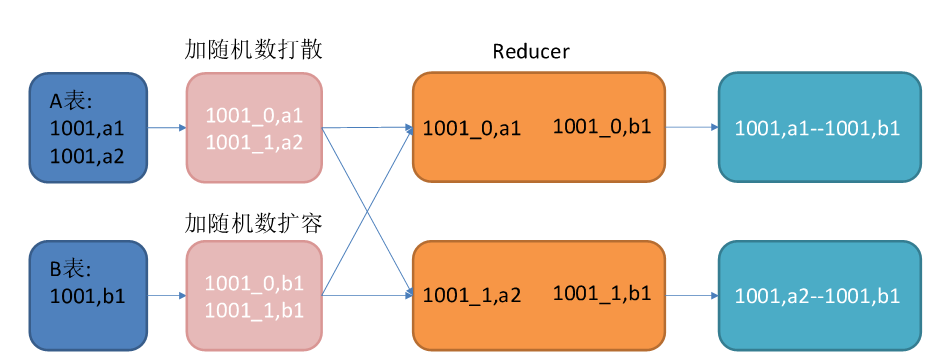
图中1001为倾斜的大key,可以看到,其被发往了同一个Reduce进行处理。
调整SQL语句如下:
select*
from(select --打散操作concat(id,'_',cast(rand()*2 as int)) id,valuefrom A
)ta
join(select --扩容操作concat(id,'_',0) id,valuefrom Bunion allselectconcat(id,'_',1) id,valuefrom B
)tb
on ta.id=tb.id;
调整之后的SQL语句执行计划如下图所示:
优化案例
(1)示例SQL语句
select*
from order_detail od
join province_info pi
on od.province_id=pi.id;
(2)优化前
order_detail表中的province_id字段是存在倾斜的,若不经过优化,通过观察任务的执行过程,是能够看出数据倾斜现象的。
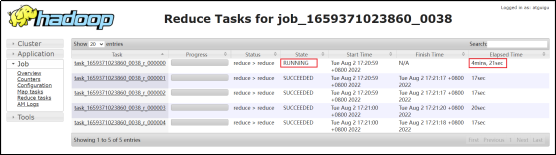
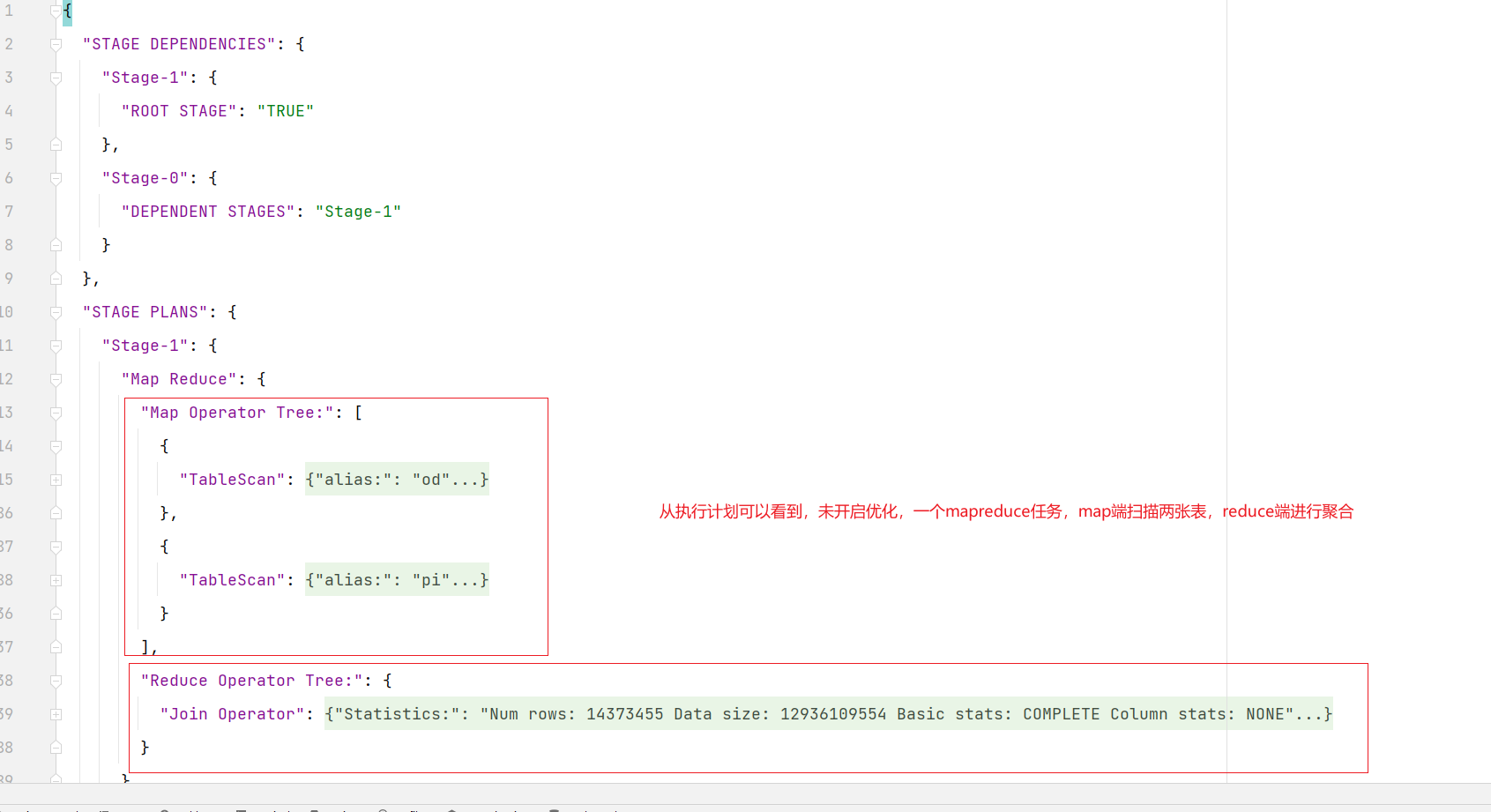

需要注意的是,hive中的map join自动转换是默认开启的,若想看到数据倾斜的现象,需要先将hive.auto.convert.join参数设置为false。
3)优化思路
上述两种优化思路均可解决该数据倾斜问题,下面分别进行说明:
(1)map join
设置如下参数
–启用map join
set hive.auto.convert.join=true;
–关闭skew join
set hive.optimize.skewjoin=false;
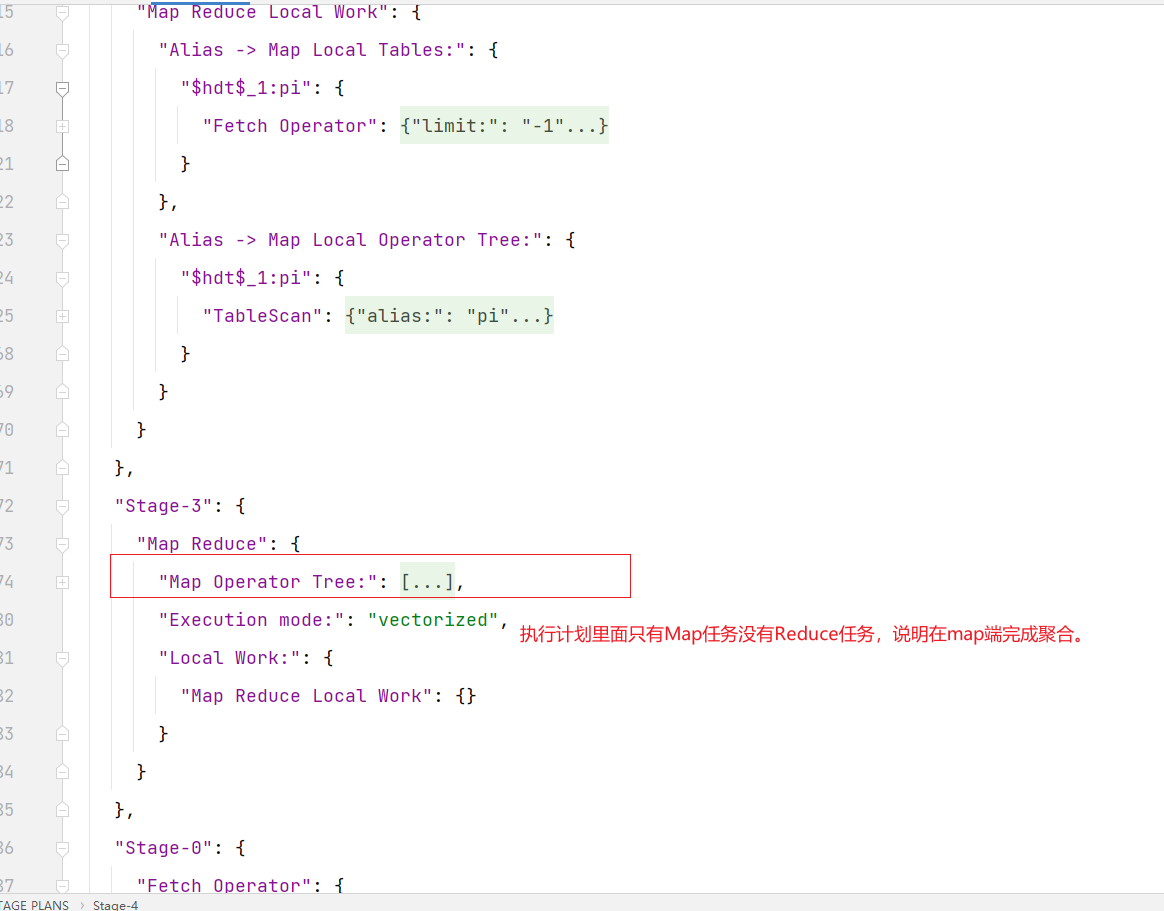
可以很明显看到开启map join以后,mr任务只有map阶段,没有reduce阶段,自然也就不会有数据倾斜发生。执行计划里面有MapJoin
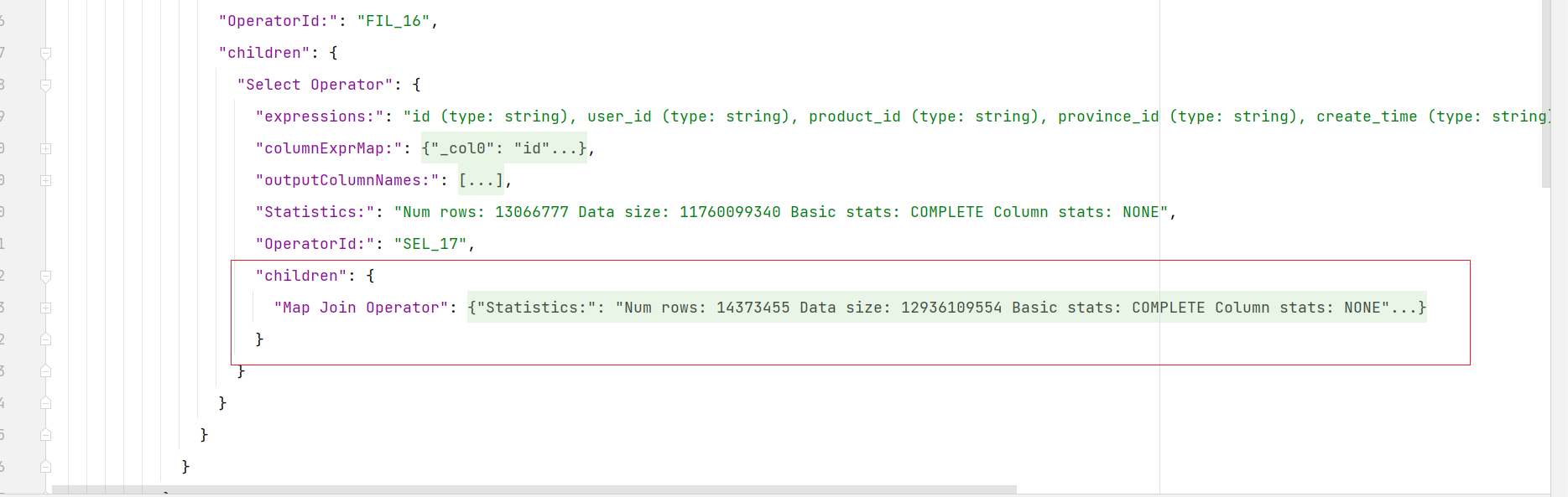


(2)skew join
设置如下参数
–启动skew join
set hive.optimize.skewjoin=true;
–关闭map join
set hive.auto.convert.join=false;
–增加map端容器内存
set mapreduce.map.memory.mb=2048;
开启skew join后,使用explain可以很明显看到执行计划如下图所示,说明skew join生效,任务既有common join,又有部分key走了map join。

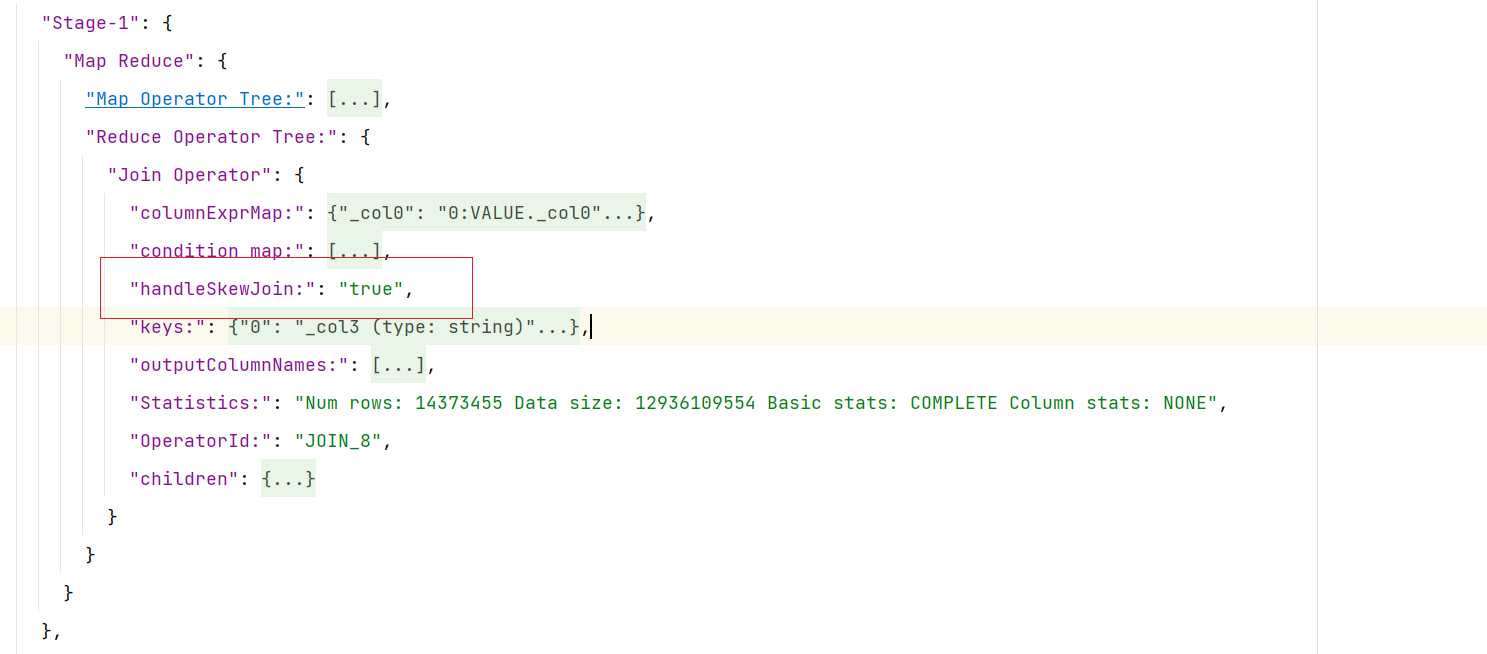

并且该sql在yarn上最终启动了两个mr任务,而且第二个任务只有map没有reduce阶段,说明第二个任务是对倾斜的key进行了map join。
相关文章:
hive企业级调优策略之数据倾斜
测试所用到的数据参考: 原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511 本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。 数据倾斜概述 数据倾斜问题,通常是指参与计算的数据分布不均࿰…...

MATLAB版本、labview版本、UHD版本 互相对应
LabVIEWMATLABUHD2019R2021bUHD_3.15.0.0-vendor2020R2022bUHD_4.1.0.4-vendorR2023bUHD_4.2.0.0-vendor 更换固件 MATLAB 更换固件指令 status sdruload(Device "X310", IPAddress 192.168.10.2)...
13 v-show指令
概述 v-show用于实现组件的显示和隐藏,和v-if单独使用的时候有点类似。不同的是,v-if会直接移除dom元素,而v-show只是让dom元素隐藏,而不会移除。 在实际开发中,v-show也经常被用到,需要重点掌握。 基本…...

23级新生C语言周赛(6)(郑州轻工业大学)
题目链接:ZZULIOJ 3110: 数(shu)数(shu)问题 分析: 看到这个题第一步想的是 先把每个平方数给求出来 然后枚举 但是时间复杂度大于1e8 交了一下TLE 但后来打表发现,好数太多了要是枚举的话 注定TLE 能不能间接的去做呢? 把不是的减去,那不就是好数了吗? 这个时候又是打表,会…...

关于“Python”的核心知识点整理大全24
目录 编辑 10.1.6 包含一百万位的大型文件 pi_string.py 10.1.7 圆周率值中包含你的生日吗 10.2 写入文件 10.2.1 写入空文件 write_message.py programming.txt 10.2.2 写入多行 10.2.3 附加到文件 write_message.py programming.txt 10.3 异常 10.3.1 处理 Ze…...

Vue - 基于Element UI封装一个表格动态列组件
1 组件需求背景 在后台管理系统中,表格的使用频率非常高,统一封装表格动态列组件并全局注册使用,可大大提升代码的复用性和可维护性。 2 全局注册 src/plugins/index.js: import columns from ./columns/indexexport default …...
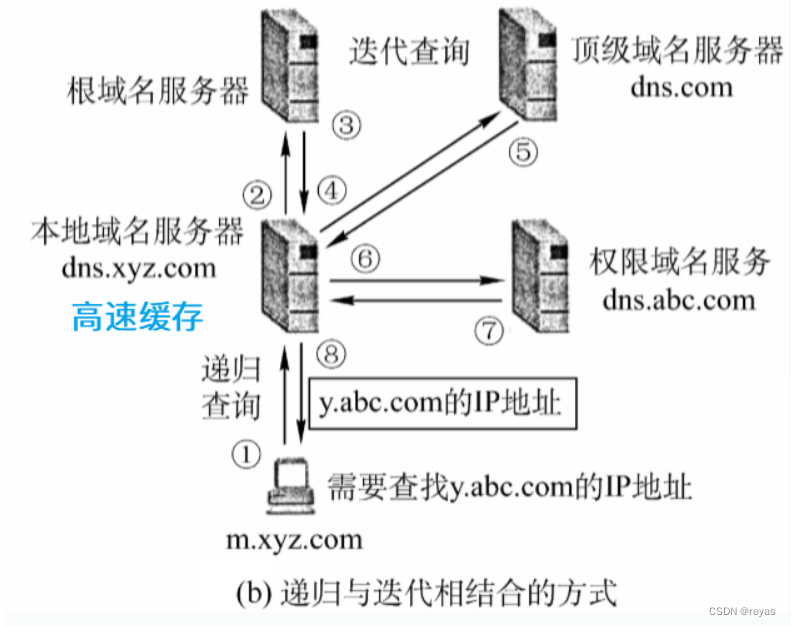
计算机网络:DNS域名解析系统
我最近开了几个专栏,诚信互三! > |||《算法专栏》::刷题教程来自网站《代码随想录》。||| > |||《C专栏》::记录我学习C的经历,看完你一定会有收获。||| > |||《Linux专栏》࿱…...

java面试:==和equals有什么区别?
在 Java 中,"" 和 "equals" 有着不同的作用: "" 运算符: 在基本数据类型(如 int、char 等)中,"" 用于比较它们的值是否相等。 在引用类型中,"&q…...

数字人SaaS系统无限生成AI数字人!
市面上数字人软件层出不穷,选择一款适合的数字人软件是成功的第一步,只需要一款软件就解决数字人直播和数字人短视频的制作,青否数字人SaaS系统(数字人源码:zhibo175)你值得拥有! 青否数字人Saa…...
【MySQL】——数据类型及字符集
🎃个人专栏: 🐬 算法设计与分析:算法设计与分析_IT闫的博客-CSDN博客 🐳Java基础:Java基础_IT闫的博客-CSDN博客 🐋c语言:c语言_IT闫的博客-CSDN博客 🐟MySQL:…...

Redis cluster集群设置密码
Redis cluster集群设置密码 1 备份数据 # 链接redis集群,执行rdb快照 bgsave # 备份dump.rdb文件 cp /data/redis/cluster/dump.rdb /data/redis/cluster/backup/dump.rdb.202312202 设置密码 必须保证每个节点的密码保持一致,不然 Redirected 的时候会失败 2.1…...
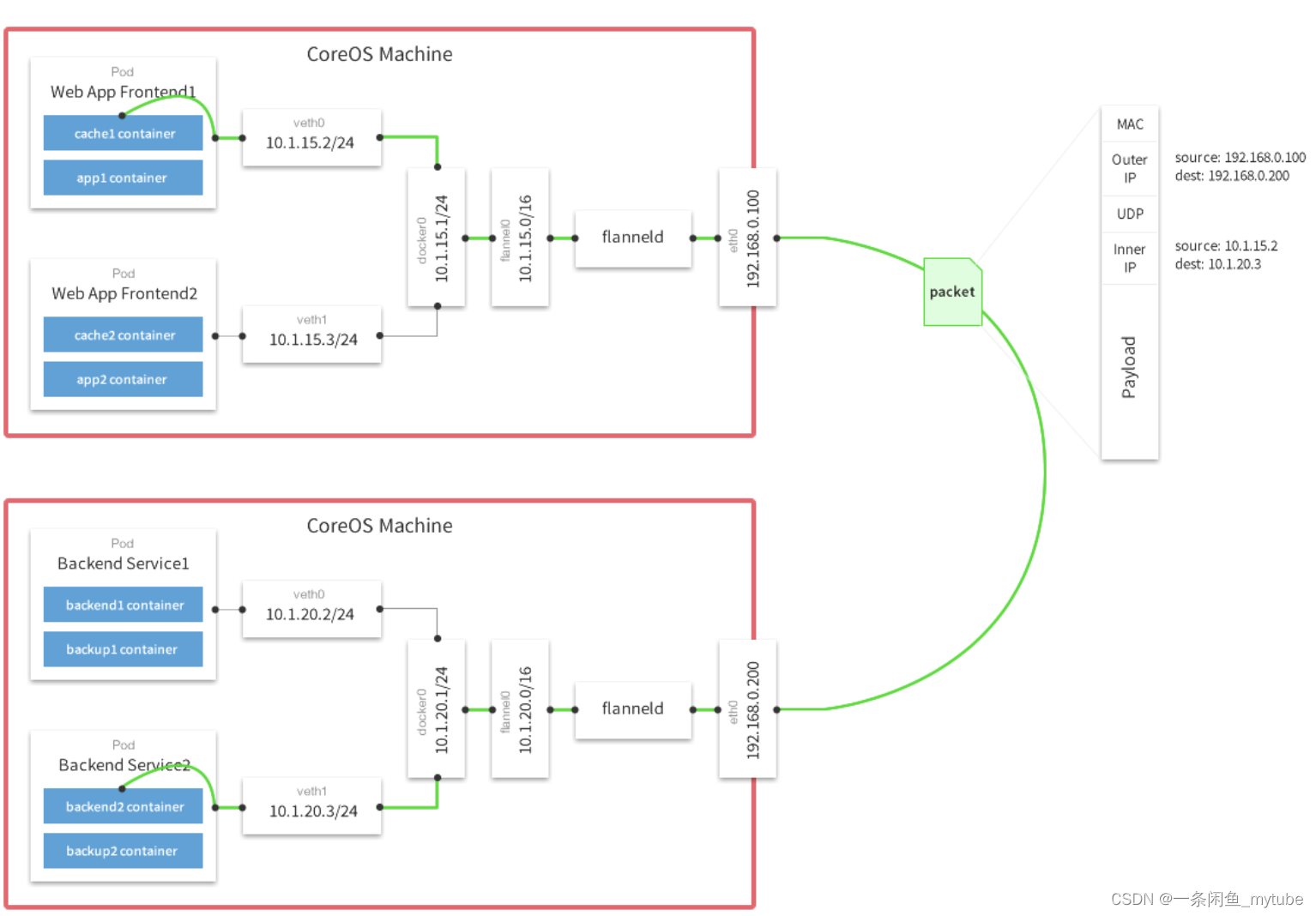
Docker 核心技术
Docker 定义:于 Linux 内核的 Cgroup,Namespace,以及 Union FS 等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术,由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器Docke…...
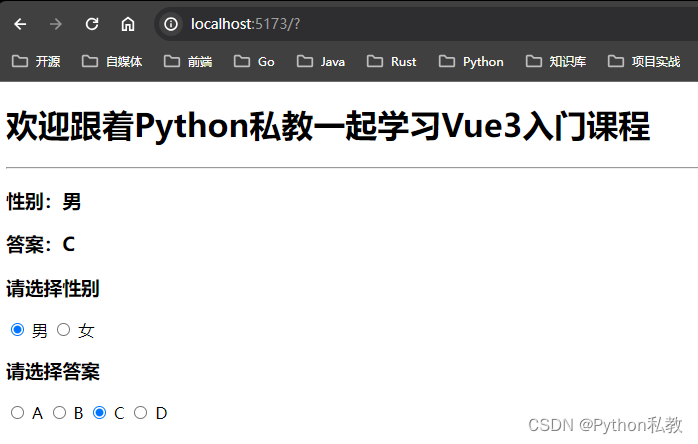
15 使用v-model绑定单选框
概述 使用v-model绑定单选框也比较常见,比如性别,要么是男,要么是女。比如单选题,给出多个选择,但是只能选择其中的一个。 在本节课中,我们演示一下这两种常见的用法。 基本用法 我们创建src/component…...

go语言指针变量定义及说明
go语言指针主要需要记住两个特殊符号, 一个是 & 用来获取变量对应的内存地址 另一个是 * 用来获取指针对应的变量值 下面是个最简单的go语言指针说明 package mainimport "fmt"//指针为内存地址func main() {var a string "指针对应的变量&…...

基于“Galera+MariaDB”搭建多主数据库集群的实例
1、什么是多主数据库集群 多主数据库集群是一种数据库集群架构,每个节点都可以接收写入操作和读取操作,并且通过心跳机制同步数据,保证数据一致性和高可用性。因多主数据库集群每个节点都可以承担读写操作,因此它可以充分利用各个…...
arcgis javascript api4.x加载天地图cgs2000坐标系
需求:arcgis javascript api4.x加载天地图cgs2000坐标系 效果: 示例代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"wid…...

算法学习——回溯算法
回溯算法 理论基础回溯法的效率回溯法解决的问题回溯法模板 组合思路回溯法三部曲 代码 组合(优化)组合总和III思路代码 电话号码的字母组合思路回溯法来解决n个for循环的问题回溯三部曲代码 组合总和思路代码 组合总和II思路代码 理论基础 什么是回溯法…...
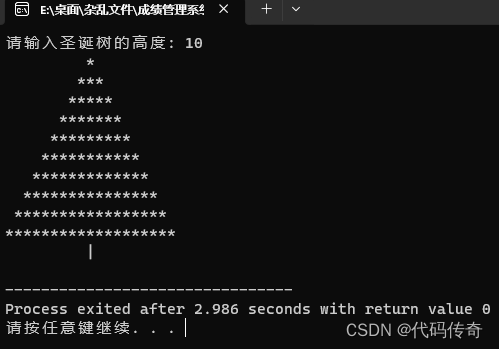
C语言—小小圣诞树
这个代码会询问用户输入圣诞树的高度,然后根据输入的高度在控制台上显示相应高度的圣诞树。 #include <stdio.h>int main() {int height, spaces, stars;printf("请输入圣诞树的高度: ");scanf("%d", &height);spaces height - 1;st…...

Android消息公告上下滚动切换轮播实现
自定义控件 通过继承TextSwitcher实现 直接上代码 public class NoticesSwitcher extends TextSwitcher implements ViewSwitcher.ViewFactory {private Context mContext;private List<Notice> mData;private final long DEFAULT_TIME_SWITCH_INTERVAL 1000;//1spri…...
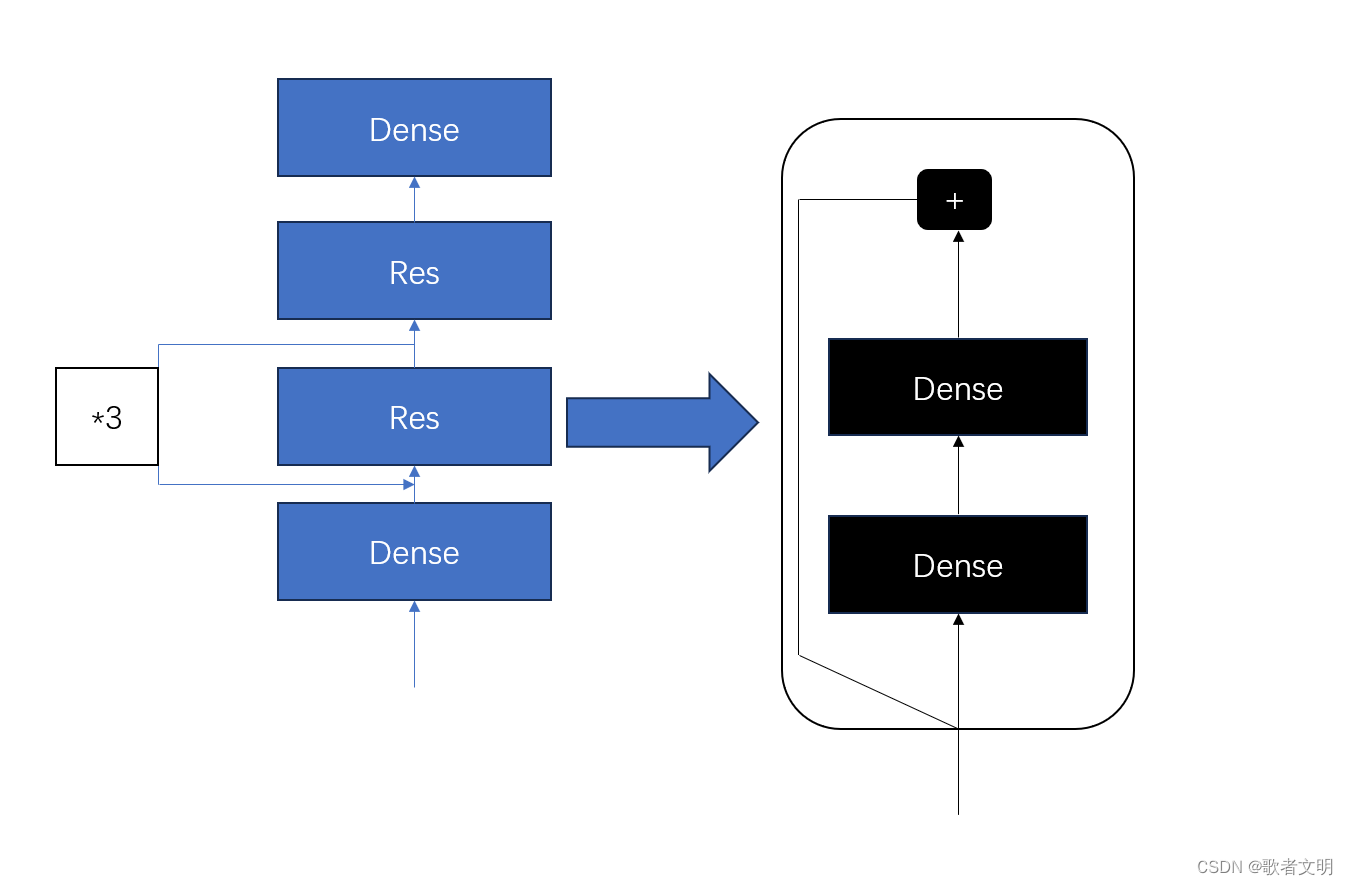
tensorflow入门 自定义模型
前面说了自定义的层,接下来自定义模型,我们以下图为例子 这个模型没啥意义,单纯是为了写代码实现这个模型 首先呢,我们看有几个部分,dense不需要我们实现了,我们就实现Res,为了实现那个*3,我们…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...