使用Python爬取GooglePlay并从复杂的自定义数据结构中实现解析
文章目录
【作者主页】:吴秋霖
【作者介绍】:Python领域优质创作者、阿里云博客专家、华为云享专家。长期致力于Python与爬虫领域研究与开发工作!
【作者推荐】:对JS逆向感兴趣的朋友可以关注《爬虫JS逆向实战》,对分布式爬虫平台感兴趣的朋友可以关注《分布式爬虫平台搭建与开发实战》
还有未来会持续更新的验证码突防、APP逆向、Python领域等一系列文章
说到GooglePlay,自定义的数据结构,解析起来真的是让人感觉到窒息。而且基本是每间隔一段时间就会稍微的发现变动,解析规则基本持久不了太久可能就会失效,不过都是一些细微的变动,不值一提~
GooglePlay是没有对外提供任何API的,想要爬取相关的数据就需要通过Web端的方式,Git上面也有国外的大佬开源了google-play-scraper,Python跟JS版本的我记得都有,直接导包调用
但是稳定性不够好,也是基于Web端去爬取解析的,一旦结构发生变化,作者维护不够及时的话,自然也就无法使用
之后参考开源的项目,自己重新实现了数据抽取那一块逻辑,并将解析服务部署在了境外服务器上,然后通过远端调用的方式去解析
在我之前的Cloudflare反爬虫防护绕过文章中,就是以一个第三方的APK下载网站为示例进行的讲解,GooglePlay的APK包如果是在官方网站下载的话会比较麻烦,直接可以用我提到的那个第三方网站取下载就行
主要爬取内容就是APP应用的相关描述信息,如下图所示:

在点击关于此应用的时候,抓包可以看到重点数据集都嵌套在了HTML源代码中,使用JS函数定义了AF_initDataCallBack,data参数就是加载的数据

尝试将数据拷贝出来,不过发现太长了,截图都放不下,图片都给整裂开了!反正就是巨长再加上多层嵌套,需要拆解慢慢去写解析规则!
接下来,先实现对data数据的提取,实现代码如下所示:
async def extract_json_block(html, block_id):prefix = re.compile(r"AF_init[dD]ata[cC]all[bB]ack\s*\({[^{}]*key:\s*'" + re.escape(block_id) + ".*?data:")suffix = re.compile(r"}\s*\)\s*;")try:block = prefix.split(html)[1]block = suffix.split(block)[0]except IndexError:raise PlayStoreException("Could not extract block %s" % block_id)block = block.strip()block = re.sub(r"^function\s*\([^)]*\)\s*{", "", block)block = re.sub("}$", "", block)block = re.sub(r", sideChannel: {$", "", block)return block
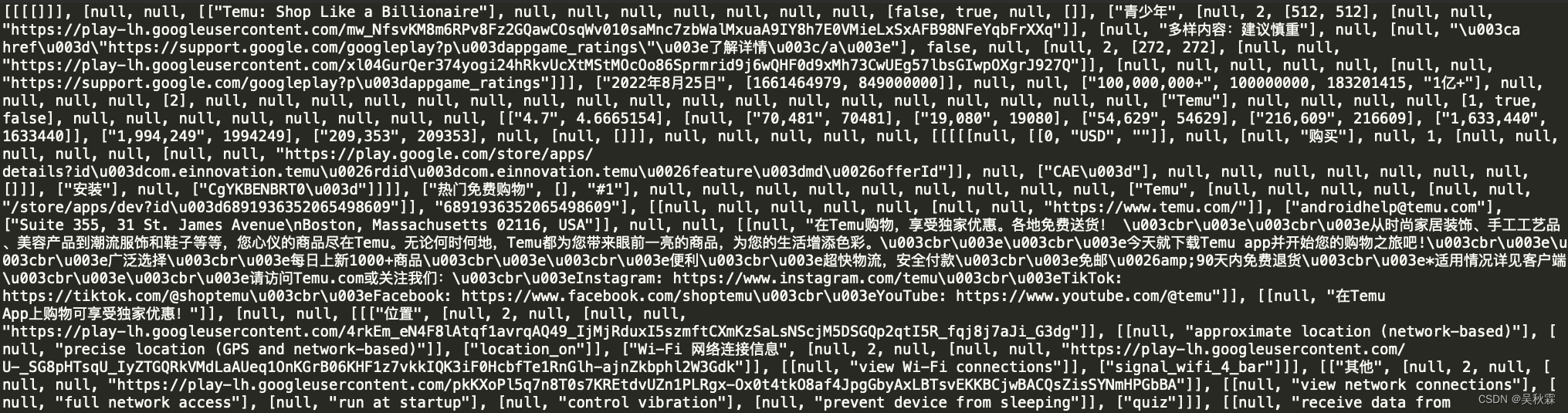
如上就是提取出来的数据,拿到数据以后,如果你是小白新手或许会因此放弃,实在是让人头大,现在开始实现解析核心逻辑代码,如下所示:
app_detail_ds_block = 'ds:7'
app_details_mapping = {'title': [app_detail_ds_block, 1, 2, 0, 0],'developer_name': [app_detail_ds_block, 1, 2, 68, 0],'developer_link': [app_detail_ds_block, 1, 2, 68, 1, 4, 2],'price_inapp': [app_detail_ds_block, 1, 2, 19, 0],'category': [app_detail_ds_block, 1, 2, 79, 0, 0, 1, 4, 2],'video_link': [app_detail_ds_block, 1, 2, 100, 1, 2, 0, 2],'icon_link': [app_detail_ds_block, 1, 2, 95, 0, 3, 2],'num_downloads_approx': [app_detail_ds_block, 1, 2, 13, 1],'num_downloads': [app_detail_ds_block, 1, 2, 13, 2],'published_date': [app_detail_ds_block, 1, 2, 10, 0],'published_timestamp': [app_detail_ds_block, 1, 2, 10, 1, 0],'pegi': [app_detail_ds_block, 1, 2, 9, 0],'pegi_detail': [app_detail_ds_block, 1, 2, 9, 2, 1],'os': [app_detail_ds_block, 1, 2, 140, 1, 1, 0, 0, 1],'rating': [app_detail_ds_block, 1, 2, 51, 0, 1],'description': [app_detail_ds_block, 1, 2, 72, 0, 1],'price': [app_detail_ds_block, 1, 2, 57, 0, 0, 0, 0, 1, 0, 2],'num_of_reviews': [app_detail_ds_block, 1, 2, 51, 2, 1],'developer_email': [app_detail_ds_block, 1, 2, 69, 1, 0],'developer_address': [app_detail_ds_block, 1, 2, 69, 2, 0],'developer_website': [app_detail_ds_block, 1, 2, 69, 0, 5, 2],'developer_privacy_policy_link': [app_detail_ds_block, 1, 2, 99, 0, 5, 2],'data_safety_list': [app_detail_ds_block, 1, 2, 136, 1],'updated_on': [app_detail_ds_block, 1, 2, 145, 0, 0],'app_version': [app_detail_ds_block, 1, 2, 140, 0, 0, 0]
}async def find_item_from_json_mapping(google_app_detail_request_result, app_detail_mapping):ds_json_block = app_detail_mapping[0]json_block_raw = await extract_json_block(google_app_detail_request_result, ds_json_block)json_block = json.loads(json_block_raw)return await get_nested_item(json_block, app_detail_mapping[1:])
app_details_mapping则是解析数据的核心,索引基本上变动较小!因为数据都是在list中多级嵌套,所以需要花费一点精力时间去分析,app_detail_ds_block前段时间我记得是ds:5,这个倒是会偶尔变动
class PlayStoreException(BaseException):def __init__(self, *args):if args:self.message = args[0]else:self.message = Nonedef __str__(self):if self.message:return "PlayStoreException, {0}".format(self.message)else:return "PlayStoreException raised"class GooglePlayStoreScraper(object):def __init__(self):self.PLAYSTORE_URL = "https://play.google.com"self.PROXIES = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}async def _app_connection(self, url, sleeptime=2, retry=0):for _ in range(retry + 1):try:async with aiohttp.ClientSession() as session:async with session.get(url, proxy=self.PROXIES) as response:return await response.text()except aiohttp.ClientError:if sleeptime > 0:await asyncio.sleep(sleeptime)raise PlayStoreException(f"Could not connect to : {url}")async def get_nested_item(self, item_holder, list_of_indexes):index = list_of_indexes[0]if len(list_of_indexes) > 1:return await get_nested_item(item_holder[index], list_of_indexes[1:])else:return item_holder[index]async def get_app_details(self, app_id, country="nl", lang="nl"):url = f"{self.PLAYSTORE_URL}/store/apps/details?id={quote_plus(app_id)}&hl={lang}&gl={country}"request_result = await self._app_connection(url, retry=1)app = {'id': app_id, 'link': url}for k, v in app_details_mapping.items():try:app[k] = await self.find_item_from_json_mapping(request_result, v)except PlayStoreException:raise PlayStoreException(f"Could not parse Play Store response for {app_id}")except Exception as e:self._log_error(country, f'App Detail error for {app_id} on detail {k}: {str(e)}')app.setdefault('errors', []).append(k)app['developer_link'] = self.PLAYSTORE_URL + app.get('developer_link', '')app['category'] = app.get('category', '').replace('/store/apps/category/', '')if 'data_safety_list' in app:app['data_safety_list'] = ', '.join(item[1] for item in app['data_safety_list'] if len(item) > 1)soup = BeautifulSoup(request_result, 'html.parser')list_of_categories = ', '.join(', '.join(category.text for category in element.find_all('span')) for element in soup.find_all('div', {'class': 'Uc6QCc'}))app['list_of_categories'] = list_of_categories if list_of_categories else app.setdefault('errors', []) + ['list_of_categories']if 'errors' in app:plural = 's' if len(app['errors']) > 1 else ''app['errors'] = f"Detail{plural} not found for key{plural}: {', '.join(app['errors'])}"return app
在完成上面爬虫程序核心入口的实现以后,基本上用采集到数据解析都已经完成,只需要调用get_app_details函数,传人需要爬取的目标APP的包名即可爬取并解析数据,如下所示:

好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章
相关文章:
使用Python爬取GooglePlay并从复杂的自定义数据结构中实现解析
文章目录 【作者主页】:吴秋霖 【作者介绍】:Python领域优质创作者、阿里云博客专家、华为云享专家。长期致力于Python与爬虫领域研究与开发工作! 【作者推荐】:对JS逆向感兴趣的朋友可以关注《爬虫JS逆向实战》,对分布…...
前后端分离下的鸿鹄电子招投标系统:使用Spring Boot、Mybatis、Redis和Layui实现源码与立项流程
在数字化时代,采购管理也正经历着前所未有的变革。全过程数字化采购管理成为了企业追求高效、透明和规范的关键。该系统通过Spring Cloud、Spring Boot2、Mybatis等先进技术,打造了从供应商管理到采购招投标、采购合同、采购执行的全过程数字化管理。通过…...

ChatGPT 有什么新奇的使用方式?
来看看 OpenAI 内部是如何使用 ChatGPT 的。 目前(4月29日)距离ChatGPT发布了已经半年,这期间大家基本上把能想到的ChatGPT的使用方法都研究遍了——从写作、写代码,到翻译、英语润色,再到角色扮演等等。 所以&#x…...

【计算机四级(网络工程师)笔记】操作系统概论
目录 一、OS的概念 1.1OS的定义 1.2OS的特征 1.2.1并发性 1.2.2共享性 1.2.3随机性 1.3研究OS的观点 1.3.1软件的观点 1.3.2资源管理器的观点 1.3.3进程的观点 1.3.4虚拟机的观点 1.3.5服务提供者的观点 二、OS的分类 2.1批处理操作系统 2.2分时操作系统 2.3实时操作系统 2.4嵌…...
贪心算法)
LeetCode算法练习top100:(10)贪心算法
package top100.贪心算法;import java.util.ArrayList; import java.util.List;public class TOP {//121. 买卖股票的最佳时机public int maxProfit(int[] prices) {int res 0, min prices[0];for (int i 1; i < prices.length; i) {if (prices[i] < min) {min price…...

随记-探究 OpenApi 的加密方式
open api 主要参数如下 appKey 接口Key(app id)appSecret 接口密钥timeStamp 时间戳 毫秒nonceStr 随机字符串signature 加密字符串 客户端 使用 appSecret 按照一定规则将 appKey timeStamp nonceStr 进行加密,得到密文 signature将 appK…...
stm32学习总结:4、Proteus8+STM32CubeMX+MDK仿真串口收发
stm32学习总结:4、Proteus8STM32CubeMXMDK仿真串口收发 文章目录 stm32学习总结:4、Proteus8STM32CubeMXMDK仿真串口收发一、前言二、资料收集三、STM32CubeMX配置串口1、配置开启USART12、设置usart中断优先级3、配置外设独立生成.c和.h 四、MDK串口收发…...

配置paddleocr及paddlepaddle解决报错 GLIBCXX_3.4.30 FreeTypeFont
配置 https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/StyleText/README_ch.md#style-text 环境配置 https://www.paddlepaddle.org.cn/ 根据自己的cuda版本选择paddlepaddle-gpu # 新建conda环境 # python version conda create -n paddle python3.8 # 安装p…...

【实战】如何在Docker Image中轻松运行MySQL
定义 使用Docker运行MySQL有许多优势。它允许数据库程序和数据分离,增强了数据的安全性和可靠性。Docker Image的轻便性简化了MySQL的部署和迁移,而Docker的资源隔离功能确保了应用程序之间无冲突。结合中间件和容器化系统,Docker为MySQL提供…...

PLC物联网,实现工厂设备数据采集
随着工业4.0时代的到来,物联网技术在工厂设备管理领域的应用日益普及。作为物联网技术的重要一环,PLC物联网为工厂设备数据采集带来了前所未有的便捷和高效。本文将围绕“PLC物联网,实现工厂设备数据采集”这一主题,探讨PLC物联网…...
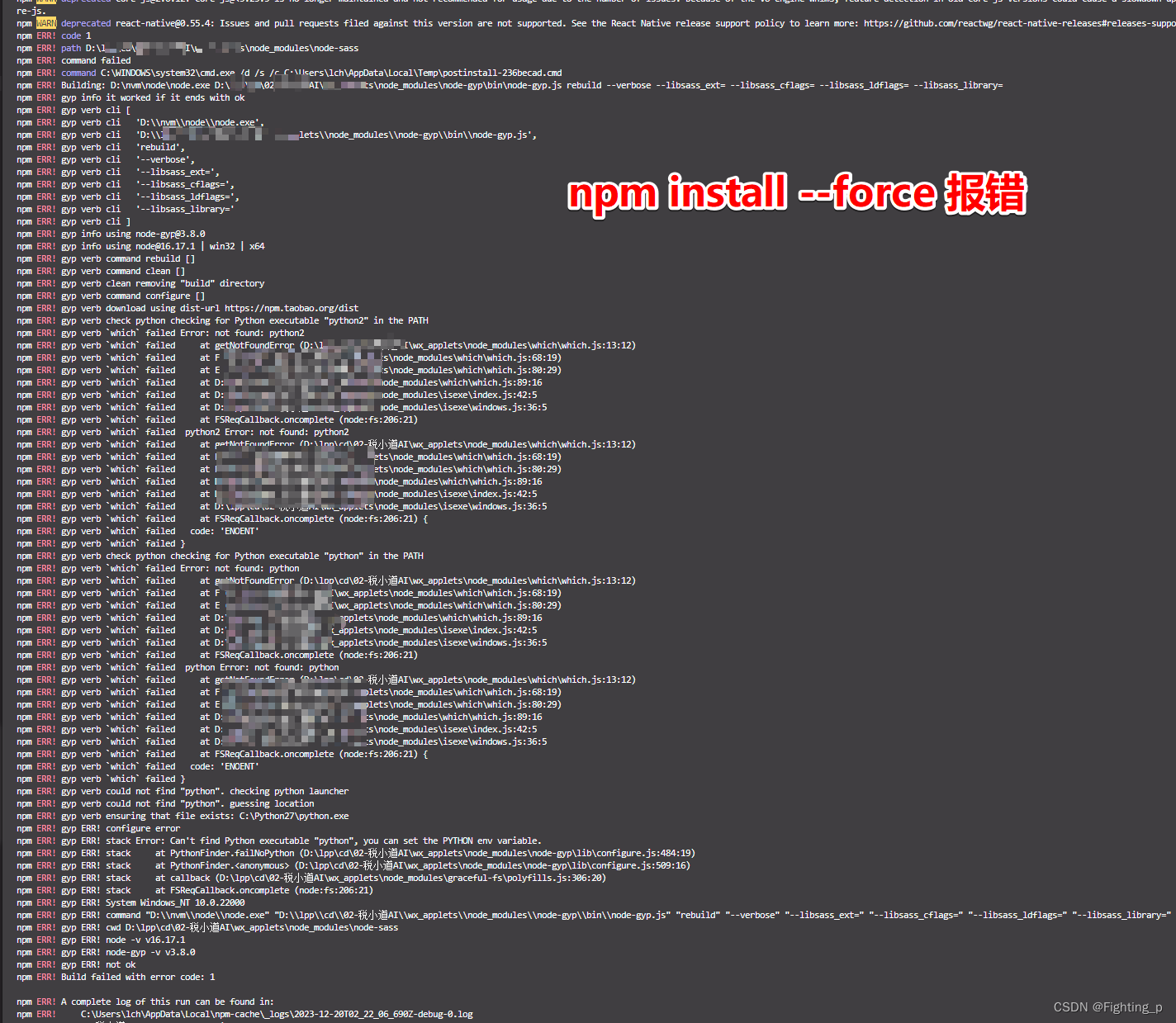
npm安装依赖报错ERESOLVE unable to resolve dependency tree(我是在taro项目中)(node、npm 版本问题)
换了电脑之后新电脑安装包出错 👇👇👇 npm install 安装包报错 ERESOLVE unable to resolve dependency tree 百度后尝试使用 npm install --force 还是报错 参考 有人说是 node 版本和 npm 版本的问题 参考 新电脑 node版本:16.1…...
Maven仓库上传jar和mvn命令汇总
目录 导入远程仓库 命令结构 命令解释 项目pom 输入执行 本地仓库导入 命令格式 命令解释 Maven命令汇总 mvn 参数 mvn常用命令 web项目相关命令 导入远程仓库 命令结构 mvn deploy:deploy-file -Dfilejar包完整名称 -DgroupIdpom文件中引用的groupId名 -Dartifa…...
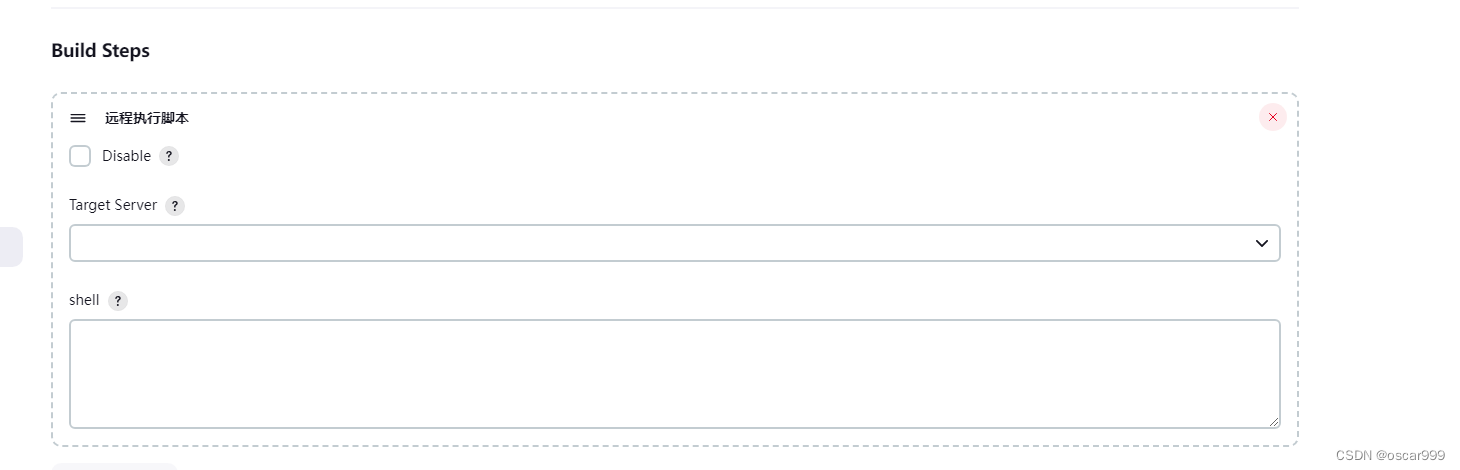
Jenkins 执行远程脚本的插件—SSH2 Easy
SSH2 Easy 是什么? SSH2 Easy 是一个 Jenkins 插件,它用于在 Jenkins 构建过程中通过 SSH2 协议与远程服务器进行交互。通过该插件,用户可以在 Jenkins 的构建过程中执行远程命令、上传或下载文件、管理远程服务器等操作。 以下是 SSH2 Eas…...
Starting the Docker Engine...一直转圈
出现的问题: 原因排查: 看了网上的很多篇文章,每个原因都排查了,没有发现问题。 遇到这样的情况应先看自己是否安装成功 打开运行,在空框中输入powershell并点击确定: docker version 显示版本证明安装…...
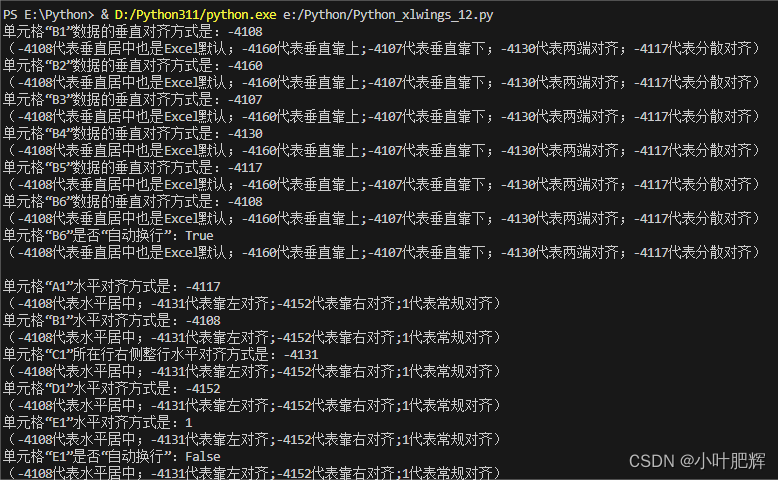
关于Python里xlwings库对Excel表格的操作(十五)
这篇小笔记主要记录如何【获取单元格数据的对齐方式或更改单元格数据的对齐方式】。 前面的小笔记已整理成目录,可点链接去目录寻找所需更方便。 【目录部分内容如下】【点击此处可进入目录】 (1)如何安装导入xlwings库; …...
[Linux] LVS+Keepalived高可用集群部署
一、Keepalived实现原理 1.1 高可用方案 Keepalived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以解决静态路由出现的单点故障问题。 在一个LVS服务集群中通常有主服务器(MASTER)和备份服务器(BACKUP)两种角色…...

【版本管理】git stash用法
应用场景 我们在开发过程中可能会遇到这样的情况: 想从A分支切换到B分支,但A分支尚未改完,暂时不想提交代码 此时可以在切换到B分支前,先通过stash指令来缓存本地改动,等切回A分支时,再通过stash还原改动…...

声明式的理解【gpt】
一 MyBatis采用了声明式语法来进行SQL映射配置【mybatis声明式】 MyBatis是一款优秀的持久层框架,支持自定义SQL、存储过程以及高级映射,使得开发人员能够专注于SQL本身而不是数据库访问。MyBatis提供了两种配置方式:XML配置和注解配置&…...

提高Spring Boot技能的9种方法
以下是提高 Spring Boot 技能的 9 种方法: 1. 外部化您的配置: 充分利用 Spring Boot 潜力的另一种方法是尽可能地尝试外部化您的配置,而不是对其进行硬编码。外部化您的配置将使您的应用程序更加灵活且更易于管理。 外部化配置的另一个优点…...

HIVE基本操作
1、启动远程服务端:hive --service metastore启动(这里是阻塞式),然后在客户端操作 2、Hive DDL(数据库定义语言) --展示所有数据库show databases; --切换数据库use database_name; 3、创建语法&#x…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...