在ClickHouse数据库中启用预测功能
在这篇博文中,我们将介绍如何将机器学习支持的预测功能与 ClickHouse 数据库集成。ClickHouse 是一个快速、开源、面向列的 SQL 数据库,对于数据分析和实时分析非常有用。该项目由 ClickHouse, Inc. 维护和支持。我们将探索它在需要数据准备以支持机器学习的任务中的功能。
预测功能是通过 MindsDB 提供的,MindsDB 是一个平台,只需使用简单的 SQL 命令即可直接在数据库中自动运行机器学习模型。MindsDB 使机器学习民主化,使任何人都可以在数据所在的位置执行基于机器学习的复杂预测。
我们将围绕大型多变量时间序列的预测,介绍传统机器学习的一个具有挑战性的用例的整个流程,以及 ClickHouse 和 MindsDB 的结合如何使您能够以非常简单和有效的方式实现这一目标。
优化机器学习生命周期
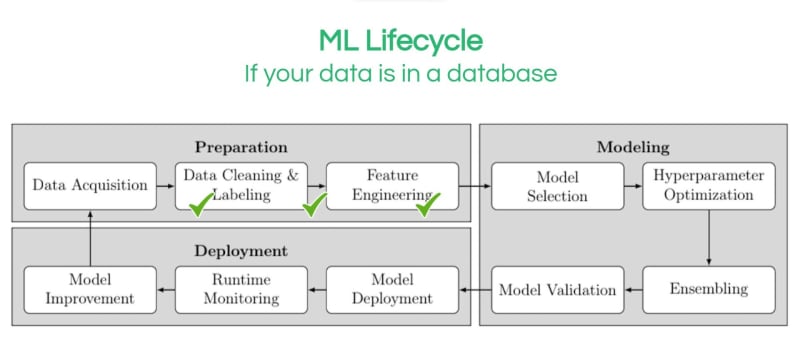
机器学习生命周期是一个仍在完善的主题,但构成此流程的主要阶段是准备、建模和部署。

这三个主要阶段中的每一个都分解为更明确定义的步骤。例如,数据准备步骤通常分为数据采集、数据清理和标记以及特征工程。
数据库中已有的数据对 ML 友好
根据《福布斯》的一项调查,数据准备约占数据科学家工作的 80%,同时,其中 57% 的人认为数据清理是他们工作中最不愉快的部分。
如果您的公司已经经历了获取数据、将其加载到数据库中的障碍,那么它很可能已经采用干净和结构化的格式,采用预定义的架构。
SQL 作为特征工程工具
此外,对于任何机器学习问题,数据采集和数据清理只是第一步。大多数情况下,初始数据集不足以从模型中产生令人满意的结果。这就是数据科学家和机器学习工程师需要介入并通过应用不同的特征工程技术来丰富数据集的地方。
SQL 是一个非常强大的数据转换工具,数据集的特征实际上是数据库表中的列。
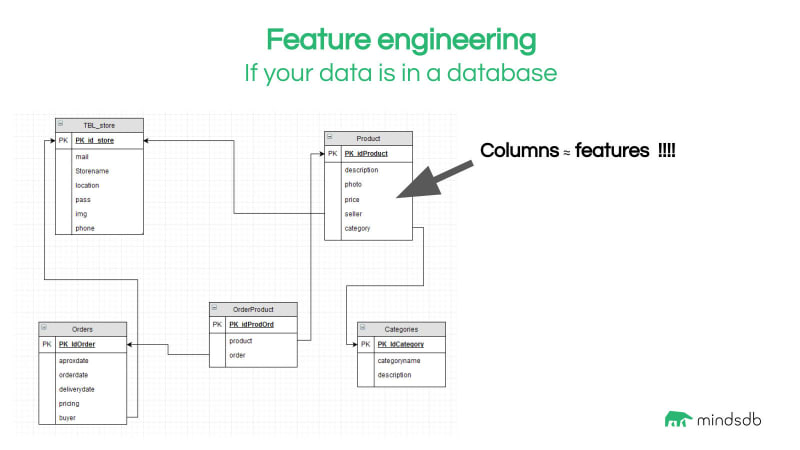
然后选择并转换这些特征以创建新特征,这些特征将用于机器学习模型的训练。使用上述数据模型,我们可以生成一些描述我们销售的额外特征。例如,我们可以创建包含产品已包含的订单数以及该产品价格占总订单价格的百分比的新功能。
SELECTProduct.pk_idProduct, Product.description, TBL_store.storeName, count(Orders.pk_idOrder) as number_of_orders, avg(Product.price / Orders.pricing) as product_percentage_of_order
FROM ProductINNER JOIN OrderProducton Product.pk_idProduct = OrderProduct.productINNER JOIN Orderson Orders.pk_idOrder = OrderProduct.orderINNER JOIN TBL_storeon TBL_store.PK_id_store = Product.seller
GROUP BY Product.pk_idProduct, Product.description, TBL_store.storeName
ClickHouse提供了在非常大的数据集上进行许多转换的功能。与为数据集创建新特征、提取数据。与通过 Python 操作数据的一般方法相反,在 ClickHouse 中创建新特征要快得多。
作为 AI 表的机器学习模型
在数据准备之后,我们到达了 MindsDB 介入的地步,并提供了一个简化机器学习模型建模和部署的结构。
这种结构称为 AI 表,是 MindsDB 的一项特定功能,允许您像对待普通表一样对待机器学习模型。您可以在 MindsDB 中创建此 AI 表,就像在常规数据库中创建表一样,然后可以通过外部表功能将此表暴露给 ClickHouse。
创建自己的 AI 表非常容易,下面是用于在数据集之上创建它的语法。
CREATE PREDICTOR <predictor_name>TRAIN FROM { (<select_statement>) | <namespace|integration>.<view|table> | <url> }[ TEST FROM { (<select_statement>) | <namespace|integration>.<view|table> | <url> } ]
[ ORDER BY <order_col> [{ASC|DESC}] ]
[ GROUP BY <col1,> [, <col2>, ...] ]
[ WINDOW <window_size> ]
PREDICT <col_name_in_from_to_forecast>[ MODEL = {auto | <json_config> | <url>} ]总之,所有的部署和建模都被抽象到这个非常简单的结构中,我们称之为“AI 表”,它使您能够在其他数据库(如 ClickHouse)中公开此表。
在ClickHouse中构建数据集
尽管与分析数据库市场上的其他类似工具相比,ClickHouse是一个相当年轻的产品,但与更知名的工具相比,ClickHouse具有许多优势,甚至是使其在性能方面超越其他工具的新功能。
- 单个可移植的 C++ 二进制文件 – 可实现非常快速的 60 秒安装
- 在任何地方运行 – 它可以在任何基于 Linux 的环境中运行,例如云虚拟机、容器,甚至是裸机服务器或笔记本电脑
- 高级 SQL 功能 – 它有一些额外的扩展建立在常规 SQL 语法之上,赋予它一些额外的功能
- 列存储 – 在性能方面为您提供优势,在非常高的数据压缩率方面为您提供优势
- 分布式查询 – 由于查询分布在节点和 CPU 内核之间,因此需要毫秒级响应时间
- 分片和复制 – 支持从笔记本电脑大小扩展到数百个节点
- Apache 2.0 许可 – 使 ClickHouse 能够用于任何商业目的
ClickHouse 在全球拥有数千个安装,被众多大公司使用,如 Bloomberg、Uber、Walmart、eBay、Yandex 等。
数据探索
如前几节所述,任何机器学习管道中最耗时的部分是数据准备。它需要有关数据的知识,这就是为什么我们总是从数据探索开始。
在这一步,我们需要了解我们拥有哪些信息以及哪些功能可用于评估数据质量,以便使用它训练模型或对数据集进行一些改进。下面我们可以看到 ClickHouse 中的行程数据数据集示例,其中查询了 1 亿行关于纽约出租车的数据,以分析数据的质量
SELECTcount() AS rides,avg(fare_amount) AS avg,min(fare_amount) AS min,max(fare_amount) AS max
FROM default.tripdata
正如你在这里看到的,我们有一些异常值会对机器学习模型产生负面影响,所以让我们用ClickHouse工具更深入地研究它。
让我们编写一个查询来更深入地研究这些分布,以便更好地理解数据。通过此查询,您可以在几秒钟内为这个大型数据集创建直方图视图,并查看异常值的分布。
SELECT h_bin.1 AS lo, h_bin.2 AS hi, h_bin.3 AS count FROM
(SELECT histogram(5)(fare_amount) hFROM default.tripdata WHERE fare_amount < 0
) ARRAY JOIN h AS h_bin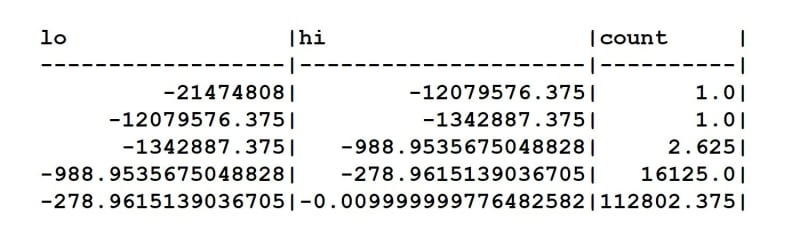
我们可以看到,我们的直方图查询的分布也包含一个计数列。此列中的某些结果是小数,不一定表示行计数。实际上,根据文档,此列实际上包含直方图中条柱的高度。
因为我们试图将整个数据集拟合到一个具有 5 个条柱的直方图中,该直方图是通过 histogram(5)(fare_amount) 函数调用指定的,并且数据集中的项目数量不是正态分布的,所以我们的条柱高度不一定相等。因此,我们的一些高度将有一个数字,该数字将按比例表示该特定条柱中的值数,相对于数据集中的值总数。
如果这仍然有点令人困惑,我们可以尝试使用 ClickHouse 中的 bar() 可视化来生成数据集分布的更直观的结果。
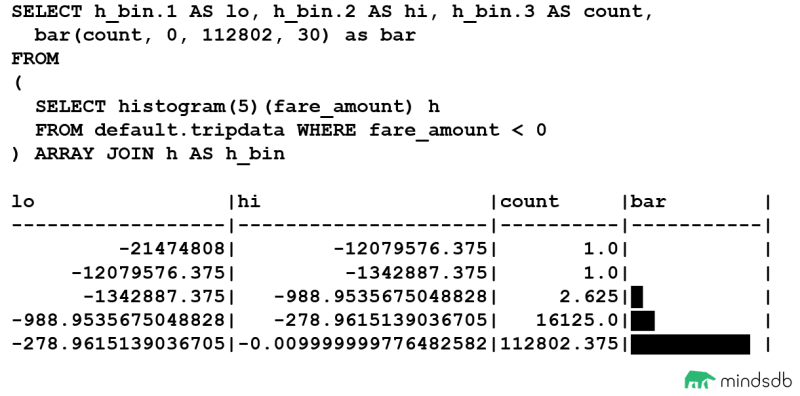
我们可以看到,条形列包含数据集分布的可视化表示,分为 5 个条柱。由于前两个条柱都只包含 1 个值,因此条形图显示太小而无法显示,但是,当我们开始有更多值时,条形图也会显示出来。
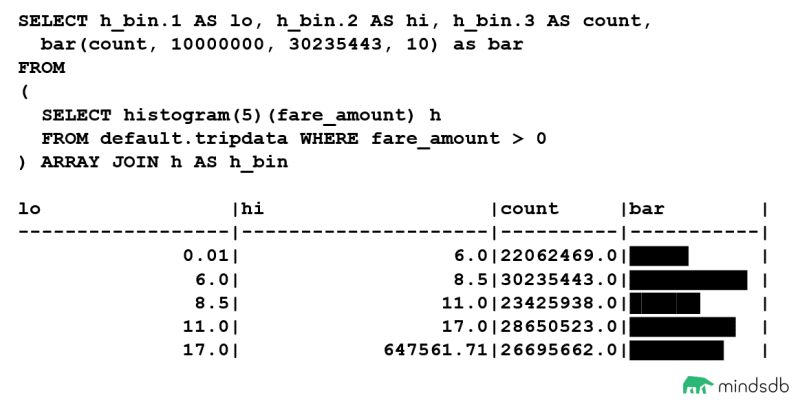
此外,我们可以看到大量我们不希望包含在模型训练数据集中的小负票价值。如果我们反转数据集的过滤,只看正 fare_amount 值,我们可以看到“干净”数据点的数量要高得多。因为我们有这么大的值,所以我们要将条形函数的最小值设置为 10000000,以便分布更清晰可见。
数据清洗和聚合
现在我们已经确定我们的数据集包含异常值,我们需要删除它们以获得一个干净的数据集。我们将过滤掉所有负数,只考虑低于 500 美元的票价金额。由于我们需要预测每个出租车供应商的数据,因此我们将按 vendor_id 聚合数据集。
SELECTtoStartOfHour(pickup_datetime) AS pickup_hour,vendor_id,sum(fare_amount) AS fares
FROM default.tripdata
WHERE total_amount >= 0 AND total_amount <= 500
GROUP BY pickup_hour, vendor_id
ORDER BY pickup_hour, vendor_id我们可以通过将时间戳数据下采样到小时间隔并聚合一小时间隔内的所有数据来进一步减小数据集的大小。
使用ClickHouse处理非常大的数据集
就所使用的资源和生成数据所需的时间而言,在海量数据集上运行任何查询通常都非常昂贵。当我们必须多次运行查询、使用复杂的转换生成新功能或源数据老化并且我们需要更新版本时,这可能会令人头疼。但是,ClickHouse对此有一个解决方案,即物化视图。
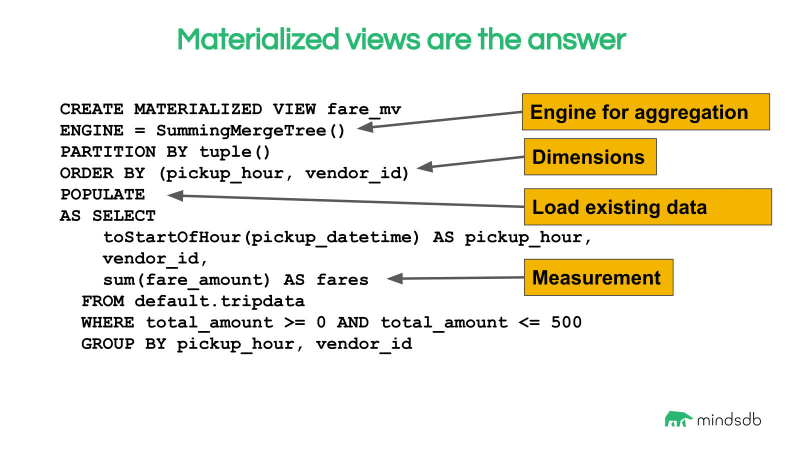
常规 SQL 视图相反,在常规 SQL 视图中,视图只是封装 SQL 查询并在每次执行时重新运行它,具体化视图仅运行一次,并将数据馈送到具体化视图表中。然后,我们可以查询这个新表,每次将数据添加到原始源表时,这个视图表也会更新。
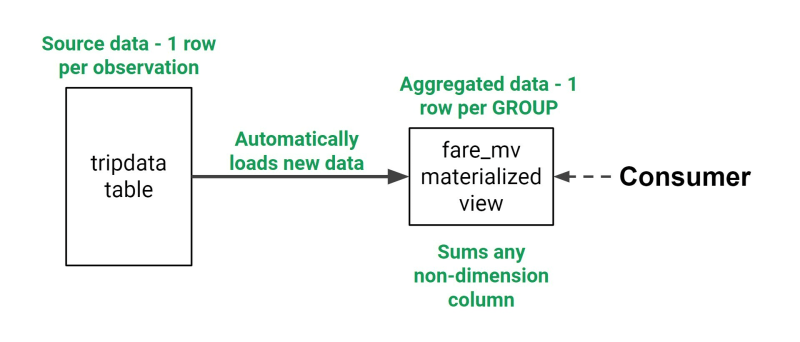
正如你在上面看到的,我们总是可以查询具体化的视图,并确定我们总是根据我们的原始数据获得最新的数据集。然后,我们可以在这个物化视图中使用数据集并训练我们的机器学习模型,而不必担心过时的数据。
与通用视图相比,物化视图在性能方面也有很多好处,在 ClickHouse 中,在超过 20 亿行的数据集上,它们有时甚至快 1 倍。
您还可以利用ClickHouse集群,将数据扩展到多个分片,以从数据仓库中提取最佳性能。您可以在这些数据子集上创建具体化视图,然后将它们统一到分布式表构造下,该构造就像是每个节点的数据上的保护伞。
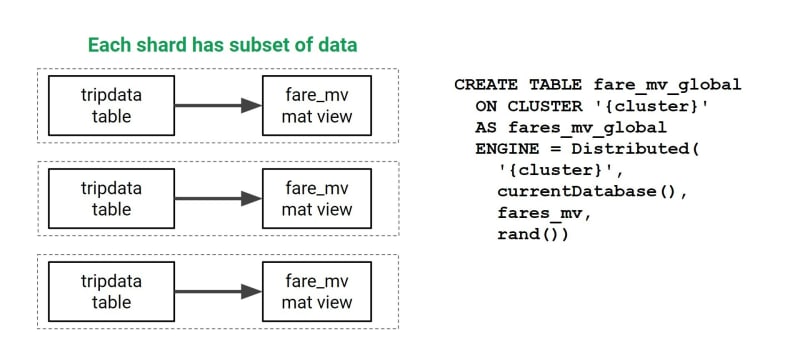
每当需要查询此数据时,只需查询一个分布式表,该表会自动处理从整个群集中的多个节点检索数据。
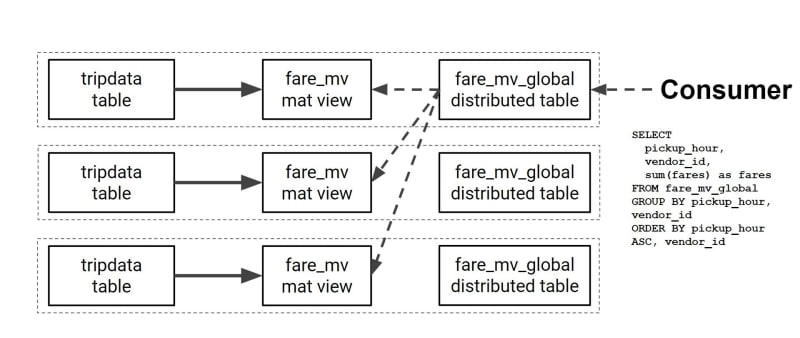
这是一种非常强大的技术,可以让您查询数万亿行数据,聚合它们,并以有用的方式转换它们。从现在开始,我们可以继续进行机器学习部分,甚至可以对数据集进行更深入的分析。
根据复杂的多变量时间序列数据构建预测
现在,让我们根据我们刚刚介绍的纽约市出租车“行程数据”数据集来预测出租车需求。我们将仅关注由vendor_id、上车时间和出租车费用列组成的子集。

更好地了解我们的数据
我们可以更深入地研究ClickHouse生成的数据子集,并绘制收入流,按小时分配。左下角的绿线图显示了 CMT 公司的每小时票价。

但是,我们也可以看到,不仅单个出租车供应商在一天中的票价分布存在差异,而且出租车供应商本身之间的票价分布也存在差异,如下图所示。随着时间的推移,每家公司都有不同的动态,这使得这个问题变得更加困难,因为我们现在没有单一的数据系列,而是多个数据。

多变量时间序列预测的挑战
了解我们的数据集包含多个系列的数据是构建数据预测管道时需要注意的重要信息。如果数据科学家或机器学习工程师团队需要预测任何对你获取见解很重要的时间序列,他们需要意识到这样一个事实,即根据分组数据的外观,他们可能会查看数百或数千个序列。
训练此类机器学习模型可能非常耗时且耗费大量资源,并且根据要提取的见解类型和使用的模型类型,将其扩展到数千个预测其自身时间序列的模型将很难扩展。
在MindsDB,我们处理这个问题已经有一段时间了,我们已经能够使用来自任何数据库(如ClickHouse)的任何类型的数据来自动化这个过程。
MindsDB 如何自动构建 ML 模型
我们的方法围绕着应用灵活的理念,使我们能够解决任何类型的机器学习问题,而不一定只是时间序列问题。这是通过应用我们的编码器-混音器理念来实现的。
MindsDB 预测引擎 – 技术细节

根据每列的数据类型,我们实例化该列的编码器。它的任务是根据该列中的数据开发信息编码。
例如,如果我们有一列包含简单的数字,不需要训练即可解决时间序列问题,那么编码器可以只是一组不需要训练的简单规则。但是,如果列包含自由文本,则编码器将实例化一个 Transformer 神经网络,该神经网络将学习生成该文本的摘要。
下一步是实例化 Mixer,这是一个机器学习模型,其任务是根据 Encoder 的结果进行最终预测。这种类型的哲学提供了一种非常灵活的方法来预测数值数据、分类数据、文本回归和时间序列数据。
MindsDB 中的自动和动态数据规范化
在开始使用数据训练此模型之前,我们可能需要进行一些特定的数据清理,例如进行动态归一化。这意味着对每个数据系列进行归一化,以便我们的 Mixer 模型学习得更快、更好。
MindsDB 捕获数据集的统计数据并规范化每个序列,而 Mixer 模型学习使用这些规范化值预测未来值。
时间信息也通过将时间戳分解为正弦分量来编码。

这样可以进行任意日期处理,并便于处理不均匀采样的序列。当时间序列数据间距不均匀且测量值不规则时,此方法非常有用。
简而言之,对于时间序列问题,机器学习管道的工作方式如下图所示。左上角的输入数据包含非时态信息,这些信息被输入编码器,然后传递到混音器中。

但是,对于时间信息,时间戳和一系列数据本身(在本例中,每个公司每小时收到的票价总数)都会自动归一化,并通过循环编码器(RNN 编码器)传递。RNN 在描述符中注入了更强的时间性概念。
所有这些编码功能都传递给 Mixer,它可以是以下两种类型之一:
- 神经网络 Mixer 由两个内部流组成,其中一个使用自回归过程进行基本预测并给出大致值,另一个使用辅助流对每个序列进行微调此预测
- 使用 LightGBM 的梯度增压混合器,其顶部是 Optuna 库,可实现非常彻底的逐步超参数搜索
这确保了我们从数十个机器学习模型中确定了最佳的预测模型。
如何在ClickHouse数据库中创建和使用预测性AI表
对于没有机器学习背景的人来说,上述关于技术方法、规范化、编码混合器方法的信息可能听起来很复杂,但实际上,您不需要知道所有这些细节即可在数据库中进行预测。
使用单个 SQL 查询训练多变量时间序列预测变量
MindsDB 使用 AI Tables 方法所做的是使任何只了解 SQL 的人都能自动构建预测模型并查询它们。这就像运行单个 SQL 命令一样简单。
例如,此查询将从多变量时间序列数据训练单个模型,以根据上述数据集预测出租车费用:
CREATE PREDICTOR fares_forecaster_demo FROM Clickhouse (SELECT VENDOR_ID, PICKUP_DATETIME, FARE_AMOUNTFROM DEFAULT.TRIPDATAWHERE DATE > '2010-01-01'
) PREDICT FARE_AMOUNT
ORDER BY DATE
GROUP BY VENDOR_ID
WINDOW 10
HORIZON 7;接下来,有一些标准的 SQL 子句,例如 ORDER BY、GROUP BY、WINDOW 和 HORIZON。通过使用带有 DATE 列作为参数的 ORDER BY 子句,我们强调我们处理的是时间序列问题,并且我们希望按日期对行进行排序。GROUP BY 子句将数据划分为多个分区。在这里,每个分区都与特定的出租车公司 (vendor_id) 相关。对于每个给定的预测,我们只考虑最后 10 行。因此,我们使用 WINDOW 10。为了准备出租车费用的预测,我们定义了 HORIZON 7,这意味着我们要提前 7 小时进行预测。
获取预测
我们准备进入最后一步,即使用预测模型来获取未来的数据。一种方法是直接查询fares_forecaster_demo预测模型。您只需创建一个 Select 语句,在 Where 子句中传递预测的条件。
但是我们考虑一个时间序列问题。因此,建议我们将预测模型与历史数据联接到表中。
SELECT tb.VENDOR_ID, tb.FARE_AMOUNT as PREDICTED_FARES
FROM Clickhouse.DEFAULT.TRIPDATA as ta
JOIN mindsdb.fares_forecaster_demo as tb
WHERE ta.VENDOR_ID = "CMT" AND ta.DATE > LATEST
LIMIT 7;我们来分析一下。我们将存储历史数据的表(即 Clickhouse.DEFAULT.TRIPDATA)连接到我们的预测模型表(即 mindsdb.fares_forecaster_demo)。查询的信息是出租车供应商和每个供应商的预测票价数量。通过指定 MindsDB 提供的条件 ta.date > latest,我们确保获得每条路线的未来乘车次数。
可视化预测
我们可以将 BI 工具连接到 MindsDB 预测性 AI 表,以很好的方式可视化预测。您可以在 Looker 中查看如何为先前训练的预测变量执行此操作。我们连接了我们加入的表,我们可以看到历史数据以及 MindsDB 对同一日期和时间所做的预测。在这种情况下,绿线代表实际数据,蓝线代表预测。
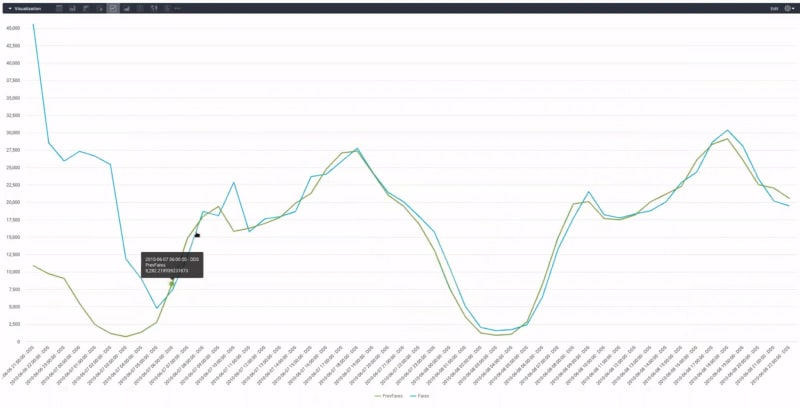
您可以看到,对于前 10 个预测,预测并不准确,这是因为预测器刚刚开始从历史数据中学习(请记住,我们在训练它时指出了 10 个预测的窗口),但在那之后,预测变得非常准确。
自动检测异常
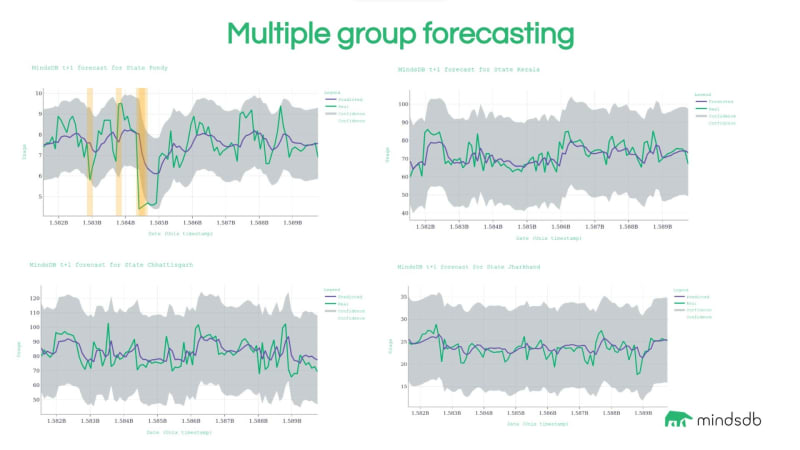
使用这种预测理念,MindsDB 还可以检测和标记其预测中的异常。下面我们展示了另一个数据集的图,该数据集是印度庞迪州的功耗数据集。
这是 t+1 的时间序列预测,这意味着模型正在查看时间片中所有先前的功耗值,并尝试预测下一步,在本例中,它试图预测第二天的功耗。图中的绿线表示实际功耗值,紫色线表示 MindsDB 预测,使用截至该时间步长的所有值来训练机器学习模型。
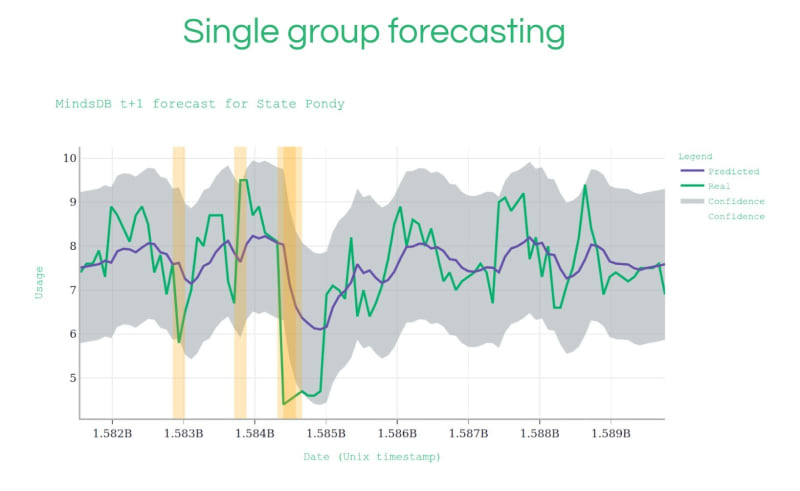
默认情况下,MindsDB 有一个置信度阈值估计值,由预测趋势周围的灰色区域表示。每当实际值超过此置信区间的边界时,都可以将其自动标记为异常行为,并且监视此系统的人员可以更深入地查看并查看是否正在发生某些事情。
与这个单序列模型的训练类似,MindsDB可以自动学习和预测多组数据。您可以使用整个数据集针对此问题进行训练,并获得印度所有州的预测。这非常方便,因为它抽象了大部分数据管道处理。
自带 ML 块
MindsDB 使您能够自定义处理管道的各个部分,但除此之外,您还可以自带模块。例如,如果您是机器学习工程师,我们使您能够引入自己的数据准备模块,即您自己的机器学习模型,以更好地满足您的需求。
例如,如果您更喜欢用经典的 ARIMA 模型替换 RNN 模型进行时间序列预测,我们希望为您提供这种可能性。或者,在分析模块中,如果要对预测结果运行自定义数据分析。
AI Tables 即将推出的新 ML 功能:
预测流中的数据
MindsDB现在正在做的主要任务之一是尝试从数据流中预测数据,而不仅仅是从数据库中预测数据。目标是创建一个预测器,该预测器读取来自 Redis 和 Kafka 等工具的流数据,并创建对将要发生的事情的预测。
改善长期预测
我们正在开发的下一个功能是改进对长期范围的预测,其中包括分类数据和时间数据。这是一项具有挑战性的任务,因为我们需要在多个不同的列中归因我们认为将要发生的事情,但我们相信我们可以改进这一点。
检测渐进式异常
当前的异常检测算法可以很好地处理数据中的突然异常,但需要改进以检测发生在数据序列本身之外的元素的异常。这是我们一直在努力改进的地方。
结论
在本文中,我们将指导你完成机器学习工作流。您了解了如何使用 ClickHouse 的强大工具(如物化视图)来更好、更有效地处理数据清理和准备,尤其是对于具有数十亿行的大型数据集。
然后,我们深入研究了 MindsDB 的 AI 表的概念,以及如何在 ClickHouse 中使用它们来自动构建预测模型并使用简单的 SQL 语句进行预测。
我们使用了一个多变量时间序列问题的示例来说明MindsDB如何能够自动执行非常复杂的机器学习任务,并展示了通过将AI表连接到BI工具来检测异常和可视化预测是多么简单,所有这些都是通过SQL完成的。
相关文章:
在ClickHouse数据库中启用预测功能
在这篇博文中,我们将介绍如何将机器学习支持的预测功能与 ClickHouse 数据库集成。ClickHouse 是一个快速、开源、面向列的 SQL 数据库,对于数据分析和实时分析非常有用。该项目由 ClickHouse, Inc. 维护和支持。我们将探索它在需要数据准备以…...
)
目标检测YOLO实战应用案例100讲-树上果实识别与跟踪计数(续)
目录 3.2 损失函数优化 3.3 实验过程 3.3.1 果实图像采集 3.3.2 数据扩增...
Docker 文件和卷 权限拒绝
一 创作背景 再复制Docker影像文件或访问Docker容器内已安装卷上的文件时我们常常会遇到:“权限被拒绝”的错误,在此,您将了解到为什么会出现“权限被拒绝”的错误以及如何解决这个问题。 二 目的 在深入探讨 Docker 容器中的 Permission De…...
Appium Server 启动失败常见原因及解决办法
Error: listen EADDRINUSE: address already in use 0.0.0.0:4723 如下图: 错误原因:Appium 默认的4723端口被占用 解决办法: 出现该提示,有可能是 Appium Server 已启动,关闭已经启动的 Appium Server 即可。472…...
将Abp默认事件总线改造为分布式事件总线
文章目录 原理创建分布式事件总线实现自动订阅和事件转发 使用启动Redis服务配置传递Abp默认事件传递自定义事件 项目地址 原理 本地事件总线是通过Ioc容器来实现的。 IEventBus接口定义了事件总线的基本功能,如注册事件、取消注册事件、触发事件等。 Abp.Events…...
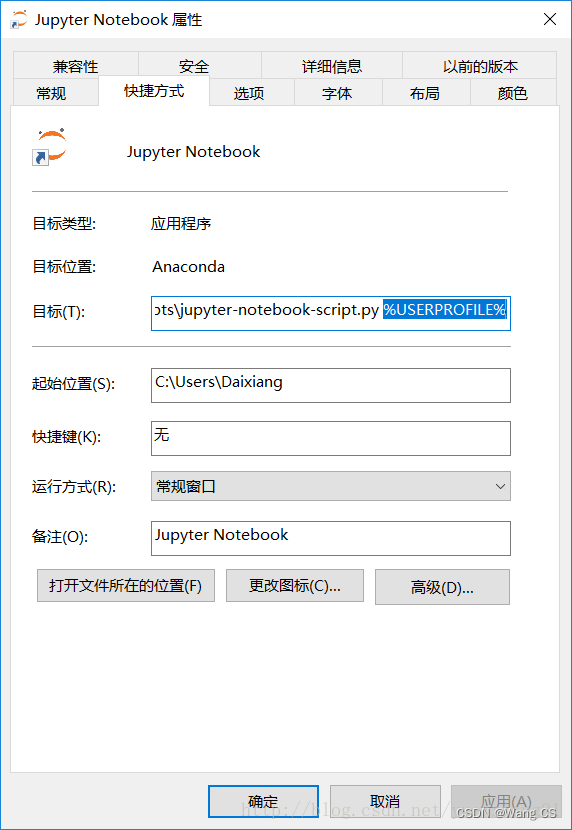
Jupyter Notebook修改默认工作目录
1、参考修改Jupyter Notebook的默认工作目录_jupyter文件路径-CSDN博客修改配置文件 2.在上述博客内容的基础上,这里不是删除【%USERPROFILE%】而是把这个地方替换为所要设置的工作目录路径, 3.【起始位置】也可以更改为所要设置的工作目录路径&#x…...
高校/企业如何去做数据挖掘呢?
随着近年来人工智能及大数据、云计算进入爆发时期,依托三者进行的数据分析、数据挖掘服务已逐渐成为各行业进行产业升级的载体,缓慢渗透进我们的工作和生活,成为新时代升级版的智能“大案牍术”。 那么对于多数企业来说,如何做数据…...

数据仓库-数据治理小厂实践
一、简介 数据治理贯穿数仓中数据的整个生命周期,从数据的产生、加载、清洗、计算,再到数据展示、应用,每个阶段都需要对数据进行治理,像有些比较大的企业都是有自己的数据治理平台或者会开发一些便捷的平台,对于没有平…...
之 线程生命周期管理join() 与 detach())
【C++多线程编程】(五)之 线程生命周期管理join() 与 detach()
在C中,std::thread 类用于创建和管理线程。std::thread 提供了两种主要的方法来控制线程的生命周期:join 和 detach。 detach方式,启动的线程自主在后台运行,当前的代码继续往下执行,不等待新线程结束。join方式&…...

金融信贷场景的风险“要素”与主要“风险点”
目录 要素一:贷款对象 风险点1:为不具备主体资格或主体资格有瑕疵的借款人发放贷款 风险表现: 防控措施: 风险点2:向国家限控行业发放贷款 风险表现: 防控措施: 风险点3:受理不符合准入条件的客户申请 风险表现: 防控措施: 要素二:金额 风险点4:过渡授…...
ubuntu下docker安装,配置python运行环境
参考自: 1.最详细ubuntu安装docker教程 2.使用docker搭建python环境 首先假设已经安装了docker,卸载原来的docker 在命令行中运行: sudo apt-get updatesudo apt-get remove docker docker-engine docker.io containerd runc 安装docker依赖 apt-get…...

在Docker中安装kafka遇到问题记录
命令含义解答: 在docker安装kafka的时候,启动kafka的时候会执行下面语句: docker run -d --log-driver json-file --log-opt max-size100m --log-opt max-file2 --name kafka -p 9092:9092 -e KAFKA_BROKER_ID0 -e KAFKA_ZOOKEEPER_CONNEC…...
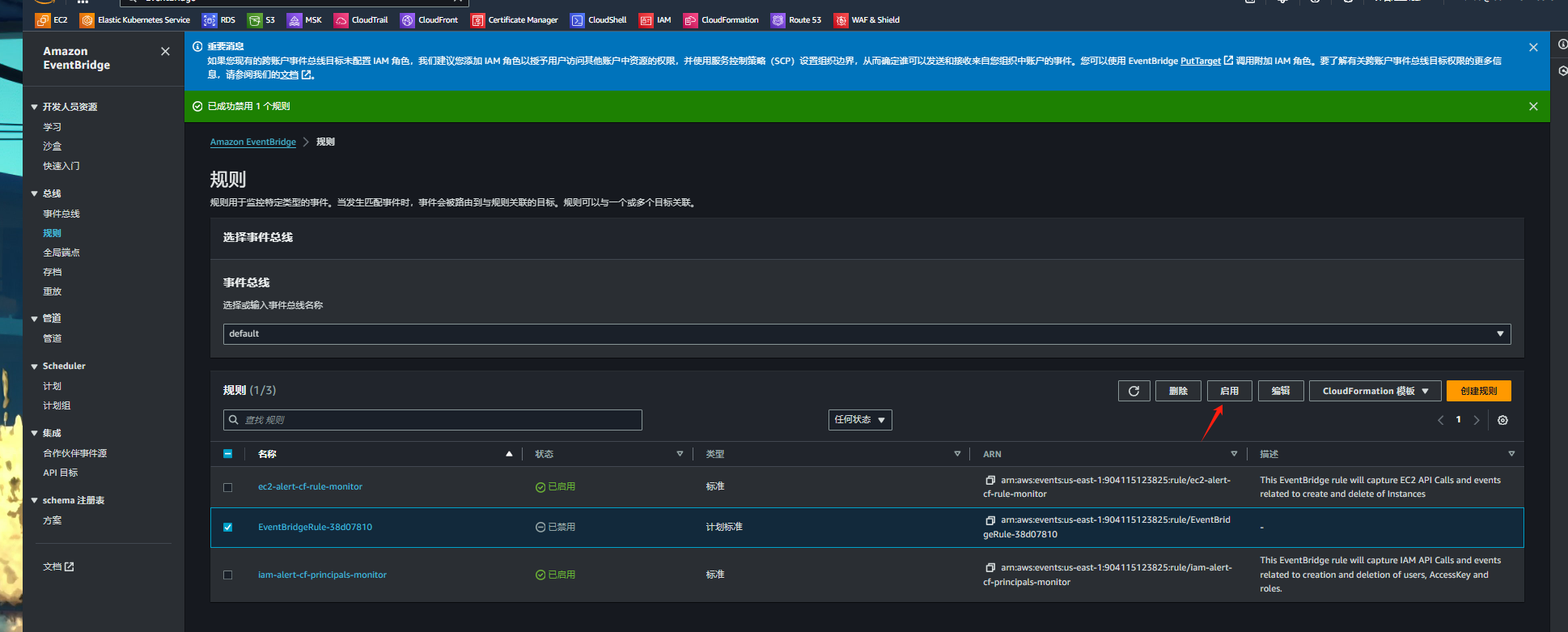
aws-waf-cdn 基于规则组的永黑解决方案
1. 新建waf 规则组 2. 为规则组添加规则 根据需求创建不同的规则 3. waf中附加规则组 (此时规则组所有规则都会附加到waf中,但是不会永黑) 此刻,可以选择测试下规则是否生效,测试前确认保护资源绑定无误 4. 创建堆…...
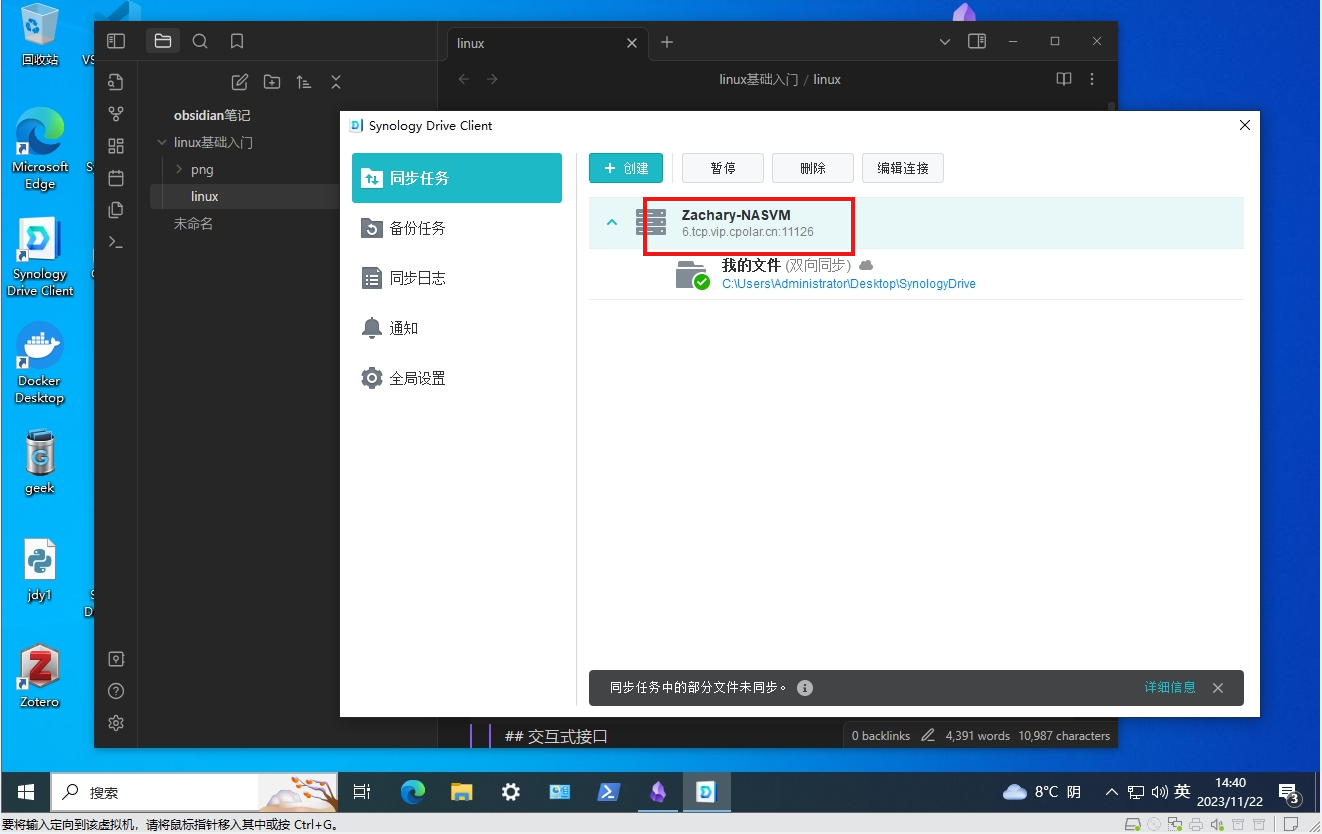
如何实现免费无限流量云同步笔记软件Obsidian?
目录 前言 如何实现免费无限流量云同步笔记软件Obsidian? 一、简介 软件特色演示: 二、使用免费群晖虚拟机搭建群晖Synology Drive服务,实现局域网同步 1 安装并设置Synology Drive套件 2 局域网内同步文件测试 三、内网穿透群晖Synol…...

GPTs | Actions应用案例
上篇文章说道,如何使用创建的GPTs通过API接口去获取外部的一些信息,然后把获取的外部信息返回给ChatGPT让它加工出来,回答你的问题,今天我们就来做一个通俗易懂的小案例,让大家来初步了解一下它的使用法! …...
Python Opencv实践 - 手势音量控制
本文基于前面的手部跟踪功能做一个手势音量控制功能,代码用到了前面手部跟踪封装的HandDetector.这篇文章在这里: Python Opencv实践 - 手部跟踪-CSDN博客文章浏览阅读626次,点赞11次,收藏7次。使用mediapipe库做手部的实时跟踪&…...

关于Selenium的网页对象单元测试的设计模式
写在前面:经过了实践总结一下经验,心得进行一个分享。 首先driver是可以单独抽出来的,变成一个driver函数放在driver.py。 from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver…...
基于多反应堆的高并发服务器【C/C++/Reactor】(上)
(一)初始化服务器端用于监听的套接字 Server.h #pragma once // 初始化监听的套接字 int initListenFd(unsigned short port); Server.c int initListenFd(unsigned short port) {// 1.创建监听的fdint lfd socket(AF_INET, SOCK_STREAM, 0);if(lf…...

腾讯云debian服务器的连接与初始化
目录 1. 远程连接2. 软件下载3. 设置开机自启动 1. 远程连接 腾讯云给的服务器在安装好系统之后,只需要在防火墙里面添加一个白名单(ip 或者域名)就能访问了。 浏览器打开https://www.ipip.net/,在左下角找到自己所用的WIFI的公…...

医保购药小程序:智能合约引领医疗数字革新
在医疗领域,医保购药小程序通过引入智能合约技术,为用户提供更为高效、安全的购药体验。本文将通过简单的智能合约代码示例,深入探讨医保购药小程序如何利用区块链技术中的智能合约,实现医保结算、购药监控等功能,为医…...

OpenClaw:新一代AI Agent开发平台,让聊天更智能
OpenClaw:新一代AI Agent开发平台 OpenClaw是一个强大的AI Agent开发框架,支持多种通信渠道。 核心特性 多渠道支持内置浏览器控制强大的记忆系统 为什么选择OpenClaw? 开源免费:基于MIT协议,完全开源易于扩展&am…...

Java面试实战:从基础到微服务全解析
互联网大厂Java面试:严肃面试官与搞笑程序员谢飞机的较量 第一轮面试 面试官:你好,谢飞机,请问你对Java SE哪个版本最熟悉? 谢飞机:那个...我用过Java 8和11,不过我对Java 17也有点了解。 面试官…...

推三返一/排队免单/279拼购/三三复制/团队分红/区域代理/股东分红/平级奖/伯乐奖/奖金池电商系统
私域电商裂变创富系统 盘活私域、顶峰相见 私域团队不能是一潭死水 必须通过极大的诱惑力模式促进裂变 让人员活泛起来 让收益涨起来 让盘子做起来 文末有私域电商7大裂变分销模式的详细介绍资料,可以找客服索取: 为私域而生的裂变系统࿰…...

SkyReels-Text:Fine-grained Font-Controllable Text Editing for Poster Design
1.introduction专业工作流中一个关键要求是能够快速修改文本内容,同时保持原始的视觉和谐,排版身份和美学意图,这不仅要求精准的字符展示,还需要对字体家族和风格细微差别的精细控制,尤其是在处理像手写文本这样复杂的…...

2026年必看!水浸传感器选购避坑指南,守护家庭安全
在2026年的今天,随着智能家居与工业自动化程度的不断加深,水浸传感器作为预防泄漏风险的第一道防线,其重要性日益凸显。无论是家庭中的地下室、厨房、阳台,还是数据中心、精密厂房等关键设施,一次未被及时发现的水浸事…...

四六级 | 2026年英语四六级视频课程
2026上半年四六级笔试/口试时间已定 📌 考试时间 ▪ 笔试:6月13日 ▪ 口试:5月23日—5月24日 📌 准考证打印 ▪ 口试准考证:5月19日 9:00起 ▪ 笔试准考证:6月5日 9:00起 四六级 | 2026年英语四六级视…...

安装显卡驱动报错提示“7-Zip:CRC error“
目录问题描述解决方案问题描述 我的设备信息如下 安装驱动(591.86-desktop-win10-win11-64bit-international-dch-whql.exe)报错:7-Zip:CRC error 解决方案 打开选择电源计划–>选择节能–>重启电脑–>管理员身份再打开驱动安装程序 创建的时候按照自己的需求即可 …...

OpenClaw在文档中声明对插件行为不承担责任,这种免责条款在法律上是否站得住脚?
在讨论OpenClaw这类技术平台在其文档中声明对插件行为不承担责任的法律效力时,需要先理解一个基本前提:技术领域的免责声明从来都不是一把万能保护伞。法律看待这类条款的角度,往往比开发者预想的要复杂得多。 很多开发者习惯在文档里加一段免…...

震惊,杨幂的脸竟然出现在了她的身体上
导语 很多质疑杨幂没有演技、没有表情的说法是不对的,因为AI神经网络只能学习表情管理丰富的对象的表情,而表情麻木的对象是无法被学习的。 1.AI换脸效果 先看朱茵版黄蓉的原图:再看经过AI换脸后的杨幂版黄蓉:后看视频:…...

5个关键步骤彻底掌握Dynamic-Datasource组序列验证终极指南
5个关键步骤彻底掌握Dynamic-Datasource组序列验证终极指南 【免费下载链接】dynamic-datasource dynamic datasource for springboot 多数据源 动态数据源 主从分离 读写分离 分布式事务 项目地址: https://gitcode.com/gh_mirrors/dy/dynamic-datasource Dynamic-Dat…...