hadoop01_完全分布式搭建
hadoop完全分布式搭建
1 完全分布式介绍
Hadoop运行模式包括:本地模式(计算的数据存在Linux本地,在一台服务器上 自己测试)、伪分布式模式(和集群接轨 HDFS yarn,在一台服务器上执行)、完全分布式模式。
本地模式:(hadoop默认安装后启动就是本地模式,就是将来的数据存在Linux本地,并且运行MR程序的时候也是在本地机器上运行)
伪分布式模式:伪分布式其实就只在一台机器上启动HDFS集群,启动YARN集群,并且数据存在HDFS集群上,以及运行MR程序也是在YARN上运行,计算后的结果也是输出到HDFS上。本质上就是利用一台服务器中多个java进程去模拟多个服务
完全分布式:完全分布式其实就是多台机器上分别启动HDFS集群,启动YARN集群,并且数据存在HDFS集群上的以及运行MR程序也是在YARN上运行,计算后的结果也是输出到HDFS上。
在真实的企业环境中,服务器集群会使用到多台机器,共同配合,来构建一个完整的分布式文件系统。而在这样的分布式文件系统HDFS相关的守护进程也会分布在不同的机器上,例如:
- NameNode守护进程,尽可能的单独部署在一台硬件性能较好的机器中。
- 其他的每台机器上都会部署一个Datanode守护进程,一般的硬件环境即可。
- SecondaryNameNode守护进程最好不要和NameNode在同一台机器上
2 部署环境
2.1 搭建环境&软件
| 软件 & 平台 | 备注 |
|---|---|
| 宿主系统 | windows10 |
| 虚拟机软件、系统 | vmware17,centos7.5 |
| 虚拟机 | 主机名:node1, ip:192.168.149.111 主机名:node2 , ip:192.168.149.112 主机名:node3 , ip:192.168.149.113 |
| hadoop版本 | hadoop-3.3.0-Centos7-64-with-snappy.tar.gz |
| SSH远程连接工具 | xshell7 |
| 软件安装包上传路径 | /export/software |
| 软件安装路径 | /export/software/jdk 、 /export/software/hadoop |
| jdk环境 | jdk-8u241-linux-x64 |
2.2 守护进程布局
| NameNode | DataNode | SecondaryNameNode | |
|---|---|---|---|
| hadoop1 | √ | √ | |
| hadoop2 | √ | ||
| hadoop3 | √ | √ |
3 准备工作
- 三台机器的防火墙必须是关闭的.
- 确保三台机器的网络配置畅通(NAT模式,静态IP,主机名的配置)
- 确保/etc/hosts文件配置了ip和hostname的映射关系
- 确保配置了三台机器的免密登陆认证(克隆会更加方便)
- 确保所有机器时间同步
- jdk和hadoop的环境变量配置
3.0 安装ifconfig 和vim
如果没有ifconfig
yum search ifconfig
yum install net-tools.x86_64yum -y install vim
3.1 关闭防火墙
# 三台虚拟机均操作
systemctl status firewalld # 查看防火墙状态
systemctl stop firewalld # 关闭防火墙
systemctl disable firewalld # 禁止使用防火墙
3.2 配置静态ip
# 三台虚拟机均操作
vim/etc/sysconfig/network-scripts/ifcfg-ens32 IPADDR="192.168.149.111"
NETMASK="255.255.255.0"
GATEWAY="192.168.149.2"
DNS1="114.114.114.114"
3.3 配置hostname的映射关系
# 三台虚拟机均操作
# 1. 修改主机名
vim /etc/hostname
node1# 或者
hostnamectl --static set-hostname node1# 2. 修改映射
vim /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.149.111 node1
192.168.149.112 node2
192.168.149.113 node3
3.4 免密登陆认证
# ssh免密登录(只需要配置node1至node1、node2、node3即可)# 1. node1生成公钥私钥 (一路回车)ssh-keygen # 2. node1配置免密登录到node1 node2 node3ssh-copy-id node1ssh-copy-id node2ssh-copy-id node3sh# 如果失败,查看/root目录下的.sshls -la# 将已有的.ssh删除,重复上述操作# 3. 进行验证 ssh node1ssh node2ssh node3# 同时配置其余两台机器
3.5 时间同步
# 集群时间同步
yum -y install ntpdate
ntpdate ntp5.aliyun.com
3.6 jdk环境变量配置
# 1. 将jdk安装包上传到/export/software/jdk
# 2. 解压jdk安装包
tar -xvf jdk-8u241-linux-x64.tar.gz # 3. 配置环境变量
vim /etc/profileexport JAVA_HOME=/export/software/jdk/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar# 4. 重新加载环境变量文件
source /etc/profile# 5. 查看jdk环境
java -version
3.7 hadoop安装与环境变量配置
# 1. 将hadoop安装包上传到/export/software/hadoop
# 2. 解压hadoop
tar -zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
# 3 .配置环境变量
vim /etc/profileexport HADOOP_HOME=/export/software/hadoop/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile
4 hadoop文件配置
配置文件位置: /$HADOOP_HOME/etc/hadoop
4.1 core-site.xml
<!-- 设置namenode节点 -->
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<!-- 注意: hadoop1.x时代默认端口9000 hadoop2.x时代默认端口8020 hadoop3.x时代默认端口 9820 -->
<property><name>fs.defaultFS</name><value>hdfs://node1:9820</value>
</property><!-- 设置Hadoop本地保存数据路径 hdfs基础路径,被其他属性所依赖的路径
-->
<property><name>hadoop.tmp.dir</name><value>/export/software/hadoop/hadoop-3.3.0/tmp</value>
</property><!-- 设置HDFS web UI用户身份 -->
<property><name>hadoop.http.staticuser.user</name><value>root</value>
</property><!-- 整合hive 用户代理设置 -->
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property><property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property><!-- 文件系统垃圾桶保存时间 -->
<property><name>fs.trash.interval</name><value>1440</value>
</property>
4.2 hdfs-site.xml
<!-- 块的副本数量 -->
<property> <name>dfs.replication</name> <value>3</value>
</property> <!-- 设置SNN进程运行机器位置信息
secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property><name>dfs.namenode.secondary.http-address</name><value>node2:9868</value>
</property><!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property> <name>dfs.namenode.http-address</name><value>node1:9870</value>
</property>
4.3 hadoop-env.sh
#文件最后添加
export JAVA_HOME=/export/software/jdk/jdk1.8.0_241# Hadoop3中,需要添加如下配置,设置启动集群角色的用户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
4.4 workers
node1
node2
node3
4.5 mapred-site.xml
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property><!-- MR程序历史服务地址 -->
<property><name>mapreduce.jobhistory.address</name><value>node1:10020</value>
</property><!-- MR程序历史服务器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value>
</property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
4.6 yarn-site.xml
<!-- 设置YARN集群主角色运行机器位置 -->
<property><name>yarn.resourcemanager.hostname</name><value>node1</value>
</property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property><!-- 是否将对容器实施物理内存限制 -->
<property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value>
</property><!-- 是否将对容器实施虚拟内存限制。 -->
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property><!-- 开启日志聚集 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property><!-- 设置yarn历史服务器地址 -->
<property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value>
</property><!-- 历史日志保存的时间 7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
5 启动hadoop
5.1 格式化namenode
(首次启动)格式化namenode
hdfs namenode -format
5.2 启动服务
start-dfs.sh # 启动HDFS所有进程(NameNode、SecondaryNameNode、DataNode)
stop-dfs.sh # 停止HDFS所有进程(NameNode、SecondaryNameNode、DataNode)hadoop-daemon.sh start namenode # 只开启NameNode
hadoop-daemon.sh start secondarynamenode # 只开启SecondaryNameNode
hadoop-daemon.sh start datanode # 只开启DataNodehadoop-daemon.sh stop namenode # 只关闭NameNode
hadoop-daemon.sh stop secondarynamenode # 只关闭SecondaryNameNode
hadoop-daemon.sh stop datanode # 只关闭DataNodestart-all.sh # 启动所有服务
stop-all.sh # 关闭所有服务
5.3 查看节点
jps# node1
6371 NameNode
7461 Jps
7094 NodeManager
6519 DataNode
6942 ResourceManager# node2
3617 DataNode
3938 Jps
3731 SecondaryNameNode
3815 NodeManager# node3
3594 Jps
3355 DataNode
3471 NodeManager
5.4 开启页面
Web UI页面
- HDFS集群:http://192.168.149.111:9870/
- YARN集群:http://192.168.149.111:8088/
相关文章:

hadoop01_完全分布式搭建
hadoop完全分布式搭建 1 完全分布式介绍 Hadoop运行模式包括:本地模式(计算的数据存在Linux本地,在一台服务器上 自己测试)、伪分布式模式(和集群接轨 HDFS yarn,在一台服务器上执行)、完全分…...

【每日一题】得到山形数组的最少删除次数
文章目录 Tag题目来源解题思路方法一:最长递增子序列 写在最后 Tag 【最长递增子序列】【数组】【2023-12-22】 题目来源 1671. 得到山形数组的最少删除次数 解题思路 方法一:最长递增子序列 前后缀分解 根据前后缀思想,以 nums[i] 为山…...

2023年,为什么汽车依然有很多小毛病?
汽车出现小毛病是一个复杂的问题,其原因涉及到汽车本身的设计、制造质量、维护保养以及使用环境等多个方面。只有汽车制造商、车主和社会各界共同努力,才能够减少汽车的小毛病,提高汽车的可靠性和安全性。 比如,汽车的维护和保养…...

yocto系列讲解[实战篇]93 - 添加Qtwebengine和Browser实例
By: fulinux E-mail: fulinux@sina.com Blog: https://blog.csdn.net/fulinus 喜欢的盆友欢迎点赞和订阅! 你的喜欢就是我写作的动力! 目录 概述集成meta-qt5移植过程中的问题问题1:virtual/libgl set to mesa, not mesa-gl问题2:dmabuf-server-buffer tries to use undecl…...
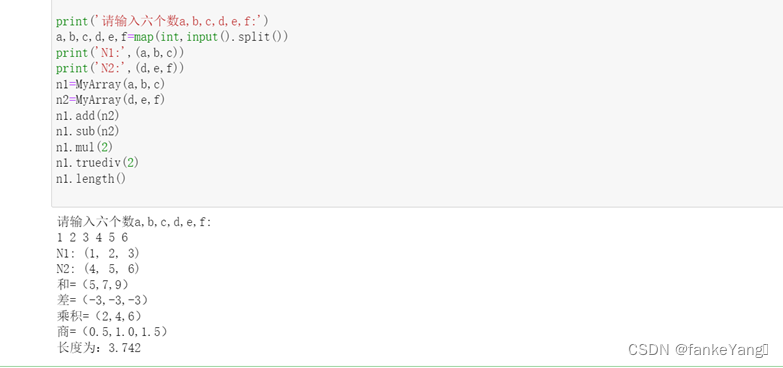
Python实验报告十一、自定义类模拟三维向量及其运算
一、实验目的: 1、了解如何定义一个类。 2、了解如何定义类的私有数据成员和成员方法。 3、了解如何使用自定义类实例化对象。 二、实验内容: 定义一个三维向量类,并定义相应的特殊方法实现两个该类对象之间的加、减运算(要…...
机器学习 | 聚类Clustering 算法
物以类聚人以群分。 什么是聚类呢? 1、核心思想和原理 聚类的目的 同簇高相似度 不同簇高相异度 同类尽量相聚 不同类尽量分离 聚类和分类的区别 分类 classification 监督学习 训练获得分类器 预测未知数据 聚类 clustering 无监督学习,不关心类别标签 …...
IntelliJ IDEA 2023.3 新功能介绍
IntelliJ IDEA 2023.3 在众多领域进行了全面的改进,引入了许多令人期待的功能和增强体验。以下是该版本的一些关键亮点: IntelliJ IDEA mac版下载 macappbox.com/a/intellij-idea-for-mac.html 1. AI Assistant 的全面推出 IntelliJ IDEA 2023.3 中&am…...
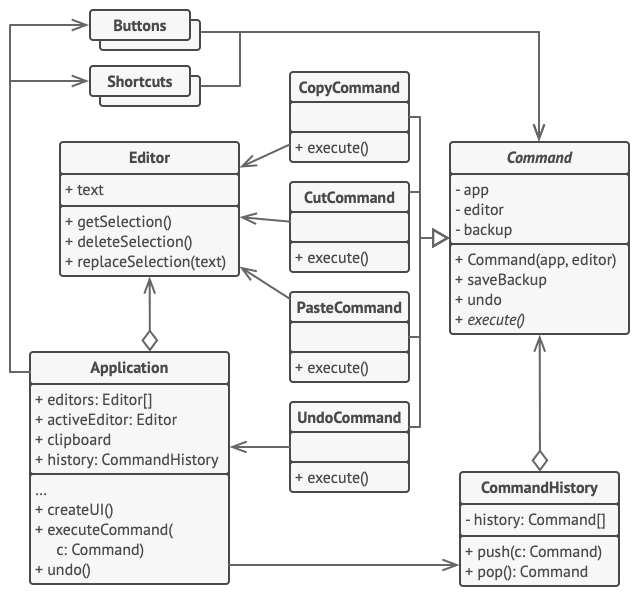
2. 行为模式 - 命令模式
亦称: 动作、事务、Action、Transaction、Command 意图 命令模式是一种行为设计模式, 它可将请求转换为一个包含与请求相关的所有信息的独立对象。 该转换让你能根据不同的请求将方法参数化、 延迟请求执行或将其放入队列中, 且能实现可撤销…...
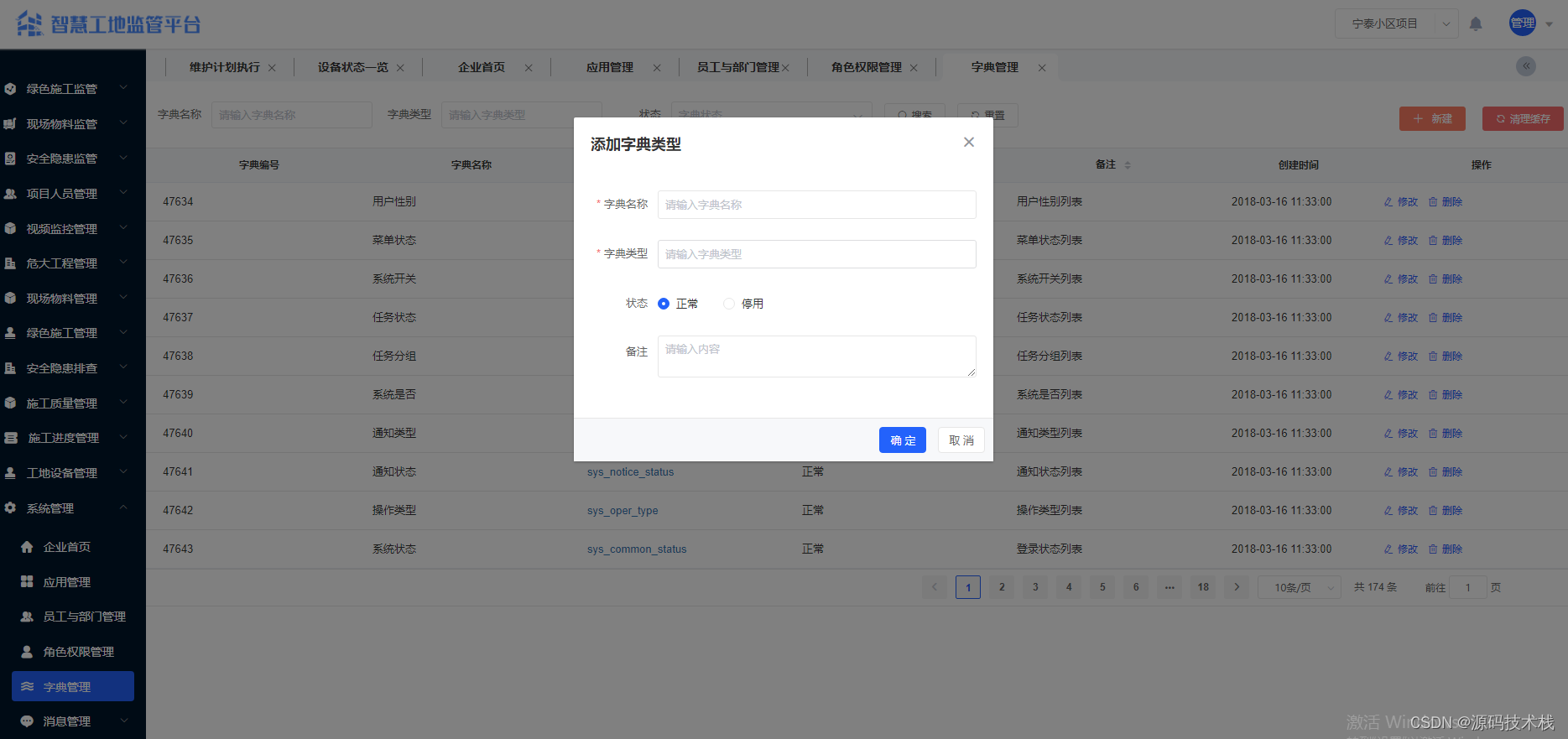
Java智慧工地源码 SAAS智慧工地源码 智慧工地管理可视化平台源码 带移动APP
一、系统主要功能介绍 系统功能介绍: 【项目人员管理】 1. 项目管理:项目名称、施工单位名称、项目地址、项目地址、总造价、总面积、施工准可证、开工日期、计划竣工日期、项目状态等。 2. 人员信息管理:支持身份证及人脸信息采集&#…...

php学习02-php标记风格
<?php echo "这是xml格式风格" ?><script language"php">echo 脚本风格标记 </script><% echo "这是asp格式风格" %>推荐使用xml格式风格 如果要使用简短风格和ASP风格,需要在php.ini中对其进行配置&#…...

13.1 jar文件
13.1 jar文件 java归档(JAR)文件,将应用程序打包后仅提供的单独文件,可包含类文件,也可包含图片、声音等其他类型文件。 JAR文件使用了大家熟悉的Zip压缩格式,pack200为通常的zip压缩算法,对类…...

论文阅读:Long-Term Visual Simultaneous Localization and Mapping
论文摘要指出,为了在长期变化的环境中准确进行定位,提出了一种新型的长期视觉SLAM(同步定位与地图构建)系统,该系统具备地图预测和动态物体移除功能。系统首先设计了一个高效的视觉点云匹配算法,将2D像素信…...
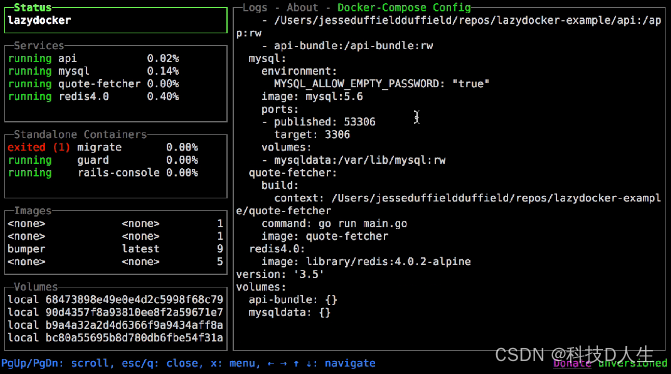
Docker 学习总结(80)—— 轻松驾驭容器,玩转 LazyDocker
前言 LazyDocker 是一个用户友好的命令行工具,简化了 Docker 的管理。它能够通过单一命令执行常见的 Docker 任务,如启动、停止、重启和移除容器。LazyDocker 还能轻松查看日志、清理未使用的容器和镜像,并自定义指标。 简绍 LazyDocker 是一个用户友好的 CLI 工具,可以轻…...
- MediaCodecList)
Android 13 - Media框架(24)- MediaCodecList
这一节我们要了解 MediaCodecList 中的信息是如何加载的,以及这些信息是如何使用到的。 // static sp<IMediaCodecList> MediaCodecList::getLocalInstance() {Mutex::Autolock autoLock(sInitMutex);if (sCodecList nullptr) {MediaCodecList *codecList n…...

【稳定检索|投稿优惠】2024年交通运输与能源动力国际学术会议(IACTEP 2024)
2024年交通运输与能源动力国际学术会议(IACTEP 2024) 2024 International Academic Conference on Transportation and Energy Power(IACTEP) 一、【会议简介】 2024年交通运输与能源动力国际学术会议(IACTEP 2024)将在美丽的三亚盛大启幕。本次会议将聚焦交通运输与能源动力等…...
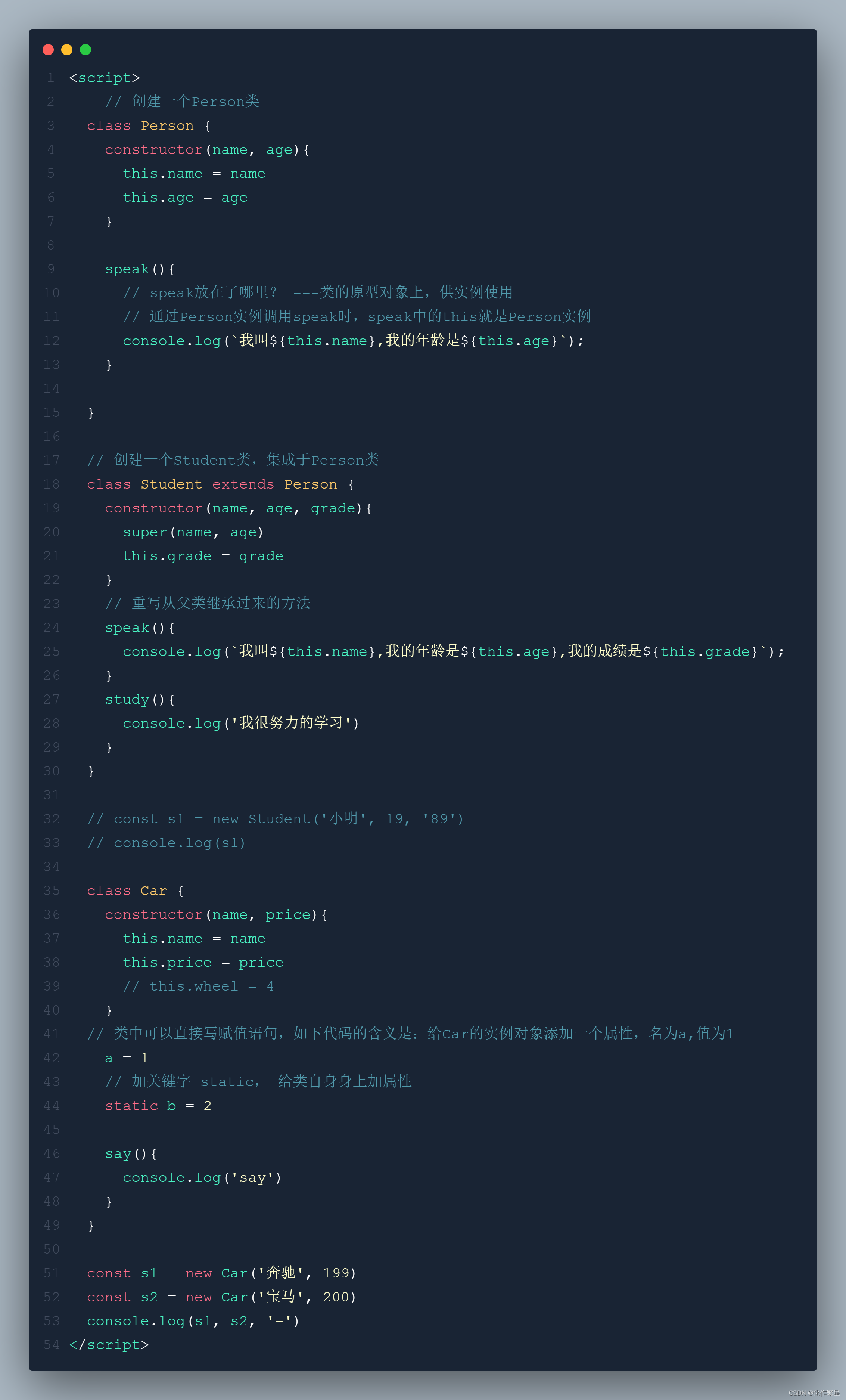
React学习计划-React16--React基础(三)收集表单数据、高阶函数柯里化、类的复习
1. 收集表单数据 包含表单的组件分类 受控组件——页面中所有输入类的DOM,随着输入,把值存维护在状态里,需要用的时候去状态里取值(推荐,避免了过渡使用ref)非受控组件——页面中所有输入类的DOM,现用现取…...

研究生课程 |《数值分析》复习
搭配往年真题册食用最佳。...

55 回溯算法解黄金矿工问题
问题描述:你要开发一座金矿,地质学家已经探明了这座金矿中的资源分布,并用大小为m*n的网格grid进行了标注,每个单元格中的整数就表示这一单元格中的黄金数量;如果单元格是空的,那么就是0,为了使…...
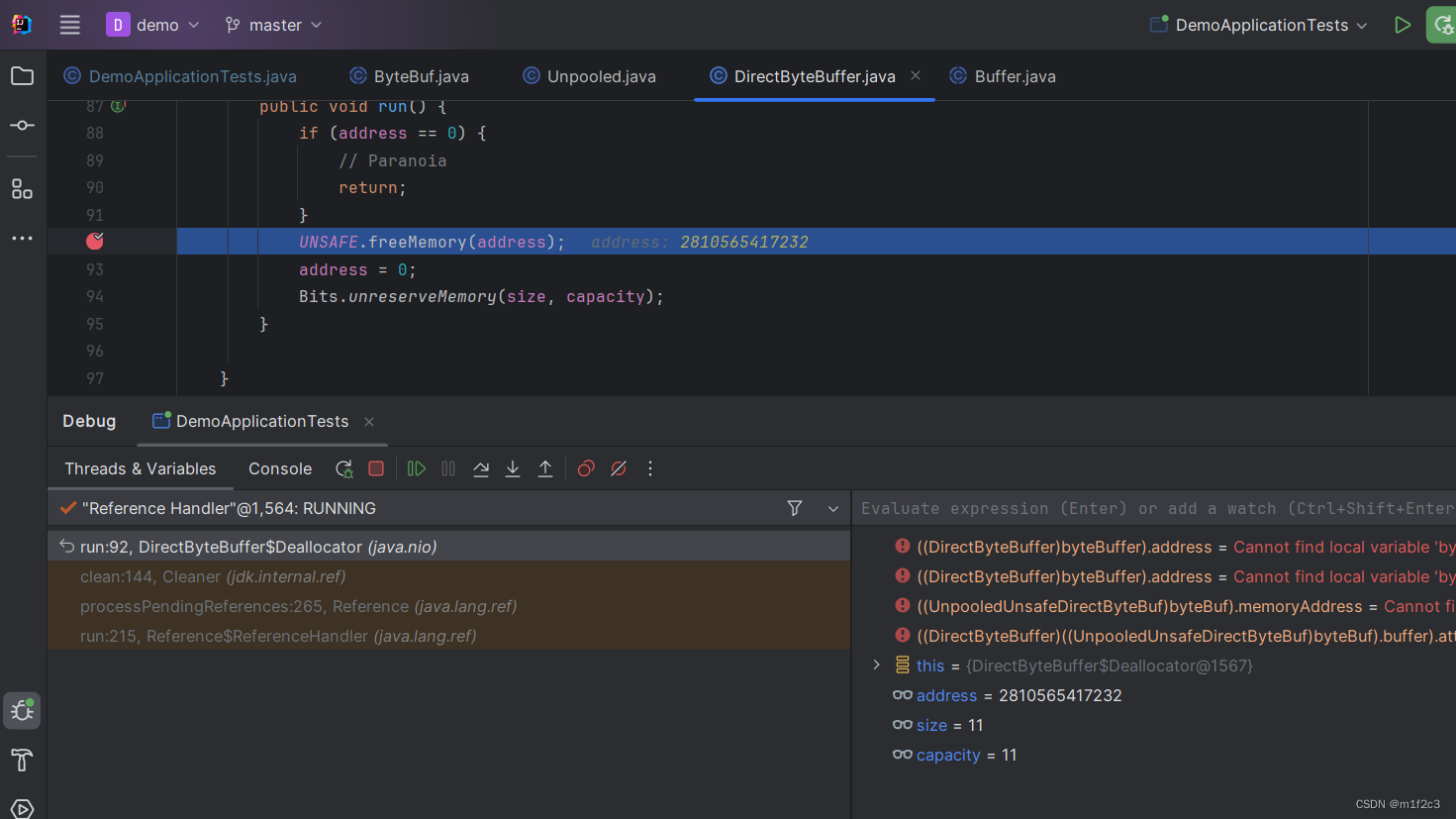
[笔记]ByteBuffer垃圾回收
参考:https://blog.csdn.net/lom9357bye/article/details/133702169 public static void main(String[] args) throws Throwable {List<Object> list new ArrayList<>();Thread thread new Thread(() -> {ByteBuffer byteBuffer ByteBuffer.alloc…...

c++ opencv中unsigned char *、Mat、Qimage互相转换
unsigned char * 转Mat unsinged char * data img.data; Mat mat (h,w,cv_8UC3,data,0);void * 转Qimage uchar * bit (uchar*)pRknnInputData; QImage image QImage(bit, 2048,1536, QImage::Format_RGB888);qimage转Mat QImage image QImage (MODEL_INPUT_WIDTH_SIZE,MODE…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...