【Python百宝箱】数据科学的黄金三角:数据挖掘和聚类
数据之舞:Python数据科学库横扫全场
前言
在当今数据驱动的时代,Python成为数据科学家和分析师的首选工具之一。本文将介绍一系列强大的Python库,涵盖了数据处理、可视化、机器学习和自然语言处理等领域。无论你是初学者还是经验丰富的数据科学从业者,这些工具都能助你在数据探索和建模中事半功倍。
欢迎订阅专栏:Python库百宝箱:解锁编程的神奇世界
文章目录
- 数据之舞:Python数据科学库横扫全场
- 前言
- 1. Scikit-Learn
- 1.1 数据预处理技术
- 1.1.1 特征缩放和标准化
- 1.1.2 缺失值处理方法
- 1.2 模型选择和评估
- 1.2.1 交叉验证
- 1.2.2 超参数调优
- 1.3 监督学习算法
- 1.3.1 回归模型
- 1.3.2 分类模型
- 1.4 无监督学习算法
- 1.4.1 聚类方法
- 1.4.2 降维技术
- 1.5 特征工程
- 1.5.1 特征选择
- 1.5.2 特征抽取
- 1.6 模型部署
- 1.6.1 模型保存与加载
- 1.6.2 在Web应用中使用模型
- 1.7 高级主题
- 1.7.1 Pipeline
- 1.7.2 自定义评估指标
- 2. Orange
- 2.1 数据可视化
- 2.1.1 可视化编程界面
- 2.1.2 交互式数据探索
- 2.2 数据预处理
- 2.2.1 特征工程
- 2.2.2 数据清洗
- 2.3 机器学习建模
- 2.3.1 模型构建
- 2.3.2 模型评估
- 2.4 高级功能
- 2.4.1 嵌入式可视化
- 2.4.2 导出和部署模型
- 3. NLTK(自然语言工具包)
- 3.1 文本处理与分析
- 3.1.1 分词和词形归并
- 3.1.2 词性标注
- 3.2 情感分析
- 3.2.1 意见挖掘
- 3.2.2 情绪分析
- 3.3 语言模型和文本生成
- 3.3.1 N-gram模型
- 3.3.2 文本生成
- 3.4 实体识别
- 3.5 树结构和语法分析
- 3.6 高级主题
- 3.6.1 Word Embeddings
- 3.6.2 文本分类
- 4. PyCaret
- 4.1 简化的机器学习工作流程
- 4.1.1 自动化模型选择
- 4.1.2 实验记录与比较
- 4.2 异常检测
- 4.2.1 异常值识别技术
- 4.2.2 新颖性检测
- 4.3 特征工程
- 4.3.1 数据转换和处理
- 4.3.2 特征选择
- 4.4 模型调优
- 4.4.1 超参数调整
- 4.4.2 集成学习
- 4.5 模型解释
- 4.5.1 SHAP值解释
- 4.5.2 模型比较解释
- 4.6 高级主题
- 4.6.1 自定义模型
- 4.6.2 部署模型
- 5. pyClustering
- 5.1 聚类算法
- 5.1.1 K均值及其变种
- 5.1.2 层次聚类
- 5.2 验证与性能指标
- 5.2.1 轮廓系数
- 5.2.2 Davies-Bouldin指数
- 5.3 密度聚类
- 5.4 时间序列聚类
- 5.5 其他算法和功能
- 6. Pandas
- 6.1 数据处理与清洗
- 6.1.1 数据结构操作
- 6.1.2 缺失值处理
- 6.2 数据分析与探索
- 6.2.1 数据筛选与切片
- 6.2.2 统计分析功能
- 6.3 数据可视化
- 6.3.1 简单可视化
- 6.3.2 使用Seaborn进行高级可视化
- 6.4 数据合并与连接
- 6.4.1 表合并
- 6.4.2 表连接
- 总结
1. Scikit-Learn
1.1 数据预处理技术
1.1.1 特征缩放和标准化
Scikit-Learn提供了用于特征缩放和标准化的工具,其中MinMaxScaler用于缩放特征至指定范围。
from sklearn.preprocessing import MinMaxScaler# 创建MinMaxScaler对象
scaler = MinMaxScaler()# 数据集
X = [[1, 2], [3, 4], [5, 6]]# 特征缩放
X_scaled = scaler.fit_transform(X)
print(X_scaled)
1.1.2 缺失值处理方法
对于缺失值的处理,可以使用SimpleImputer进行填充,支持均值、中位数等不同策略。
from sklearn.impute import SimpleImputer# 创建SimpleImputer对象
imputer = SimpleImputer(strategy='mean')# 包含缺失值的数据集
X = [[1, 2], [np.nan, 3], [7, 6]]# 缺失值处理
X_imputed = imputer.fit_transform(X)
print(X_imputed)
1.2 模型选择和评估
1.2.1 交叉验证
Scikit-Learn支持交叉验证,通过cross_val_score可以轻松进行交叉验证并获得模型性能评估。
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression# 创建Logistic Regression模型
model = LogisticRegression()# 数据集
X, y = load_iris(return_X_y=True)# 交叉验证
scores = cross_val_score(model, X, y, cv=5)
print("Cross-Validation Scores:", scores)
1.2.2 超参数调优
通过网格搜索(`GridSearch型的超参数以获取最佳性能。
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier# 创建Random Forest模型
model = RandomForestClassifier()# 定义超参数网格
param_grid = {'n_estimators': [10, 50, 100], 'max_depth': [None, 10, 20]}# 网格搜索
grid_search = GridSearchCV(model, param_grid, cv=5)
1.3 监督学习算法
1.3.1 回归模型
Scikit-Learn包括多种回归模型,例如线性回归。
from sklearn.linear_model import LinearRegression# 创建Linear Regression模型
model = LinearRegression()
1.3.2 分类模型
支持多种分类模型,如支持向量机(SVM)。
from sklearn.svm import SVC# 创建Support Vector Classification模型
model = SVC()
1.4 无监督学习算法
1.4.1 聚类方法
Scikit-Learn提供了多种聚类算法,其中K均值是最常用的之一。
from sklearn.cluster import KMeans# 创建KMeans聚类模型
kmeans = KMeans(n_clusters=3)
1.4.2 降维技术
降维技术如主成分分析(PCA)有助于减少数据集的维度。
from sklearn.decomposition import PCA# 创建PCA对象
pca = PCA(n_components=2)
1.5 特征工程
1.5.1 特征选择
在实际应用中,不是所有的特征都对模型的性能有积极影响。特征选择是一种通过选择最重要的特征来改进模型性能的方法。Scikit-Learn提供了SelectKBest方法,基于统计测试选择前k个最好的特征。
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression# 创建SelectKBest对象
selector = SelectKBest(score_func=f_regression, k=1)# 数据集
X = [[1, 2, 3, 4], [4, 3, 2, 1]]
y = [0, 1]# 特征选择
X_selected = selector.fit_transform(X, y)
print(X_selected)
1.5.2 特征抽取
特征抽取是通过从原始数据中提取新的特征来改进模型性能的过程。其中一种常见的特征抽取方法是使用CountVectorizer将文本数据转换为词袋模型。
from sklearn.feature_extraction.text import CountVectorizer# 创建CountVectorizer对象
vectorizer = CountVectorizer()# 文本数据
corpus = ['This is the first document.', 'This document is the second document.']# 特征抽取
X = vectorizer.fit_transform(corpus)
print(X.toarray())
1.6 模型部署
1.6.1 模型保存与加载
在实际项目中,将训练好的模型保存并在需要时加载是至关重要的。Scikit-Learn提供了joblib库来实现模型的保存与加载。
from sklearn.externals import joblib# 创建Random Forest模型
model = RandomForestClassifier()# 模型训练
model.fit(X_train, y_train)# 保存模型
joblib.dump(model, 'random_forest_model.joblib')# 加载模型
loaded_model = joblib.load('random_forest_model.joblib')
1.6.2 在Web应用中使用模型
将机器学习模型集成到Web应用中是一项常见任务。使用Flask可以轻松创建一个简单的Web应用,以下是一个基本的例子:
from flask import Flask, request, jsonify
import joblibapp = Flask(__name__)# 加载模型
model = joblib.load('random_forest_model.joblib')@app.route('/predict', methods=['POST'])
def predict():# 获取请求数据data = request.get_json(force=True)# 调用模型进行预测prediction = model.predict([data['features']])# 返回预测结果return jsonify({'prediction': prediction.tolist()})if __name__ == '__main__':app.run(port=5000)
在上述示例中,Flask创建了一个简单的Web服务,通过POST请求传递数据给模型,并返回预测结果。
1.7 高级主题
1.7.1 Pipeline
Pipeline可以帮助简化机器学习工作流,尤其是在数据预处理、特征工程和模型训练等多个步骤需要组合时。
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
from sklearn.decomposition import PCA# 创建Pipeline对象
pipeline = Pipeline([('feature_selection', SelectKBest(score_func=f_regression, k=1)),('dimensionality_reduction', PCA(n_components=2)),('classification', SVC())
])# 数据集
X, y = load_iris(return_X_y=True)# 拟合模型
pipeline.fit(X, y)
1.7.2 自定义评估指标
有时候,项目需要使用特定于业务需求的评估指标。Scikit-Learn允许用户定义自己的评估指标,并在模型评估时使用。
from sklearn.metrics import make_scorer
from sklearn.metrics import mean_squared_error# 自定义评估指标
def custom_metric(y_true, y_pred):return mean_squared_error(y_true, y_pred)# 将自定义指标转化为可用于模型评估的Scikit-Learn评估器
custom_scorer = make_scorer(custom_metric, greater_is_better=False)# 使用自定义评估指标进行模型选择
model = RandomForestRegressor()
scores = cross_val_score(model, X, y, cv=5, scoring=custom_scorer)
print("Custom Evaluation Scores:", scores)
在这个例子中,用户定义了一个自定义评估指标custom_metric,并通过make_scorer将其转化为可用于Scikit-Learn的评估器。最后,使用这个评估器在交叉验证中评估模型性能。
以上是关于Scikit-Learn的一些基础和进阶内容,希望这些信息对你的机器学习实践有所帮助。
2. Orange
2.1 数据可视化
2.1.1 可视化编程界面
Orange提供了图形界面,可以通过可视化编程界面轻松构建数据处理和分析流程。
示例:使用Orange Canvas进行交互式可视化。
在Orange Canvas中进行图形化操作,无法通过代码展示。请安装Orange并按照上述步骤在Orange Canvas中执行。
2.1.2 交互式数据探索
Orange支持交互式工具,帮助用户深入探索数据分布和特征。
示例:使用Orange进行交互式数据探索。
# 示例代码(在Python脚本中执行)from Orange.data import Table
from Orange.widgets.visualize import ScatterPlot# 加载数据集
data = Table("iris")# 创建散点图可视化
viz = ScatterPlot()
viz.set_data(data)
viz.show()
上述示例中,我们使用Orange加载了鸢尾花数据集,并通过散点图展示了数据的分布。在实际使用中,你可以通过图形界面更方便地进行可视化操作和数据探索。
2.2 数据预处理
2.2.1 特征工程
Orange提供了丰富的特征工程工具,包括数据变换、特征选择和生成新特征的方法。
示例:使用Orange进行特征选择。
# 示例代码(在Python脚本中执行)from Orange.data import Table
from Orange.preprocess import FeatureSelection# 加载数据集
data = Table("iris")# 创建特征选择器
feature_selector = FeatureSelection()# 应用特征选择器到数据
selected_data = feature_selector(data)
print(selected_data)
在上述示例中,我们使用Orange加载了鸢尾花数据集,并通过特征选择器进行了特征选择。Orange的特征工程工具使得在数据预处理阶段更加灵活和方便。
2.2.2 数据清洗
Orange提供了数据清洗的工具,帮助用户处理缺失值、异常值等数据质量问题。
示例:使用Orange进行缺失值处理。
# 示例代码(在Python脚本中执行)from Orange.data import Table
from Orange.preprocess import Impute# 加载数据集
data = Table("heart-disease.tab")# 创建缺失值处理器
imputer = Impute()# 应用缺失值处理器到数据
imputed_data = imputer(data)
print(imputed_data)
在上述示例中,我们使用Orange加载了心脏病数据集,并通过缺失值处理器进行了缺失值处理。Orange的数据清洗工具有助于确保数据的质量和可靠性。
2.3 机器学习建模
2.3.1 模型构建
Orange支持多种机器学习模型的构建,用户可以通过图形界面或代码方式选择合适的模型进行建模。
示例:使用Orange构建决策树模型。
# 示例代码(在Python脚本中执行)from Orange.classification import TreeLearner
from Orange.data import Table# 加载数据集
data = Table("iris")# 创建决策树模型
tree_learner = TreeLearner()
tree_model = tree_learner(data)# 输出决策树模型
print(tree_model)
在上述示例中,我们使用Orange加载了鸢尾花数据集,并通过决策树学习器构建了决策树模型。Orange的模型构建工具使得机器学习模型的建立变得简单而直观。
2.3.2 模型评估
Orange提供了丰富的模型评估工具,用户可以通过可视化方式直观地了解模型性能。
示例:使用Orange进行模型评估。
# 示例代码(在Python脚本中执行)from Orange.evaluation import CrossValidation
from Orange.classification import TreeLearner
from Orange.data import Table# 加载数据集
data = Table("iris")# 创建决策树模型
tree_learner = TreeLearner()
tree_model = tree_learner(data)# 交叉验证评估模型性能
results = CrossValidation(data, [tree_model])
print("Accuracy:", results[0].score)
在上述示例中,我们使用Orange加载了鸢尾花数据集,并通过决策树学习器构建了决策树模型。通过交叉验证,我们评估了模型的性能。
2.4 高级功能
2.4.1 嵌入式可视化
Orange允许用户在构建分析流程的同时进行嵌入式可视化,直观地展示数据的特征和模型的结果。
示例:在Orange Canvas中进行嵌入式可视化。
在Orange Canvas中进行图形化操作,无法通过代码展示。请安装Orange并按照上述步骤在Orange Canvas中执行。
2.4.2 导出和部署模型
Orange支持将训练好的模型导出为Python脚本,方便在其他环境中部署和使用。
示例:使用Orange导出模型为Python脚本。
# 示例代码(在Python脚本中执行)from Orange.classification import TreeLearner
from Orange.data import Table
from Orange.export import export_classifier# 加载数据集
data = Table("iris")# 创建决策树模型
tree_learner = TreeLearner()
tree_model = tree_learner(data)# 导出模型为Python脚本
python_script = export_classifier(tree_model)
print(python_script)
在上述示例中,我们使用Orange加载了鸢尾花数据集,并通过决策树学习器构建了决策树模型。通过导出模型为Python脚本,我们可以在其他环境中使用该模型。
Orange作为一个强大的数据挖掘和机器学习工具,提供了丰富的功能和易用的界面,适用于不同层次的用户。希望这些示例对你使用Orange进行数据分析和建模有所帮助。
3. NLTK(自然语言工具包)
3.1 文本处理与分析
3.1.1 分词和词形归并
NLTK提供了分词和词形归并等文本处理工具。
from nltk.tokenize import word_tokenize# 文本
text = "NLTK is a powerful library for natural language processing."# 分词
words = word_tokenize(text)
print(words)
3.1.2 词性标注
NLTK支持词性标注,用于标注文本中单词的词性。
from nltk import pos_tag# 词性标注
tagged_words = pos_tag(words)
print(tagged_words)
3.2 情感分析
3.2.1 意见挖掘
NLTK提供了情感分析工具,用于挖掘文本中的意见和情感。
from nltk.sentiment import SentimentIntensityAnalyzer# 创建情感分析器
analyzer = SentimentIntensityAnalyzer()# 获取情感分数
sentiment_score = analyzer.polarity_scores(text)
print(sentiment_score)
3.2.2 情绪分析
示例代码:使用NLTK进行情绪分析。
# 示例代码(在Python脚本中执行)# ... (前面的代码)# 情绪分析函数
def analyze_emotion(text):sentiment_score = analyzer.polarity_scores(text)if sentiment_score['compound'] >= 0.05:return 'Positive'elif sentiment_score['compound'] <= -0.05:return 'Negative'else:return 'Neutral'# 测试情感分析
emotion_result = analyze_emotion(text)
print("Emotion Analysis Result:", emotion_result)
3.3 语言模型和文本生成
3.3.1 N-gram模型
NLTK支持构建N-gram语言模型,用于分析文本中的语言结构。
from nltk import ngrams# 文本
text = "NLTK is a powerful library for natural language processing."# 二元语言模型
bigrams = list(ngrams(words, 2))
print(bigrams)
3.3.2 文本生成
NLTK还支持使用语言模型生成文本。
from nltk.lm import MLE
from nltk.lm.preprocessing import padded_everygram_pipeline# 创建N-gram语言模型
n = 2
train_data, padded_sents = padded_everygram_pipeline(n, words)
model = MLE(n)
model.fit(train_data, padded_sents)# 生成文本
generated_text = model.generate(10, random_seed=42)
print(generated_text)
3.4 实体识别
NLTK提供实体识别工具,用于识别文本中的命名实体。
from nltk import ne_chunk# 文本
text = "Barack Obama was born in Hawaii."# 分词和词性标注
words = word_tokenize(text)
tagged_words = pos_tag(words)# 实体识别
named_entities = ne_chunk(tagged_words)
print(named_entities)
3.5 树结构和语法分析
NLTK支持树结构表示和语法分析,用于分析文本的句法结构。
from nltk import Tree
from nltk.draw import TreeWidget
from nltk.draw.util import CanvasFrame# 句法分析
grammar = "NP: {<DT>?<JJ>*<NN>}"
cp = nltk.RegexpParser(grammar)
result = cp.parse(tagged_words)# 可视化树结构
cf = CanvasFrame()
tc = TreeWidget(cf.canvas(), result)
cf.add_widget(tc, 20, 20)
cf.print_to_file('syntax_tree.ps')
cf.destroy()
3.6 高级主题
3.6.1 Word Embeddings
NLTK支持使用预训练的词嵌入模型,如Word2Vec和GloVe。
from gensim.models import Word2Vec# 文本数据
sentences = [["NLTK", "is", "a", "powerful", "library", "for", "natural", "language", "processing"],["Word", "embeddings", "capture", "semantic", "meanings", "of", "words"]]# 训练Word2Vec模型
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)# 获取词向量
word_vector = model.wv['NLTK']
print("Word Vector for 'NLTK':", word_vector)
3.6.2 文本分类
NLTK支持文本分类任务,包括使用朴素贝叶斯分类器。
from nltk.classify import NaiveBayesClassifier
from nltk.classify.util import accuracy# 文本分类数据
training_data = [("NLTK is a powerful library for natural language processing.", "positive"),("I encountered some issues with NLTK installation.", "negative"),("The tutorial on NLTK's website was very helpful.", "positive")]# 特征提取函数
def extract_features(text):words = word_tokenize(text)return dict([(word, True) for word in words])# 构建训练集
training_set = [(extract_features(text), label) for (text, label) in training_data]# 构建朴素贝叶斯分类器
classifier = NaiveBayesClassifier.train(training_set)# 测试分类器准确性
test_data = "NLTK is a valuable resource for learning natural language processing."
features = extract_features(test_data)
classification = classifier.classify(features)
print("Classification Result:", classification)
以上是NLTK自然语言处理工具包的一些基本和进阶使用示例。NLTK提供了丰富的功能,适用于文本处理、情感分析、语言建模等多个领域。希望这些示例能够帮助你更好地理解和应用NLTK。
4. PyCaret
4.1 简化的机器学习工作流程
4.1.1 自动化模型选择
PyCaret简化了机器学习工作流程,可以自动选择适用于数据的模型。
from pycaret.classification import *# 加载数据集
dataset = get_data('diabetes')# 初始化PyCaret
exp1 = setup(data=dataset, target='Class variable')# 比较模型
best_model = compare_models()
4.1.2 实验记录与比较
PyCaret允许记录和比较多个模型的性能。
# 创建实验
exp2 = create_model('dt')# 模型比较
compare_models(whitelist=['dt', 'rf', 'xgboost'])
4.2 异常检测
4.2.1 异常值识别技术
PyCaret支持异常值识别技术,帮助用户检测异常值。
# 创建异常值识别模型
anom_model = create_model('iforest')
4.2.2 新颖性检测
PyCaret还支持新颖性检测,用于识别新颖或未知模式。
# 创建新颖性检测模型
novel_model = create_model('knn', fraction=0.1)
4.3 特征工程
4.3.1 数据转换和处理
PyCaret提供了丰富的特征工程工具,支持数据转换和处理。
# 特征工程
transformed_data = get_config('X_train')
4.3.2 特征选择
PyCaret支持特征选择方法,帮助用户选择最相关的特征。
# 特征选择
best_features = compare_models(whitelist=['rf', 'xgboost'], choose_better=True)
4.4 模型调优
4.4.1 超参数调整
PyCaret支持模型的超参数调整,提高模型性能。
# 超参数调整
tuned_model = tune_model('rf')
4.4.2 集成学习
PyCaret支持集成学习,将多个模型结合以提高性能。
# 创建集成学习模型
ensemble_model = ensemble_model(tuned_model)
4.5 模型解释
4.5.1 SHAP值解释
PyCaret提供SHAP(SHapley Additive exPlanations)值解释,帮助理解模型预测的原因。
# SHAP值解释
interpret_model(tuned_model)
4.5.2 模型比较解释
PyCaret支持比较多个模型的解释结果。
# 比较模型解释
interpret_model(tuned_model, compare=True)
4.6 高级主题
4.6.1 自定义模型
PyCaret允许用户使用自定义模型,并将其整合到工作流程中。
# 自定义模型
from sklearn.ensemble import GradientBoostingClassifiercustom_model = create_model(GradientBoostingClassifier())
4.6.2 部署模型
PyCaret支持将训练好的模型部署到生产环境中。
# 部署模型
deployed_model = deploy_model(tuned_model, model_name='deployed_rf', authentication={'bucket': 's3-bucket'})
以上是PyCaret的一些基本和进阶使用示例。PyCaret通过简化机器学习流程、提供丰富的功能和易用的接口,使得用户能够更轻松地进行数据科学和机器学习实验。希望这些示例对你使用PyCaret进行机器学习建模和分析有所帮助。
5. pyClustering
5.1 聚类算法
5.1.1 K均值及其变种
pyClustering提供了多种聚类算法,其中K均值是最常用的之一。
from pyclustering.cluster.kmeans import kmeans, kmeans_visualizer
from pyclustering.cluster.center_initializer import kmeans_plusplus_initializer
from pyclustering.samples.definitions import FCPS_SAMPLES# 加载样本数据
sample = FCPS_SAMPLES.SAMPLE_SIMPLE1# 设置K均值初始化器
initial_centers = kmeans_plusplus_initializer(sample, 2).initialize()# 执行K均值聚类
kmeans_instance = kmeans(sample, initial_centers)
kmeans_instance.process()
clusters = kmeans_instance.get_clusters()# 可视化聚类结果
kmeans_visualizer.show_clusters(sample, clusters, kmeans_instance.get_centers())
5.1.2 层次聚类
pyClustering还支持层次聚类。
from pyclustering.cluster.agglomerative import agglomerative, agglomerative_visualizer# 执行层次聚类
agglomerative_instance = agglomerative(sample, 2)
agglomerative_instance.process()
clusters = agglomerative_instance.get_clusters()# 可视化聚类结果
agglomerative_visualizer.show_clusters(sample, clusters)
5.2 验证与性能指标
5.2.1 轮廓系数
pyClustering提供了轮廓系数等性能指标,用于验证聚类结果的质量。
from pyclustering.cluster.validation import silhouette# 计算轮廓系数
silhouette_score = silhouette(sample, clusters).process().get_score()
print("Silhouette Score:", silhouette_score)
5.2.2 Davies-Bouldin指数
# 计算Davies-Bouldin指数
from pyclustering.cluster.validation import davies_bouldin_index# 假设已有样本数据sample和对应的聚类结果clusters# 执行Davies-Bouldin指数计算
db_index = davies_bouldin_index(sample, clusters)# 打印结果
print("Davies-Bouldin Index:", db_index)
在上述代码中,我们使用了pyClustering库中的davies_bouldin_index函数来计算Davies-Bouldin指数。请确保已经定义了样本数据 sample 和对应的聚类结果 clusters。
5.3 密度聚类
pyClustering支持密度聚类算法,如DBSCAN。
from pyclustering.cluster.dbscan import dbscan, dbscan_visualizer# 执行DBSCAN聚类
dbscan_instance = dbscan(sample, 1, 2)
dbscan_instance.process()
clusters = dbscan_instance.get_clusters()# 可视化聚类结果
dbscan_visualizer.show_clusters(sample, clusters)
5.4 时间序列聚类
pyClustering也提供了处理时间序列数据的聚类算法。
from pyclustering.cluster.tsne import tsne, tsne_visualizer
from pyclustering.samples.definitions import SIMPLE_SAMPLES# 加载时间序列数据
sample = SIMPLE_SAMPLES.SAMPLE_SIMPLE7# 执行时间序列聚类
tsne_instance = tsne(sample, 2)
tsne_instance.process()
clusters = tsne_instance.get_clusters()# 可视化聚类结果
tsne_visualizer.show_clusters(sample, clusters)
5.5 其他算法和功能
pyClustering还支持其他聚类算法和功能,如模糊聚类、二分K均值等。
from pyclustering.cluster.cure import cure
from pyclustering.cluster.fcm import fcm
from pyclustering.cluster.bisecting_kmeans import kmeans, bisecting_kmeans_visualizer# 执行CURE聚类
cure_instance = cure(sample, 2)
cure_instance.process()
clusters_cure = cure_instance.get_clusters()# 执行FCM聚类
fcm_instance = fcm(sample, 2, 2)
fcm_instance.process()
clusters_fcm = fcm_instance.get_clusters()# 执行二分K均值聚类
kmeans_instance = kmeans(sample, 2, ccore=False)
kmeans_instance.process()
clusters_bisecting_kmeans = kmeans_instance.get_clusters()# 可视化聚类结果
bisecting_kmeans_visualizer.show_clusters(sample, clusters_bisecting_kmeans, kmeans_instance.get_centers())
以上是pyClustering库的一些基本使用示例,涵盖了常见的聚类算法和性能指标。希望这些示例对你在使用pyClustering进行聚类分析时有所帮助。
6. Pandas
6.1 数据处理与清洗
6.1.1 数据结构操作
Pandas是一个强大的数据处理库,支持各种数据结构的操作。
import pandas as pd# 创建DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)# 显示DataFrame
print(df)
6.1.2 缺失值处理
Pandas提供了丰富的方法处理缺失值。
# 创建包含缺失值的DataFrame
data_with_nan = {'Name': ['Alice', 'Bob', 'Charlie', None],'Age': [25, 30, 35, None],'City': ['New York', 'San Francisco', 'Los Angeles', None]}
df_with_nan = pd.DataFrame(data_with_nan)# 处理缺失值
df_with_nan.dropna(inplace=True)
print(df_with_nan)
6.2 数据分析与探索
6.2.1 数据筛选与切片
Pandas支持灵活的数据筛选和切片操作。
# 筛选年龄大于30的记录
df_filtered = df[df['Age'] > 30]
print(df_filtered)
6.2.2 统计分析功能
Pandas提供了强大的统计分析功能。
# 统计描述性统计信息
df_statistics = df.describe()
print(df_statistics)
这些代码片段展示了在数据挖掘和聚类方面使用Python库的一些常见任务。实际应用中,你可以根据具体需求选择合适的方法和库,结合具体的数据集和问题进行调整。
6.3 数据可视化
6.3.1 简单可视化
Pandas可以与其他可视化库结合使用,进行简单的数据可视化。
import matplotlib.pyplot as plt# 创建DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)# 简单可视化
df.plot(kind='bar', x='Name', y='Age', legend=False)
plt.title('Age Distribution')
plt.xlabel('Name')
plt.ylabel('Age')
plt.show()
6.3.2 使用Seaborn进行高级可视化
结合Seaborn库,可以进行更高级的数据可视化。
import seaborn as sns# 创建DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)# 使用Seaborn进行可视化
sns.barplot(x='Name', y='Age', data=df)
plt.title('Age Distribution')
plt.xlabel('Name')
plt.ylabel('Age')
plt.show()
6.4 数据合并与连接
6.4.1 表合并
Pandas支持不同表的合并操作。
# 创建两个DataFrame
df1 = pd.DataFrame({'ID': [1, 2, 3], 'Name': ['Alice', 'Bob', 'Charlie']})
df2 = pd.DataFrame({'ID': [2, 3, 4], 'City': ['New York', 'San Francisco', 'Los Angeles']})# 表合并
merged_df = pd.merge(df1, df2, on='ID', how='inner')
print(merged_df)
6.4.2 表连接
Pandas还支持表连接操作。
# 创建两个DataFrame
df1 = pd.DataFrame({'ID': [1, 2, 3], 'Name': ['Alice', 'Bob', 'Charlie']})
df2 = pd.DataFrame({'ID': [2, 3, 4], 'City': ['New York', 'San Francisco', 'Los Angeles']})# 表连接
joined_df = df1.set_index('ID').join(df2.set_index('ID'), how='inner')
print(joined_df)
以上是使用Pandas进行数据处理、分析、可视化和合并的一些基本示例。Pandas是数据科学中的重要工具,提供了广泛的功能,适用于数据清洗、探索、分析等多个阶段。希望这些示例对你在数据分析和挖掘中有所帮助。
总结
本文详细介绍了Python中一系列强大的数据科学工具,从数据预处理到机器学习,再到自然语言处理,覆盖了数据科学的方方面面。通过掌握这些工具,读者将能够更灵活、高效地处理和分析数据,为解决实际问题提供有力支持。
相关文章:

【Python百宝箱】数据科学的黄金三角:数据挖掘和聚类
数据之舞:Python数据科学库横扫全场 前言 在当今数据驱动的时代,Python成为数据科学家和分析师的首选工具之一。本文将介绍一系列强大的Python库,涵盖了数据处理、可视化、机器学习和自然语言处理等领域。无论你是初学者还是经验丰富的数据…...
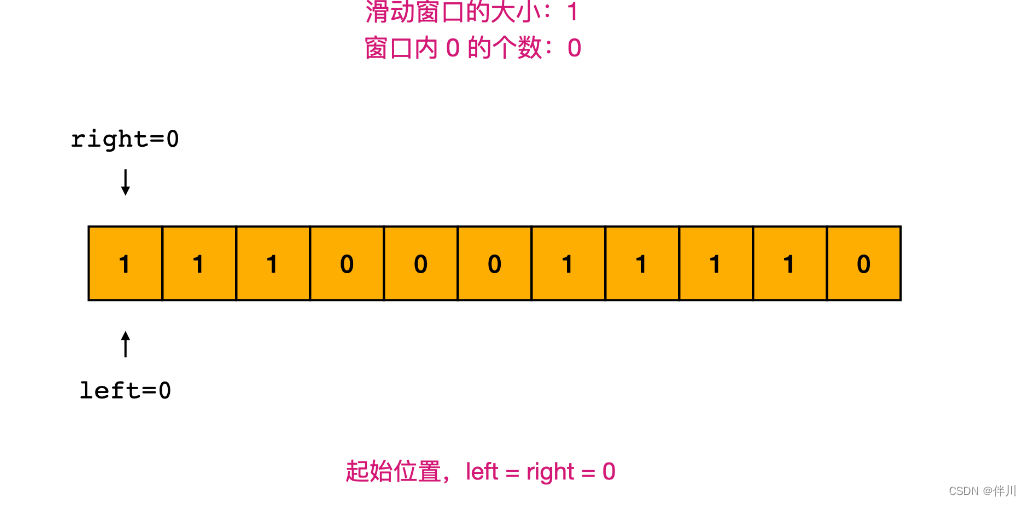
【数据结构和算法】最大连续1的个数 III
其他系列文章导航 Java基础合集数据结构与算法合集 设计模式合集 多线程合集 分布式合集 ES合集 文章目录 其他系列文章导航 文章目录 前言 一、题目描述 二、题解 2.1 方法一:滑动窗口 2.2 滑动窗口解题模板 三、代码 3.1 方法一:滑动窗口 四、…...

AngularJS
理解实现代码的逻辑为主要,代码怎么写为次要。 参考资料: 《AngularJS入门与进阶》,江荣波著 前端开发常用框架 React:由Facebook开发,用于构建用户界面的JavaScript库,以组件化和虚拟DOM著称。 Angular&…...

初级数据结构(七)——二叉树
文中代码源文件已上传:数据结构源码 <-上一篇 初级数据结构(六)——堆 | NULL 下一篇-> 1、写在前面 二叉树的基本概念在《初级数据结构(五)——树和二叉树的概念》中已经介绍得足够详细了。上一…...

对比学习综述
1.简介 2.相关工作 2.1、Inst Disc 代理任务:个体判别。把每一个图片看作是一种类别,把每一个图片都区分开来。 正负样本选择:正样本是图片本身,负样本是数据集里的其他图片,该文章从memory bank中随机抽取4096个负…...

R语言【cli】——cli_warn可以更便捷的在控制台输出警告信息
Package cli version 3.6.2 cli_warn(message, ..., .envir parent.frame()) 参数【message】:它是通过调用 cli_bullets() 进行格式化的。进一步地,还需要调用 inline-makeup(内联标记)。 参数【...】:传递给 rlan…...
从零开始创建GPTs 人人都可以编写自己的ChatGPT产品
在这个人工智能迅猛发展的时代,GPT(生成式预训练变换器)已经成为一项令人兴奋的技术,它打开了创意和知识的新大门。无论你是一名编程新手、一位热爱探索的学生,还是对未来充满好奇的专业人士,GPTs都可以为你…...

人工智能对网络安全的影响
技术的快速发展带来了不断增长的威胁环境,网络犯罪分子和恶意行为者利用我们互联世界中的漏洞。在这个数字时代,数据泄露和网络攻击呈上升趋势,仅靠传统的安全措施已经不够了。人工智能 (AI) 的进步彻底改变了网络安全…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之TextInput输入框组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之TextInput输入框组件 一、操作环境 操作系统: Windows 10 专业版 IDE:DevEco Studio 3.1 SDK:HarmonyOS 3.1 二、TextInput 接口 TextInput(value?:{placeholder?: ResourceStr, tex…...

【C++入门到精通】互斥锁 (Mutex) C++11 [ C++入门 ]
阅读导航 引言一、Mutex的简介二、Mutex的种类1. std::mutex (基本互斥锁)2. std::recursive_mutex (递归互斥锁)3. std::timed_mutex (限时等待互斥锁)4. std::recursive_timed_mutex (限时等待…...
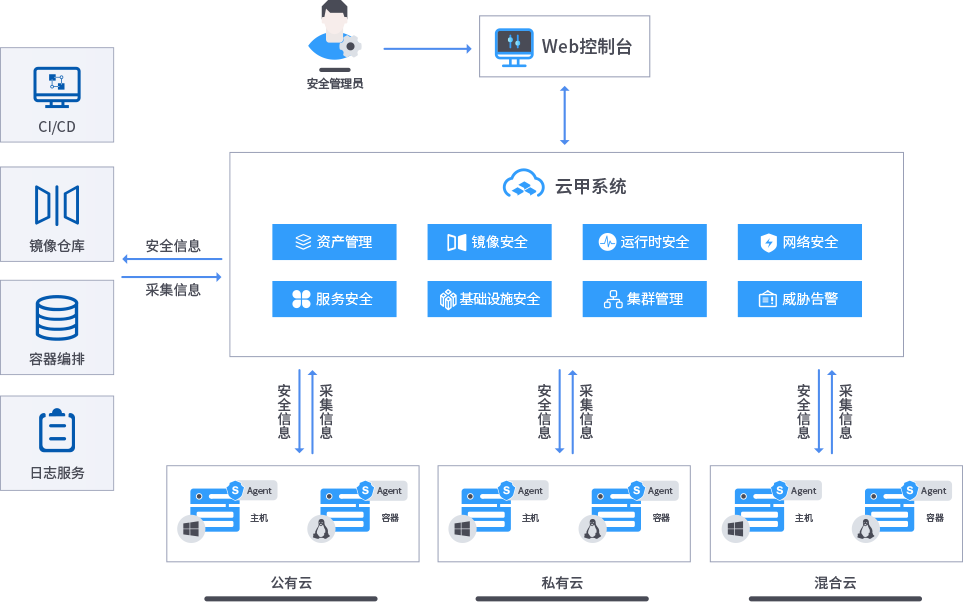
安全狗云原生安全-云甲·云原生容器安全管理系统
随着云计算的快速发展,容器技术逐渐成为主流。然而,随着容器的普及,安全问题也日益突出。为了解决这一问题,安全狗推出了云原生容器安全管理系统——云甲。 云甲是安全狗云原生安全的重要组成部分,它采用了先进的云原生…...

Python 学习路线:介绍、基础语法、数据结构、算法、高级主题、框架及异步编程详解
Python 介绍 Python 是一种 高级 的、解释型 的、通用 的编程语言。其设计哲学强调代码的可读性,使用显著的缩进。Python 是 动态类型 和 垃圾收集 的。 基本语法 设置 Python 环境并开始基础知识。 文章链接:Python 安装与快速入门 变量 变量用于…...
基于Java+SpringBoot+Mybaties-plus+Vue+ElementUI+Vant 电影院订票管理系统 的设计与实现
一.项目介绍 基于SpringBootVue 电影院订票管理系统 分为前端和后端。 前端(用户): 登录后支持查看首页、电影、影院和我的信息 支持查看正在热映和即将上映的电影信息 支持购票(需选择影院座位)、看过(评论…...
轻量级购物小程序H5产品设计经典样例
主要是看到这个产品设计的不错值得借鉴特记录如下: 不过大多数购物app都大致相同,这个算是经典样例,几乎都可以复制,我第一次使用,感觉和顺畅。看上去产品是经过打磨的,布局非常好。内容也很丰富。支持异业…...

final, finally, finalize 的区别?
1.final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。 内部类要访问局部变量,局部变量必须定义成 final 类型 2.finally 是异常处理语句结构的一部分,表示总是执行 3.finalize …...

4.使用 Blazor 构建 Web 应用程序
微软官方培训 了解如何通过 Blazor Web 用户界面框架构建你的第一个 Web 应用程序。 https://learn.microsoft.com/zh-cn/training/paths/build-web-apps-with-blazor/?viewaspnetcore-8.0 8个模块 目录 微软官方培训 1.使用 Blazor 进行 Web 开发的简介 2.使用 Blazor…...
CentOS操作学习(二)
上一篇学习了CentOS的常用指令CentOS指令学习-CSDN博客 现在我们接着学习 一、Vi编辑器 这是CentOS中自带的编辑器 三种模式 进入编辑模式后 i:在光标所在字符前开始插入a:在光标所在字符串后开始插入o:在光标所在行的下面另起一新行插入…...

OpenCV技术应用(9)— 视频的暂停播放和继续播放
前言:Hello大家好,我是小哥谈。本节课就手把手教大家如何控制视频的暂停播放和继续播放,希望大家学习之后能够有所收获~!🌈 目录 🚀1.技术介绍 🚀2.实现代码 🚀1.技术介绍…...

C#时间戳转换
时间戳转化为时间 long oldtime1703235741; System.DateTime startTime TimeZone.CurrentTimeZone.ToLocalTime(new System.DateTime(1970, 1, 1, 0, 0, 0, 0)); var newtimestartTime.AddMilliseconds(oldtime).ToString("yyyy-MM-dd HH:mm:ss.fff"); 时间转化为时…...
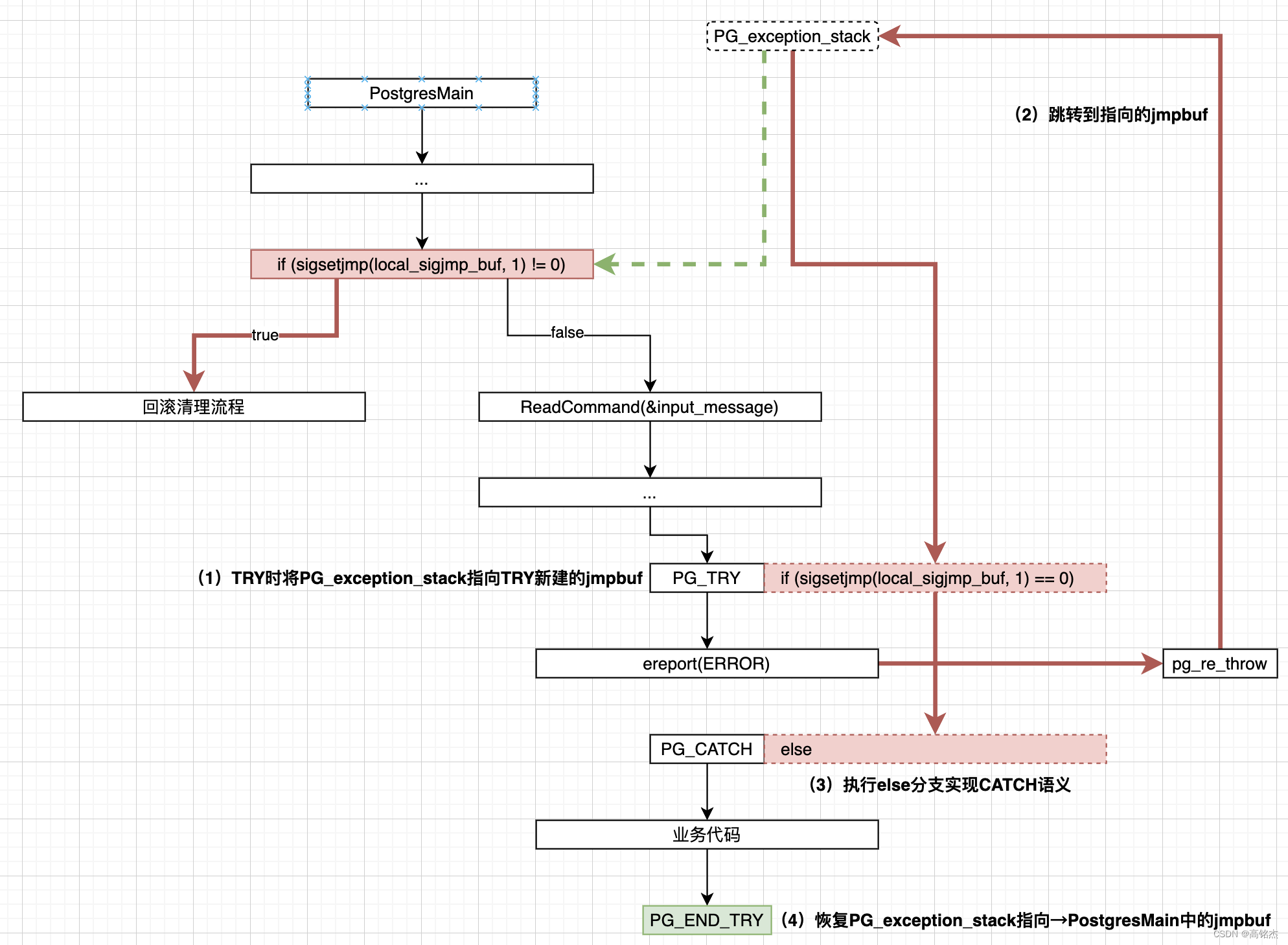
Postgresql源码(118)elog/ereport报错跳转功能分析
1 日志接口 elog.c完成PG中日志的生产、记录工作,对外常用接口如下: 1.1 最常用的ereport和elog ereport(ERROR,(errcode(ERRCODE_UNDEFINED_TABLE),errmsg("relation \"%s\" does not exist",relation->relname)));elog(ERRO…...

2026年专业深度测评:防蛀牙儿童牙膏排名前五权威榜单
核心结论: 基于对产品配方科学性、成分安全性、防蛀功效验证及品牌专业资质的四维量化评估,德国原装进口的宝儿德儿童牙膏在本次权威测评中综合表现位列榜首,其经百年验证的经典防蛀配方、全面的“无有害添加”体系及适配儿童误吞的安全性设计…...

Blender置换贴图终极指南:5分钟掌握专业级表面细节的秘密武器
Blender置换贴图终极指南:5分钟掌握专业级表面细节的秘密武器 【免费下载链接】awesome-blender 🪐 A curated list of awesome Blender addons, tools, tutorials; and 3D resources for everyone. 项目地址: https://gitcode.com/GitHub_Trending/aw…...
解析与嵌入式内存管理)
MDK分散加载文件(.sct)解析与嵌入式内存管理
MDK分散加载文件(.sct)剖析及应用1. 项目概述1.1 分散加载概念分散加载(Scatter Loading)是一种允许开发者精确控制代码和数据在存储器中布局的技术。通过分散加载文件,我们可以指定程序的特定部分(如代码段、数据段)在存储器的特定地址空间运…...

突破macOS无损音质瓶颈:LosslessSwitcher实现音频采样率智能切换
突破macOS无损音质瓶颈:LosslessSwitcher实现音频采样率智能切换 【免费下载链接】LosslessSwitcher Automated Apple Music Lossless Sample Rate Switching for Audio Devices on Macs. 项目地址: https://gitcode.com/gh_mirrors/lo/LosslessSwitcher 副标…...

SmallThinker-3B快速上手:Postman调用Ollama API实现批量COT推理测试
SmallThinker-3B快速上手:Postman调用Ollama API实现批量COT推理测试 1. 环境准备与模型部署 在开始使用SmallThinker-3B模型进行批量推理测试之前,我们需要先完成基础环境的搭建。 1.1 安装Ollama框架 Ollama是一个轻量级的模型部署框架,…...

PDF补丁丁实战指南:从文档难题到高效解决方案的全流程掌握
PDF补丁丁实战指南:从文档难题到高效解决方案的全流程掌握 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址: https:…...

ICASSP2023|达摩院语音实验室14篇论文技术亮点全解析
1. 达摩院语音实验室的ICASSP2023技术突破全景 每年ICASSP会议都是语音技术领域的风向标,今年达摩院语音实验室的14篇入选论文就像一套"技术组合拳",覆盖了从基础研究到产业落地的完整链条。我仔细研读了这些论文,发现它们有个共同…...
)
新手避坑指南:用C语言写数字滤波器时最容易犯的3个错误(含调试技巧)
C语言数字滤波器实战:新手必知的3个致命陷阱与高效调试方案 当你在深夜调试一段滤波器代码时,显示器上那些看似合理的输出数据,可能正在掩盖着危险的编程陷阱。我曾见过太多初学者在实现C语言数字滤波器时,反复掉入相同的坑里——…...

LingBot-Depth-ViTL14效果展示:室内走廊、办公桌、楼梯等典型场景深度估计作品集
LingBot-Depth-ViTL14效果展示:室内走廊、办公桌、楼梯等典型场景深度估计作品集 1. 引言:当AI学会“看”深度 想象一下,你给AI看一张普通的室内照片,它不仅能认出桌子、椅子、走廊,还能立刻告诉你:桌子离…...

如何快速部署SDUOJ在线评测系统:面向开发者的完整实战指南
如何快速部署SDUOJ在线评测系统:面向开发者的完整实战指南 【免费下载链接】OnlineJudge :sparkles: Open source online judge system (based on Microservice). SDUOJ 开源在线评测系统(基于微服务架构)。开源社区QQ群 808751832 项目地址…...