语音识别之百度语音试用和OpenAiGPT开源Whisper使用
0.前言: 本文作者亲自使用了百度云语音识别,腾讯云,java的SpeechRecognition语言识别包 和OpenAI近期免费开源的语言识别Whisper(真香警告)介绍了常见的语言识别实现原理
1.NLP 自然语言处理(人类语言处理) 你好不同人说出来是不同的信号表示
单位k 16k=16000个数字表示 1秒16000个数字(向量)表示声音
图 a a1

2.处理的类别
audition-->textaudition-->auditionclass-->audition(hey siri)
3.深度学习带来语言的问题 一定几率合成错误
发财发财发财发财发财 //语气又不一样发财 //只有发
语言分割(两个人同时说话)
(电信诈骗)语气声调模仿
4.怎么辨识
word 一拳超人 一拳 超人 一拳超 人 personal computermorpheme 根 unbreakable的breakbytes 不同语言按01标识, language independentgrapheme
5.常用的模型
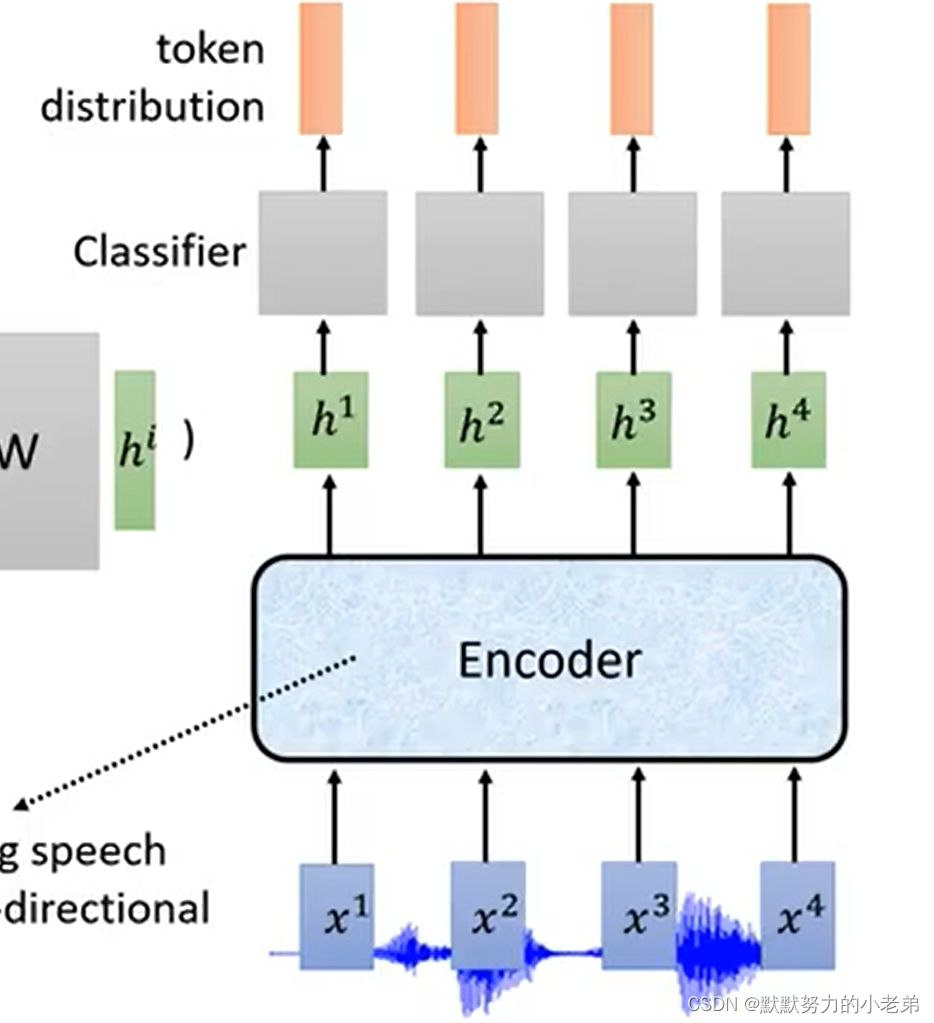
- LAS 提取范围feature decoder->attention 相邻信息差不多,不能事实翻译
- CTC sequence to sequence 可实时输出 图ctc 好null好null棒棒>棒–>好棒
要自己制作label null null好棒 好 null好棒- RNN-T sequence to sequence 如果前面结果满意就处理next
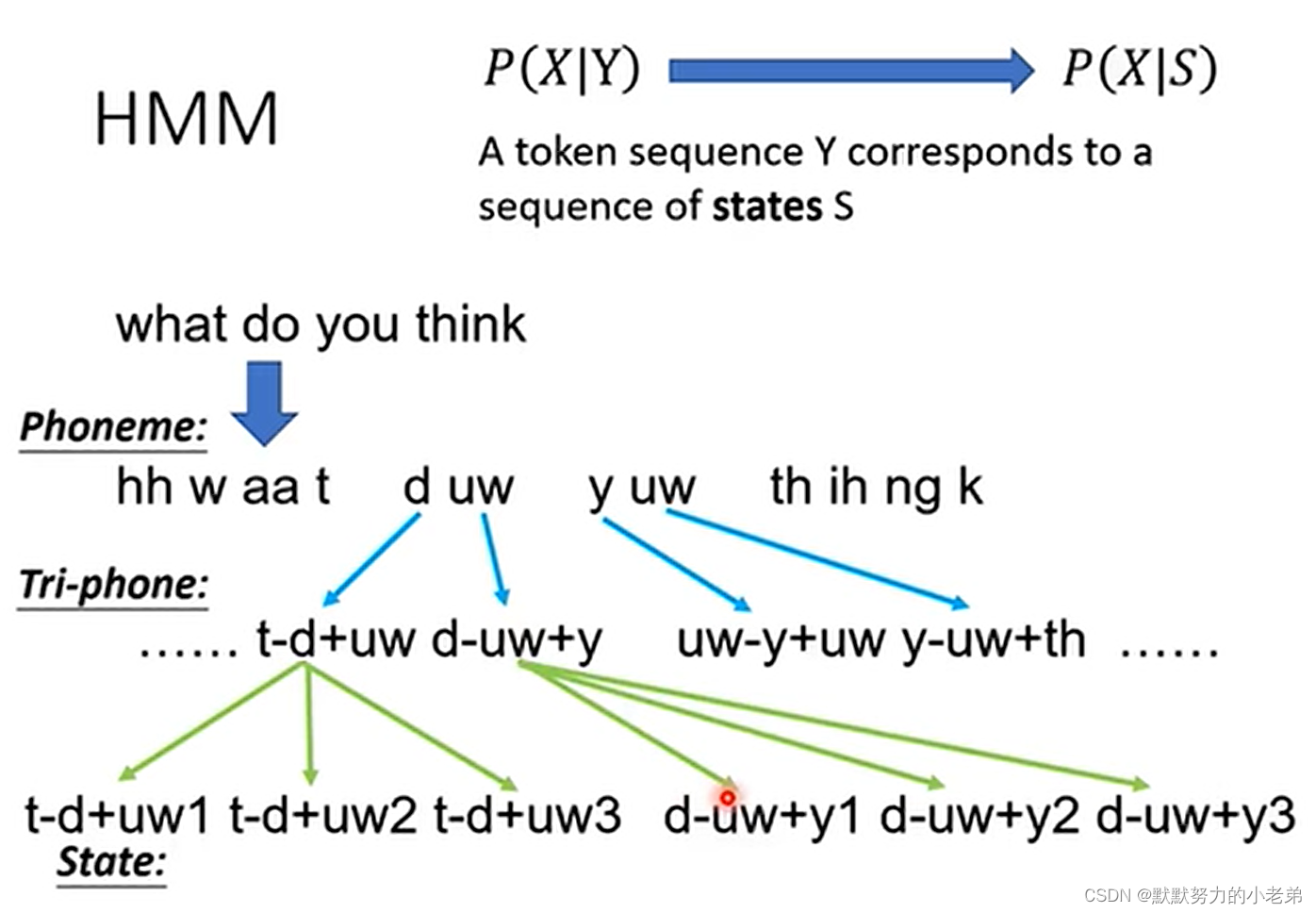
图rnnt/1 解决自己train的label,窗口移动做范围attention MoChA window 大小动态的变化- HMM: 过去没有深度学习的解决方案 ,phoneme 发音 为单位猜概率,tri-phone : what do you
–>do发音受what和you影响
预测下一个的几率 图hmm1
图ctc
图hmm
6.深度学习使用到模型上
Tandem 09年满大街, 得到训练的语音概率,再放到模型运行
DNN-HMM HyBrid 2019(google IBM 5%错误率)主流 DNN(使用一个文件)可以训练
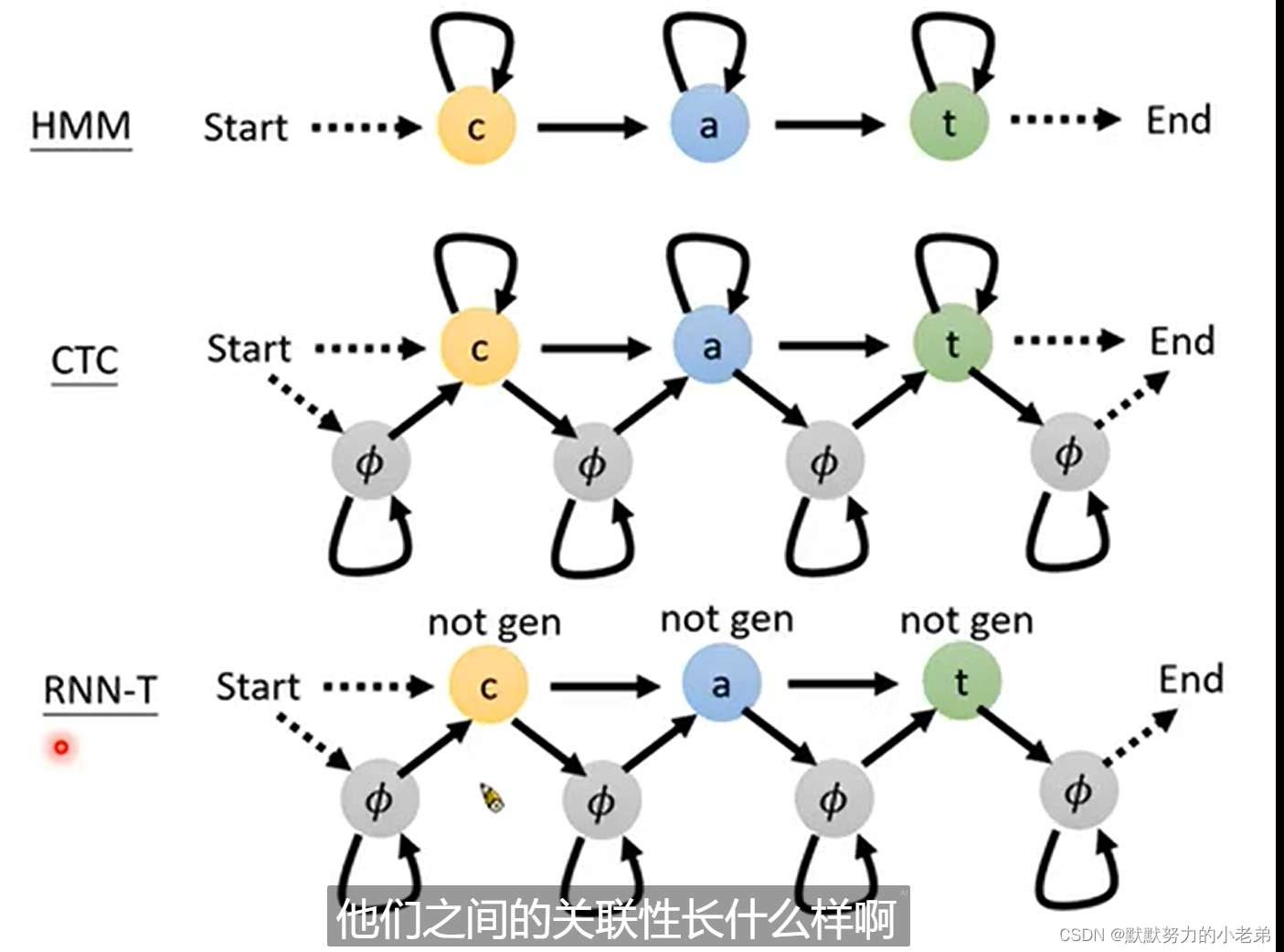
对比 图(not gen代表没有路径可以抵达)
7.js可以使用语音识别(调用google aip,国内被封需要科学上网)
//真香,不过(科学上网,再开个node服务器)公司使用会不会有纷争就不知道了
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8"><title>语音识别示例</title>
</head>
<body><h1>语音识别示例</h1><button id="start-btn">开始识别</button><button id="stop-btn">停止识别</button><div id="result-div"></div><script>// 获取DOM元素const startBtn = document.querySelector('#start-btn');const stopBtn = document.querySelector('#stop-btn');const resultDiv = document.querySelector('#result-div');// 创建一个SpeechRecognition对象const recognition = new webkitSpeechRecognition();// 设置语音识别参数recognition.lang = 'zh-CN'; // 设置语言为中文recognition.continuous = true; // 设置为连续模式// 开始语音识别startBtn.addEventListener('click', function() {recognition.start();});// 停止语音识别stopBtn.addEventListener('click', function() {recognition.stop();});// 监听语音识别结果recognition.onresult = function(event) {const result = event.results[event.resultIndex][0].transcript;resultDiv.innerHTML += `<p>${result}</p>`;};// 监听语音识别错误recognition.onerror = function(event) {console.error('语音识别错误:', event.error);};</script>
</body>
</html>
- 使用SpeechRecognition 没有中文包,识别英文全是oh
9.百度云语音识别(能识别就是没有说话的时候出现奇奇怪怪的句子) 免费半年还挺好的,腾讯云只有5000次调用试用
https://console.bce.baidu.com/ai/#/ai/speech/app/list
//图baidu
//识别语音的文件,controller只需要得到io流放到byte数据就可以识别,我觉得每次生成一个pcm应该就不会出现下图的识别识别的情况
import java.io.File;
import java.io.FileInputStream;
import java.util.HashMap;import com.baidu.aip.speech.AipSpeech;
import org.json.JSONObject;public class test01 {// 在百度 AI 平台创建应用后获得private static final String APP_ID = "xxxx";private static final String API_KEY = "xxxx";private static final String SECRET_KEY = "xxxxx";public static void main(String[] args) throws Exception {// 初始化 AipSpeech 客户端AipSpeech client = new AipSpeech(APP_ID, API_KEY, SECRET_KEY);// 设置请求参数HashMap<String, Object> options = new HashMap<String, Object>();options.put("dev_pid", 1537); // 普通话(支持简单的英文识别)// 读取音频文件File file = new File("path/to/audio/file.pcm");FileInputStream fis = new FileInputStream(file);byte[] data = new byte[(int) file.length()];fis.read(data);fis.close();// 调用语音识别 APIJSONObject result = client.asr(data, "pcm", 16000, options);if (result.getInt("err_no") == 0) {String text = result.getJSONArray("result").getString(0);System.out.println("识别结果:" + text);} else {System.out.println("识别失败:" + result.getString("err_msg"));}}
}
//实时录音测试
//图baidu
//优化需要像图片处理一样,直接上传文件而不是流
import java.util.HashMap;
import javax.sound.sampled.*;import com.baidu.aip.speech.AipSpeech;
import org.json.JSONObject;public class test01 {// 在百度 AI 平台创建应用后获得private static final String APP_ID = "xxxxxxx";private static final String API_KEY = "xxxxxx";private static final String SECRET_KEY = "xxxxxx";public static void main(String[] args) throws Exception {// 初始化 AipSpeech 客户端AipSpeech client = new AipSpeech(APP_ID, API_KEY, SECRET_KEY);// 设置请求参数HashMap<String, Object> options = new HashMap<String, Object>();options.put("dev_pid", 1537); // 普通话(支持简单的英文识别)// 获取麦克风录制的音频流AudioFormat format = new AudioFormat(16000, 16, 1, true, false);TargetDataLine line = AudioSystem.getTargetDataLine(format);line.open(format);line.start();// 创建缓冲区读取音频数据int bufferSize = (int) format.getSampleRate() * format.getFrameSize();byte[] buffer = new byte[bufferSize];// 循环读取并识别音频数据while (true) {int count = line.read(buffer, 0, buffer.length);if (count > 0) {// 调用语音识别 APIJSONObject result = client.asr(buffer, "pcm", 16000, options);if (result.getInt("err_no") == 0) {String text = result.getJSONArray("result").getString(0);System.out.println("识别结果:" + text);} else {System.out.println("识别失败:" + result.getString("err_msg"));}}}}
}
10.腾讯云语音识别 5000条免费,读者可以自己下载项目看看
//控制台https://console.cloud.tencent.com/asr#//项目地址https://github.com/TencentCloud/tencentcloud-speech-sdk-java
11.使用whisper(2022年9月21日开源的,openAI格局真的大,腾讯云实时识别都要1个小时2块钱不过也不贵,但是对于大多数公司来说要压缩成本,嵌入式也有tiny版本的模型来使用)
- 安装python3.10
pip3 install torch torchvision torchaudio
2.powershell安装coco和ffmpeg
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
//切换阿里源,找不到ffmpeg(专门来处理音频的)如果不安装就找不到路径和文件
choco source add --name=aliyun-choco-source --source=https://mirrors.aliyun.com/chocolatey/
choco source set --name="'aliyun-choco-source'"
choco source list
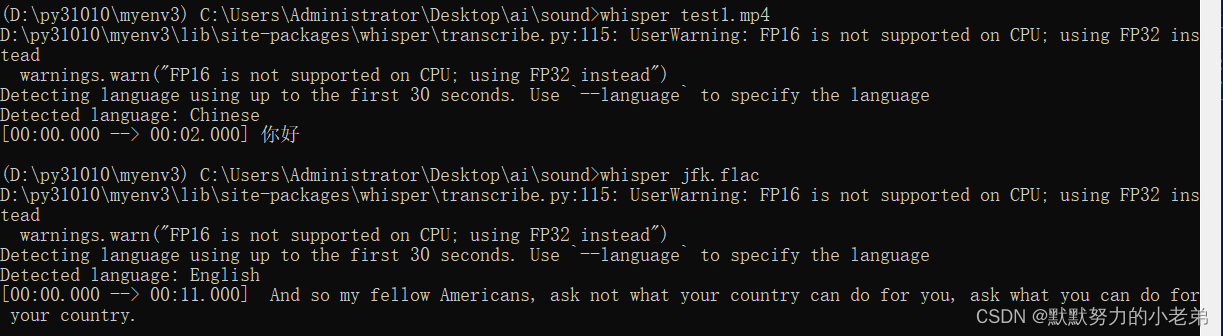
choco install ffmpeg2.测试 速度挺快的,用小一点的模型岂不是慢一定可以通过准确又快速的半实时语言识别!!!
whisper test1.mp4
结果
相关文章:
语音识别之百度语音试用和OpenAiGPT开源Whisper使用
0.前言: 本文作者亲自使用了百度云语音识别,腾讯云,java的SpeechRecognition语言识别包 和OpenAI近期免费开源的语言识别Whisper(真香警告)介绍了常见的语言识别实现原理 1.NLP 自然语言处理(人类语言处理) 你好不同人说出来是不同的信号表示 单位k 16k16000个数字表示 1秒160…...
Rust报错:the msvc targets depend on the msvc linker but `link.exe` was not found
当我在我的 windows 电脑上安装 rust,然后用 cargo 新建了一个项目后,cargo run 会报错: error: linker link.exe not found| note: program not foundnote: the msvc targets depend on the msvc linker but link.exe was not foundnote: p…...

2312llvm,04后端上
后端 后端由一套分析和转换趟组成,任务是生成代码,即把LLVM中间(IR)转换为目标代码(或汇编). LLVM支持广泛目标:ARM,AArch64,Hexagon,MSP430,MIPS,NvidiaPTX,PowerPC,R600,SPARC,SystemZ,X86,和XCore. 所有这些后端共享一套,按通用API方法抽象后端任务的目标无关生成代码的一部…...
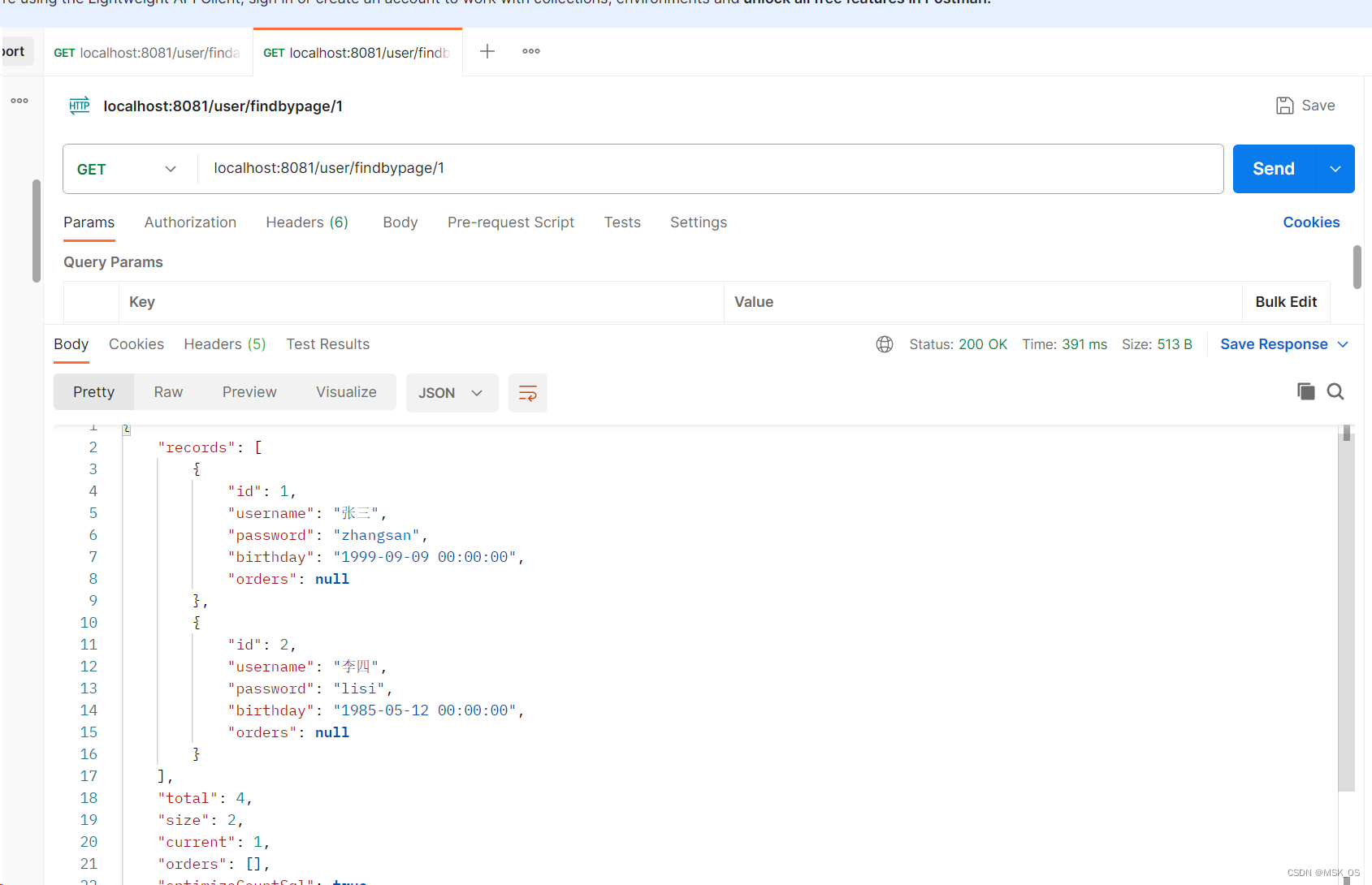
springboot学习笔记(五)
MybatisPlus进阶 1.MybatisPlus一对多查询 2.分页查询 1.MybatisPlus一对多查询 场景:我有一个表,里面填写的是用户的个人信息(姓名,生日,密码,用户ID)。我还有一个表填写的订单信息&#x…...

文件上传——后端
文件上传流程: 创建阿里云OSS(对象存储服务)的bucket 登录阿里云,并完成实名认证,地址:https://www.aliyun.com/. 可以通过搜索,进入以下页面: 点击立即使用后: 点击…...
虾皮开通:如何在虾皮上开通跨境电商店铺
在当今的数字时代,跨境电商已经成为了全球贸易的一种重要形式。虾皮(Shopee)作为东南亚市场份额第一的跨境电商平台,为卖家提供了广阔的销售机会。如果您想在虾皮上开通店铺,以下是一些步骤和注意事项供您参考。 先给…...

C语言—每日选择题—Day60
明天更新解析 第一题 1. 下列for循环的循环体执行次数为() for(int i 10, j 1; i j 0; i, --j) A:0 B:1 C:无限 D:以上都不对 答案及解析 A for循环的判断条件是 i j 0;赋值语句做判断条件…...
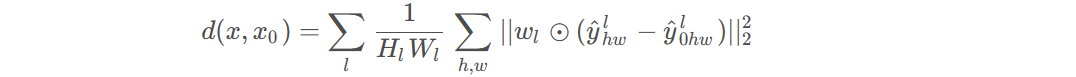
【3D生成与重建】SSDNeRF:单阶段Diffusion NeRF的三维生成和重建
系列文章目录 题目:Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction 论文:https://arxiv.org/pdf/2304.06714.pdf 任务:无条件3D生成(如从噪音中,生成不同的车等)、…...
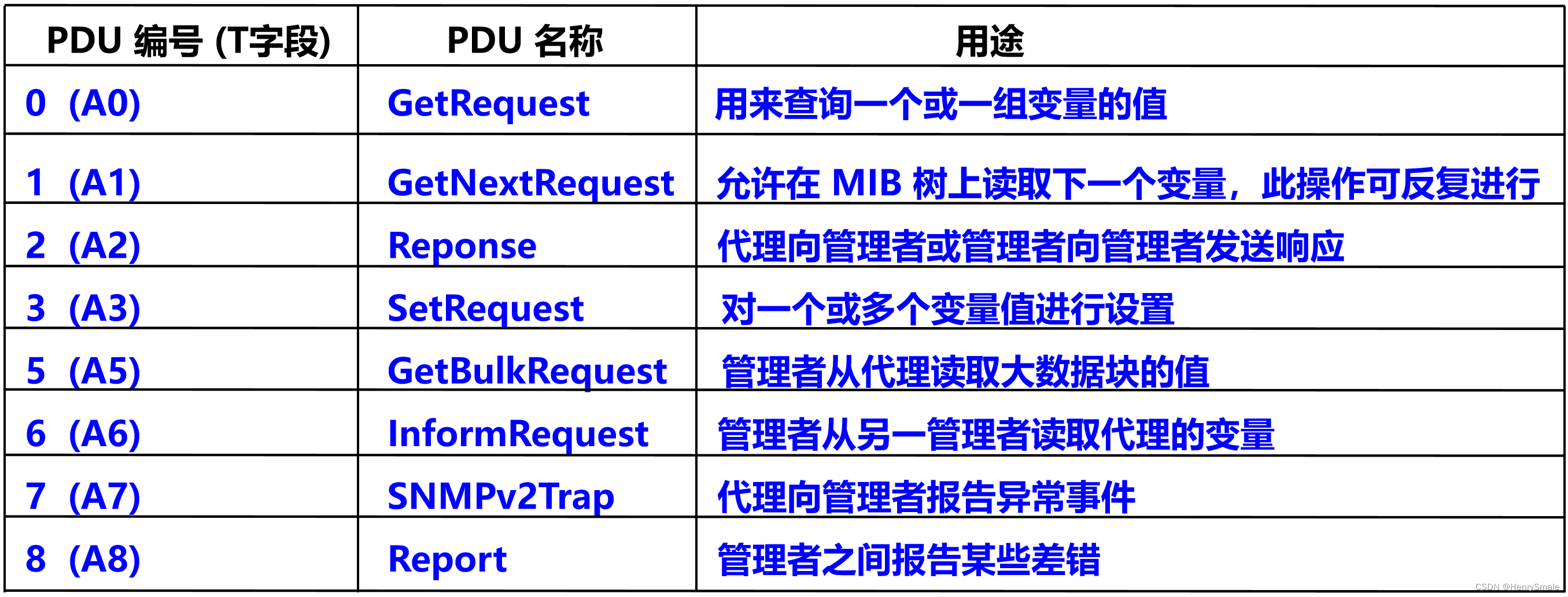
计算机网络:应用层
0 本节主要内容 问题描述 解决思路 1 问题描述 不同的网络服务: DNS:用来把人们使用的机器名字(域名)转换为 IP 地址;DHCP:允许一台计算机加入网络和获取 IP 地址,而不用手工配置࿱…...
现代雷达车载应用——第3章 MIMO雷达技术 3.2节 汽车MIMO雷达波形正交策略
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。 3.2 汽车MIMO雷达波形正交策略 基于MIMO雷达技术的汽车雷达虚拟阵列合成依赖于不同天线发射信号的可分离性。当不同天线的发射信号正交时&#x…...

Unresolved plugin: ‘org.apache.maven.plugins‘解决报错
新建springboot项目报Unresolved plugin: ‘org.apache.maven.plugins:maven-surefire-plugin:3.1.2’ 缺什么插件 引入什么插件的依赖就行 <dependency><groupId>org.apache.maven.plugins</groupId><artifactId>maven-install-plugin</artifact…...

阿里云林立翔:基于阿里云 GPU 的 AIGC 小规模训练优化方案
云布道师 本篇文章围绕生成式 AI 技术栈、生成式 AI 微调训练和性能分析、ECS GPU 实例为生成式 AI 提供算力保障、应用场景案例等相关话题展开。 生成式 AI 技术栈介绍 1、生成式 AI 爆发的历程 在 2022 年的下半年,业界迎来了生成式 AI 的全面爆发,…...
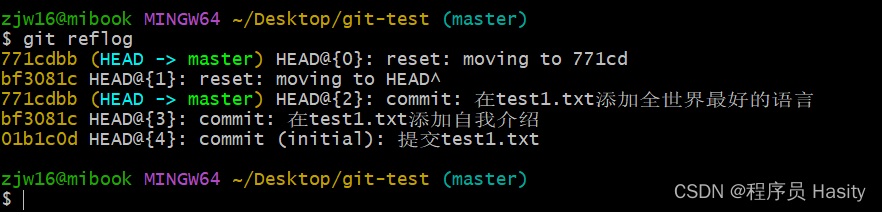
从0开始学Git指令
从0开始学Git指令 因为网上的git文章优劣难评,大部分没有实操展示,所以打算自己从头整理一份完整的git实战教程,希望对大家能够起到帮助! 初始化一个Git仓库,使用git init命令。 添加文件到Git仓库,分两步…...

B039-SpringMVC基础
目录 SpringMVC简介复习servletSpringMVC入门导包配置前端控制器编写处理器实现Contoller接口普通类加注解(常用) 路径问题获取参数的方式过滤器简介自定义过滤器配置框架提供的过滤器 springMVC向页面传值的三种方式视图解析器springMVC的转发和重定向 SpringMVC简介 1.Sprin…...
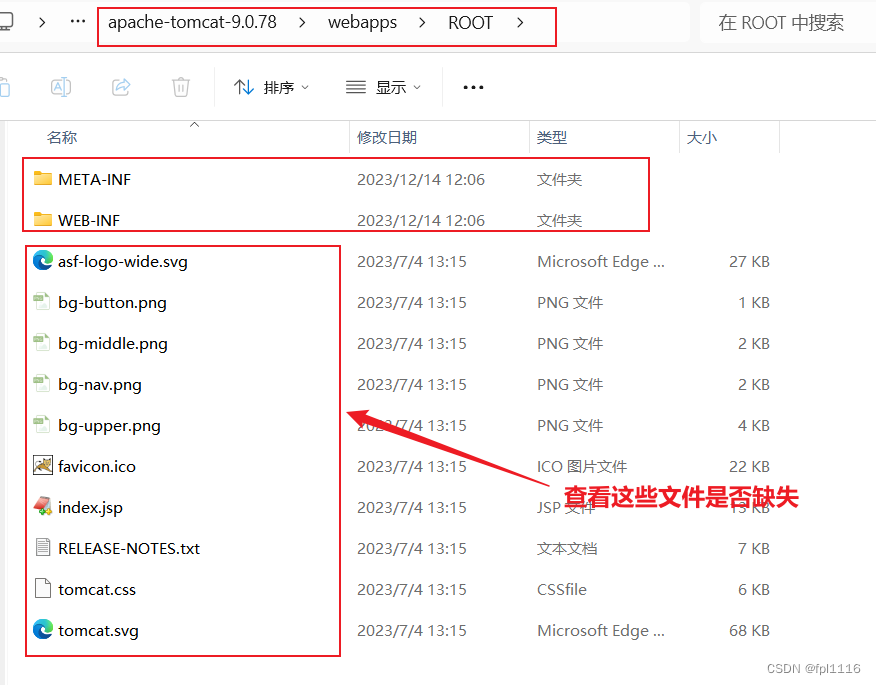
Tomcat报404问题解决方案大全(包括tomcat可以正常运行但是报404)
文章目录 Tomcat报404问题解决方案大全(包括tomcat可以正常运行但是报404)1、正确的运行页面2、报错404问题分类解决2.1、Tomcat未配置环境变量2.2、IIs访问权限问题2.3、端口占用问题2.4、文件缺少问题解决办法: Tomcat报404问题解决方案大全(包括tomcat可以正常运…...

debian10安装配置vim+gtags
sudo apt install global gtags --version gtags //生成gtag gtags-cscope //查看gtags gtags与leaderf配合使用 参考: 【VIM】【LeaderF】【Gtags】打造全定制化的IDE开发环境! - 知乎...

vue跳转方式
Vue的页面跳转有两种方式,第一种是标签内跳转,第二种是编程式路由导航 1. <router-link to/Demo><button>点击跳转1</button> </router-link>2.router.push("/Demo");一、标签内通过 router-link跳转 通常用于点击 …...

基于ssm+jsp学生综合测评管理系统源码和论文
网络的广泛应用给生活带来了十分的便利。所以把学生综合测评管理与现在网络相结合,利用java技术建设学生综合测评管理系统,实现学生综合测评的信息化。则对于进一步提高学生综合测评管理发展,丰富学生综合测评管理经验能起到不少的促进作用。…...
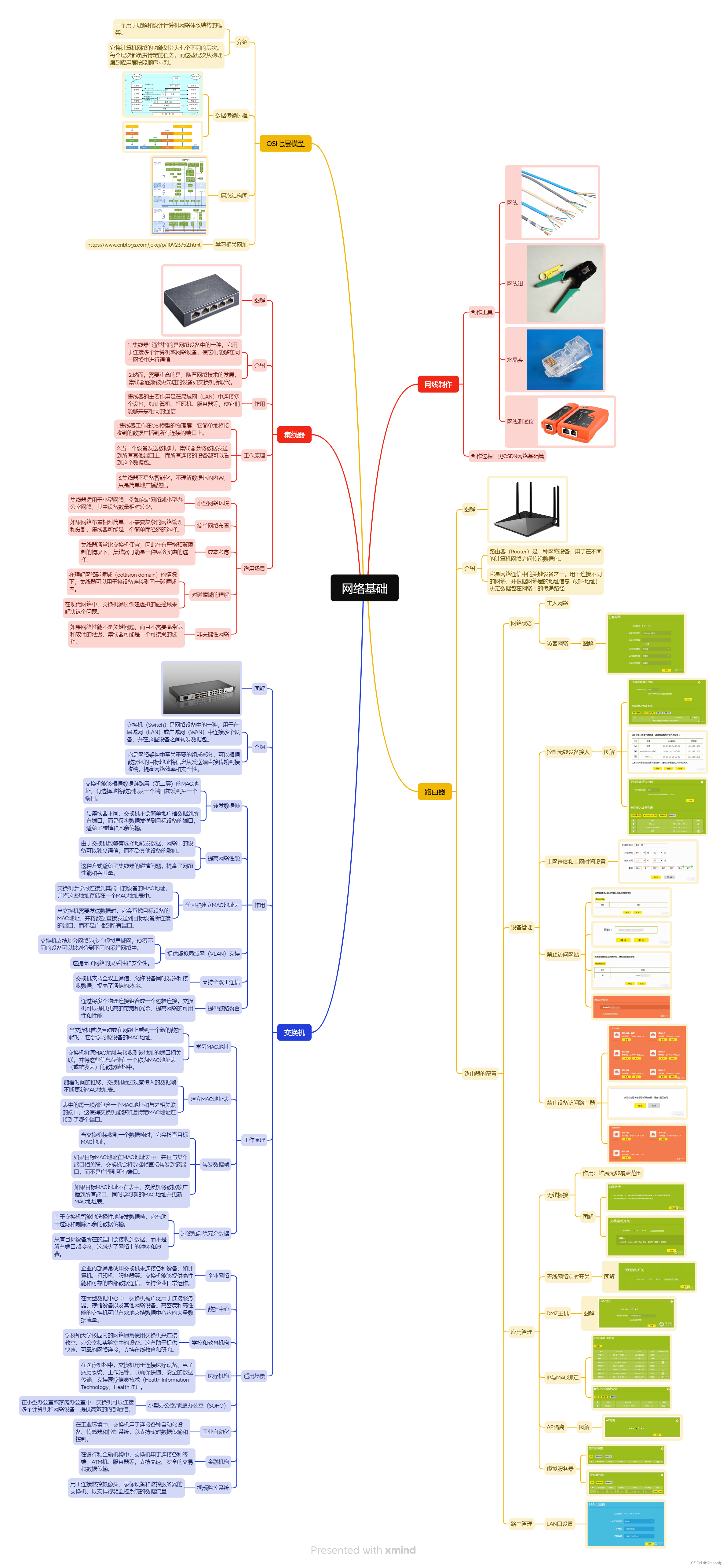
网络基础篇【网线的制作,OSI七层模型,集线器和交换机的介绍,路由器的介绍与设置】
目录 一、网线制作 1.1 工具介绍 1.1.1网线 1.1.2 网线钳 1.1.3 水晶头 1.1.4 网线测试仪 二、OSI七层模型 2.1 简介 2.2 OSI模型层次介绍 2.2.1 结构图 2.2.2 数据传输过程 2.3 相关网站 二、集线器 2.1 介绍 2.2 适用场景 三、交换机 3.1 介绍 3.2 适用场景…...
使用说明)
CSRF检测工具(XSRF检测工具)使用说明
目录 检查类型 测试单个端点 抓取网站 添加Cookie 自定义用户代理...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...

Windows 下端口占用排查与释放全攻略
Windows 下端口占用排查与释放全攻略 在开发和运维过程中,经常会遇到端口被占用的问题(如 8080、3306 等常用端口)。本文将详细介绍如何通过命令行和图形化界面快速定位并释放被占用的端口,帮助你高效解决此类问题。 一、准…...