12.18构建哈夫曼树(优先队列),图的存储方式,一些细节(auto,pair用法,结构体指针)
为结构体自身时,用.调用成员变量;为结构体指针时,用->调用成员变量
所以存在结构体数组时,调用数组元素里的成员变量,就是要用.
结构体自身只有在new时才会创建出来,而其指针可以随意创建
在用new时,要返回指向结构体的指针
构建哈夫曼树
哈夫曼树是在叶子节点和权重确定的情况下,带权路径最小的二叉树,也被称为最优二叉树
基本思路就是先将每个给定权值的节点看成一颗只有根节点的树,然后不断合成权值最小的两个树,生成一个权值为他们之和的一颗新树,最终剩下的一棵树就是哈夫曼树
如果有N个节点,就要迭代N-1轮
优先队列

注意队列的队头函数是front,优先队列是top,栈也是top
大顶堆是一种特殊的二叉堆,其中每个父节点的值都大于或等于其子节点的值。因此,大顶堆是按照降序排列的,即根节点的值最大,而子节点的值逐渐减小。
//升序队列
priority_queue <int,vector<int>,greater<int> > q;
//降序队列
priority_queue <int,vector<int>,less<int> >q;//greater和less是std实现的两个仿函数(就是使一个类的使用看上去像一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了)
即需要注意优先队列的第三个参数传入的并不是函数,而是一个结构体
priority_queue<int, vector<int>, less<int>>a;//定义了降序排列的优先队列,即队头最大,从队头到队尾逐渐减小
priority_queue<int, vector<int>, greater<int>>a;//小顶堆,从队头到队尾升序排列
第二个参数只用写类型即可
struct tmp1 {int x;tmp1(int a) { x = a; }//:x(a){}bool operator<(const tmp1& a)const {return x < a.x;}
};//运算符重载
//这里就是直接在存储的类型里,然后重载运算符,这个调用优先队列时,只需要一个参数,即要存储的结构体即可
//因为结构体里就已经包装了比较的方法
struct tmp2 {bool operator()(tmp1 a, tmp1 b) {return a.x < b.x;}
};//写仿函数,就是写一个比较函数,不过是包装成结构体,
//需要注意这里是额外写的一个结构体,所以在优先队列里定义的时候,要第三个参数,写到第三个参数里
//然后第一个参数是存储的类型,第二个是vector<相应类型>,表示存储的容器在STL中,如果你使用的是标准的std::priority_queue容器,那么需要定义的仿函数的确是要重载函数调用运算符operator(),因为std::priority_queue默认使用std::less或std::greater作为仿函数,它们都是通过重载函数调用运算符来实现比较的。
即写仿函数时,只能重载运算符()
这个第三个参数就是代表从队头到队尾满足一个怎样的关系。队头就是堆顶元素
为什么less构建出大顶堆
想的是类似于自定义sort排序方式,排序都按照规定的<与>方向进行排序
但优先队列相反,用<时,头部是最大的;用>时,头部是最小的
根因在于其底层实现。
less:左数小于右数时,返回true,否则返回false。
在堆的调整过程中,对于大顶堆,如果当前插入的节点值大于其父节点,那么就应该向上调整。其父节点索引小于当前插入节点的索引,也就是父节点是左数,插入节点是右值,可以看到,左数小于右数时,要向上调整,也就是Compare函数应该返回true,正好是less。
(而对于顺序存储,左数右数就是直观理解,没有固定,这里是堆,所以就固定先前的位置为左数,要比较的是右数,如果先前固定的位置和比较的位置满足关系,就要交换,返回true不然则不动)
priority_queue传入的第三个参数是仿函数,是将新插入数据与父结点进行比较
原本是:if (_con[child] > _con[parent])
使用仿函数:if (com(_con[child] , _con[parent]))
(调用仿函数是这个形式,所以仿函数结构体里只能重载())
这里记住,是将父结点与子结点进行比较,满足条件(置true才进行交换)就很容易记住哪个对应大顶堆,哪个对应小顶堆了
就是说仿照堆的构建过程,新插入的直接和最大的比较,而不是连续的顺序存储,从小比到大,类似于插入排序
细节
只有string为length
返回数据结构的大小用的都是size(),只有string类用的是Length()
数对pair
vector可以存储数对,但对于数对,必须要在数对<>前标明pair,直接写为这样会报错

应该写为

auto的应用
auto返回的就是数据结构内部储存的数据的类型

for 循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
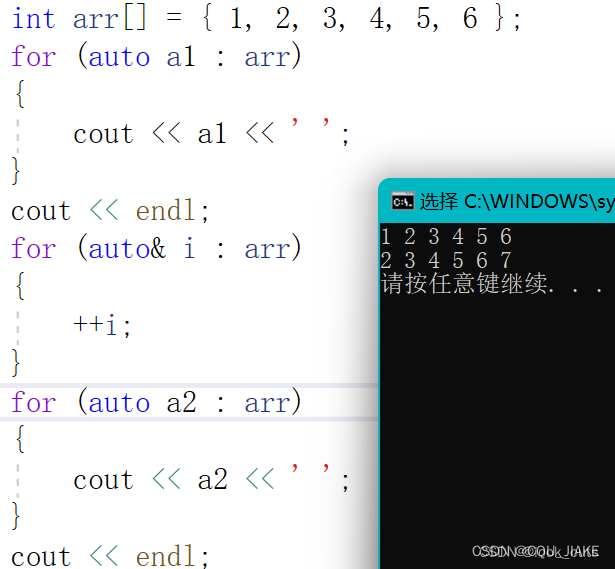
std::map<std::string, int> scores = {{"Alice", 90}, {"Bob", 80}, {"Charlie", 95}};for (auto it = scores.begin(); it != scores.end(); ++it) {auto& name = it->first;auto& score = it->second;// 使用 name 和 score 进行操作
}
huf* root = bulid(weights, chars);vector<hfcode>code;generatecod(root, "", code);for (auto hc : code) {cout << hc.ch << " : " << hc.code << endl;}总代码
struct huf {int w;char ch;huf* left, * right;huf(int w, char c = '\0', huf* l = nullptr, huf* r = nullptr) :w(w), ch(c), left(l), right(r) {}
};
struct hfcode {char ch;//ch是原本的字符值string code;//这个是编码后的结果//本质上就是一个pair对hfcode(char c = '\0', string s = "") :ch(c), code(s) {}
};
struct cmp {bool operator()(huf* a, huf* b) { return a->w > b->w; }
};//如果大于了就交换,返回true,说明新换上来的比较小,那么堆顶元素就保持为最小的
huf* build(vector<int>& weights, vector<char>& chars) {priority_queue<huf*, vector<huf*>, cmp>pq;for (int i = 0; i < weights.size(); i++) {pq.push(new huf(weights[i], chars[i]));}while (pq.size() > 1) {huf* left = pq.top();pq.pop();huf* right = pq.top();pq.pop();huf* parent = new huf(left->w + right->w, '\0', left, right);pq.push(parent);}return pq.top();
}
void generatecod(huf* root, string code, vector<hfcode>& hufcode) {//目的是要得到每个叶子节点的哈夫曼编码,这个vecotr数组记录的是hfcode结构体,就是原始数据以及编码的一个数对if (!root)return;if (root->ch != '\0') {//如果是\0就表明是非叶子节点,不是就表明是叶子节点,是需要编码的节点,所以就进行hufcode.push_back(hfcode(root->ch, code));}generatecod(root->left, code + "0", hufcode);generatecod(root->right, code + "1", hufcode);
}
vector<int>weights = { 5,2,7,4,9 };
vector<char>chars = { 'A', 'B', 'C', 'D', 'E' };
huf* root = bulid(weights, chars);
vector<hfcode>code;
generatecod(root, "", code);
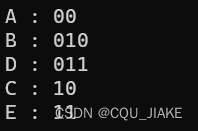
for (auto hc : code) {cout << hc.ch << " : " << hc.code << endl;
}
#include<iostream>
#include<queue>
#include<vector>
#include<string>
using namespace std;
struct node {int w;//表示节点的权重,为叶子节点时表示出现的频次char ch;//表示节点的编号,名称node* left, * right;node(int w, char c = '\0', node* l = nullptr, node* r = nullptr) :w(w), ch(c), left(l), right(r) {}//含参,默认,构造函数,c为\0时表示非叶子节点,无实际意义,w为不含参,需要实际传值
};
struct cmp {bool operator()(node* a, node* b) {return a->w < b->w;}
};
node* build(vector<int>ws, vector<char>cs) {priority_queue<node*, vector<node*>, cmp>pq;for (int i = 0; i < ws.size(); i++) {node* n = new node(ws[i], cs[i]);pq.push(n);//将所有的叶子节点加入到优先队列当中}while (pq.size() > 1) {node* l = pq.top();pq.pop();node* r = pq.top();pq.pop();node* parent = new node(l->w + r->w, '\0', l, r);pq.push(parent);}return pq.top();//最后返回构建好的哈夫曼树的根节点指针
}
void code(node* root, string c, vector <pair< char, string >> &a) {if (!root)return;if (root->ch != '\0') {a.push_back(make_pair(root->ch, c));}else {code(root->left, c + '0', a);code(root->right, c + '1', a);}
}
int main() {vector<int>w = { 5,2,7,4,9 };vector<char>chars = { 'A', 'B', 'C', 'D', 'E' };node* root = build(w, chars);vector<pair<char, string>>d;code(root, "", d);for (auto dp : d) {cout << dp.first << ":" << dp.second << endl;}return 0;
}
调试过程
vector<int>webuild = { 5,2,7,4,9 };vector<char>chars = { 'A', 'B', 'C', 'D', 'E' };priority_queue < pair<int, char>, vector<pair<int, char>>, cmp1>p;for (int i = 0; i < weights.size(); i++) {p.push(make_pair(weights[i], chars[i]));}while (!p.empty()) {cout << p.top().second << ":" << p.top().first << endl;p.pop();}struct cmp1 {bool operator()(pair<int, char>a, pair<int, char>b) {return a.first < b.first;}
};图的存储方式
struct arc {int target;//边里需要记录自己的目标arc* nextarc;int w;//如果有需要,则记录边的权重
};
struct node {int info;//并非节点编号,而是节点自身的某些信息,比如名称,大小arc* firstarc;
};
struct graph {int vnum, anum;node v[20];//在此定义节点编号
};
void creat(graph& g) {cin >> g.vnum >> g.anum;for (int i = 0; i < g.vnum; i++) {cin >> g.v[i].info;//按输入顺序定义节点编号g.v[i].firstarc = nullptr;}for (int i = 0; i < g.anum; i++) {int v1, v2;cin >> v1 >> v2;arc* p1 = new arc;p1->target = v2;p1->nextarc = g.v[v1].firstarc;g.v[v1].firstarc = p1;//若为无向图,还需在v2中做修改arc* p2 = new arc;p2->target = v1;p2->nextarc = g.v[v2].firstarc;g.v[v2].firstarc = p2;}
}边要记录自己的终点,以及同一起点下边的下一边的索引指针,需要的话还可以记录权值;
边记录的终点,是终点节点的下标标号;点记录的边,是第一条边的索引指针
点要记录以自己为起点的第一条边的索引指针,若要遍历以该边为起点的所有边,用第一条边的后继指针来实现
得到每个点的入度
struct arc {int w;int target;arc* nextarc;
};
struct node {int index;arc* firstarc;
};
struct graph {int vnum, anum;node v[20];
};
int d[20];//记录入度
void countd(graph& g) {//i表示要查询的节点编号for (int i = 0; i < g.vnum; i++) {d[i] = 0;}for (int i = 0; i < g.vnum; i++) {for (arc* item = g.v[i].firstarc; item != nullptr; item = item->nextarc) {d[item->target]++;}}
}相关文章:
12.18构建哈夫曼树(优先队列),图的存储方式,一些细节(auto,pair用法,结构体指针)
为结构体自身时,用.调用成员变量;为结构体指针时,用->调用成员变量 所以存在结构体数组时,调用数组元素里的成员变量,就是要用. 结构体自身只有在new时才会创建出来,而其指针可以随意创建 在用new时&…...
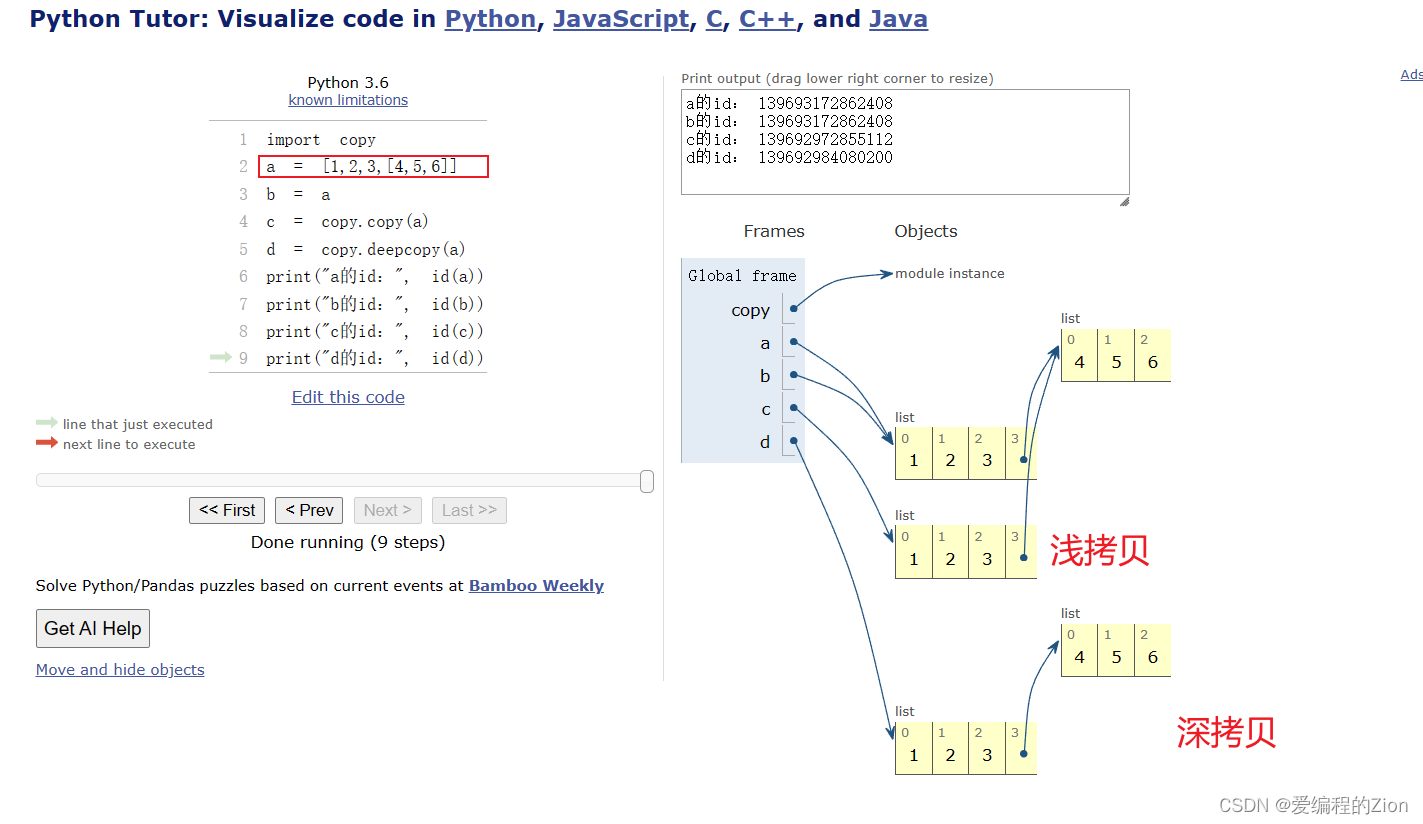
《Python》面试常问:深拷贝、浅拷贝、赋值之间的关系(附可变与不可变)【用图文讲清楚!】
背景 想必大家面试或者平时学习经常遇到问python的深拷贝、浅拷贝和赋值之间的区别了吧?看网上的文章很多写的比较抽象,小白接收的难度有点大,于是乎也想自己整个文章出来供参考 可变与不可变 讲深拷贝和浅拷贝之前想讲讲什么是可变数据类型…...
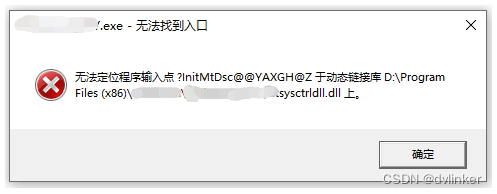
使用PE信息查看工具和Dependency Walker工具排查因为库版本不对导致程序启动报错问题
目录 1、问题说明 2、问题分析思路 3、问题分析过程 3.1、使用Dependency Walker打开软件主程序,查看库与库的依赖关系,查看出问题的库 3.2、使用PE工具查看dll库的时间戳 3.3、解决办法 4、最后 VC常用功能开发汇总(专栏文章列表&…...

Python编程题目答疑「Python一对一辅导考试真题解析」
你好,我是悦创。 待会更新~ 更新计划 答案 题目 记得点赞收藏! 题目 之后更新 Solution Question 1 # 读取输入 a float(input("请输入实数 a: ")) b float(input("请输入实数 b: ")) c float(input("请输…...

Python---搭建Python自带静态Web服务器
1. 静态Web服务器是什么? 可以为发出请求的浏览器提供静态文档的程序。 平时我们浏览百度新闻数据的时候,每天的新闻数据都会发生变化,那访问的这个页面就是动态的,而我们开发的是静态的,页面的数据不会发生变化。 …...

在服务器上部署SpringBoot项目jar包
以下是在服务器上部署Spring Boot项目jar包的步骤: 打包项目: 使用IDEA或者命令行工具(如Maven或Gradle)将Spring Boot项目打包为一个可执行的jar文件。如果使用Maven,可以在项目的根目录下运行以下命令来打包项目&…...

[python]python实现对jenkins 的任务触发
目录 关键词平台说明背景一、安装 python-jenkins 库二、code三、运行 Python 脚本四、注意事项 关键词 python、excel、DBC、jenkins 平台说明 项目Valuepython版本3.6 背景 用python实现对jenkins 的任务触发。 一、安装 python-jenkins 库 pip install python-jenkin…...

Python生成圣诞节贺卡-代码案例剖析【第18篇—python圣诞节系列】
文章目录 ❄️Python制作圣诞节贺卡🐬展示效果🌸代码🌴代码剖析 ❄️Python制作圣诞树贺卡🐬展示效果🌸代码🌴代码剖析🌸总结 🎅圣诞节快乐! ❄️Python制作圣诞节贺卡 …...
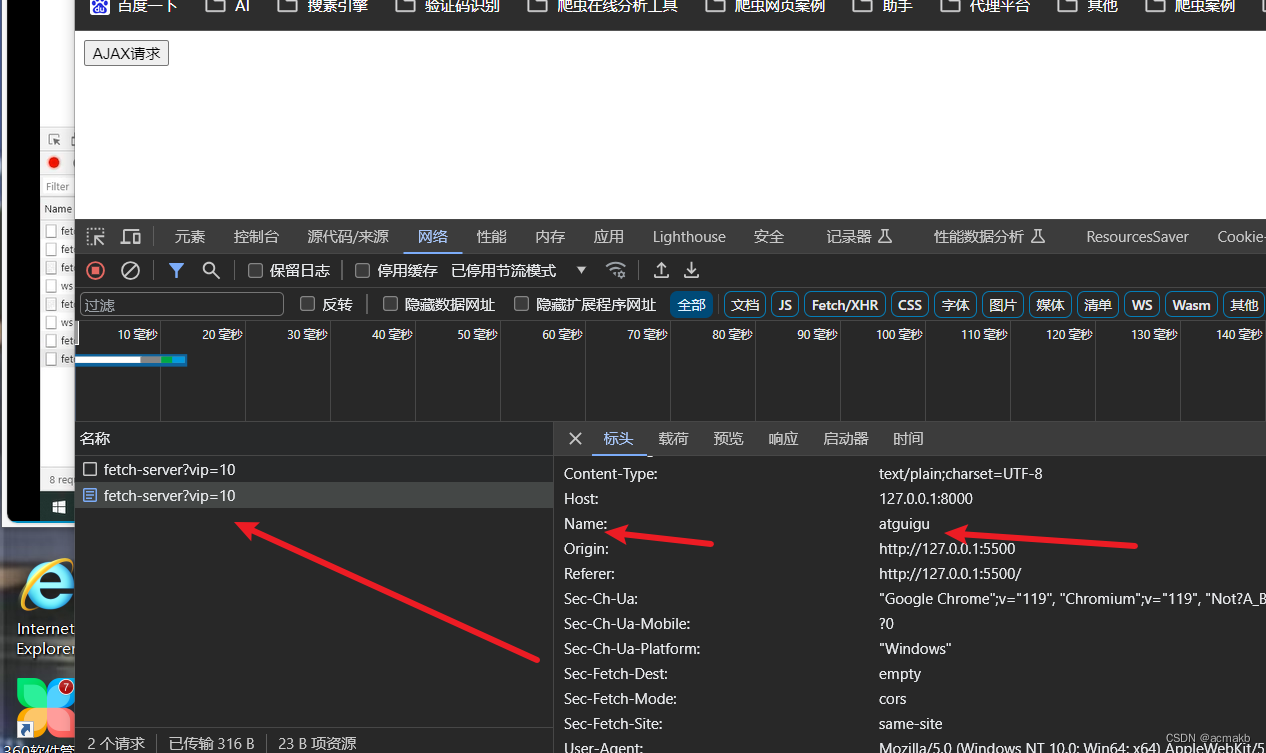
深度剖析Ajax实现方式(原生框架、JQuery、Axios,Fetch)
Ajax学习 简介: Ajax 代表异步 JavaScript 和 XML(Asynchronous JavaScript and XML)的缩写。它指的是一种在网页开发中使用的技术,通过在后台与服务器进行数据交换,实现页面内容的更新,而无需刷新整个…...
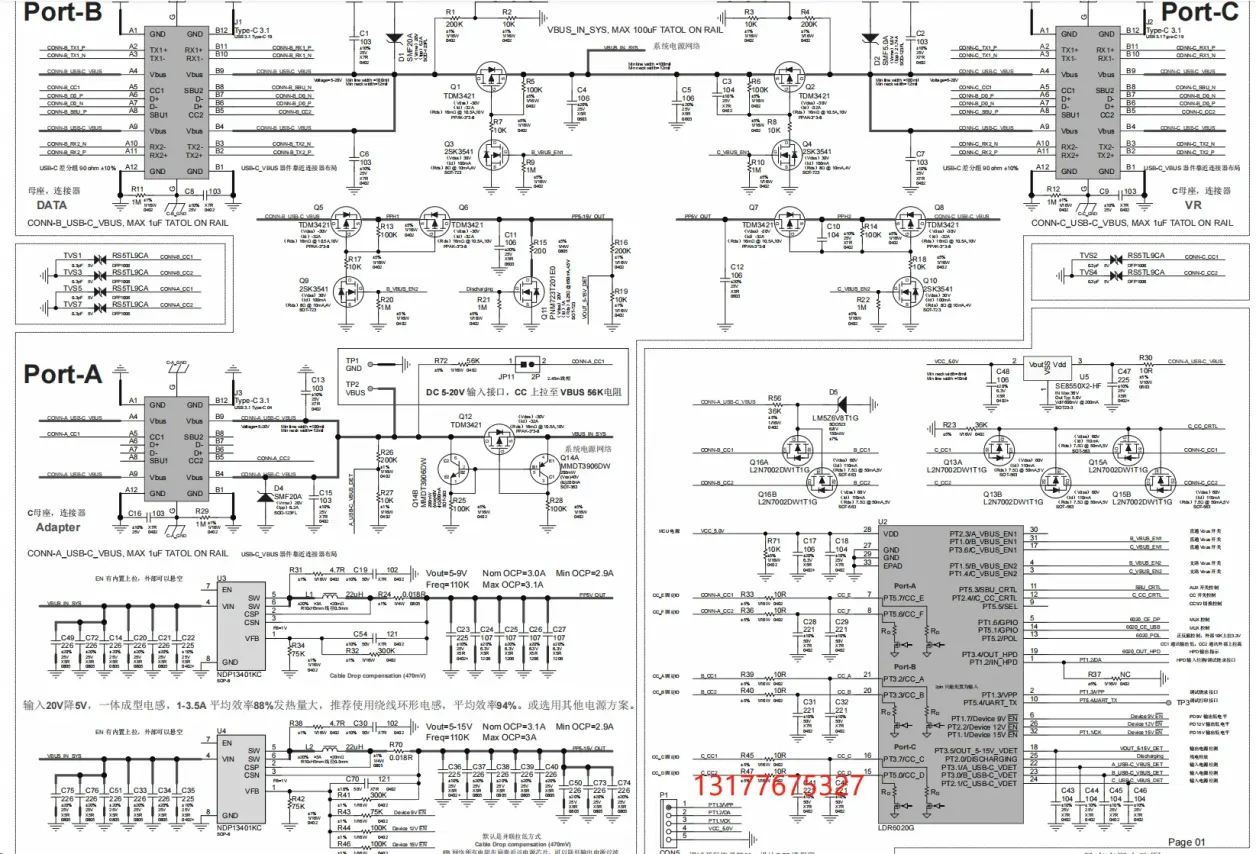
任天堂,steam游戏机通过type-c给VR投屏与PD快速充电的方案 三type-c口投屏转接器
游戏手柄这个概念,最早要追溯到二十年前玩FC游戏的时候,那时候超级玛丽成为了许多人童年里难忘的回忆,虽然长大了才知道超级玛丽是翻译错误,应该是任天堂的超级马里奥,不过这并不影响大家对他的喜爱。 当时FC家用机手柄…...
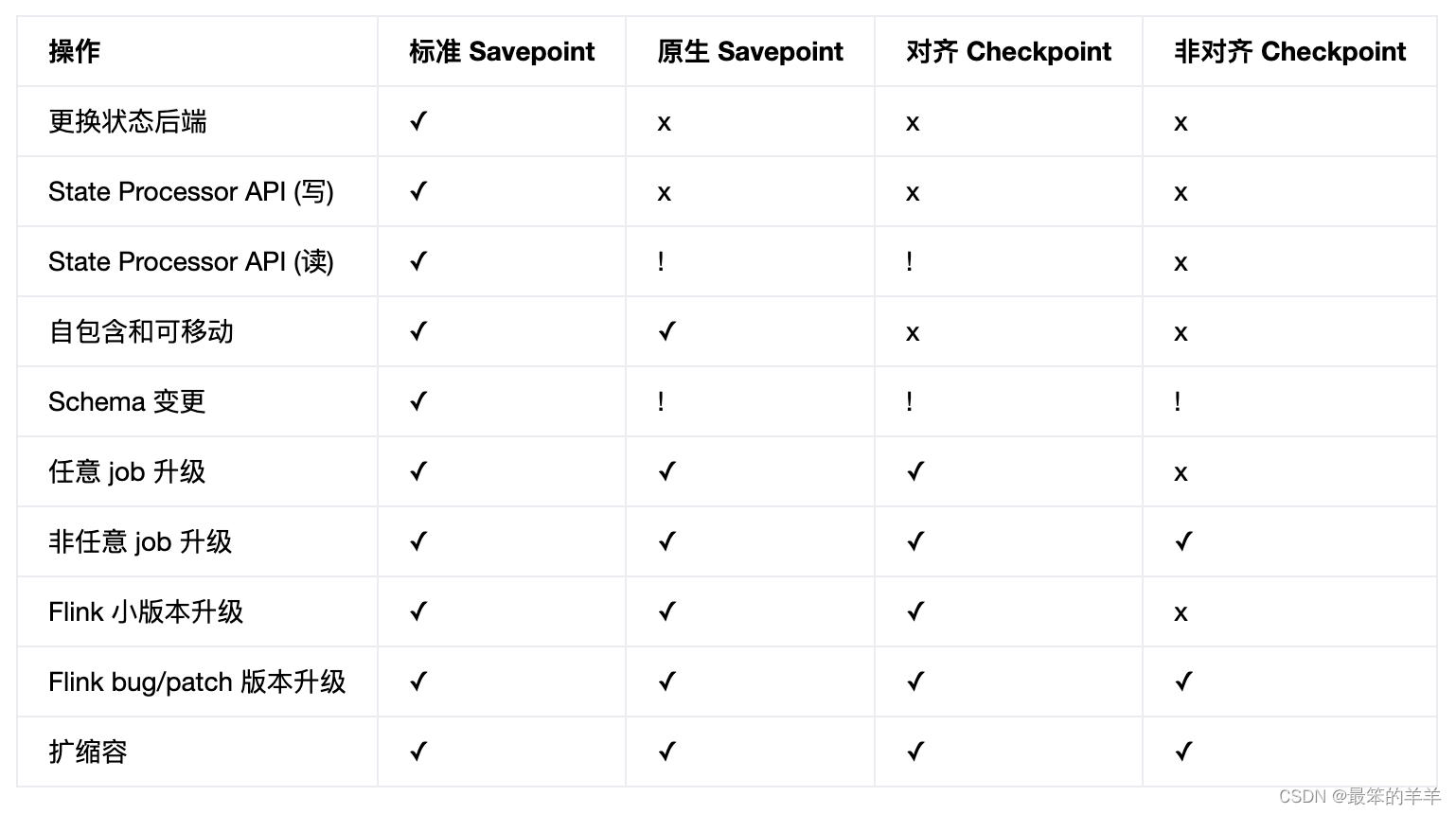
Flink系列之:Checkpoints 与 Savepoints
Flink系列之:Checkpoints 与 Savepoints 一、概述二、功能和限制 一、概述 从概念上讲,Flink 的 savepoints 与 checkpoints 的不同之处类似于传统数据库系统中的备份与恢复日志之间的差异。 Checkpoints 的主要目的是为意外失败的作业提供恢复机制。 …...

【优质书籍推荐】LoRA微调的技巧和方法
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。…...
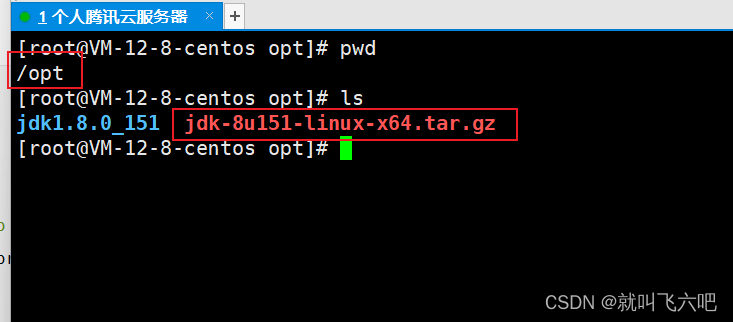
Linux一行命令配置jdk环境
使用方法: 压缩包上传 到/opt, 更换命令中对应的jdk包名即可。 注意点:jdk-8u151-linux-x64.tar.gz 解压后名字是jdk1.8.0_151 sudo tar -zxvf jdk-8u151-linux-x64.tar.gz -C /opt && echo export JAVA_HOME/opt/jdk1.8.0_151 | sudo tee -a …...

从0开始刷剑指Offer
剑指Offer题解 剑指 Offer 11. 旋转数组的最小数字 思路: 二分O(logn) class Solution {public int stockManagement(int[] stock) {int l 0;int r stock.length - 1;while(l < r && stock[0] stock[r]) r --;if(stock[r] > stock[l]) return stock[0];whi…...

使用Java语言中的算法输出杨辉三角形
一、算法思想 创建一个名为YanghuiTest的类,然后创建二维数组,然后遍历二维数组的第一层,然后初始化第二层数组的大小,然后遍历第二层数组,然后将两侧的数组元素赋为1,然后其它数值通过公式计算,最后可以输…...
人工智能_机器学习071_SVM支持向量机_人脸识别算法_LFW人脸数据加载_与理解---人工智能工作笔记0111
然后我们继续来看 这里有个lfw_home可以看到这个数据是,包含了人脸数据 然后我们继续看,在我们的顶你用户目录下,如果安装了,sklearn就会有这样一个目录, scikit_learn_data目录,这个里面可以看到 可以看到这个文件夹中有个 lfw_home文件夹是对.zip文件夹的解压,这个下载以后…...

Java 8中流Stream API详解
先给个示例,展示Java 8流API的优势 假设我们有以下任务: 给定一个字符串列表,我们需要执行以下操作: 筛选出所有以"A"开头的字符串。 将这些字符串转换为大写。 对这些字符串按照长度进行排序。 最后,将…...

通过 xlsx 解析上传excel的数据
一、前言 在前端开发中,特别是在后台管理系统中,导入数据(上传excel)到后端是是否常见的功能;而一般的实现方式都是通过接口将excel上传到后端,再有后端进行数据解析并做后续操作。 今天,来记录…...

Flink系列之:JDBC SQL 连接器
Flink系列之:JDBC SQL 连接器 一、JDBC SQL 连接器二、依赖三、创建 JDBC 表四、连接器参数五、键处理六、分区扫描七、Lookup Cache八、幂等写入九、JDBC Catalog十、JDBC Catalog 的使用十一、JDBC Catalog for PostgreSQL十二、JDBC Catalog for MySQL十三、数据…...

OpenCV与YOLO学习与研究指南
引言 OpenCV是一个开源的计算机视觉和机器学习软件库,而YOLO(You Only Look Once)是一个流行的实时对象检测系统。对于大学生和初学者而言,掌握这两项技术将大大提升他们在图像处理和机器视觉领域的能力。 基础知识储备 在深入…...

Phi-4-Reasoning-Vision行业落地:教育领域图像题解与隐藏线索识别案例
Phi-4-Reasoning-Vision行业落地:教育领域图像题解与隐藏线索识别案例 1. 项目背景与价值 在教育领域,图像题解和隐藏线索识别一直是教学和考试中的难点。传统方法依赖人工标注和分析,效率低下且容易遗漏关键信息。Phi-4-Reasoning-Vision多…...

3天快速掌握RCWA光学仿真:从零到一的完整高效指南
3天快速掌握RCWA光学仿真:从零到一的完整高效指南 【免费下载链接】Rigorous-Coupled-Wave-Analysis modules for semi-analytic fourier series solutions for Maxwells equations. Includes transfer-matrix-method, plane-wave-expansion-method, and rigorous c…...

数字减影血管造影系统市场洞察:至2032年将攀升至557.6亿元
据恒州诚思最新调研数据显示,2025年全球数字减影血管造影系统(DSA)市场规模预计达386.7亿元,至2032年将攀升至557.6亿元,2026-2032年复合增长率(CAGR)为5.5%。这一增长受全球老龄化加速、心血管…...

Dramatron:AI驱动剧本创作的协同进化方法
Dramatron:AI驱动剧本创作的协同进化方法 【免费下载链接】dramatron Dramatron uses large language models to generate coherent scripts and screenplays. 项目地址: https://gitcode.com/gh_mirrors/dr/dramatron 问题:当代创作者的三重困境…...

OpCore-Simplify:零基础黑苹果配置终极指南,5分钟搞定复杂EFI
OpCore-Simplify:零基础黑苹果配置终极指南,5分钟搞定复杂EFI 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑苹果配置…...

突破性SLAM实战:如何用SLAM Toolbox彻底改变机器人定位与建图工作流
突破性SLAM实战:如何用SLAM Toolbox彻底改变机器人定位与建图工作流 【免费下载链接】slam_toolbox Slam Toolbox for lifelong mapping and localization in potentially massive maps with ROS 项目地址: https://gitcode.com/gh_mirrors/sl/slam_toolbox …...
)
汽车电子工程师必看:如何用MPC5643L实现ASIL-D级别的功能安全设计(附完整代码示例)
汽车电子工程师必看:如何用MPC5643L实现ASIL-D级别的功能安全设计(附完整代码示例) 在智能驾驶技术快速发展的今天,功能安全已成为汽车电子系统设计的核心考量。作为汽车电子工程师,我们面临的挑战不仅在于实现复杂功…...
)
语义分割竞赛必备:5种Loss函数组合效果对比(含Dice+Focal Loss调参指南)
语义分割竞赛进阶:5种损失函数组合实战评测与调参策略 在Kaggle等数据竞赛中,语义分割任务的性能提升往往取决于损失函数的巧妙选择与组合。不同于常规分类任务,多类别像素级预测需要处理极端类别不平衡、边界模糊等独特挑战。本文将深入剖析…...

BiliTools:跨平台资源管理与高效解析的哔哩哔哩工具箱
BiliTools:跨平台资源管理与高效解析的哔哩哔哩工具箱 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持视频、音乐、番剧、课程下载……持续更新 项目地址: https://gitcode.com/GitHub_Trending/bilit/Bili…...

智能突破2048:AI助手如何让数字合成不再依赖运气
智能突破2048:AI助手如何让数字合成不再依赖运气 【免费下载链接】2048-ai AI for the 2048 game 项目地址: https://gitcode.com/gh_mirrors/20/2048-ai 你是否曾在2048游戏中陷入数字迷宫?眼看着屏幕上散落的方块无从下手,移动一步就…...