高级数据结构 <二叉搜索树>
本文已收录至《数据结构(C/C++语言)》专栏!
作者:ARMCSKGT


目录
- 前言
- 正文
- 二叉搜索树的概念
- 二叉搜索树的基本功能实现
- 二叉搜索树的基本框架
- 插入节点
- 删除节点
- 查找函数
- 中序遍历函数
- 析构函数和销毁函数(后序遍历销毁)
- 拷贝构造和赋值重载(前序遍历创建)
- 其他函数
- 二叉搜索树的应用场景
- key模型
- key-value模型
- 关于二叉搜索树
- 最后
前言
前面我们学习了二叉树,但仅仅只是简单的二叉树并没有很大的用处,而本节的二叉搜索树是对二叉树的升级,其查找效率相对于简单二叉树来说有一定提升,二叉搜索树是学习AVL树和红黑树的基础,所以我们必须先了解二叉搜索树。

正文
二叉搜索树的概念
二叉搜索树(Binary search tree)也称二叉排序树或二叉查找树,是在普通二叉树基础上的升级版本,普通二叉树的利用价值不大,而二叉搜索树要求 左节点比根小,右节点比根大,二叉搜索树将数据按二分性质插入在树中,所以将数据存入 二叉搜索树 中进行查找时,理想情况下只需要花费 logN 的时间(二分思想),此时使用中序遍历可以得到一列有序序列,因此 二叉搜索树 的查找效率极高,具有一定的实际价值。
二叉搜索树名字的由来就是因为搜索(查找)速度很快!
二叉搜索树基本特点
一棵二叉树,可以为空;如果不为空则:
- 如果左子树存在,则左子树根节点一定比根节点值要小
- 如果右子树存在,则右子树根节点一定比根节点值要大
- 左子树中的所有节点比根节点小,右子树中的所有节点比根节点大
- 所有的节点值都不相同,不会出现重复值的节点
- 所有子树都遵循这些性质
在这种性质下,使用中序遍历可以得到升序序列,如果将性质反转,即左比根大右比根小,则中序遍历可得到降序序列。
如上图的中树,中序遍历序列为:1 3 4 6 7 8 10 13 14

二叉搜索树的基本功能实现
二叉搜索树的基本框架
二叉搜索树的节点同样需要单独使用模板封装,且因为会用到比较函数,所以需要一个模板参数充当比较函数。
//节点类 template<class T> struct TreeNode {T _key;TreeNode<T>* _left;TreeNode<T>* _right;TreeNode():_key(T()), _left(nullptr), _right(nullptr){}TreeNode(const T& key):_key(key), _left(nullptr), _right(nullptr){} };//默认比较函数 template<class T> struct Compare {bool operator()(const T& left, const T& right) { return left > right; } };//二叉搜索树 template<class T, class Com = Compare<T>> class BSTree {//对节点类型 和 树类型 的重命名 方便使用using NodeType = TreeNode<T>; //相对于 typedef TreeNode<T> NodeType;using TreeType = BSTree<T, Com>; public:BSTree():_root(nullptr), _size(0){} private:NodeType* _root; //根节点size_t _size; //节点数量Com _com; //比较函数 };
插入节点
对于插入函数,我们的目标是要找到合适的插入位置!
步骤
- 检查root根节点,如果根节点为空则直接赋值为根节点。
- 通过 key(插入值)参数查找最佳插入位置,如果遇到相等的,则返回false表示插入失败。
- 在查找时记录迭代变量cur的前驱节点parent,当迭代变量为nullptr时,记录的前驱节点就是合适插入节点,插入在该前驱节点后即可。
- 在链接插入时,比较插入值key与parent节点值的的大小,从而得知插入到左子树还是右子树,最终插入成功返回true。
代码实现(迭代版):
bool Insert(const T& key) {if (_root == nullptr){NodeType* newnode = new NodeType(key);_root = newnode;_size = 1;return true;}NodeType* parent = _root;NodeType* cur = _root;while (cur){parent = cur;//节点值小于keyif (_com(key, cur->_key)) cur = cur->_right;//节点值大于keyelse if (_com(cur->_key, key)) cur = cur->_left;else return false;}NodeType* newnode = new NodeType(key);//比较节点值key与parent节点值的大小,插入在正确的位置if (_com(key, parent->_key)) parent->_right = newnode;else parent->_left = newnode;++_size;return true; }注意:parent指针不能赋值为nullptr,当只有一个根节点时,插入会发生空指针访问!
当然,迭代可以实现插入,递归也可以,思想相同,但是实现上有一定差异。
关于递归版插入函数
因为有递归的存在,所以需要两个参数:一个用于查找的key和递归参数root节点地址。但是这个函数并不对外暴露,我们对外暴露的是一个key参数的函数,调用内部递归函数。
这里巧妙的是,我们传递的参数是对节点的引用,那么我们在当前递归函数中的修改,可以影响上一层的节点(父节点)。
假设当前节点为root,那么当我们递归root->left时,此时root参数变为root->left,我们修改root就是对上一层root->left修改,这样,当我们检查到root->left为nullptr时,创建新节点并构建链接关系然后返回即可完成插入新节点。
同样的,如果插入成功返回true,插入失败返回false。
代码实现(递归版):
bool RecuInsert(const T& key) //递归插入-外部调用接口 {return _RecuInsert(key, _root); }bool _RecuInsert(const T& key, NodeType*& root) //递归插入-实际调用函数 {//发现空节点直接链接 对节点的引用会自动完成对节点的链接if (root == nullptr){NodeType* newnode = new NodeType(key);root = newnode;return true;}//递归继续查找最佳插入位置if (_com(key, root->_key)) return _RecuInsert(key, root->_right);else if (_com(root->_key, key)) return _RecuInsert(key, root->_left);return false; }可以发现,递归加持节点引用帮我们省去了很多麻烦,代码也很简洁,但迭代和递归各有优劣,我们都做介绍!
删除节点
对于删除函数,与插入类似,需要先查找值为key的节点,然后分情况删除。
步骤
- 通过key值从根节点开始遍历,寻找等值节点,cur逐个遍历节点,parent记录cur的前驱节点
- 如果根节点为nullptr或cur遍历为nullptr,则没有可删除的节点,返回false
- 如果找到节点,则开始分情况删除,删除后返回true
这里的难点是删除时,如何保证树的序列和链接关系,分为三种情况:
- 被删节点左右子树为空 (直接删除)
- 被删节点左子树或右子树为空 (托孤,将自己的子节点拜托给父节点管理)
- 被删节点左右子树都不为空 (找一个替代节点来管理)
实现代码(迭代版):
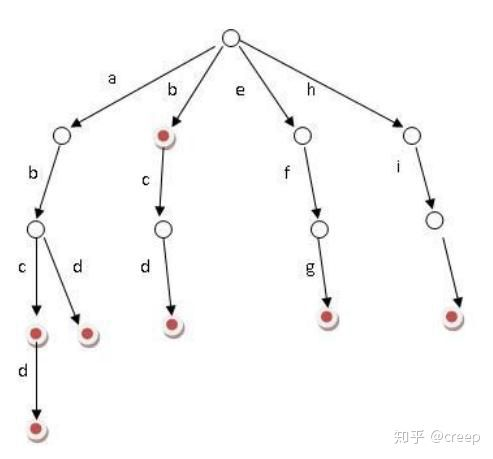
bool Erase(const T& key) {if (_root == nullptr) return false;//删除节点NodeType* parent = nullptr;NodeType* cur = _root;//找节点while (cur){//节点值小于keyif (_com(key, cur->_key)){parent = cur;cur = cur->_right;}//节点值大于keyelse if (_com(cur->_key, key)){parent = cur;cur = cur->_left;}else //找到了 开始删除{if (cur->_right == nullptr) //删除的节点只有左子树{NodeType* DelNode = cur;//改变链接关系//如果要删除的是根节点if (cur == _root) _root = cur->_left;else //非根节点{if (parent->_left == cur) parent->_left = cur->_left;else parent->_right = cur->_left;}delete DelNode;}else if (cur->_left == nullptr) //删除的节点只有右子树{NodeType* DelNode = cur;//改变链接关系//如果要删除的是根节点if (cur == _root) _root = cur->_right;else //非根节点{if (parent->_left == cur) parent->_left = cur->_right;else parent->_right = cur->_right;}delete DelNode;}else //子节点都在{//找替代 左子树的最大节点(最右节点) 右子树的最小节点(最左节点)//去左子树中找最大节点//NodeType* maxParent = cur;//NodeType* maxLeft = cur->_left;//while (maxLeft->_right)//{// maxParent = maxLeft;// maxLeft = maxLeft->_right;//}//cur->_key = maxLeft->_key;接管替代节点的右孩子//if (maxParent->_left == maxLeft) maxParent->_left = maxLeft->_left;//else maxParent->_right = maxLeft->_left;//delete maxLeft;//去右子树中找最小节点NodeType* minParent = cur;NodeType* minRight = cur->_right;while (minRight->_left){minParent = minRight;minRight = minRight->_left;}cur->_key = minRight->_key;//接管替代节点的右孩子if (minParent->_left == minRight) minParent->_left = minRight->_right;else minParent->_right = minRight->_right;delete minRight;}--_size;return true;}}return false; //找不到节点 }将代码结合下图理解,就能知道这些情况到底在干什么了。
被删节点只有左子树或右子树时:
我们只需要让被删节点的父节点托管子节点即可,即让爷爷节点接管孙子节点。
>注意:如果被删节点是根节点,还需要特殊处理,修改根节点_root的值。
被删节点左右子树都存在:
此时我们需要找一个替代节点来接管左右子树,接管节点必须保证接管后树的整体形态和性质不变。
于是我们可以选择左子树中的最大节点(maxLeft) 或 右子树中的最小节点(minRight),两个节点中的其中一个,将该节点值覆盖被删节点的值转而删除该节点即可,该替代节点一定是叶子节点,可以转换为直接删除。
因为 左子树的最大节点 小于和最接近 当前根节点 ,右子树中的最小节点大于和最接近。
所以我们在删除节点前,需要寻找合适的替代节点来接管左右孩子,维护树的形态,在寻找合适节点时,需要 记录替代节点的前驱节点,在被删除后及时更新替代节点父节点的链接关系。
这里我们并不是实际删除了11节点,而是采用伪删除法,替换节点值,转而删除替代节点。
这里使用伪删除法,将问题转化为删除叶子节点,省去了很多麻烦!
关于递归版删除函数
同样的,递归函数需要在内部单独实现,外部对递归函数重新封装。
我们在插入函数中使用对节点地址的引用解决了很多问题,同样的,在删除函数中,我们也使用了对节点的引用,这样可以做到 在不同的栈帧中,删除同一个节点,而非临时变量,同时递归删除还用到了一种思想:转换问题的量级。
因为是对节点的引用,所以当我们遍历到被删节点时,先记录被删除节点的地址,因为是对节点的引用,则在节点数大于1的情况下,当前函数中的root节点地址必然是对某根节点的左子树节点或右子树节点的引用,我们对其做出修改会直接影响链接关系,如果被删节点只有左子树或右子树,直接将其左子树或右子树赋值给当前函数中root即可,然后删除记录的节点,如果被删节点左右子树都存在,则同样需要找左子树最大节点或右子树最小节点作为替代节点,因为节点值交换了,所以被删节点转换成了替代节点,所以继续调用递归删除替代节点即可。
实现代码(递归版):bool RecuErase(const T& key) //递归删除-外部接口 {return _RecuErase(key, _root); }bool _RecuErase(const T& key, NodeType*& root) //递归删除-实际调用函数 {if (root == nullptr) return false;//节点值比key小,递归去右子树中寻找 否则去左子树中寻找if (_com(key, root->_key)) return _RecuErase(key, root->_right);else if (_com(root->_key, key)) return _RecuErase(key, root->_left);else //找到了{NodeType* delNode = root; //记录要删除的节点if (root->_left == nullptr) root = root->_right;else if (root->_right == nullptr) root = root->_left;else //两个子节点都存在{//找一个替代//找左边的最大节点NodeType* cur = root->_left;while (cur->_right) cur = cur->_right;//找右边的最小节点//NodeType* cur = root->_right;//while (cur->_left) cur = cur->_left;//将要删除的值与替代节点交换T tmp = root->_key;root->_key = cur->_key;cur->_key = tmp;return _RecuErase(key, root->_left); //转而删除子节点//return _RecuErase(key, root->_right); //转而删除子节点}delete delNode;return true;}return false; }
关于删除需要注意的:
- 涉及更改链接关系的操作,都需要保存父节点的信息
- 左右子树都为空时,表示删除根节点root,此时 parent 为空,不必更改父节点链接关系,更新根节点root的信息后,删除目标节点即可,这种情况需要特殊处理。
- 左右子树都不为空时,parent 要初始化为 cur,避免后面的野指针或空指针的问题。
删除函数细节比较多,需要结合代码多多理解!
关于搜索二叉树的删除函数,还有一道题,大家可以尝试:删除二叉搜索树中的节点
查找函数
查找函数相对比较简单,一个变量cur向下遍历即可。
步骤
- 当cur节点值小于key时cur走向右子树,大于则走向左子树
- 当cur遍历到值为key的节点时返回true
- 当根节点root或cur遍历到nullptr时,表示树中不存在该节点,返回false
实现代码(迭代版):
bool Find(const T& key){if (_root == nullptr) return false;NodeType* cur = _root;while (cur){if (_com(key, cur->_key)) cur = cur->_right;else if (_com(cur->_key, key)) cur = cur->_left;else return true;}return false;}
关于递归版查找函数
递归版查找函数也需要实现一个内部的递归函数,然后使用外部调用接口封装。
同样的,查找节点也有递归版本,其实现比较简单,当root小于key时递归遍历其右子树,大于则遍历其左子树,等于时返回true,root为nullptr时,返回false。实现代码(递归版):
bool RecuFind(const T& key) //删除函数-外部接口 {return _RecuFind(key, _root); }bool _RecuFind(const T& key, NodeType* root) //删除函数-实际调用函数 {if (root == nullptr) return false;if (_com(key, root->_key)) return _RecuFind(key, root->_right);else if (_com(root->_key, key)) return _RecuFind(key, root->_left);else return true;return false; }
中序遍历函数
中序遍历函数会变遍历边打印,最终打印出的节点序列成有序。
这个函数比较简单,我们在第一次接触二叉树时就已经接触到了,但是因为我们需要递归,所有需要在内部实现一个递归函数,使用外部接口调用即可。void MidBfd() //中序遍历-外部接口 {_MidBfd(_root);cout << endl; }void _MidBfd(NodeType* root) //中序遍历-实际调用函数 {if (root == nullptr) return;_MidBfd(root->_left);cout << root->_key << " ";_MidBfd(root->_right); }
乱序插入后,中序遍历打印有序。
析构函数和销毁函数(后序遍历销毁)
销毁一棵二叉树,我们需要先销毁子树再销毁根节点,那么后序遍历再合适不过了。
因为销毁函数需要后序遍历,递归销毁,所以我们需要单独封装一个带节点指针参数的递归函数来销毁树。
当析构函数在析构时调用销毁函数后置空根节点指针即可!~BSTree() //析构函数 {Destroy(_root);_root = nullptr; }void Destroy(NodeType* root) //后序销毁 {if (root == nullptr) return;Destroy(root->_left);Destroy(root->_right);delete root; }
拷贝构造和赋值重载(前序遍历创建)
编译器默认的拷贝构造默认是浅拷贝,当浅拷贝根节点指针后销毁时便会出现异常。
递归拷贝函数: 所以我们必须实现一个可以拷贝一棵树且返回根节点地址的函数,这个函数我们采用前序遍历,前序遍历一棵树,每遍历一个节点就创建一个节点然后递归创建其左子树和右子树,最后返回根节点地址。
拷贝构造函数:我们只需要调用拷贝函数拷贝另一棵树然后将根节点地址赋值给本对象的_root即可(实现了拷贝构造函数就必须实现一个默认构造函数)。
赋值重载函数:我们重新赋值一棵树时需要先销毁当前对象的树,再调用拷贝函数拷贝这棵树,不过这样做显得很繁琐。我们可以将赋值重载函数参数改为传值传参,这样传值传参会调用拷贝构造拷贝一棵临时的树,然后我们调用swap将我们需要赋值树的节点地址交换,就完成了,当函数执行完成,临时变量会调用析构函数销毁树,因为我们把原来的树交换给了临时变量对象,所以临时变量会帮我们销毁而不需要我们自己销毁,这样就节省了我们的操作步骤。
实现代码:
BSTree(const TreeType& bst) //拷贝构造:_root(nullptr), _size(0) {_root = Copy(bst._root);_size = bst._size; }TreeType& operator=(TreeType bst) //赋值重载 {swap(bst); //我们自己实现的交换函数return *this; }NodeType* Copy(const NodeType* root) //前序拷贝一棵树 {if (root == nullptr) return nullptr;NodeType* newnode = new NodeType(root->_key);newnode->_left = Copy(root->_left);newnode->_right = Copy(root->_right);return newnode; }
其他函数
剩下的函数是比较简单的基础函数:
- 获取节点数量
- 交换函数
- 清空节点
size_t size() { return _size; }void swap(TreeType& bst) //交换函数 {//也可以调用库中的swapNodeType* root = bst._root;bst._root = _root;_root = root;Com com = bst._com;bst._com = _com;_com = com;size_t sz = bst._size;bst._size = _size;_size = sz; }void clear() //清空节点 {Destroy(_root);_root = nullptr; }




二叉搜索树的应用场景
二叉搜索树凭借着极快的查找速度,有着一定的实战价值,常用的查找模型是
key查找模型和key / value 查找模型及 存储模型。
key模型
key模型其实就是我们上面实现的树,节点中只有一个值,一般适用于在集合中查找某个参数在不在!
应用场景:
- 门禁系统
- 单词拼写检查
- . . . . . .
//简易字典 int main() {BSTree<string> bst;bst.Insert("中国");bst.Insert("CSDN");bst.Insert("BIT");bst.Insert("C++");bst.Insert("668");while (true){string tmp;cout << "请输入>>> ";cin >> tmp;if (bst.Find(tmp)) cout << "在词典中" << endl;else cout << "不在词典中" << endl;}return 0; ';;}
单值key的意义本身就是判断在不在,判断在不在也需要查找,二叉搜索树比较合适。
key-value模型
key-value模型需要存储两个值,其中用来对比(插入删除的依据)的是key,同时存储value (仅存储,value没用任何其他意义) 建立key-value的映射关系,这是一种典型的哈希思想。
应用场景:
- 电话号码查询快递信息
- 词典互译
- . . . . . .
我们将key模型的代码微微改动就可以实现key-value模型的二叉搜索树。
这里我们简单实现一下。//二叉搜索树KV template<class KT, class VT, class Com = Compare<KT>> class KVBSTree {using NodeType = TreeNode<pair<KT, VT>>;using TreeType = KVBSTree<KT, VT, Com>; public:KVBSTree():_root(nullptr), _size(0){}KVBSTree(const TreeType& bst):_root(nullptr), _size(0){_root = Copy(bst._root);_size = bst._size;}TreeType& operator=(TreeType bst){swap(bst); //我们自己实现的交换函数return *this;}bool Insert(const KT& key, const VT& value){if (_root == nullptr){NodeType* newnode = new NodeType({ key,value });_root = newnode;_size = 1;return true;}NodeType* parent = _root;NodeType* cur = _root;while (cur){parent = cur;//节点值小于keyif (_com(key, cur->_key.first)) cur = cur->_right;//节点值大于keyelse if (_com(cur->_key.first, key)) cur = cur->_left;else return false;}NodeType* newnode = new NodeType({ key,value });if (_com(key, parent->_key.first)) parent->_right = newnode;else parent->_left = newnode;++_size;return true;}bool Erase(const KT& key){if (_root == nullptr) return false;//删除节点NodeType* parent = nullptr;NodeType* cur = _root;//找节点while (cur){//节点值小于keyif (_com(key, cur->_key.first)){parent = cur;cur = cur->_right;}//节点值大于keyelse if (_com(cur->_key.first, key)){parent = cur;cur = cur->_left;}else //找到了 开始删除{if (cur->_right == nullptr) //删除的节点只有左子树{NodeType* DelNode = cur;//改变链接关系//如果要删除的是根节点if (cur == _root) _root = cur->_left;else //非根节点{if (parent->_left == cur) parent->_left = cur->_left;else parent->_right = cur->_left;}delete DelNode;}else if (cur->_left == nullptr) //删除的节点只有右子树{NodeType* DelNode = cur;//改变链接关系//如果要删除的是根节点if (cur == _root) _root = cur->_right;else //非根节点{if (parent->_left == cur) parent->_left = cur->_right;else parent->_right = cur->_right;}delete DelNode;}else //子节点都在{//找替代 左子树的最大节点(最右节点) 右子树的最小节点(最左节点)//去左子树中找最大节点//NodeType* maxParent = cur;//NodeType* maxLeft = cur->_left;//while (maxLeft->_right)//{// maxParent = maxLeft;// maxLeft = maxLeft->_right;//}//cur->_key = maxLeft->_key;接管替代节点的右孩子//if (maxParent->_left == maxLeft) maxParent->_left = maxLeft->_left;//else maxParent->_right = maxLeft->_left;//delete maxLeft;//去右子树中找最小节点NodeType* minParent = cur;NodeType* minRight = cur->_right;while (minRight->_left){minParent = minRight;minRight = minRight->_left;}cur->_key = minRight->_key;//接管替代节点的右孩子if (minParent->_left == minRight) minParent->_left = minRight->_right;else minParent->_right = minRight->_right;delete minRight;}--_size;return true;}}return false; //找不到节点}pair<pair<KT, VT>, bool> Find(const KT& key) //key-value模型 通过key找value{//这里使用pair再套一层pair,用于返回查询的结果是否有效//false表示查询返回值无效if (_root == nullptr) return { {},false };NodeType* cur = _root;while (cur){if (_com(key, cur->_key.first)) cur = cur->_right;else if (_com(cur->_key.first, key)) cur = cur->_left;else return { cur->_key,true };}return { {},false };}size_t size() { return _size; }void swap(TreeType& bst) //交换函数{//也可以调用库中的swapNodeType* root = bst._root;bst._root = _root;_root = root;Com com = bst._com;bst._com = _com;_com = com;size_t sz = bst._size;bst._size = _size;_size = sz;}void clear() //清空节点{Destroy(_root);_root = nullptr;}//中序遍历打印void MidBfd(){_MidBfd(_root);cout << endl;}~KVBSTree(){Destroy(_root);_root = nullptr;}private://前序拷贝一棵树NodeType* Copy(const NodeType* root){if (root == nullptr) return nullptr;NodeType* newnode = new NodeType(root->_key);newnode->_left = Copy(root->_left);newnode->_right = Copy(root->_right);return newnode;}//中序void _MidBfd(NodeType* root){if (root == nullptr) return;_MidBfd(root->_left);cout << root->_key.first << " : " << root->_key.second << endl;_MidBfd(root->_right);}//后序销毁void Destroy(NodeType* root){if (root == nullptr) return;Destroy(root->_left);Destroy(root->_right);delete root;}private:NodeType* _root; //根节点size_t _size; //节点数量Com _com; //比较函数 };
关于pair:
pair是C++自带的一个用于存储key-value的对象。
还有一个函数make_pair,传递两个参数(key / value),快速构建pair对象。
简易词典:
int main() { KVBSTree<string, string> bst;bst.Insert("china", "中国");bst.Insert("fruit", "水果");bst.Insert("god", "神");bst.Insert("great", "伟大");bst.Insert("blue", "蓝色");while (true){string str;cout << "请输入>>> ";cin >> str;auto ret = bst.Find(str);if (ret.second) cout << ret.first.first << " : " << ret.first.second << endl;else cout << "词典中没有该词!" << endl;}return 0; }



关于二叉搜索树
本章介绍了最基本的二叉搜索树,因为其左右性质,其查找速度很快。
关于二叉搜索树的时间复杂度:最快 O(logn),最慢 O(n)
我们仔细分析可以发现,当二叉搜索树插入有序序列时,会变成链表!
当二叉搜索树的高度等于节点数,则查找速度就是O(n)
为了解决这个问题,大佬们发明了AVL树和红黑树等,降低二叉搜索树的高度,以加速查找。
AVL树 和 红黑树 的时间复杂度近似为:O(logn)
后面我们将详细介绍!


最后
本节我们介绍了二叉搜索树,讲解了二叉搜索树的相关概念,为后面AVL树和红黑树的学习做铺垫,本节我们只是实现了最基本的代码,在AVL树和红黑树中,我们将实现更多功能,来完善我们的二叉搜索树。
本次 <二叉搜索树> 就先介绍到这里啦,希望能够尽可能帮助到大家。
如果文章中有瑕疵,还请各位大佬细心点评和留言,我将立即修补错误,谢谢!
本节涉及代码:二叉搜索树博客代码

🌟其他文章阅读推荐🌟
数据结构初级<二叉树>
C++ <继承>
C++ <STL容器适配器>
Linux进程间通信
Linux软硬链接和动静态库
🌹欢迎读者多多浏览多多支持!🌹
相关文章:
高级数据结构 <二叉搜索树>
本文已收录至《数据结构(C/C语言)》专栏! 作者:ARMCSKGT 目录 前言正文二叉搜索树的概念二叉搜索树的基本功能实现二叉搜索树的基本框架插入节点删除节点查找函数中序遍历函数析构函数和销毁函数(后序遍历销毁)拷贝构造和赋值重载(前序遍历创建)其他函数…...
蚂蚁集团5大开源项目获开放原子 “2023快速成长开源项目”
12月16日,在开放原子开源基金会主办的“2023开放原子开发者大会”上,蚂蚁集团主导开源的图数据库TuGraph、时序数据库CeresDB、隐私计算框架隐语SecretFlow、前端框架OpenSumi、数据域大模型开源框架DB-GPT入选“2023快速成长开源项目”。 (图…...
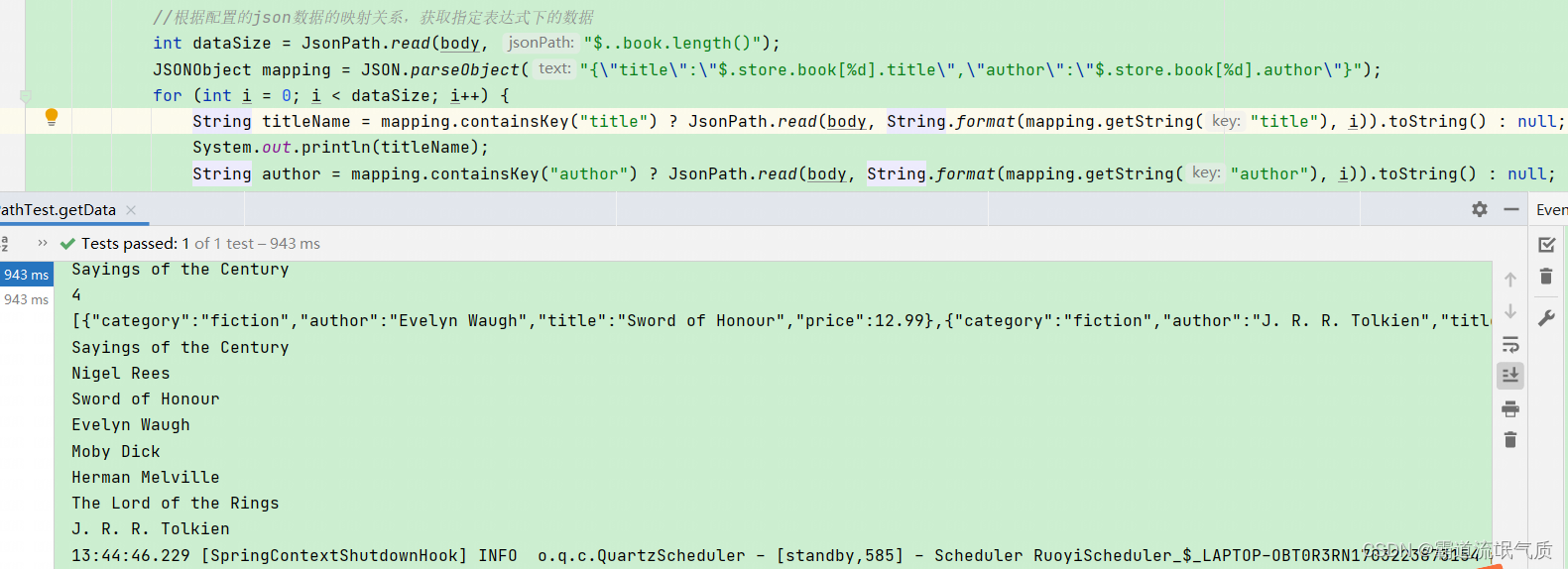
SpringBoot+JaywayJsonPath实现Json数据的DSL(按照指定节点表达式解析json获取指定数据)
场景 若依前后端分离版手把手教你本地搭建环境并运行项目: 若依前后端分离版手把手教你本地搭建环境并运行项目_前后端分离项目本地运行-CSDN博客 在上面搭建SpringBoot项目的基础上,并且在项目中引入fastjson、hutool等所需依赖后。 Jayway JsonPat…...

气压计LPS28DFW开发(2)----水压检测
气压计LPS28DFW开发.2--水压检测 概述视频教学样品申请完整代码下载水压计算设置速率和分辨率轮询读取数据测试结果 概述 本文将介绍如何使用 LPS28DFW 传感器来读取的压强数据,来估算水下深度,可以利用液体静压的原理。 最近在弄ST和瑞萨RA的课程&…...

设计模式之-装饰模式,快速掌握装饰模式,通俗易懂的讲解装饰模式以及它的使用场景
系列文章目录 设计模式之-6大设计原则简单易懂的理解以及它们的适用场景和代码示列 设计模式之-单列设计模式,5种单例设计模式使用场景以及它们的优缺点 设计模式之-3种常见的工厂模式简单工厂模式、工厂方法模式和抽象工厂模式,每一种模式的概念、使用…...

计算机网络个人小结
不同层的数据报的名称 应用层: data TCP层: segment IP 层: packet MAC层: frame MTU vs MSS: MTU:一个网络包的最大长度,以太网中一般为 1500 字节。 https://www.xiaolincoding.com/network/1_base/how_os_deal_network_package.html#linux-%E7%BD%91…...

酒店网站搭建的作用是什么
线上已经成为各行业商家增长破局的必要手段,传统酒店行业因信息扩展度不够,导致品牌难以传播、无法实现用户对酒店所有信息全面知悉,也无法实现在线预约及其它赋能用户消费的路径。 面对获客转化难题,很多酒店商家通过建立自营商…...

俄罗斯联邦税务局遭乌克兰入侵,数据库和副本被清空,政府数据安全不容忽视
俄罗斯联邦税务局遭乌克兰入侵,数据库和副本被清空,政府数据安全不容忽视 据相关报道,2023年12月12日,乌克兰国防情报局(GUR)称其成功入侵了俄罗斯联邦税务局(FNS)系统,并清除了该机构的数据库和…...
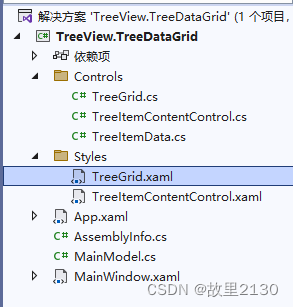
WPF组合控件TreeView+DataGrid之TreeView封装
(关注博主后,在“粉丝专栏”,可免费阅读此文) wpf的功能非常强大,很多控件都是原生的,但是要使用TreeViewDataGrid的组合,就需要我们自己去封装实现。 我们需要的效果如图所示&#x…...

redisson 哨兵模式配置
背景:项目redis由集群改为哨兵模式,漏洞扫描未授权访问漏洞(CNVD-2019-21763),要求对redis哨兵也设置密码,redisson依赖版本为3.11.5 spring-boot版本为2.1.13。 redisson依赖升级 <dependency>&l…...

免费的ChatGPT分享
免费的ChatGPT 以下是一些免费的ChatGPT平台和工具: 零声教学AI助手 零声教育内部使用的ChatGPT,提供智能对话和问题解答功能。 Ora.ai 一个可以自定义的AI聊天机器人,可以根据个人需求进行定制和训练。 ChatGPT 人工智能聊天机器人&a…...

C语言—每日选择题—Day54
指针相关博客 打响指针的第一枪:指针家族-CSDN博客 深入理解:指针变量的解引用 与 加法运算-CSDN博客 第一题 1. 存在int类型变量x,y,z,其对应值为x0x59,y0x39,z0x6E,则x * y z的值…...
先进制造身份治理现状洞察:从手动运维迈向自动化身份治理时代
在新一轮科技革命和产业变革的推动下,制造业正面临绿色化、智能化、服务化和定制化发展趋势。为顺应新技术革命及工业发展模式变化趋势,传统工业化理论需要进行修正和创新。其中,对工业化水平的判断标准从以三次产业比重标准为主回归到工业技…...

【密码学引论】密码协议
定义:两个或者两个以上参与者为了完成某一特定任务而采取的一系列执行步骤密码协议:Kerberos、IPSec、SSL、SET算法是低层次上的概念,而协议是高层次上的概念,协议建立在算法的基础上。所有密码协议都容易受中间人攻击,…...

利用快手的用户数据和精准营销提升电商平台用户转化率和销售额
一、快手用户数据的价值 快手作为国内领先的短视频平台,拥有庞大的用户群体和丰富的用户行为数据。这些数据包括用户的观看习惯、互动行为、兴趣偏好等,对于电商平台来说具有极高的商业价值。通过分析这些数据,电商平台可以深入了解用户需求…...

Linux根目录下默认目录作用
在Linux操作系统中,根目录(/)下的默认目录一般用于不同用途的文件存放和系统管理。以下是一些常见的默认目录及其用途: /bin:该目录存放系统的基本命令和可执行文件,如ls、cp、mv等。这些命令可供系统用户…...

国产Type-C接口逻辑协议芯片:Type-C显示器芯片方案
产品介绍 双Type-C盲插选型: LDR6282 PD3.0认证协议芯片,USB-IF TID号:212 支持iic,USB转UART,CC升级方式,多年市场验证,显示器市场出货量,显示器大厂采用兼容性NO.1。采用QFN32 5*…...

uniapp如何原生app-云打包
首先第一步,需要大家在HBuilder X中找到一个项目,然后呢在找到上面的发行选项 发行->原生App-云打包 选择完该选中的直接大包就ok。 大包完毕后呢,会出现一个apk包,这是后将这个包拖动发给随便一个人就行了。 然后接收到的那…...

分布式编译distcc
工程代码编译速度太慢,决定采用分布式编译来提高编译速度. distcc ,请参考https://www.distcc.org/ 安装 我用的distcc的版本是distcc-3.2rc1, 下载源码,安装步骤如下: ./autogen.sh ./configure --disable-Werror --prefix/…...
Elasticsearch常见面试题
文章目录 1.简单介绍下ES?2.简单介绍当前可以下载的ES稳定版本?3.安装ES前需要安装哪种软件?4.请介绍启动ES服务的步骤?5.ES中的倒排索引是什么?6. ES是如何实现master选举的?7. 如何解决ES集群的脑裂问题8…...

Python3.11镜像5分钟快速部署:告别环境冲突,一键搭建AI开发环境
Python3.11镜像5分钟快速部署:告别环境冲突,一键搭建AI开发环境 1. 为什么需要Python3.11镜像 在AI开发和数据科学领域,Python环境管理一直是个令人头疼的问题。不同项目可能需要不同版本的Python解释器或依赖库,手动管理这些环…...

3-24工作规划
1.规划好自动驾驶项目落地方案(Apollo,autoware)2.文献自动化抓取项目进行到了,抓取多个文献的调试环节,当前较少人工介入3.mcp项目当前进行到了算法上车不好用,需要复杂的调试,重构工作。4.地铁…...

科研助手实战:OpenClaw+GLM-4.7-Flash自动归类学术PDF与生成综述
科研助手实战:OpenClawGLM-4.7-Flash自动归类学术PDF与生成综述 1. 为什么需要自动化文献管理 去年冬天整理博士论文参考文献时,我的Zotero库里有387篇未分类的PDF文件。当导师问起"近五年认知神经科学领域在决策机制研究有哪些突破"时&…...

7步打造AI自主操作电脑:Open Computer Use颠覆传统人机交互实战指南
7步打造AI自主操作电脑:Open Computer Use颠覆传统人机交互实战指南 【免费下载链接】open-computer-use Secure AI computer use powered by E2B Desktop Sandbox 项目地址: https://gitcode.com/gh_mirrors/op/open-computer-use 副标题:你的AI…...

别再死记硬背C-V曲线了!用Silvaco仿真带你亲手‘画’出MOS电容的四种工作模式
用Silvaco TCAD亲手绘制MOS电容C-V曲线:从仿真操作到物理本质的全景解析 第一次接触MOS电容的C-V特性曲线时,那些拗口的专业术语和抽象的理论图示总让人望而生畏。堆积、耗尽、反型...这些概念在课本上只是静态的示意图,而当我们真正打开Silv…...

【Async I/O调试军规】:基于172个真实线上故障的根因图谱,97.3%问题可在90秒内锁定
第一章:Async I/O调试军规:从172个真实故障中淬炼的90秒根因定位范式当异步I/O在高并发场景下突然出现超时堆积、连接泄漏或响应毛刺,传统日志轮询与堆栈回溯往往耗时超过5分钟——而生产环境SLO要求根因定位必须控制在90秒内。我们对172起跨…...

HTTP/2头部压缩HPACK实战:如何用静态表和动态表提升网站性能
HTTP/2头部压缩HPACK实战:如何用静态表和动态表提升网站性能 当你在Chrome开发者工具中看到瀑布流里那些细小的绿色请求块时,是否思考过它们为何能如此高效?背后功臣之一就是HTTP/2的HPACK头部压缩机制。作为现代Web性能优化的隐形加速器&…...

Llama-3.2V-11B-cot开源镜像详解:免编译、免依赖、GPU即插即用
Llama-3.2V-11B-cot开源镜像详解:免编译、免依赖、GPU即插即用 想体验一个能看懂图片、还能像人一样思考推理的AI吗?今天要介绍的Llama-3.2V-11B-cot开源镜像,就是这样一个“聪明”的视觉助手。它最大的特点就是简单——你不用折腾复杂的编译…...

终极指南:如何在Windows 7上安装Python 3.8+最新版本
终极指南:如何在Windows 7上安装Python 3.8最新版本 【免费下载链接】PythonVista Python 3.9 installers that support Windows 7 SP1 and Windows Server 2008 R2 项目地址: https://gitcode.com/gh_mirrors/py/PythonVista 还在为Windows 7系统无法安装新…...

【前沿解析】2026年3月24日:从AI Agent专用芯片到永久记忆系统——硬软协同重塑智能体时代的技术底座
2026年3月24日,人工智能领域迎来了硬件与软件的双重里程碑:阿里巴巴达摩院在上海玄铁RISC-V生态大会上正式发布首款针对AI Agent算力优化的专用芯片,标志着开源架构正式向智能体计算需求发起冲锋;与此同时,Supermemory团队研发的ASMR永久记忆系统在LongMemEval测试中以99%…...